Guaranteed satisficing and finite regret: Analysis of a cognitive satisficing value function
Akihiro Tamatsukuri, Tatsuji Takahashi

TL;DR
This paper introduces a risk-sensitive satisficing (RS) model for reinforcement learning that guarantees finding satisfactory actions and ensures finite regret in bandit problems, offering a practical alternative to optimality-focused methods.
Contribution
The paper presents the RS model that guarantees satisficing solutions and finite regret, with theoretical proofs and empirical validation in bandit tasks.
Findings
RS guarantees finding an action above the aspiration level.
Expected regret of RS is finite under optimal aspiration levels.
Numerical simulations confirm theoretical results and compare favorably with other algorithms.
Abstract
As reinforcement learning algorithms are being applied to increasingly complicated and realistic tasks, it is becoming increasingly difficult to solve such problems within a practical time frame. Hence, we focus on a \textit{satisficing} strategy that looks for an action whose value is above the aspiration level (analogous to the break-even point), rather than the optimal action. In this paper, we introduce a simple mathematical model called risk-sensitive satisficing () that implements a satisficing strategy by integrating risk-averse and risk-prone attitudes under the greedy policy. We apply the proposed model to the -armed bandit problems, which constitute the most basic class of reinforcement learning tasks, and prove two propositions. The first is that is guaranteed to find an action whose value is above the aspiration level. The second is that the regret (expected…
Click any figure to enlarge with its caption.
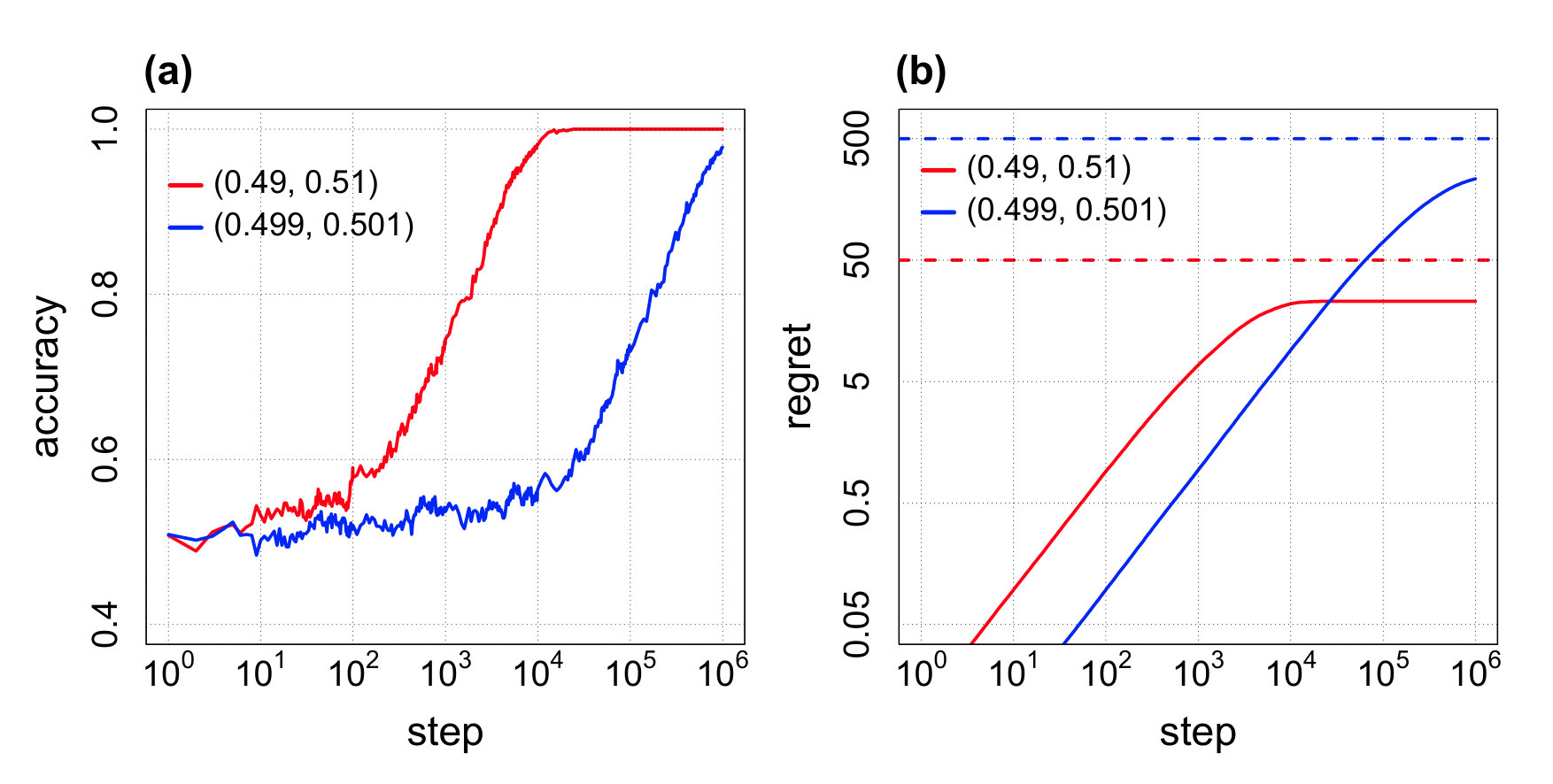 Figure 1
Figure 1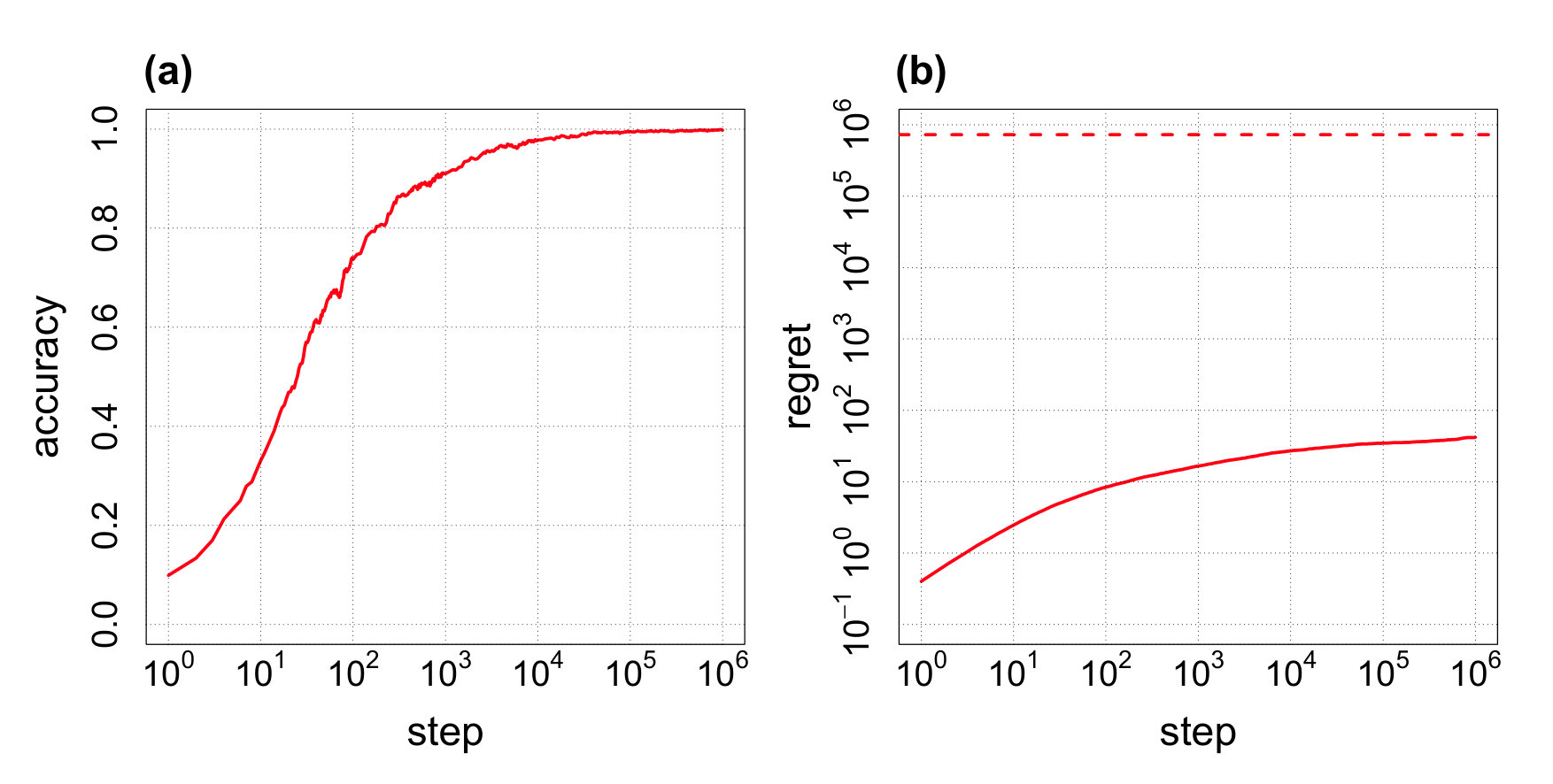 Figure 2
Figure 2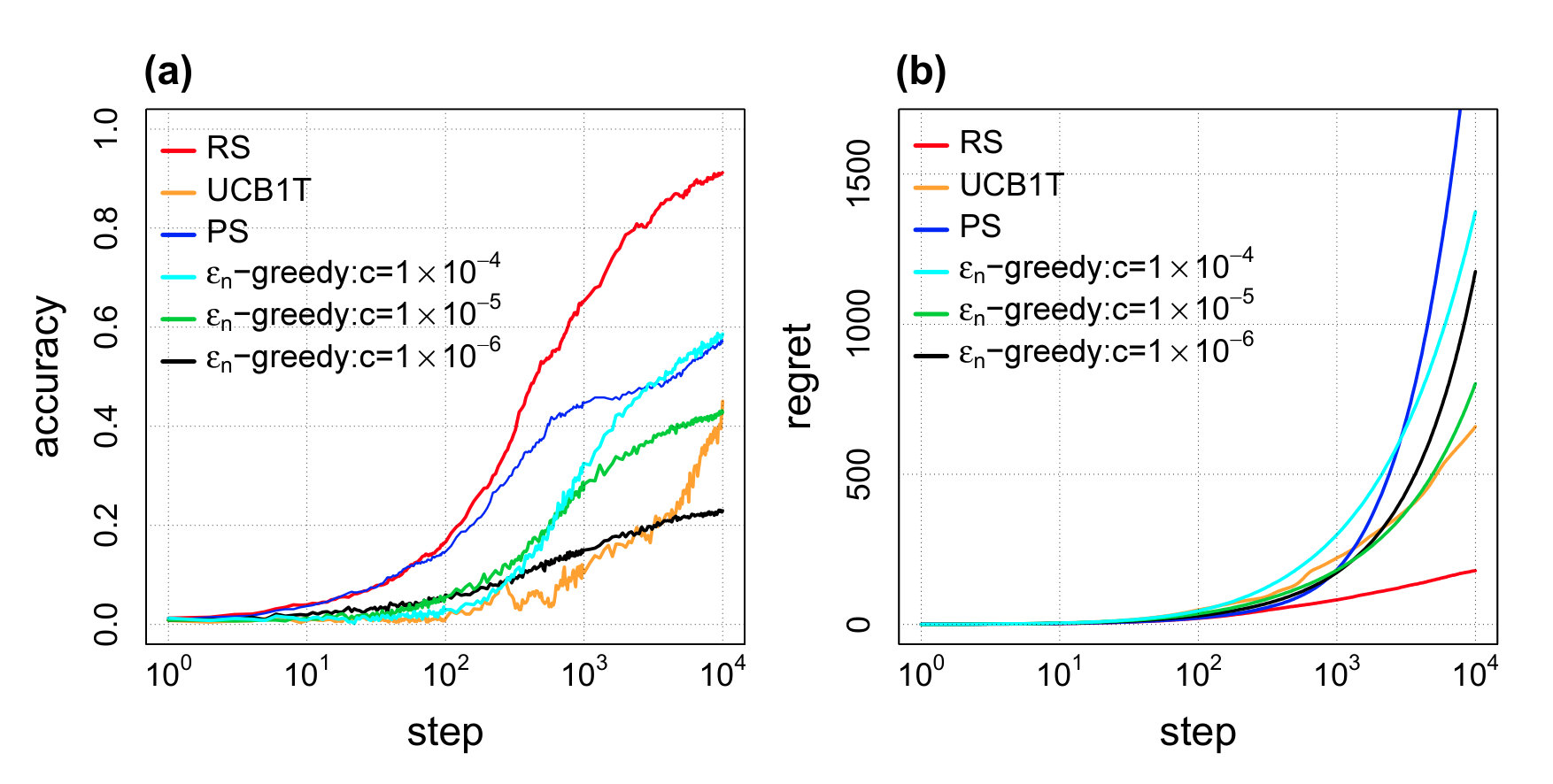 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Bandit Algorithms Research · Reinforcement Learning in Robotics · Smart Grid Energy Management
Guaranteed satisficing and finite regret: Analysis of a cognitive satisficing value function
Akihiro Tamatsukuri
Graduate School of Advanced Science and Engineering, Tokyo Denki University, Ishizaka, Hatoyama, Hiki, Saitama 350-0394, Japan
Tatsuji Takahashi
School of Science and Engineering, Tokyo Denki University, Ishizaka, Hatoyama, Hiki, Saitama 350-0394, Japan
Dwango Artificial Intelligence Laboratory, 5-24-5 Hongo, Bunkyo, Tokyo 113-0033, Japan
Abstract
As reinforcement learning algorithms are being applied to increasingly complicated and realistic tasks, it is becoming increasingly difficult to solve such problems within a practical time frame. Hence, we focus on a satisficing strategy that looks for an action whose value is above the aspiration level (analogous to the break-even point), rather than the optimal action. In this paper, we introduce a simple mathematical model called risk-sensitive satisficing () that implements a satisficing strategy by integrating risk-averse and risk-prone attitudes under the greedy policy. We apply the proposed model to the -armed bandit problems, which constitute the most basic class of reinforcement learning tasks, and prove two propositions. The first is that is guaranteed to find an action whose value is above the aspiration level. The second is that the regret (expected loss) of is upper bounded by a finite value, given that the aspiration level is set to an “optimal level” so that satisficing implies optimizing. We confirm the results through numerical simulations and compare the performance of with that of other representative algorithms for the -armed bandit problems.
Introduction
Reinforcement learning (RL), a framework for learning and control in which agents search for proper actions in an environment through trial and error, has witnessed rapid development in recent years, as evidenced by the super-human performances of deep Q-networks (DQN) [1] in video game playing and AlphaGo [2] in the game of Go. Moreover, the application range of RL extends not only to more complicated tasks on computers but also to the control of robots [3] and unmanned aerial vehicles (UAVs) [4] in the real world.
As RL algorithms are being applied to increasingly complicated and realistic tasks, the limits of sensors, processors, and actuators of agents are posing serious obstacles for conventional optimization algorithms. Simon proposed the notion of bounded rationality as the principle underlying agents’ behavior under resource limits [5]. A bounded rational agent may appear to behave irrationally, but by considering the limits and constraints, the agent’s behavior can be understood as rational. Bounded rationality has attracted considerable attention in recent years. Computational rationality [6], which has been claimed to integrate the three fields of neuroscience (brain), cognitive science (mind), and artificial intelligence (machine) [7], is an updated form of bounded rationality. Further, it has been proposed that abstraction and hierarchy, which have been considered to enable flexible and efficient cognition of humans [8], result from the above-mentioned limitations and are bounded rational [9].
The representative decision making policy in the theory of bounded rationality is satisficing [10, 11]. Satisficing agents do not keep searching for the optimal action; instead, they stop searching when an action whose quality is above a certain level (aspiration) is found. The satisficing strategy has not attracted much attention in reinforcement learning, except for a few studies [12, 13] (to be discussed later). In previous studies [14, 15], one of the authors proposed a simple satisficing value function called risk-sensitive satisficing () and empirically validated its effectiveness through numerical simulations of reinforcement learning tasks.
In this paper, we apply to the -armed bandit problems, which constitute the most basic class of reinforcement learning tasks, and prove two propositions. First, we prove that is guaranteed to find a satisfactory action: if the agent chooses an action in each trial and the number of trials is sufficient, the agent can stably choose an action whose value is above the aspiration level. Second, we prove the finiteness of the regret of . In general, the performance of algorithms in the -armed bandit problems is measured by how small their regret (expected loss) is. It is known that the regret increases at least in the logarithmic order with the number of trials [16]. Therefore, the regret increases infinitely as the trials are repeated. However, we prove that if a small amount of information on the reward distributions is available so that the aspiration level is set to an “optimal level” (hence, satisficing entails optimizing), then the regret of is upper bounded by a finite value. We confirm these results by numerical simulations and compare the performance of with that of other representative algorithms for the -armed bandit problems. Finally, we conclude the paper with a discussion on the possible applications of and the theoretical significance of this work.
Methods
-armed Bandit Problems
The -armed bandit problems that we deal with in this paper are as follows. Let there be actions that lead to a reward of 1 or 0 according to the reward probabilities , which are unknown to the agent. If the agent chooses action , it acquires a reward of 1 with probability or a reward of 0 with probability . The goal of the repetition of choice is maximization of the expected accumulated rewards, which is measured by minimization of regret (the expected cumulative loss). denotes the action with the maximal reward probability (i.e., ). The regret when the -th step (one step means one trial) ends is defined as follows.
[TABLE]
where is the number of times action is chosen from the first to the -th step (simply written as when the number of steps is not explicitly indicated) and is the expectation. Regret represents the expected loss, i.e., “how inferior the cumulative expected reward from the actual chosen actions is to the cumulative expected reward when the optimal action continues to be chosen from the first step?” The smaller the regret, the better is the performance of the algorithms. The minimum value of the regret is zero when the optimal action has been chosen in all the steps. It has been proven that the regret increases at least in with the number of steps [16].
As for action selection by the agent, the basic policy is to take the action with the highest value (the greedy method). The basic valuation of action is based on its mean reward:
[TABLE]
where is the number of times is chosen and the reward is acquired. , i.e., the number of times the action is chosen, satisfies and . Under the greedy method with the mean reward valuation, if there is a non-optimal action that has a high value in early trials, there is a risk of being chosen all along. Each of the other actions must be tried for an appropriate number of times so that the optimal action is found in a timely manner. Merely choosing the action with the highest value based on the accumulated knowledge (exploitation) does not suffice, and various actions must be tried (exploration). Various algorithms have been proposed to balance exploitation and exploration.
Models of Satisficing
We introduce two models of satisficing at the levels of policy and value function. The policy model follows the standard description of satisficing. The second model is the risk-sensitive value function that we analyze and test in this paper. The former is tested through simulations for comparison with the latter.
Policy Satisficing () Model
A standard definition of satisficing is to keep exploring until an action whose value is above the aspiration level is found and to then stop searching and keep choosing the action (exploit). Satisficing, unlike optimization, can reduce the search cost because it does not involve searching for all actions and deciding on the optimal action. This is formulated as a policy (of reinforcement learning) as follows. If there exists at least one action whose mean reward is above the aspiration level , exploitation (following the greedy method) is executed. Otherwise, when the mean reward of all the actions is below the aspiration level , an action is randomly chosen. We refer to this algorithm as policy satisficing ().
Risk-sensitive Satisficing () Value Function
One of the authors has proposed a value function called risk-sensitive satisficing () that realizes satisficing action selection behavior when operated under the greedy policy [14, 15] (see Supplementary Information for its relationship with other models). Before introducing the model, we first define the difference between the mean reward of action and the aspiration level :
[TABLE]
If there exists a positive , then the agent will choose such and be satisfied; otherwise, it will be unsatisfied. is defined as follows [14]:
[TABLE]
This value is used under the greedy policy: the agent chooses the action with the maximal value.
integrates two risk-sensitive satisficing behaviors. When unsatisfied, is risk-seeking, leading to optimistic exploration. If for all , then actions with smaller are prioritized. Let and let there be two unsatisfactory actions and with and . Then, ; hence, is chosen. This preference of a less tried action can be interpreted as the optimistic expectation of the action’s actual reward probability being set above . There might be some ; however, thus far, for all the actions. In terms of looking for a satisfactory action, it is rational to try actions with smaller . This accords with the motto “optimism in the face of uncertainty,” which is considered a general and rational exploration strategy in reinforcement learning [17]. The UCB model described later implements this idea [18].
When satisfied, is risk-averse, performing pessimistic exploitation. If there is only one for which is positive, the agent will keep choosing it. If there are multiple actions with positive , then the actions with larger are prioritized. Let , and let there be two satisfactory actions and with and that are equivalent to the example above. Then, ; hence, is chosen. In this case, a more tried action is preferred. This can be interpreted as the pessimistic expectation of the action’s actual reward probability being set below . It is possible that is a spuriously satisfactory action with ; however, . In terms of looking for a truly satisfactory action and avoiding spuriously satisfactory ones, it is rational to try actions with for a larger .
Setting of the Aspiration Level
The aspiration level defines the boundary between satisfactory and unsatisfactory, analogous to the break-even point between gain and loss or the neutral reference outcome in prospect theory [19]. It can be set according to the internal need for it or its knowledge of the environment. As an ecological example, let the agent be an animal, and let the rewards 1 and 0 represent the presence and absence of food. If the action is to look for food at a feeding ground from among multiple grounds and the agent has to obtain food around once every two days for survival, then would be or higher.
Optimization can be viewed as a special case of satisficing. If lies between the two reward probabilities of the optimal and second-optimal actions, then satisficing above means optimizing. Let us call such “an optimal aspiration level”. Let the highest reward probability be and the second-highest one be . can be set optimally as follows:
[TABLE]
It is known that the regret increases at least in with the number of steps [16]. This is the result of assuming no knowledge of the agent on the reward distribution. By relaxing this assumption and allowing to be set as in Eq. 5, it will be shown that the regret is upper bounded by a finite value as in Proposition 2 described later.
Note that having an optimal aspiration level does not make a -armed bandit problem trivial. Even if we know a point between the optimal and second-optimal actions, we do not know exactly which action is optimal. Efficient identification of such an action is not trivial. In the next section, will be compared in terms of its performance with other algorithms, one of which needs some similar information on the reward distribution to be optimal.
Results
Analysis
We perform theoretical analysis of the basic satisficing and optimizing properties of . First, in Proposition 1, we prove that can stably choose actions above the aspiration level after a sufficient number of steps. Second, in Proposition 2, we prove that the regret of is upper bounded when an optimal aspiration level is given and satisficing becomes optimizing.
Guarantee of Satisficing
In the proof of Proposition 1, we adopt symbols clearly indicating the step number () and the chosen action () as follows. Both of the following represent values after steps: the mean reward
[TABLE]
and the value
[TABLE]
Proposition 1** (Theoretical Guarantee of Satisficing).**
Let be the reward probability of action . Let be the set of actions whose reward probability is greater than the aspiration level , and let be the set of actions whose reward probability is smaller than . Let , and , , where is supposed to be a non-empty set. Then, the following holds for .
After a sufficient number of steps, a satisfactory action with will be always chosen, and this state is stable.
In other words, by letting be the probability that event will occur,
[TABLE]
Subsequently, by N_{j}=\Bigl{\{}s\Bigm{|}\operatorname*{\mathrm{arg\leavevmode\nobreak\ max}}\limits_{a}RS(a,s)=a_{j}\Bigl{\}}, we denote the set of steps in which action is chosen. Let be the number of elements in set . First, we prove two claims.
Claim A**.**
[TABLE]
Proof.
(Claim A) () Suppose that and . If , is constant for greater than or equal to some number. This is a contradiction; hence, we have . () Suppose that and . By the law of large numbers, for any positive number , there exists some such that we have P\bigl{(}|E(a_{i},s)-p_{i}|<(R-p_{i})/2\bigr{)}>1-\epsilon for any integer greater than . Now, if , we have
[TABLE]
As , we have ; hence, . Therefore, P\bigl{(}RS(a_{i},s)\rightarrow-\infty\bigm{|}\#N_{i}=\infty\bigr{)}>1-\epsilon. Since is arbitrary, we obtain P\bigl{(}RS(a_{i},s)\rightarrow-\infty\bigm{|}\#N_{i}=\infty\bigr{)}=1. ∎
Claim B**.**
[TABLE]
Proof.
(Claim B) We assume that for any , . Then, for any , is constant for any greater than or equal to some number. Furthermore, for some , we have . Hence, by Claim A, we have
[TABLE]
However, the following statements contradict each other: (i) , (ii) , for any greater than or equal to some number. Hence, we obtain
[TABLE]
Now, the following formula holds.
[TABLE]
Therefore, we must have . ∎
Proposition 1** (again).**
[TABLE]
Proof.
(Proposition1) By Claim B, we have , . By the law of large numbers, for any positive number , there exists some such that we have P\bigl{(}|E(a_{k},s)-p_{k}|<(p_{k}-R)/2\bigr{)}>1-\epsilon for any integer greater than . Now, if , we have
[TABLE]
Hence, we have P\bigl{(}\text{for sufficiently large }s,\,\,\,RS(a_{k},s)>0\bigr{)}>1-\epsilon. Since is arbitrary, we obtain P\bigl{(}\text{for sufficiently large }s,\,\,\,\allowbreak RS(a_{k},s)>0\bigr{)}=1.
Here, we assume that there exists such that . Then, we may have by Claim A. On the other hand, follows from because for any sufficiently large . However, and contradict each other, which means that the initial assumption must be false. Hence, for any , holds. Therefore, the results obtained are summarized as , and , . From these results, the following follows immediately. \displaystyle P\Bigl{(}\operatorname*{\mathrm{arg\leavevmode\nobreak\ max}}_{a_{i}}RS(a_{i},s)\in A_{U}\Bigr{)}=1\,\,\,(s\rightarrow\infty). ∎
Theoretical Analysis of Regret
We prove that is upper bounded by a finite value when the level is set to the optimal aspiration level.
Proposition 2** (Finiteness of Regret of ).**
Let the highest reward probability of all the actions be and the second-highest reward probability be . Further, we set as (an optimal aspiration level). Then, the following holds for :
“There exists a monotonically increasing function for step number such that . Then, , where is constant. Thus, ”.
We conceived the following proof by referring the papers[20, 21, 22] on TOW (tug-of-war) dynamics model (hereinafter simply referred to as TOW). TOW is similar to (See Supplementary Information for the similarities and differences between and TOW). However, in their paper, the analysis of the finiteness of the regret by TOW was strictly limited to cases in which there are only two actions and the variances of the reward probabilities are equal. In the case of the bandit problems with the reward following the Bernoulli distributions, equal variance implies or . (Let be the variance of action . or .) Thus, the equal variance is a strong assumption. Here, we generalize the proof to prove finite regret with arms () and without assuming equal variance.
Proof.
(Proposition2) Suppose that . Let RS(a_{i},s)=n_{i}(s)\cdot\bigl{(}E(a_{i},s)-R\bigr{)}\,\,\,(i=1,2,\dotsc,K). The expectation and the variance of are and , respectively, where .
Note that
[TABLE]
holds, where , indicating the reward when action was chosen in the -th time. Let . Then,
[TABLE]
Since ,
[TABLE]
By Proposition 1, if the step number is sufficiently large, then with probability 1111This is an approximation. Also, it is not mathematically strict to fix when calculating the expected value and the variance of , and to assume that the trials are independent, when applying the central limit theorem. It is possible that the calculated upper bound of the regret is not accurate due to the errors resulting from the approximation and/or the above-mentioned assumption. However, the validity of the upper bound is empirically confirmed as shown in Fig. 1 and 2..
Hence,
[TABLE]
By Eq. (16) and the central limit theorem, follows the normal distribution with expectation and variance . The probability that is . Here, is the -function, which represents the tail distribution function of the standard normal distribution. Thus, . Let be the probability that action is chosen in the -th step.
Then, is given by
[TABLE]
where we set .
By using the Chernoff bound , we evaluate the upper bound of the regret.
[TABLE]
Therefore,
[TABLE]
This concludes the proof.
∎
When the Aspiration Level is Variable
Both of Propositions 1 and 2 assumed that the aspiration level is constant. When is variable or stochastic, similar propositions can be established just by slightly modifying the previous proofs assuming that is within a certain range. See Supplementary Information C for the modifications. The generalization assures that the upper bound of regret stays finite even when is not initially set but converges within after some finite time step.
Empirical Verification
We verify the proven properties through simulations. As in Proposition 2, , where . All the results below are the averaged results of 1,000 simulations. As an additional performance index, we consider accuracy, which is the proportion of the simulations in which the algorithm chose the optimal action in each step. Thus, the accuracy in the -th step is as follows.
accuracy = (Number of times action with the highest reward probability is chosen in the -th step) / (Total number of simulations).
First, we test whether the difference in reward probabilities can be detected, even if the difference is small, when the optimal aspiration level is set for . We test it with where . The result is shown in Fig. 1. The dotted line at the top in Fig. 1 (b) represents the upper bound of the regret shown by Proposition 2. We see that the accuracy nearly reaches 1 after steps, even if the difference is only 0.002 as in . Moreover, we see that the regret does not exceed the upper bound (Eq. (27)) calculated by Proposition 2.
Next, we conduct simulations to confirm the propositions with . The reward probability of each action is generated uniformly randomly from . The result is shown in Fig. 2. We can see that the accuracy converges to 1 and the regret does not exceed the upper bound (Eq. (27)) calculated by Proposition 2. Here, the calculated upper bound of the regret for is considerably higher than the actual regret compared with the case of . As we evaluate the probability of choosing action only by comparing with action having the highest reward probability as shown in Eq. (22) in the proof of Proposition 2, the probability of choosing is increasingly overestimated as the number of actions increases.
Comparison with Other Algorithms
Here, we clarify the performance and properties of by comparing it with some representative algorithms for the -armed bandit problems, namely UCB1-Tuned and [18]
UCB1-Tuned
Upper confidence bound (UCB) is an algorithm based on the idea that the value of relatively less tried actions (more uncertain) is potentially high, similar to ’s risk-seeking evaluation when unsatisfied [18]. The regret of UCB is guaranteed to increase in the logarithmic order, which is the theoretical limit [16]. We include the result of UCB1-Tuned (hereinafter referred to as UCB1T), which shows better performance compared to UCB1.
[TABLE]
Here, , and is the variance of the reward from choosing action . Further, 1/4 is the upper bound of the variance of the random variable following the binomial distribution. In the algorithm, the action with the highest UCB1T value is chosen (the greedy method). The first term of UCB1T, which is the mean reward, represents the already acquired knowledge (and its exploitation), whereas the second term, which decreases as action is tried more, expresses the (un-)reliability of (which leads to exploration). When , the second term cannot be calculated, but in the first steps, each action is chosen once so that the value of the second term for all the actions is subsequently finite.
To set the level such that satisficing implies optimization, it is necessary to have some point in the interval between the highest and second-highest reward probabilities, usually unknown to the agent. Thus, having such “optimal” is a type of “cheating”. However, when such information is available, it should be utilized well, and does so.
Furthermore, there is another algorithm, namely [18], which requires similar information for optimal performance. In this algorithm, the probability of random action selection, , is gradually reduced by annealing so that the regret of is guaranteed to be of the logarithmic order. It starts with maximal exploration (random action selection) and then gradually shifts to more exploitation as the information of the environment gets accumulated. In , there are two parameters and that are set as and . When there are arms, the stepwise decreasing sequence is defined as follows:
[TABLE]
The agent chooses action with the highest mean reward with probability , and it chooses a random action with probability for Let be the highest reward probability, and define . Then, the parameter needs to satisfy
[TABLE]
Further, needs to be known in advance. Thus, some information about the reward probabilities is required, as in the case of with the optimal aspiration level. In addition, the performance of is sensitive to the value of the parameter , and it is difficult to find the optimal value of [18].
On the other hand, determining the optimal aspiration level for may be easier. It does not require a parameter like , and is sufficient. More generally, it is sufficient to obtain the interval or the value of any point within the interval.
Existing Satisficing Models
Here, we introduce the existing satisficing models and briefly explain the difference between those models and . First, the framework that is the closest to ours is that of Bendor et al. on the heuristics of satisficing [12], which analyzes the two-armed bandit problems when the rewards are Bernoulli distributed. They mainly analyzed the limiting behavior of the policy model similar to . Their model is different from in that it gives a probability parameter of switching actions with a certain probability (not always), when unsatisfied. Therefore, the performance of their model is lower than that of .
The most recent and comprehensive study was conducted by Reverdy et al. [13] They decomposed satisficing into “satisfy” and “suffice” (from which the word “satisfice” is formed) and presented general problem settings that include the standard bandit problems and algorithms with optimal order. As their algorithm is an adaptation of the standard UCB [18], the difference between and their algorithm is similar to the difference between and UCB as described above. Furthermore, their analysis is limited to the bandit problems where the reward distributions are Gaussian. In their study, they extended the concept of regret and developed an algorithm that searches for actions that exceed the aspiration level with probability . They proved the finiteness of the regret for their algorithm when .
However, it should be noted that in their study, the definition of regret is changed. Specifically, the regret of their algorithm is calculated according to whether or not the expected reward exceeds the aspiration level with probability , and the definition that regards the regret occurring with probability as zero is adopted. If , their regret is calculated according to whether the expected reward always exceeds the aspiration level or not; therefore, it becomes the same framework as that of the ordinary bandit problems. In such cases, the regret of their algorithm increases in the logarithmic order, which is the theoretical limit, and it does not become finite. On the other hand, can achieve the finite regret without changing the definition of regret. Therefore, the purposes and problem settings are different in our study and their study.
According to the above-mentioned discussion, it is difficult to compare our study with other satisficing algorithms for reinforcement learning proposed in previous studies because the purposes and frameworks are different. It is sufficient to compare our approach with and UCB1. Accordingly, the other algorithms will not be handled directly hereafter.
Performance Comparison
We compare the performance of UCB1T, , , and with through numerical simulations. Furthermore, the reward probabilities are uniformly randomly selected from , and the average is over 1,000 simulations. As mentioned above, it is difficult to determine the parameter of . In this simulation, the regret of in the 10,000-th step is taken as a reference. It is empirically found by a long parameter sweep such that the regret of in the 10,000-th step is minimized at around . Hence, the results of are shown as comparison targets. We set as . As for and , we set the aspiration level to an optimal level, , so that we can evaluate the efficiency when satisficing implies optimization.
The results are shown in Fig. 3. As for accuracy, approaches 1 the fastest among these algorithms. As for regret, increases rapidly because it randomly chooses actions unless an action whose reward is above is found. The regret of remains small (and bound finitely), whereas UCB1T and diverge at a logarithmic order. In summary, we can see that with the optimal aspiration level shows better performance than UCB1T, , and .
Analysis of the Expected Change in Value Functions
Here, we qualitatively consider why with the optimal aspiration level performs better than the other algorithms. Let us consider how the value of in the -th step changes when action is chosen in the -th step. In the following formula,
[TABLE]
is the number of times a reward of 1 is obtained in the choice of action from the first to the -th step. In the -th step, the value of changes with probability to
[TABLE]
whereas it otherwise changes with probability to
[TABLE]
Let . Then, the expected value of the change, , is as follows:
[TABLE]
Thus, we see that the following relationships hold in any step:
[TABLE]
Let be set to an optimal level. Then, relationship 35 means that once the optimal action is chosen, will keep increasing on average, and it will continue to be chosen. On the other hand, relationship 36 means that if a non-optimal action has the highest value, and continues to be chosen for a while, then the value keeps decreasing on average. The value for other actions remains invariant. Therefore, at some point, another action than will start to be chosen. Further, note that the value decreases at an average rate of . Therefore, on average, the lower the reward probability of an action, the faster the action will stop being chosen, and another action will start being chosen.
To clarify the idiosyncrasies of , we carry out similar analyses for other value functions. First, let us analyze the mean reward. The value function is . When action is chosen, is given by
[TABLE]
whereas the values for other actions do not change. Further, is positive if and negative if , and both cases may occur regardless of the reward probability because is a variable, in contrast to the constant for . If action is chosen for a sufficient number of times, holds. Then, it leads to , and remains nearly unchanged. This implies that there is a possibility that a non-highest action keeps to be chosen (trapped into a local optimum). Let us consider the simplest example where there are only two actions (with ), and choosing the optimal action does not give much rewards, leading to and . As increases, converges to , and the relationship of becomes fixed because of . This leads to being chosen constantly. To avoid the local optima, prevents a non-highest action from being continuously chosen by randomly choosing actions with probability . With the mean reward, unlike , we cannot say that the smaller the reward probability of the action chosen once, the faster on average is the switching of the agent to choose another action.
Next, let us analyze UCB1, which is the simplest algorithm in the UCB family.
[TABLE]
When action is chosen, the expected change in the UCB1 value is
[TABLE]
whereas the expected change of non-chosen action is as follows:
[TABLE]
In Eq. (39), the first term is the same as that in Eq. (37). In Eq. (39), the second and third terms approach zero if action continues to be chosen. Hence, if we consider only Eq. (39), there is a possibility that the non-highest action continues to be chosen, as with Eq. (37). However, in UCB1, the value function of non-chosen action also changes, as in Eq. (40). Moreover, we can see that the value of the non-chosen action increases infinitely because of the second term of Eq. (38). As a result, a non-highest action does not continue to be chosen.
In Eq. (39), the first term is positive if and negative if , and both cases may occur regardless of the reward probability because is a variable, as it is for above. On the other hand, the second term between the parentheses is negative if , which results from the fact that monotonically decreases with . As a result, may be positive or negative, regardless of the reward probability. Therefore, UCB1 does not have the property of whereby the action with a lower reward probability will be switched from earlier.
Based on the analyses presented above, let us reconsider the form of . Starting from the most basic value function of the mean reward, , is formed through two operations, and . If it is merely , the value function works exactly as the original under the greedy policy. On the other hand, if only is applied, the value function is , and it is a special case of with where any action is satisfactory. With , the agent will continue to choose the first action that gives a reward of 1. By applying the two operations, we acquire the property of , the constant change in the value, regardless of the step number . Therefore, the value of an unsatisfactory action (with the reward probability below the aspiration level) constantly decreases on average; as a result, the action will cease to be chosen at some point. Furthermore, we can say that the smaller the reward probability of the action chosen once, the faster on average is the switching of the agent to the choice of other actions. As shown above, UCB and have no such property. Therefore, this property is considered to be one of the reasons why the performance of using the optimal aspiration level is superior to that of other basic algorithms.
Discussion
In this paper, we introduced a simple model called that implements a satisficing strategy for the -armed bandit problems, which constitute one of the most basic classes of reinforcement learning tasks. We proved two propositions. One is that is guaranteed to find a satisfactory action with the reward probability above the aspiration level. The other is that the regret (expected loss) of is upper bounded by a finite value when an optimal aspiration level (where satisficing implies optimizing) is given. Then, we confirmed the results through numerical simulations and compared the performance of with that of other representative algorithms for the -armed bandit problems. In addition, we analyzed the property of relative to other algorithms and validated why has its own form.
Except in Proposition 1, we assumed that we can set the aspiration level to an optimal level. As the optimal aspiration is not always available to the agent, a future research direction would be to develop an algorithm that can learn an optimal aspiration level online. As a preliminary result, an algorithm that exploits the properties of has shown performance comparable to that of Thompson sampling [23], although it has not been theoretically guaranteed thus far [24].
There are many other advantages of besides those mentioned in this paper. For example, the satisficing behavior is scalable in the sense that its performance does not depend on the scale of the problems, such as the number of actions, but rather on the proportion of satisfactory actions, unlike optimization algorithms [15]. In addition, as is a simple value function without assumptions such as the family of reward probability distributions, it can be applied to other reinforcement learning tasks through some straightforward generalization. In fact, it has been shown that the generalized can conduct autonomous and efficient searches in a robotic motion learning task in which a robot learns to perform giant swings (acrobot) [14].
One of the computational advantages of satisficing, compared to optimization, is that it can convert an optimization problem into a decision problem. With , the guaranteed satisficing algorithm, and at a certain level, we can efficiently determine whether there is an action whose value is above . The decision framework is especially useful when a certain level of reward, rather than the optimal level, is necessary. It also facilitates parallelization. For example, we can set the aspiration levels to agents in ascending order, respectively, and make the agents execute a certain task in parallel. If the task succeeds at the level and fails at the level , we can see that the optimal solution exists somewhere in , and the interval may be incrementally narrowed down. This is somewhat close to human learning for solving a task. When trying to solve a task, we usually do not randomly try and err in a purely bottom-up manner. Instead, we tend to adopt a top-down constraint in our trials, such as trying to run one mile in four minutes. Guaranteed satisficing may lead to reinforcement learning methods that solve tasks somewhat similarly to humans.
Acknowledgements
This work was partially supported by JSPS KAKENHI Grant Number 17H04696.
Author contributions statement
T.T. and A.T. conceived the analyses. A.T. conducted the proofs and experiments. Both the authors wrote and reviewed the manuscript.
Additional information
Competing interests: The authors declare no competing interests.
Supplementary information
In this supplementary material, two distinctive aspects of and a generalization of the two propositions in the main text are discussed. First, we show that can be considered as a generalization of another model, [25]. in the bandit setting is based on the premise that high performance can be achieved through competitive evaluation of actions. However, our generalization from to shows that competitive evaluation appears only in the two-armed settings, and in general (in the -armed settings), the fundamental is the risk-sensitive satisficing behavior. Second, we compare with the Tug-of-war (TOW) dynamics models [20, 21, 22], which was referred to in the proof of Proposition 2. TOW is based on the notion of conservation of physical quantities, and it leads to competitive evaluation. We show that, under certain conditions, has the same mathematical form as a part of the recent TOW dynamics models. In addition, and TOW are both limited in terms of their application to the evaluation of only two actions (or two classes of actions). On the other hand, as materialized in , the notion of risk-sensitive satisficing enables generalization (to an arbitrary number of actions), simplification, conceptual clarity, and high performance in terms of satisficing, as suggested in the main text of the paper. Third, we slightly generalize Propositions 1 and 2 and their proofs in the main text assuming that the aspiration level is within a certain range.
A. as a generalization of
First, we show that is a generalization of another value function , from the number of actions to arbitrary and from constant aspiration level 0.5 to variable . discussed in this paper was formerly called reference satisficing [14, 15]. It was subsequently renamed as risk-sensitive satisficing to characterize it more specifically, and abbreviated invariantly as . contains model in a special form, which was first introduced by Shinohara et al. as a causal reasoning model [25]. The model was later termed as the (rigidly symmetric) model [26], and was then used as a value function [27] in the bandit problems. Subsequent studies applied in the two-armed bandit problems, and the performance of was found to be similar to that of [27], which is a more complicated model. An analysis of these behaviors from a satisficing perspective was first published in 2013 [28, 29]. The aspiration level for satisficing was made variable in 2011 [30]. Subsequently, in 2012[31], its generalization from two to any arbitrary number of actions of the model was proposed. However, is much more complicated than , and the analysis was rather indirect. Hereafter, we show the equivalence of and under certain conditions (for two actions with ).
Let and be actions in a two-armed bandit problem. Let be the number of times the choice of action has given reward 1, and let be the number of times the choice of action X has given reward 0 (no reward). Thus, the mean reward is . Here, defines the values of actions and as follows:
[TABLE]
These comparative evaluations identify both the obtaining of reward from action and not obtaining of reward from action . Hence, holds. Because the denominator is common, the comparison of the two values eventually results in the selection of action if the following inequality holds; if the inequality does not hold, action is selected:
[TABLE]
From the above inequality, we can see that transitive law is established when adding action . That is, let the evaluation of in comparison with be represented as . If and , then . Thus, we see that the comparable number of actions is not necessarily . The inequality (43) can be expressed as
[TABLE]
Using the notations presented in this paper, and holds. Then,
[TABLE]
It can be seen that both sides of inequality (47) are identical to the form of (equation (4) in the main article) with . Because the value of a set of arbitrary actions can be totally ordered thanks to the property of transitivity, it is only necessary to calculate the value for each action, independently of all the other actions, and choose the action with the maximum value.
B. Comparison of and TOW
We referred to the TOW dynamics model [20, 21, 22] (hereafter simply referred to as TOW) in the proof of Proposition 2. Here, we compare and TOW, and describe the relative advantages of over TOW. There are many variations of TOW, starting from around 2010 [32]. Here, we focus on recent papers [21, 22] where the proposed model of TOW is the closest to that of . Let be a random variable, representing the reward obtained by the -th choice of the action . Something like the value of action in TOW can be expressed as
[TABLE]
where is a parameter.
Let be the number of time action is chosen, and be the average rewards obtained by choosing action , such that . Although in the main text of the paper, the probability distributions of the rewards were assumed to be the Bernoulli distributions, herein, the distribution does not necessarily have to be Bernoulli. The value function of the action of is equivalent to the following form, as given in the proof of Proposition 2:
[TABLE]
When parameter in (48) is interpreted as the aspiration level in equation (49), has the same mathematical form as a part of the recent TOW dynamics models under certain conditions. Hence, the regret calculation of TOW can be applied to as well, and the regret of also is upper bounded like TOW. In this work, we relaxed the assumption of equal variance in the proof for TOW.
However, there exist certain differences between and TOW. The primary difference is that they model totally different phenomena. is modeled on how humans make decisions (satisficing), while taking into account the associated risks. Moreover, as explained in Supplementary information A, is also a generalized model of model in causal reasoning. On the other hand, TOW is derived from physical laws like volume conservation. An advantage of over TOW lies in its simplicity, clarity, and generalizability. As regards clarity, is the product of “reliability of obtained information” and “degree of satisficing,” and the parameter is associated to “aspiration.” On the other hand, the interpretation of the parameter of TOW, which corresponds to in , is not necessarily clear. Therefore, through straightforward generalization of these two constituent concepts, need to be applied not only to the -armed bandit problems (instead of two-armed) but also generally to reinforcement learning settings [14].
C. Propositions 1 and 2 When the Aspiration Level is Variable
Both of Propositions 1 and 2 assume that the aspiration level is constant. When is variable or stochastic, similar propositions can be established just by slightly modifying the previous proofs assuming that is within a certain range. We show only the changes made in Proposition 3 from Proposition 1, and in Proposition 4 from 2. In the proofs below, the symbols are the same as Propositions 1 and 2 except for the ones specified below. Let the minimum and the maximum of the variable aspiration level be and , respectively.
Proposition 3** (Modified Proposition 1 for Variable Aspiration Level ).**
We assume that the both of and are invariant even if the aspiration level changes temporally or stochastically. More specifically, we assume that holds, where and are the maximum of the reward probabilities in and the minimum of the reward probabilities in , respectively. Under this assumption, Proposition 1 is established as it is.
Proof.
The proof of Claim A for Proposition 1 needs to be changed as follows in the part where the law of large numbers is used. For any positive number , there exists some such that we have P\bigl{(}|E(a_{i},s)-p_{i}|<(R_{\min}-p_{i})/2\bigr{)}>1-\epsilon for any integer greater than . Now, if , we have RS(a_{i},s)=n_{i}(s)\cdot\bigl{(}E(a_{i},s)-R\bigr{)}<n_{i}(s)\cdot\bigl{(}p_{i}+(R_{\min}-p_{i})/2-R_{\min}\bigr{)}=n_{i}(s)\cdot(p_{i}-R_{\min})/2<0. Hereafter the proof is the same as that of Claim A in Proposition 1. The proof of Claim B needs no change.
The proof of Proposition 1 needs to be similarly changed as follows. For any positive number , there exists some such that we have P\bigl{(}|E(a_{k},s)-p_{k}|<(p_{k}-R_{\max})/2\bigr{)}>1-\epsilon for any integer greater than . Now if , we have RS(a_{k},s)=n_{k}(s)\cdot\bigl{(}E(a_{k},s)-R\bigr{)}>n_{k}(s)\cdot\bigl{(}p_{k}+(R_{\max}-p_{k})/2-R_{\max}\bigr{)}=n_{k}(s)\cdot(p_{k}-R_{\max})/2>0. Hereafter the proof is the same as that of Proposition 1. ∎
Proposition 4** (Modified Proposition 2 for the Variable Aspiration Level ).**
We assume that the aspiration level satisfies , even if the aspiration level changes temporally or stochastically. Under this assumption, we can still prove that the regret is upper bounded by a finite value.
Proof.
Let RS(a_{i},s)=n_{i}(s)\cdot\bigl{(}E(a_{i},s)-R\bigr{)}\,\,\,(i=1,2,\dotsc,K). Here, we define as follows: RS_{bd}(a_{1},s)=n_{1}(s)\cdot\bigl{(}E(a_{1},s)-R_{\max}\bigr{)}\leq n_{1}(s)\cdot\bigl{(}E(a_{1},s)-R\bigr{)}=RS(a_{1},s). Also, we define for , as follows: RS_{bd}(a_{i},s)=n_{i}(s)\cdot\bigl{(}E(a_{i},s)-R_{\min}\bigr{)}\geq n_{i}(s)\cdot\bigl{(}E(a_{i},s)-R\bigr{)}=RS(a_{i},s). The suffix means using the boundary of the aspiration level . If we let , then, we have RS_{bd}(a_{i},s)=n_{i}(s)\cdot\bigl{(}E(a_{i},s)-R_{i}\bigr{)}\,\,\,(i=1,2,\dotsc,K).
The expectation and the variance of are and , respectively, where . Let , and . Note that holds because and .
, which is the expectation of , is evaluated as follows:
[TABLE]
By Proposition 3, if the step number is sufficiently large, then with probability 1 (the same approximation as in the proof of Proposition 2, hence the same note applies). Hence, E[\Delta RS_{bd,i}(s)]\geq s\cdot\leavevmode\nobreak\ \min\bigl{(}(p_{1}-R_{\max}),(R_{\min}-p_{2})\bigr{)}. Also, of the variance of is evaluated as follows: , where .
By the central limit theorem, follows the normal distribution with expectation and variance . The probability that is . Then, , which the probability that action is chosen in the -th step, is given by
[TABLE]
where we set \phi_{i}=\min\bigl{(}(p_{1}-R_{\max}),(R_{\min}-p_{2})\bigr{)}/(\sigma_{1,i}). Hereafter the proof is the same as that of Proposition 2. As a result, the upper bound of regret is obtained by replacing in Eq. (27) with set in Eq. (51). ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Mnih, V. et al. Human-level control through deep reinforcement learning. \Journal Title Nature 518 , 529–533, DOI: 10.1038/nature 14236 (2015).
- 2[2] Silver, D. et al. Mastering the game of go with deep neural networks and tree search. \Journal Title Nature 529 , 484–489, DOI: 10.1038/nature 16961 (2016).
- 3[3] Muse, D. & Wermter, S. Actor-critic learning for platform-independent robot navigation. \Journal Title Cognitive Computation 1 , 203–220, DOI: 10.1007/s 12559-009-9021-z (2009).
- 4[4] Zhao, F., Zeng, Y., Wang, G., Bai, J. & Xu, B. A brain-inspired decision making model based on top-down biasing of prefrontal cortex to basal ganglia and its application in autonomous uav explorations. \Journal Title Cognitive Computation 10 , 296–306, DOI: 10.1007/s 12559-017-9511-3 (2018).
- 5[5] Simon, H. A. Models of Man: Social and Rational (John Wiley and Sons, Inc., New York, 1957).
- 6[6] Lewis, R. L., Howes, A. & Singh, S. Computational rationality: Linking mechanism and behavior through bounded utility maximization. \Journal Title Topics in Cognitive Science 6 , 279–311, DOI: 10.1111/tops.12086 (2014).
- 7[7] Gershman, S. J., Horvitz, E. J. & Tenenbaum, J. B. Computational rationality: A converging paradigm for intelligence in brains, minds, and machines. \Journal Title Science 349 , 273–278, DOI: 10.1126/science.aac 6076 (2015).
- 8[8] Tenenbaum, J. B., Kemp, C., Griffiths, T. L. & Goodman, N. D. How to grow a mind: Statistics, structure, and abstraction. \Journal Title Science 331 , 1279–1285, DOI: 10.1126/science.1192788 (2011).