Unsupervised Image Decomposition in Vector Layers
Othman Sbai, Camille Couprie, Mathieu Aubry

TL;DR
This paper introduces a novel unsupervised deep image decomposition method that produces layered vector images, enabling easier editing, high-resolution generation, and versatile applications like vectorization and image search.
Contribution
It proposes a new layered vector image generation paradigm inspired by vector graphics, allowing structured, editable, and resolution-independent image synthesis.
Findings
Outperforms state-of-the-art baselines in reconstruction quality.
Enables intuitive user interactions for editing images.
Supports high-resolution image generation with a compact representation.
Abstract
Deep image generation is becoming a tool to enhance artists and designers creativity potential. In this paper, we aim at making the generation process more structured and easier to interact with. Inspired by vector graphics systems, we propose a new deep image reconstruction paradigm where the outputs are composed from simple layers, defined by their color and a vector transparency mask. This presents a number of advantages compared to the commonly used convolutional network architectures. In particular, our layered decomposition allows simple user interaction, for example to update a given mask, or change the color of a selected layer. From a compact code, our architecture also generates vector images with a virtually infinite resolution, the color at each point in an image being a parametric function of its coordinates. We validate the efficiency of our approach by comparing…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22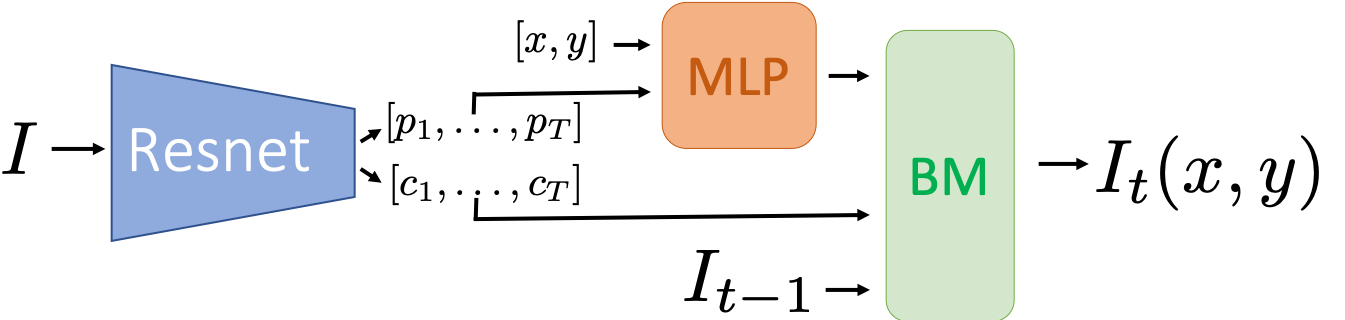 Figure 23
Figure 23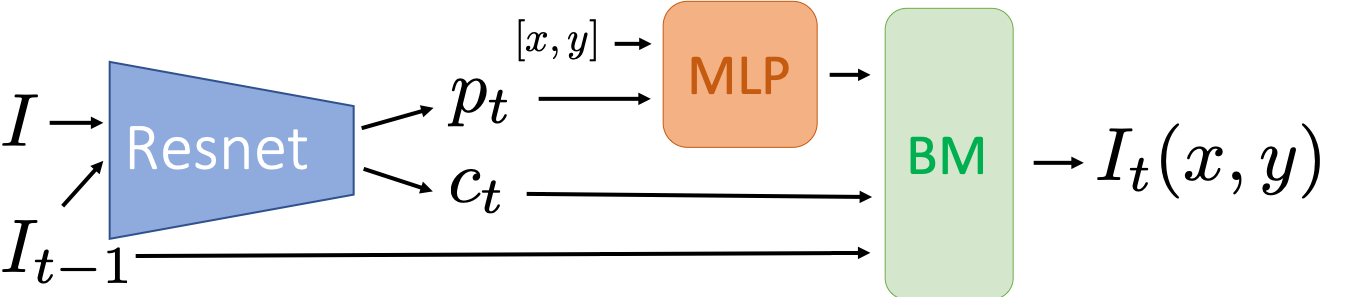 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| ImageNet | CelebA | |||
| PSNR | MSSIM | PSNR | MSSIM | |
| A. MLP AE | 16.45 | 0.46 | 19.69 | 0.78 |
| C. Vect. AE | 17.95 | 0.62 | 20.99 | 0.82 |
| D. Ours One-shot | 20.00 | 0.77 | 23.13 | 0.89 |
| E. Ours Resnet | 21.05 | 0.82 | 24.67 | 0.92 |
| F. Ours | 21.03 | 0.82 | 24.02 | 0.90 |
| One-shot | Ours | One-shot | Ours | One-shot | Ours | |
| PSNR | 21.97 | 23.07 | 22.25 | 24.2 | 22.37 | 24 |
| Time(h) PSNR | 7.6 | 9.8 | 12.1 | 16.9 | 19.8 | 36.5 |
| Testing time (ms) | 12 | 32 | 18 | 65 | 31 | 129 |
| ImageNet | CelebA | |||||||
| 10 | 20 | 40 | 80 | 10 | 20 | 40 | 80 | |
| PSNR | 20.97 | 21.72 | 21.83 | 21.84 | 24.02 | 24.82 | 24.86 | 24.86 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Unsupervised Image Decomposition in Vector Layers
Othman Sbai1,2
Camille Couprie1
Mathieu Aubry2
1 Facebook AI Research, 2 LIGM (UMR 8049) - École des Ponts, UPE
Abstract
Deep image generation is becoming a tool to enhance artists and designers creativity potential. In this paper, we aim at making the generation process more structured and easier to interact with. Inspired by vector graphics systems, we propose a new deep image reconstruction paradigm where the outputs are composed from simple layers, defined by their color and a vector transparency mask. This presents a number of advantages compared to the commonly used convolutional network architectures. In particular, our layered decomposition allows simple user interaction, for example to update a given mask, or change the color of a selected layer. From a compact code, our architecture also generates vector images with a virtually infinite resolution, the color at each point in an image being a parametric function of its coordinates. We validate the efficiency of our approach by comparing reconstructions with state-of-the-art baselines given similar memory resources on CelebA and ImageNet datasets. Most importantly, we demonstrate several applications of our new image representation obtained in an unsupervised manner, including editing, vectorization and image search.
1 Introduction
Deep image generation models demonstrate breathtaking and inspiring results, e.g. [52, 51, 26, 5], but usually offer limited control and little interpretability. It is indeed particularly challenging to learn end-to-end editable image decomposition without relying on either expensive user input or handcrafted image processing tools. In contrast, we introduce and explore a new deep image generation paradigm, which follows an approach similar to the one used in interactive design tools. We formulate image generation as the composition of successive layers, each associated to a single color. Rather than learning high resolution image generation, we produce a decomposition of the image in vector layers, that can easily be used to edit images at any resolution. We aim at enabling designers to easily build on the results of deep image generation methods, by editing layers individually, changing their characteristics, or intervening in the middle of the generation process.
Our approach is in line with the long standing Computer Vision trend to look for a simplified and compact representation of the visual world. For examples, in 1971 Binford [4] proposes to represent the 3D world using generalized cylinders and in 1987 the seminal work of Biederman [3] aims at explaining and interpreting the 3D world and images using geons, a family of simple parametric shapes. These ideas have recently been revisited using Neural Networks to represent a 3D shape using a set of blocks [44] or, more related to our approach, a set of parametric patches [18]. The idea of identifying elementary shapes and organizing them in layers has been successfully applied to model images [1, 22] and videos [45]. A classical texture generation method, the dead leaves model [29] which creates realistic textures by relying on the iteration of simple patterns addition, is particularly related to our work.
We build on this idea of composing layers of simple primitives in order to design a deep image generation method, relying on two core ingredients. First, the learning of vector transparency masks as parametric continuous function defined on the unit square. In practice, this function is computed by a network applied at 2D coordinates on a square grid, to output mask values at each pixel coordinates. Second, a mask blending module which we use to iteratively build the images by superimposing a mask with a given color to the previous generation. At each step of our generation process, a network predicts both parameters and color for one mask. Our final generated image is the result of blending a fixed number of colored masks. One of the advantages of this approach is that, differently to most existing deep generation setups where the generation is of fixed size, our generations are vector images defined continuously, and thus have virtually infinite resolution. Another key aspect is that the generation process is easily interpretable, allowing simple user interaction.
To summarize, our main contribution is a new deep image generation paradigm which:
- •
builds images iteratively from masks corresponding to meaningful image regions, learned without any semantic supervision.
- •
is one of the first to generate vector images from a compact code.
- •
is useful for several applications, including image editing using generated masks, image vectorization, and image search in mask space.
Our code will be made available111http://imagine.enpc.fr/~sbaio/pix2vec/.
2 Related work
We begin this section by presenting relevant works on image vectorization, then focus on most related unsupervised image generation strategies and finally discuss applications of deep learning to image manipulation.
Vectorization. Many vector-based primitives have been proposed to allow shape editing, color editing and vector image processing ranging from paths and polygons filled with uniform color or linear and radial gradients [40, 12], to region based partitioning using triangulation [8, 30, 10], parametric patches (Bezier patches) [47] or diffusion curves [36]. We note that traditionally, image vectorization techniques were handcrafted using image smoothing and edge detectors. In contrast, our approach parametrizes the image using a function defined by a neural network.
Differentiable image parametrizations with neural networks were first proposed by Stanley et al. [43] which introduced Compositional Pattern Producing Networks (CPPNs) that are simply neural networks that map pixel coordinates to image colors at each pixel. The architecture of the network determines the space of images that can be generated. Since CPPNs learn images as functions of pixel coordinates they provide the ability to sample images at high resolution. The weights of the network can be optimized to reconstruct a single image [25] or sample randomly in which case each network results in abstract patterns [19]. In contrast with these approaches, we propose to learn the weights of this mapping network and condition it on a an image feature so that it can generate any image without image-specific weight optimization. Similarly, recent works have modeled 2D and 3D shapes using parametric and implicit functions [18, 34, 37, 6]. While previous attempts to apply this idea on images has focused on directly generating images on simple datasets such as MNIST [20, 6], we obtain a layer decomposition allowing various applications such as image editing and retrieval on complex images.
Deep, unsupervised, sequential image generation.
We now present deep unupervised sequential approaches to image generation, the most related to our work. [41] uses a recurrent auto-encoder to reconstruct images iteratively, and employs a sparsity criterion to make sure that the image parts that are added at each iteration are simple. A second line of approaches [17, 11, 16] are designed in a VAE framework. Deep Recurrent Attentive Writer (DRAW) [17] frames a recurrent approach using reinforcement learning and a spatial attention mechanism to mimic human gestures. A potential application of DRAW arises in its extension to conceptual image compression [16], where a recurrent convolutional and hierarchical architecture allows to obtain various levels of lossy compressed images. Attend, Infer, Repeat [11] models scenes by latent variables of object presence, content, and position. The parameters of presence and position are inferred by an RNN and a VAE decodes the objects one at a time to reconstruct images. A third strategy for learning sequential generative models is to employ adversarial networks. Ganin et al. [13] employ adversarial training in a reinforcement learning context. Specifically, their method dubbed SPIRAL, trains an agent to synthesize programs executed by a graphic engine to reconstruct images. The Layered Recursive GANs of [48] learn to generate foreground and background images that are stitched together using STNs to form a consistent image. Although presented in a generic way that generalizes to multiple steps, the experiments are limited to foreground and background separation, made possible by the definition of a prior on the object size contained in the image. In contrast, our method (i) does not rely on STNs; (ii) extends to tens of steps as demonstrated in our experiments; (iii) relies on simple architectures and losses, without the need of LSTMs or reinforcement learning.
Image manipulation. Some successful applications of deep learning to image manipulation have been demonstrated, but they are usually specialized and offer limited user interaction. Image colorization [49] and style transfer [14] are two popular examples. Most approaches that allow user interaction are supervised. Zhu et al. [50] integrate user constraints in the form of brush strokes in GAN generations. More recently, Park et al. [38] use semantic segmentation layouts and brush strokes to allow users to create new landscapes. In a similar vein, [2] locates sets of neurons related to different visual components of images, such as trees or artifacts, and allows their removal interactively. Approaches specialized in face editing, such as [42] and [39] demonstrate the large set of photo-realistic image manipulations that can be done to enhance quality, for instance background removal or swapping, diverse stylization effects, changes of the depth of field of the background, etc. These approach typically require precise label inputs from users, or training on heavily annotated datasets. Our approach provides an unsupervised alternative, with similar editing capacities.
3 Layered Vector Image Generation
We frame image generation as an alpha-blending composition of a sequence of layers starting from a canvas of random uniform color . Given a fixed budget of iterations, we iteratively blend generated colored masks onto the canvas. In this section, we first present our new architecture for vector image generation, then the training loss and finally discuss the advantages of our new architecture compared to existing approaches.
3.1 Architecture
The core idea of our approach is visualized in Fig. 2. At each iteration , our model takes as input the concatenation of the target image and the current canvas , and iteratively blends colored masks on the canvas resulting in :
[TABLE]
where consists of:
- (i)
a Residual Network (ResNet) that predicts mask parameters , with the corresponding color triplet , 2. (ii)
a mask generator module , which generates an alpha-blending mask from the parameters , and 3. (iii)
our mask blending module that blends the masks with their color on the previous canvas .
We represent the function generating the mask from as a standard Multi-Layer Perceptron (MLP), which takes as input the concatenation of the mask parameters and the two spatial coordinates of a point in image space. This MLP defines the continuous 2D function of the mask by:
[TABLE]
In practice, we evaluate the mask at discrete spatial locations corresponding to the desired resolution to produce a discrete image. We then update at each spatial location using the following blending:
[TABLE]
where is the RGB value of the resulting image at position . We note that, at test time, we may perform a different number of iterations than the one during training . Choosing may help to model accurately images that contain complex patterns, as we show in our experiments.
All the design choices of our approach are justified in detail in Section 3.3 and supported empirically by experiments and ablations in Section 4.3.
3.2 Training losses
We learn the weights of our network end-to-end by minimizing a reconstruction loss between the target and our result . We perform experiments either using an loss, which enables simple quantitative comparisons, or a perceptual loss [24], leading to visually improved results. Our perceptual loss is based on the Euclidean norm between feature maps extracted from a pre-trained VGG16 network and the Frobenius norm between the Gram matrices obtained from these feature maps :
[TABLE]
where
[TABLE]
[TABLE]
and is a non-negative scalar that controls the relative influence of the style loss. To obtain even sharper results, we may optionally add an adversarial loss. In this case, a discriminator is trained to recognize real images from generated ones, and we optimize our generator to fool this discriminator. We train to minimize the non saturating GAN loss from [15] with R1 Gradient Penalty loss [33]. The architecture of is the patch discriminator defined in [23].
3.3 Discussion
Architecture choices.
Our architecture choices are related to desirable properties of the final generation model:
Layered decomposition: This choice allows us to obtain a mask decomposition which is a key component of image editing pipelines. Defining one color per layer, similar to image simplification and quantization approaches, is important to obtain visually coherent regions. We further show that a single layer baseline does not perform as well.
Vectorized layers: By using a lattice input for the mask generator, it is possible to perform local image editing and generation at any resolution without introducing up-sampling artifacts or changing our model architecture. This vector mask representation is especially convenient for HD image editing.
Recursive vs one-shot: We generate the mask parameters recursively to allow the model to better take into account the interaction between the different masks. We show that a one-shot baseline, where all the mask parameters are predicted in a single pass leads to worse results. Moreover, as mentioned above and demonstrated in the experiments, our recursive procedure can be applied a larger number of times to model more complex images.
Number of layers vs. size of the mask parameter.
Our mask blending module iteratively adds colored masks to the canvas to compose the final image. The size of the mask parameter controls the complexity of the possible mask shapes, while the number of masks controls the amount of different shapes that be used to compose the image. Since we aim at producing a set of layers that can easily be used and interpreted by a human, we use a limited number of strokes and masks.
Complexity of the mask generator network.
Interestingly, if the network generating the masks from the parameters was very large, it could generate very complex patterns. In fact, one could show using the universal approximation theorem [7, 21] that, with a large number of hidden units in the MLP , an image could be approximated with only three layers () of our generation process, using one mask for each color channel. Thus it is important to control the complexity of to obtain meaningful primitive shapes. For example, we found that replacing our MLP by a ResNet leads to less interpretable masks (see Section 4.3 and Fig. 10).
4 Experiments
In this section we first introduce the datasets, the training and network architecture details, then we demonstrate the practical interest of our approach in several applications, and justify the architecture choices in extensive ablation studies.
4.1 Datasets and implementation details
Datasets.
Our models are trained on two datasets, CelebA [31] (202k images of celebrity faces) and ImageNet [9] (1.28M natural images of 1000 classes), using images downsampled to .
Training details.
The parameters of our generator are optimized using Adam [27] with a learning rate of , and no weight decay. The batch size is set to 32 and training image size is fixed to pixel images.
Network architectures.
The mask generator consists of an MLP with three hidden layers of 128 units with group normalization [46], tanh non-linearities, and an additional sigmoid after the last layer. takes as input a parameter vector and pixel coordinates , and outputs a value between 0 and 1. The parameter and the color are predicted by a ResNet-18 network. Further details about the network architectures are in the supplementary material.
4.2 Applications
We now demonstrate how our image decomposition may serve different purposes such as image editing, retrieval and vectorization.
Image editing.
Image editing from raw pixels can be time consuming. Using our generated masks, it is possible to alter the original image by applying edits such as luminosity or color modifications on the region specified by a mask. Fig. 3 shows an interface we designed for such editing showing the masks corresponding to the image. It avoids going through the tedious process of defining a blending mask manually. The learned masks capture the main components of the image, such as the background, face, hairs, lips. Fig. 4 demonstrate a variety of editing we performed and the associated masks. Our approach works well on the CelebA dataset, and allows to make simple image modifications on the more challenging ImageNet images. To optimize our results on ImageNet, the edits of Fig. 4 are obtained by finetuning our model on images of each object class.
Attribute-based image retrieval.
A t-SNE [32] visualization of the mask parameters obtained on CelebA is shown in Fig. 5. Different clusters of masks are clearly visible, for backgrounds, hairs, face shadows, etc. This experiment highlights the fact our approach naturally extract semantic components of face images.
Our approach may be used in an image search content: given a query image, a user can select a mask that displays a particular attribute of interest and search for images which decomposition includes similar masks. Suppose we would like to retrieve pictures of people wearing a hat as displayed in a query image, we can easily extract the mask that corresponds to the hat in our decomposition and its parameters. Nearest neighbor for different masks, using a cosine similarity distance between mask parameters are provided in Fig. 6. Note how different masks extracted from the same query image lead to very different retrieved images. Such a strategy could potentially be used for efficient image annotation or few-shot learning. We evaluated oneshot nearest neighbor classification for the ”Wearing Hat” and ”Eyeglasses” categories in CelebA using the hat and glasses examples shown in Fig. 6, and obtained respectively and average precision. Results for eyeglasses attribute were especially impressive with recall at precision, compared to a low recall (less than at precision) for a baseline using cosine distance between features of a Resnet18 trained on ImageNet.
Vector image generation.
Producing vectorized images is often essential for design applications. We demonstrate in Fig. 7(a) the potential of our approach for producing a continuous vector image from a low resolution bitmap. Here, we train our network on the MNIST dataset (), but generate the output at resolution . Compared to bilinear interpolation, the image we generate presents less artifacts.
We finally compare our model with SPIRAL [13] on a few images from CelebA dataset published in [13]. SPIRAL is the approach the most closely related to ours in the sense that it is an iterative deep approach for reconstructing an image and extracting its structure only using a few color strokes and that it can produce vector results. We report SPIRAL results using 20-step episodes. In each episode, a tuple of 8 discrete decisions is estimated, resulting in a total of 160 parameters for reconstruction. Our results shown in Fig. 7(b) are obtained with a model using 10 iterations and 10 mask parameters. Although we do not reproduce the stroke gesture for drawing each mask as it is the case in SPIRAL, our results reconstruct the original images much better.
4.3 Architecture and training choices
L1, perceptual and adversarial loss.
In Fig. 8, we show how the perceptual loss allows to obtain qualitatively better reconstructions than these obtained with an loss. Training our model with an additional adversarial loss enhances further the sharpness of the reconstructions.
In the remainder of this section, we trained our models with an loss which results in easier quality assessment using standard image similarity metrics.
Comparison to baselines.
As discussed in Section 3.3, every component of our model is important to obtain reconstructions similar to the target. To show that, we provide comparisons between different versions of our model and baselines using PSNR and MS-SSIM metrics. Each baseline consists of an auto-encoder where the encoder is a residual network (ResNet-18, same as our model) producing a latent code and different types of decoders. The different baselines, depicted in Fig. 9 with a summary of their properties, are designed to validate each component of our architecture:
- A.
ResNet AE: using as a decoder a ResNet with convolutions, residual connections, and upsampling similarly to the architecture used in [35, 28]. 2. B.
MLP AE: using as decoder an MLP with a output. 3. C.
Vect. AE: the decoder computes the resulting image as a function of the coordinates of a pixel in image space and the latent code as . Here is an MLP similar to the one used in our mask generation network, but with a 3-channel output instead of a 1-channel as for the mask. 4. D.
Ours One-shot: generates all the mask parameters and colors in one pass, instead of recursively. The MLP then processes each separately leading to different masks to be assembled in the blending module as in our approach. 5. E.
Ours ResNet: using a ResNet decoder to generate masks and otherwise similar to our method, iteratively blending the masks with one color onto the canvas, in our experiments we started with a black canvas.
Table 1 shows a quantitative comparison of results obtained by our model and baselines trained with loss and for the same bottleneck . This corresponds to a size of parameters of where 3 is the number of parameters used for color prediction. On both datasets, our approach (F) clearly outperforms the baselines which produce vector outputs, either in one layer (C) or with one-shot parameters prediction (D). Interestingly, a parametric generation (C) is itself better than directly using an MLP to predict pixel values (B). Finally, our approach (F) has quantitative reconstruction results similar to the ResNet baselines (A and E).
However, our method has two strong advantages over Resnet generations. First, it produces vector outputs. Second, it produces more interpretable masks. This can be seen in Fig. 10 where we compare the masks resulting from (E) and (F). Our method (F) captures much better the different components of face images, notably the hairs, while the masks of (E) include several different component in the image, with a first mask covering both hairs and faces. In the supplementary material, we show that a qualitatively similar difference can be observed for our method when reducing the number of masks while increasing their number of parameters to keep a constant total code size.
Recursive setup and computational cost.
There is of course a computational cost to our recursive approach. In Table 2, we compare the PSNR and computation time for the same total number of parameters (320) but using different number of masks , both for our approach and the one-shot baseline. Interestingly, the quality of the reconstruction improves with the number of masks for both approaches, our approach being consistently more than a point PSNR better than the one-shot baseline. However, as expected our approach is slower than the baseline both for training and testing, and the cost increases with the number of masks.
Table 3 evaluates the reconstruction quality when recomposing images at test time with a larger number of masks than the masks used at training time. On both datasets, the PSNR increases by almost a point with additional masks. This is another advantage of our recursive approach.
5 Conclusion
We have presented a new paradigm for image reconstruction using a succession of single-color parametric layers. This decomposition, learned without supervision, enables image editing from the masks generated for each layer.
We also show how the learned mask parameters may be exploited in a retrieval context. Moreover, our experiments prove that our image reconstruction results are competitive with convolution-based auto-encoders.
Our work is the first to showcase the potential of a deep vector image architecture for real world applications. Furthermore, while our model is introduced in an image reconstruction setting, it may be extended to adversarial image generation, where generating high resolution images is challenging. We’re aware of risks surrounding manipulated media but we believe the importance of publishing this work openly may have benefits in AR filters or more realistic VR.
We think that because of its differences and its advantages for user interaction, our method will inspire new approaches.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] E. Adelson. Layered representations for image coding . Vision and Modeling Group, Media Laboratory, Massachusetts Institute of Technology, 1991.
- 2[2] D. Bau, J.-Y. Zhu, H. Strobelt, B. Zhou, J. B. Tenenbaum, W. T. Freeman, and A. Torralba. Gan dissection: Visualizing and understanding generative adversarial networks. ar Xiv:1811.10597 , 2018.
- 3[3] I. Biederman. Recognition-by-components: a theory of human image understanding. Psychological review , 1987.
- 4[4] I. Binford. Visual perception by computer. In IEEE Conference of Systems and Control , 1971.
- 5[5] A. Brock, J. Donahue, and K. Simonyan. Large scale GAN training for high fidelity natural image synthesis. In ICLR , 2019.
- 6[6] Z. Chen and H. Zhang. Learning implicit fields for generative shape modeling. In CVPR , 2019.
- 7[7] G. Cybenko. Approximation by superpositions of a sigmoidal function. Mathematics of control, signals and systems , 1989.
- 8[8] L. Demaret, N. Dyn, and A. Iske. Image compression by linear splines over adaptive triangulations. Signal Processing , 2006.