A Preliminary Study of Neural Network-based Approximation for HPC Applications
Wenqian Dong, Anzheng Guolu, Dong Li

TL;DR
This paper explores neural network-based approximation techniques to enhance high-performance computing applications, demonstrating significant speedups in specific case studies by replacing code regions with learned models.
Contribution
It introduces a general framework for applying neural networks to HPC applications, focusing on code region approximation to improve performance.
Findings
Achieved up to 2.7x speedup in Newton-Raphson method
Achieved up to 2.46x speedup in Lennard-Jones potential simulation
Demonstrated feasibility of neural network approximation in HPC contexts
Abstract
Machine learning, as a tool to learn and model complicated (non)linear relationships between input and output data sets, has shown preliminary success in some HPC problems. Using machine learning, scientists are able to augment existing simulations by improving accuracy and significantly reducing latencies. Our ongoing research work is to create a general framework to apply neural network-based models to HPC applications. In particular, we want to use the neural network to approximate and replace code regions within the HPC application to improve performance (i.e., reducing the execution time) of the HPC application. In this paper, we present our preliminary study and results. Using two applications (the Newton-Raphson method and the Lennard-Jones (LJ) potential in LAMMP) for our case study, we achieve up to 2.7x and 2.46x speedup, respectively.
Click any figure to enlarge with its caption.
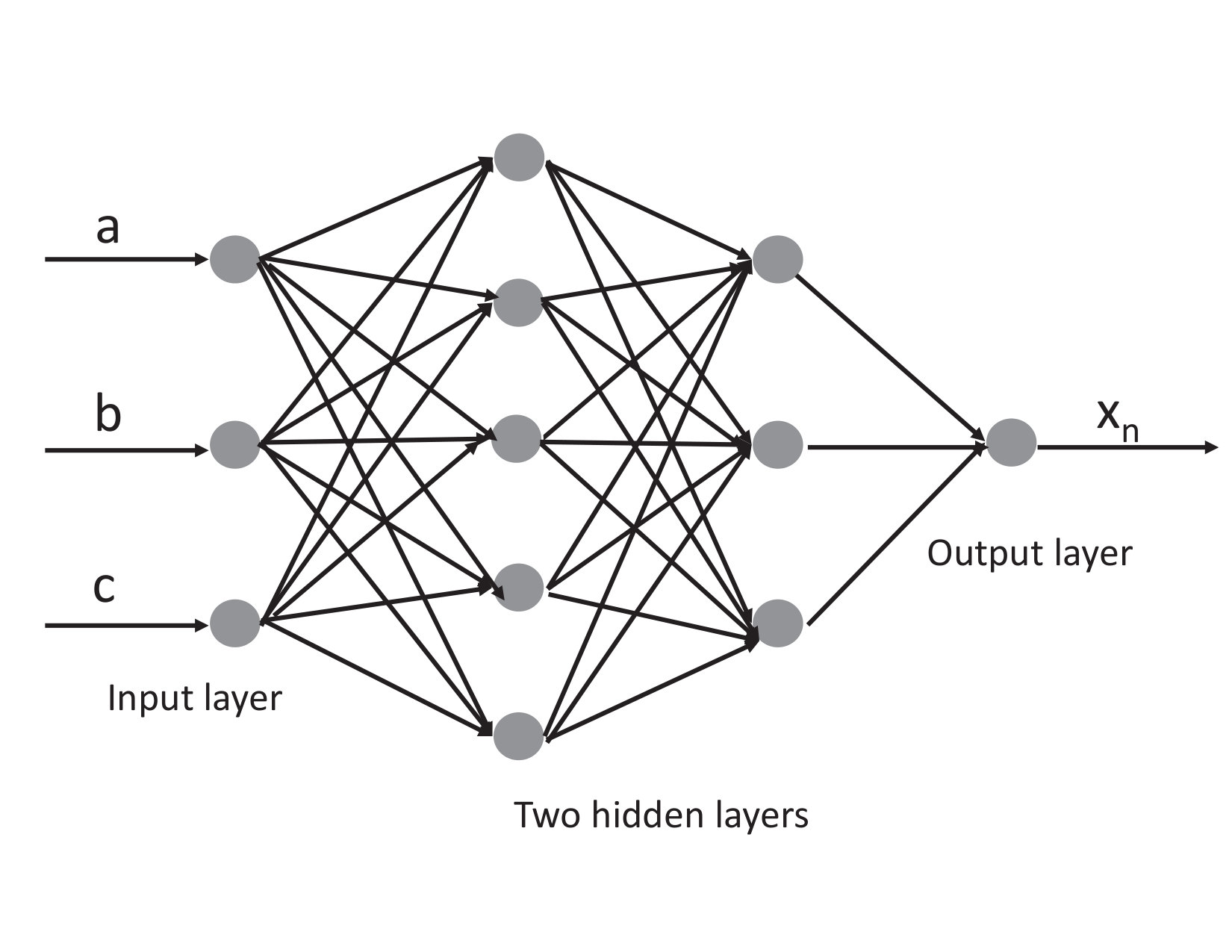 Figure 3
Figure 3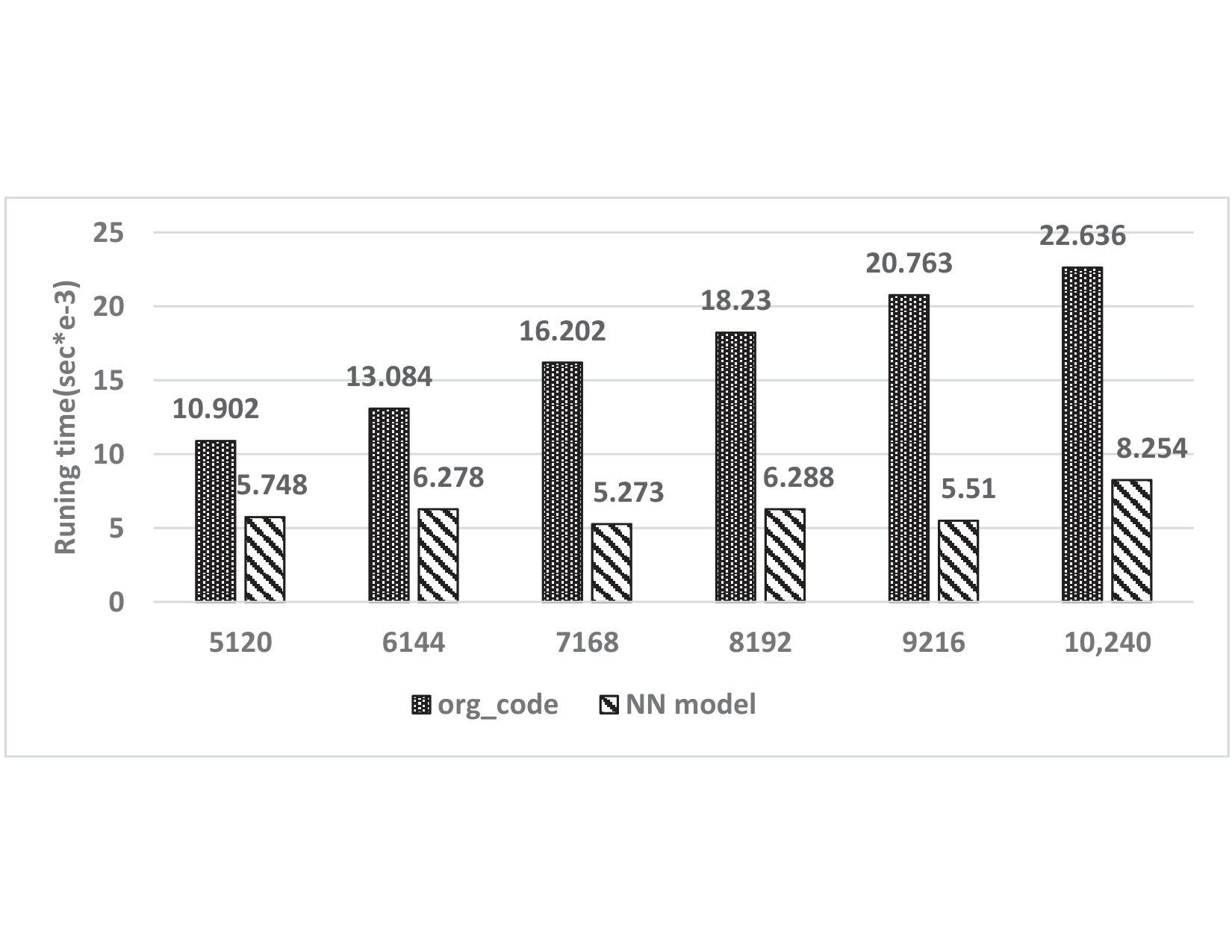 Figure 2
Figure 2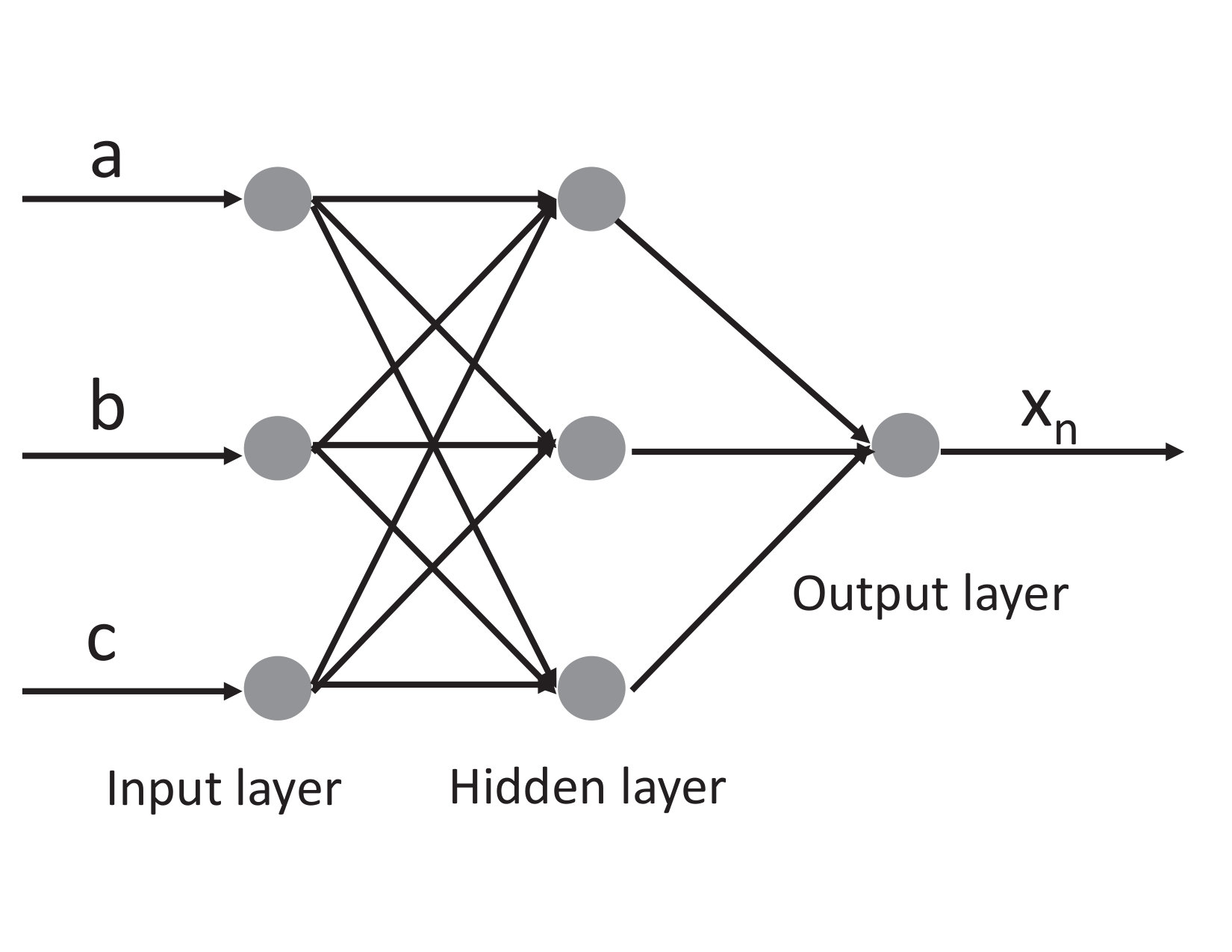 Figure 3
Figure 3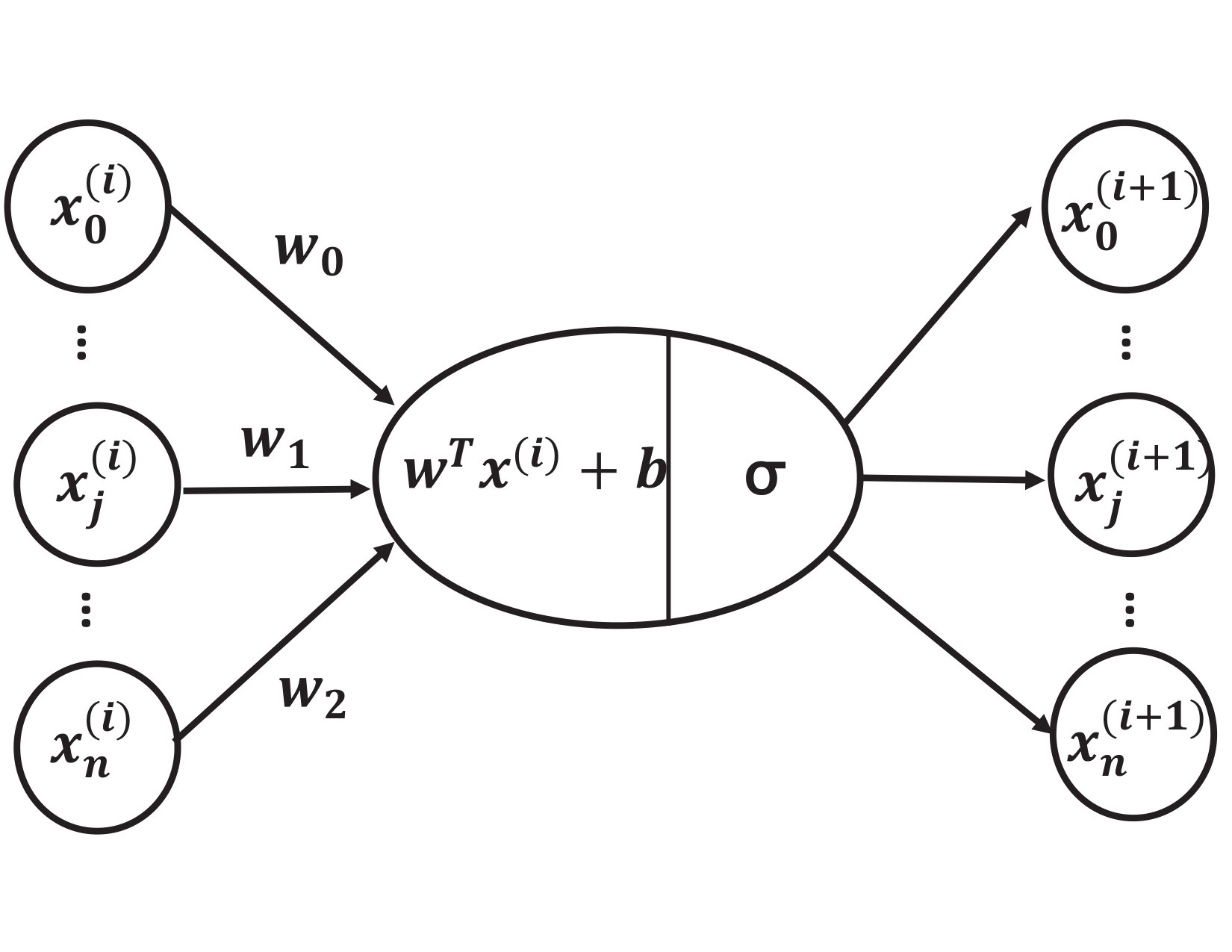 Figure 4
Figure 4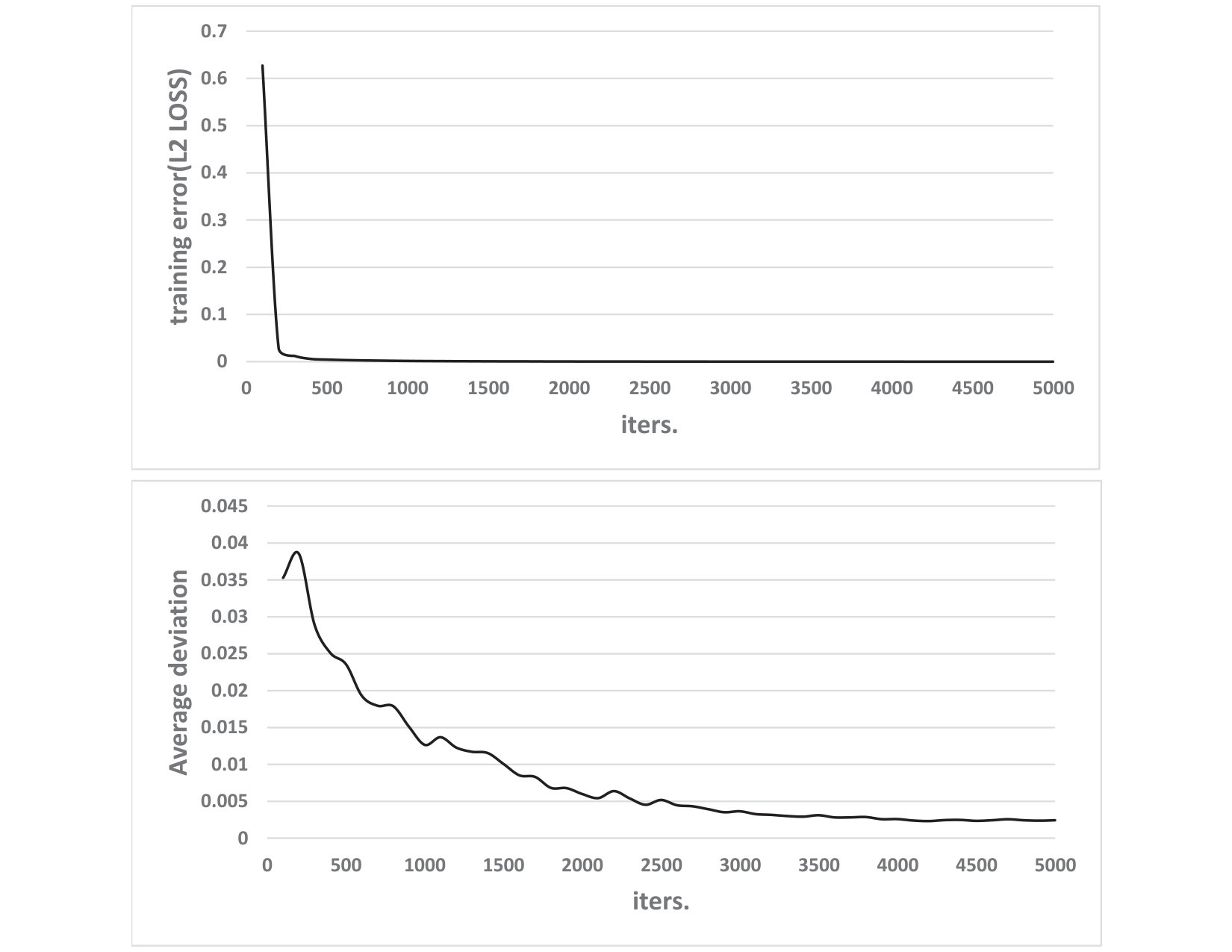 Figure 5
Figure 5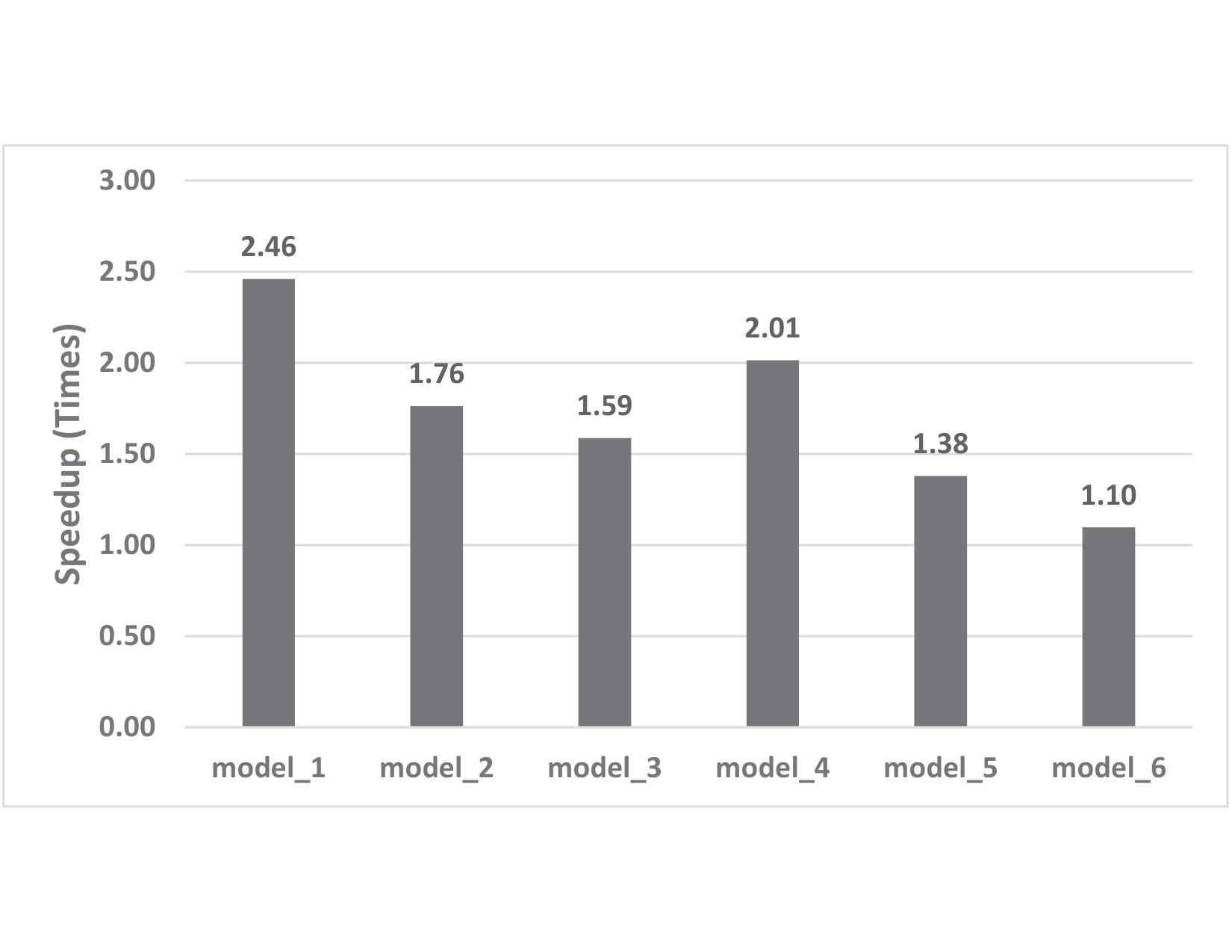 Figure 6
Figure 6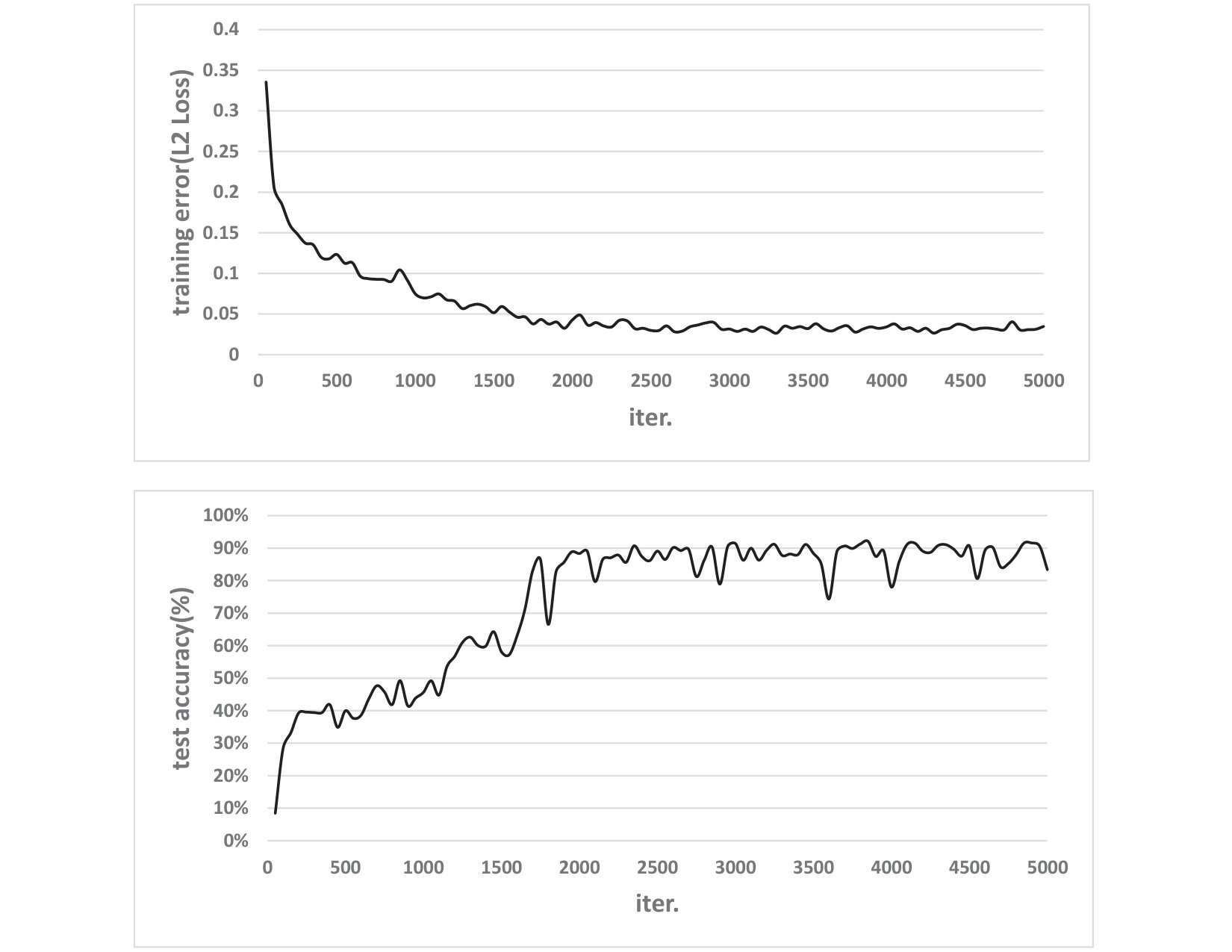 Figure 7
Figure 7 Figure 8
Figure 8| Section | min time(sec) | avg time(sec) | max time(sec) | total |
|---|---|---|---|---|
| Pair(the LJ potential) | 12.609 | 12.609 | 12.609 | 92.58% |
| Neigh | 0.93452 | 0.93452 | 0.93452 | 6.86% |
| Comm | 0.033068 | 0.033068 | 0.033068 | 0.24% |
| Output | 0.00012207 | 0.00012207 | 0.00012207 | 0.00% |
| Modify | 0.034445 | 0.034445 | 0.034445 | 0.25% |
| Others | 0.008681 | 0.06% |
| Model topology | Training time(sec*e) | training steps | L2 Loss | Running time(sec) | Average prediction accuracy |
|---|---|---|---|---|---|
| 66.50 | 5,000 | 0.056 | 4,407 | 51% | |
| 59.33 | 5,000 | 0.032 | 5,190 | 54% | |
| 61.14 | 5,000 | 0.032 | 4,700 | 73% | |
| 69.95 | 5,000 | 0.040 | 5,852 | 69% | |
| 66.18 | 5,000 | 0.032 | 5,922 | 89% | |
| 75.87 | 5,000 | 0.026 | 6,579 | 93% | |
| 98.36 | 5,000 | 0.039 | 8,931 | 89% | |
| 94.45 | 5,000 | 0.035 | 7,751 | 94% | |
| 82.38 | 5,000 | 0.031 | 7,453 | 95% |
| Model topology | Training time(sec) | training steps | L2 Loss(e-5) | Learning rate | Running time(sec*e-6) | Average absolute error |
|---|---|---|---|---|---|---|
| 48.51 | 10,000 | 7.14 | 0.005 | 5118 | 0.00261 | |
| 49.92 | 10,000 | 21.85 | 0.005 | 3970 | 0.0036 | |
| 48.90 | 10,000 | 11.49 | 0.005 | 5085 | 0.0023 | |
| 60.58 | 10,000 | 9.12 | 0.01 | 6585 | 0.0028 | |
| 60.64 | 10,000 | 12.28 | 0.01 | 7522 | 0.0022 | |
| 66.27 | 10,000 | 12.15 | 0.01 | 7104 | 0.0015 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsParallel Computing and Optimization Techniques · Low-power high-performance VLSI design · Numerical Methods and Algorithms
A Preliminary Study of Neural Network-based Approximation for HPC Applications
Wenqian Dong
EECS, UC Merced
Luanzheng Guo
EECS, UC Merced
Dong Li
EECS, UC Merced
Abstract
Training neural network often uses a machine learning framework such as TensorFlow and Caffe2. These frameworks employ a dataflow model where the NN training is modeled as a directed graph composed of a set of nodes. Operations in neural network training are typically implemented by the frameworks as primitives and represented as nodes in the dataflow graph. Training NN models in a dataflow-based machine learning framework involves a large number of fine-grained operations. Those operations have diverse memory access patterns and computation intensity. How to manage and schedule those operations is challenging, because we have to decide the number of threads to run each operation (concurrency control) and schedule those operations for good hardware utilization and system throughput.
In this paper, we extend an existing runtime system (the TensorFlow runtime) to enable automatic concurrency control and scheduling of operations. We explore performance modeling to predict the performance of operations with various thread-level parallelism. Our performance model is highly accurate and lightweight. Leveraging the performance model, our runtime system employs a set of scheduling strategies that co-run operations to improve hardware utilization and system throughput. Our runtime system demonstrates a big performance benefit. Comparing with using the recommended configurations for concurrency control and operation scheduling in TensorFlow, our approach achieves 33% performance (execution time) improvement on average (up to 49%) for three neural network models, and achieves high performance closing to the optimal one manually obtained by the user.
I Introduction
Large-scale scientific simulations drive scientific discovery across many domains. Those scientific simulations increasingly face performance problems, because of hardware heterogeneity, deep memory hierarchy, and massive thread-level parallelism. Addressing those problems often requires domain scientists to use sophisticated compiler and runtime techniques to optimize HPC programs. However, domain scientists are often not skillful computer scientists and may find program optimization time-consuming and daunting. In this project, we study how to use an alternative approach, machine learning, to effectively improve the performance of scientific simulations without losing simulation quality.
Machine learning, as a tool to learn and model complicated (non)linear relationships between input and output data sets, has shown preliminary success in some HPC problems. Using machine learning, scientists are able to augment existing simulations by improving accuracy and significantly reducing latencies. For example, scientists working to detect neutrinos at Fermi National lab have realized a 33% improvement in neutrinos detection using a convolutional neural network [1]; Scientists achieve Bose-Einstein Condensates state in only 10-12 experiments using machine learning instead of 140 experiences using traditional models, which reduces the simulation time by 10 times [2]. Other successful examples of using machine learning for HPC include recognizing extreme weather events in large-scale climate simulations at Lawrence Berkeley National Lab (LBNL) [3], and precision medicine for cancer [4] at Argonne National Lab.
However, our current methodology to apply machine learning to scientific simulations has limitations. In particular, the current methodology is rather ad-hoc and application-specific. There is no systematic and principled approach to enable general application of machine learning methods to scientific simulations. The lack of a systematic and principled approach is especially problematic to ensure high simulation quality when using machine learning. Furthermore, using machine learning requires domain scientists to have machine learning knowledge, while they usually do not have sufficient machine learning background. How to make machine learning techniques widely accessible and usable to domain scientists is largely unexplored.
Our ongoing research work is to create a general framework to apply neural network-based models to HPC applications. In particular, we want to use the neural network to approximate and replace code regions within the application to improve performance (i.e., reducing the execution time) of the application. In this paper, we present our preliminary study and results.
To use a neural network model to replace a code region, we face multiple research challenges in our preliminary work. First, we must make sure that our neural network can bring a performance benefit. This means the execution time (inference time) of the neural network should be shorter than that of the replaced code region. To address this issue, we use a trial-and-error method to try different neural network models based on the performance of the original code to decide which model should be used. Using such a performance-driven approach to select the model separates us from the existing work where the model accuracy is often used to select the model.
Secondly, we must determine the appropriate input and output variables for the neural network models. Those variables are also the input and output variables of the replaced code region. We define the input and output variables of a code region based on the memory access pattern (i.e., the read/write) and variable liveness analysis.
We make the following contributions in this paper:
- •
We explore the feasibility of using neural networks to approximate certain computation in HPC applications. Using the Newton-Raphson method and L-J potential in LAMMPS (a molecular dynamics simulation code) as examples, we show up 2.7x and 2.46x speedup, respectively.
- •
We study performance (execution time) implications of using different neural network models on the HPC applications. We also study the impact of using different neural network models on the approximation accuracy.
- •
We introduce a general and preliminary workflow to identify code regions and apply neural network models to replace them.
As a preliminary work, for our study of the L-I potential, we have not considered the impact of using neural networks on the application result correctness (we consider so for the Newton-Raphson method). We hope to extend our study in the future work.
II Background
We reveal the relevant background information in this section.
II-A Machine Learning-based Approximation
Machine learning-based approximation is in essence approximate computing. We study machine learning-based approximation rather than other approximate computing techniques because it has big advantages over other approximate computing techniques. (1) Other techniques, such as loop perforation [5, 6], random task discarding [7], and synchronization relaxation [8, 9], have specific requirements on the code structure to be approximated. The requirement could be a loop structure, a task-based execution model, or communication synchronization. Machine learning-based approximation does not have such a constraint on code structures. (2) Other techniques cannot provide portability on heterogeneous hardware as machine learning-based approximation. (3) Other techniques cannot provide flexible quality control as machine learning-based approximation. Quality control means controlling the output quality of the replaced code region. Having flexibility for quality control gives us a large room to explore the tradeoff between performance and accuracy. The quality control in other techniques is typically constrained by the code structure to implement approximation (e.g., the number of iterations in a loop structure for loop perforation), while machine learning does not have such constraint. We can use different machine learning models with different configurations to provide a variety of output quality with different performance.
II-B Two Applications for Study
We study two HPC applications, which are an implementation of the Newton-Raphson method and LAMMPS.
Newton-Raphson method. Newton-Raphson method is a root-finding algorithm to successively search for a better approximation of the roots to a real-valued function. To achieve the goal, the Newton-Raphson method repetitively uses a derivation to to find the best way to approach the optimal solution. Assuming a root for a function is needed (the function is defined over the real numbers ) and the function satisfies the assumptions made in the derivation of the formula, i.e., , the function can be expressed as follows according to the Taylor series.
[TABLE]
To search an approximate root of the equation, an initial solution (a random real-value or a value defined by users) is used as the first step to find the root of the function . After that, we repeatedly use Equation 2 to find a new solution.
[TABLE]
The above iterative process continues until a termination condition is satisfied. The termination condition is defined as or , where or are defined by the user.
The Lennard-Jones (LJ) potential in LAMMPS. LAMMPS [10] is a molecular dynamic simulation tool developed by Sandia National Laboratory. LAMMPS can be used for modeling particles movement at multiple scales (atomic, meso, continuum scales) in parallel. In LAMMPS, we often calculate a “potential function” for a pair of atoms. The L-J potential is a potential function in LAMMPS. It is a simple model to approximate the force interaction between a pair of neutral atoms or molecules. Equation 3 shows the computation of the L-J potential.
[TABLE]
In Equation 3, for a pair of atoms and located at and , we have and . In Equation 3, the parameter governs the strength of atom interaction, and the parameter defines the length scale.
II-C Neural Network
The existing work shows that the neural network can be used to approximate code regions for applications in diverse domains [11, 12, 13, 14, 15]. In this paper, we also use the neural network to replace computation- or memory-intensive code regions. We briefly review the neural network as follows.
Neural network(NN) is a popular machine learning model and it broadly includes CNN (convolutional neural network), RNN (recurrent neural network), and GAN (generative adversarial network). A neural network is composed of nodes (i.e., neurons) and edges. Nodes are organized into layers in the neural network; nodes across layers are connected by edges; each edge has a weight. We learn the weights when training the neural network. Typically, there are three types of layers: the input layer, the hidden layer, and the output layer. A node of an input layer is some input data of the neural network; a node of a hidden/output layer is the weighted sum of the input data of the node; an output layer can have one or more nodes: it depends on whether the neural network is for a classification problem or a regression problem. In addition, there are bias nodes at each layer, which are used for compromising noise in the input data to avoid overfitting. There can be an activation function such as sigmoid or rectifier for a layer to rectify the incoming data for the next layer.
In our work, we use the supervised learning to replace computation in HPC applications with neural networks such as CNN.
III Problem Definition
This paper particularly targets the following research problem. We characterize HPC applications as a set of code regions. A code region is simply a block of code. It can be a loop structure; it can also be a function.
We selectively replace code regions with neural networks to improve performance (i.e., shortening execution time) of HPC applications. The neural network should use the same input and output variables as the original code region.
We choose code regions to replace, based on two criteria: (1) The code region must be time-consuming and its execution time takes a large portion of the total execution time of the application. (2) Replacing the code region should not impact the correctness of the application outcome. This indicates that the application itself should be able to tolerate the approximation introduced by the replacement of the code region.
Time-consuming code regions. According to Amdahl’s law, we can achieve the theoretical maximum speedup by improving the performance of the most time-consuming portion of a workload. In our work, we claim a code region is time-consuming, if a single invocation of the code region takes a large portion of the total execution time of the application, or the code region is repeatedly executed and the accumulated execution time of the code region takes a large portion of total execution time of the application.
To select a code region to replace, besides measuring its execution time, we particularly pay attention to controlling flows in the code region. The control flows can prevent compiler optimization and effective instruction scheduling, hence causing performance loss. Furthermore, When running the code region on a SIMD architecture such as GPU, the control flows can cause idling threads and decrease hardware utilization. Hence, we want to replace such a code region with a neural network, such that we can remove control flows within the code region.
Approximability of HPC applications. Many HPC applications can tolerate computation inaccuracy caused by approximate computation. This has been demonstrated in the existing work [16, 17, 18, 19]. In fact, HPC applications themselves are approximate in nature. For example, the molecular dynamic simulation only models the force between atoms that are close enough in the physical space. The long-distance force is just ignored. Hence, even without introducing machine learning-based approximation, HPC applications already have some approximation.
Furthermore, many HPC applications have a threshold to determine when the final application outcome is acceptable or when the simulation should be terminated. Such a threshold-based approach allows the HPC applications to tolerate approximate computation.
In our study, we assume that HPC applications have explicit requirements on the final simulation quality (e.g., a threshold) to ensure approximation correctness. Using neural networks to replace code regions can generate computation inaccuracy in the middle of scientific simulations (i.e., HPC applications), but the final simulation result must meet the requirements of domain scientists on the final simulation quality.
Input and output variables of code regions. Given a code region, we classify the variables within the code region as input variables, output variables, and internal variables. Input variables are those that are declared outside of the code region and referenced in the code region. Output variables are those that are written in the code region and read after the code region. Other variables that the region writes to or reads from are internal variables. A code region can be executed many times during the application execution.
Concerns on training time. A neural network must be trained before it is deployed in an HPC application to replace a code region. When evaluating performance benefit of the neural network, the training time must be considered. A trained neural network is expected to give a prediction of the values of output variables. Note that if an input or output variable changes its size (e.g., an input 2D matrix changes its size from 512x512 to 1024x1024), then the neural network must be re-trained. Hence, the replaced code region should have fix-sized input and output variables, and must be repeatedly executed to have sufficient performance benefit, such that we can avoid repeatedly training the model and the overhead of modeling, training is amortized and justified.
A large number of scientific simulation applications have code regions that meet the above requirements. For those code regions, we only need to train the neural network once. Training time should be less than the performance benefits of using the neural network-based approximation. We give two example cases as follows.
- •
The Lattice Boltzmann method (LBM) has been widely employed in computational fluid dynamics with broad applications (e.g., multiphase flows, reacting flows, phase-change heat transfer, complex flows in porous media, simulations of microfluidics and nanofluids). In the parallel implementation of LBM, the computational domain is divided into subdomains with fixed-size input and out variables. The sizes of those variables are independent of the input problem size of LBM method.
- •
Climate modeling (including atmosphere modeling CAM, ocean modeling POP2, land surface modeling CLM4 and sea ice modeling CICE4 [20]) can take a very long time (weeks or even months) to solve different equations. During the model simulation, many code regions have fixed-size input and output variables, and repeatedly executed.
In this paper, we choose the Newton-Raphson method and L-J potential in LAMMPS as our targets to replace, because they are very frequently used. The performance benefit of replacing them can easily overweight the training time.
IV Neural Network-based Approximation
We discuss how to use the neural network to approximate code regions in this section.
IV-A General Methodology
Given an application, we use gprof to identify the most time-consuming functions. Those functions are candidate code regions to be replaced. In our study, we replace the whole Newton-Raphson method, because its implementation is simple enough to be treated as a function to replace. We replace the computation of the L-J potential in LAMMPS because it is simple enough for our preliminary study. Also, the L-J potential is the most time-consuming computation for some input problems of LAMMPS (we use in.lj.5 as the input problem of LAMMPS).
After code regions are selected, we need to determine the input and output variables of the code region. This can be done based on compiler analysis.
After the input and output variables of the code region are decided, we need to build a neural network. Building a neural network involves a determination of the network topology (e.g., how many layers and how many neurons in each layer and what are the activation functions in the neural network). Furthermore, there are various types of neural network, such as Convolutional Neural Network (CNN) and Recurrent neural network (RNN). We need to decide which type of neural work should be chosen. From the performance perspective (execution time), we decide the network topology and which type of neural network should be chosen based on the computation complexity of each candidate neural network. The execution time (i.e., inference time) of the neural network should be shorter than the replaced code region.
We extract the code region out of the application as a standalone application. Then we randomly generate input data, feed them into the code region, and then collect output data. Each pair of input and output data is a training example. Note that when we generate random input data, the input data must meet the requirement of the application on the input data.
We describe how to replace the Newtwo-Raphson method and the computation of the L-J potential in LAMMPS as follows.
IV-B Newton-Raphson method
The Newton-Raphson method is widely used in finding an approximation root of an equation. Algorithm 1 generally depicts the Newton-Raphson method. The Newton-Raphson method can be time-consuming because it iteratively uses a derivation to find the best way to approach the optimal solution. Sometimes the Newton-Raphson method has to use a large number of iterations to find a good solution. To determine if a solution is good, the Newton-Raphson method examines if the difference between the current solution and the immediately last solution is smaller than a threshold (see Line 3 in Algorithm 1). Such a threshold-based approach allows the Newton-Raphson method to tolerate approximate computation.
We can easily identify the input and output variables of the Newton-Raphson method. Assuming that the target equation for the Newton-Raphson method to solve is a quadratic function , then the input variables are and , and the output variable is the final solution .
we use a fully-connected NN model to replace the whole Newton-Raphson code in our study. Our model is shown in Figure 1 consists of fully connected neurons. Those neurons are organized as an input layer, two hidden layers, and an output layer. The input of the model is three variables and the output of the model is a single variable. We use a NN and use the Momentum backpropagation approach when training the neural network.
We use samples for model training and samples for model validation. Using this 4-layers fully connected neural network, we achieve good modeling accuracy, after training steps.
Figure 2 shows how the training error and test accuracy vary as we increase the number of training steps. The training error is measured by L2 loss (squared error). From the figure, we can see the convergence of the L2 loss and prediction accuracy after 5,000 training steps,
Figure 1 shows and compares the execution times of the Newton-Raphson method and the NN model solving a number of equations (from 5120 to 10240 equations). In general, the NN model has better performance than the Newton-Raphson method. We have up to 2.7x performance speedup. We also notice that as the number of equations increases, the execution time of the NN increases slowly, while the execution time of the Newton-Raphson method increases almost linearly. Intuitively, the execution time of the neural network should increase linearly. We attribute such a slow increase in the execution time to the possible internal parallelism in the machine learning framework (particularly TensorFlow) we use to run the model.
Discussion. The execution time (or the number of iterations to converge) of the Newton-Raphson method has a strong correlation to the initial guess of the solution (i.e., ). If the initial guess is close to the final solution, the equation can be solved quickly with the Newton-Raphson method. For such case, it is difficult to use a neural network to perform better than the Newton-Raphson method (in terms of execution time). However, finding a good initial guess of the solution is challenging, especially for a high-order equation. We expect that in most cases, using a neural network to replace the Newton-Raphson method is promising.
In our study, we choose a random data as the initial guess for the Newton-Raphson method and the neural network. Both of them use the same initial guess. Also, to counter the potential effect of the initial guess on the execution time, we solve a number of equations, each of which uses different initial guess. We measure the execution time of solving all of the equations instead of solving the individual equations, shown in Figure 1.
IV-C The L-J potential in LAMMPS
The L-J potential is the most time-consuming computation in our study (we use in.lj.5 as the input problem of LAMMPS). Table I shows the profiling results of LAMMPS. The L-J potential takes more than 90% of the total execution time.
Algorithm 2 shows the major computation of the L-J potential. The algorithm involves a two-level loop: the outer loop uses the iterator , and the inner loop uses the iterator . The inner loop traverses all neighbors of the atom , calculates forces, and accumulates each force to the total force of atom (Line 6 in Algorithm 2.).
We first consider replacing the inner loop with a neural network. The inner loop calculates the interaction between atoms and . As the following force calculation step is based on the neighbor cell space, it involves frequent calculation and memory access. However, due to the irregular arrangement of molecular position, the numbers of atoms in different neighbor cells are different from each other. Furthermore, impacted by the L-J force, atoms involving plenty of motions move frequently through a neighbor cell, which means the number of atoms in the same neighbor cell even change after several simulation time steps. The changed data size creates a major obstacle for model training and model reuse. In the meanwhile, the average atoms in each neighbor cell are in our experiments, which requires a more sophisticated and elaborate model to learn motion patterns.
In the molecular simulation with the force of the LJ potential, interactions (repellent and attraction) usually take place at a pair of atoms. Although a pair of atoms is almost the smallest unit during the L-J force calculation, most of these events are executed on atom pairs, illustrated at Line in Algorithm 2. Taking the consideration of efficiency, the same-sized chunk of data enable to utilize the simplest neural network topology to offer the greatest rewards of QoR and model reuse. Hence, we use a pair of atoms as our input data size. It is guaranteed that this same-sized chunk of data enables be read and write at the peer start and end points of procedure.
For the calculation of the L-J force, not only the force calculation but also the condition of distance (Line 4 in Algorithm 2) should be involved in the consideration of model design. The reason is that the condition statement can prevent compiler optimization and efficient instruction scheduling. Removing the condition statement is beneficial for performance.
We use a simple 3-layers fully connected model (i.e., a model) to replace the original code. We use an activation function which is a combination of ReLU and Tahn.
After training steps, we achieve a speedup with an average derivation of on the overall data. Figure 4 illustrates how the training error (L2 loss) and test accuracy vary as we increase the number of training steps. The figure shows that the training error and test accuracy converge after steps.
V Evaluation (2pages)
V-A Newton-Raphson method
We use NNs of different topologies to replace the Newton-Raphson Method. We then study the accuracy and efficiency of the new Newton-Raphson method. The accuracy of the new Newton-Raphson method using NN models of different topologies is presented in Table II. In the table, The first column is the topology for NN models; the second column is the time spent in training; the third column is the training step; the fourth column is the L2 loss; the next column is the time spent in testing; the last column is the prediction accuracy; each row shows the result for a specific topology when we use a NN of the specific topology to replace the Newton-Raphson method.
We can see that when a NN of a more complex topology is used, we spend more time on training and testing but we get a smaller L2 loss in training and better accuracy in testing. In other words, a more complex topology can help decrease the L2 loss in training and increase the accuracy in testing, but doesn’t cause overfitting. This means that a prediction accuracy of 95% is not our upper bound — we can achieve an even better prediction accuracy than 95% when we use a more complex topology than for NN.
Furthermore, the best prediction accuracy we achieve is 73% when a three-layered topology is used; the best prediction accuracy we achieve is 93% when a four-layered topology is used; the best prediction accuracy we achieve is 95% when a five-layered topology is used. This result suggests that the number of layers to the model topology to NN has huge impact on the prediction accuracy. The more layers in the topology, the better prediction accuracy we can achieve. However, this benefit cannot sustain and decrease shortly when more layers are added to the topology. Moreover, for the same number of layers, more nodes in the hidden layer help increase the prediction accuracy. For example, for four-layered topologies, when the hidden layer is , the prediction accuracy is 69%; the prediction accuracy is 89% when the hidden layer is ; the prediction accuracy is 93% when the hidden layer is .
V-B The L-J potential in Lammps
Similar to what we perform to the Newton-Raphson method, we replace the L-J potential in LAMMPS with NNs of various topologies. We present the result for prediction accuracy in Table III. Note that we cannot calculate the prediction error in this experiment because some of the ground-truth values are zero; we cannot calculate the relative error when the denominator is zero. Thus, we use the absolute error, which is counted by the difference between the predicted value and the ground truth, as the metric for accuracy.
From the results, we can make the same conclusion that the addition of more neurons and layers leads to better prediction accuracy. The best prediction accuracy (0.0015 for the absolute error) is achieved by using the NN with the topology of .
Figure 5 presents the result for the efficiency study. We show the speedup achieved by using NN models in Table II compared to the original execution as the baseline. We achieve 1.7X speedups on average by using different topologies for NN. The variation in speedup depends on the complexity of model topology. We can see a trend that the more nodes and more layers a NN has, the less speedup we can achieve.
VI Related Work (1 page)
Machine learning has shown preliminary success when it is applied in HPC recently. We classify how machine learning is used in HPC into the following three cases.
Enhancement Methods. Machine learning has been used to enhance and augment scientific applications to analyze very large data sets to reveal properties that are too complex to be discovered by previous systems. From predicting Molecular energetics to tracking neutrinos, machine learning-driven enhancement dramatically advances the efficiency and accuracy of the solution of well-known scientific problems [21]. There are couples of simulation examples that successfully apply enhancement methods to their research field.
In weather prediction, Racah et al. [3] use a semi-supervised multichannel spatiotemporal CNN model to realize a better localization of extreme weather. In cancer treatment, U.S. DOE laboratories, as well as the National Institutes of Health (NIH), have recently launched a synthetic project, CANDLE [22], targeting the top challenges in cancer diagnosis and treatment. At the current stage, researchers are leveraging information of millions of cancer patient records to diagnose cancer and figure out the best treatment strategy using a scalable DNN for modeling.
Moreover, in particle physics, George and Huerta [23] use GPUs to accelerate training DNN for fast detection and processing gravitational wave data; the new machine learning-based approach is much efficient and resilient to noise than established gravitational wave detection algorithms. Seismologists and geophysicists recently reveal that machine learning techniques can help them identify earthquake patterns from three years of earthquake records at The Geysers in California, one of the world’s oldest and largest geothermal reservoirs [24]. This is an unprecedented achievement. The subtle difference between patterns is unseen by traditional methods, which are less accurate. The patterns help researchers find the fluctuating amounts of water injected belowground during the energy-extraction process.
Modulation Methods. Besides that, machine learning has also be used to create refined input data for the next iteration round in a scientific simulation to modulate the simulation process. There are several successful examples. B. Wigley et al. [2] propose a machine learning-based online optimization process for the production of Bose-Einstein condensates (BEC). With the repeated machine learning led learning, the optimization process finds the optimal evaporation ramp for BEC production shortly in fewer iterations. In Thermal–hydraulic modeling [25], an NN is trained using the output from simulations and then used to learn the dynamic behavior of the heated line. The NN is then added to the 4C circuit model as a new part. The NN model enables online control and fast assessment of the dynamic thermal-hydraulic system. Similarly, Richard et al. [26] apply an NN to ITER magnets aiming to predict when a disruption will occur in order to avoid damage to ITER and to adjust the reaction to keep generating power. The NN-based approach exceeds the best traditional methods in accuracy (95% v.s. 85%).
Approximation Methods. Approximation Methods becomes a favorite field in the last two years. Our work, in essence, belongs to approximation methods. Approximation methods can be leveraged to shorten execution or save energy by trading computation accuracy. Approximation Methods use machine learning approximation to replace scientific simulation Those code replacements happen at a coarse granularity. Typically the whole scientific simulation (instead of the fine-grained code regions) is replaced.
There are a couple of successful cases, such as using machine learning to reproduce molecular energy surfaces [14] and simulate infrared spectra for molecular dynamics [15]. In [14], researchers use a DNN to replace Discrete Fourier Transform (DFT). By doing so, the Quantum chemistry (QC) simulation achieves 10e4x speedup with a high accuracy. After that, developing new drugs can be accomplished in minutes that would have taken more than 10 years. Similarly, in [15], an NN is used to reproduce the potential energy surface (PES) of a chemical system using the data computed by quantum chemistry methods. NN potentials can realize the accuracy of the underlying quantum chemical method, but also can be several-orders-of-magnitude faster using only several hundreds of electronic structure points.
Machine learning approximation is also managed to be used to speed up quantum computing kernels [13], in which Carleo and Troyer apply machine learning approximation on one of greatest challenges in quantum physics: the many-body problem, which describes the complex correlations within the many-body wave function. Carleo and Troyer use an NN to reproduce the quantum many-body wave function. This forces the neural network to learn properties of the ground state of the wave function. This machine learning-based approach outperforms the state-of-the-art numerical simulation methods in accuracy.
In Computer Science, Approximation methods has been explored in many sub-fields, including hardware [12, 27, 28, 29], compilers [30, 31, 32, 5], programming languages [33, 7, 34, 35], and runtime systems [9, 36, 37]. Approximate methods have been applied to many applications, such as streaming applications [16, 17, 18], However, there are only a few cases in HPC applications (e.g., molecular dynamics simulation [13], atmospheric modeling [38] and large-scale eigen decomposition [19]). We want to test more HPC applications to extend approximation methods in HPC.
VII Conclusion
Neural networks have gained prominence in recent years and we deploy them on approximate computing to chase for better performance. This work motivates and introduces the machine learning-based approximate approach to mimic and replace original code regions. We find that the potential code regions may gain best rewards from transformation with similar intrinsic characteristics. Based on these insights, we follow these guidelines for selecting a target code region to replace and designing a corresponding NN model. We implement two applications, the Newton-Raphson method, and Lennard-Jones (LJ) potential in LAMMPS, to realize our assumption. As the result clearly show, NN models accelerate the original code region without introducing a huge deviation. Various NN models provide appreciable speedup and accurate data depends on the data types, model complexity, and model reusability.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Radovic, “Neutrino Identification with a Convolutional Neural Network in the N Ov A Detectors,” in International Conference on High Energy Physics , 2016.
- 2[2] P. B. Wigley, P. J. Everitt, A. Hengel, J. Bastian, M. A. Sooriyabandara, G. Mc Donald, K. Hardman, C. D. Quinlivan, M. Perumbil, C. c. Noschang kuhn, I. R. Petersen, A. Luiten, J. Hope, N. Robins, and M. Hush, “Fast machine-learning online optimization of ultra-cold-atom experiments,” vol. 6, 07 2015.
- 3[3] E. Racah, C. Beckham, T. Maharaj, S. Kahou, M. Prabhat, and C. Pal, “Extreme Weather: A Large-scale Climate Dataset for Semi-supervised Detection, Localization, and Understanding of Extreme Weather Events,” in NIPS , 2017.
- 4[4] Argonne National Lab, “CANDLE: Exascale Deep Learning and Simulation Enabled Precision Medicine for Cancer,” http://candle.cels.anl.gov.
- 5[5] S. Sidiroglou-Douskos, S. Misailovic, H. Hoffmann, and M. Rinard, “Managing performance vs. accuracy trade-offs with loop perforation,” in Proceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering , 2011.
- 6[6] J. Mengte, A. Raghunathan, S. Chakradhar, and S. Byna, “Exploiting the forgiving nature of applications for scalable parallel execution,” in IEEE International Symposium on Parallel Distributed Processing (IPDPS) , 2010.
- 7[7] M. Rinard, “Probabilistic accuracy bounds for fault-tolerant computations that discard tasks,” in P International Conference on Supercomputing , 2006.
- 8[8] M. C. Rinard, “Using early phase termination to eliminate load imbalances at barrier synchronization points,” in Proceedings of the 22Nd Annual ACM SIGPLAN Conference on Object-oriented Programming Systems and Applications , 2007.