TL;DR
This paper introduces sampling-based iterative methods for large-scale inverse problems, enabling Tikhonov regularization with adaptive parameter updates and demonstrating effectiveness in super-resolution imaging.
Contribution
It proposes a family of sampled iterative methods that incorporate data as it becomes available, with adaptive regularization parameter updates for improved convergence.
Findings
Methods converge to Tikhonov-regularized solutions
Adaptive regularization improves solution quality
Numerical examples demonstrate practical effectiveness
Abstract
In this paper, we investigate iterative methods that are based on sampling of the data for computing Tikhonov-regularized solutions. We focus on very large inverse problems where access to the entire data set is not possible all at once (e.g., for problems with streaming or massive datasets). Row-access methods provide an ideal framework for solving such problems, since they only require access to "blocks" of the data at any given time. However, when using these iterative sampling methods to solve inverse problems, the main challenges include a proper choice of the regularization parameter, appropriate sampling strategies, and a convergence analysis. To address these challenges, we first describe a family of sampled iterative methods that can incorporate data as they become available (e.g., randomly sampled). We consider two sampled iterative methods, where the iterates can be…
Click any figure to enlarge with its caption.
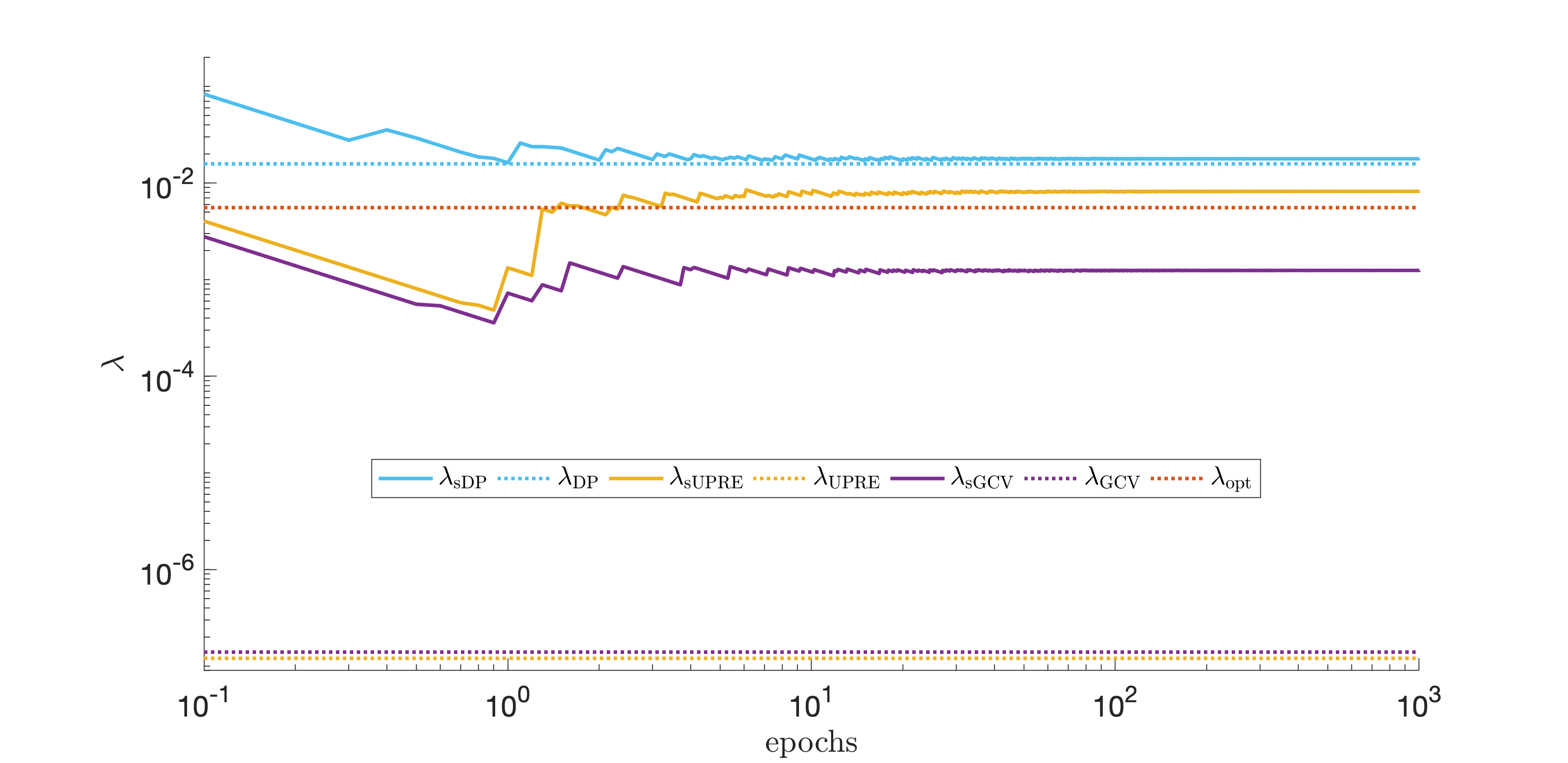 Figure 1
Figure 1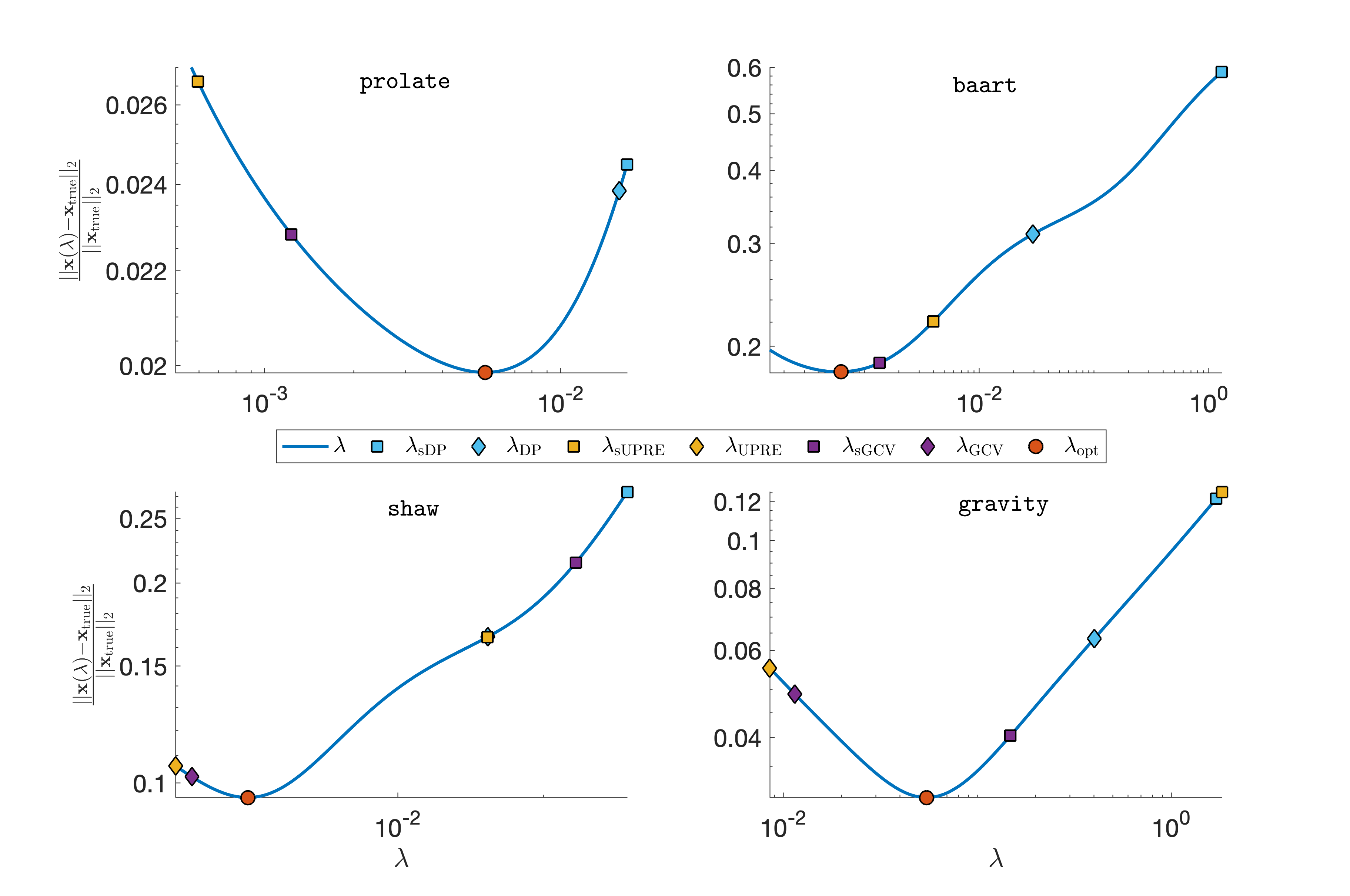 Figure 2
Figure 2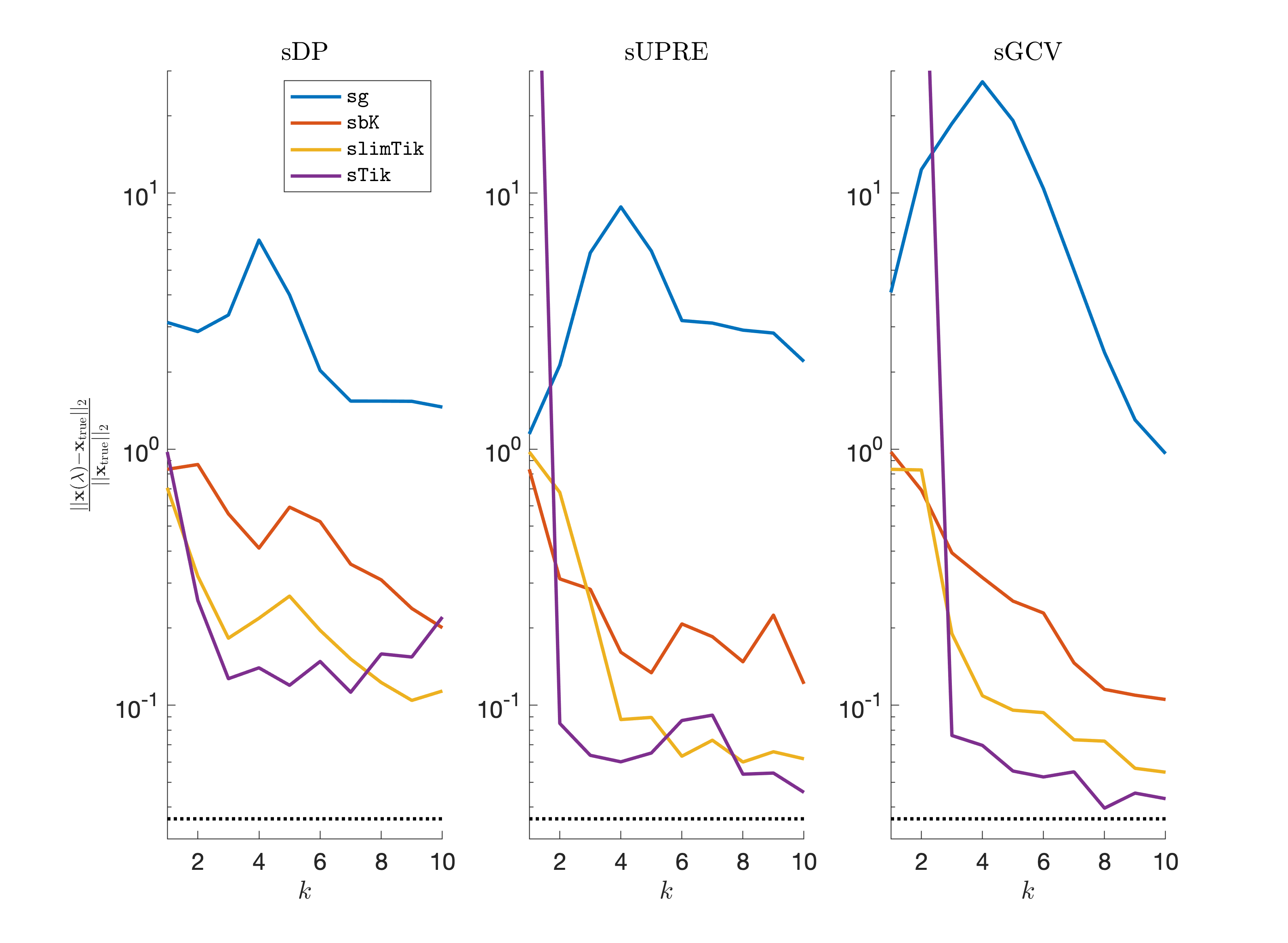 Figure 3
Figure 3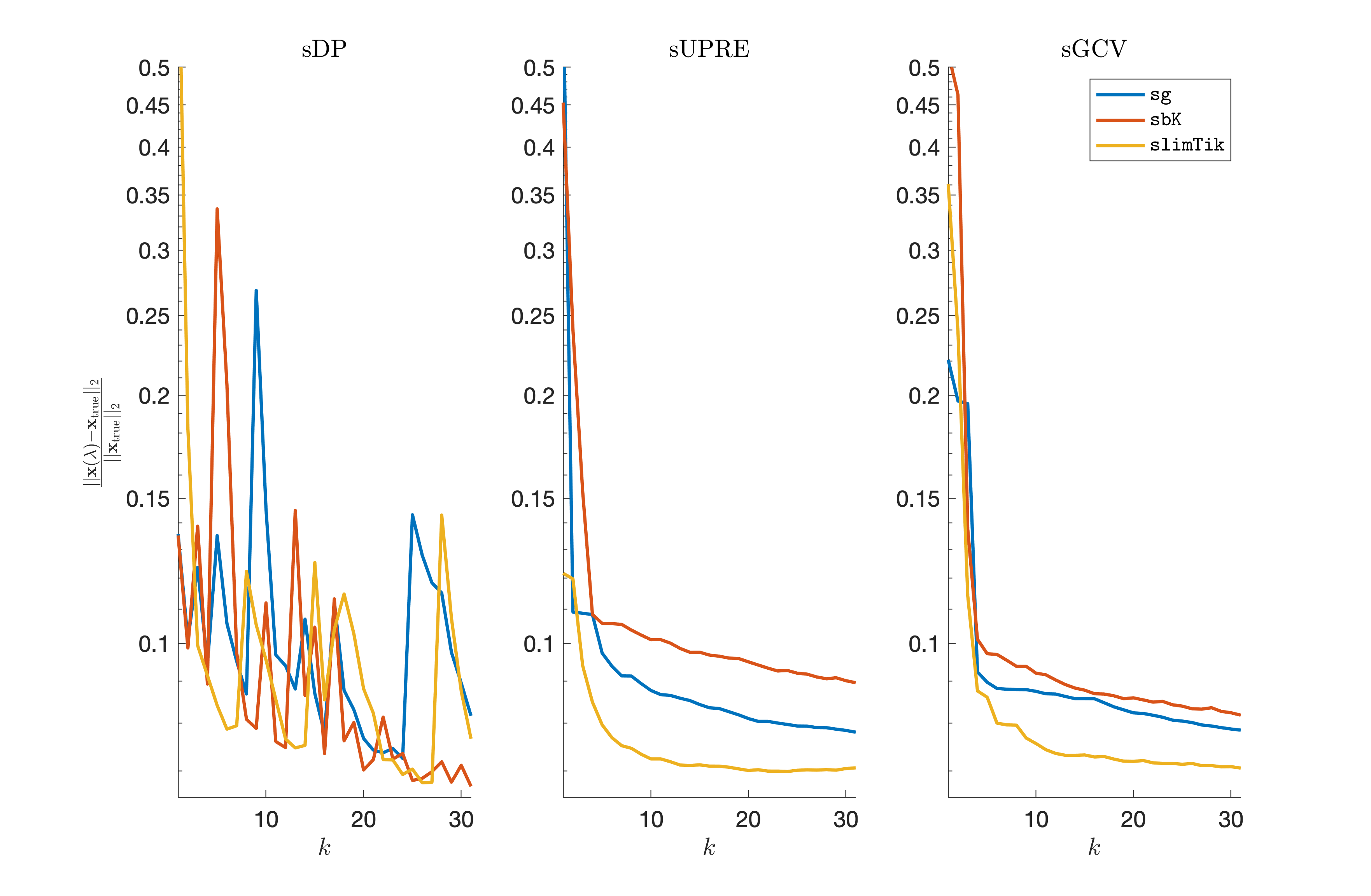 Figure 4
Figure 4 Figure 5
Figure 5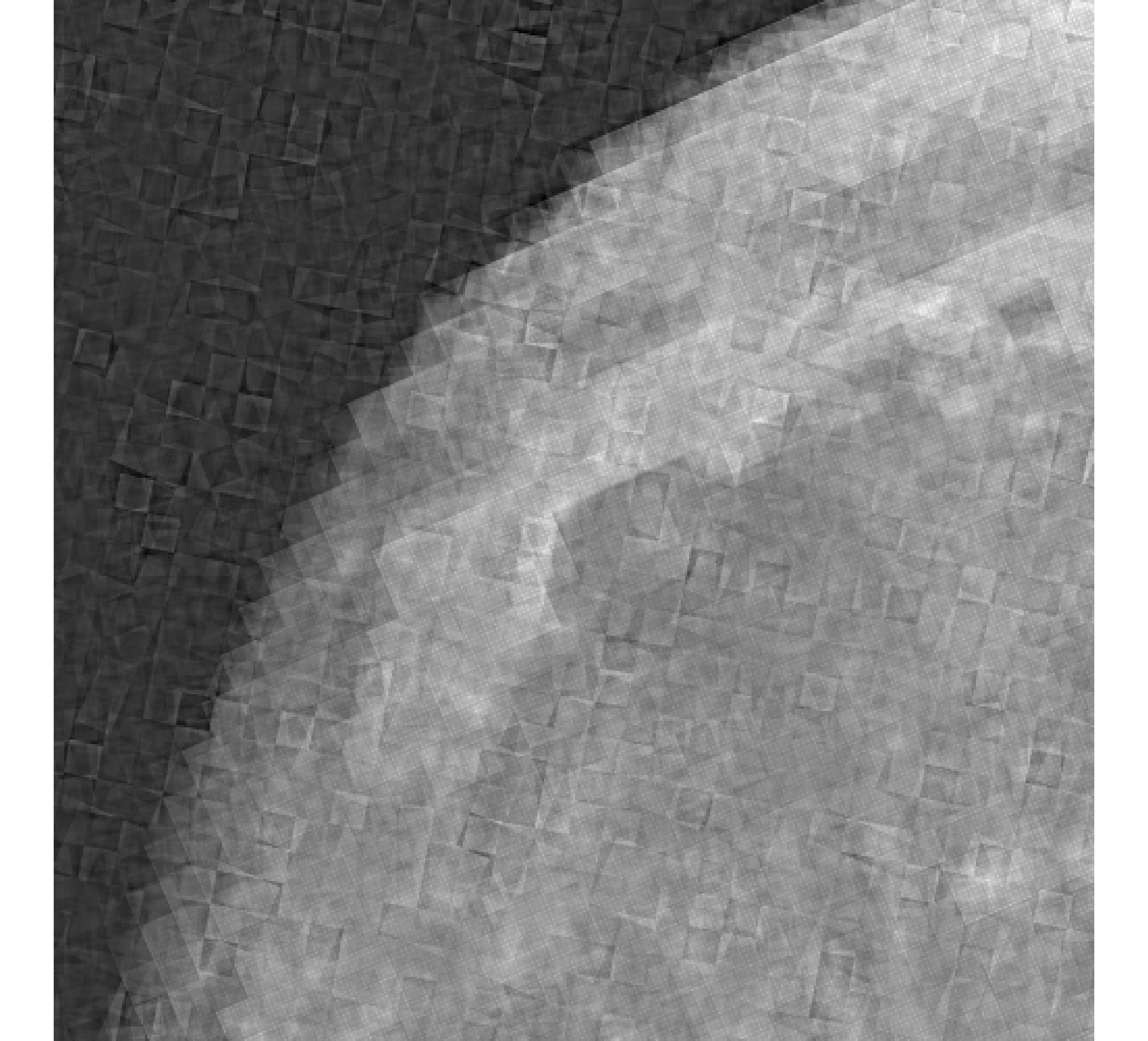 Figure 6
Figure 6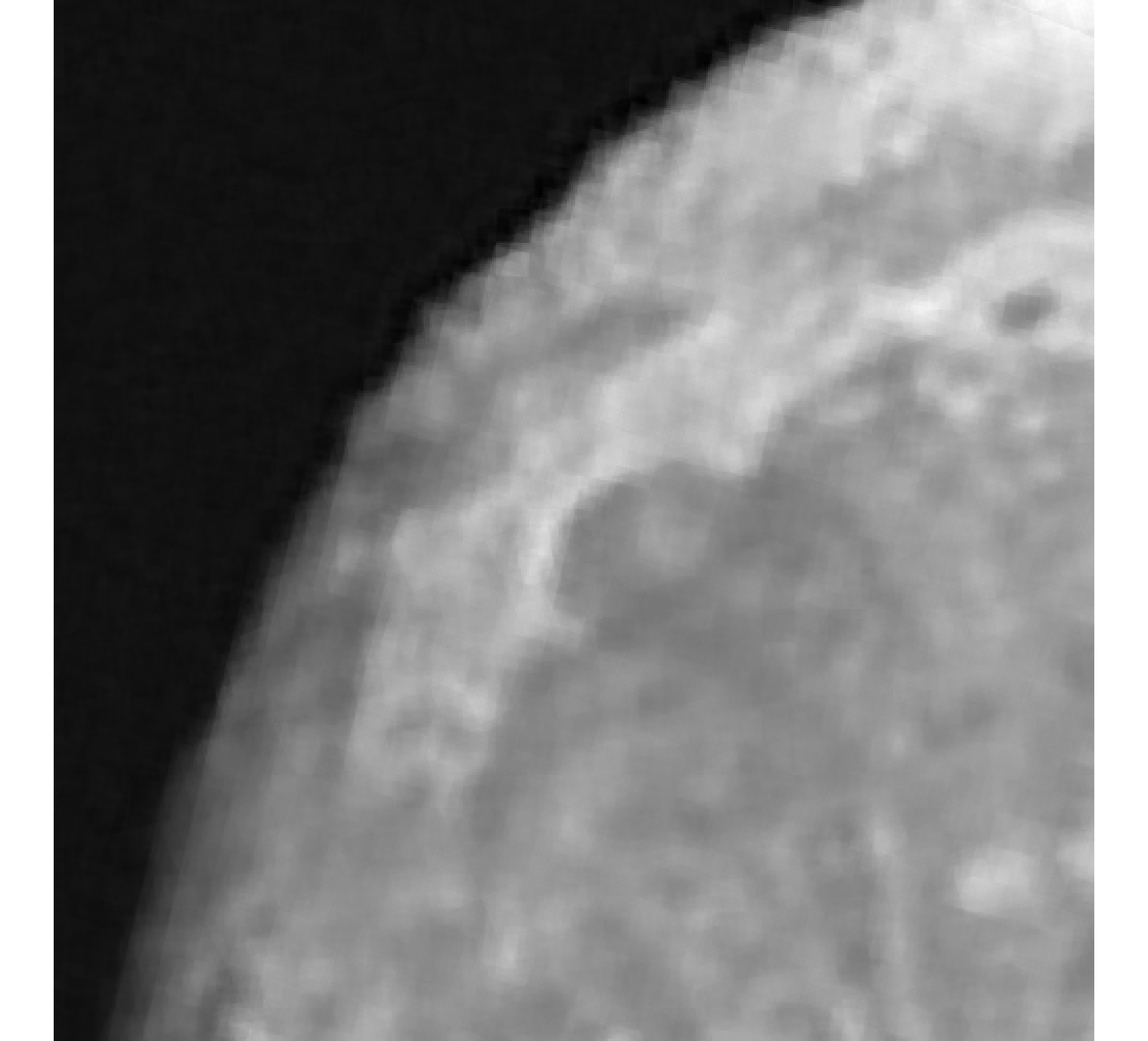 Figure 7
Figure 7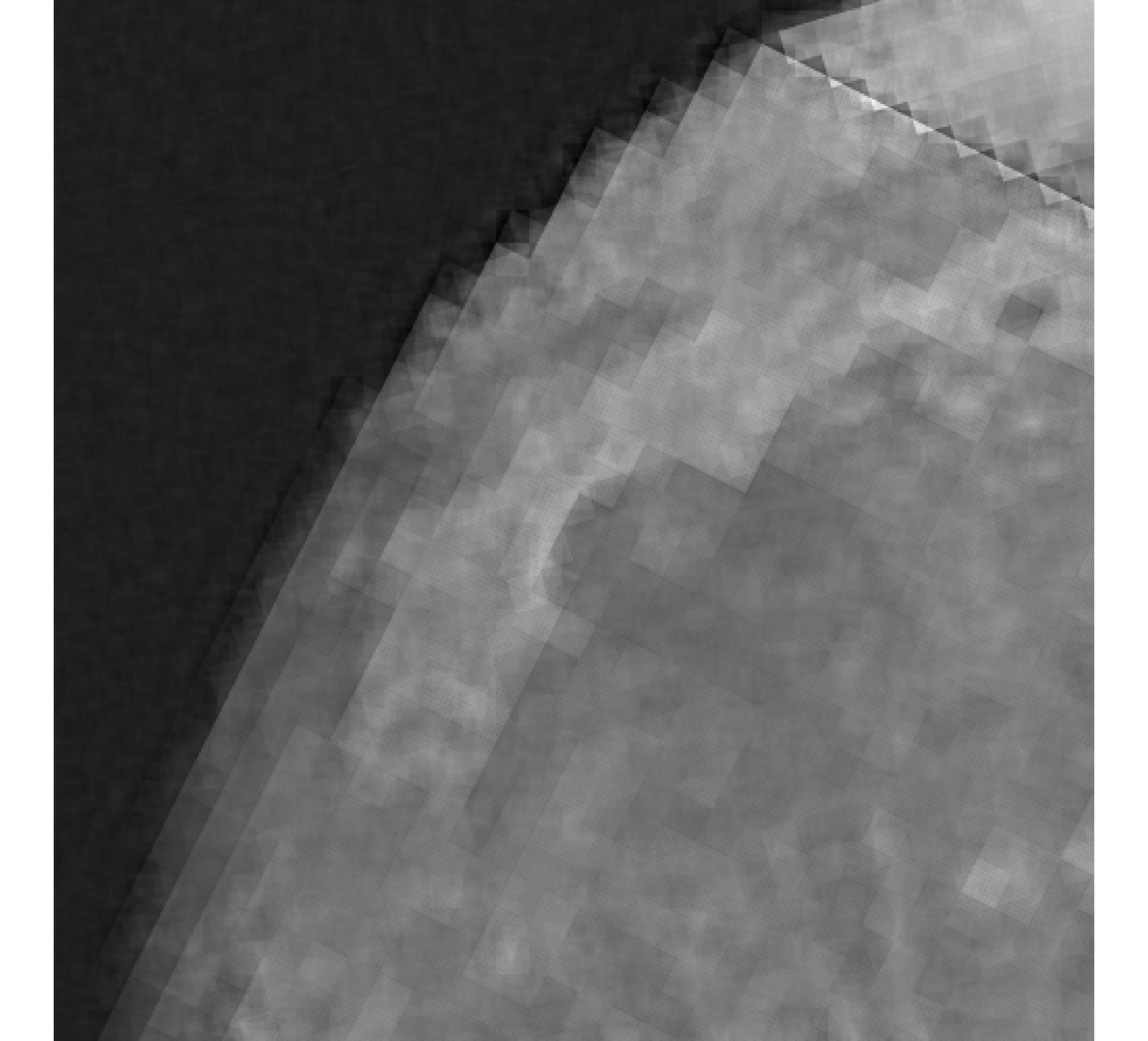 Figure 8
Figure 8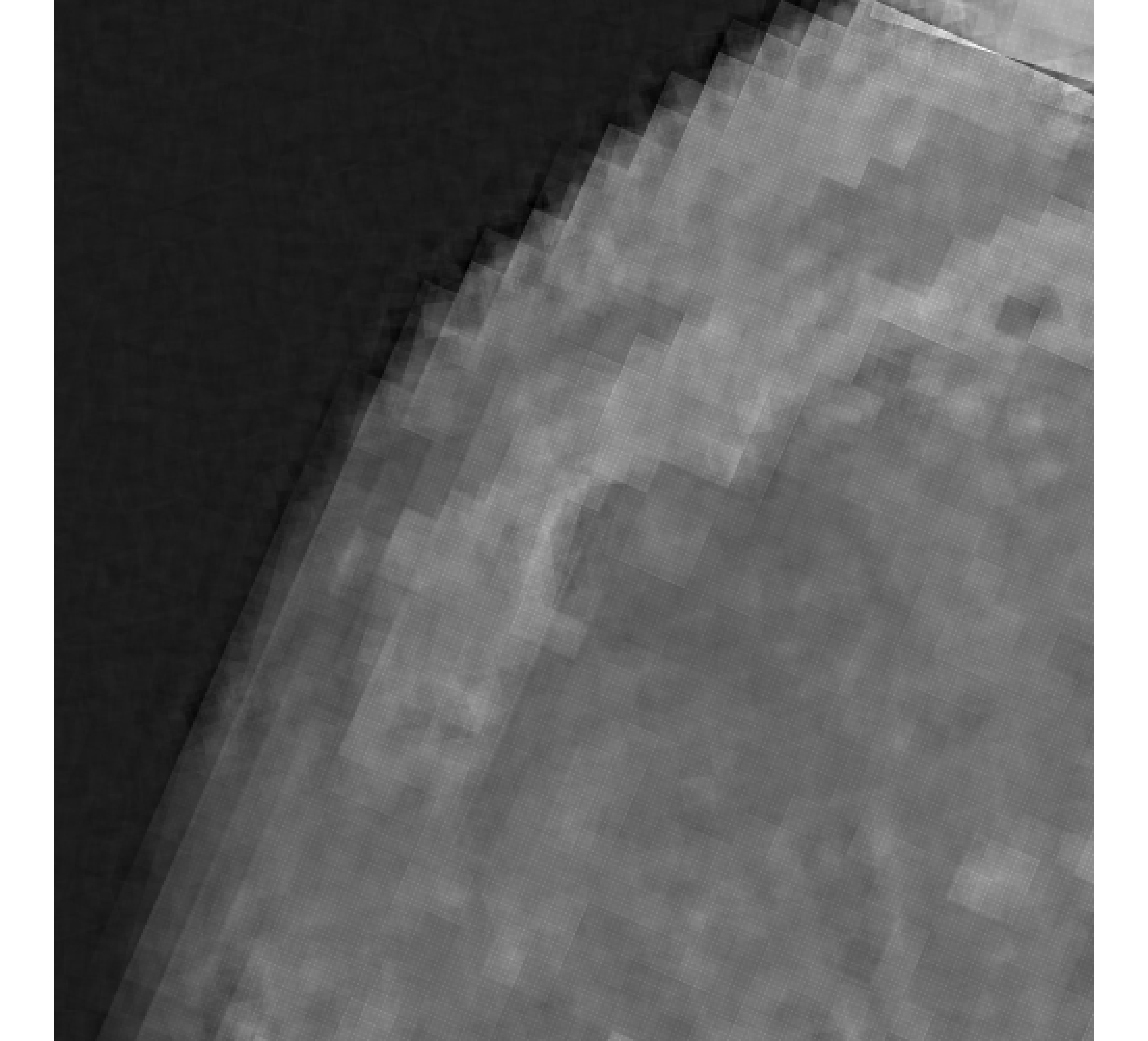 Figure 9
Figure 9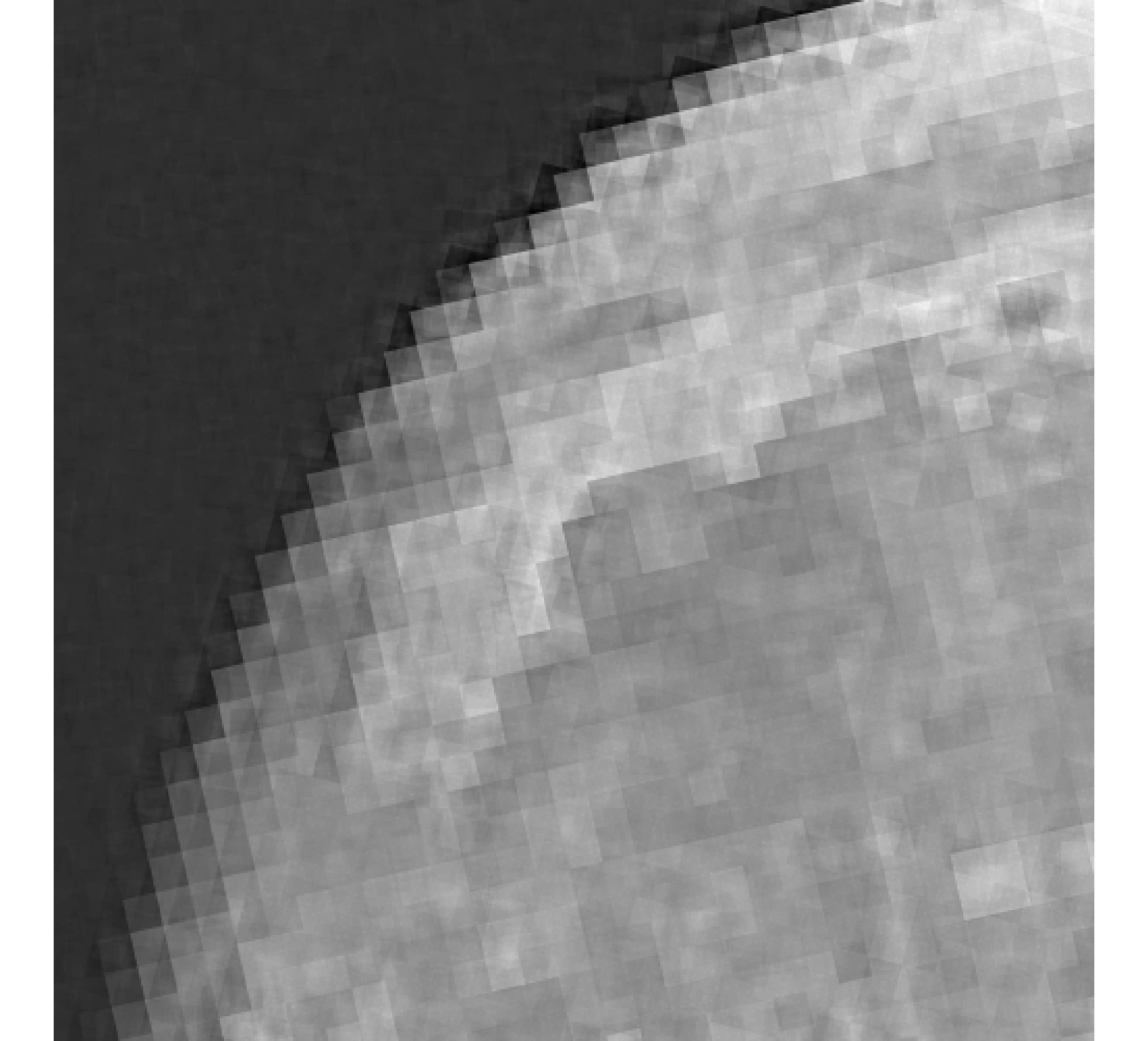 Figure 10
Figure 10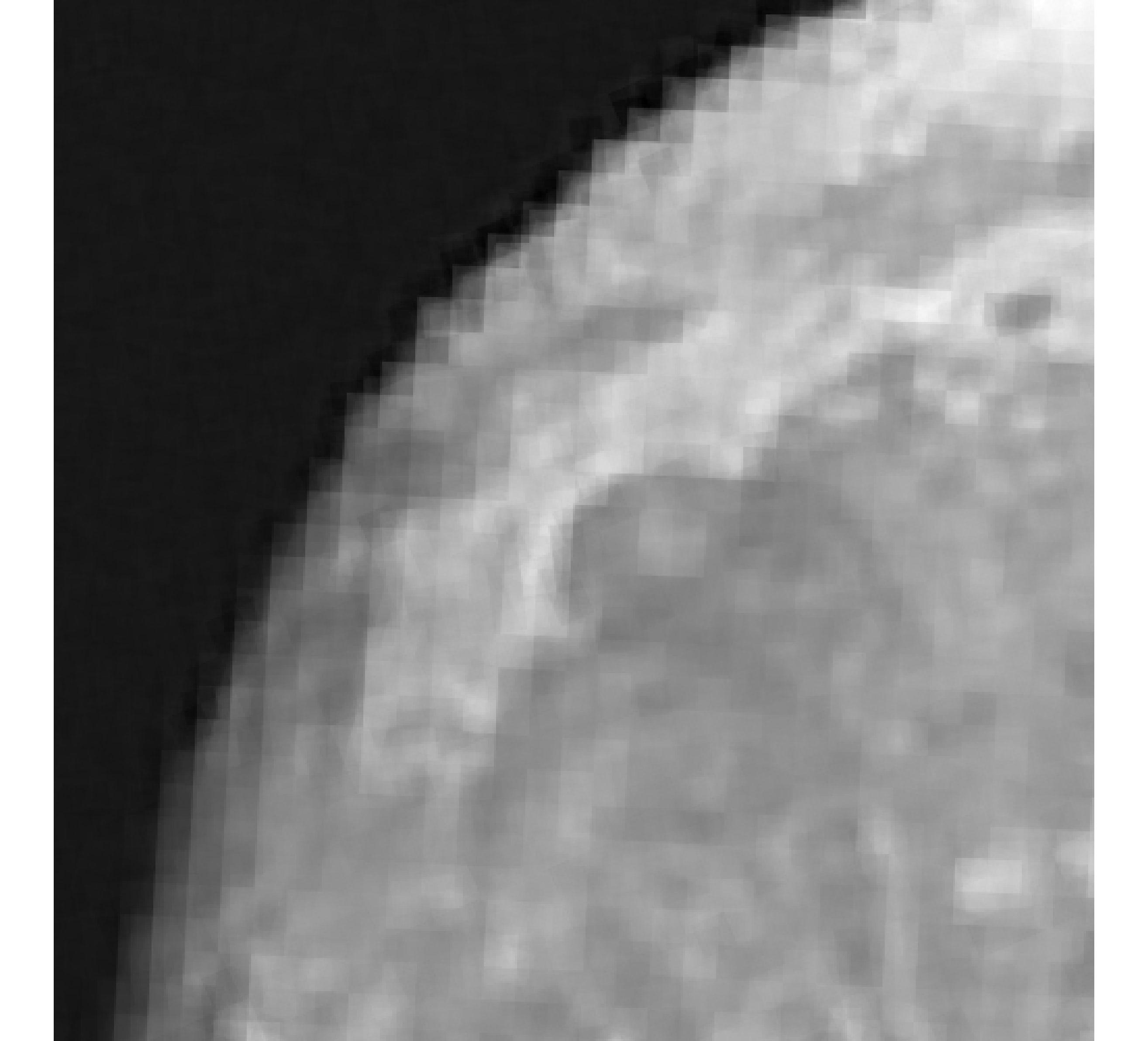 Figure 11
Figure 11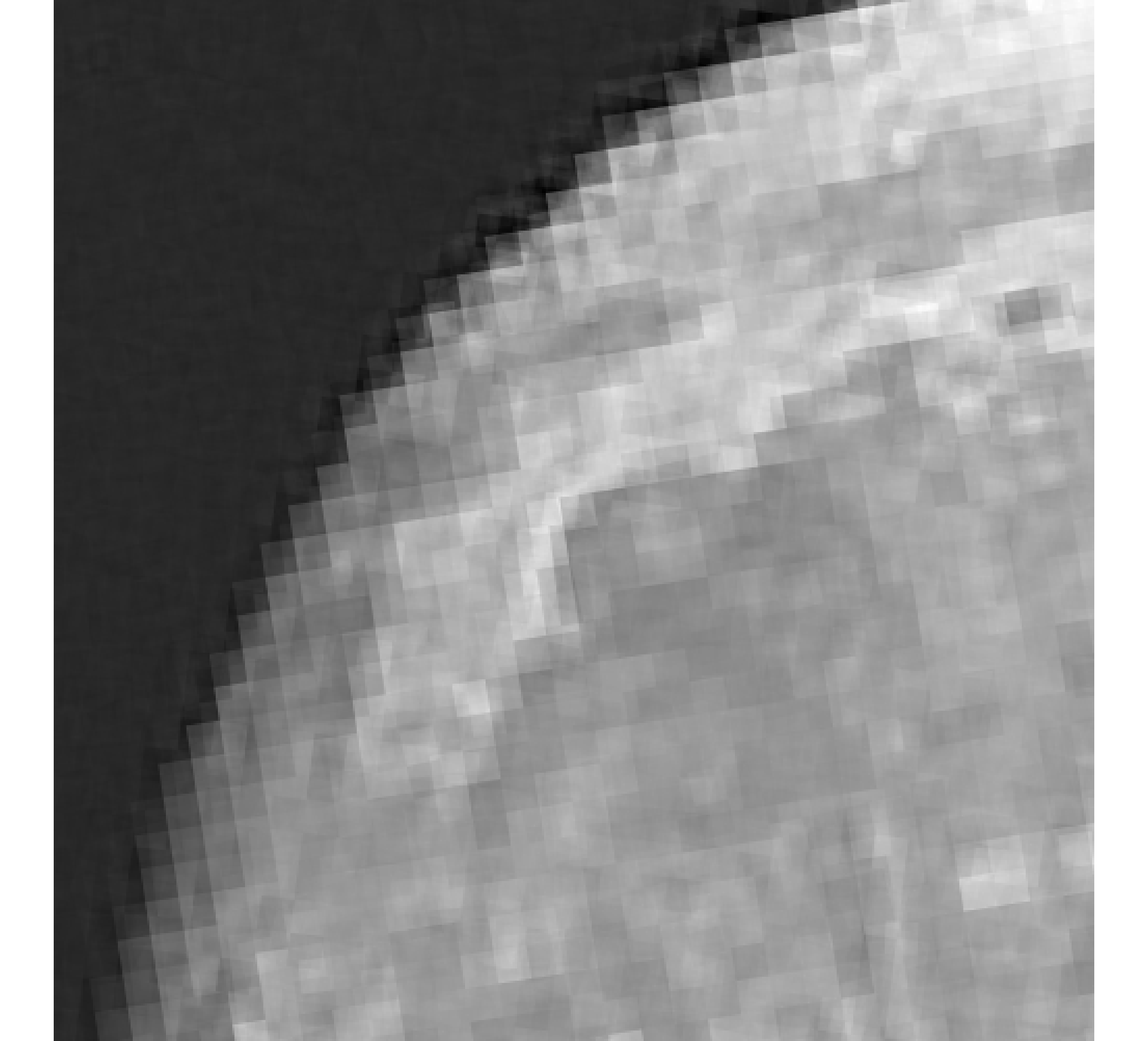 Figure 12
Figure 12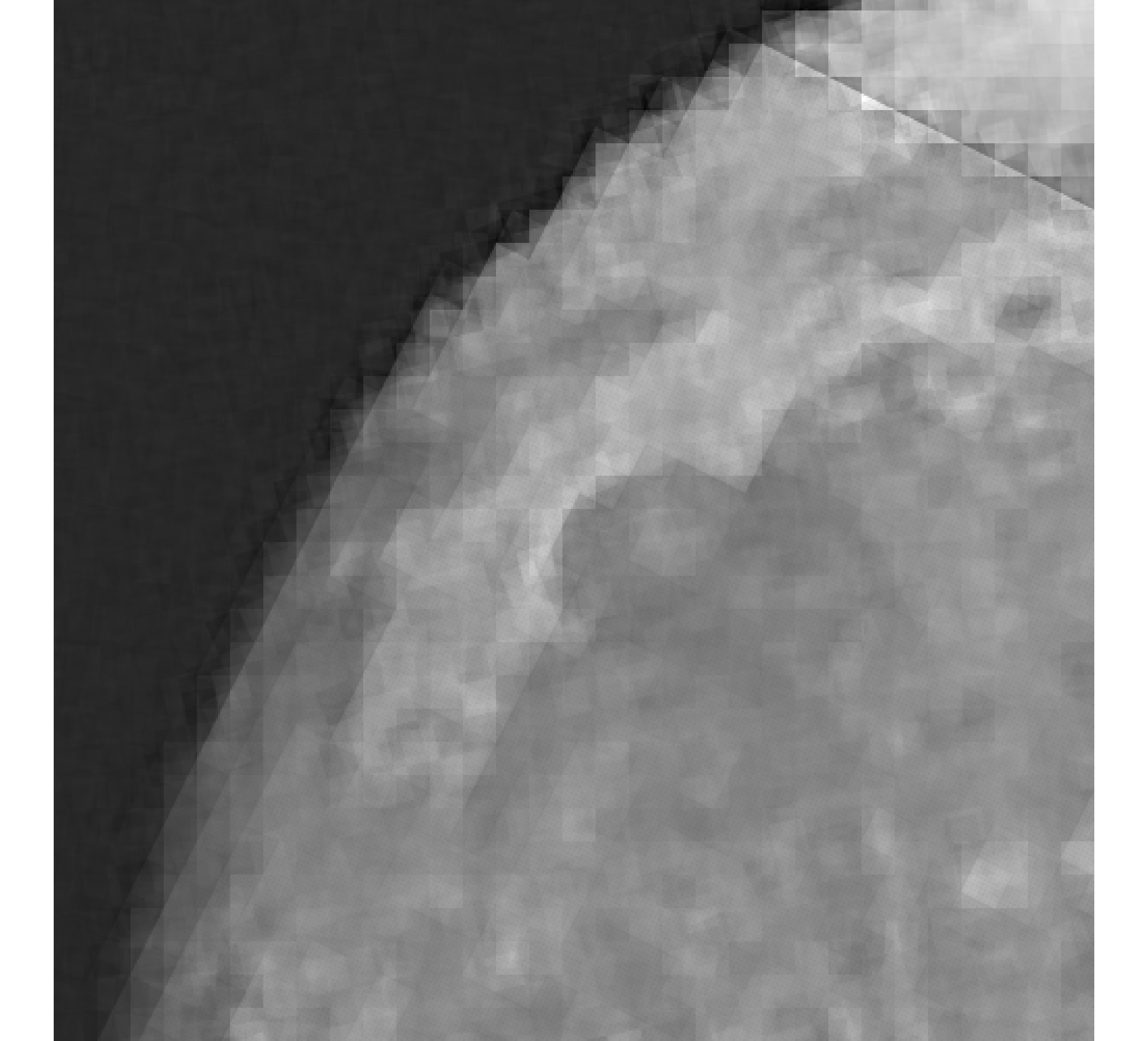 Figure 13
Figure 13 Figure 14
Figure 14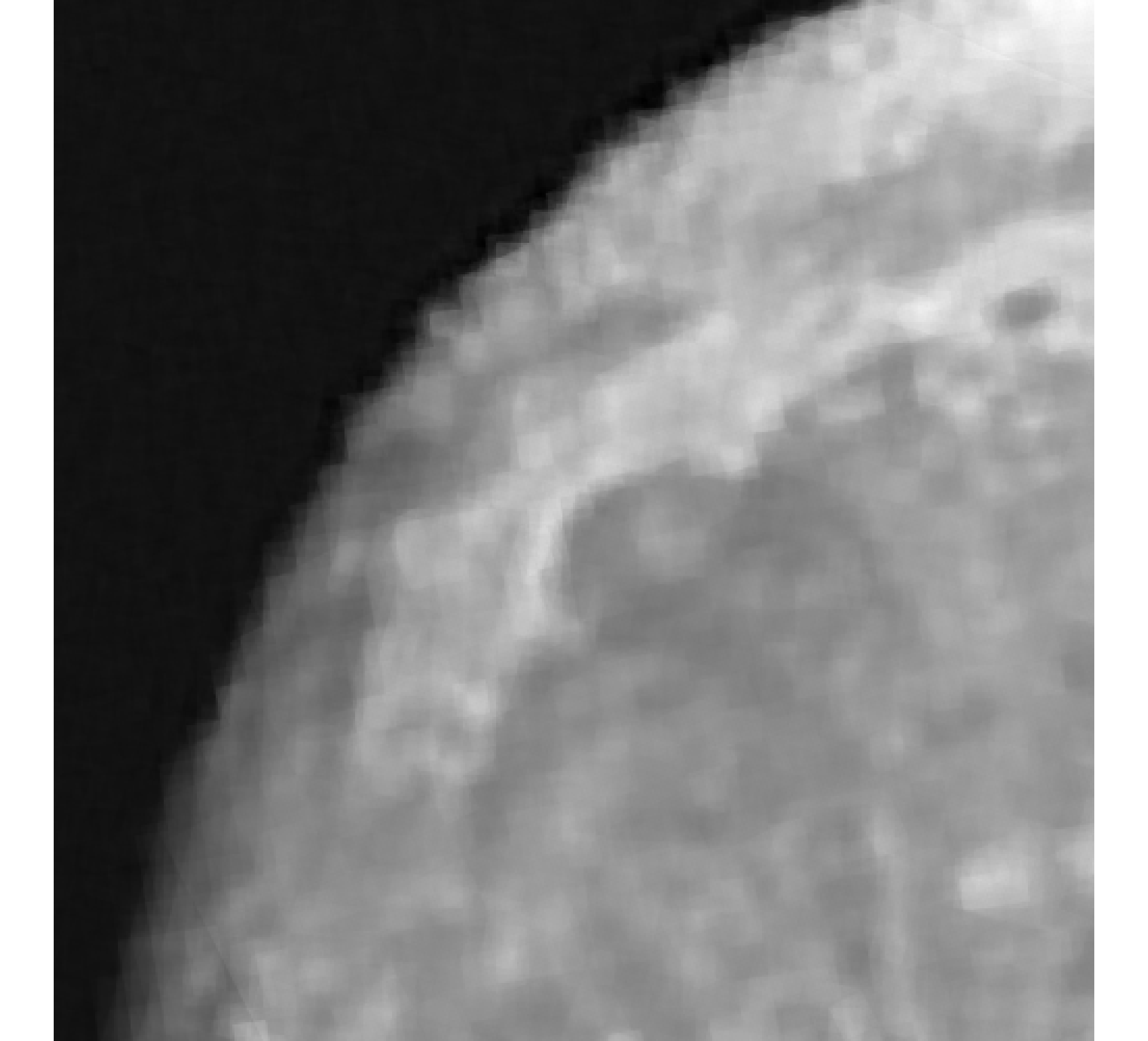 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17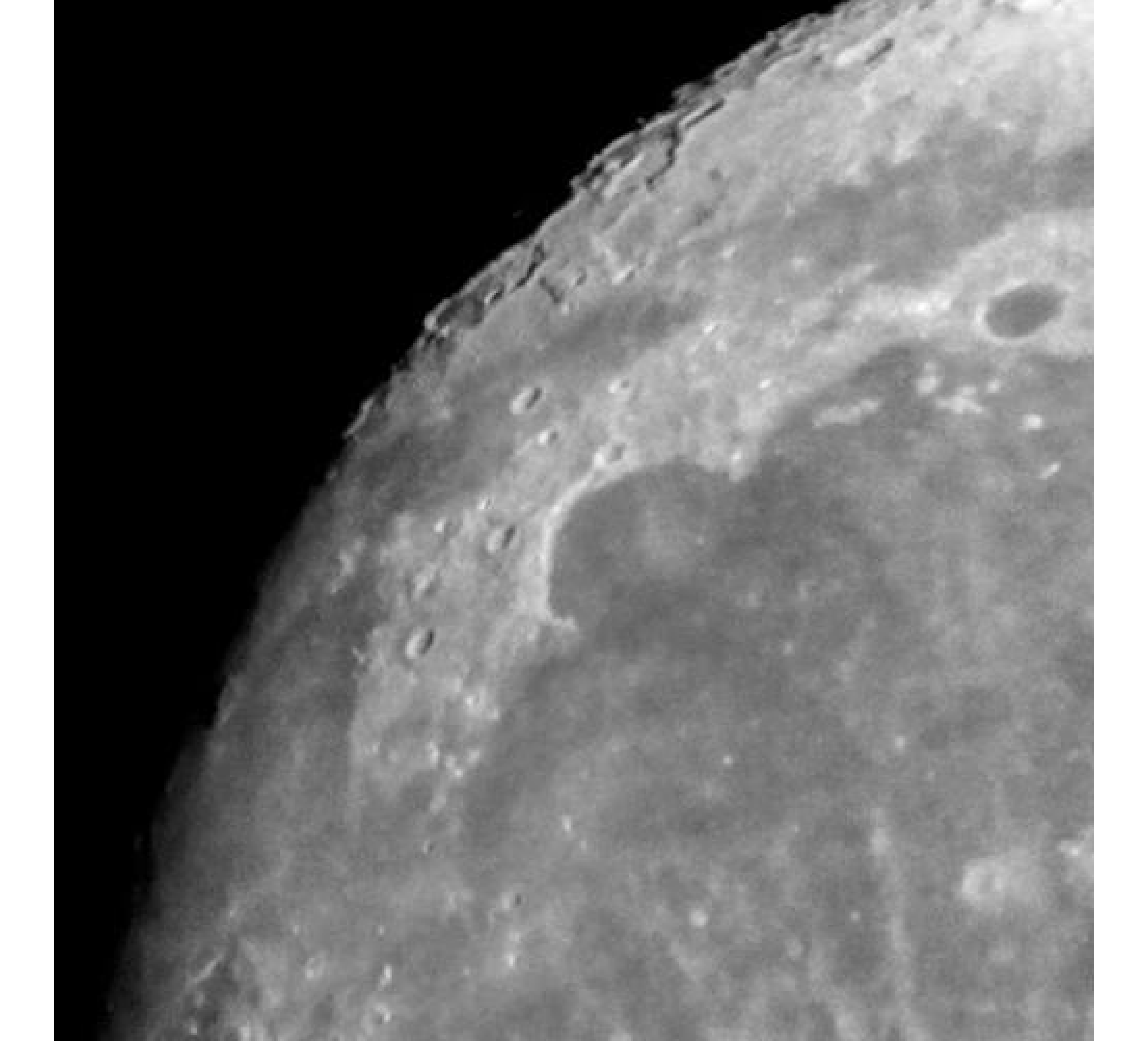 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21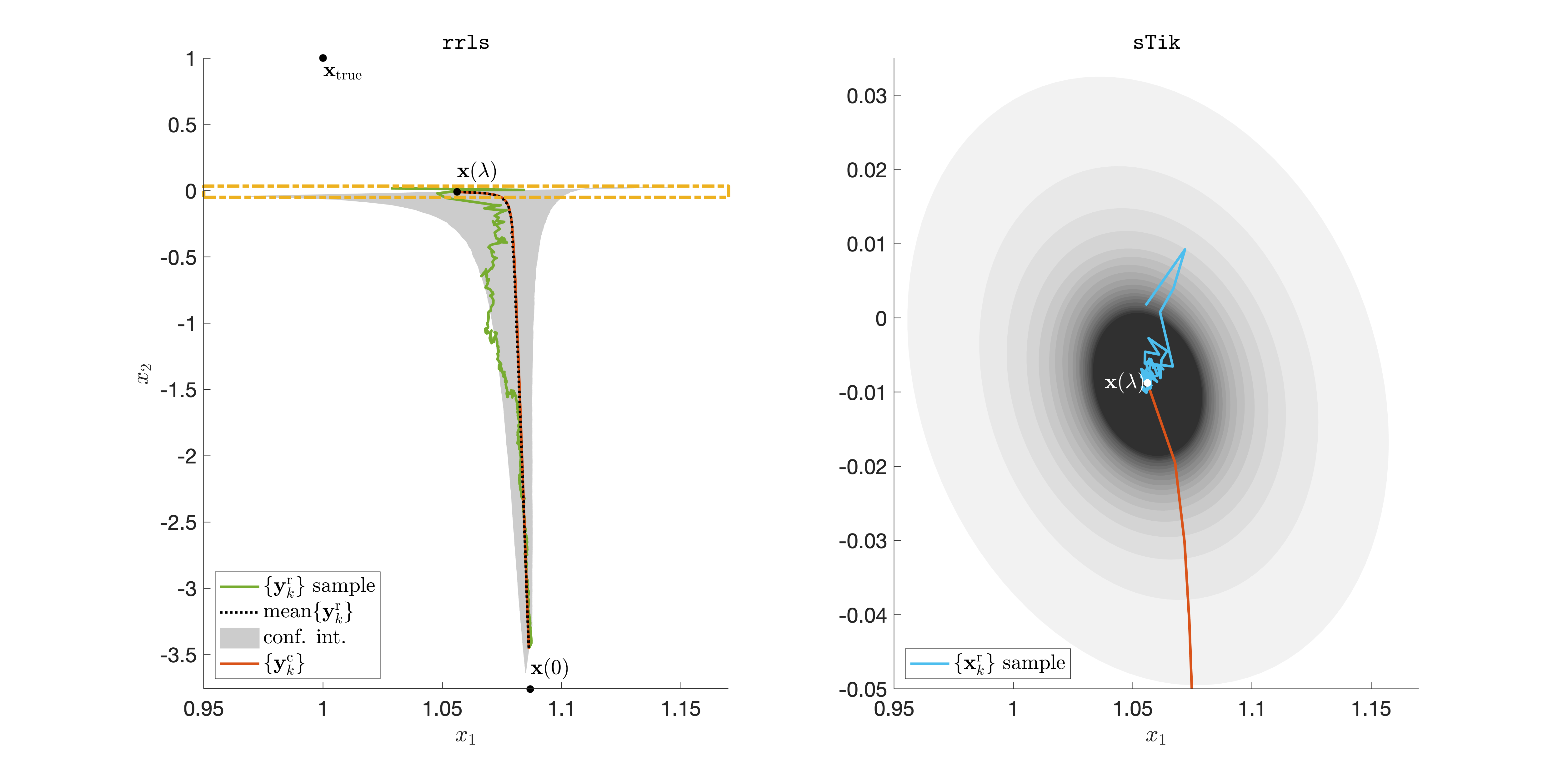 Figure 22
Figure 22 Figure 23
Figure 23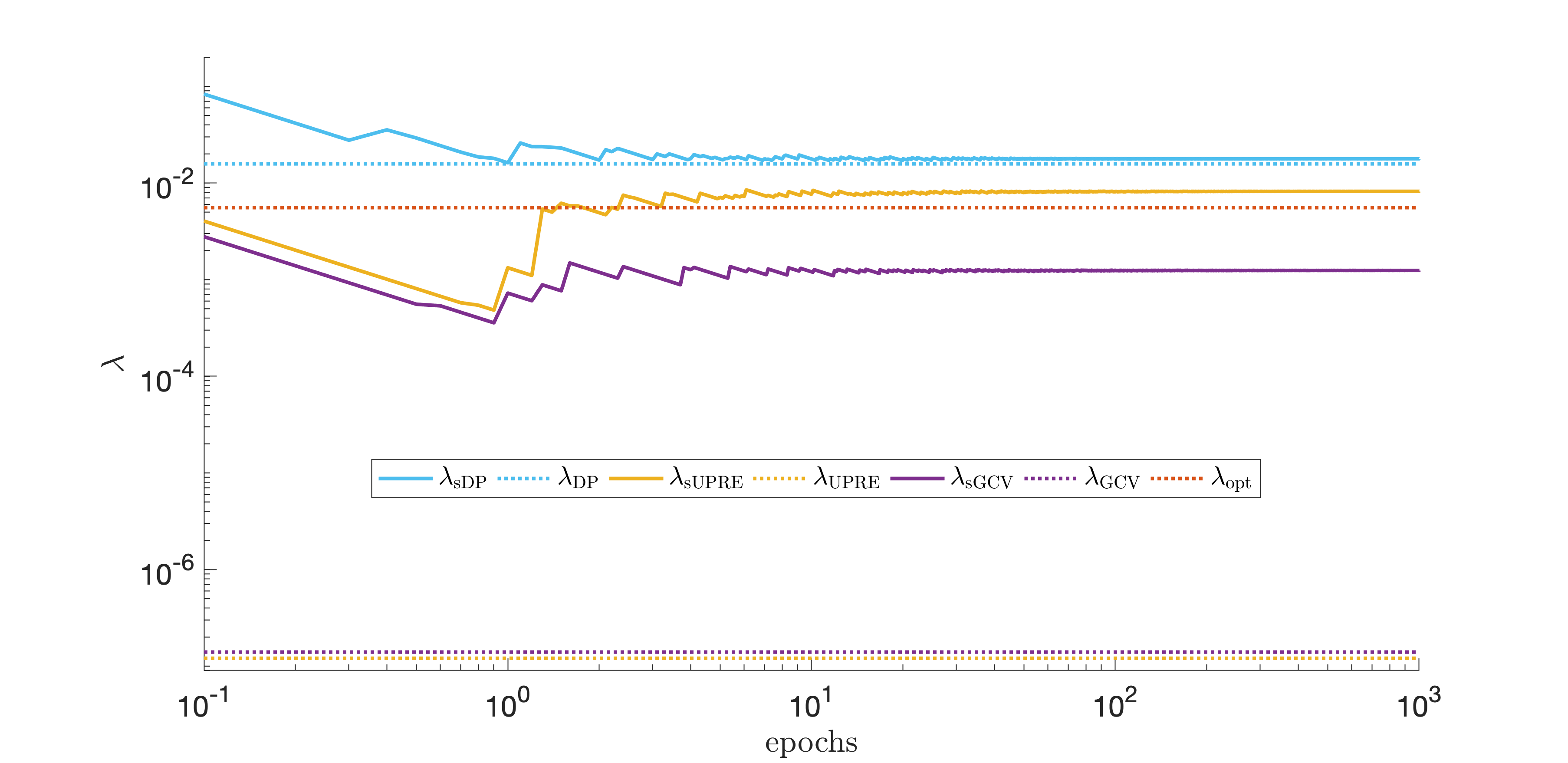 Figure 24
Figure 24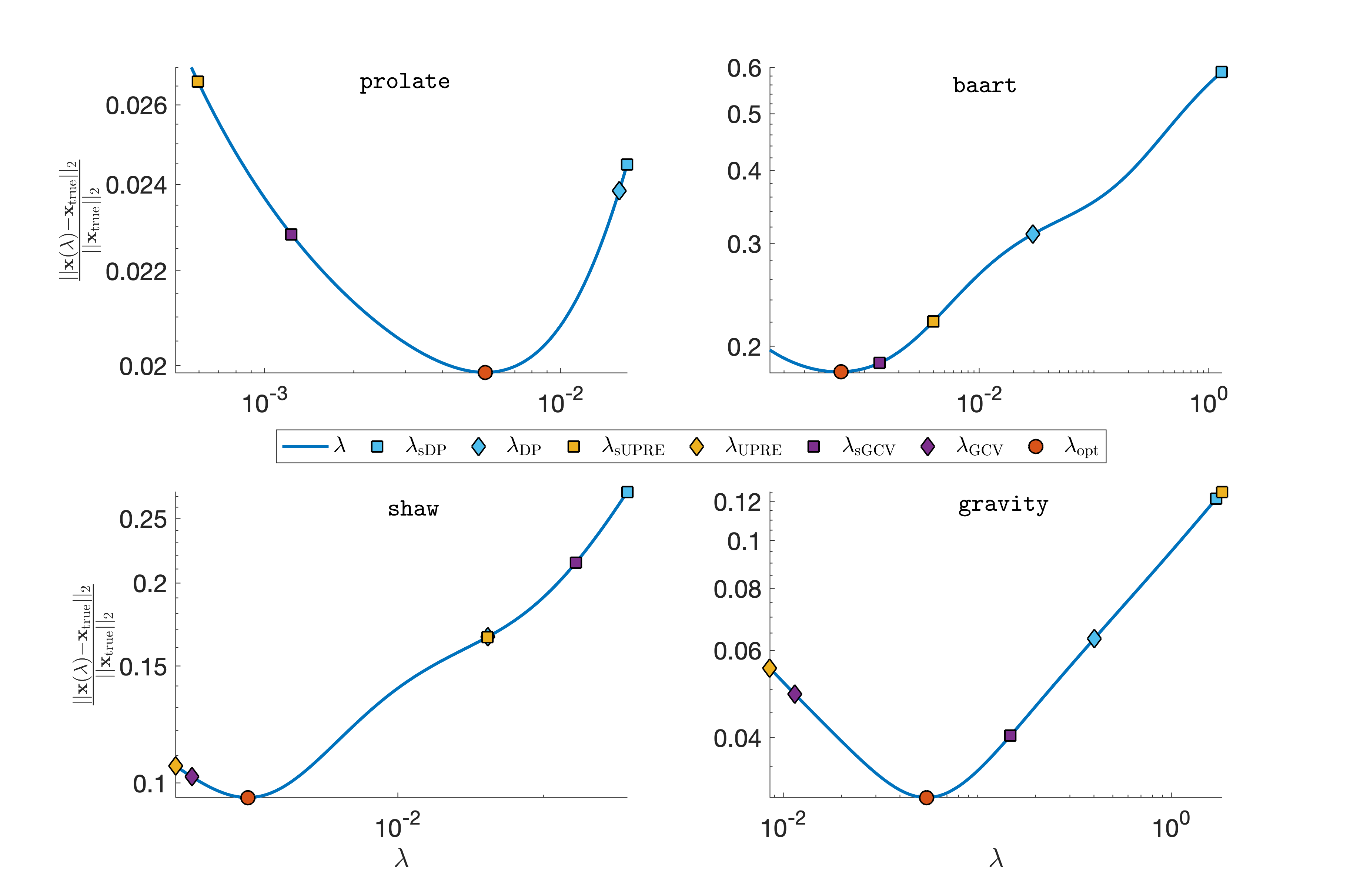 Figure 25
Figure 25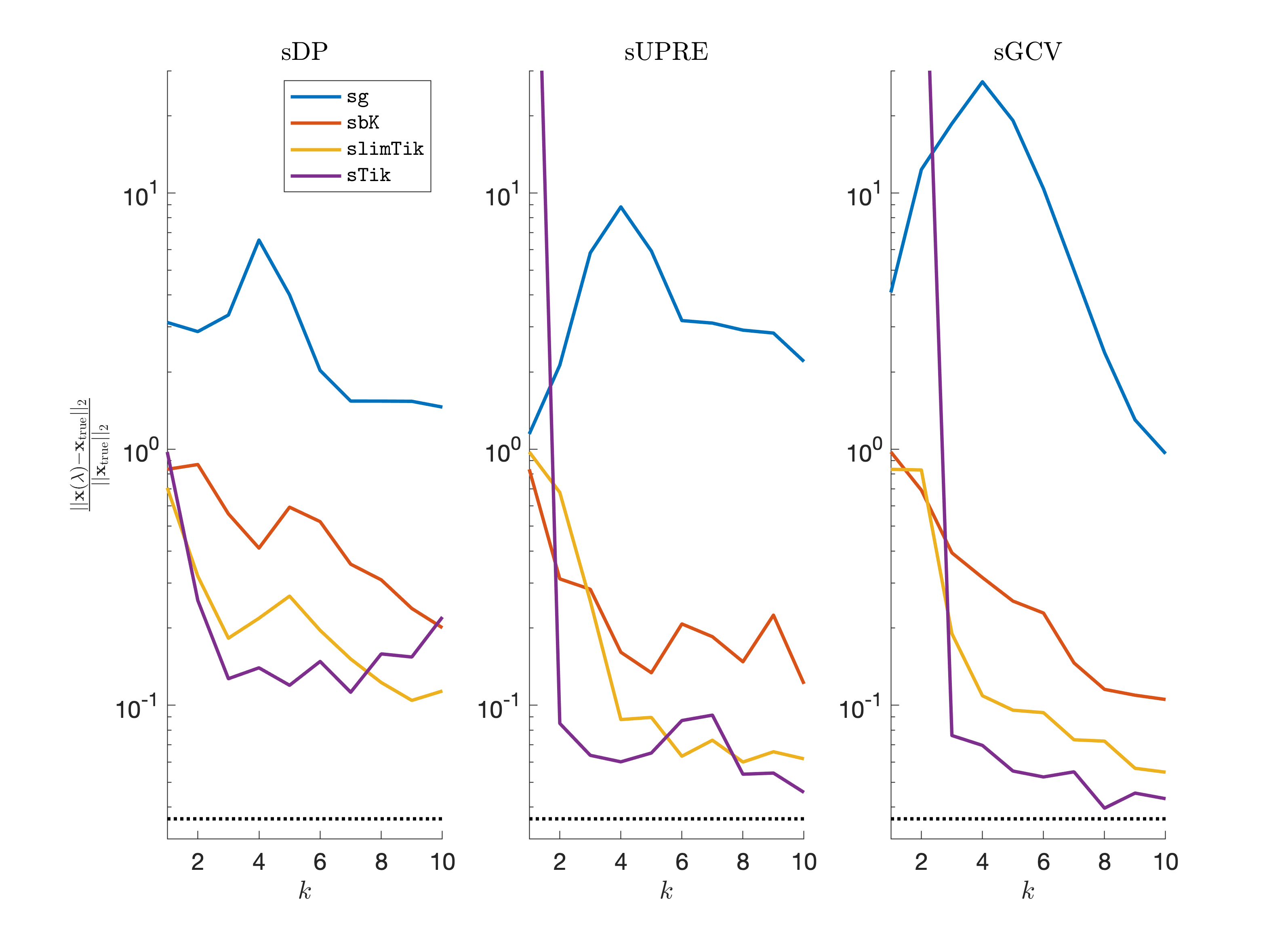 Figure 26
Figure 26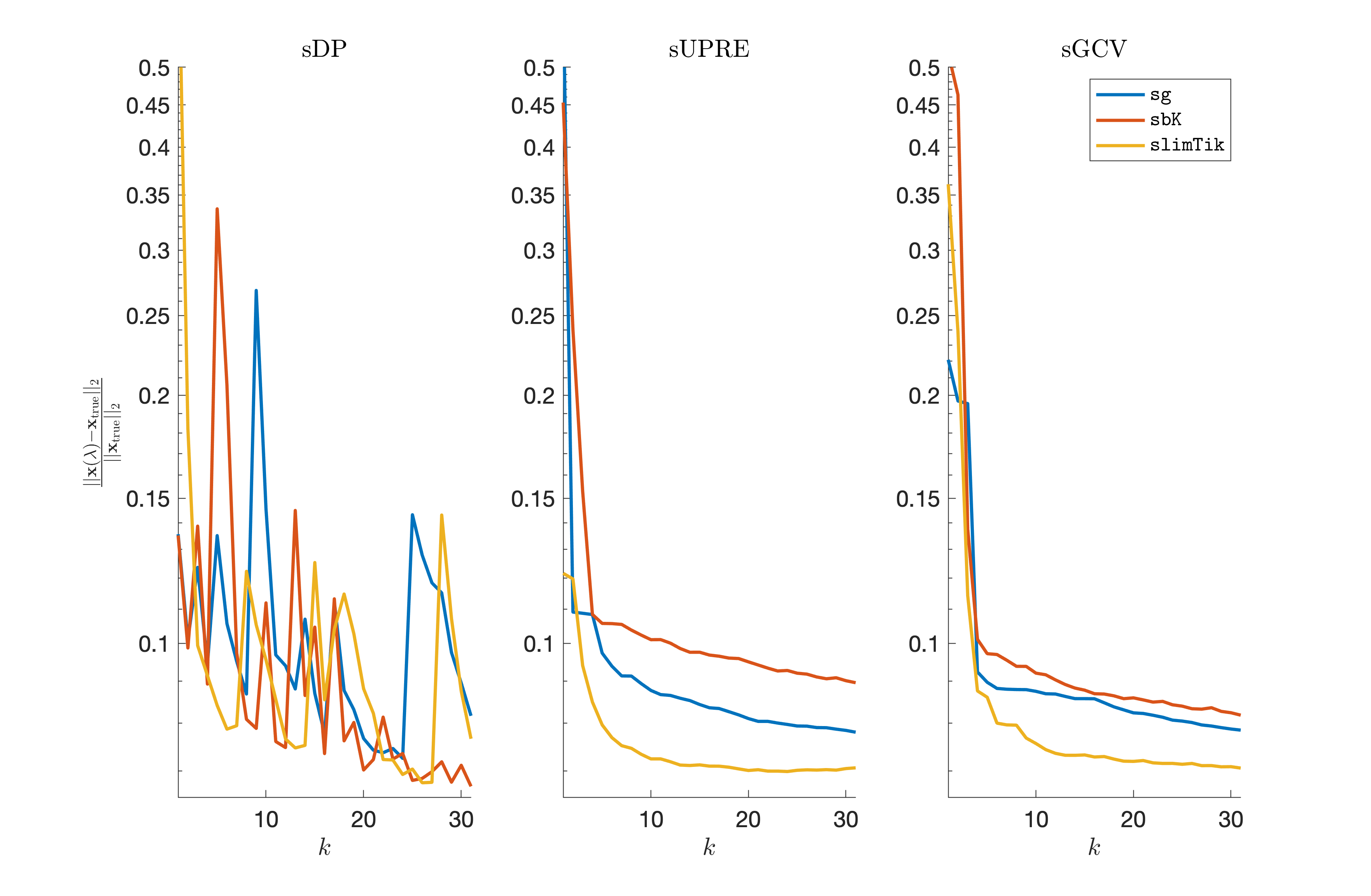 Figure 27
Figure 27 Figure 28
Figure 28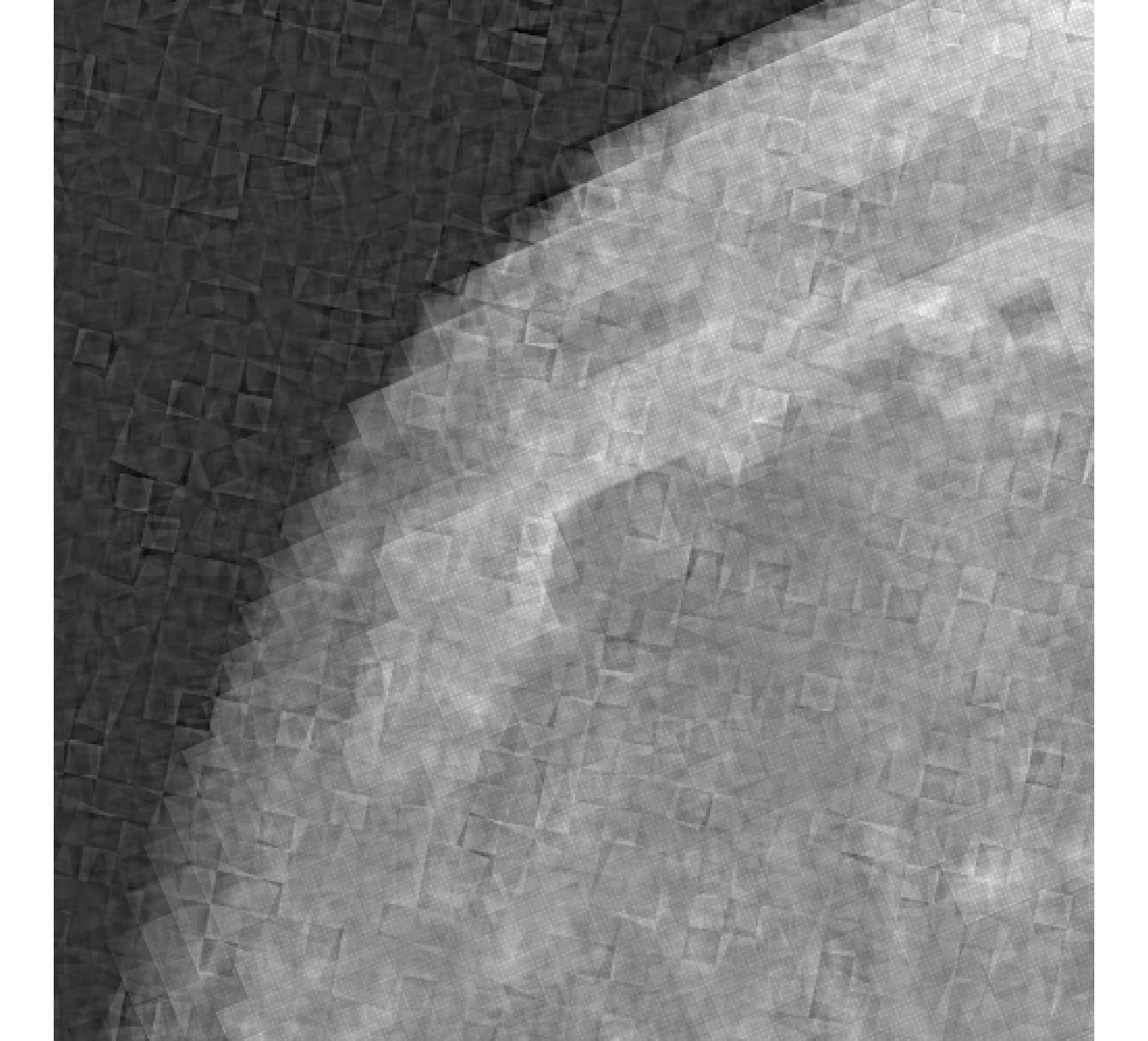 Figure 29
Figure 29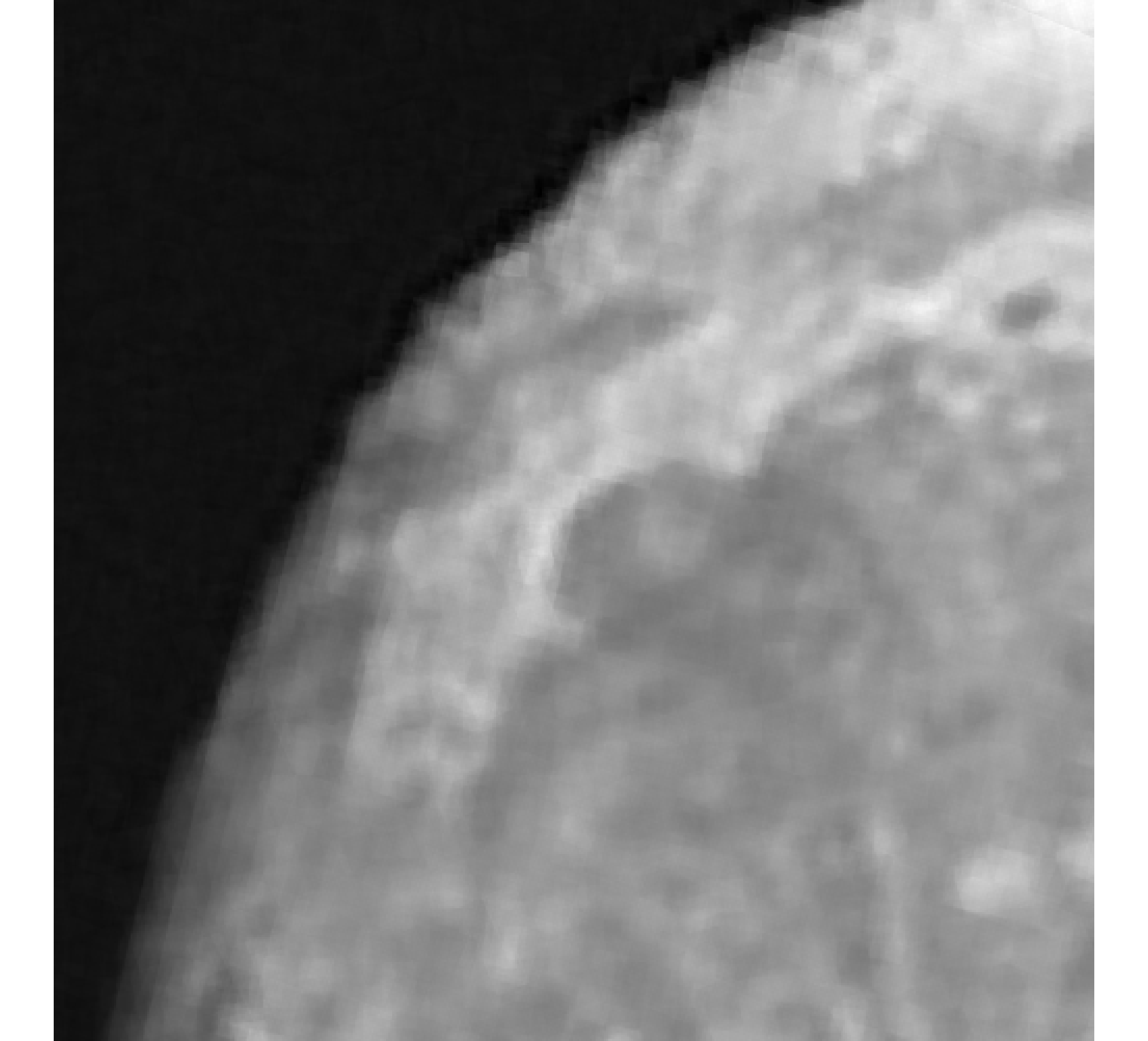 Figure 30
Figure 30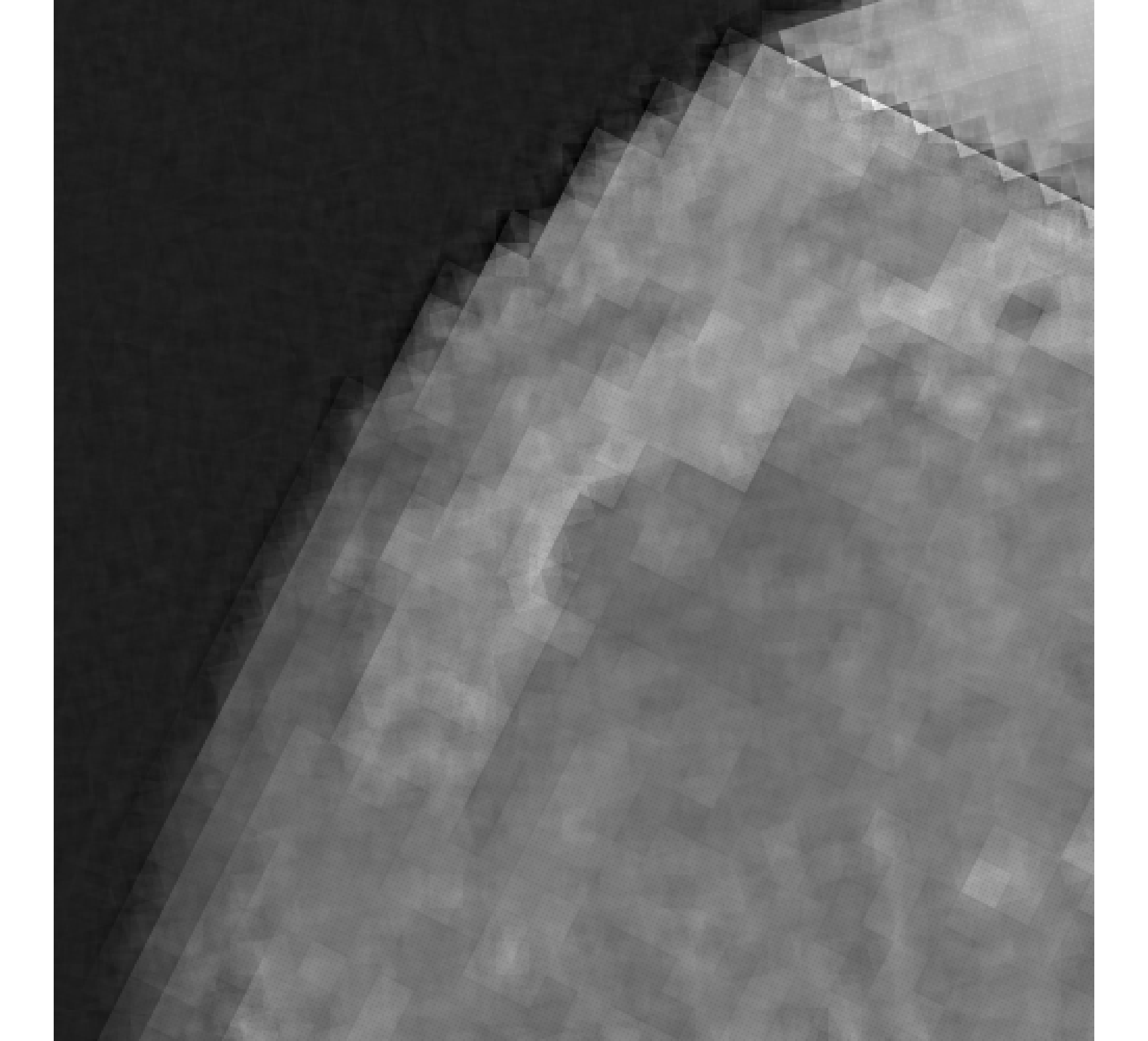 Figure 31
Figure 31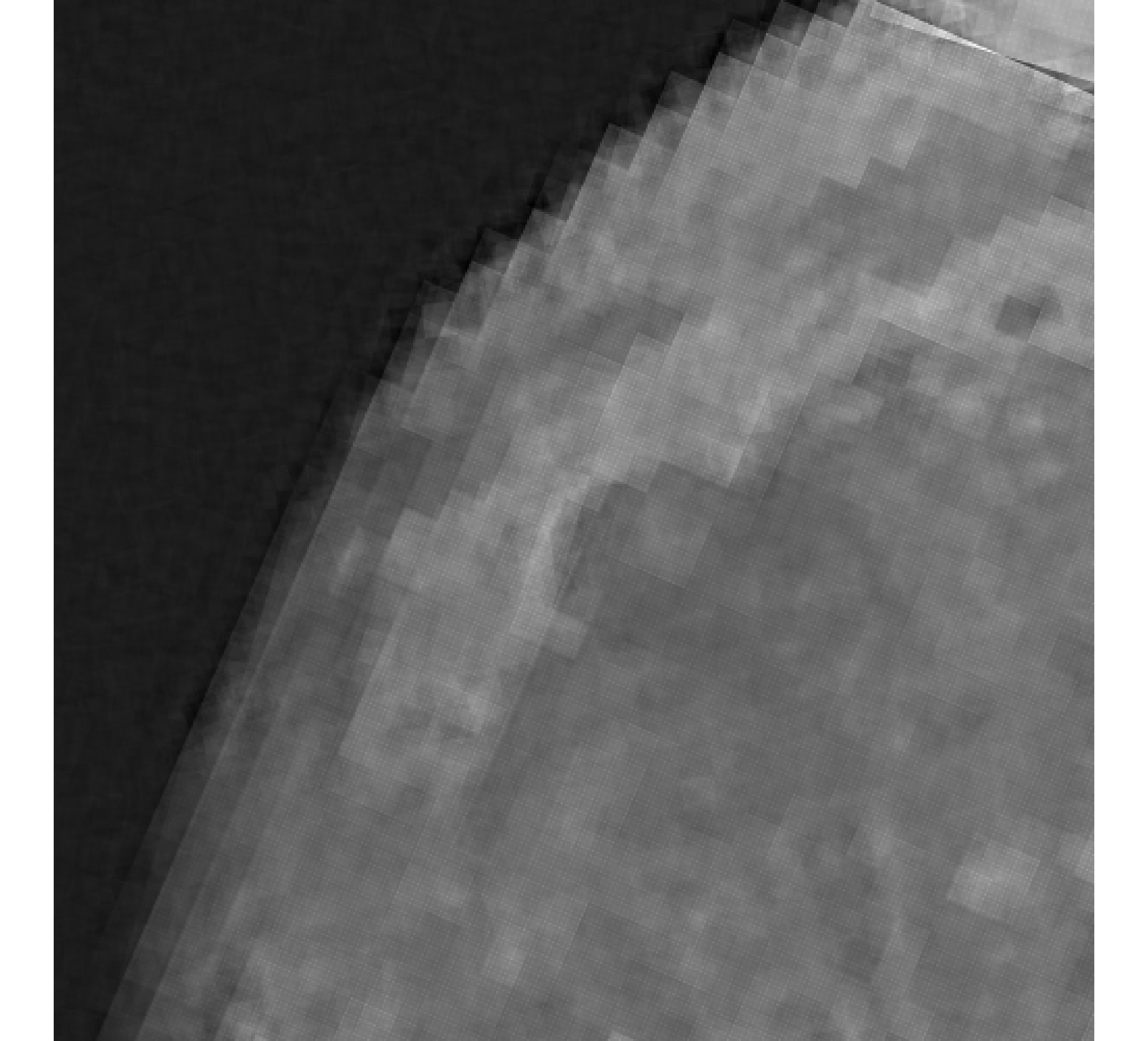 Figure 32
Figure 32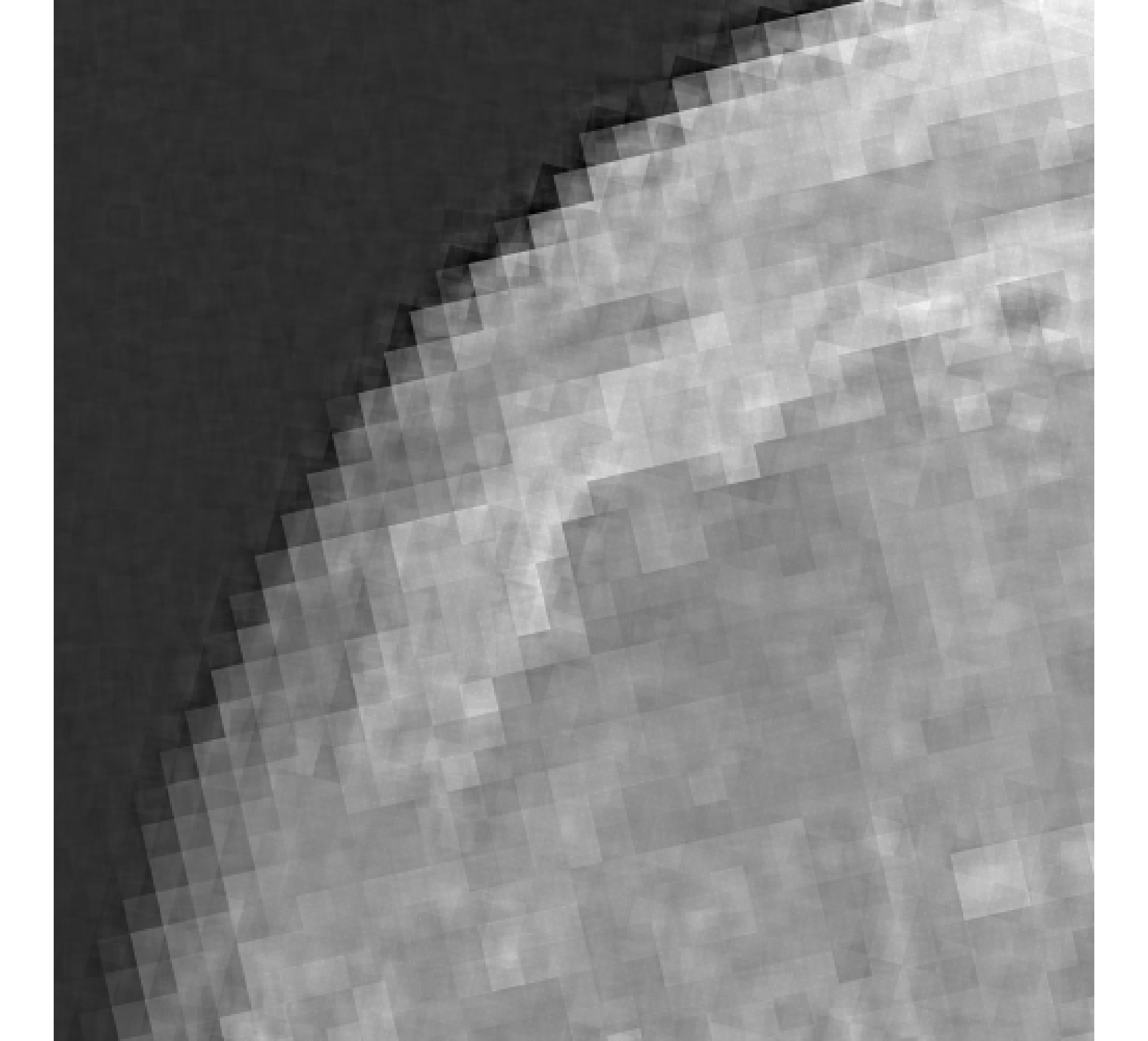 Figure 33
Figure 33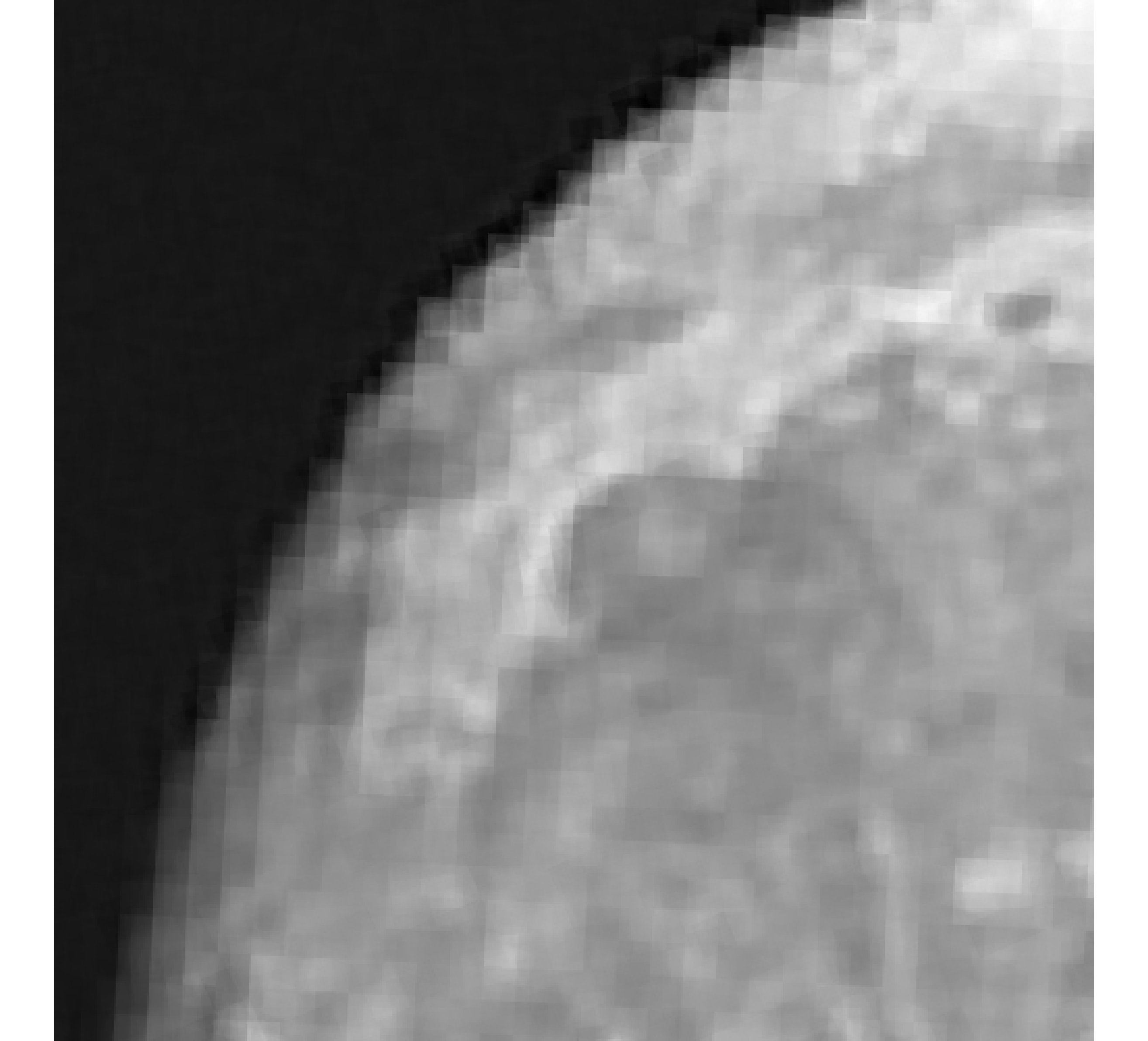 Figure 34
Figure 34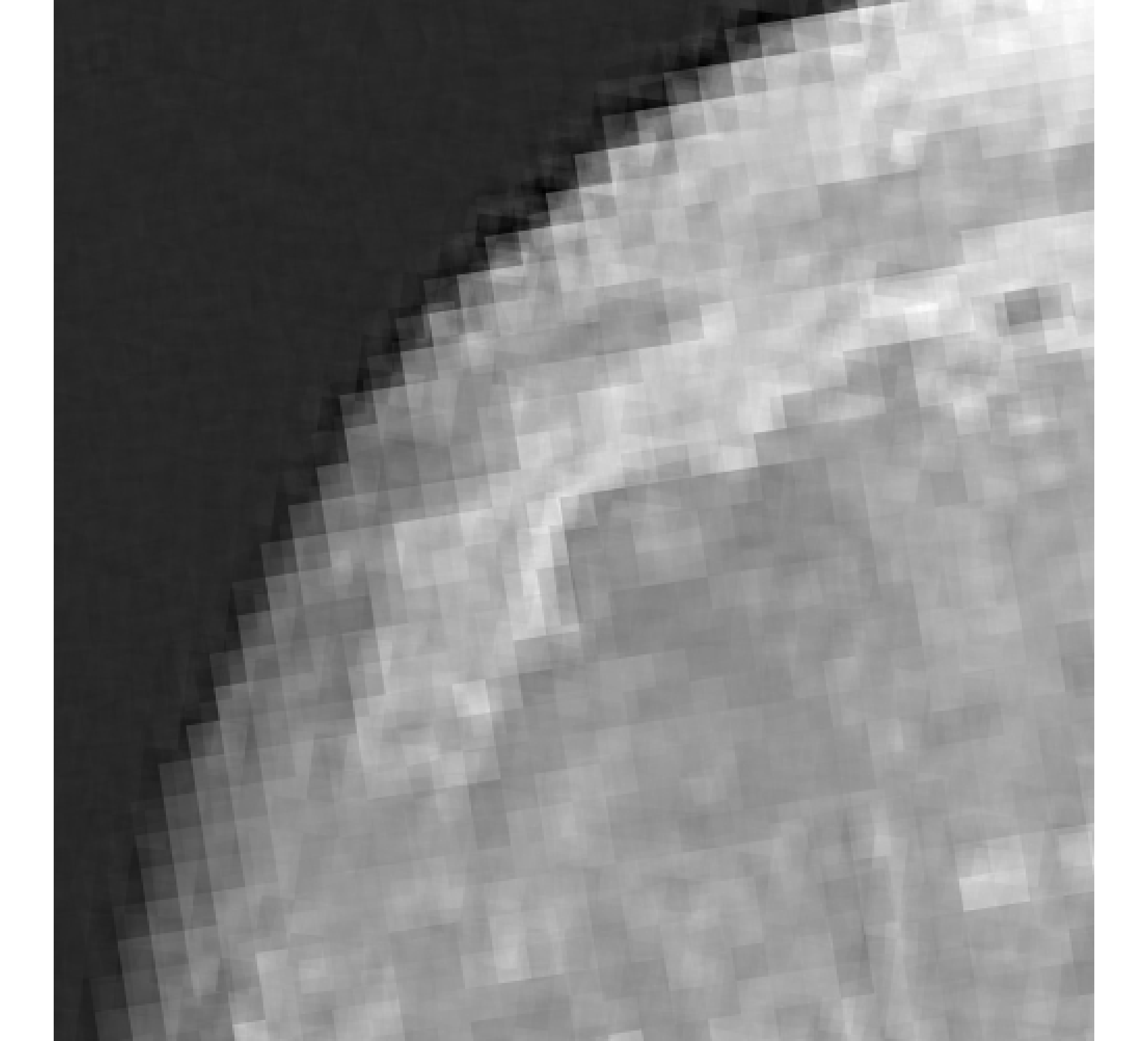 Figure 35
Figure 35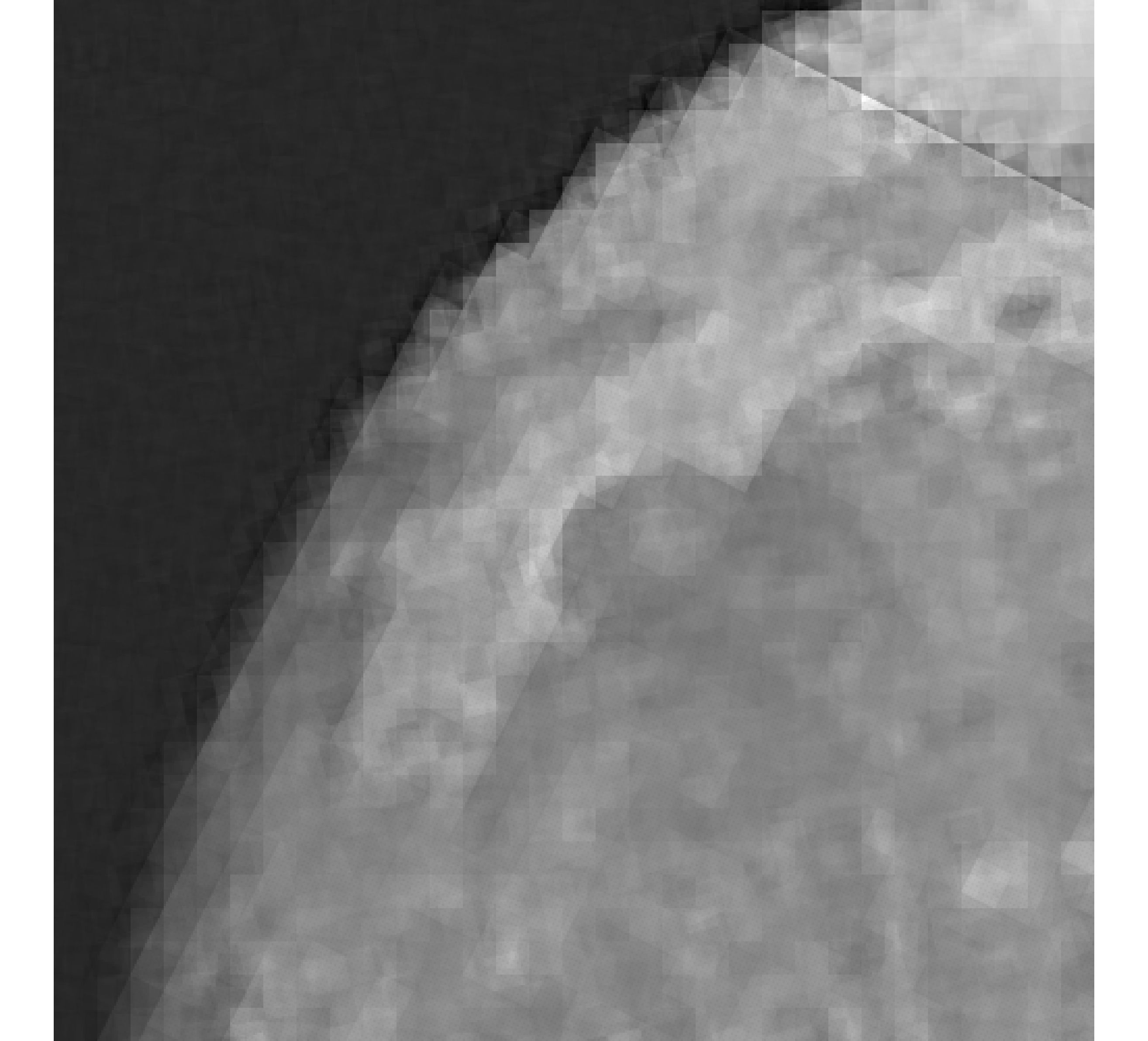 Figure 36
Figure 36 Figure 37
Figure 37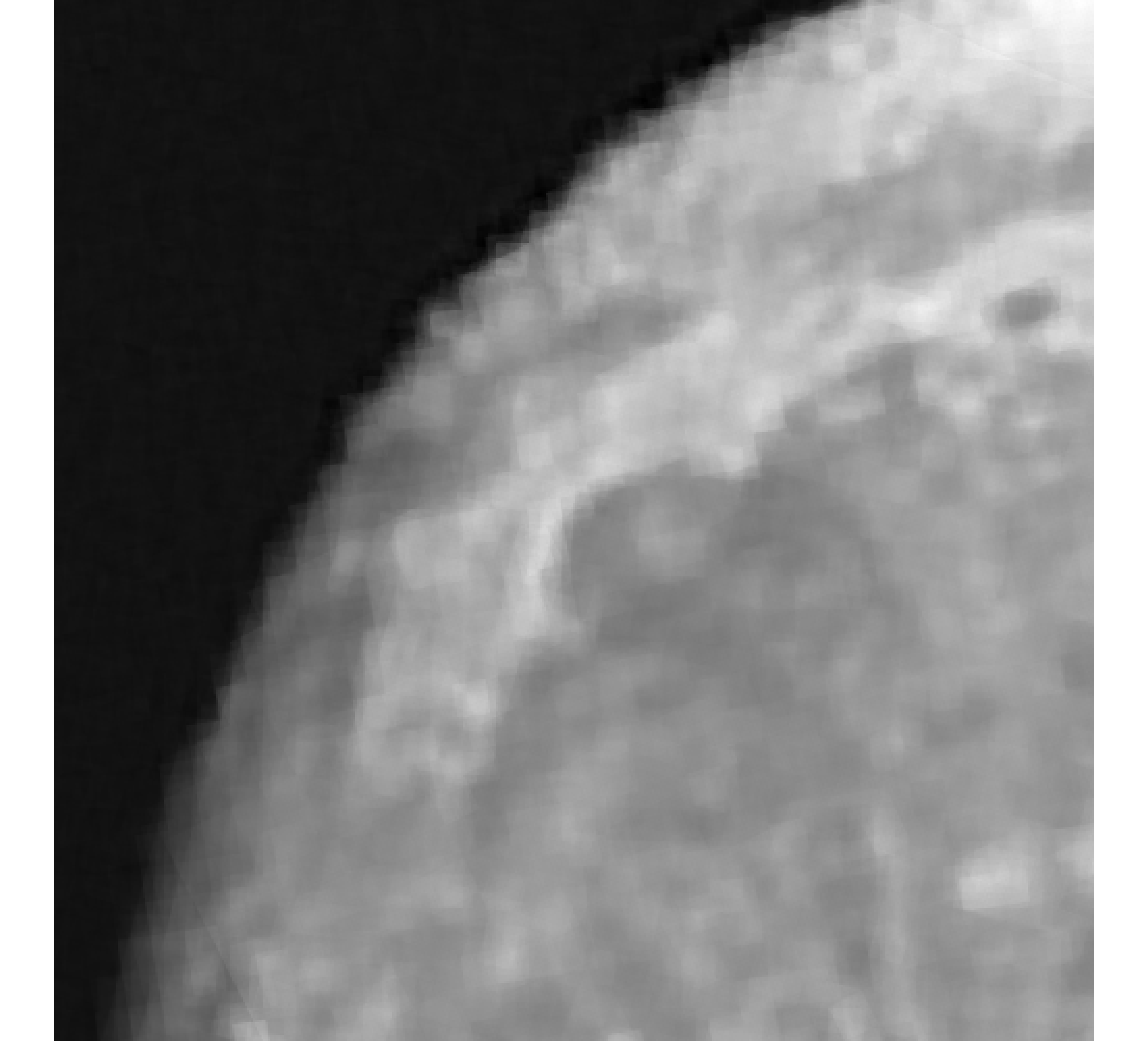 Figure 38
Figure 38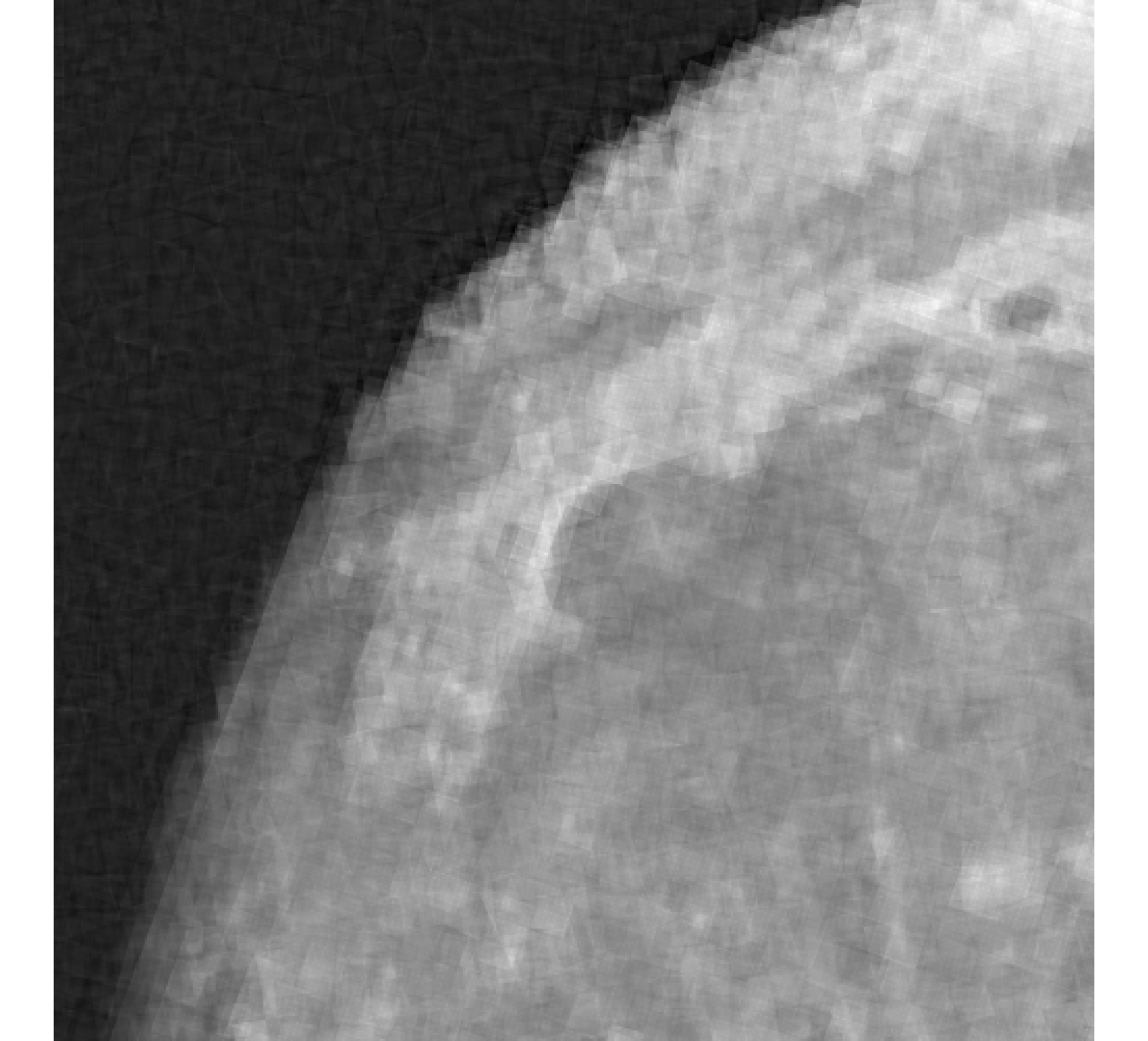 Figure 39
Figure 39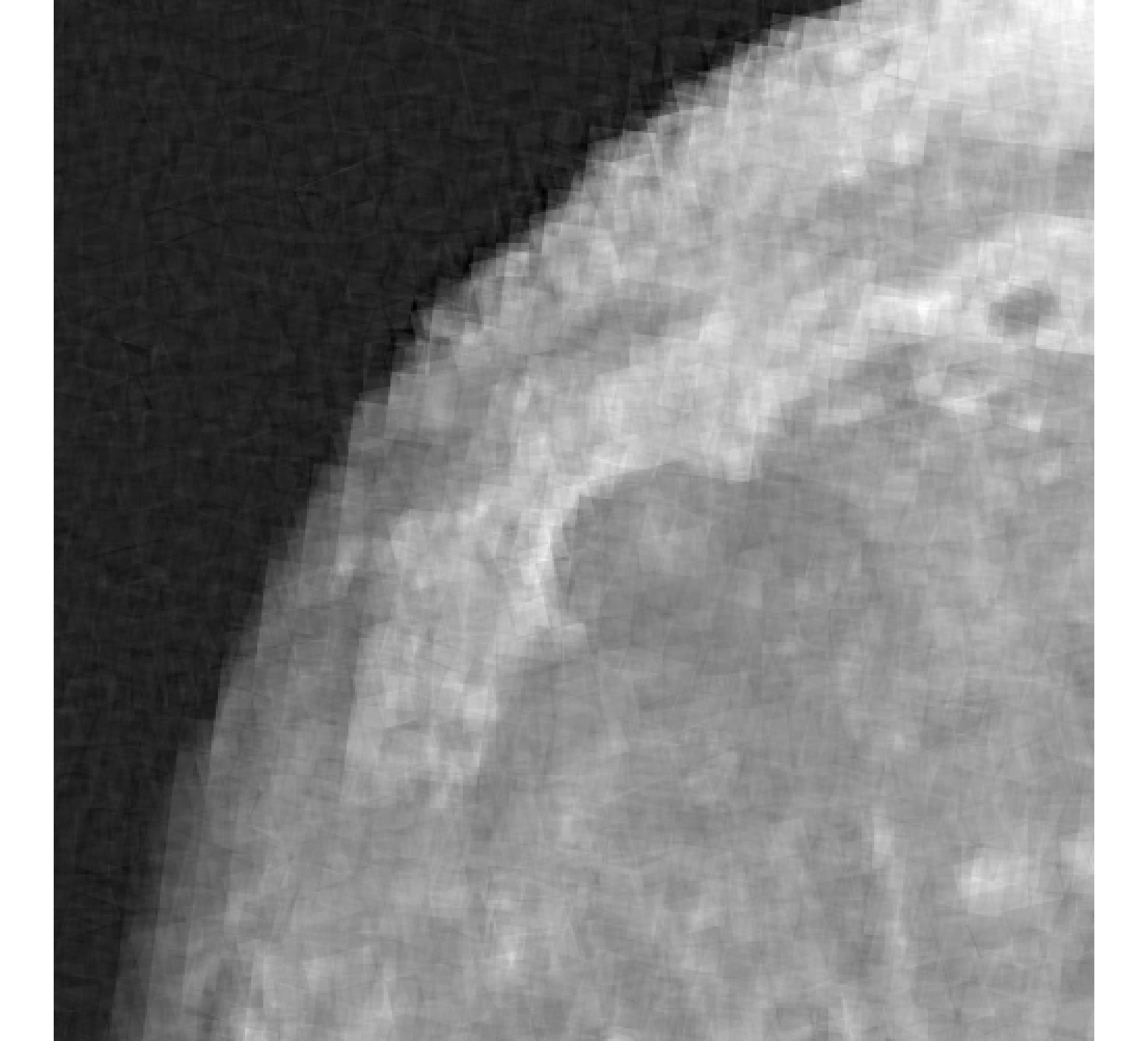 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Sampled Tikhonov Regularization for Large Linear Inverse Problems
J. Tanner Slagel
Department of Mathematics, Virginia Tech, Blacksburg, VA
Julianne Chung
Department of Mathematics, Computational Modeling and Data Analytics Division, Academy of Integrated Science, Virginia Tech, Blacksburg, VA
Matthias Chung
Department of Mathematics, Computational Modeling and Data Analytics Division, Academy of Integrated Science, Virginia Tech, Blacksburg, VA
David Kozak
Applied Mathematics and Statistics, Colorado School of Mines, Golden, CO
Luis Tenorio
Applied Mathematics and Statistics, Colorado School of Mines, Golden, CO
Abstract
In this paper, we investigate iterative methods that are based on sampling of the data for computing Tikhonov-regularized solutions. We focus on very large inverse problems where access to the entire data set is not possible all at once (e.g., for problems with streaming or massive datasets). Row-access methods provide an ideal framework for solving such problems, since they only require access to “blocks” of the data at any given time. However, when using these iterative sampling methods to solve inverse problems, the main challenges include a proper choice of the regularization parameter, appropriate sampling strategies, and a convergence analysis. To address these challenges, we first describe a family of sampled iterative methods that can incorporate data as they become available (e.g., randomly sampled). We consider two sampled iterative methods, where the iterates can be characterized as solutions to a sequence of approximate Tikhonov problems. The first method requires the regularization parameter to be fixed a priori and converges asymptotically to an unregularized solution for randomly sampled data. This is undesirable for inverse problems. Thus, we focus on the second method where the main benefits are that the regularization parameter can be updated during the iterative process and the iterates converge asymptotically to a Tikhonov-regularized solution. We describe adaptive approaches to update the regularization parameter that are based on sampled residuals, and we describe a limited-memory variant for larger problems. Numerical examples, including a large-scale super-resolution imaging example, demonstrate the potential for these methods.
1 Introduction
There have been significant developments in variational methods for solving large inverse problems [20]. However, with recent advances in imaging technologies and new applications to computer vision and machine learning, datasets are becoming so large that existing methods, which often follow an “all-at-once” approach for processing the data, are no longer feasible. Instead, we consider randomized or sampling methods where only “blocks” of the data are required at a given time. Such methods are ideal for streaming problems, where data are generated or collected during the process of solution computation.
In this paper, we focus on linear inverse problems of the form,
[TABLE]
where contains the desired, unknown parameters, models the data acquisition process, contains the observed data (which may be streaming), and represents noise or errors in the data. We assume that has mean zero and a finite second moment. In the generic setup, the goal of the inverse problem is to estimate , given a model and observations . Typically, the matrix represents a discrete and linear version of a given model stemming for instance from a discretized PDE network, integral equation, or regression model [24, 33]. For the problems of interest, and may be so large that accessing and/or storing all rows of at once is infeasible.
In this work we consider ill-posed inverse problems where regularization is required to compute reasonable solutions. Here, we focus on solving the Tikhonov-regularized problem,
[TABLE]
where is the regularization parameter, and for simplicity we assume that has full column rank. For the scenario where all of and are available or can be accessed at once (e.g., via matrix-vector multiplication with ), the Tikhonov solution,
[TABLE]
can be computed using a plethora of existing iterative methods (e.g., Krylov or other optimization methods [23, 27]). Note that is the unregularized solution which is defined if has full column rank.
For the problems of interest, we consider sampled iterative methods of the form,
[TABLE]
where is an initial iterate, is a vector (carrying gradient information of the least squares problem), matrix is updated at each iteration (carrying curvature information of the least squares problem). A learning rate or line search parameter is not required in this case and is set to its “natural” value of 1, [10]. Specific choices for and will be described in 2, with connections to other known stochastic approximation methods described in 2.3.
Note that iterative methods of this form typically stem from nonlinear optimization problems where is an approximation to the inverse Hessian and contains curvature information and is the gradient at the current iterate [35]. Such methods would take only one step to converge for the linear problem (e.g., take , , and ). However, this is not possible if and are so large that not all information is available at a certain time or fits into computer memory. Furthermore, determining a suitable choice of can be computationally infeasible in such settings, and the information available, i.e., and , may be subject to noise or other uncertainties. Thus, we consider nonlinear methods of the form (2) for Tikhonov regularization with massive data, where the main benefits are that (i) the data is sampled (e.g., randomly) or streamed, (ii) the regularization parameter can be adapted, and (iii) the methods converge asymptotically and in one epoch to a Tikhonov-regularized solution. Sophisticated regularization parameter selection methods are well-established if the full system is available (for example, see [28, 40]); however, the ability to update the regularization parameter within iterative methods of the form (2) while also ensuring convergence of iterates to a regularized solution is, to the best of our knowledge, an unresolved problem.
Problem Formulation.
In the following, we describe a mathematical formulation of the problem that allows us to solve (1) in situations where samples of and become available over time. Such scenarios are common in medical imaging, e.g. in tomography where data is being processed as it is being collected [3], and in astronomy, e.g. in super-resolution imaging where a high-resolution image is constructed from low-resolution images that are being video streamed [26].
Formally, at the -th iteration, we assume that a set of rows of and corresponding elements of become available, which we denote by and respectively. Here the matrix can be seen as a sampling matrix, which selects rows of and . For a fixed we assume that matrices satisfy the following properties:
for each , , where 111To avoid a notational distraction, we assume all matrices are of the same dimension and ; hence, . However a generalization with different matrix sizes is straightforward. and 2. 2.
the sum .
The first assumption implies that the size of is smaller than the size of , and thus computationally manageable. The second assumption guarantees that all rows of are given equal weight overall.
Notice that if is sparse with only a few non-zero elements in a subset of the columns, extracts only rows of where has nonzero entries. Hence, these methods are commonly known as row action methods [19, 3]. Randomized or sketching methods are also related in that a single realization of is used to project a large system onto a small dimensional subspace [16, 39]. However, these methods typically require access to all of the data at once (e.g. is not sparse).
Overview and Outline.
In this paper, we describe iterative sampling methods for solving Tikhonov-regularized problems, where the main distinction from existing methods such as hybrid Krylov methods and iterated Tikhonov methods is that we do not require “all-at-once” access to the forward model. In terms of theoretical results, the main contributions include the characterization of iterates as solutions to partial or full Tikhonov problems and asymptotic convergence results. In terms of methodology, we highlight the sampled Tikhonov method where the regularization parameter can be updated during the iterative process and the iterates are Tikhonov-regularized solutions after each epoch of data. Additionally, the sampled Tikhonov method converges asymptotically to a Tikhonov-regularized solution. Other developments include methods for updating the regularization parameter using sampled data and limited-memory variants for problems with many unknowns.
The paper is organized as follows. In Section 2 we describe two iterative methods for Tikhonov regularization with sampling. Various theoretical results are provided, including asymptotic convergence results. In Section 3 we describe sampled regularization parameter selection methods that can be used to update and adapt the regularization parameter. Numerical illustrations are provided throughout, and a limited-memory variant of these methods is described in Section 4, along with results for a large-scale imaging problem. Conclusions and future work are discussed in Section 5.
2 Iterative sampling methods for Tikhonov regularization
Iterative sampling methods for Tikhonov regularization can be used to solve massive linear inverse problems. We will investigate two methods. Let be initial iterates and let , be arbitrary matrices. For notational convenience, we denote and . Assuming a fixed regularization parameter , the first method that we consider is regularized recursive least squares (rrls), which is defined as
[TABLE]
where . If is the -th column of the identity matrix, rrls is an extension of the recursive least squares algorithm [7] that includes a Tikhonov term. Since it may be difficult to know a good regularization parameter in advance, we propose a sampled Tikhonov (sTik) method, where the iterates are defined as
[TABLE]
where Compared to rrls, the main advantages of the sTik method are that the regularization parameter can be updated during the iterative process and that in a sampled framework, the sTik iterates converge asymptotically to a Tikhonov solution whereas the rrls iterates converge asymptotically to an unregularized solution. Of course, selecting a good regularization parameter can be difficult, especially for problems with a small range of good values. However, if a good parameter estimate is available or can be estimated (see Section 3), it is desirable that the numerical method for solution computation converges to a regularized solution.
In this section, we begin by showing that for arbitrary matrices , both rrls and sTik iterates can be recast as solutions to regularized least squares problems (c.f. Theorem 2.1). See A for proofs for all theorems from Section 2.
Theorem 2.1**.**
Let and . Let have full column rank and , be an arbitrary sequence of matrices.
- (i)
For and arbitrary, the rrls iterate (3) with is the solution of the least squares problem
[TABLE]
- (ii)
For for any and arbitrary, the sTik iterate (4) with is the solution of the least squares problem
[TABLE]
The above results are true for any arbitrary sequence of matrices . Next, we consider a fixed set of matrices, as described in the introduction, and allow random sampling from this set. To be precise, define to be a random variable at the -th iteration, where is a random variable that indicates a sampling strategy. For example, if we let be a uniform random variable on the set , then we would be sampling with replacement. For this random sampling strategy, we prove asymptotic convergence of rrls and sTik iterates in Section 2.1. Then, we focus on random cyclic sampling, where for each , is a random permutation on the set . Note, cyclic sampling, where , is a special case of random cyclic sampling. We note that, until all blocks have been sampled, random cyclic sampling is nothing more than sampling without replacement. For random cyclic sampling, we characterize iterates after each epoch and prove asymptotic convergence of rrls and sTik iterates in Section 2.2. An illustrative example comparing the behavior of the solutions is provided in Section 2.4. For notational simplicity we denote and .
Notice that for both random sampling and random cyclic sampling, we have the following property,
[TABLE]
There are many choices for , see e.g., [13, 30, 31], but a simple choice is a block column partition of a permutation matrix. For this choice of , is just a predefined block of rows of . This is the primary choice of we will consider.
2.1 Random sampling
Next we investigate the asymptotic convergence of rrls and sTik iterates for the case of random sampling. This is also referred to as sampling with replacement.
Theorem 2.2**.**
Let and . Let have full column rank and be a set of real valued matrices with the property that , and let be a uniform random variable on the set .
- (i)
Let , be arbitrary, and define the sequence as
[TABLE]
where . If has full column rank, then
- (ii)
Let for all , and be finite. Let be arbitrary, and define the sequence as
[TABLE]
where . Then .
The significance of Theorem 2.2 is that the rrls iterates converge asymptotically to the unregularized least-squares solution, , which is undesirable for ill-posed inverse problems. On the other hand, the sTik iterates converge asymptotically to a Tikhonov-regularized solution. Note that for a given , convergence to is ensured by setting . A more realistic scenario would be to adapt as data become available, since the desired regularization parameter is typically not known before the data is received. Parameter selection strategies for selecting are addressed in Section 3, and empirically we observe favorable asymptotic properties (see Example 2).
2.2 Random Cyclic Sampling
Next we investigate rrls and sTik with random cyclic sampling. In addition to proving asymptotic convergence in this case, we can also describe the iterates as Tikhonov solutions after each epoch, where an epoch is defined as a sweep through all the data.
Theorem 2.3**.**
Let and . Let have full column rank and be a set of real valued matrices with the property that , and let be a random variable such that for , is a random permutation on the set
If , , and the sequence is defined as (8) with , then the rrls iterate at the -th epoch is given as . 2. 2.
Let be an infinite sequence with the property that . If is arbitrary and the sequence is defined as (9) with , then the sTik iterate at the -th epoch is given as .
Notice that at every epoch, the effective regularization parameter for rrls, i.e., , is reduced. Also, if has full column rank, we have On the other hand, the sTik iterates do not converge to the unregularized solution but do converge to a Tikhonov-regularized solution, since at each epoch and we have and . In Section 2.4, we illustrate the convergence behavior of the rrls and sTik iterates, but first we make some connections to existing optimization methods.
2.3 Connections to stochastic approximation methods
There is a connection between the iterative methods with sampling presented in Section 2 and stochastic approximation methods. First we recast the Tikhonov problem (1) as a stochastic optimization problem. For simplicity, consider random sampling (i.e., with replacement), where is a uniform random variable on the set . Then if we define , it is easy to show that
[TABLE]
and therefore
[TABLE]
There are a number of stochastic optimization methods that can be used to compute solutions to the expectation minimization problem on the left. Stochastic approximation methods represent one class of methods [42]. For the Tikhonov problem, a stochastic approximation method has the form,
[TABLE]
where is the sample gradient for the Tikhonov problem. Different choices of can be used in (11). If , then all of the previously computed global curvature information is encoded in and we recover the sTik method with . Theorem 2.2 (ii) shows that these iterates will converge asymptotically to the minimizer of (10), but storage can get costly. Another option is to take , which corresponds to the stochastic gradient method [8]. For faster convergence closer to the minimizer, there are various methods in the stochastic optimization literature that can be used to approximate the global curvature information [9, 29]. For example, a stochastic LBFGS method stores a small set of vectors, rather than matrix , and can perform multiplications in an efficient manner [32, 11].
We are most interested in the Tikhonov problem (1), but we note that there exists methods for the case where that have connections to stochastic optimization methods. Using the same reformulation as above, a stochastic approximation method would have the form (11). If we take , then we get the randomized block Kaczmarz method [34, 43, 3]. Notice that the curvature information comes only from the current sample. On the other hand, if is chosen to contain all previous curvature information, we get the rrls iterates
[TABLE]
Note that is included to ensure invertibility and is often replaced with . Regardless, the iterates converge to the unregularized problem, c.f., Theorem 2.2 (i). The connection between recursive least squares and stochastic approximation methods was noted in [29], and the approximation can be interpreted as a regularized stochastic approximation method that was considered, e.g., in [13, 10].
2.4 An Illustration
In the following illustration, we use a small toy example to highlight the convergence behaviors of rrls and sTik iterates. We investigate both random sampling and random cyclic sampling, and we demonstrate convergence by plotting solutions after multiple epochs of the data. The example we use is a Tikhonov problem of the form (1), where
[TABLE]
The vectors and are realizations from the normal distributions and respectively, and is the vector of ones of appropriate length. We further choose and fix for the rrls iterates . For sTik iterates , we choose the parameters such that the regularization is constant at each epoch, i.e., . With this setup we have and . We let be the -th column of the identity matrix, and set .
In Figure 1, we provide two illustrations. In the left panel, we provide the true solution , the unregularized solution , the Tikhonov solution , and the rrls iterates after each epoch. The rrls iterates with random sampling with replacement are denoted by , and the rrls iterates with random cyclic sampling are denoted by . Notice that by Theorem 2.3, at each epoch is a Tikhonov solution, i.e., after the -th epoch . Thus, we get a set of Tikhonov solutions with vanishing regularization parameters, and these iterates asymptotically converge to the unregularized solution. For rrls with random sampling, we run simulations and provide one sample path, along with the mean (dotted line) and region of the -th percentile shaded in grey. We note that the mean of is almost identical to the random cyclic sequence (orange line) suggesting that the random sequence is an unbiased estimator of the deterministic sequence (at each epoch). In the right panel of Figure 1, we provide the sTik iterates with random sampling, which are denoted by . Again, we run simulations and provide one simulation along with the shaded percentiles. It is evident that with more epochs, the iterates get closer to the desired Tikhonov solution. To aid with visual scaling, the axis for the right figure corresponds to the dotted rectangular box in the left figure. The sTik iterates with random cyclic sampling are omitted since (i.e., we get the Tikhonov solution after each epoch).
We observe that for random sampling, both rrls and sTik iterates contain undesirable uncertainties in the estimates. Although rrls iterates provide approximations to the Tikhonov solution, the main disadvantages are that the regularization parameter cannot be updated during the process and the iterates converge asymptotically to the unregularized solution. Hence we disregard the rrls method and focus on sTik with random cyclic sampling, where can be updated through .
3 Sampled regularization parameter selection methods
The ability to update the regularization parameter while still exhibiting favorable convergence properties makes the sTik method appealing for massive inverse problems. However, sampled regularization parameter selection methods must be developed to enable proper choices of updates . Unfortunately, standard regularization parameter selection methods are not feasible in this setting because many of them require access to the full residual vector, , which is not available. In this section, we investigate variants of existing regularization parameter selection methods [4, 44, 6] that are based on the sample residual.
In the following we assume that at the -th iteration , have been determined. Then the goal is to determine an appropriate update parameter . Notice that from Theorems 2.1 and 2.3, the -th sTik iterate can be represented as
[TABLE]
Sampled discrepancy principle.
The basic idea of the sampled discrepancy principle (sDP) is that at the -th iteration, the goal is to select parameter so that the sum of squared residuals for the current sample is equal to . Using properties of conditional expectation, we find
[TABLE]
where corresponds to the matrix trace function. Thus, at the -th iteration and for a given realization, we select such that
[TABLE]
where is some predetermined real number, see [24, 44] for details.
Sampled unbiased predictive risk estimator.
Next, we describe a method to select based on a sampled unbiased predictive risk estimator (sUPRE). The basic idea is to find to minimize the sampled predictive risk,
[TABLE]
which is equivalent to
[TABLE]
See B.1 for details of the derivation. Then, similar to the approach used in the standard UPRE derivation, the parameter is selected by finding a minimizer of the unbiased estimator for the sampled predictive risk,
[TABLE]
for a given realization. Similar to the standard methods, both sDP and sUPRE require estimates of . For Gaussian noise, there are various ways that one can obtain such an estimate, see e.g., [15, 44].
Sampled generalized cross validation.
Lastly, we describe the sampled generalized cross validation (sGCV) method for selecting and point the interested reader to B.2 for details of the derivation. The basic idea is to use a “leave-one-out” cross validation approach to find a value of , but the main differences compared to the standard GCV method are that at the -th iteration, we only have access to the sample residual and the iterates only correspond to Tikhonov solutions with only partial data. The parameter is selected by finding a minimizer of the sGCV function,
[TABLE]
Adapting regularization parameters during an iterative processes is not a new concept; however, much of the previous work in this area utilize projected systems, see e.g., [40, 28], or are specialized to applications such as denoising [25]. Another common approach is to consider the unregularized problem and to terminate the iterative process before noise contaminates the solution. This phenomenon is called semiconvergence, and selecting a good stopping iteration can be very difficult. There have been investigations into semiconvergence behavior of iterative methods such as Kaczmarz, e.g., [18].
Example 2.
In this example, we investigate the behavior of the previously discussed sampled regularization parameter update strategies, i.e., sDP, sUPRE, and sGCV, for multiple ill-posed inverse problems from the Matlab matrix gallery and from P. C. Hansens’ Regularization Tools toolbox [2, 1]. For simplicity, we set and use the true solutions that are provided by the toolbox. If none is provided, we set . We let , and set . Sampling matrices are given as for , such that and are sampled in 10 consecutive blocks. Here, we sample in a random cyclic fashion and let be the true noise variance for sDP and sUPRE. For sDP, we set , in accordance with [24, 44].
We first consider the prolate example, where is an ill-conditioned Toeplitz matrix that comes from Matlab’s matrix gallery. In Figure 2 we illustrate the asymptotic behavior of these sampled parameter selection strategies by plotting the number of epochs versus the value of for sDP, sUPRE, and sGCV. For comparison, we provide the regularization parameter for the full problem corresponding to DP, UPRE, and GCV. DP and UPRE use the true noise variance, and is as above for DP. For comparison, we also provide the optimal parameter for the full problem, which is the parameter that minimizes the 2-norm of the error between the reconstruction and the true solution. This last approach is not possible in practice. Empirically, we observe that with more iterations, the sampled regularization parameter selection methods tend to “stabilize”. The sDP regularization parameter stabilizes near the DP parameter for the full problem, but both sUPRE and sGCV stabilize closer to the optimal regularization parameter.
While we observe similar results for other test problems (results not shown), the sampled regularization parameters may not necessarily be close to the corresponding parameter for the full system. Nevertheless, the sampled regularization parameter selection methods often lead to appropriate reconstructions after a moderate number of iterations . Next, we investigate the relative reconstruction error of sampled regularization methods after one epoch. Figure 3 illustrates results from four test problems (prolate, baart, shaw, and gravity). First note that by Theorem 2.3, all solutions are Tikhonov solutions for a determined by the method, hence all relative reconstruction errors lie on a curve of relative errors for Tikhonov solutions. We observe that in terms of relative reconstruction error, the sampled regularization methods do not differ significantly from the full regularization methods. Note that all of the above parameter selection methods (including the standard DP, UPRE, and GCV) provide empirical estimations and thus may fail to provide good regularization parameters. Nevertheless, all of our sampled regularization parameter selection methods perform reasonably well on the test problems.
4 Numerical Results
For problems with a very large number of unknowns, such as those arising in pixel or voxel based image reconstruction, the described sTik method is not feasible due to the construction of matrix Although reduced models or subspace projection methods may be used to reduce the number of unknowns, obtaining a realistic basis for the solution may be difficult. Instead, we describe various approximations of , which are related to methods described in Section 2.3. In addition to being computationally feasible, all of these methods can take advantage of the adaptive regularization parameter selection methods described in Section 3.
These methods are based on the sTik method. In particular, we consider a sampled gradient (sg) method where the iterates are defined as (4) where and a sampled block Kaczmarz (sbK) method where the iterates are defined as (4) with , hence just including the recent block . We also consider a limited-memory version of sTik called slimTik, which we describe below. First notice that the -th sTik iterate is given by where
[TABLE]
Note that with this reformulation, we must solve a least-squares problem with matrix , which may get large for many samples. Thus, we select a memory parameter and define and for non-positive integers . Then slimTik iterates are given as where
[TABLE]
Notice that in the case where , slimTik and sbK iterates are identical. First, we investigate the performance of sg, sbK, and slimTik while taking advantage of the regularization parameter update described in Section 3. We use the gravity example from Regularization Tools, where , , and the noise level defined as is . The samples consist of blocks, each comprised of 100 consecutive rows of . The initial guess for the regularization parameter is chosen to be (the optimal overall regularization parameter in this example is approximately 0.0196), and we iterate for one epoch.
In Figure 4 we provide the relative reconstruction errors per iteration for sg, sbK, slimTik, and sTik. Overall, we notice a correspondence between the amount of curvature information used to approximate the Hessian and an improvement in the relative reconstruction error. Although including more curvature results in greater computational costs and storage requirements, e.g., sTik may be infeasible for very large problems, the number of row accesses is the same for each method. In terms of parameter selection methods, sGCV performs better than sUPRE and sDP for this example. The relative reconstruction error corresponding to the best overall Tikhonov solution is provided as the horizontal line. Although the results are not shown here, we note that the relative reconstruction errors will become very large for all of these methods if we do not include regularization.
Having demonstrated that regularization parameter update methods can be incorporated in a variety of stochastic optimization methods, we next investigate the performance of these limited-memory methods for super-resolution image reconstruction. The basic goal of super-resolution imaging is to reconstruct an high-resolution image represented by a vector given low-resolution images of size represented by where The forward model for each low-resolution image is given as
[TABLE]
where is a restriction matrix, represents an affine transformation that may account for shifts, rotations, and scalar multiplications, and . To reconstruct a high-resolution image, we solve the Tikhonov problem,
[TABLE]
For cases where the low-resolution images are being streamed or where the number of low-resolution images is very large, standard iterative methods may not be feasible. Furthermore, it can be very challenging to determine a good choice of prior to solution computation [14, 26, 38].
For our example, we have images of size , and we wish to reconstruct a high-resolution image of size . In Figure 5, we provide the true high-resolution image, which is an image of the moon [12], and three of the low-resolution images. Here, . Due to the inherent partitioning of the problem, we take to be a matrix such that ; certainly these matrices are never computed. For the simulated low-resolution images, Gaussian white noise was added such that the noise level for each image is and take .
We compare the performances of sg, sbK, and slimTik, including our sampled regularization parameter update methods sDP, sUPRE, and sGCV. The true noise variance is used for sDP and sUPRE, and the memory parameter for slimTik is . Each iteration of sbK and slimTik requires a linear solve, which can be handled efficiently by reformulating the problem as a least squares problem as in equation (15), and using standard techniques such as LSQR [36, 37]. These iterative methods can also be used to update the regularization parameter. Furthermore, we use the Hutchison trace estimator to efficiently evaluate the trace term in sGCV and sUPRE, see (13) and (14). More specifically, rather than compute linear solves, we note that if is a random variable such that , then
[TABLE]
Here we use the Rademacher distribution where the entries of are with equal probability. We use a single realization of to approximate the trace, hence resulting in just one linear solve [22, 5, 41].
Relative reconstruction errors are provided in Figure 6, and sub-images of the reconstructions are provided in Figure 7. We observe that, in general, sDP errors perform more erratically compared to sUPRE and sGCV. Notice that for sUPRE and sGCV, sbK produces higher reconstruction errors compared to sg, which may be attributed to insufficient global curvature information. Furthermore, we observe that slimTik reconstructions contain more details than sg and sbK reconstructions and reconstructions without regularization may become contaminated with noise.
5 Conclusions
In this work we describe iterative sampled Tikhonov methods for solving inverse problems for which it is not feasible to access the data “all-at-once”. Such methods are necessary when handling data sets that do not fit in memory and also can naturally handle streaming data or “online” problems.
We investigate two iterative methods, rrls and sTik, and show that under various sampling schemes, rrls iterates converge asymptotically to the unregularized solution, while sTik iterates converge to a Tikhonov-regularized solution. Although the sampling mechanisms that we discuss do not play a role in the asymptotic convergence, they do allow for interesting interpretations. In particular, for random cyclic sampling we can characterize the iterates as Tikhonov solutions after every epoch, providing insight into the path that the iterates take towards the solution. Note that this primarily applies to the massive-scale inverse problems where we have the opportunity to choose a sampling method. Furthermore, for iterative methods where the regularization parameter can be updated during the iterative process (e.g., sTik), we describe sampled variants of existing regularization parameter selection methods to update the parameter. Using a number of well-known data sets, we show empirically that sampled Tikhonov methods with automatic regularization parameter updates can be competitive. For very large inverse problems, we describe a limited-memory version of sTik, and we demonstrate the efficacy of the limited-memory approach on a standard benchmark dataset as well as on a streaming super-resolution image reconstruction problem.
Future directions of research include developing an asymptotic analysis of slimTik and a non-asymptotic analysis of the general sampling algorithms. This would involve bounding the mean square error at a fixed iteration , which may help to explain the quick initial convergence seen in the numerical experiments. Another open question is how to accelerate convergence by selecting to sample “important” parts of the problem, e.g., using sketching matrices [16, 17]. Finally, extensions to nonlinear inverse problems would require more advanced convergence analyses and further algorithmic developments, e.g., incorporating adaptive regularization parameter selection within stochastic LBFGS [11, 32].
Appendix A Proofs for Section 2
Proof of Theorem 2.1.
For (ii), note that the solution of the least squares problem (6) is given by
[TABLE]
Noticing the relationship , we get the following equivalencies for the sTik iterates
[TABLE]
A similar proof can be made for (i). ∎
Proof of Theorem 2.2.
From Theorem 2.1 for any we have
[TABLE]
Using the fact that (see equation (7)), by the law of large numbers and Slutsky’s theorem for a.s. convergence [44]
[TABLE]
and
[TABLE]
and therefore
[TABLE] 2. 2.
In a similar fashion, for any we have
[TABLE]
Using the fact that and , we have
[TABLE]
and
[TABLE]
and thus we conclude that
[TABLE]
∎
Proof of Theorem 2.3.
Notice that for random cyclic sampling schemes and for any iteration , and are deterministic. Hence
[TABLE]
and
[TABLE]
∎
Appendix B Derivations for sampled UPRE and sampled GCV
In this section, we provide derivations for (13) and (14). To estimate the overall regularization parameter at the -th iteration we are just required to update since the estimate is uniquely determined by the preceding ’s, and . Hence, for ease of notation we will drop the iteration count on .
B.1 Derivation of the Sampled UPRE
The basic idea is to find by minimizing an estimate of the predictive error. Let the sampled predictive error be given by
[TABLE]
Using the notation from (12), the expected sampled predictive error, , can be written as
[TABLE]
where the mixed term vanishes due to independence of and and since . Similar to the derivation for standard UPRE, the predictive error is not computable in practice since is not available. Thus, we perform a similar calculation for the expected sampled residual norm,
[TABLE]
Next, notice that using the trace lemma for a symmetric matrix [6], the second term in (17) can be written as
[TABLE]
Combining (16) with (17) and (18), we get
[TABLE]
Finally for a given realization, we get an estimator for the predictive risk
[TABLE]
which is equivalent to (13).
B.2 Derivation of the Sampled GCV
Next, we derive the sampled generalized cross validation function, following a similar derivation of the cross validation and generalized cross validation function found in [21]. For notational simplicity, we denote and . Then, notice that the -th iterate of sTik, which is given by is the solution to the following problem,
[TABLE]
To derive sampled GCV, at the -th iterate, define the identity matrix with [math] is the -th entry, i.e.,
[TABLE]
here is the -th column of the identity matrix. Our goal is to find , which is the solution to
[TABLE]
Then, the sampled cross-validation estimate for minimizes the average error,
[TABLE]
Using the normal equations and the fact that , an explicit expression for is given as
[TABLE]
where . Next defining and using the Sherman-Morrison-Woodbury formula, we get
[TABLE]
and after some algebraic manipulations, we arrive at
[TABLE]
Thus,
[TABLE]
and we can write the sampled cross-validation function as
[TABLE]
where . Now the extension from the sampled cross-validation to the sampled generalized cross validation function is analogous to the generalization process from cross-validation to GCV provided in [21].
Acknowledgments
This work was partially supported by NSF DMS 1723005 (J. Chung, M. Chung, Tenorio) and NSF DMS 1654175 (J. Chung).
References
- [1]
Matlab Test Matrices Gallery.
https://www.mathworks.com/help/matlab/ref/gallery.html.
Accessed: 2018-11-16.
- [2]
Regularization Tools Version 4.1 (for Matlab).
http://www.imm.dtu.dk/~pcha/Regutools/.
Accessed: 2018-11-16.
- [3]
M S Andersen and P C Hansen.
Generalized row-action methods for tomographic imaging.
Numerical Algorithms, 67(1):121–144, 2014.
- [4]
R C Aster, B Borchers, and C H Thurber.
Parameter Estimation and Inverse Problems.
Elsevier, New York, 2018.
- [5]
H Avron and S Toledo.
Randomized algorithms for estimating the trace of an implicit symmetric positive semi-definite matrix.
Journal of the ACM, 58(2):8, 2011.
- [6]
J M Bardsley.
Computational Uncertainty Quantification for Inverse Problems.
SIAM, Philadelphia, 2018.
- [7]
A Björck.
Numerical Methods for Least Squares Problems.
SIAM, Philadelphia, 1996.
- [8]
L Bottou.
Online Learning in Neural Networks, chapter 2. Online learning and stochastic approximations, pages 9–42.
Cambridge University Press, 1998.
- [9]
L Bottou and Y L Cun.
Large scale online learning.
In Advances in Neural Information Processing Systems, pages 217–224, 2004.
- [10]
L Bottou, F E Curtis, and J Nocedal.
Optimization methods for large-scale machine learning.
SIAM Review, 60(2):223–311, 2018.
- [11]
R H Byrd, S L Hansen, J Nocedal, and Y Singer.
A stochastic quasi-Newton method for large-scale optimization.
SIAM Journal on Optimization, 26(2):1008–1031, 2016.
- [12]
NASA Goddard Space Flight Center.
Image from NASA’s lunar reconnaissance orbitor.
https://lunar.gsfc.nasa.gov/imagesandmultimedia.html, 2014.
- [13]
J Chung, M Chung, J T Slagel, and L Tenorio.
Stochastic Newton and quasi-Newton methods for large linear least-squares problems.
arXiv preprint arXiv:1702.07367, 2017.
- [14]
J Chung, E Haber, and J Nagy.
Numerical methods for coupled super-resolution.
Inverse Problems, 22(4):1261, 2006.
- [15]
D L Donoho.
De-noising by soft-thresholding.
IEEE Transactions on Information Theory, 41(3):613–627, 1995.
- [16]
P Drineas, M Magdon-Ismail, M W Mahoney, and D P Woodruff.
Fast approximation of matrix coherence and statistical leverage.
Journal of Machine Learning Research, 13(Dec):3475–3506, 2012.
- [17]
P Drineas, M W Mahoney, S Muthukrishnan, and T Sarlós.
Faster least squares approximation.
Numerische Mathematik, 117(2):219–249, 2011.
- [18]
T Elfving, P C Hansen, and T Nikazad.
Semi-convergence properties of Kaczmarz’s method.
Inverse Problems, 30(5):055007, 2014.
- [19]
R Escalante and M Raydan.
Alternating Projection Methods.
SIAM, Philadelphia, 2011.
- [20]
O Ghattas.
Computational Inverse Problems Can Drive a Big Data Revolution.
In A. M. Bruaset and A. Tveito, editors, Conversations About Challenges in Computing, pages 43–50. Springer International Publishing, New York, 2013.
- [21]
G H Golub, M Heath, and G Wahba.
Generalized cross-validation as a method for choosing a good ridge parameter.
Technometrics, 21(2):215–223, 1979.
- [22]
E Haber, M Chung, and F Herrmann.
An effective method for parameter estimation with PDE constraints with multiple right-hand sides.
SIAM Journal on Optimization, 22(3):739–757, 2012.
- [23]
P C Hansen.
Discrete Inverse Problems: Insight and Algorithms.
SIAM, 2010.
- [24]
P C Hansen, J G Nagy, and D P O’Leary.
Deblurring Images: Matrices, Spectra, and Filtering.
SIAM, Philadelphia, 2006.
- [25]
S Hashemi, S Beheshti, R Cobbold, and N Paul.
Adaptive updating of regularization parameters.
Signal Processing, 113:228–233, 2015.
- [26]
B Huang, W Wang, M Bates, and X Zhuang.
Three-dimensional super-resolution imaging by stochastic optical reconstruction microscopy.
Science, 319(5864):810–813, 2008.
- [27]
J Kaipio and E Somersalo.
Statistical and Computational Inverse Problems, volume 160.
Springer Science & Business Media, 2006.
- [28]
M E Kilmer and D P O’Leary.
Choosing regularization parameters in iterative methods for ill-posed problems.
SIAM Journal on Matrix Analysis and Applications, 22(4):1204–1221, 2001.
- [29]
H J Kushner and G G Yin.
Stochastic Approximation Algorithms and Applications.
Springer, New York, 1997.
- [30]
E B Le, A Myers, T Bui-Thanh, and Q P Nguyen.
A data-scalable randomized misfit approach for solving large-scale PDE-constrained inverse problems.
Inverse Problems, 33(6):065003, 2017.
- [31]
J Matoušek.
On variants of the Johnson–Lindenstrauss lemma.
Random Structures & Algorithms, 33(2):142–156, 2008.
- [32]
A Mokhtari and A Ribeiro.
Global convergence of online limited memory BFGS.
The Journal of Machine Learning Research, 16(1):3151–3181, 2015.
- [33]
J L Mueller and S Siltanen.
Linear and Nonlinear Inverse Problems with Practical Applications.
SIAM, 2012.
- [34]
D Needell and J A Tropp.
Paved with good intentions: Analysis of a randomized block Kaczmarz method.
Linear Algebra and its Applications, 441:199–221, 2014.
- [35]
J Nocedal and S J Wright.
Numerical Optimization.
Springer, New York, second edition, 2006.
- [36]
C C Paige and M A Saunders.
Algorithm 583, LSQR: Sparse linear equations and least-squares problems.
ACM Transactions on Mathematical Software, 8(2):195–209, 1982.
- [37]
C C Paige and M A Saunders.
LSQR: An algorithm for sparse linear equations and sparse least squares.
ACM Transactions on Mathematical Software, 8(1):43–71, 1982.
- [38]
S Park, M Park, and M Kang.
Super-resolution image reconstruction: A technical overview.
IEEE signal processing magazine, 20(3):21–36, 2003.
- [39]
M Pilanci and M J Wainwright.
Iterative Hessian sketch: Fast and accurate solution approximation for constrained least-squares.
Journal of Machine Learning Research, 17(53):1–38, 2016.
- [40]
R A Renaut, S Vatankhah, and V E Ardestani.
Hybrid and iteratively reweighted regularization by unbiased predictive risk and weighted GCV for projected systems.
SIAM Journal on Scientific Computing, 39(2):B221–B243, 2017.
- [41]
A K Saibaba, Al Alexanderian, and I Ipsen.
Randomized matrix-free trace and log-determinant estimators.
Numerische Mathematik, 137(2):353–395, 2017.
- [42]
A Shapiro, D Dentcheva, and A Ruszczyński.
Lectures on Stochastic Programming: Modeling and Theory.
SIAM, Philadelphia, 2009.
- [43]
T Strohmer and R Vershynin.
A randomized Kaczmarz algorithm with exponential convergence.
Journal of Fourier Analysis and Applications, 15(2):262–278, 2009.
- [44]
L Tenorio.
An Introduction to Data Analysis and Uncertainty Quantification for Inverse Problems.
SIAM, Philadelphia, 2017.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Matlab Test Matrices Gallery. https://www.mathworks.com/help/matlab/ref/gallery.html . Accessed: 2018-11-16.
- 2[2] Regularization Tools Version 4.1 (for Matlab). http://www.imm.dtu.dk/~pcha/Regutools/ . Accessed: 2018-11-16.
- 3[3] M S Andersen and P C Hansen. Generalized row-action methods for tomographic imaging. Numerical Algorithms , 67(1):121–144, 2014.
- 4[4] R C Aster, B Borchers, and C H Thurber. Parameter Estimation and Inverse Problems . Elsevier, New York, 2018.
- 5[5] H Avron and S Toledo. Randomized algorithms for estimating the trace of an implicit symmetric positive semi-definite matrix. Journal of the ACM , 58(2):8, 2011.
- 6[6] J M Bardsley. Computational Uncertainty Quantification for Inverse Problems . SIAM, Philadelphia, 2018.
- 7[7] A Björck. Numerical Methods for Least Squares Problems . SIAM, Philadelphia, 1996.
- 8[8] L Bottou. Online Learning in Neural Networks , chapter 2. Online learning and stochastic approximations, pages 9–42. Cambridge University Press, 1998.
