Parameterization of Sequence of MFCCs for DNN-based voice disorder detection
Tomasz Grzywalski, Adam Maciaszek, Adam Biniakowski, Jan, Orwat, Szymon Drgas, Mateusz Piecuch, Riccardo Belluzzo and, Krzysztof Joachimiak, Dawid Niemiec, Jakub Ptaszynski, Krzysztof, Szarzynski

TL;DR
This paper presents a DNN-based system for detecting common voice disorders from sustained vowel sounds, achieving high accuracy in a competitive challenge, with specific focus on parameterizing MFCC sequences.
Contribution
The study introduces a novel parameterization approach for MFCC sequences tailored for DNN input in voice disorder detection, and reports competitive results in a standardized challenge.
Findings
Achieved second-best score in the 2018 FEMH Voice Data Challenge
Parameterization of MFCC sequences improved DNN performance
Final model showed a 0.6% score improvement after adjustments
Abstract
In this article a DNN-based system for detection of three common voice disorders (vocal nodules, polyps and cysts; laryngeal neoplasm; unilateral vocal paralysis) is presented. The input to the algorithm is (at least 3-second long) audio recording of sustained vowel sound /a:/. The algorithm was developed as part of the "2018 FEMH Voice Data Challenge" organized by Far Eastern Memorial Hospital and obtained score value (defined in the challenge specification) of 77.44. This was the second best result before final submission. Final challenge results are not yet known during writing of this document. The document also reports changes that were made for the final submission which improved the score value in cross-validation by 0.6% points.
Click any figure to enlarge with its caption.
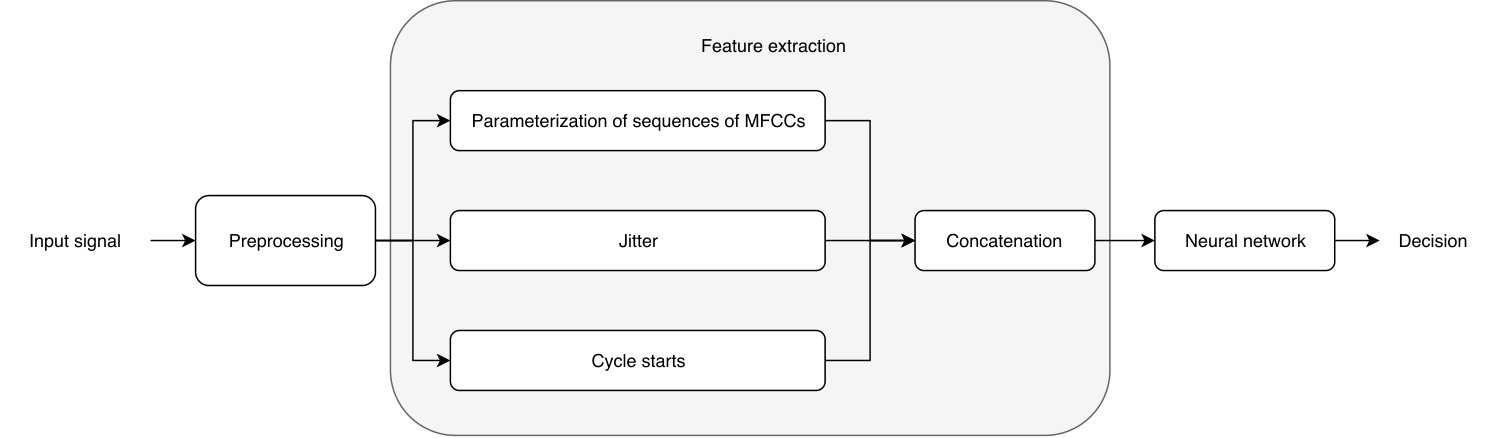 Figure 1
Figure 1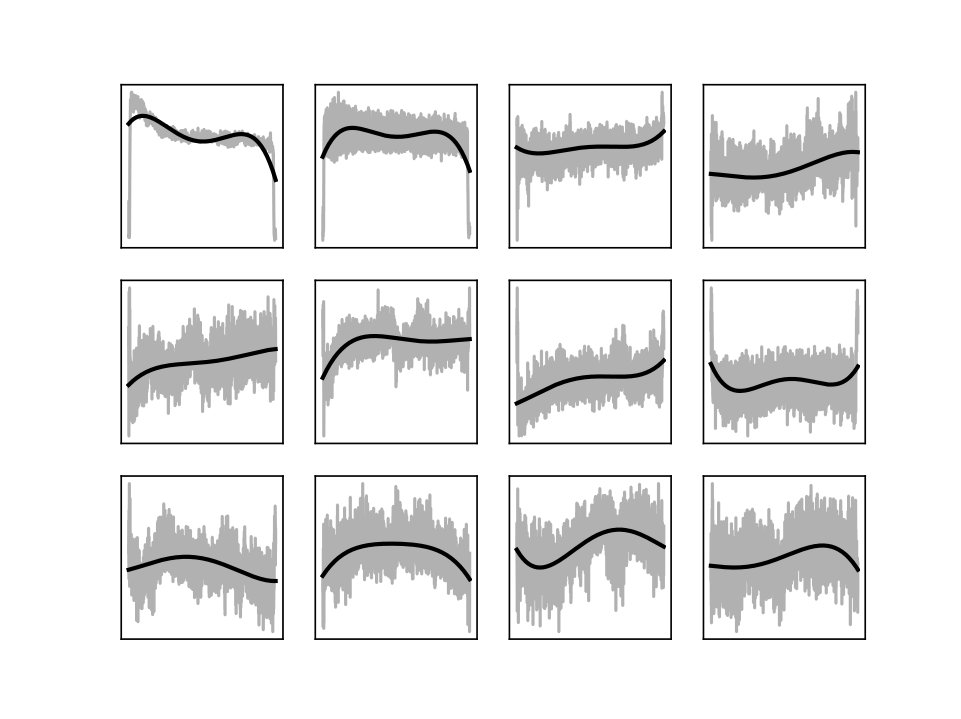 Figure 2
Figure 2| Class | Normal | Neoplasm | Phonotrauma | Vocal palsy |
|---|---|---|---|---|
| Num. of recordings | ||||
| in train set | 50 | 40 | 60 | 50 |
| Submission | Sensitivity | Specificity | UAR | Score |
| August | 89.9% | 80.5% | 67.47% | 79.03 |
| mid-October | 90.7% | 86.9% | 60.63% | 77.91 |
| final | 92.0% | 85.9% | 62.00% | 78.52 |
| Submission | Sensitivity | Specificity | UAR | Score |
|---|---|---|---|---|
| August | 93.2% | 50.0% | 72.63% | 76.33 |
| mid-October | 89.4% | 66.0% | 71.20% | 77.44 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Parameterization of Sequence of MFCCs for DNN-based voice disorder detection
Tomasz Grzywalski
StethoMe®
Poznan, Poland
Adam Maciaszek
StethoMe®
Poznan, Poland
Adam Biniakowski
StethoMe®
Poznan, Poland
Jan Orwat
StethoMe®
Poznan, Poland
Szymon Drgas
StethoMe®
Poznan, Poland
Mateusz Piecuch
StethoMe®
Poznan, Poland
Riccardo Belluzzo
StethoMe®
Poznan, Poland
Krzysztof Joachimiak
StethoMe®
Poznan, Poland
Dawid Niemiec
StethoMe®
Poznan, Poland
Jakub Ptaszynski
StethoMe®
Poznan, Poland
Krzysztof Szarzynski
StethoMe®
Poznan, Poland
Abstract
In this article a DNN-based system for detection of three common voice disorders (vocal nodules, polyps and cysts; laryngeal neoplasm; unilateral vocal paralysis) is presented. The input to the algorithm is (at least 3-second long) audio recording of sustained vowel sound /a:/. The algorithm was developed as part of the ”2018 FEMH Voice Data Challenge” organized by Far Eastern Memorial Hospital and obtained score value (defined in the challenge specification) of 77.44. This was the second best result before final submission. Final challenge results are not yet known during writing of this document. The document also reports changes that were made for the final submission which improved the score value in cross-validation by 0.6% points.
Index Terms:
machine learning, voice disorders, FEMH voice data challenge
I Introduction
††footnotetext: ©2018 IEEE
Common voice pathologies include structural lesions, neoplasms, and neurogenic disorders. These disorders are typically diagnosed using laryngeal endoscopy. Non-invasive screening methods, based on analysis of acoustic recordings, provide means to assess the health of vocal apparatus without expensive equipment operated by well-trained specialists.
The detection of voice pathologies can be performed from recordings of sustained vowels or continuous speech [10]. While continuous speech contains variations of pitch and loudness which can be important for detection of voice pathologies, sustained vowels provide more reliable parameters, as characteristics of the voice source, vocal tract, and articulators are relatively time-invariant. In contrast to continuous speech, for sustained vowels individual speech characteristics such as speaking rate, speaker’s dialect does not affect the detection. The use of sustained vowel samples is expected to generate a simpler acoustic structure that might lead to consistent and reliable decisions.
In many works in the literature about automatic voice pathology detection from sustained vowels, acoustic features are extracted which are next classified using various machine learning methods. Most of the acoustic features are related to perturbations like jitter and schimmer [12]. As it may be difficult to extract fundamental frequency for pathological voice, a feature which is needed to extract jitter, it was proposed in [1, 8] to extract features based on modulation spectrum.
Another class of features broadly used in voice pathology detection and classification contains compact representations of short-time spectra of speech like MFCCs (mel-frequency cepstral coefficients) or LPC (linear prediction coding). This kind of features was used in [4]. Distributions of such features can be modeled using GMMs (Gaussian mixture models), or using neural networks where each feature vector is classified individually, and classification scores are combined, for example by averaging.
In [13] convolutive neural network was trained to classify whole spectrograms. The Experiments were performed on Saarbruecken voice database, which contains recordings from 2000 individuals.
Many voice pathology detection systems known from the literature, detection is based on statistics of perturbations parameterized locally. However, some temporal information is used in detection when HMMs (hidden Markov models) are applied [9].
In this work, we propose features, which carry information about time trends of cepstral coefficients representing spectra in a compact way, i.e. time sequences of MFCCs are modeled by polynomials. The polynomial coefficients are concatenated with jitter and cyclestarts features [5]. This approach can carry information about onset and offset of the sustained vowel. Such a compact representation allowed us to apply deep neural network for FEMH database.
II Proposed method
II-A General architecture
The overall architecture of our proposed system is depicted in Figure 1, it consists of the following steps:
Preprocessing - The purpose of this pre-processing stage is to extract each separate vowel sound from recordings. Few recordings in the dataset included couple attempts made by the patient to pronounce the vowel. We want to extract each separate sound and precisely crop it so that beginnings of vowel sounds align. All further operations are performed individually for each vowel sound. If a recording contained multiple sounds, in the test phase each sound was individually classified and class scores were averaged. 2. 2.
Feature extraction - In this stage from each vowel sound a feature vector is extracted. In the described system three types of features are extracted and the resulting vectors are concatenated into one feature vector. In this paper, we propose to model sequences of MFCCs as described in sections II-B and II-C. Feature vector resulting from the proposed extractor is concatenated with features widely used for detection of pathologies: cyclestarts [5] and jitter [12]. 3. 3.
Neural network - Our classifier of choice is neural network that accepts on input a set of features and produces a probability of the sound belonging to one of the four defined classes.
II-B Modeling sequences of cepstral coefficients with splines
In order to provide a compact representation of the evolution of short-time spectra during realization of sustained vowel, we propose to model sequences of MFCCs with polynomials. Let denote ’th MFCC in ’th frame as , where and . For each of sequences of points
[TABLE]
where is the number of points used in the analysis, a polynomial is fitted using least squared error criterion. Two variants of polynomial fitting are proposed. In the first one all points were used ().
We have observed that patients with vocal pathologies tend to have much longer onset of a vowel, therefore we designed a features that represent only the beginning of the vowel sound. In this case, and MFCCs from about 50 first frames are used. In this case spline with explicit internal knots is fitted. The first coordinates of internal knots are distributed uniformly from [math] to . Finally, values of the fitted spline for arguments form a feature vector.
II-C MFCC-FFT
Previous two set of features described the whole sample length and very beginning of the sample. To complete this description we introduce a third set of features that captures characteristics from the initial fragment of the vowel example but with the length equal to the average length of vowel examples in our dataset (that is about two seconds). In this case, instead of using polynomials to model time courses of MFCCs, FFT was computed from each sequence for , and absolute values of its first coefficients were used as features. Thus, in contrast to the polynomial-based features, only rates of changes of MFCCs are represented but not the shapes of time courses.
III Evaluation
III-A Data
Data provided for the challenge consisted of training dataset comprising 200 recordings with known labels of 4 classes (normal; vocal nodules, polyps and cysts; laryngeal neoplasm and unilateral vocal paralysis) and test set comprising 400 recordings with unknown labels. Predicting correct labels for the 400 test recordings was the aim of the challenge.
Number of recording for each of the four classes is presented in Table I.
Each recording was a single-channel audio file with 44100 Hz sampling rate.
III-B Cropping
The first stage of data preprocessing was extraction of separate vowel sounds. We determined when the signal exceeds a particular volume level and extracted time excerpts in which the sound is present, including an offset of 0.15s before and 0.25s after the determined signal excerpt. Detailed algorithm for cropping is following:
Low-pass filtering of the input signal at 1000 Hz using 6th order IIR Butterworth filter 2. 2.
Computation of Hilbert envelope from signal 3. 3.
Filtering the envelope (moving average, window length of 1100 samples) 4. 4.
Computation of signal level over time from the filtered envelope according to equation: where is the index of a sample. 5. 5.
Compute threshold level where and are 2 and 95 percentiles of distribution of signal level 6. 6.
Get fragments of signals where level is above and remove fragments shorter than 500 ms 7. 7.
Merge fragments if they are separated by less than 200ms 8. 8.
Cut the input signal according to the detected fragments extended 150 ms and 250 ms before and after each fragment
After this stage we obtained 213 vowel sounds from 200 training recordings.
III-C Data augmentation
For every vowel sound extracted as described in Section III-B, we created three data augmentations which were used alongside the original example during model training. Each augmentation was an original vowel sound with randomly applied: volume level change, pitch shift and time stretch. The parameters of the modifiers were following:
- •
volume change by simple multiplication by a random value uniformly sampled from range 0.4 to 1.2,
- •
random pitch shift drawn from normal distribution with mean equal 0.0 and standard deviation equal 0.5,
- •
time stretch with stretch rate sampled uniformly from range 0.85 to 1.5.
After this stage we gathered 852 training samples including original and augmented ones.
III-D Feature extraction
III-D1 MFCC
Part of elements of feature vector were computed from mel-frequency cepstrum (MFCC) coefficients. Parameters of the MFCC extraction were following:
- •
Preemphasis filter with coefficient = 0.97
- •
Window length = 0.008s
- •
Window step = 0.011s
- •
FFT size (n_fft) = 512
- •
Number of mel filters = 26
- •
Number of returned MFCCs = 13
Provided parameters were selected after a series of experiments where window lengths from 0.0027s to 0.019s and windows steps from 0.0027s to 0.044s were tested in a grid-search manner. Based on MFCC extracted using these parameters, two main sets of features were extracted from each sample:
- •
mfcc_polynomials: For each sequence of the 13 MFCCs a polynomial of 4-th degree was fitted as described in Section II-B. This resulted with features. Examples of obtained polynomials are depicted in Figure 2
- •
mfcc_splines: Splines were fitted to the sequences of MFCCs from the first 50 frames (about 544ms of recording length) (see Section II-C). In case the sample was shorter - last frame was repeated till a total length of 50 was obtained. Knots of the splines were fixed at 0th, 10th, 20th, 30th, 40ht, 50th element of each modeled sequence. Next, approximated values of modeled sequence in splines knots locations were extracted. There were a total of such features extracted this way from each sample.
- •
mfcc_fft: Similar as in mfcc_splines we parameterize MFCCs from the first 150 frames. In this case, however, parameterization is done by means of fast Fourier transform (FFT). From each obtained magnitude spectrum of size 76 (half of spectrum which is symmetric), the first 6 coefficients are extracted which becomes a set of features.
III-D2 Jitter and cycle starts
Additional to features extracted from MFCC we also included two other set of features that we hoped would capture different characteristics of the vowel sounds:
- •
jitter: Five types of jitter parameters have been extracted as in [12]: absolute jitter, relative average perturbation (), the 5-point period pertubation quotient (), and the difference of differences of periods (). Additionally, we extract F0 and HNR. Finally a feature vector from this extractor has 7 elements.
- •
cyclestarts: Comprises of two features: Turbulent Noise Index (TNI) and Normalized First Harmonic Energy (NFHE) as defined in [5] (2 values).
III-E Neural network
Our classifier was a neural network containing 2 hidden layers and an output layer. All hidden layers and the output layer were fully-connected. Each hidden layer featured 128 neurons with Exponential Linear Units (ELUs) nonlinearities [3] and batch normalization [6]. Output layer contained 4 neurons with softmax nonlinearity so that the output values could be interpreted as probability.
To reduce over-fitting in training phase we used dropout [11] before every layer in our network. The dropout rates before first, second and third layer were accordingly: 55%, 25% and 10%.
All mentioned parameters were subject to manual optimization. Among tested options were: different number of hidden layers (2 and 3), different number of neurons in hidden layers (from 32 to 512), hidden layer’s nonlinearities and presence/absence of batch normalization.
III-F Training
We split the dataset using 5-fold crossvalidation into three parts: training set (64%), validation set (16%), test set (20%). We repeated this splitting process 20 times using different random seeds (we call each repetition an experiment). Training sets were used for networks training. By measuring trained network accuracy on validation set after each epoch, we selected the best model version for given seed and fold. Test sets were used for final performance evaluation, the results were aggregated across all folds and averaged across all 20 experiments. For the submission we used all 5 models from 20 experiments (100 models in total) and averaged obtained class probability scores.
All models were trained to minimize categorical crossentropy between network’s predictions and target labels. Optimization was performed using Adam algorithm [7]. Each fold was trained for 100 epochs with batch size of 32. Initial learning rate was 0.001 and was multiplied by weight decay factor of 0.985 after each epoch. Initially in one epoch each vowel sound from train set was used once, but starting from mid-October submission we used ”Normal” sounds two times in each epoch to account for the fact that the train set contained fewer normal sounds (50) compared to pathological (150) [2].
III-G Scoring
All challenge submissions were evaluated and ranked using ”score” value defined as weighted average of Sensitivity, Specificity and Unweighted Average Recall (UAR) with respective weights: 0.4, 0.2 and 0.4. Sensitivity and Specificity were defined for 2-class classification (normal vs any pathology) while UAR described model’s ability to distinguish between three pathologies (neoplasm, phonotrauma and vocal palsy).
III-H Evaluated models
During the competition we have submitted number of models for evaluation. Three of them, including our best performing model and final submission, are different variations of the system described in previous sections. The details of the three models are following:
August submission: This version used mfcc_polynomials, jitter and cycle starts (65 + 7 + 2 = 74) features. Dropout before first layer was set to 10% and ”Normal” sounds appeared only once in each epoch 2. 2.
mid-October submission: This version used mfcc_polynomials, mfcc_splines, jitter and cycle starts (65 + 78 + 7 + 2 = 152) features and dropout of 55% before first layer 3. 3.
final submission: This version used mfcc_polynomials, mfcc_splines and mfcc_fft (65 + 78 + 78 = 221) and dropout of 60% before first layer
III-I Results
Table II contains results obtained by different versions of our system using 5-fold cross-validation procedure described in section III-F. Table III contains results on the test set as reported by the Challenge organizers.
IV Conclusions
In this article a system for detection of voice disorders was presented. Developed as part of the FEMH Voice data Challenge 2018, the system achieved second best score value (77.44) across all pre-final model evaluation rounds. In our final submission we have introduced changes that improved our results in cross-validation by 0.6 percent points.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Julián David Arias-Londoño, Juan I Godino-Llorente, Maria Markaki, and Yannis Stylianou. On combining information from modulation spectra and mel-frequency cepstral coefficients for automatic detection of pathological voices. Logopedics Phoniatrics Vocology , 36(2):60–69, 2011.
- 2[2] Nitesh V Chawla. Data mining for imbalanced datasets: An overview. In Data mining and knowledge discovery handbook , pages 875–886. Springer, 2009.
- 3[3] Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). ar Xiv preprint ar Xiv:1511.07289 , 2015.
- 4[4] Shih-Hau Fang, Yu Tsao, Min-Jing Hsiao, Ji-Ying Chen, Ying-Hui Lai, Feng-Chuan Lin, and Chi-Te Wang. Detection of pathological voice using cepstrum vectors: A deep learning approach. Journal of Voice , 2018.
- 5[5] Stefan Hadjitodorov and Petar Mitev. A computer system for acoustic analysis of pathological voices and laryngeal diseases screening. Medical engineering & physics , 24(6):419–429, 2002.
- 6[6] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. ar Xiv preprint ar Xiv:1502.03167 , 2015.
- 7[7] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. ar Xiv preprint ar Xiv:1412.6980 , 2014.
- 8[8] Maria Markaki and Yannis Stylianou. Voice pathology detection and discrimination based on modulation spectral features. IEEE Transactions on Audio, Speech, and Language Processing , 19(7):1938–1948, 2011.