Model-free Training of End-to-end Communication Systems
Fay\c{c}al Ait Aoudia, Jakob Hoydis

TL;DR
This paper introduces a novel training algorithm for end-to-end communication systems that does not require a differentiable channel model, enabling effective training with unknown or non-differentiable channels, demonstrated through hardware implementation.
Contribution
The paper presents a new learning algorithm that trains communication systems without relying on a differentiable channel model, applicable to real-world unknown or complex channels.
Findings
Works as well as model-based training across various channels
Effective in hardware implementations with SDRs
Achieves state-of-the-art performance over cable and wireless channels
Abstract
The idea of end-to-end learning of communication systems through neural network-based autoencoders has the shortcoming that it requires a differentiable channel model. We present in this paper a novel learning algorithm which alleviates this problem. The algorithm enables training of communication systems with an unknown channel model or with non-differentiable components. It iterates between training of the receiver using the true gradient, and training of the transmitter using an approximation of the gradient. We show that this approach works as well as model-based training for a variety of channels and tasks. Moreover, we demonstrate the algorithm's practical viability through hardware implementation on software-defined radios where it achieves state-of-the-art performance over a coaxial cable and wireless channel.
Click any figure to enlarge with its caption.
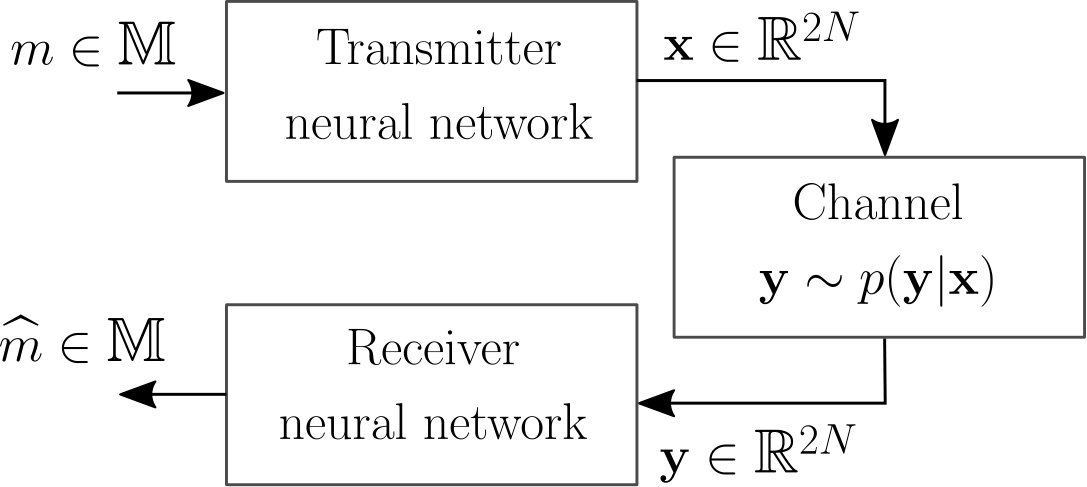 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3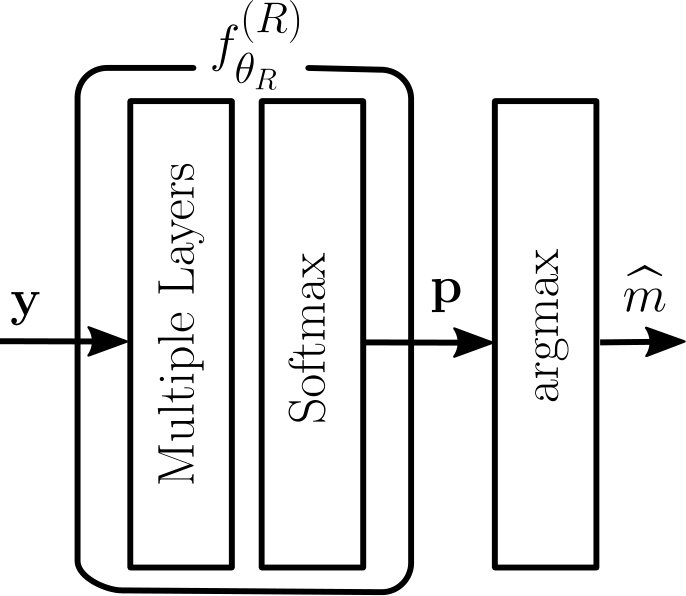 Figure 4
Figure 4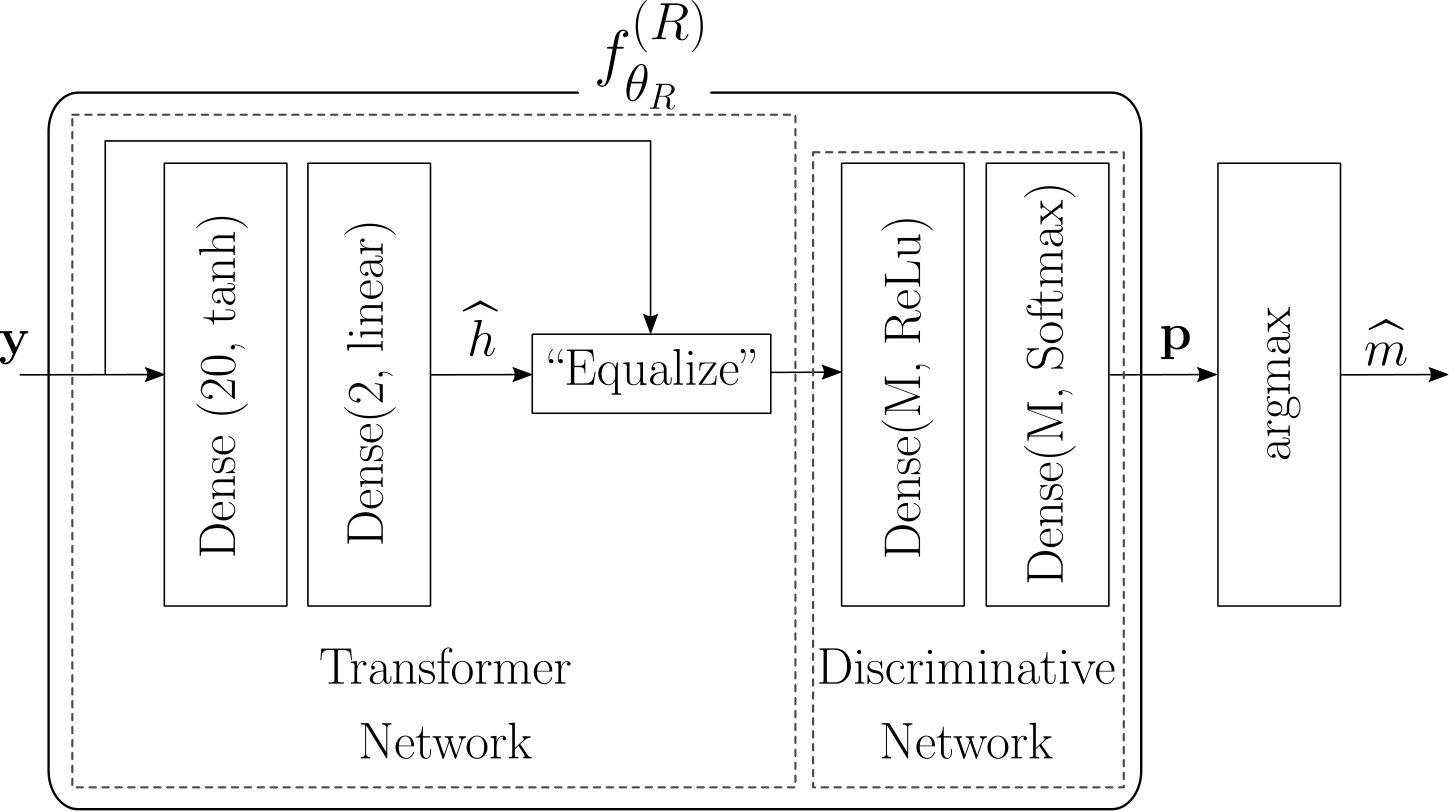 Figure 5
Figure 5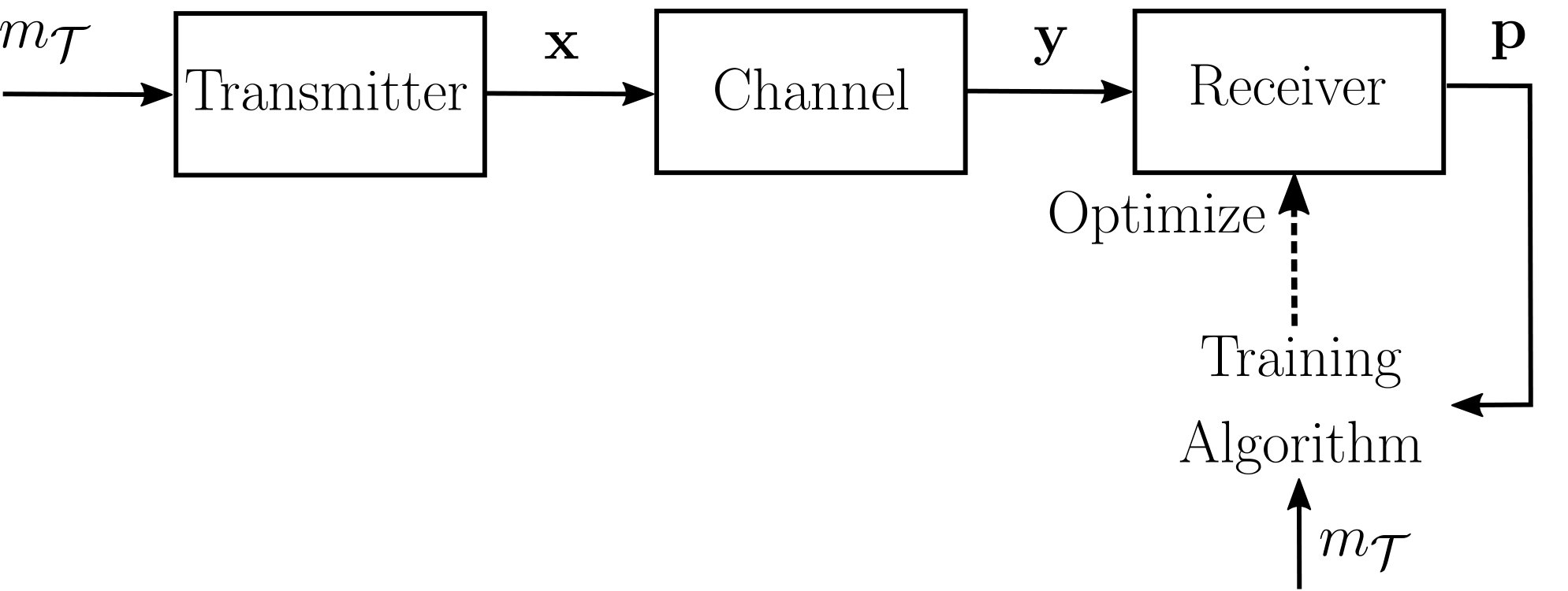 Figure 6
Figure 6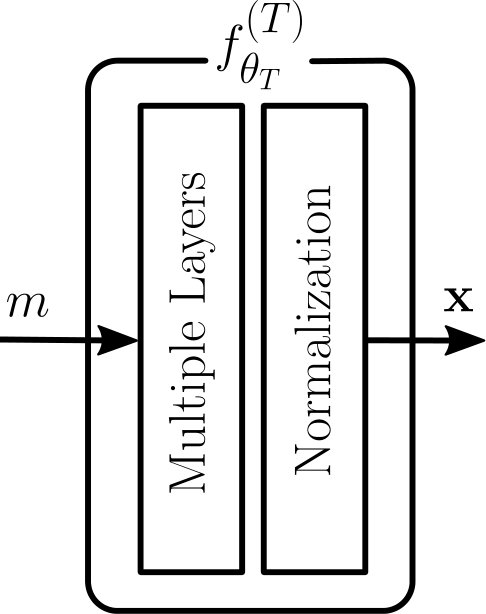 Figure 7
Figure 7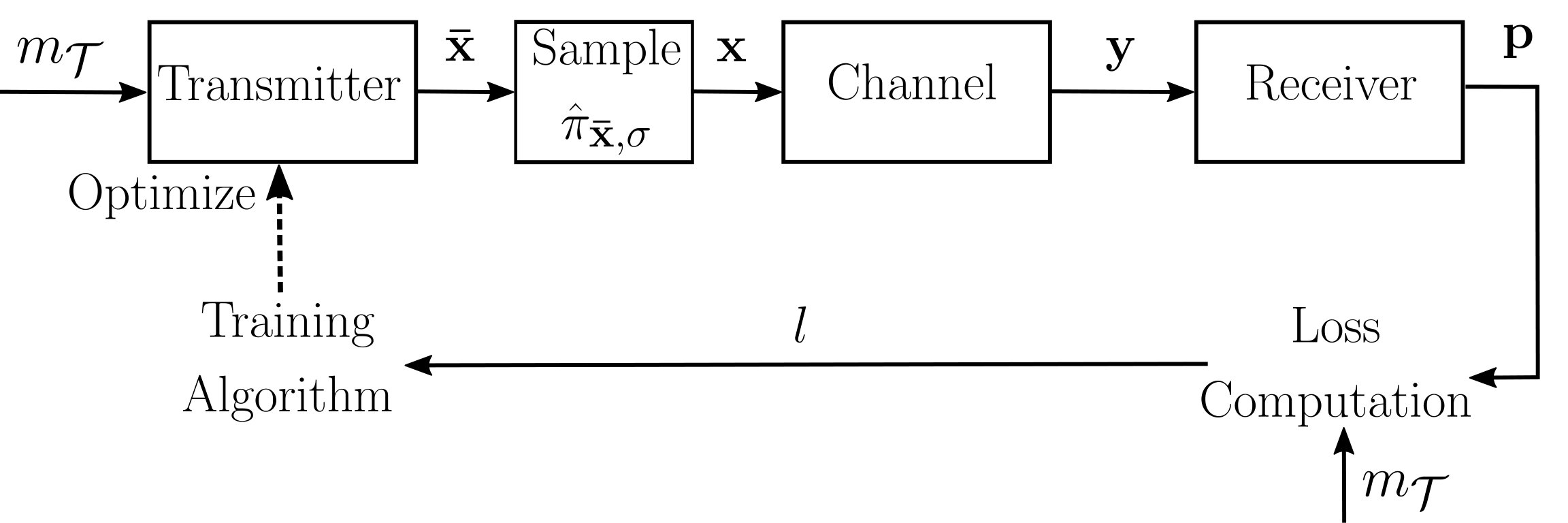 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10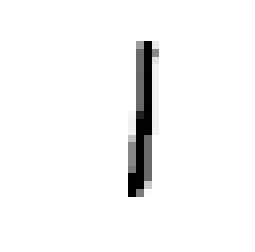 Figure 11
Figure 11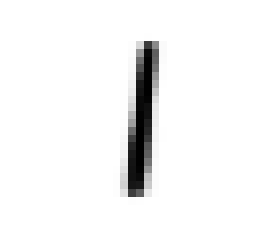 Figure 12
Figure 12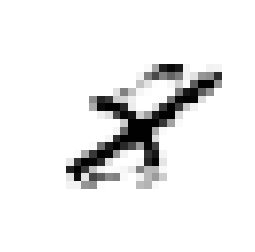 Figure 13
Figure 13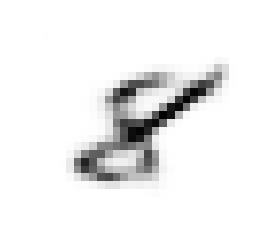 Figure 14
Figure 14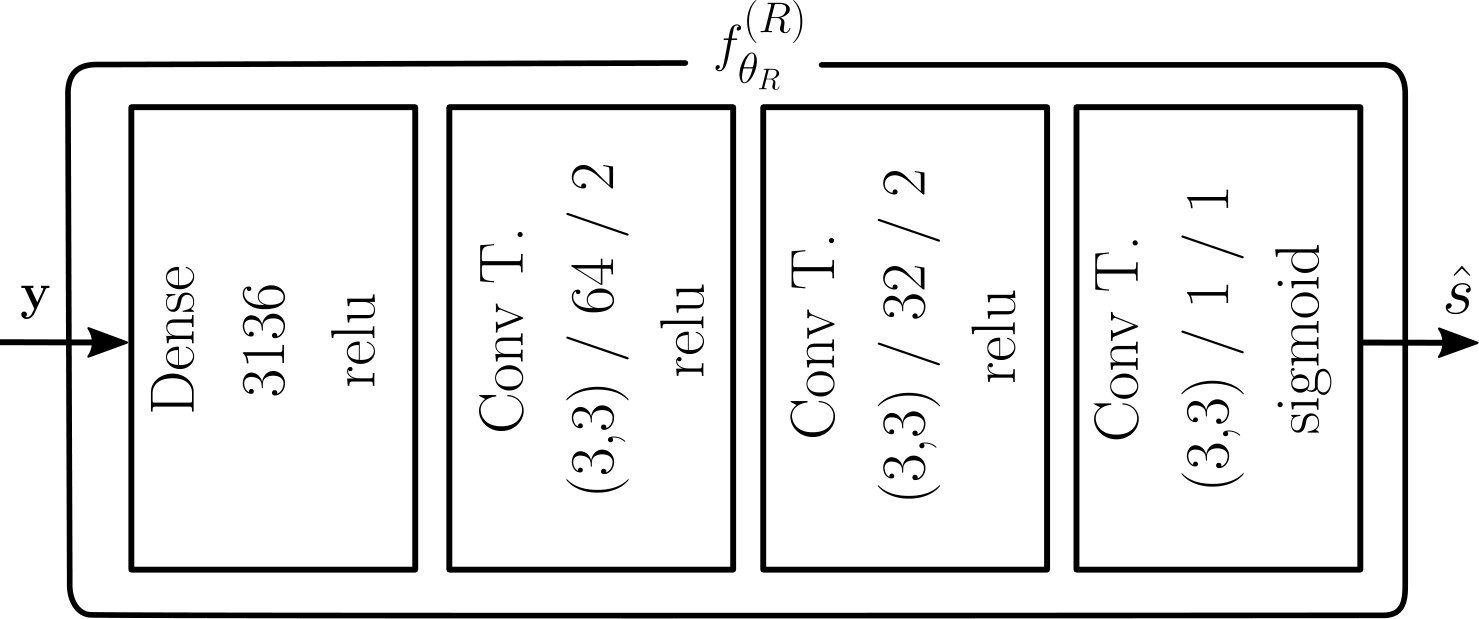 Figure 15
Figure 15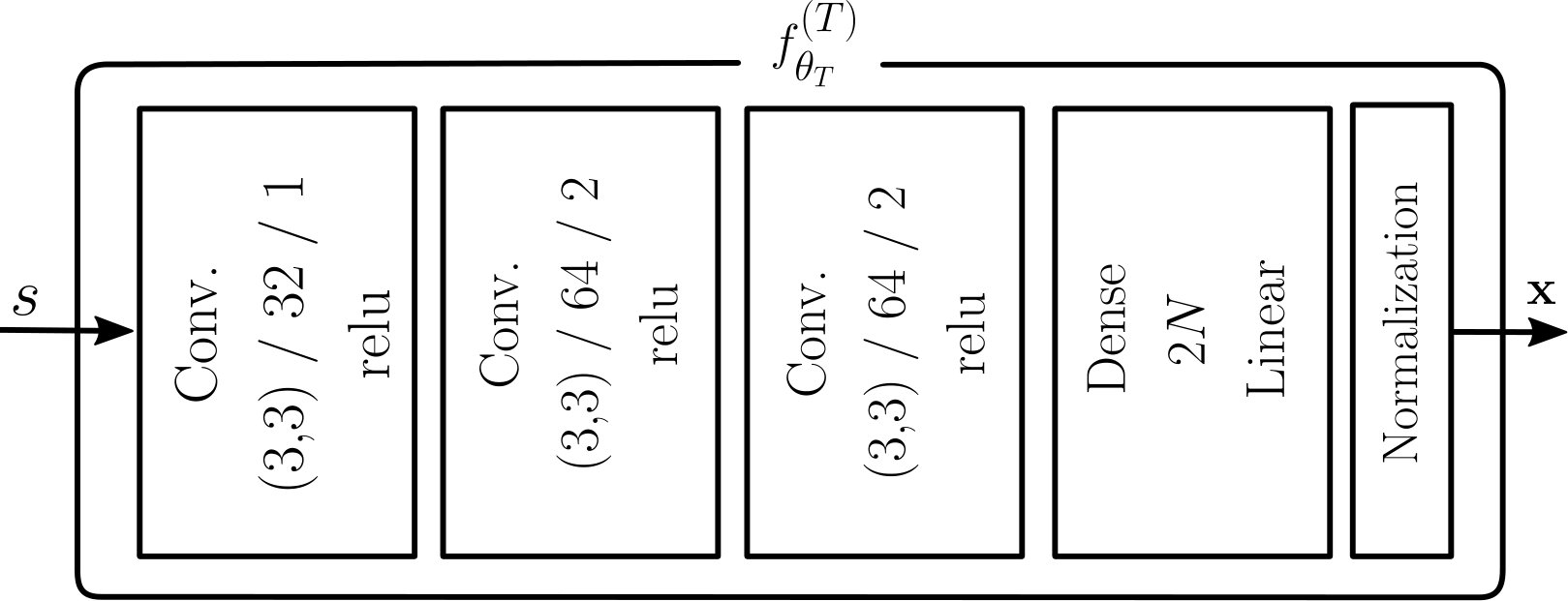 Figure 16
Figure 16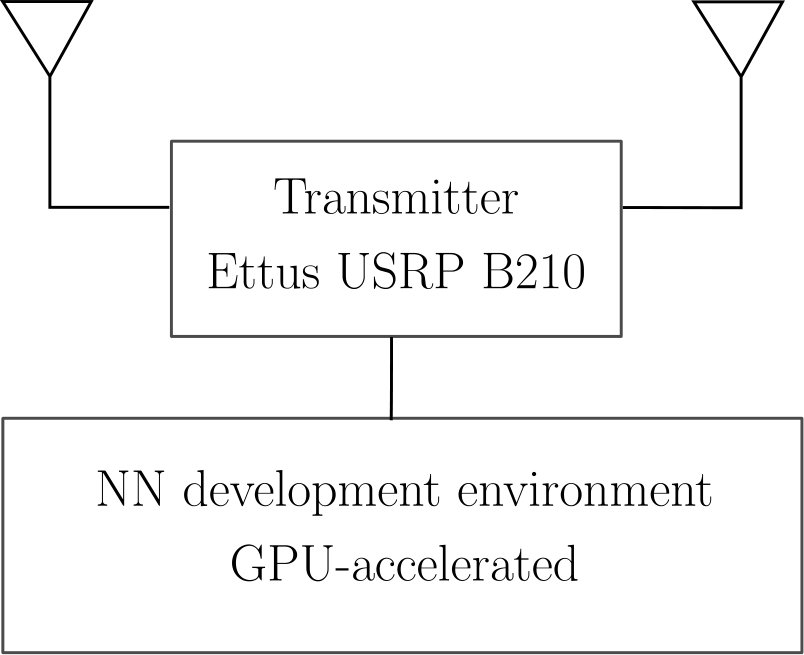 Figure 17
Figure 17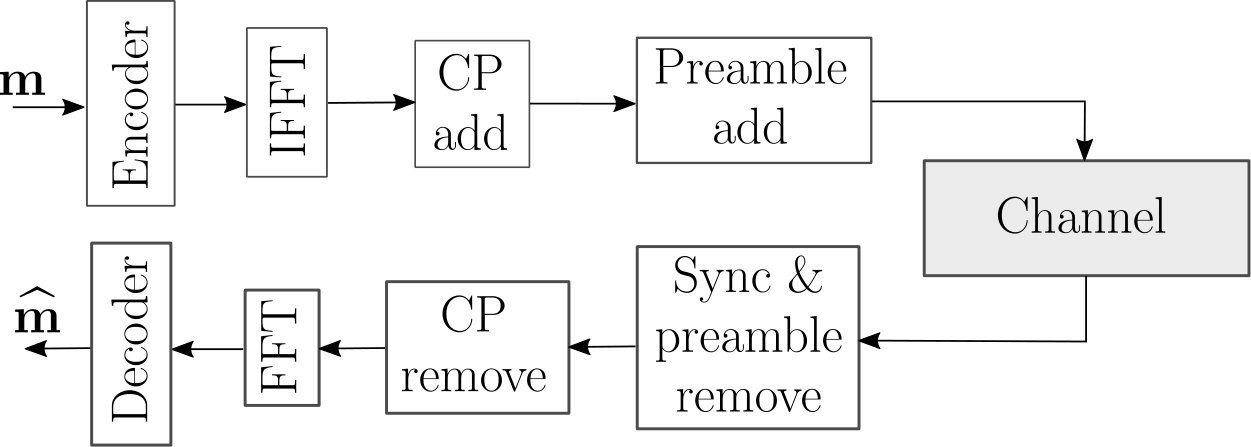 Figure 18
Figure 18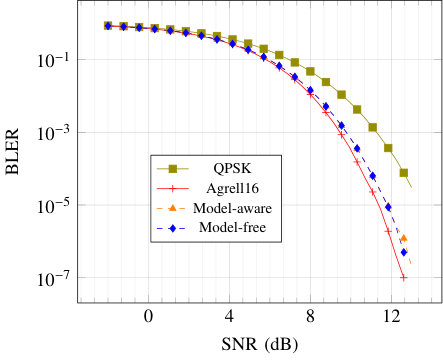 Figure 0
Figure 0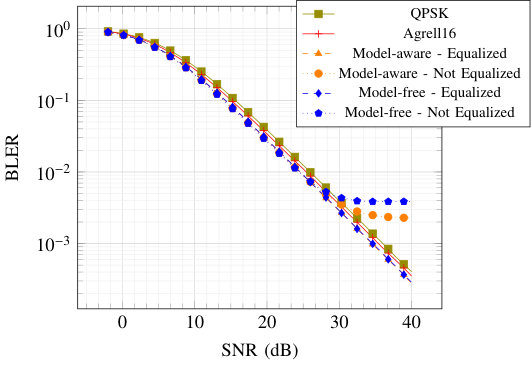 Figure 1
Figure 1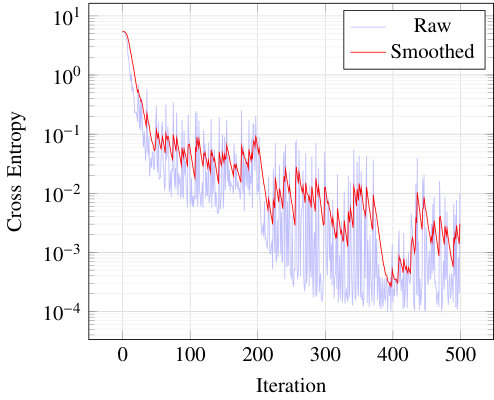 Figure 10
Figure 10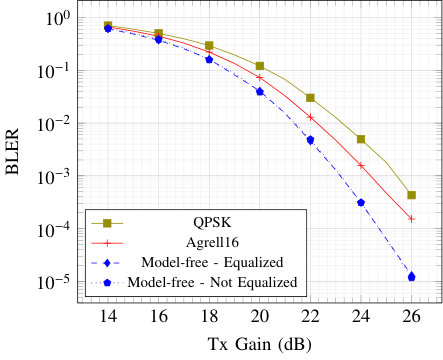 Figure 11
Figure 11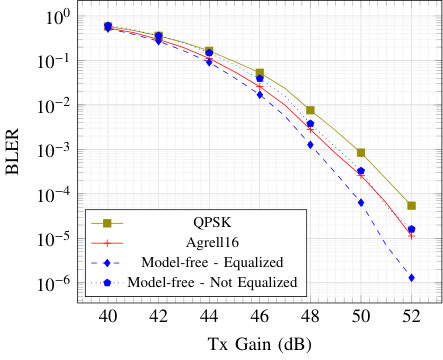 Figure 12
Figure 12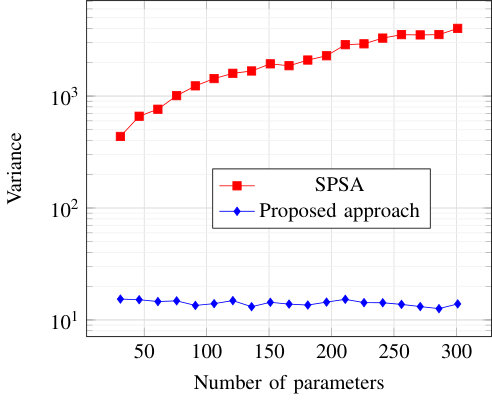 Figure 13
Figure 13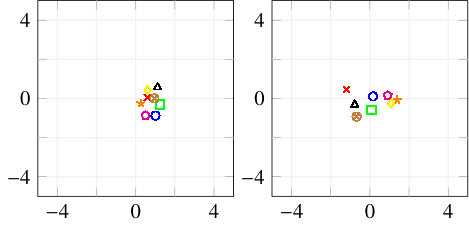 Figure 2
Figure 2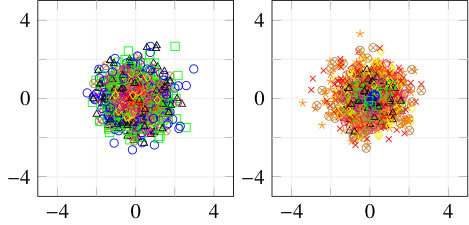 Figure 3
Figure 3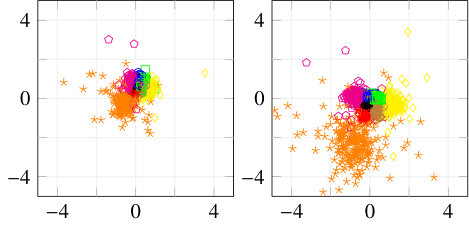 Figure 4
Figure 4 Figure 5
Figure 5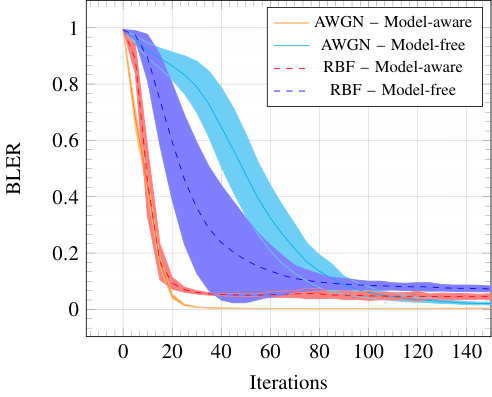 Figure 6
Figure 6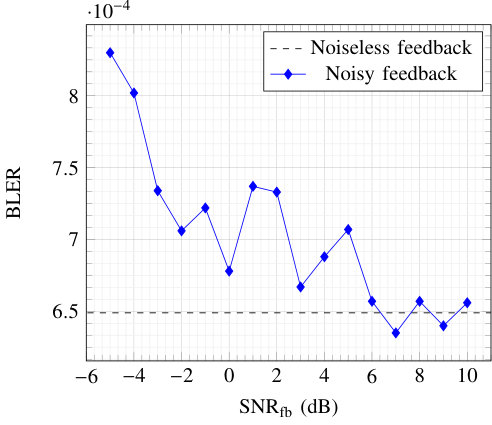 Figure 7
Figure 7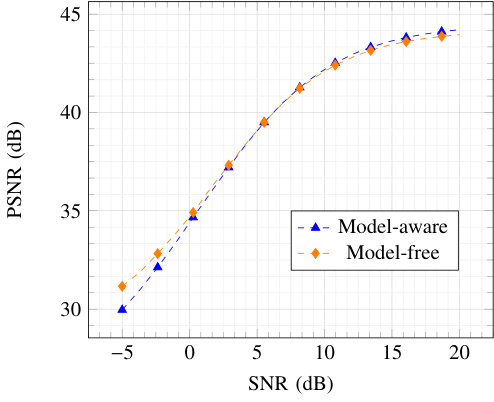 Figure 8
Figure 8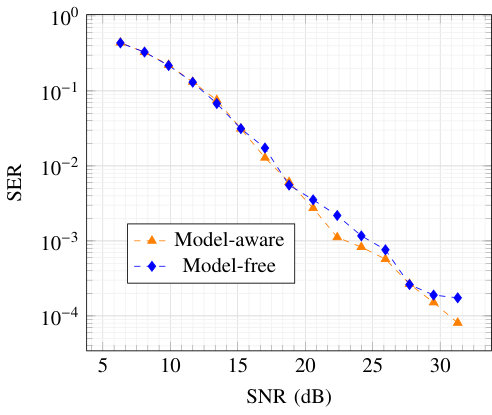 Figure 9
Figure 9| Schemes | Pilot | Block Length | NN Receiver Architecture | |
| AWGN | ||||
| QPSK | None | 4 | 4 | (Not applicable) |
| Agrell16 | None | 4 | 4 | (Not applicable) |
| Model-aware/Model-free | None | 4 | 4 | Discriminative Network |
| RBF | ||||
| QPSK | 1 | 4 | 5 | (Not applicable) |
| Agrell16 | 1 | 4 | 5 | (Not applicable) |
| Model-aware/ Model-free Equalized | 1 | 4 | 5 | Discriminative Network |
| Model-aware/ Model-free Not Equalized | None | 5 | 5 | Transformer & Discriminative Networks |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Model-free Training of End-to-end Communication Systems
Fayçal Ait Aoudia and Jakob Hoydis
F. Ait Aoudia and J. Hoydis are with Nokia Bell Labs, Paris-Saclay, 91620 Nozay, France ({faycal.ait_aoudia, jakob.hoydis}@nokia-bell-labs.com). Parts of this work have been presented at the ASILOMAR Conference 2018 [1].
Abstract
The idea of end-to-end learning of communication systems through neural network (NN)-based autoencoders has the shortcoming that it requires a differentiable channel model. We present in this paper a novel learning algorithm which alleviates this problem. The algorithm enables training of communication systems with an unknown channel model or with non-differentiable components. It iterates between training of the receiver using the true gradient, and training of the transmitter using an approximation of the gradient. We show that this approach works as well as model-based training for a variety of channels and tasks. Moreover, we demonstrate the algorithm’s practical viability through hardware implementation on software defined radios (SDRs) where it achieves state-of-the-art performance over a coaxial cable and wireless channel.
Index Terms:
Autoencoder, deep learning, end-to-end learning, neural network, software-defined radio, reinforcement learning
I Introduction
End-to-end learning of communication systems is a fascinating novel concept [2] whose goal is to learn full transmitter and receiver implementations which are optimized for a specific performance metric and channel model. This can be achieved by representing transmitter and receiver as neural networks (NNs), as illustrated in Fig. 1, and by interpreting the whole system as an autoencoder [3] which can be trained in a supervised manner using stochastic gradient descent (SGD). Although a theoretically very appealing idea, its biggest drawback hindering practical implementation is that a channel model or, more precisely, the gradient of the instantaneous channel transfer function, must be known [4]. For an actual system, this is hardly the case since the channel is generally a black box for which only inputs and outputs can be observed. Moreover, the channel typically comprises some parts of the transceiver, such as quantization, which are non-differentiable and hence forbid gradient-based training through backpropagation.
In this work, we provide a method to circumvent the problem of a missing channel gradient. The key idea is to approximate the loss function gradient with respect to (w.r.t.) the transmitter parameters by relaxing the channel input to a random variable. The proposed approach removes the requirement of channel model knowledge, which implies that the autoencoder can be trained from pure observations alone. We develop a novel alternating algorithm for end-to-end training without channel model knowledge which iterates between two phases: (i) training of the receiver using the true gradient of the loss and (ii) training of the transmitter based on an approximation of the loss function gradient.
We compare the performance of the proposed scheme against that of training with a channel model using usual backpropagation [2] for a variety of channel models and tasks. Specifically, on additive white Gaussian noise (AWGN) and Rayleigh block-fading (RBF) channels, both approaches achieve identical performance. On the AWGN channel, the learned system outperforms quaternary phase-shift keying (QPSK) and comes close to Agrell [5], a close-to-optimal solution to the sphere packing problem. On the RBF channel, it outperforms both QPSK and Agrell. Evaluation on a simplified fiber-optic channel model also reveals identical performance of the model-based and model-free training algorithms, illustrating the universality of the proposed scheme. Finally, we show experimental results for the first autoencoder-based communication system trained directly over actual channels (wireless and coaxial cable). In contrast to [4], the learned system is now able to achieve competitive performance w.r.t. to a well designed baseline.
Notations: Boldface upper-case (lower-case) letters denote matrices (column vectors). () is the set of real (complex) numbers. is the Gaussian distribution with mean and covariance . For a function , we denote by its Jacobian.
II Background
A point-to-point communication system consists of two nodes that aim to reliably exchange information over a channel. The channel is a stochastic system whose output follows a probability distribution conditional on its input , i.e., . This is equivalent to the complex baseband representation with . The transmitter wants to communicate messages uniformly drawn from a discrete set , while the receiver tries to detect the sent messages from the received signals, as illustrated in Fig. 1. Typically, the design of communication systems relies on dividing transmitter and receiver into individual blocks, each performing one task, such as modulation or channel coding. However, this component-wise approach is not guaranteed to lead to the best possible performance and the attempts to jointly optimize components revealed intractable or too computationally complex [6]. This motivates the use of machine learning (ML) to enable optimization of communication systems for end-to-end performance without the need for compartmentalization of transmitter and receiver [2].
The key idea of autoencoder-based communication systems is to represent the transmitter, channel, and receiver as a single NN—the autoencoder—which aims to reproduce its input at its output. If a differentiable model of the channel is available, it can be implemented as non-trainable layers, between the transmitter and the receiver, and the end-to-end system is trained using SGD. This idea was pioneered in [2] and the first proof-of-concept using off-the-shelf software defined radios (SDRs) was described in [4]. Numerous extensions of the original idea towards channel coding [7], orthogonal frequency-division multiplexing (OFDM) [8, 9, 10], multiple-input multiple-output (MIMO) [11], as well as simultaneous wireless information and power transfer (SWIPT) [12] have been made, which all demonstrate the versatility of this approach. Another line of work considers the autoencoder idea for joint source-channel coding [13, 14].
A limitation of the original approach [2] is the requirement of a differentiable channel model to train the transmitter, by backpropagating the gradient through the channel layers. However, in practice, such a channel model is hardly available, and training using inaccurate channel models leads to significant performance loss once the system is deployed [4]. A simple work-around proposed in this latter work consists of fine-tuning of the receiver based on measured data after initial training on a channel model. However, with this approach, the transmitter cannot be fine-tuned to the actual channel, resulting in sub-optimal performance. An alternative approach was proposed in [15, 16]. The key idea is to learn a differentiable generative model of the channel in the form of a generative adversarial network (GAN), which can then be used to train the autoencoder. However, it has not yet been not shown that this approach works for practical channels. The idea of training an NN-based transmitter using policy gradient was explored in [17] for a non-differentiable receiver which treats detection as a clustering problem. Their approach does not outperform a standard modulation baseline and was only evaluated on the AWGN channel. We have proposed in [1] an alternating algorithm for autoencoder training without channel model. In the current paper, we provide a theoretical understanding of this algorithm, carry out a wide set of simulation-based experiments, and report on results from a first hardware implementation. The follow-up work [18] to [1] explores simultaneous perturbation stochastic approximation (SPSA) for approximating the loss function gradient. However, as shown in Appendix B, this method does not scale well with the number of trainable parameters of the transmitter NN.
III Gradient Estimation Without Channel Model
The key idea behind the approach proposed in this work is to implement transmitter and receiver as two separate parametric functions that are jointly optimized to meet application specific performance requirements. The transmitter maps a message to channel symbols , and is represented by the mapping , where is the number of complex channel uses and is the vector of parameters. The receiver is implemented as , where is the vector of parameters and a probability vector over the messages. We assume that and are differentiable w.r.t. their parameters, which are adjusted through gradient descent on the loss function
[TABLE]
where is the expectation taken over the messages , and is the categorical cross-entropy (CE). It is assumed that is bounded, which is achieved by adding a small positive constant inside the logarithm. This trick is widely used in practice to ensure numerical stability. Parameter optimization is performed using gradient descent, or a variant, which at each iteration requires the computation of the loss function gradient .
III-A Gradient of the receiver
The gradient of w.r.t. the receiver parameters is
[TABLE]
The exchange of integration and differentiation, performed here and in the rest of this section, requires regularity conditions, discussed, for example, in [19]. Note that does not need to be differentiable. The gradient in (2) can be estimated through sampling as
[TABLE]
where is the batch size, i.e., the number of samples used to estimate the loss value, is the th training sample, and is the corresponding received signal. This estimator is valid if the training samples are independent and identically distributed (i.i.d.). Since computing (3) requires only sampling of the channel output, training of the receiver can be performed without knowledge of the actual channel model .
III-B Gradient of the transmitter
Regarding the transmitter, the gradient of w.r.t. is
[TABLE]
where is the Jacobian of the transmitter output and \nabla_{\mathbf{x}}p\left(\mathbf{y}|\mathbf{x}\right)\big{|}_{\mathbf{x}=f^{(T)}_{\bm{\theta}_{T}}(m)} is the gradient of the channel w.r.t. to its input evaluated at . As is not known, and may not be differentiable, its gradient cannot be calculated and might even be undefined.
A workaround is to see the channel input as a random variable that follows a distribution parametrized by , with the Dirac distribution, and rewrite the loss (1) as
[TABLE]
We then relax to follow a distribution parametrized by and its standard deviation . We denote by the associated loss
[TABLE]
with gradient
[TABLE]
where the second equality leverages the chain rule, and the third equality uses the log-trick . Computing does not require differentiability of , and it can be simply estimated through sampling of the channel distribution:
[TABLE]
The gradient estimate in (8) allows optimization of the transmitter w.r.t. without knowledge of the underlying channel model and has multiple interpretations. From the viewpoint of reinforcement learning (RL) (as done in our previous work [1]), the transmitter is an agent in state , which interacts with an environment formed by the {channel, receiver} system, taking actions following the policy , and receiving penalties conditional to the chosen action and current state. The goal of the RL agent is to optimize its policy which indicates which action to take given the current state in order to minimize the average received penalty. Note that RL is widely used to optimize agents when no model of the environment is available and/or when the penalty function is not differentiable. From this viewpoint, relaxation of the transmitter outputs to a random distribution can be seen as relaxing a deterministic policy, which maps each input message to channel symbols in a deterministic way, to a stochastic policy which enables exploration of the set of possible actions.
A second interpretation of (8) and an understanding of the relationship between and , when the later is defined, can be obtained from studying the difference
[TABLE]
One can see that the difference between the two gradients goes to zero when the true channel gradient is well approximated by {\mathbb{E}}_{\mathbf{x}}\left\{p\left(\mathbf{y}|\mathbf{x}\right)\nabla_{\bar{\mathbf{x}}}\mathop{\mathrm{log}}\left(\hat{\pi}_{\bar{\mathbf{x}},\sigma}(\mathbf{x})\right)\big{|}_{\bar{\mathbf{x}}=f^{(T)}_{\bm{\theta}_{T}}(m)}\right\}. Therefore, the relaxation of the transmitter output to a random variable can be seen as a way to estimate and approximate the unknown channel gradient. This intuition is comforted by the following theorem, which holds under some requirements on and the channel distribution.
Theorem 1**.**
Assume that and satisfy conditions given in the Appendix A, then
[TABLE]
Proof:
See the Appendix A. ∎
Theorem 1 states that, under some conditions, the true loss function gradient w.r.t. transmitter parameters can be approximated with arbitrarily small error by the substitute loss gradient . A similar results was provided in [20, Theorem 2] in the context of RL. However, to approximate the true gradient, a function, denoted by , which provides the expected loss given the state and action is needed [20, Theorem 1]. In practice, this function is approximated using an additional NN that is trained together with the NN implementing the policy. Although this approach might work well when the channel and receiver are fixed, it is unpractical in our case. Since the receiver is jointly trained with the transmitter, one would need to re-train the NN approximating the function at every update of receiver parameters. Moreover, the NN approximating the function needs to be compatible, i.e., it must satisfy some conditions which are hard to achieve in practice (see [20, Theorem 3] and the following discussion).
We have so far provided a theoretical motivation for the gradient approximation in (7), by showing that approximates under some reasonable conditions. In particular, we assumed that is differentiable w.r.t. . However, the gradient estimators in (3) and (8) do not require differentiability of and can even be computed in cases where is not differentiable. Providing theoretical guarantees in this case is an open problem.
IV Training End-to-End Communication Systems
We now present an alternating training algorithm which works for any pair of differentiable parametric functions . We choose to implement them here as NNs. Since this algorithm does not require a channel model, we will refer to it also as the model-free training method. Model-aware training is used to refer to training with channel model knowledge. With model-aware training, transmitter, channel model, and receiver form a single NN which is trained using the usual backpropagation as in [2]. However, this approach requires the use (and knowledge) of a differentiable channel model.
IV-A Generic transmitter and receiver architectures
The architectures of the transmitter and the receiver can take multiple forms. However, in the context of communication systems, the transmitter must ensure the fulfillment of power and possibly other hardware-dependent constraints. Therefore, its last layer performs normalization which guarantees, e.g., that the average energy per symbol or per message is one. All non-differentiable operations on the transmitter output, e.g., quantization, can be assumed to be part of the channel. A generic architecture of the transmitter is shown in Fig. 2(a).
The receiver task is to detect the sent message from the received signal. The received signal is fed to a succession of layers that can be arbitrarily chosen. The last layer of is a softmax layer to ensure that the output activations form a probability vector over [3]. Finally, the index with the highest probability is chosen as a hard decision on the sent message. A generic architecture of the receiver is shown in Fig. 2(b). As for the transmitter, one can model non-differentiable receiver components as parts of the channel.
IV-B Training process overview
The key idea of the proposed training algorithm is to alternately train the receiver using the true gradient (2), and the transmitter using the gradient approximation (7). When training the receiver (transmitter), the parameters of transmitter (receiver) are kept fixed. Therefore, an iteration of the training algorithm is made of two phases, one for the receiver (Sec. IV-C), and one for the transmitter (Sec. IV-D), as shown in Algorithm 1. This training process is carried out until a stop criterion is satisfied (e.g., a fixed number of iterations, a fixed number of iterations during which the loss has not decreased, etc.).
It is assumed that transmitter and receiver have access to a sequence of training examples . This can be achieved through pseudorandom number generators initialized with the same seed. Training of transmitter and receiver is done by gradient descent or, more precisely, SGD [3] or one of its numerous variants. The true gradient in (2) for the receiver is estimated by (3), while the gradient approximation (7) used to train the transmitter is estimated by (8). Both training phases are described next. For convenience, we adopt a matrix notation, commonly used in ML, where each row of a matrix corresponds to a training example of a minibatch.
IV-C Receiver training
The receiver training process is illustrated in Fig. 3(a), and the pseudocode is given in Algorithm 2. First, the transmitter generates a minibatch of messages of size . Then, each message is encoded into () real (complex) channel symbols, where is the -by- matrix containing the symbols (lines 4–5). No relaxation of the transmitter output is performed, as it is not required to approximate the receiver gradient. The encoded minibatch is then sent over the channel. The receiver obtains the altered symbols , from which it generates for each training example a probability vector over , stacked into a matrix of size by (lines 6–9). Finally, an optimization step is performed using the estimated gradient (3) (line 10).
IV-D Transmitter training
The pseudocode of the transmitter training process is shown in Algorithm 3, and illustrated in Fig. 3(b). First, a minibatch of size is generated, and each training example is encoded into channel symbols to form the -by- matrix (lines 4–5). Then, relaxation of the transmitter output to a random variable is made by sampling the distribution , and the so-obtained samples are stacked to form the -by- matrix (line 6). These symbols are then sent over the channel. The receiver obtains the altered symbols and generates for each training example a probability vector over , stacked to form the matrix (lines 9–10). Per-example losses are then computed based on these probability vectors and the sent messages (line 11). Next, the per-example losses are sent to the transmitter over a reliable feedback link, present only during training (lines 12–14). Finally, an optimization step is performed, using SGD or a variant, where the loss gradient is estimated by (8).
V Evaluation by Simulations
In this section, we evaluate the performance of the model-free algorithm by simulations. Relaxation is achieved by adding a zero-mean Gaussian vector to the transmitter output:
[TABLE]
where scaling is done to ensure conservation of the average energy, and must be chosen in the range . From Theorem 1, one may want to set to arbitrary small values, as it should lead to a better approximation of the true loss gradient. However, setting to small values increases the variance of the estimator (8), which leads to slow convergence. This unwanted effect was experimentally observed, and can be shown analytically in simple settings. The variance increase due to small values of can be compensated for by bigger batch sizes, at the cost of a higher computational demand. Therefore, controls a tradeoff between the accuracy of the loss function gradient approximation and the estimator variance. From the viewpoint of RL, one can see this also as an interesting tradeoff between the power used for exploration and communication, which would merit an independent study.
The signal-to-noise ratio (SNR) is defined as
[TABLE]
where is the variance per complex baseband noise symbol. The last equality follows from the normalization step performed by the transmitter, which ensures that =1. Normalization is done by scaling the symbols forming a batch. Note that this is only an approximation for small minibatches. Training of the communication systems was done using the Adam [21] optimizer, and with a fixed number of iterations which were chosen experimentally. A training iteration of the alternating algorithm consisted of ten gradient descent steps on the receiver followed by ten gradient descent steps on the transmitter. The proposed scheme was implemented using the TensorFlow framework [22], and evaluated on AWGN and RBF channels. For these channels, the corresponding probability distributions are respectively and , where and are -dimensional vectors whose components are the real followed by the imaginary parts of the complex baseband symbols, is the probability density function of the multivariate normal distribution with mean and covariance matrix , and is the matrix defined as where is the zero square matrix of size and is the identity matrix of size .
V-A Transmitter and receiver architectures
We implement transmitter and receiver as feedforward NNs that leverage only dense layers. The messages are fed to the transmitter using the one-hot representation, i.e., each message is encoded as a vector of dimension which takes as values only zeros, except for the th entry which takes as value one. The transmitter consists of a dense layer of units with ELU activation functions [3], followed by a dense layer of units with linear activations. This layer outputs the channel symbols, that are finally normalized as shown in Fig. 2(a).
Regarding the receiver, the last layer is a dense layer of units with softmax activations which outputs a probability distribution over , as shown in Fig. 2(b). For the AWGN channel, a single dense layer with units and ReLu activation function [3] was used as hidden layer. This hidden layer combined with the softmax layer form a discriminative network, as its task is to separate the received symbols and assign labels to them, corresponding to guesses of the transmitted messages.
For the RBF channel, using only the discriminative network led to poor performance and, therefore, an architecture which incorporates some knowledge about the channel behavior was used [2, Sec. III C.]. It is well known in ML that incorporating expert knowledge through the NN architecture can heavily improve the performance of learning systems. Accordingly, a transformer network, which first transforms the received signal, is added before the discriminative network, as shown in Fig. 4. The transformer network was designed with the intuition that the two first hidden layers produce a value interpreted as an estimate of the channel response . As an example, in the case of the RBF channel, the channel response is such that .
The received signal is then “equalized” using the estimated channel response by computing the product of and , and we refer to the so-obtained signal as the transformed signal.
V-B Evaluation on AWGN and RBF channels
The size of was set to , corresponding to messages of length 8 bits. Comparison is done to the QPSK and Agrell [5] modulation schemes. For QPSK, a message is transmitted by independently sending symbols, corresponding to complex channel uses, each modulating 2 bits of information. Agrell is a subset of the E8 lattice designed by numerical optimization to approximately solve the sphere packing problem for in eight dimensions (corresponding to four channel uses). Model-aware training is also considered, which has been shown to achieve performance close to the best baselines in some scenarios [2].
Training was done with an SNR set to dB (dB) for the AWGN (RBF) channel. For the alternating training algorithm, we used . Using QPSK and Agrell with the RBF channel, an additional pilot symbol was used to perform explicit equalization. Regarding the model-aware and model-free schemes with the RBF channel, two approaches were considered. In the first one, the receiver was made of a transformer and a discriminative network. No pilots were used, was set to 5 for fairness, and the received symbols were directly fed to the receiver NN. In the second approach, was set to 4, and a pilot symbol was used to estimate the channel and equalize the received symbols before feeding them to the receiver NN, which only consisted of a discriminative network, similarly to the AWGN case. Table I summarizes the most important parameters of the evaluated schemes.
Fig. 5 shows the block error rate (BLER) of the compared schemes over the AWGN and RBF channels. These results demonstrate that training using the model-free algorithm achieves a similar BLER as with the model-aware scheme. For the AWGN channel, the model-aware and alternating algorithms outperform QPSK, but not Agrell. This is not surprising as Agrell is a highly optimized solution of the sphere packing problem, leading to probably optimal performance. However, the learning-based algorithms outperform both QPSK and Agrell on the RBF channel, showing their ability to learn robust schemes w.r.t. channel estimation errors.
Fig. 5(b) also reveals that equalizing the received symbols using a pilot before feeding them to the receiver NN leads to the same performance as without prior equalization, but with the additional transformer network. Interestingly, for SNRs above the training SNR, a “saturation effect” appears in Fig. 5(b) for both model-aware and model-free methods.
To get insight into how the receiver achieves signal detection for the RBF channel when no prior equalization is done, the t-SNE [23] visualization algorithm was used. t-SNE is a probabilistic dimensionality reduction algorithm which maps high-dimensional points into low dimensions (typically 2 or 3) to enable visualization. Moreover, objects close to each other in the high-dimensional space are mapped to points close to each other in the low-dimensional representation with high probability. For readability, we used and for this study, and consider only alternating training. Fig. 6 shows the constellation corresponding to the transmitted, received, and transformed signals, as well as the t-SNE visualization. It can be seen in Fig. 6(a) that the transmitted constellation of the first channel use is not centered, which indicates that the transmitter has learned to add super-imposed pilots which allow the receiver to detect the sent message. The same observation was made in [4]. The received signal (in Fig. 6(b)) does not seem to present any structure from which it is easy to extract information. Visualization of this signal using t-SNE also fails to reveals clusters, as shown in Fig. 6(d) (left). On the other hand, t-SNE reveals clusters corresponding to the 8 possible messages when considering the transformed signal, as shown in Fig. 6(d) (right). One can hence speculate that the transformer network uses the super-imposed pilots to transform the received signal such that signals corresponding to different messages are separable by the discriminative network. Interestingly, visual inspection of the constellations associated to the transformed signal, shown in Fig. 6(c), does not reveal any obvious separations between the messages, meaning that clusters appear only in high dimensions. A key point to understand the saturation effect in Fig. 5(b) is that, as opposite to when explicit prior estimation/equalization is performed, the receiver does not have a perfect knowledge of the pilot signal, leading to a permanent residual error. This residual error is negligible at SNRs below the training SNR, but becomes significant at SNRs considerably higher, leading to the observed saturation effect.
V-C Evaluation of the convergence rate
The evolution of the BLER of the model-aware and the model-free algorithm is shown in Fig. 7, averaged over 200 seeds used for initialization of the NN weights. Because each iteration of model-free training consists of ten gradient descent steps on the receiver and the transmitter, respectively, we assume for fairness that each iteration of model-aware training corresponds to ten gradient descent steps on the end-to-end system. As significant differences in convergence speed are only observed at the beginning of the training process, only the first 150 iterations are shown for readability. Shaded areas around the curves correspond to one standard deviation in each direction. For the RBF channel, only the case with no prior equalization is shown. For both the AWGN and RBF channels, the model-aware method leads to faster convergence compared to the alternating method. This is expected since the true loss gradient is used to train the transmitter, in contrast to an approximation of the loss gradient when no model of the channel is provided. Significant differences in convergence speed are only observed at the beginning of the training process, showing that model-free training does not lead to a significantly slower convergence compared to model-aware training. Moreover, as previous results show, once properly trained, both model-free and model-aware training achieve the same performance.
V-D Evaluation with a noisy feedback link
The proposed algorithm requires a feedback link to send the per-example losses computed by the receiver to the transmitter (line 12 in Algorithm 3). Knowledge of these losses is required at the transmitter for training. However, in practice, this feedback link may be error-prone, or the losses may be quantized. Both situations result in erroneous losses used for gradient estimation. Their impact will be investigated in the remainder of this section.
For simplicity, errors are modeled by adding independent zero-mean Gaussian noise with variance to the losses, i.e., , where denotes an erroneous loss, and . The feedback link SNR is defined as
[TABLE]
Fig. 8 shows the BLER of the communication system trained using the alternating method with erroneous feedback and for various values of SNR fb. The number of messages was set to 256, the number of channel uses to 4, and both training and evaluation were performed at an SNR of dB over an AWGN channel. Surprisingly, erroneous losses have a negligible impact on the BLER for positive values of SNR fb. Moreover, for SNR fb higher than dB, no BLER increase is observed. This result suggests that the proposed training algorithm is robust to erroneous feedback, which is encouraging with regards to its practical use.
V-E Joint source-channel coding of images
By modifying transmitter and receiver NN architectures in Fig. 2 to real-valued vector inputs, one can train communication systems for other tasks than transmitting messages drawn from a discrete set. One recent example is joint source-channel coding for images, which was recently addressed in [14, 24]. We will now show that model-free training can be applied in these settings, too.
The MNIST [25] dataset of handwritten digits is considered, in which each example is a 28-by-28 grayscale image. The generic architectures of transmitter and receiver presented in Section IV-A are adapted to image processing. Especially, the receiver does not output a probability vector in this application, but an image with the same dimensions as the input. The used autoencoder architecture is shown in Fig. 9. Convolutional layers [3] are used in the transmitter to exploit the spatial structure of images, with strides higher than one to achieve compression. A dense layer is leveraged to generate the channel symbols, which are then normalized to ensure the power constraint. The receiver is designed symmetrical to the transmitter, and leverages transposed convolutional layers to reconstruct images from low-dimensional inputs. Sigmoid activation functions are used in the last convolutional layer to output grayscale pixel values in the range . The loss function is the mean squared error (MSE), and reconstruction quality is measured by the peak signal-to-noise ratio (PSNR), defined as:
[TABLE]
An AWGN channel is considered with channel uses and training is performed at an SNR of dB. We observed experimentally that training using the model-free algorithm requires larger batch sizes for the transmitter than for the receiver. We believe that this unwanted effect is due to an increased estimator variance as the number of transmitter outputs increases. Similar effects were observed in RL, where the difficulty of training systems with continuous and high dimensional output spaces is well-known in [26]. Note that this effect is different from the one described for SPSA (see Appendix B), for which the estimator variance increases with the number of trainable parameters. Indeed, the number of trainable parameters typically increases at a faster rate than the number of outputs. As an example, the transmitter architecture used in this study has only twenty outputs, but more than ten thousand trainable parameters. This effect can however be compensated for by larger batch sizes.
Therefore, using the alternating approach, training of the transmitter was done with a fixed batch size of 128 examples, while training of the receiver was done with a progressively increasing batch size, up to 128. When training with channel model knowledge, the batch size was progressively increased up to 128. Fig. 10 shows the PSNR of the model-free and model-aware algorithms as a function of the SNR. It can be seen that model-free training incurs no performance penalty, showing that alternating training can handle complex transmitter architectures and end-to-end tasks.
Examples of images generated by the autoencoder trained with the alternating algorithm are shown in Fig. 11.
V-F Evaluation on a fiber-optical channel
We conclude this section by evaluating the alternating algorithm on a simplified fiber-optical channel model. The simplified model is obtained from the nonlinear Schrödinger equation, by neglecting dispersion [27], which leads to a recursive per-sample model
[TABLE]
where is the channel input, and the channel output. The complex-valued channel input was created by interpreting the first elements of the transmitter NN output as the real and the second part as the imaginary part of . The inverse operation was performed at the receiver side. is the fiber length, the nonlinearity parameter, and , where is the noise power. is assumed large.
While the generic architectures presented in Section IV-A are valid for any channel, the architecture introduced in Section V-A is not suited to fiber-optical channels. Instead, the transmitter is made of two hidden dense layers of 64 neurons each with ReLu activation, followed by a hidden dense layer of neurons with linear activation. The normalization layer is such that the average energy per symbol is set to a controllable parameter . The receiver is made of 2 hidden dense layers of 64 neurons each with ReLu activation, followed by the output softmax layer. As in [27], the channel parameters were km, W/km, and was set to 50, which is sufficient to approximate the asymptotic channel model. was set to 16, to 1, and to 0.05 for alternating training. For these parameters, Li et al. [27] showed that an autoencoder-based communication system trained with model knowledge outperforms 16-QAM modulation under maximum likelihood detection. Therefore, we take the autoencoder trained with model knowledge as a baseline to evaluate the performance of the alternating algorithm.
Fig. 12 shows the symbol error rate (SER) of the autoencoder trained with the model-aware and model-free approaches. As in [27], a separate NN is trained for each SNR value as the trained NNs struggle to generalize to other SNR values. It can be seen that the model-aware and model-free approaches achieve the same SER. These results are encouraging as they illustrate the universality of the alternating training algorithm, which achieves competitive results on both wireless and fiber-optical channels.
VI Over-the-air experiments
The first proof-of-concept of an autoencoder-based communication system was described in [4]. This prototype was trained using a channel model, and then deployed and evaluated over the actual channel. One of the main difficulties encountered by the authors of this early work was the difference between the actual channel and the channel model used for training, which led to significant performance loss after deployment. Most of this mismatch comes from imperfections of the transmitter and receiver hardware, which are hard to model. The alternating algorithm proposed in this work removes the need for an accurate model of the channel. In this section, we describe a proof-of-concept using the alternating algorithm to train an autoencoder for communications over wireless and coaxial cable channels. The performance is compared to that of QPSK and Agrell [5]. To the best of our knowledge, this is the first prototype of an autoencoder-based communication system trained over actual channels.
VI-A Experimental setup
Similarly to [9], the autoencoder is extended to OFDM with cyclic prefix (CP), as shown in Fig. 13. A (discrete) inverse fast Fourier transform (IFFT) of size is performed on the IQ-symbols generated by the encoder from a set of independent messages . The DC subcarrier, and guard subcarriers on each side, are not used, leading to data-carrying subcarriers. To avoid inter-symbol interference (ISI), a CP of length is further added. An additional preamble made of repetitions of the Barker sequence of length 13 is added for synchronization. On the receiver side, synchronization is performed through correlation with peak detection. Finally, after removing the CP, the input to the decoder is recovered through fast Fourier transform (FFT). The use of OFDM with cyclic-prefix enables single-tap equalization. Similarly to previous evaluations, the autoencoder-based communication system relies on the transmitter and receiver architectures introduced in Section V-A, including the transformer network. Each message was assigned to a subcarrier, and a single decoder, which includes the transformer network, operates on a per-subcarrier basis. It is possible to learn synchronization with additional NNs, as done in [4]. However, we could not observe any gain for our setup and, therefore, resorted to classical approaches.
Fig. 14 gives an overview of the experimental testbed. A single Ettus USRP B210 board, connected to a computer equipped with an NVIDIA 1080 consumer class Graphics Processing Unit (GPU) and running the TensorFlow framework, was used as transmitter and receiver. The testbed was deployed in our offices, the antennas had an unobstructed line-of-sight (LOS) path, and were kept unmoved during data transmission. The carrier frequency was GHz, and the bandwidth was MHz. The number of subcarriers was , and the CP length symbols. guard subcarriers were used on each side. The considered schemes were the same as for the RBF channel in Table I.
VI-B Results
The evolution of the CE as a function of the number of training iterations is shown in Fig. 15 for the first 500 iterations of training over a coaxial cable. The CE serves as loss function for training. It can be seen that after only a few hundred of iterations, the loss has decreased by three orders of magnitude. With our setup based on consumer class hardware, training for a few hundred iterations takes only a few minutes.
The BLER of various schemes over a coaxial cable and wireless channel are compared in Fig. 16. The alternating algorithm outperforms QPSK in both settings. For the coaxial cable (Fig. 16(a)), it also outperforms Agrell. Manual equalization leads to identical performance as with the transformer network. On the wireless channel (Fig. 16(b)), the autoencoder with prior equalization achieves better performance than Agrell, while it does not without. The reason for this is under investigation, but we expect that it could be resolved with longer training time, or different NN architectures. Compared to the results presented in [4], where no gains over a well-designed baseline were obtained experimentally, we demonstrate here clear benefits of training over the actual channel with the proposed alternating training algorithm.
VII Discussion and Outlook
We have introduced an alternating algorithm for training of autoencoder-based communication systems without a channel model. Our simulation results show that an autoencoder trained with the proposed method achieves the same performance as when trained using usual backpropagation assuming perfect knowledge of the channel model. The universality of the alternating algorithm was illustrated by showing that it is able to train complex autoencoders, e.g., for joint source-channel coding, and enables the same performance as model-aware training on a simplified fiber-optical channel model. We have also presented experimental results of the first prototype of an autoencoder-based communication system trained directly over actual channels. In contrast to prior work, our setup achieves gains over well-known baselines. The main reason for this is that transmitter and receiver can be jointly optimized for the actual channel.
A drawback of the alternating algorithm is the requirement of a feedback link at training, which might be unpractical in some settings. It was also observed that training of the transmitter using the proposed gradient approximation method does not scale with the number of channel uses. This is due to the variance of the loss function gradient estimator, which increases with the number of channel uses. However, we believe that this drawback can be addressed using variance reduction techniques, such as [28]. Another open issue of training of communication systems over actual channels is the relatively long coherence time compared to the rate at which examples can be processed at training. As a consequence, only a few channel realizations are observed (at best) over a single minibatch, leading to poor sample efficiency and slow (if any) convergence. This is an important obstacle to training communication systems that are able to generalize well to a wide range of channel realizations, which may be solved by artificially introducing channel variations, e.g., by training on channel emulators.
Appendix A Proof of Theorem 1
We denote by and the domains of and respectively. The proof of Theorem 1 is given in Appendix A-A. In Appendix A-B, the case where and are compact sets is considered. Under this assumption, which is valid for any hardware implementation, the sufficient conditions for the result to hold take a much simpler form as for the general case.
A-A * and are not compact*
Assume the following conditions hold true:
- (C1)
is invariant to translation, i.e., if then .
- (C2)
converges to the Dirac distribution as decreases towards [math], i.e, given a continuous and bounded function : .
- (C3)
There exists a function integrable w.r.t. and such that
[TABLE]
where the inequality holds element-wise, and was introduced for readability.
Note that (C1) and (C2) are valid for a normal distribution with mean and standard deviation . Intuitively, (C3) requires that the gradient of the channel distribution w.r.t. smoothed by averaging over , using as weights, is dominated by some function independent of and integrable w.r.t. .
One can check by direct calculation that
[TABLE]
where . The first equality is based on the log-trick, while the second equality is obtained through the change of variable and using the translation invariance of (C1). Note that the exchange of integration and differentiation requires regularity conditions, discussed, for example, in [19]. From the convergence of to the Dirac distribution (C2), it follows that
[TABLE]
Intuitively, this equality means that, by relaxing the transmitter output to a random variable, the channel gradient can be approximated with arbitrarily good precision. One can combine the gradient of given in (7) and (A-A) as
[TABLE]
Since is bounded and (C3) holds true, we can conclude by Lebesgue’s dominated convergence theorem that
[TABLE]
where the last equality is due to (4). This concludes the proof.
A-B * and are compact*
Assume that and are compact sets and (C1) and (C2) hold true. We require the following additional conditions:
- (C4)
is continuous jointly in and .
- (C5)
uniformly converges to the Dirac distribution as decreases towards [math], i.e,
:
[TABLE]
The required conditions on are similar to the ones required in [20, Appendix]. As it was noticed by the authors of this work, any function that is continuously differentiable, supported on a compact set , and with unit total integral can be used to construct a distribution that satisfies (C1) and (C5): .
Lemma 1**.**
Assuming (C1), (C2), (C4), (C5) hold true, then
[TABLE]
Proof:
Because and are compact sets, and is assumed to be continuous (C4), from the boundedness theorem, there exists a strict finite bound of denoted by . Define
[TABLE]
As is strict, it follows that . Because uniformly converges to the Dirac distribution as decreases (C5), there exists such that ,
[TABLE]
leading to, for any , , and ,
[TABLE]
and, therefore,
[TABLE]
Hence, \Big{|}{\mathbb{E}}_{\mathbf{x}}\left\{\nabla_{\mathbf{z}}p(\mathbf{y}|\mathbf{z})\lvert_{\mathbf{z}=\mathbf{x}}\right\}\Big{|} is dominated by for . Moreover, because is compact, . Therefore, the conditions required in Appendix A-A hold true, which concludes the proof. ∎
Appendix B Gradient estimation with SPSA
A different line of work [18] proposed the use of SPSA [29] to address the missing gradient problem. With this approach, gradient descent is performed using the following gradient substitute at each iteration
[TABLE]
where is a decreasing sequence of positive real numbers, and is a random vector following a Rademacher distribution. Despite the promising results in [18], where transmitters of low complexity were considered, we experimentally found that this approach fails to scale to a large number of trainable parameters . This is because (28) does not take advantage of the knowledge of when estimating the loss function gradient, as opposed to our method which only needs to estimate the gradient of w.r.t. to its inputs .
To illustrate this effect, let us consider the simple regression problem
[TABLE]
where follows a uniform distribution on , and the function should try to approximate the mapping . Assume that is a NN made of two dense layers which use biases, the first with units and ReLu activation, the second with a single unit and linear activation. We choose to be a normal distribution with mean and variance . For both SPSA and the proposed approach, the variance of the estimators used to perform gradient descent are numerically evaluated for a batch size of samples, and over 1000 initializations of the NN parameters , with set to and the SPSA hyper-parameters values suggested in [18]. No training was performed so that the variance was estimated after the random NN initialization. This numerical evaluation is performed for a number of units in the first layer varying from 5 to 100, so that the total number of parameters is . Fig. 17 shows the impact of the number of parameters on the estimators’ variances. The variance is significantly larger using SPSA and, moreover, increases linearly with the number of parameters. This is not the case of the proposed approach, which achieves much lower variance which also does not increase with the number of parameters. As a consequence of high gradient estimator variance, SPSA struggles to train complex transmitter architectures with a large number of parameters.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] F. Ait Aoudia and J. Hoydis, “End-to-end learning of communications systems without a channel model,” in 52nd Proc. Asilomar Conf. Signals, Syst., Comput. , Oct. 2018.
- 2[2] T. O’Shea and J. Hoydis, “An introduction to deep learning for the physical layer,” IEEE Trans. on Cogn. Commun. Netw. , vol. 3, no. 4, pp. 563–575, Dec. 2017.
- 3[3] I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning . MIT Press, 2016. [Online]. Available: http://www.deeplearningbook.org
- 4[4] S. Dörner, S. Cammerer, J. Hoydis, and S. ten Brink, “Deep learning-based communication over the air,” IEEE J. Sel. Topics Signal Process. , vol. 12, no. 1, pp. 132–143, Feb. 2018.
- 5[5] E. Agrell, “Database of sphere packing,” accessed: 2018-12-04. [Online]. Available: https://codes.se/packings/8.htm
- 6[6] A. Goldsmith, “Joint source/channel coding for wireless channels,” in IEEE Proc. Veh. Tech. Conf. (VTC) , vol. 2, Jul. 1995, pp. 614–618.
- 7[7] H. Kim, Y. Jiang, R. B. Rana, S. Kannan, S. Oh, and P. Viswanath, “Communication algorithms via deep learning,” in Int. Zurich Seminar Inf. Commun. (IZS) , Feb. 2018, pp. 48 – 50.
- 8[8] M. Kim, W. Lee, and D. H. Cho, “A novel PAPR reduction scheme for OFDM system based on deep learning,” IEEE Commun. Lett. , vol. 22, no. 3, pp. 510–513, Mar. 2018.