TAN: Temporal Aggregation Network for Dense Multi-label Action Recognition
Xiyang Dai, Bharat Singh, Joe Yue-Hei Ng, Larry S. Davis

TL;DR
The paper introduces TAN, a deep hierarchical network that efficiently captures multi-scale spatio-temporal features for dense multi-label action recognition, outperforming existing methods on key datasets.
Contribution
TAN decomposes 3D convolutions into spatial and temporal blocks, reducing complexity and improving multi-label action recognition accuracy.
Findings
Outperforms state-of-the-art on Charades by 5%.
Outperforms state-of-the-art on Multi-THUMOS by 3%.
Efficient multi-scale spatio-temporal feature aggregation.
Abstract
We present Temporal Aggregation Network (TAN) which decomposes 3D convolutions into spatial and temporal aggregation blocks. By stacking spatial and temporal convolutions repeatedly, TAN forms a deep hierarchical representation for capturing spatio-temporal information in videos. Since we do not apply 3D convolutions in each layer but only apply temporal aggregation blocks once after each spatial downsampling layer in the network, we significantly reduce the model complexity. The use of dilated convolutions at different resolutions of the network helps in aggregating multi-scale spatio-temporal information efficiently. Experiments show that our model is well suited for dense multi-label action recognition, which is a challenging sub-topic of action recognition that requires predicting multiple action labels in each frame. We outperform state-of-the-art methods by 5% and 3% on the…
Click any figure to enlarge with its caption.
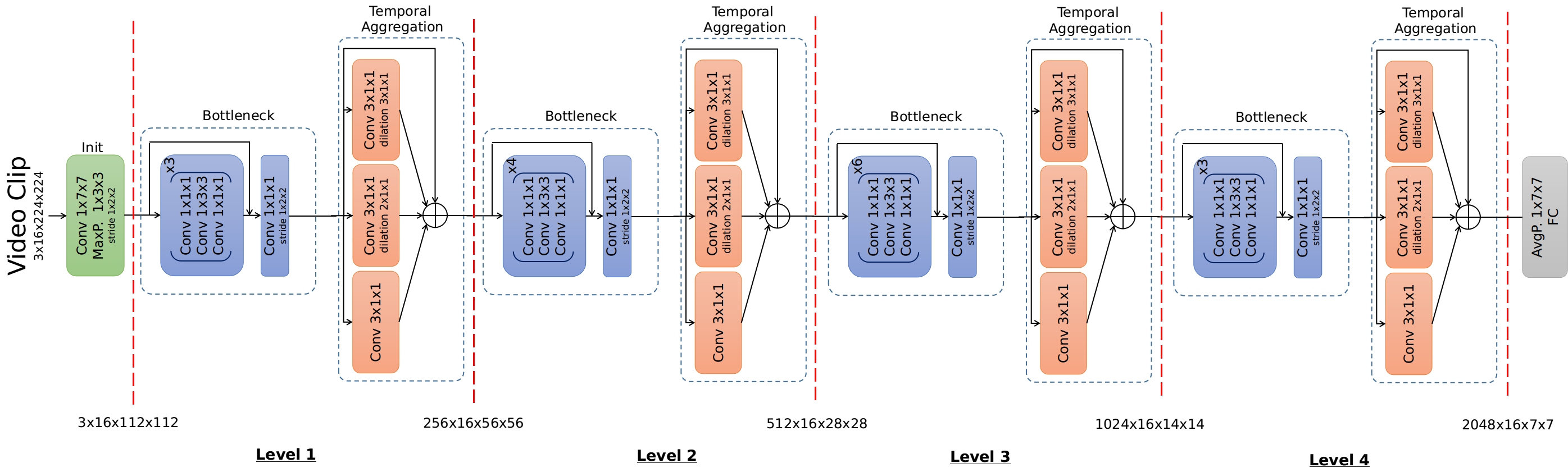 Figure 1
Figure 1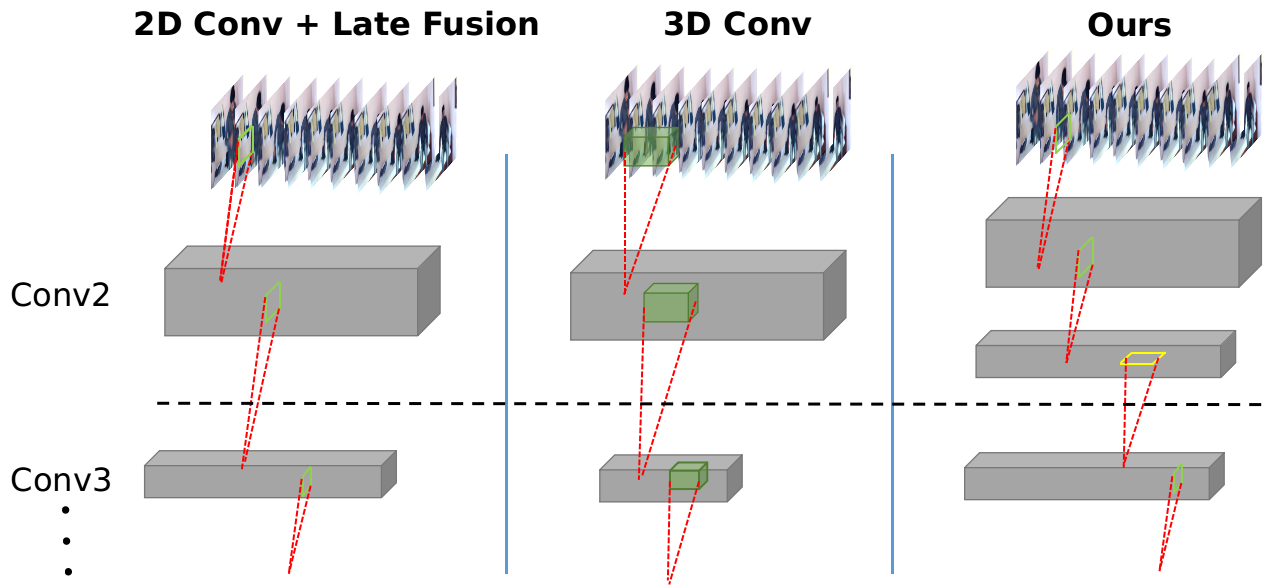 Figure 2
Figure 2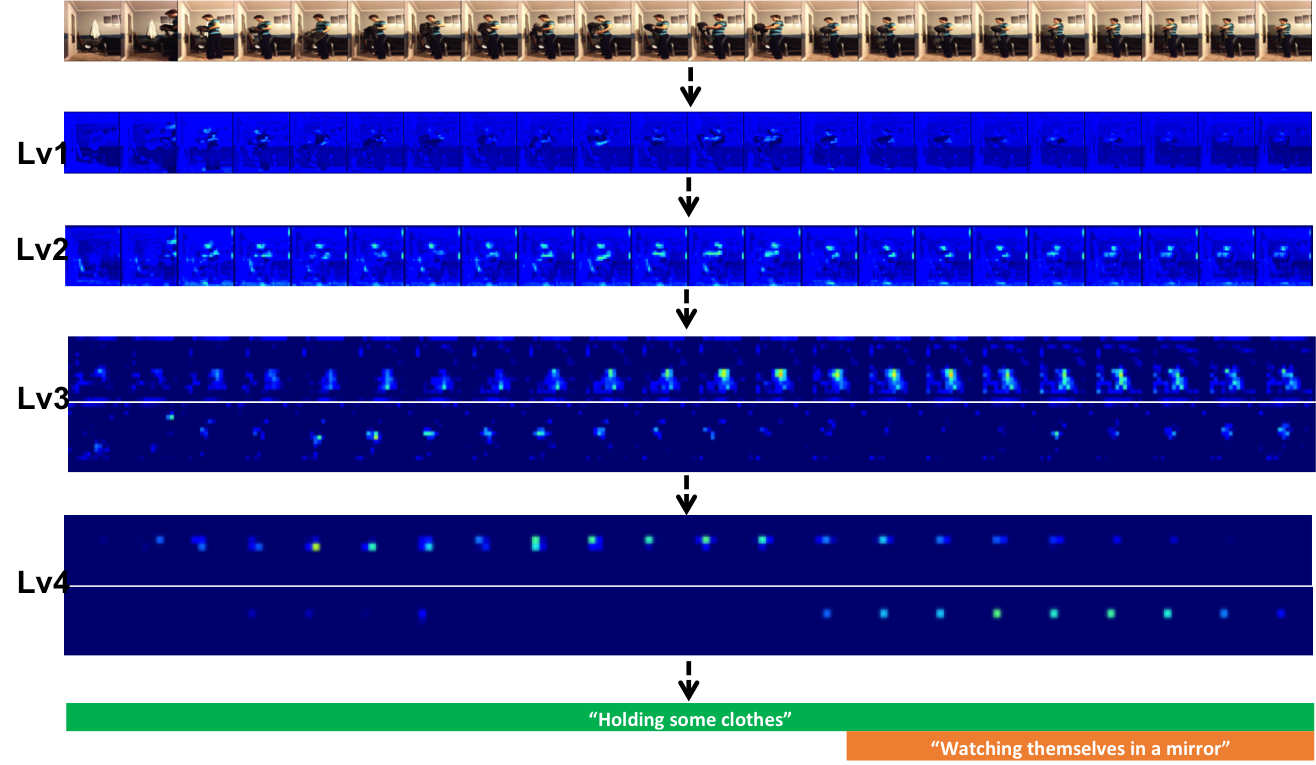 Figure 3
Figure 3 Figure 4
Figure 4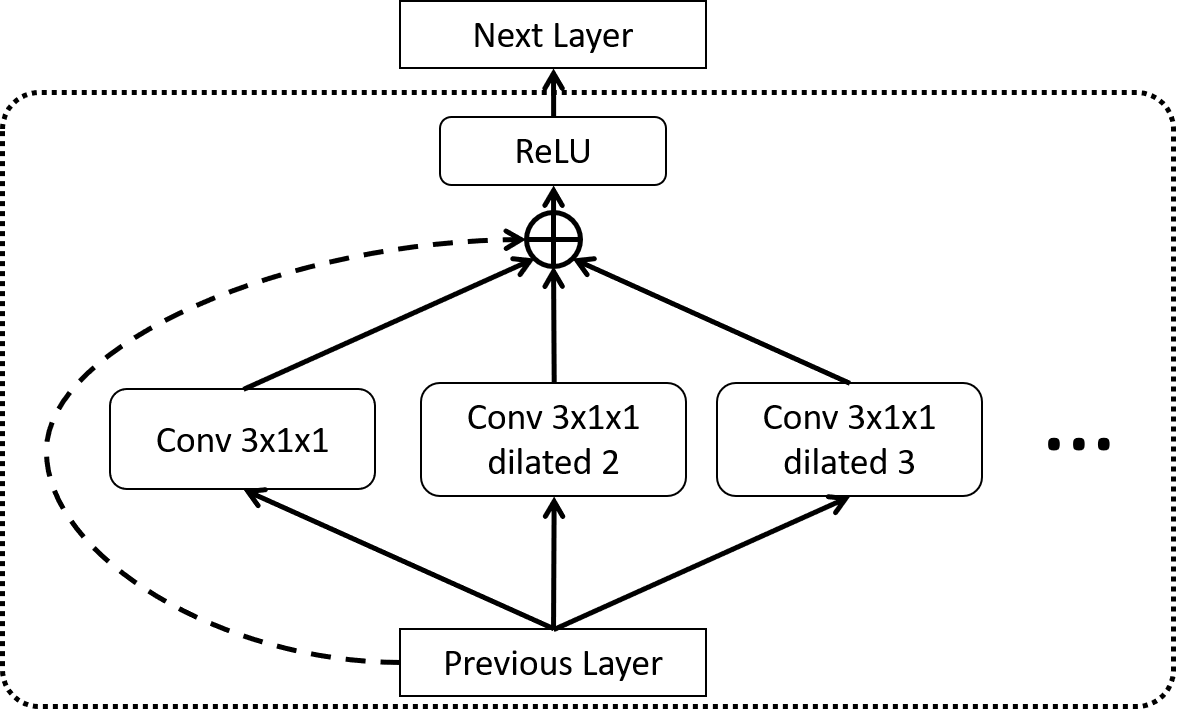 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7| Method | Frame mAP | Video mAP |
|---|---|---|
| Res50-2D | 11.7 | 21.1 |
| Res50-3D | 10.3 | 19.0 |
| Res50-TAN (Ours) | 14.2 | 25.5 |
| Components | Frame mAP | Video mAP | ||||
| Lv. 4 | Lv. 3 | Lv. 2 | Lv. 1 | Dilation | ||
| ✓ | ✓ | 12.2 | 22.1 | |||
| ✓ | ✓ | ✓ | 13.1 | 23.6 | ||
| ✓ | ✓ | ✓ | ✓ | 13.7 | 24.9 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 14.2 | 25.5 |
| ✓ | ✓ | ✓ | ✓ | 12.2 | 22.4 | |
| Sampling rates | 1 FPS | 2 FPS | 4 FPS | 8 FPS |
|---|---|---|---|---|
| Video mAP | 21.3 | 25.3 | 25.5 | 24.1 |
| Number of layers | |||
|---|---|---|---|
| Frame mAP | 14.2 | 15.5 | 17.6 |
| Video mAP | 25.5 | 27.5 | 31.0 |
| Method | Frame mAP | Video mAP |
|---|---|---|
| Ours w/o pretraining | 14.0 | 25.3 |
| Ours w/ pretraining | 17.6 | 31.0 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHuman Pose and Action Recognition · Anomaly Detection Techniques and Applications · Multimodal Machine Learning Applications
TAN: Temporal Aggregation Network for Dense Multi-label Action Recognition
Xiyang Dai Bharat Singh Joe Yue-Hei Ng Larry S. Davis
Institution for Advanced Computer Studies
University of Maryland, College Park
{xdai, bharat, yhng, lsd}@umiacs.umd.edu
Abstract
We present Temporal Aggregation Network (TAN) which decomposes 3D convolutions into spatial and temporal aggregation blocks. By stacking spatial and temporal convolutions repeatedly, TAN forms a deep hierarchical representation for capturing spatio-temporal information in videos. Since we do not apply 3D convolutions in each layer but only apply temporal aggregation blocks once after each spatial downsampling layer in the network, we significantly reduce the model complexity. The use of dilated convolutions at different resolutions of the network helps in aggregating multi-scale spatio-temporal information efficiently. Experiments show that our model is well suited for dense multi-label action recognition, which is a challenging sub-topic of action recognition that requires predicting multiple action labels in each frame. We outperform state-of-the-art methods by 5% and 3% on the Charades and Multi-THUMOS dataset respectively.
1 Introduction
Convolutional Neural Networks (CNNs) have seen tremendous success across different problems including image classification [20, 17, 9], object detection [16, 23, 6, 32, 42], style transfer [14, 3, 7, 4, 12], action recognition [30, 35, 2, 21] and action localization [8, 44, 47, 48]. In each of these problems, several application specific changes to network design have been proposed. In particular, for action recognition, a two-stream network comprising two parallel CNNs, one trained on RGB images and another trained on stacked optical flow fields, showed that incorporating temporal information into the network architecture provides a significant benefit in performance [30]. Since optical flow computation is an additional overhead, network architectures like C3D [35] operate only on a sequence of images and perform 3D convolutions in each layer of the network. However, 3D convolutions in each layer increase the model complexity and with just 3x3x3 convolutions, it is hard to capture larger temporal context. Therefore, we need to design a network architecture which can learn semantic representations of actions efficiently.
While it is important to design efficient network architectures, they should also be capable of learning all the variations which appear in videos during training. In a video, multiple frames aggregated together represent a semantic label, so the amount of computation needed per semantic label is an order-of-magnitude larger compared to recognition tasks on images. The difficulty is further amplified because actions can span multiple temporal and spatial scales in videos. Short actions like micro-expressions (raising an eyebrow) require high-resolution spatio-temporal reasoning, while other longer actions like running or dancing involve large spatial movements, which can be identified with features with lower spatial resolution. Therefore, it is essential to aggregate multi-resolution spatio-temporal information without blowing up network complexity.
For image recognition tasks like object detection and semantic segmentation, dilated convolutions [22, 5] have been widely adopted to increase receptive field sizes without increasing model complexity. By applying dilated convolutions with different filter sizes, multi-scale context can be efficiently captured. Multi-scale spatio-temporal context is important for video recognition tasks. To this end, we propose TAN, which applies multi-scale dilated temporal convolutions after every spatial downsampling layer in the network. Since the spatial receptive field of the network doubles after each downsampling layer, our network has the capacity to learn fine-grained motion patterns in the feature-maps generated closer to the input. Large scale spatio-temporal patterns are captured in deeper layers which have coarse resolution. By only applying temporal convolutions after each downsampling layer, the computational burden and model complexity are reduced when compared to methods which apply 3D convolutions in each layer of the network. The use of dilated convolutions also facilitates capturing larger temporal context efficiently. We conducted extensive ablation studies to verify the effectiveness of our approach.
Our architecture is especially suitable for the dense action labeling task as it offers a good balance between temporal context and bottom up visual features computed at a particular time instant. By modeling short-term context efficiently with convolutions, TAN obtains state-of-the-art results on two benchmark datasets, Charades and Multi-THUMOS for the dense action prediction task, outperforming existing methods by 5% and 3% respectively. Although TAN is designed for dense action prediction, we also applied it to action detection where it obtains state-of-the-art results, showing the effectiveness of TAN in a variety of tasks.
2 Related Work
Action recognition. Action recognition is one of the core components of video understanding. In early works, 3D motion templates [1], or features such as SIFT-3D [24] were used for representing temporal information for action recognition. Later, the introduction of dense trajectories [37] and improved dense trajectories [38] provided a significant boost in performance for feature based pipelines.
After the early success of deep learning [20, 31, 34] on image classification, early deep learning based video recognition methods focused on utilizing deep features. Karpathy et al. [19] evaluated different fusion methods for deep features. Wang et al. [39] pooled deep-learned features based on trajectory constraints. Simonyan et al. [30] proposed a two-stream network which learns temporal dynamics on both stacked optical flow and appearance. Feichtenhofer et al. [13] further analyzed different ways to fuse two-stream networks. Wang et al. [40] further improved the two-stream network by introducing a temporal sampling strategy and training on video-level instead of short snippets to enable efficient learning on full videos.
Meanwhile, researchers started to design novel deep architectures specifically for video tasks. Tran et al. [35] first proposed to utilize 3D convolution, which naturally extends convolutional filters to temporal domain. Then, Carreira et al. [2] proposed to build a 3D convolution variant of inception architecture and trained on a newly collected large-scale dataset of actions. This network achieved impressive performances on multiple benchmarks but was computationally costly. Very recently, Qiu et al. [21] proposed P3D to simplify 3D convolutions with 2D convolutional filters in the spatial domain followed by 1D convolutional filters in the temporal domain. This method is most relevant to proposed work. We also decompose 3D convolutions into separate spatial and temporal convolutions. However, unlike P3D, which replaces 3D convolution with 2D + 1D convolutions, we design a dedicated temporal aggregation block to capture context among multiple temporal levels and meanwhile preserving the temporal resolution. We only place a single layer of temporal block after each downsampling layer to reduce the filters needed for performing video recognition tasks. By stacking these two types of blocks repeatedly, we effectively capture appearance and spatio-temporal motion pattern which is important for localization tasks in videos.
Multi-label prediction. Multi-label dense action recognition is a considerably harder task than action recognition as it requires labeling frames with all the actions occurring in them. Yeung [43] first proposed this task by densely labeling every frame within a popular sports action dataset [18]. They further applied standard techniques such as LSTM, two-steam networks and created a very strong baseline. Sigurdsson et al. [29] collected another multi-label dataset by crowd-souring everyday activities at home. For recognizing these actions, Girdhar et al. [15] proposed ActionVLAD, that aggregates appearance and motion features from two-stream networks. Sigurdsson et al. [27] used a fully-connected temporal CRF model for reasoning over various aspects of activities. Dave et al. [10] employed RNNs to sequentially make top-down predictions and later then corrected them by bottom-up observations. Most recently, Sigurdsson et al. [28] performed a detailed analysis on what kinds of information are needed to achieve substantial gains for activity understanding among objects, verbs, intent, and sequential reasoning.
Our approach is suitable for dense multi-label action recognition because we learn dense spatio-temporal information efficiently without the need to reduce temporal resolution. Our model creates a hierarchical spatio-temporal representation that captures context among different temporal frequencies, which significantly improves performance on benchmark datasets.
Temporal action localization. Unlike action recognition where we predict a label per video, action detection requires predicting temporal boundaries of an action in an untrimmed video. Recent methods mainly focus on two types of approaches: making dense predictions or predict temporal boundaries (like proposals). Escorcia et al. [11] encoded a stream of frames into a single feature vector using an LSTM which was then used to rank proposals. Singh et al. [33] used a bi-directional LSTM on multi-stream features and performed fine-grained action detection. Shou et al. [26] utilized multiple temporal scales to rank candidate segments. Later, they [25] refined this work by designing a convolution de-convolution network to generate dense predictions for refining action boundaries. Zhao et al. [49] decomposed their model into separate classifiers for classifying actions and determining completeness. Meanwhile, due to success in object detection for localizing objects in images, recent works started applying similar ideas to videos. Xu et al. [41] presented a R-CNN like action detection framework from C3D features. Dai et al. [8] argued for the importance of sampling at two temporal scales to capture temporal context in a faster R-CNN architecture.
Our model is also capable of performing action detection, as we generate a dense labeling of videos. When combined with pre-trained action proposals, our model can be used for classifying these proposals (by average pooling the per-frame classification score computed by TAN and multiplying it with the actionness score of the proposal), which demonstrates that it can also be useful in other video recognition tasks.
3 Architecture
In this section, we introduce our Temporal Aggregation Network (TAN) in detail. We summarize existing methods and describe the difference. A detailed analysis and intuition of our key building blocks is then provided.
3.1 Temporal Modeling
Current approaches to temporal modeling generally fall in two categories:
2D Convolution + Late fusion. Many previous works treat video as a collection of frames. A common approach is to extract frame-by-frame features from deep networks pre-trained on the ImageNet classification task. Subsequently, these frame-wise features are fused using variants of pooling, temporal convolutions or LSTMs. To compensate for missing motion cues from static image features, a second network extracts motion features from flow or improved dense trajectories (IDT) separately - commonly known as two-stream approaches.
3D Convolution. Alternatively, 3D convolutions can be used to model video directly. 3D convolutions are a natural extension to traditional 2D convolutions with an extra dimension spanning the temporal domain. 3D convolution networks form a hierarchical representation of spatio-temporal data. However, because of an additional dimension in the convolution kernels, 3D convolutional networks have significantly more parameters compared to 2D networks, which leads to difficulty in optimization and over-fitting.
Temporal Aggregation Network. Our approach differs from both previous approaches. Our goal is to model spatio-temporal information by decomposing 3D convolutions into spatial and temporal dilated convolutions. By stacking both types of convolutions repeatedly, we form a temporal aggregation network (TAN) that not only captures spatio-temporal information but also creates hierarchical representations.
3.2 Proposed Temporal Aggregation Module
A Temporal Aggregation module combines multiple temporal convolutions with different dilation factors (in the temporal domain) and stacks them across the entire network. This supports the capture of context information across multiple spatio-temporal scales. Temporal convolution is a simple 1D convolution. A dilated convolution is a convolution whose filter has been dilated in space by a specific factor. They have been widely used in semantic segmentation and object detection tasks [45] to capture spatial context across scales. Here, we apply 1D dilated convolutions in the temporal dimension, see Fig. 2. They enable capturing larger context without reducing the resolution of the feature-map. Multiple temporal dilated convolutions not only help to model context across temporal scales but also form an internal attention mechanism to match a large range of motion frequencies.
Implementation. Given any feature inputs from previous layers, we apply one temporal convolution with a filter size of 3 and two dilated temporal convolutions with filter size 3 and dilation factors 2 and 3 respectively. All temporal convolutions are applied across all spatial positions and channels, which help to learn temporal patterns among different filter activations. Inspired by the recent success of residual networks [17], we also add a residual identity connection from previous layers. The responses from all convolutions are further accumulated by conducting element-wise sum followed by a ReLU non-linear activation, which together behave as a soft attention based weighted selection among different temporal resolutions. The proposed module is illustrated in Figure 2.
Relation to LSTM. Long short term memory (LSTM) units are normally used in sequence modeling. By using a gated connection, LSTM allows a network to ”remember” important context clues over time. Our temporal aggregation network behaves similarly by modeling temporal information using temporal convolutions. Additionally, our module is capable of distinguishing motion frequency differences among temporal resolutions, which is particularly useful when applied to action recognition tasks where actions having varying lengths.
Relation to Wavenet. Our temporal aggregation module is partially inspired by the Wavenet [36] model. Our module also uses dilated convolutions to model different temporal context at many time-scales. But there are significant differences. The major one is that our module is used in conjunction with spatial convolutions to capture both low-level and high-level temporal consistency among spatial positions, which is critical for modeling spatio-temporal relationships. Additionally, since we apply our module across different channels of spatial filter responses, it also behaves as a object instance trajectory learner similar to [39].
Relation to stack of convolutions with different filter sizes. It is possible to model multiple temporal resolutions by just stacking convolutions with different filter sizes. However, one of the main reasons we choose dilated convolution over convolution is computing cost. Multi-scale convolutions such as those used in models like inception [34], have to largely increase the size of learnable filters. To accomplish effective learning, one usually needs to resort to dimensionality reduction as the response channels increase in size rapidly. By using dilated convolution, we are able to achieve the same goal without reducing temporal resolution.
3.3 Spatial and Temporal Convolution Stacking
As discussed previously, we repeatedly stack spatial and temporal convolutions to model spatio-temporal information and create a hierarchical spatio-temporal representation. We need a deep architecture that can be effectively trained. Multi-entity actions, like “person picking a book”, typically involve larger and semantically richer spatio-temporal motion patterns which are better represented in deeper layers. On the other hand, other actions may be specific to an object instance, like “person smiling” which require high resolution spatio-temporal features (for smiling) while still understanding deeper semantic concepts like “person”. We seek to capture high-level semantic concepts while preserving high-resolution features generated in the early layers of the network. Residual networks are a good candidate since their linear structure with residual connections preserves information learned across different convolution levels.
To model spatial information, we borrow the bottleneck structure from residual networks. A bottleneck block is a stack of 3 convolution layers with filter size 1x1, 3x3 and 1x1. The 1x1 convolution layers are used to adjust dimensions and the 3x3 convolution layer behaves as a bottleneck with smaller input/output dimensions. A residual identity connection is also attached to accelerate learning. Each bottleneck block is followed by a ReLU non-linear activation.
The intuition behind repeatedly stacking spatial and temporal blocks among different levels is straight-forward. In the early stage of the network, we capture small spatio-temporal patterns using temporal convolutions as the spatial receptive field is small. In the deeper stages of the network, we progressively capture larger spatio-temporal patterns using temporal convolutions as the spatial receptive field increases. Meanwhile, our temporal aggregation blocks support capturing both fast and slow actions across temporal scales and across spatial levels. In this way, we form hierarchical spatio-temporal representations.
Stacking filters in the same block was first proposed in the VGG network [31] in which a single large convolution of size 7x7 was broken down into three successive kernels. Such a stacking of convolution kernels increased the depth of the network and also reduced the model complexity (as three 3x3 kernels have fewer parameters than one 7x7 kernel). The receptive field of the network was also the same as the original network which used 7x7 convolutions. Since neural networks are prone to over-fitting, by reducing the model complexity while preserving the desirable characteristics of the network (Zeiler and Fergus [46]), the VGG network reduced over-fitting and hence was able to improve its performance significantly on the image classification task. Our approach of stacking temporal convolutions after spatial convolutions employs a similar strategy for reducing model complexity - albeit for modelling spatio-temporal patterns, where over-fitting is a serious concern.
3.4 Full Model
The final architecture consists of four levels of bottleneck blocks for spatial modeling and temporal aggregation blocks for temporal modeling. In each level, there are multiple bottleneck blocks following by one temporal aggregation block similar to a residual network.
The weights of bottleneck blocks can be initialized using pre-trained ImageNet models. The spatial resolution is reduced after the initial convolution and pooling layers and after every level with max pooling. Notice that there is no temporal resolution reduction due to dilated convolutions in our temporal aggregation blocks. After all four levels of feature learning, the final feature outputs are pooled by average pooling and mapped to semantic space by a fully connected layer. Depending on the specific task, our network can both output an aggregated prediction or dense predictions with no extra cost. Our full model is illustrated in Figure 3.
4 Experiments
We conducted a series of ablation studies to illustrate the efficiency and effectiveness of our model. We then compare to state-of-the-art methods on dense multi-label action recognition tasks.
4.1 Datasets
Charades [29] contains 157 action classes from common everyday activities collected by 267 people at home. It has 7986 untrimmed videos for training and 1864 untrimmed videos for validation with an average length of 30 seconds. It is considered as one of the most challenging multi-label action recognition dataset.
MultiTHUMOS [43] contains 65 action classes and another 413 videos apart from the original THUMOS datatset [18] and extends it to a dense multi-label task with 1.5 labels per frame and 10.5 distinct action categories per video. It is suitable for an in-depth study of simultaneous human actions in video.
THUMOS14 [18] contains 20 sport action classes from over 24 hours of videos. The detection task contains 2765 trimmed videos for training, 1,010 untrimmed videos for validation, but only 200 untrimmed videos in validation and 213 untrimmed videos in testing set have foreground labels. This dataset is quite challenging because it contains long videos of multiple short action instances.
4.2 Ablation Study
Analysis of Temporal Modeling Methods. We first compare our model with two baselines. The three models are:
- •
Res50-2D: A model based on ResNet-50, trained frame-by-frame and with an LSTM at the end to generate predictions.
- •
Res50-3D: A model using 3D convolutions to replace all 2D convolutions in ResNet-50. For example, we use 3x3x3 convolutions instead of 3x3 convolutions and use a stride size of 2x2x2 instead of 2x2 when needed.
- •
Res50-TAN: Our proposed method with spatial convolution layers initialized from ResNet-50.
All models take a 16 frame clip with 224x224 resolution as input in 4 FPS, which corresponds to about 4 seconds. As 3D convolutions require large number of training data, to maintain fairness in experiments, all models are pre-trained on the recently released large scale Kinetics dataset [2] and then fine-tuned and tested on the Charades dataset [29]. The results are shown in Table 1. We evaluated on both frame-level mAP and video-level mAP. Our proposed TAN clearly outperforms the baseline methods, while the 3D convolution version performs worst due to the reduction of temporal resolution.
Effectiveness of the Temporal Aggregation Module. We evaluate the effectiveness of our network architecture by conducting an ablation study by varying the position of the temporal aggregation module in the network, such as only at the final level 4, only at level 3,4 and at level 2,3,4. We also describe an experiment by replacing our temporal aggregation module with a simple 3x1x1 temporal convolution. Table 2 shows the comparative results. As more temporal aggregation modules are added, performance improves. This shows that our model can learn hierarchical spatio-temporal patterns. Meanwhile, we also evaluate the effectiveness of temporal dilated convolutions in the temporal aggregation module. When we replace our temporal aggregation module with a simple temporal convolution, performance drops significantly by 2% on Frame mAP and 3.1% on Video mAP. This shows that our temporal aggregation module is more effective at modeling temporal information from multiple temporal scales.
Impact of Sampling Rate in Videos. We train and test our model with four different video sampling rates of 1,2,4,8 FPS. As seen in Table 3, the performance doesn’t drop significantly until we aggressively drop the video sampling rate to 1FPS. Our model shows reasonable immunity to variances of temporal resolution.
Impact of Networks Layers. We also conduct an ablation study to investigate the influence of depth of networks. Here, we only vary the number of bottleneck blocks used in level 3 and level 4, similar to ResNet, leaving the temporal blocks unchanged at the end of each level. Table 4 shows that our model can further benefit from deeper networks.
Impact of Pretraining. Finally, we conduct an ablation study to investigate the influence of pretraining. Table 5 shows that our model can further benefit from larger dataset, meanwhile even without pretraining, our method still achieves state-of-the-art performance compared to previous approaches.
4.3 Multi-label Action Recognition
We conduct experiments on two popular multi-label action recognition datasets and compare our results to state-of-the-art methods.
Implementation details. For all datasets, we use a temporal aggregation network based on ResNet-152 with a 16 frame temporal resolution. It is pre-trained on the Kinetics dataset and fine-tuned later. For the Charades dataset, we use a sampling rate of 4 FPS. We optimized our model using the Adam optimizer with a learning rate of for the first 10 epochs and in the following 10 epochs. It is evaluated using two metrics following [29]: one is a video level mAP for video based multi-label classification and the other is a frame level mAP uniformly extracted at 25 frames per video to approximate the multi-label action detection task. For video level classification, average pooling is used to map dense frame level labels to video level labels. For MultiTHUMOS, we use a sampling rate of 10 FPS following [43]. We also optimized our model using the Adam optimizer with a learning rate of for the first 10 epochs and in the following 5 epochs. Finally, MultiTHUMOS is also evaluated using the standard frame level mAP metric.
Comparison with state-of-the-art. On Charades, we compare with several state-of-the-art methods such as [29, 35, 38, 13, 27, 15, 10]. Our results are shown in Table 6. We first show results of our model without Kinetics pre-training, and it still outperforms state-of-the-art methods by 1.2% on frame level mAP and 2.9% on video level mAP. Our model with Kinetics pre-training obtains a significant improvement over other methods and outperforms them by 4.8% on frame level mAP and 8.6% on video level mAP respectively. On MultiTHMOS, we compare with [31, 13, 43, 10] in Table 7. Our model performs 3.6% better than the previous state-of-the-art method [10]. We also compare our model with several recent network on THUMOS14, such as [31, 13, 43, 25, 10]. As seen in Table 8, our model again outperforms previous state-of-the-art methods [25] by 2.4% on frame-level evaluation.
4.4 Visualization
We visualize the filter responses of our network to better understand what is learned in different levels in Figure 4. In the example, we observe that the early layer filters have responses spread over a larger part of the image, while the later layers learn to focus where the action is present. To better understand how the network learns spatial-temporal consistency, we also visualize representative filter responses after each level of temporal aggregation block, shown in Figure 5. In spatial domain, the sallow layers tend to highlight fine-grained movement (such as facial, hand movement) and the deep layers tend to highlight large movement (such as body movement), due to the spatial effective receptive window increases as network goes deep. In temporal domain, the network is capable of capturing action sequence of variable length, thanks to our temporal aggregation blocks. Meanwhile, it is interesting to see that how spatial-temporal responses group up as the network advances. This demonstrates that our model progressively constructs hierarchical spatio-temporal representations for recognizing human actions.
We also present qualitative results for different samples in Figure 6. These results show that our network is effective in localizing both long and short duration actions simultaneously. Notice that it also predicts labels of multiple actions happening at the same time instance.
5 Conclusion
We presented a temporal aggregation module that combines temporal convolution with varying levels of dilated temporal convolutions to capture spatio-temporal information across multiple scales. We compare our design with multiple temporal modeling methods. Based on this, we designed a deep network architecture for video applications. Our model stacks spatial convolutions and the new temporal aggregation module repeatedly to learn a hierarchical spatio-temporal representation. It is both efficient and effective compared to existing methods such as 3D convolution networks and two-stream networks. We conduct ablation studies to analyze our model and experiments on multi-label action recognition and pre-frame action recognition datasets prove the effectiveness of our method.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. F. Bobick and J. W. Davis. The recognition of human movement using temporal templates. IEEE Transactions on pattern analysis and machine intelligence , 23(3):257–267, 2001.
- 2[2] J. Carreira and A. Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , July 2017.
- 3[3] D. Chen, L. Yuan, J. Liao, N. Yu, and G. Hua. Stylebank: An explicit representation for neural image style transfer. In Proc. CVPR , volume 1, page 4, 2017.
- 4[4] D. Chen, L. Yuan, J. Liao, N. Yu, and G. Hua. Stereoscopic neural style transfer. CVPR 2018 , 2018.
- 5[5] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. ar Xiv preprint ar Xiv:1606.00915 , 2016.
- 6[6] J. Dai, Y. Li, K. He, and J. Sun. R-FCN: object detection via region-based fully convolutional networks. Co RR , abs/1605.06409, 2016.
- 7[7] X. Dai, J. Y.-H. Ng, and L. S. Davis. Fason: First and second order information fusion network for texture recognition. In IEEE Conference on Computer Vision and Pattern Recognition , pages 7352–7360, 2017.
- 8[8] X. Dai, B. Singh, G. Zhang, L. S. Davis, and Y. Qiu Chen. Temporal context network for activity localization in videos. In The IEEE International Conference on Computer Vision (ICCV) , Oct 2017.