Deep Face Image Retrieval: a Comparative Study with Dictionary Learning
Ahmad S. Tarawneh, Ahmad B. A. Hassanat, Ceyhun Celik, Dmitry, Chetverikov, M. Sohel Rahman, Chaman Verma

TL;DR
This study compares various deep learning models and dictionary learning techniques for face image retrieval, demonstrating that deep features outperform traditional local descriptor methods in accuracy.
Contribution
It provides a comprehensive comparison of deep learning models and dictionary learning methods for face retrieval, highlighting the most effective combinations.
Findings
Deep features outperform local descriptor methods in face retrieval.
Alexlayer7 with K-means and SSF achieves top performance.
Deep learning methods show practical advantages for face image retrieval.
Abstract
Facial image retrieval is a challenging task since faces have many similar features (areas), which makes it difficult for the retrieval systems to distinguish faces of different people. With the advent of deep learning, deep networks are often applied to extract powerful features that are used in many areas of computer vision. This paper investigates the application of different deep learning models for face image retrieval, namely, Alexlayer6, Alexlayer7, VGG16layer6, VGG16layer7, VGG19layer6, and VGG19layer7, with two types of dictionary learning techniques, namely -means and -SVD. We also investigate some coefficient learning techniques such as the Homotopy, Lasso, Elastic Net and SSF and their effect on the face retrieval system. The comparative results of the experiments conducted on three standard face image datasets show that the best performers for face image retrieval are…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1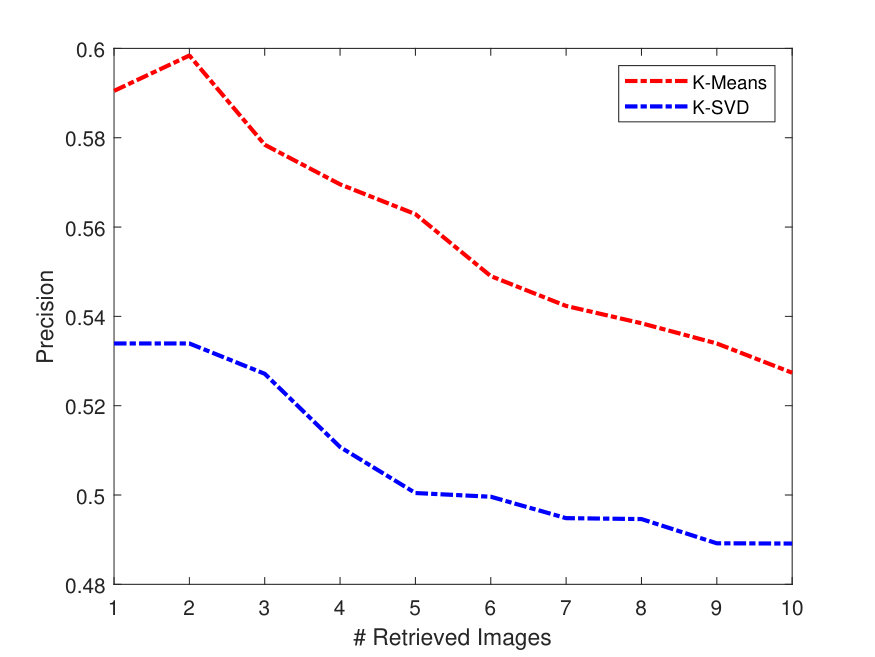 Figure 2
Figure 2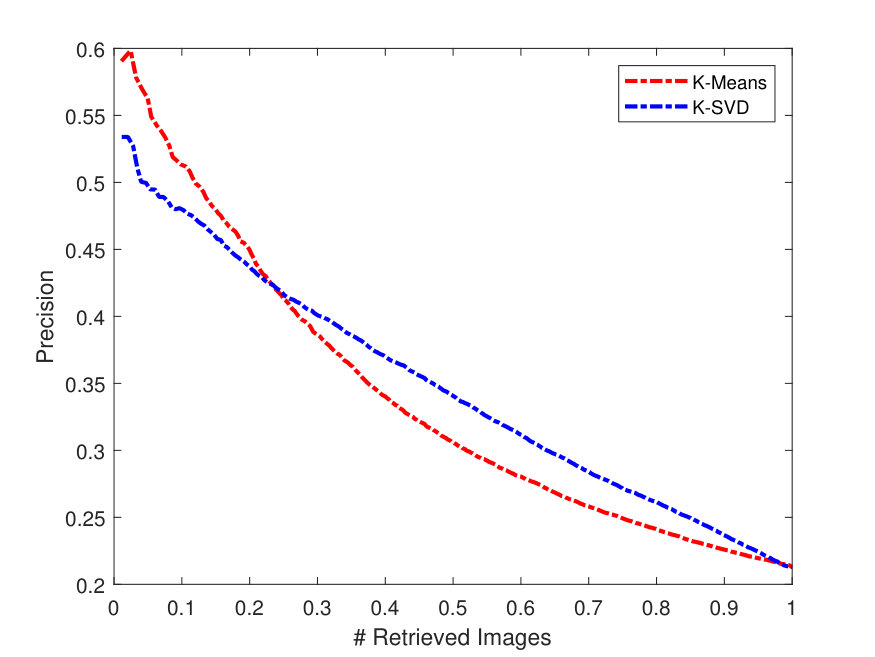 Figure 3
Figure 3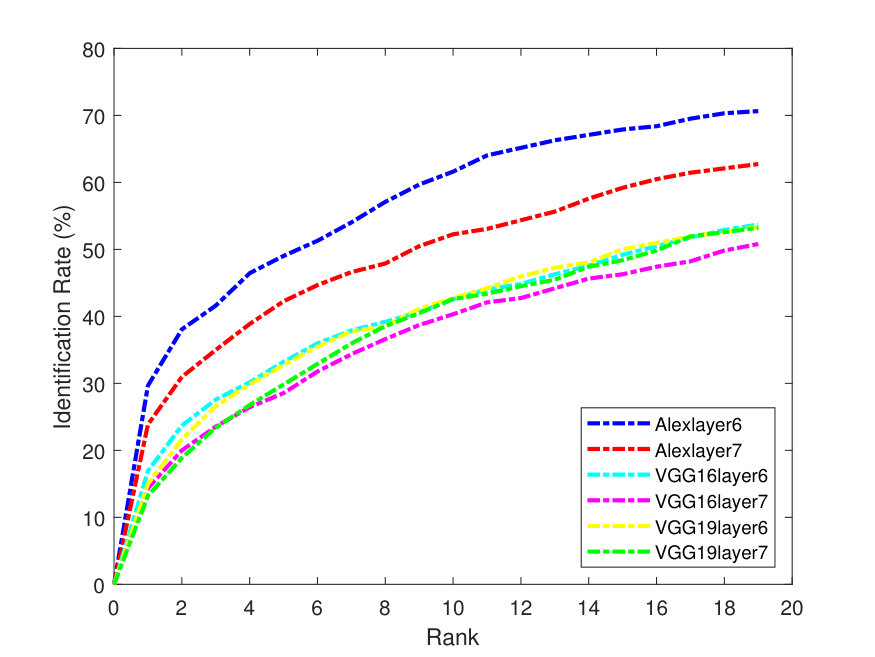 Figure 4
Figure 4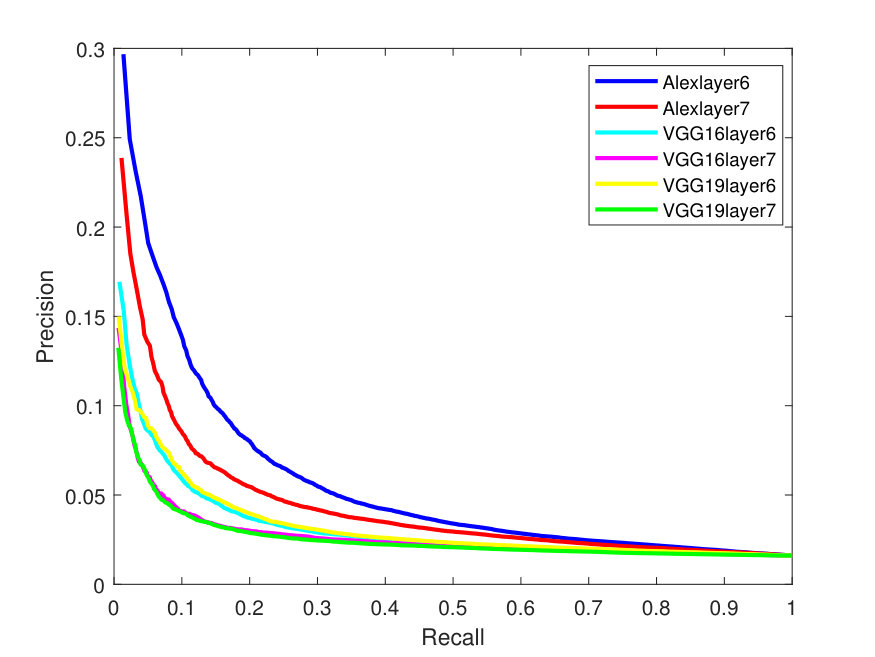 Figure 5
Figure 5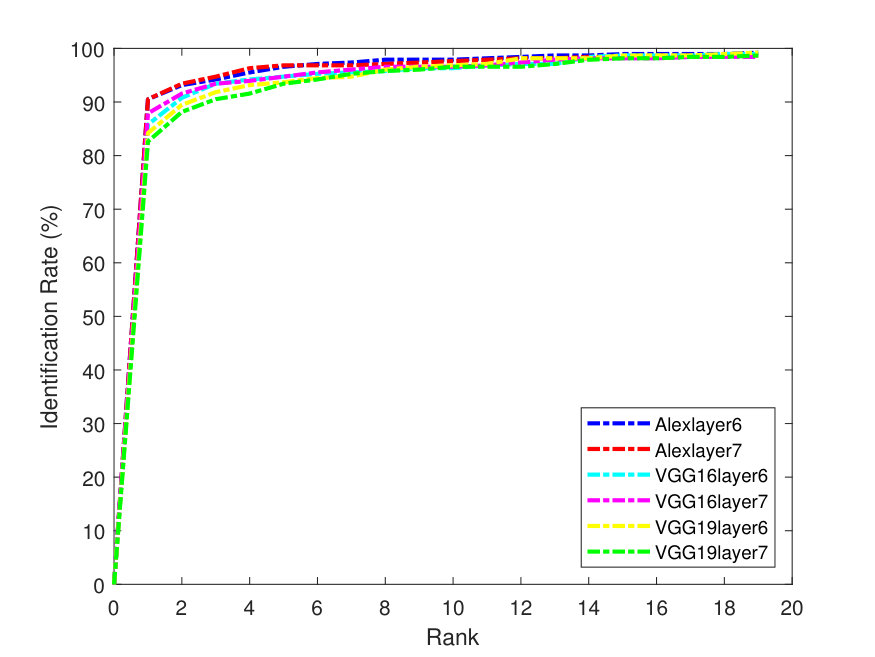 Figure 6
Figure 6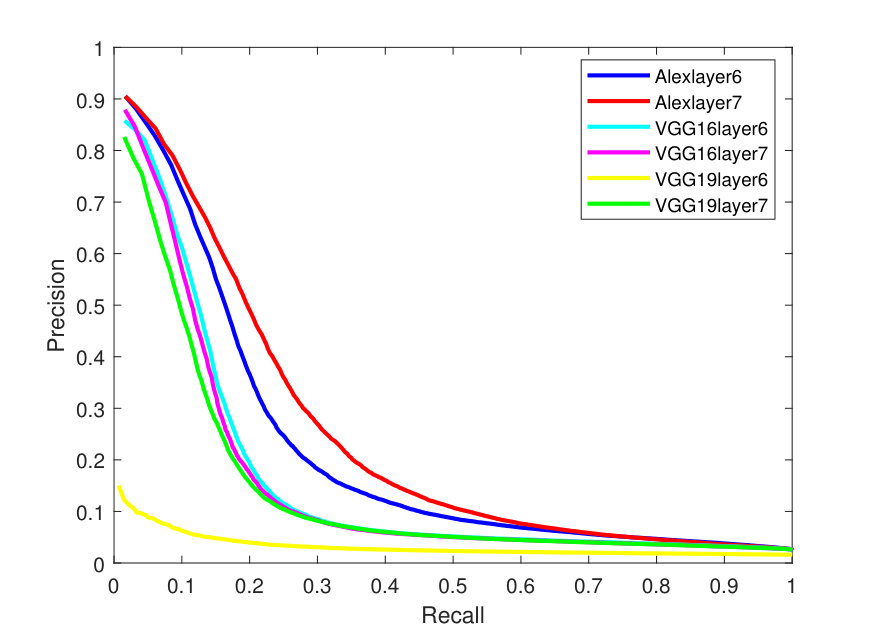 Figure 7
Figure 7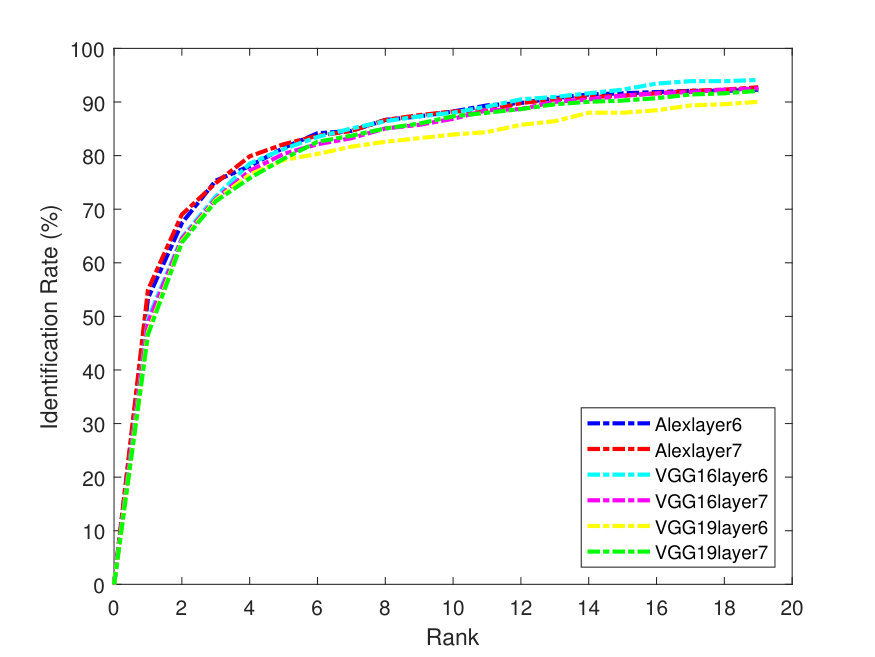 Figure 8
Figure 8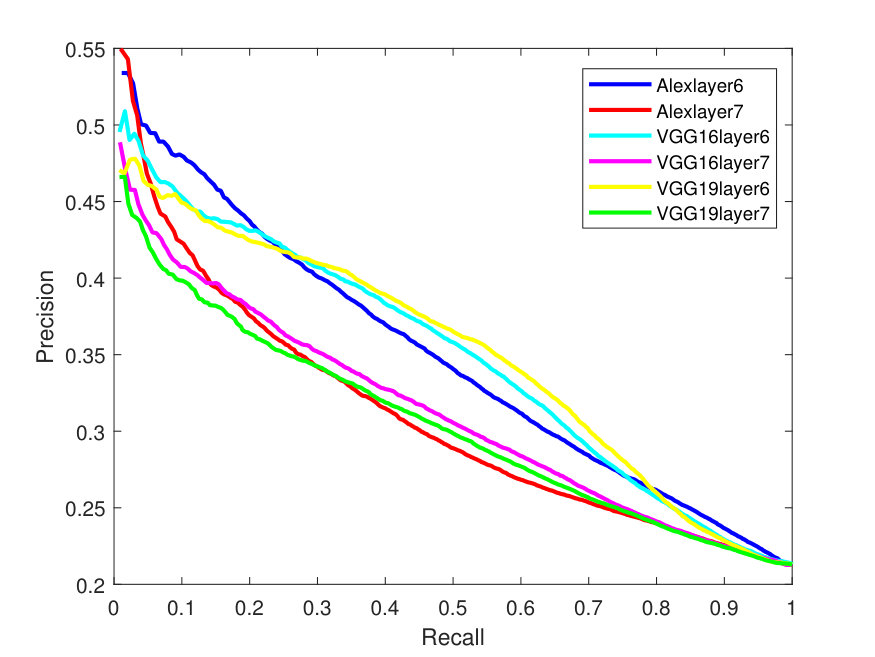 Figure 9
Figure 9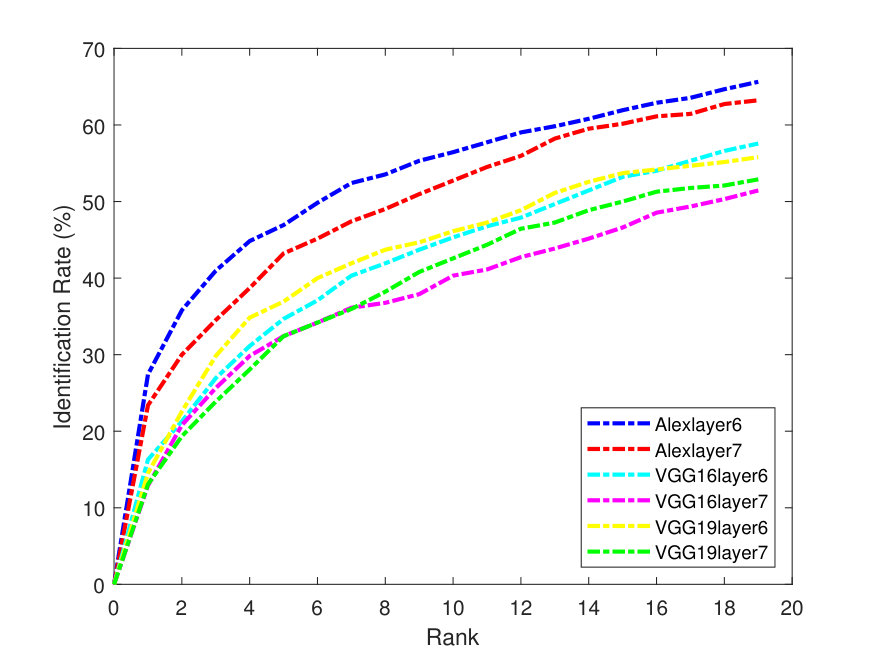 Figure 10
Figure 10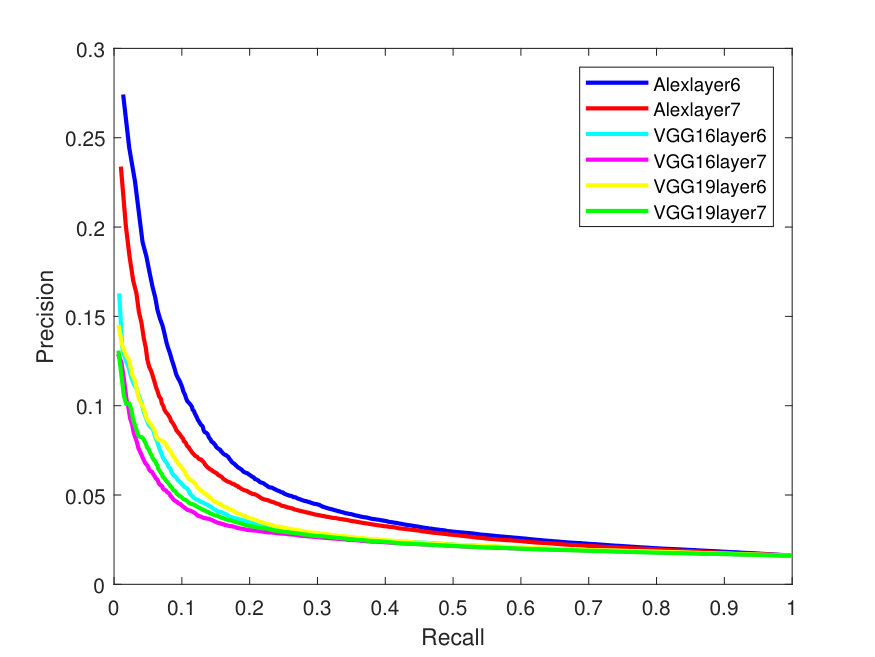 Figure 11
Figure 11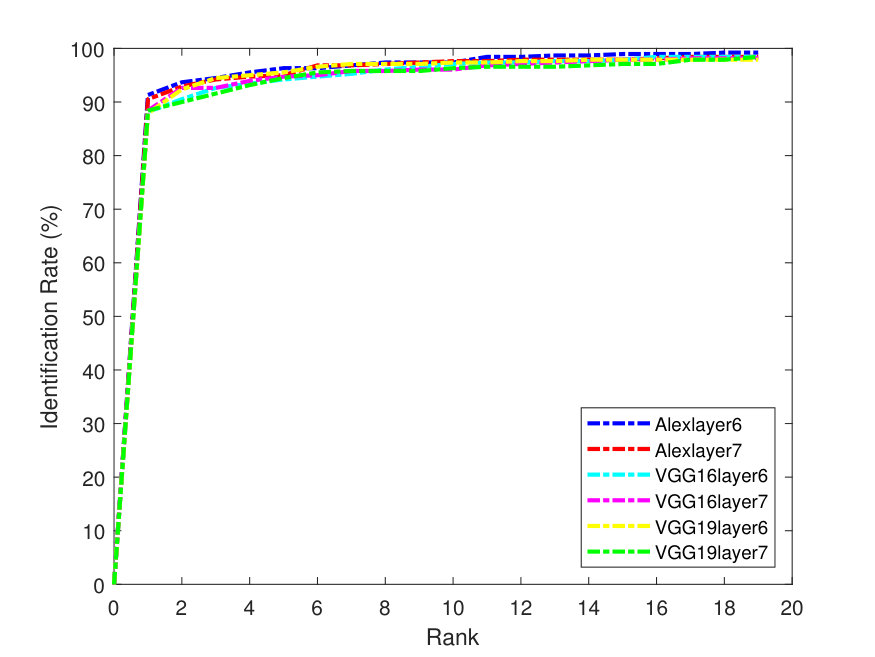 Figure 12
Figure 12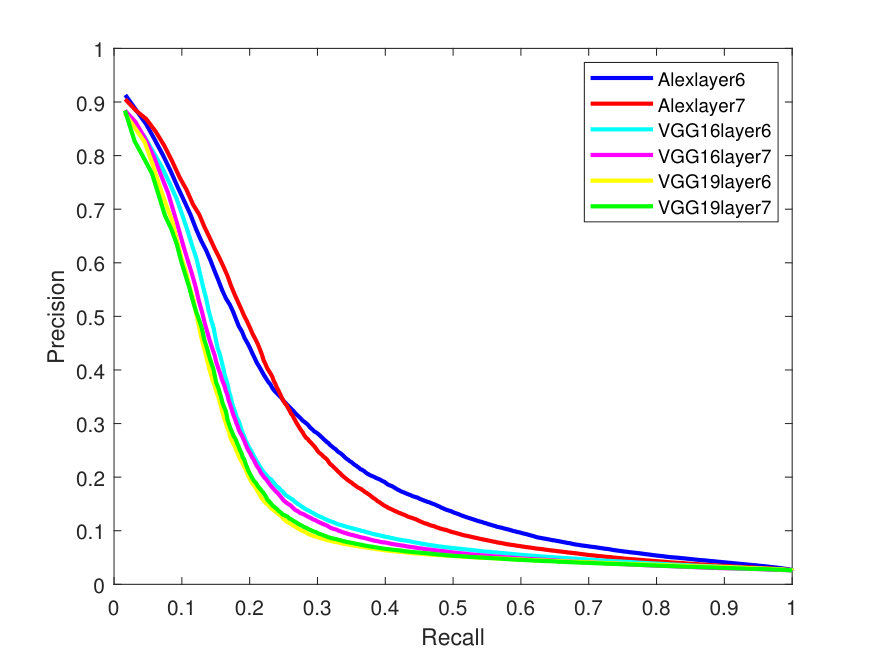 Figure 13
Figure 13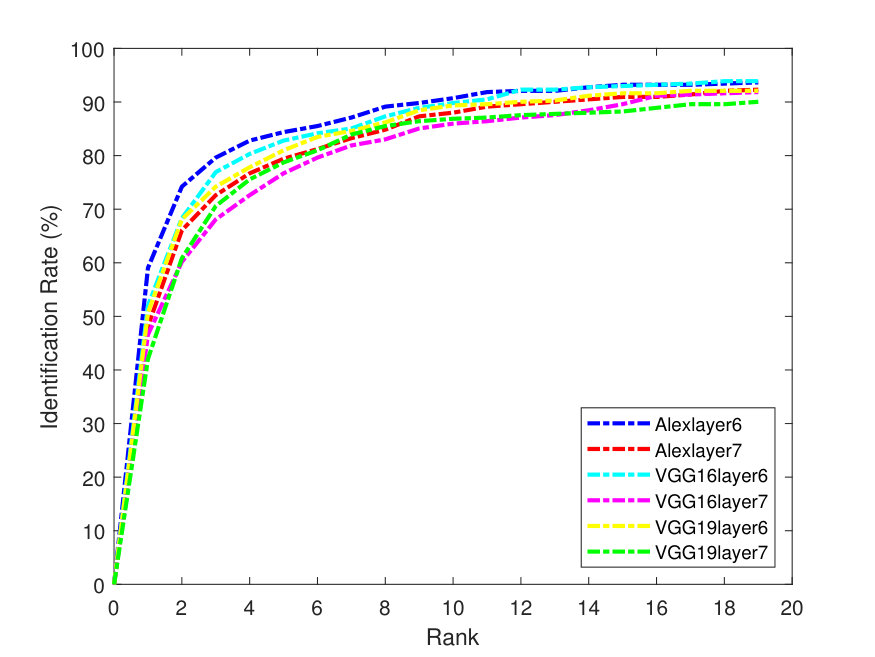 Figure 14
Figure 14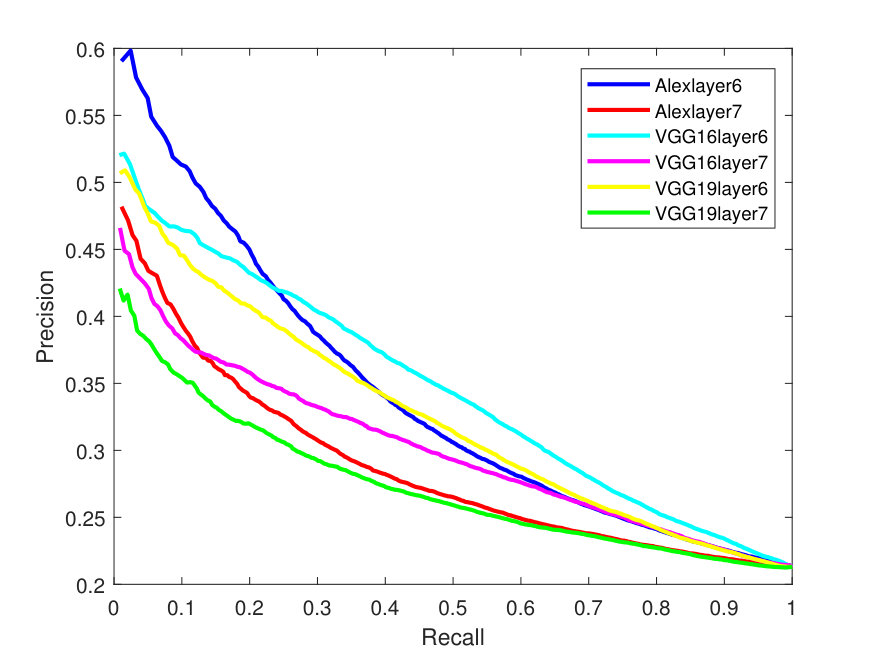 Figure 15
Figure 15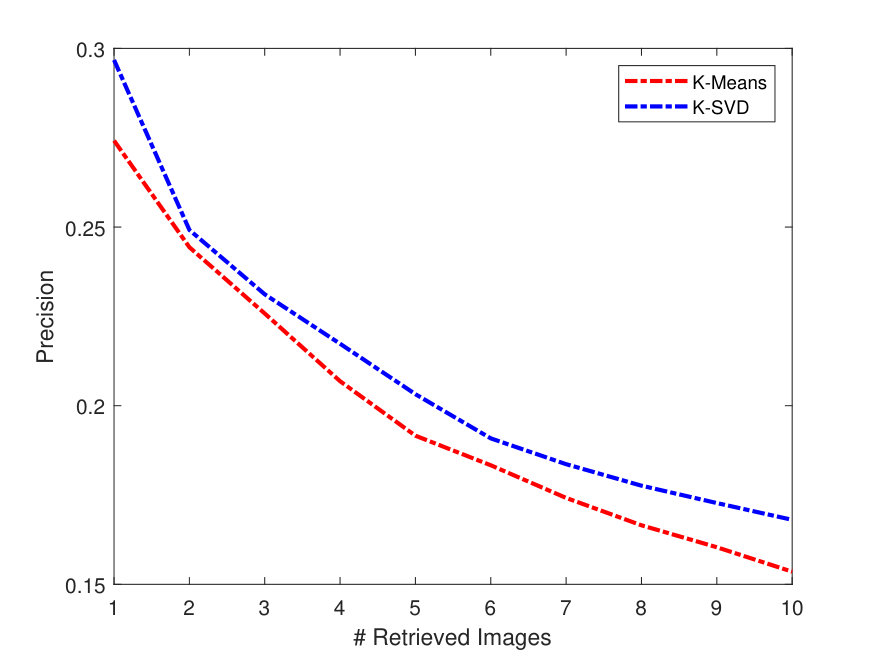 Figure 16
Figure 16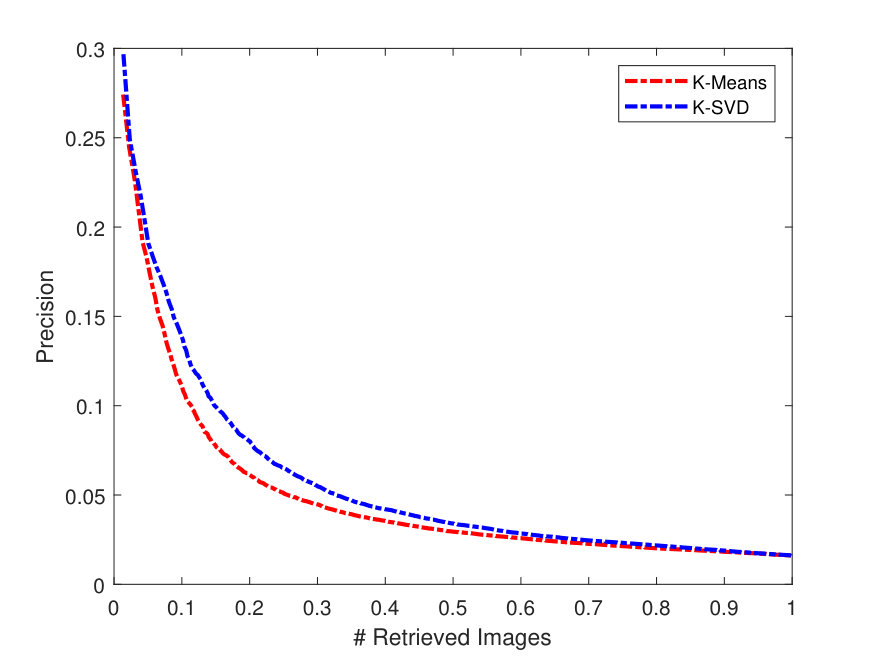 Figure 17
Figure 17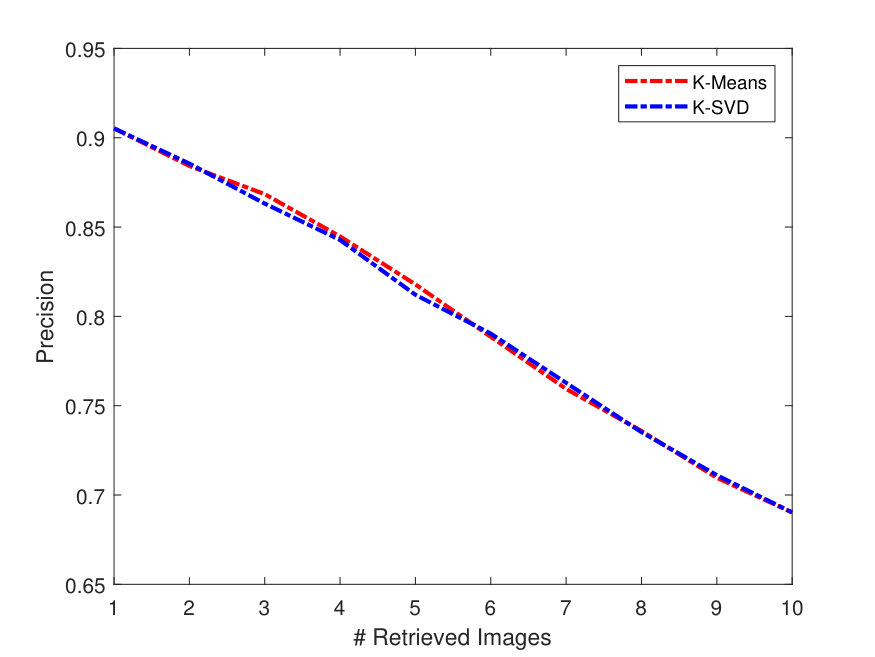 Figure 18
Figure 18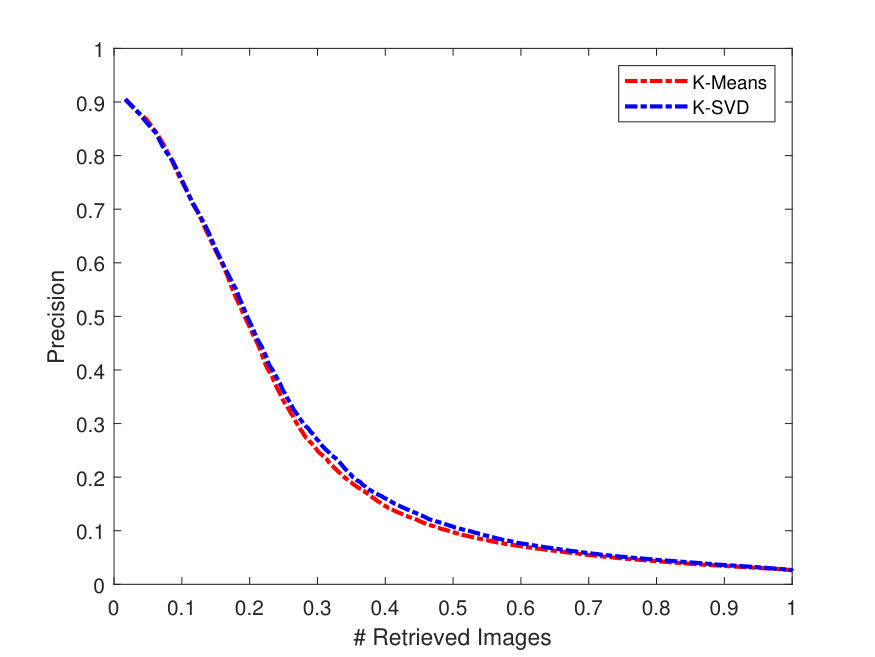 Figure 19
Figure 19| 38-D -Means | 38-D -SVD | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Homo | Lasso |
|
SSF | Homo | Lasso |
|
SSF | |||||
| Alexlayer6 | 0.39 | 0.24 | 0.08 | 0.48 | 0.3 | 0.26 | 0.1 | 0.45 | ||||
| Alexlayer7 | 0.37 | 0.26 | 0.08 | 0.49 | 0.37 | 0.31 | 0.14 | 0.49 | ||||
| VGG16layer6 | 0.34 | 0.19 | 0.03 | 0.42 | 0.25 | 0.21 | 0.04 | 0.39 | ||||
| VGG16layer7 | 0.32 | 0.19 | 0.06 | 0.41 | 0.24 | 0.18 | 0.08 | 0.38 | ||||
| VGG19layer6 | 0.29 | 0.17 | 0.05 | 0.39 | 0.19 | 0.15 | 0.05 | 0.34 | ||||
| VGG19layer7 | 0.3 | 0.23 | 0.05 | 0.39 | 0.22 | 0.18 | 0.07 | 0.35 | ||||
| 38-D -Means | 38-D -SVD | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Homo | Lasso |
|
SSF | Homo | Lasso |
|
SSF | |||||
| Alexlayer6 | 0.66 | 0.35 | 0.12 | 0.79 | 0.5 | 0.41 | 0.17 | 0.78 | ||||
| Alexlayer7 | 0.67 | 0.4 | 0.15 | 0.8 | 0.55 | 0.44 | 0.22 | 0.8 | ||||
| VGG16layer6 | 0.62 | 0.29 | 0.03 | 0.76 | 0.42 | 0.31 | 0.04 | 0.73 | ||||
| VGG16layer7 | 0.61 | 0.29 | 0.08 | 0.75 | 0.39 | 0.26 | 0.12 | 0.71 | ||||
| VGG19layer6 | 0.55 | 0.25 | 0.06 | 0.73 | 0.31 | 0.22 | 0.07 | 0.67 | ||||
| VGG19layer7 | 0.57 | 0.34 | 0.07 | 0.72 | 0.38 | 0.29 | 0.09 | 0.66 | ||||
| 38-D -Means | 38-D -SVD | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Homo | Lasso |
|
SSF | Homo | Lasso |
|
SSF | |||||
| Alexlayer6 | 0.74 | 0.39 | 0.13 | 0.86 | 0.56 | 0.44 | 0.18 | 0.85 | ||||
| Alexlayer7 | 0.74 | 0.45 | 0.16 | 0.86 | 0.61 | 0.48 | 0.24 | 0.86 | ||||
| VGG16layer6 | 0.7 | 0.32 | 0.03 | 0.83 | 0.48 | 0.34 | 0.05 | 0.81 | ||||
| VGG16layer7 | 0.69 | 0.32 | 0.08 | 0.83 | 0.45 | 0.29 | 0.13 | 0.8 | ||||
| VGG19layer6 | 0.64 | 0.29 | 0.06 | 0.82 | 0.37 | 0.25 | 0.07 | 0.76 | ||||
| VGG19layer7 | 0.66 | 0.37 | 0.08 | 0.8 | 0.45 | 0.32 | 0.1 | 0.75 | ||||
| 38-D -Means | 38-D -SVD | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Homo | Lasso |
|
SSF | Homo | Lasso |
|
SSF | |||||
| Alexlayer6 | 0.11 | 0.12 | 0.07 | 0.16 | 0.13 | 0.1 | 0.08 | 0.17 | ||||
| Alexlayer7 | 0.08 | 0.08 | 0.06 | 0.13 | 0.12 | 0.1 | 0.09 | 0.13 | ||||
| VGG16layer6 | 0.06 | 0.06 | 0.05 | 0.1 | 0.07 | 0.06 | 0.06 | 0.1 | ||||
| VGG16layer7 | 0.05 | 0.07 | 0.07 | 0.08 | 0.08 | 0.06 | 0.06 | 0.08 | ||||
| VGG19layer6 | 0.06 | 0.06 | 0.05 | 0.1 | 0.07 | 0.06 | 0.06 | 0.09 | ||||
| VGG19layer7 | 0.05 | 0.06 | 0.07 | 0.08 | 0.07 | 0.06 | 0.06 | 0.08 | ||||
| 38-D -Means | 38-D -SVD | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Homo | Lasso |
|
SSF | Homo | Lasso |
|
SSF | |||||
| Alexlayer6 | 0.15 | 0.13 | 0.06 | 0.2 | 0.15 | 0.11 | 0.07 | 0.21 | ||||
| Alexlayer7 | 0.1 | 0.09 | 0.05 | 0.16 | 0.14 | 0.11 | 0.08 | 0.17 | ||||
| VGG16layer6 | 0.08 | 0.06 | 0.04 | 0.12 | 0.08 | 0.06 | 0.05 | 0.12 | ||||
| VGG16layer7 | 0.06 | 0.08 | 0.07 | 0.1 | 0.09 | 0.07 | 0.07 | 0.1 | ||||
| VGG19layer6 | 0.08 | 0.07 | 0.05 | 0.12 | 0.08 | 0.07 | 0.05 | 0.11 | ||||
| VGG19layer7 | 0.06 | 0.07 | 0.06 | 0.1 | 0.09 | 0.07 | 0.06 | 0.1 | ||||
| 38-D -Means | 38-D -SVD | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Homo | Lasso |
|
SSF | Homo | Lasso |
|
SSF | |||||
| Alexlayer6 | 0.17 | 0.14 | 0.07 | 0.23 | 0.17 | 0.12 | 0.08 | 0.24 | ||||
| Alexlayer7 | 0.12 | 0.1 | 0.05 | 0.19 | 0.15 | 0.12 | 0.08 | 0.19 | ||||
| VGG16layer6 | 0.08 | 0.07 | 0.04 | 0.13 | 0.08 | 0.07 | 0.06 | 0.14 | ||||
| VGG16layer7 | 0.07 | 0.09 | 0.07 | 0.11 | 0.1 | 0.07 | 0.07 | 0.12 | ||||
| VGG19layer6 | 0.09 | 0.07 | 0.05 | 0.13 | 0.09 | 0.07 | 0.05 | 0.13 | ||||
| VGG19layer7 | 0.07 | 0.07 | 0.07 | 0.11 | 0.1 | 0.07 | 0.06 | 0.11 | ||||
| 38-D -Means | 38-D -SVD | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Homo | Lasso |
|
SSF | Homo | Lasso |
|
SSF | |||||
| Alexlayer6 | 0.4 | 0.42 | 0.24 | 0.44 | 0.39 | 0.38 | 0.34 | 0.43 | ||||
| Alexlayer7 | 0.34 | 0.36 | 0.25 | 0.37 | 0.37 | 0.36 | 0.34 | 0.39 | ||||
| VGG16layer6 | 0.38 | 0.41 | 0.35 | 0.42 | 0.43 | 0.43 | 0.39 | 0.42 | ||||
| VGG16layer7 | 0.34 | 0.37 | 0.36 | 0.37 | 0.37 | 0.37 | 0.38 | 0.38 | ||||
| VGG19layer6 | 0.36 | 0.38 | 0.33 | 0.41 | 0.41 | 0.41 | 0.38 | 0.43 | ||||
| VGG19layer7 | 0.29 | 0.33 | 0.33 | 0.34 | 0.36 | 0.35 | 0.35 | 0.38 | ||||
| 38-D -Means | 38-D -SVD | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Homo | Lasso |
|
SSF | Homo | Lasso |
|
SSF | |||||
| Alexlayer6 | 0.52 | 0.49 | 0.19 | 0.56 | 0.47 | 0.44 | 0.31 | 0.51 | ||||
| Alexlayer7 | 0.41 | 0.45 | 0.21 | 0.45 | 0.44 | 0.42 | 0.34 | 0.49 | ||||
| VGG16layer6 | 0.46 | 0.47 | 0.29 | 0.5 | 0.47 | 0.46 | 0.38 | 0.48 | ||||
| VGG16layer7 | 0.4 | 0.43 | 0.41 | 0.43 | 0.42 | 0.42 | 0.39 | 0.45 | ||||
| VGG19layer6 | 0.44 | 0.42 | 0.23 | 0.49 | 0.43 | 0.42 | 0.43 | 0.47 | ||||
| VGG19layer7 | 0.35 | 0.38 | 0.34 | 0.4 | 0.4 | 0.39 | 0.37 | 0.44 | ||||
| 38-D -Means | 38-D -SVD | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Homo | Lasso |
|
SSF | Homo | Lasso |
|
SSF | |||||
| Alexlayer6 | 0.55 | 0.5 | 0.2 | 0.58 | 0.49 | 0.45 | 0.3 | 0.52 | ||||
| Alexlayer7 | 0.42 | 0.47 | 0.23 | 0.46 | 0.46 | 0.43 | 0.34 | 0.52 | ||||
| VGG16layer7 | 0.41 | 0.44 | 0.4 | 0.45 | 0.43 | 0.43 | 0.4 | 0.46 | ||||
| VGG19layer6 | 0.45 | 0.43 | 0.24 | 0.5 | 0.44 | 0.42 | 0.43 | 0.47 | ||||
| VGG19layer7 | 0.36 | 0.39 | 0.33 | 0.41 | 0.42 | 0.4 | 0.38 | 0.45 | ||||
| Method | YaleB (%) | ||
|---|---|---|---|
| APR@1 | APR@5 | APR@8 | |
| Alexnet layer 7+ SSF + Kmeans | 90.5 | 81.8 | 73.6 |
| LGHP | 85 | 65 | 55 |
| LDP | 55 | 42 | 40 |
| LTrP | 37 | 30 | 25 |
| LVP | 81 | 60 | 50 |
| LFW (%) | |||
| APR@1 | APR@5 | APR@10 | |
| Alexnet layer 6+ SSF + KSVD | 29.68 | 20.32 | 16.81 |
| LGHP | 13.5 | 7.5 | 6 |
| LDP | 8.5 | 5.5 | 4.5 |
| LTrP | 6.5 | 4.3 | 4 |
| LVP | 11 | 6.5 | 5.5 |
| Gallagher(%) | |||
| APR@1 | APR@3 | APR@5 | |
| Alexnet layer 6+ SSF + Kmeans | 59.1 | 57.8 | 56.3 |
| LGHP | 51.8 | 39 | 30 |
| LDP | 36.5 | 27 | 25 |
| LTrP | 23.1 | 17 | 15 |
| LVP | 41.5 | 33 | 27 |
| Method | YaleB (%) | ||
| ARR@1 | ARR@5 | ARR@8 | |
| Alexnet layer 7+ SSF + Kmeans | 1.7 | 7.4 | 12.6 |
| LGHP | 1.4 | 5 | 6.2 |
| LDP | 1 | 3 | 4.5 |
| LTrP | 0.5 | 2 | 2.9 |
| LVP | 1 | 4.9 | 6 |
| LFW (%) | |||
| ARR@1 | ARR@5 | ARR@10 | |
| Alexnet layer 6+ SSF + KSVD | 1 | 3.4 | 5.3 |
| LGHP | 0.4 | 1 | 1.6 |
| LDP | 0.25 | 0.75 | 1.2 |
| LTrP | 0.2 | 0.5 | 1 |
| LVP | 0.3 | 0.8 | 1.4 |
| Gallagher(%) | |||
| ARR@1 | ARR@3 | ARR@5 | |
| Alexnet layer 6+ SSF + Kmeans | 1.1 | 3.2 | 5 |
| LGHP | 4.1 | 8 | 9.5 |
| LDP | 2.9 | 5.1 | 7 |
| LTrP | 1.6 | 3 | 3.5 |
| LVP | 3.1 | 6.5 | 8.3 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Deep Face Image Retrieval: a Comparative Study with Dictionary Learning
Ahmad S. Tarawneh
Department of Algorithms and Their Applications , Eötvös Loránd University, Budapest, Hungary
Ahmad B. A. Hassanat
Department of Information Technology, Mutah University, Karak, Jordan
Ceyhun Celik
Department of Computer Engineering, Gazi University, Ankara, Turkey
Dmitry Chetverikov
Department of Algorithms and Their Applications , Eötvös Loránd University, Budapest, Hungary
M. Sohel Rahman
Department of CSE, BUET, ECE Building, West Palasi, Dhaka 1205, Bangladesh
Chaman Verma
Department of Algorithms and Their Applications , Eötvös Loránd University, Budapest, Hungary
Abstract
Facial image retrieval is a challenging task since faces have many similar features (areas), which makes it difficult for the retrieval systems to distinguish faces of different people. With the advent of deep learning, deep networks are often applied to extract powerful features that are used in many areas of computer vision. This paper investigates the application of different deep learning models for face image retrieval, namely, Alexlayer6, Alexlayer7, VGG16layer6, VGG16layer7, VGG19layer6, and VGG19layer7, with two types of dictionary learning techniques, namely -means and -SVD. We also investigate some coefficient learning techniques such as the Homotopy, Lasso, Elastic Net and SSF and their effect on the face retrieval system. The comparative results of the experiments conducted on three standard face image datasets show that the best performers for face image retrieval are Alexlayer7 with -means and SSF, Alexlayer6 with -SVD and SSF, and Alexlayer6 with -means and SSF. The APR and ARR of these methods were further compared to some of the state of the art methods based on local descriptors. The experimental results show that deep learning outperforms most of those methods and therefore can be recommended for use in practice of face image retrieval
keywords:
CBIR ; Deep learning ; Dictionary learning ; Deep features; Sparse representation, Coefficient learning; Image retrieval; Face recognition
1 Introduction
Both facial recognition and facial image retrieval (FIR) are important problems of computer vision and image processing. The main difference between the two problems is that in the former we try to identify or verify a person from a digital image of person’s face, while in the latter we need to retrieve facial images that are relevant to a query face image [1][2][3][4]. Similar to face recognition systems, a facial image retrieval (FIR) system works by extracting useful features to be used in the retrieval process. The focus of this study is the latter which is the more difficult problem of the two. The main difference between both systems is that in retrieval systems you need to retrieve N facial images which are relevant to a query face image.
Facial image retrieval has been under investigation for years and a lot of methods have been employed to develop this field. FIR can be seen as a content-based image retrieval (CBIR) problem that focuses on extracting and retrieving facial images rather than any other content. The major challenge in FIR is that the features of human faces can change due to various expressions, poses, hair style as well as through artificial manipulations (e.g., tattoo or painting on the face). All these factors make it difficult for a system to extract stable and robust features to be used in face recognition and FIR systems.
A number of algorithms have been developed to enhance the accuracy of FIR. For example, Chen et al. [5] proposed enhancements for FIR by extracting semantic information and used the datasets LFW [6] and Pubfig [7] to test the methods. They used small number of query images (120) and their results on LFW were worse than that on Pubfig. Notably, the random selection of query images in their experiments makes it difficult to make a fair comparison with their work. Local Gradient Hexa Pattern (LGHP) [8] was also proposed to extract descriptive features for face recognition and retrieval. The proposed features were invariant to pose and illumination variation. A number of datasets were used to test the proposed method including two challenging datasets, namely, Yale-B [9, 10] and LFW. However, the results on LFW were not satisfactory as the highest retrieval rate achieved was around 13.5% on the first retrieved image.
In recent times, Deep Learning techniques are widely being used to solve many problems of computer vision (e.g., [11][12][13] [14][15]). Although Deep learning is preferred to Sparse Representations (SR) to improve retrieval accuracy in content-based image retrieval (CBIR) problems [16][17][18][19], these approaches can also be combined for the same purpose [20][21][22][23]. This was the main motivation of the current research. In particular, our current study conducts extensive experiments to find out the best combination of these two approaches with a goal to improve the performance of FIR systems and thereby advance the state of the art.
The main contribution of this paper is as follows. We make a fusion of DL and SR to make the best out of the two approaches.
In addition, we combine deep features (DF) with a coefficient learning method, namely, separable surrogate function (SSF), which, to the best of our knowledge, has not been used before in the literature in the context of FIR. We have extracted different DFs from the most popular deep network models, namely, Alexnet [24] and VGG [25] to ensure a robust FIR system. To evaluate our approach, we have conducted a thorough experimental analysis using two of the most challenging datasets, namely, LFW, YAL-B and Gallagher. Our experiments show that combining DF with SR enhances FIR considerably.
2 Methods
Several approaches exist to use the deep learning. For example, Convolutional Neural Networks (CNN) can be employed with full-training on a new dataset from scratch. However, this approach requires a large amount of data since a lot of parameters of CNN need to be tuned. Another approach is based on fine-tuning a specific layer or several of them and changing/updating their parameters to fit the new data. The third, and perhaps the most common, approach uses a pre-trained CNN model that has already been adequately trained using a huge dataset that contains millions of images (e.g., Imagenet database [26]), albeit with a different goal: in this case, the pre-trained CNN is used to extract descriptive features to be exploited for different tasks such as face image retrieval and recognition. In this work we opt for the third approach and make an effort to extract deep features from different layers of the pre-trained models, such as AlexNet [24], VGG-16 and VGG-19 [25].
Each of the models we use provides a 4096 dimensional feature vector to represent the content of each image. We also have used different fully-connected layers (FCL), FCL-6 and FCL-7, to extract the features from each model. In other words, we investigate the use of Alexnet with FCL-6 (Alexlayer6), Alexnet with FCL-7 (Alexlayer7), VGG-16 with FCL-6 (VGG16layer6), VGG-16 with FCL-7 (VGG16layer7), VGG-19 with FCL-6 (VGG19layer6), and VGG-19 with FCL-7 (VGG19layer7) to experimentally analyze which one is preferable for face image retrieval. Furthermore, we use two types of dictionary learning methods, namely, -means and -singular value decomposition (-SVD) [27], while Homotopy, Lasso, Elastic Net and SSF [28][29] are used as coefficient learning techniques with each method.
Both Alexnet and VGG networks extract the features in almost the same way. The input image is provided to the input layer of each model, and then it is processed through the different convolutional layers to obtain different representations using several filters. Figure 1 shows how a single face image is represented by different CNN layers.
2.1 Sparse Representation
Based on the principle of sparsity, any vector could be represented with a few non-zero element according to a base. If this idea is applied to the problem of extracting meaningful information from a bunch of vectors, all of the vectors will be represented with a simple coefficients on the same base. Solving the problem is thus simplified with Sparse Representations (SRs) of vectors. Although this technique has been applied in signal processing for many years, during the last two decades it has also been used for solving computer vision problems, such as, image retrieval, image denoising, and image classification [30]. The goal of SR is achieved by solving following problem:
[TABLE]
Here is the signal, the dictionary and the sparse coefficient of signal ; could be any value from . Solving this problem is realized in two steps, namely, Dictionary Learning (DL) and Coefficient Learning (CL). The base is built in the DL step and the sparse coefficients of vectors are obtained in the CL step. In the literature, DL algorithms are categorized as offline or online [31, 32]. Offline DL algorithms, such as, -Means algorithm, build the dictionary without any help of sparse coefficients. On the other hand, online algorithms, such as, -Singular Value Decomposition (-SVD), incorporate the sparse coefficients in the dictionary building process. On line DL algorithms thus make use of CL algorithms to build the dictionary as follows. First, they obtain the sparse coefficients with a random dictionary. Then, the dictionary is trained with the obtained sparse coefficients. These two steps are repeated iteratively, until a stopping criteria is achieved.
Unlike the DL step, there are many solutions for the CL step [33]. Solutions like Homotopy, Lasso, Elastic Net are generally greedy approaches [34]. Unfortunately however these greedy solutions are inefficient for high-dimensional problems [34]. On the other hand, iterative-shrinkage algorithms, such as, SSF and Parallel Coordinate Descent (PCD) are reported to produce effective solutions to high-dimensional problems like image retrieval [29]. Here, instead of solving the SR problem (Eq. 1), a surrogate function is applied to obtain sparse coefficients as follows:
[TABLE]
This surrogate function is obtained with the following additional term:
[TABLE]
The setting of the parameter should guarantee that the function is strictly convex. The surrogate function takes place of the minimization term. Thus, the task of obtaining sparse coefficient becomes much simpler and can be solved efficiently, since the minimization term is nonlinear[34].
In this study, two traditional DL algorithms, -Means as an offline approach and -SVD as an online approach, are used to build the dictionary. Then, sparse coefficients are obtained by greedy approaches (Homotopy, Lasso, Elastic Net) as well as by an iterative shrinkage algorithm (SSF).
2.2 Datasets
In our experiments, we have used three of the most common and challenging face image benchmark datasets, namely, the Cropped Extended Yale B (Yale-B) [9] [10], the Labeled Faces in the Wild (LFW) [6] and Gallagher [35]. The YAL-B dataset consists of 38 classes (different subjects) each having 65 images. The LFW dataset consists of 5749 subjects each having different number of images ranging from 1 to 530. Since most of the subjects in the LFW dataset have only one image, following [8] we have used a subset of LFW by choosing only the subjects that contain at least 20 images. Thus, we were left with only 62 subjects each having different number (at least 20) of images.
3 Results
All the aforementioned methods for deep feature extraction and different dictionary learning approaches have been implemented using Matlab 2018b and run in a machine with NVIDIA GeForce GTX 1080 GPU having windows 10 as the OS. We have run the methods on all three datasets to extract the features from the face images. In our experiments, 10 images of each subject from the datasets have been used as query images, while we have used the rest for training. Tables 1, 2 and 3 show the Mean Average Precision (MAP) of the face image retrieval from the Yale-B dataset.
As is evident from the results on the Yale-B dataset, SSF is quite convincingly the best performer among the coefficient learning techniques and among the two dictionary learning techniques, -Means performs slightly better. It is also evident that AlexNet features have a slight edge over the the VGG-16 and VGG-19 features.
Now we focus on the results of the LFW dataset which have been presented in Tables 4, 5 and 6.
On LFW dataset, we get mixed results with respect to the dictionary learning approaches. As we can see, considering all retrievals, -Means still has a small edge over -SVD but that quickly diminishes as we become selective: for the first 5 images retrieved, the latter in fact shows better performance than the former. SSF however, consistently achieves the best performance as it did on Yale-B dataset. AlexNet features are still found to be superior here.
The best results on Gallagher dataset switch between -Means and -SVD. However, SSF is still the best with AlexNet features. The best MAP on the whole dataset is 44% using AlexNet layer 6 with SSF and -Means.
Noticeably, AlexNet performs better than VGG across all three datasets. Although it is unlikely for AlexNet to achieve higher precision than VGG, in practical applications the information density provided by AlexNet is better than that of VGG, and therefore, AlexNet provides better utilization for its parameter space than VGG, particularly, for face image retrieval systems. This claim is also supported by [36] According to the above experiments, we can say with certain confidence that AlexNet layers 6 and 7 have performed the best in terms of MAP, particularly, when using -SVD dictionary learning with SSF coefficient learning. Therefore, we compare their results with the state-of-the-art face image retrieval methods. Since local descriptors explore higher order derivative space and tend to achieve better results under pose, expression, light, and illumination variations [8], we consider four of popular descriptors, namely, local gradient hexa pattern (LGHP) [8], local derivative pattern (LDP) [37], local tetra pattern (LTrP) [38] and local vector pattern (LVP) [39]. These methods calculated the Average Precision of Retrieval (APR) of each dataset using the first retrieved face image, the first 5 retrieved face images, and the first (8 or 10) retrieved face images; therefore we also calculated the APR of AlexNet FC6 and AlexNet FC7 similarly. Tables 10 reports the results of this comparative analysis. As can be seen from Tables 10, the combination of AlexNet features with SSF enhances the results as it outperforms all four methods under consideration on all of the datasets. This significant increase of the APR can be attributed to the power of the deep features as compared to hand-crafted features, in general.
However, in certain cases/datasets, Deep features might not be the magic tool for computer vision tasks. This is evident from another analysis reported in Table 11, where the Average Recall of Retrieval (ARR) have been reported instead of APR. Here we can see that while the ARR results in Yale-B and LFW datasets are dominated by our combined method involving deep features, on the Gallagher dataset, ARRs obtained by the LGHP, LDP, and LVP are found to be better.
Figures 2 - 3 illustrate the Precision-Recall (PR) and cumulative matching characteristic (CMC) curves of the face retrieval experiments. These figures show PR and CMC curves on the evaluated datasets using all the tested CNN models with their different layers with -Means and -SVD and SSF.
As it can be seen from the above figures, in terms of dictionaries, -SVD performs better than -means in most cases. AlexNet obtains better precision than the very deep models. This is due to its better utilization ability for the parameters, especially, for the full face features. In addition, the top matches (CMC) (at the right of Figures 3-7) are identified correctly and more accurately on the Yale-B dataset, where the retrieval rate starts to approach 100% at rank 13. On the other hand, the retrieval rates are lower on LFW. Alexlayer6 with -SVD and SSF obtains the best retrieval rate at rank 14, which is very close to 70%. This is followed by the Alexlayer7 as it achieves 60% at the same rank. The other models with different layers achieve almost 50% at the same rank. The low retrieval rates of the LFW is probably due to the small number of images left for the training data.
Figure 4 presents the PR curves for the best retrieval results on all datasets. The left side of each figure illustrates the PR curves on the whole dataset, while the right one shows the precision as a function of the top matches.
As one can see in Figure 4, the -SVD performs better than the -means with SSF on LFW dataset, whereas both dictionaries perform almost the same on the Yale-B dataset. This is also the case for Gallagher dataset as -SVD results are superior to -means on average. For the Yale-B dataset, the retrieval precision starts from 91% and continues to decrease reaching 70% when 10 images are retrieved. This dramatic decrease in the retrieval precision can be attributed to the nature of the images in the Yale-B dataset having dark images and various facial expressions. The situation is similar for LFW; however, the latter has more challenging images with various backgrounds in addition to different hair style, cloths and facial expressions.
Localizing the face within these images may improve the retrieval results. However, localizing the faces in order to focus on the main features of the face in the LFW dataset is out of the scope of this paper and may be taken up as a future work. In the Gallagher dataset, the faces are localized but the pose varies significantly; in addition, this dataset poses the same challenges as the previous datasets, including varying illumination and real-life facial expressions.
4 Conclusion
This paper investigates the use of different deep learning models for face image retrieval, namely, AlexNet FC6, AlexNet FC7, VGG16layer6, VGG16layer7, VGG19layer6, and VGG19layer7. The models utilize two types of dictionary learning techniques, -means and -SVD, in addition to the use of some coefficient learning techniques such as the Homotopy, Lasso, Elastic Net and SSF. The comparative results of the experiments conducted on three standard challenging face image datasets show that the best performers for face image retrieval are Alexlayer7 with -means and SSF, Alexlayer6 with -SVD and SSF, and Alexlayer6 with -means and SSF. The APR and ARR of these methods were further compared to some of the local descriptor-based methods found in the literature. The experimental results show that the deep learning approaches outperform most of the methods compared, and therefore they can be recommended for practical use in face image retrieval.
Despite the good performance of the deep features, the retrieval process is still not perfect. In particular, when tested on non-cropped face images, such imperfect performance might be attributed to several challenges posed by the images found in the datasets we used, namely, (1) complex and different backgrounds; (2) darknes of the images; and (3) different facial expressions. The first problem can be solved by localizing the faces in order to focus on the main features of the face rather than the complex background; this can be done efficiently using the method proposed in [40]. The second problem can be solved using image enhancement in a preprocessing stage. Finally, the third problem can be solved using some transformation of the face image to alleviate the differences in facial expressions of the same subject; this can be done using the method proposed in [41]. We plan to include these components in our methodology in future. Our future works will also include the use of deep features with dictionary learning to solve other relevant problems handled in [42], [43] and [44]. We also plan to increase the speed of the retrieval process using efficient indexing techniques, such as, [45], [46] and [47].
Acknowledgements
The first author would like to thank Tempus Public Foundation for sponsoring his PhD study, also, this paper is under the project EFOP-3.6.3-VEKOP-16-2017-00001 (Talent Management in Autonomous Vehicle Control Technologies), and supported by the Hungarian Government and co-financed by the European Social Fund.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Gudivada and Raghavan [1995] Venkat N Gudivada and Vijay V Raghavan. Content based image retrieval systems. Computer , 28(9):18–22, 1995.
- 2HASSANAT and TARAWNEH [2016] AHMAD HASSANAT and AHMAD S TARAWNEH. Fusion of color and statistic features for enhancing content-based image retrieval systems. Journal of Theoretical & Applied Information Technology , 88(3), 2016.
- 3Tarawneh et al. [2018 a] Ahmad S Tarawneh, Dmitry Chetverikov, Chaman Verma, and Ahmad B Hassanat. Stability and reduction of statistical features for image classification and retrieval: Preliminary results. In Information and Communication Systems (ICICS), 2018 9th International Conference on , pages 117–121. IEEE, 2018 a.
- 4Tarawneh et al. [2018 b] Ahmad S Tarawneh, Ceyhun Celik, Ahmad B Hassanat, and Dmitry Chetverikov. Detailed investigation of deep features with sparse representation and dimensionality reduction in cbir: A comparative study. ar Xiv preprint ar Xiv:1811.09681 , 2018 b.
- 5Chen et al. [2013] Bor-Chun Chen, Yan-Ying Chen, Yin-Hsi Kuo, and Winston H Hsu. Scalable face image retrieval using attribute-enhanced sparse codewords. IEEE Trans. Multimedia , 15(5):1163–1173, 2013.
- 6Huang et al. [2008] Gary B Huang, Marwan Mattar, Tamara Berg, and Eric Learned-Miller. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Workshop on faces in’Real-Life’Images: detection, alignment, and recognition , 2008.
- 7Kumar et al. [2009] Neeraj Kumar, Alexander C Berg, Peter N Belhumeur, and Shree K Nayar. Attribute and simile classifiers for face verification. In Computer Vision, 2009 IEEE 12th International Conference on , pages 365–372. IEEE, 2009.
- 8Chakraborty et al. [2018] Soumendu Chakraborty, Satish Kumar Singh, and Pavan Chakraborty. Local gradient hexa pattern: A descriptor for face recognition and retrieval. IEEE Transactions on Circuits and Systems for Video Technology , 28(1):171–180, 2018.