Multi-hypothesis contextual modeling for semantic segmentation
Hasan F. Ates, Sercan Sunetci

TL;DR
This paper introduces a novel Markov Random Field framework that leverages multiple segmentation hypotheses to enhance semantic segmentation accuracy by modeling and optimizing contextual dependencies across alternative segmentations.
Contribution
It proposes a flexible, generalized MRF model that fuses information from multiple segmentation hypotheses, improving spatial consistency and accuracy in semantic segmentation.
Findings
Significant accuracy improvements over baseline methods.
Effective fusion of multiple segmentation hypotheses.
Enhanced modeling of contextual dependencies.
Abstract
Semantic segmentation (i.e. image parsing) aims to annotate each image pixel with its corresponding semantic class label. Spatially consistent labeling of the image requires an accurate description and modeling of the local contextual information. Segmentation result is typically improved by Markov Random Field (MRF) optimization on the initial labels. However this improvement is limited by the accuracy of initial result and how the contextual neighborhood is defined. In this paper, we develop generalized and flexible contextual models for segmentation neighborhoods in order to improve parsing accuracy. Instead of using a fixed segmentation and neighborhood definition, we explore various contextual models for fusion of complementary information available in alternative segmentations of the same image. In other words, we propose a novel MRF framework that describes and optimizes the…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1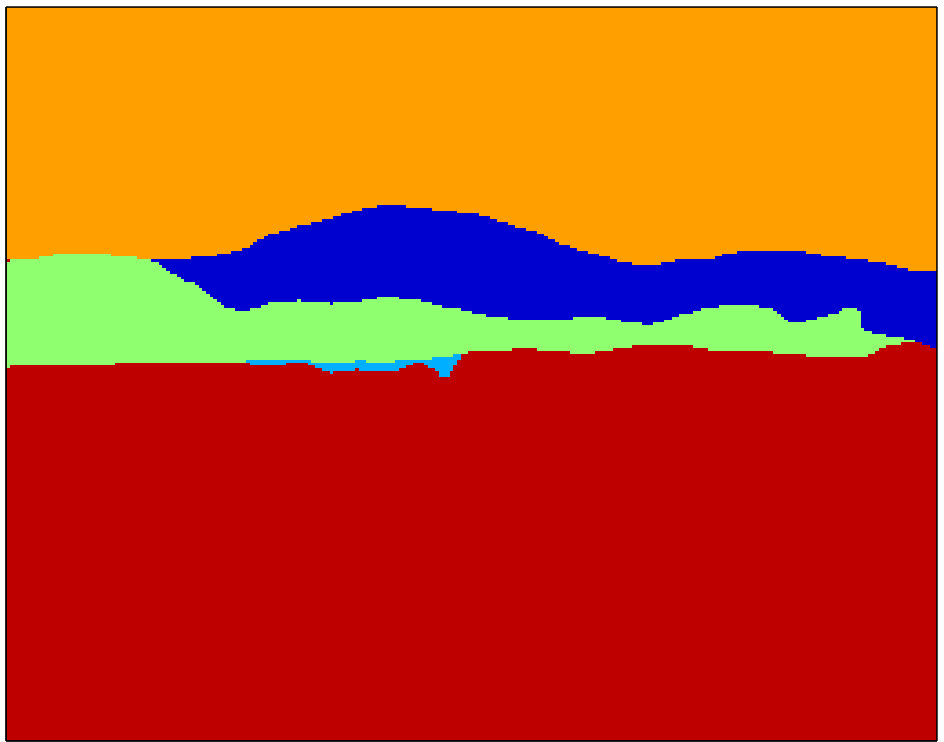 Figure 2
Figure 2 Figure 3
Figure 3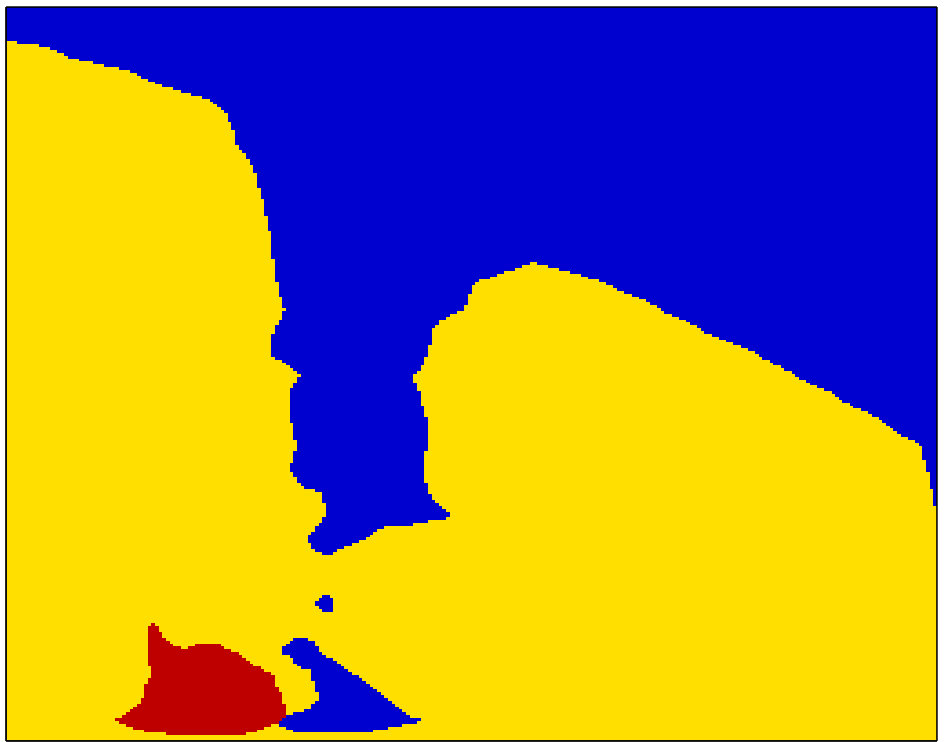 Figure 4
Figure 4 Figure 5
Figure 5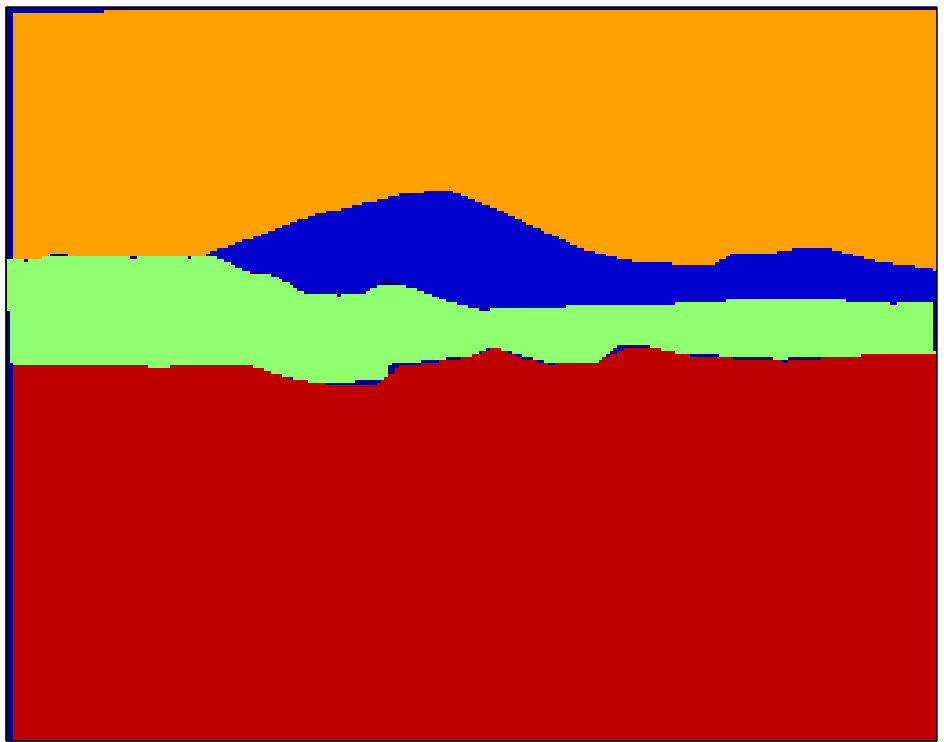 Figure 7
Figure 7 Figure 8
Figure 8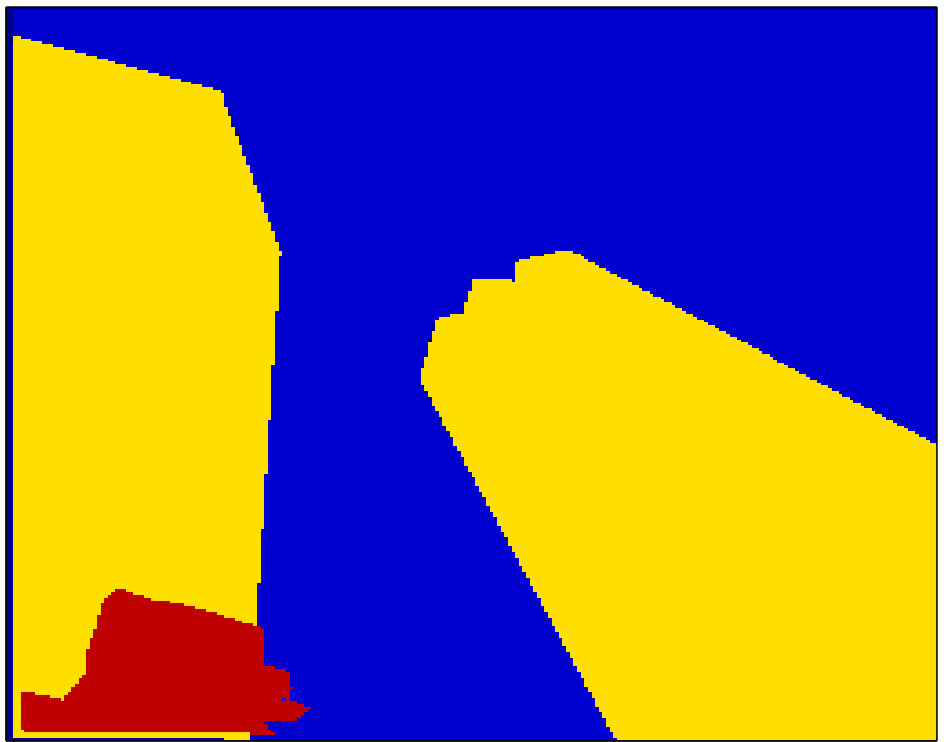 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20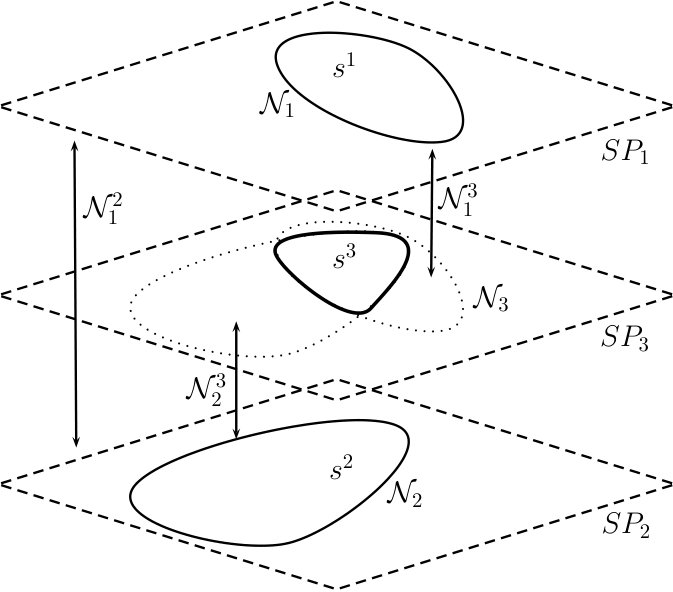 Figure 21
Figure 21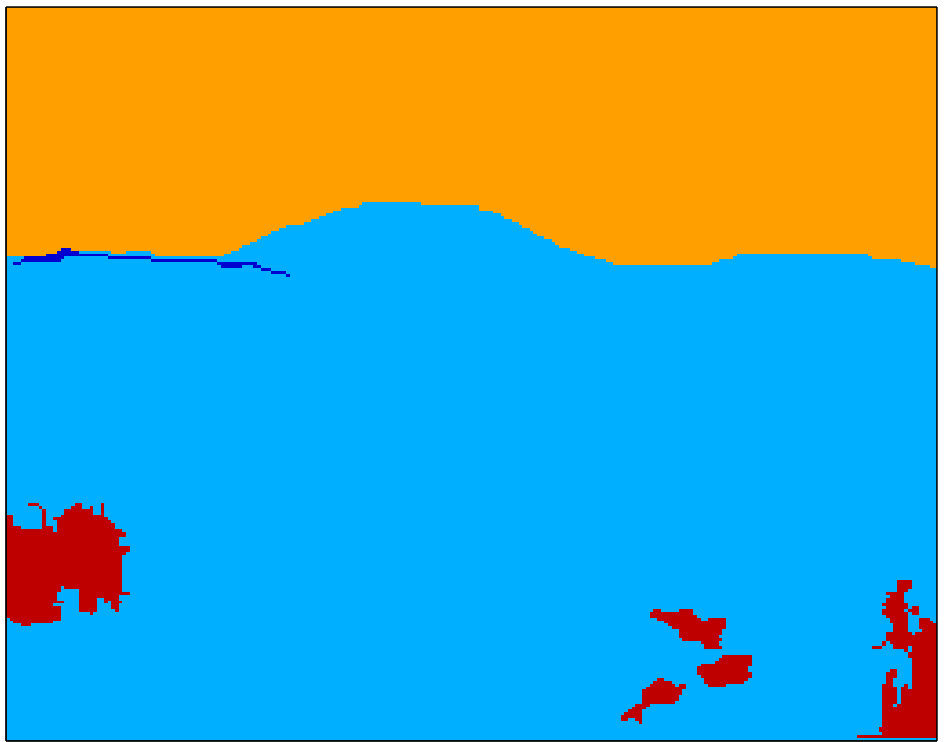 Figure 22
Figure 22 Figure 23
Figure 23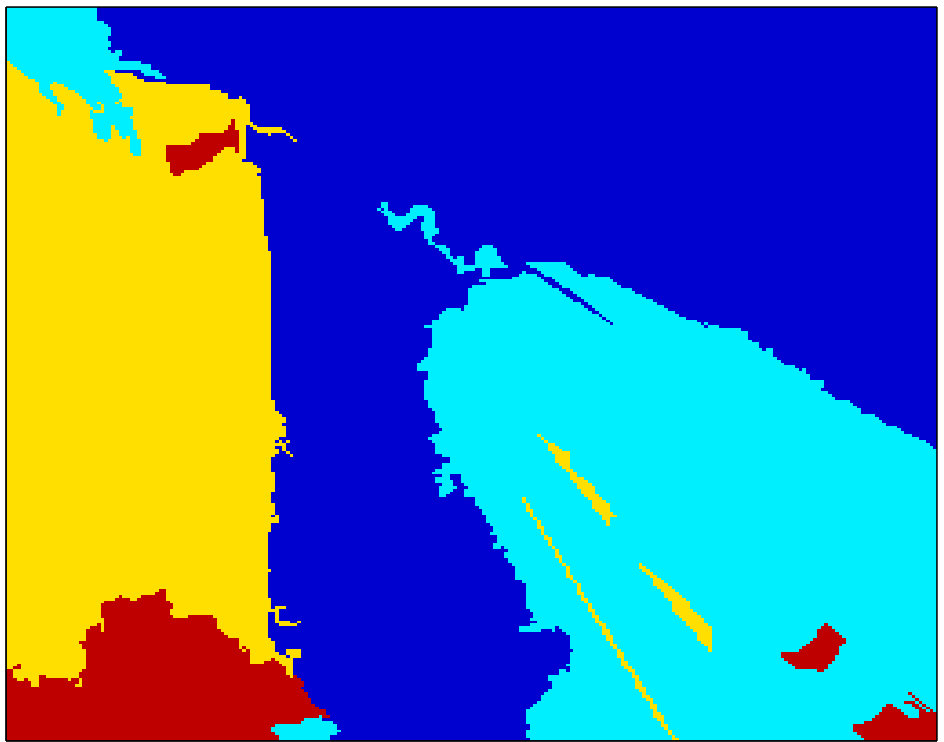 Figure 24
Figure 24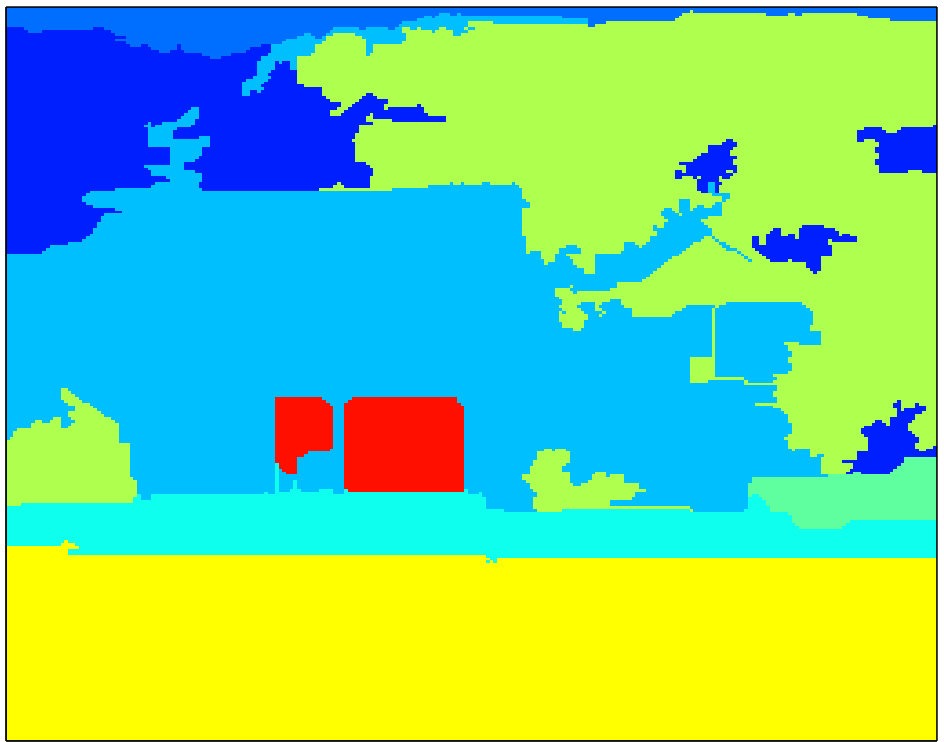 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30| Percentage Accuracy | ||
| Method | Per-pixel (%) | Per-class (%) |
| DC1 (Seg1,Seg2) | 86.8 | 50.8 |
| DC2 (Seg1,Seg2) | 87.2 | 50.4 |
| DC1 (Seg2,Seg3) | 88.7 | 55.2 |
| DC2 (Seg2,Seg3) | 88.4 | 54.2 |
| Seg1+MRF | 80.9 | 37.2 |
| Seg2+MRF | 86.0 | 51.6 |
| Seg3+MRF | 87.8 | 50.0 |
| SuperParsing | 76.2 | 29.1 |
| FCN-8s (Seg2) | 85.9 | 53.9 |
| PSP (Seg3) | 87.7 | 51.7 |
| Ates and Sunetci (2017) | 80.6 | 31.8 |
| George (2015) | 81.7 | 50.1 |
| Nguyen et al. (2016) | 83.3 | 49.4 |
| Liu et al. (2016) | 86.8 | 52.0 |
| Cheng et al. (2017) | 86.4 | 49.4 |
| Shuai et al. (2016) | 85.3 | 55.7 |
| Per-class Accuracy (%) | ||||||
| Class | Seg1+MRF | FCN-8s | Seg2+MRF | PSP | DC2(Seg1,Seg2) | DC1(Seg2,Seg3) |
| sky | 93.9 | 97.3 | 97.4 | 97.5 | 97.5 | 98.0 |
| building | 90.4 | 91.8 | 92.9 | 94.6 | 94.0 | 95.2 |
| car | 66.3 | 86.1 | 84.7 | 89.7 | 84.4 | 91.0 |
| window | 28.4 | 50.8 | 35.3 | 18.1 | 48.4 | 33.3 |
| person | 3.1 | 25.8 | 24.7 | 34.9 | 26.1 | 39.4 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Multi-hypothesis contextual modeling for semantic segmentation
Hasan F. Ates
Sercan Sunetci
Dept. of Computer Engineering, Istanbul Medipol University, Istanbul, 34810 TURKEY
Dept. of Electrical & Electronics Engineering, Isik University, Istanbul, 34980 TURKEY
Abstract
Semantic segmentation (i.e. image parsing) aims to annotate each image pixel with its corresponding semantic class label. Spatially consistent labeling of the image requires an accurate description and modeling of the local contextual information. Segmentation result is typically improved by Markov Random Field (MRF) optimization on the initial labels. However this improvement is limited by the accuracy of initial result and how the contextual neighborhood is defined. In this paper, we develop generalized and flexible contextual models for segmentation neighborhoods in order to improve parsing accuracy. Instead of using a fixed segmentation and neighborhood definition, we explore various contextual models for fusion of complementary information available in alternative segmentations of the same image. In other words, we propose a novel MRF framework that describes and optimizes the contextual dependencies between multiple segmentations. Simulation results on two common datasets demonstrate significant improvement in parsing accuracy over the baseline approaches.
keywords:
\KWDImage parsing , Segmentation , Superpixel , MRF
††journal: Pattern Recognition Letters
1 Introduction
Semantic segmentation (i.e. image parsing) is a fundamental problem in computer vision. The goal is to segment the image accurately and annotate each segment with its true semantic class. Recent literature has seen two major trends in this problem. Superpixel-based segmentation and parsing algorithms (Tighe and Lazebnik (2013); George (2015); Tighe et al. (2015)) are able to achieve much higher accuracy than similar pixel-based approaches. In superpixel-based segmentation, the image is segmented into visually meaningful atomic regions that agree with object boundaries. Then the parsing algorithm assigns the same semantic label to all the pixels of a superpixel, resulting in a spatially smooth labeling of the whole image. However, with the advent of deep networks in machine learning, state-of-the-art accuracy is obtained by dense labeling of image pixels through the use of convolutional neural network (CNN) architectures (Shelhamer et al. (2016); Liu et al. (2016); Liang et al. (2015)). Convolutional nets provide spatially dense but smooth classification by utilizing multiple pooling and upsampling layers (Shelhamer et al. (2016)).
00footnotetext: ©2018. This manuscript version is made available under the CC-BY-NC-ND 4.0 license http://creativecommons.org/licenses/by-nc-nd/4.0/
Detailed but spatially consistent labeling is essential for accurate segmentation of the image. In order to improve parsing consistency and accuracy, superpixel-based methods typically incorporate Markov Random Field (MRF) modeling and inference in superpixel neighborhoods (Nguyen et al. (2015); Yang et al. (2014)). Conditional Random Fields (CRFs) are also integrated in deep networks for further improvement (Liang-Chieh et al. (2018); Zheng et al. (2015)). However this improvement is limited by the accuracy of initial result and how the contextual neighborhood is defined. In this paper, we claim that committing to a single segmentation method and fixed neighborhood definition is rather restrictive for describing the rich contextual information in an image. Several works have shown before that parsing performance benefits from the fusion of multiple segmentations (Ak and Ates (2015); Vieux et al. (2012)) and/or object detectors (Tighe et al. (2015); Nguyen et al. (2016)). Nevertheless, these approaches fail to address the problem of contextual inference among alternative descriptions.
In this paper we extend our previous work in (Ates and Sunetci (2017)) and investigate various adaptive contextual models to combine complementary information available in alternative scene segmentations. These models incorporate not only the spatial neighborhood of adjacent segments/superpixels within the same segmentation but also the neighborhood of intersecting superpixels from different segmentations. We claim that these segmentations provide complementary information about the underlying object classes in the image. The proposed approach provides a unified framework to fuse the information obtained from multiple segmentations. In other words, MRF optimization is used to code contextual constraints both in the spatial and inter-segmentation neighborhoods for more consistent labeling. As a result, a more flexible description of neighborhood context is achieved, when compared to the fixed context of a single segmentation. In particular, this paper provides contributions in the following two aspects:
Alternative labelings of the same image are produced by using multiple segmentation methods and/or parameter/feature settings. Tested parsing methods include superpixel-based SuperParsing (Tighe and Lazebnik (2013)), Fully Convolutional Neural Network (FCN) (Shelhamer et al. (2016)) and Pyramid Scene Parsing Network (PSP) (Zhao et al. (2017)).
- 2.
A generalized model of local context is proposed to encode contextual constraints between alternatives and to fuse complementary information available in different segmentations.
The proposed MRF models are tested and compared on SIFT Flow (Liu et al. (2011)) and 19-class subset of LabelMe (Jain et al. (2010)) datasets. Simulation results demonstrate significant improvement in parsing accuracy over the baseline approaches. When compared to (Ates and Sunetci (2017)), this paper provides substantially better results, due to use of both CNN features and FCN/PSP networks. Parsing accuracies are also better than or competitive with the state-of-the-art in semantic scene segmentation.
In the next section we review the related work in contextual modeling for image parsing and contrast our approach with existing models. Section 3 develops the general framework of the proposed MRF contextual model. Section 4 gives the details of the model and the parsing algorithms. Section 5 provides and discusses the simulations results. Section 6 concludes the paper with ideas for future work.
2 Related Work
Context in image parsing is typically introduced in the form of MRF or CRF models that describe the local and/or global dependencies among object labels and scene content. Several CNN-based parsing methods adopt CRFs as a post-processing step to refine their outputs (Bell et al. (2015); Yu and Koltun (2016)). Liang-Chieh et al. (2018) employs a fully connected CRF among pixels to capture both local and global context. These methods require separate training steps for learning the CNN and CRF. Recurrent neural networks (RNNs) are also used to model context among pixels/objects (Byeon et al. (2015); Li et al. (2016)), hence introducing context information into the neural network architecture. Zheng et al. (2015) shows how to formulate CRF model as an RNN; in this manner CRF can be combined with any CNN-based parser for end-to-end training of the whole network.
There exist multi-scale approaches that model multi-scale context as well (Farabet et al. (2013); Eigen and Fergus (2015); Liu et al. (2016); Zhao et al. (2017)). Farabet et al. (2013) uses a multiscale set of segmentations, including superpixels, to train a deep network, learn hierarchical features and find an optimal cover of the image out of many segmentations. In the end, this method also commits to a final fixed segmentation, which is claimed to be optimal, but does not consider a joint optimization of alternative representations. Eigen and Fergus (2015) progressively refine its network output using a sequence of scales to provide dense labeling. FCN combines coarse layer features with fine, low-layer features for fusion of contextual information at different resolutions. Liu et al. (2016) and Zhao et al. (2017) use pooling of local features at different scales to capture global context. However network layers are generated by rectangular convolution and regular downsampling, which does not comply with the actual geometry of the objects in the scene.
In spite of the success of CRFs and multi-scale models for semantic scene segmentation, these approaches are computationally costly both for learning and inference. In this paper, we focus on context models that require minimal training and that can be optimized efficiently. In literature, several superpixel-based parsing algorithms use MRF-based post-processing to smooth out superpixel labels and improve labeling consistency among neighboring superpixels (Tighe and Lazebnik (2013); Nguyen et al. (2015)). Then MRF inference is achieved with fast and effective min-cut/max-flow optimization algorithm. However, typically, these parsing algorithms commit to a single pre-segmentation of the image, which is not always consistent with the boundaries of object classes.
To circumvent the shortcomings of previous models, our generalized MRF model defines a flexible framework to combine information coming from multiple segmentations and parsing methods. The closest work to our proposal is Associative Hierarchical Random Fields (AHRF) of Ladicky et al. (2014). AHRF provides a hierarchical MRF model for multiple segmentations at different scales. AHRF is introduced as a generalization of different MRF models defined over pixels, superpixels or a hierarchy of segmentations (such as Pantofaru et al. (2008)). While AHRF defines a strict hierarchy between pixels, segments and super-segments, our model allows for combination of different segmentations without any fixed parent-child or coarse-fine scale relationship in between. In addition, we investigate the fusion of decisions from different (superpixel-based and CNN-based) parsers, while Ladicky et al. (2014) does not explain how to extend AHRF to incorporate several different classifiers.
The main novelty of this paper is the fusion of multiple parsing methods within MRF formalism. Vieux et al. (2012) also labels segments by late fusion of SVM classifiers over multiple segmentations; however, fusion is simply performed by taking the mean/max/multiplication of classifier probabilities in intersecting regions and label smoothing by relaxation labeling is treated as a post-processing step on the fused result. Methods such as Dong et al. (2016), Yao et al. (2012), Morales-Gonzalez et al. (2018) define hierarchical MRF models over multiple segmentations but do not consider segmentations and class scores coming from alternative methods. In these approaches, since the segmentations and their unary potentials at different levels of the hierarchy are not independently generated, there will be no significant complementary information for fusion over the hierarchical MRF. As a result, gains in labeling accuracy are limited. On the other hand, our MRF framework allows for the fusion of independent segmentations and class likelihoods coming from much different classifiers.
3 Contextual Modeling of Alternative Segmentations
In superpixel image parsing, a fixed segmentation is typically used to derive local features, estimate class likelihoods, label each segment and perform MRF smoothing of labels. Hence parsing performance heavily depends on how well the size, shape, boundary and content of superpixels represent the underlying object classes.
In this paper we further develop “Multi-hypothesis MRF model” of Ates and Sunetci (2017) and show that labeling accuracy could benefit from the joint use of multiple initial segmentations, which are possibly generated by different methods. In our approach the local context incorporates not only the spatial neighborhood of adjacent superpixels within the same segmentation but also the neighborhood of intersecting superpixels from different segmentations. These inter-segmentation neighborhoods help fuse alternative representations coming from multiple segmentations. Hence, the proposed MRF model describes both intra-segmentation and inter-segmentation contextual information. Intra- neighborhood contains adjacent superpixels of a given segmentation. Inter- neighborhood contains intersecting superpixels from different segmentations. The MRF model is used to code contextual constraints in both intra- and inter- neighborhoods for more consistent labeling. We explore different data and neighborhood models for a more generalized contextual framework within the MRF formalization.
In the following, the generalized MRF model is described for two alternative segmentations; but it could be easily generalized to any number of alternatives. Let the set of segments/superpixels be defined as (). We define a third segmentation based on the intersection of the superpixels of the two alternatives (see Figure 1):
[TABLE]
For each segmentation, let represent the contextual neighborhood that contains pairs of adjacent superpixels. In addition to these intra- neighborhoods, we define inter-segmentation context as follows:
[TABLE]
The image is parsed by assigning to each superpixel a class label . Each segmentation produces an alternative parsing result, . We formulate the labeling problem as an MRF energy minimization over the whole set of superpixel labels as follows:
[TABLE]
where and are appropriate data cost and smoothness cost terms, respectively, of related label assignments; is the set of inter-segmentation neighborhoods (), and are smoothness constants for each corresponding context. In the next section we discuss the details of the MRF model, in particular how to define data and smoothness costs and how to select the smoothness constants.
4 Image Parsing with Multi-hypothesis MRF Model
In the MRF formulation given above, the data cost represents the confidence with which a superpixel is assigned to a class ; the smoothness cost , on the other hand, is a measure of likelihood that two neighboring superpixels are assigned to distinct class labels . Any parsing algorithm can be integrated into this MRF formulation, as long as it produces class-conditional likelihood scores that can be used to define the data costs of the model. In this paper we test three methods, SuperParsing, FCN and PSP, with optimized parameter settings.
SuperParsing is a data-driven, nonparametric parsing algorithm that tries to match the superpixels of a test image with the superpixels of a suitable subset of the training images, i.e. “retrieval set” (Tighe and Lazebnik (2013)). A scene-level comparison is performed to find a good retrieval set that contains images similar to the tested image. For each test superpixel, a rich set of features are computed and matched with the superpixels from the retrieval set. The labels of these matching superpixels are used to compute class-conditional log-likelihood ratio scores, , for each class . Then the data term is defined as , where is the superpixel weight, and is the sigmoid function. Here , where is the number of pixels in , is the mean of (see Tighe and Lazebnik (2013) for details).
FCN/PSP architectures provide dense pixel-level class scores and labels at the output layer. These scores change smoothly between neighboring pixels, due to the interpolation at the deconvolution layers. We determine the connected components of the FCN/PSP outputs, where neighboring pixels with the same class label are assigned to the same component/segment (see Fig. 2). Then the segment score is set equal to the mean score of its pixels. These scores are used to define the data terms of the MRF model, as described above. As seen in Fig. 2(c), when the connected components are very large, intra- and inter-segmentation neighborhoods will also be large and therefore will not capture the local context effectively. To overcome this, we intersect these connected components with superpixels of the image and test the use of intersecting regions in the MRF model, as well.
The smoothness costs for and are based on probabilities of label co-occurrence, as given in Tighe and Lazebnik (2013):
[TABLE]
where is the conditional probability of one superpixel having label given that its neighbor has label , estimated by counts from the training set. The delta function is used to assign zero cost when .
Since is generated from the other two segmentations, its data and smoothness costs are defined as functions of the corresponding costs in and . In order to fuse the complementary information coming from the two segmentations, we differentiate the set of classes in segment and and select from the union of those two sets for segment . In other words, there are two separate labels in , and , which correspond to the semantic class coming from and , respectively (Note that, represents the class label assigned to superpixel , while represents any given class of segmentation ). Then the data cost for is given by ():
[TABLE]
where and . Likewise, the smoothness costs in inter- neighborhoods are based on the costs in and as follows:
[TABLE]
The specifics of and will be discussed in the next section.
The smoothness constants control the level of contextual dependency in different neighborhoods of the MRF model in Eq. (3). These values are determined from the training set by a leave-one-out strategy: each training image is removed from the training set, and then parsed by the proposed algorithm to obtain its labeling accuracy under different parameter settings. Then, the set of parameters that maximize the mean pixel accuracy in the training set is chosen.
The MRF energy function is minimized by the -expansion method of Boykov and Kolmogorov (2004). The outcome leads to three alternative labelings . The set of labels of the segmentation is selected as the final labeling of the image.
5 Simulations and Discussions
5.1 Implementation Details
The smoothness constants of the MRF model are selected from the set . The function is set as . For data costs of , we test two alternatives :
DC1: ()
[TABLE]
- 2.
DC2:
[TABLE]
where and .
The first model uses a weighted average of two data costs from and for superpixels of and does not differentiate labels and . The second model assigns two different data costs to the labels and of the same class under two different hypotheses of and . Therefore the second model enables the algorithm to choose between the two hypotheses, depending on the contextual information. The superpixel weight is set proportional to the relative size of with respect to and ; if the intersection of the two superpixels is small, then the data cost for is assigned lower weight since it is deemed unreliable for labeling . The data weights represent the confidence in the segmentation result of the two hypotheses; hence the better algorithm is assigned a higher weight.
SuperParsing uses graph-based superpixel segmentation (Felzenszwalb and Huttenlocher (2004)). In this algorithm, parameter controls superpixel color consistency and determines the smallest superpixel size. is the number of nearest neighbor matches for each superpixel feature. Several superpixel features, including shape (e.g. superpixel area), location (e.g. superpixel mask), texture (e.g. SIFT), color (e.g. color histogram) descriptors, are used to find matching superpixels from the retrieval set. There are six SIFT features that are defined over different subregions of the superpixel. These SIFT features are encoded using LLC (Locality-constrained Linear Coding) (Wang et al. (2010)) or KCB (Kernel Codebook Encoding) (van Gemert et al. (2008)) algorithms.
In addition, we use CNN features both for global matching to determine the retrieval set and for local superpixel matching. These are learned features extracted from the last layer of the network before the final classification layer. CNN features are extracted from the trained networks of VGG-F (Chatfield et al. (2014)) and AlexNet (Krizhevsky et al. (2012)), which are trained on ILSVRC ImageNet dataset (Deng et al. (2009)). For each superpixel, its CNN feature is obtained by setting the whole image to zero except for the superpixel region and computing the network output.
In the following section, simulation results are provided for the following three alternative segmentations:
Seg1: SuperParsing (K=200, S=100, R=30). VGG-F/AlexNet features are used both for global matching and for superpixel matching.
- 2.
Seg2: FCN-8s segmentation (Shelhamer et al. (2016)) is used to define superpixels and data costs, as described in the previous section.
- 3.
Seg3: PSP segmentation, no cropping, single scale evaluation (Zhao et al. (2017)), usage similar to FCN-8s.
5.2 Results and Comparisons
The proposed models are evaluated on two well-known datasets, namely SIFT Flow (Liu et al. (2011)) and 19-class subset of LabelMe (Jain et al. (2010)). In experiments overall pixel-level classification accuracy (i.e. correctly classified pixel percentage) and average per-class accuracies are compared.
SIFT Flow dataset contains 2,688 images and 33 labels. This dataset includes outdoor scenery such as mountain view, streets, etc. There are objects from 33 different semantic classes, such as sky, sea, tree, building, cars, at various densities. There are also 3 geometric classes, which are not considered in our simulations. Dataset is separated into 2 subsets; 2,488 training images and 200 test images. The retrieval set size is set at 200 images, as in original SuperParsing. LLC encoding is used for SIFT features.
Table 1 reports the pixel-level and average per-class labeling accuracies of DC1 and DC2 models with optimized parameter settings. We also provide Seg1, Seg2 and Seg3 results with MRF smoothing, but without using the inter- neighborhoods (i.e. ). For comparison, results are provided for original SuperParsing, original FCN-8s, PSP and for some other recent superpixel-based and CNN-based methods evaluated on SIFT Flow dataset.
Table 1 includes results for two alternatives, i.e. (Seg1,Seg2) and (Seg2,Seg3). (Seg1,Seg3) combination is inferior to (Seg2, Seg3) and hence not reported. For (Seg1,Seg2), DC2 improves the pixel accuracy of FCN-8s by 1.3% through the use of proposed multi-hypothesis MRF model. DC1 accuracy is 0.4% lower than DC2, showing that it is more effective to keep data costs separate when fusing the complementary information of the two hypotheses. Note that, without the inter- neighborhoods, Seg2+MRF could only achieve 0.1% improvement over FCN-8s through MRF smoothing. This shows that our proposed MRF framework successfully fuses the segmentation decisions of alternative methods. In addition, when compared to our previous results in Ates and Sunetci (2017), parsing accuracy is substantially better, due to use of CNN features and FCN segmentation.
For (Seg2,Seg3), DC1 is the better model and improves the pixel accuracy of PSP by 1.0%. DC2 accuracy is 0.3% lower than DC1 this time. When combining FCN and PSP results, the connected components are intersected with superpixels of Seg1 to provide finer segmentation, as explained in Section 4. This improves both pixel accuracy and average per-class accuracy of MRF fusion. The accuracy of Seg3+MRF is much lower than our results, once again showing the importance of inter- neighborhoods in the model. As seen from Table 1, DC1(Seg2,Seg3) outperforms other recent superpixel-based and CNN-based segmentation methods in terms of per-pixel labeling accuracy,
The average per-class accuracy of DC1(Seg2,Seg3) is 1.3% better than FCN-8s and 3.5% better than PSP. However, for (Seg1,Seg2), the average per-class accuracies of both DC2 and DC1 are lower than that of FCN-8s, both due to the spatial smoothing of labels by MRF optimization and also because mean class accuracy of Seg1 is significantly lower and therefore not helping to boost the overall performance.
Note that using MRF smoothing alone on both FCN and PSP outputs reduces mean class accuracies with marginal improvement on per-pixel accuracies. This is because MRF optimization favors dominant classes covering large areas (such as sky, building) and smooths out rare classes with smaller areas (such as car, window). As a result per-class accuracies of dominant classes are slightly increased at the expense of significant drop in per-class accuracies of rare classes. On the other hand, our MRF framework is capable of increasing both per-pixel and per-class accuracies, when smoothness constants in the model are carefully selected and when both hypotheses have comparable performance. Therefore we believe that per-class accuracy of (Seg1,Seg2) could also be improved within the proposed MRF framework, if Seg1 is assigned to a better performing superpixel-based parsing algorithm (such as George (2015)).
Table 2 lists per-class accuracies of the tested algorithms for some dominant (sky, building) and rare (car, window, person) classes. As explained above, MRF smoothing improves the parsing performance of dominant classes that cover large regions in tested images; however many segments from rare classes are also mistakenly assigned to labels of their dominant neighbors (e.g. window vs. building), which decreases the accuracies of these rare classes. While (Seg1,Seg2) also suffers from this problem due to the poor performance of Seg1, rare class accuracies of (Seg2,Seg3) are generally better than those of both FCN and PSP. Therefore our MRF framework is effective in combining the best of both segmentations without over-smoothing the label assignments.
19-class LabelMe dataset contains 350 images with 19 classes (such as tree, field, building, rock, etc.). The dataset is split into 250 training images and 100 test images. The retrieval set size is set at 50 images, due to the smaller size of training set. KCB encoding is used for SIFT features. FCN-8s network architecture is transferred from SIFT Flow, adapted for 19-class evaluation and re-trained with the given 250 image LabelMe training set. PSP architecture is not tested due to the small size of training set.
Table 3 reports the pixel-level and average per-class labeling accuracies of (Seg1,Seg2) using DC1 and DC2 for LabelMe. Results from literature are provided for Nguyen et al. (2016), Nguyen et al. (2015), Myeong and Lee (2013) and our initial work in Ates and Sunetci (2017). Our proposed algorithms surpass the state-of-art in this dataset, improving pixel accuracy by 4.9% and mean class accuracy by 12.9% over Nguyen et al. (2016). We also outperform FCN-8s result by 3.5% and 6.1% in pixel and mean class accuracies, respectively.
For LabelMe dataset, DC1 is better than DC2 by 0.5% in pixel accuracy, but DC2 gives higher mean class accuracy. DC1 improves the pixel and mean class accuracies of Seg2+MRF by 1.4% and 3.0%, respectively. This result indicates the importance of inter- neighborhoods in combining the complementary information of alternative methods. As opposed to SIFT Flow, (Seg1,Seg2) provides improvement in mean class accuracy in this dataset. This implies that, when both Seg1 and Seg2 have comparable performance, our multi-hypothesis MRF framework boosts not only the pixel accuracies but also the mean class accuracies of the tested methods.
At Figure 3, parsing results of Seg1+MRF, Seg2+MRF and DC2(Seg1,Seg2) are compared visually for some selected test images from SIFT Flow. DC2 labelings are generally more consistent and accurate than those of both Seg1+MRF and Seg2+MRF. In the top figure, field is correctly identified, even though both tested methods label the area as grass. In the other three figures, and typically throughout the SIFT Flow dataset, DC2 outcome is at least as good as the better result of Seg1+MRF and Seg2+MRF. In other words, the proposed approach manages to select correctly the more probable label between the two hypotheses by making use of the intricate contextual constraints in intra- and inter- neighborhoods.
5.3 Computational Cost
The time complexity of the proposed approach is dominated by the running times of individual parsing algorithms. MRF optimization is carried out by the fast -expansion method of Boykov and Kolmogorov (2004). The computational cost of this optimization is proportional to the total number of superpixels in , and .
Simulations are carried out on a single PC with 4-core CPU at 3.70 GHz and 16 GB RAM. Caffe implementations of FCN and PSP are used for testing. For SIFT Flow dataset, FCN and PSP take 2.2 and 5.9 secs, respectively, per image. SuperParsing labels images in 8 secs on average, using its unoptimized and un-parallelized MATLAB implementation. Multi-hypothesis MRF model optimization takes merely 0.25 secs on average, using unoptimized MATLAB interface. Hence the proposed framework provides fast inference for contextual modeling and fusion of parsing algorithms with different levels of performance and complexity.
6 Conclusion
In this paper a novel contextual modeling framework is introduced for semantic scene segmentation. This framework defines contextual constraints over inter- and intra- neighborhoods for multiple segmentations of the same image. In addition to producing spatially more consistent parsing results, the proposed approach carries out labeling at a finer scale over the intersecting regions of alternative segmentations. We have shown that, when both alternatives have comparable labeling performance, our contextual models improve both the pixel and the mean class accuracies of tested methods. We have used this framework as a post-processing step at the outputs of deep FCN-8s and PSP architectures and obtained state-of-the-art parsing results in two well-known datasets.
As future work, we plan to advance our contextual inference approach using more advanced data cost and smoothness models. Other CNN architectures and superpixel-based parsing methods could be tested within the given framework. Also this MRF framework could be integrated into the CNN architecture and the model parameters could be learned using end-to-end training of the whole system.
Acknowledgments
This work is supported in part by TUBITAK project no: 115E307 and by Isik University BAP project no: 14A205.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ak and Ates (2015) Ak, K.E., Ates, H.F., 2015. Scene segmentation and labeling using multi-hypothesis superpixels, in: Signal Process. and Comm. Appl. Conf. (SIU), pp. 847–850.
- 2Ates and Sunetci (2017) Ates, H.F., Sunetci, S., 2017. Improving semantic segmentation with generalized models of local context, in: 17th Int. Conf. Computer Analysis Images Patterns (CAIP), pp. 320–330.
- 3Bell et al. (2015) Bell, S., Upchurch, P., Snavely, N., Bala, K., 2015. Material recognition in the wild with the materials in context database, in: Proc. IEEE Conf. Comp. Vision Pattern Recog. (CVPR), pp. 3479–3487.
- 4Boykov and Kolmogorov (2004) Boykov, Y., Kolmogorov, V., 2004. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. IEEE Trans. Pattern Anal. Mach. Intell 26, 1124–1137.
- 5Byeon et al. (2015) Byeon, W., Breuel, T.M., Raue, F., Liwicki, M., 2015. Scene labeling with lstm recurrent neural networks, in: Proc. IEEE Conf. Computer Vision Pattern Recog., pp. 3547–3555.
- 6Chatfield et al. (2014) Chatfield, K., Simonyan, K., Vedaldi, A., Zisserman, A., 2014. Return of the devil in the details: Delving deep into convolutional nets, in: Proc. British Machine Vision Conf.
- 7Cheng et al. (2017) Cheng, F., He, X., Zhang, H., 2017. Stacked learning to search for scene labeling. IEEE Trans. Image Process. 26, 1887–1898.
- 8Deng et al. (2009) Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L., 2009. Imagenet: A large-scale hierarchical image database, in: Proc. IEEE Conf. Comp. Vision Pattern Recog. (CVPR), pp. 248–255.