TL;DR
TraPHic introduces a novel LSTM-CNN hybrid model for predicting trajectories of diverse road-agents in dense, heterogeneous traffic, outperforming existing methods by 30% on standard datasets.
Contribution
The paper presents a new trajectory prediction algorithm that models heterogeneous interactions and horizon-based behaviors in dense traffic using a hybrid neural network.
Findings
Outperforms state-of-the-art methods by 30% on dense traffic datasets.
Introduces a new dense, heterogeneous traffic dataset from urban Asian videos.
Effectively models diverse agent interactions and behaviors.
Abstract
We present a new algorithm for predicting the near-term trajectories of road-agents in dense traffic videos. Our approach is designed for heterogeneous traffic, where the road-agents may correspond to buses, cars, scooters, bicycles, or pedestrians. We model the interactions between different road-agents using a novel LSTM-CNN hybrid network for trajectory prediction. In particular, we take into account heterogeneous interactions that implicitly accounts for the varying shapes, dynamics, and behaviors of different road agents. In addition, we model horizon-based interactions which are used to implicitly model the driving behavior of each road-agent. We evaluate the performance of our prediction algorithm, TraPHic, on the standard datasets and also introduce a new dense, heterogeneous traffic dataset corresponding to urban Asian videos and agent trajectories. We outperform…
Click any figure to enlarge with its caption.
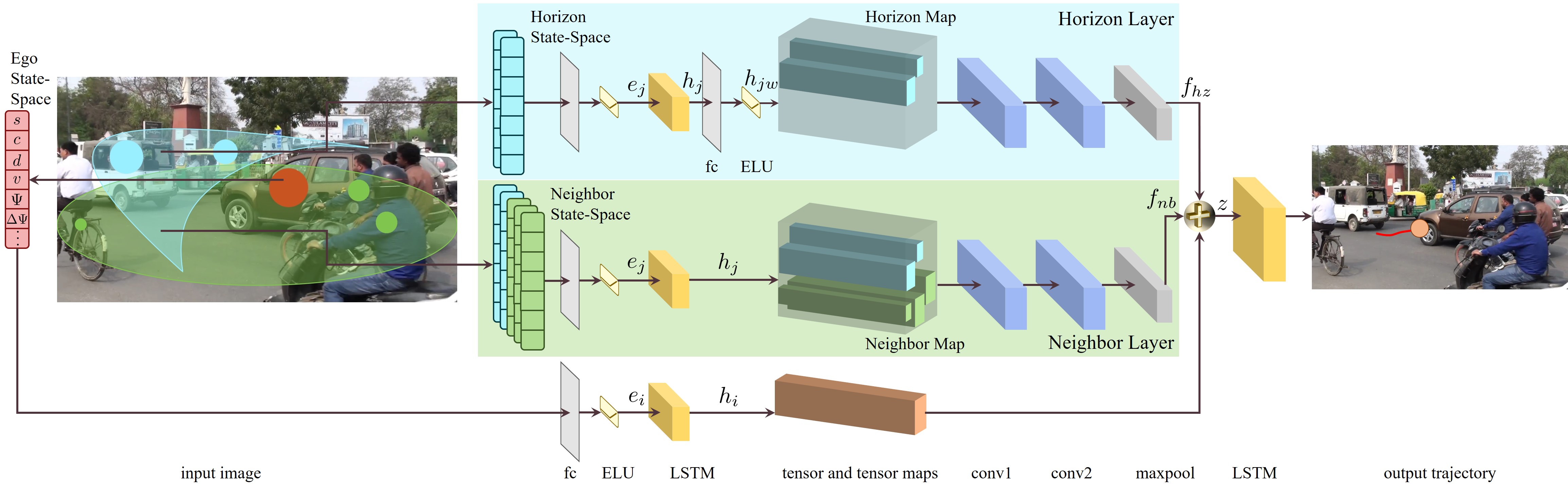 Figure 1
Figure 1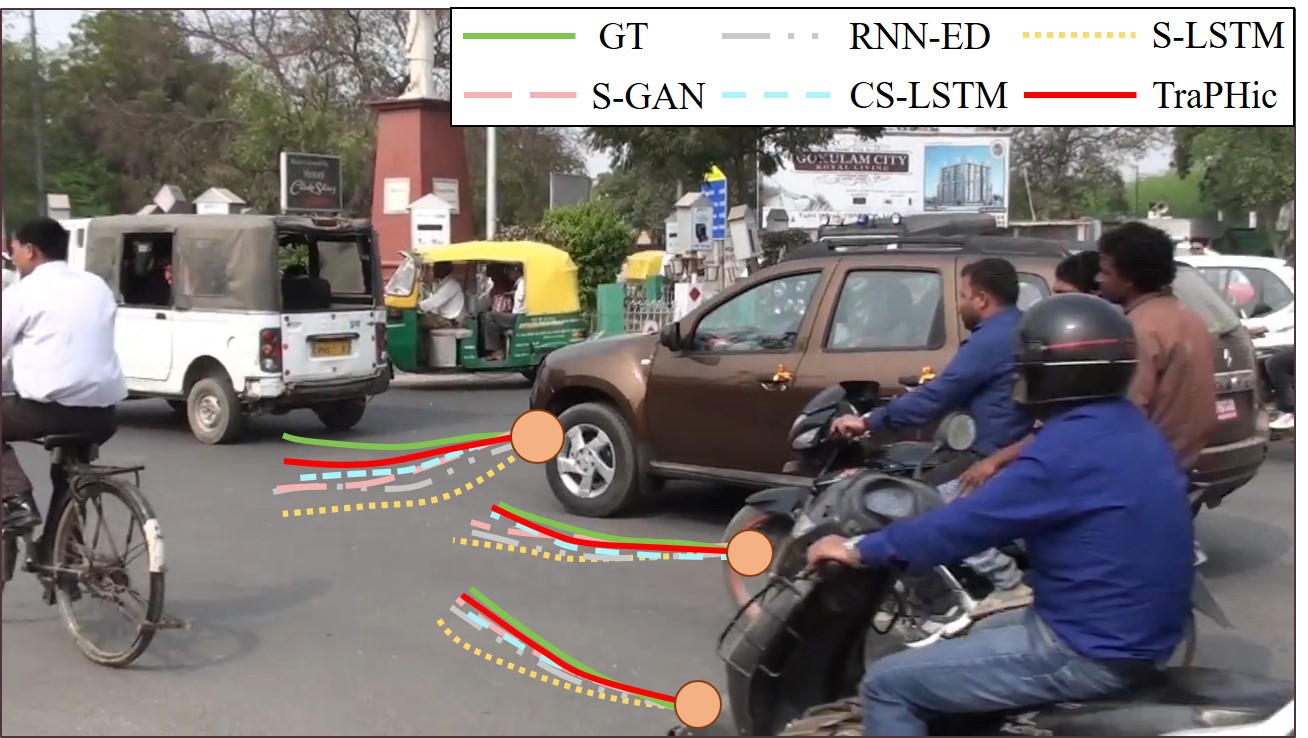 Figure 2
Figure 2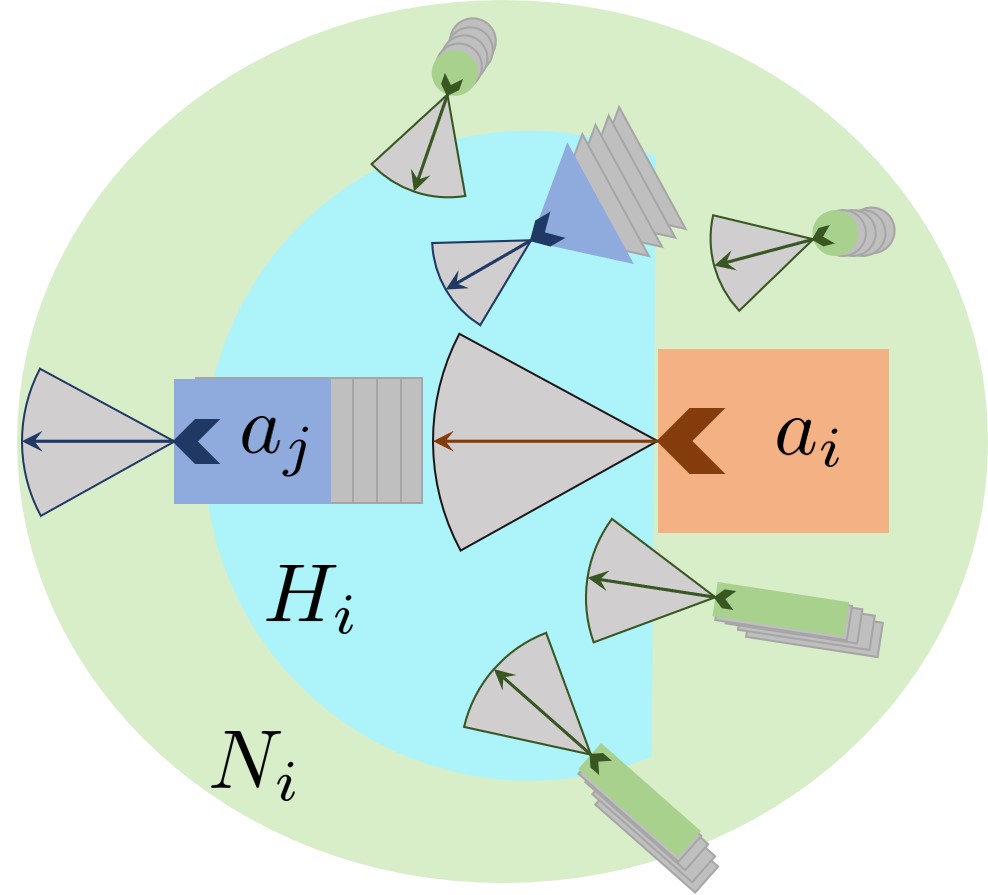 Figure 3
Figure 3 Figure 4
Figure 4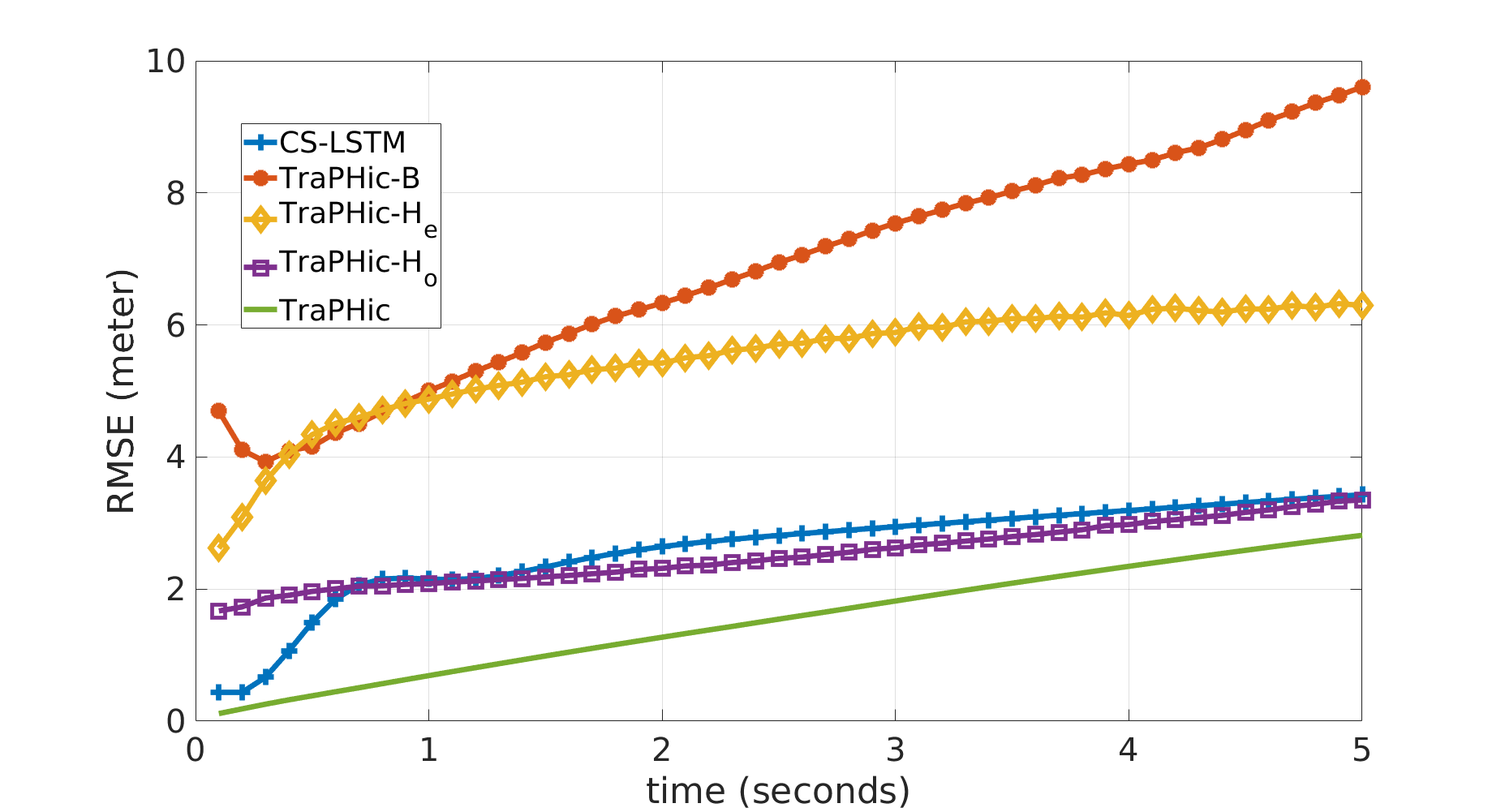 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8| Dataset | Method | ||||
|---|---|---|---|---|---|
| RNN-ED | S-LSTM | S-GAN | CS-LSTM | TraPHic | |
| NGSIM | 6.86/10.02 | 5.73/9.58 | 5.16/9.42 | 7.25/10.05 | 5.63/9.91 |
| Beijing | 2.24/8.25 | 6.70/8.08 | 4.02/7.30 | 2.44/8.63 | 2.16/6.99 |
| Methods Evaluated on TRAF | ||||||||||
| RNN-ED | S-LSTM | S-GAN | CS-LSTM | TraPHic | ||||||
| Original | Learned | Original | Learned | Original | Learned | B | Combined | |||
| 3.24/5.16 | 6.43/6.84 | 3.01/4.89 | 2.89/4.56 | 2.76/4.79 | 2.34/8.01 | 1.15/3.35 | 2.73/7.21 | 2.33/5.75 | 1.22/3.01 | 0.78/2.44 |
| Dataset | # Frames | Agents | Visibility | Density | #Diff | ||||||||
| Ped | Bicycle | Car | Bike | Scooter | Bus | Truck | Rick | Total | (Km) | Agents | |||
| NGSIM | 10.2 | 0 | 0 | 981.4 | 3.9 | 0 | 0 | 28.2 | 0 | 1013.5 | 0.548 | 1.85 | 3 |
| Beijing | 93 | 1.6 | 1.9 | 12.9 | 16.4 | 0.005 | 3.28 | 3 | |||||
| TRAF | 12.4 | 4.9 | 1.5 | 3.6 | 1.43 | 5 | 0.15 | 0.2 | 3.1 | 19.88 | 0.005 | 3.97 | 8 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
TraPHic: Trajectory Prediction in Dense and Heterogeneous Traffic Using Weighted Interactions
Rohan Chandra
University of Maryland
College Park
Uttaran Bhattacharya
University of Maryland
College Park
Aniket Bera
University of North Carolina
Chapel Hill
Dinesh Manocha
University of Maryland
College Park
Video, Code, and Dataset: https://gamma.umd.edu/traphic
Abstract
We present a new algorithm for predicting the near-term trajectories of road agents in dense traffic videos. Our approach is designed for heterogeneous traffic, where the road agents may correspond to buses, cars, scooters, bi-cycles, or pedestrians. We model the interactions between different road agents using a novel LSTM-CNN hybrid network for trajectory prediction. In particular, we take into account heterogeneous interactions that implicitly account for the varying shapes, dynamics, and behaviors of different road agents. In addition, we model horizon-based interactions which are used to implicitly model the driving behavior of each road agent. We evaluate the performance of our prediction algorithm, TraPHic, on the standard datasets and also introduce a new dense, heterogeneous traffic dataset corresponding to urban Asian videos and agent trajectories. We outperform state-of-the-art methods on dense traffic datasets by 30%. Code for our implementation can be found on our project webpage.
1 Introduction
The increasing availability of cameras and computer vision techniques has made it possible to track traffic road agents in realtime. These road agents may correspond to vehicles such as cars, buses, or scooters as well as pedestrians, bicycles, or animals. The trajectories of road agents extracted from a video can be used to model traffic patterns, driver behaviors, that are useful for autonomous driving. In addition to tracking, it is also important to predict the future trajectory of each road agent in realtime. The predicted trajectories are useful for performing safe autonomous navigation, traffic forecasting, vehicle routing, and congestion management [32, 11].
In this paper, we deal with dense traffic composed of heterogeneous road agents. The heterogeneity corresponds to the interactions between different types of road agents such as cars, buses, pedestrians, two-wheelers (scooters and motorcycles), three-wheelers (rickshaws), animals, etc. These agents have different shapes, dynamic constraints, and behaviors. The traffic density corresponds to the number of distinct road agents captured in a single frame of the video or the number of agents per unit length (e.g., a kilometer) of the roadway. High density traffic is described as traffic with more than 100 road agents per Km. Finally, an interaction corresponds to how two road agents in close proximity affect each other’s movement or avoid collisions.
There is considerable work on trajectory prediction for moving agents [2, 18, 36, 12, 26, 30, 12, 26]. Most of these algorithms have been developed for scenarios with single type of agents (a.k.a. homogeneous agents), which may correspond to human pedestrians in a crowd or cars driving on a highway. Furthermore, many prior methods have been evaluated on traffic videos corresponding to relatively sparse scenarios with only a few heterogeneous interactions, such as the NGSIM [1] and KITTI [15] datasets. In these cases, the interaction between agents can be modeled using well-known models based on social forces [19], velocity obstacles [35], or LTA [31].
Prior prediction algorithms do not work well on dense, heterogeneous traffic scenarios because they do not model the interactions accurately. For example, the dynamics of a bus-pedestrian interaction differs significantly from a pedestrian-pedestrian or a car-pedestrian interaction due to the differences in shape, size, maneuverability, and velocities. The differences in the dynamic characteristics of road agents affect their trajectories and how they navigate around each other in dense traffic situations [29]. Moreover, prior learning-based prediction algorithms typically model the interactions uniformly for all other road agents in its neighborhood and the resulting model assigns equal weight to each interaction. This method works well for homogeneous traffic. However, it does not work well for dense heterogeneous traffic, and we need methods to assign different weights to different pairwise interactions.
Main Contributions: We present a novel traffic prediction algorithm, TraPHic, for predicting the trajectories of road agents in realtime. The input to our algorithm is the trajectory history of each road agent as observed over a short time-span (- seconds), and the output is the predicted trajectory over a short span (- seconds). In order to develop a general approach to handle dense traffic scenarios, our approach models two kinds of weighted interactions, horizon-based and heterogeneous-based.
Heterogeneous-Based: We implicitly take into account varying sizes, aspect ratios, driver behaviors, and dynamics of road agents. Our formulation accounts for several dynamic constraints such as average velocity, turning radius, spatial distance from neighbors, and local density. We embed these functions into our state-space formulation and use them as inputs to our network to perform learning. 2. 2.
Horizon-Based: We use a semi-elliptical region (horizon) based on a pre-defined radius in front of each road agent. We prioritize the interactions in which the road agents are within the horizon using a Horizon Map. Our approach learns a weighting mechanism using a non-linear formulation, and uses that to assign weights to each road agent in the horizon automatically.
We formulate these interactions within an LSTM-CNN hybrid network that learns locally useful relationships between the heterogeneous road agents. Our approach is end-to-end and does not require explicit knowledge of an agent’s behavior. Furthermore, we present a new traffic dataset (TRAF) comprising of dense and heterogeneous traffic. The dataset consists of the following road agents: cars, buses, trucks, rickshaws, pedestrians, scooters, motorcycles, carts, and animals and is collected in dense Asian cities. We also compare our approach with prior methods and highlight the accuracy benefits. Overall, TraPHiC offers the following benefits as a realtime prediction algorithm:
TraPHIC outperforms prior methods on dense traffic datasets with - road agents by meters on the root mean square error (RMSE) metric, which is a improvement over prior methods. 2. 2.
Our algorithm offers accuracy similar to prior methods on sparse or homogeneous datasets such as the NGSIM dataset [1].
The rest of the paper is organized as follows. We give a brief overview of prior work in Section 2. Section 3 presents an overview of the weighted interactions. We present the overall learning algorithm in Section 4 and evaluate its performance on different datasets in Section 5.
2 Related Work
In this section, we give a brief overview of some important classical prediction algorithms and recent techniques based on deep neural networks.
2.1 Prediction Algorithms and Interactions
Trajectory prediction has been researched extensively. Approaches include the Bayesian formulation [27], the Monte Carlo simulation [10], Hidden Markov Models (HMMs) [14], and Kalman Filters [23].
Methods that do not model road-agent interactions are regarded as sub-optimal or as less accurate than methods that model the interactions between road agents in the scene [34]. Examples of methods that explicitly model road-agent interaction include techniques based on social forces [19, 37], velocity obstacles [35], LTA [31], etc. Many of these models were designed to account for interactions between pedestrians in a crowd (i.e. homogeneous interactions) and improve the prediction accuracy [3]. Techniques based on velocity obstacles have been extended using kinematic constraints to model the interactions between heterogeneous road agents [29]. Our learning approach does not use any explicit pairwise motion model. Rather, we model the heterogeneous interactions between road agents implicitly.
2.2 Deep-Learning Based Methods
Approaches based on deep neural networks use variants of Recurrent Neural Networks (RNNs) for sequence modeling. These have been extended to hybrid networks by combining RNNs with other deep learning architectures for motion prediction.
RNN-Based Methods RNNs are natural generalizations of feedforward neural networks to sequence [33]. The benefits of RNNs for sequence modeling makes them a reasonable choice for traffic prediction. Since RNNs are incapable of modeling long-term sequences, many traffic trajectory prediction methods use long short-term memory networks (LSTMs) to model road-agent interactions. These include algorithms to predict trajectories in traffic scenarios with few heterogeneous interactions [12, 30]. These techniques have also been used for trajectory prediction for pedestrians in a crowd [2, 36].
Hybrid Methods Deep-learning-based hybrid methods consist of networks that integrate two or more deep learning architectures. Some examples of deep learning architectures include CNNs, GANs, VAEs, and LSTMs. Each architecture has its own advantages and, for many tasks, the advantages of individual architectures can be combined. There is considerable work on the development of hybrid networks. Generative models have been successfully used for tasks such as super resolution [25], image-to-image translation [22], and image synthesis [17]. However, their application in trajectory prediction has been limited because back-propagation during training is non-trivial. In spite of this, generative models such as VAEs and GANs have been used for trajectory prediction of pedestrians in a crowd [18] and in sparse traffic [26]. Alternatively, Convolutional Neural Networks (CNNs or ConvNets) have also been successfully used in many computer vision applications like object recognition [38]. Recently, they have also been used for traffic trajectory prediction [8, 13]. In this paper, we present a new hybrid network that combines LSTMs with CNNs for traffic prediction.
2.3 Traffic Datasets
There are several datasets corresponding to traffic scenarios. ApolloScape [20] is a large-scale dataset of street views that contain scenes with higher complexities, 2D/3D annotations and pose information, lane markings and video frames. However, this dataset does not provide trajectory information. The NGSIM simulation dataset [1] consists of trajectory data for road agents corresponding to cars and trucks, but the traffic scenes are limited to highways with fixed-lane traffic. KITTI [15] dataset has been used in different computer vision applications such as stereo, optical flow, 2D/3D object detection, and tracking. There are some pedestrian trajectory datasets like ETH [31] and UCY [28], but they are limited to pedestrians in a crowd. Our new dataset, TRAF, corresponds to dense and heterogeneous traffic captured from Asian cities and includes 2D/3D trajectory information.
3 TraPHic: Trajectory Prediction in Heterogeneous Traffic
In this section, we give an overview of our prediction algorithm that uses weighted interactions. Our approach is designed for dense and heterogeneous traffic scenarios and is based on two observations. The first observation is based on the idea that road agents in such dense traffic do not react to every road agent around them; rather, they selectively focus attention on key interactions in a semi-elliptical region in the field of view, which we call the “horizon”. For example, consider a motorcyclist who suddenly moves in front of a car and the neighborhood of the car consists of other road agents such as three-wheelers and pedestrians (Figure 2). The car must prioritize the motorcyclist interaction over the other interactions to avoid a collision.
The second observation stems from the heterogeneity of different road agents such as cars, buses, rickshaws, pedestrians, bicycles, animals, etc. in the neighborhood of an road agent (Figure 2). For instance, the dynamic constraints of a bus-pedestrian interaction differs significantly from a pedestrian-pedestrian or even a car-pedestrian interaction due to the differences in road agent shapes, sizes, and maneuverability. To capture these heterogeneous road agent dynamics, we embed these properties into the state-space representation of the road agents and feed them into our hybrid network. We also implicitly model the behaviors of the road agents. Behavior in our case the different driving and walking styles of different drivers and pedestrians. Some are more aggressive while others more conservative. We model these behaviors as they directly influence the outcome of various interactions [7], thereby affecting the road agents’ navigation.
3.1 Problem Setup and Notation
Given a set of road agents , trajectory history of each road agent over frames, denoted , and the road agent’s size , we predict the spatial coordinates of that road agent for the next frames. In addition, we introduce a feature called traffic concentration , motivated by traffic flow theory [21]. Traffic concentration, , at the location is defined as the number of road agents between and for some predefined . This metric is similar to traffic density, but the key difference is that traffic density is a macroscopic property of a traffic video, whereas traffic concentration is a mesoscopic property and is locally defined at a particular location. So we achieve a representation of traffic on several scales.
Finally, we define the state space of each road agent as
[TABLE]
where is a derivative operator that is used to compute the velocity of the road agent, and .
**2D Image Space to 3D World Coordinate Space: ** We compute camera parameters from given videos using standard techniques [4, 5], and use the parameters to estimate the camera homography matrices. The homography matrices are subsequently used to convert the location of road agents in 2D pixels to 3D world coordinates w.r.t. a predetermined frame of reference, similar to approaches in [18, 2]. All state-space representations are subsequently converted to the 3D world space.
**Horizon and Neighborhood Agents: ** Prior trajectory prediction methods have collected neighborhood information using lanes and rectangular grids [12]. Our approach is more generalized in that we pre-process the trajectory data by assuming a lack of lane information. This assumption is especially true in practice in dense and heterogeneous traffic conditions. We formulate a road agent ’s neighborhood, , using an elliptical region and selecting a fixed number of closest road agents using the nearest-neighbor search algorithm in that region. Similarly, we define the horizon of that agent, , by selecting a smaller threshold in the nearest-neighbor search algorithm, and in a semi-elliptical region in front of .
4 Hybrid Architecture for Traffic Prediction
In this section, we present our novel network architecture for performing trajectory prediction in dense and heterogeneous environments. In the context of heterogeneous traffic, the goal is to predict trajectories, i.e. temporal sequences of spatial coordinates of a road agent. Temporal sequence prediction requires models that can capture temporal dependencies in data, such as LSTMs [16]. However, LSTMs cannot learn dependencies or relationships of various heterogeneous road agents because the parameters of each individual LSTM are independent of one another. In this regard, ConvNets have been used in computer vision applications with greater success because they can learn locally dependent features from images. Thus, in order to leverage the benefits of both, we combine ConvNets with LSTMs to learn locally useful relationships, both in space and in time, between the heterogeneous road agents. We now describe our model to predict the trajectory for each road agent . A visualization of the model is shown in Figure 3.
We start by computing and for the agent . Next, we identify all road agents . Each has an input state-space that is used to create the embeddings , using
[TABLE]
where and are conventional symbols denoting the weight matrix and bias vector respectively, of the layer in the network, and is the non-linear activation on each node.
Our network consists of three layers. The horizon layer (top cyan layer in Figure 3) takes in the embedding of each road agent in , and the neighbor layer (middle green layer in Figure 3) takes in the embedding of each road agent in . The input embeddings in both these layers are passed through fully connected layers with ELU non-linearities [9], and then fed into single-layered LSTMs (yellow blocks in Figure 3). The outputs of the LSTMs in the two layers are hidden state vectors, , that are computed using
[TABLE]
where refers to the corresponding road agent’s hidden state vector from the previous time-step . The hidden state vector of a road agent is a latent representation that contains temporally useful information. In the remainder of the text, we drop the parameter for the sake of simplicity, i.e., is understood to mean for any .
The hidden vectors in the horizon layer are passed through an additional fully connected layer with ELU non-linearities [9]. We denote the output of the fully connected layer as . All the ’s in the horizon layer are then pooled together in a “horizon map”. The hidden vectors in the neighbor layer are directly pooled together in a “neighbor map”. These maps are further elaborated in Section 4.1. Both these maps are then passed through separate ConvNets in the two layers. The ConvNets in both the layers are comprised of two convolution operations followed by a max-pool operation. We denote the output feature vector from the ConvNet in the horizon layer as , and that from the ConvNet in the neighbor layer as .
Finally, the bottom-most layer corresponds to the ego agent . Its input embedding, , passes sequentially through a fully connected with ELU non-linearities [9], and a single-layered LSTM to compute its hidden vector, . The feature vectors from the horizon and neighbor layers, and , are concatenated with to generate a final vector encoding
[TABLE]
Finally, the concatenated encoding passes through an LSTM to compute the prediction for the next seconds.
4.1 Weighted Interactions
Our model is trained to learn weighted interactions in both the horizon and neighborhood layers. Specifically, it learns to assign appropriate weights to various pairwise interactions based on the shape, dynamic constraints and behaviors of the involved agents. The horizon-based weighted interactions takes into account the agents in the horizon of the ego agent, and learns the “horizon map” , given as
[TABLE]
Similarly, the neighbor or heterogeneous-based weighted interactions accounts for all the agents in the neighborhood of the ego agent, and learns the “neighbor map” , given as
[TABLE]
During training, back-propagation optimizes the weights corresponding to these maps by minimizing the loss between predicted output and ground truth labels. Our formulation results in higher weights for prioritized interactions (larger tensors in Horizon Map or blue vehicles in Figure 2) and lower weights for less relevant interactions (smaller tensors in Neighbor Map or green vehicles in Figure 2).
4.2 Implicit Constraints
Turning Radius: In addition to constraints such as position, velocity and shape, constraints such as the turning radius of a road agent also affects its maneuverability, especially as it interacts with other road agents within some distance. For example, a car (a non-holonomic agent) cannot alter its orientation in a short time frame to avoid collisions, whereas a bicycle or a pedestrian can.
However, the turning radius of a road agent can be determined by the dimensions of the road agent, i.e., its length and width. Since we include these parameters into our state-space representation, we implicitly take into consideration each agent’s turning radius constraints as well.
Driver Behavior: As stated in [7], velocity and acceleration (both relative and average ) are clear indicators of driver aggressiveness. For instance, a road agent with a relative velocity (and/or acceleration) much higher than the average velocity (and/or acceleration) of all road agents in a given traffic scenario would be deemed as aggressive. Moreover, given the traffic concentrations at two consecutive spatial coordinates, and , where , aggressive drivers move in a “greedy” fashion in an attempt to occupy the empty spots in the subsequent spatial locations. For each road agent, we compute its concentration with respect to its neighborhood and add this value to its input state-space.
Finally, the relative distance of a road agent from its neighbors is another factor pertaining to how conservative or aggressive a driver is. More conservative drivers tend to maintain a healthy distance while aggressive drivers tend to tail-gate. Hence, we compute the spatial distance of each road agent in the neighborhood and encode this in its state-space representation.
4.3 Overall Trajectory Prediction
Our algorithm follows a well-known scheme for prediction [2]. We assume that the position of the road agent in the next frame follows a bi-variate Gaussian distribution with parameters , and correlation coefficient . The spatial coordinates are thus drawn from . We train the model by minimizing the negative log-likelihood loss function for the road agent trajectory,
[TABLE]
We jointly back-propagate through all three layers of our network, optimizing the weights for the linear blocks, ConvNets, LSTMs, and Horizon and Neighbor Maps. The optimized parameters learned for the Linear-ELU block in the horizon layer indicates the priority for the interaction in the horizon of an road agent .
5 Experimental Evaluation
We describe our new dataset in Section 5.1. In Section 5.2, we list all implementation details used in our training process. Next, we list the evaluation metrics and methods that we compare with, in Section 5.3. Finally, we present the evaluation results in Section 5.4.
5.1 TRAF Dataset: Dense & Heterogeneous Urban Traffic
We present a new dataset, currently comprising of videos of dense and heterogeneous traffic. The dataset consists of the following road agent categories: car, bus, truck, rickshaw, pedestrian, scooter, motorcycle, and other road agents such as carts and animals. Overall, the dataset contains approximately motorized vehicles, pedestrians and bicycles per frame. Annotations were performed following a strict protocol and each annotated video file consists of spatial coordinates, an agent ID, and an agent type. The dataset is categorized according to camera viewpoint (front-facing/top-view), motion (moving/static), time of day (day/evening/night), and difficulty level (sparse/moderate/heavy/challenge). All the videos have a resolution of . We present a comparison of our dataset with standard traffic datasets in Table 3. The dataset is available at https://gamma.umd.edu/traphic/dataset.
5.2 Implementation Details
We use single-layer LSTMs as our encoders and decoders with hidden state dimensions of and , respectively. Each ConvNet is implemented using two convolutional operations each followed by an ELU non-linearity [9] and then max-pooling. We train the network for epochs using the Adam optimizer [24] with a batch size of and learning rate of . We use a radius of meters to define the neighborhood and a minor axis length of meters to define the horizon, respectively. Our approach uses seconds of history and predicts spatial coordinates of the road agent for up to seconds ( seconds for KITTI dataset). We do not down-sample on the NGSIM dataset due to its sparsity. However, we use a down-sampling factor of on the Beijing and TRAF datasets due to their high density. Our network is implemented in Pytorch using a single TiTan Xp GPU. Our network does not use batch norm or dropout as they can decrease accuracy. We include the experimental details involving batch norm and dropout in the appendix due to space limitations.
5.3 Evaluation Metrics and Comparison Methods
We use the following commonly used metrics [2, 18, 12] to measure the performances of the algorithms used for predicting the trajectories of the road agents.
Average displacement error (ADE): The root mean square error (RMSE) of all the predicted positions and real positions during the prediction time. 2. 2.
Final displacement error (FDE): The RMSE distance between the final predicted positions at the end of the predicted trajectory and the corresponding true location.
We compare our approach with the following methods.
- •
RNN-ED (Seq2Seq): An RNN encoder-decoder model, which is widely used in motion and trajectory prediction for vehicles [6].
- •
Social-LSTM (S-LSTM): An LSTM-based network with social pooling of hidden states to predict pedestrian trajectories in crowds [2].
- •
Social-GAN (S-GAN): An LSTM-GAN hybrid network to predict trajectories for large human crowds [18].
- •
Convolutional-Social-LSTM (CS-LSTM): A variant of S-LSTM adding convolutions to the network in [2] in order to predict trajectories in sparse highway traffic [12].
We also perform ablation studies with the following four versions of our approach.
- •
TraPHic-B: A base version of our approach without using any weighted interactions.
- •
TraPHic-: A version of our approach without using Heterogeneous-Based Weighted interactions, i.e., we do not take into account driver behavior and information such as shape, relative velocity, and concentration.
- •
TraPHic-: A version of our approach without using Horizon-Based Weighted interactions. In this case, we do not explicitly model the horizon, but account for heterogeneous interactions.
- •
TraPHic: Our main algorithm using both Heterogeneous-Based and Horizon-Based Weighted interactions. We explicitly model the horizon and implicitly account for dynamic constraints and driver behavior.
5.4 Results on Traffic Datasets
In order to provide a comprehensive evaluation, we compare our method with state-of-the-art methods on several datasets. Table 1 shows the results on the standard NGSIM dataset and an additional dataset containing heterogeneous traffic of moderate density. We present results on our new TRAF dataset in Table 2.
TraPHic outperforms all prior methods we compared with on our TRAF dataset. For a fairer comparison, we trained these methods on our dataset before testing them on the dataset. However, the prior methods did not generalize well to dense and heterogeneous traffic videos. One possible explanation for this is that S-LSTM and S-GAN were designed to predict trajectories of humans in top-down crowd videos whereas the TRAF dataset consists of front-view heterogeneous traffic videos with high density. CS-LSTM uses lane information in its model and weight all agent interactions equally. Since the traffic in our dataset does not include the concept of lane-driving, we used the version of CS-LSTM that does not include lane information for a fairer comparison. However, it still led to a poor performance since CS-LSTM does not account for heterogeneous-based interactions. On the other hand, TraPHic considers both heterogeneous-based and horizon-based interactions, and thus produces superior performance on our dense and heterogeneous dataset.
We visualize the performance of the various trajectory prediction methods on our TRAF dataset Figure 5. Compared to the prior methods, TraPHic produces the least deviation from the ground truth trajectory in all the scenarios. Due to the significantly high density and heterogeneity in these videos, coupled with the unpredictable nature of the involved agents, all the predictions deviate from the ground truth in the long term (after seconds).
We demonstrate that our approach is comparable to prior methods on sparse datasets such as the NGSIM dataset. We do not outperform the current sate-of-the-art in such datasets, since our algorithm tries to account for heterogeneous agents and weighted interactions even when interactions are sparse and mostly homogeneous. Nevertheless, we are at par with the state-of-the-art performance. Lastly, we note that our RMSE value on the NGSIM dataset is quite high, which we attribute to the fact that we used a much higher (2X) sampling rate for averaging than prior methods.
Finally, we perform an ablation study to highlight the contribution of our weighted interaction formulation. We compare the four versions of TraPHic as stated in Section 5.3. We find that the Horizon-based formulation contributes more significantly to higher accuracy. TraPHic- reduces ADE by and FDE by over TraPHic-B, whereas TraPHic- reduces ADE by and FDE by over TraPHic-B. Incorporating both formulations results in the highest accuracy, reducing the ADE by and the FDE by over TraPHic-B.
6 Conclusion, Limitations, and Future Work
We presented a novel algorithm for predicting the trajectories of road agents in dense and heterogeneous traffic. Our approach is end-to-end, dealing with traffic videos without assuming lane-based driving. Furthermore, we are able to model the interactions between heterogeneous road agents corresponding to cars, buses, pedestrians, two-wheelers, three-wheelers, and animals. We use an LSTM-CNN hybrid network to model two kinds of weighted interactions between road agents: horizon-based and heterogeneous-based. We demonstrate the benefits of our model over state-of-the-art trajectory prediction methods on standard datasets and on a novel dense traffic dataset. We observe up to improvement in prediction accuracy.
Our work has some limitations. Our model design is motivated by some of the characteristics observed in dense heterogeneous traffic. As a result, we do not outperform prior methods on sparse or homogeneous traffic videos, although our prediction results are comparable to prior methods. In addition, modeling heterogeneous constraints requires the knowledge of the shapes and sizes of different road agents. This information could be tedious to collect. In the future, we plan to design a system that eliminates the need for ground truth trajectory data and can directly predict the trajectories from an input video. We also intend to use TraPHic for autonomous navigation in dense traffic.
7 Acknowledgments
This research is supported in part by ARO grant W911NF19-1- 0069, Alibaba Innovative Research (AIR) program, and Intel.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] U.S. Federal Highway Administration. U.s. highway 101 and i-80 dataset. 2005.
- 2[2] Alexandre Alahi, Kratarth Goel, Vignesh Ramanathan, Alexandre Robicquet, Li Fei-Fei, and Silvio Savarese. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 961–971, 2016.
- 3[3] Aniket Bera, Sujeong Kim, Tanmay Randhavane, Srihari Pratapa, and Dinesh Manocha. Glmp-realtime pedestrian path prediction using global and local movement patterns. In Robotics and Automation (ICRA), 2016 IEEE International Conference on , pages 5528–5535. IEEE, 2016.
- 4[4] Jean-Yves Bouguet. Complete camera calibration toolbox for matlab.
- 5[5] Gary Bradski and Adrian Kaehler. Learning Open CV: Computer vision with the Open CV library . ” O’Reilly Media, Inc.”, 2008.
- 6[6] D. Britz, A. Goldie, T. Luong, and Q. Le. Massive Exploration of Neural Machine Translation Architectures. Ar Xiv e-prints , Mar. 2017.
- 7[7] Ernest Cheung, Aniket Bera, Emily Kubin, Kurt Gray, and Dinesh Manocha. Identifying driver behaviors using trajectory features for vehicle navigation. ar Xiv preprint ar Xiv:1803.00881 , 2018.
- 8[8] Fang-Chieh Chou, Tsung-Han Lin, Henggang Cui, Vladan Radosavljevic, Thi Nguyen, Tzu-Kuo Huang, Matthew Niedoba, Jeff Schneider, and Nemanja Djuric. Predicting motion of vulnerable road users using high-definition maps and efficient convnets. 2018.
