Generative One-Shot Learning (GOL): A Semi-Parametric Approach to One-Shot Learning in Autonomous Vision
Sorin Grigorescu

TL;DR
This paper introduces GOL, a semi-parametric generative framework that creates synthetic training data from one-shot objects to reduce manual annotation in autonomous driving perception systems.
Contribution
It presents a novel generative approach for one-shot learning that bypasses manual annotation, specifically tailored for autonomous vision applications.
Findings
GOL effectively generates synthetic data from one-shot objects.
The approach improves perception system training with minimal data.
GOL performs well on autonomous driving perception challenges.
Abstract
Highly Autonomous Driving (HAD) systems rely on deep neural networks for the visual perception of the driving environment. Such networks are trained on large manually annotated databases. In this work, a semi-parametric approach to one-shot learning is proposed, with the aim of bypassing the manual annotation step required for training perceptions systems used in autonomous driving. The proposed generative framework, coined Generative One-Shot Learning (GOL), takes as input single one-shot objects, or generic patterns, and a small set of so-called regularization samples used to drive the generative process. New synthetic data is generated as Pareto optimal solutions from one-shot objects using a set of generalization functions built into a generalization generator. GOL has been evaluated on environment perception challenges encountered in autonomous vision.
Click any figure to enlarge with its caption.
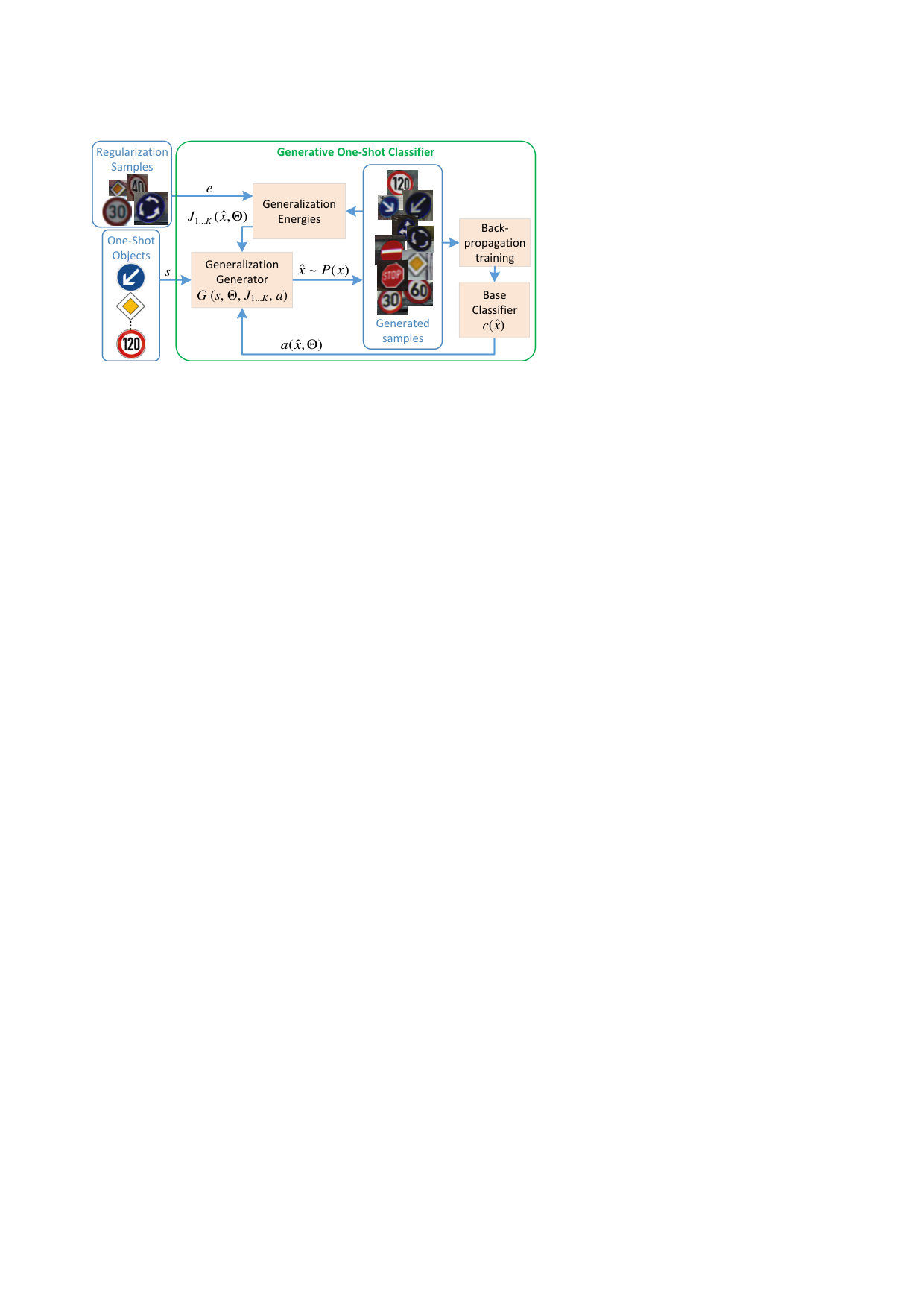 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4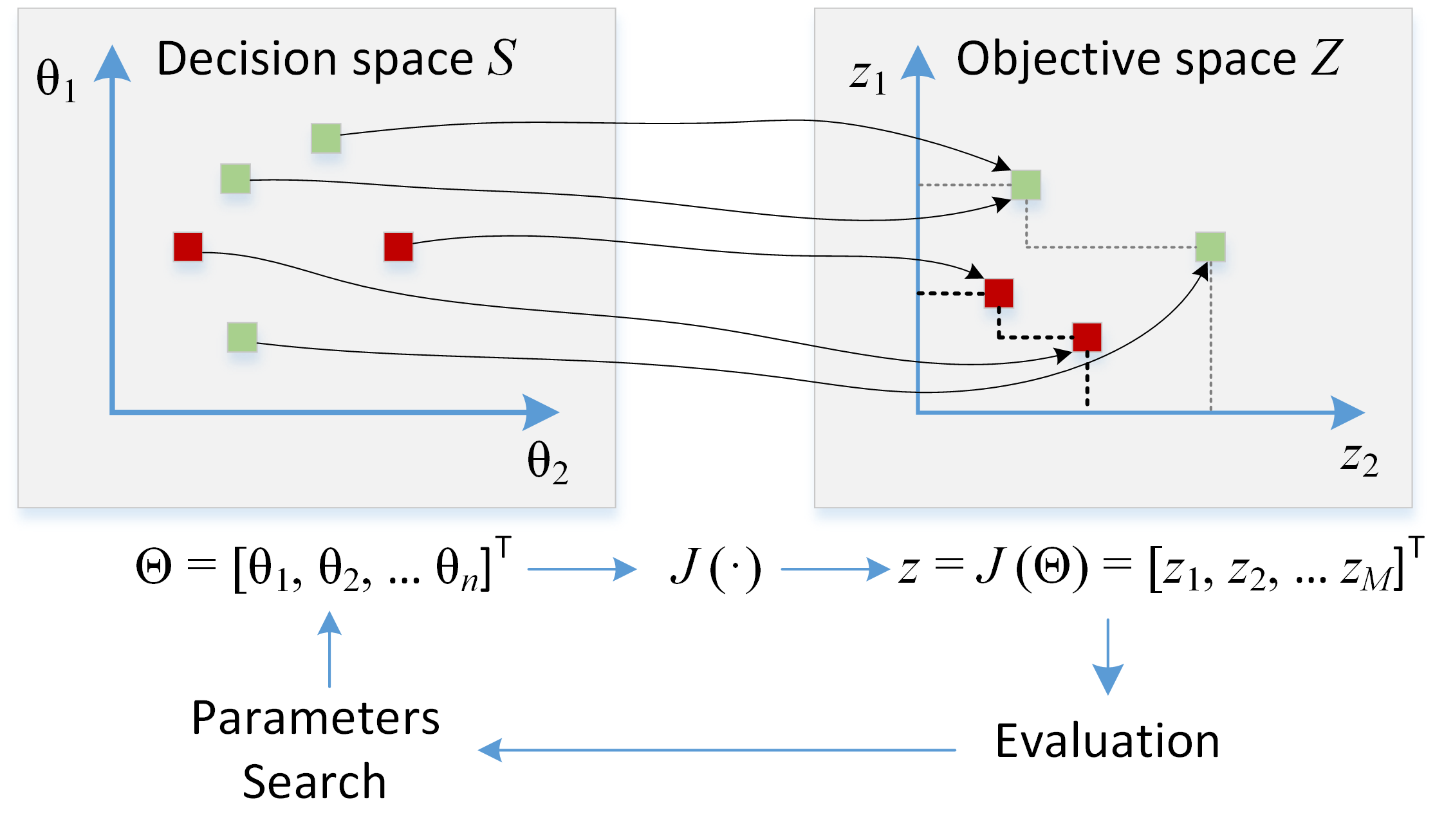 Figure 5
Figure 5 Figure 6
Figure 6| Speed limits | Other prohibitions | Derestriction | Mandatory | Danger | Unique | |
| Human (best individual) [25] | 98.32 | 99.87 | 98.89 | 100.00 | 99.21 | 100.00 |
| Human (average) [25] | 97.63 | 99.93 | 98.89 | 99.72 | 98.67 | 100.00 |
| Committee of CNNs [26] | 99.47 | 99.93 | 99.72 | 99.89 | 99.07 | 99.22 |
| Multi-Scale CNN [27] | 98.61 | 99.87 | 94.44 | 97.18 | 98.03 | 98.63 |
| Random Forests [28] | 95.95 | 99.13 | 87.50 | 99.27 | 92.08 | 98.73 |
| LDA (baseline) [29] | 95.37 | 96.80 | 85.83 | 97.18 | 93.73 | 98.63 |
| GOL [LeNet] | 98.79 | 99.47 | 96.61 | 97.43 | 98.48 | 99.16 |
| GOL [AlexNet] | 99.49 | 99.93 | 99.74 | 99.89 | 99.53 | 99.28 |
| GOL [GoogleNet] | 99.51 | 99.95 | 99.74 | 99.90 | 99.86 | 99.45 |
| Speed limits | Other prohibitions | Derestriction | Mandatory | Danger | Unique | |
|---|---|---|---|---|---|---|
| GOL [LeNet] | 82.27 | 85.21 | 83.37 | 81.64 | 83.11 | 79.80 |
| GOL [AlexNet] | 91.16 | 90.95 | 84.38 | 89.72 | 88.22 | 87.18 |
| GOL [GoogleNet] | 92.52 | 93.20 | 87.96 | 90.38 | 90.04 | 88.31 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Generative One-Shot Learning (GOL): A Semi-Parametric Approach to One-Shot Learning in Autonomous Vision
Sorin M. Grigorescu Sorin M. Grigorescu is with Elektrobit Automotive and the Faculty of Electrical Engineering and Computer Science, Transilvania University of Brasov, Romania. [email protected]
Abstract
Highly Autonomous Driving (HAD) systems rely on deep neural networks for the visual perception of the driving environment. Such networks are trained on large manually annotated databases. In this work, a semi-parametric approach to one-shot learning is proposed, with the aim of bypassing the manual annotation step required for training perceptions systems used in autonomous driving. The proposed generative framework, coined Generative One-Shot Learning (GOL), takes as input single one-shot objects, or generic patterns, and a small set of so-called regularization samples used to drive the generative process. New synthetic data is generated as Pareto optimal solutions from one-shot objects using a set of generalization functions built into a generalization generator. GOL has been evaluated on environment perception challenges encountered in autonomous vision.
I Introduction
As with many artificial intelligence systems nowadays, autonomous driving makes use primarily of supervised deep learning techniques, where object detection algorithms are trained on large manually annotated databases. The traditional processing pipeline for such methods is mainly based on two stages, where the first stage detects a potential interest region (e.g. a rectangle bounding an object of interest in an image), while the second stage classifies that region according to a set of learned object classes.
The deep learning revolution brought major improvements in the autonomous driving technology, where the environment surrounding a car can now be understood through vision and information fusion systems, as presented in the computer vision for autonomous vehicles survey from [1]. Although great progress has been made in this area, fully autonomous driving in complex and arbitrarily environments is still an open challenge. In order for autonomous driving cars to be deployed on a mass scale, their artificial intelligence systems have to possess the capability to generalize and understand in real-time unpredictable scenes and situations. As stated in [1], the current perception systems used for autonomous driving are producing error rates which are not acceptable for their commercial and large scale deployment, exhibiting less robustness than a human driver.
In this paper, a generative semi-parametric algorithm for one-shot learning, entitled Generative One-Shot Learning (GOL) is proposed. Its purpose is to replace supervised trained classifiers which rely on the manual collection and annotation of training data. In particular, GOL is intended to act as an AI system for environment perception in autonomous driving, which can organically adapt to new complex situations and learn from the scarce available information describing these new driving scenes. The training of GOL is performed based on conflicting objectives which imply the usage of so-called Pareto optimal solutions, which model the fact that, for a given problem, there exists a (possible infinite) number of Pareto optimal solutions. The multi-objective optimization is also called Pareto optimization. We introduce the Pareto optimal classifier concept for an estimator obtained from Pareto optimal solutions.
The main contributions of this paper are summarized as follows:
- •
the GOL generative one-shot learning framework depicted in Fig. 1, which uses a set of generalization functions to map a single training example to a base classifier;
- •
a Pareto optimization procedure for training the GOL framework through the maximization of a multi-objective function composed of generalization energies and a classification accuracy measure;
- •
the Visual GOL algorithm for environment perception in autonomous vision.
The rest of the paper is organized as follows. The GOL algorithm will be detailed in the next section, while the state of the art and the relation of GOL to other approaches will be given in the related work Section III. The performance of GOL in autonomous vision tasks is presented in Section IV. Finally, conclusions are stated in Section V.
II Generative One-Shot Learning
II-A GOL Model
The GOL approach to one-shot learning, illustrated in Fig. 1, is based on three components:
- •
a Generalization Generator composed of a set of generalization functions used to generate synthetic sets of training samples from a single one-shot object instance;
- •
a Generalization Energy measure which calculates the generalization error between synthetic generated samples and a small set of regularization samples;
- •
a Base Classifier, implemented as a deep neural network trained on Pareto optimal synthetic samples.
The proposed model architecture aims at obtaining a stable base classifier trained on a set of synthetic samples generated from one-shot instances of objects of interest. The generative nature of the model tries to capture the Probability Density Function (PDF) as close as possible to the real data PDF , from which real samples are drawn. Each one-shot object is stored in the one-shot objects set :
[TABLE]
where is a one-shot instance of an object with label , meaning that the size of corresponds to the number of object classes which the base classifier will learn. Each synthetic sample from will have a corresponding label :
[TABLE]
where . Typically, the number of generated synthetic samples has a very large value, depending on the number of classes we want to classify, as well as on the size of the feature vector describing an object.
The goal of the generalization generator is to generate a set which describes as close as possible the real probability density from which real-objects are drawn: . The synthetic descriptions are obtained by applying a series of generalization functions from the generalization generator :
[TABLE]
where is a family of functions which, applied iteratively on a one-shot instance , will generate a set of synthetic descriptions . holds the parameters of function . For the sake of clarity, although might have variable size, depending on the number of parameters a function takes, we will consider to be a scalar. The parameters of all functions from the generalization generator, where , are stored in the parameters vector :
[TABLE]
As it is shown in the next subsection, the Pareto optimization procedure of GOL learns a collection of optimal generalization functions parameters:
[TABLE]
where is the number of Pareto optimal solutions obtained via GOL training. Each will generate an optimal synthetic samples set describing a one-shot object.
In order to improve the convergence of the algorithm, the concept of regularization samples, or experiences is introduced. In comparison to the number of generated samples, the number of regularization samples is much smaller: . The goal of the regularization samples is to ensure that is as close as possible to the real data distribution . The base classifier cannot be trained solely on regularization samples due to their small number, which would, in turn, create a very large generalization error in . The probability of class for example is computed using standard softmax function.
At its core, GOL models a mapping between one-shot objects and a base classifier, , based on calculated synthetic samples . The probabilistic model of GOL can be described as a PDF which generates from the Generalization Generator , given a set of one-shot objects and a small set of regularization samples:
[TABLE]
The semi-parametric nature of GOL lies in the way in which the model in Eq. 6 is learned. The algorithm determines its parameters as a set of Pareto optimal solutions by iteratively generating synthetic samples, thus driving the classification accuracy and the values of the generalization energies. As described in the next section, a generalization energy is a distance metric specifying how well GOL generalizes classification through its base classifier.
II-B Training Strategy
GOL is intended to generalize on unseen data, while increasing the classification accuracy on synthetic data as well as possible. The training of GOL implies the learning of a set of optimal parameters which maximize the generalization energies and classification accuracy. A Pareto optimization procedure is proposed for training the GOL system. The multi-objective nature of the training is due to the multitude of functional values that have to be optimized and also because there exists not only one instance of optimal GOL parameters, but a number of Pareto optimal solutions defined as in Eq. 5. Due to the very scarce information on the real data’s PDF, a single objective training approach would create a base classifier which would overfit. In order to distinguish between the overall multi-objective training of GOL and the training of the base classifier on generated synthetic samples, we will refer to a Pareto optimization iteration as a training episode, while each learning iteration of the base classifier will be referred to as a training epoch. One GOL training episode contains several hundred training epochs.
II-B1 Introduction to Pareto Optimization
GOL training aims to simultaneously maximize the generalization energies and classification accuracy in a Pareto optimization manner. The optimization procedure does not search for a fixed size, or even finite, set of model parameters, but for a Pareto optimal solutions set.
In the following, from Eq. 4 will be called a solution vector, composed of decision variables , with and .
In scalarized multi-objective learning, the different measures are aggregated into a single scalar cost function , which is to be either minimized or maximized:
[TABLE]
where is a function which aggregates all cost functions based on the scalarization values given by vector , such that :
[TABLE]
The main issue with scalarized optimization is the a-priori knowledge required in setting up the weighting vector . This means that the importance of each cost function in Eq. 8 has to be manually defined in advance, thus possibly driving the optimization to local minimas or maximas.
Generalizing from Eq. 7, the multi-objective optimization problem takes into account a number of functional values which have to be either minimized or maximized, subject to a number of possible constraints that any feasible solution must satisfy [2]:
[TABLE]
where is the -th objective function, with , and is the number of objectives. and are constraints set on the optimization process. and are lower, respectively upper, variable constraint bounds set on each decision variable.
The solutions satisfying and and the variable bounds form the so-called feasible decision variable space , or simply decision space. A core difference between single and multi-objective optimization is that, in the latter case, the objective functions make up a -dimensional space entitled objective space . A visual illustration of a 2D decision and objective space is visible in Fig. 2. For each solution in the decision variable space, there exists a coordinate in the objective space:
[TABLE]
A solution is a variable vector in decision space, with a coordinate as a corresponding objective vector. In Pareto optimization there exists a set of optimal solutions , none of them usually minimizing, or maximizing, all objective functions simultaneously. Optimal solutions are called Pareto optimal, meaning that they cannot be improved in any of the objectives without degrading at least one objective. A feasible solution is said to Pareto dominate another solution if:
for all and 2. 2.
for at least one index .
A solution is called Pareto optimal if there is no other solution that dominates it. The set of Pareto optimal solutions is entitled Pareto boundary, or Pareto front. As shown in Fig. 2, the search for optimal solutions is performed in decision space, while their evaluation takes place in objective space. State of the art methods for calculating Pareto boundaries are based on evolutionary computing, which is out of the scope of this paper. Further details on Pareto optimization using evolutionary methods can be found in [2], while a few case studies in the field of machine learning are available in [3].
II-B2 GOL Training via Pareto Optimization
Within GOL, the optimization objective is to find the set of Pareto optimal solutions which can be used to generate synthetic data from one-shot objects. The training is made in variable episodes, making it possible to constantly improve the generalization capabilities of the functions, once new regularization samples are available. For the sake of simplicity, we will write a vector of generalization energies as .
Following the Pareto optimization framework from Eq. 9, the GOL Pareto optimization problem can be formulated as:
[TABLE]
where to and are the generalization energies and classification accuracy cost functions, respectively. is the number of input one-shot objects and . The proposed GOL training procedure is not driven by the inequality and equality constraints from Eq. 9, but bounded by the lower and upper variable constraint bounds and .
The generalization energies are a vector of real-valued functions defined as log-likelihood similarity metrics between the regularization samples and the synthetic data , for each object class :
[TABLE]
where is a training episode. Eq. 12 expresses the probability of the synthetic data to be drawn from the regularization samples. varies depending on the model and can be described as the following error cost:
[TABLE]
where is a norm function, represents the -norm (also called -norm) and is a random variable chosen based on the variance of the Gaussian distribution implied by the GOL model in Eq. 6.
is the classification accuracy, which has a probability value of if all synthetic samples have been classified correctly and [math] if none is correctly classified:
[TABLE]
where returns the predicted class of the classifier, is the softmax function and represents the number of synthetic samples. is an indicator function which returns if the expression evaluated within the brackets is true and [math] otherwise.
With each training episode, the variance of the GOL’s parameters is increased by an additive factor , where the number of elements in is equal to the number of generalization parameters. At the end of an episode, pairs of solutions - objective functional values are stored in a container variable:
[TABLE]
The Pareto optimal solutions , are determined from the set, based on the evolutionary computation approach described in [2]. We call the final estimator a Pareto optimal classifier, obtained by regenerating synthetic data for all Pareto optimal parameters:
[TABLE]
III Related Work
Similar approaches to GOL can be classified into zero-shot learning, focused on learning based on attribute-level descriptions of object classes, one-shot learning, aiming to train classifiers based on a The challenge of one-shot learning has been treated broadly in the work of Fei-Fei [4, 5] for the case of visual object recognition. Their approach is based on a Bayesian framework, named ”Bayesian One-Shot”, which learns new object categories based on knowledge, or priors, acquired from previously learned categories. In comparison to Bayesian One-Shot, GOL does not rely on large training databases priors for learning object classes. Also, the ”Bayesian One-Shot” framework was built for the explicit purpose of visual recognition, as opposed to GOL, which is a general one-shot learning framework that can be adapted to completely new problems solely by changing the structure of the Generalization Generator’s functions .
Hand-crafted attribute descriptions of novel categories have been used in [6, 7, 8] for training classifiers for image recognition. Methods based on metric learning for automatic feature representation of object classes have been reported in [9, 10, 11]. Apart from the strictly image domain application of these algorithms, one of the main constraints of these methods is that the features of the objects of the same class should be clustered together.
OpenAI published an interesting robotics application of one-shot learning, described in [12]. Their algorithm, named one-shot imitation learning, uses a meta-learning framework for training robotic systems in performing certain tasks based only on a couple of demonstrations. Also, the large amount of data required by Deep Reinforcement Learning systems has been approached in [13] through the introduction of their deep meta-reinforcement learning algorithm.
Siamese Neural Networks have been investigated for the purpose of one-shot character recognition in images in the work of Koch et. al. [14]. Such networks have a structure which allows them to naturally rank similarity between inputs. Deep reinforcement learning is used in [15] for active one-shot learning, where a recurrent neural network has been trained to estimate an action-value function which indicates what examples from a stream of images are worth labeling. A low-shot visual object recognition method was proposed by Facebook AI Research in [16], where the focus is on datasets with object categories that have high intra-class variation. In comparison to the GOL approach, the siamese networks [14], as well as the low-shot algorithm from [16], rely on extensively pre-trained models which must discriminate between class-identity of image pairs. The basic assumptions encountered in both papers is that a deep neural network which performs well when tested against images belonging to the learned categories, should generalize well to one-shot learning classification when an image belonging to a new category is presented. This statement is not entirely true, since there exist very similar objects in appearance, but actually belonging to different classes. As it will also be shown in the next subsection, the necessity of a pre-trained classifier on which the learning of new object classes leverages on is the core difference between GOL and deep one-shot learning. Also, in both methods, a high intra-class variance between object categories is a necessary prior, the algorithms accuracies decreasing proportional to the decrease of intra-class variance.
The output of the GOL’s training loop can be compared to a form of automatic data augmentation. In [17], two data augmentation methods are used for increasing the size of the training database. The first form of data augmentation generates images by translations and reflections, while the second form uses PCA for altering the pixels values. Within GOL, data augmentation is a side effect produced by its training loop, where the augmentation parameters are automatically determined by the optimization procedure. Common data augmentation approaches, like the ones in [17], use fixed, manually determined, parameters for generating new samples, without taking into consideration any quality measurement regarding the nature of the synthetic data.
Google’s DeepMind approached the one-shot learning problem through the usage of Memory Augmented [18] and Matching Neural Networks [19]. Such networks allow more expressive models based on the introduction of ”content” based attention and ”computer-like” architectures such as the Neural Turing Machine [20], or Memory Networks [21]. The DeepMind research group that introduced matching networks to one-shot learning, also reported the usage of memory-augmented neural networks for attacking the same problem [18]. For this task, an external-memory equipped network has been used. In comparison to GOL, matching and memory-augmented networks require not a single one-shot example for learning, but an external pre-trained neural net, on which later learning is leveraged on, thus failing to avoid the standard supervised training of their systems from large labeled training databases. As in [4], previously supervised learned classes are required as a base for one-shot learning with matching and memory-augmented networks, making the presented solutions to fall more into the area of transfer learning than one-shot learning. Also, for incorporating newly unseen information, these networks require a support set of labeled examples. Even if small, the labeled support set is required for training, as opposed to GOL, where the regularization samples are not strictly necessary, their purpose being only to drive the learning process, if such regularization samples exist.
One of the most influential work on GOL is the research on Generative Adversarial Nets (GAN) [22]. The major difference between GOL and the adversarial nets is that, within GOL, the generation of synthetic information is performed based on the generalization functions which generate new data from a one-shot object, thus making GOL a pure one-shot learning framework.
The Deep Recurrent Attentive Writer (DRAW) [23] is a variational auto-encoder composed of a pair of recurrent neural networks, one functioning as an encoder, while the other one acts as a decoder that reconstitutes images after receiving codes. More focused on the problem of one-shot learning, the work in [24] focuses on the introduction of sequential generative models which, once trained, can generate new object samples. If the objective of these methods is the generation of new synthetic samples, the GOL approach differs in the sense that GOL generates samples in order to train its classifier and not the other way around. Hence, in GOL we are obtaining a large bundle of synthetic data, where the inner class boundaries are calculated using the generalization energies and the classification accuracy. Also, as deep learning techniques, GANs [22], DRAW [23] and the sequential generative models [24] require large labeled training databases for training. In GOL, the learning starts from generated synthetic data which is very similar to the one-shot input object. As the training progresses, the new synthetic data is generalized into the neural classifier until the generalization loss and classification accuracy constraints are broken. Due to this different generative starting point in training, the convergence of GOL to an optimal classifier is much faster than in, for example, GANs.
IV Performance of Visual Object Recognition of GOL in Autonomous Vision
IV-A Generative One-Shot Learning for Visual Perception
With the advent of deep learning, the performance of visual recognition systems surpassed in some use cases even the recognition capabilities of humans [17]. Visual object recognition nowadays relies mainly on large manually labeled training databases with which deep convolutional neural networks are trained in a supervised manner. The acquisition and manual labeling of such databases is a tedious and prone to error task, especially when many object categories are involved, each category requiring thousands of manually labeled image samples. This is a common case in autonomous vision [1], as shown in the traffic signs example from Fig. 3, where speed limits have different pictograms, depending on their country of origin. In order for traffic signs recognition methods to perform well, specific training data composed of thousands, or even millions, of manually labeled training samples is required for each country. The manual acquisition of a sufficient amount of labeled traffic signs is a time consuming process, due to different positions, illuminations or weather conditions that have to be taken into consideration.
In order to overcome the supervised training challenge based on manually annotated data, the Visual GOL algorithm has been implemented in autonomous vision for the recognition of objects of interest on the road, objects such as traffic signs. Provided a set of one-shot road sign templates and a small set of regularization samples , Visual GOL is able to obtain a deep convolutional neural network which can reliably recognize road sign categories in real-world images. The adaptation of GOL to the image domain implies the definition of the Generalization Generator and the structure of the generalization energies.
The Generalization Generator of Visual GOL is composed of a set of image based generalization functions , defined as in Eq. 11. Once applied on one-shot objects, the functions will generate synthetic data. Fig. 4 shows coupled stages of these function defined in the image domain. The stages are realized as an ordered list of different image alteration methods, applied on the input one-shot object. Each of the functions is described in the following paragraphs.
The one-shot input data for the Generalization Generator in Fig. 4 is a list of images, each of them representing an object category that has to be learned by Visual GOL.
The generalization energies are defined as Bhattacharyya distances between the synthetic data and the regularization samples:
[TABLE]
where , is the number of regularization samples of object class , is the number of generated synthetic samples and is the feature vector’s length. denotes the -th sample in the dataset corresponding to the -th object of the same class . In other words, the comparison between the synthetic and the regularization samples is made only between objects of the same class. and are the mean vectors of the two sample sets, respectively.
IV-B Performance Evaluation on the German Traffic Sign Recognition Benchmark
To the best of the author’s knowledge, this paper is the first one to consider the application of one-shot learning to the traffic signs recognition challenge.
Road signs recognition is a mandatory functionality of highly autonomous driving cars. The German Traffic Sign Recognition Benchmark (GTSRB) [25] is a publicly available collection of images of German road signs, organized in classes. Since 2011 it has been a benchmark for testing traffic sign recognition systems, considering also as baseline the performance of human subjects at recognizing signs.
The dataset has been created from 10 hours of video recorded while driving on different road types. The images are stored in raw Bayer-pattern format and have a resolution of pixels. In each image, the size of the traffic sign varies from to pixels. The signs are annotated using a Region of Interest (ROI) which has a % margin of approximately pixels. The resulted image collection has been divided into a full training set and a test set. The full training set is ordered by class and has been further splitted into training and validation sets. On top of the collected raw color images, the database also provides features computed from raw data, such as Histogram of Oriented Gradients, HAAR-like features and color histograms.
The supervised learning algorithms used for comparison are two types of Convolutional Neural Networks (CNN), a Random Forest and a Linear Discriminant Analysis (LDA) learning algorithm, the latter two being trained on Histogram of Oriented Gradients features. LDA [29] is considered as a baseline classifier, assuming that the class densities are multi-variate Gaussians with a common covariance matrix. The Random Forest classifier [28] is composed of trees, trained also on Histogram of Oriented Gradients features. The neural network based classifiers are a committee of CNNs forming a multi-column deep neural network [26] and a multi-scale CNN [27].
Visual GOL has been trained on 43 road type object classes belonging to road sign categories, as described in [25]. The 43 classes are composed of the following signs: speed limits ranging from kmh to kmh, prohibitory signs, derestriction signs, mandatory signs, danger signs and uniques signs. Similar to the approach used when testing on Omniglot, during the training of GOL each traffic sign was used as a one-shot object, while the other signs of the same class were taken as regularization samples. A bundle of synthetic samples are generated while training. As in the pedagogical example from Section II-B, a generalization energy is calculated for each road sign class.
Apart from the synthetic data obtained based on each image in GTSRB, an additional artificial set was generated from template images of road signs, as the ones shown in the first column of Fig. 5. The rest of the columns in Fig. 5 show synthetic images derived solely from the template road signs.
Experimental results obtained on the GTRSB database are presented in Table I. Due to the generalization effect obtained through its generative process, Visual GOL is able to surpass the other methods when the base classifier is either AlexNet or GoogleNet. This result is mainly achieved by incorporating variance in the training data through the algorithm’s generative process, as well as based on the information gathered from the template objects.
Another experimental trial covered here is one-shot object recognition of road signs when training only on template objects, such as the ones visible in the first column of Fig. 5. For this case, a number of road sign templates are used as training data, while images from GTSRB act as regularization samples for each template object of the same class. Recognition accuracy results are presented in Table II. Although the precision is decreased when compared to the values in Table I, it is important to note that a fairly high degree of accuracy is reached, even if the method has been trained solely on template objects. This highlights the potential of GOL to overcome the rigidity of traditional supervised training approaches which leverage on large training databases.
V Conclusions
A current challenge in Artificial Intelligence is the development of methods that can learn and generalize well from single training examples, a problem also known as one-shot learning. In this paper, the Generative One-Shot Learning approach has been proposed, which combines a generalization generator and a multi-objective optimization framework, that maximizes a set of generalization functions along with a classification accuracy, with the purpose of obtaining an optimal one-shot classifier. As opposed to other state-of-the-art one-shot learning methods, GOL does not require large training databases, but single object, or pattern instances. During its training, the algorithm generates various synthetic samples describing the given one-shot objects. As seen in the performance evaluation section, GOL can be successfully applied on various challenges, such as hand-written characters recognition or visual perception.
The implementation of GOL for other non-image based machine learning challenges is taken into account. One such application in the field of autonomous driving is learning the model of the human driver in order to tailor the behavior of the car to the preferences of the driver. The driver model would in this case include knowledge ranging from in-car parameters settings, such as the inner temperature, to how the driver likes to drive his/her’s car when the autonomous driving functions are off (e.g. how fast he/she is going, the driver likes to overtake other cars fast? etc.)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Janai, F. Güney, A. Behl, and A. Geiger, “Computer vision for autonomous vehicles: Problems, datasets and state-of-the-art,” Co RR , 2017.
- 2[2] K. Deb, “Multi-objective optimisation using evolutionary algorithms: An introduction.” in Multi-objective Evolutionary Optimisation for Product Design and Manufacturing , L. Wang, A. H. C. Ng, and K. Deb, Eds. Springer, 2011, pp. 3–34.
- 3[3] Y. Jin and B. Sendhoff, “Pareto-based multiobjective machine learning: An overview and case studies,” IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) , vol. 38, no. 3, pp. 397–415, May 2008.
- 4[4] L. Fei-Fei, R. Fergus, and P. Perona, “One-shot learning of object categories,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 28, no. 4, pp. 594–611, April 2006.
- 5[5] L. Fei-Fei, “Knowledge transfer in learning to recognize visual objects classes,” in International Conference on Development and Learning , 2006, pp. 1–8.
- 6[6] A. Farhadi, I. Endres, and D. Hoiem, “Attribute-centric recognition for cross-category generalization.” in CVPR . IEEE Computer Society, 2010, pp. 2352–2359.
- 7[7] C. H. Lampert, H. Nickisch, and S. Harmeling, “Attribute-based classification for zero-shot visual object categorization,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 36, no. 3, pp. 453–465, March 2014.
- 8[8] B. Romera-Paredes and P. H. S. Torr, An Embarrassingly Simple Approach to Zero-Shot Learning . Cham: Springer International Publishing, 2017, pp. 11–30.