Generating Summaries for Methods of Event-Driven Programs: an Android Case Study
Alireza Aghamohammadi, Maliheh Izadi, Abbas Heydarnoori

TL;DR
This paper introduces a deep learning-based method for generating summaries of methods in event-driven Android programs, effectively capturing interactions among elements to improve comprehension.
Contribution
It presents a novel approach combining deep neural networks and dynamic call graphs specifically tailored for event-driven applications, addressing limitations of previous code summarization techniques.
Findings
Achieved 32.3% BLEU4 score, outperforming existing methods.
Summaries are considered understandable and informative by developers.
Method effectively captures interactions in event-driven programs.
Abstract
The lack of proper documentation makes program comprehension a cumbersome process for developers. Source code summarization is one of the existing solutions to this problem. Lots of approaches have been proposed to summarize source code in recent years. A prevalent weakness of these solutions is that they do not pay much attention to interactions among elements of a software. An element is simply a callable code snippet such as a method or even a clickable button. As a result, these approaches cannot be applied to event-driven programs, such as Android applications, because they have specific features such as numerous interactions between their elements. To tackle this problem, we propose a novel approach based on deep neural networks and dynamic call graphs to generate summaries for methods of event-driven programs. First, we collect a set of comment/code pairs from Github and train a…
Click any figure to enlarge with its caption.
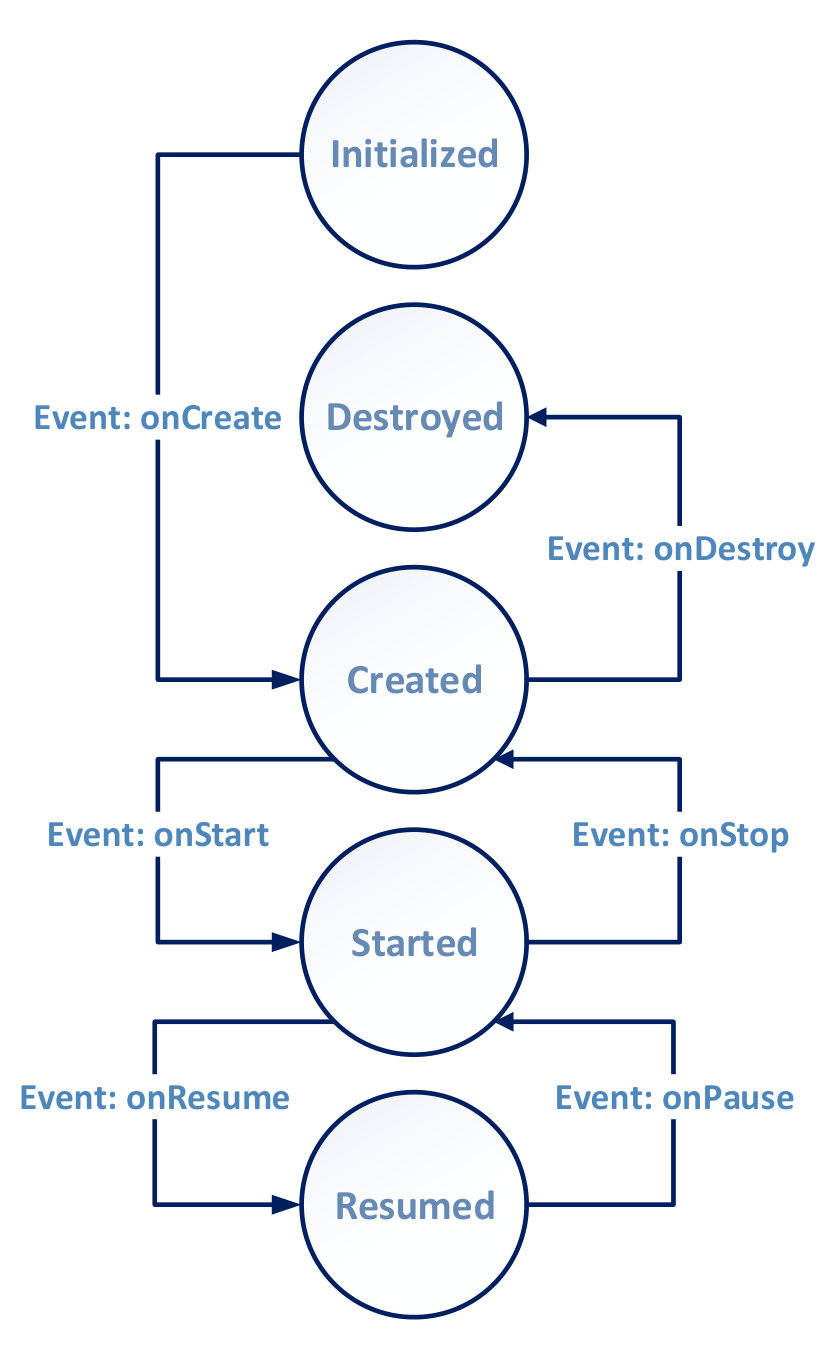 Figure 1
Figure 1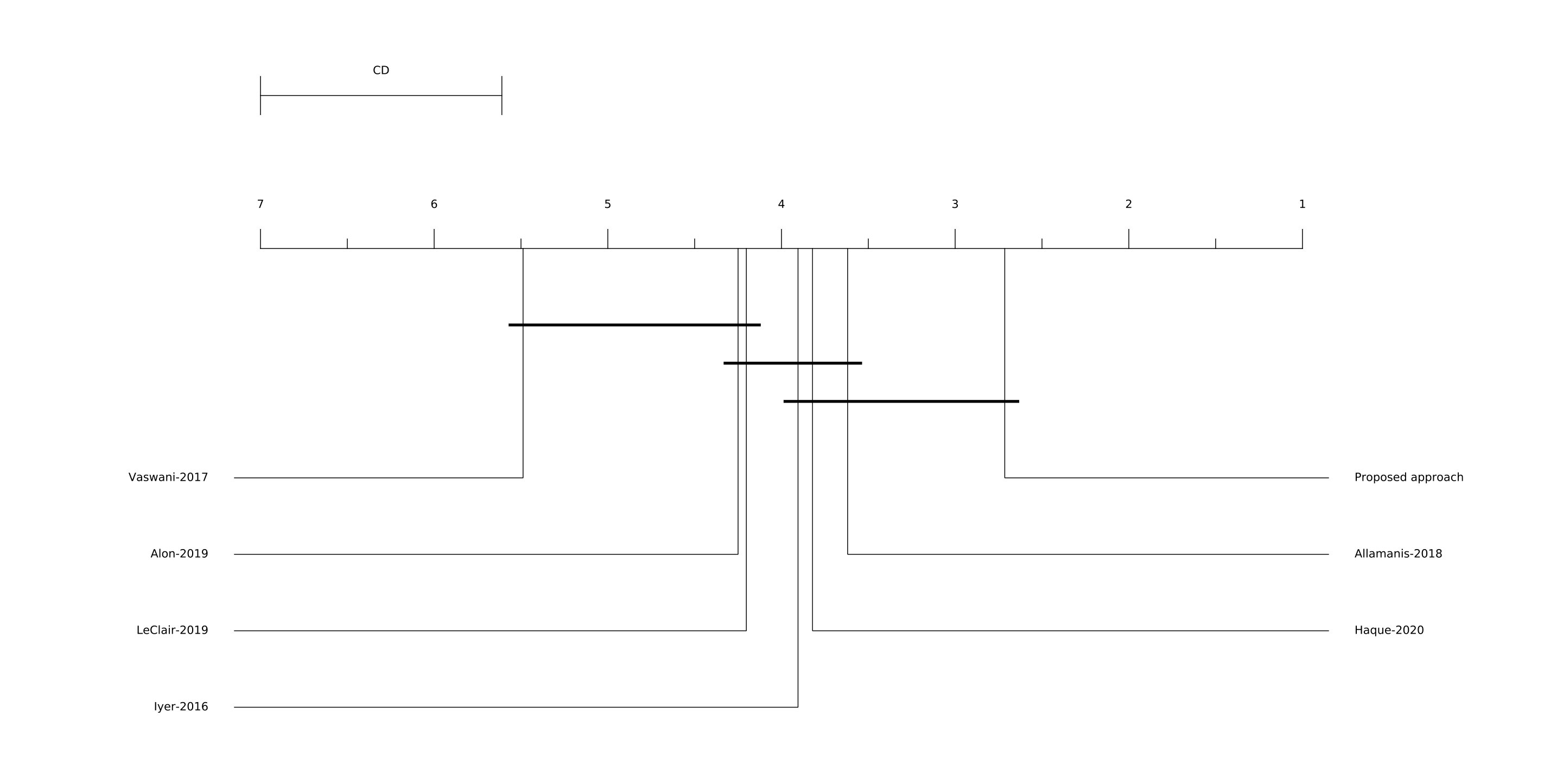 Figure 2
Figure 2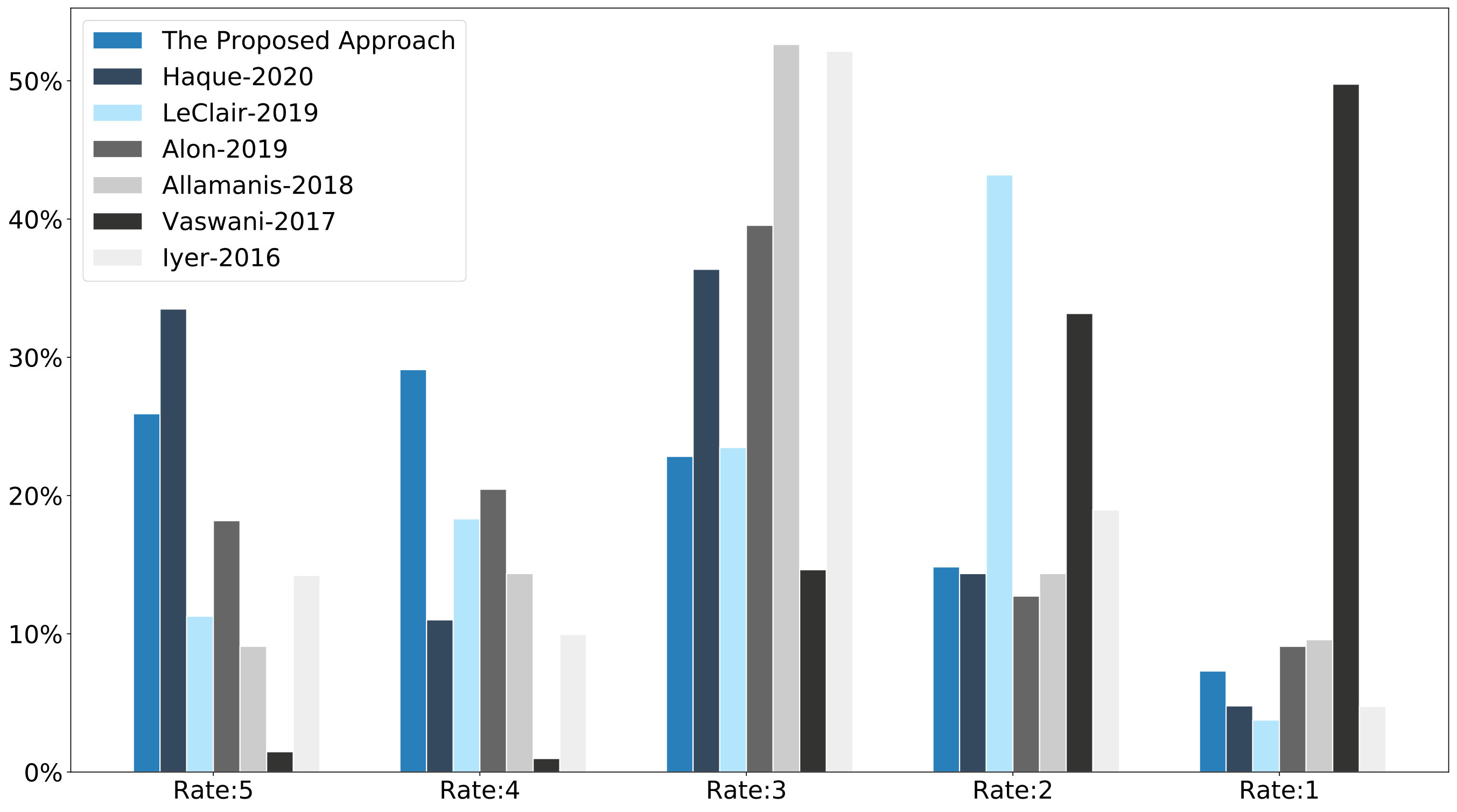 Figure 3
Figure 3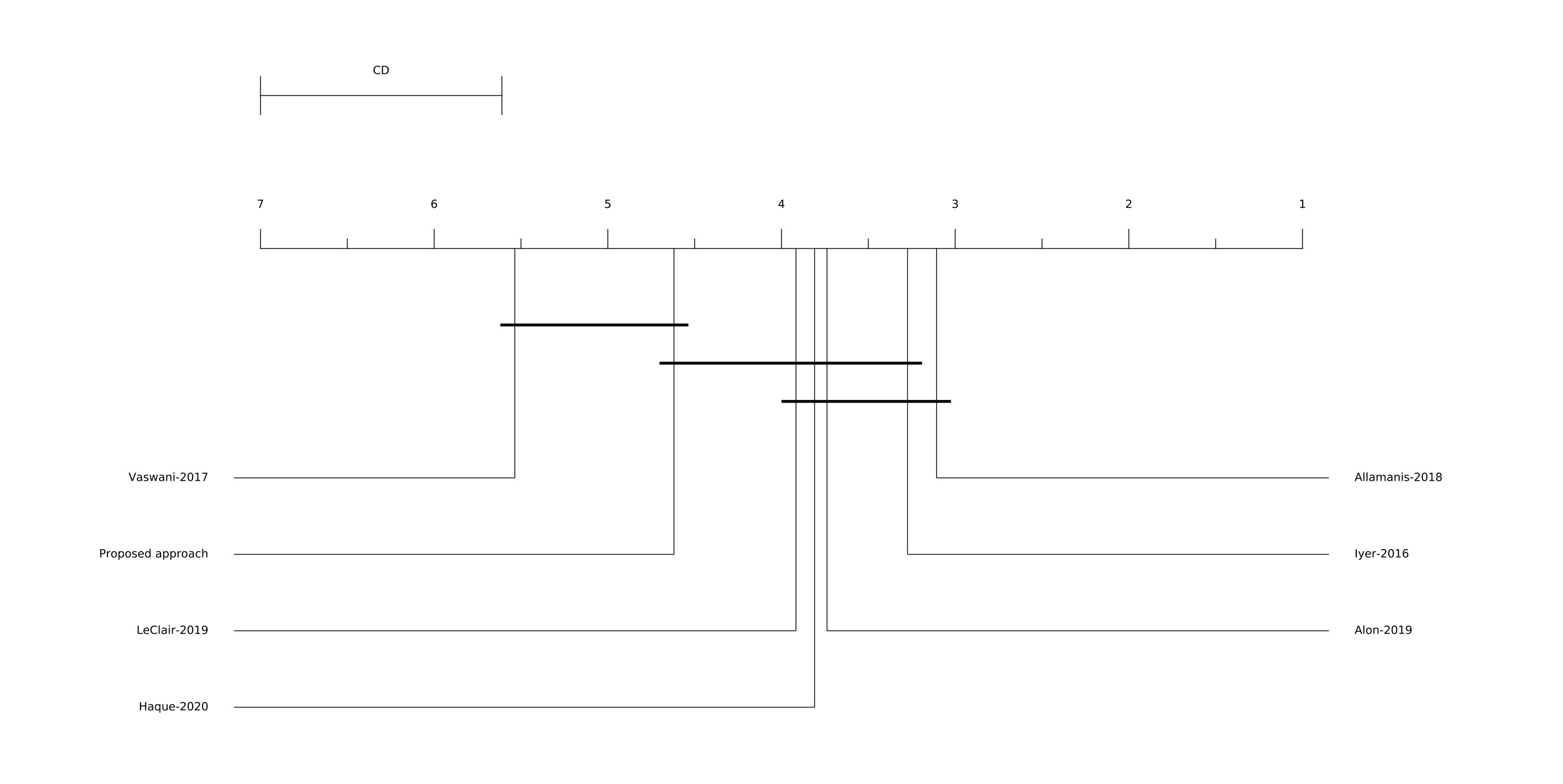 Figure 4
Figure 4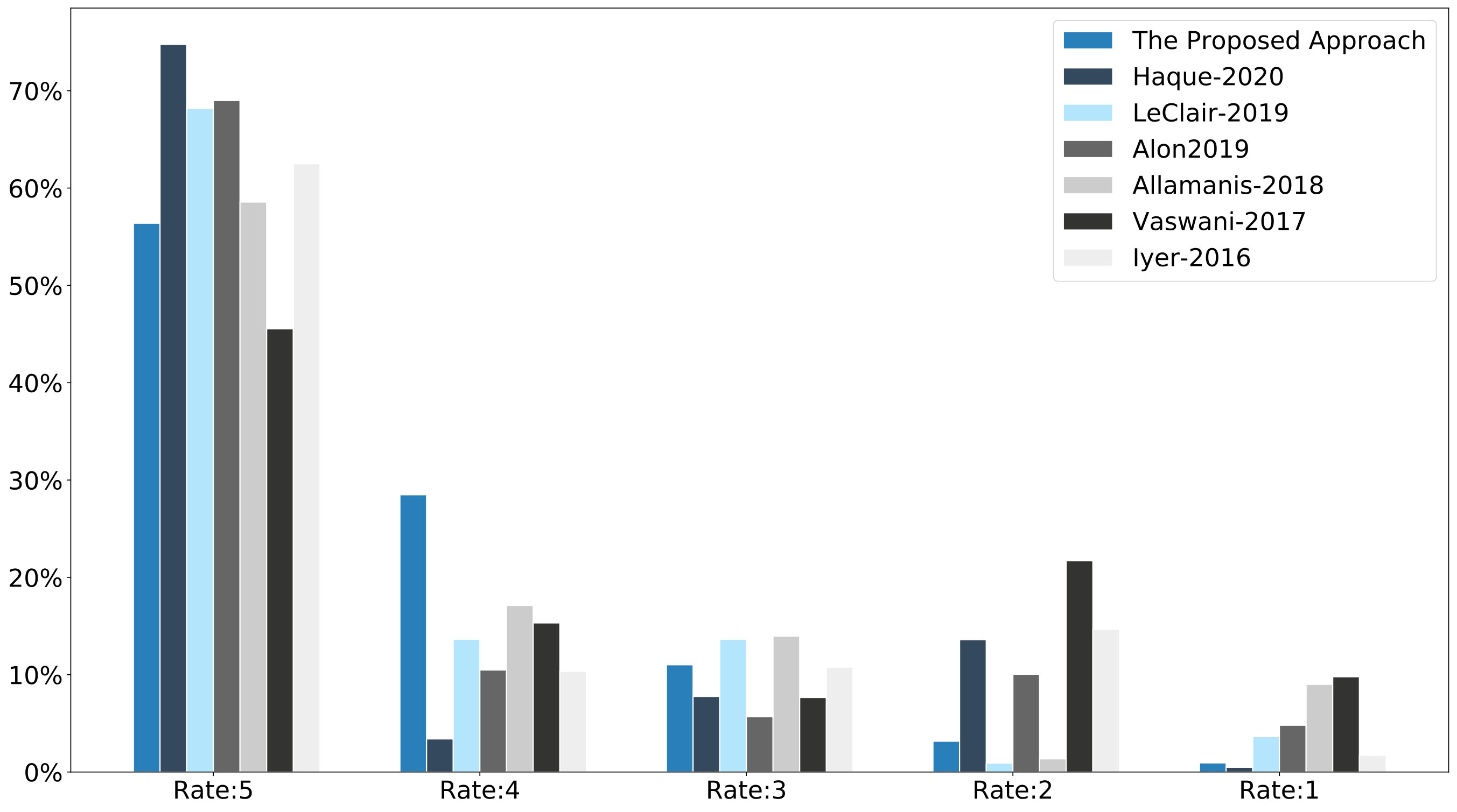 Figure 5
Figure 5 Figure 6
Figure 6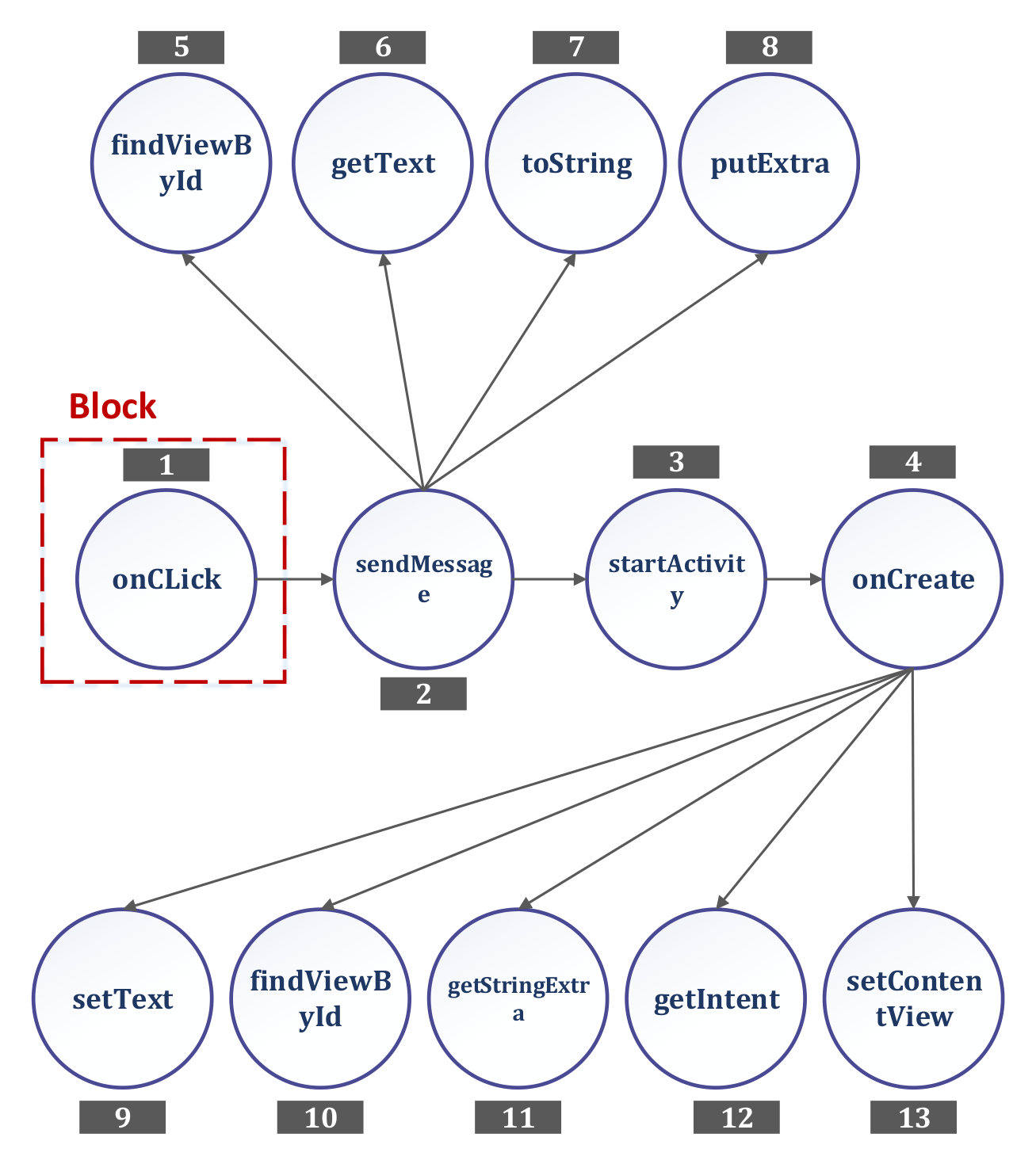 Figure 7
Figure 7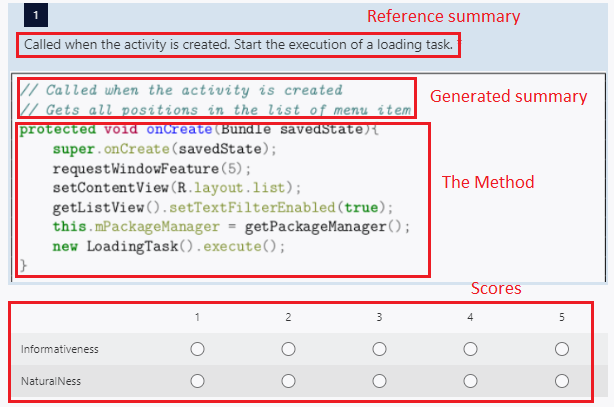 Figure 8
Figure 8| Mean | Q1 | Q2 | Q3 | # Unique tokens | |
|---|---|---|---|---|---|
| Comment length | |||||
| Code length |
|
# of layers |
|
SBT |
BLEU4 |
METEOR |
Perplexity |
||
| ✓ | ✗ | ||||||
| ✗ | ✗ | ||||||
| ✓ | ✗ | ||||||
| ✓ | ✗ | ||||||
| ✗ | ✓ | ||||||
| ✓ | ✓ |
| Application Name | # of lines | # of Methods | # of Classes |
|---|---|---|---|
| Tister | |||
| Hashpass | |||
| Munchlife | |||
| Justsit | |||
| Blinkenlightsbattery | |||
| Autoanswer | |||
| Anycut | |||
| Dofcalculator | |||
| Divideandconquer | |||
| Passwordmakerpro | |||
| TippyTipper | |||
| Tokenlist | |||
| Httpmon | |||
| Remembeer |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Generating Summaries for Methods of Event-Driven Programs: an Android Case Study
Alireza Aghamohammadi111The first two authors contributed equally to this work.
Maliheh Izadi222The first two authors contributed equally to this work.
Abbas Heydarnoori
A. Aghamohammadi, M. Izadi, and A. Heydarnoori are with the Department of Computer Engineering, Sharif University of Technology, Iran.
Abstract
The lack of proper documentation makes program comprehension a cumbersome process for developers. Source code summarization is one of the existing solutions to this problem. Lots of approaches have been proposed to summarize source code in recent years. A prevalent weakness of these solutions is that they do not pay much attention to interactions among elements of a software. An element is simply a callable code snippet such as a method or even a clickable button. As a result, these approaches cannot be applied to event-driven programs, such as Android applications, because they have specific features such as numerous interactions between their elements. To tackle this problem, we propose a novel approach based on deep neural networks and dynamic call graphs to generate summaries for methods of event-driven programs. First, we collect a set of comment/code pairs from Github and train a deep neural network on the set. Afterward, by exploiting a dynamic call graph, the Pagerank algorithm, and the pre-trained deep neural network, we generate summaries. An empirical evaluation with 14 real-world Android applications and 42 participants indicates 32.3% BLEU4 which is a definite improvement compared to the existing state-of-the-art techniques. We also assessed the informativeness and naturalness of our generated summaries from developers’ perspectives and showed they are sufficiently understandable and informative.
keywords:
Source Code Summarization , Neural , Machine Translation, Event-Driven Programs , Deep Learning
††journal: Journal of Systems and Software
1 Introduction
During the software development life cycle, various reports and documentation such as requirements specification, architecture documents, design documents, bug reports and so forth need to be generated. Unfortunately, lack of direct motivation in software teams results in inadequate, out-of-date and unqualified documentation. This in return makes program comprehension a difficult and time-consuming task for other team members. Xia et al. [1] attest to this fact by claiming that on average developers spend about 58% of their time understanding a program [1]. Source code summarization aids developers in understanding how a program works better and faster. This technique is used for describing the goal or functionality of different parts of a software program, namely methods, classes, or packages in a comment [2]. Figure 1 depicts a code snippet with its accompanied comment.
Many approaches for source code summarization have been proposed over the course of past years. For instance, exploiting knowledge of the crowd [2, 4, 5, 6, 7], information retrieval [8, 9, 10], machine learning [11, 12, 13, 14, 15], neural networks [16, 17, 18], or even tracking eye-movements of developers [19] are among the approaches for addressing this issue. The main limitation of these approaches is that they do not pay much attention to interactions among elements of a software while generating summaries. McBurney and McMillan [20] regarded the context of a program as a critical factor. They defined a method based on its invocations. However, they did not consider events in a software program. Event-driven programs contain a cycle which waits for events. When an event triggers, the program runs it. Therefore, interactions among elements are specified at run-time in these programs. An Android application is an excellent example of an event-driven program. As a result, these approaches cannot be applied to event-driven programs because of characteristics of those programs such as numerous interactions between their elements. Figure 2 demonstrates the life cycle of Android applications.
Consider a program presenting one Button and one TextBox in the main display page. A user types an arbitrary text and pushes the Button which leads to another page. The new page shows the user’s text. Figure 3 is a source code that demonstrates the behavior of this program. When a user pushes the Button, the functions sendMessage() from the MainActivity class and onCreate() from the DisplayMessageActivity class are invoked, respectively. Unlike how trivial it may seem, this is not an easy task for a Java code. Indeed, when a user pushes the Button, the Android framework calls the onClick() API related to that Button. In other words, the developer must set the onClick attribute to sendMessage for the Button in res/layout/activity_main.xml. Therefore, finding relations between elements statically is a cumbersome task.
In this paper, we try to solve the problem of generating summaries for methods of event-driven programs by extracting the interactions between their elements at run-time. To this end, we used a deep neural network to generate summaries. Additionally, to capture interactions at run-time, we utilized dynamic call graphs.
The main contributions of this work are:
We propose an approach to generate summaries for methods of event-driven programs. The proposed approach exploits deep neural networks and dynamic call graphs as the key components of the solution to produce meaningful summaries which not only address the semantics of the source code but also have a well-formed grammar. 2. 2.
Unlike existing work, we introduce a novel technique for generating summaries that concentrates on run-time execution.
The rest of the paper is organized as follows. In Section 2, we review related work. We provide background and preliminary information in Section 3. In Section 4, we describe our proposed approach. In Section 5, we evaluate the proposed approach by answering seven research questions. We assessed our deep neural network model using different evaluation metrics. Furthermore, we set up a user study to evaluate the generated summaries on real-world Android applications. We conducted an experiment with 14 real-world Android applications and 42 participants to measure the quality of our approach. The experimental results show 32.3% BLEU4 and 11.2% METEOR. Next, Section 6 presents threats to the validity of our results. Finally, we conclude this paper and present potential future work in Section 7.
2 Related Work
In this section, we review three previous types of approaches to code summarization, namely information retrieval, machine learning, and crowdsourcing. In recent years, neural networks have been used as a new path to source code summarization. As for evaluation, BLEU4 and METEOR has been recently favored over precision and recall measures. The Java programming language is the most popular language used in source code summarization techniques. We present an overview of these approaches in the following.
2.1 Code Summarization via Information Retrieval
Sridhara et al. [8], proposed an algorithm for automatic description of Java methods. They preprocessed Java methods using the Software Word Usage Model (SWUM). SWUM is a technique for displaying methods of a program in the form of noun, verb, and adverb groups. McBurney et al. [20], introduced an approach for the automatic generation of documents for Java methods based on the context. In summary, this approach uses PageRank [22] to find the most important methods for the given context. SWUM helps determine what these most important methods do. Finally, natural language generation system generates a human-readable summary. Rodeghero et al. [19] proposed a method for choosing essential words of a code segment. They analyzed developers’ eye-movements and their focused attention while writing summaries for a method, and then used their findings to weight the words subsequently. Antoniol et al. [9] proposed an approach for improving trace-ability links between a code segment and its document. They utilized the unigram language model and Vector Space Model (VSM). Moreno et al. [10, 23] presented an approach for summarizing Java classes. They primarily focused on each class content and tasks but did not heed the connection between classes. They first found a class’s stereotypes and its methods. Then classified stereotypes into 13 groups. Afterward, using natural language rules, they generated a summary for each class based on a specific format.
2.2 Code Summarization via Machine Learning
McBurney et al. [11], presented a code summarization method using hierarchical topic modeling. The most abstract description of program’s tasks is given in the highest level of the hierarchy in a Hierarchical Document Topic Model (HDTM) algorithm. As one goes down the hierarchy, descriptions become more precise and clear. Authors first formed the call graph with methods as nodes and caller-callee among methods as edges of the graph. Then, HDTM was performed on the graph. Haiduc et al. [12], considered code as text and exploited previous text summarization methods for summarizing code snippets as well. They used the VSM and Latent Semantic Indexing (LSI) [24] in their work. Eddy et al. [15], proposed a code summarization algorithm using hierarchical topic modeling. In fact, this study is a replica of the Haiduc et al. work [12], with the distinction that they utilized HPAM instead of VSM and LSI. Programming tools help developers hide or reveal some parts of their code. This feature is known as code folding. Fowkes et al. [14], introduced an approach for code summarization using code folding and an Abstract Syntax Trees (ASTs).
Recently, researchers have been using neural networks as a method for generating summaries. Iyer et al. [17], proposed CODE-NN, a neural attention model for summarizing source code. They used LSTM networks for generating descriptions of C# code snippets and SQL queries. Allamanis et al. [16], introduced a novel attention mechanism using Convolutional Neural Networks (CNN) [25]. Their goal was to generate the name of a method from its code. Vaswani et al. [26], were the first to introduce the Transformer. Their model exploits the multi-head attention mechanism while removing recurrence and convolutions from the network. The Transformer is parallelizable and requires significantly less training time. Hu et al. [18], produced descriptions for Java methods using a sequence-to-sequence model. To improve performance, they exploited the structured form of code and introduced a novel method named SBT to parse ASTs. Allamanis et al. [27], represented programs with graphs to exploit the syntactic and semantic structure of source code using Gated Graph Neural Networks (GGNN). They evaluated their models based on two tasks of predicting variable names (VarNaming) and predicting variable misuse (VarMisuse). Wan et al. [28] exploited ASTs and sequential data of code snippets in a reinforcement learning framework. The next word is predicted using the actor network and the critical component of the network evaluates the reward value. CODE2SEQ, proposed by Alon et al. [29], uses syntactic structure of source code and represents each code snippet as a set of paths in an AST. Using attention mechanism of a sequence-to-sequence model, it selects relevant paths in the decoder. LeClair et al. [30] also used a sequence-based model, but they treated each input data source separately. This helped the model learn the structure of code independent of other textual information in the code snippet. Haque et al. [31] claim the information inside a subroutine is not sufficient for summarizing it. Therefore, they proposed a sequence-based model using the attention mechanism to predict the context of subroutines.
2.3 Code Summarization via CrowdSourcing
Badihi et al. [2], proposed a code summarization model for Java language using the power of crowdsourcing. They built a web-based system for developers and encouraged them to write summaries for various methods using gamification techniques. Then they collected these summaries and analyzed them to identify the most significant parts of methods from developers’ point of view. Nazar et al. [4], presented a code-by-code summarization approach using crowd source knowledge and supervised learning. First, they extracted code snippets from the most frequently asked questions (FAQ) section of Integrated Development Environment (IDE). Then they used four developers for labeling these code segments. They extracted 21 features. Then, they utilized Support Vector Machine (SVM) and Naïve Bayes algorithms to classify results, and finally generated summaries using these two supervised learning algorithms. Guerrouj et al. [5], used the context available in posts of Stack Overflow Q&A website in order to generate code summaries. Using an Island parser, they extracted identifiers from discussions about an element. Rahman et al. [6], proposed an approach to generate summaries to recommend to developers through analyzing discussions and comments of users on Stack Overflow posts. Wong et al. [7], introduced a method for automatic documentation of codes using Github and clone detection techniques.
As reviewed above, there are many approaches to code summarization. However, they have their limitations. One major defect of existing solutions is that to the best of our knowledge they do not consider dynamic interactions among elements of a software program. As interactions are triggered at run-time, they cannot be inferred statically. Therefore, to exploit this information to generate better summaries for code snippets, one needs to investigate these codes at run-time. In this work, we utilize these valuable interactions to generate more useful summaries.
Another frequent shortcoming of the existing approaches is related to their evaluations. Most of the current models are evaluated using precision and recall metrics. As shown in Section 5, these metrics lack the validity for evaluating machine translations tasks. That is why we have used BLEU and METEOR to better evaluate the performance of our proposed model.
Moreover, most of these approaches are template-based, that is they generate summaries based on predefined rules. Therefore, these summaries neglect the essential semantics of a task/code, which renders them not very useful for end users in real-world cases. In this work, we have used deep learning methods to overcome this issue and generate more meaningful summaries.
3 Background and Terminology
In this section, we provide preliminary information on the notation and methods we have used in our proposed approach. Recently, researchers has turned to applying deep learning methods to various fields of software engineering such as commit message generation [32, 33], intention mining [34], and code search [35]. Among these fields, is code summarization via deep learning [18], which has attained promising results so far. The deep neural network is used as a pre-built model to generate final summaries. The notation of our deep model is as follows333We followed the notation described at the deeplearning.ai video tutorial [36].:
- •
: set of source codes written in Java programming languages.
- •
: th source code in the set of .
- •
: th token in the above sequence.
- •
: is the length of the sequence .
- •
: set of comments written in natural language.
- •
: th comment in the set of .
- •
: th term in the above sequence.
3.1 Sequence-to-sequence Model
Recurrent Neural Network (RNN) is suitable for sequences of inputs [37]. RNN generates sequence from input sequence . Recently, the sequence-to-sequence model has yielded valuable results in the neural machine translation [38]. In the traditional sequence-to-sequence model [39], the decoder uses the last hidden state of the encoder as an input for generating the output sequence. The decoder generates summaries in a deep neural network. We aim at finding the sequence from the sequence , given that it applies in equation (1):
[TABLE]
Suppose there are layers, and and are the forward and backward states of the RNN for the term . Therefore, is computed as . We defined a context matrix denoted as . is the th column of the context matrix and is called a context vector. indicates how much attention the output term pays to the terms of input sequence . In other words, each of the members of to what extent contributes to generating the output . States of the RNN of the decoder element are denoted as . represents how much should of the decoder element (the th term of the summary) pay attention to of the decoder element (the th term of the code).
[TABLE]
[TABLE]
3.2 PageRank Algorithm
The PageRank algorithm was developed by Page and Brin [22] to sort webpages based on their popularity in Google’s search engine. McBurney et al. [20] used the same concept for measuring the importance of different methods.
Damping factor, denoted as , indicates how likely is it for a specific node to be visited through time. It is conventional to set [40]. The PageRank algorithm assigns a rank to each node. These ranks determine the importance of nodes in the corresponding graph. Ranks are calculated using equation (4) [22] which shows the rank of :
[TABLE]
In equation (4), is the number of outgoing edges from and is the set of nodes which have outgoing edges to .
4 Proposed Approach
In this section, we present our approach to generate summaries for methods of event-driven programs. We consider the sendMessage() method described in Section 1 as a running example. This running example is used throughout this paper to show our process of generating summaries.
As shown in Figure 4, our proposed approach consists of five steps. In the first step, we used a dataset of comment/code pairs from the Github repository. Then, applied a few preprocessing tasks on the data such as deleting blank lines, removing code snippets without summaries, and refining code-words based on the Java naming convention.
In the second step, we built a deep neural network for the comment/code pairs. This model was used to generate the code summaries. The architecture of our proposed deep neural network consists of three components, namely encoder, decoder, and attention mechanism. This kind of network is mainly used for sequential data in summarization and machine translation tasks. We include the encoder element for encoding source code and the decoder element for decoding the encoded output to summaries. Moreover, we exploit the attention layer to put more emphasis on more important parts of the data as is frequently applied in the NLP field, specifically for machine translation and summarization tasks.
In the third step, we constructed a dynamic call graph of Android applications which were selected to generate summaries for. In the fourth step, the PageRank algorithm was applied to the graph mentioned above to sort the methods of an application and better understand the context of a given method.
We use PageRank to identify the most important information for generating comments. Statically finding relations among methods is not a trivial task. However, during run-time, each block (callable code snippets or methods) is identifiable through using dynamic call graphs. By analyzing the dynamic flow of event-driven programs, through using dynamic call graphs and then ranking them using the PageRank, we can capture long-range dependencies inside the source code and between code elements. Consequently, we can exploit the context and find the higher purpose behind a code snippet more accurately compared to when we just consider the method.
In the end, using our deep neural network of step two and outputs of the PageRank algorithm, we generated human-readable summaries for the selected methods of applications. In the following, we will elaborate more on the steps of our approach.
4.1 Step1: Preprocess Data
In this part, we elucidate the first step of our approach. First, we performed preprocessing steps on comment/code pairs extracted from Github. Hu et al. [18], extracted more than 500 thousand comment/code pairs from Github and applied a few heuristic methods to extract 69708 pairs from this data. Although the 500 thousand pairs are available online, the preprocessed data are not accessible. As a result, we explored their raw data as a starting point. These source codes are written in Java, and Java programs follow specific naming conventions. The main preprocess steps used in this study are:
First, the blank lines ($\mathrm{n}) and tabular characters (\\mathrm{t}$) were removed and replaced by space character. 2. 2.
Afterward, we identified and tokenized words with all capital letters that came before words that had capital first-letters. For instance, The following regular expression does the above task:
//SQLDatabase --> SQL Database
//Regular Expression: [A-Z]+(?=[A-Z][a-z]) 3. 3.
Furthermore, words with capital first-letters or all lowercase letters are extracted as well. The corresponding regular expression comes as follows:
//Regular Expression: [A-Z]?[a-z]+ 4. 4.
Finally, we extracted words that all their letters were capital. We also kept special tokens (e.g., curly brackets and parentheses) in the final preprocessed data.
Figure 6(a) demonstrates the output of our running example after the first step.
4.2 Step2: Train a Deep Neural Network
Our deep neural network tries to translate to for every in a comment/code pair. In the following, we describe each component of the architecture in detail.
4.2.1 Encoder, Decoder, and Attention Mechanism
There have been many pieces of research on the semantic representation of terms in a vector format with real numbers, namely Continuous Bag of Words (CBOW) [41], SKIP-GRAM [42, 43, 44], and Global Vectors (GLOVE) [45]. The benefit of this approach is that as much as the terms are semantically similar, their vectors are similar as well. Therefore, we used one embedding layer in the encoder and decoder components, for which the weights are tuned during the deep neural network learning phase. However, to reduce the learning time and to obtain more accurate weights, we used the pre-built model introduced in the GloVe website [46].
Dropout is a simple solution to avoid overfitting [47]. Dropout randomly omits neural network units. We used in the neural network layers similar to Luong et al. research [48].
Vanishing gradient is a problem in simple RNNs [49]. It happens when a gradient is very small. This hinders changing values of weights and stops the neural network’s training. To solve this issue, various methods such as Gated Recurrent Unit (GRU) [50] and Long Short-Term Memory (LSTM) [51] have been proposed. We applied the latter in this work similar to Luong et al. study [48].
Unidirectional RNNs use only past data. However, knowing about the future helps as well. Bidirectional RNNs (BRNN) process sequences on both directions and two different layers [52]. Graves and Schmidhuber [53], combined bidirectional recurrent neural networks with LSTM. Moreover, one can stack layers of neural networks to build a deep network [54]. We have used a stack of BRNNs on top of the embedding layer in the encoder element.
When generating summaries in the decoder, one approach is to test all possible cases, which is definitely costly, with the computational complexity of ( denotes the vocabularies’ set size). Another approach is to use a greedy search algorithm. These algorithms select a term that maximizes the value of in each step. However, if one utilizes a greedy search algorithm, she cannot change the term in the future. Furthermore, greedy search algorithms do not guarantee to produce good results since the co-occurrence probability of some terms is higher than others.
A better solution is to exploit the beam search algorithm [55]. In the beam search algorithm, the top probabilities, are recorded partially for every step. denotes as the width of the beam. This heuristic algorithm does not necessarily optimize results; however, its computational complexity equals to which is immensely faster than computing all cases. It is worth mentioning that if , this heuristic algorithm acts like a greedy one. As increases, the quality of generated summaries improves, however, the learning time rises as well.
We have used the attention mechanism introduced by Bahdanau et al. [56]. The next step is to train a model on the preprocessed data, which will be used to generate summaries in the final step.
Implementation details
for the deep neural network are discussed in the following. The operational environment for the deep neural network was the Ubuntu16.04. Our hardware included 40 processing cores and 64GB RAM. We used Tensorflow library to build the neural network model [57] and Pandas library to preprocess the data [58]. Embedding layers included vectors with dimensions of 300. If the input word already exists in the pre-built model, its weights from the model are used. Otherwise, the corresponding vector to the input word is initialized with uniformly distributed real numbers between -1 and 1. The pre-built model contains about 2.2 million words.
The maximum length of summaries and codes are set to 35 and 100 tokens, respectively. In cases where the length of the input code is less than 100, remaining elements of the vector are replaced with zeros. Moreover, four words are pre-allocated namely , , , and . refers to an unknown word, which means the word does not exist in the deep neural network dictionary. Furthermore, and represent the start and end of each sentence, respectively.
In the learning process of deep neural networks, the goal is to minimize the loss function. We have used cross-entropy loss function in this study. The set of generated summaries is represented by , in which is the number of generated summaries and denotes as the th generated summary. Therefore, the cross-entropy loss function can be calculated using equation (5):
[TABLE]
Exploding gradient is one of the problems with long sequences. To prevent this, given that the gradient’s size is more than a specific threshold such as , one should decrease its value using the approach introduced by Pascanu et al. [59]. In other words, its value should be updated using equation (6):
[TABLE]
Adam is used for parameters’ optimization [60]. As suggested by Kingma and Ba study [60], we used , , and as default input values for the Adam algorithm.
Overfitting is another problem that may occur while applying machine learning techniques. It happens when a technique matches too closely with a specific set of data. Therefore, rendering the aforesaid technique unfits for predicting other data sets reliably. To avoid overfitting, we randomly split the deep model’s inputs into three categories, namely train (), valid (), and test () sets.
We generated checkpoints for every epochs during the training phase. Then, the best model for the validation set was selected (in terms of the BLEU score) to evaluate on the final test set.
4.3 Step3: Create a Dynamic Call Graph
Event-driven programs depend on the occurrence of events at run-time. Consider the running example illustrated in Section 1. The method sendMessage() is invoked every time a user clicks the Button. However, it is not a trivial task to find out why pushing the button is followed by running the sendMessage() method. In this step, we tackle this problem by leveraging the power of dynamic call graphs. Yuan et al. [61], proposed an approach to generate a dynamic call graph for Android applications. Authors created a tool named Rundroid to create these graphs. This tool not only considers invocations between methods in static time but also recognizes messages transferred between an application and the Android framework at run-time. However, the Rundroid lacks automation, and users have to manually run and test programs to generate call graphs. Therefore, to automatize this task through generating random test with desired time intervals, we used a tool developed by Google, known as Monkey [62]. Figure 5 depicts a part of the dynamic call graph generated for the running example.
4.4 Step4: Apply PageRank
We applied the PageRank algorithm to the dynamic call graph generated in the previous step. Consider the dynamic call graph of Figure 5. This graph consists of 13 nodes denoted as and 12 edges. Table 1 shows normalized results of the PageRank algorithm applied to the running example.
4.5 Step5: Generate Summaries
In this step, final summaries are generated from the pre-trained model and ranks of nodes in the dynamic call graph produced in the second and fourth steps, respectively.
We first extract methods of the selected application. SupposesendMessage() is one of these methods. First, we applied preprocessing tasks to the sendMessage() method. Figure 6(a) illustrates the output of this step. Then, by using the pre-trained model from the second step, a summary was produced for the preprocessed running example (Figure 6(b)). From the nodes in the dynamic call graph that have outgoing edges to the selected node (method), we selected the node with the highest rank. In case of a tie, we randomly chose one of them. We call this node a block. If the block has a corresponding method in the source code of the program, we use that source code as an input for the pre-trained model. Otherwise, the block is related to the Android framework. In this case, we create a dummy method by adding a signature to the block. For instance, in Figure 5, there is only one node called onClick(). Since the onClick() is related to the Android framework, we created a dummy method for the onClick() element and passed it to the pre-trained model (Figure 6(c)). As an example, we add “” as a dummy method for onClick() After adding the output of the latter step, the summary for the given method was generated (Figure 6(d)).
Note that we do not take the Android framework’s implementation as the dummy method because of following reasons. First, all the implementations are not open-sourced. Second, implementations are not necessarily purely in Java. Third, it is possible to have multiple implementations for a given block in the Android framework, but finding the appropriate implementation can be very complicated and time-consuming. Therefore, we simply add a signature and build a dummy method. Signature addition is employed to change the format of inputs of our neural network to be like a method.
5 Evaluations
In this section, we present the results of both qualitative and quantitative evaluation of our proposed approach. First, the pre-trained deep neural network was assessed using BLEU4 and METEOR metrics. Then, using an empirical study, we examined the usefulness of our approach in aiding developers understand the objective of methods. This qualitative assessment was performed on 14 Android applications and 42 methods, using three highly skilled experts for generating reference summaries and 42 Android developers for evaluating generated summaries.
5.1 Evaluations of Deep Neural Network
We first present Research Questions (RQs), evaluation metrics and the evaluation process. Afterward, we discuss results of our evaluations and analyze them subsequently.
5.1.1 Research Questions
To evaluate our deep neural network, we answer the following four questions:
RQ1:
How much the proposed model has been successful in learning comments/codes sets?
RQ2:
What is the precision of the generated summaries by the proposed model?
RQ3:
What proportion of reference summaries were retrieved as the final generated summaries?
RQ4:
How well has the proposed deep neural network performed compared to the other baseline deep neural networks?
5.1.2 Evaluation Metrics
Here, we investigate the evaluation metrics used in this study, namely BiLingual Evaluation Understudy (BLEU) and Metric for Evaluation of Translation with Explicit ORdering (METEOR).
BLEU
is used for automated evaluation of machine translation algorithms [63]. Since code summarization is a type of translation of code snippets to human-readable summaries, BLEU can be used for evaluating abstractive code summarization. BLUE refines precision by valuing each term exactly for as many times as it has appeared in the reference translations. considers every term separately. has a similar concept as , except that it computes the precision of bigrams.
We compute the precision for different values of in n-grams. The final score is calculated using equation (7). In this equation, is a penalty for short summaries, which are identified using equation (8). In equation (8), and are the lengths of reference and generated summaries, respectively.
[TABLE]
[TABLE]
METEOR
was proposed to mitigate BLEU’s shortcomings [64]. METEOR focuses mainly on recall, unlike BLEU which pays more attention to precision. METEOR is based on the term-to-term mapping of the generated summary with its corresponding reference summary.
METEOR is calculated using equation (9). In equation (9), is the refined recall, is the refined precision and is the penalty (which is issued for having only unigrams).
[TABLE]
In equation (10), is the number of common chunks between the generated and reference summaries. In cases that the reference and generated summaries are identical, there is only one chunk. On the other hand, if there exists only uni-grams, number of chunks equals to the number of term-to-term mappings denoted as .
[TABLE]
5.1.3 Evaluations Setup
Our deep neural network uses Github data as an input resource. Some of the pairs did not have enough comment length. Therefore, we removed pairs with comments shorter than four words. Furthermore, some of the comments are too long to be used for training deep neural networks. Ying et al. [65], claimed that most of the summaries are less than three sentences. Moreno et al. [10], stipulated that summaries with less than 20 terms are suitable for comment generation. Consequently, comments with more than 35 words were removed from the pairs. Similarly, source codes with more than 100 tokens were removed. Some of the comments neither were written in English nor were produced by a human. We removed these automatically generated comments as well. Finally, by applying a few minor heuristics (e.g., converting tokens to lowercase), we selected 71257 pairs of comment/code. Table 2 describes statistical information about these pairs.
5.1.4 Evaluations Results
To answer the RQ1, we used perplexity metric [66]. Perplexity estimates how well a deep neural network can perform on a training dataset. It is calculated using , in which is the cross-entropy loss function. Table 3 shows the best perplexity values in the 10 last epochs. Moreover, Figure 7 presents cross-entropy loss function based on different epochs.
To answer the RQ2, we used the BLEU4 metric. The maximum number of terms for generated summaries is , which is considered short. Therefore, based on the suggestion of Papineni et al. [63], we used the maximum four-grams in calculating the value of this metric. Table 3 illustrates BLEU4 results based on different parameters. We set the number of epochs, batch size, and beam width in all cases to 200, 512, and 50, respectively. We achieved the best BLEU4 score, , using a network of two layers, employing both pre-trained embedding layer and SBT.
To answer the RQ3, we used METEOR metric. We achieved the best METEOR score, , using a network with the same properties mentioned above. Table 3 presents the values of discussed metrics for different parameters.
To answer the RQ4, we used six code summarization techniques proposed by Haque et al. [31], LeClair et al. [30], Alon et al. [29], Allamanis et al. [27], Vaswani et al. [26], and Iyer et al. [17] as our baselines. We selected these approaches because they are the state-of-the-art in the field of code summarization ranging from traditional sequence-based neural networks such as the RNN to the Transformer. Furthermore, they have been published in the leading venues of both SE and NLP. We used the publicly available implementation provided by Haque et al. [31]. Table 4 presents results of the proposed deep neural network’s performance in compared with the baselines.
5.1.5 Quantitative Analysis of Results
According to Table 3, cross-entropy loss function has decreased per word in perplexity. This indicates that the proposed model has efficiently performed on the training dataset. Furthermore, according to Figure 7, the model has not progressed significantly after epoch number 170. Therefore, we believe increasing the epoch number to more than does not improve the performance of the model very much. It is worth mentioning that our proposed model does not necessarily compete with Hu et al. [18]. In fact, our model can complement their approach. To demonstrate this, we applied SBT to our model and obtained higher scores in terms of BLEU4 (31.4) comparing to the previous result without SBT (30.9). Table 4 compares the proposed neural network with the state-of-the-art. Our model significantly improved BLEU4 comparing to those approaches. In particular, comparing to Haque et al. [31], our model improved BLEU4 from to . However, except from Vaswani et al. [26], other approaches have better METEOR than our model ( compared to ).
5.2 Evaluations of Generated Summaries
Here, we evaluate the usefulness of our model in aiding Android applications’ comprehension using an empirical study.
5.2.1 Research Questions
To evaluate generated summaries, we investigate the following questions:
RQ1
Considering the reference summaries, how accurate have been the generated summaries?
RQ2
How well has the proposed model performed compared to other approaches?
RQ3
How good is the quality of the generated summaries?
5.2.2 Evaluations Setup
We used a dataset of 14 open-source Android applications with different sizes and features from previous studies [67, 68] to evaluate generated summaries. Table 5 presents some information about these applications.
First, we randomly selected three methods from each application and two experts who are not the authors of this paper, worked with the 14 applications and investigated the related parts of the source code to know more about the context of each selected method. Then, wrote summaries for the 42 methods independently. After that, they compared their comments in a session and chose a common comment for each method. In case of disagreement, they asked a third expert for his opinion and they all came to an agreement for the comments of these methods together. It is worth mentioning that the two experts’ average Android programming experience was 5.5 years and the third expert was a senior Android developer with 8 years of experience. Also, there was about 18% of disagreement between the first two experts, which all were resolved with the help of the third expert. Afterward, using the proposed model and the baseline approaches, we generated candidate summaries for each method. Note that our baselines are not specifically designed for event-driven programs, so the comparison may not be completely fair. However, these are the closest approaches to our problem that we are aware of so far. We designed an online questionnaire to qualitatively assess the performance of these models. Each question in the questionnaire contains (1) a method, (2) its reference summary, and (3) a generated summary by one of the baselines. Figure 8 presents a question from the questionnaire. We asked the participants to score the generated summary based on the method itself and the reference summary provided to them. The method along with its reference summary help the participants obtain a better understanding of each method and its context. Note that by knowing what exactly each method does, participants were stricter in evaluating the generated summaries. This helped us remove the chance of careless or wrong scoring. Note that the generated summaries were presented in random orders, to remove any bias from the experiment. That is participants did not know which comment was written by which approach. As both the number of methods and baselines in our study are high, we could not evaluate each method with all the six baselines plus our approach using all participants. This would require a very long questionnaire which subsequently would result in a decline in the accuracy of evaluations. Therefore, we randomly assigned the questions to them and made sure to cover each of the 42 methods at least by 7 participants for each baseline.
The 42 participants were majored in computer science, with an average of 7.6 years of general programming experience, 5.8 years of Java programming experience, and 4.3 years of Android programming experience. It took each participant on average 73 minutes to finish the questionnaire. We analyzed the generated summaries from two perspectives; their informativeness and naturalness [17];
Informativeness:
What proportion of the important parts of the code does the generated summary cover.
Naturalness:
How smooth and human-readable is the generated summary. Naturalness also takes into account the syntax of each sentence.
Participants scored the generated summaries for each method based on a 1-5 star scaling. Description of each score is as follows:
- •
Informativeness:
The output does not describe the method’s functionality to any extent. 2. 2.
Only insignificant parts of the code are covered in the summary. 3. 3.
Some important parts of the code are covered in the summary. 4. 4.
Most of the important parts are covered in the summary. 5. 5.
All significant and essential parts of the code are well summarized.
- •
Naturalness:
The output is not readable by humans at all. 2. 2.
The output is barely understandable with many errors. 3. 3.
The output is understandable but has noticeable syntax errors. 4. 4.
The output is understandable but has negligible syntactical errors. 5. 5.
The output is completely understandable with no syntactical errors.
5.2.3 Evaluations Results
To answer the RQ1, we calculated BLEU4 and METEOR metrics for each method. We compared our new results to the Iyer et al. [17], Vaswani et al. [26], Allamanis et al. [27], Alon et al. [29], LeClair et al. [30], and Haque et al. [31] approaches to answer the RQ2. Tables 6 presents the comparison results of these approaches.
To answer the RQ3, Figure 9 and Figure 10 present the distribution of informativeness and naturalness variables. The mean scores for informativeness and naturalness of our proposed approach for all participants are and . The results indicate that if one only considers rating 5 (perfect summaries) and rating 4 (good enough summaries with negligible mistakes) as desirable outcomes of a summarization method, our approach outperforms all the others regarding both informativeness and naturalness.
5.2.4 Quantitative Analysis of Results
According to Table 6, average BLEU4 and METEOR of the proposed approach are and , respectively. To investigate whether there is a significant difference between the results of our proposed approach and other existing approaches, we followed the guideline and the tool provided by Herbold [69]. We conducted a statistical analysis for 7 approaches with 42 samples. We used the non-parametric Friedman test to investigate difference between the median values of the approaches [70]. We employed the post-hoc Nemenyi test to determine which aforementioned differences are statistically significant [71]. The Nemenyi test used critical distance (CD) to evaluate which one is significant. If the difference is greater than CD, then the two approaches are statistically significant different.
Figure 11 depicts the results of tests for BLEU4. The Friedman test rejects the null hypothesis that there is no difference between median values of the approaches. Consequently, we accept the alternative hypothesis that there is a difference between the approaches. Based on the Figure 11 and the post-hoc Nemenyi test, we cannot say that there are significant differences within the following approahces: (the proposed approach, Allamanis et al. [27], Haque et al. [31] and Iyer et al. [17]); (Allamanis et al. [27], Haque et al. [31], Iyer et al. [17], LeClair et al. [30], and Alon et al. [29]); (LeClair et al. [30], Alon et al. [29], and Vaswani et al. [26]). All of the other differences are statistically significant.
Figure 12 shows the results of tests for METEOR. The Friedman test rejects the null hypothesis that there is no difference between median values of the approaches. Consequently, we accept the alternative hypothesis that there is a difference between the approaches. Based on the Figure 12 and the post-hoc Nemenyi test, we cannot say there are significant differences within the following approaches: (Allamanis et al. [27], Iyer et al. [17], Alon et al. [29], Haque et al. [31], and LeClair et al. [30]); (Iyer et al. [17], Alon et al.[29], Haque et al. [31], LeClair [30], and the proposed approach); (the proposed approach and Vaswani et al. [26]). All of the other differences are statistically significant.
Sample means for informativeness and naturalness of the proposed approach are and , respectively. We applied t-distribution to estimate mean and standard deviation of informativeness and naturalness results. Using equation (11), and the confidence level of 95% (),
[TABLE]
We can compute equation (12),
[TABLE]
Therefore, we can conclude that
[TABLE]
Equation (13) shows that with the confidence level of 95%, by increasing the number of participants, in the worst case the mean scores for informativeness and naturalness will be greater than and , respectively.
5.2.5 Qualitative Analysis of Results
According to Figure 9, Figure 10 and our definition of informativeness and naturalness metrics, we conclude as follows:
Participants in % of cases reported that generated summaries cover all essential parts of the codes. 2. 2.
Participants in % of cases reported that in the worst case, generated summaries cover many salient features of the code. 3. 3.
Participants only in % of cases reported that generated summaries are not related to the codes or document just trivial code snippets. 4. 4.
Participants in % of cases reported that generated summaries have neglected a few necessary parts of the codes. 5. 5.
Participants in % of cases reported that generated summaries are human-readable and do not have any syntactical error. 6. 6.
Participants in % of cases reported that in the worst case, the generated summaries have minor syntactical errors. 7. 7.
Participants in % of cases reported that generated summaries are human-readable but have major syntactical errors. 8. 8.
Finally, participants only in % of cases reported that generated summaries are barely human-readable.
5.2.6 Threats to Validity of the Empirical Study
In this section we discuss the threats to validity of our empirical study. We evaluated the quality of final summaries extracted from 14 Android applications and 42 methods. It is reasonable that the quality of extracted methods affects results. To reduce this threat, we sampled randomly from extracted methods. Moreover, 42 individuals performed our qualitative assessment. Therefore, the outcome of this section depends on characteristics of the individuals taking the questionnaire, such as their mood, the time it took them to fill the questionnaire, and other natural factors. To reduce this threat, we tried to have a large number of participants. Note that for a large-scale evaluation, we need a dataset of Android methods, their comments and the APK file as the requirement for the Rundroid tool. However, to the best of our knowledge, available datasets only contain Java methods, and unfortunately, we were unable to collect such a large dataset for Android methods. It is worth mentioning that one can collect a dataset for a large-scale study; however, this is not a trivial task. But we plan to address this issue in future work. Moreover, we investigated whether there is a significant difference between the results of our proposed approach and other existing approaches using the Friedman and post-hoc Nemenyi test. We have reported the results in Section 5.2.4. The results indicate that there is a significant difference between our approach and other baselines regarding performance based on BLEU and METEOR. Also, in the same section, we proved that with the confidence level of 95%, by increasing the number of participants, in the worst case the mean scores for informativeness and naturalness of our approach will be greater than 3.13 and 4.09 (scale of 5 stars), respectively. We believe all these can attest to the good performance of our approach in a large-scale study.
As mentioned above, 42 individuals performed our qualitative assessment of the generated summaries for the selected real-world Android applications’ methods. Because the number of participants is limited, we cannot extend our results to the rest of the developers’ community. To reduce this threat, we have tried to select a well-distributed sample of developers to assist in the evaluation phase. We also investigated whether there is a significant difference between our results and other existing approaches’ results. We performed the Friedman and post-hoc Nemenyi test and reported the results.
5.3 Discussion
Here, we discuss the limitations of our proposed approach. The quality of generated comments would be restricted when a target method did not represent the characteristics of event-driven programs. Helper functions (e.g., math functions), utility functions (e.g., logging) and interfaces are among these methods. Figure 13 demonstrates a utility function which calculates the time elapsed from the start. This function is used in various methods to compute the elapsed time. Indeed, there is no meaningful context for this method. Consequently, the second generated comment does not relate to the method’s functionality or context. Our proposed approach fail to generate high quality comments for this method. One way to handle this situation is to apply threshold analysis. For example, if the block rank is less than given threshold, it means that the method does not have meaningful context and one could simply ignore that block. However, in practice, determining the threshold value automatically is not a trivial task, and can be addressed in future work.
6 Threats to Validity
In this section, we review threats to the validity of our research findings, categorizing possible threats into four groups of internal, external, construct and dependability ones [72].
6.1 Internal Validity
Internal validity asks whether the variables used in the proposed approach affect the outcomes and whether they are the only influential factors in the study [72].
The dynamic call graph in Rundroid is constructed based on tests that are run on Android applications. These tests are run manually in the original version of the study [61]. Therefore, how the tests are run and their runtime impact results. To reduce this threat, authors generated 5000 random events using the Monkey tool to minimize human intervention in the tests.
We believe the quality of code snippets affects the quality of generated summaries as well. Logically training the models on high-quality source codes can help the model generate better summaries. However, not all real-life projects benefit from high-quality source code. Moreover, quality is a subjective concept and can be interpreted differently in various cases. Therefore, it is not a trivial task to collect a high-quality dataset of code snippets.
In case of a tie in Section 4.5, we randomly choose a node. We did not investigate the effects of this choice since they were rare cases that a tie happened. So we believe it was not necessary. But we acknowledge that different decisions in these cases can provide different outcome.
6.2 External Validity
External validity includes how expandable are results of a study, can they be used in other contexts, and do cause and effect relationships hold with other conditions as well [72].
In this study, we have used Rundroid to build call graphs. Rundroid is developed for generating call graphs in the Android framework. Therefore, it is not suitable for usage in other event-driven programs. To reduce this threat, we plan to investigate and use other tools in near future. In the first and second phase of the proposed approach, we have used deep neural networks. The deep neural network architecture can be employed in other contexts, namely other natural language processing fields.
Moreover, in the evaluation phase, we have only used the Android framework’s examples as event-driven programs. Thus, it is not guaranteed that our approach will perform the same on other event-driven programs such as web-based programs. In future, we plan to address this threat by evaluating our model on other event-driven platforms.
6.3 Construct Validity
Construct validity includes theoretical concepts and discussions of the experiment and the use of appropriate evaluation metrics [72].
Theoretical concepts used in this work, have been already evaluated and proved by the academic society. The proposed approach is a combination of different methods in a new context. We have evaluated the generated summaries not only by valid and reliable quantitative metrics but also through human qualitative judgment. Results indicate that the employed approach has been successful in generating summaries.
6.4 Dependability
Dependability validity answers to questions such as whether the findings are compatible, and whether the experiment and its results are reproducible [72].
Compatibility
We evaluated the final generated summaries quantitatively and qualitatively. As shown in previous sections, their outcomes are compatible.
Reproducibility
We have used deep neural networks (which are inherently based on probability) to generate the summaries of event-driven programs’ methods. To reduce this threat, we have set the number of epochs to 200. This is because cross-entropy loss function is almost stable after the 170th epoch and did not decrease in our experiments. Also, the preprocessed input data is available online for other researchers at https://github.com/ase-sharif/deep-code-document-pairs. It is worth mentioning that we have tried our best to minimize human intervention in all steps to make results more independent and reliable.
7 Conclusions and Future Work
Code summarization is a useful technique for helping developers comprehend and maintain software programs more efficiently. There are different approaches for summarizing code segments, namely utilizing information retrieval, machine learning, and crowdsourcing knowledge. However, existing approaches do not take into account the interactions between different parts of the code while the program is running. Through exploiting deep neural networks and dynamic generation of the call graph, we tried to overcome the deficiencies of previous work and generate summaries that are more suitable. Results of the proposed approach were evaluated both qualitatively and quantitatively. We used BLEU4, METEOR, precision and recall metrics for quantitative assessment and an online questionnaire for assessing the informativeness and naturalness of generated summaries from developers’ perspectives as a means of qualitative assessment. Our results indicate that the proposed approach outperforms state-of-the-art techniques.
As for future work, one of the conventional solutions while using the sequence-to-sequence models is to employ a convolutional layer in the encoding component [73]. Adding this layer helps the deep neural network attain additional information about the words around each word. The use of a convolutional layer has improved results in machine translation studies. We intend to exploit this layer in future and analyze its effect on the proposed model.
Moreover, the Android framework is only one example of event-driven applications. In the future, we are going to examine other frameworks to evaluate the proposed approach and expand our findings.
Acknowledgment
The authors would like to thank the participants who assessed the quality of our proposed approach.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] X. Xia, L. Bao, D. Lo, Z. Xing, A. E. Hassan, S. Li, Measuring program comprehension: A large-scale field study with professionals, IEEE Transactions on Software Engineering 44 (10) (2018) 951–976. doi:10.1109/tse.2017.2734091 . · doi ↗
- 2[2] S. Badihi, A. Heydarnoori, Crowd Summarizer: Automated generation of code summaries for Java programs through crowdsourcing, IEEE Software 34 (2) (2017) 71–80. doi:10.1109/ms.2017.45 . · doi ↗
- 3[3] Android play location, https://github.com/googlesamples/android-play-location/blob/master/Location Address/java/app/src/main/java/com/google/android/gms/location/sample/locationaddress/Main Activity.java , accessed: 2018-10-14.
- 4[4] N. Nazar, H. Jiang, G. Gao, T. Zhang, X. Li, Z. Ren, Source code fragment summarization with small-scale crowdsourcing based features, Frontiers of Computer Science 10 (3) (2016) 504–517. doi:10.1007/s 11704-015-4409-2 . · doi ↗
- 5[5] L. Guerrouj, D. Bourque, P. C. Rigby, Leveraging informal documentation to summarize classes and methods in context, in: Proceedings of the 37th IEEE/ACM International Conference on Software Engineering, IEEE, 2015, pp. 639–642. doi:10.1109/icse.2015.212 . · doi ↗
- 6[6] M. M. Rahman, C. K. Roy, I. Keivanloo, Recommending insightful comments for source code using crowdsourced knowledge, in: Proceedings of the 15th IEEE International Working Conference on Source Code Analysis and Manipulation, IEEE, 2015, pp. 81–90. doi:10.1109/scam.2015.7335404 . · doi ↗
- 7[7] E. Wong, T. Liu, L. Tan, Clo Com: Mining existing source code for automatic comment generation, in: Proceedings of the 22nd IEEE International Conference on Software Analysis, Evolution, and Reengineering, IEEE, 2015, pp. 380–389. doi:10.1109/saner.2015.7081848 . · doi ↗
- 8[8] G. Sridhara, E. Hill, D. Muppaneni, L. L. Pollock, K. Vijay-Shanker, Towards automatically generating summary comments for Java methods, in: Proceedings of the 25th IEEE/ACM International Conference on Automated Software Engineering, 2010, pp. 43–52. doi:10.1145/1858996.1859006 . · doi ↗