TL;DR
This paper introduces Trollslayer, a new dataset and method for identifying abusive users on Twitter by combining user attributes and social-graph features, including a novel similarity metric, to better understand abuse dynamics.
Contribution
The paper presents a custom Twitter crawler, a comprehensive feature set for user and message analysis, and introduces the Jaccard index as a novel metric for abuse characterization.
Findings
The Jaccard index effectively distinguishes benign from malicious messages.
The dataset enables detailed analysis of abusive user behaviors.
Graph-based features reveal information dissemination patterns.
Abstract
As of today, abuse is a pressing issue to participants and administrators of Online Social Networks (OSN). Abuse in Twitter can spawn from arguments generated for influencing outcomes of a political election, the use of bots to automatically spread misinformation, and generally speaking, activities that deny, disrupt, degrade or deceive other participants and, or the network. Given the difficulty in finding and accessing a large enough sample of abuse ground truth from the Twitter platform, we built and deployed a custom crawler that we use to judiciously collect a new dataset from the Twitter platform with the aim of characterizing the nature of abusive users, a.k.a abusive birds, in the wild. We provide a comprehensive set of features based on users' attributes, as well as social-graph metadata. The former includes metadata about the account itself, while the latter is computed from…
Click any figure to enlarge with its caption.
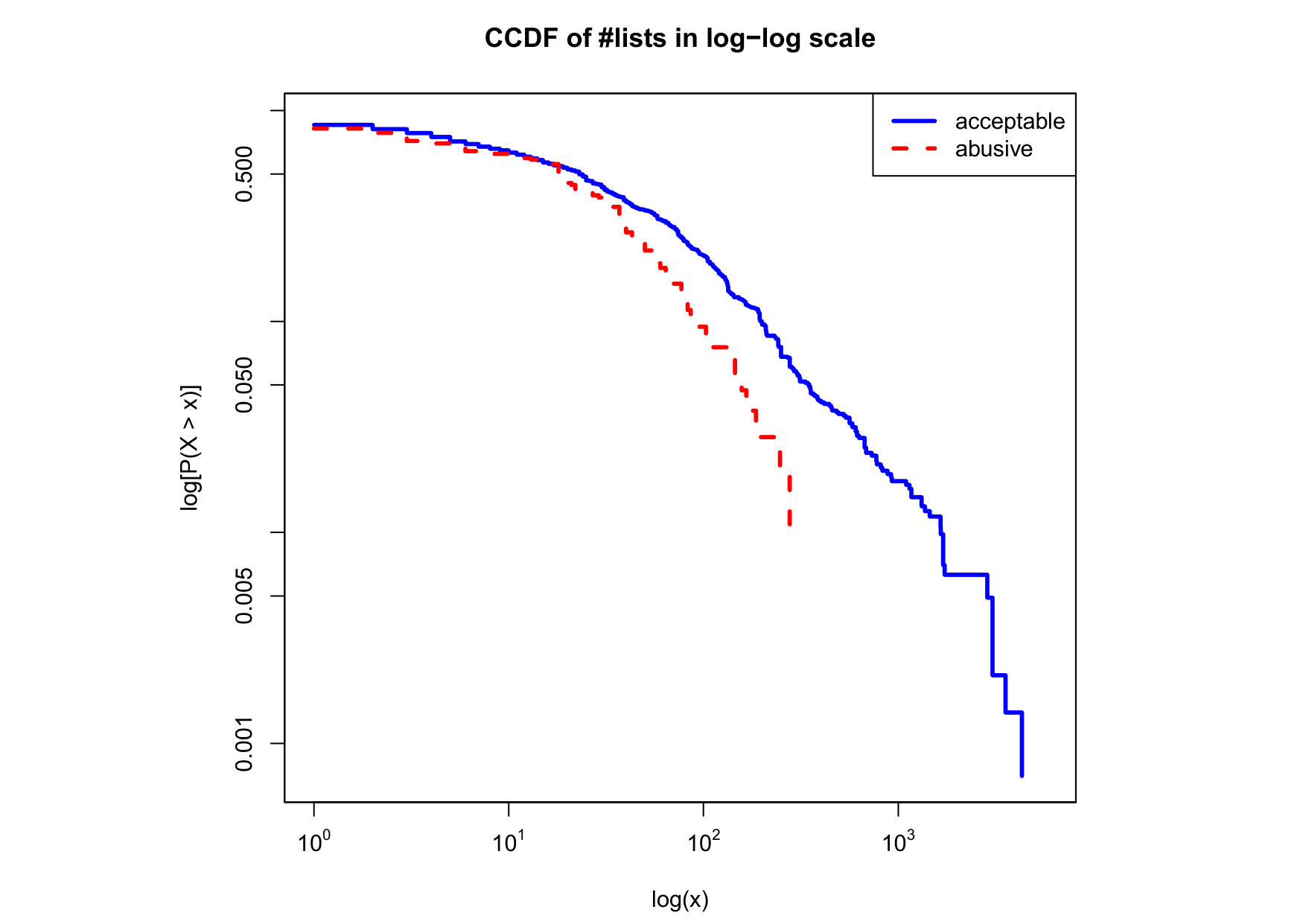 Figure 1
Figure 1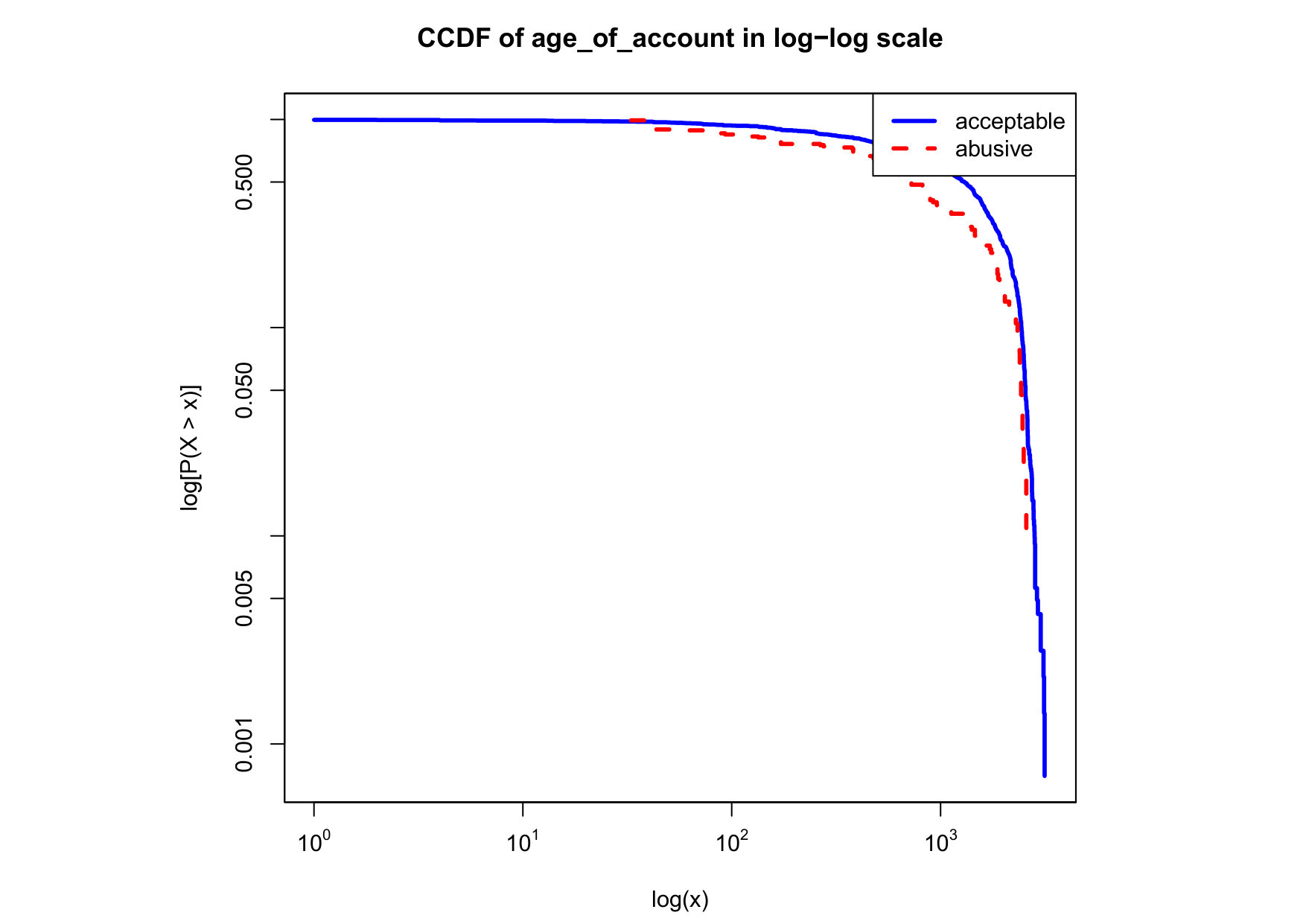 Figure 2
Figure 2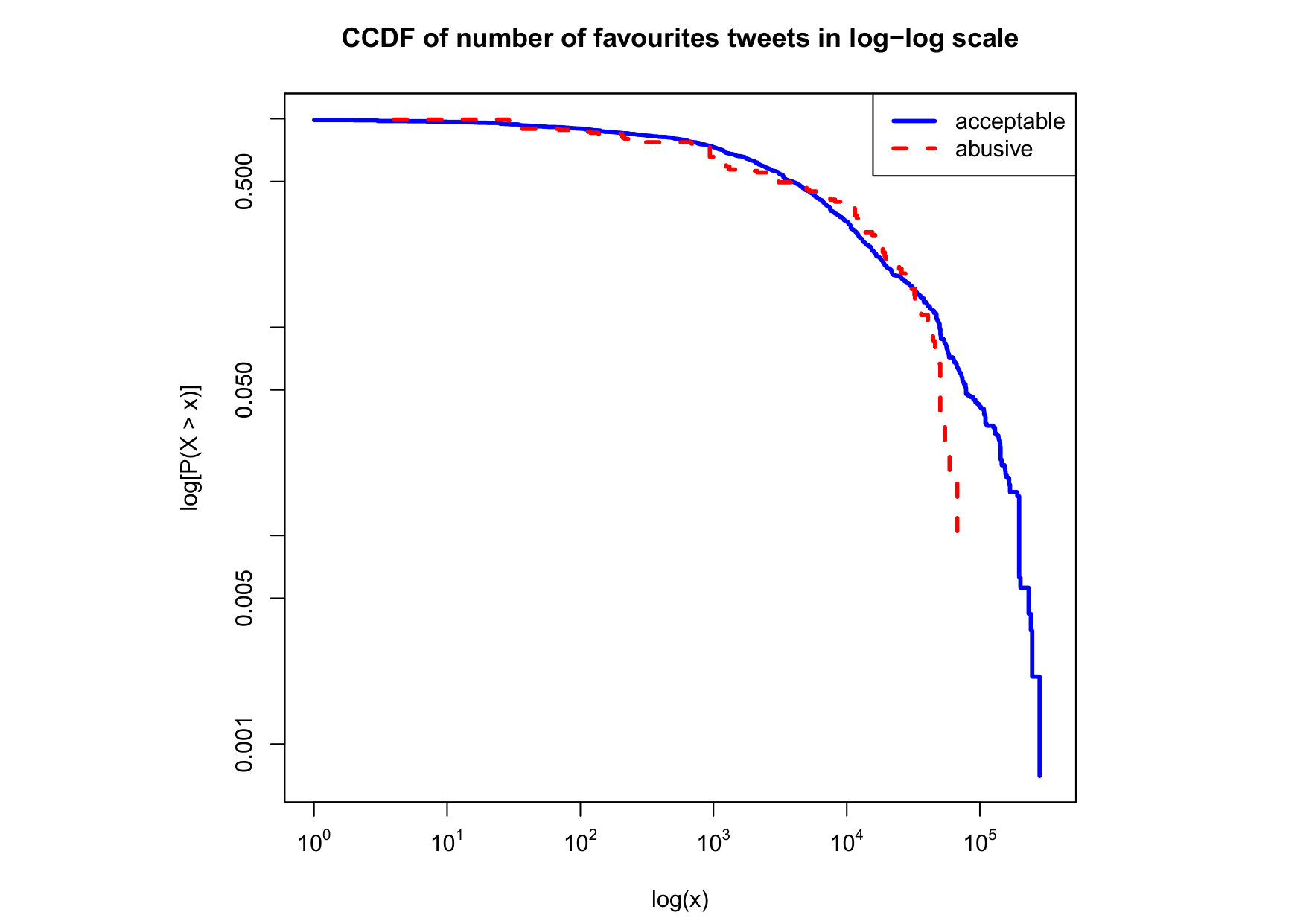 Figure 3
Figure 3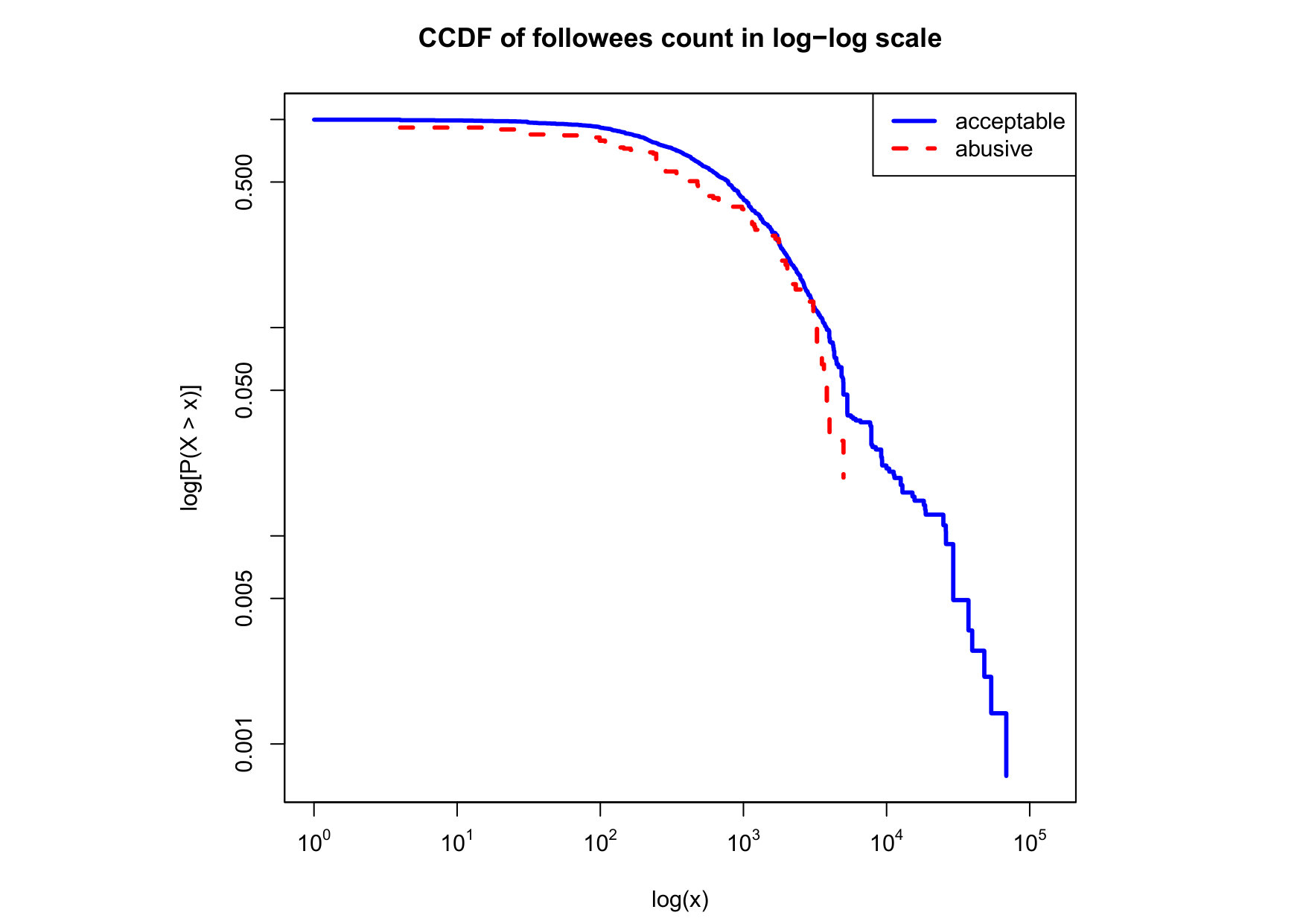 Figure 4
Figure 4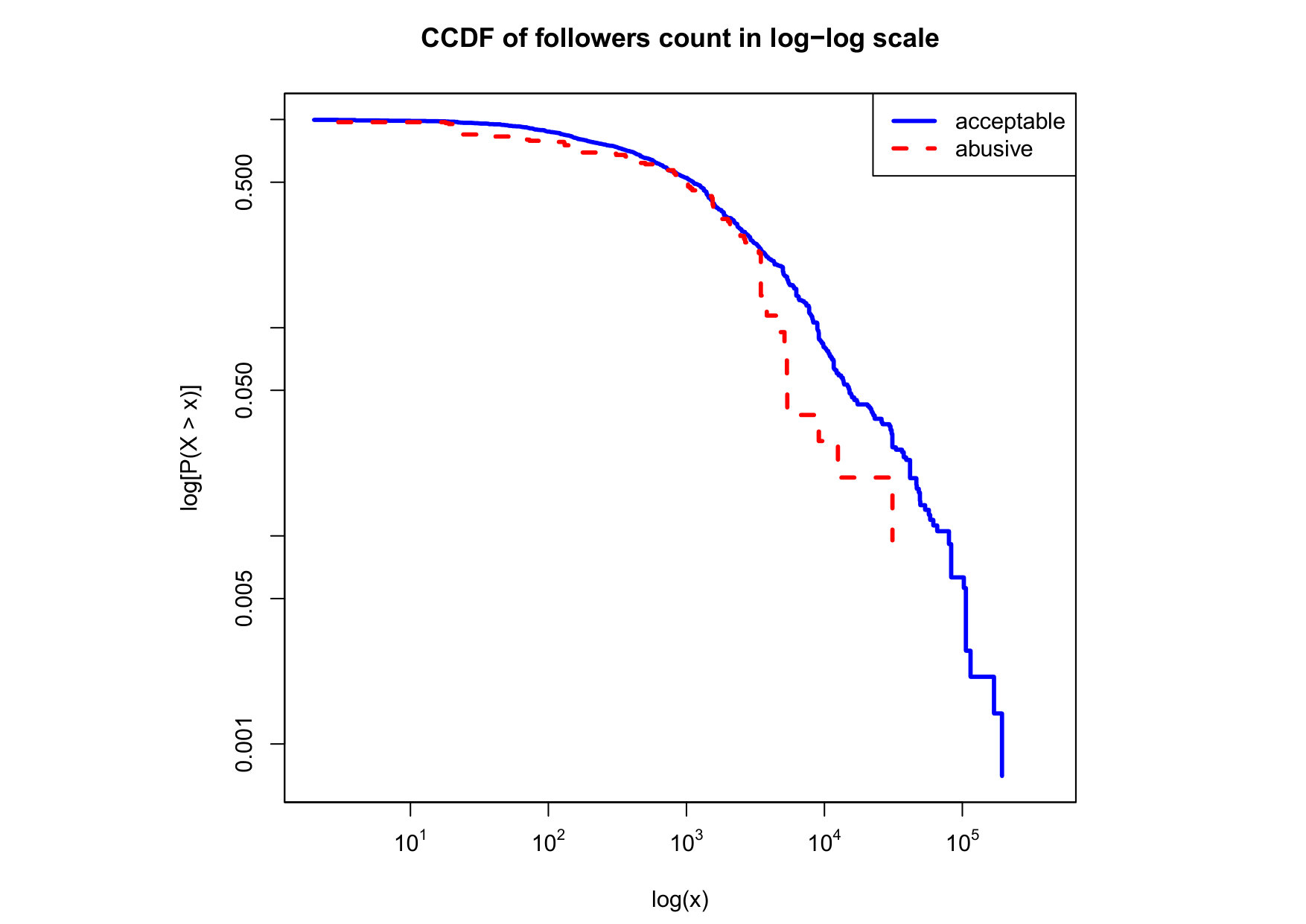 Figure 5
Figure 5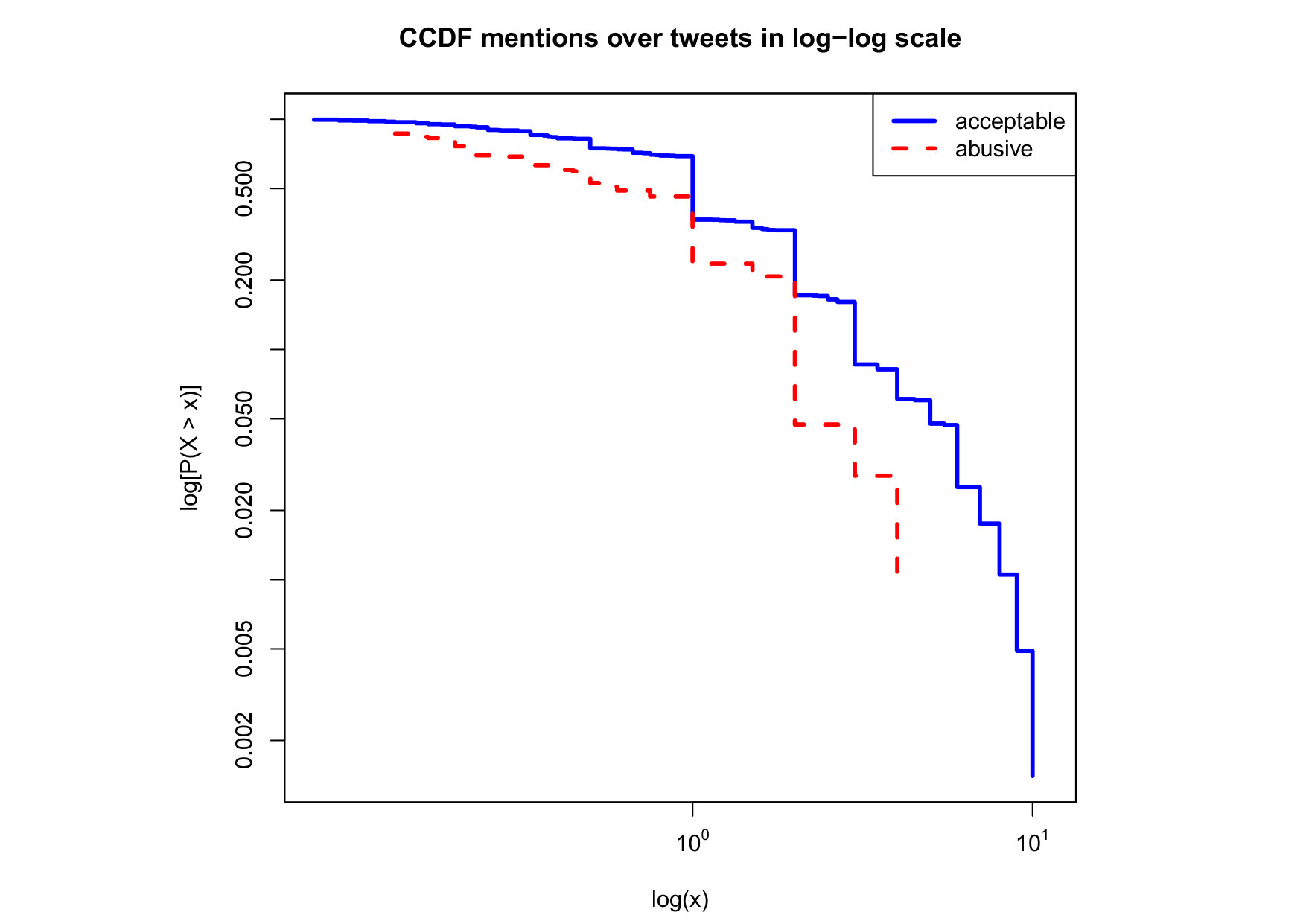 Figure 6
Figure 6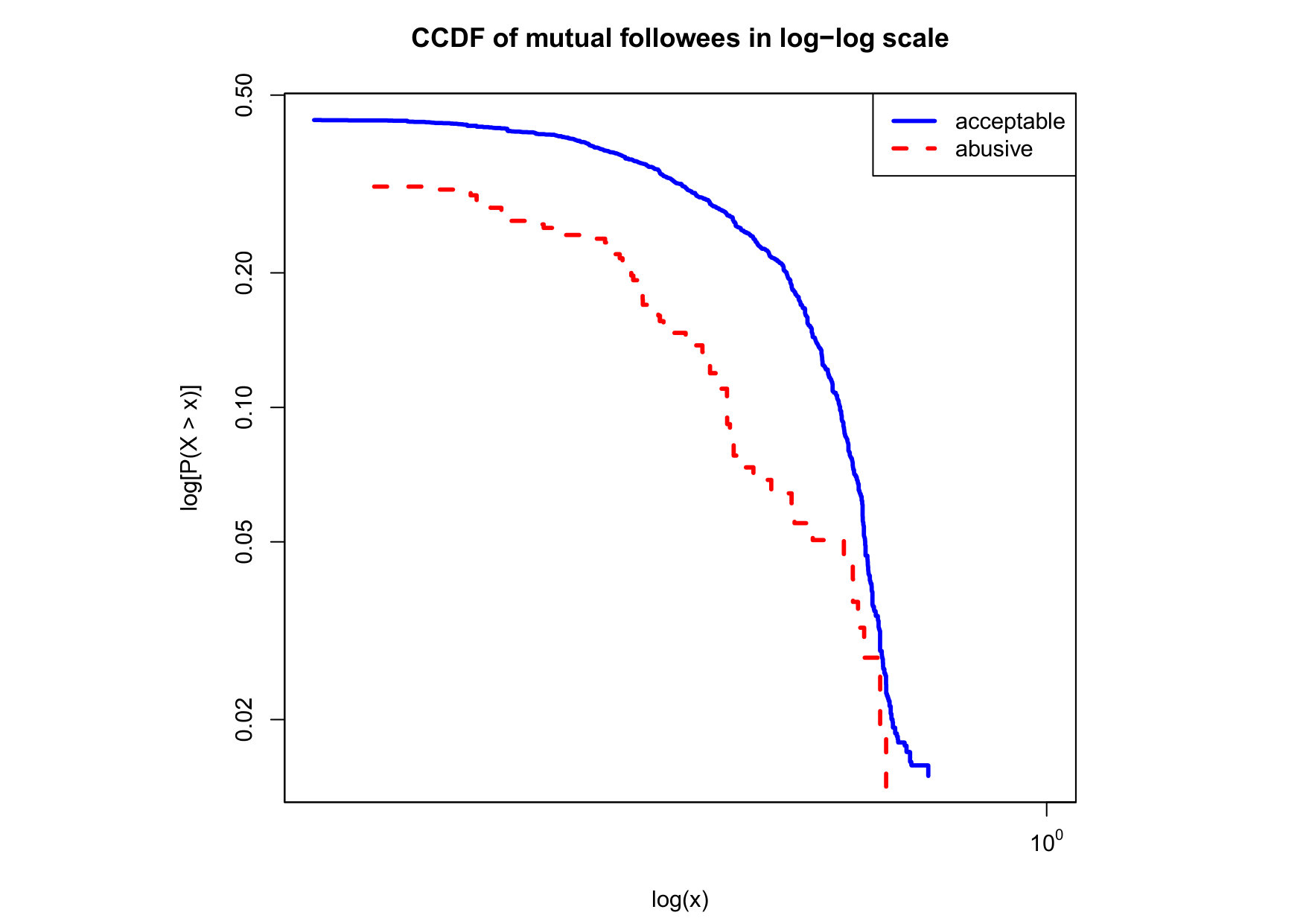 Figure 7
Figure 7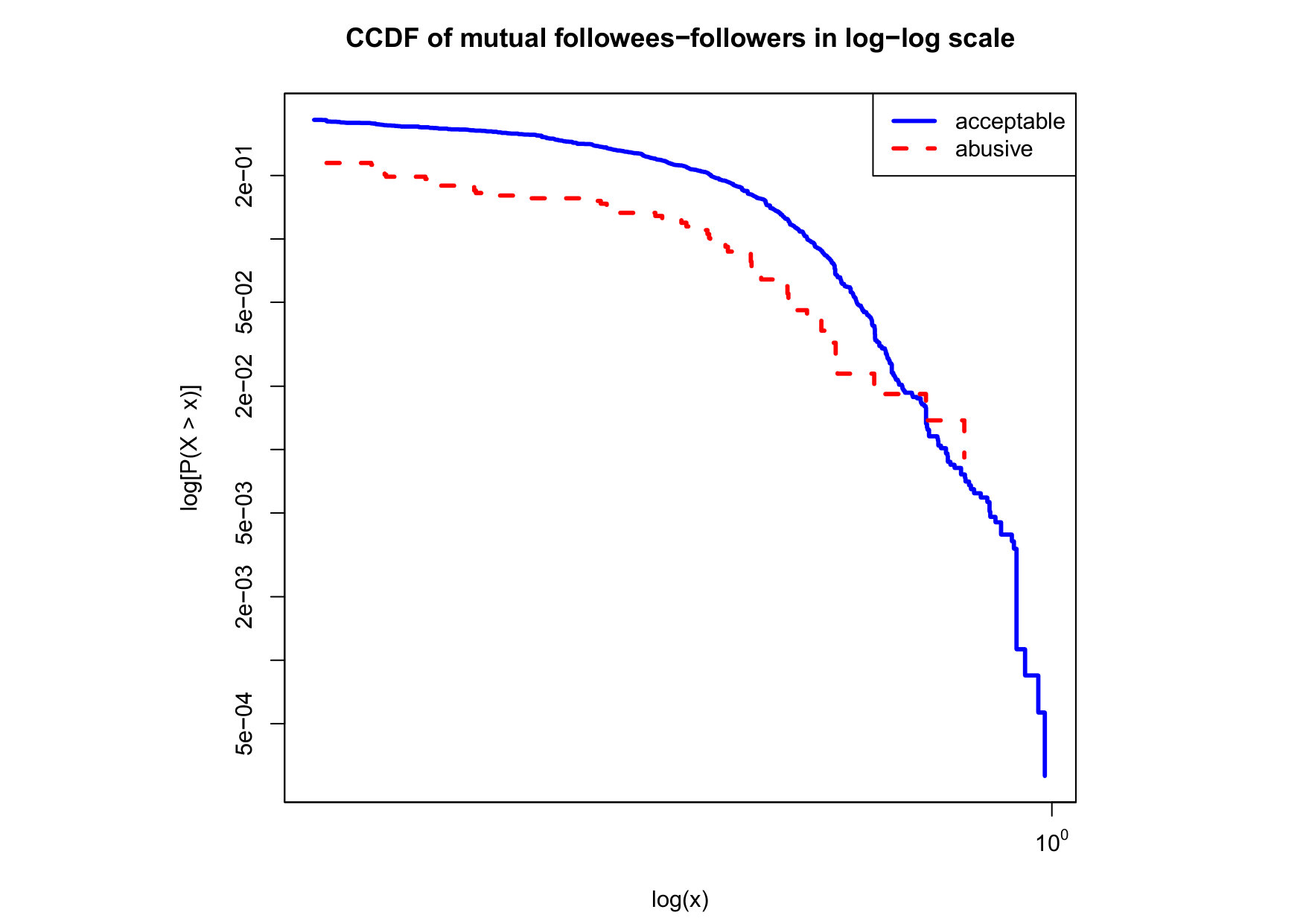 Figure 8
Figure 8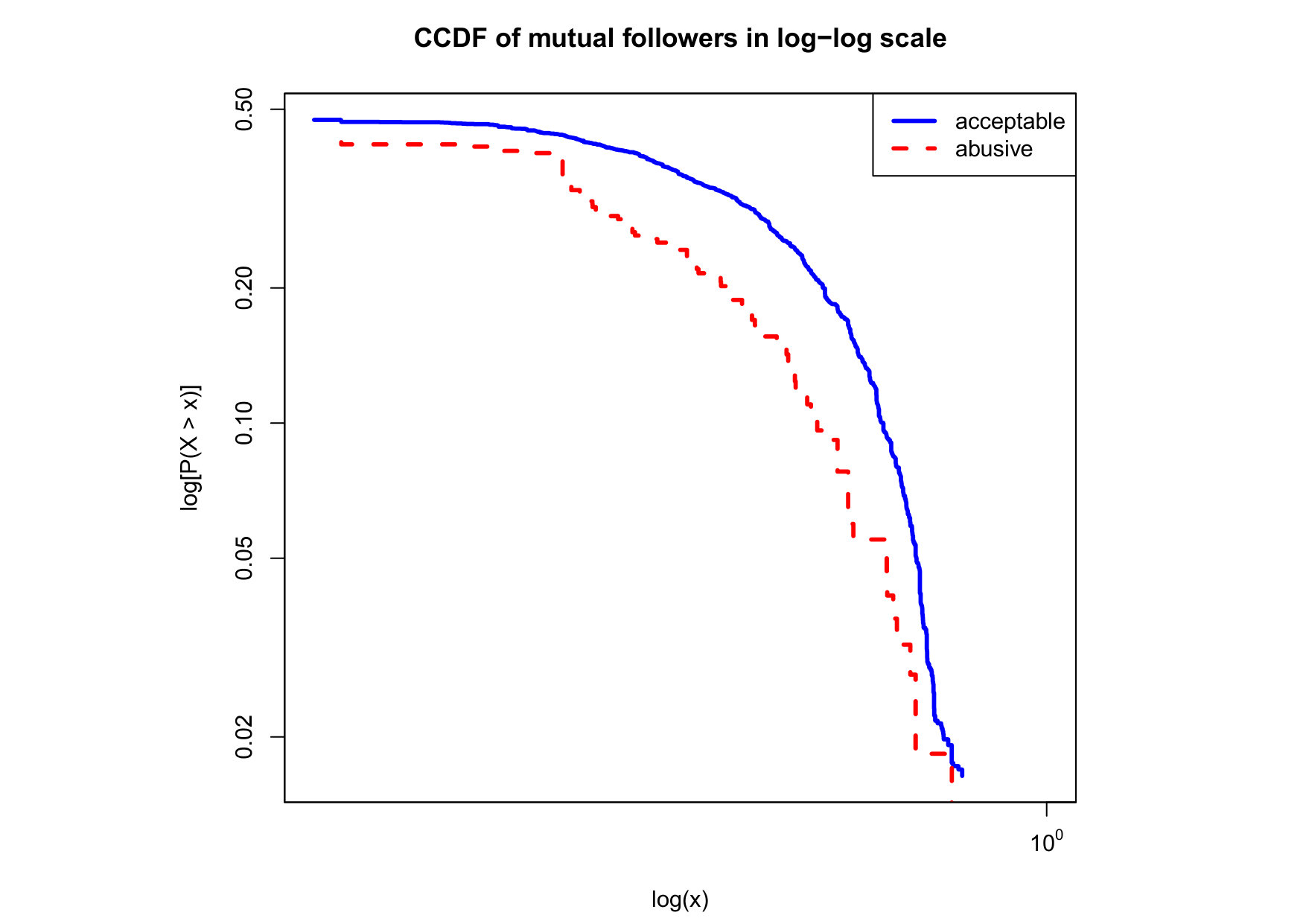 Figure 9
Figure 9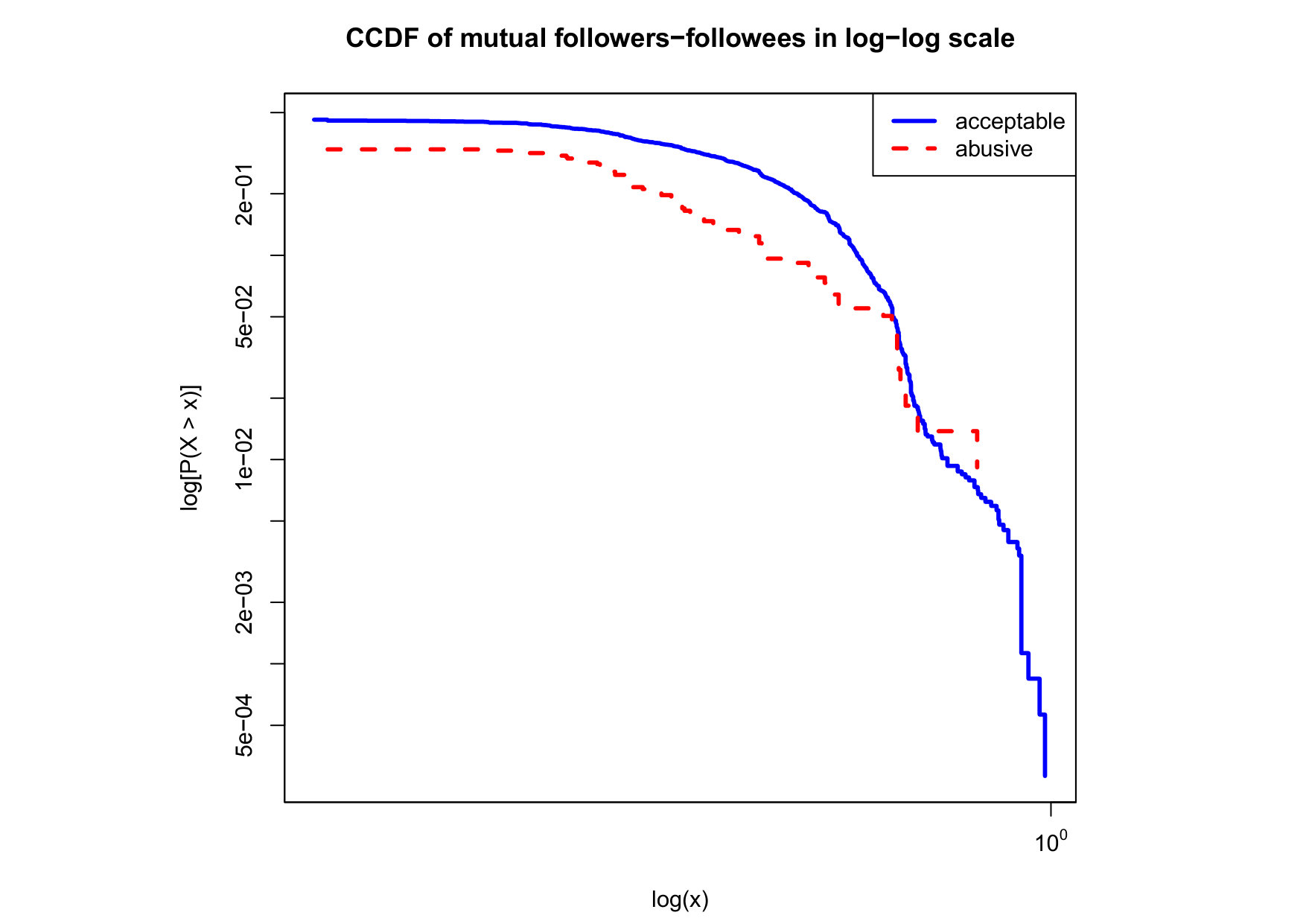 Figure 10
Figure 10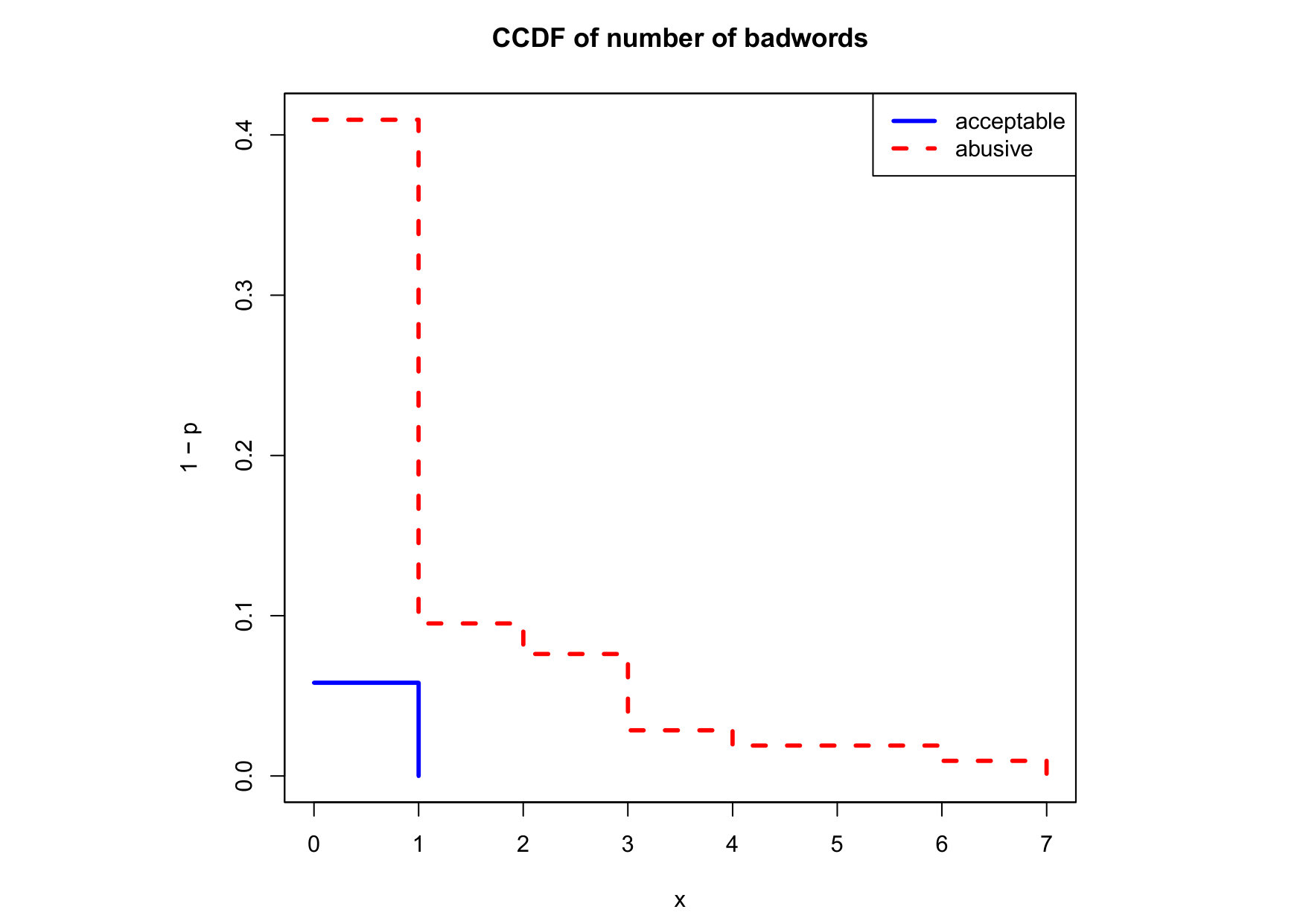 Figure 11
Figure 11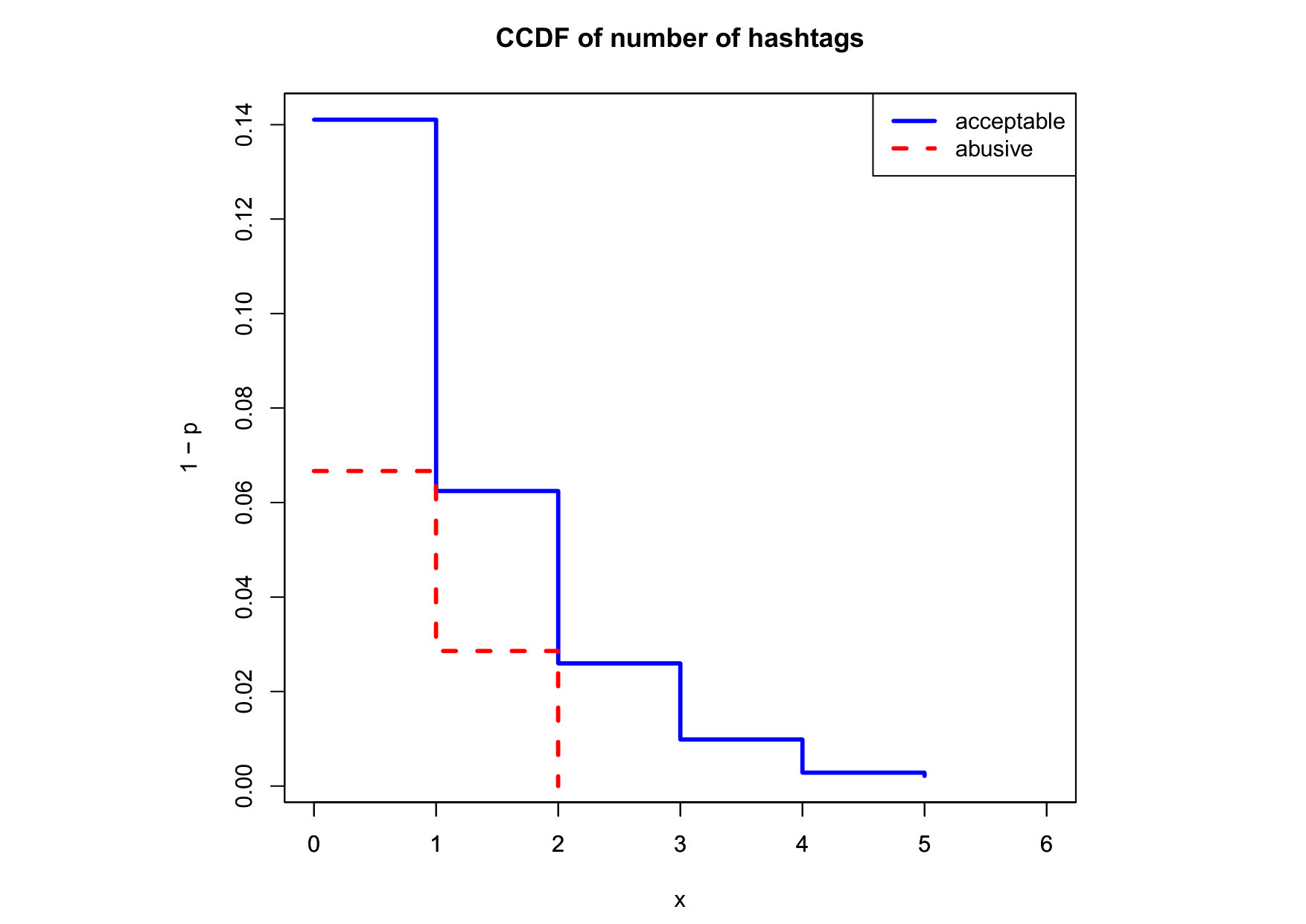 Figure 12
Figure 12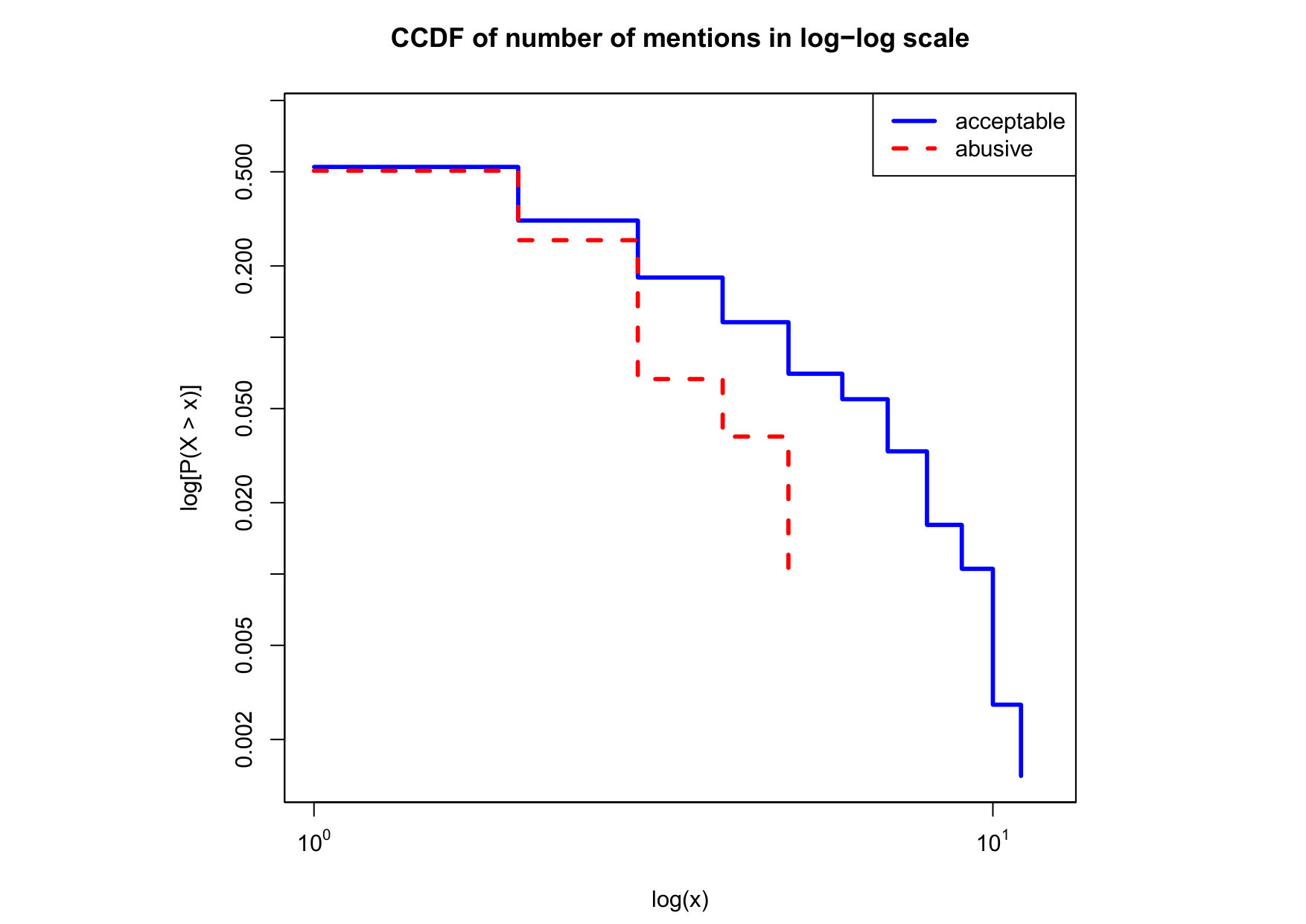 Figure 13
Figure 13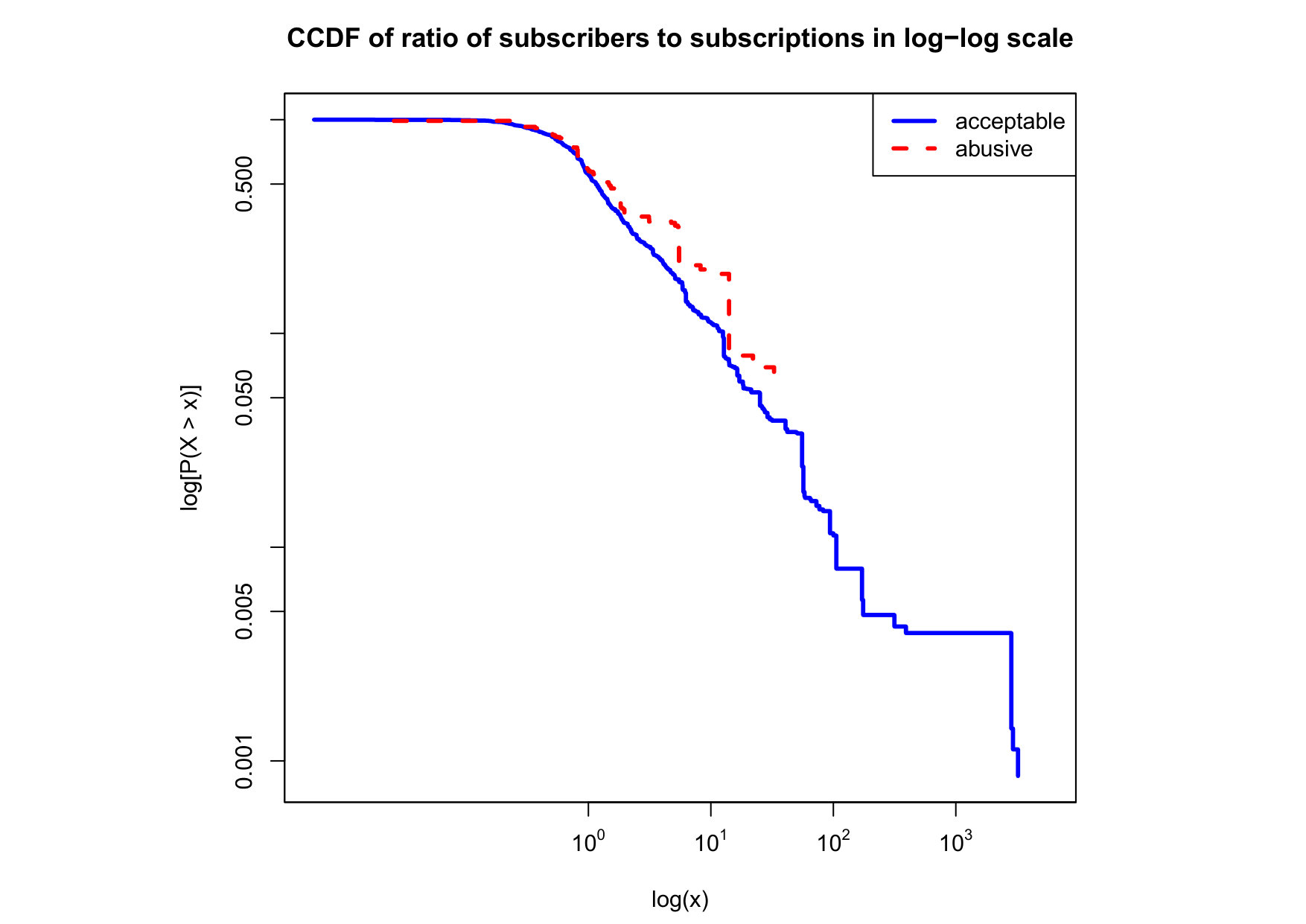 Figure 14
Figure 14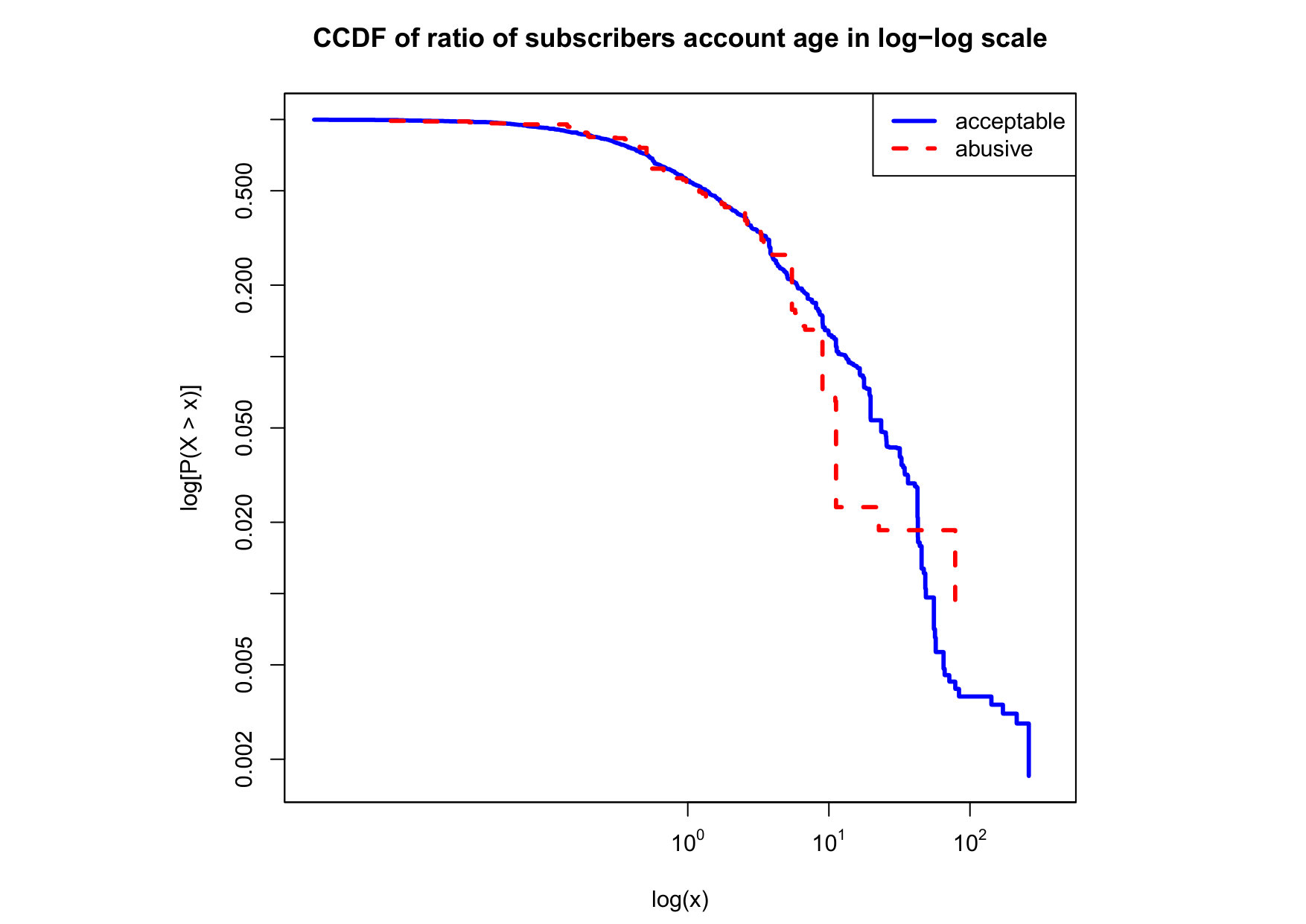 Figure 15
Figure 15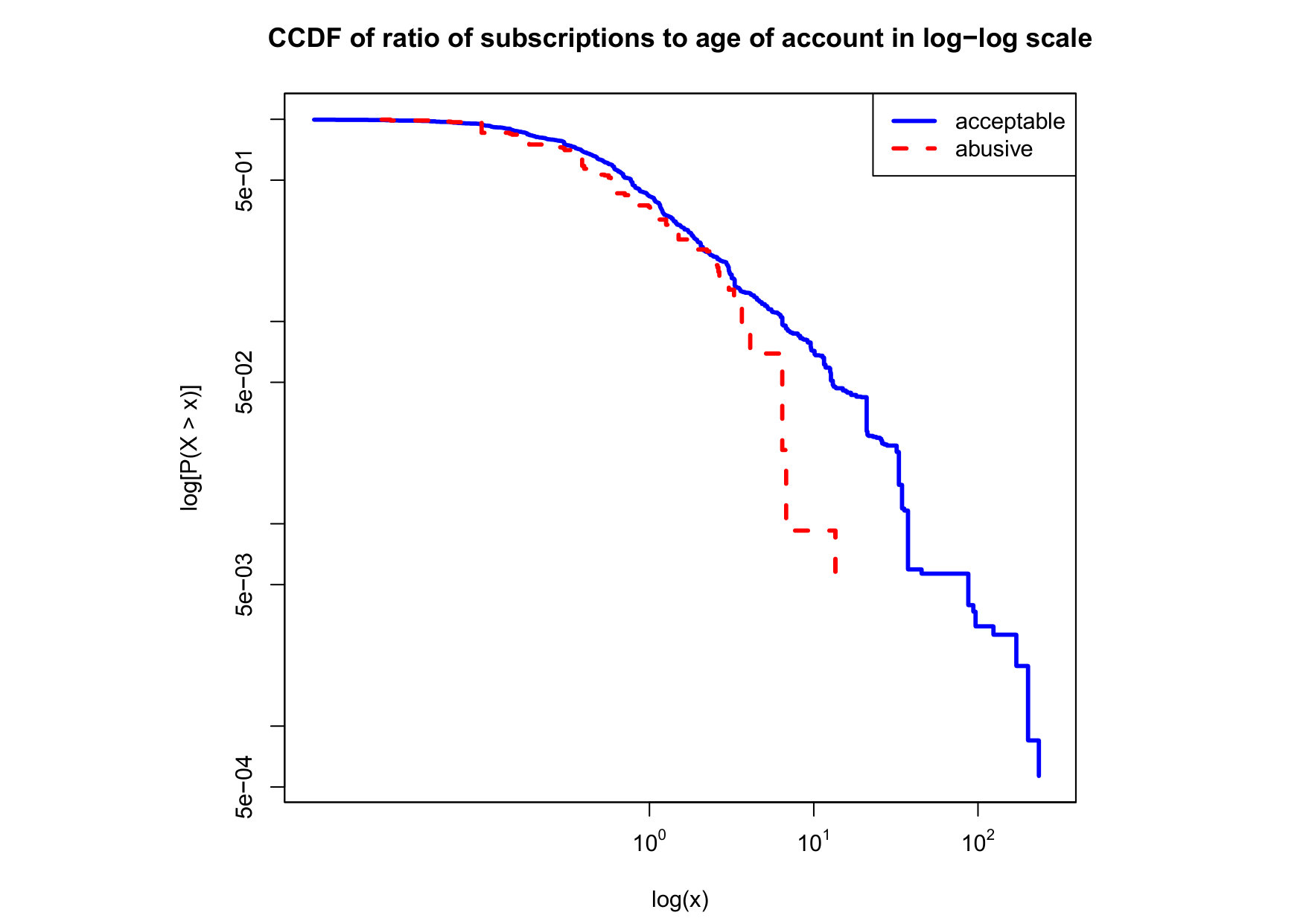 Figure 16
Figure 16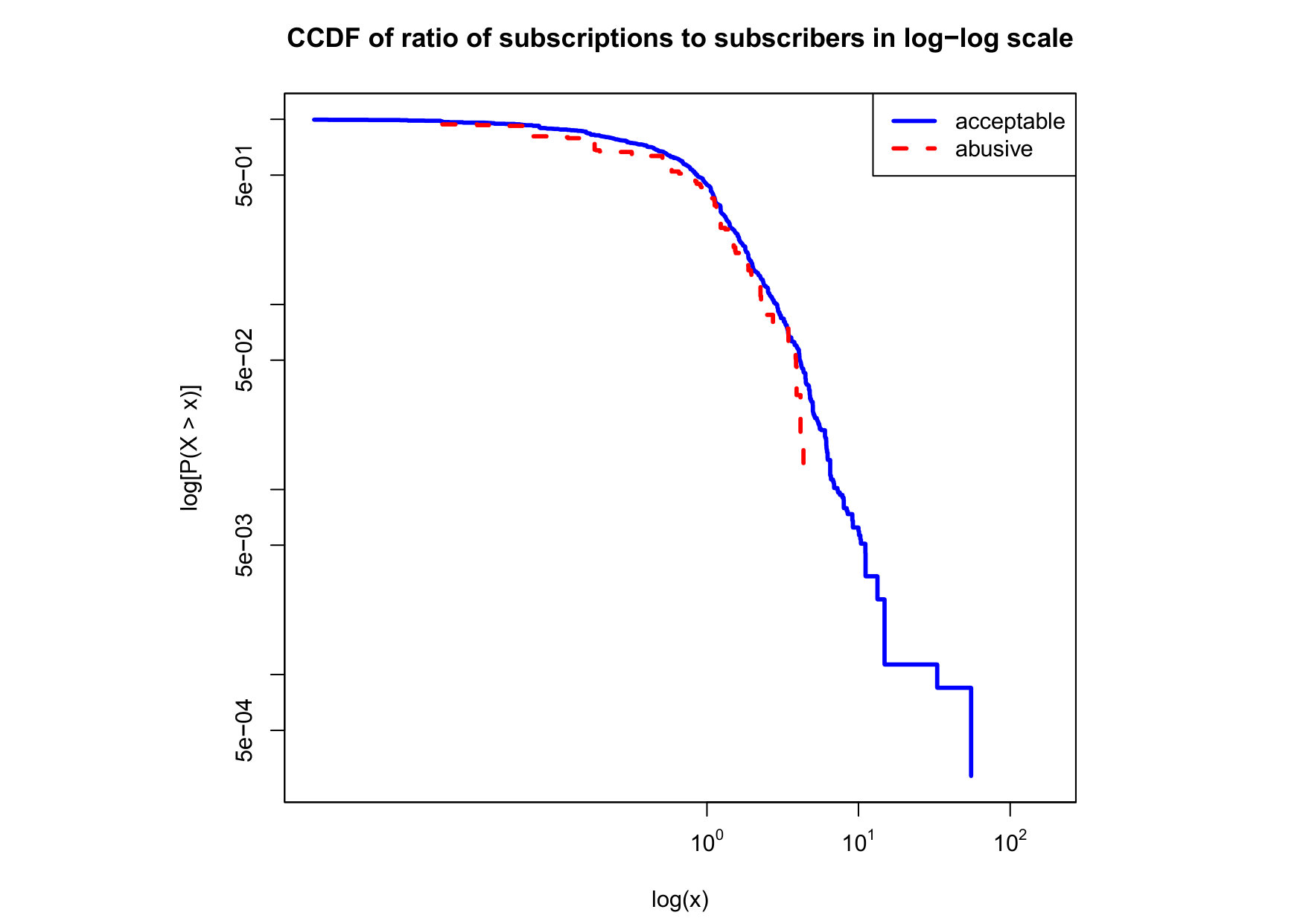 Figure 17
Figure 17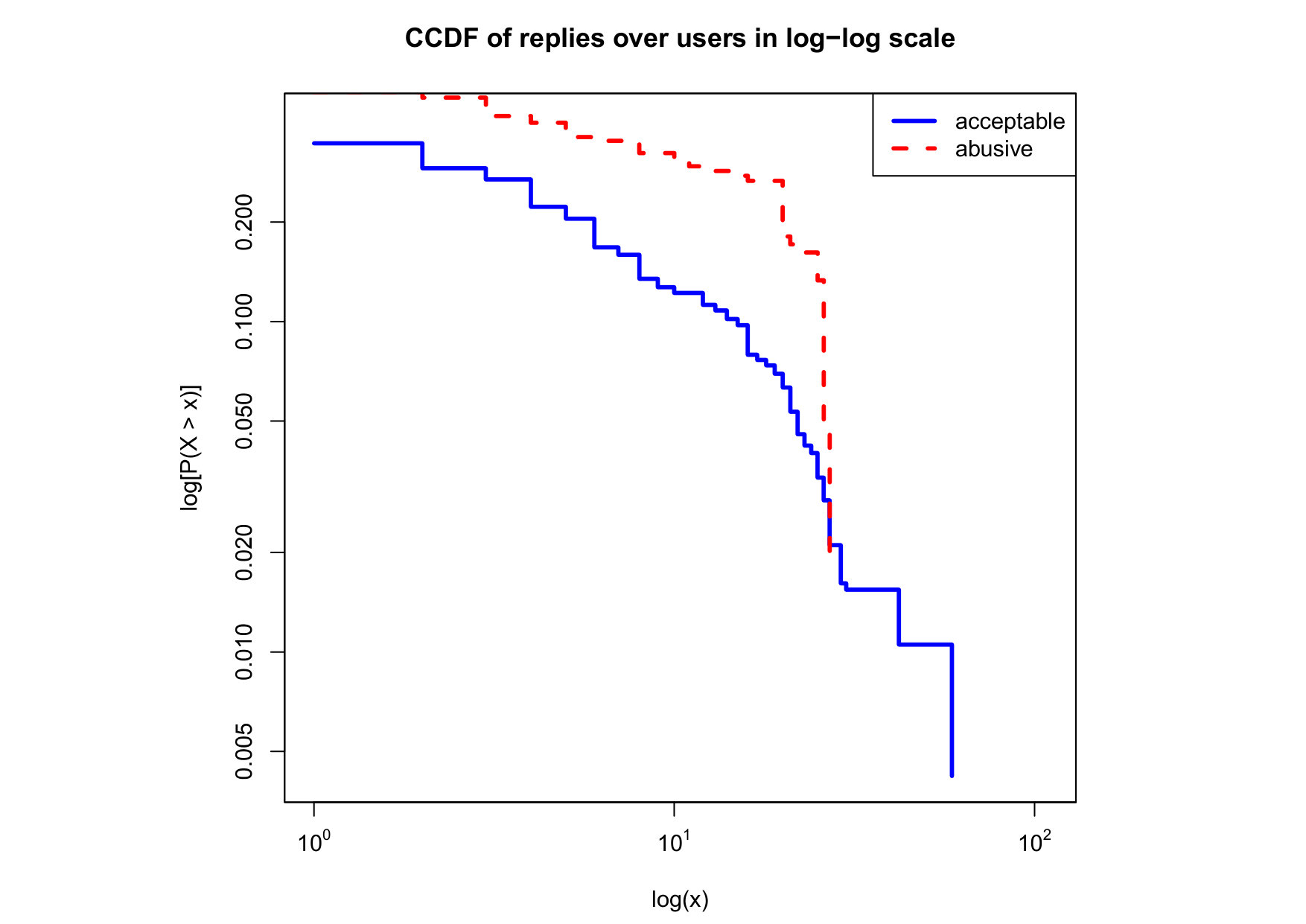 Figure 18
Figure 18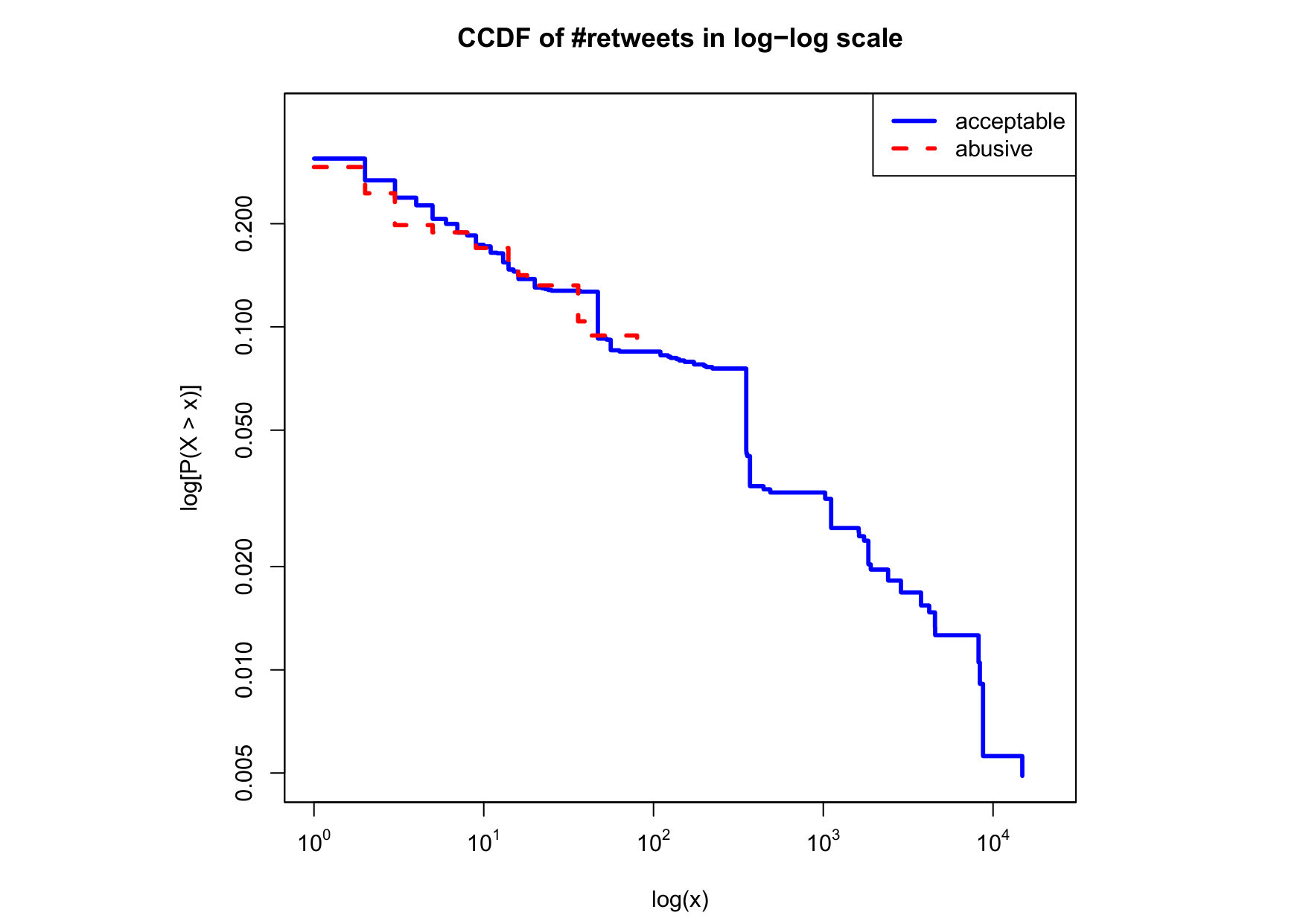 Figure 19
Figure 19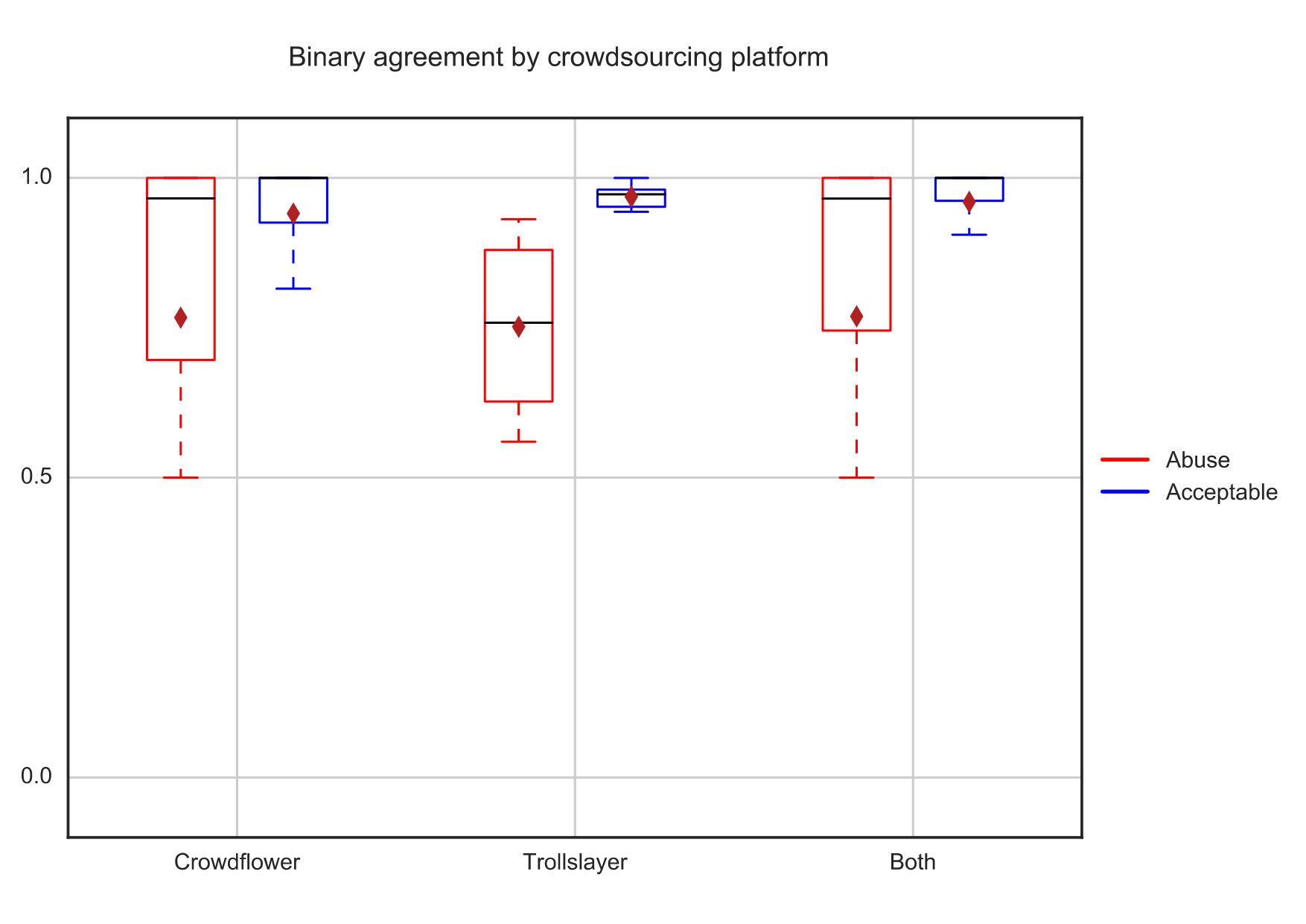 Figure 20
Figure 20 Figure 21
Figure 21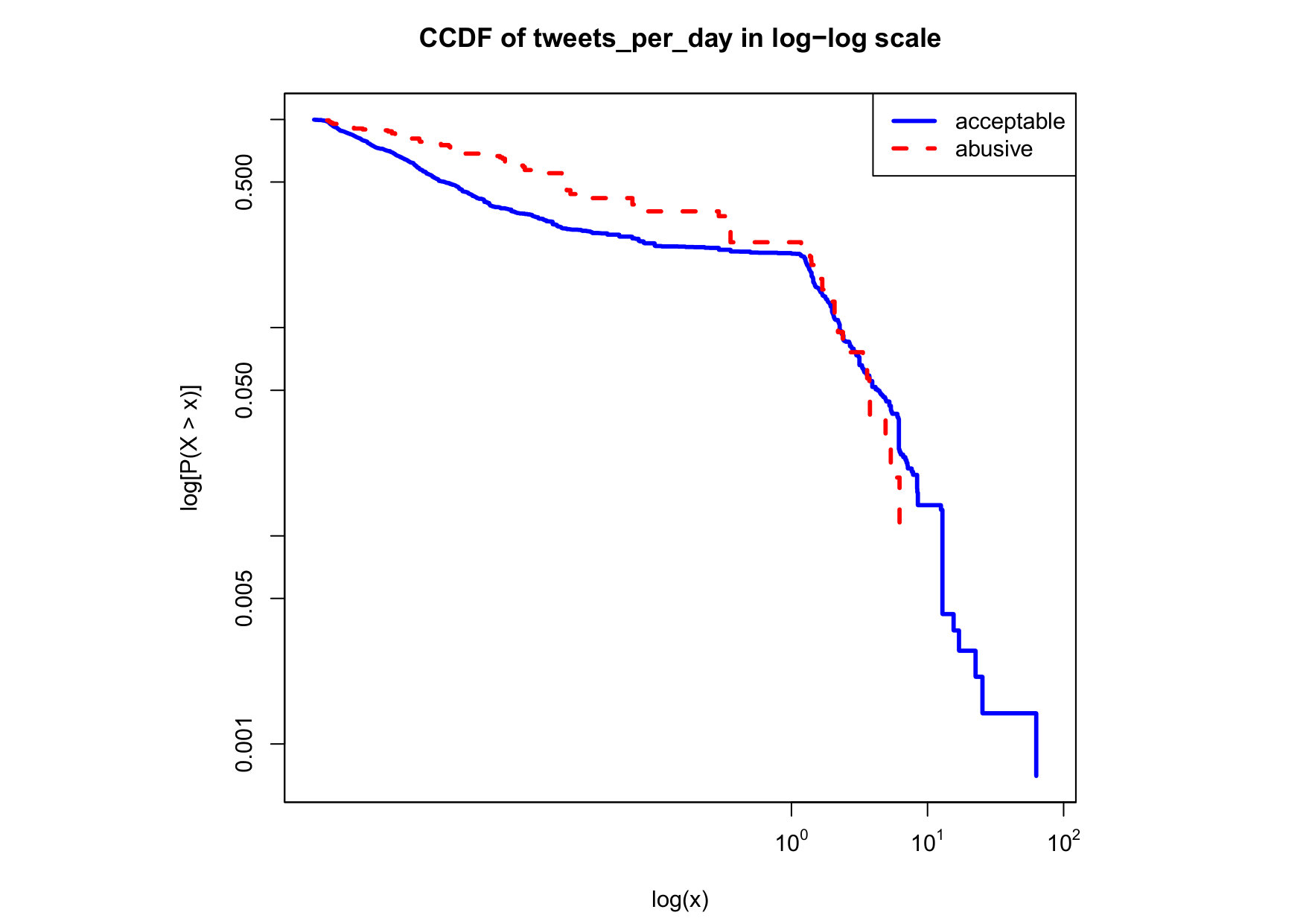 Figure 22
Figure 22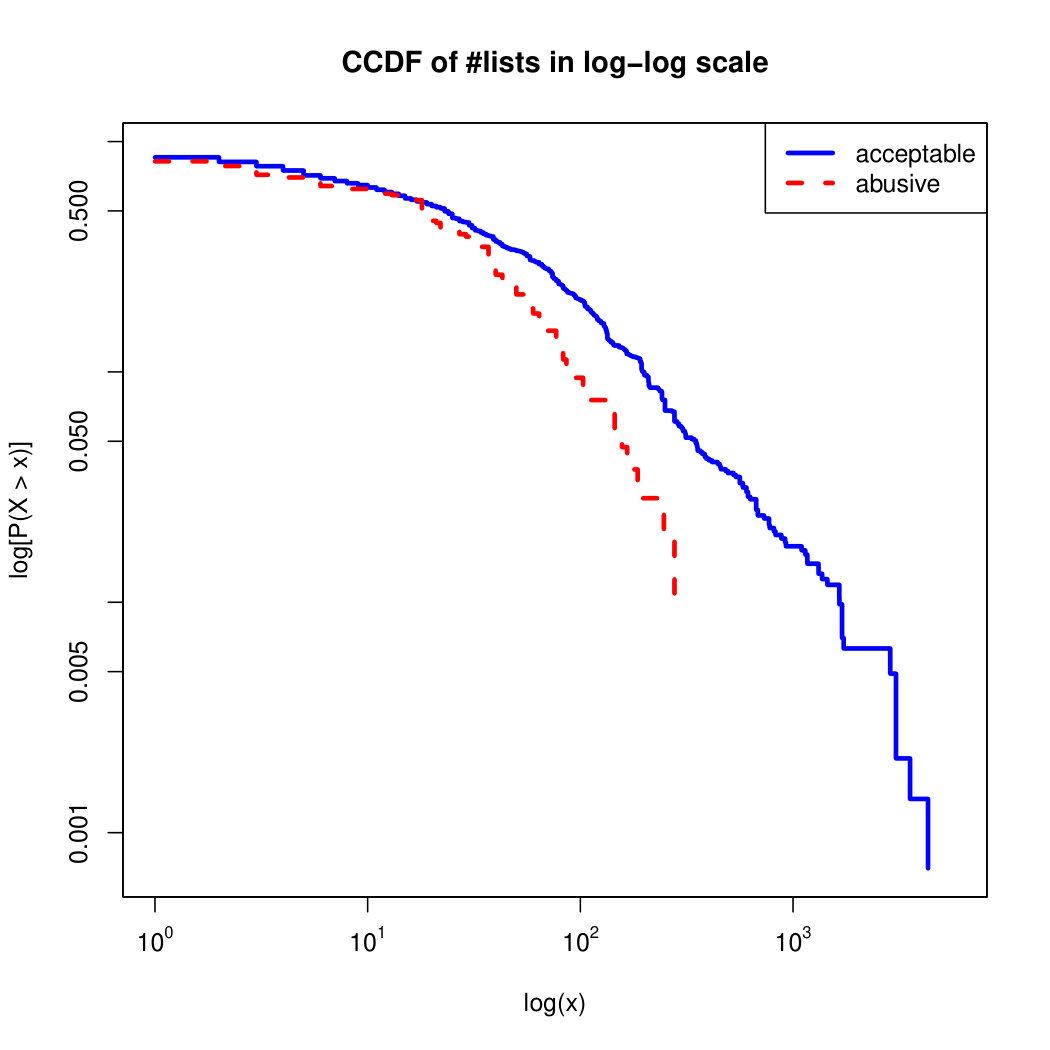 Figure 23
Figure 23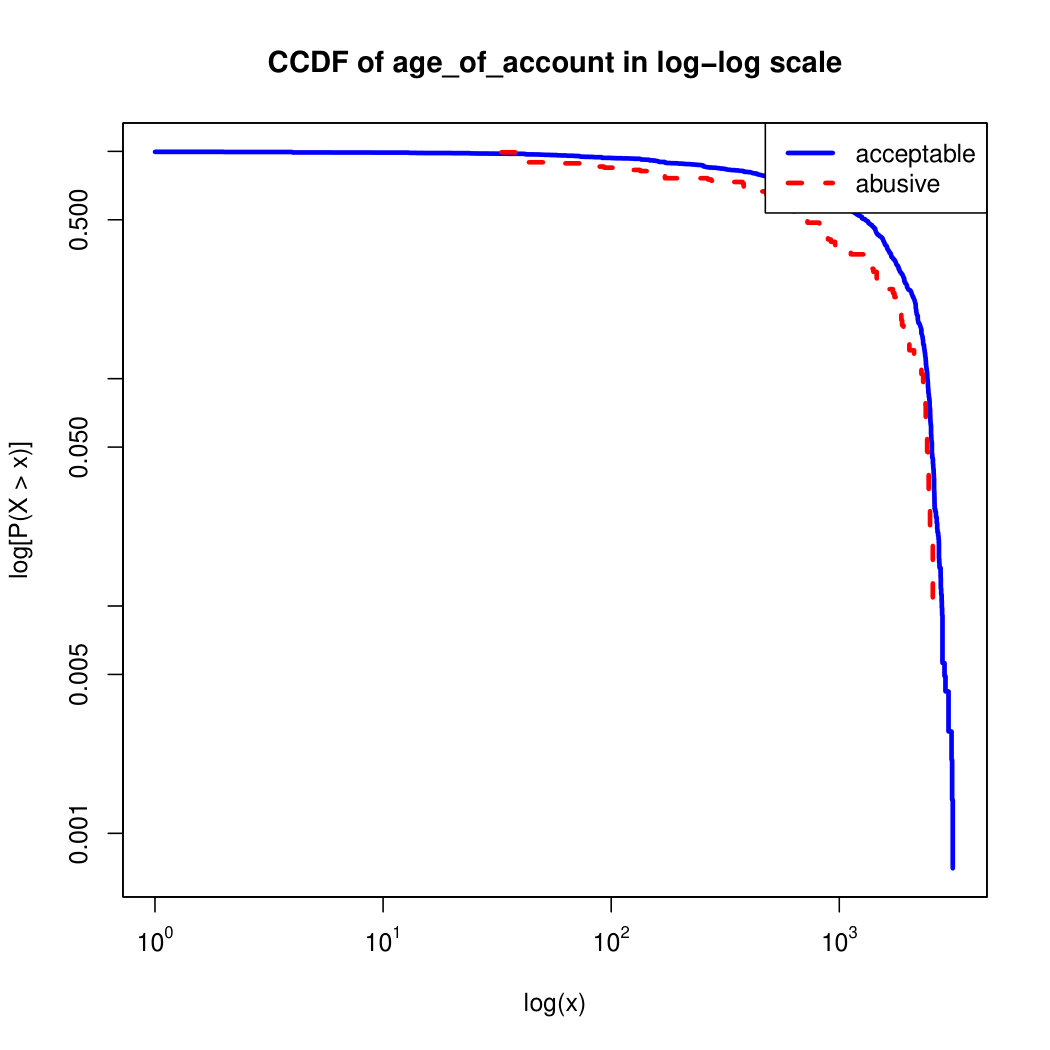 Figure 24
Figure 24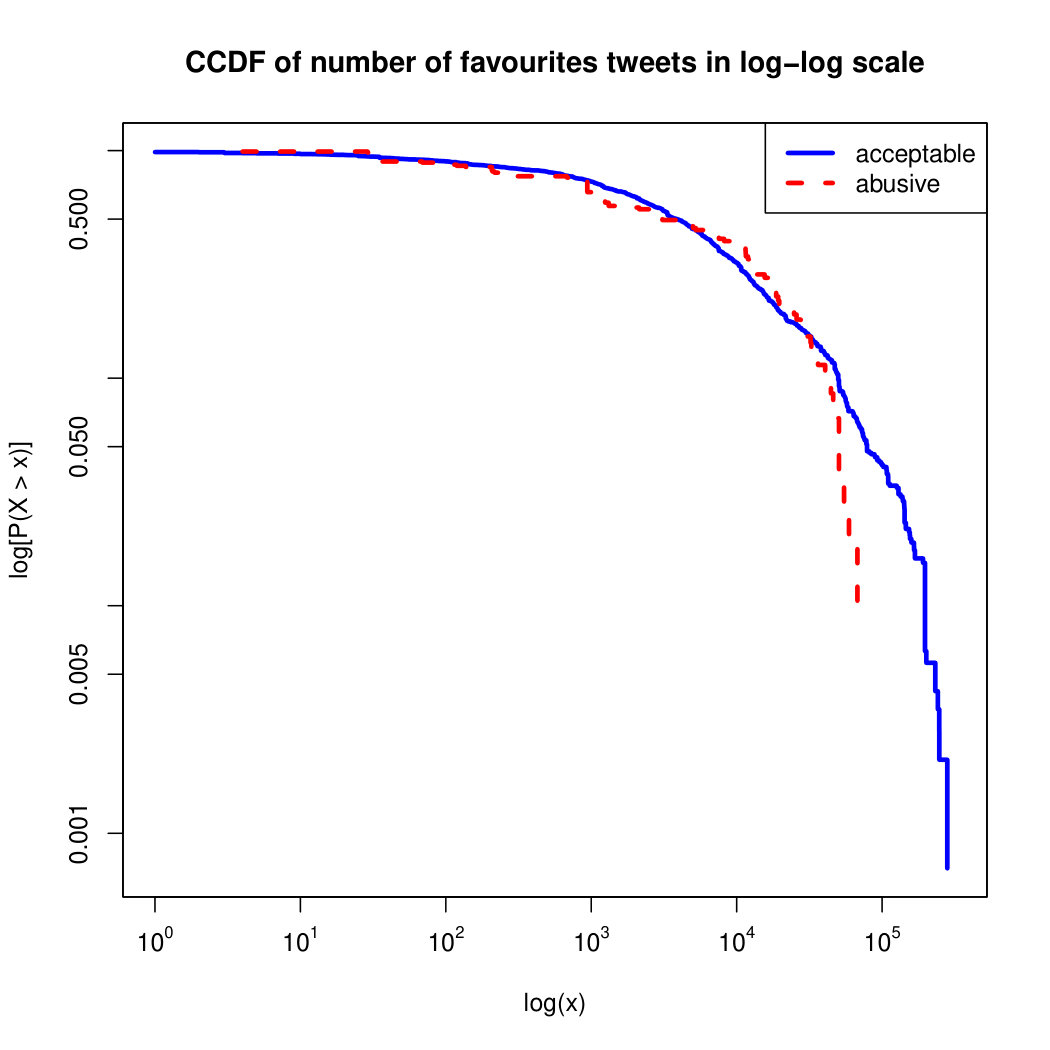 Figure 25
Figure 25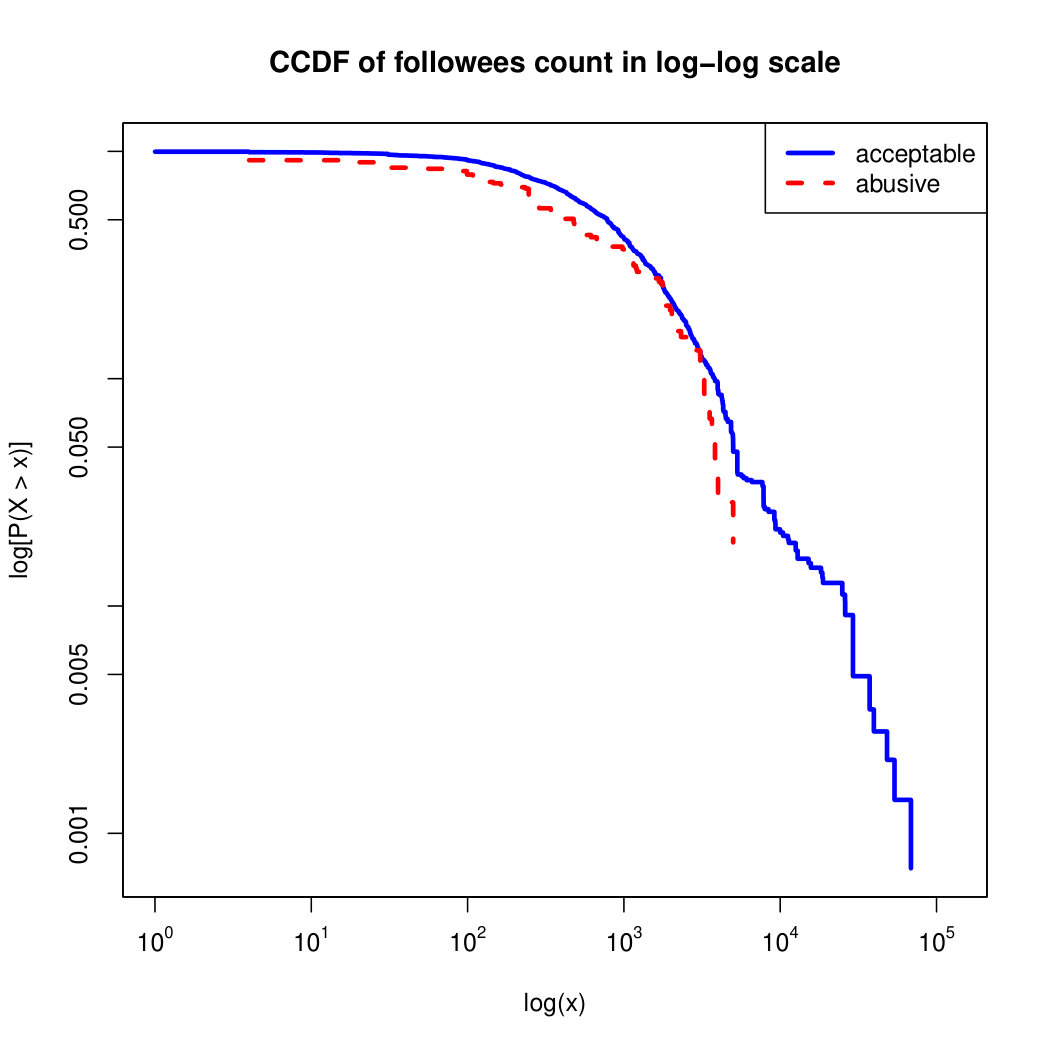 Figure 26
Figure 26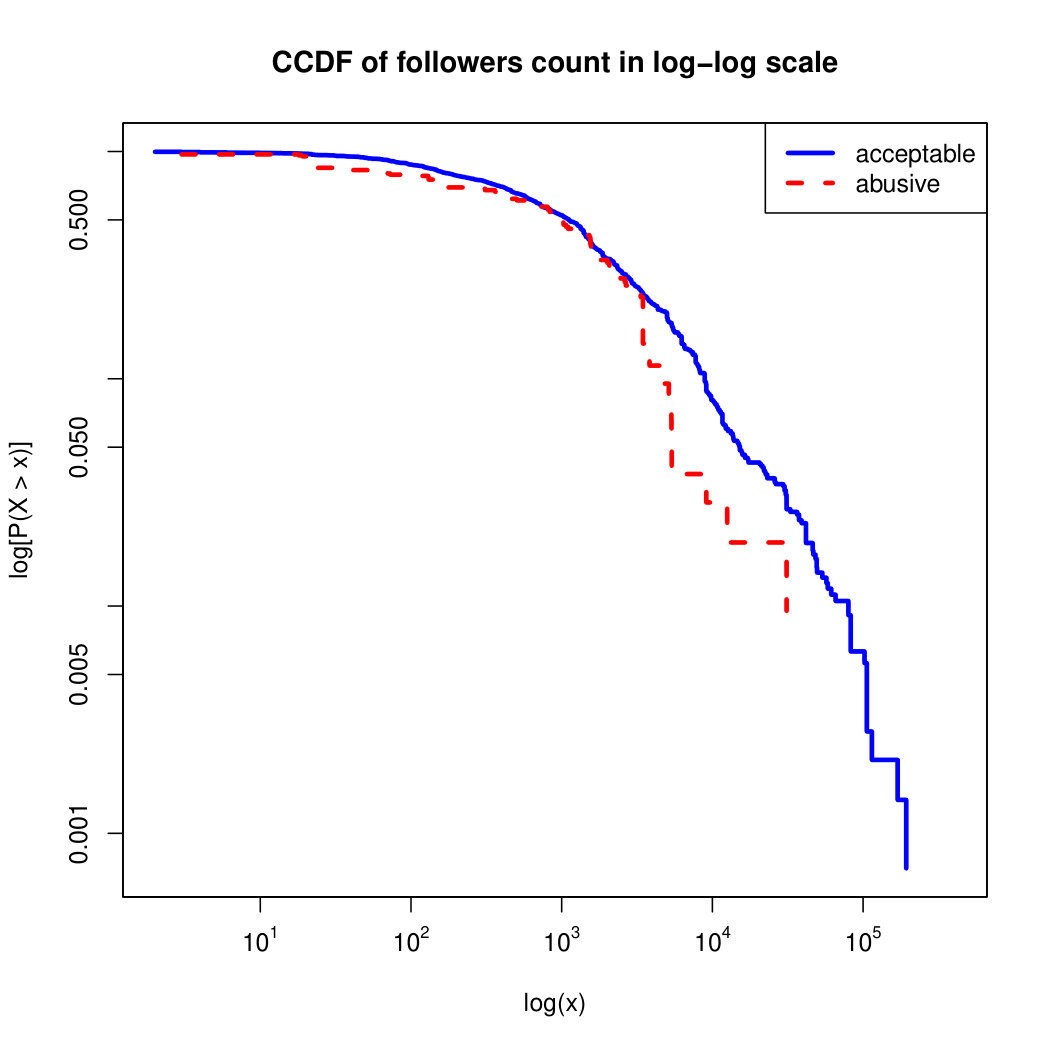 Figure 27
Figure 27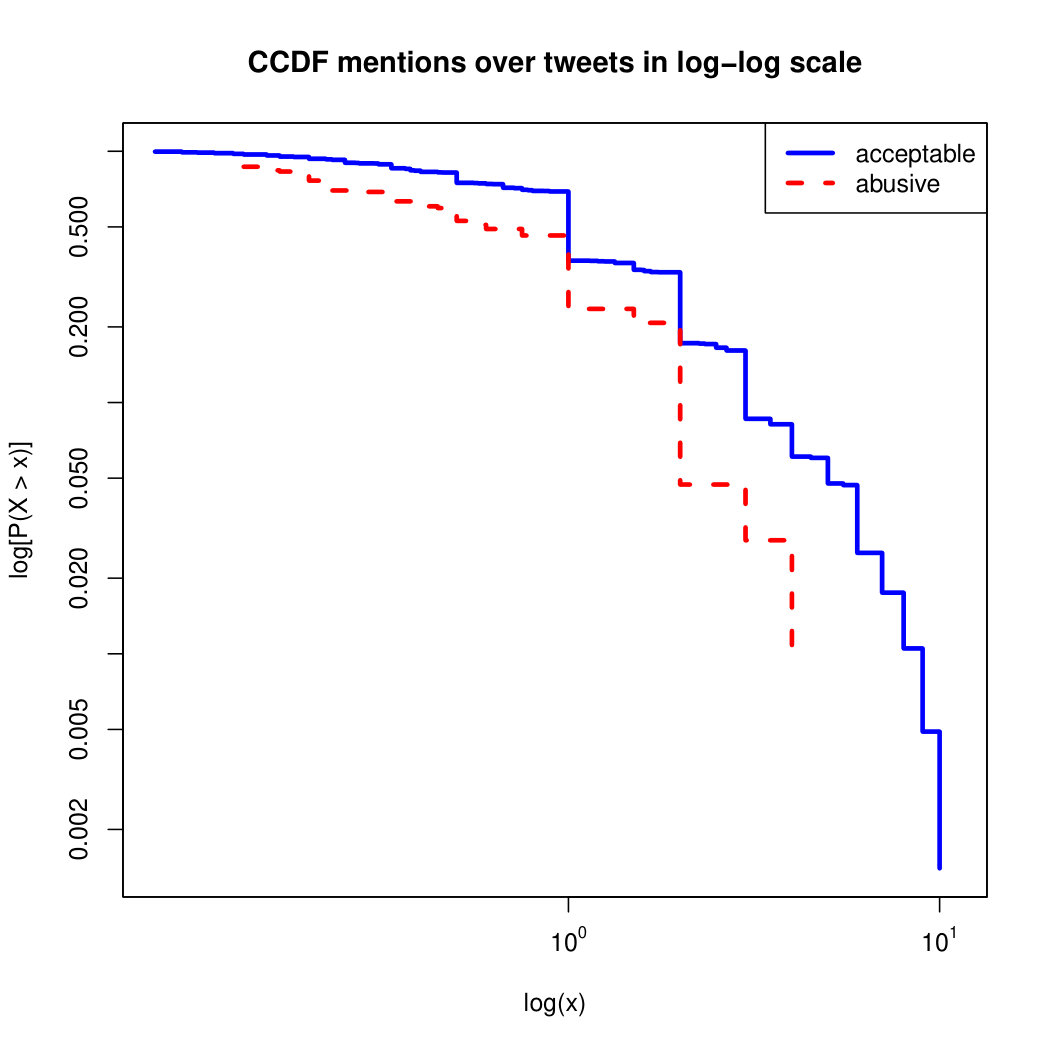 Figure 28
Figure 28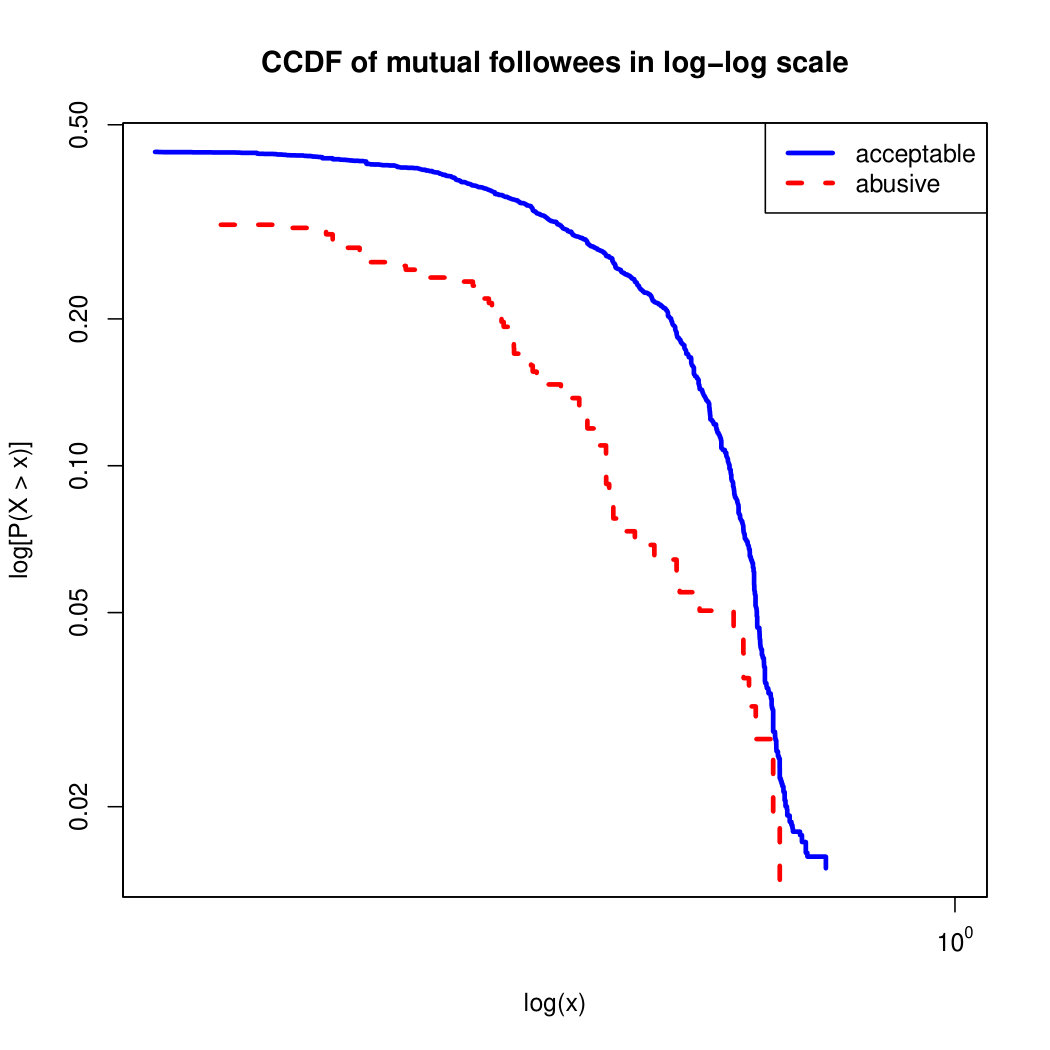 Figure 29
Figure 29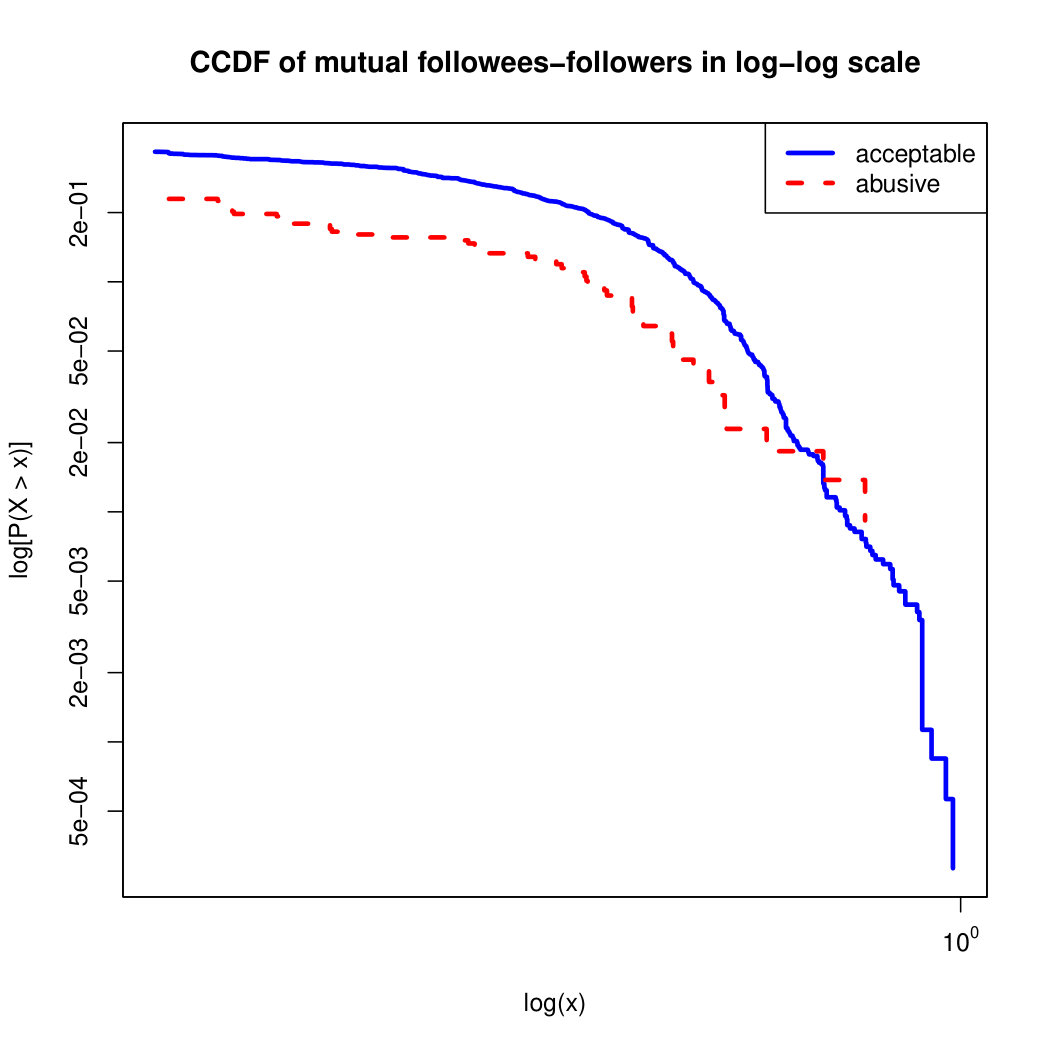 Figure 30
Figure 30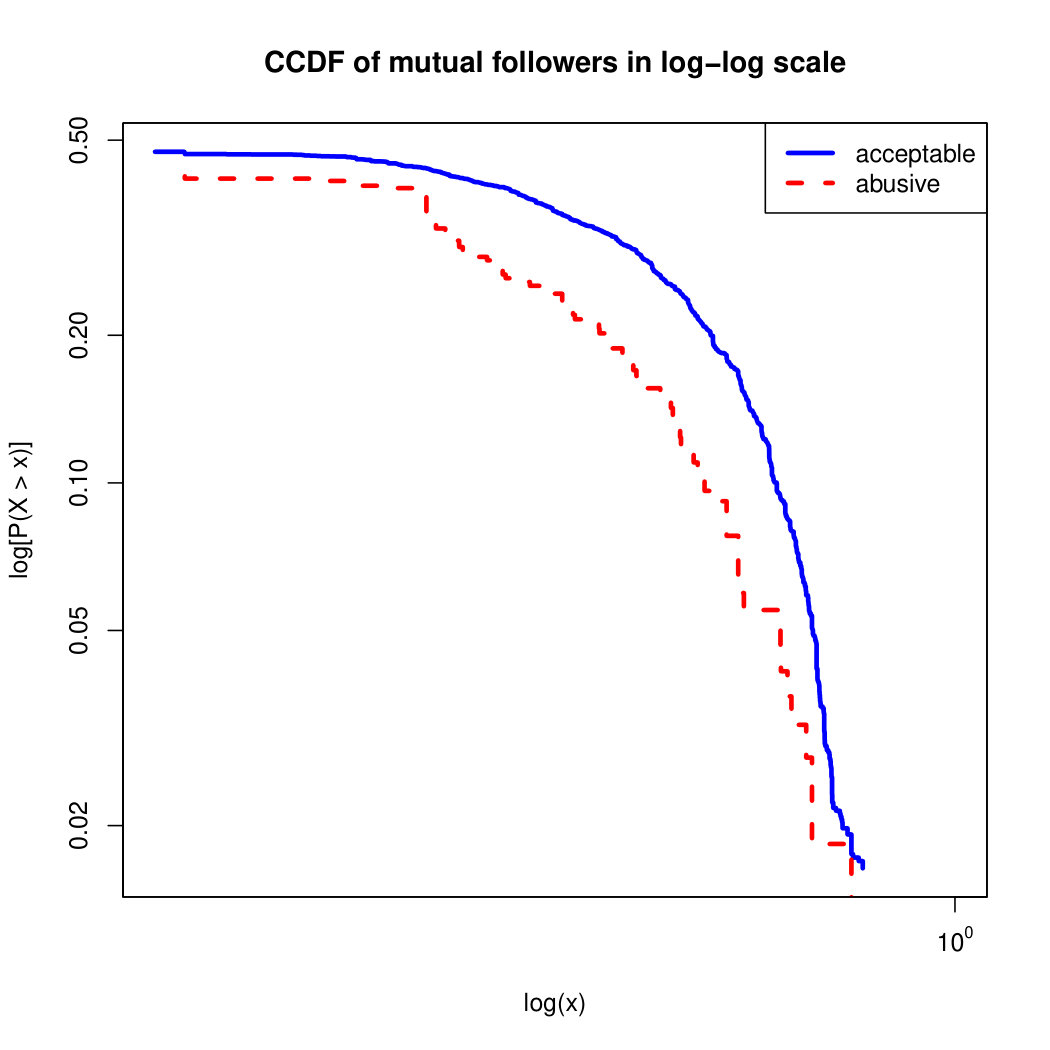 Figure 31
Figure 31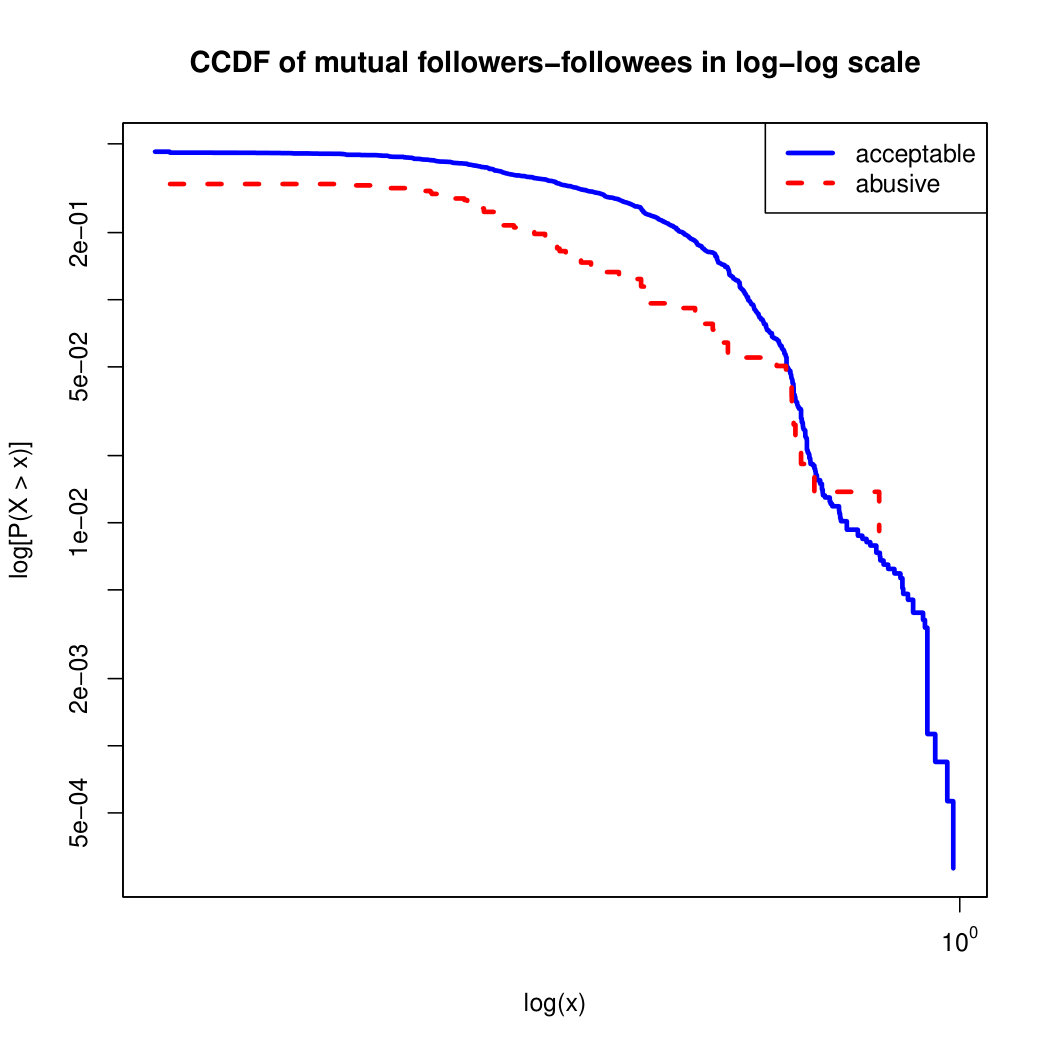 Figure 32
Figure 32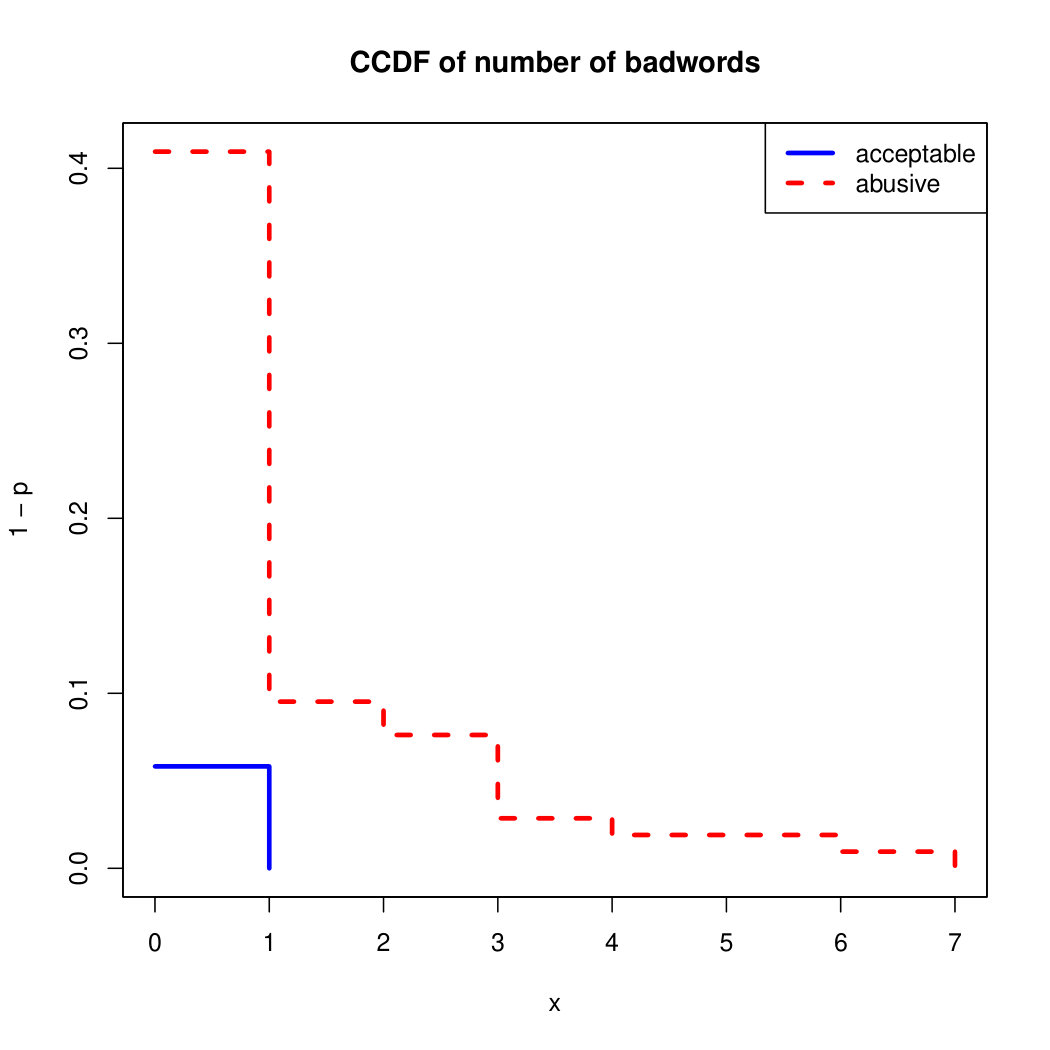 Figure 33
Figure 33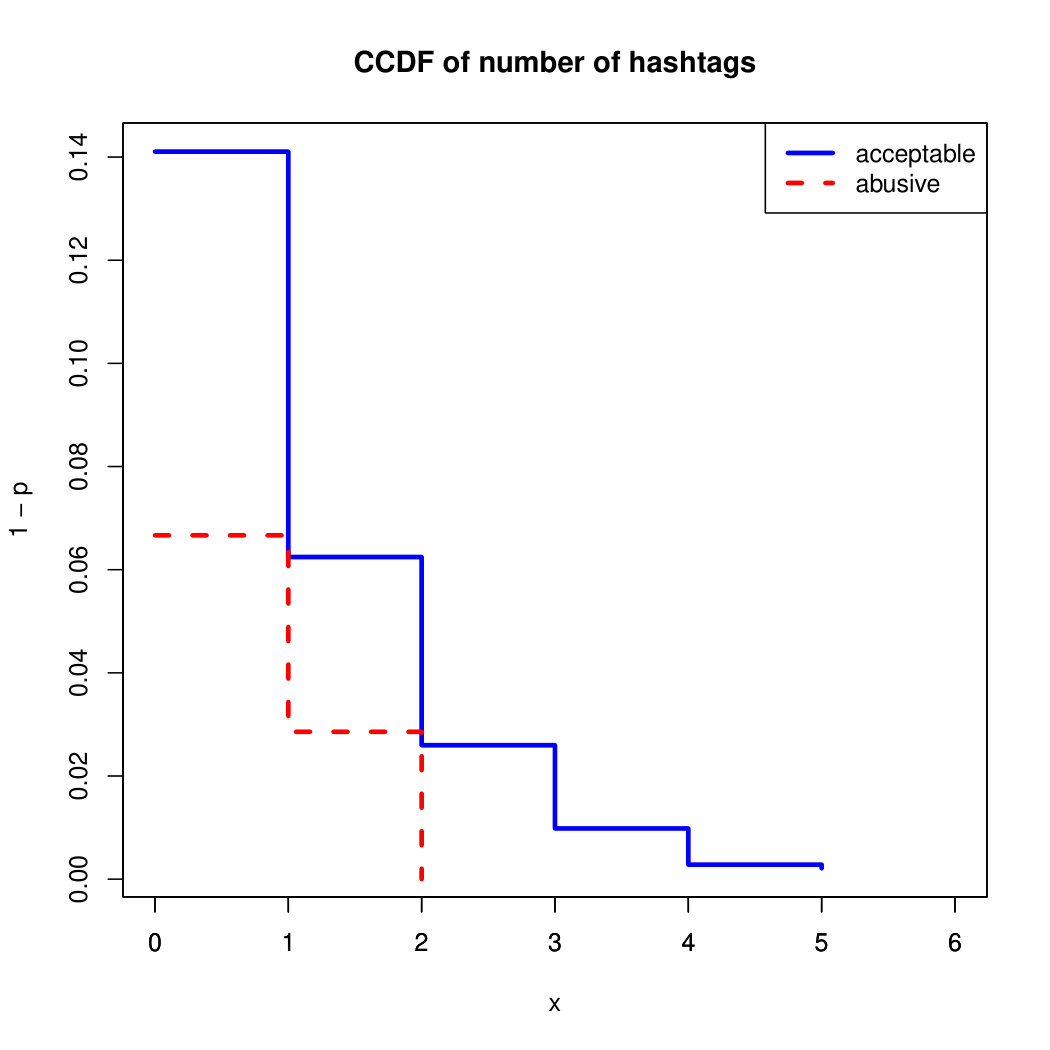 Figure 34
Figure 34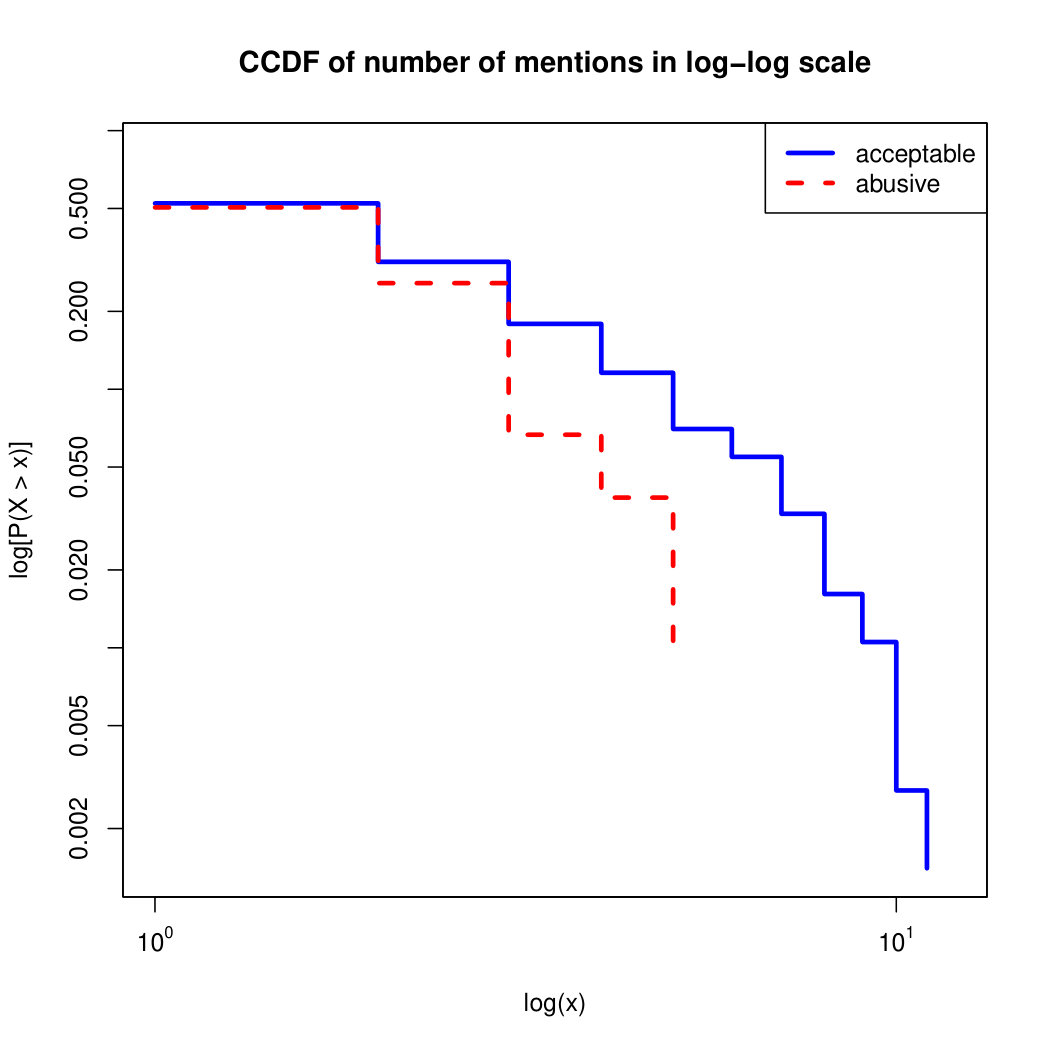 Figure 35
Figure 35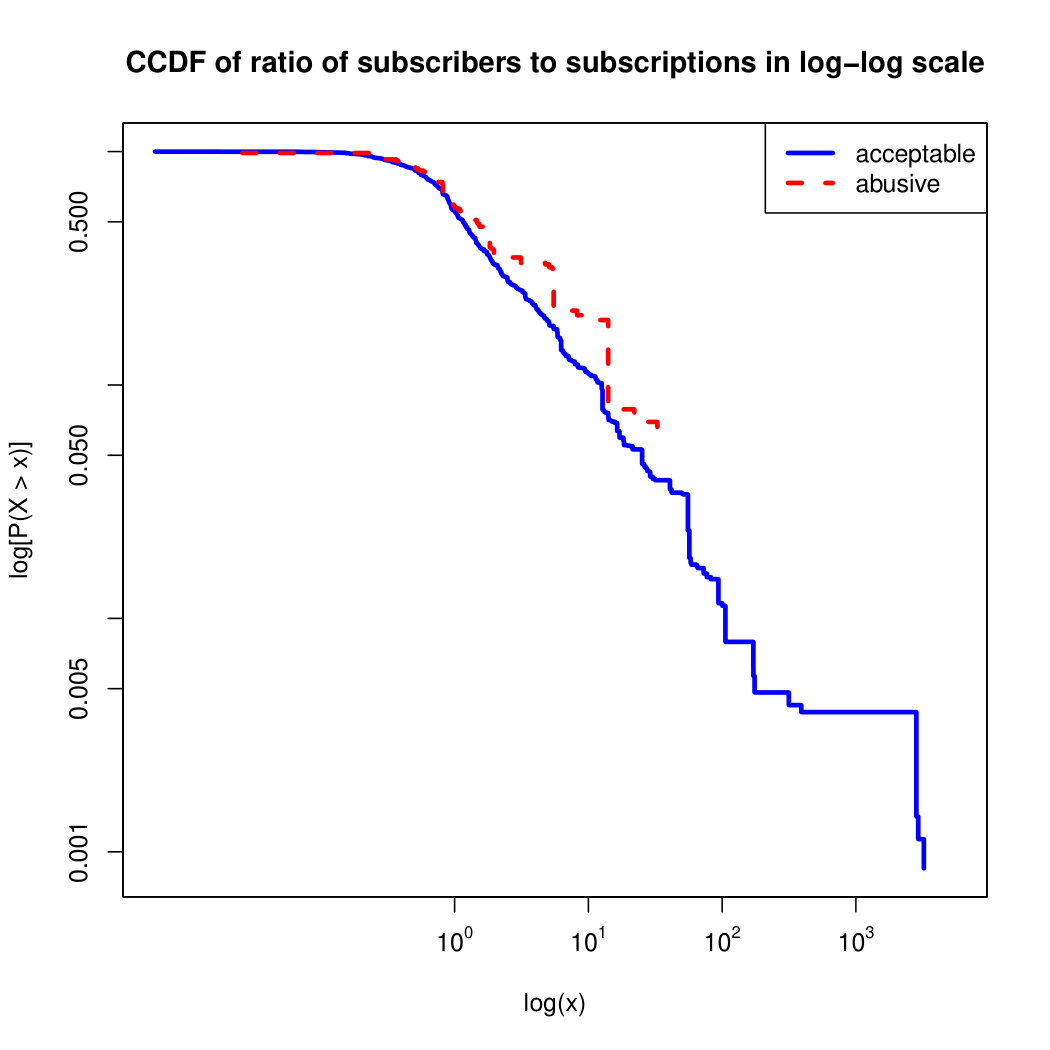 Figure 36
Figure 36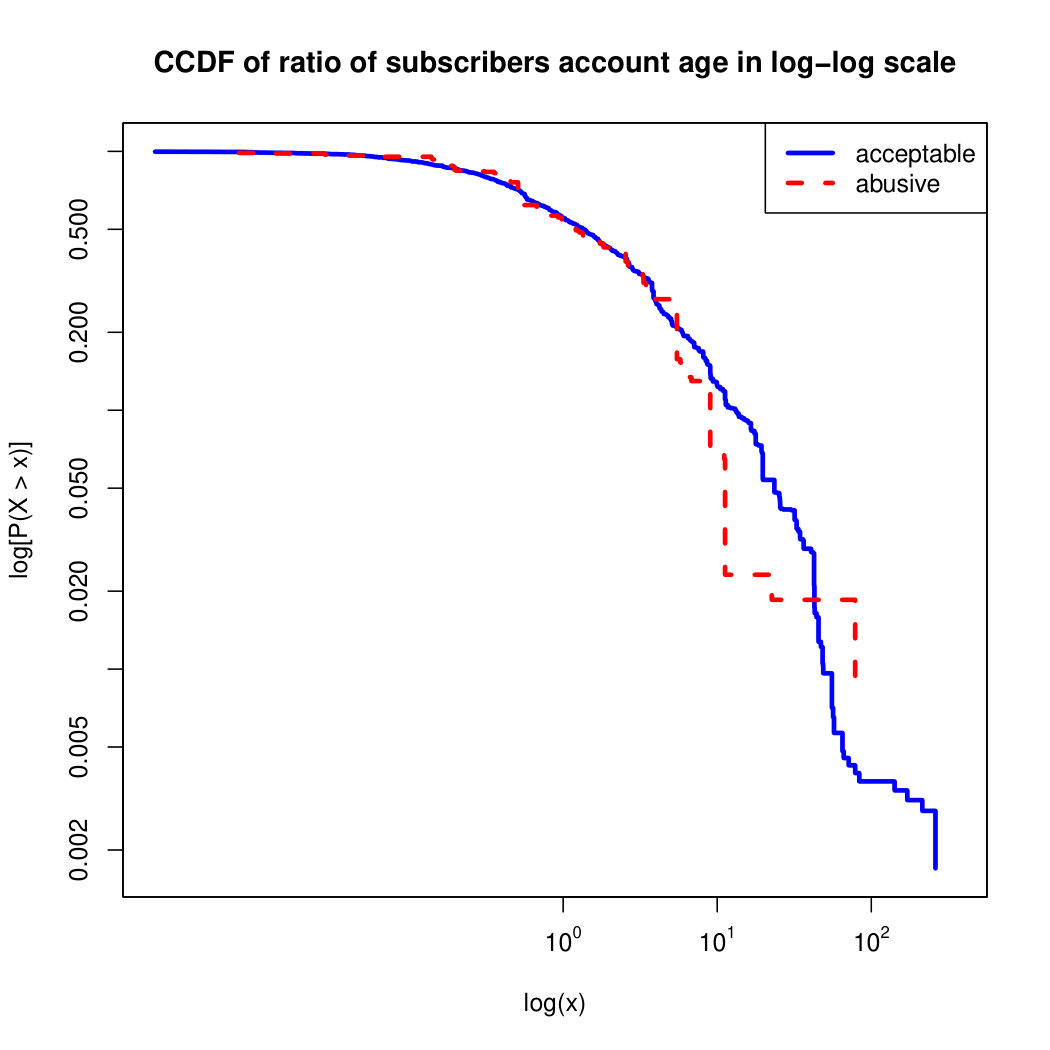 Figure 37
Figure 37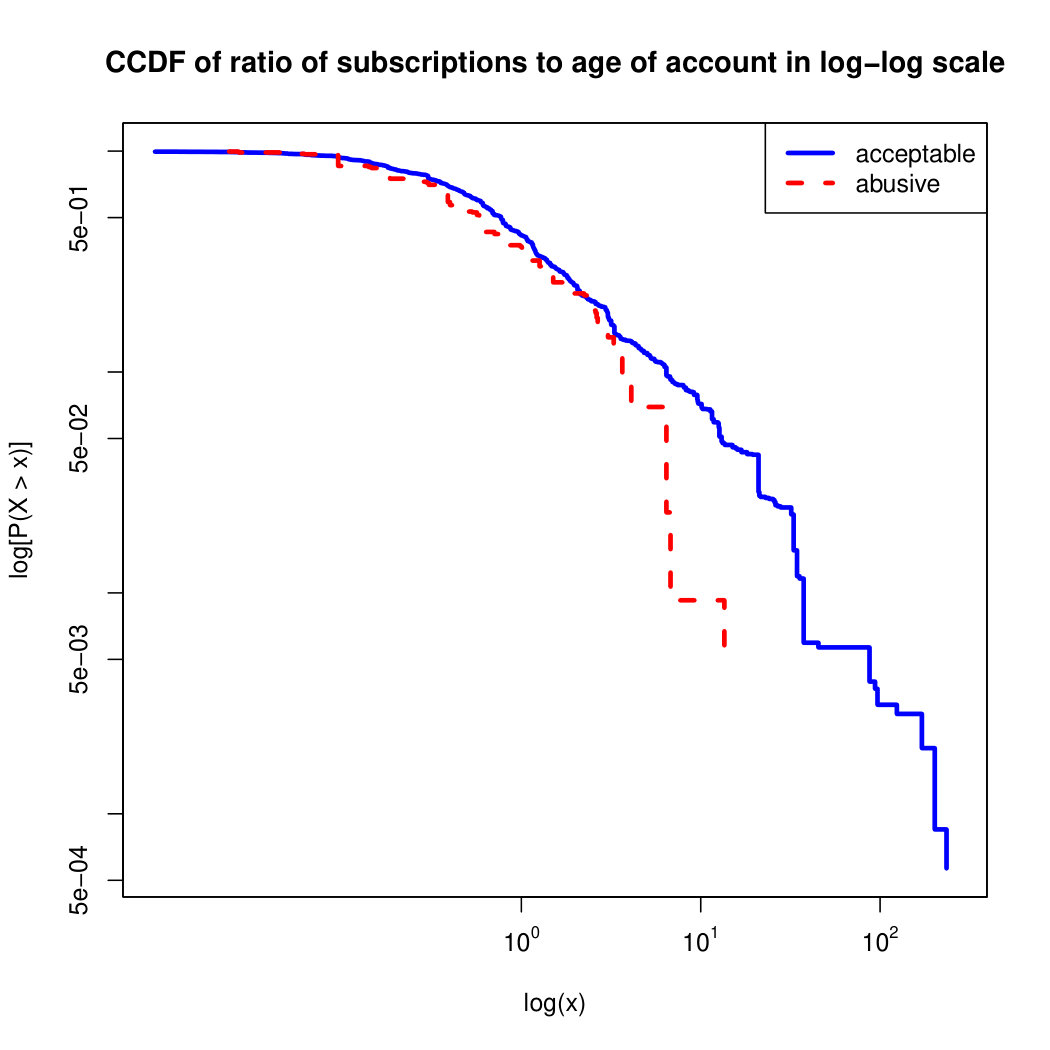 Figure 38
Figure 38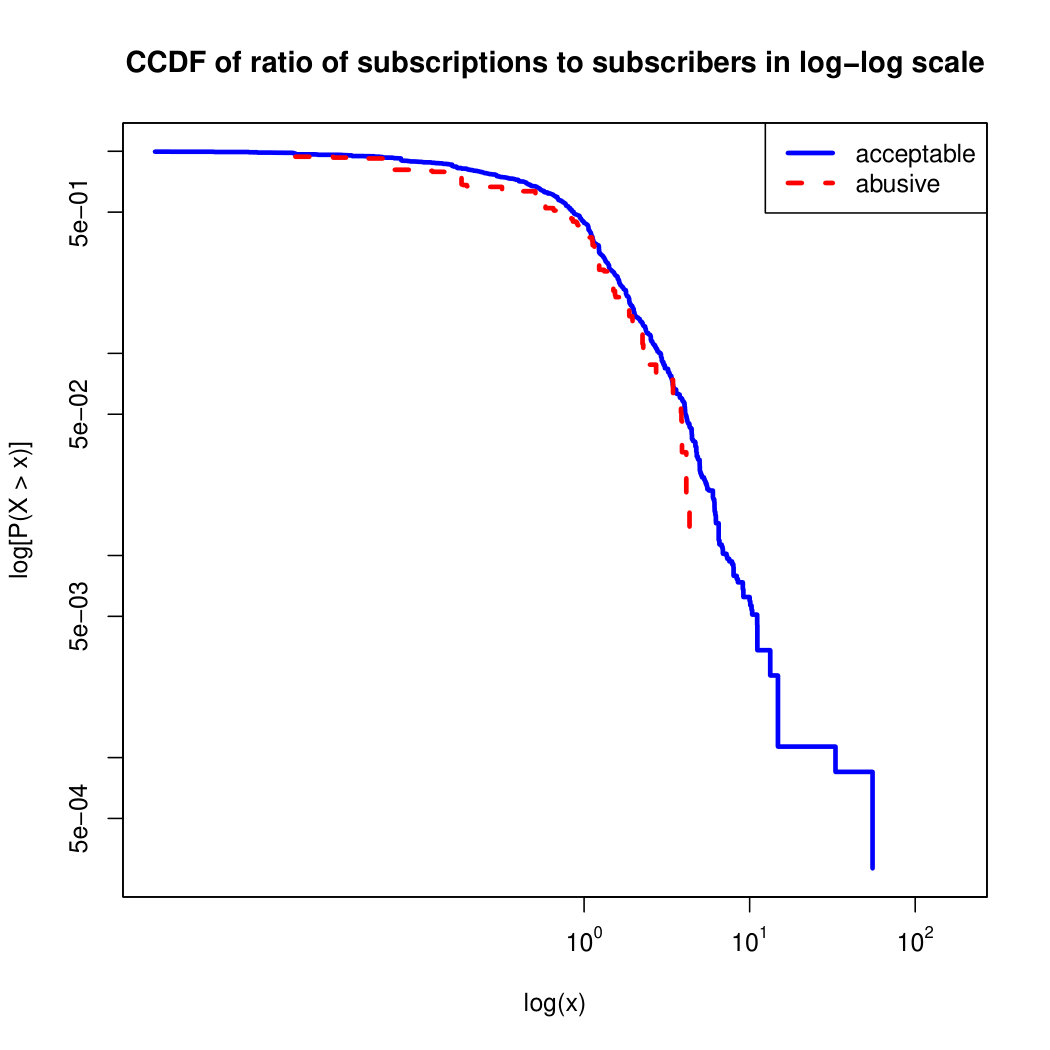 Figure 39
Figure 39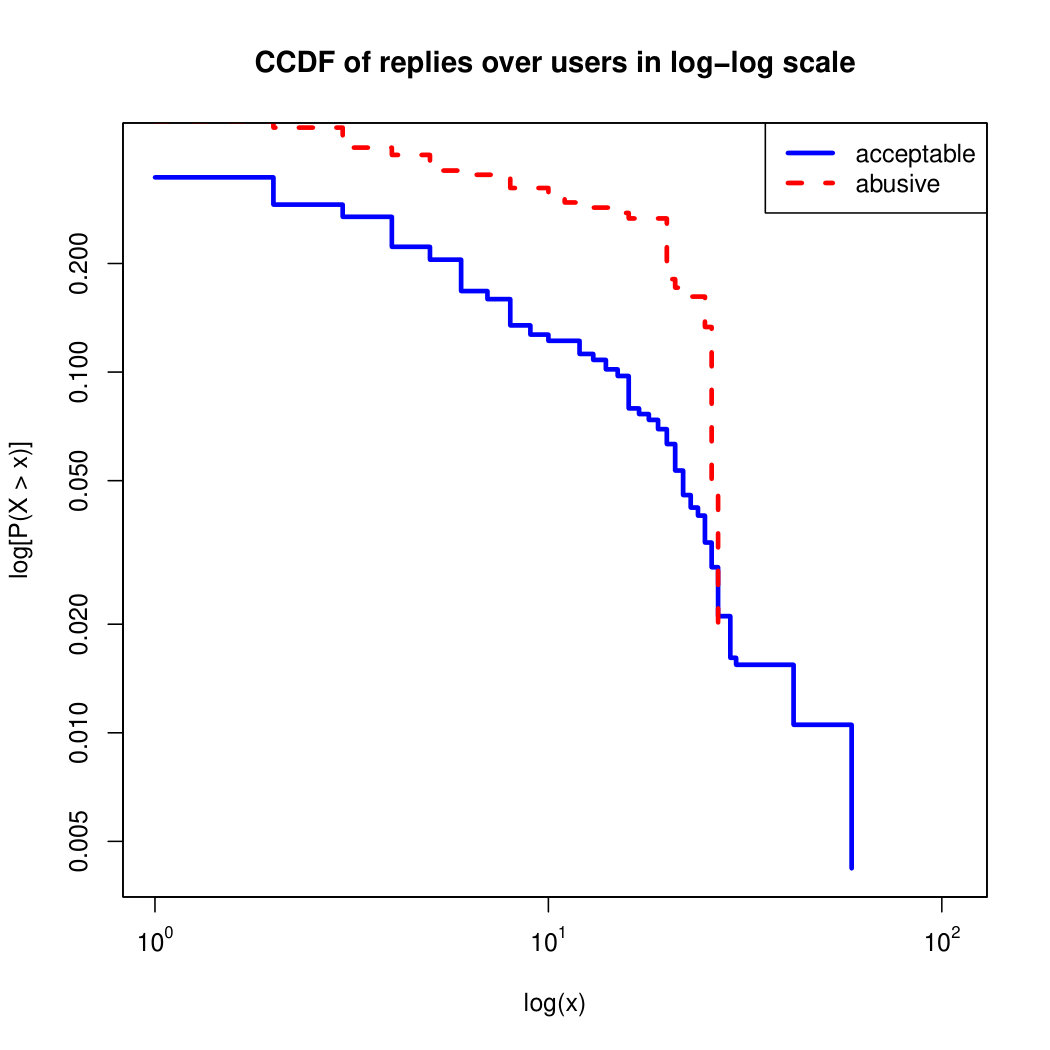 Figure 40
Figure 40| Time | Text |
|---|---|
| 2015-11-26 20:51:49 | RT @Lo100La: @VABVOX @CoralieAlison @caitlin_roper @MelTankardReist @MelLiszewski If you stand and wait somewhere, men just come and grab you |
| 2015-11-23 20:41:52 | Yes! Do not submit to the temptation, unless you want to experience an ice pick being driven slowly into your brain @enbrown @MattWelch |
| 2015-11-29 11:59:25 | @reynardvi @BasimaFaysal @avinashk1975 @SamBamDamdaMan People will literally kill to prove themselves ”virtuous”. Kill themselves too. |
| Time | Text | Mentions | Hashtags |
|---|---|---|---|
| 2015-12-11 23:16:25 | TY4follow @CPCharter @EJGirlPolitico @Daboys75! My #socialentrepreneur #socialenterprise #socent @ https://t.co/SgTj5PXJ7H What do U do? | @CPCharter @EJGirlPolitico @Daboys75 | #socialentrepreneur #socialenterprise #socent |
| 2015-12-11 23:16:27 | TY4follow @CPCharter @EJGirlPolitico @Daboys75! My #socialentrepreneur #socialenterprise #socent @… https://t.co/3t1Kepp8Q5 | @CPCharter @EJGirlPolitico @Daboys75 | #socialentrepreneur #socialenterprise #socent |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Trollslayer: Crowdsourcing and Characterization of Abusive Birds in Twitter
Álvaro García-Recuero
- The first and main author of this work developed Trollslayer at INRIA since 2015, published as https://doi.org/10.1109/SNAMS.2018.8554898.
Queen Mary University of London
Aneta Morawin
INRIA Rennes, France
Gareth Tyson
Queen Mary University of London
Abstract
As of today abuse is a pressing issue to participants and administrators of Online Social Networks (OSN). Abuse in Twitter can spawn from arguments generated for influencing outcomes of a political election, the use of bots to automatically spread misinformation, and generally speaking, activities that deny, disrupt, degrade or deceive other participants and, or the network. Given the difficulty in finding and accessing a large enough sample of abuse ground truth from the Twitter platform, we built and deployed a custom crawler that we use to judiciously collect a new dataset from the Twitter platform with the aim of characterizing the nature of abusive users, a.k.a abusive “birds”, in the wild. We provide a comprehensive set of features based on users’ attributes, as well as social-graph metadata. The former includes metadata about the account itself, while the latter is computed from the social graph among the sender and the receiver of each message. Attribute-based features are useful to characterize user’s accounts in OSN, while graph-based features can reveal the dynamics of information dissemination across the network. In particular, we derive the Jaccard index as a key feature to reveal the benign or malicious nature of directed messages in Twitter. To the best of our knowledge, we are the first to propose such a similarity metric to characterize abuse in Twitter.
1 Introduction
Users of OSN are exposed to abuse by other participants, who typically send their victims harmful messages designed to deny, disrupt, degrade and deceive among a few, as reported by top secret methods for online cyberwarfare in JTRIG [1]. In Twitter, these practices have a non-negligible impact in the manipulation of political elections [2], fluctuation of stock markets [3] or even promoting terrorism [4]. As of today, and in the current turmoil of fake news and hate speech, we require a global definition for “abuse”. We find the above definition from JTRIG to be able to cover all types of abuse we find in OSN as of today. Secondly, to identify abuse the Twitter platform often relies on participants reporting such incidents of abuse. In other OSN as Facebook this is also the case, as suggested by the large number of false positives encountered by [5] in the Facebook Immune System [6]. In addition, Twitter suspending abusive participants can be seen as censorship, as it effectively limits free speech of users in the Internet. Finally, user’s privacy is today an increasing concern for users of large OSN. Privacy often clashes with efforts for reducing abuse in these platforms [7] because even disclosing metadata that holds individuals accountable in such cases violates the fundamental right to privacy according to the Universal Declaration of Human Rights [8]. In the same vein, and back to the Twitter platform, we observe a constant trading of individuals’ privacy for granting governments access to private metadata. This endangers citizens well-being and puts them into the spotlight for law enforcement to charge them with criminal offenses, even when no serious criminal offense has been committed [9].
The main contribution of this paper is a large-scale study of the dynamics of abuse in a popular online social micro-blogging media platform, Twitter. For that, we collect a dataset where we annotate a subset of the messages received by potential victims of abuse in order to characterize and assess the prevalence of such malicious messages and participants. Also, we find it revealing to understand how humans agree or not in what represents abuse during the crowd sourcing. In summary, the aim of the study is to answer the following research questions (RQ):
RQ.1: Can we obtain relevant abuse ground truth from a large OSN such as Twitter using BFS (Bread-First-Search) sampling for data collection and crowd-sourcing for data annotation? We show statistics about the dataset collected and the annotated dataset respectively.
RQ.2: Does it make sense to characterize abuse from a victim’s point of view? We provide a list of user attributes (local) and graph-based (global) features that can characterize abusive behavior.
RQ.3: What are the dynamics of abusive behavior? Does it appear as an isolated incident or is it somehow organized? We show that the source of several messages comes from an automated social media scheduling platform that redirects Twitter users to a doubtful site about a fund-raising campaign for a charity (considered as deceive in the abuse definition we employ).
2 Victim-Centric Methodology
In order to collect data from Twitter we adapt the usual BFS for crawling social media and start crawling data from a sufficiently representative number of accounts for our measurement, which we we call the victims’ seed set. The first half of accounts are likely victims, chosen independently of any sign or trace of abuse in their public Twitter timeline in order to account for randomness in the measurements. The second half is selected based in their public timeline containing traces or likelihood of abuse, namely potential victims of abuse. Therefore, we define the seed set as made up of potential victims and likely victims. We then bootstrap our crawler, following the recursive procedure in Algorithm 1, which collects messages directed towards each of the seeds. If a message is directed towards or mentioning two or more victims, we consider it several times for the same message sender but with different destinations. We also collect the subscription and subscriber accounts of sender and receiver in the Twitter social graph, namely follower and followee relationships.
2.1 Data model
Consider a seed set of nodes for forming a graph = containing the nodes in the seed set (victims) and their potential perpetrators as the two entities defining the edge relationships in . Given that is a directed graph made of vertices and edges making up a connection or defining a message sent among a pair of nodes , we derive two specialized directed graphs with their corresponding relationships, messaging or social follow in the network.
Firstly, let = be a directed graph of social relationships where the vertices represent users and a set of directed edges representing subscriptions:
[TABLE]
Secondly, let = be a directed messaging multi-graph with a set of users as vertices , and a set of directed edges representing messages sent by user mentioning user :
[TABLE]
models the tweets that are shown to users with or without explicit subscription by the recipient to the sender. Thus, these messages represent a vector for abusive behavior.
To bootstrap our crawler, we start with the mentioned seed set and run an adapted and recursive bounded breath-first-search (bBFS) procedure on the Twitter input seeds to cover up to a maximum depth maxdepth we pass as parameter to it. In Algorithm 1 we summarize the operational mode of bBFS.
2.2 Boundaries of the data crawl
The configuration of the crawler controls from where the crawl starts and puts some restrictions on where it should stop. The first one of such restrictions during the graph traversal is collecting incoming edges a.k.a followers in Twitter when the number does not exceed an upper bound, depending on the chosen maxfollowers as node popularity. Secondly, the followers must be within a maximum depth we call maxdepth in order to collect the related metadata in the graph belonging to them.
For each node meeting the above constraints, we also collect user account metadata as well as their respective public timeline of messages metadata in Twitter; then we start crawling the followers of nodes at depth 1, and next depth 2 (followers of followers)and so on as set by the parameter mentioned. In our dataset, we never go any further than second degree followers to collect relationships among users in the social graph crawled.
2.3 Data annotation
To annotate abuse we have developed an in-house crowd-sourcing platform, Trollslayer 111https://github.com/algarecu/trollslayer, where we enlisted ourselves and various colleagues to assist with the tedious effort of annotating abuse. However, we decide to enlarge our annotations with the support of a commercial crowd-sourcing platform named Crowdflower, where we spent around $30 in credit using a student data for everyone pack. In the crowd sourcing process we account for scores collected from 156 crowd workers in Crowdflower and 7 trusted crowd workers in Trollslayer, accounting to 163 crowd workers overall. In these two platforms we display the same tweets and the same guidelines to crowd workers that annotate messages. Therefore, we are able to compute the global scores from both platforms on the same tweets to end up with at least 3 annotations per tweet inthe worst case.
3 Dataset
So far we have judiciously collected a dataset from Twitter to characterize abuse in Twitter. Using crowd workers we obtain abuse ground truth. Next we extract relatively simple features from the collected dataset. Given that the features are largely based on data that is available in the proximity of the potential victim, we aim to characterize the distribution of abuse in an online micro-blogging platform from the view of the victim. This also avoids the Big Data mining that can only be effectively performed by large micro-blogging service providers.
3.1 Statistics
Table I shows statistics about the dataset collected such as the number of tweets directed toward the list of victims in our seed set. In total, we account for 1648 tweets directed to our seed set at depth 1. Then we show the same statistics organized by depth in the recursive crawl performed to obtain the dataset. Note that for the purpose of the statistical analysis of the dataset and findings presented here, we will only take into consideration nodes for which the social graph has been fully collected. Due to Twitter Terms and Conditions (TTC) we plan to make available and public only the identifiers of the messages annotated but not the rest of the information associated to the message, graph or private information that identifies the crowd-workers.
3.1.1 Ground Truth
Following a voting scheme we explain here, we aggregate the votes received for each tweet into a consensus score. We take a pessimistic approach to ensure that a single vote is not decisive in the evaluation of a tweet as abusive (e.g., unlike in Brexit affairs). That is, if the aggregated score is between -1 and 1 the message is considered undecided. The sum of scores will render a tweet as abusive in the ground truth when >1 and for acceptable when <-1 . The final annotated dataset is comprised of labeled messages, out of which are marked as acceptable and as abusive and undecided.
Figure 1 shows the result of crowdsourcing abuse annotation when asking crowd-workers to mark messages as either, abusive, acceptable or undecided. Agreement is high in both platforms, even so for abusive messages, but as expected lower than acceptable due to perfect disagreement in a number of tweets as the ones we show in Table II. There are tweets with perfect disagreement in Trollslayer out of around annotated, in Crowdflower out of , and in the aggregate out of mentioned above accounting for aggregated voting of all annotations from both platforms. Generally speaking, we see an upper bound of about 3.75% disagreement for Crowdflower, 2% in Trollslayer and lower bound of 1.3% among both, which highlights the importance of employing a minimal set of trusted crowd workers in the annotations (as we did with Trollslayer).
3.1.2 Agreement
To ensure agreement among crowd workers is valid, we calculate the inter-assessor agreement score of Randolph’s multi-rater kappa [10] among the crowd workers with common tweets annotated. Similarly to Cohen’s kappa or Fleiss’ Kappa, the Randolph’s kappa descriptive statistic is used to measure the nominal inter-rater agreement between two or more raters in collaborative science experiments. We choose Randolph’s kappa over the others by following Brennan and Predige suggestion from 1981 of using free-marginal kappa when crowd workers can assign a free number of cases to each category being evaluated (e.g., abusive, acceptable) and using fixed-marginal otherwise [11]. Our case considers different crowd workers assigning a different number of annotations to each class or category, which satisfies Randolph’s kappa requirement.
Note that in contrast to simple agreement scores, descriptive statistics consider agreement on all three possibilities, abusive, acceptable and undecided, thus providing a more pessimistic measure of agreement among crowd workers. There are number of descriptive statistics [12] such as Light’s kappa and Hubert’s kappa, which are multi-rater versions of Cohen’s kappa. Fleiss’ kappa is a multi-rater extension of Scott’s pi, whereas Randolph’s kappa generalizes Bennett’ to multiple raters.
Given this setting, values of kappa can range from -1.0 to 1.0, with -1.0 meaning a complete disagreement below random, 0.0 meaning agreement equal to chance, and 1.0 indicating perfect agreement above chance. According to Randolph, usually a kappa above 0.60 indicates very good inter-rater agreement. Across all annotations we obtain overall agreement of 0.73 and a a Randolph’s free-marginal of 0.59 which is about the recommended value in Randolph’s kappa (0.60).
We inspect some of the annotations manually and discover that some scores are aggregated as undecided and not as abusive due to their crowd-workers annotating as undecided several of these tweets serially. That shows the cognitive difficulty in the task of annotating abuse or the tedious nature which we mention before (despite having rewarded the crowd-workers in both platforms). On the other hand, we noticed it is easy for crowd workers to spot offensive messages containing hate speech or similar (which in fact is abuse but only a subset according to the JTRIG definition) but not so for deceitful messages or content.
4 Characterization of Abuse
This section shows that our method can indeed capture all type of abusive behavior in Twitter and that while humans still have a hard time identifying as abuse deceitful activity, our latest findings suggest the use of network level features to identify some abuse automatically instead.
4.1 Incidents
In several cases we find where there is perfect disagreement among crowd workers, see Table II; while in others some of the actual abusive “birds” are just too difficult to spot for humans given just a tweet but more likely if we inspect an exhaustive list of similar messages from the potential perpetrators’ timeline as shown in Table III. In that case the abusive “bird” is repeatedly mentioning the same users through the special character “@” that Twitter enables in order to direct public messages to other participants. Besides, he repeatedly adds a link to a doubtful fund-raising campaign.
We investigate the owner of the Twitter public profile @jrbny: titled “Food Service 4 Rochester Schools”, which is also related to a presumed founder @JohnLester and both belonging to “Global Social Entrepreneurship”.
Firstly, we look into the JSON data of the tweet and check the value of the field source in the Twitter API just to confirm that it points to “https://unfollowers.com”, which in turn redirects to “https://statusbrew.com/”, a commercial site to engage online audiences through social media campaigns. This confirms our suspicions about the nature of the profile and its use for a public fundraising campaign. After a quick inspection at the products offered by this social media campaign management site, indeed we see that the site offers an option to automatically “schedule content” for publishing tweets online. In summary, this Twitter account is controlled by humans but uses an automatic scheduling service to post tweets and presumably follow/unfollow other accounts in the hope of obtaining financial donations through an online website. Secondly, expanding the shortened URL linked to tweets as the ones from Table III, we find out that indeed the user is redirected to a donation website 222Campaign site: www.pureheartsinternational.com from this organization. The site is hosted in Ontario and belongs to the Autonomous System AS62679, namely Shopify, Inc., which reportedly serves several domains distributing malware. We also acknowledge the difficulty in automating crowdsourcing and characterization of the type of abuse deceive.
Finally, in order to highlight the effect of automated campaign management tools as the ones used in the above case, we crawled the same profile again in 2016-01-10 23:02:59, and the account had only 16690 followers compared to the current 36531 as of January 2017, therefore showing a successful use of semi-automated agents on Twitter for fund-raising activities.
4.2 Features of Abusive Behavior
In order to characterize abuse we extract and build a set of novel features, categorized as Attribute or Graph based, which measure abuse in terms of the Message, User, Social and Similarity. We apply Extraction, Transformation and Loading (ETL) on the raw data in order to obtain the inputs to each of the features in those subcategories. The most readily available properties from the tweet are extracted. Then we also capture a number of raw inputs in the tweet that identify the features for a particular user. The next, and more complex subset of features involve Social graph metadata, which also enables the computation of the novel Similarity feature subset, namely the Jaccard index (). Table IV summarizes the complete set of features we have developed to evaluate abusive behavior in Twitter.
To visualize the data distribution of the most relevant features from Table IV in detail we show the complementary cumulative distribution function (CCDF), which represents the probability that a feature having value of in the x axis does not exceed in the y axis. We use the CCDF in log-log scale to be able to pack a large range of values within the axis of the plot.
In Figures 2 and 3 we compare the characteristic distribution among abuse and acceptable content in our annotated dataset. The dotted line here represents abusive while the continuous one acceptable.
For the Attribute based features we notice the most significant gap among acceptable and abusive is the Message category, in particular the number of replies that a sender user has authored, meaning that abusive “birds” reply more often and seek controversy as part of their public speech in Twitter. This makes sense from a “trolling” perspective if we consider that the definition of troll is a user that posts controversial, divisive and at times inflammatory content. Secondly, and to the contrary of what we expected, we observe that humans agree on abuse when there are fewer receivers or mentioned users, so the abuse is less likely to be directed to multiple victims according to this. Otherwise, Table II shows that no agreement is reached with multiple targets if addressing users as a group, which can not be correlated into a personal attack to the potential victim. We see this as an indication of perpetrators sending disguising messages to their victims in order to decrease the visibility of their abusive behavior.
Finally, the distribution presented in the “badwords” feature shows that at least one “badword” exist for many of tweets annotated as abusive by our crowd workers, showing a light tailed distribution with smaller probabilities for a larger number of “badwords”. Firstly, this confirms that human crowd workers are notably good at flagging abusive content when it is related to the language itself and secondly, that abusive messages flagged as such by humans did not contain many “badwords”. That is also confirmed by the fact that “bad words” have a negligible value in the distribution of acceptable for such feature. On the contrary, with hashtags we mostly observe acceptable messages in the CCDF thus indicating that messages from our ground truth flagged as abusive barely contain any hashtags.
We observe that some of the similarity features in the graph-based category exhibit a distinguishable pattern among acceptable and abusive messages. In particular, this is the case for mutual subscribers and mutual subscriptions, where the feature is calculated using Social graph metadata from a pair of users, namely sender and receiver. The most interesting CCDF is perhaps the mutual subscriptions one, Figure 3g, in which there is a significant initial gap between the social graph of acceptable and abusive messages in the log probability () in the y axis for nearly about two-thirds of the distribution. Note that here the maximum value of the axis runs from zero to given that we compute similarity using Jaccard. Considering that we did not present crowd workers with information about the social graph, it is quite surprising that some of these the graph-based features show a characteristic pattern.
5 Related Work
The following section covers works similar to ours that fall in the categories of the included subsections.
5.1 Graph-based
To characterize abuse without considering the content of the communication, graph-based techniques have been proven useful for detecting and combating dishonest behavior [14] and cyberbullying [15], as well as to detect fake accounts in OSN [16]. However, they suffer from the fact that real-world social graphs do not always conform to the key assumptions made about the system. Thus, it is not easy to prevent attackers from infiltrating the OSN or micro-blogging platform in order to deceive others into befriending them. Consequently, these Sybil accounts can still create the illusion of being strongly connected to a cluster of legitimate user accounts, which in turn would render such graph-based Sybil defenses useless. On the other hand and yet in the context of OSN, graph-based Sybil defenses can benefit from supervised machine learning techniques that consider a wider range of metadata as input into the feature set in order to predict potential victims of abuse [17]. Facebook Immune System (FIS) uses information from user activity logs to automatically detect and act upon suspicious behaviors in the OSN. Such automated or semi-automated methods are not perfect. In relation to the FIS, [5] found that only about 20% of the deceitful profiles they deployed were actually detected, which shows that such methods result in a significant number of false negatives.
5.2 Victim-centric
The data collection in [18] was partially inspired by the idea of analyzing the victims of abuse to eventually aid individual victims in the prevention and prediction of abusive incidents in online forums and micro-blogging sites as Twitter. One observation from previous research [19] that we have embedded into some of our features is that abusive users can only befriend a fraction of real accounts. Therefore, in the case of Twitter that would mean having bidirectional links with legitimate users. We capture that intuition during data collection by scraping in real-time the messages containing mentions to other users (@user) and thus we are able to extract features such as ratio of follows sent/received, mutual subscribers/subscriptions, etc.
5.3 Natural Language Processing and text based
Firstly, previous datasets in this area are not yet released or in their infancy for verification of their applicability as abuse ground truth gold standard. The authors of [20] claim to outperform deep learning techniques to detect hate speech, derogatory language and profanity. They compare their results with a previous dataset from [21] and assess the accuracy of detecting abusive language with distributional semantic features to find out that it does largely depends upon the evolution of the content that abusers post in the platform or else having to retrain the model.
Finally, it is worth mentioning we in our feature set do not include sentiment analysis inputs as [22] did; simply because we are interested in complex types of abuse that require more than just textual content analysis. Additionally, we have noticed that while some words or expressions may seem abusive at first (e.g., vulgar language), they are not when the conversation takes place between participants that know each other well or are mutually connected in the social graph (e.g., family relatives).
5.4 Other datasets
Following the above classifications, we compile a number of previous works [23, 24, 25, 26] that collected a large portion of the Twitter graph for its characterization but not really meant for abusive behavior. Note some of these datasets can provide some utility from their social-graph for characterization of abusive behaviour but they are either anonymized or we are not able to get access to them. Naturally, social-graph metadata is not available due to restrictions imposed by Twitter Terms and Conditions (TTC) for data publishing. We also find the Impermium dataset, from a public Kaggle competition [27] that provides the text of a number of tweets and labels for classifying such messages as an insult or not. This can be useful for textual analysis of abuse (only for non-subtle insults), which can be supported by application of NLP based techniques, but it does not contain any social graph related metadata that we use in our characterization of abuse. Besides, as the tweet identifiers from the Imperium dataset are anonymized, it is not possible to reproduce data collection.
6 Conclusion
We concluded that identifying abuse is a hard cognitive task for crowd workers and that it requires employing specific guidelines to support them. It is also necessary to provide a platform as we created or questionnaires to ask crowd workers to flag a tweet as abusive if it falls within any of the categories of the guidelines, in our case the 4 D’s of JTRIG, deny, disrupt, degrade, deceive. As a crowd worker provides a non-binary input value from acceptable, abusive, undecided to annotate tweets from , the latter option is important; even with relatively clear guidelines, crowd workers are often unsure if a particular tweet is abusive. To further compensate for this uncertainty, each tweet has been annotated multiple times by independent crowd workers (at least 3). We highlight the reason for the disagreement we encountered by listing a few tweets in Table II. Table III contains metadata from a user that consistently tweets from a third-party tweet scheduling service.
Additionally, using the set of features presented here one could provide semi-automated abuse detection in order to help humans to act as judges of abuse. Filtering “badwords” is not quite enough to judge a user as abusive or not, so in order to provide a better context to human crowd workers one could imagine coupling the score of attribute based features with those graph-based features that can provide an implicit nature of the relationships between senders and receivers of the content, thus flagging messages or users as abusive “bird” (or not) in Twitter. This will also present an scenario where abuse is a less tedious and self-damaging tasks for human crowd workers reading abusive content during annotation.
Acknowledgments
Thank you to the anonymous Trollslayer crowd workers.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P. Mandeep K. Dhami, “Behavioural Science Support for JTRIG’s Effects and Online HUMINT Operations,” GCHQ, Tech. Rep., March 2011. [Online]. Available: http://www.statewatch.org/news/2015/jun/behavioural-science-support-for-jtrigs-effects.pdf
- 2[2] E. Ferrara, “Manipulation and abuse on social media,” SIGWEB Newsl. , no. Spring, pp. 4:1–4:9, Apr. 2015.
- 3[3] J. Bollen, H. Mao, and X. Zeng, “Twitter mood predicts the stock market,” Journal of Computational Science , vol. 2, no. 1, pp. 1–8, 2011. [Online]. Available: http://dx.doi.org/10.1016/j.jocs.2010.12.007 · doi ↗
- 4[4] M. Isaac, “Twitter steps up efforts to thwart terrorists tweets,” http://www.nytimes.com/2016/02/06/technology/twitter-account-suspensions-terrorism.html , February 2016, [Online; accessed 31-Jan-2018].
- 5[5] Y. Boshmaf, I. Muslukhov, K. Beznosov, and M. Ripeanu, “The socialbot network: When bots socialize for fame and money,” in Proceedings of the 27th Annual Computer Security Applications Conference , ser. ACSAC ’11. New York, NY, USA: ACM, 2011, pp. 93–102.
- 6[6] T. Stein, E. Chen, and K. Mangla, “Facebook immune system,” in Proceedings of the 4th Workshop on Social Network Systems . ACM, 2011, p. 8.
- 7[7] P. Jackson, “French court orders twitter to reveal racists’ details,” http://www.bbc.com/news/world-europe-21179677 , 2013, [Online; accessed 06-Jan-2017].
- 8[8] U. G. Assembly, “Universal declaration of human rights, 10 december 1948, 217 a (iii,” http://www.refworld.org/docid/3ae 6b 3712 c.html , December, 1948, [Online; accessed 12-Jan-2017].
