Network effects in default clustering for large systems
Konstantinos Spiliopoulos, Jia Yang

TL;DR
This paper models how defaults spread in large interconnected systems using graph theory, proving a law of large numbers and identifying key components with high contagion impact through spectral analysis.
Contribution
It introduces a law of large numbers for default clustering in large systems and uses spectral decomposition to identify influential components.
Findings
Law of large numbers for default measures
Identification of high-impact components via eigenvalues
Numerical validation of theoretical results
Abstract
We consider a large collection of dynamically interacting components defined on a weighted directed graph determining the impact of default of one component to another one. We prove a law of large numbers for the empirical measure capturing the evolution of the different components in the pool and from this we extract important information for quantities such as the loss rate in the overall pool as well as the mean impact on a given component from system wide defaults. A singular value decomposition of the adjacency matrix of the graph allows to coarse-grain the system by focusing on the highest eigenvalues which also correspond to the components with the highest contagion impact on the pool. Numerical simulations demonstrate the theoretical findings.
Click any figure to enlarge with its caption.
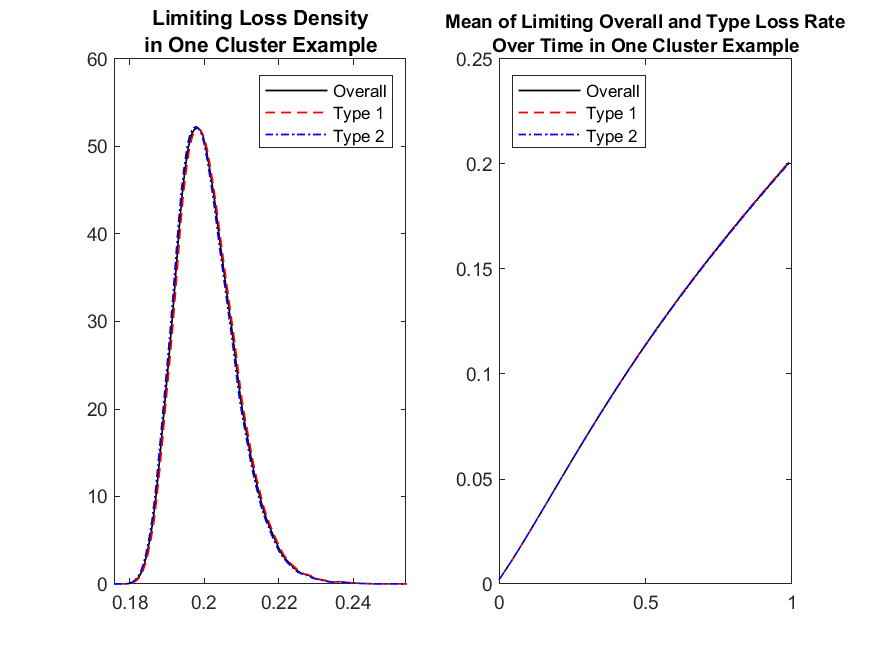 Figure 1
Figure 1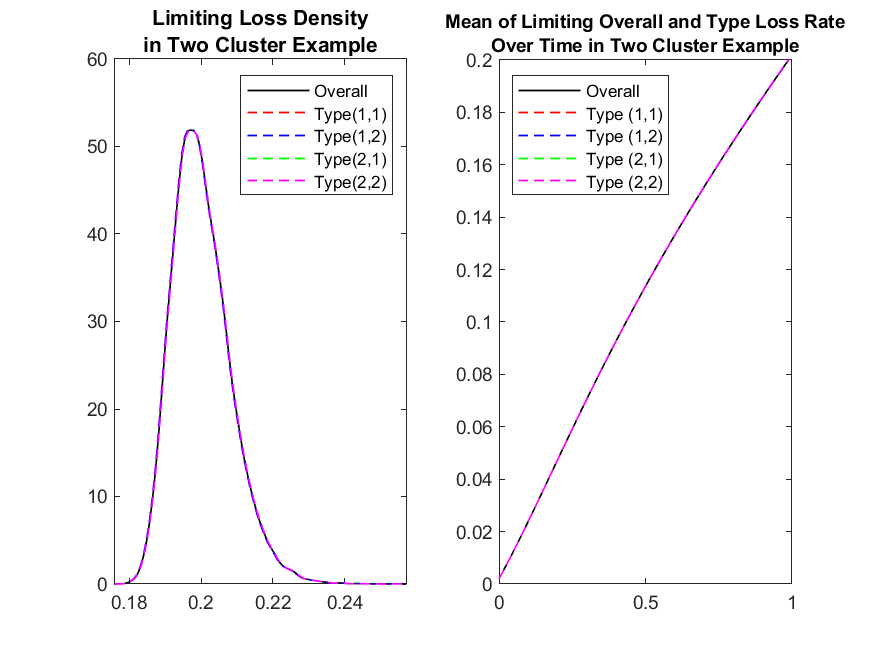 Figure 2
Figure 2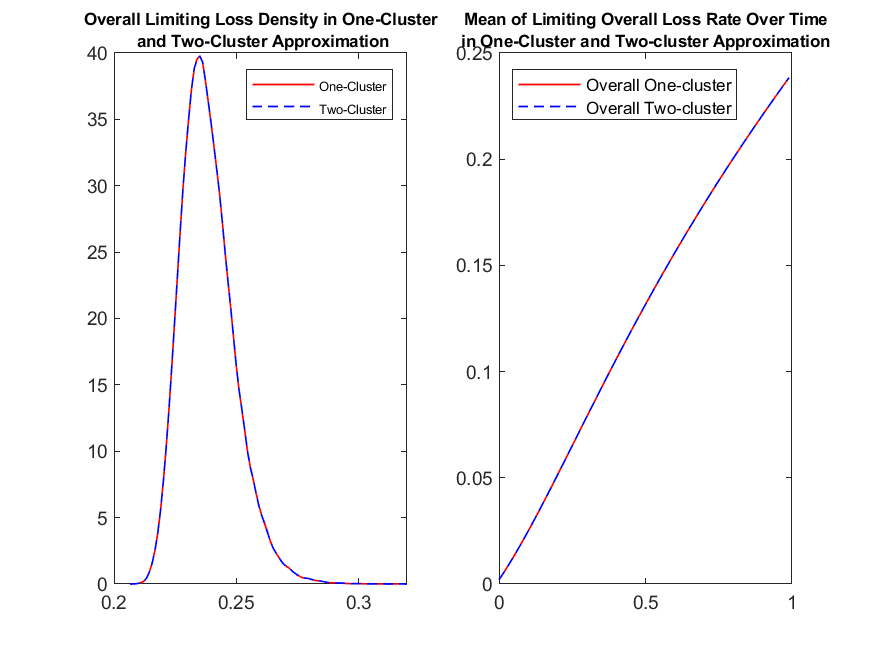 Figure 3
Figure 3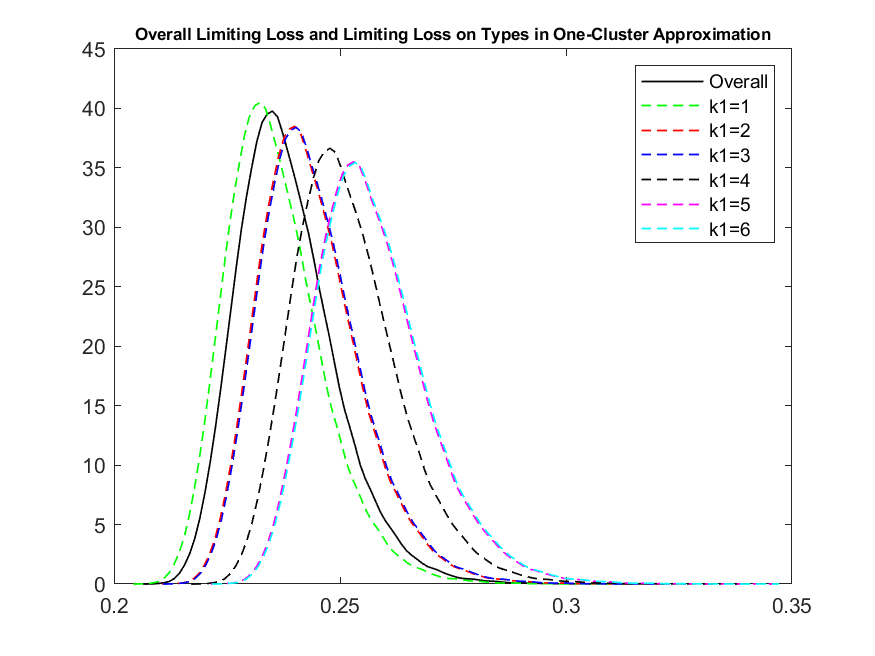 Figure 4
Figure 4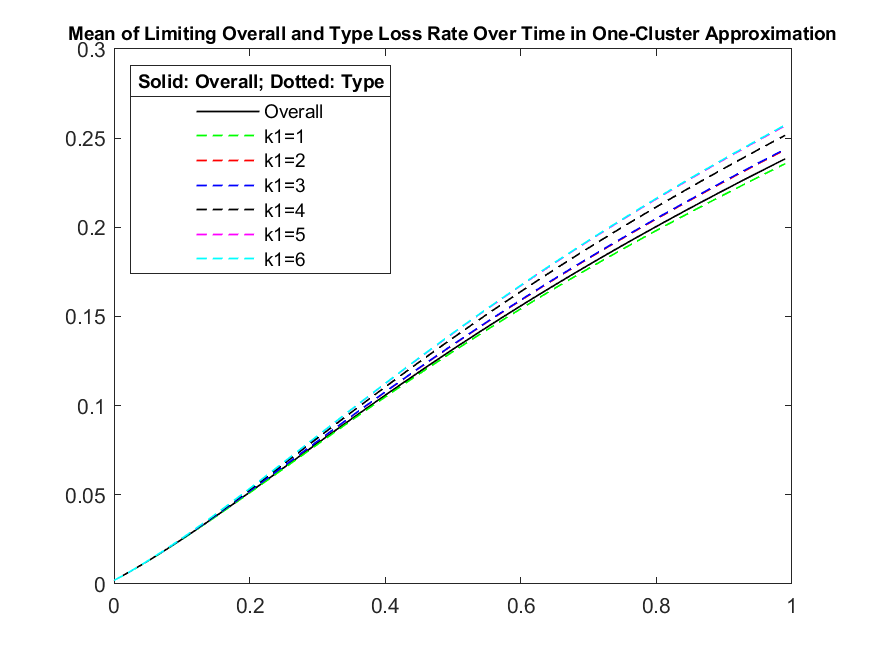 Figure 5
Figure 5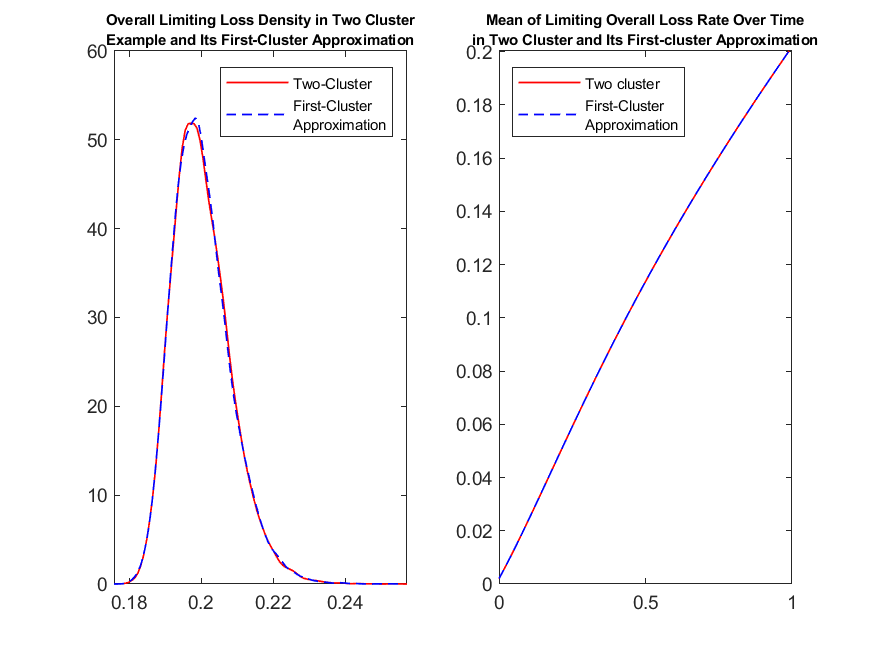 Figure 6
Figure 6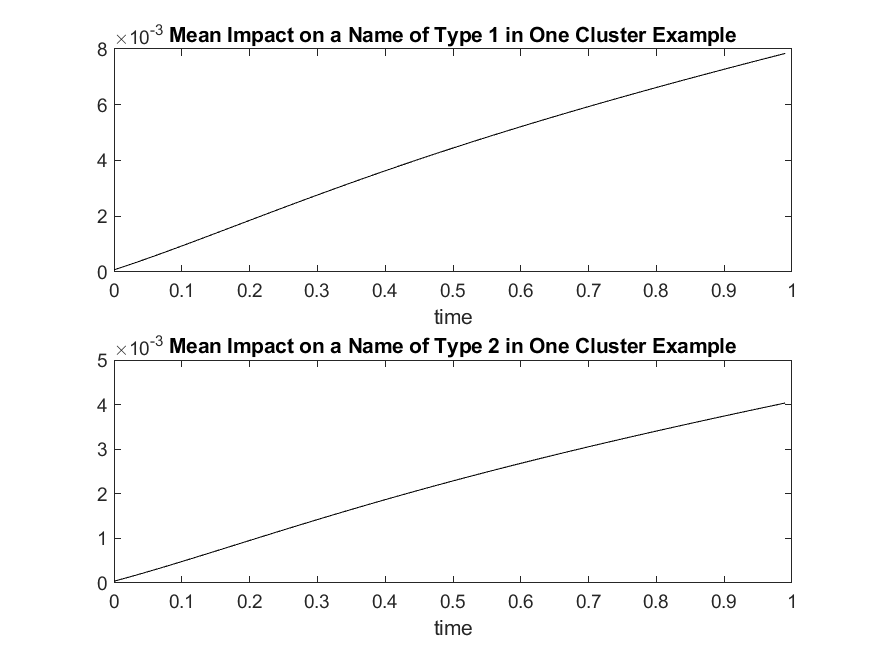 Figure 7
Figure 7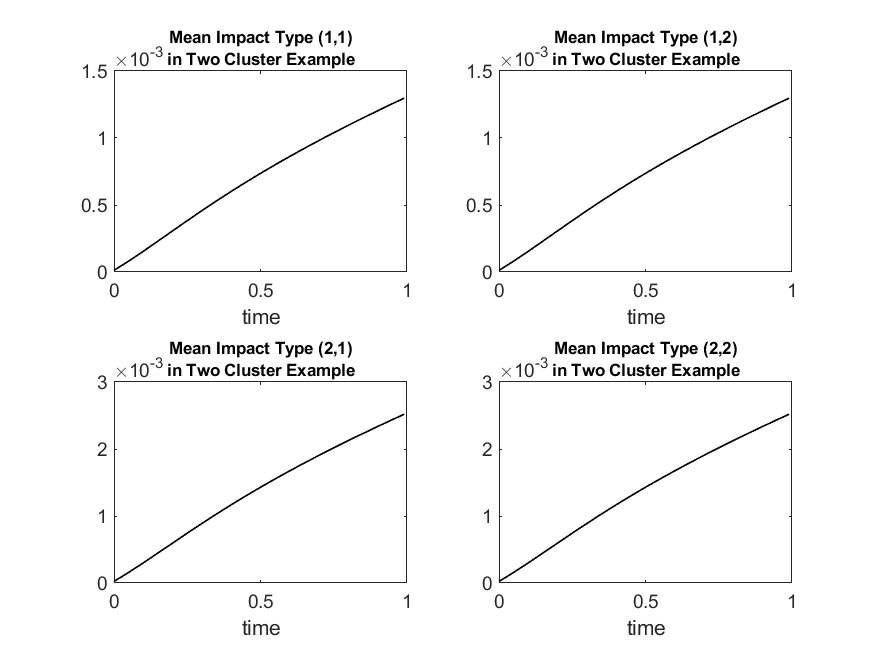 Figure 8
Figure 8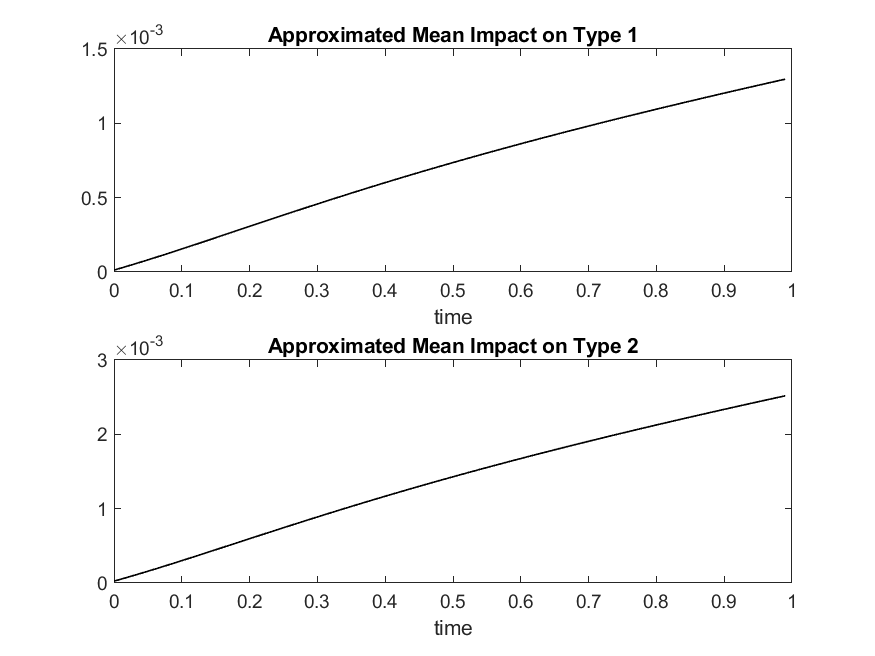 Figure 9
Figure 9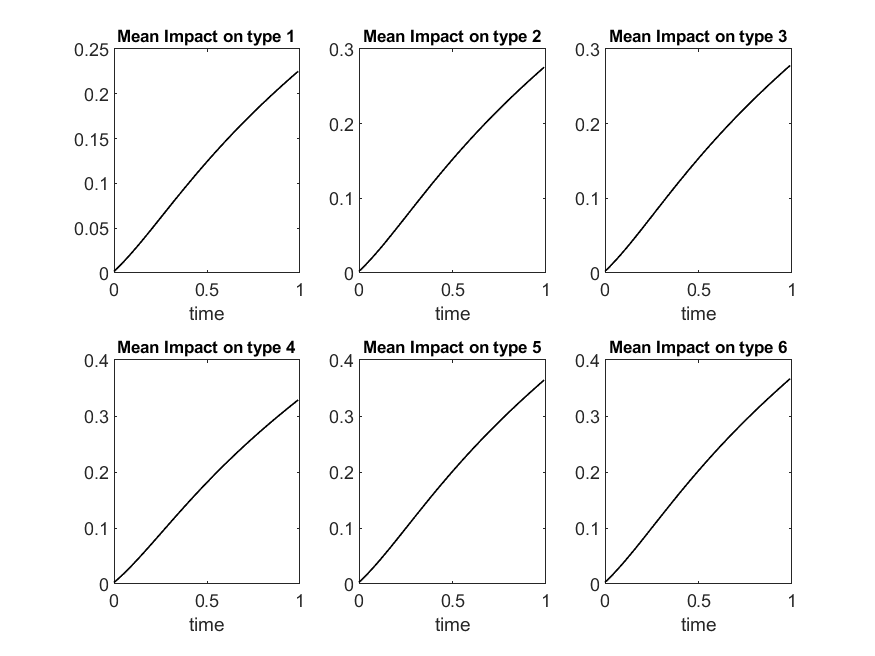 Figure 10
Figure 10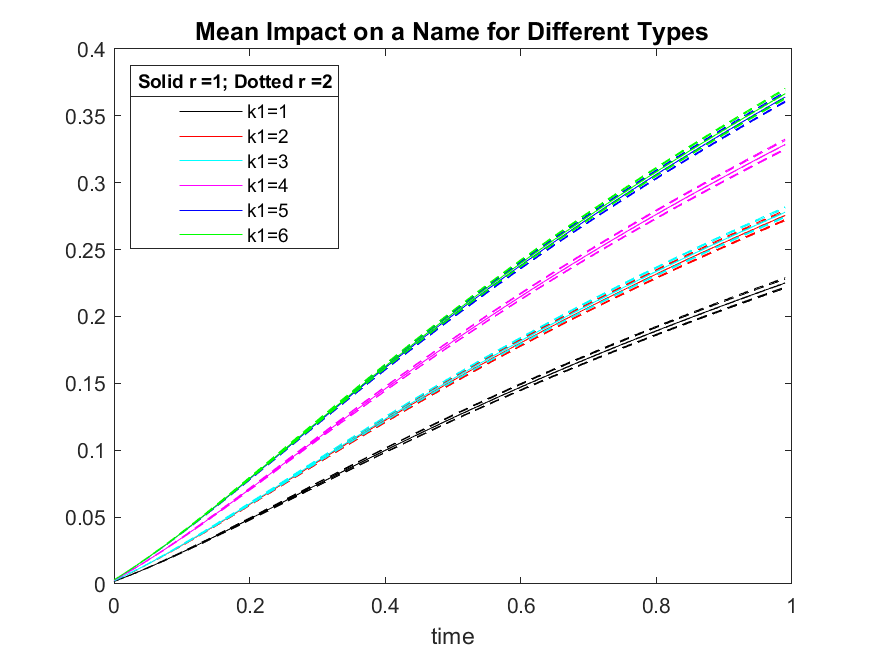 Figure 11
Figure 11| value | 31.0514 | 32.4883 | 32.5136 | 33.9505 | 73.6927 | 74.4088 |
| value | 0.0308 | 0.1597 | 0.1625 |
| probability | |||
|---|---|---|---|
| 6 | 3 | 0.001 | |
| 5 | 2 | 0.001 | |
| 4 | 1 | 0.227 | |
| 3 | 1 | 0.238 | |
| 2 | 1 | 0.228 | |
| 1 | 1 | 0.305 |
| value | -12.7072 | -12.1454 | -5.7944 | 0.2753 | 0.2777 | 0.5080 | 0.5105 | 6.5777 | 6.5801 |
| value | -0.0107 | -0.0081 | -0.0054 | 0.6674 | 0.7002 |
| probability | |||||
|---|---|---|---|---|---|
| 6 | 1 | 3 | 5 | 0.001 | |
| 5 | 2 | 2 | 4 | 0.001 | |
| 4 | 9 | 1 | 2 | 0.089 | |
| 4 | 9 | 1 | 1 | 0.120 | |
| 4 | 8 | 1 | 3 | 0.018 | |
| 3 | 7 | 1 | 2 | 0.171 | |
| 3 | 6 | 1 | 3 | 0.067 | |
| 2 | 5 | 1 | 2 | 0.172 | |
| 2 | 4 | 1 | 3 | 0.056 | |
| 1 | 3 | 1 | 3 | 0.305 |
| probability | ||||
|---|---|---|---|---|
| 6 | 3 | 1 | 0.001 | |
| 5 | 2 | 1 | 0.001 | |
| 4 | 1 | 2 | 0.227 | |
| 3 | 1 | 2 | 0.238 | |
| 2 | 1 | 2 | 0.228 | |
| 1 | 1 | 2 | 0.305 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComplex Network Analysis Techniques · Stochastic processes and statistical mechanics · Random Matrices and Applications
Network effects in default clustering for large systems
Konstantinos Spiliopoulos and Jia Yang
Department of Mathematics and Statistics
Boston University
Boston, MA 02215
Abstract.
We consider a large collection of dynamically interacting components defined on a weighted directed graph determining the impact of default of one component to another one. We prove a law of large numbers for the empirical measure capturing the evolution of the different components in the pool and from this we extract important information for quantities such as the loss rate in the overall pool as well as the mean impact on a given component from system wide defaults. A singular value decomposition of the adjacency matrix of the graph allows to coarse-grain the system by focusing on the highest eigenvalues which also correspond to the components with the highest contagion impact on the pool. Numerical simulations demonstrate the theoretical findings.
The present research was partially supported by the National Science Foundation (DMS 1412529 and DMS 1550918). We would like to thank Kay Giesecke and Paolo Guasoni for discussions on this project.
1. Introduction
The financial crisis of 2007-2009 made clear to the mathematical finance community that connectedness and network effects in financial systems need to be better understood and modelled. Risk can propagate through the system and network topology can affect its propagation.
Exogenous risks acting as initial shocks, such as devaluation of mortgage-backed securities, changes in interest rates or commodity prices cannot fully explain crisis events, but can lead to contagion effects, [29, 2]. In particular, shocks can lead to spiral events within the system and the topology and connectedness of the system can then affect how these spiral events unfold and propagate. This can then lead to systemic risk events, see for example [30], which has been by now widely accepted to be a dynamic event, [2, 4].
In the past ten years researchers have tried to understand and model such behavior in different ways. A significant body of literature has emerged that is aiming at understanding and modeling complex financial systems. Before describing the main contributions of this paper, let us first briefly describe the three main different lines of research that have emerged in the study of systemic risk. Firstly, there is the network models for clustering and contagion that follow the earlier work of [1, 16], see also [23] for a review. Secondly, there is the dynamic mean field type of models literature, see for example [5, 6, 8, 14, 18, 22, 7, 24, 19]. Thirdly, there is the reduced form credit and portfolio risk literature that is using intensity models of correlated default, [10, 20, 21, 31, 33, 32]. Despite this significant progress, many questions are still wide open.
Our work falls in the last category, i.e., in the reduced form credit risk literature. Motivated by the empirical work of [2] and following [20, 21], the intensity to default process for each individual name in the pool is characterized by three terms: an idiosyncratic term, which is specific to each name, a contagion term, which is responsible for clustering of defaults, and an exogenous risk term common to all names in the pool. When considering a large system, we will often refer to this as pool of names where names are the system’s components. As it has been established in [2, 20, 21], see also [31] for a review, these terms give important insights on how risk propagates and on how defaults cluster. Due to the interconnectedness of the system, the failure of a single component increases the likelihood of failure of other components in the system. Uncertainty becomes an issue which then leads market participants to fear even more losses in asset prices disproportional to the magnitude of the crisis. Reduce-form point process models of correlated default are many times used to assess portfolio credit risk and are based on counting processes. We use dynamic portfolio credit risk models to understand large financial systems asymptotics and default clustering.
Our contribution in this paper is twofold. Firstly, we consider network effects, a feature missing from the earlier work of [10, 20] and its follow ups. To be more precise, we specify the interaction of names by a weighted, directed graph where is the set of vertices (i.e., names), is the set of (directed) edges and is a function assigning weights to edges (as a convention we could define whenever ). An edge implies a directed interaction, the impact that the default of name has on name . The weight measures the strength of the interaction. For example, could represent the loss of name at the default of counterparty (the loss is usually the positive part of the mark-to-market value of the contract at default). As we shall see, the weight also represents the magnitude of the increase in the default intensity of name due to counterparty losses at the default of name . Let be the matrix with elements for . As it turns out, a singular value decomposition (SVD) of allows us to quantify contagion effects. In addition, the SVD allows us to quantify the levels of interaction (this is the number of non-zero eigenvalues of and it will become precise in Section 2) that we need in order to effectively coarse-grain the heterogeneous system. It also allows us to reduce the dimensionality of the system via appropriate low-rank approximations. In this paper, we theoretically analyze the limit of the empirical measure of surviving names as and we also showcase the different cases by numerical studies. We demonstrate numerically that if there is sufficient spectral gap in the eigenvalues of from the SVD, then the probability distribution of stochastic processes of interest is very well approximated by appropriate low rank approximations. This becomes practically useful, since without the low-rank approximation, as we will see, the computation of the quantities of interest can become prohibitively expensive.
In this paper, we assume that we are given an adjacency matrix with sufficiently regular behavior (see Sections 2-3 for details). Then, our goals are to study the typical behavior of the loss rate both in the overall pool and within names of the same type. In addition, we study the mean impact to default on a given name from system wide defaults as the number of components . We allow the pool to be heterogeneous with stochastic intensity that evolves dynamically in time and with different weights for different . In addition, the loss rate (either overall in the pool or for names of specific types) and the mean default impact on a given name from system wide defaults are dynamic quantities and their computations can be numerically cumbersome. We show numerically that low-rank approximations motivated through the SVD can be very effective in accurately reducing the dimension of the system and thus making their evaluation numerically tractable.
Therefore, the procedure developed in this paper allows to quantify the effect of the given adjacency matrix on dynamic quantities that are of interest, such as distribution of the loss rate in the pool, distribution of the loss rate within names of specific types, mean effect on given names from system wide defaults, etc. Note that evaluation of quantities such as loss rate of the whole pool and loss rate within names of specific types offers additional insights into the possibility of many names defaulting within short periods of time from each other (i.e. of default clustering). Indeed, an increase of the mean of the loss rate of the pool at a given time signals higher likelihood of many defaults. Then, studying the loss rates within names of specific types indicates which types of names are more likely to default. Naturally, names of types with larger mean loss rate will be more likely to default, revealing the structure of the cascade event. In addition, we find, via the SVD, that the mean loss rate in the pool is positively correlated with a specific coefficient, later on called the contagion coefficient. In particular, the contagion coefficient is a function of the corresponding singular values and of the orthogonal vector coefficients capturing the exposure of the network to contagion. We demonstrate these findings in our numerical studies of Section 5, where we demonstrate how these issues can be quantified.
Secondly, we consider general stochastic intensity-to-default processes where the drift coefficient of the idiosyncratic component is only required to satisfy appropriate dissipative properties instead of requiring it to be affine. We prove well-posedness of the related stochastic intensity models and rigorously characterize the limit of the empirical survival distribution of the names in the pool as their number grows to infinity.
In the recent related work [8], that falls in the literature of dynamic mean field models, the authors consider a model of interbank lending (not a reduced form credit risk model that we consider here) which accounts for network topology and propagation of systemic risk and perform asymptotic analysis as the number of banks as well. In the present paper we also look at the limit as and account for network topology, but we focus on the impact of the network matrix through spectral analysis on the evolution of default intensities and on specific statistics of interest such as loss rate in the pool and mean impact on specific types of network components.
At this point, we want to mention that even though our primary motivation comes from interacting particle systems in financial mathematics, our results are broader applicable. In a given system with many different components, not all components are equally connected to other components or equally affected by the default of other components. The failure of one component due to external forcing giving rise to failure of other components of a given system is of broader interest.
The rest of the paper is organized as follows. In Section 2 we describe our model in detail. In Section 3 we lay down our assumptions that are assumed to hold throughout the paper. Section 4 contains the main results of this paper. The proof of the main theorem is in the subsequent sections. In particular, tightness and characterization of the limit points of the empirical measure is discussed in Section 6 followed by uniqueness of the limiting point in Section 7. Section 5 contains our simulation studies and numerical results on low-rank approximations. Technical results and their proofs have been gathered in Appendix A. Section 8 is about our conclusions and outlook for future work.
2. Model description
The model considered in this paper models the evolution of a system consisting of names which are subject to default risk. The model for the default risk takes into account three terms: an idiosyncratic risk (specific to a given name), a systematic risk (common to all names) and a term modeling default contagion and spiral events. The last term takes into account the network topology.
Fix a probability space where all random variables are defined. Let be a collection of i.i.d. standard Brownian motions which are used to model the idiosyncratic risk for each component of the pool. Let be a standard Brownian motion independent from the ’s, driving the randomness of the systematic risk factor process . Let , where is the set of null sets. Let be a collection of independent standard exponential random variables.
For and , denote by the stopping time at which the -th component of the system fails. The failure time has stochastic intensity process to be described below. The default time is
[TABLE]
We can also write
[TABLE]
where is the indicator function for a set .
Recall the network structure of the system, which is described by a directed graph where is the set of components in the system, is the set of directed edges and is the function assigning weights to edges. represents the default impact the -th name has on the -th firm.
Then, the total loss experienced by name due to system wide defaults by time is
[TABLE]
and, as we shall see, it also represents the total increase in the default intensity of the -th name in the pool. Let be the adjacency matrix of , i.e. the -th entry of is given by for and [math] if .
Then, the classical singular value decomposition (SVD in short) yields
[TABLE]
where are orthonormal vectors (spanning columns of ), are orthonormal vectors (spanning rows of ) and are real numbers known as the singular values.
Here, is called the rank of . In a sense represents the complexity of the system. The larger is, the more complex the structure of the interaction becomes.
Let be the -th entry of in (2) and similarly let be the -th entry of the vector . The mean default impact on the -th name from system wide defaults up to time , can be written as
[TABLE]
where and the vector-valued process has elements
[TABLE]
The -th entry of can be loosely interpreted as the stochastic loss rate of the -th level of interaction of the network.
The element of the vector can be interpreted as the contribution of the -th bank on the -th level of interaction, for . Analogously, the element of the vector can be interpreted as the exposure of the -th bank on the -th level of interaction for .
Notice that can be interpreted as the mean increase over the -th bank’s intensity to default due to the default of other banks by time .
We are interested in the behavior of quantities like when the system is large, i.e. when . As we elaborate in more detail in Remark 3.4, in large systems it is reasonable to rely on a low rank approximation. In addition, for purposes of computational feasibility one would like to approximate by an appropriate low rank approximation.
One popular way to do so, is to use a classical result from matrix algebra stating that if is a positive integer, then the minimal value of the distance (the standard Frobenius norm) over all matrices with rank less or equal to is achieved at
[TABLE]
with in decreasing order. In addition, we actually have
[TABLE]
Such a reduction is especially meaningful if the rank of , , is large but there are only a few dominant eigenvalues. In such a situation one typically would like to take advantage of this. This is the practical perspective that we take here. In fact, given a large matrix one would first investigate the possibility of a good low rank approximation, then choose a certain low rank approximation that is comfortable with and work with that. As we shall see in Section 5, such an approximation in combination with the coars-graining achieved by Theorem 4.3 makes the problem computationally more tractable.
At this point, let us also mention that while the elements of the original matrix , i.e. , are nonnegative, it is likely that an arbitrarily chosen low-rank approximation to could have some of its elements to be negative. Therefore, some financial meaning could be lost sometimes depending on the chosen low-rank approximation. However, one does not expect this to be the case if the spectral gap in the eigenvalues is sufficiently large and one chooses a low rank approximation consistent with the spectral gap (i.e. one that corresponds to (4) with small right hand side). The numerical examples in Section 5 demonstrate that in this case the value of the statistics of interest (financial indicators of interest), up to negligible approximation errors, are not affected by such a good low-rank approximation.
The previous discussion then motivates us to replace by and to subsequently define the quantity
[TABLE]
where and the vector-valued process . For simplicity of notation we use the same notation for the components for both A and , even though we always work with , so there should be no confusion.
Now that we have discussed the matrix defining the network structure, let us be more specific in regards to the dynamics. An intensity is driven by an idiosyncratic risk represented by a Brownian motion , a systematic risk represented by the process , and spillover risk represented by the process (defined via , the low-rank approximation to ). In particular, we consider the following interacting system
[TABLE]
Notice that (6) has been defined in terms of and not in terms of the original . This represents what one would do in practice, in order to simplify the system as it will become clearer in Sections 3 and 4.
In addition, we allow for a heterogeneous pool, which means that the intensity dynamics of different names can be different. In the model , for some , are constants and . Let us set and . For all , we capture these different dynamics by defining the “types”
[TABLE]
and
[TABLE]
Furthermore, we let .
From now on we suppress the superindex , and we simply write in place of . It will always be clear from context which matrix is being used.
As just mentioned represents the (approximate, due to the potential low-rank approximation) mean impact on the -th name from system wide defaults up to time . The vector with will be interpreted as a contagion coefficient vector. Higher values of imply higher impact on the default intensity of the -th name. This is natural to expect as the -th column of the matrix represents the impact from defaults when claims of the th institution towards all other institutions are present. Other network performance indicators of interest are and with (we use the notation to distinguish names of type ), the overall loss rate in the pool and the loss rate for names of the same type, say type , respectively. When is large, numerical approximation of the distribution of these quantities becomes possible through the approximation theorem (Theorem 4.3) of this paper. As we shall see in Section 5, names of types with large contagion coefficients will tend to have larger mean losses.
In addition, for or for its low-rank approximation reveals a hierarchical structure of or levels respectively. For example, a rank one approximation of the matrix will have a more homogeneous structure than a rank two approximation of the matrix . In particular, names that are of the same type in a rank one approximation of (in terms of the dynamic evolution of their intensity process from (6)), may be of different type in a rank two approximation (and thus have different intensity to default process in terms of (6)). Said otherwise, a network system corresponding to a matrix with a large number of non-zero eigenvalues will have a finer structure than a system with a smaller number of . One can interpret as the number of levels of interaction in the system. We will discuss this again in Sections 3 and 5.
Our paper extends significantly the result of [21]. Firstly, the drift term only needs to have certain dissipative properties with respect to . Secondly, we now have a network structure described through the adjacency matrix . As we shall see, the analysis of this model is not only more challenging, but it also requires new arguments and ideas. While the main arguments and overall proof strategy is based on the methods of [20, 21], the new mathematical arguments that are needed, are presented in the Appendix A. The introduction of the network structure through the adjacency matrix , allows for a far richer set of questions to be asked.
3. Notation and Assumptions
In this section, we go over our assumptions that are assumed to hold throughout the paper.
We start with Assumptions 3.1, 3.2 and 3.3 that are related to the importance of having sufficiently regular behavior of the adjacency matrix , or more specifically of its low-rank approximation , and of the vector of parameters and defined via (7) and (8) respectively. In addition to the rest of the assumptions, Assumptions 3.1, 3.2 and 3.3 guarantee well defined limits later on as well as computational feasibility of the limit equation.
Assumption 3.1**.**
Assume that there is a constant such that all the coefficients , , , and and are bounded by and there exists a that .
Assumptions 3.2 and 3.3 that follow are phrased in terms of because the model (6) is based on . Clearly, if they already hold for the ordinal matrix , then can be used directly in place of in (6).
In practice one is typically given a large matrix , chooses a good low-rank approximation to and works with that specific approximation. In other words, for all practical purposes, one would like to be able to work with low-rank approximations . In fact, for theoretical reasons, we will assume a little bit more as Assumption 3.2 specifies.
Assumption 3.2**.**
We assume that as grows, the rank of the matrix that is used in the model (6) stays bounded.
Next, let us define
[TABLE]
The measures and belong to the space of Borel probability measures on and respectively. These spaces will be denoted by and respectively.
Assumption 3.3**.**
Assume that the limits
[TABLE]
[TABLE]
exist on and respectively.
Undoubtedly Assumptions 3.1, 3.2 and 3.3 imply certain behavior of the network of institutions. The following Remarks 3.4 and 3.5 are related.
Remark 3.4**.**
Assumption 3.1 on the boundedness of and for and all allows us to prove tightness of the measure valued process keeping track of the defaults (see Section 4) but it also implies that the original matrix can be very well approximated by setting equal to zero singular values lower than a given threshold, see [9]. In particular, [9] shows that for given , the -rank of (i.e. the smallest possible rank of matrices whose distance from in terms of the maximum absolute entry norm is less than ) is at most of order . This result is then strengthened in [35] to order of , if in addition each element of the matrix can be generated by applying a piecewise analytic function to potentially high dimensional but bounded latent variables.
These results imply that sufficiently large data sets tend to have low rank structure even if there may be no underlying physical reason, see [35]. These suggest that when is large one can reasonably expect that the matrix is well approximated by a low-rank matrix . This is the regime of interest in this paper. Low rank approximations are not new in the financial literature, see for example [27]. Low rank structure is evident in block-models networks and low-rank approximations can be used to identify core-periphery structures (a well known financial network of interest) see [12].
The empirical results of [11] demonstrate that the core-periphery structure is a financial network of interest. It is found empirically in [11] for the German interbank network that interbank markets are tiered which means that most banks do not lend to each other directly but through intermediaries. This phenomenon can be captured by a core-periphery model. The network observed in [11] is sparse, directed and valued.
In this paper, we are interested in studying the limit behavior of dynamic quantities such as and loss rate in the pool or within names of given type as and in order to be able to do so, both mathematically and numerically, we need to assume that we can work with a matrix (or an appropriate low-rank approximation ) such that its rank can be taken, or approximately considered to be bounded as . Assumption 3.2 makes this restriction precise, in which case the theoretical results of Section 4 hold. In addition, Assumption 3.2 also holds in the numerical examples, including the core-periphery one, that we numerically study in Section 5. In the numerical experiments presented in Section 5, it will be clear which matrix is being used to define and consequently the model (6). The conclusions section 8 discusses the possibility of treating the case where the rank increases with as well, but we do not elaborate more on this in this work.
Assumption 3.3 on implies that the empirical distribution of the spanning columns and rows of the adjacency matrix have a well defined limit in distribution. For example, this assumption holds if there is only a finite number of non-zero entries in the vectors for each with specific frequencies. This will be the case for example in all of the numerical studies of Section 5. In practice given a specific large , one would use Theorem 4.3 to approximate the probability distribution of quantities of interest, but of course use the empirical distribution and as approximations to and respectively.
Remark 3.5**.**
For completeness, let us present a simple example of a core-periphery model that has bounded rank as grows to infinity, i.e., it satisfies Assumption 3.2. The model presented here, also satisfies Assumption 3.3. Consider a base model
[TABLE]
where is a matrix (representing the base model for the core), is a matrix, is a matrix (representing the base model for the interactions between core and periphery) and . Then, for , let and consider the network matrix
[TABLE]
* is constructed via by extending the core banks in the base model to banks and the periphery banks in the base model to banks. The rank of the matrix is bounded form above by . In addition, a simple computation shows that for every and therefore for every the rank of is also bounded from above by .*
For such a model we assume that each one of the -copies of the original institutions has a corresponding intensity to default process defined with the same values (or i.i.d copies if randomly chosen) for the defining parameters with the corresponding original institution in the base model.
For the drift coefficient function we assume the following growth and regularity conditions.
Assumption 3.6**.**
The mapping is locally Lipschitz and there exists finite constants , , and positive bounded functions and with and such that
[TABLE]
[TABLE]
and
[TABLE]
Furthermore we assume that for any , is a continuous function.
A remark in regards to Assumption 3.6 follows.
Remark 3.7**.**
If we take and , then the idiosyncratic part of the intensity process becomes the classical CEV model. Notice that in this case with and the function has a single minimum point at . In turn this mean reversion of implies that the impact of a default fades away with time and the intensity will tend to revert back to the level .
Assumption 3.6 relaxes the affine structure to a requirement about appropriate dissipativity of the drift coefficient . This enlarges the class of drifts that one can consider. For example, one could consider situations where with being a bistable potential. Such situations could correspond to situations where the creditworthiness of certain names might have two equilibria, corresponding to two different parts of the business cycle.
The goal of this paper is to explore (Section 5) the potential effects of the network structure and of low-rank approximations on the distribution of dynamically evolving stochastic processes of interest. The aforementioned numerical exploration is based on the rigorous mean field limit of the empirical survival distribution of the names in the pool (Theorem 4.3). Theorem 4.3 proves that appropriate dissipative conditions on the drift coefficient are enough to guarantee well defined intensity-to-default processes and subsequently well defined mean field limits of the empirical survival distribution. See also Section 8 for a more elaborate related discussion and potential future directions.
The rest of the assumptions are related to the exogenous risk process .
Assumption 3.8**.**
Assume that the function is bounded, that is there exists a constant such that . For assume for some .
Let us define
[TABLE]
Assumption 3.9**.**
Assume that for some , and are bounded.
The last Assumption 3.10 makes sure that we can extend some technical lemmas from bounded drifts to potentially unbounded ones.
Assumption 3.10**.**
Assume there is a function such that and for any we have
[TABLE]
and that for any there is a such that
[TABLE]
An example where Assumptions 3.8, 3.9 and 3.10 hold is to take and , which is the mean reverting example that is studied in [20].
4. Well-posedness of the model and main results
In this section we prove that the model is well-possed and we present our main results. Let us begin with well-posedness of the model, Lemma 4.1.
Lemma 4.1**.**
Let be a vector of processes having components, predictable, right-continuous, monotone and bounded with . Let Assumptions 3.1-3.10 hold. There exists a unique nonnegative solution of the following SDE:
[TABLE]
Lemma 4.2 is about an essential a-priori bound that will be used in many places of the subsequent proofs.
Lemma 4.2**.**
Let be the unique solution to (6), guaranteed under the assumptions of Lemma 4.1. Let be such that Assumptions 3.8 and 3.9 hold. Then, for such and for every ,
[TABLE]
is finite.
Proofs of Lemmas 4.1 and 4.2 are in Appendix A. Let us denote the survival indicator process for a given name in the pool by
[TABLE]
and define the empirical distribution of the ’s corresponding to the names that have survived up to time as follows:
[TABLE]
Notice that captures the entire dynamics of the model (including the effect of the heterogeneities and network topology).
In order to study the convergence of , we need to set up the appropriate topological framework. That is, let be the collection of sub-probability measures on , i.e., consists of those Borel measures on such that . Then fix a point which is not in and let (the so-called one-point compactification of ). Open sets are those which are open subsets of (endowed with the original topology) or complements in of closed subsets of (again, in the original topology of ).
Define a bijection from to the Borel probability measures on as
[TABLE]
for any . Then we can make a Polish space.
We define the Skorokhod topology on , and define a corresponding metric on by requiring to be an isometry. Then, the space will be Polish.
Thus, is an element of , i.e., is a map from into which is right-continuous and has left-hand limits. The space will be endowed with the Skorohod metric, which we denote by , see [15].
Next, for each define
[TABLE]
In addition, define the generators
[TABLE]
with are vector valued, of the form and respectively. We write for . After presenting Theorem 4.3 we shall elaborate on the meaning of the operators defined in (9).
Recall that , where is the set of null sets. Introduce the notation .
Now, we are in position to state the main result of the paper.
Theorem 4.3**.**
Let Assumptions 3.1-3.10 hold. We have that converges in distribution to the measure valued process with values in . The evolution of is given by the measure evolution equation
[TABLE]
In addition, if , where , is the unique pair satisfying
[TABLE]
[TABLE]
then for any and , is given by
[TABLE]
Proof of Theorem 4.3.
The ingredients of the proof are in Sections 6 and 7. In Section 6 we state that the family is relatively compact (as a -valued random variable). Therefore is also relatively compact. Hence, it (or a subsequence) converges in distribution to a stochastic process . By the Skorokhod representation theorem, one can find a probability space and realizations, still denoted for convenience, and such that converges almost surely to . By the calculations in Section 6 we obtain that will satisfy (10). The results of Section 7 show that is actually unique and given by (11). The pair exists and is unique via Lemma 7.1. These results complete the proof of the theorem. ∎
The operator represents the idiosyncratic risk of the default intensity and notice that a killing term is also included due to the defaults. The operators and represent the effect of the exogenous risk . The most intriguing term, perhaps, is the nonlinear term of the equation , which is the term responsible for the contagion effects and possible default clusters. In particular, as we shall also see in the numerical experiments of Section 5, larger values of the contagion vector parameter (element-wise) lead to larger mean losses in the overall pool as well as in individual levels of interaction. In addition, the mean impact on given names from system wide defaults is larger when the associated contagion parameter is larger. The limiting term is a sum of components, which shows the need to have bounded for the limiting procedure to go through. Potential weakening of this is discussed in the Conclusions Section 8.
We end this section with a discussion on Theorem 4.3.
Remark 4.4**.**
Theorem 4.3 will be used in Section 5 to approximate dynamic quantities of interest such as , the overall loss rate in the pool or the loss within collections of names of the same type as . To be more specific, let the -th name be of type . Then, Theorem 4.3 implies that as one can approximate quantities like and by the corresponding limiting objects and . Theorem 4.3 allows for a more efficient numerical computation because it replaces a system of SDE’s, model (6), by a single limiting equation, (10), that can be efficiently computed (see Section 5 for details). The limit object (10) is the weak formulation of a non-local PDE for the density of the measure , say . Due to its non-local form, it involves computation of integral terms coming from the product term . In turn, the term is an integral over the whole parameter space that also includes the vectors , for , arising from the SVD. In order to compute the latter with an exogenously given adjacency matrix that has a large, but finite, dimension , and its SVD, we approach the computation of the integral term as a finite sum based on the empirical distribution of , for each . In Section 5 we make this precise on specific examples of interest and collect the main findings of our numerical studies.
5. Numerical studies and simulation results
In this section we demonstrate numerically the theoretical results of the paper. Before presenting the numerical studies, we first describe the numerical method that we follow and we also comment on general aspects and issues that are common in all examples.
One of the quantities that we are interested in is the overall loss rate in the pool, defined by
[TABLE]
Related to this quantity is also the loss rate for names of the same type, say type , denoted by :
[TABLE]
where is the total number of names of type in the pool.
We are also interested in the mean impact on name from system wide defaults by time , which is defined by
[TABLE]
with the contagion coefficient vector being
[TABLE]
and the -dimensional vector .
Recall that can be interpreted as the mean increase of the -th default intensity due to defaults of other banks by time .
In order to be able to compute we need to be able to compute , which is associated to the -th level of interaction of the network
[TABLE]
where we recall that .
The asymptotic result from Theorem 4.3 is used to evaluate network performance indicators such as , and . For large , quantities like , and are approximated by , and respectively; made possible via Theorem 4.3. In order to be able to numerically compute the latter quantities, we first write with . A formal integration by parts on the stochastic evolution equation that satisfies gives that, in distributional sense, the density satisfies
[TABLE]
where the adjoint operators are given by:
[TABLE]
Now, motivated by Theorem 4.3 we approximate,
[TABLE]
[TABLE]
where if the limit exists.
[TABLE]
Hence, it is enough to be able to compute . In order to do so, we first define the -th moment to be, see also [21],
[TABLE]
The moment can be calculated from the evolution function of , by multiplying it with and integrating by parts over . As it will become clearer in the examples that follow, will satisfy a system of equations. However, this system is not a closed system in that for any , depends on . To resolve this, we follow the method of truncation and in particular for a large enough , we set and then we solve backwards. As we shall see later on (see also [21] for related results) this truncation is a sufficiently good and computationally efficient approximation of and, in addition that can typically be taken to be small. Our numerical studies showed that choosing is more than sufficient to guarantee good approximation properties, at least for the numerical examples studied in this paper. In addition, as it is demonstrated numerically in the Appendix A of [33], in the simpler case without the network structure, such a mean field type of approximation is advantageous from numerical point of view as opposed to direct simulation of the finite system.
Now, if the number of levels of interaction is large or if the pool has a large degree of heterogeneity, then the number of equations in the system can be prohibitively large. To resolve this and make the computation numerically feasible one can result in appropriate low-rank approximations as dictated by the SVD. The SVD facilitates the decomposition of the network interaction into mean-field type levels of interaction.
This singles out the contribution of the most important level of interaction. To support this claim further note that the orthonormality of the vectors and the definition gives that for every
[TABLE]
which immediately gives a ranking of based on the eigenvalues .
We will see the power of the low-rank approximation in the examples that follow. In particular, if there is enough of spectral gap in the eigenvalues given by the SVD, then the limiting loss rate as well as the limiting mean impact on a given name , , are very well approximated by only considering the levels of interaction associated to the first few large eigenvalues and ignoring the rest.
Before presenting the numerical studies, let us collect here their main findings and state some useful observations (see Figures 2-16):
- •
A rank one approximation to is a coarser approximation to the network structure than a rank two approximation in terms of the description of the intensity-to-default dynamics of the model (6). Similarly a rank two approximation is a coarser approximation to the network structure than a rank three approximation, and so on and so forth, leading to a hierarchical structure. This is a simple consequence of the SVD.
- •
The ranking of the eigenvalues of , , gives a clear ranking of the importance of the different levels of interaction in explaining the heterogeneity of the pool.
- •
The ranking of the corresponding contagion parameter, , gives a clear ranking of the mean impact on names belonging to the same level of interaction from system wide defaults.
- •
Given that the other parameters of the model are the same, names of a type with larger value for , the contagion coefficient, will have larger mean default rate than names of types with smaller value for . This means that if the overall loss rate in the pool is large, signaling the existence of contagion clustering, names of types with large values for will be more prone to default if the rest of the parameters in the model description are the same.
- •
Larger values of imply larger mean impact on the name from system wide defaults and, as we see in the subsequent sub sections, we are able to quantify this precisely, see for example the Figures in the example presented in Subsection 5.3.
- •
The level of mean reversion also has an important effect on the losses experienced by names of the same type, see Example 5.4. Names with smaller mean reversion rate will be less likely to default.
- •
In complicated networks with many different levels of interaction or high degree of heterogeneity, the numerical computation of quantities like or can be prohibitively large. The singular value decomposition together with the limiting result Theorem 4.3 allow us to reduce the dimension of the system making such computations feasible, while maintaining accuracy, via low-rank approximations and large approximations.
The effect of the exogenous risk component is quantified via the parameter . As in [21] larger values of naturally lead to larger losses, due to an increase in the default intensities. Given that this effect here is analogous to what was observed in [21] and because in this paper our focus is on studying network effects through the contagion term, we do not study the effect of further here.
In all the numerical examples that follow, we consider for simplicity a specific form of function and , and take the systematic risk process to be a CIR process . For the numerical purposes of this paper, we have restricted attention to the aforementioned choices as we want to be able to compare and draw intuition from the existing literature which is largely based on the affine model (see also the Conclusions Section 8 for related future directions).
We consider below four different numerical studies. The first example has one level of interaction, i.e. in the SVD, and the second example has two levels of interaction, i.e. in the SVD. The third and fourth examples are motivated by the well documented core-periphery network structure for financial models, see for example [11, 25]. In the third example all the names have the same mean-reversion coefficient. In example four, we choose different mean reversion coefficient for the core and for the periphery institutions. Notice that names of different types may belong to the same level of interaction. Namely each level of interaction does not need to be homogenous. This becomes clear in the specific examples below. The matrix for the core-periphery examples is chosen to reflect the empirical evidence [11, 17] that periphery banks are smaller and less active than core banks.
5.1. One level of interaction case
In this example, we consider a situation where the adjacency matrix has only one positive eigenvalue. This corresponds to having one level of interaction, , but of course the pool can still be heterogenous.
Let us start by fixing some values for the parameters , , , , , , , and . Also, let us consider a pool of names.
In addition, assume that 50% of the ’s are taking the value and the rest 50% of the ’s are taking the value , while all ’s take value . To describe this more effectively, we slightly abuse notation and consider discrete random variables and defined by
[TABLE]
The corresponding adjacency matrix has a singular value decomposition with only one nonnegative eigenvalue 10. The first column of the left matrix takes one value 0.0316. The first column of the right matrix takes two values 0.12361 and 0.06362 with same frequencies. Notice that we indeed have and , as expected.
Hence, we have a heterogeneous pool with two different types, where however both of them belong to the same level of interaction.
In this case, the moments, as defined by (12) satisfy the following pair of coupled equations
[TABLE]
[TABLE]
with .
Then, we have that the overall loss rate, for large , is
[TABLE]
The loss rate for type , is
[TABLE]
The mean impact, from the system wide defaults by time t, on name , which comes from type , is
[TABLE]
where
[TABLE]
Now notice that the system which the moments satisfy is a non-closed system, since the equation for the -th moment depends on the moment. In order to solve this we truncate the system at a certain level , by setting and solve backwards. This will then give us and for any time . Here we choose the time endpoint to be . We do the numerical iteration with time step being 0.01. We run 50,000 Carlo trials and plot the overall limiting loss at different truncation levels in Figure 1. It is clear from Figure 1 that the results are visually indistinguishable for all those different truncation levels, meaning that the truncation mechanism is reliable even for a low level of truncation.
In the following experiments we will use with the same number of Monte Carlo trials. We plot the overall limiting loss and limiting loss for Type , , in Figure 2 left plot. We also plot the empirical mean of overall limiting loss rate and the empirical mean of limiting loss rate for two types , , up to time in Figure 2 right plot.
In Figure 3, we plot the mean impact on a name , i.e., , from system wide default as a function of time for the two different types of names. Here the name , can be one of two types, type or type , as indicated by the parameters . It is instructive to notice from the plots that , which is to be expected due to the relation of the contagion coefficients.
5.2. Two levels of interaction case
In this example now we consider the case where has two positive eigenvalues. This corresponds to having a heterogeneous pool with two levels of interaction, . In this example, we will also test numerically the effect of the low-rank approximation on the limiting loss and on the mean impact on given names by system wide defaults.
Let us choose the following values for the parameters , , , , , , , and . Also, let us consider a pool of names.
Furthermore, we assume that 50% of the ’s (first level of interaction) are taking the value and the rest 50% of the ’s are taking . All the ’s take the value .
In addition, of the ’s (second level of interaction) are taking the value and the rest 1/3 of the ’s are taking the value . Finally, 50% of the ’s are taking the value whereas the rest 50% of the ’s are taking the value .
As with the previous example, we slightly abuse notation and define discrete random variables , , and such that
[TABLE]
We assume that the random variables , , , are independent.
For the corresponding adjacency matrix , the SVD has two nonnegative eigenvalues 10 and 1. The first column of the right matrix takes two values 0.0205 and 0.0398 with same frequencies. This indeed corresponds to the two values and . The second column of the right matrix takes two values 0.0009 and 0.0022 with ratio of frequencies being 2:1. This indeed corresponds to the two values and . The first column of the left matrix takes only one value 0.0316. The second column of the left matrix takes two values 0.0043 and -0.0022 with equal frequencies.
Let us now denote by to be the th moment at time t with being the choice index for , and respectively. For example, corresponds to the choice , and . Then there will totally be equations in the coupled system. However because of the special structure we end up with only 4 different equations. In particular, for we have
[TABLE]
Notice that for . We supplement with initial conditions together with and we define
[TABLE]
where . Then we have that the overall loss rate is
[TABLE]
The loss rate for type , where essentially changes only with and and takes the form,
[TABLE]
The mean impact on name from system wide defaults up to time is determined only via the choices for and through and respectively. In particular, we have
[TABLE]
where for the th level of interaction, , we have
[TABLE]
[TABLE]
Due to the assumed independence, all the joint probabilities can be written as the product of marginals, for example, .
As with the previous example, we choose the time endpoint to be . We do the numerical iteration with time step being 0.01. We run 50,000 Monte Carlo trials. In Figure 4, we show the densities for the overall limiting loss rate in the pool for different truncation levels . Again, the results are visually indistinguishable for all those different truncation levels, meaning that the truncation mechanism is reliable even for a low level of truncation.
In the following experiments we still choose the truncation level and plot overall limiting loss rate and the limiting loss rate for different types , in the left plot of Figure 5. We also plot the empirical mean of the overall limiting loss rate and the empirical mean of the loss rate for different types over time , in the right plot of Figure 5.
In Figure 6 we plot the mean impact on a name from type , due to system wide defaults up to time .
As we discussed in the beginning of this section, the SVD facilitates the decomposition of the network interaction into mean-field type levels of interaction.
We test the effect of the low-rank approximation by only keeping the first level of interaction. This singles out the contribution of the most important level of interaction.
In other words, we replace by
[TABLE]
which reduces the problem to a one level of interaction problem. Comparing the overall limiting loss that we get from the two level of interaction case and its first level of interaction approximation , see left plot of Figure 7, we get that the distribution of the limiting loss processes are practically indistinguishable. Similar conclusion can be made from the right plot of Figure 7, where we plot the empirical mean of overall limiting loss rate over time in the two level of interaction example and it first-level of interaction approximation . These in turn imply that the second level of interaction can be neglected for the purposes of these computations.
Lastly, we investigate how the mean impact on a name from system wide defaults for the two level of interaction case and its one level of interaction approximated version compare. In Figure 6, we see that the mean impact on given names depends mainly on , and not so much on . This will be further verified in the one level of interaction approximation case, where we calculate the approximated mean impacts on these two types by using the information only from first entries of and , i.e., by using only the information from the first level of interaction, shown in Figure 8.
[TABLE]
Comparing Figures 6 and 8 we see that the first level of interaction, which has the largest eigenvalue, indeed captures the behavior on the mean impact on a given name of type defined by . In addition, notice that the mean default impact on names of type 2 is larger than the mean default impact on names of type 1 for all . This is to be expected due to the relation .
5.3. Core-Periphery example one: homogeneous mean-reverting coefficient
A reasonably realistic model for financial related applications is the core-periphery case, see for example [11, 25]. In a core-periphery model, one has a few names that constitute the core of the network and considerably depend on each other, in a sense forming the most influential part of the network, and the periphery which is composed by the rest of the names in the pool which depend less on each other. Core institutions borrow from, and lend to, at least one institution in the periphery.
Motivated by this structure, let us consider the case of names and an appropriate adjacency matrix . For illustration purposes a block of is given by:
[TABLE]
The SVD for such a matrix gives 5 eigenvalues 1029, 143, 137.8, 59.9 and 58.5 significantly larger than the rest, with the first one being dominantly big. Therefore, motivated by the low rank approximation, we can use the first few levels of interaction to approximate the behavior of the network.
5.3.1. One level of interaction approximation for core-periphery
Let us choose the first eigenvalue to do the low rank approximation. Similarly to what was done for the previous examples, we define discrete random variables and taking values from the SVD with corresponding relative frequencies. It turns out that the SVD composition yields six different values for and three different values for . We record the values in Tables 1 and 2 respectively.
Let us choose the following values for the parameters , , , , , , , and .
Let us denote by to be the -th moment at time t with and being the index choice for , and respectively. For example, corresponds to the choice and . The empirical joint distribution of and is summarized as follows.
In general there would have been in total equations in the coupled system. However, because of the special structure we end up with only 6 different equations. Based on the available combinations of as indicated in Table 3 we have
[TABLE]
together with and where we define
[TABLE]
In particular is only affected by the index through . The overall loss rate in the one-level of interaction approximation is
[TABLE]
The loss rate for type where and in the one-level of interaction approximation are actually falling into 6 distinct categories indexed by , the choice of .
[TABLE]
The mean impact, from system wide defaults up to time t, on name , turns out to be characterized only by the first index
[TABLE]
for any with
[TABLE]
As with the previous two examples, we truncate at the level , and choose the time endpoint to be . We do the numerical iteration with time step being 0.01. We run 50,000 Monte Carlo trials and plot overall limiting loss rate and the limiting loss rate for different types , in Figure 9. Notice how the mean of the distribution shifts to the right as the value for increases, indicating an increase to the value that the random variable takes. We plot the mean of the loss rate over time for the whole pool and for individual types in Figure 10. We observe that the plot indicates larger losses as the value for increases, signaling that names with large value for will be more likely to default and thus contribute more to a potential default clustering event.
In Figure 11, we plot the mean impact on a name from system wide defaults up to time . There are totally 6 different categories indexed by , the choice of , as we discussed before.
5.3.2. Two levels of interaction approximation for core-periphery
Let us now investigate the core-periphery case by doing a low rank approximation based on the first two levels of interaction. From the SVD decomposition, the second largest eigenvalue is 143. Below, we summarize the empirical distributions of coefficients from the second columns of the matrices from the SVD decomposition. Table 4 is for coefficient and Table 5 is for coefficient .
Let us now denote by to be the -th moment by time t with , , , and being the index choice for , , and respectively. For example, corresponds to the choice , , and .
The empirical joint distribution of , , and is summarized as follows.
In general there would have been in total equations in the coupled system. However, because of the special structure we end up with only different equations. Based on the allowable choices for as indicated in Table 6 we have
[TABLE]
together with where we have defined
[TABLE]
In particular, is only affected by the choices of through . The overall loss rate is
[TABLE]
[TABLE]
The mean impact on name from type , where , , and , is again determined by the choice and for and respectively
[TABLE]
where for the -th level of interaction, , in the two-level of interaction approximation we have
[TABLE]
[TABLE]
As with the previous example, we truncate at the level , and choose the time endpoint to be . We do the numerical iteration with time step being 0.01. We run 50,000 Monte Carlo trials and plot the overall limiting loss in the two level of interaction approximation. In the left plot of Figure 12, we see that the two approximations perform similarly in estimating the overall loss rate. This can be also verified via the plot of the mean of overall loss rate over time for each one of the two approximations in the right plot of Figure 12.
We can also investigate the mean impact on a name in the two-level of interaction approximation case. By Table 6 we will have different types of mean impacts in the two-level of interaction approximation case. These are demonstrated in Figure 13.
It is instructive to compare the low rank approximation based on just the first level of interaction with the low rank approximation based on the first two levels of interaction. The dotted lines are very well approximated by the solid line in Figure 13. In fact, we computed numerically the percent error of the mean impact on a name from the two different approximations, that is,
[TABLE]
and in all cases the percent error made by using the one-level of interaction approximation versus the two-level of interaction approximation was not greater than for all times . For comparison purposes we also mention that the computation of and based on the two-level of interaction approximation took about two times larger than the their computation based on the one-level of interaction approximation, indicating savings in computational time while maintaining accuracy. Lastly, notice that the mean default impact on names of type from system wide defaults is ordered according to the order of the corresponding contagion coefficients via Table 1.
5.4. Core-periphery example two: nonhomogeneous mean-reverting coefficients
Now we investigate the core-periphery case with nonhomogeneous mean-reverting coefficients. We assume that the mean-reverting coefficient takes different values for names in the core and in the periphery component of the network: and and the rest of the coefficients as well as the network structure are the same from the one level approximation example of the previous Subsection 5.3.
Notice that the choices and represent the anticipation that it is harder for a core institution to default than it is for a periphery institution. In the intensity model that we study, smaller mean-reverting parameter means smaller intensity to default process. In this example, we only investigate the rank one approximation. After all, as we showed in Subsection 5.3, this approximation is sufficient to accurately capture the dynamical quantities we are interested in.
Let us denote by to be the -th moment by time t with , and being the choice index for , and respectively. For example, corresponds to the choice , and . The empirical joint distribution of , and is summarized as follows.
Because of the special structure of our system we end up with 6 different equations as indicated by Table 7:
[TABLE]
together with and where we define
[TABLE]
In particular, depends only on via and . The overall loss rate in the one-level of interaction approximation is
[TABLE]
The loss rate for type where , and in the one-level of interaction approximation are actually falling into 6 distinct categories indexed by , the choice of .
[TABLE]
The mean impact on name , from system wide defaults up to time t, associated to type as described in Table 7, turns out to be characterized by the first index
[TABLE]
for any and with
[TABLE]
As with the previous examples, we truncate at the level , and choose the time endpoint to be . We do the numerical iteration with time step being 0.01. We run 50,000 Monte Carlo trials and plot overall limiting loss rate and the limiting loss rate for different types , in Figure 14. We also plot the mean of the loss rate over time for the whole pool and for individual types in Figure 15. We observe due to the smaller mean-reverting value, the names from the core component of the network are less likely to default than those in the periphery part of the network. This essentially confirms and quantifies what we expect to happen in this case. At this point it is indicative to compare Figure 14 with Figure 9, as well as Figure 15 with Figure 10.
In Figure 16, we plot the mean impact on a name from system wide defaults up to time . As we discussed before, there are totally 6 different categories indexed by the choice of .
6. Tightness and Characterization of the limit
Let us now discuss relative compactness of the family and characterize its limit as .
Lemma 6.1**.**
The family is relatively compact as a valued random variable.
Proof.
Due to Lemma 4.2 proven in Appendix A, the proof of the lemma is as in Section 6 of [20]. Hence, the details are omitted. ∎
Next, we want to use the martingale problem to identify the limit of ’s as grows. Let be the collection of elements in of the form
[TABLE]
for some , some , and some in . Then separates the probability measure space . Then it is enough to consider the martingale convergence problem on .
Let’s fix and understand what happens to when one of the firms defaults. Suppose that the -th firm defaults at time and that none of the other names defaults at time (defaults occur simultaneously with probability zero). We have that
[TABLE]
where we used the fact that the jump size in at time t when there is a default in the th firm is . In addition, noting that (since -th firm defaults at time t means ), gives
[TABLE]
Therefore, we have that
[TABLE]
where
[TABLE]
For define the operator
[TABLE]
In addition, define the operators
[TABLE]
and
[TABLE]
Then, Theorem 6.2 characterizes the possible limit points.
Theorem 6.2**.**
We have that
[TABLE]
for any and and .
Proof.
First, we notice that,
[TABLE]
is a martingale. This means that we can write
[TABLE]
By Itô’s formula we obtain
[TABLE]
Again, by Itô’s formula for we subsequently obtain that
[TABLE]
[TABLE]
where, for , represents the term in the right hand side of the last display. Notice that,
[TABLE]
and
[TABLE]
where the is defined as
[TABLE]
and is defined as
[TABLE]
Notice that we have
[TABLE]
where and .
Recalling that
[TABLE]
where , we get that
[TABLE]
Therefore we obtain that
[TABLE]
Now we prove that as . Denote the operator
[TABLE]
Denote the jump term in the expression as . Now we look at the limit of this term as .
Hence there exists a constant which depends on the uppper bound of the coefficients such that
[TABLE]
Hence, we get that
[TABLE]
Let us next show that . The term above can be written as,
[TABLE]
This term goes to zero as goes to infinity. Indeed, for the given and and there exists a constant depending on and and the upper bound of the coefficients such that,
[TABLE]
Lastly, we treat the terms and . Notice that the second to the last term is a Brownian martingale and the term is also a martingale. Denote their sum as a martingale . Calculations similar to the ones done above yield that
[TABLE]
and the proof of the theorem is complete.
∎
7. Identification of the unique limit point
The uniqueness of the solution to the limiting martingale problem implied by Theorem 6.2 is analogous to the duality argument of Lemma 7.1 of [20] and the proof will not be repeated here.
Let us now identify this unique solution in the following two lemmas. Lemma 7.1 will give us the existence of a unique solution to a certain stochastic differential equation which will then be used in identifying the unique limiting solution in Lemma 7.2.
Lemma 7.1**.**
Let be a reference Brownian motion and . For each , with , each there is a unique pair of
[TABLE]
[TABLE]
Lemma 7.1 is proven in the Appendix.
Lemma 7.2**.**
Let , with , be the unique pair from Lemma 7.1 with the filtration generated by the limiting . For any and , is given by
[TABLE]
Proof.
For any , define a adapted random element of by the action
[TABLE]
By Itô’s formula, we obtain, using Lemmas B.1 and B.2 in [21], that
[TABLE]
where . Define now
[TABLE]
Then, we have that
[TABLE]
On the other hand by Lemma 7.1, we have , concluding the proof of the lemma due to uniqueness. ∎
8. Conclusions and further research work
We consider a general point process model of correlated default timing in a pool of components (e.g. firms or names) interacting via a weighted directed graph which determines the impact of default among the different components. The model is empirically motivated and incorporates contagion effects, common systematic risk factors as well as idiosyncratic effects.
We prove a law of large numbers for the empirical survival distribution. This is then used to study the behavior of dynamic quantities of interest, such as mean loss rate in the pool or mean impact on given names from system wide defaults. The presence of the network structure enlarges the set of interesting questions that we can ask and at the same time allows via singular value decomposition arguments to reduce the computational burden via low rank approximations.
One of the interesting questions that we did not address here is that of the effect of choices such as bistability in the idiosyncratic component of the intensity-to-default process. Questions motivated by such choices, as well as others including the study of most likely paths to default, are more suitable for large deviations analysis in the spirit of [32], which will be done in a follow up work. In the present work we focus on establishing mathematical well-posedness of such models and on numerically exploring the effects of the network structure and low rank approximations on the typical behavior of quantities of interest.
Another potential interesting question is what happens when one wants to allow the rank of the low-rank approximation to to increase with , say . In such a case, we expect that the term in equation (6) should be scaled by and thus be replaced by . We do not study this question in this paper, but we believe that the techniques developed in this paper will be useful in order to address this question.
Appendix A Appendix
In this appendix we prove lemmas used throughout the paper. We remark here that most of the technical difficulties arising from dropping the affine structure in the idiosyncratic part of the intensity process are encountered in the proofs of the results in this Appendix.
Let be a vector of processes having components, predictable, bounded, right continuous, monotone with . Define the process
[TABLE]
Lemma A.1**.**
Let be such that Assumptions 3.8 and 3.9 hold. Then we have that
[TABLE]
In particular, we have that there is a finite constant such that .
Proof of Lemma A.1.
Notice that can be written as
[TABLE]
Next given that , we obtain
[TABLE]
By Cauchy-Schwartz inequality and Hölder inequality, we have
[TABLE]
By Holder inequality,
[TABLE]
So, we have that
[TABLE]
Similarly, we get
[TABLE]
Therefore, we have
[TABLE]
concluding the proof of the lemma. ∎
Proof of Lemma 4.1.
The proof of this lemma will be given in several steps. Let us first discuss existence and uniqueness of the equation for assuming that is uniformly bounded.
The existence and uniqueness of the solution follows along similar lines as in chapter V.11 in [34]. However, due to the peculiarities of the model considered here, the derivation of the bounds for the necessary norms are more complicated. Below we mention the adjustments needed for the proof of uniqueness as the adjustments needed for the proof of existence are basically the same.
For any , let us set
[TABLE]
Let satisfy the equation
[TABLE]
where is the random time defined via
[TABLE]
It is clear that up to time , the process will be the same as the process , which has in place of as its corresponding drift coefficient.
Now, we assume that the equation for has one more solution, potentially different than , denoted by , and we denote by the corresponding random time.
Let us consider and define the function
[TABLE]
Notice that is an even function. In addition, its first and second derivatives satisfy
[TABLE]
for all . Monotonicity arguments then show that for all and , , and
[TABLE]
Additionally, we note that
[TABLE]
and that for all .
We have
[TABLE]
where is a martingale, and
[TABLE]
where is the Lipschitz constant for the truncated function . Also,
[TABLE]
for some constant , where (16) was used. Here is the Lipschitz coefficient of the locally Lipschitz function for . Similarly, using (16) and Assumption 3.8 we can show
[TABLE]
Therefore, we get that
[TABLE]
By Gronwall’s lemma, we obtain that
[TABLE]
Let , we have for any .
[TABLE]
That is for any and . Then let and together with the observation that increase to infinity almost surely, which follows by Lemma A.2, we obtain uniqueness of the solution to the following SDE
[TABLE]
Let us set now . Then, satisfies
[TABLE]
It is easy to see now that is the unique solution defined in the lemma 4.1. Next we show that . First, we notice that .
By Itô’s formula for the function
[TABLE]
where is a martingale. Notice that for at least one of and have to be zero, then taking expectation for both sides:
[TABLE]
Notice that can only take the nonzero value when . Also notice takes non-positive values when and is 0 when . Thus, if we let the right hand side of the above equation is no greater than zero. On the left hand side, recall that as , goes to . Therefore, letting , we have
[TABLE]
Hence, we get that
[TABLE]
i.e., is nonnegative and as a consequence is also nonnenative. This concludes the proof of the lemma. ∎
Proof of Lemma 4.2.
For each and define
[TABLE]
[TABLE]
[TABLE]
Then . So, we have
[TABLE]
Hence, due to Assumption 3.9, it is enough to show that for some appropriate finite constant .
Apply Itô’s formula to . We claim that without loss of generality the martingale terms that appear in the Itô formula can be considered to be true martingales and thus have zero expectation. With this in mind, is a martingale and we write .
Then, we can write down
[TABLE]
By Assumption 3.6, we have that there is some such that for . Without loss of generality, we can assume that the dissipativity condition holds everywhere (if not we just consider separately the cases and ). Then, we have the estimate
[TABLE]
For the second term, we have
[TABLE]
The third term is similar with the second term with the help of Assumption 3.8 on the bound for .
[TABLE]
For the fourth term we apply subsequently Young’s inequality, use Assumption 3.9 and we get
[TABLE]
for appropriate constants .
Notice now that
[TABLE]
Next step is to bound (A) using (A), (A), (A), (22). First we average equations (A), (A), (A), (22) over and together with Assumption 3.1, Assumption 3.8, Assumption 3.9, Lemma A.1, we have that there is a constant such that
[TABLE]
By Gronwall lemma, we obtain that
[TABLE]
In addition, notice that using (24) now, (A) together with (A), (A), (A), (22), also gives that for any
[TABLE]
for an appropriate constant with the upper bounds being independent of .
Together with Assumption 3.9 and Lemma A.1 we can finally get from (24) the bound advertised in the lemma.
It remains to address the claim on the martingale property of the stochastic integrals. Indeed, using the same truncation argument as in the proof of Lemma 4.1 we get that for each fixed the terms in question are true martingales. Then, because the corresponding upper bound in (24) turns out to be uniform with respect to and due to Lemma A.2 the claim is proven, concluding the proof of the lemma. ∎
Proof of Lemma 7.1.
As in the proof of Lemma 4.1, if we can prove that the result holds for the truncated processes which has in place of , then, due to Lemma A.2, the result will be true for the limit as as well. Therefore, we can restrict attention to the case where is replaced by for an arbitrary constant .
In addition, let be the set of valued, adapted, continuous processes such that
[TABLE]
The space endowed with the norm is a Banach space.
Consider a nonnegative process and set
[TABLE]
For given , we consider , . Define the map by letting denoting the unique solution to the SDE
[TABLE]
Similarly, we define for the solution of the equation with in place of . Then, the process satisfies
[TABLE]
Apply Itô’s formula to where is defined in Equation (15), and get
[TABLE]
Taking expectation of we get
[TABLE]
As in Lemma A.2. in [21], the latter expression yields
[TABLE]
Therefore, we have
[TABLE]
At the same time, we have
[TABLE]
For the third term we obtain
[TABLE]
Now, let us assume is bounded. Then we have
[TABLE]
For the last term
[TABLE]
For any , we have that the both terms and go to zero as or .
Thus, for any , we have
[TABLE]
Then applying and using Gronwall’s Lemma we have
[TABLE]
Send and notice that we can pick small enough such that . Hence, we obtain
[TABLE]
where .
Hence, we have obtained that the map defined by with is a contraction on equipped with the norm. Standard Picard iteration shows that there is a fixed point such that for with . This fixed point is unique, since
[TABLE]
So, we have that
[TABLE]
Thus, we have proven uniqueness of on . Then, starting from we obtain uniqueness on in the same way and we conclude by filling in the whole interval .
Next, letting , and using Lemma A.2 which implies that converge to infinity almost surely, we have the proof of the lemma for bounded .
For the case of general , Assumption 3.10 guarantees that
[TABLE]
is a martingale by Novikov’s condition. Assumption 3.10 also assumes . Then the result follows from the proof of Lemma A.6. in [21]. ∎
Lemma A.2**.**
For any and for defined via (14), we have that
[TABLE]
Proof of Lemma A.2.
For any ,
[TABLE]
Due to Assumption 3.9 and Lemma A.1, it is enough to prove that
[TABLE]
where is independent of . Now can be estimated similarly as before. Indeed, applying Itô’s formula to , we get
[TABLE]
The first line in the right hand side of the expression above is bounded due to Assumption 3.6 (similarly to (A) we can assume without loss of generality that the dissipativity condition holds everywhere) and we have
[TABLE]
Therefore, if we square both sides in the Itô’s formula expression, we will get
[TABLE]
Taking expectation of the supremum of the second term and using Hölder inequality, together with the fact that and Assumption 3.9 we have
[TABLE]
for some constant . Similar calculations together with Assumption 3.8, gives a similar bound for the third term as well. Using Burkholder-Davis-Gundy inequality for the fourth term, together with Young’s inequality, the fact that and Assumption 3.9 we get
[TABLE]
where , and are some positive constants. The stochastic integral term with respect to the Brownian motion is treated analogously using Assumption 3.8. For the last term, we use Young’s inequality and Assumptions 3.1 and 3.8. We obtain
[TABLE]
for any and correspondent constant . Therefore we can choose small enough so and we can move this term to the left hand side.
Thus, combining all the terms together with Assumption 3.1 leads to the estimate
[TABLE]
Then by Gronwall lemma, the term is bounded by a constant which is independent of and we conclude by Fatou’s lemma followed Jensen’s inequality. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Franklin Allen, and Douglas Gale. Financial Contagion. Journal Political Economy 108, (2000), pp. 1-33.
- 2[2] Shahriar Azizpour, Kay Giesecke, and Gustavo Schwenkler. Exploring the sources of default clustering. Journal of Financial Economics , 129(1), (2018), pp. 154-183.
- 3[3] Yacine Ait-Sahalia, Cacho-Diaz, Julio, and Roger Laeven. Modeling financial contagion using mutually exciting jump processes. Journal of Financial Economics , Vol. 117, Issue 3, (2015), pp. 585-606.
- 4[4] Brunnermeier, Markus K, Gary Gorton, and Arvind Krishnamurthy. Risk Topography. NBER Macroeconomics Annual , Vol. 26, (2012), pp. 149-176.
- 5[5] Lijun Bo and Agostino Capponi. Bilateral credit valuation adjustment for large credit derivatives portfolios. Finance and Stochastics , Vol. 18, Issue 2, (2014), pp. 431-482.
- 6[6] Lijun Bo and Agostino Capponi. Systemic Risk in Interbanking Networks. SIAM Journal of Finanical Mathematics , 6, (2015), pp. 386-424.
- 7[7] Nick Bush, Ben Hambly, Helen Haworth, Lei Jin, and Christoph Reisinger. Stochastic evolution equations in portfolio credit modelling. SIAM Journal on Financial Mathematics , 2, (2011), pp. 627-664.
- 8[8] Agostino Capponi, Xu Sun, and David Yao. A Dynamic Network Model of Interbank Lending: Systemic Risk and Liquidity Provisioning. Mathematics of Operations Research , (2019), forthcoming.