TL;DR
This paper introduces AU R-CNN, a novel model that incorporates expert prior knowledge into region definitions for improved facial action unit detection, achieving state-of-the-art results using only static images.
Contribution
The paper proposes AU R-CNN, which encodes expert prior knowledge into region and label definitions, and demonstrates its superiority over existing methods and dynamic models.
Findings
AU R-CNN outperforms existing approaches on BP4D and DISFA datasets.
Static RGB image-based AU R-CNN surpasses models with dynamic information.
AU R-CNN achieves state-of-the-art AU detection performance.
Abstract
Detecting action units (AUs) on human faces is challenging because various AUs make subtle facial appearance change over various regions at different scales. Current works have attempted to recognize AUs by emphasizing important regions. However, the incorporation of expert prior knowledge into region definition remains under-exploited, and current AU detection approaches do not use regional convolutional neural networks (R-CNN) with expert prior knowledge to directly focus on AU-related regions adaptively. By incorporating expert prior knowledge, we propose a novel R-CNN based model named AU R-CNN. The proposed solution offers two main contributions: (1) AU R-CNN directly observes different facial regions, where various AUs are located. Specifically, we define an AU partition rule which encodes the expert prior knowledge into the region definition and RoI-level label definition. This…
Click any figure to enlarge with its caption.
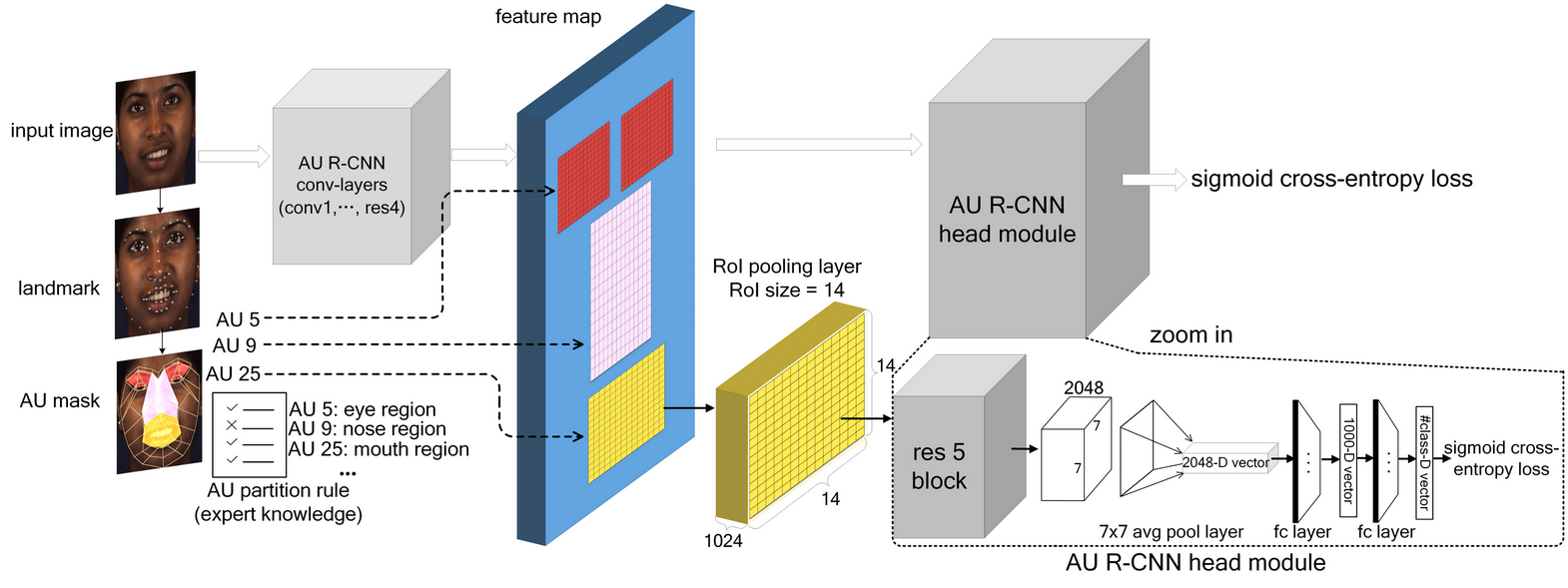 Figure 1
Figure 1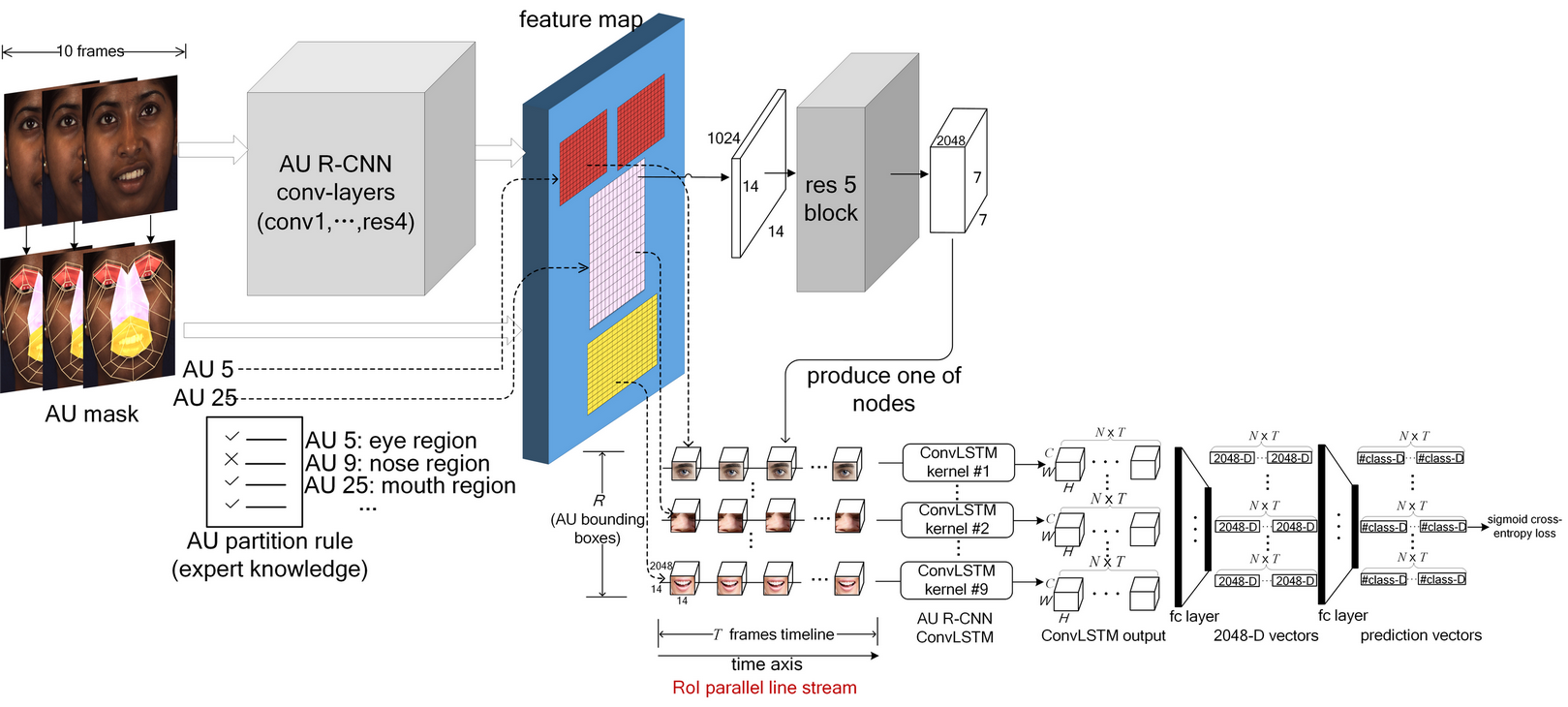 Figure 2
Figure 2 Figure 3
Figure 3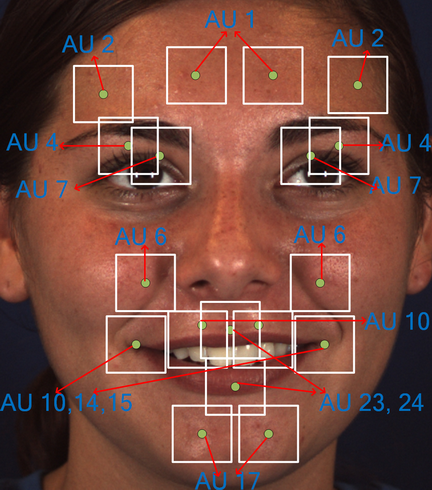 Figure 4
Figure 4 Figure 5
Figure 5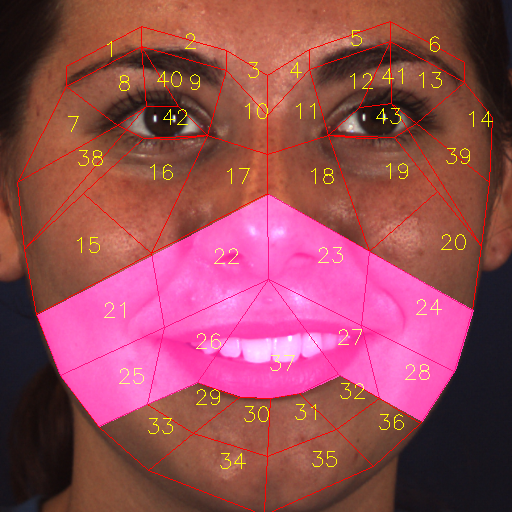 Figure 6
Figure 6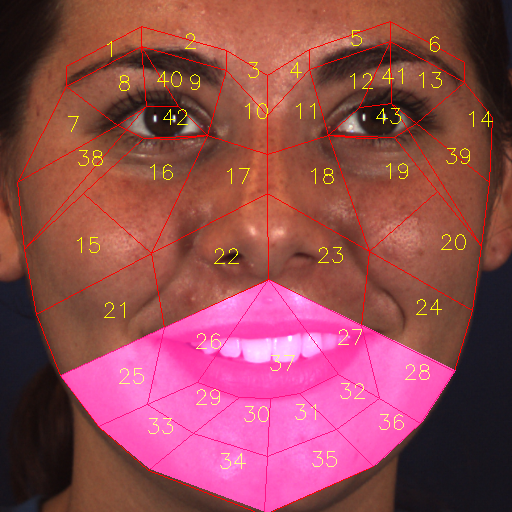 Figure 7
Figure 7 Figure 8
Figure 8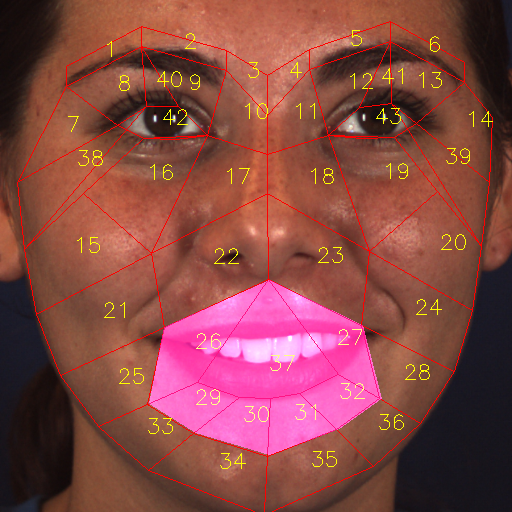 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11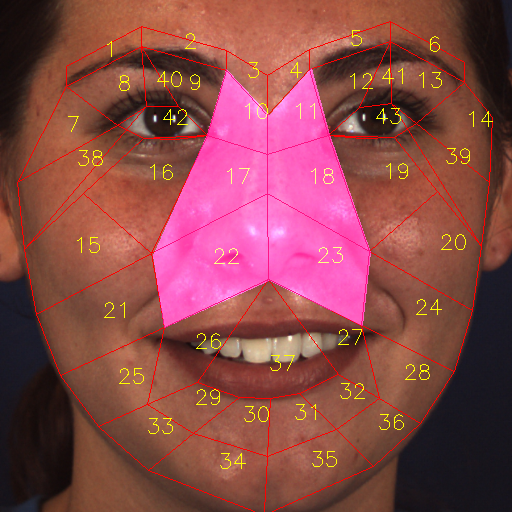 Figure 12
Figure 12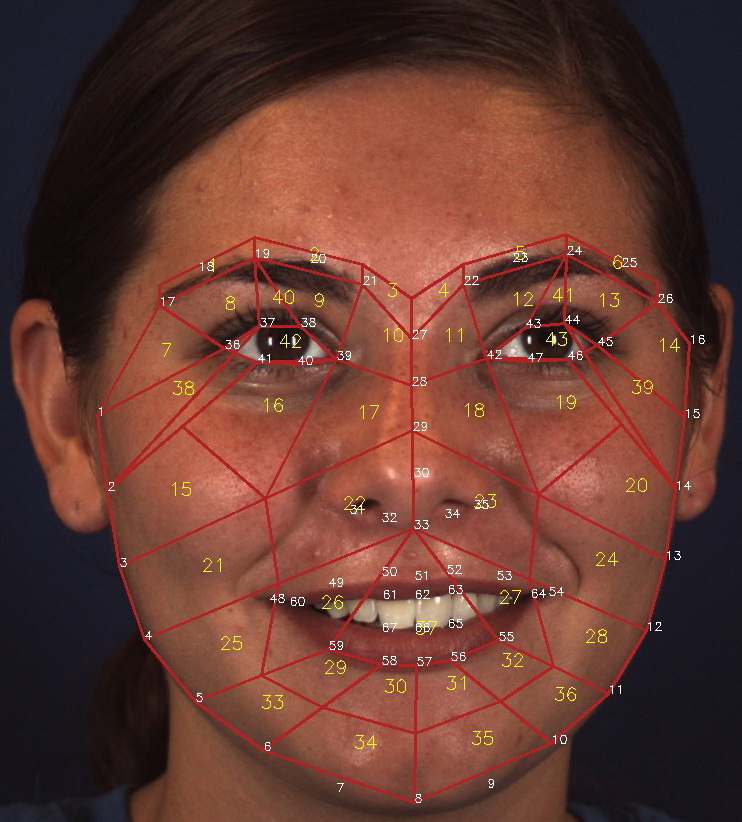 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24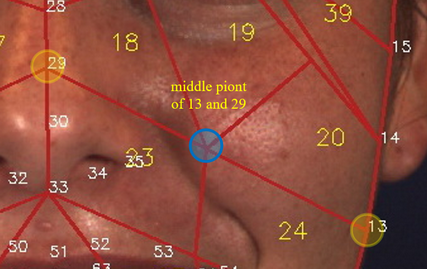 Figure 25
Figure 25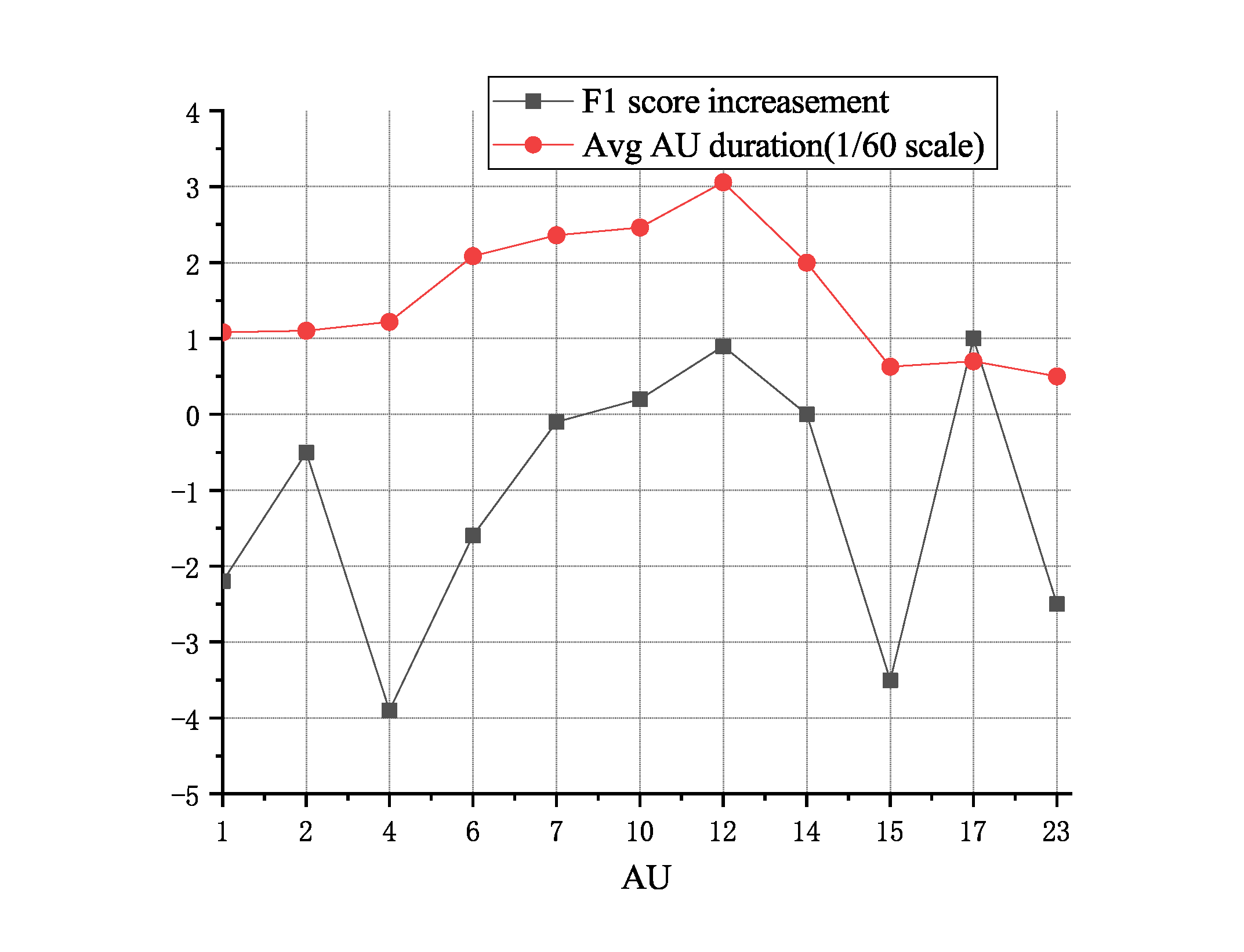 Figure 26
Figure 26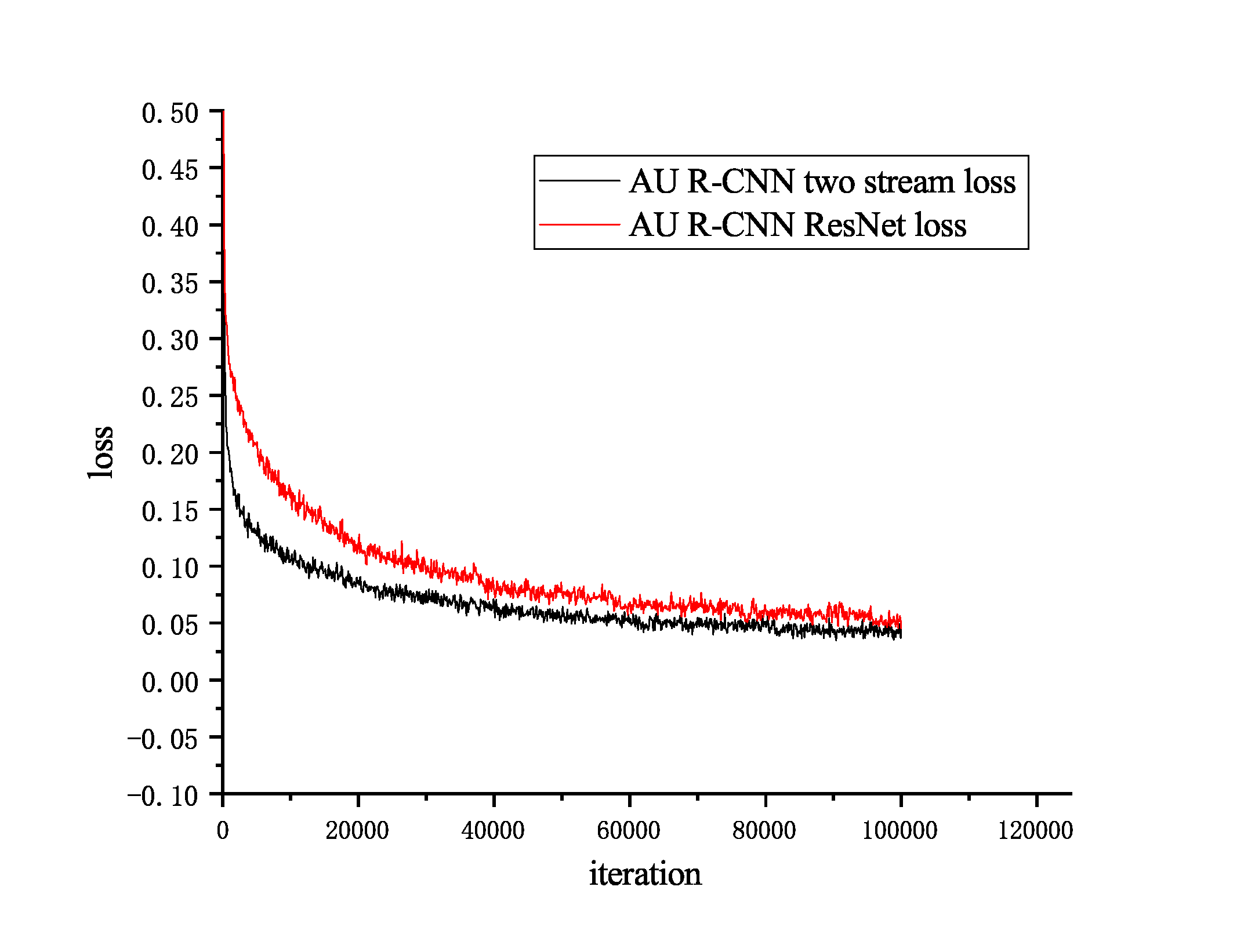 Figure 27
Figure 27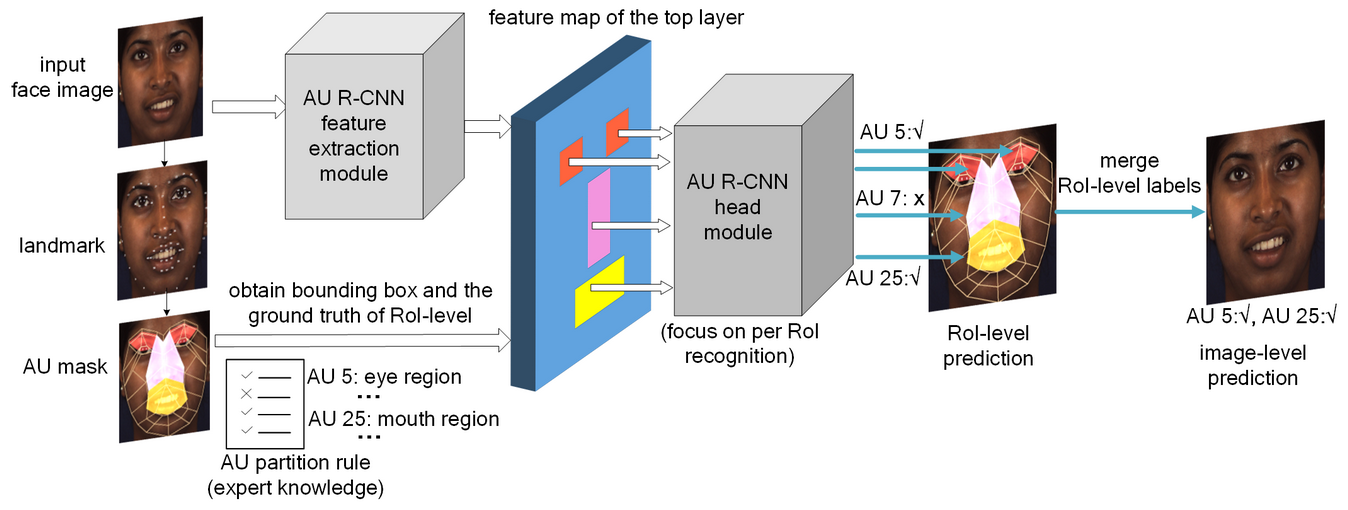 Figure 28
Figure 28| AU number | AU name | Muscle Basis |
| 1 | Inner brow raiser | Frontalis |
| 2 | Outer brow raiser | Frontalis |
| 4 | Brow lowerer | Corrugator supercilii |
| 6 | Cheek raiser | Orbicularis oculi |
| 7 | Lid tightener | Orbicularis oculi |
| 10 | Upper lip raiser | Levator labii superioris |
| 12 | Lip corner puller | Zygomaticus major |
| 14 | Dimpler | Buccinator |
| 15 | Lip corner depressor | Depressor anguli oris |
| 17 | Chin raiser | Mentalis |
| 23 | Lip tightener | Orbicularis oris |
| 24 | Lip pressor | Orbicularis oris |
| 25 | Lips part | Depressor labii inferioris |
| 26 | Jaw drop | Masseter |
| AU group | AU NO | RoI NO |
| # (# ) | AU 1 , AU 2 , AU 5 , AU 7 | 1, 2, 5, 6, 8, 9, 12, 13, 40, 41, 42, 43 |
| # | AU 4 | 1, 2, 3, 4, 5, 6, 8, 9, 12, 13, 40, 41 |
| # | AU 6 | 16, 17, 18, 19, 42, 43 |
| # ( # ) | AU 9 | 10, 11, 17, 18, 22, 23 |
| # ( # ) | AU 10 , AU 11 , AU 12 , AU 13 , AU 14 , AU 15 | 21, 22, 23, 24, 25, 26, 27, 28, 37 |
| # ( # ) | AU 16 , AU 20 , AU 25 , AU26 , AU 27 | 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37 |
| # ( # ) | AU 17 | 29, 30, 31, 32, 33, 34, 35, 36 |
| # ( # , # ) | AU 18 , AU 22 , AU 23 , AU 24 , AU 28 | 26, 27, 29, 30, 31, 32, 37 |
| Model | E2E | ML | RGB | LANDMARK | CONVERGE | VIDEO |
| CNNres | ||||||
| ARvgg16 | ||||||
| ARvgg19 | ||||||
| ARres | ||||||
| ARmean_box | ||||||
| ARFPN | ||||||
| ARConvLSTM | ||||||
| AR2stream | ||||||
| ARCRF | ||||||
| ARTAL |
| AU | LSVM | JPML [13] | DRML [14] | CPM [10] | CNN+LSTM [38] | EAC-Net [4] | OFS-CNN [15] | ROI-Nets [3] | FERA [46] | ARvgg16 | ARvgg19 | ARres |
| 1 | 23.2 | 32.6 | 36.4 | 43.4 | 31.4 | 39 | 41.6 | 36.2 | 28 | 47.5 | 44.8 | [50.2] |
| 2 | 22.8 | 25.6 | 41.8 | 40.7 | 31.1 | 35.2 | 30.5 | 31.6 | 28 | 40.5 | 43.5 | [43.7] |
| 4 | 23.1 | 37.4 | 43 | 43.4 | [71.4] | 48.6 | 39.1 | 43.4 | 34 | 55.1 | 52.2 | 57 |
| 6 | 27.2 | 42.3 | 55 | 59.2 | 63.3 | 76.1 | 74.5 | 77.1 | 70 | 73.8 | 75.7 | [78.5] |
| 7 | 47.1 | 50.5 | 67 | 61.3 | 77.1 | 72.9 | 62.8 | 73.7 | 78 | 76.6 | 75.2 | [78.5] |
| 10 | 77.2 | 72.2 | 66.3 | 62.1 | 45 | 81.9 | 74.3 | [85] | 81 | 82 | 82.7 | 82.6 |
| 12 | 63.7 | 74.1 | 65.8 | 68.5 | 82.6 | 86.2 | 81.2 | [87] | 78 | 85.2 | 85.9 | [87] |
| 14 | 64.3 | 65.7 | 54.1 | 52.5 | 72.9 | 58.8 | 55.5 | 62.6 | [75] | 64.9 | 63.4 | 67.7 |
| 15 | 18.4 | 38.1 | 36.7 | 34 | 34 | 37.5 | 32.6 | 45.7 | 20 | 48.8 | 45.3 | [49.1] |
| 17 | 33 | 40 | 48 | 54.3 | 53.9 | 59.1 | 56.8 | 58 | 36 | 60.6 | 60 | [62.4] |
| 23 | 19.4 | 30.4 | 31.7 | 39.5 | 38.6 | 35.9 | 41.3 | 38.3 | 41 | 43.9 | 46.1 | [50.4] |
| 24 | 20.7 | 42.3 | 30 | 37.8 | 37 | 35.8 | - | 37.4 | - | [49.3] | 48.3 | [49.3] |
| Avg | 35.3 | 45.9 | 48.3 | 50 | 53.2 | 55.9 | 53.7 | 56.4 | 51.7 | 60.7 | 60.3 | [63] |
| AU | CNNres | ARvgg16 | ARvgg19 | ARres | ARmean_box | ARFPN | ARConvLSTM | AR2stream | ARCRF | ARTAL |
| 1 | 45.8 | 47.5 | 44.8 | [50.2] | 45.8 | 46.4 | 48 | 46.6 | 50.1 | 41.3 |
| 2 | 43.2 | 40.5 | 43.5 | [43.7] | 41.1 | 40.7 | 43.2 | 42.1 | 35 | 37.4 |
| 4 | 54.3 | 55.1 | 52.2 | [57] | [57] | 47.5 | 53.1 | 52.4 | 45.2 | 44.5 |
| 6 | 77.4 | 73.8 | 75.7 | [78.5] | 75.1 | 76.4 | 76.9 | 75.4 | 71.4 | 64.4 |
| 7 | 77.9 | 76.6 | 75.2 | [78.5] | 77.7 | 76.9 | 78.4 | 77.3 | 77.7 | 73.6 |
| 10 | 81.8 | 82 | 82.7 | 82.6 | 82.2 | 81.3 | [82.8] | 82.1 | 82.1 | 76.2 |
| 12 | 85.8 | 85.2 | 85.9 | 87 | 86.5 | 85.4 | [87.9] | 87.1 | 86.9 | 80 |
| 14 | 60.8 | 64.9 | 63.4 | [67.7] | 62 | 63.5 | [67.7] | 62.7 | 67.2 | 64.9 |
| 15 | [50] | 48.8 | 45.3 | 49.1 | 48 | 44.9 | 45.6 | 49.6 | 47.6 | 45.7 |
| 17 | 58.3 | 60.6 | 60 | 62.4 | 61.5 | 57.9 | [63.4] | 63.2 | 58.7 | 53.3 |
| 23 | 47.6 | 43.9 | 46.1 | [50.4] | 48.7 | 42.3 | 47.9 | 49.9 | 36.8 | 39.1 |
| 24 | 48.4 | 49.3 | 48.3 | 49.3 | 53.2 | 46.6 | 56.4 | [57.6] | 51.6 | 49.5 |
| Avg | 60.9 | 60.7 | 60.3 | [63] | 61.6 | 59.2 | 62.6 | 62.2 | 59.2 | 55.8 |
| resolution | ||||||||
| AU | CNNres | ARres | CNNres | ARres | CNNres | ARres | CNNres | ARres |
| 1 | 45.6 | 50.1 | 47.4 | 49.3 | 45.8 | 50.2 | 44.3 | 47.5 |
| 2 | 43.6 | 46.5 | 38.3 | 42.1 | 43.2 | 43.7 | 40.1 | 39.2 |
| 4 | 52.2 | 54.6 | 53.3 | 50.0 | 54.3 | 57.0 | 49.5 | 53.5 |
| 6 | 74.9 | 77.7 | 75.7 | 75.2 | 77.4 | 78.5 | 76.3 | 76.9 |
| 7 | 76.3 | 78.3 | 75.7 | 78.7 | 77.9 | 78.5 | 76.4 | 78.6 |
| 10 | 82.5 | 81.7 | 82.4 | 82.3 | 81.8 | 82.6 | 81.5 | 82.7 |
| 12 | 86.5 | 87.5 | 87.2 | 86.5 | 85.8 | 87.0 | 87.5 | 85.5 |
| 14 | 55.4 | 62.1 | 59.5 | 61.9 | 60.8 | 67.7 | 59.5 | 62.0 |
| 15 | 48.0 | 51.2 | 44.1 | 49.2 | 50.0 | 49.1 | 44.9 | 49.6 |
| 17 | 59.9 | 61.8 | 57.5 | 61.4 | 58.3 | 62.4 | 57.4 | 61.3 |
| 23 | 44.7 | 46.2 | 41.2 | 44.9 | 47.6 | 50.4 | 45.6 | 45.1 |
| 24 | 46.9 | 52.3 | 44.5 | 47.7 | 48.4 | 49.3 | 48.2 | 51.1 |
| Avg | 59.7 | 62.5 | 58.9 | 60.8 | 60.9 | 63.0 | 59.3 | 61.1 |
| AU | LSVM | APL [43] | DRML [14] | ROI-Nets [3] | CNNres | ARvgg16 | ARvgg19 | ARres |
| 1 | 10.8 | 11.4 | 17.3 | [41.5] | 26.3 | 24.9 | 26.9 | 32.1 |
| 2 | 10 | 12 | 17.7 | [26.4] | 23.4 | 23.5 | 21 | 25.9 |
| 4 | 21.8 | 30.1 | 37.4 | [66.4] | 51.2 | 55.5 | 59.6 | 59.8 |
| 6 | 15.7 | 12.4 | 29 | 50.7 | 48.1 | 51 | [56.5] | 55.3 |
| 9 | 11.5 | 10.1 | 10.7 | 8.5 | 29.9 | 41.8 | [46] | 39.8 |
| 12 | 70.4 | 65.9 | 37.7 | [89.3] | 69.4 | 68 | 67.7 | 67.7 |
| 25 | 12 | 21.4 | 38.5 | [88.9] | 80.1 | 74.9 | 79.8 | 77.4 |
| 26 | 22.1 | 26.9 | 20.1 | 15.6 | 52.4 | 49.4 | 47.6 | [52.6] |
| Avg | 21.8 | 23.8 | 26.7 | 48.5 | 47.6 | 48.6 | 50.7 | [51.3] |
| AU | CNNres | ARvgg16 | ARvgg19 | ARres | ARmean_box | ARFPN | ARConvLSTM | AR2stream | ARCRF |
| 1 | 26.3 | 24.9 | 26.9 | 32.1 | 31.3 | [39.9] | 26.9 | 34.3 | 24.1 |
| 2 | 23.4 | 23.5 | 21 | 25.9 | 28.3 | [33.3] | 24.4 | 27.4 | 26.5 |
| 4 | 51.2 | 55.5 | 59.6 | [59.8] | 59.3 | 59.3 | 58.6 | 59.4 | 51.7 |
| 6 | 48.1 | 51 | 56.5 | 55.3 | 55.4 | 49.3 | 49.7 | [59.8] | 57.8 |
| 9 | 29.9 | 41.8 | [46] | 39.8 | 38.4 | 32.5 | 34.2 | 42.1 | 33 |
| 12 | 69.4 | 68 | 67.7 | 67.7 | 67.7 | 65.5 | [71.3] | 65 | 65.5 |
| 25 | 80.1 | 74.9 | 79.8 | 77.4 | 77.2 | 72.6 | [83.4] | 77.4 | 71 |
| 26 | 52.4 | 49.4 | 47.6 | 52.6 | 52.8 | 47.9 | 51.4 | 50.1 | [53.5] |
| Avg | 47.6 | 48.6 | 50.7 | 51.3 | 51.3 | 50 | 50 | [51.9] | 47.9 |
| AU group | # 1 | # 2 | # 3 | # 5 | # 7 | # 8 |
| AU index | 1,2,7 | 4 | 6 | 10,12, 14,15 | 17 | 23,24 |
| Avg box area (pixels) | 17785 | 46101 | 54832 | 103875 | 42388 | 38470 |
| Area proportion | 6.8% | 17.6% | 20.9% | 39.6 % | 16.2 % | 14.7 % |
| AU group | # 1 | # 2 | # 3 | # 4 | # 5 | # 6 |
| AU index | 1,2 | 4 | 6 | 9 | 12 | 25,26 |
| Avg box area (pixels) | 17545 | 45046 | 46317 | 48393 | 78131 | 69624 |
| Area proportion | 6.7% | 17% | 17.7% | 18.5 % | 29.8 % | 26.6 % |
| AU group | AU index | Mean boxes coordinates (, , , format) |
| # 1 | 1,2,7 | (30.4, 58.1, 140.3, 222.5), (30.1, 297.2, 140.9, 456.5) |
| # 2 | 4 | (23.9, 57.8, 139, 455.9) |
| # 3 | 6 | (109.4, 79.8, 264.5, 431.8) |
| # 5 | 10,12,14,15 | (198.9, 35.2, 437.0, 472.6) |
| # 7 | 17 | (378.7, 94.5, 510.9, 416.6) |
| # 8 | 23,24 | (282.7,145.5,455.0,368.3) |
| AU group | AU index | Mean boxes coordinates (, , , format) |
| # 1 | 1,2 | (55.5, 71.3, 168.6, 220.0), (53.5, 277.6, 167.6, 431.4) |
| # 2 | 4 | (48.5, 58.7, 165.1, 444.0) |
| # 3 | 6 | (141.4, 86.7, 281.5, 418.9) |
| # 4 | 9 | (107.8, 152.2, 348.8, 352.8) |
| # 5 | 12 | (236.9, 53.5, 433.3, 454.4) |
| # 6 | 25,26 | (316.4, 73.8, 511.0, 433.4) |
| AU | 1 | 2 | 4 | 6 | 7 | 10 | 12 | 14 | 15 | 17 | 23 | 24 |
| Avg duration | 65 | 66 | 73 | 125 | 142 | 148 | 184 | 120 | 38 | 42 | 30 | 49 |
| Seg count | 474 | 380 | 408 | 540 | 569 | 591 | 448 | 571 | 647 | 1203 | 806 | 458 |
| AU | 1 | 2 | 4 | 6 | 9 | 12 | 25 | 26 |
| Avg duration | 55 | 68 | 112 | 115 | 96 | 133 | 154 | 82 |
| Seg count | 320 | 218 | 438 | 340 | 148 | 464 | 600 | 606 |
| Model | Application | Training speed | Feature |
| ARres | Most cases, no need for the video context | Fast | High accuracy and universal application |
| ARFPN | Inappropriate | Medium | Low accuracy and has more layers than ARres |
| ARConvLSTM | Suitable for long AU activity duration case | Slow | Accuracy can be improved in long duration activities |
| AR2stream | Suitable for AUs in small sub-regions especially eye or mouth area | Fast but need pre-compute optical flow | Need pre-compute optical flow first |
| ARCRF | Application in the case of CPU only | Medium and need pre-computed features | Small model parameter size and no need to use GPU |
| ARTAL | Inappropriate | Fast | The training cannot fully converged |
| Chen Ma is currently pursuing the Ph.D. degree with the School of Software Department, Tsinghua University, Beijing, China. He received the Master degree from Beijing University of Posts and Telecommunications, in 2015. His research interests include facial expression analysis, action unit detection, and deep learning interpretability. | |
| Li Chen received the Ph.D. degree in visualization from Zhejiang University, Hangzhou, China, in 1996. She is currently an Associate Professor with the Institute of Computer Graphics and Computer Aided Design, School of Software, Tsinghua University, Beijing, China. Her research interests include data visualization, mesh generation, and parallel algorithm. | |
| Jun-Hai Yong is currently a Professor with the School of Software, Tsinghua University, Beijing, China, where he received the B.S. and Ph.D. degrees in computer science, in 1996 and 2001, respectively. He held a visiting researcher position with the Department of Computer Science, Hong Kong University of Science and Technology, Hong Kong, in 2000. He was a Post-Doctoral Fellow with the Department of Computer Science, University of Kentucky, Lexington, KY, USA, from 2000 to 2002. He received several awards, such as the National Excellent Doctoral Dissertation Award, the National Science Fund for Distinguished Young Scholars, the Best Paper Award of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation, the Outstanding Service Award as an Associate Editor of the Computers and Graphics (Elsevier) journal, and several National Excellent Textbook Awards. His main research interests include computer-aided design and computer graphics. |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
AU R-CNN: Encoding Expert Prior Knowledge into R-CNN for Action Unit Detection
Chen Ma
Li Chen
Junhai Yong
School of Software, Tsinghua University, Beijing 100084, China
Beijing National Research Center for Information Science and Technology (BNRist)
Abstract
Detecting action units (AUs) on human faces is challenging because various AUs make subtle facial appearance change over various regions at different scales. Current works have attempted to recognize AUs by emphasizing important regions. However, the incorporation of expert prior knowledge into region definition remains under-exploited, and current AU detection approaches do not use regional convolutional neural networks (R-CNN) with expert prior knowledge to directly focus on AU-related regions adaptively. By incorporating expert prior knowledge, we propose a novel R-CNN based model named AU R-CNN. The proposed solution offers two main contributions: (1) AU R-CNN directly observes different facial regions, where various AUs are located. Specifically, we define an AU partition rule which encodes the expert prior knowledge into the region definition and RoI-level label definition. This design produces considerably better detection performance than existing approaches. (2) We integrate various dynamic models (including convolutional long short-term memory, two stream network, conditional random field, and temporal action localization network) into AU R-CNN and then investigate and analyze the reason behind the performance of dynamic models. Experiment results demonstrate that only static RGB image information and no optical flow-based AU R-CNN surpasses the one fused with dynamic models. AU R-CNN is also superior to traditional CNNs that use the same backbone on varying image resolutions. State-of-the-art recognition performance of AU detection is achieved. The complete network is end-to-end trainable. Experiments on BP4D and DISFA datasets show the effectiveness of our approach. The implementation code is available in https://github.com/sharpstill/AU_R-CNN.
keywords:
Action unit detection, Expert prior knowledge, R-CNN, Facial Action Coding System
††journal: Journal of Neurocomputing
1 Introduction
Facial expressions reveal people’s emotions and intentions. Facial Action Coding System (FACS) [1] has defined 44 action units (AUs) related to the movement of specific facial muscles; these units can anatomically represent all possible facial expressions, considering the crucial importance of facial expression analysis. AU detection has been studied for decades and its goal is to recognize and predict AU labels on each frame of the facial expression video. Automatic detection of AUs has a wide range of applications, such as human-machine interfaces, affective computing, and car-driving monitoring.
Since the human face may present complex facial expression, and AUs appear in the form of subtle appearance changes on the local regions of face, that current classifiers cannot easily recognize. This problem is the main obstacle of current AU detection systems. Various approaches focus on fusing with extra information in convolutional neural networks (CNNs), e.g. , the optical flow information [2] or landmark information [3, 4], to help AU detection systems capture such subtle facial expressions. However, these approaches have high detection error rates, due to the lack of using prior knowledge. Human can easily recognize micro facial expression by their long accumulated experience. Hence, integrating the expert prior knowledge of FACS [1] to AU detection system is promising. With fusing of this prior knowledge, our proposed approach addresses the AU detection problem by partitioning the face to easily recognizable AU-related regions, then the prediction of each region is merged to obtain the image-level prediction. Fig. 1 shows our approach’s framework, we design an “AU partition rule” to encode the expert prior knowledge. This AU partition rule decomposes the image into a bunch of AU-related bounding boxes. Then AU R-CNN head module focuses on recognizing each bounding box. This design can well address the three problems of existing approaches.
First, existing approaches [5, 6, 7, 8, 9, 10, 11, 12, 13, 4, 3] have been proposed to extract features near landmarks (namely, “AU center”), which is trivially defined and leading to emphasize on inaccurate places. AUs occur in regions around specific facial muscles that may be inaccurately located on a landmark or an AU center due to the limitation of the facial muscle’s activity place. Thus, most AUs limit their activities in specific irregular regions of a face, and we call this limitation the “space constraint”. Our approach reviews the FACS and designs the “AU partition rule” to represent this space constraint accurately. This well-designed “AU partition rule” is called the “expert prior knowledge” in our approach which is built on the basis of the space-constraint for regional recognition, so it reduces the detection error rate caused by inaccurate landmark positioning (see experiment Section 4.3.1).
Second, existing approaches still use CNNs to recognize a full face image [14, 4, 3, 15] and do not learn to recognize individual region’s labels, which may not use the correct image context to detect. For example, a CNN may use an unreliable context, such as mouth area features, to recognize eye-area-related AUs (e.g. AU 1, AU 2). Recent success in the object detection model of Fast/Faster R-CNN [16, 17] has inspired us to utilize the power of R-CNN based models to learn the accurate regional features of AUs under space constraints. We propose AU R-CNN to detect AUs only from AU-related regions by limiting its vision inside space-constrained areas. In this process, unrelated areas can be excluded to avoid interference, which is key to improve detection accuracy.
Third, the multi-label learning problem in AU detection can be addressed at a fine-grained level under AU-related RoI space constraint. Previous approaches [14, 3, 4] adopt the sigmoid cross-entropy cost function to learn the image-level multi-label and emphasize the important regions, but such a solution is not sufficiently fine-grained. The multi-label relationship can be captured more accurately in the RoI-level supervised information constraint. Most facial muscles can show diverse expressions that lead to RoI-level multi-label learning. For example, AU 12 (lip corner puller) is often present in a smile, which may also occur together with AU 10 (upper lip raiser), and deepen the nasolabial fold, as shown in Fig. 2. Therefore, in the definition of the AU partition rule, AUs are grouped by the definition of FACS and related facial muscles. Each AU group shares the same region, and such AU group can be represented by a binary vector with element of 1 if the corresponding AU occurs in the ground truth and 0 otherwise. The sigmoid cross-entropy cost function is adopted in the RoI-level learning. In our experiments, we determine that using RoI-level labels to train and predict and then merging the RoI-level prediction result to that of the image level surpasses the previous approaches.
Furthermore, we analyze the effects of fusing temporal features into AU R-CNN (dynamic model extension). We conduct complete comparison experiments to investigate the effects of integrating dynamic models, including convolutional long short-term memory (ConvLSTM) [18], two-stream network [19], general graph conditional random field (CRF) model, and TAL-Net [20], into AU R-CNN. We analyze the reason behind such effects and the cases under which the dynamic models are effective. Our AU R-CNN with only static RGB images and no optical flow achieves 63% average F1 score on BP4D, and outperforms all dynamic models. The main contributions of our study are as follows.
(1) AU R-CNN is proposed to learn regional features adaptively by using RoI-level multi-label supervised information. Specifically, we encode the expert prior knowledge by defining the AU partition rule, including the AU groups and related regions, according to FACS [1].
(2) We investigate the effects of integrating various dynamic models, including two-stream network, ConvLSTM, CRF model and TAL-Net, in the experiments of BP4D [21] and DISFA [22] databases. The reasons behind such experiment effects and the effective cases are analyzed. The experiment results show that our static RGB image-based AU R-CNN achieves the best average F1 score in BP4D and is close to the performance of the best dynamic model in DISFA. Our approach achieves state-of-the-art performance in AU detection.
2 Related Work
Extensive works on AU detection have been proposed to extract effective facial features. The facial features in AU detection can be grouped into appearance and geometric features. Appearance features portray the local or global changes in facial components. Most popular approaches in this category adopt Haar feature [23], local binary pattern [24], Garbor wavelets [25, 26], and canonical appearance feature [27]. Geometric features represent the salient facial point or skin changing direction or distance. Geometric changes can be measured by optical flows [28] or displacement of facial landmark points [29, 27]. Landmark plays an important role in geometry approaches, and many methods have been proposed to extract features near landmark points [5, 6, 7, 8, 9, 10, 11, 12, 30]. Fabian et al. [31] proposed a method that combines geometric changes and local texture information. Wu and Ji [32] investigated the combination of facial AU recognition and facial landmark detection. Zhao et al. [13] proposed joint patch and multi-label learning (JPML) for AU detection with a scale-invariant feature transform descriptor near landmarks. These traditional approaches focus on extracting handcraft features near landmark points. With the recent success of deep learning, CNN has been widely adopted to extract AU features [15]. Zhao et al. [14] proposed a deep region and multi-label learning (DRML) network to divide the face images into blocks and used individual convolutional kernels to convolve each block. Although this approach treats each face as a group of individual parts, it divides blocks uniformly and does not consider the FACS knowledge, thereby leading to the poor performance. Li et al. [4] proposed Enhancing and Cropping Net (EAC-Net), which intends to give significant attention to individual AU centers. However, this approach defines the AU center trivially and it uses image-level context to learn. Its CNN backbone may use incorrect context to classify and the lack of RoI-level supervised information can only give coarse guidance. Song et al. [33] studied the sparsity and co-occurrence of AUs. Han et al. [15] proposed an Optimized Filter Size CNN (OFS-CNN) to simultaneously learn the filter sizes and weights of all conv-layer. Other related problems, including the effects of dataset size [34], the action detection in videos [35], the pose-based feature of action recognition [36], and generalized multimodal factorized high-order pooling for visual question answering [37] have also been studied. Previous works have mainly focused on landmark-based regions or learning multiple regions with convolutional kernels separately. Detection with the expert prior knowledge and utilizing RoI-level labels are important but have been undervalued in previous methods.
Researchers have utilized temporal dependencies in video sequences over the last few years. Romero et al. [2] advocated a two-stream CNN model that combines optical flow and RGB information, and their result was promising. However, they used one binary classification model for each AU, which caused their approach to be time consuming to train and yield numerous model parameters. The CNN and LSTM hybrid network architectures are studied in Chu et al. [38], Li et al. [3] and He et al. [39], which feed the CNN-produced features to LSTM to improve performance by capturing the temporal relationship across frames. However, their solutions are inefficient because they are not an end-to-end networks. In our experiments, we also investigate the effects of using temporal feature relationships in the time axis of videos. We use various dynamic models (including two-stream network, ConvLSTM etc.) that are incorporated into AU R-CNN. Such temporal dependency cannot always improve performance in all cases (Section 4.5).
Unlike existing approaches, AU R-CNN is a unified end-to-end learning model that encodes expert prior knowledge and outperforms state-of-the-art approaches. Thus, it is a simple and practical model.
3 Proposed Method
3.1 Overview
AU detection can be considered a multi-label classification problem. The most popular image classification approach is the CNN, and the basic assumption for a standard CNN is the shared convolutional kernels for an entire image. For a highly structural image, such as a human face, a standard CNN will fail to capture subtle appearance changes. To address this issue, we propose AU R-CNN, in which expert prior knowledge is encoded. We review FACS [1] and define a rule (“AU partition rule”) for partitioning a face on the basis of FACS knowledge using landmarks. With this rule, we can treat each face image as a group of separate regions and AU R-CNN is proposed to recognize each region. The overall procedure is composed of two steps. First, the face image’s landmark points are obtained, and then the face is partitioned into regions on the basis of the AU partition rule and the landmark coordinates. The “AU masks” are generated in this step, and the expert prior knowledge is encoded into the AU masks. Second, the face images are input into the AU R-CNN’s backbone, the produced feature map and the minimum bounding boxes of the AU mask are then fed into AU R-CNN’s RoI pooling layer together. The final fully-connected (fc) layer’s output can be treated as classification probabilities. The image-level ground truth label is also partitioned to RoI-level in the learning. After AU R-CNN is trained over, the prediction is performed on the RoI-level. Then, we use a “bit-wise OR” operator to merge RoI-level prediction labels to image-level ones. In this section, we introduce the AU partition rule and then AU R-CNN. We also introduce a dynamic model extension of AU R-CNN in Section 3.4.
3.2 AU partition rule
AUs appear in specific regions of a face but are not limited to facial landmark points; previous AU feature extraction approaches directly use facial landmarks or offsets of the landmarks as AU centers [4, 13, 3], but the actual places where activities occur may be missed, and sensitivity of the system may be increased. Instead of identifying the AU center, we adopt the domain-related expertise to guide the partition of AU-related RoIs. The first step is to utilize the dlib [40] toolkit to obtain 68 landmark points. The landmark points provide rich information about the face, and the landmark points help us focus on areas where AUs may occur. Fig. 2 shows the region partition of a face, and several extra points are calculated using 68 landmarks. A typical example is shown in Fig. 2 right. The face image is partitioned into 43 basic RoIs using landmarks. Then, on the basis of FACS definition111https://www.cs.cmu.edu/~face/facs.htm (Table 1) and the anatomy of facial muscle structure222https://en.wikipedia.org/wiki/Facial_muscles, the AU partition rule and the AU mask can be defined for representing the expert prior knowledge. For this purpose, we classify AUs into four cases.
(1) The RoIs defined in Fig. 2 are the basic building blocks, named basic RoIs. One AU contains multiple basic RoIs; hence, multiple basic RoIs are selected to be grouped and assigned to AUs by RoI numbers (Table 2). The principle of such RoI assignment is the FACS muscle definition (Table 1). The region of the grouped RoIs is called the “AU mask”.
(2) Most muscles can present multiple AUs—in other words, some AUs can co-occur in the same place. For example, AU 12 (lip corner puller) and AU 10 (upper lip raiser) are often present together in a smile, which requires lifting of the muscle and may also deepen the nasolabial fold, as shown in Fig. 4(e). Therefore, we group AUs into 8 “AU groups” on the basis of AU-related muscles defined in FACS (Table 1) and the AU co-occurrence statistics of the database. Each AU group has its own mask, whose region is shared by the AUs. One AU group contains multiple basic RoIs, which are defined in Fig. 2, to form an AU mask (Fig. 4).
(3) Some AU groups are defined in a hierarchical structure, that is, these AU group masks have a broad area, which may contain other AU groups’ small areas. For example, AU group # 6 contains AU group # 7 (Fig. 4). The reason behind such a design is that AU group # 7 (AU 17) is caused by the movement of the mentalis (Table 1), which is in the chin. The bone structure of the chin makes it a relatively stable area, which limits the possible occurrence of AU 17. Therefore, we can define a detailed area in AU group # 7 (Fig.4(g)). However, AU group # 6 consists of AU 16, AU 20, AU 25 and AU 26, and it is located in the mouth area. The mouth area contains several possible movement locations (mouth open, mouth close, smell, laugh, etc.), and the chin area follows mouth opening and closing. Therefore we define AU group # 6 to contain the area of AU group # 7 (Fig. 4(f)). The partition of the face image naturally leads to the RoI-level label assignment. In this case, the AU group # 6 must contain RoI-level labels of AU group # 7. We define operator “label fetch” #7#6 to enable AU group # 6 to fetch labels from AU group #7 (Table 2).
(4) Some AU groups have overlapping areas with other AU groups’ areas. For example, AU group # 3’s mask, which is across the nose area (Fig. 4(c)), will also contain labels of AU group # 4 (Fig. 4(d)); thus, we also use the operator “label fetch” #4#3 to fetch labels from AU group # 4 in this case. (Table 2).
In summary, Table 2 and Fig. 4 show the AU partition rule and the AU mask. The AU group definition is related not only to the RoI partition of the face, but also to the RoI-level label assignment.
3.3 AU R-CNN
AU R-CNN is composed of two modules, namely, feature extraction and head modules. This model can use ResNet [41] or VGG [42] as its backbone. Here, we use ResNet-101 to illustrate (Fig. 3). The feature extraction module comprises conv-layers that produce the feature maps (ResNet-101’s conv1, bn1, res2, res3, res4 layers), and the head module includes an RoI pooling layer and the subsequent top layers (res5, avg-pool, and fc layers). After AU masks are obtained, unrelated areas can be excluded. However, each AU mask is an irregular polygon area, which means it cannot be directly fed into the fc layer. Therefore, we introduce the RoI pooling layer originally from Fast R-CNN [16]. The RoI pooling layer is designed to convert the features inside any rectangle RoI (or bounding box) into a small feature map with a fixed spatial extent of . To utilize the RoI pooling layer, each AU mask is converted into a minimum bounding box (named “AU bounding box”) around the mask to input 333AU group #1 contains two separate symmetrical regions, thus it contains two bounding boxes, which results in total 9 AU bounding boxes, one more than AU group number.(Fig. 6). The RoI pooling layer needs a parameter named “RoI size”, indicates the RoI’s height and width after pooling. In our experiment, we set RoI size to in ResNet101 backbone and in VGG-16 and VGG-19 backbone.
Object detection networks, such as Fast R-CNN, aim to identify and localize the object. Benefiting from the design of the AU mask, we have strong confidence in where the AUs should occur; thus, we can concentrate on what the AUs are. Fig. 3 depicts the AU R-CNN’s forward process. In the RoI pooling layer, we input the AU bounding box and feature map (The bounding box coordinates and feature map are usually smaller than the input image resolution). We treat the last fully connected layer’s output vector as predicted label probabilities. The total AU category number we wish to discriminate is set as 444 in BP4D database and in DISFA database.; the number of bounding boxes in each image is 555 in BP4D database (Fig. 6) and in DISFA database (since DISFA doesn’t contain AU group# 7 and AU group # 8).; the ground truth , indicates the -th element of , where denotes AU is inactive in bounding box , and AU is active if . The ground truth must satisfy the AU partition rule’s space constraint: if AU does not belong to bounding box ’s corresponding AU group (Fig. 6 and Table 2). The RoI-level prediction probability is . Given multiple labels inside each RoI (e.g. AU 10 and AU 12 often occur together in the mouth area), we adopt the multi-label sigmoid cross-entropy loss function, namely,
[TABLE]
Unlike ROI-Nets [3] and EAC-Net [4], AU R-CNN has considerably fewer parameters due to the sharing of conv-layer in the feature extraction module, which leads to space and time saving. The RoI pooling layer and RoI-level label also help improve classifier performance through the space constraint and supervised information of the RoIs.
In the inference stage, the last fc layer’s output is converted to a binary integer prediction vector using the threshold of zero (the elements that greater than 0 set to 1, others set to 0). Multiple RoIs’ prediction results are merged via a “bit-wise OR” operator to obtain the image-level label. We report F1 scores of this merged image-level prediction results in Section 4.
3.4 Dynamic model extension of AU R-CNN
AU R-CNN can use only static RGB images to learn. A natural extension is to use the RoI feature map extracted from AU R-CNN to model the temporal dependency of RoIs across frames. In this extension, we can adopt various dynamic models to observe RoI-level appearance changes (Experiments are shown in Section 4.5). In this section, we introduce one extension that integrates ConvLSTM [18] into the AU R-CNN architecture.
Fig. 5 shows the AU R-CNN integrated with ConvLSTM architecture. In each image, we first extract nine AU group RoI features () corresponding to nine AU bounding boxes of Fig. 6 from the last conv-layer. To represent the evolvement of facial local regions, we construct an RoI parallel line stream with nine timelines. The timeline is constructed by skipping four frames per time-step in the video to eliminate the similar frames. In total, we set 10 time-steps for each iteration. In each timeline, we connect the RoI at the current frame to the corresponding RoI at the adjacent frames, e.g. the mouth area has only temporal correlation to the next/previous frame’s mouth area. Therefore, each timeline corresponds to an AU bounding box’s evolution across time. Nine ConvLSTM kernels are used to process on the nine timelines. The output of each ConvLSTM kernel are fed into two fc layers to produce the prediction probability. More specifically, Let’s denote the mini-batch size as . the time-steps as , the channel, height and width of RoI feature as , and respectively. The concatenation of ConvLSTM’s all time-step’s output is a five-dimensional tensor of shape . We reshape this tensor to a two-dimensional tensor of shape , the first dimension is treated as the mini-batch of shape . This reshaped tensor is input to two fc layers to get a prediction probability vector of shape , where denotes AU category number. We adopt the sigmoid cross-entropy loss function to minimize difference between the prediction probability vector and ground truth, which is the same as Eq. 1. In the inference stage, we use the last frame’s prediction result of the 10-frame video clip to evaluate. This model, named “ARConvLSTM”, is trained together with AU R-CNN in an end-to-end form.
The introduction of the dynamic model extension brings new issues, as shown in our experiments (Section 4.5), the dynamic model cannot always improve overall performance as expected. We use database statistics and a data visualization technique to identify the effective cases. Various statistics of BP4D and DISFA databases are collected, including the AU duration of each database and the AU group bounding box areas. Liet al. [4] found that the occurrence of AUs in the database has the influence of static-image-based AU detection classifiers. However, in the ConvLSTM extension model, the average AU activity duration of videos and ARConvLSTM classification performance are correlated. Fig. 9 provides an intuitive figure of such correlation, when the AU duration increases at high peak, the performance of ARConvLSTM can be always improved. Therefore, in situations such as long-duration activities, ARConvLSTM can be adopted to improve the performance. Other dynamic models can also be integrated into AU R-CNN, including the two-stream network, TAL-Net, and the general graph CRF model. In Section 4.5, we collect the experiment results and analyze various dynamic models in detail.
4 Experiments and Results
4.1 Settings
4.1.1 Dataset description
We evaluate our method on two datasets, namely, BP4D dataset [21] and DISFA dataset [22]. For both datasets, we adopt a 3-fold partition to ensure that the subjects are mutually exclusive in the train/test split sets. AUs that present more than base rate are included for evaluation. In total, we select 12 AUs on BP4D and 8 AUs on DISFA to report the experiment results.
(1) BP4D [21] contains young adults of different races and genders ( females and males). We use videos ( participants videos) captured in total, which result in 140000$$ valid face images. We select positive samples as those with AU intensities equal to or higher than A-level, and the rest are negative samples. We use 3-fold splits exactly the same as [4, 3] partition to ensure that the training and testing subjects are mutually exclusive. The average AU activity duration of all videos in BP4D and the total activity segment count are shown in Table 14. The average AU mask bounding box area is provided in Table 9.
(2) DISFA [22] contains subjects. We use 260000$$ valid face images and 54 videos (27 videos captured by left camera and 27 videos captured by right camera). We also use the 3-fold split partition protocol in the DISFA experiment. The average AU activity duration of all videos in DISFA and the total activity segment count are shown in Table 15. The average AU mask bounding box area is given in Table 10.
4.1.2 Evaluation metric
Our task is to detect whether the AUs are active, which is a multi-label binary classification problem. Since our approach focuses on RoI prediction for each bounding box (Fig. 6), the RoI-level prediction is a binary vector with elements, where denotes the total AU category number we wish to discriminate. We use the image-level prediction to evaluate, which is obtained by using a “bit-wise OR” operator for merging an image’s RoI-level predictions. After obtaining the image-level prediction, we directly use the database provided image-level ground truth labels to evaluate, which are binary vectors with elements equal 1 for active AUs and equal 0 for inactive AUs. The F1 score can be used as an indicator of the performances of the algorithms on each AU and is widely employed in AU detection. In our evaluation, we compute frame-based F1 score [9] for 12 AUs in BP4D and 8 AUs in DISFA on image-level prediction. The overall performance of the algorithm is described by the average F1 score(denoted as Avg.).
4.1.3 Compared methods
We collect the F1 scores of the most popular state-of-the-art approaches that used the same 3-fold protocol in Table 4 and Table 7 to compare our approaches with other methods. These techniques include a linear support vector machine (LSVM), active patch learning (APL [43]), JPML [13], a confidence-preserving machine (CPM [10]), a block-based region learning CNN (DRML [14]), an enhancing and cropping nets (EAC-net [4]), an ROI adaption net (ROI-Nets [3]), and LSTM fused with a simple CNN (CNN+LSTM [38]), an optimized filter size CNN (OFS-CNN [15]). We also conduct complete control experiments of AU R-CNN in Table 5 and Table 8, including ResNet-101 based traditional CNN that classifies the entire face images (CNNres), ResNet-101 based AU R-CNN (ARres), VGG-16 based AU R-CNN (ARvgg16), VGG-19 based AU R-CNN (ARvgg19), mean bounding boxes version AU R-CNN (ARmean_box), AU R-CNN incorporate with Feature Pyramid Network [44](ARFPN), AU R-CNN integrated with ConvLSTM [18] (ARConvLSTM), AU R-CNN with optical flow and RGB feature fusion two-stream network architecture [19](AR2stream), general graph CRF with features extracted by AU R-CNN(AR), and AU R-CNN with a temporal action localization in video network, TAL-Net [20](ARTAL). We use ResNet-101 based CNN(CNNres) as our baseline model. The details of the compared models are summarized in Table 3.
4.1.4 Implementation details
We resize the face images to after cropping the face areas. Each image and bounding boxes are horizontally mirrored randomly before being sent to AU R-CNN for data augmentation. We subtract the mean pixel value from all the images in the dataset before sending to AU R-CNN. We use dlib [40] to landmark faces, and the landmark operator is consequently time consuming. We cache the mask in the memcached database to accelerate speed in later epochs. The VGG and ResNet-101 backbones of AU R-CNN use pre-trained ImageNet ILSVRC dataset [45] weights to initialize. AU R-CNN is initialized with a learning rate of 0.001 and further reduced by a factor of 0.1 after every 10 epochs. In all experiments, we select momentum stochastic gradient descent to train AU R-CNN for 25 epochs and set momentum to 0.9 and weight decay to 0.0005. The mini-batch size is set to 5.
4.2 Conventional CNN versus AU R-CNN
AU R-CNN is proposed for adaptive regional learning in Section 3.3. Thus, our first experiment aims to determine whether it can perform better than the baseline conventional CNN, which uses entire face images to learn. We suppose that by learning the adaptive RoIs separately, recognition capability can be improved. We train CNNres and ARres on the BP4D and DISFA datasets using the same ResNet-101 backbone for comparison. Twelve AUs in BP4D and eight AUs in DISFA are used; therefore, ARres and CNNres use the sigmoid cross-entropy loss function, as shown in Eq. 1. Both models are based on static images. During each iteration, we randomly select five images to comprise one mini-batch to train and initialize the learning rate to 0.001.
Fig. 7 demonstrates the example detection results of our approach. Table 5 and Table 8 show the BP4D and DISFA results, in which the margin is larger in DISFA (3.69%) than in BP4D (2.1%). These results can be attributed to the relatively lower resolution images in DISFA, which cause ARres to benefit more. We also show that AU R-CNN performs efficiently with varying image resolutions. Experiments have been conducted to compare the proposed AU R-CNN and baseline CNN with the same ResNet-101 backbone on the BP4D database with different resolutions of the input image. Table 6 shows the result, and the resolutions of images are set to , , , and . Most AU results prefer AU R-CNN model by observing subtle cues of facial appearance changes. In , although the resolution is nearly half of that in , the performance is close to that in . This similarity leads to efficient detection when using . But in the highest resolution , the F1 score is lower than that of , we believe this performance drop can be attribute to two possible reasons. (1) As pointed out by Han et al. [15], when the image resolution increases to , the receptive field covers a smaller actual area of the entire face when using the same convolution filter size. The smaller receptive field deteriorates the vision. (2) Larger images produce larger feature maps before RoI pooling layer in ARres, or larger feature maps before the final avg pooling layer in CNNres. The increase of feature map size also increases each pooling grid cell’s covered size dramatically in RoI pooling/avg pooling layer, which has negative impact on high level features. Regardless of the overall improvement of AU R-CNN across the 12 AUs. In AU 10 and AU 12, CNN and AU R-CNN obtain similar results. One explanation is that AU 10 and AU 12 have relatively sufficient training samples compared with other AUs.
In the DISFA dataset (Table 8, Table 7), ARres outperforms CNNres in six out of eight AUs. The two remaining AUs are AU 12 and AU 25. As shown in Table 10, AU 12 and AU 25 have the largest area proportions (29.8 % and 26.6 %) on the face images. In BP4D and DISFA, AU 1 (inner brow raiser) has a significant improvement in ARres because of the relatively small area on the face.
4.3 ROI-Nets versus AU R-CNN
Our proposed AU R-CNN in Section 3.3 is designed to recognize local regional AUs in static images under AU mask. Previous state-of-the-art static image AU detection approach ROI-Nets [3] also focuses on regional learning. It attempts to learn regional features by using individual conv-layers over regions centered on AU center (Fig. 8). The two models are based on static images, whereas our AU R-CNN uses the shared conv-layer in feature extraction module and RoI-level supervised information. This choice saves space and time, and provides accurate guidance. Instead of using the concept of the AU center area, we introduce the AU mask. We believe that AU mask can preserve more context information than cropping the bounding box from AU center. ROI-Nets adopts VGG-19 as backbone. For fair comparison, we adopt VGG-19 based AU R-CNN (denoted as ARvgg19) to compare. ARvgg19 outperforms ROI-Nets in 8 out of 12 AUs in BP4D (Table 4).
The interesting part lies in AU 23 (lip pressor) and AU 24 (lip tighter), in which ARvgg19 significantly outperforms ROI-Nets by 7.8% and 10.9%, respectively. This superiority is because the lip area is a relatively small area on face; AU R-CNN uses AU mask and RoI-level label so that it can concentrate on this area. This fact can be verified from Table 9 that the AU 23 and AU 24 bounding box only occupies 14.7% area of the face image. Other typical cases are AU 1, AU 2, and AU 4, which are located in the areas around eyebrows and eyes; ARvgg19 outperforms ROI-Nets by 8.5%, 11.9%, and 8.8%, respectively. In AU 6 (cheek raiser, see Fig. 4(c)), AU 10, AU 12, AU 14, and AU 15 results, ROI-Nets and AU R-CNN achieve close results. These areas occupy relatively large proportions in the image (Table 9), and ROI-Nets focuses on the central large area of the image. The experiment in DISFA dataset (Table 7) demonstrates the similar result. The above comparisons prove that, AU R-CNN better expresses the classification information of local regions than ROI-Nets. We also found that the ResNet-based AU R-CNN (ARres) outperforms ARvgg19 in the BP4D and DISFA datasets, and achieves the best performance over all static-image-based approaches. For better representation of AU features, we conduct our remaining experiments on the basis of ARres features.
We further evaluate the inference time of our approach, LCN (CNN with locally connected layer [47]) and ROI-Nets on a Nvidia Geforce GTX 1080Ti GPU. We run each network for 20 trails over iterations with the mini-batch size sets to 1; then we evaluate the running time for each iteration, and finally compute the mean and standard deviation over the 20 trials. The inference time is showed in Table 11, we can see our approach benefits from the RoI pooling layer’s parallel computing over multiple bounding boxes, its inference time is lower than LCN and ROI-Nets. The RoI-Nets adopt 20 individual conv-layers for 20 bounding boxes, thus it results worst performance.
4.3.1 AU R-CNN + Mean Box
The computation of each image’s precise landmark point location is time consuming. We believe it is enough to use the “mean” AU bounding box coordinates to represent all images’ bounding boxes. In this section, we collect the average coordinates of all images of nine AU group bounding boxes in each database to form a unified “mean box” across all images (Table 12 and Table 13). We use this “mean box” coordinates to replace the real bounding box coordinates calculated from the landmark in each image to evaluate. The experiment results are shown in Table 5 and Table 8, denoted as ARmean_box. Although most images of BP4D and DISFA dataset are the frontal face, the deviation of mean bounding box coordinates from real box location exists. However, the F1 score is remarkably close to ARres, because the RoI pooling layer in AU R-CNN performs a coarse spatial quantization. This performance similarity demonstrates that AU R-CNN is robust to small landmark location error, and the computation consumption of each image’s landmark can be saved via using “mean box”.
4.4 AU R-CNN + Feature Pyramid Network
In the previous sections, we use the single scale ( smaller scale) RoI feature to detect. Feature Pyramid Network (FPN) [44] is a popular architecture for leveraging a CNN’s pyramidal features in the object detection field, which has semantics from low to high levels. In this experiment, FPN is integrated into AU R-CNN’s backbone as feature extractor that extracts RoI features from the feature pyramid. The assignment of an RoI of width and height to the level of FPN is as follows [44]:
[TABLE]
The experiment results (denoted as ARFPN) are shown in Table 5 and Table 8. The ARFPN performs worse than the single-scale RoI feature counterpart ARres. This is because AU R-CNN needs high-level RoI features to classify AUs well and does not need to perform box coordinate regression. Furthermore, the bounding boxes in AU R-CNN are not too small to detect compared with those in the object detection scenario. Therefore, pyramidal features are not necessary in detection.
4.5 Static versus Dynamic
Can the previous state of facial expression action always improve AU detection? In this section, we conduct a series of experiments using the most popular dynamic models that are integrated into AU R-CNN, including ARConvLSTM, as described in Section 3.4, to determine the answer.
4.5.1 AU R-CNN + ConvLSTM
In this section, we conduct experiments on ARConvLSTM, whose architecture is described in Section 3.4. Table 5 and Table 8 present that ARConvLSTM has a slightly lower average F1 score than ARres. The main reason of the overall performance drop is that the action duration varies drastically in different AUs (Table 14 and Table 15); if the temporal length of AU duration is short, ConvLSTM model does not have sufficient capability to observe such actions. The switch of action is so rapid that ConvLSTM cannot infer such label change when processing in the video. We draw a plot of F1 score improvement of ARConvLSTM over ARres and average AU duration (rescale to 1/60 scale) in Fig. 9 to justify our hypothesis. Other factors also influence the performance of ConvLSTM, we can see the red line and the black line have strong correlation in most AUs except AU 1, 2, 4 and AU 15, 17, 23. The reason of high F1 score improvement in AU 17 is that AU 17 has much more segment count (1203) than AU 15 and AU 23 (Table 14), which results in sufficient training samples of AU 17. The AU 4 has lower F1 score improvement than that of AU 1, 2, because AU 4’s bounding box (corresponding AU group #2) is double the size of the area of AU 1 and AU 2 (Fig. 6), the larger bounding box leads to weaker recognition capability of capturing the subtle skin change between eyebrows. Most AUs do not have long activity duration; hence, ARres surpasses ARConvLSTM in average F1 score.
4.5.2 AU R-CNN + Two-Stream Network
Convolutional two-stream network [19] achieves impressive results in video action recognition. In this experiment, we experiment a two-stream network integrated into the AU R-CNN architecture for comparison, denoted as “AR2stream”. We use a 10-frame optical flow and a single corresponding RGB image,666This corresponding RGB image is in the corresponding location that centers on 10 flow frames which are fed into two AU R-CNNs. Both AU R-CNN branches use the same bounding boxes, which is the corresponding bounding boxes of RGB image branch, for classification. Two produced RoI features are concatenated along the channel dimension. The channel size of 4096 feature map is yielded, which will be reduced to 2048 channels using one kernel size of 1 conv-layer. The features are sent to two fc layers to obtain the classification scores. The ground truth label involved in calculating the loss function adopts the single RGB image’s labels.
The performance of the two-stream network AR2stream is remarkably close to that of RGB-image-based ARres, which is slightly worse in the BP4D database (Table 5) and is better in the DISFA database (Table 8). In BP4D, the score significantly increases in AU 17 and AU 24 in ARres. All these AUs are in the lip area. We attribute this result to the relative small area in the lip area causes the optical flow to be an obvious signal to classify. If we check the result in DISFA dataset in Table 8, this reason can be verified — AU 1, AU 6, and AU 9 in the DISFA dataset have the smallest AU group areas (Table 10), and the F1 scores of these AUs increase. However, the performance of ARConvLSTM in these AUs cannot be improved compared with AR2stream. This justifies that AU group bounding box area is not the reason of the performance improvement in ARConvLSTM but is the reason of performance improvement in AR2stream. Although the average F1 score of AR2stream is worse than that of ARres in the BP4D database, an interesting property exists in AR2stream— the training convergence speed is faster than that in ARres (see loss curve comparison in Fig. 10).
4.5.3 AU R-CNN + TAL-Net
TAL-Net [20] follows the Faster R-CNN detection paradigm for temporal action location, and its goal is to detect 1D temporal segments in the time axis of videos. In this experiment, we regard the video sequence as separate segments, and each segment has one label with it. We use the same RoI parallel line stream with the ARConvLSTM because we want to detect each region’s activity temporal segments. We reformulate the labels of segments in the AU video sequence as a label inside a start and end time interval. In TAL-Net, we use pre-computed AR2stream features. We stack 10 1-D kernel conv-layer on the 1-D feature map in the segment proposal network module to generate segment proposals, and we directly feed the pre-computed 1-D feature map into the SoI pooling layer and subsequent fc layers. This network is denoted as “ARTAL”.
In our experiment, we determine that ARTAL cannot converge easily, and the loss can only decrease to approximately 1.3 at most (starting from approximately 2.7), which causes ARTAL to perform worse than ARConvLSTM (Table 5). We can attribute this result to two reasons. First, facial expression is more subtle than the obvious human body action, and the temporal action localization mechanism cannot work efficiently. Second, training 1-D conv-layer and fc layers requires millions of data samples, which cannot be satisfied when converting an entire video to a 1-D feature map. Therefore, this model has the worst performance among all dynamic models.
4.5.4 AU R-CNN + General Graph CRF
CRF model is a classical model for graph inference. We experiment with an interesting idea that involves connecting all separate parts of faces in a video to construct a spatio-temporal graph and then using the general graph CRF to learn from such a graph. This model is denoted as “ARCRF”. We not only connect RoIs with the same AU group number in the adjacent frames of the time axis but also fully connect different RoIs inside each frame, thereby yielding a spatio-temporal graph. In this method, the entire facial expression video is converted to a spatio-temporal graph using pre-computed 2048-D features extracted by ARres (average pooling layer’s output). This graph encodes not only the temporal dependencies of RoIs but also the spatial dependencies of each frame’s RoIs. Table 5 and Table 8 present that ARCRF has a lower score than does ARres in BP4D and DISFA. We attribute this score decrease to the number of weight parameters. In ARCRF, we have only weight parameters in total (in BP4D, it is ), where denotes the feature dimension, denotes the class number, and denotes the number of edge type. We extract 2048-D features from the average pooling layer. Two other fc layers exist on top of the average pooling layer in ARres, and their weight matrices are and , which result in parameters that are much more than in ARCRF. Therefore, classification performance is influenced not only by correlation but also by model capacity (including the number of learned parameters).
4.5.5 Dynamic models summary
After above discussion, the features and application of dynamic models extension can be summarized in Table 16.
5 Conclusion
In this paper, we present AU R-CNN for AU detection. It focuses on adaptive regional learning using expert prior knowledge, whose introduction provides accurate supervised information and fine-grained guidance for detection. Complete comparison experiments are conducted, and the results show that the presented model outperforms state-of-the-art approaches and the conventional CNN baseline model which uses the same backbone, proving the benefit of introducing the expert prior knowledge. We also investigate various dynamic architectures that are integrated into AU R-CNN, which demonstrate that the static-image-based AU R-CNN outperforms all the dynamic models. Experiments conducted on the BP4D and DISFA databases manifest the effectiveness of our approach.
Acknowledgement
This research is partially supported by the National Key R&D Program of China (Grant No. 2017YFB1304301) and National Natural Science Foundation of China (Grant Nos. 61572274, 61672307, 61272225).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P. Ekman, W. V. Friesen, Facial action coding system.
- 2[2] A. Romero, J. León, P. Arbeláez, Multi-view dynamic facial action unit detection, Image and Vision Computing.
- 3[3] W. Li, F. Abtahi, Z. Zhu, Action unit detection with region adaptation, multi-labeling learning and optimal temporal fusing, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 1841–1850.
- 4[4] W. Li, F. Abtahi, Z. Zhu, L. Yin, Eac-net: A region-based deep enhancing and cropping approach for facial action unit detection, in: 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), IEEE, 2017, pp. 103–110.
- 5[5] S. Eleftheriadis, O. Rudovic, M. Pantic, Multi-conditional latent variable model for joint facial action unit detection, in: Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 3792–3800.
- 6[6] S. Koelstra, M. Pantic, I. Patras, A dynamic texture-based approach to recognition of facial actions and their temporal models, IEEE transactions on pattern analysis and machine intelligence 32 (11) (2010) 1940–1954.
- 7[7] Z. Wang, Y. Li, S. Wang, Q. Ji, Capturing global semantic relationships for facial action unit recognition, in: Proceedings of the IEEE International Conference on Computer Vision, 2013, pp. 3304–3311.
- 8[8] W.-S. Chu, F. De la Torre, J. F. Cohn, Selective transfer machine for personalized facial action unit detection, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 3515–3522.
