Deep learning based track reconstruction on CEPC luminometer
Liu Yang, Hao Cai, Kai Zhu

TL;DR
This paper introduces a deep neural network-based track reconstruction method for the CEPC luminometer, significantly improving efficiency and resolution over traditional techniques, especially in problematic tile gap regions.
Contribution
The paper presents a novel deep learning approach that replaces conventional methods for improved track reconstruction in the CEPC luminometer.
Findings
Reconstruction efficiency improved significantly.
Energy and direction resolutions enhanced.
Effective in tile gap regions.
Abstract
We study the track reconstruction algorithms of the CEPC luminometer. Depend on the current geometry design, the conventional track reconstruction method is applied, but it suffers the energy leakage problem when tracks falling into the tile gaps regions. To solve this problem, a novel reconstruction method based on deep neural networks has been investigated, and the reconstruction efficiency has been improved significantly, as well as the energy and direction resolutions. This new reconstruction method is proposed to replace the conventional one for the CEPC luminometer.
Click any figure to enlarge with its caption.
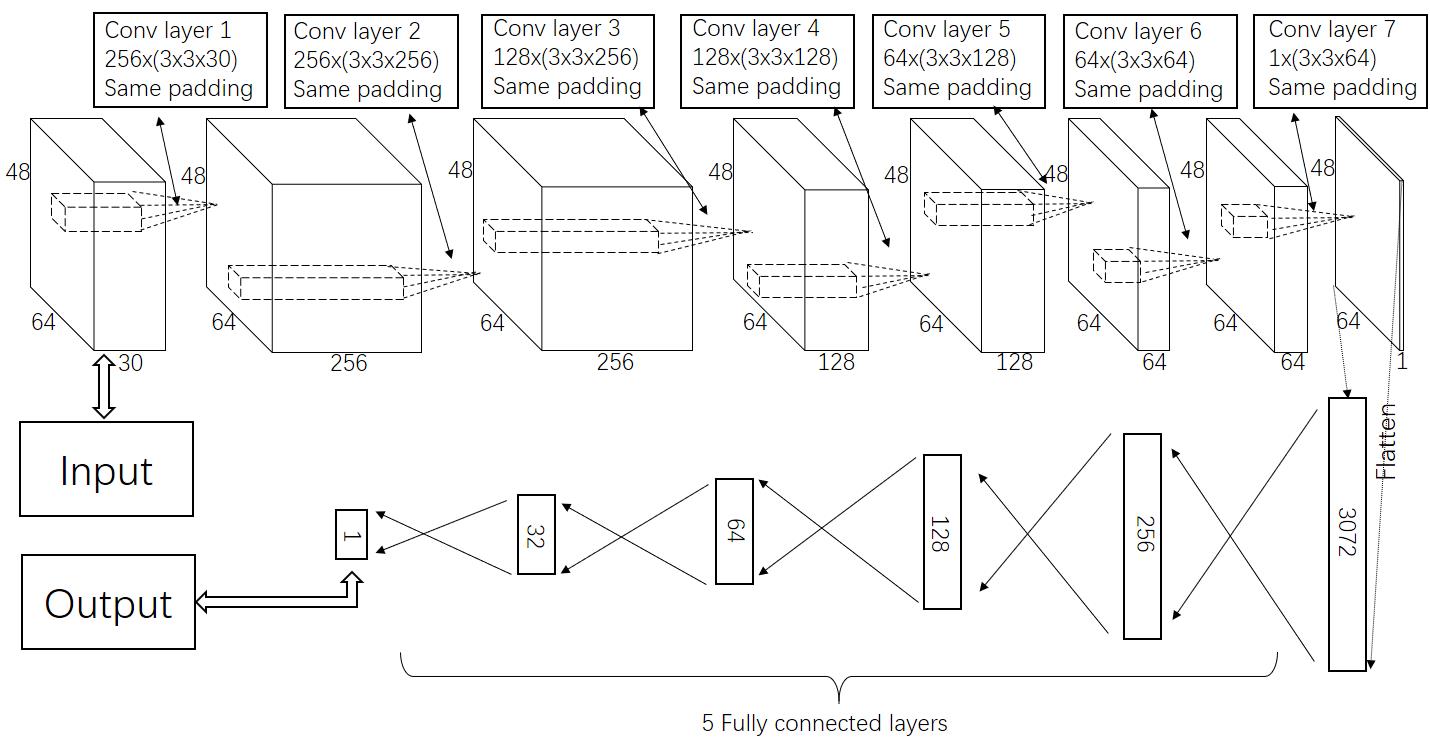 Figure 1
Figure 1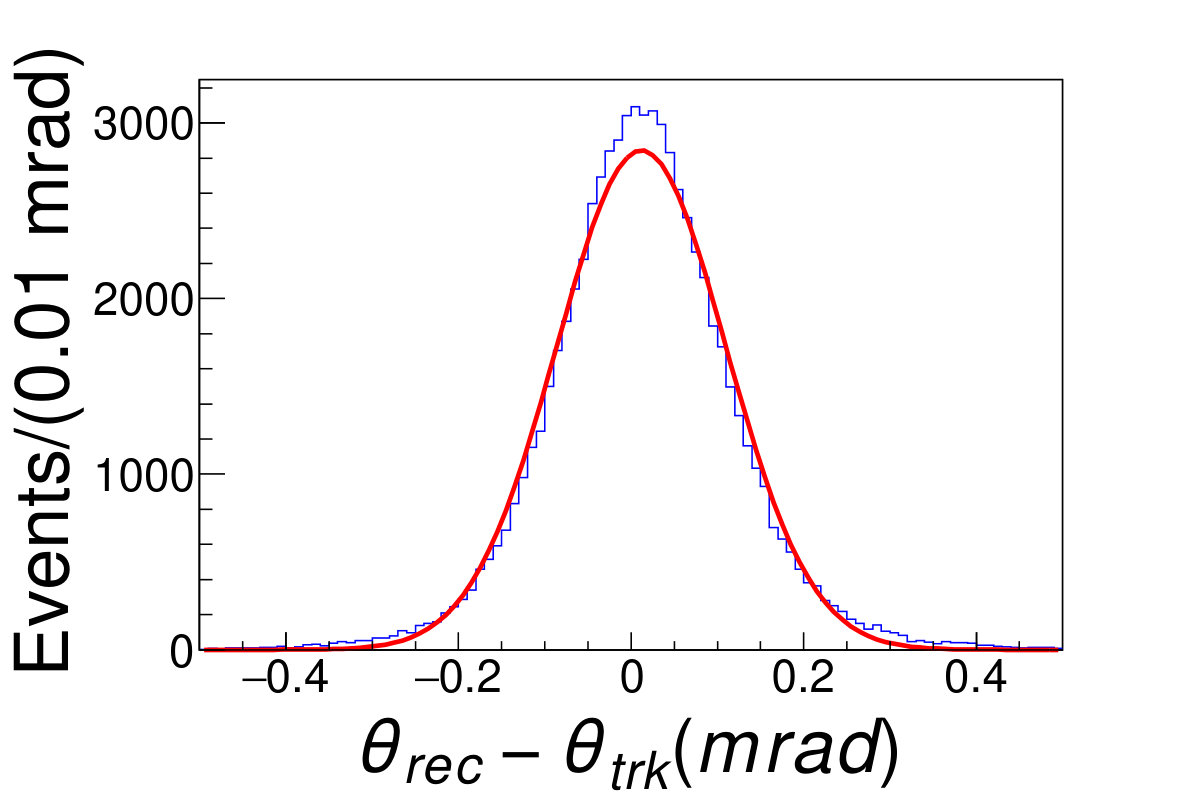 Figure 2
Figure 2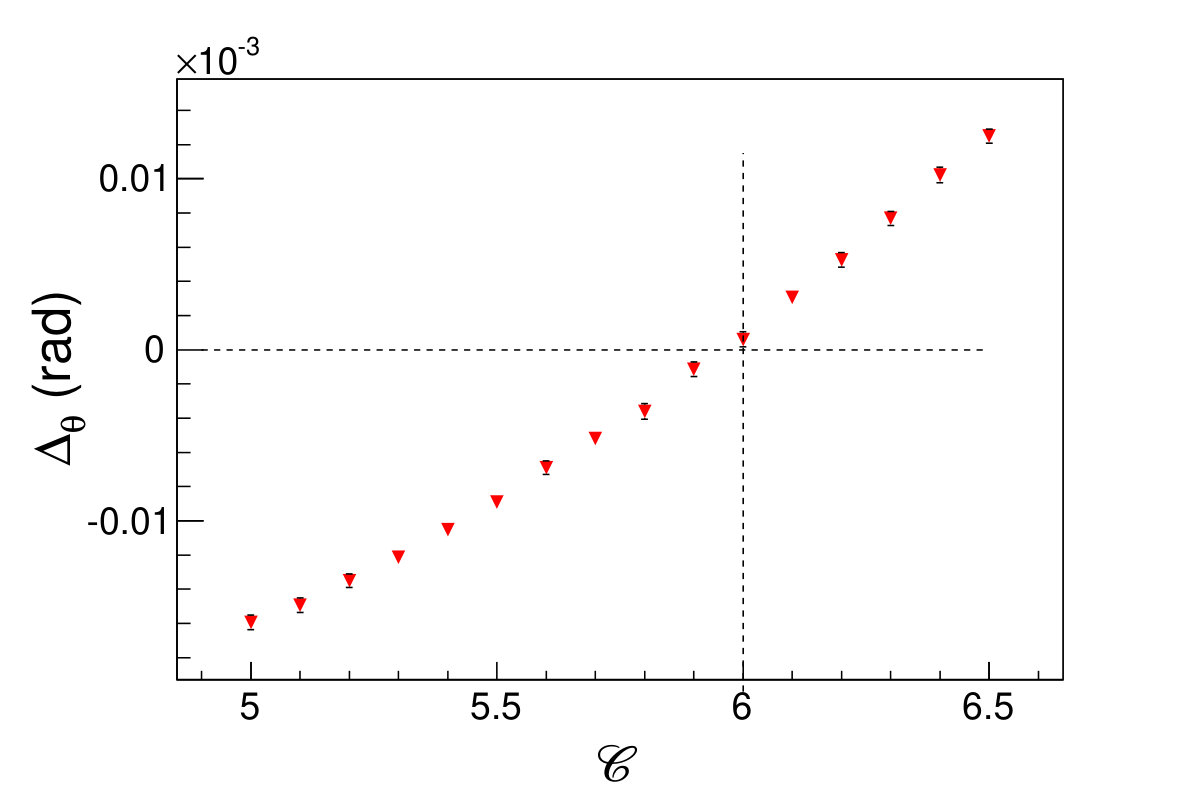 Figure 3
Figure 3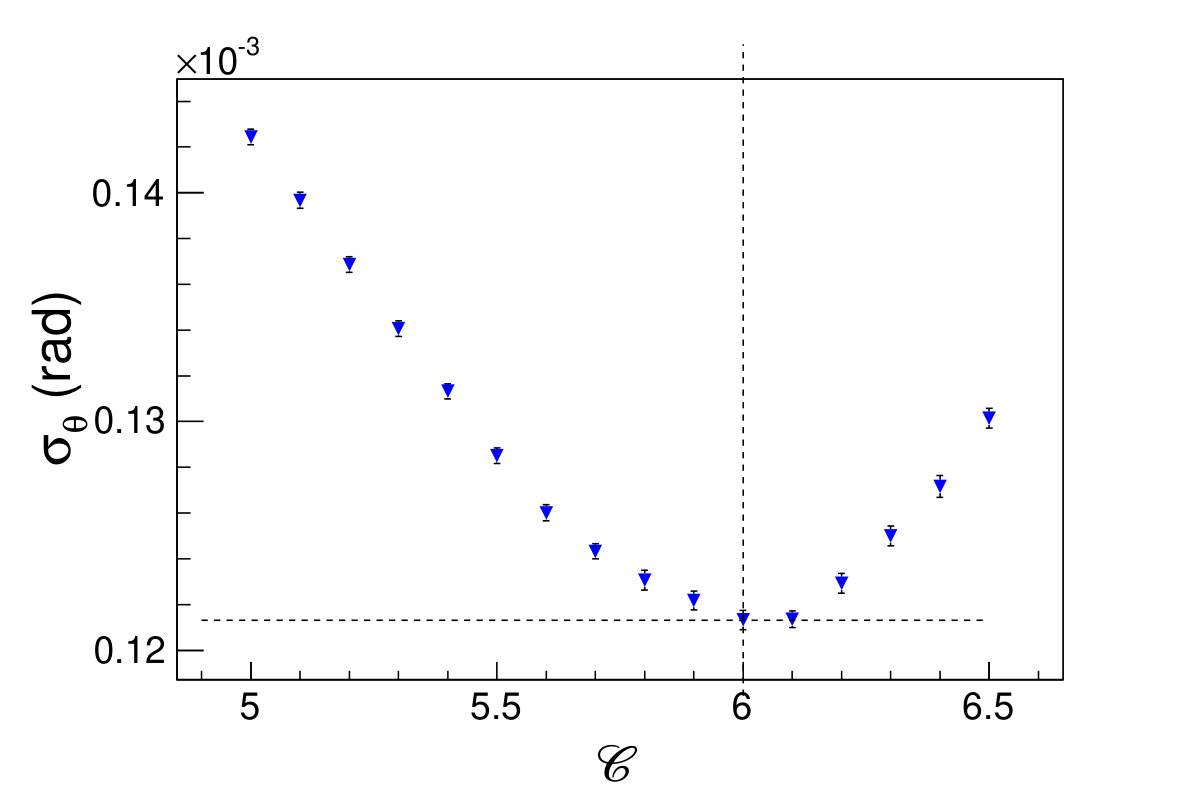 Figure 4
Figure 4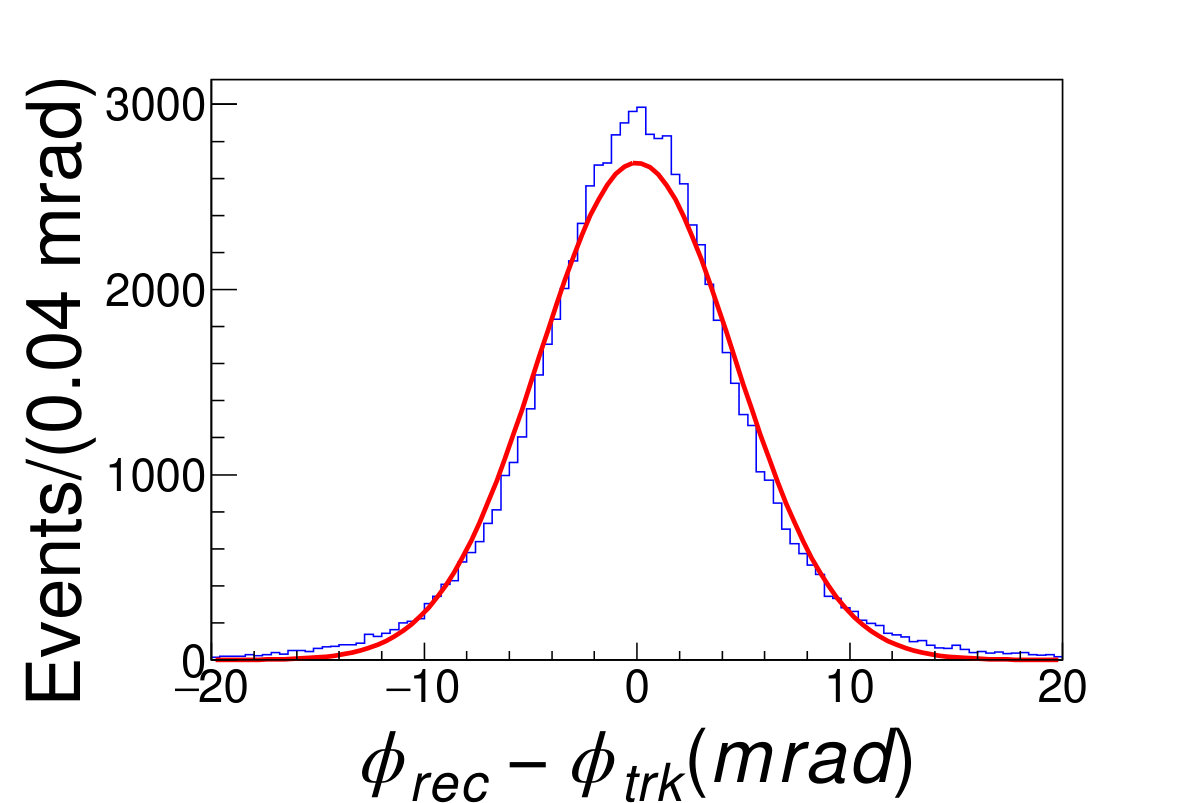 Figure 5
Figure 5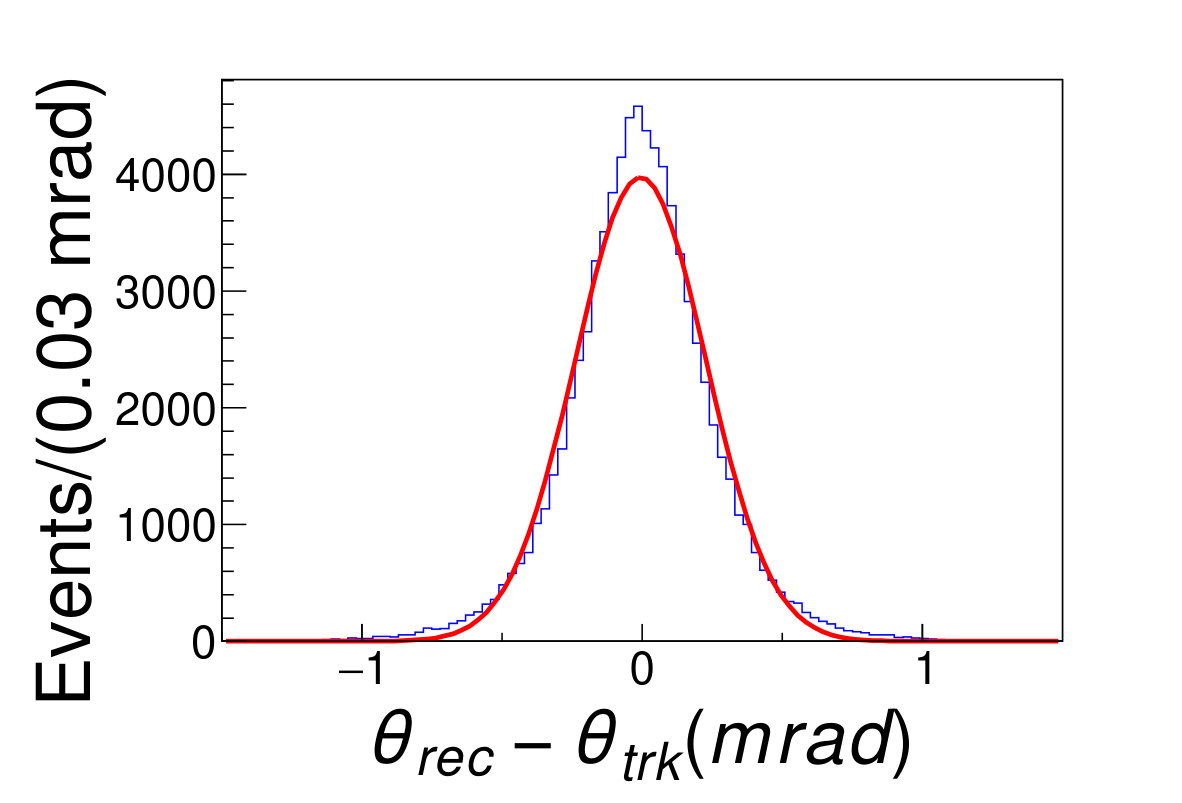 Figure 6
Figure 6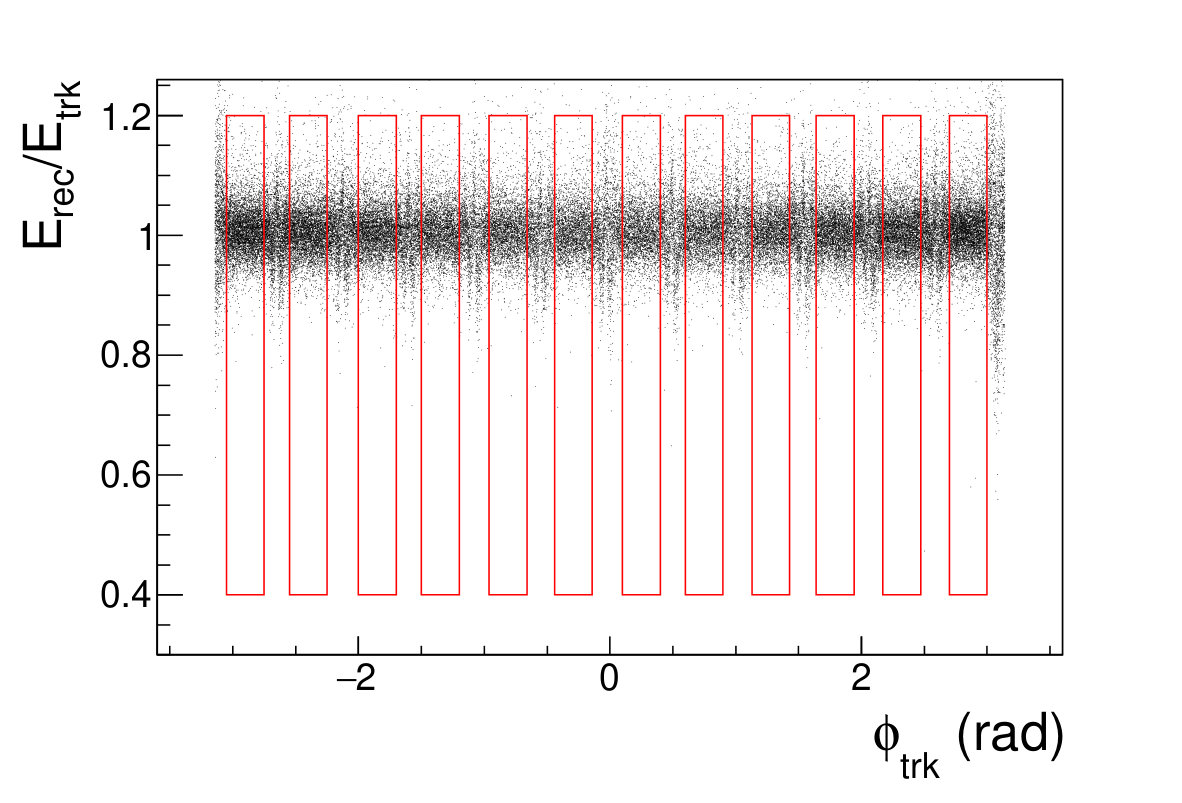 Figure 7
Figure 7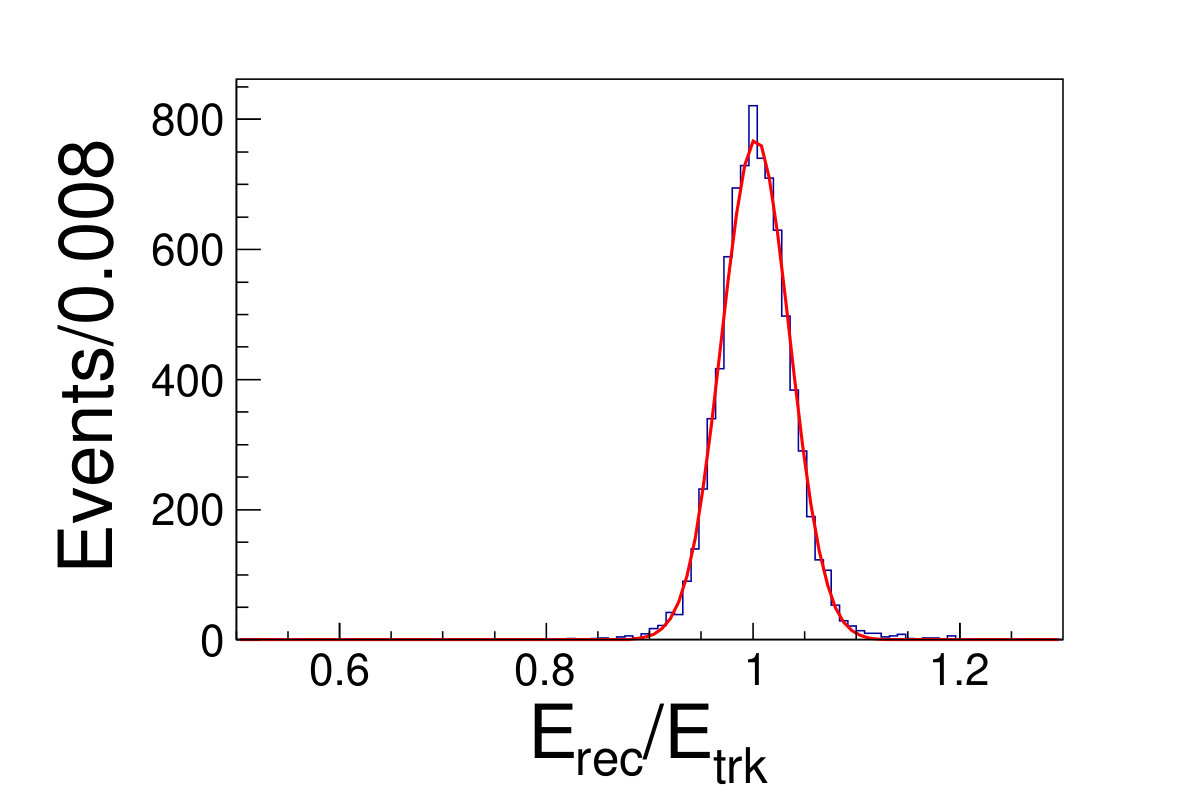 Figure 8
Figure 8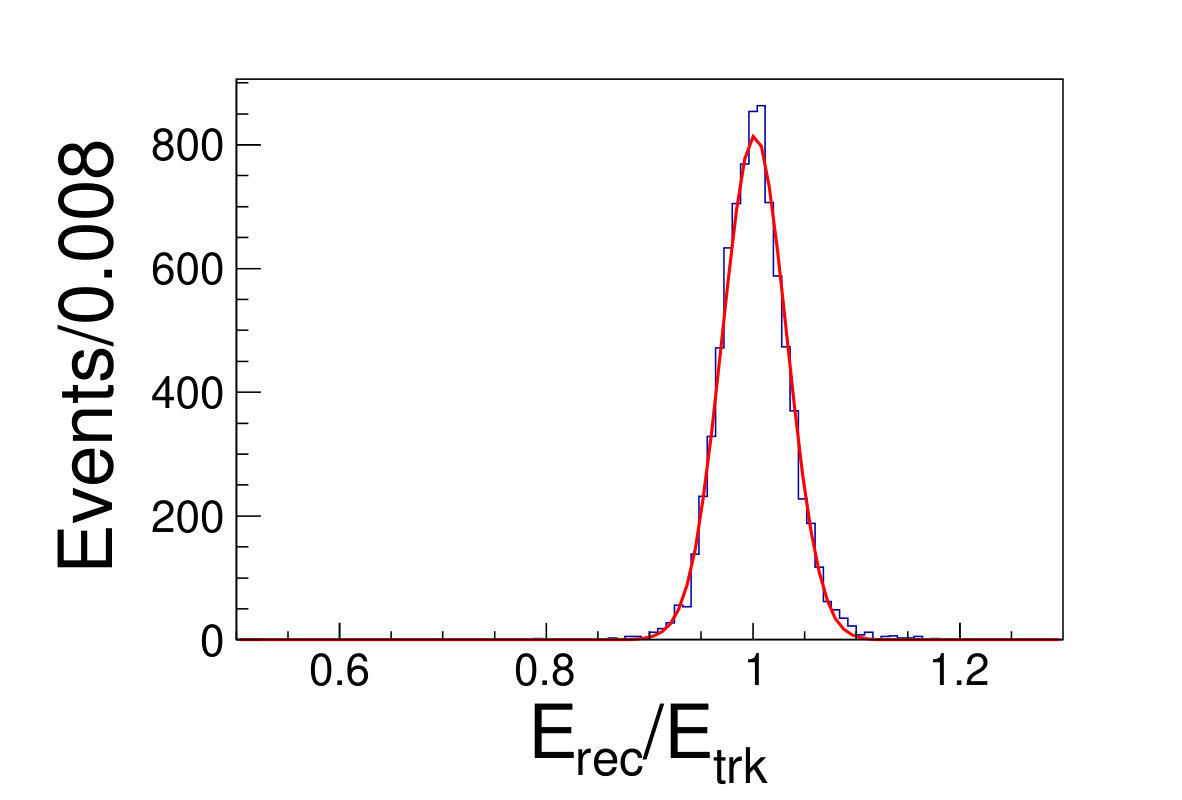 Figure 9
Figure 9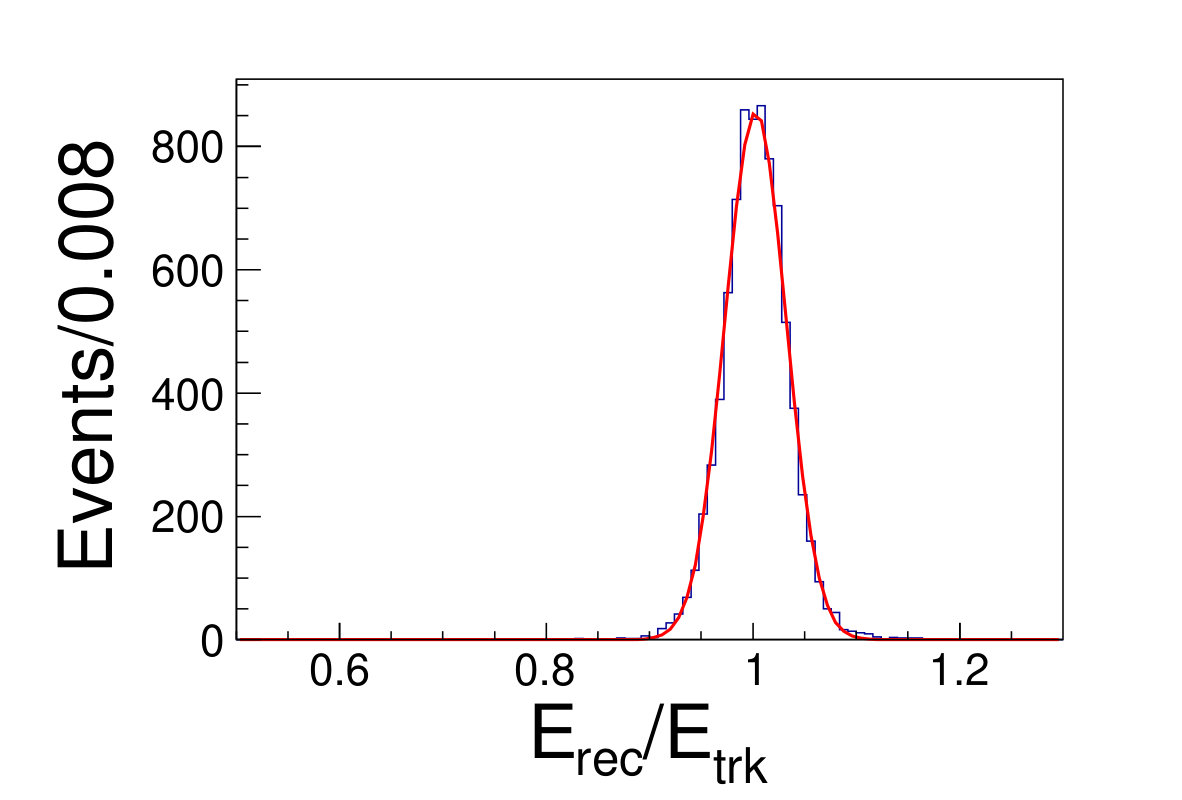 Figure 10
Figure 10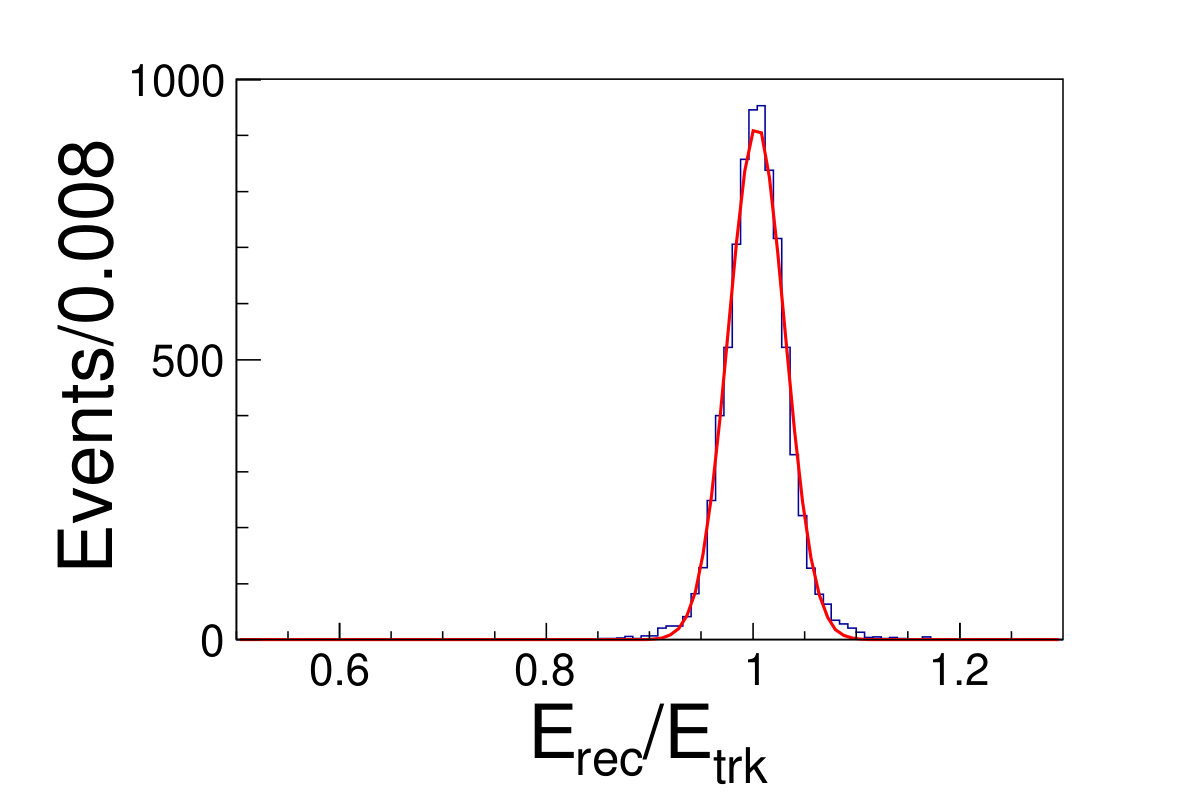 Figure 11
Figure 11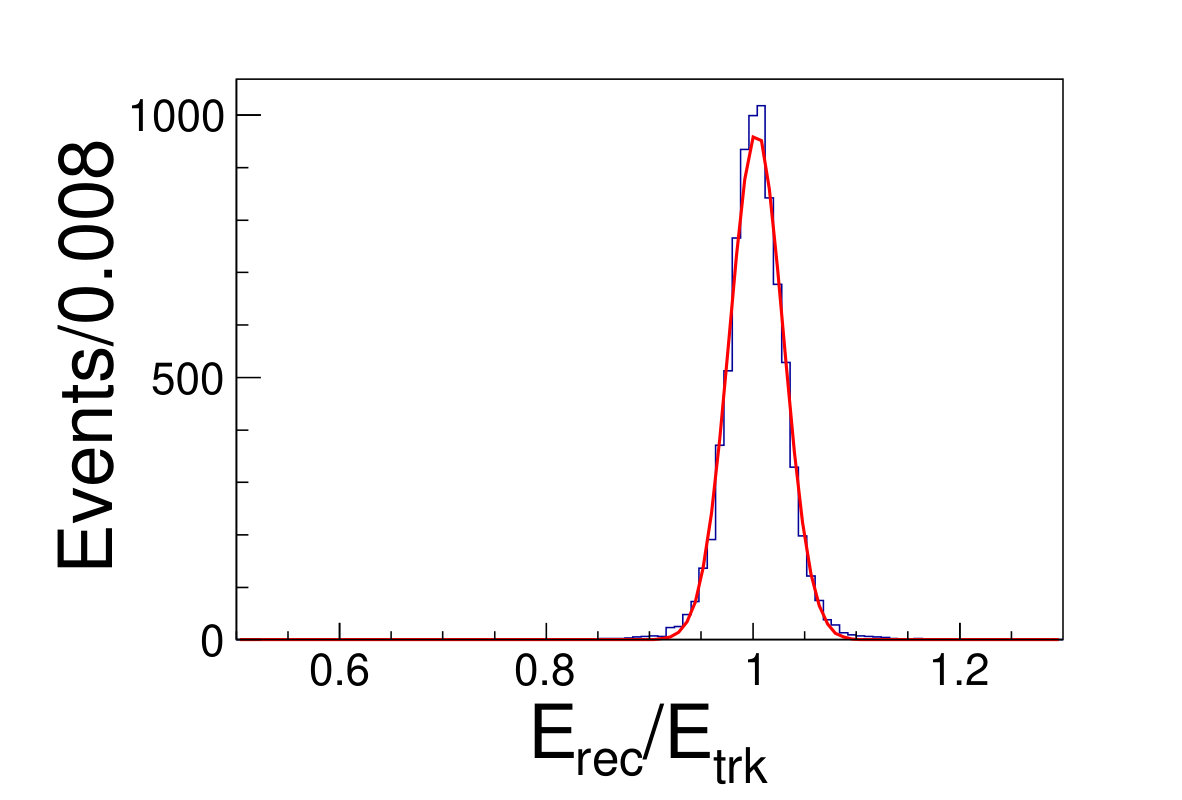 Figure 12
Figure 12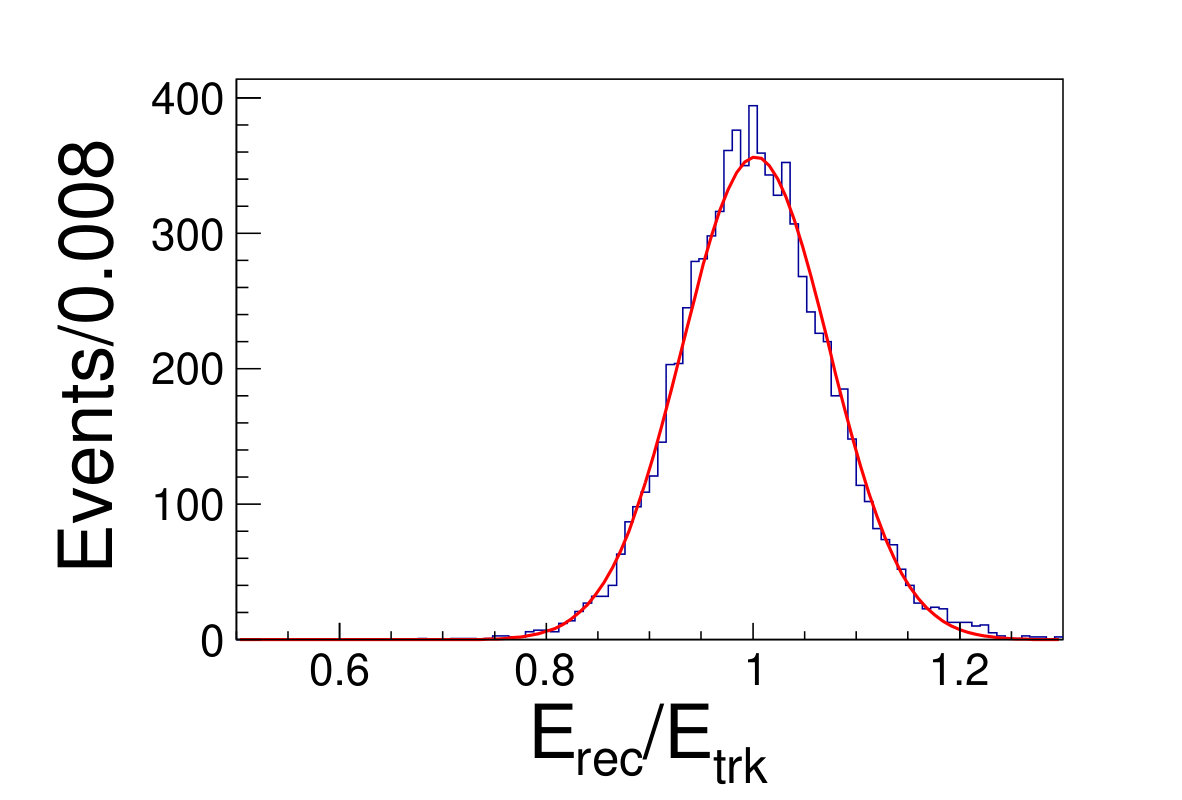 Figure 13
Figure 13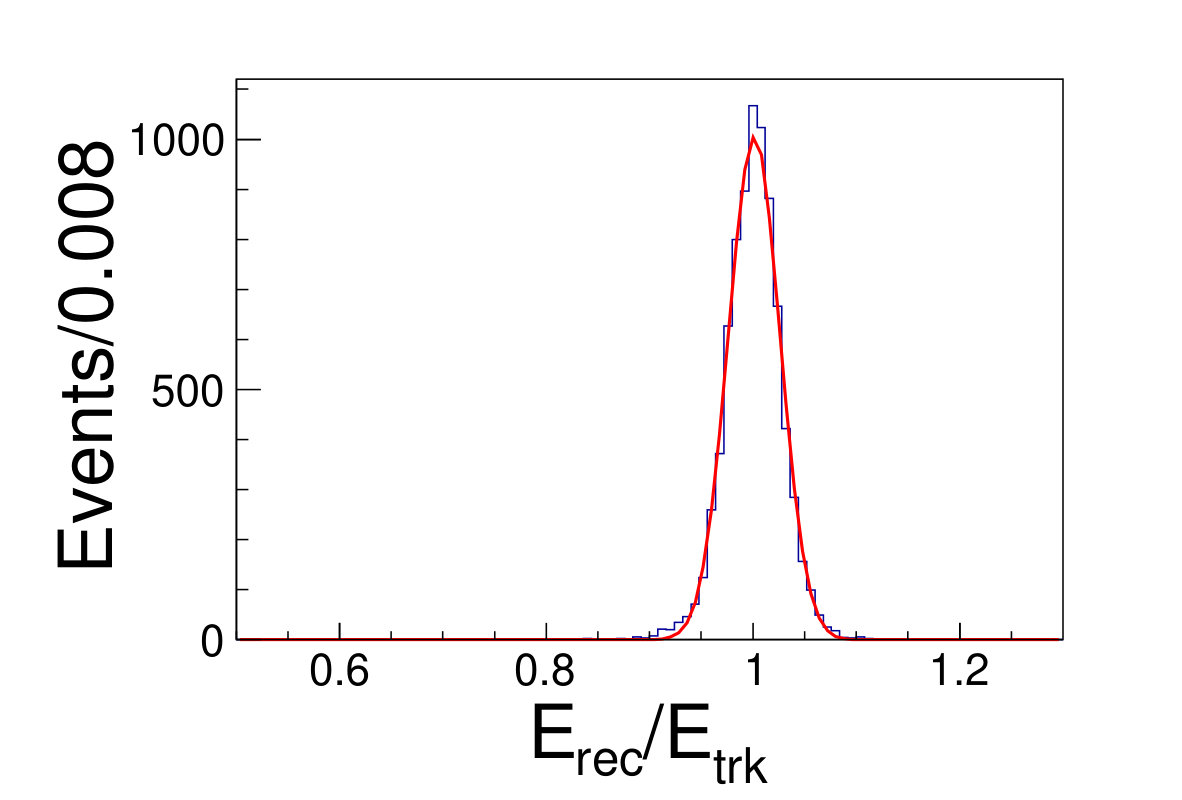 Figure 14
Figure 14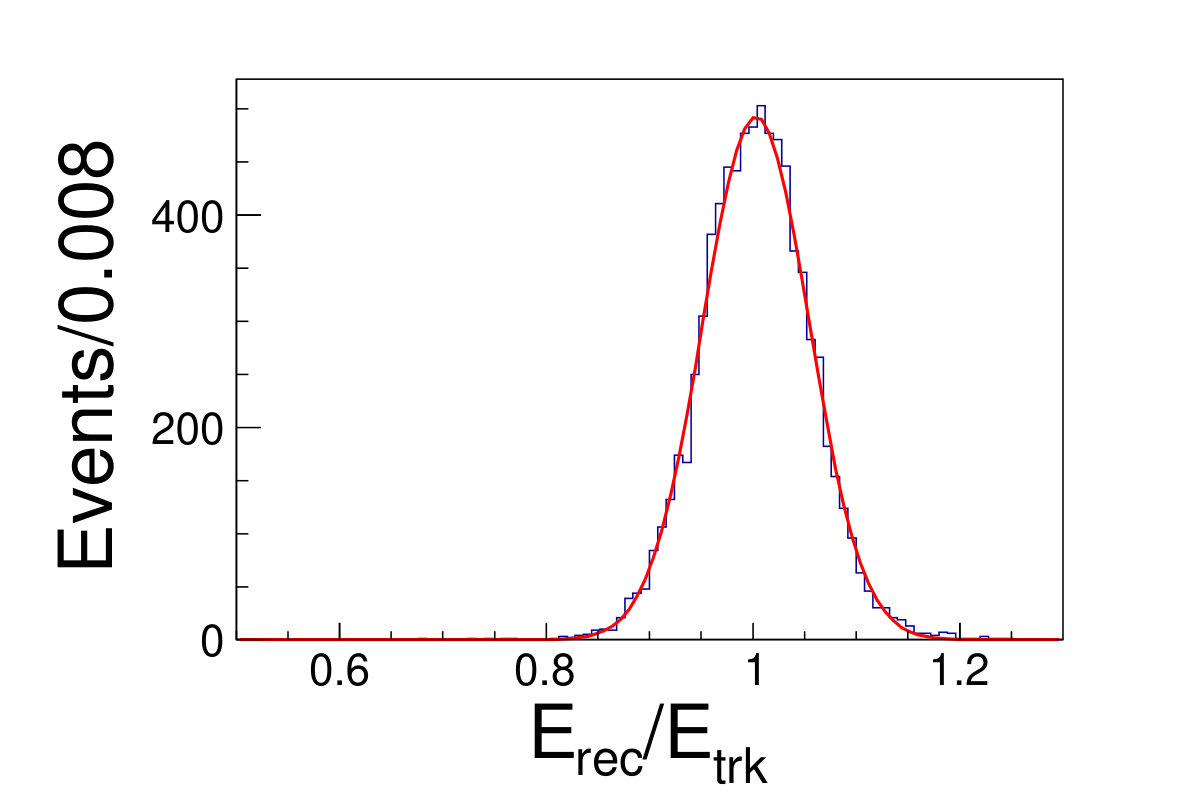 Figure 15
Figure 15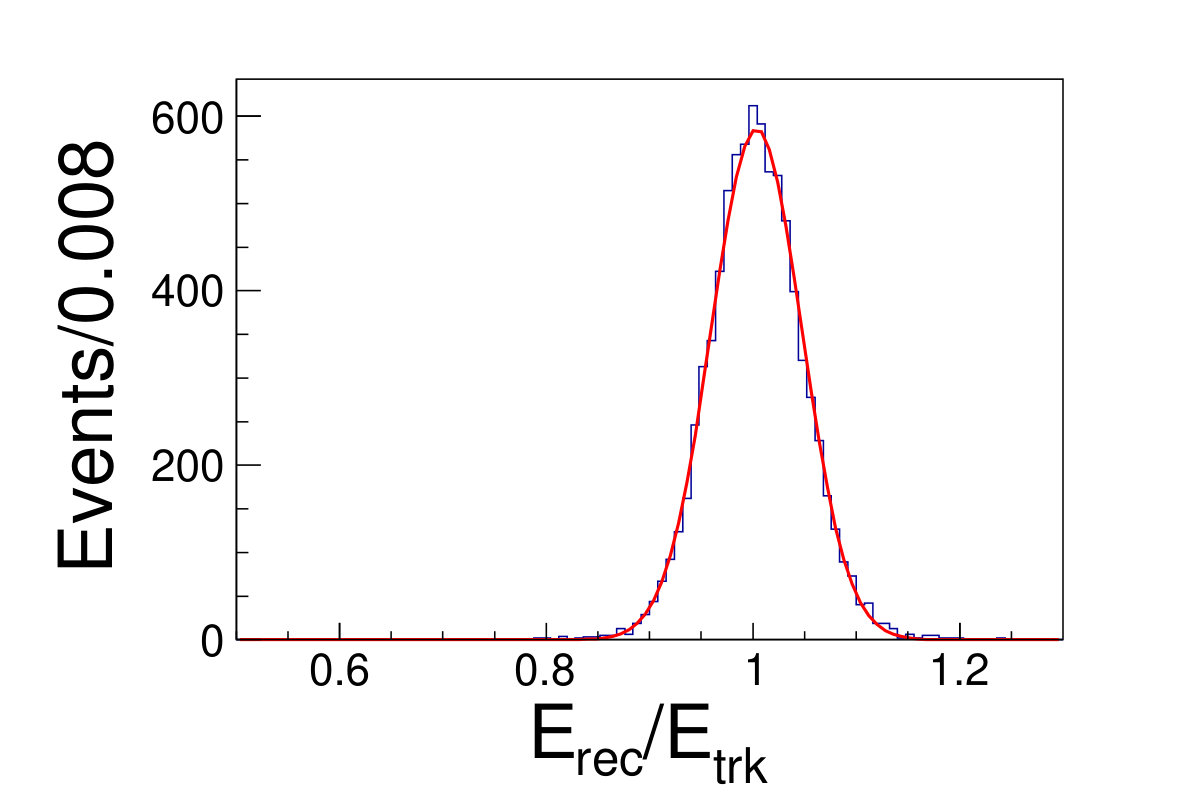 Figure 16
Figure 16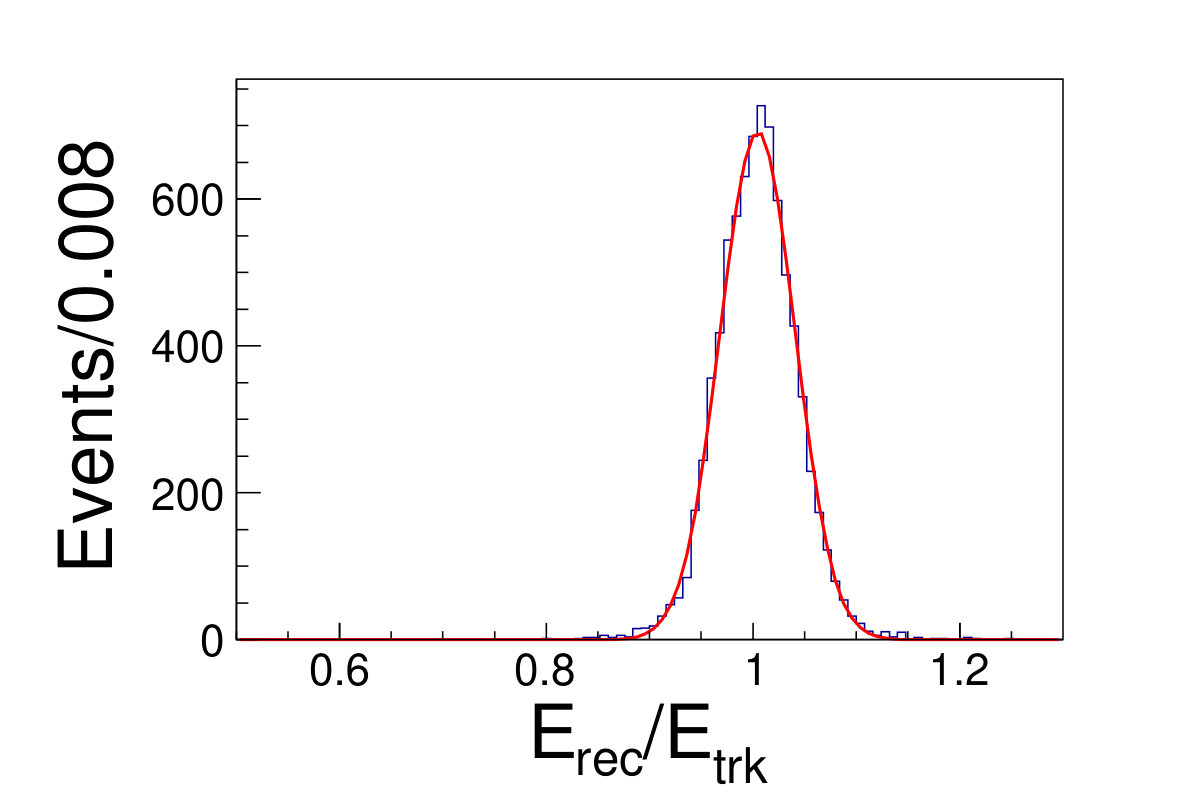 Figure 17
Figure 17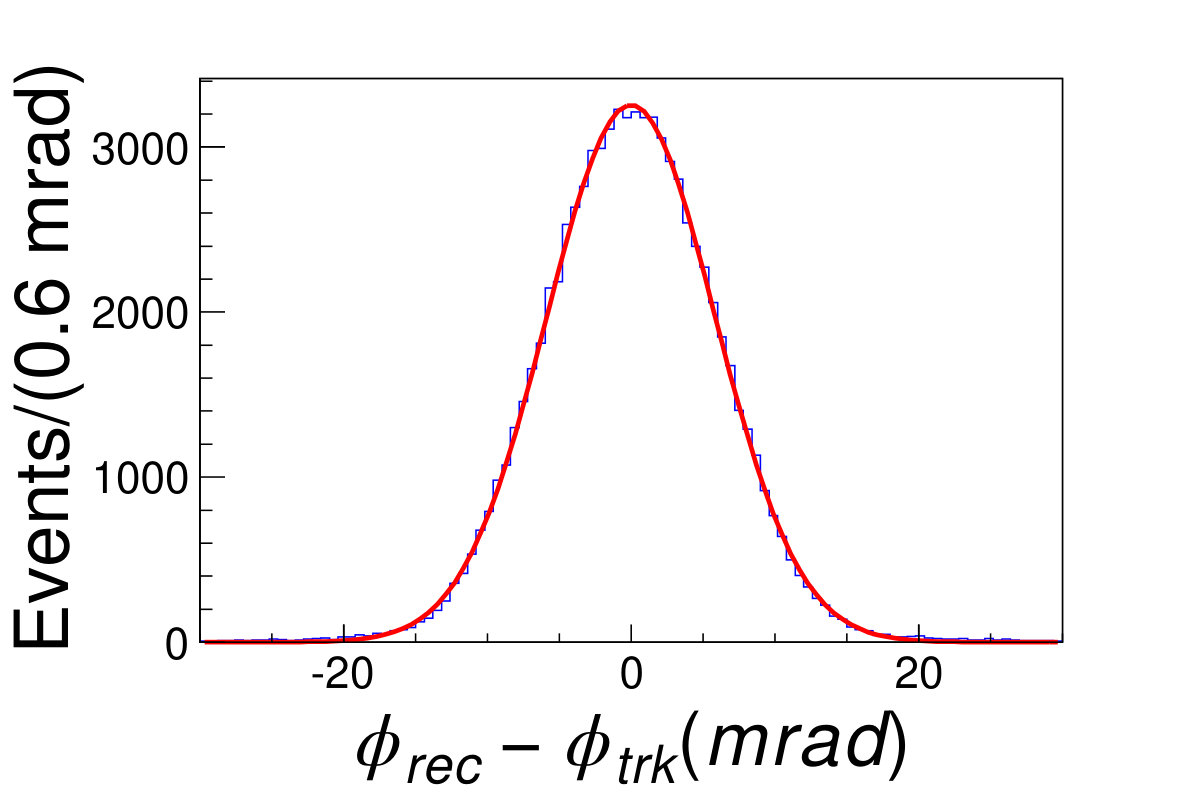 Figure 18
Figure 18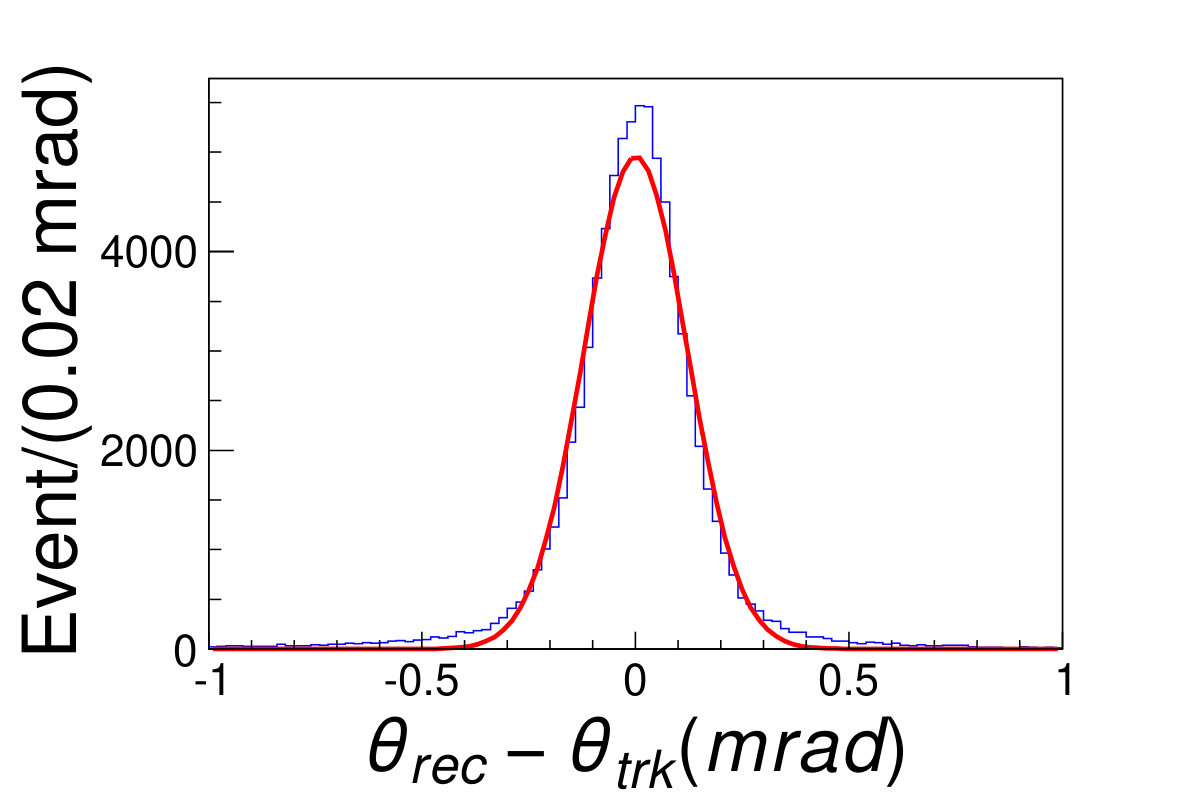 Figure 19
Figure 19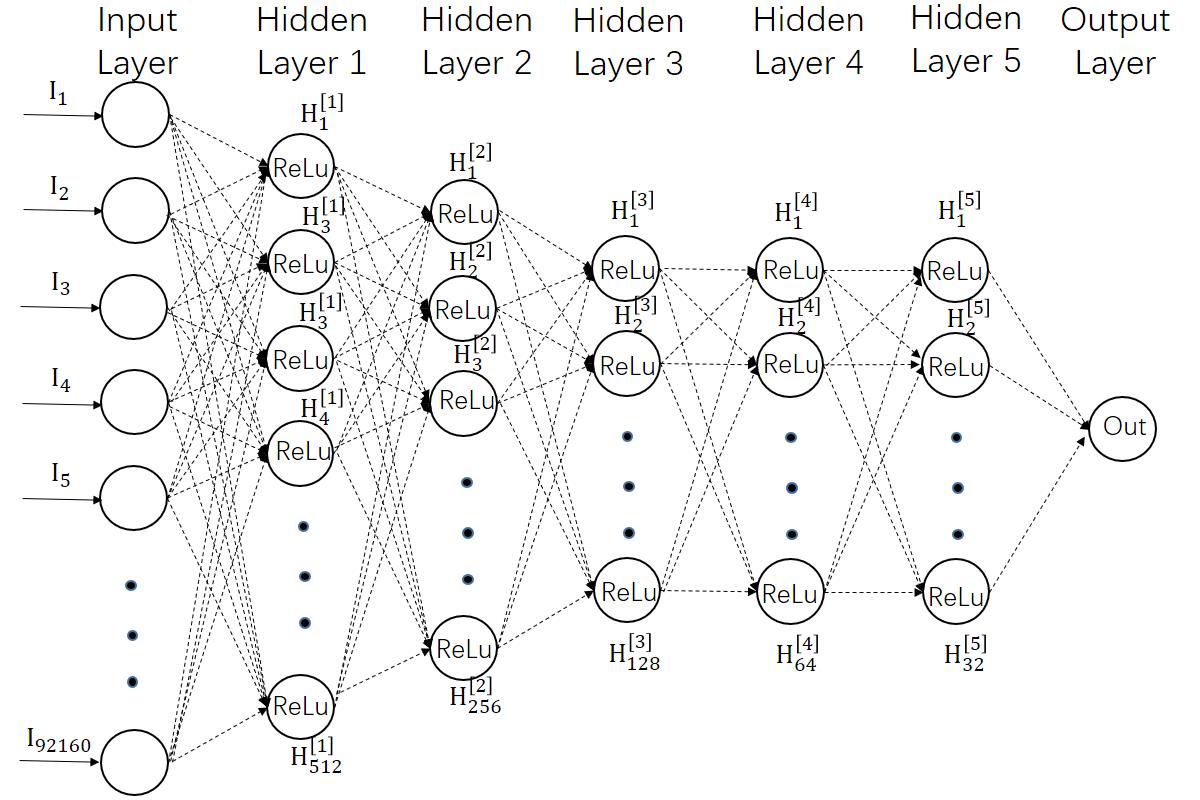 Figure 20
Figure 20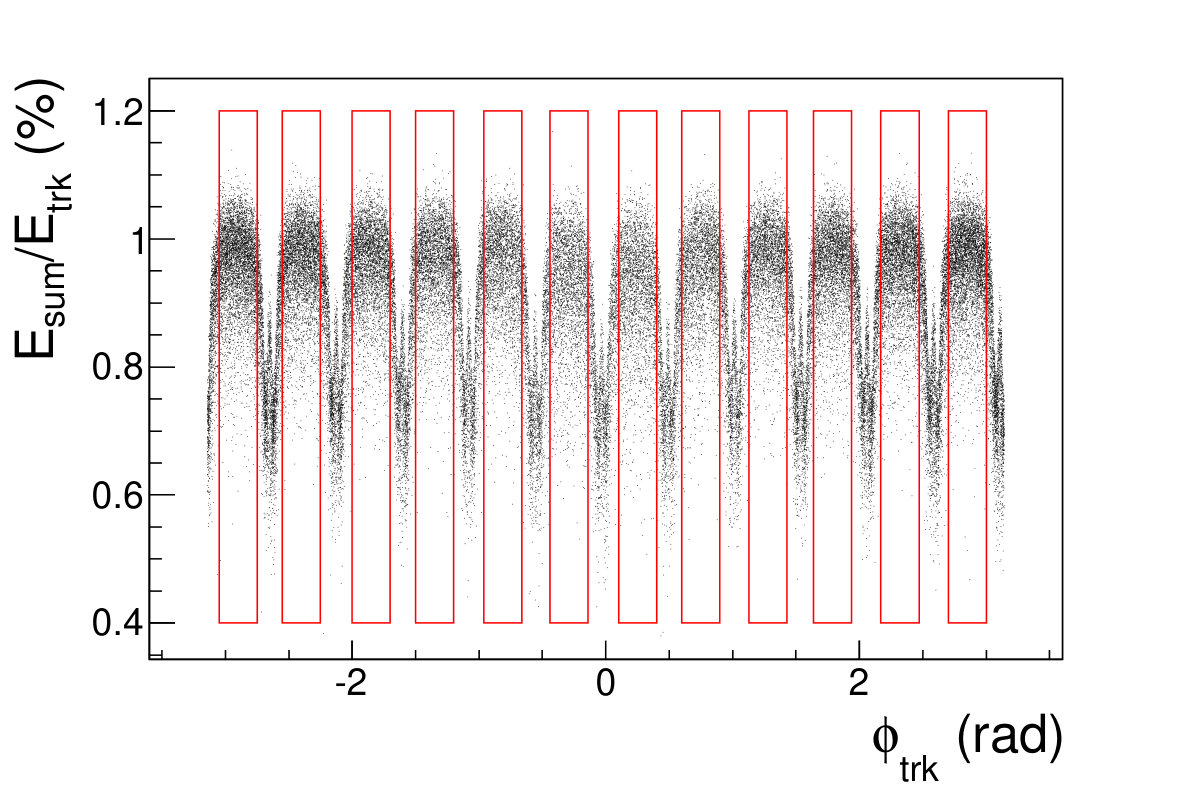 Figure 21
Figure 21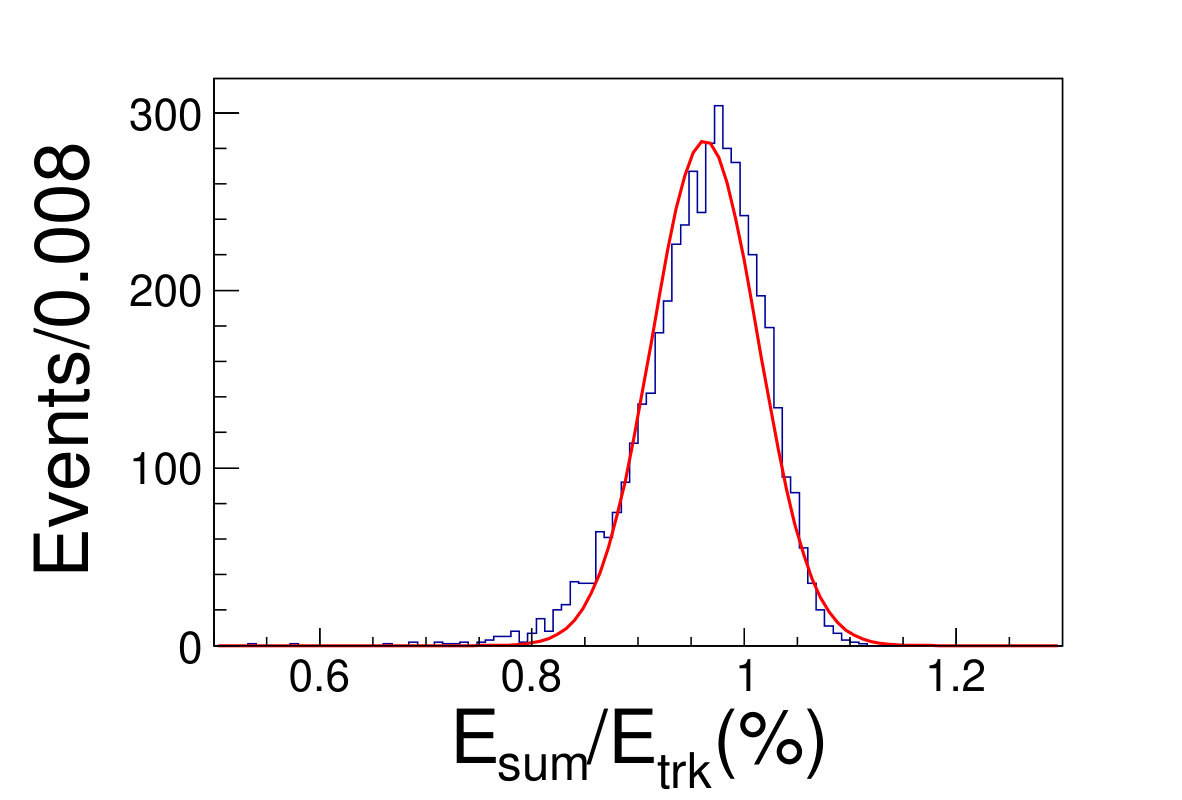 Figure 22
Figure 22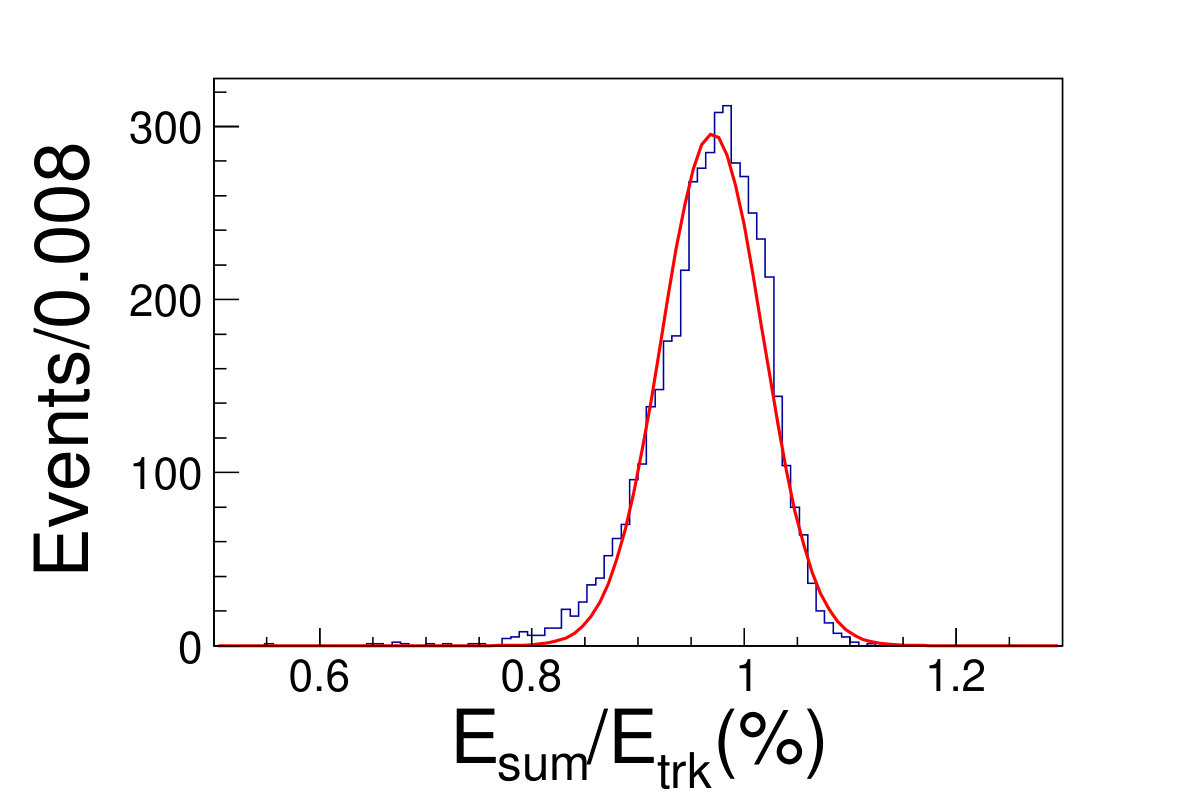 Figure 23
Figure 23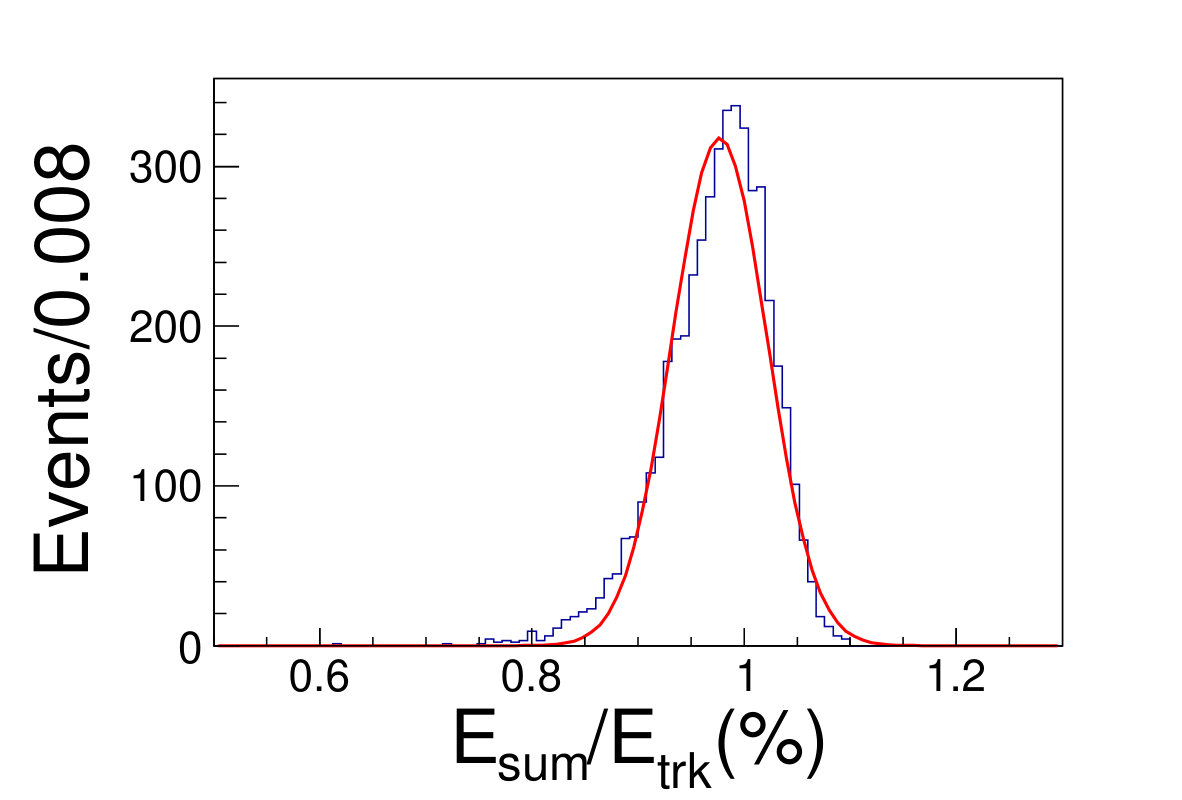 Figure 24
Figure 24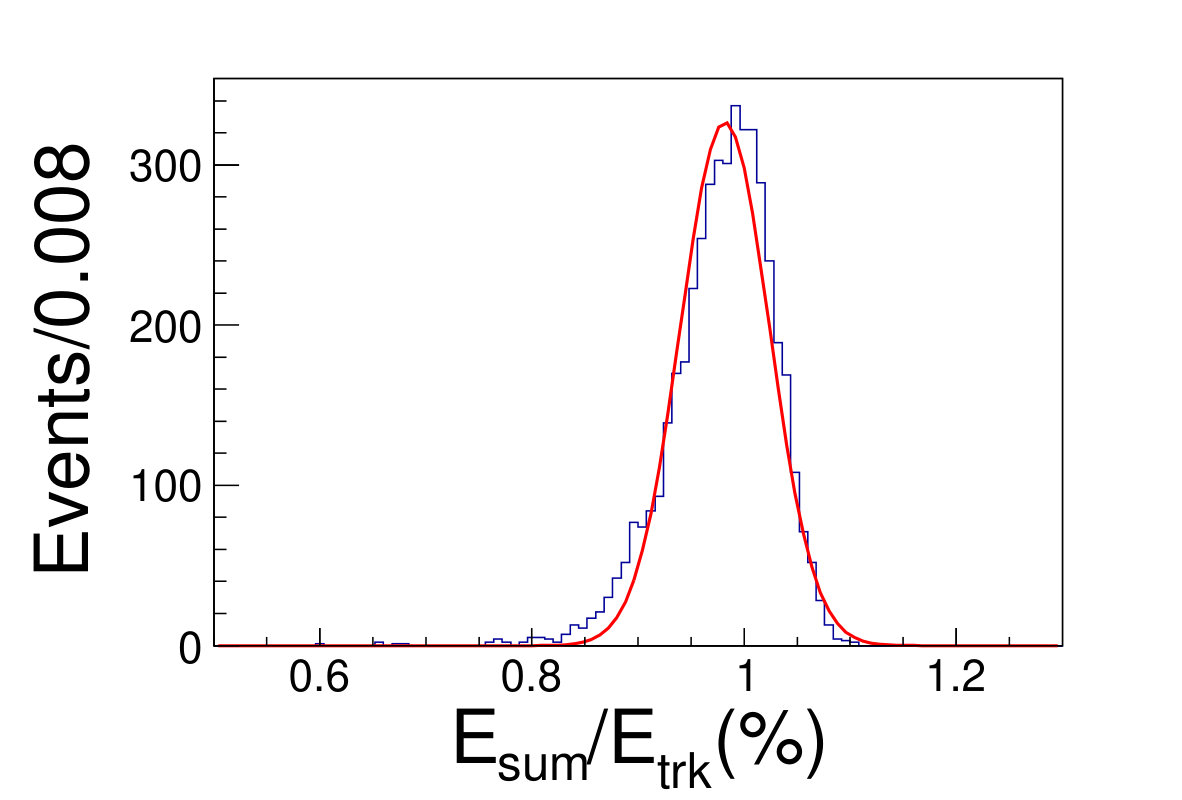 Figure 25
Figure 25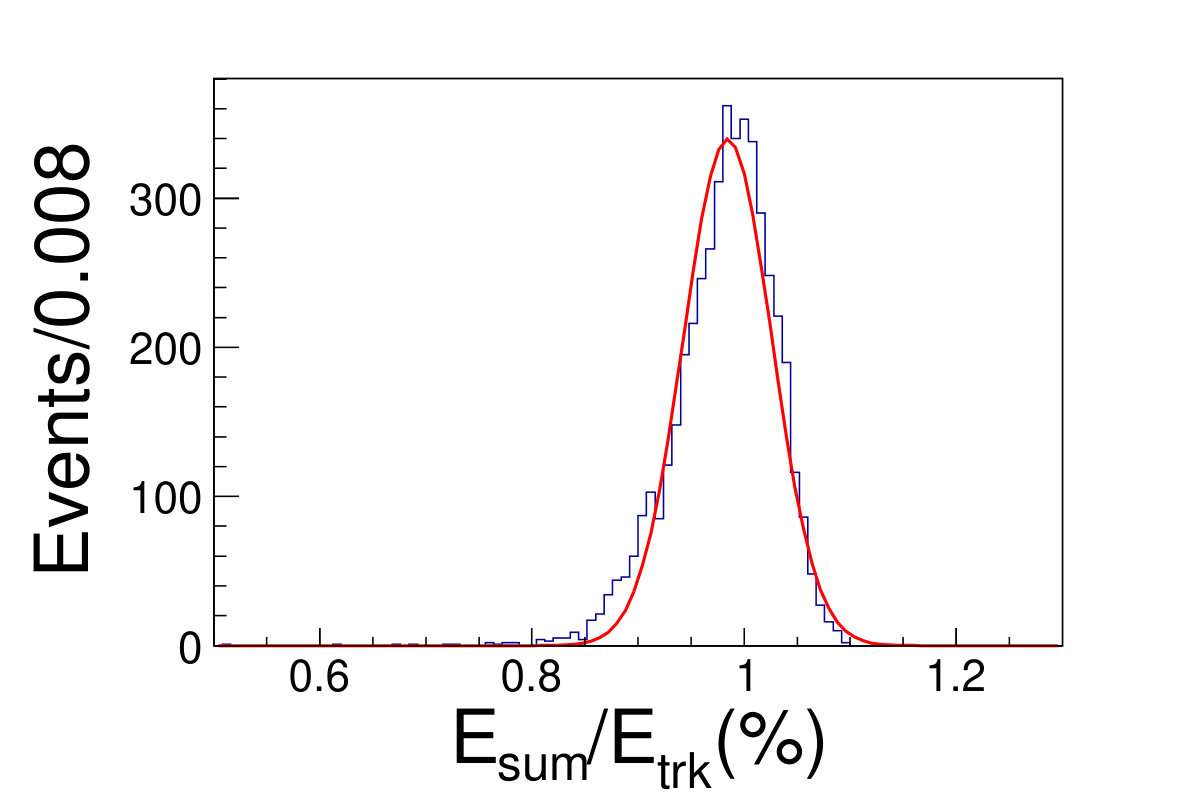 Figure 26
Figure 26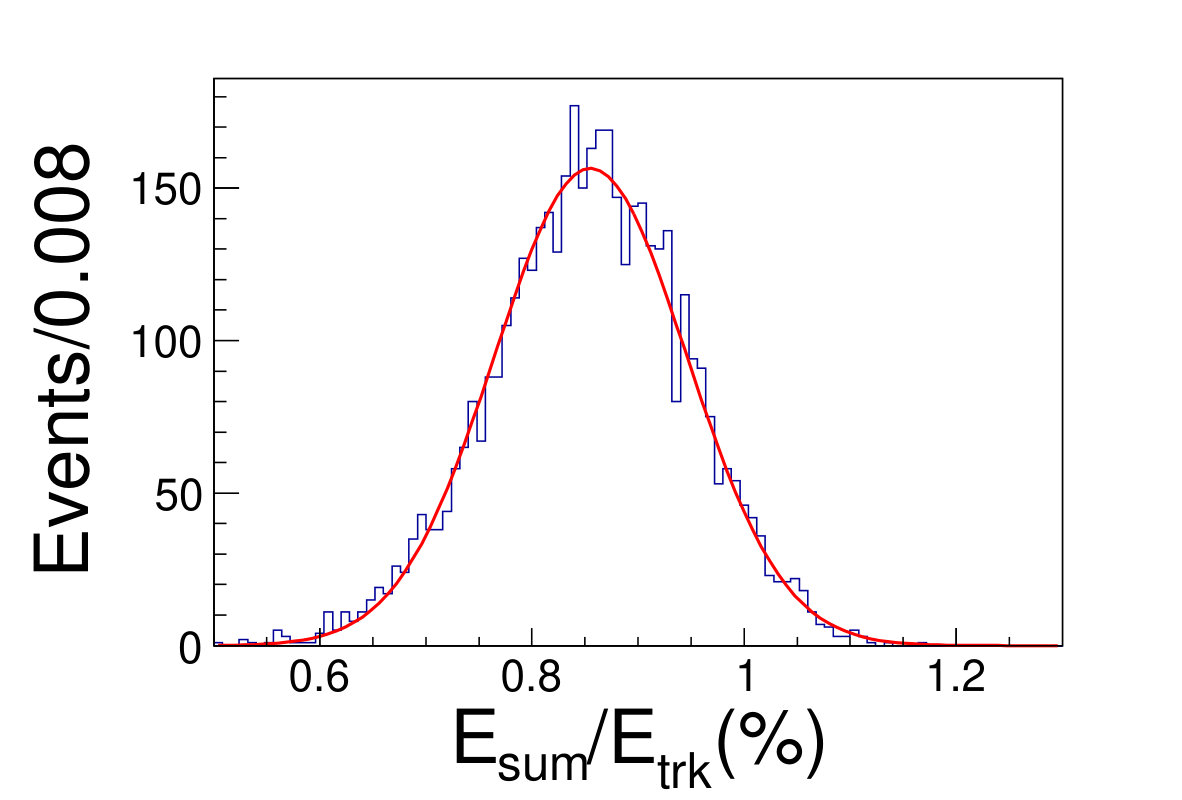 Figure 27
Figure 27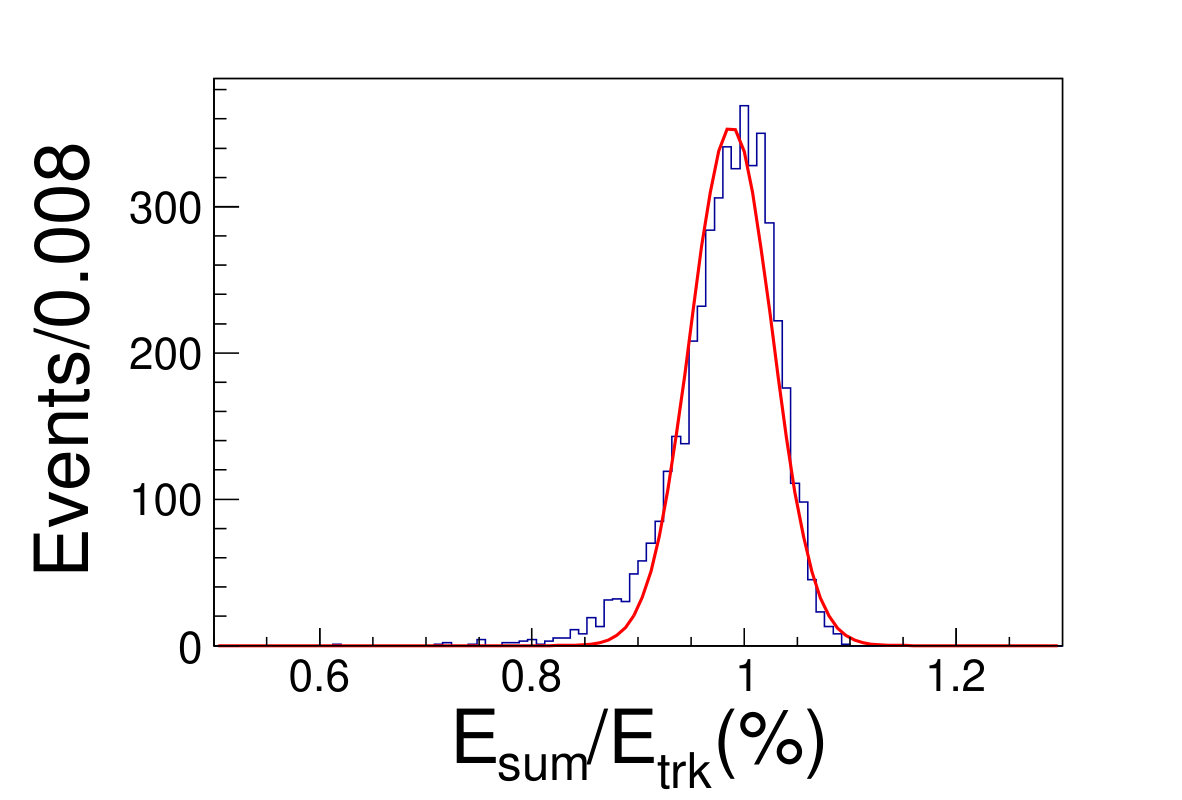 Figure 28
Figure 28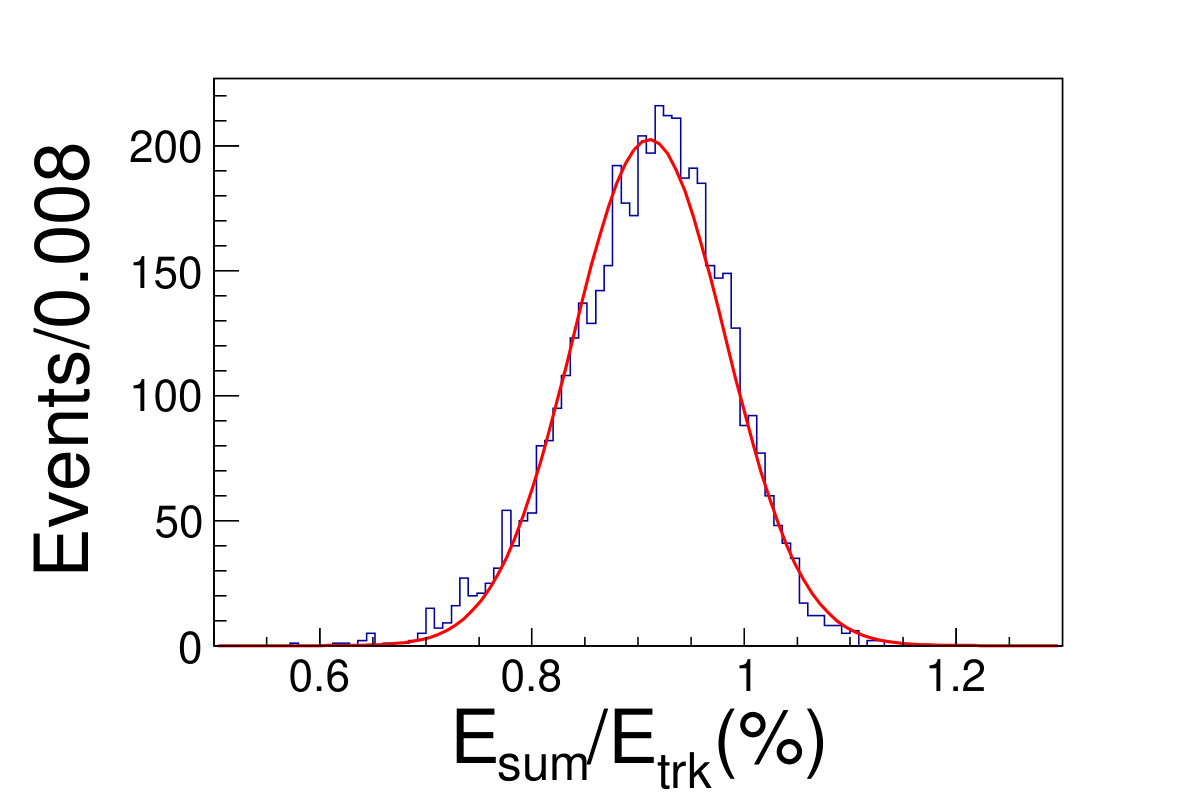 Figure 29
Figure 29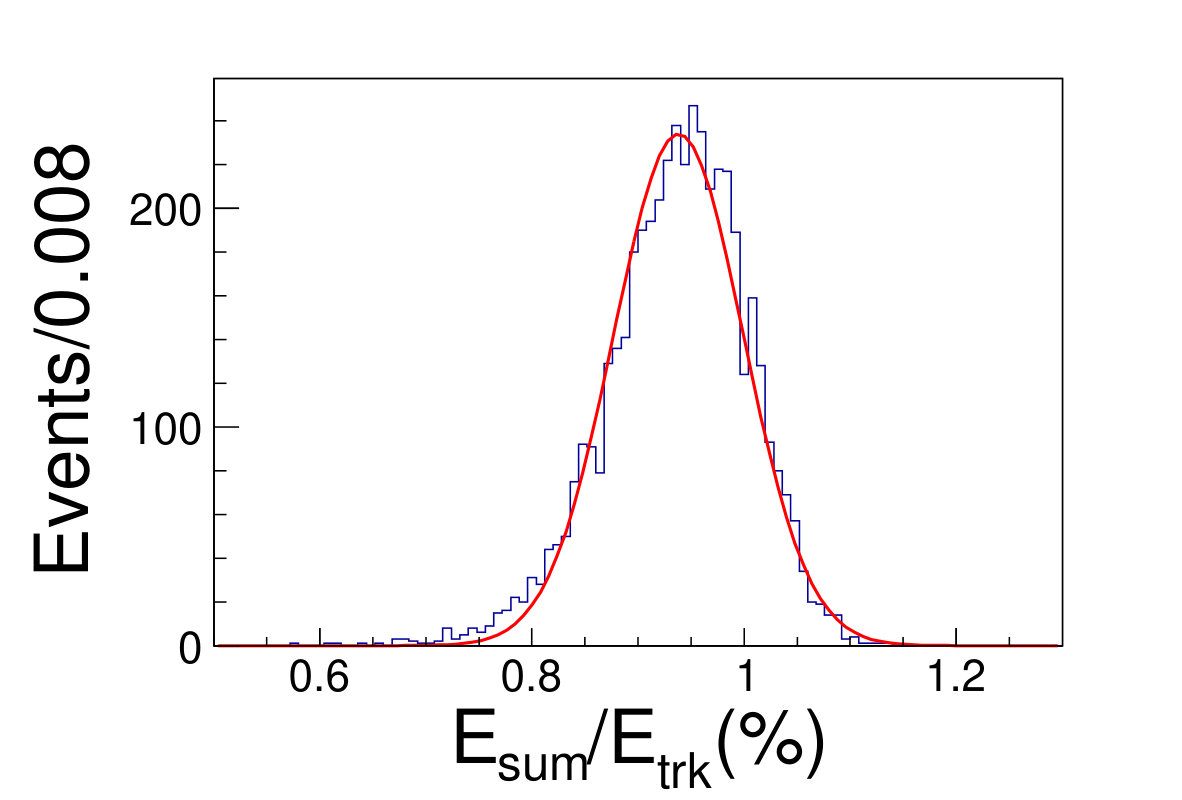 Figure 30
Figure 30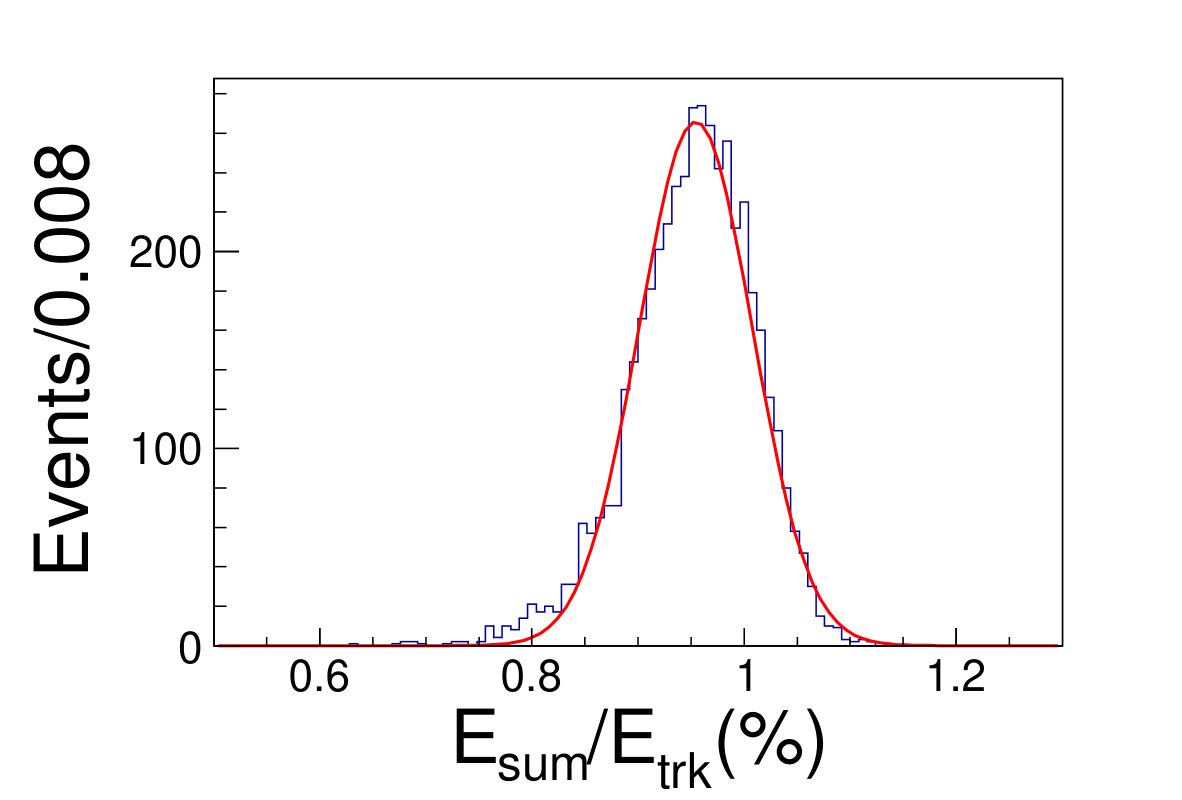 Figure 31
Figure 31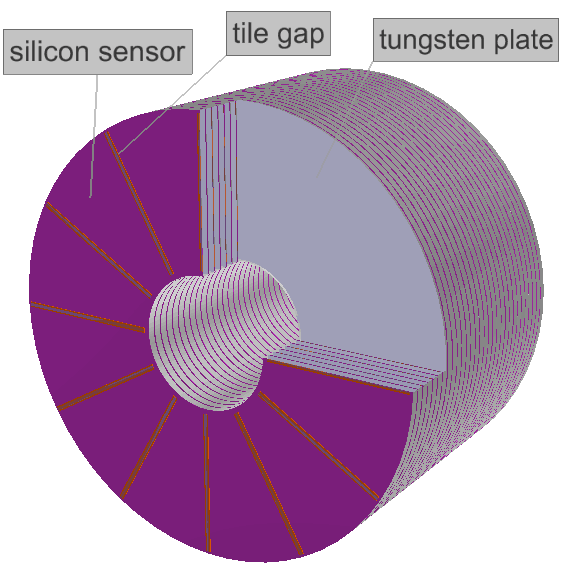 Figure 32
Figure 32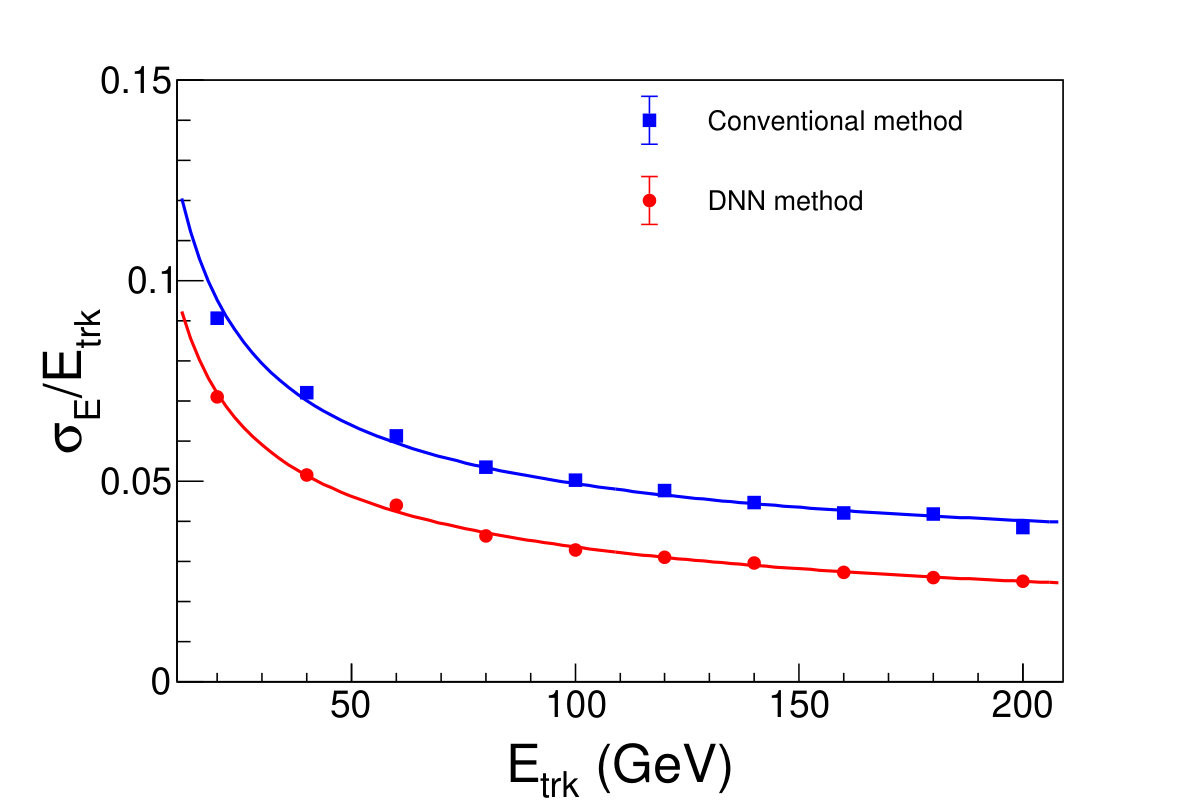 Figure 33
Figure 33Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Deep learning based track reconstruction on CEPC luminometer††thanks: supported by Joint Large-Scale Scientific Facility Funds of the NSFC and CAS, U1632104.
YANG Liu1 CAI Hao1 ZHU Kai2
1 School of Physics and Technology, Wuhan University, Wuhan 430072, China
2 Institute of High Energy Physics, Chinese Academy of Sciences, Beijing 100049, China
Abstract
We study the track reconstruction algorithms of the CEPC luminometer. Depend on the current geometry design, the conventional track reconstruction method is applied, but it suffers the energy leakage problem when tracks falling into the tile gaps regions. To solve this problem, a novel reconstruction method based on deep neural networks has been investigated, and the reconstruction efficiency has been improved significantly, as well as the energy and direction resolutions. This new reconstruction method is proposed to replace the conventional one for the CEPC luminometer.
keywords:
luminometer, track reconstruction, CEPC, tile-gap, DNN
pacs:
2
9.40.Vj, 29.85.-c
1 Introduction
The future Circular Electron Positron Collider (CEPC), which is proposed by Chinese high energy physics community, will run as a Higgs factory at a center-of-mass energy of to precisely study the properties of Higgs boson and also be operated at Z pole, ZH threshold, WW threshold, and Z line shape to precisely measure the W and Z boson masses, widths, and couplings [2]. The physics goals of CEPC require that the relative uncertainty of measured luminosity is smaller than . The precision can not be reached by the measurements via main detectors of CEPC, so a specific luminosity calorimeter is required.
The luminosity is determined by counting the small angle Bhabha events with
[TABLE]
where is the luminosity to be determined; , , are the number of signal events, detection efficiency, and the cross section of Bhabha process, respectively. The cross section is given by
[TABLE]
Here and are the luminometer inner and outer fiducial polar angles, respectively; is the square of center-mass-energy of Bhabha event; is the fine-structure constant. This formula tells that the precision of cross section of Bhabha process heavily relies on the direction reconstruction, especially the polar angle determination, of the incident track. For small angle, a small bias of polar angle determination leads to larger variation on the luminosity determination, which is
[TABLE]
Here and are the uncertainty of luminosity and the uncertainty of the measured polar angle, respectively.
\figcaption
(Color online) Sketch of mechanical structure of luminometer.
The integrated luminosity calorimeter will be at the very forward region of CEPC. At present, it is designed as a sandwich-type silicon-tungsten calorimeter, which is similar to the future International Linear Collider’s (ILC) sub-detector LumiCal [3]. The luminometer has two modules separately positioned at two sides of the interaction point along the beam axis in away, and has a polar angle coverage from to . Each module consists of 30 layers of tungsten with 1 radiation length thickness. Each tungsten layer is followed by segmented silicon sensors planes. Radial outside space of the silicon/tungsten region is the electric readout. There are thin gaps between silicon/tungsten layers. Each sensor plane has divisions and divisions in azimuthal and radial direction, respectively. Mechanically, only four sectors can fit on a single tile of silicon, so there is an uninstrumented tie gap of 1.2 mm width between every four sectors. To compensate for the energy loss of electrons transporting through these gaps, every other layer is designed to be rotated by .
Accurate identification of Bhabha events depends in part on matching the energies, polar angle and azimuthal angle of particles that strike the opposing luminometer modules. Therefore, the reconstruction of the incident track direction and energy plays a very important role in the luminosity measurement.
Many successful applications of deep neural network (DNN) are established in various fields (a general introduction of DNN can be found in Ref. [4]), including some exciting works in experimental high energy physics, such as, track reconstruction in complex detector [5], discriminating signal events from background events [6, 7, 8, 9, 10] and simulations of particle collisions [11]. In this paper, we first introduce the track reconstruction result which is based on the conventional methods. Then, to deal with the tracks falling into tile gaps, which will result in lower efficiency or worse resolutions with the conventional method, we investigate a novel method based on the DNN. It turns out the DNN based method can solve this problem and provide higher reconstruction efficiency and better resolutions in both energy and direction than the conventional method.
2 Monte Carlo simulation
A Geant4 [12] application Mokka [13] is used to implement the detector geometry and supply a valid way to simulate the physics processes of incident tracks transporting through the luminometer and calculate the energy deposition in each sensor cell. The parameters of the luminometer used in simulation are listed in Table. 2.
To study the performance of the luminometer, we have generated a Monte Carlo sample with single positron track events, which is used as the training set for the DNN based track reconstruction method. The energy, polar angle (), and azimuthal angle () of positrons distribute uniformly between , , and , respectively. Another 10 Monte Carlo samples with track energies from 20 to 200 GeV with step 20 GeV, each of which contains events, are generated as the test sets.
\tabcaption
Geometric parameters used for simulation.
Element Value Unit
planes/module
tiles/plane
sectors/tile
cells/sector
Length
Position(z)
inner radius
outer radius
layer gap
silicon thickness
support thickness
tile gap
tungsten thickness
sensor phi rotate degree
3 Hit clustering
For a physical event, it is possible that multiple incident tracks shoot into one luminometer module simultaneously. The clustering method is aiming at grouping the hit cells into different clusters, each of which is generated from a primary incident track. We adopted the clustering method used in the ILC group, that is composed by steps of selection of shower-peak layers, shower-peak layer clustering, and 3D global clustering. The details of the clustering method can be found in the Ref. [14], and is implemented by us with a series of Marlin [15] processors.
4 The conventional track reconstruction algorithm
4.1 Energy reconstruction
The conventional energy reconstruction for a sampling calorimeter works in a simple way. Usually, the total deposition energy in the sensitive region is a proportion of the incident particle energy. To reconstruct the original energy of one particle, a correction factor (CF) is multiplied by the summation of the deposition energy in the sensitive sensor cells. Generally, the CF is relative to the incident track energy. Due to the effect of the tile gap, the total deposited energy in the luminometer with a track shotting nearby a tile gap is obviously lower than other regions as shown in Fig. 4.1.
\figcaption
(Color online) The sum of deposited energy in sensor cells () divided by the origin track energy () versus the incident track azimuthal angle ().
The tile gap effect will result in worse energy resolution. To improve the resolution, we adopt the method that only take tracks shooting into non-gap regions (region within 0.3 rad of each tile center is chosen as the non-gap region). Then we get the distributions of the as shown in Fig. 4.1, where is the sum of the deposited energy in the sensor cells and is the original energy of the track. We fit the distributions with Gaussian functions to extract the mean and width values, where the inverse of the mean is taken as the CF and the width is taken as the energy resolution.
( =20 GeV)( =40 GeV)( =60 GeV)( =80 GeV)( =100 GeV)( =120 GeV)( =140 GeV)( =160 GeV)( =180 GeV)( =200 GeV)\figcaption(Color online) The blue histograms are the distributions of for tracks shooting into non-gap regions with track energy vary from 20 to 200 GeV. The red curves are the fit lines with Gaussian functions, which give the mean and the width values of relative deposited energy.
4.2 Direction reconstruction
The center point coordinate of a track cluster is calculated by averaging over all the hits in the global cluster,
[TABLE]
where is the coordinate of each hit cell center determined by the detector structure and geometry, is the weight function defined by
[TABLE]
Here is the individual cell energy, and is the sum of the energies of all the cluster cells, is a constant optimized to be , for minimizing the polar angle resolution (seeing in Fig. 4.2), which means the low energy deposited hit cell (smaller than 0.25% of total deposited energy) has a weight factor 0.
(a)(b)\figcaption(Color online) (a) The polar angle resolution, , and (b) the polar angle bias, as a function of the constant, . .
Any direction from the interaction point to each cluster center is taken as the track strike direction. The distributions of the difference between the reconstructed and the original polar angles and azimuthal angles are shown in Fig. 4.2, and fitted with Gaussian functions. It turns out that the reconstruction bias of the polar angle and azimuthal angle are and , respectively; the resolution of polar angles and azimuthal angles are and .
(a)(b)\figcaption(Color online) The direction reconstruction result. (a) The blue histogram is the distribution of , where the and are the reconstructed and the original polar angles of the tracks, respectively. (b) The blue hisgogram is the distribution of , where the and are the reconstructed and original azimuthal angles of the tracks, respectively. The red lines are the fit results with the Gaussian functions. .
5 DNN based track reconstruction method
5.1 Energy reconstruction
To deal with the tracks falling into the tile gap regions, a neural network consisting fully connected layers are built for the energy reconstruction. The architecture of the network is illustrated in Fig. 5.1.
A neuron in a layer connects with a certain weight vector to all neurons in the following layers. The number of neurons per layer gradually decreases from 512 to 32 in the hidden layer 1 to hidden layer 5 with a factor of 2. Rectified Linear Units (ReLu) are chosen as activation functions throughout the system except to the input layer, which is currently the most commonly used activation function [4] and defined as
[TABLE]
The energy deposited values (in unit ) in all sensor cells of one track cluster are set as the input of our DNN model. There are cells in one module, thus the input of our network is a () matrix. The output value of the model is taken as the energy prediction. Before training, all weight matrix elements are initialized randomly with uniform distribution of interval (-0.05, 0.05) and bias values are initialled to 0.
\ruleup\figcaption
Architecture of the DNN used for the energy reconstruction. The input layer represents the 92,160 deposited energy values of all hit cells. It is fed to the first hidden layer, which has 512 neurons with rectified linear unit activation functions. The number of neurons per layer is gradually decreased from 512 to 256, 128, 64, 32, then to 1 in the output layer. The DNN is trained to obtain the true energy in the output layer. The model contains 47,361,025 trainable parameters.
To train the network we use mini-batch gradient descent to minimize the loss function. In this approach, the gradient of the loss is computed using a subset of the training set, called a mini-batch, which is chosen randomly during each minimization step. Therefore, it takes more than one step to go through all the training set; the corresponding number of steps is called epoch. We use a simple mean-square-error as the loss function of our model, which is defined as
[TABLE]
where , , and are the size of the mini-batch, the true of energy, and the predict energy of event j, respectively. Taking the Monte Carlo events as the training set, the DNN model is trained using the Adam [16] optimizer. The model is trained for epochs in the rough training period with learning rate 0.001 and another epochs with learning rate 0.0001 for final training. During training, the size of mini-batch is set to 100. The total number of neurons is 47,361,025 for the 6 layers DNN model. Most of the neurons are placed in the first layer due to the large input dimension. The total number of neurons will not change too much even if we add or delete some layers with small dimension. In fact, we tried different neural network models from 1 layer to 20 layers. The experience tells that the more layers a DNN model has, the faster to train but the model became more easily to be overfitting, and oppositely, the less layers the slower to train, thus 6 layers is a proper balance. Especially, the shallow net is very unstable, that indicates a simple weight method is difficult to be implemented reliably.
\figcaption
(Color online) The reconstructed energy by DNN method () divided by the origin track energy () versus the incident track azimuthal angle ().
Different from the conventional method, we do not discard any events falling into tile gap regions neither in training nor testing. The reconstructed energy divide the original energy of incident track versus the azimuthal angle is shown in Fig. 5.1. The DNN reconstructed energy versus the origin track energy for different energies are illustrated in Fig. 5.1.
( =20 GeV)( =40 GeV)( =60 GeV)( =80 GeV)( =100 GeV)( =120 GeV)( =140 GeV)( =160 GeV)( =180 GeV)( =200 GeV)\figcaption(Color online) The distributions of from DNN method for track energy varying from 20 to 200 GeV. The red lines are the fit results with gaussian functions.
5.2 Direction reconstruction
We reuse the same 6-layers DNN model architecture in Fig. 5.1 to reconstruct the tracks incident direction (, ). To avoid the periodicity of azimuthal angle, we choose x-y coordinate at z = 1000 mm as the output value of the model prediction (in unit mm). In order to make the model easier to train, we construct two models with same structure but training separately for predicting x and y coordinate other than one model with two dimension output to predict x and y simultaneously. Then we combine the result of x prediction and y prediction to calculate the polar angle and azimuthal angle. Also the energy deposited values (in units GeV) regard as a matrix with shape are set as the input of these DNN models and mean-square-error is chosen as the loss function for these two models. We find the normal initial strategy will lead to vanishing gradient problem for these two models and the transfer learning can deal with the problem well, which the weight matrix elements of these two models are initialized with that of the trained energy reconstruction model. When training, the size of mini-batch is set to 100; the learning rate decreases from to . These two models are trained with the Adam optimizer [16] for about 100 epoches on the Monte Carlo events till the loss function of the model does not decrease. Using these two trained models, the reconstruction biases of polar angle and azimuthal angle can reach to and , respectively; the resolutions of polar angle and azimuthal angle can reach to and , respectively, as shown in Fig 5.2.
(a)(b)\figcaption(Color online) The direction reconstruction results. (a) The blue histogram is the distribution of , where the and are the reconstructed and the original polar angles of the tracks, respectively. (b) The blue histogram is the distribution of , where the and are the reconstructed and original azimuthal angles of the tracks, respectively. The red lines are the fit results with the Gaussian functions.
\figcaption
Architecture of the deep neural network for the polar angle reconstruction. The input layer represents the 92,160 (in shape ()) deposited energy values of all hit cells. It is followed with 7 convolutional layers. Each convolutional layer uses the same padding method to keep the shape of output matrix the same as the input matrix. The numbers of convolutional kernels for each convolutional layers are 256, 256, 128, 128, 64, 64 and 1. A flatten layer, which flatten the input matrix to one dimensional output matrix, is following the last convolutional layer. Following the flatten layer is 5 fully connected layers with a final output layer consisting one unit, which is taken as the polar angle prediction. The model contains 2,043,330 trainable parameters.
Comparing to the conventional method, we can get a better azimuthal resolution, but worse polar angle resolution. To get a more precision polar angle resolution, we construct a new DNN model which consists of 7 two-dimension convolutional layers, and 5 fully connected layers. In all of the convolutional layers, the shape of the convolutional kernels are set to , where denotes the number of channels for the input of each layer. The energy deposited values (in unit GeV) are set as the input of this model with a shape of , which is directly from the geometry structure of the luminometer. Here 30 is taken as the number of channels for the model input. ReLu activation function is used for all neurons of fully connected layers. The architecture of the neural network is illustrated in Fig. 5.2.
The mean-square-error is taken as the loss function. The size of mini-batch is also set to 100 when training. All elements in weight matrix and convolutional kernels are initialized randomly with uniform distribution of interval (-0.05, 0.05) and the bias values are initialled to 0. Also taking the Monte Carlo events as the training set, the DNN model is trained sufficiently using the Adam [16] optimizer. The trained model can predict the polar angle in a bias of and a resolution of . The distribution of difference between the reconstructed polar angle and the original polar angle is illustrated in Fig 5.2.
\figcaption
(Color online) The blue histogram is the distribution of , where the and are the reconstructed polar angle obtained from CNN model and the original polar angles of the tracks, respectively. The red line is the fit result with the Gaussian function.
Keras [17] (v2.2.2) with the TensorFlow [18] backend (v1.10.0) is used to construct all the models above. Four NVIDIA Tesla V100-SXM2 graphics cards are used for the training and testing.
6 Comparison of two methods
6.1 Energy reconstruction performance
Comparing Fig. 4.1 and Fig. 5.1, it is obvious that the DNN method can deal with the tracks falling in the tile gap regions well. No obvious energy leakage is observed as in the conventional method. Those results are directly shown in Fig. 5.1, where the shapes from the DNN method are obvious more symmetric and sharper compared with the conventional method shown in Fig. 4.1. The energy resolution distribution is fitted with following formula provided in Ref. [19], which is for the energy resolution of a sampling calorimeter defined as
[TABLE]
where the first term corresponds to stochastic shower processes and the second corresponds to energy leakage. In Fig. 6.1, we illustrate the energy resolution of the two methods mentioned above, and fitting results with this formula. Comparing to the conventional method, the DNN method gives better energy resolution at all energy points.
\figcaption
(Color online) The comparison of energy resolution between two energy reconstruction methods. (tracks which shoots into tile gap are excluded only for conventional method.) The red (blue) line is the fit result with Eq. (8). For the red line, the value of parameter a is determined to 0.34, and b is . For the blue line, a is 0.40, and b is 0.030. The error bars, caused by the Monte Carlo statistics, are too small to be seen at this scale.
6.2 Direction reconstruction performance
In Table 6.2, we list the polar angle and azimuthal angle reconstruction result of the conventional method and the DNN method. Obviously, the DNN solutions can give smaller resolutions, both for polar angle and azimuthal angle reconstruction. The azimuthal angle reconstruction bias is also smaller than that from conventional method. Though the polar angle reconstruction bias is larger than that from conventional method, the bias can be calibrated.
\tabcaption
Comparison of the tracks direction reconstruction results between two methods.
Conventional method
DNN method
7 Summary and discussion
This work has studied the incident track energy and direction reconstruction method of the CEPC luminometer and presents the performance about the energy and position resolution of the luminometer, based on the current structure and geometry design. Firstly, we has introduced the conventional track reconstruction method presents the track reconstruction results of it. The conventional energy reconstruction method can not deal with the tracks falling into the tile gap regions in energy reconstruction, which causes about efficiency loss. To solve the problems of the conventional method, we introduce a 6 layers DNN model working on the energy reconstruction. Without discarding the gap region events, the DNN method can reach a better energy resolution than the conventional way. Encouraged by the good performance of the DNN energy reconstruction method, we extend the DNN method to the track direction reconstruction and also get better performance than the conventional method. This means we can use the deep learning method to extract original track information from the deposited energies in sensor cells, and provide a more precise result than the conventional method. The DNN method can be applied as benchmark reconstruction algorithm for the CEPC luminometer, and further detector optimization will rely on it. As a promising method, DNN will be used in more CEPC technique studies such as reconstruction of tracks in other sub-detectors, trigger system, fast simulation, physics analysis, and so on.
Acknowledgements.
The numerical calculations in this paper have been done on the supercomputing system in the Supercomputing Center of Wuhan University.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1]
- 2[2] CEPC-SPPC Study Group, “CEPC-SPPC Preliminary Conceptual Design Report. 1. Physics and Detector,” IHEP-CEPC-DR-2015-01, IHEP-TH-2015-01, IHEP-EP-2015-01.
- 3[3] J. Blocki, W. Daniluk, E. Kielar, J.Kotula, A.Moszczy n ´ ´ 𝑛 \acute{n} ski, K.Oliwa, B. Pawlik, W. Wierba, L. Zawiejski and J. Aguilar on behalf of the FCAL collaboration, “Lumi- Cal new mechanical structure”, https://www.eudet.org/e 26 /e 28/e 42441/index_eng.html
- 4[4] Y. Le Cun, Y. Bengio, and G.Hinton, Nature, 2015, 521 : 436—444
- 5[5] S. Delaquis et al. JINST, 2018, 13 : P 08023
- 6[6] R. Acciarri et al. JINST, 2017, 12 : P 03011 · doi ↗
- 7[7] P. Baldi, P. Sadowski and D. Whiteson, Nature Commun. 2014, 5 : 4308
- 8[8] A. Aurisano et al. JINST, 2016, 11 : P 09001 · doi ↗