TL;DR
This paper introduces a runtime detection method for adversarial samples in deep neural networks by measuring their sensitivity to random model mutations, effectively distinguishing adversarial from normal inputs.
Contribution
It proposes a novel sensitivity-based detection approach using model mutation testing and statistical hypothesis testing, improving adversarial sample detection accuracy.
Findings
Effective detection of adversarial samples on MNIST and CIFAR10
High detection accuracy with low false positives
Detects samples generated by state-of-the-art attacks
Abstract
Deep neural networks (DNN) have been shown to be useful in a wide range of applications. However, they are also known to be vulnerable to adversarial samples. By transforming a normal sample with some carefully crafted human imperceptible perturbations, even highly accurate DNN make wrong decisions. Multiple defense mechanisms have been proposed which aim to hinder the generation of such adversarial samples. However, a recent work show that most of them are ineffective. In this work, we propose an alternative approach to detect adversarial samples at runtime. Our main observation is that adversarial samples are much more sensitive than normal samples if we impose random mutations on the DNN. We thus first propose a measure of `sensitivity' and show empirically that normal samples and adversarial samples have distinguishable sensitivity. We then integrate statistical hypothesis testing…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2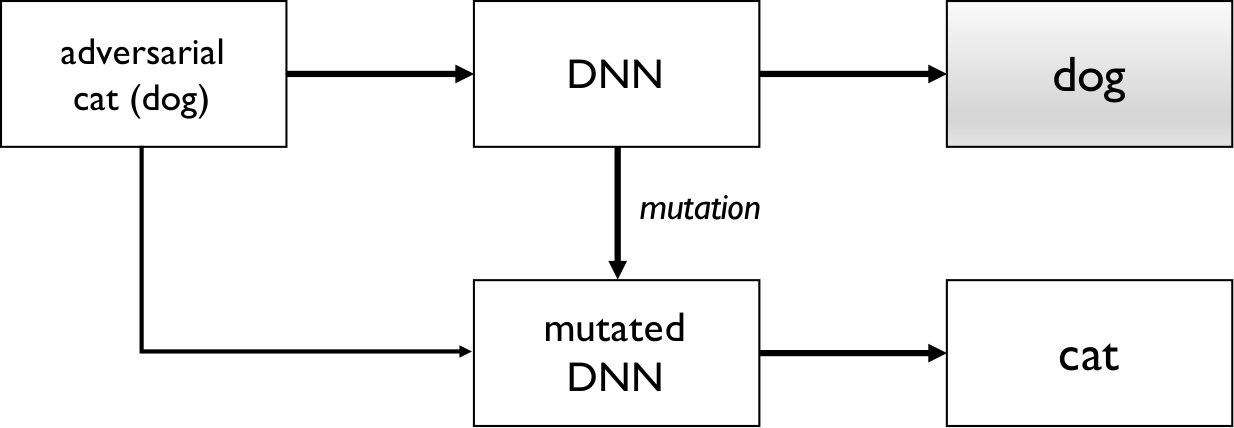 Figure 3
Figure 3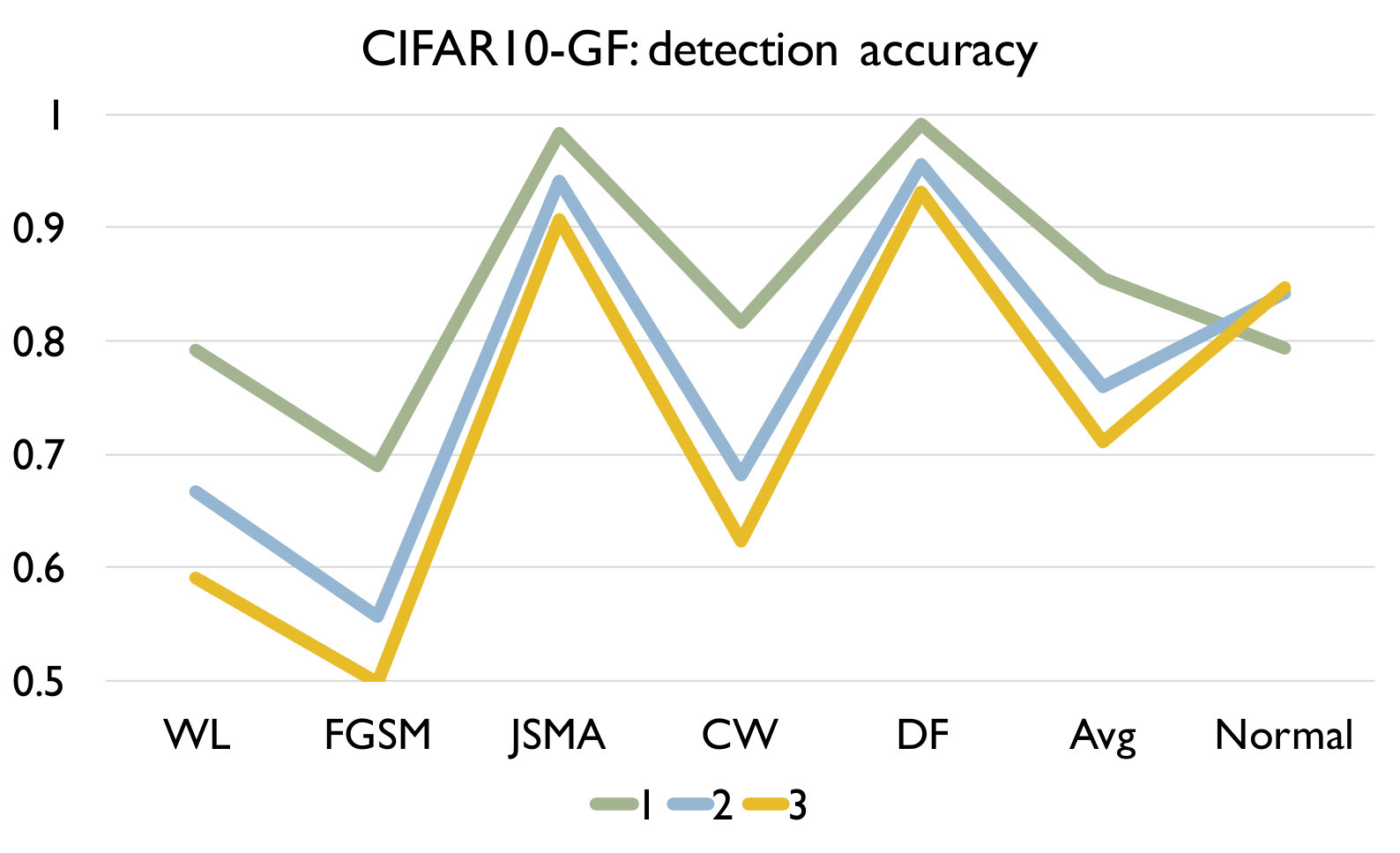 Figure 4
Figure 4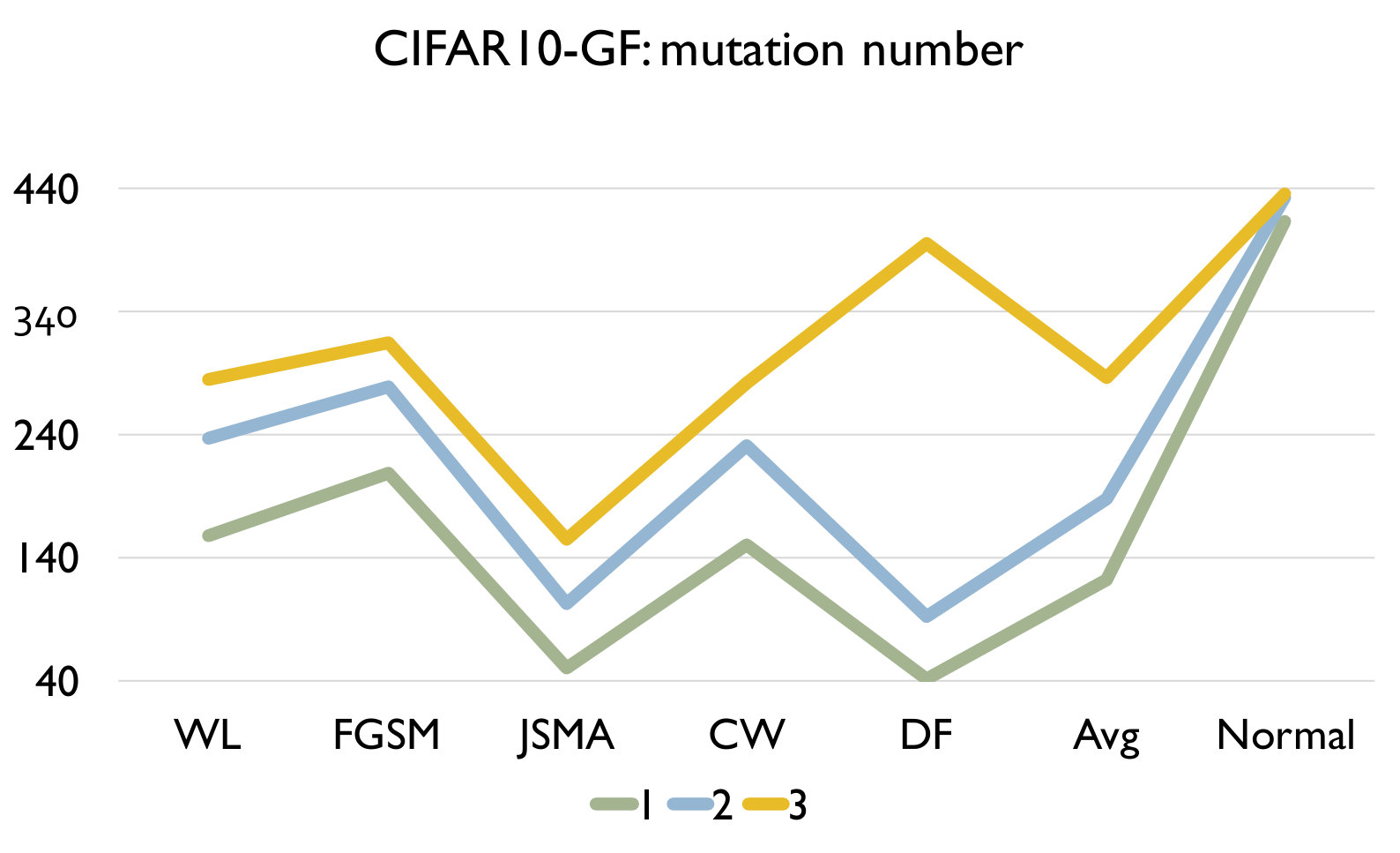 Figure 5
Figure 5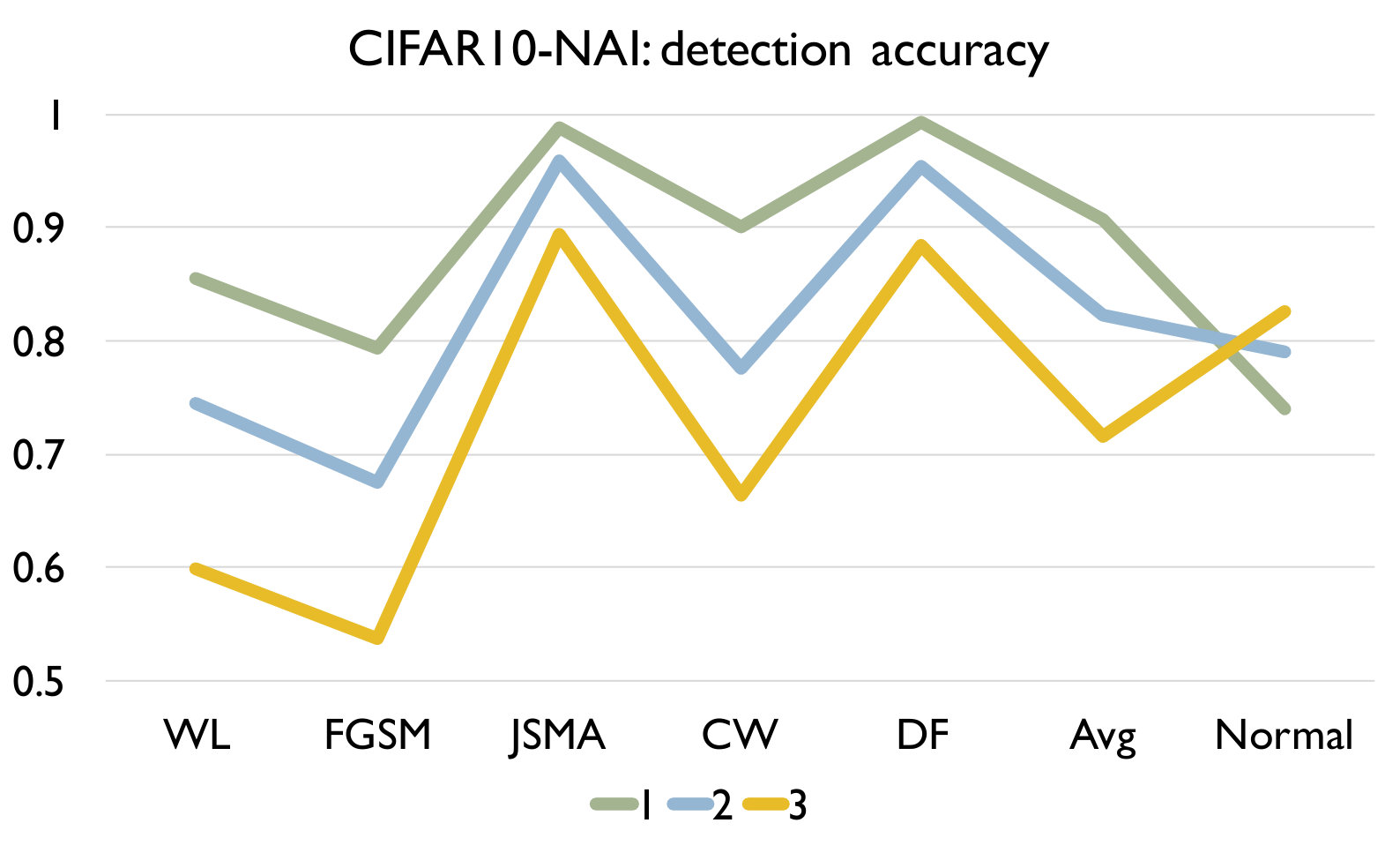 Figure 6
Figure 6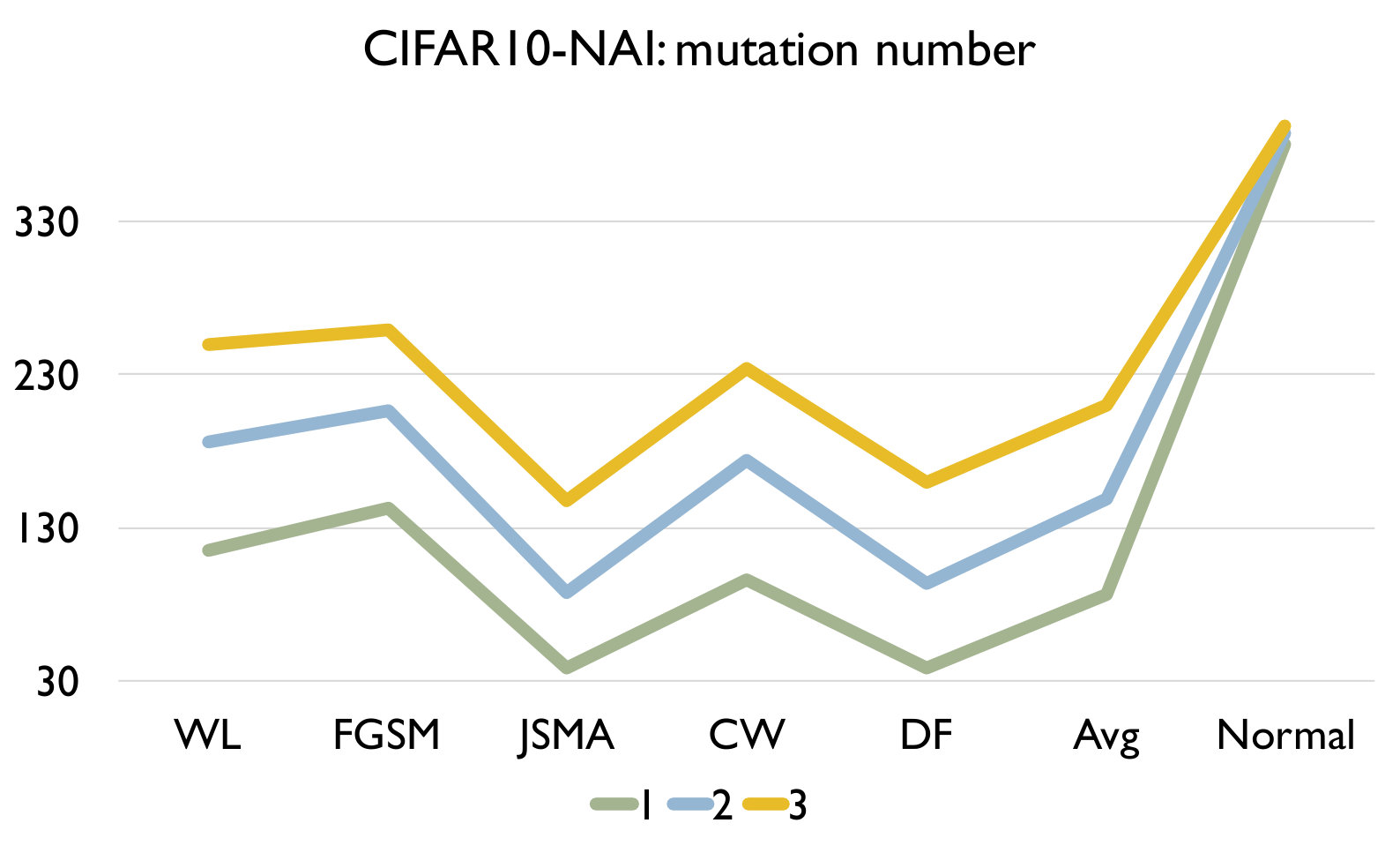 Figure 7
Figure 7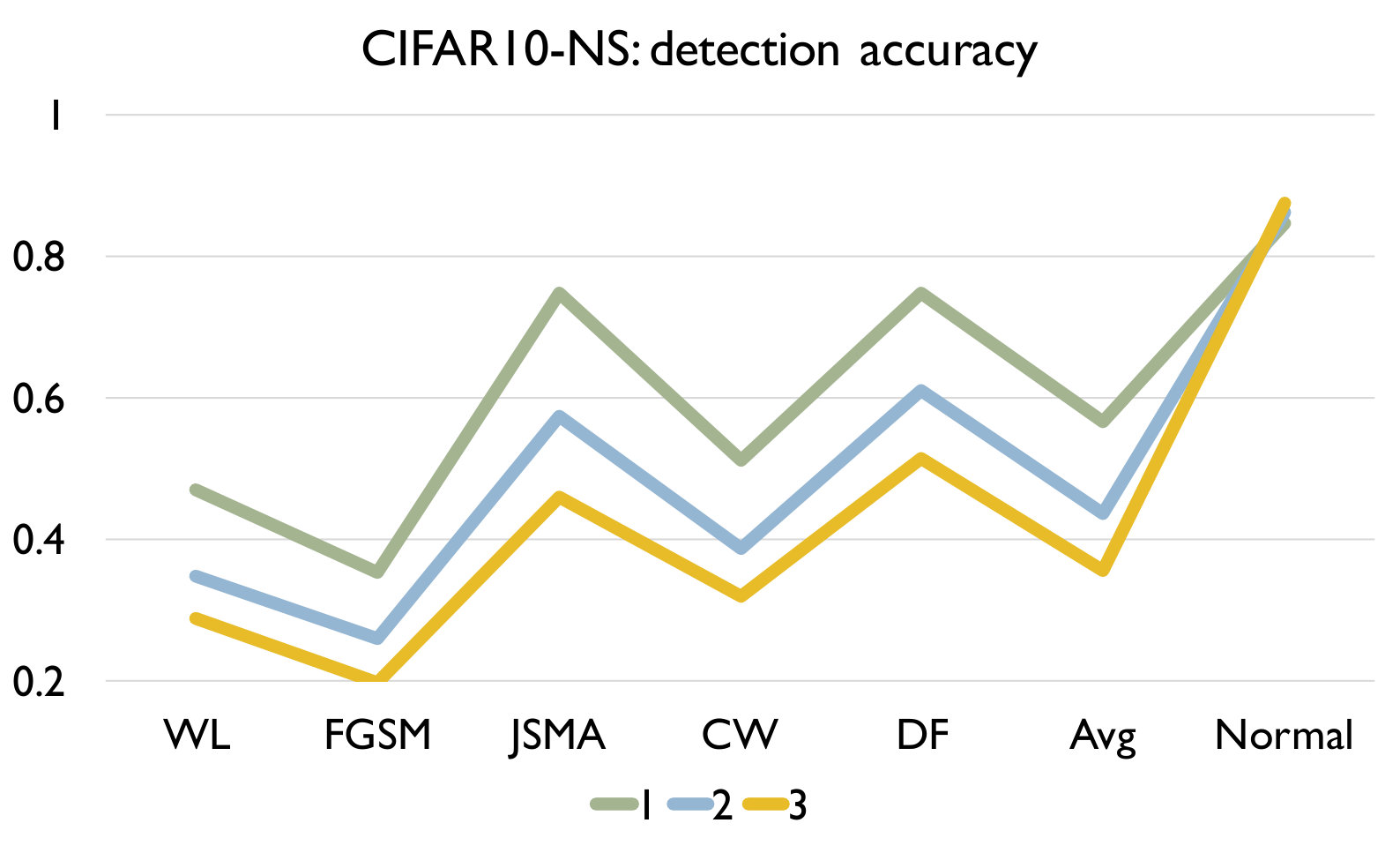 Figure 8
Figure 8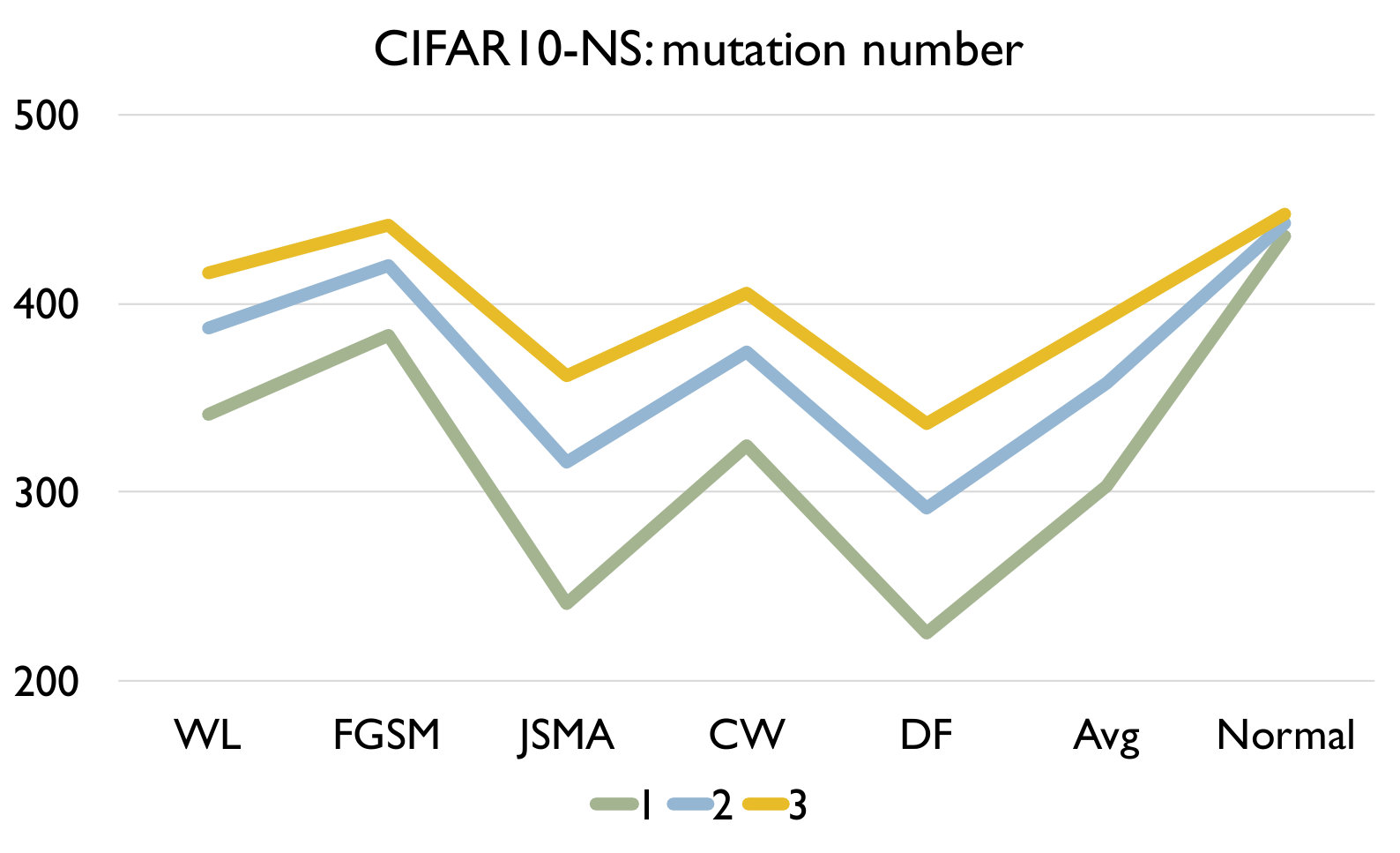 Figure 9
Figure 9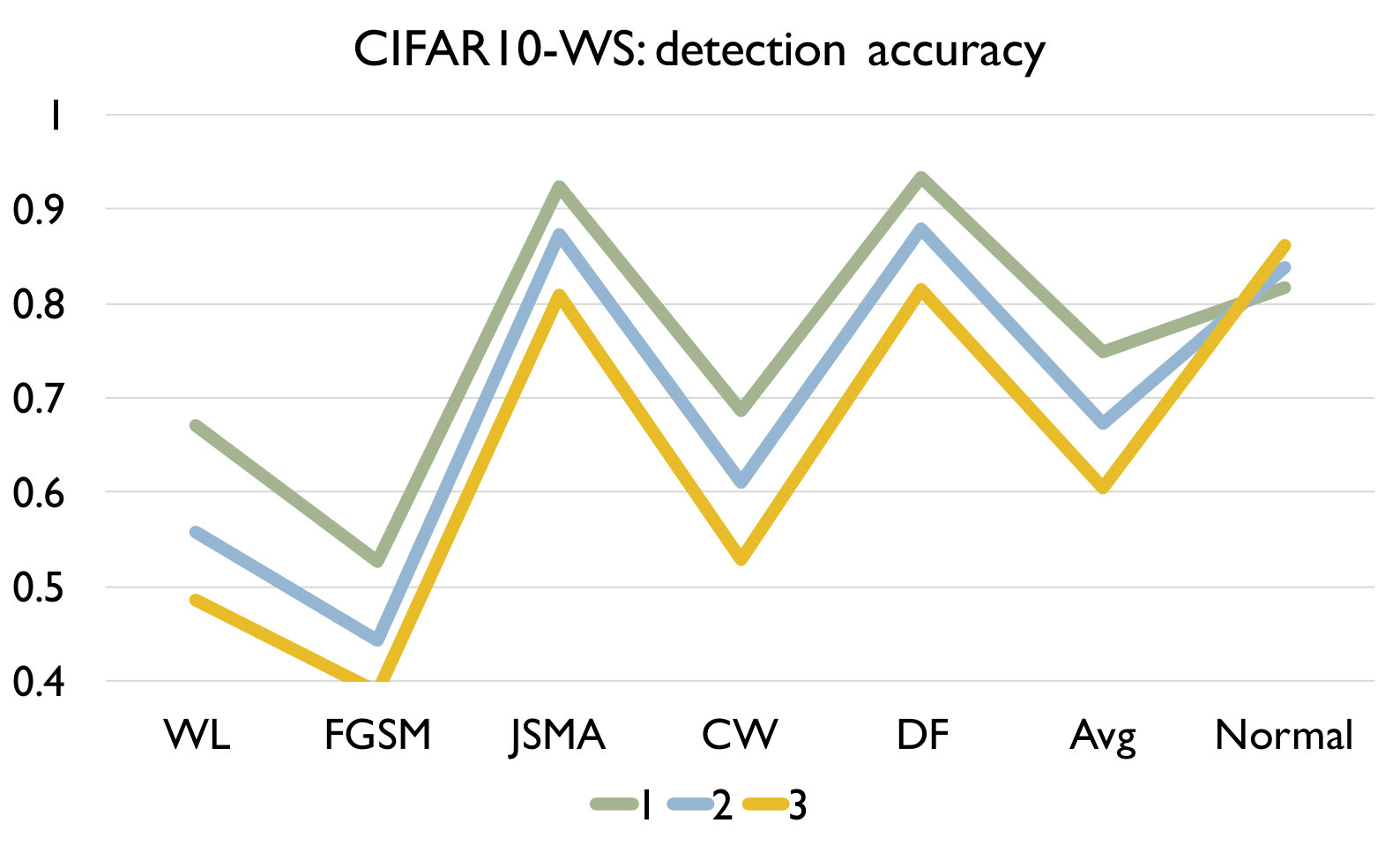 Figure 10
Figure 10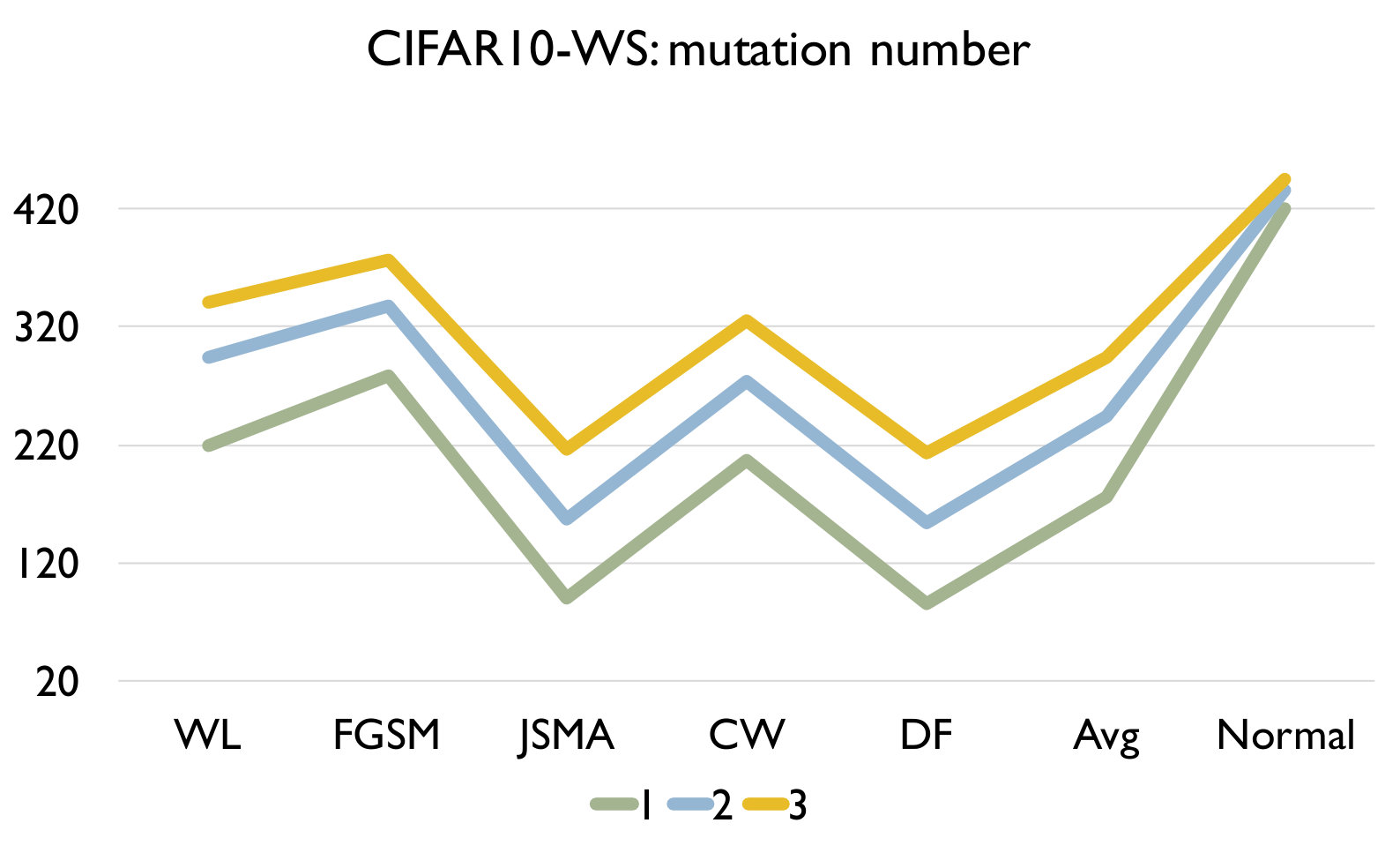 Figure 11
Figure 11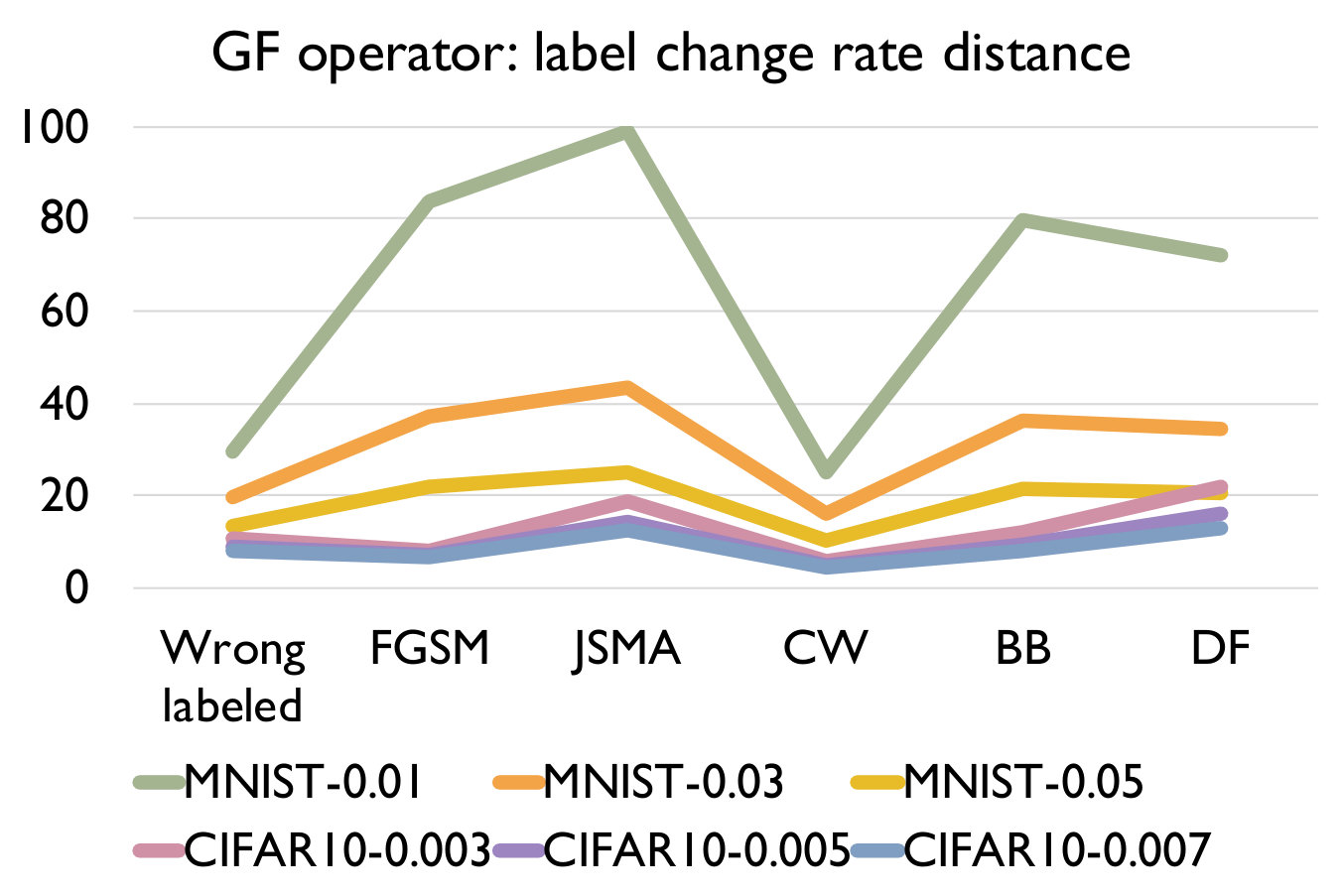 Figure 12
Figure 12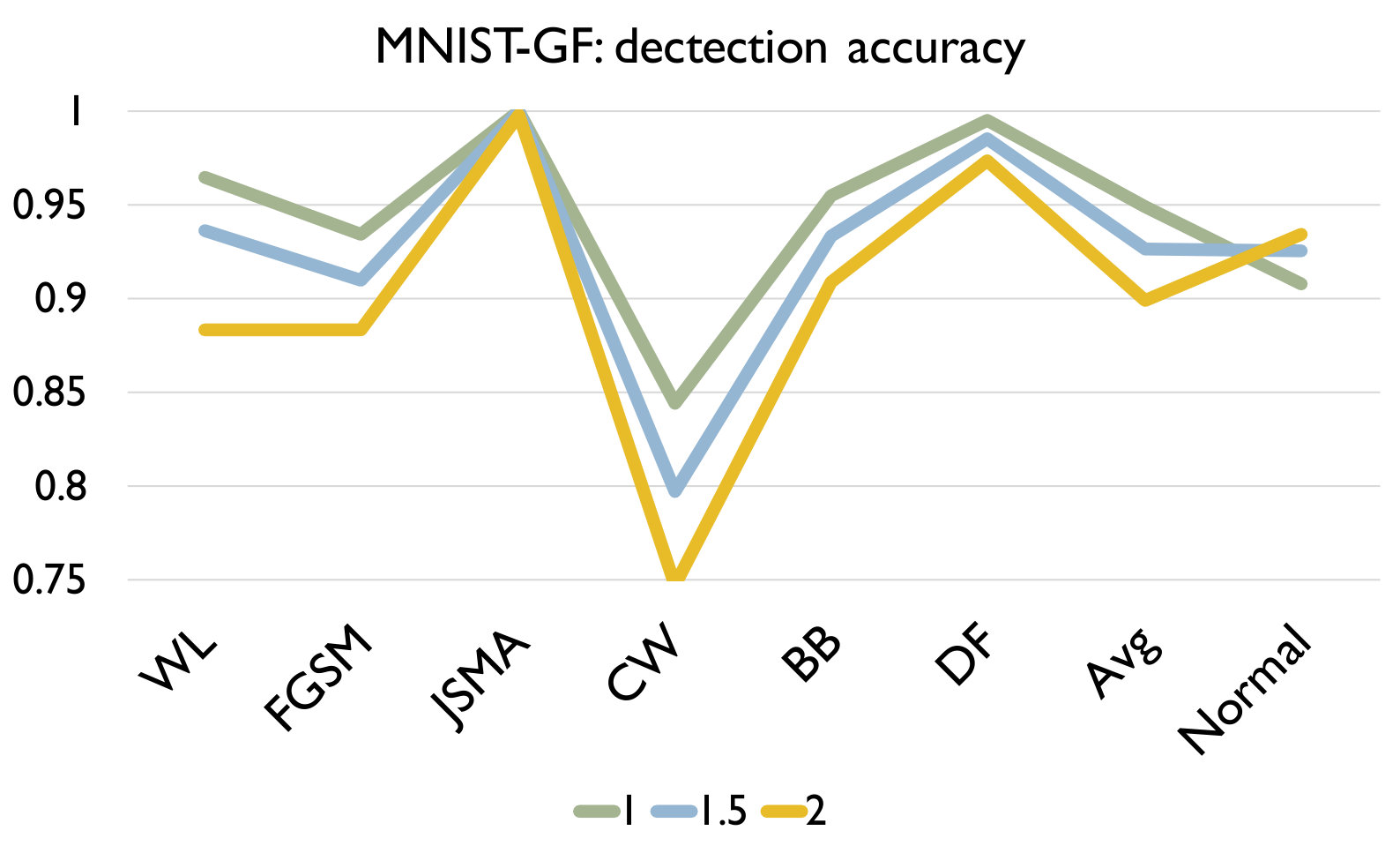 Figure 13
Figure 13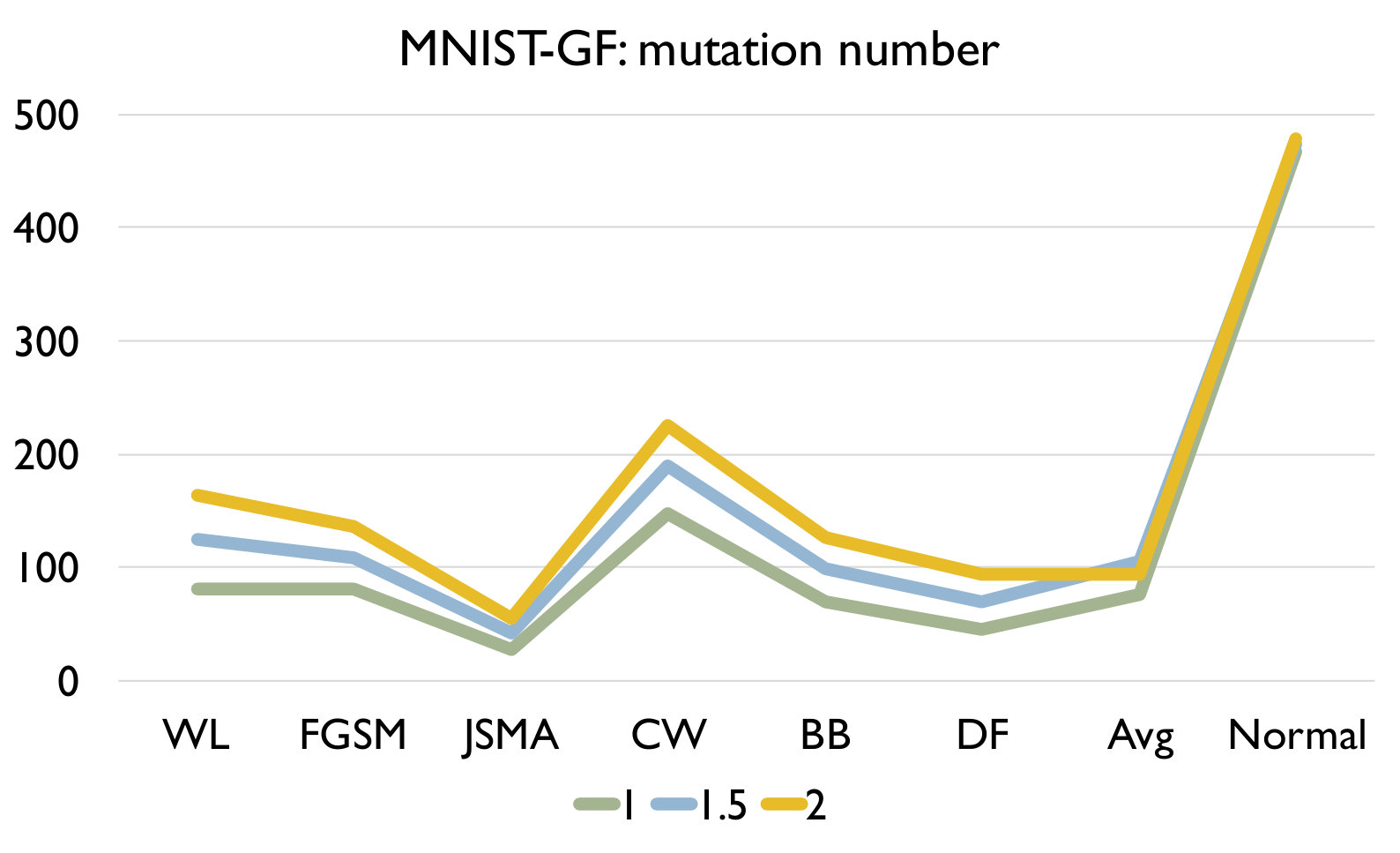 Figure 14
Figure 14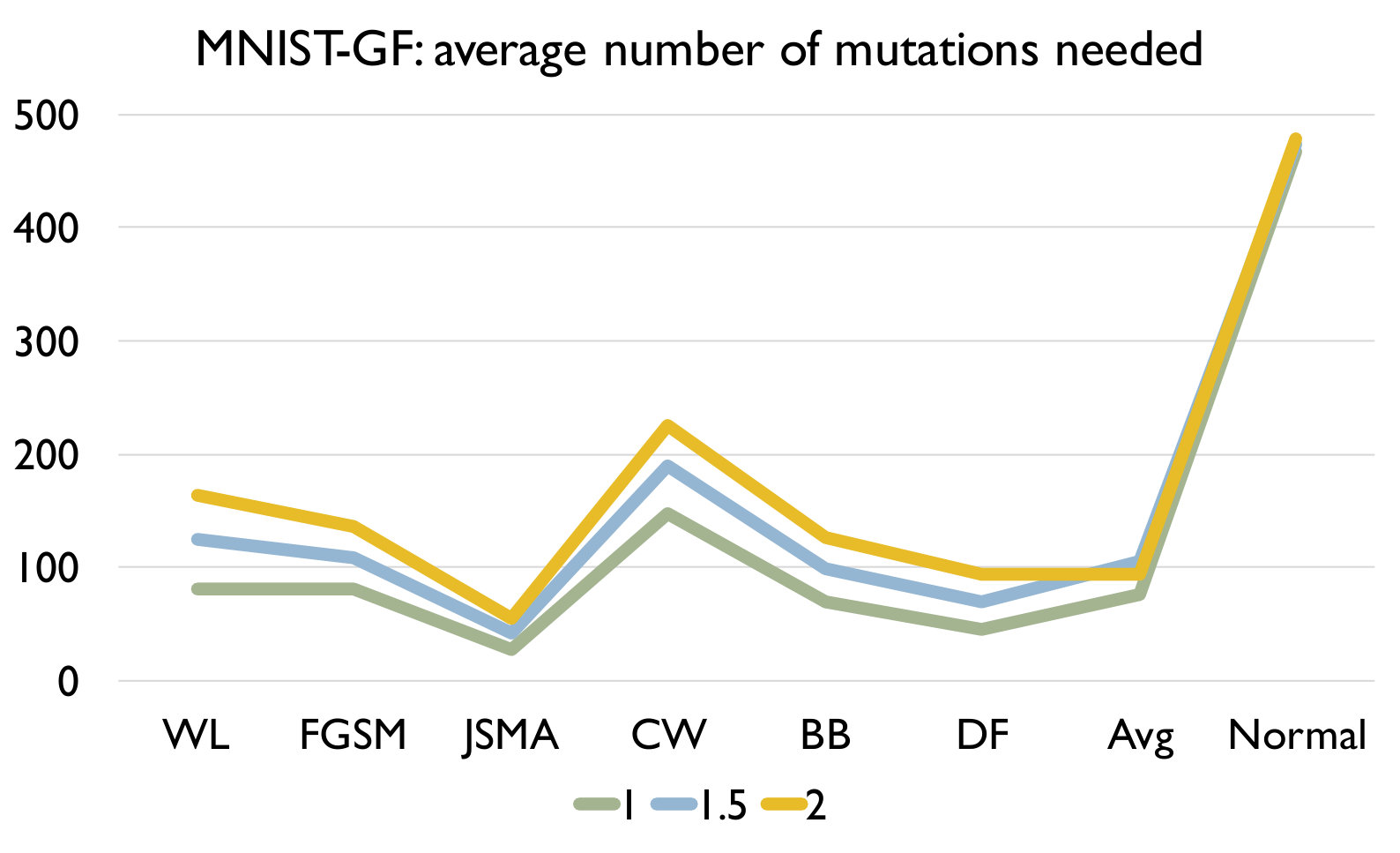 Figure 15
Figure 15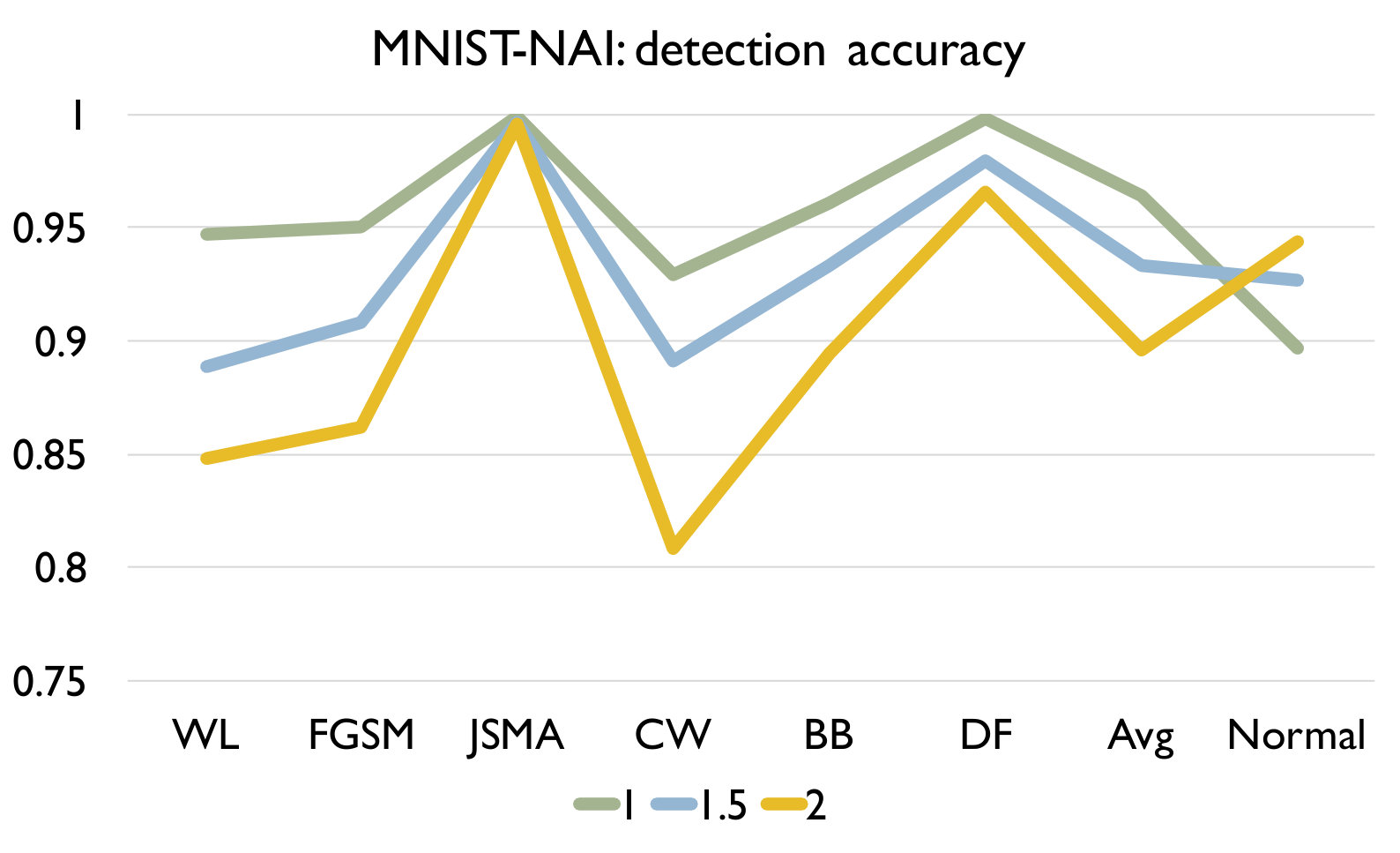 Figure 16
Figure 16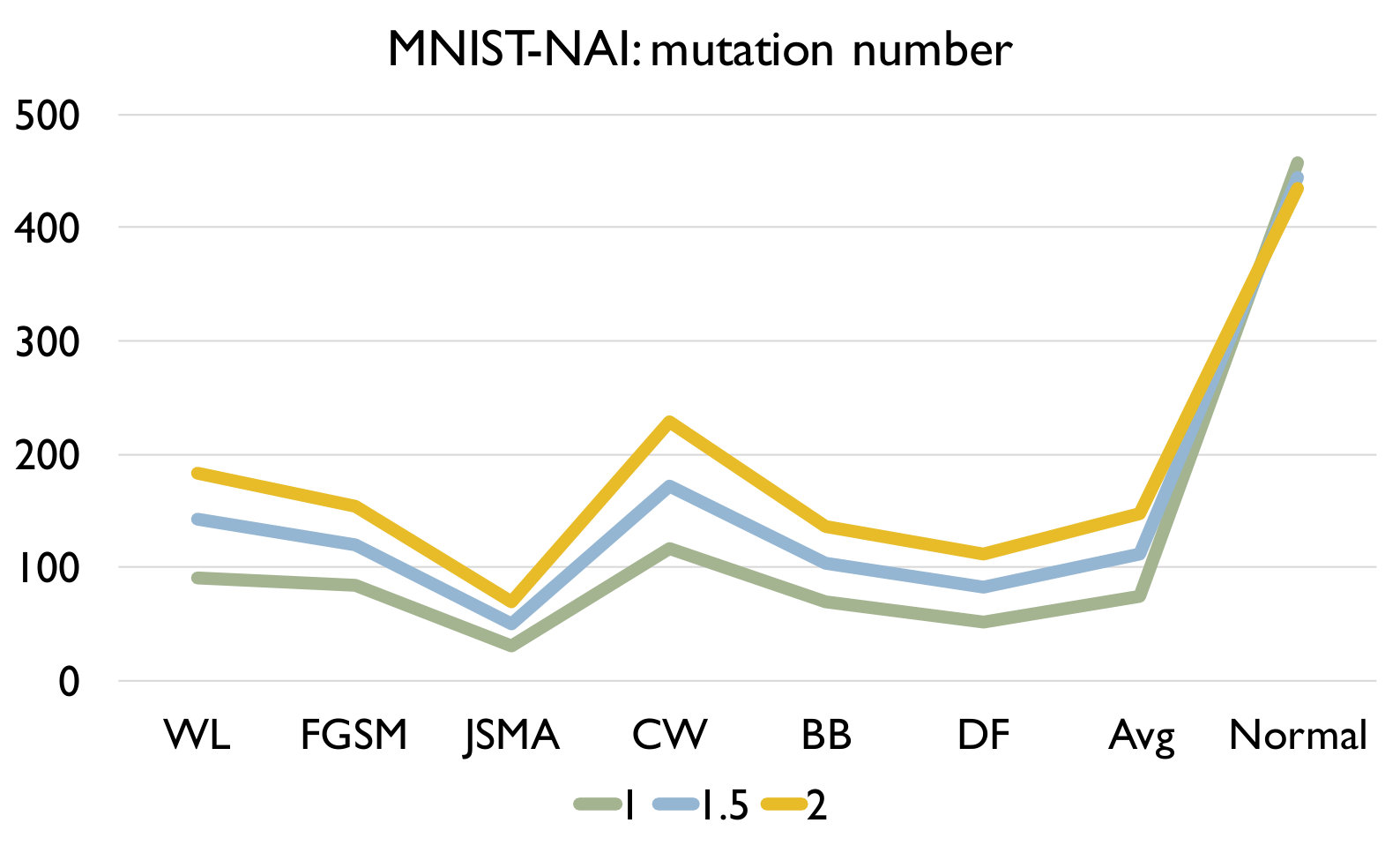 Figure 17
Figure 17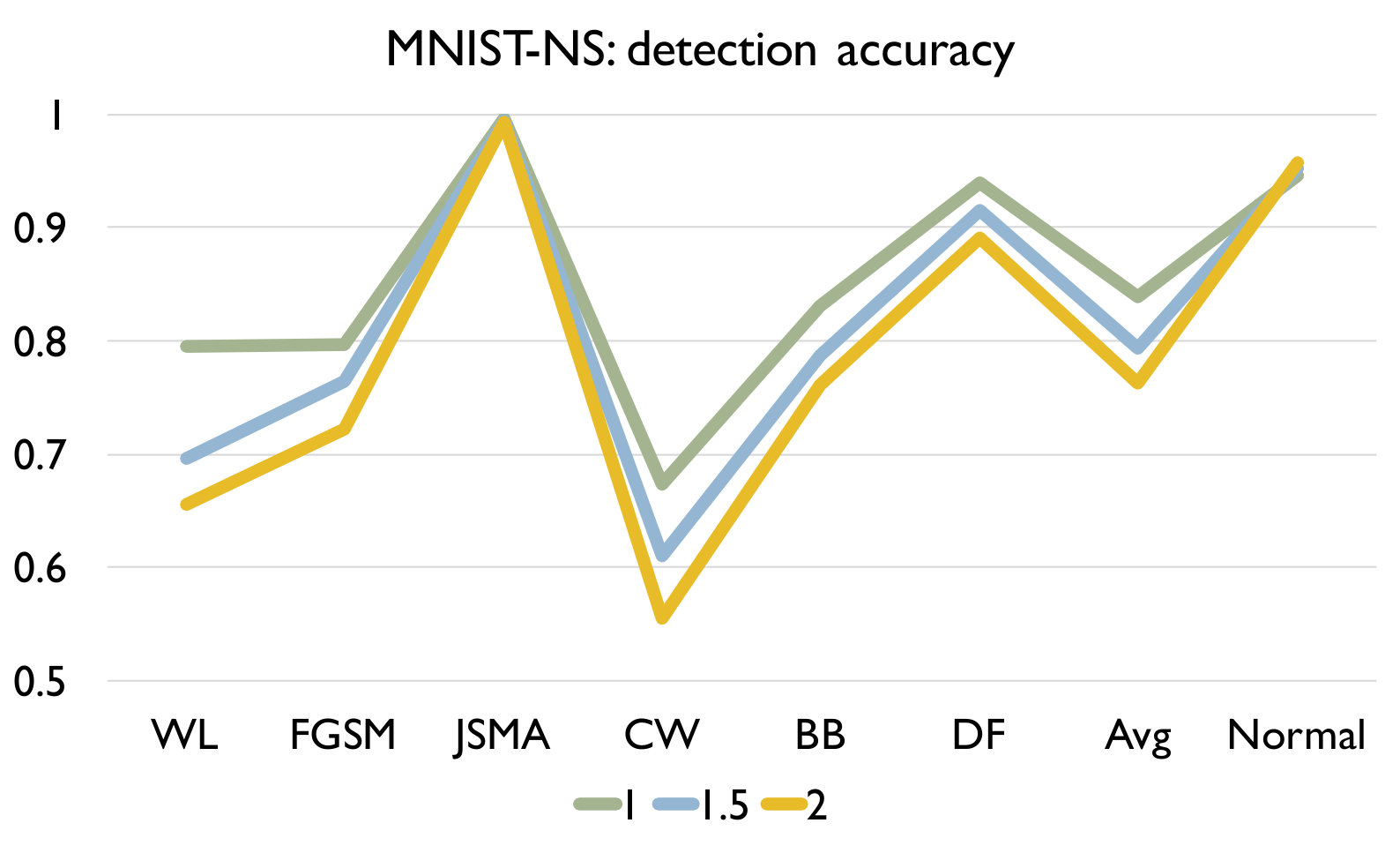 Figure 18
Figure 18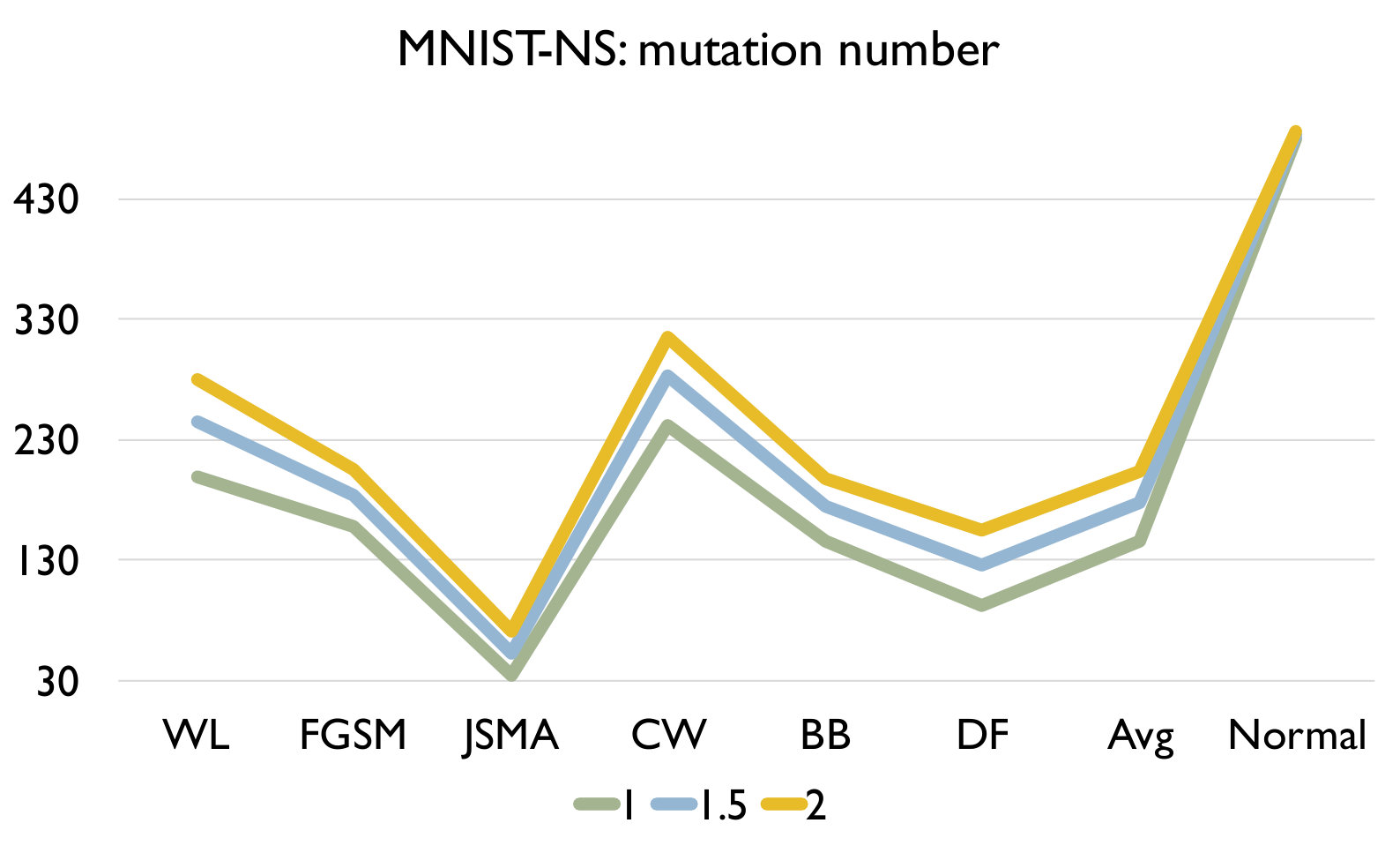 Figure 19
Figure 19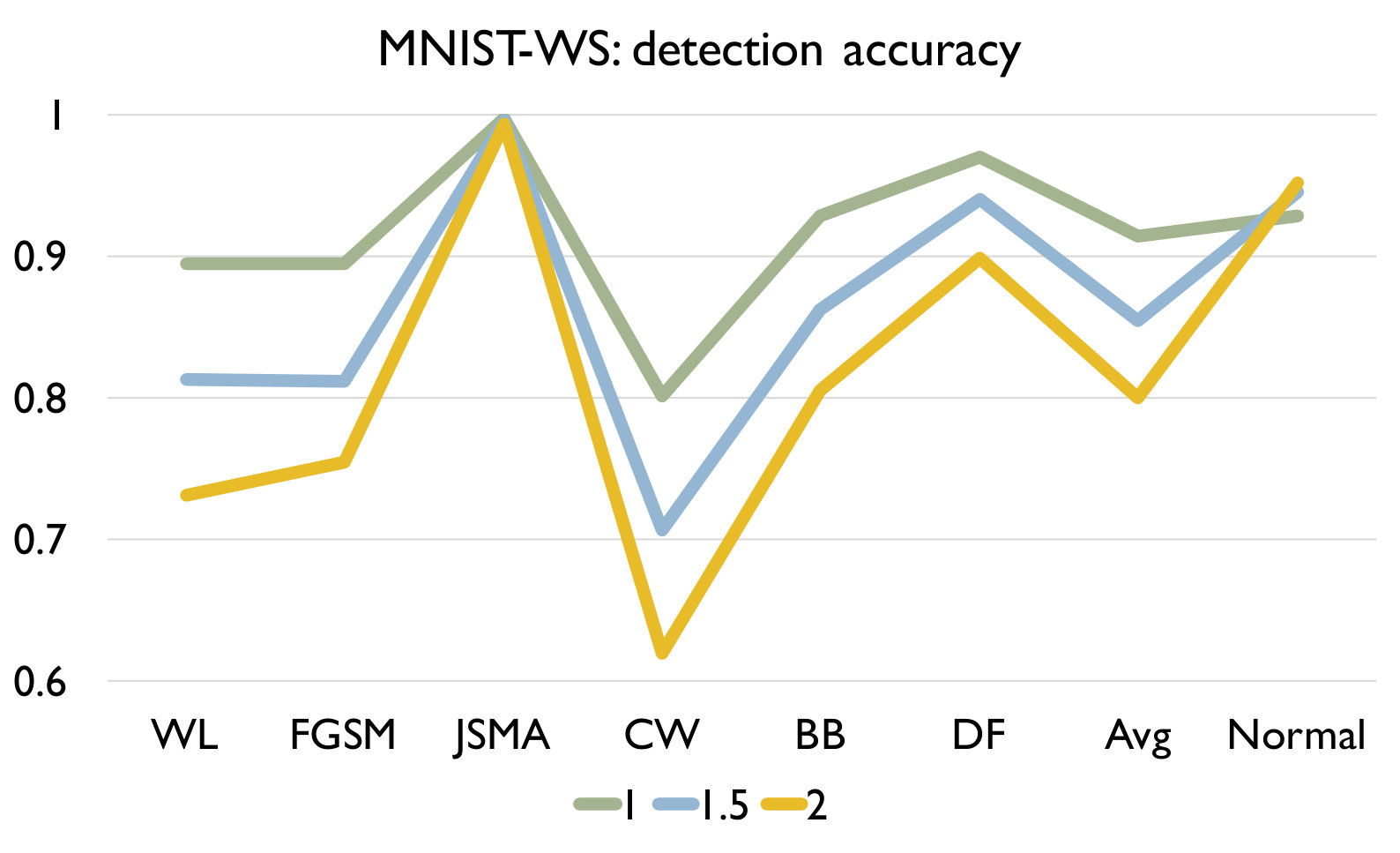 Figure 20
Figure 20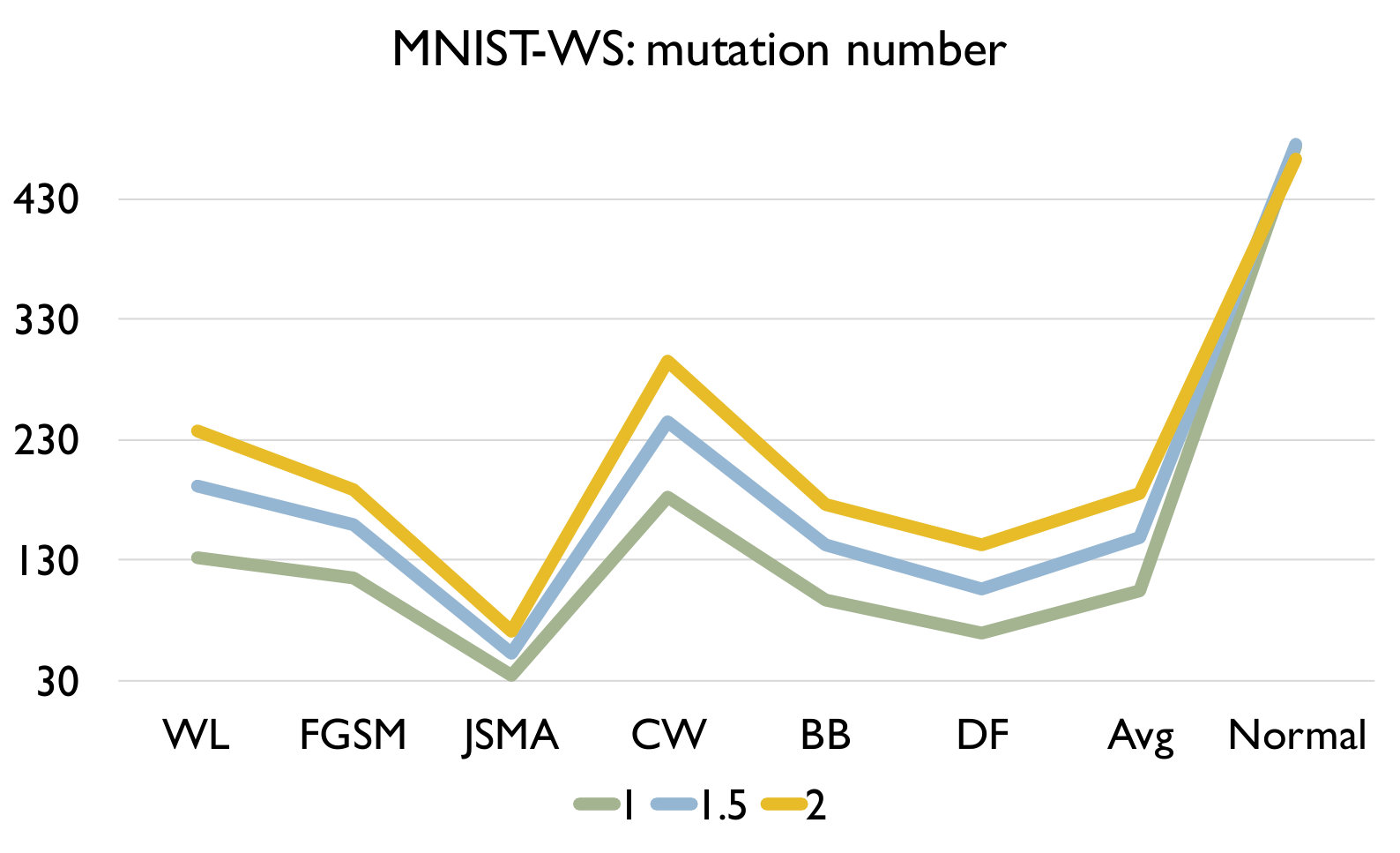 Figure 21
Figure 21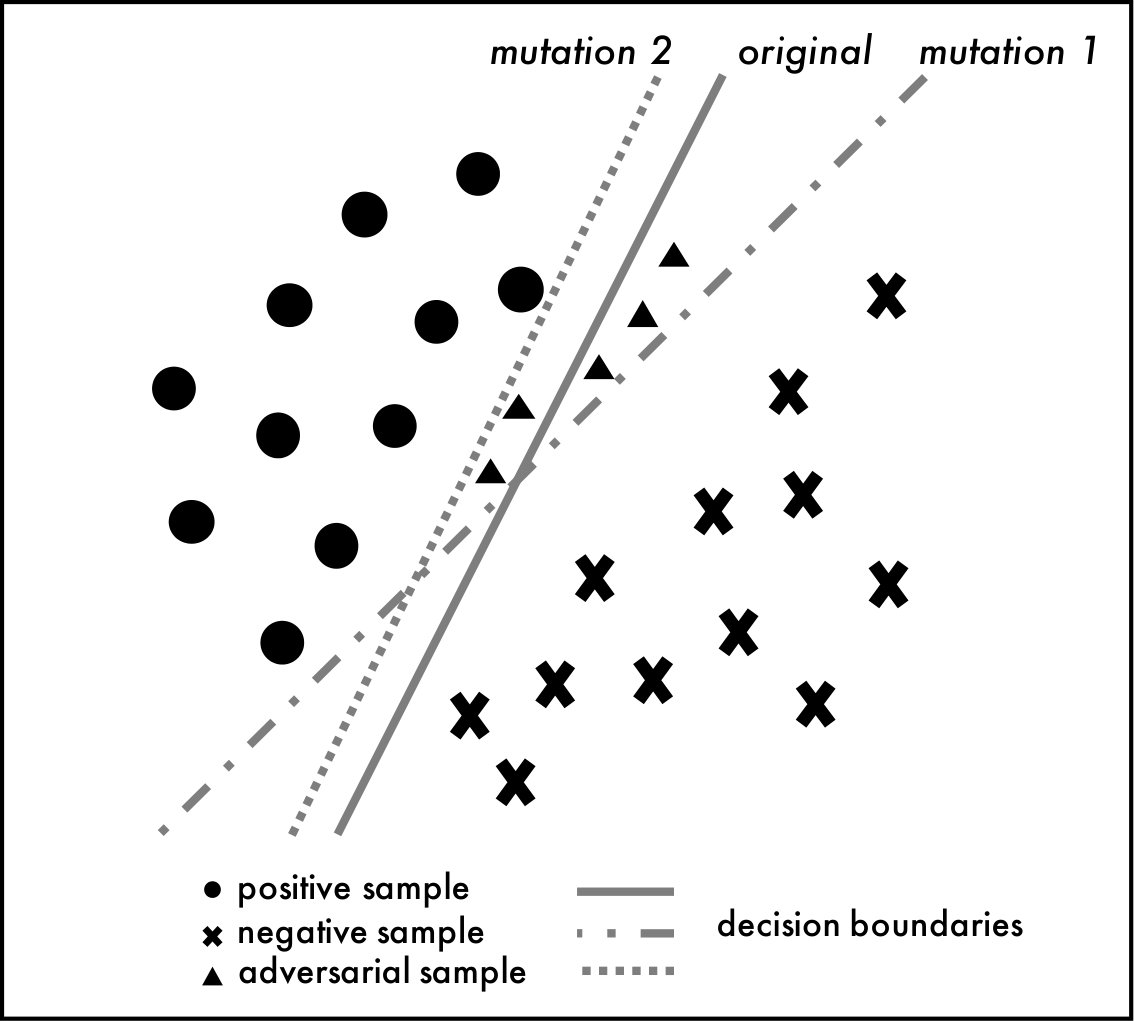 Figure 22
Figure 22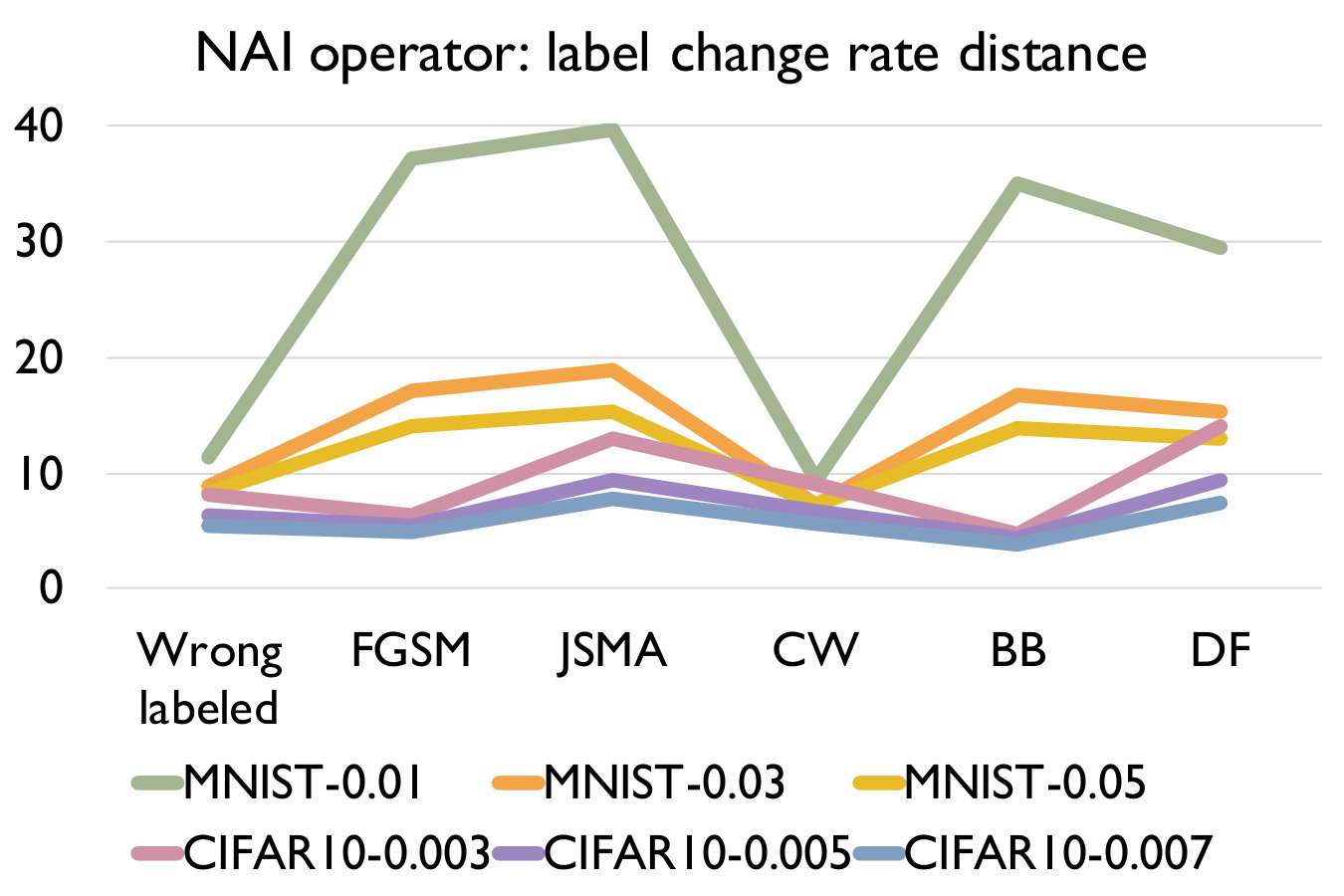 Figure 23
Figure 23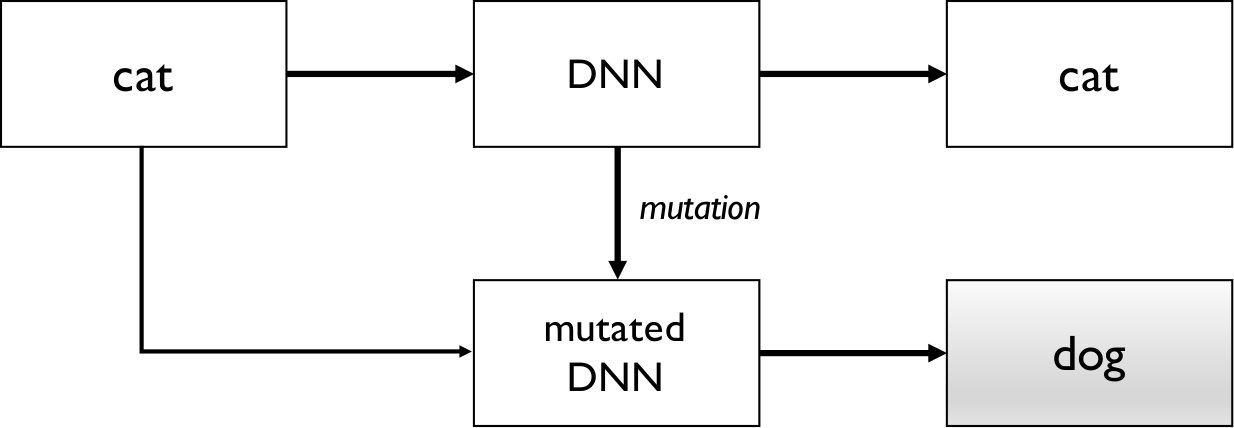 Figure 24
Figure 24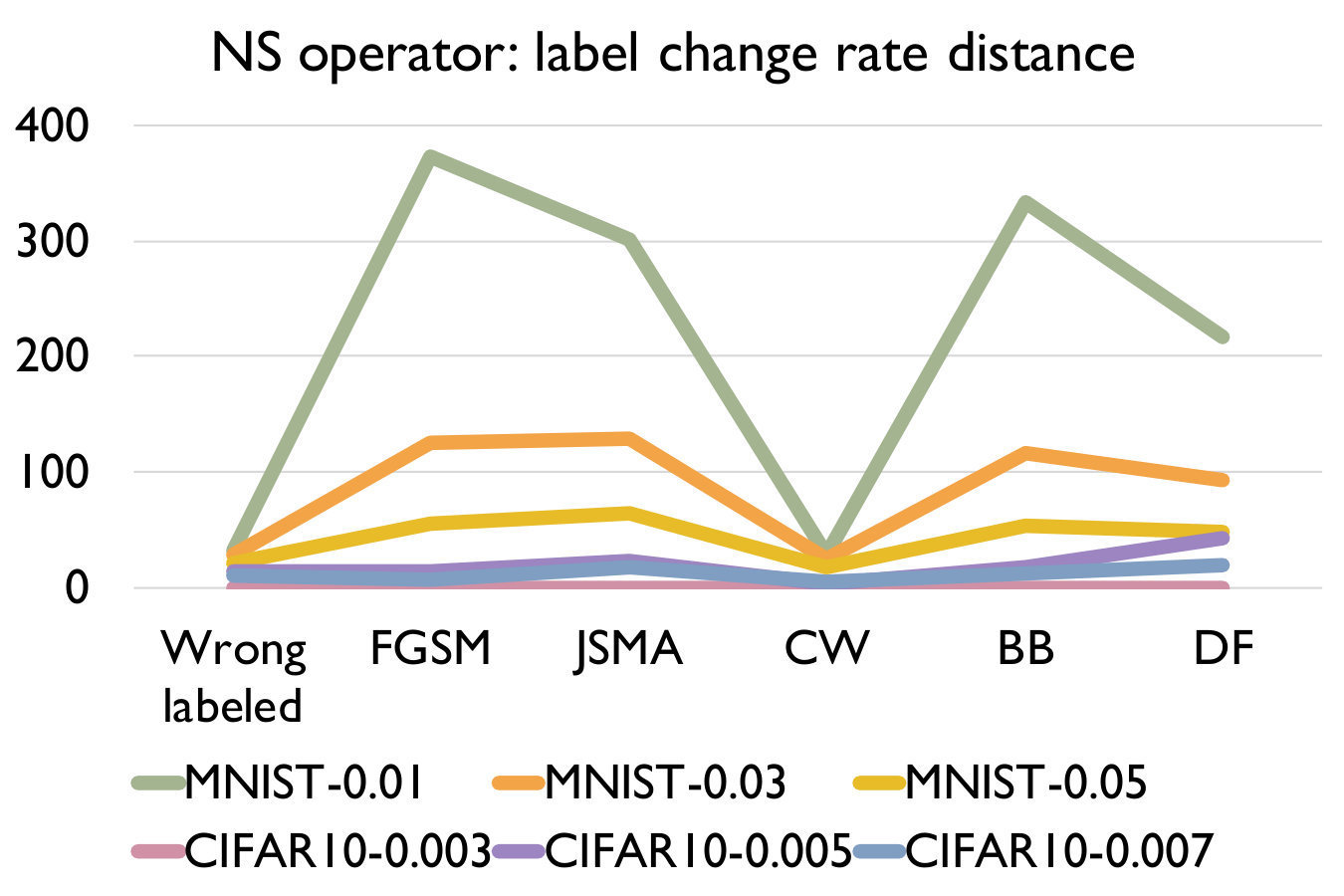 Figure 25
Figure 25 Figure 26
Figure 26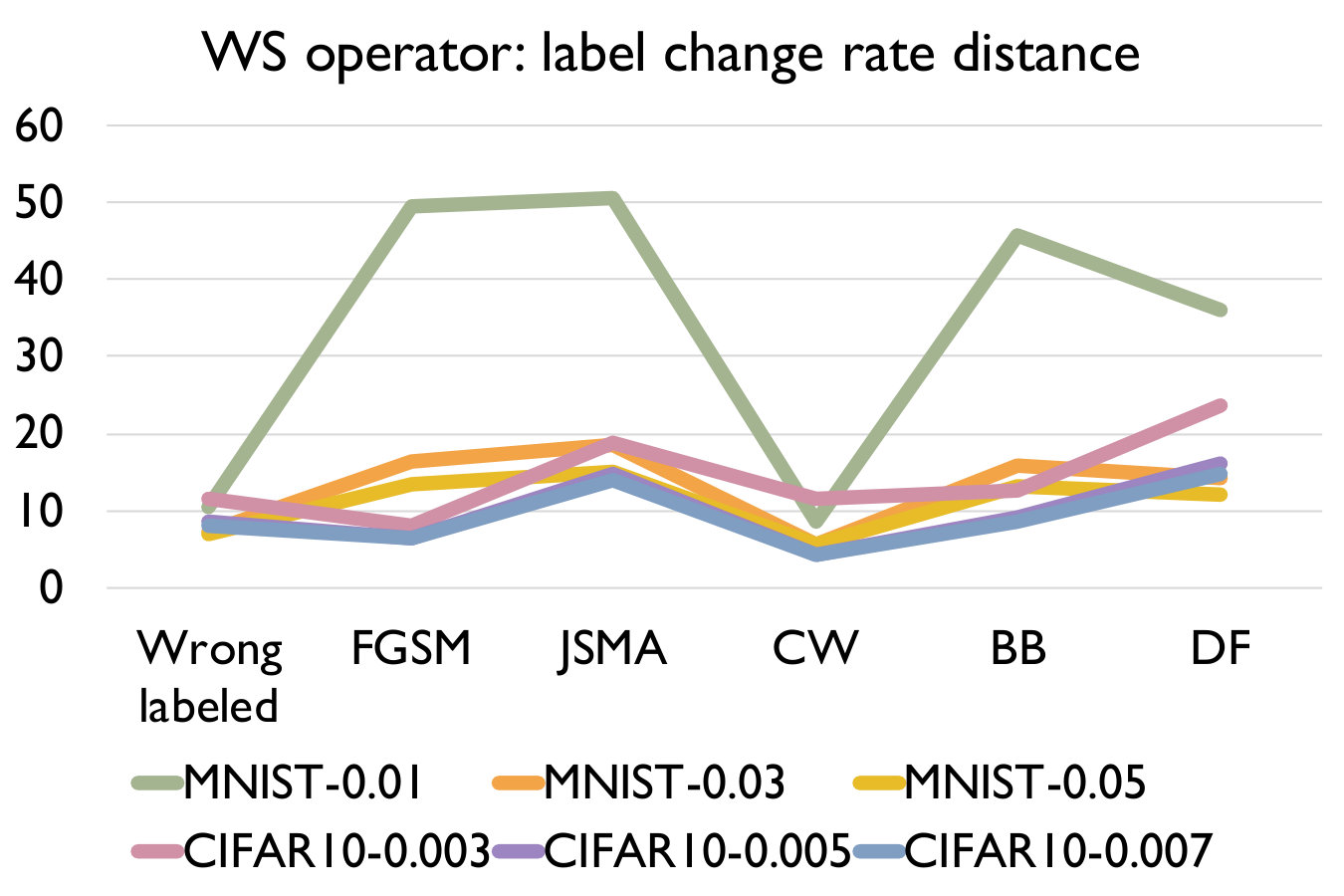 Figure 27
Figure 27| Dataset | Mutation rate | Normal samples | Adversarial samples | |||||
| Wrong labeled | FGSM | JSMA | C&W | Black-Box | Deepfool | |||
| MNIST | 0.01 | |||||||
| 0.03 | ||||||||
| 0.05 | ||||||||
| CIFAR10 | 0.003 | |||||||
| 0.005 | ||||||||
| 0.007 | ||||||||
| Dataset | Attack | Samples |
| MNIST | Normal | 1000 |
| Wrongly-labeled | 171 | |
| FGSM | 1000 | |
| JSMA | 1000 | |
| BB | 1000 | |
| C&W | 743 | |
| Deepfool | 1000 | |
| CIFAR10 | Normal | 1000 |
| Wrongly-labeled | 951 | |
| FGSM | 1000 | |
| JSMA | 1000 | |
| BB | 1000 | |
| C&W | 1000 | |
| Deepfool | 1000 |
| Dataset | operator | |||
| MNIST | 0.7 ms | NAI | 6.191 s | 68.7789 |
| 0.5 ms | NS | 6.336 s | 173.0040 | |
| 0.3 ms | WS | 7.657 s | 107.6702 | |
| 0.3 ms | GF | 1.398 s | 91.1747 | |
| CIFAR10 | 0.3 ms | NAI | 16.101 s | 69.0873 |
| 0.5 ms | NS | 9.475 s | 283.9628 | |
| 0.4 ms | WS | 9.251 s | 165.6373 | |
| 0.4 ms | GF | 11.894 s | 127.2767 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Adversarial Sample Detection for Deep Neural Network through Model Mutation Testing
Jingyi Wang2, Guoliang Dong3, Jun Sun2, Xinyu Wang3, Peixin Zhang3
2Singapore University of Technology and Design
3Zhejiang University
Abstract
Deep neural networks (DNN) have been shown to be useful in a wide range of applications. However, they are also known to be vulnerable to adversarial samples. By transforming a normal sample with some carefully crafted human imperceptible perturbations, even highly accurate DNN make wrong decisions. Multiple defense mechanisms have been proposed which aim to hinder the generation of such adversarial samples. However, a recent work show that most of them are ineffective. In this work, we propose an alternative approach to detect adversarial samples at runtime. Our main observation is that adversarial samples are much more sensitive than normal samples if we impose random mutations on the DNN. We thus first propose a measure of ‘sensitivity’ and show empirically that normal samples and adversarial samples have distinguishable sensitivity. We then integrate statistical hypothesis testing and model mutation testing to check whether an input sample is likely to be normal or adversarial at runtime by measuring its sensitivity. We evaluated our approach on the MNIST and CIFAR10 datasets. The results show that our approach detects adversarial samples generated by state-of-the-art attacking methods efficiently and accurately.
I Introduction
In recent years, deep neural networks (DNN) have been shown to be useful in a wide range of applications including computer vision [16], speech recognition [52], and malware detection [56]. However, recent research has shown that DNN can be easily fooled [43, 14] by adversarial samples, i.e., normal samples imposed with small, human imperceptible changes (a.k.a. perturbations). Many DNN-based systems like image classification [30, 33, 7, 50] and speech recognition [8] are shown to be vulnerable to such adversarial samples. This undermines using DNN in safety critical applications like self-driving cars [5] and malware detection [56].
To mitigate the threat of adversarial samples, the machine learning community has proposed multiple approaches to improve the robustness of the DNN model. For example, an intuitive approach is data augmentation. The basic idea is to include adversarial samples into the training data and re-train the DNN [35, 22, 44]. It has been shown that data augmentation improves the DNN to some extent. However, it does not help defend against unseen adversarial samples, especially those obtained through different attacking methods. Alternative approaches include robust optimization and adversarial training [37, 45, 55, 28], which take adversarial perturbation into consideration and solve the robust optimization problem directly during model training. However, such approaches usually increase the training cost significantly.
Meanwhile, the software engineering community attempts to tackle the problem using techniques like software testing and verification. In [44], neuron coverage was first proposed to be a criteria for testing DNN. Subsequently, multiple testing metrics based on the range coverage of neurons were proposed [25]. Both white-box testing [34], black-box testing [44] and concolic testing [41] strategies have been proposed to generate adversarial samples for adversarial training. However, testing alone does not help in improving the robustness of DNN, nor does it provide guarantee that a well-tested DNN is robust against new adversarial samples. The alternative approach is to formally verify that a given DNN is robust (or satisfies certain related properties) using techniques like SMT solving [20, 47] and abstract interpretation [13]. However, these techniques usually have non-negligible cost and only work for a limited class of DNN (and properties).
In this work, we provide a complementary perspective and propose an approach for detecting adversarial samples at runtime. The idea is that, given an arbitrary input sample to a DNN, to decide at runtime whether it is likely to be an adversarial sample or not. If it is, we raise an alarm and report that the sample is ‘suspicious’ with certain confidence. Once detected, it can be rejected or checked depending on different applications. Our detection algorithm integrates mutation testing of DNN models [26] and statistical hypothesis testing [3]. It is designed based on the observation that adversarial samples are much more sensitive to mutation on the DNN than normal samples, i.e., if we mutate the DNN slightly, the mutated DNN is more likely to change the label on the adversarial sample than that on the normal one. This is illustrated in Figure 1. The left figure shows a label change on a normal sample, i.e., given a normal sample which is classified as a cat, a label change occurs if the mutated DNN classifies the input as a dog. The right figure shows a label change on an adversarial sample, i.e., given an adversarial sample which is mis-classified as a dog, a label change occurs if the mutated DNN classifies the input as a cat. Our empirical study confirms that the label change rate (LCR) of adversarial samples is significantly higher than that of normal samples against a set of DNN mutants. We thus propose a measure of a sample’s sensitivity against a set of DNN mutants in terms of LCR. We further adopt statistical analysis methods like receiver operating characteristic (ROC [9]) to show that we can distinguish adversarial samples and normal samples with high accuracy based on LCR. Our algorithm then takes a DNN model as input, generates a set of DNN mutants, and applies statistical hypothesis testing to check whether the given input sample has a high LCR and thus is likely to be adversarial.
We implement our approach as a self-contained toolkit called mMutant [10]. We apply our approach on the MNIST and CIFAR10 dataset against the state-of-the-art attacking methods for generating adversarial samples. The results show that our approach detects adversarial samples efficiently with high accuracy. All four DNN mutation operators we experimented with show promising results on detecting 6 groups of adversarial samples, e.g., capable of detecting most of the adversarial samples within around 150 DNN mutants. In particular, using DNN mutants generated by Neuron Activation Inverse (NAI) operator, we manage to detect 96.4% of the adversarial samples with 74.1 mutations for MNIST and 90.6% of the adversarial samples with 86.1 mutations for CIFAR10 on average.
II Background
In this section, we review state-of-the-art methods for generating adversarial samples for DNN, and define our problem.
II-A Adversarial Samples for Deep Neural Networks
In this work, we focus on DNN classifiers which take a given sample and label the sample accordingly (e.g., as a certain object). In the following, we use to denote an input sample for a DNN . We use to denote the ground-truth label of . Given an input sample and a DNN , we can obtain the label of the input under by performing forward propagation. is regarded as an adversarial sample with respect to the DNN if . is regarded as a normal sample with respect to the DNN if . Notice that under our definition, those samples in the training/testing dataset wrongly labeled by are also adversarial samples.
Since Szegedy et al. discoveried that neural networks are vulnerable to adversarial samples [43], many attacking methods have been developed on how to generate adversarial samples efficiently (e.g., with minimal perturbation). That is, given a normal sample , an attacker aims to find a minimum perturbation which satisfies . In the following, we briefly introduce several state-of-the-art attacking algorithms.
FGSM: The Fast Gradient Sign Method (FGSM) [14] is designed based on the intuition that we can change the label of an input sample by changing its softmax value to the largest extent, which is represented by its gradient. The implementation of FGSM is straightforward and efficient. By simply adding up the sign of gradient of the cost function with respect to the input, we could quickly obtain a potential adversarial counterpart of a normal sample by the follow formulation:
[TABLE]
, where is the cost used to train the model, is the attacking step size and are the parameters. Notice that FGSM does not guarantee that the adversarial perturbation is minimal.
JSMA: Jacobian-based Saliency Map Attack (JSMA) [33] is devised to attack a model with minimal perturbation which enables the adversarial sample to mislead the target model into classifying it with certain (attacker-desired) label. It is a greedy algorithm that changes one pixel during each iteration to increase the probability of having the target label. The idea is to calculate a saliency map based on the Jacobian matrix to model the impact that each pixel imposes on the target classification. With the saliency map, the algorithm picks the pixel which may have the most significant influence on the desired change and then increases it to the maximum value. The process is repeated until it reaches one of the stopping criteria, i.e., the number of pixels modified has reached the bound, or the target label has been achieved. Define
[TABLE]
Then, the saliency map at each iteration is defined as follow:
[TABLE]
However, it is too strict to select one pixel at a time because few pixels could meet that definition. Thus, instead of picking one pixel at a time, the authors proposed to pick two pixels to modify according to the follow objective:
[TABLE]
where is the candidate pair, and is the target class.
JSMA is relatively time-consuming and memory-consuming since it needs to compute the Jacobian matrix and pick out a pair from nearly candidate pairs at each iteration.
DeepFool: The idea of DeepFool (DF) is to make the normal samples cross the decision boundary with minimal perturbations [30]. The authors first deduced an iterative algorithm for binary classifiers with Tayler’s Formula, and then analytically derived the solution for multi-class classifiers. The exact derivation process is complicated and thus we refer the readers to [30] for details.
C&W: Carlini et al. [7] proposed a group of attacks based on three distance metrics. The key idea is to solve an optimization problem which minimizes the perturbation imposed on the normal sample (with certain distance metric) and maximizes the probability of the target class label. The objective function is as follow:
[TABLE]
where is defined according to some distance metric, e.g, , , , is the clipped adversarial sample and is its target label. The idea is to devise a clip function for the adversarial sample such that the value of each pixel dose not exceed the legal range. The clip function and the best loss function according to [7] are shown as follows.
[TABLE]
where denotes the output vector of a model and is the target class. Readers can refer to [7] for details.
Black-Box: All the above mentioned attacks are white-box attacks which means that the attackers require the full knowledge of the DNN model. Black-Box (BB) attack only needs to know the output of the DNN model given a certain input sample. The idea is to train a substitute model to mimic the behaviors of the target model with data augmentation. Then, it applies one of the existing attack algorithm, e.g., FGSM and JSMA, to generate adversarial samples for the substitute model. The key assumption to its success is that the adversarial samples transfer between different model architectures [43, 14].
II-B Problem Definition
Observing that adversarial samples are relatively easy to craft, a variety of defense mechanisms against adversarial samples have been proposed [15, 28, 51, 27, 38], as we have briefly introduced in Section I. However, Athalye et al. [2] systematically evaluated the state-of-the-art defense mechanisms recently and showed that most of them are ineffective. Alternative defense mechanisms are thus desirable.
In this work, we take a complementary perspective and propose to detect adversarial samples at runtime using techniques from the software engineering community. The problem is: given an input sample to a deployed DNN , how can we efficiently and accurately decide whether (i.e., a normal sample) or not (i.e., an adversarial sample)? If we know that is likely an adversarial sample, we could reject it or further check it to avoid bad decisions. Furthermore, can we quantify some confidence on the drawn conclusion?
III Our approach
Our approach is based on the hypothesis that, in most cases adversarial samples are more ‘sensitive’ to mutations on the DNN model than normal samples. That is, if we generate a set of slightly mutated DNN models based on the given DNN model, the mutated DNN models are more likely to label an adversarial sample with a label different from the label generated by the original DNN model, as illustrated in Figure 1. In other words, our approach is designed based on a measure of sensitivity for differentiating adversarial samples and normal samples. In the literature, multiple measures have been proposed to capture their differences, e.g., density estimate, model uncertainty estimate [11], and sensitivity to input perturbation [46]. Our measure however allows us to detect adversarial samples at runtime efficiently through model mutation testing.
III-A Mutating Deep Neural Networks
In order to test our hypothesis (and develop a practical algorithm), we need a systematic way of generating mutants of a given DNN model. We adopt the method developed in [26], which is a proposal of applying mutation testing to DNN. Mutation testing [19] is a well-known technique to evaluate the quality of a test suiteand, and thus is different from our work. The idea is to generate multiple mutations of the program under test, by applying a set of mutation operators, in order to see how many of the mutants can be killed by the test suite. The definition of the mutation operators is a core component of the technique. Given the difference between traditional software systems and DNN, mutation operators designed for traditional programs cannot be directly applied to DNN. In [26], Ma et al. introduced a set of mutation operators for DNN-based systems at different levels like source level (e.g., the training data and training programs) and model level (e.g., the DNN model).
In this work, we require a large group of slightly mutated models for runtime adversarial sample detection. Of all the mutation operators proposed in [26], mutation operators defined at the source level are not considered. The reason is that we would need to train the mutated models from scratch which is often time-consuming. We thus focus on the model-level operators, which modify the original model directly to obtain mutated models without training. Specifically, we adopt four of the eight defined operators from [26] shown in Table I. For example, NAI means that we change the activation status of a certain number of neurons in the original model. Notice that the other four operators defined in [26] are not applicable due to the specific architecture of the deep learning models we focus on in this work.
III-B Evaluating Our Hypothesis
We first conduct experiments to measure the label change rate (LCR) of adversarial samples and normal samples when we feed them into a set of mutated DNN models. Given an input sample (either normal or adversarial) and a DNN model , we first adopt the model mutation operators shown in Table I to obtain a set of mutated models. Note that some of the resultant mutated models may be of low quality, i.e., their classification accuracy on the test data drops significantly. We discharge those low quality ones and only keep those accurate mutated models which retain an accuracy on the test data, i.e., at least 90% of the accuracy of the original model, to ensure that the decision boundary does not perturb too much. Once we obtain such a set of mutated models , we then obtain the label of the input sample on every mutated model . We define LCR on a sample as follows (with respect to ).
[TABLE]
, where is the number of elements in a set . Intuitively, measures how sensitive an input sample is on the mutations of a DNN model.
Table II summarizes our empirical study on measuring using two popular dataset, i.e., the MNIST and CIFAR10 dataset, and multiple state-of-the-art attacking methods. A total of 500 mutated models are generated using NAI operator which randomly selects some neurons and changes their activation status. The first column shows the name of the dataset. The second shows the mutation rate, i.e., the percentage of the neurons whose activation status are changed. The third shows the average LCR (with confidence interval of 99% significance level) of 1000 normal samples randomly selected from the testing set. The remaining columns show the average LCR (with confidence interval of 99% significance level) of 1000 adversarial samples which are generated using state-of-the-art methods. Note that column ‘Wrongly Labeled’ are samples from the testing set which are wrongly labeled by the original DNN model.
Based on the results, we can observe that at any mutation rate, the values of the adversarial samples are significantly higher than those of the normal samples.
is significantly larger than .
Further study on the LCR distance between normal and adversarial samples with respect to different model mutation operators is presented in Section IV. The results are consistent. A practical implication of the observation is that given an input sample , we could potentially detect whether is likely to be normal or adversarial by checking .
III-C Explanatory Model
In the following, we use a simple model to explain the above observation. Recall that adversarial samples are generated in a way which tries to minimize the modification to a normal sample while is still able to cross the decision boundary. Different kinds of attacks use different approaches to achieve this goal. Our hypothesis is that most adversarial samples generated by existing methods are near the decision boundary (to minimize the modification). As a result, as we randomly mutate the model and perturb the decision boundary, adversarial samples are more likely to cross the mutated decision boundaries, i.e., if we feed an adversarial sample to a mutated model, the output label has a higher chance to change from its original label. This is illustrated visually in Figure 2.
III-D The Detection Algorithm
The results shown in Table II suggests that we can use LCR to distinguish adversarial samples and normal samples. In the following, we present an algorithm which is designed to detect adversarial samples at runtime based on measuring the LCR of a given sample. The algorithm is based on the idea of statistical model checking [3, 1].
The inputs of our algorithm are a DNN model , a sample and a threshold which is used to decide whether the input is adversarial. We will discuss later on how to identify systematically. The basic idea of our algorithm is to use hypothesis testing to decide the truthfulness of two mutual exclusive hypothesis.
[TABLE]
Three (standard) additional parameters, , and , are used to control the probability of making an error. That is, we would like to guarantee that the probability of a Type-I (respectively, a Type-II) error, which rejects (respectively, ) while (respectively, ) holds, is less or equal to (respectively, ). The test needs to be relaxed with an indifferent region , where neither hypothesis is rejected and the test continues to bound both types of errors [1]. In practice, the parameters (i.e., , and ) can often be decided by how much testing resources are available. In general, more resource is required for a smaller error bound.
Our detection algorithm keeps generating accurate mutated models (with an accuracy more than certain threshold on the testing data) from the original model and evaluating until a stopping condition is satisfied. We remark that in practice we could generate a set of accurate mutated models before-hand and simply use them at runtime to further save detection time.
There are two main methods to decide when the testing process can be stopped, i.e., we have sufficient confidence to reject a hypothesis. One is the fixed-size sampling test (FSST), which runs a predefined number of tests. One difficulty of this approach is to find an appropriate number of tests to be performed such that the error bounds are valid. The other approach is the sequential probability ratio test (SPRT [3]). SPRT dynamically decides whether to reject or not a hypothesis every time after we update , which requires a variable number of mutated models. SPRT is usually faster than FSST as the testing process ends as soon as a conclusion is made.
In this work, we use SPRT for the detection. The details of our SPRT-based algorithm is shown in Algorithm 1. The inputs of the detection algorithm include the input sample , the original DNN model , a mutation rate , and a threshold of LCR . Besides, the detection is error bounded by and relaxed with an indifference region . To apply SPRT, we keep generating accurate mutated models at line 5. The details of generating mutated models using the four operators in Table I are shown in Algorithm 2, Algorithm 3, Algorithm 4, and Algorithm 5 respectively. We then evaluate whether at line 7. If we observe a label change of using the mutated model , we calculate and update the SPRT probability ratio at line 9 as:
[TABLE]
, with and . The algorithm stops whenever a hypothesis is accepted either at line 11 or line 14. We remark that SPRT is guaranteed to terminate with probability 1 [3].
We briefly introduce the NAI operator shown in Algorithm 2 as an example of the four mutation operators. We first obtain the set of unique neurons111For convolutional layer, each slide of convolutional kernel is regarded as a neuron at line 1. Then we randomly select neurons ( is the mutation rate) for activation status inverse at line 2. Afterwards, we traverse the model layer by layer at line 3 and take those selected neurons at line 4. We then inverse the activation status of the selected neurons by multiplying their weights with -1 at line 7.
IV Implementation and Evaluation
We have implemented our approach in a self-contained toolkit which is available online [10]. It is implemented in Python with about 5k lines of code. In the following, we evaluate the accuracy and efficiency of our approach through multiple experiments.
IV-A Experiment Settings
Datasets and Models
We adopt two popular image datasets for our evaluation: MNIST and CIFAR10. Each dataset has 60000/50000 images for training and 10000/10000 images for testing. The target models for MNIST and CIFAR10 are LeNet [23] and GooglLeNet [42] respectively. The accuracy of our trained models on training and testing dataset are 98.5%/98.3% for MNIST and 99.7%/90.5% for CIFAR10 respectively, which both achieve state-of-the-art performance.
Mutated models generation
We employ the four mutation operators shown in Table I to generate mutated models. In total, we have neurons for the MNIST model and neurons for the CIFAR10 model. For each mutation operator, we generate three groups of mutation models from the original trained model using different mutation rate to see its effect. The mutation rate we use for the MNIST model is and for the CIFAR10 model (since there are more neurons). Note that some mutation models may have significantly worse performance, so not all mutated models are valid. In our experiment, we only keep those mutation models whose accuracy on the testing dataset is not lower than of that of its seed model. For each mutation rate, we generate 500 such accurate mutated models for our experiments.
Adversarial samples generation
We test our detection algorithm against four state-of-the-art attacks in Clverhans [31] and Deepfool [30] (detailed in Section II). For each kind of attack, we generate a set of adversarial samples for evaluation. The parameters for each kind of attack to generate the adversarial samples are summarized as follows.
- •
FGSM: There is only one parameter to control the scale of perturbation. We set it as 0.35 for MNIST and 0.03 for CIAFR10 according to the original paper.
- •
JSMA: There is only one parameter to control the maximum distortion. We set it as for both datasets, which is slightly smaller than the original paper.
- •
C&W: There are three types of attacks proposed in [7]: , and . We adopt attack according to the author’s recommendation. We also set the scale coefficient to be 0.6 for both datasets. We set the iteration number to be 10000 for MNIST and 1000 for CIFAR10 according to the original paper.
- •
Deepfool: We set the maximum number of iterations to be 50 and the termination criterion (to prevent vanishing updates) to be 0.02 for both datasets, which is a default setting in the original paper.
- •
Black-Box: The key setting of the Black-Box attack is to train a substitute model of the target model. The substitute model for MNIST is the first model defined in Appedix A of [32]. For CIFAR10, we use the LeNet [23] as the surrogate model. Afterwards, the attack algorithm we used for the surrogate model is FGSM.
For each attack, we make 1000 attempts to generate adversarial samples. Notice that not all attempts are successful and as a result we manage to generate no more than 1000 adversarial samples for each attack. Further recall that according to our definition, those samples in the testing dataset which are wrongly labeled by the trained DNN are also adversarial samples. Thus, in addition to the adversarial samples generated from the attacking methods, we attempt to randomly select 1000 samples from the testing dataset which are wrongly classified by the target model as well. Table III summarizes the number of normal samples and valid adversarial samples for each kind of attack used for the experiments.
IV-B Evaluation Metrics
Distance of label change rate
We use where (and ) is the average LCR of adversarial samples (and normal samples) to measure the distance between the LCR of adversarial samples and normal samples. The larger the value is, the more significant is the difference.
Receiver characteristics operator
Since our detection algorithm works based on a threshold LCR , we first adopt receiver characteristic operator (ROC) curve to see how good our proposed feature, i.e., LCR under model mutation, is to distinguish adversarial and normal samples [9, 11]. The ROC curve plots the true positive rate () against false positive rate () for every possible threshold for the classification. From the ROC curve, we could further calculate the area under the ROC curve (AUROC) to characterize how well the feature performs. A perfect classifier (when all the possible thresholds yield true positive rate 1 and false positive rate 0 for distinguishing normal and adversarial samples) will have AUROC 1. The closer is AUROC to 1, the better is the feature.
Accuracy of detection
The accuracy of the detection is defined in a standard way as follows. Given a set of images (labeled as normal or adversarial), what is the percentage that our algorithm correctly classifies it as normal or adversarial? Notice that the accuracy of detecting adversarial samples is equivalent to and the accuracy of detecting normal samples is equivalent to . The higher the accuracy, the better is our detection algorithm.
IV-C Research Questions
RQ1: Is there a significant difference between the LCR of adversarial samples and normal samples under different model mutations? To answer the question, we calculate the average LCR of the set of normal samples and the set of adversarial samples generated as described above with a set of mutated models using different mutation operators. A set of 500 mutants are generated for each mutation operator (note that mutation rate 0.003 is too low for NS to generate mutated models for CIFAR10 model and thus omitted). According to the detailed results summarized in Tabel II and IV, we have the following answer.
Answer to RQ1: Adversarial samples have significantly higher LCR under model mutation than normal samples.
In addition, we have the following observations.
- •
Adversarial samples generated from every kind of attack have significantly larger LCR than normal samples under a set of mutated models under any mutation rate, and different kind of attack have different LCR. We can see that the LCR of normal samples are very low (i.e., comparable to the testing error) and that of adversarial samples are much higher. Figure 3 shows the distance between LCR of adversarial samples and normal samples for different mutation operators. We can see that the distance is mostly larger than 10 and can be up to 375, which well supports our answer to RQ1. We can also observe that adversarial samples generated by FGSM/JSMA/Deepfool/Black-box have relatively higher LCR distance than those generated by CW and those wrong-labeled samples in the original dataset. In general, our detection algorithm is able to detect attacks with larger distance faster and better.
- •
As we increase the model mutation rate, the LCR of both normal samples and adversarial samples increase (as expected) and the distance between them decreases. We can observe from Table IV that the LCR increases with an increasing model mutation rate in all cases. From Figure 3, we see that a smaller model mutation rate like 0.01 for MNIST and 0.003 for CIFAR10 have the largest LCR distance. This is probably because as we increase the mutation rate, normal samples are more sensitive in terms of the change of LCR since it is a much smaller number.
- •
Like adversarial samples generated by different attacking methods, wrongly labeled samples also have significantly larger LCR than normal samples. This suggests that wrongly labeled samples are also sensitive to the change of decision boundaries from model mutations as adversarial samples. They are the same as the adversarial samples which are near to the decision boundary and thus can be potentially detected.
RQ2: How good is the LCR under model mutation as an indicator for the detection of adversarial samples? To answer the question, we further investigate the ROC curve using LCR as the indicator of classifying an input sample as normal or adversarial. We compare our proposed feature, i.e., LCR under model mutations with two baseline approaches. The first baseline (referred as baseline 1) is a combination of density estimate and model uncertainty estimate as joint features [11]. The second baseline (referred as baseline 2) is based on the label change rate of imposing random perturbations on the input sample [46].
Table V presents the AUROC results under different model mutation operators. We compare our results with two baselines introduced above. The best AUROC results among the three approaches are in bold. We could observe that our proposed feature beats both baselines in over half the cases (excluding Deepfool which we do not have any reported baseline results), while baseline 1 and baseline 2 only win 1 and 3 cases respectively. We could also observe that the AUROC results are mostly very close to 1 (a perfect classifier), i.e., usually larger than 0.9, which suggests that we could achieve high accuracy using the proposed feature to distinguish adversarial samples. We thus have the following answer to RQ2.
Answer to RQ2: LCR under model mutation could outperform current baselines to detect adversarial samples.
RQ3: How effective is our detection algorithm based on LCR under model mutation? To answer the question, we apply our detection algorithm (Algorithm 1) on each set of adversarial samples generated using each attack and evaluate the accuracy of the detection in Figure 4. We also report the accuracy of our algorithm on a set of normal samples. The results are based on the set of models generated using mutation rate 0.05 for MNIST and 0.005 for CIFAR10 as they have good balance between detecting adversarial and normal samples.
We set the parameters of Algorithm 1 as follows. Since different kind of attacks have different LCR but the LCR of normal sample is relatively stable, we choose to test against the LCR of normal samples. Specifically, we set the threshold to be , where is the upper bound of the confidence interval of and () is a hyper parameter to control the sensitivity of detecting adversarial samples in our algorithm. The smaller is, the more sensitive our algorithm is to detect adversarial samples. The error bounds for SPRT is set as . The indifference region is set as .
Figure 4 shows the detection accuracy and average number of model mutants needed for the detection using the 4 mutation operators for MNIST and CIFAR10 dataset respectively. We could observe that our detection algorithm achieves high accuracy on every kind of attack for every mutation operator. On average, the GF/NAI/NS/WS operators achieves accuracy of 94.9%/96.4%/83.9%/91.4% with 75.5/74.1/145.3/105.4 mutated models for MNIST (with =1) and 85.5%/90.6%/56.6%/74.8% (with =1) with 121.7/86.1/303/176.2 mutated models for CIFAR10 on detecting the 6 kinds of adversarial samples. Meanwhile, we maintain high detection accuracy of normal samples as well, i.e., 90.8%/89.7%/94.7%/92.9% for MNIST (with =1) and 79.3%/74%/84.6%/81.6% (with =1) for CIFAR10 for the above 4 operators respectively. Notice that for CIFAR10, we could not train a good substitute model (the accuracy is below 50%) using Black-box attack and thus have no result. The results show that our detection algorithm is able to detect most of adversarial samples effectively. In addition, we observe that the more accurate is the original (and as a result the mutated) DNN model is (e.g., MNIST), the better is our algorithm. Besides, we are able to achieve accuracy close to 1 for JSMA and DF. We also recommend to use NAI/GF operators over NS/WS operators as they have consistently better performance than the others. We thus have the following answer to RQ3.
Answer to RQ3: Our detection algorithm based on statistical hypothesis testing could effectively detect adversarial samples.
Effect of In this experiment, we vary the hyper parameter to see its effect on the detection. As shown in Figure 4, we set as for MNIST and for CIFAR10. We could observe that as we increase , we have a lower accuracy on detecting adversarial samples but a higher accuracy on detecting normal samples. The reason is that as we increase , the threshold for the detection increases. In this case, our algorithm will be less sensitive to detect adversarial samples since the threshold is higher. We could also observe that we would need more mutations with a higher threshold. In summary, the selection of could be application specific and our practical guide is to set a small if the application has a high safety requirement and vice versa.
RQ4: What is the cost of our detection algorithm? The cost of our algorithm mainly consists of two parts, i.e., generating mutated models (denoted by ) and performing forward propagation (denoted by ) to obtain the label of an input sample by a DNN model. The total cost of detecting an input sample is thus , where is the number of mutants needed to draw a conclusion based on Algorithm 1.
We estimate by performing forward propagation for 10000 images on a MNIST and CIFAR10 model respectively. The detailed results are shown in Tabel VI. Note that is the time used to generate an accurate model (retaining at least 90% accuracy of the original model) and the cost to generate an arbitrary mutated model is much less. In practice, we could generate and cache a set of mutated models for the detection of a set of samples. Given a set of samples, the total cost for the detection is reduced to . In practice, our algorithm could detect an input sample within 0.1 second (with cached models) using a single machine. We remark that our algorithm can be parallelized easily by evaluating a set of models at the same time which would reduce the cost significantly. We thus have the following answer to RQ4.
Answer to RQ4: Our detection algorithm is lightweight and easy to parallel.
IV-D Threats to Validity
First, our experiment is based on a limited set of test subjects so far. Our experience is that the more accurate the original model and the mutated models are, the more effective and more efficient our detection algorithm is. The reason is that the LCR distance between adversarial samples and normal samples will be larger if the model is more accurate, which is good for our detection. In some applications, however, the accuracy of the original models may not be high. Secondly, the detection algorithm will have some false positives. Since our detection algorithm is threshold-based, there will be some false alarms along with the detection. Meanwhile, there is a tradeoff between avoiding false positives or false negatives as discussed above (i.e., in the selection of ). Thirdly, the detection of normal samples typically needs more mutations. The reason is that we choose to test against since we do not know for an unknown attack. Since normal samples have lower LCR under mutated models in general, they would need more mutations than adversarial samples to draw a conclusion.
V Related works
This work is related to studies on adversarial sample generation, detection and prevention. There are several lines of related work in addition to those discussed above.
Adversarial training
The key idea of adversarial training is to augment training data with adversarial samples to improve the robustness of the trained DNN itself. Many attack strategies have been invented recently to effectively generate adversarial samples like DeepFool [30], FGSM [14], C&W [7], JSMA [33], black-box attacks [32] and others [39, 36, 12, 6, 50]. However, adversarial training in general may overfit to the specific kinds of attacks which generate the adversarial samples for training [28] and thus can not guarantee robustness on new kinds of attacks.
Adversarial sample detection
Another direction is to automatically detect those adversarial samples that a DNN will mis-classify. One way is to train a ‘detector’ subnetwork from normal samples and adversarial samples [29]. Alternative detection algorithms are often based on the difference between how an adversarial sample and a normal sample would behave in the softmax output [54, 17, 24, 11] or under random perturbations [46].
Model robustness
Different metrics has been proposed in the machine learning community to measure and provide evidence on the robustness of a target DNN [53, 48]. Besides, in [34] and the following work [40, 25], neuron coverage and its extensions are argued to be the key indicators of the DNN robustness. In [4], they proposed adversarial frequency and adversarial severity as the robustness metrics and encode robustness as a linear program.
Testing and formal verification
Testing strategies including white-box [34, 44], black-box [49] and mutation testing [26] have been proposed to generate adversarial samples more efficiently for adversarial training. However, testing can not provide any safety guarantee in general. There are also attempts to formally verify certain safety properties against the DNN to provide certain safety guarantees [18, 20, 21, 47].
VI Conclusion
In this work, we propose an approach to detect adversarial samples for Deep Neural Networks at runtime. Our approach is based on the evaluated hypothesis that most adversarial samples are much more sensitive to model mutations than normal samples in terms of label change rate. We then propose to detect whether an input sample is likely to be normal or adversarial by statistically checking the label change rate of an input sample under model mutations. We evaluated our approach on MNIST and CIFAR10 datasets and showed that our algorithm is both accurate and efficient to detect adversarial samples.
Acknowledgment
Xinyu Wang is the corresponding author. This research was supported by grant RTHW1801 in collaboration with the Shield Lab of Huawei 2012 Research Institute, Singapore. We are thankful to the discussions and feedbacks from them. This research was also partially supported by the National Basic Research Program of China (the 973 Program) under grant 2015CB352201 and NSFC Program (No. 61572426).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Gul Agha and Karl Palmskog. A survey of statistical model checking. ACM Trans. Model. Comput. Simul. , 28(1):6:1–6:39, January 2018.
- 2[2] Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. ar Xiv preprint ar Xiv:1802.00420 , 2018.
- 3[3] A.Wald. Sequential Analysis . Wiley, 1947.
- 4[4] Osbert Bastani, Yani Ioannou, Leonidas Lampropoulos, Dimitrios Vytiniotis, Aditya Nori, and Antonio Criminisi. Measuring neural net robustness with constraints. In Advances in neural information processing systems , pages 2613–2621, 2016.
- 5[5] Mariusz Bojarski, Davide Del Testa, Daniel Dworakowski, Bernhard Firner, Beat Flepp, Prasoon Goyal, Lawrence D Jackel, Mathew Monfort, Urs Muller, Jiakai Zhang, et al. End to end learning for self-driving cars. ar Xiv preprint ar Xiv:1604.07316 , 2016.
- 6[6] Wieland Brendel, Jonas Rauber, and Matthias Bethge. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. ar Xiv preprint ar Xiv:1712.04248 , 2017.
- 7[7] Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In Security and Privacy (SP), 2017 IEEE Symposium on , pages 39–57. IEEE, 2017.
- 8[8] Nicholas Carlini and David Wagner. Audio adversarial examples: Targeted attacks on speech-to-text. ar Xiv preprint ar Xiv:1801.01944 , 2018.
