Achieving Data Truthfulness and Privacy Preservation in Data Markets
Chaoyue Niu, Zhenzhe Zheng, Fan Wu, Xiaofeng Gao, and Guihai Chen

TL;DR
This paper introduces TPDM, a system that ensures data truthfulness and privacy preservation in data markets through cryptographic techniques, enabling efficient verification and confidentiality in large-scale data trading.
Contribution
The paper presents TPDM, a novel framework combining data truthfulness verification with privacy preservation using homomorphic encryption and identity-based signatures.
Findings
TPDM effectively verifies data truthfulness and privacy in large-scale markets.
It maintains low computational and communication overheads.
Performance evaluated on real-world datasets shows promising results.
Abstract
As a significant business paradigm, many online information platforms have emerged to satisfy society's needs for person-specific data, where a service provider collects raw data from data contributors, and then offers value-added data services to data consumers. However, in the data trading layer, the data consumers face a pressing problem, i.e., how to verify whether the service provider has truthfully collected and processed data? Furthermore, the data contributors are usually unwilling to reveal their sensitive personal data and real identities to the data consumers. In this paper, we propose TPDM, which efficiently integrates data Truthfulness and Privacy preservation in Data Markets. TPDM is structured internally in an Encrypt-then-Sign fashion, using partially homomorphic encryption and identity-based signature. It simultaneously facilitates batch verification, data processing,…
Click any figure to enlarge with its caption.
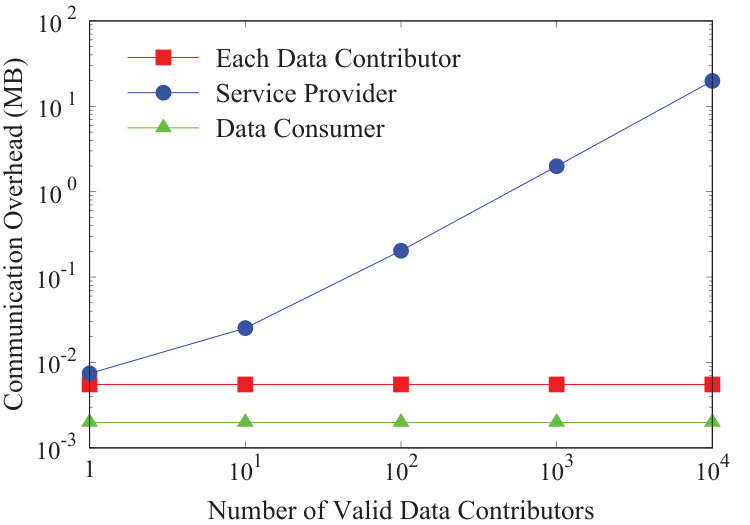 Figure 1
Figure 1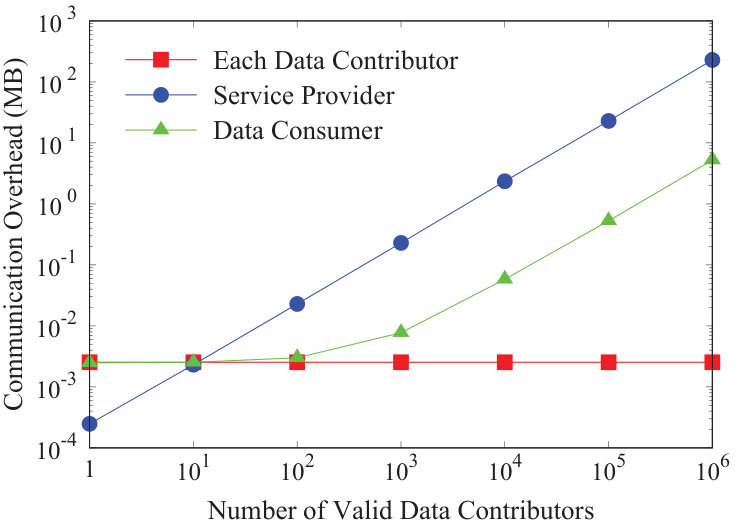 Figure 2
Figure 2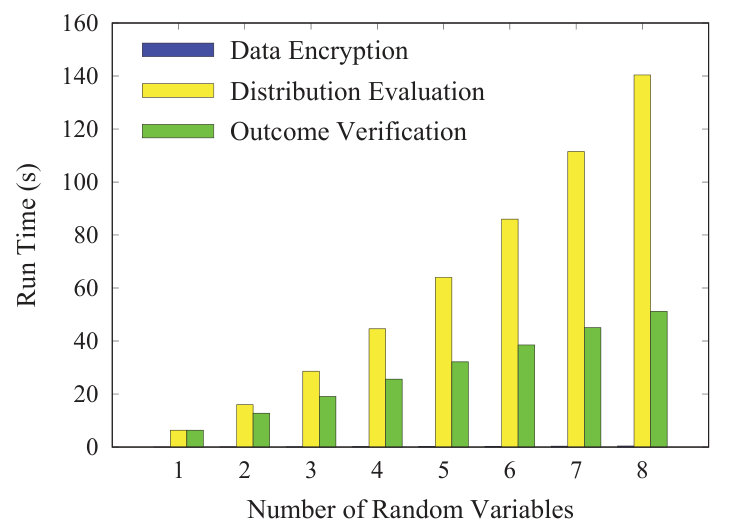 Figure 3
Figure 3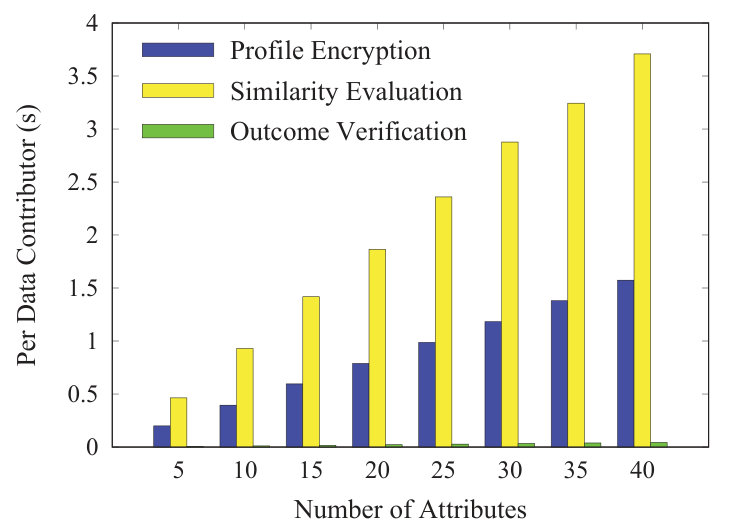 Figure 4
Figure 4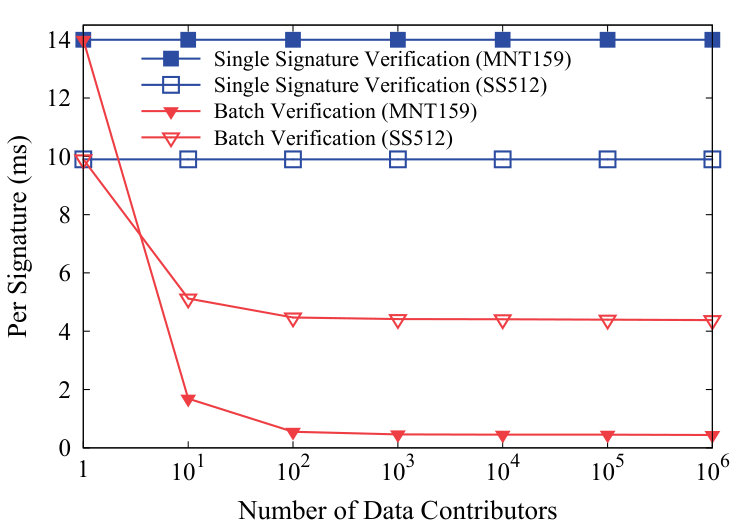 Figure 5
Figure 5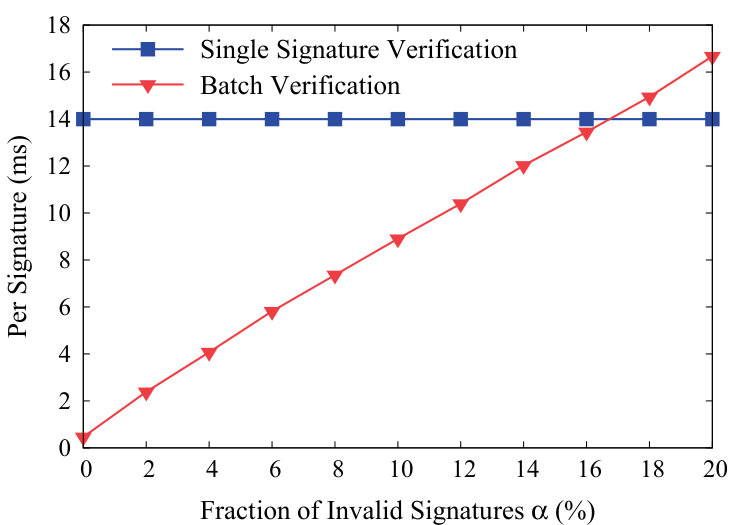 Figure 6
Figure 6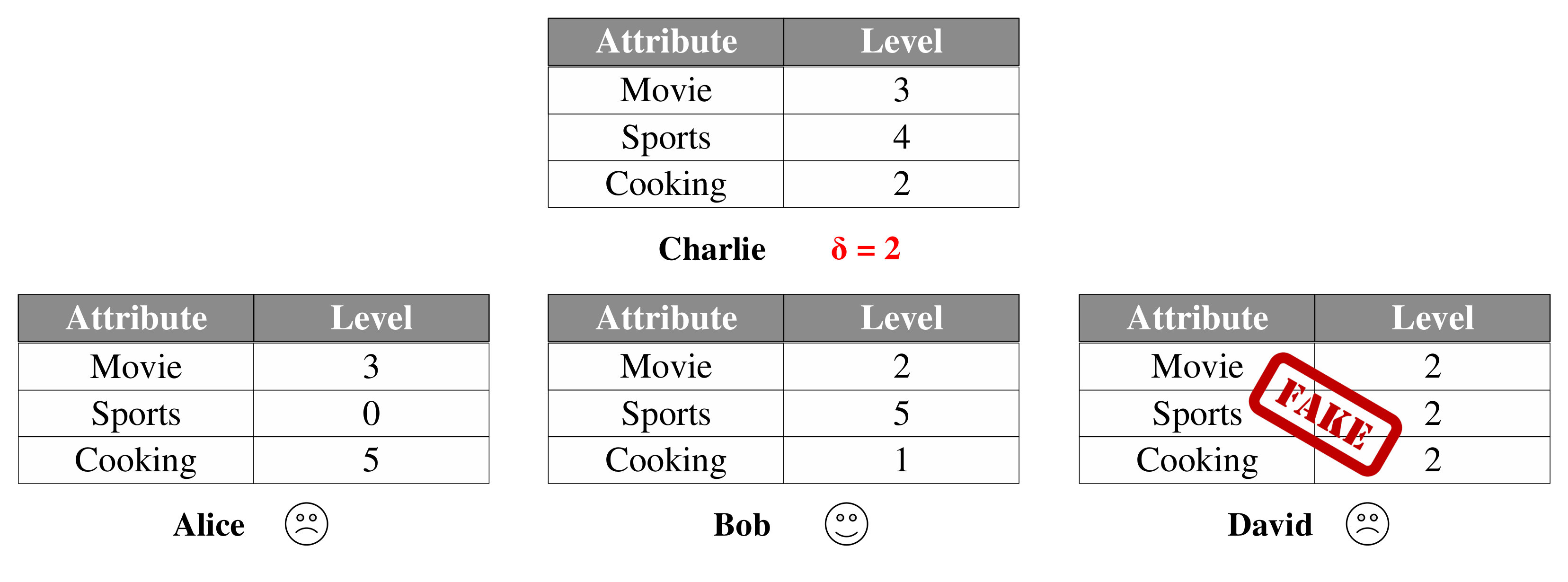 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14| Curve | Pairing | MapToPoint | Exponentiation | |
|---|---|---|---|---|
| SS512 | 512 bits | 0.999ms | 3.203ms | 1.179ms |
| MNT159 | 160 bits | 3.102ms | 0.029ms | 0.413ms |
| Preparation | Operation | ||
|---|---|---|---|
| Setting | Pseudo Identity Generation | Secret Key Generation | Signing |
| SS512 | 4.698ms (39.40%) | 6.023ms (50.53%) | 1.201ms (10.07%) |
| MNT159 | 1.958ms (57.33%) | 1.028ms (30.10%) | 0.429ms (12.57%) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Achieving Data Truthfulness and Privacy Preservation in Data Markets
Chaoyue Niu, Zhenzhe Zheng, Fan Wu, Xiaofeng Gao, and Guihai Chen The authors are with the Shanghai Key Laboratory of Scalable Computing and Systems, Department of Computer Science and Engineering, Shanghai Jiao Tong University, Shanghai, 200000, China.
E-mail: {rvincency, zhengzhenzhe220}@gmail.com; {fwu, gao-xf, gchen}@cs.sjtu.edu.cnManuscript received 11 Aug. 2017; revised 3 Dec. 2017; accepted 19 Mar. 2018. Date of publication XXXX 2018; date of current version 13 May 2018.
Recommended for acceptance by J. Chen.
For information on obtaining reprints of this article, please send e-mail to [email protected], and reference the Digital Object Identifier below.
Digital Object Identifier no. 10.1109/TKDE.2018.2822727
Abstract
As a significant business paradigm, many online information platforms have emerged to satisfy society’s needs for person-specific data, where a service provider collects raw data from data contributors, and then offers value-added data services to data consumers. However, in the data trading layer, the data consumers face a pressing problem, i.e., how to verify whether the service provider has truthfully collected and processed data? Furthermore, the data contributors are usually unwilling to reveal their sensitive personal data and real identities to the data consumers. In this paper, we propose TPDM, which efficiently integrates data Truthfulness and Privacy preservation in Data Markets. TPDM is structured internally in an Encrypt-then-Sign fashion, using partially homomorphic encryption and identity-based signature. It simultaneously facilitates batch verification, data processing, and outcome verification, while maintaining identity preservation and data confidentiality. We also instantiate TPDM with a profile matching service and a distribution fitting service, and extensively evaluate their performances on Yahoo! Music ratings dataset and 2009 RECS dataset, respectively. Our analysis and evaluation results reveal that TPDM achieves several desirable properties, while incurring low computation and communication overheads when supporting large-scale data markets.
Index Terms:
Data markets, data truthfulness, privacy preservation
1 Introduction
In the era of big data, society has developed an insatiable appetite for sharing personal data. Realizing the potential of personal data’s economic value in decision making and user experience enhancement, several open information platforms have emerged to enable person-specific data to be exchanged on the Internet [1, 2, 3, 4, 5]. For example, Gnip, which is Twitter’s enterprise API platform, collects social media data from Twitter users, mines deep insights into customized audiences, and provides data analysis solutions to more than 95 of the Fortune 500 [1].
However, there exists a critical security problem in these market-based platforms, i.e., it is difficult to guarantee the truthfulness in terms of data collection and data processing, especially when the privacies of the data contributors are needed to be preserved. Let’s examine the role of a pollster in the presidential election as follows. As a reliable source of intelligence, the Gallup Poll [6] uses impeccable data to assist presidential candidates in identifying and monitoring economic and behavioral indicators. In this scenario, simultaneously ensuring data truthfulness and preserving privacy require the Gallup Poll to convince the presidential candidates that those indicators are derived from live interviews without leaking any interviewer’s real identity (e.g., social security number) or the content of her interview. If raw data sets for drawing these indicators are mixed with even a small number of bogus or synthetic samples, it will exert bad influence on the final election result.
Ensuring data truthfulness and protecting the privacies of data contributors are both important to the long term healthy development of data markets. On one hand, the ultimate goal of the service provider in a data market is to maximize her profit. Therefore, in order to minimize the expenditure for data acquisition, an opportunistic way for the service provider is to mingle some bogus or synthetic data into the raw data set. Yet, to reduce operation cost, a cunning service provider may provide data services based on a subset of the whole raw data set, or even return a fake result without processing the data from designated sources. However, if such speculative and illegal behaviors cannot be identified and prohibited, it will cause heavy losses to data consumers, and thus destabilize the data market. On the other hand, while unleashing the power of personal data, it is the bottom line of every business to respect the privacies of data contributors. The debacle, which follows AOL’s public release of “anonymized” search records of its customers, highlights the potential risk to individuals in sharing personal data with private companies [7]. Besides, according to the survey report of 2016 TRUSTe/NCSA Consumer Privacy Infographic - US Edition [8], of consumers say they avoid companies that do not respect privacy. Therefore, the content of raw data should not be disclosed to the data consumers to guarantee data confidentiality, even if the real identities of the data contributors are hidden.
To integrate data truthfulness and privacy preservation in a practical data market, there are four major challenges. The first and the thorniest design challenge is that verifying the truthfulness of data collection and preserving the privacy seem to be contradictory objectives. Ensuring the truthfulness of data collection allows the data consumers to verify the validities of data contributors’ identities and the content of raw data, whereas privacy preservation tends to prevent them from learning these confidential contents. Specifically, the property of non-repudiation in classical digital signature schemes implies that the signature is unforgeable, and any third party is able to verify the authenticity of a data submitter using her public key and the corresponding digital certificate, i.e., the truthfulness of data collection in our model. However, the verification in digital signature schemes requires the knowledge of raw data, and can easily leak a data contributor’s real identity [9]. Regarding a message authentication code (MAC), each pair of a data contributor and a data consumer need to agree on a shared secret key, which is unpractical in data markets.
Yet, another challenge comes from data processing, which makes verifying the truthfulness of data collection even harder. Nowadays, more and more data markets provide data services rather than directly offering raw data. The following reasons account for this trend: 1) For the data contributors, they have severe privacy concerns [8]. Nevertheless, the service-based trading mode, which has hidden the sensitive raw data, alleviates their concerns; 2) For the service provider, comprehensive and insightful data services can bring in more profits [10]; 3) For the data consumers, data copyright infringement [11] is serious. However, such a data trading mode differs from most of conventional data sharing scenarios, e.g., data publishing [12]. Besides, the data services, as the results of data processing, may no longer be semantically consistent with the raw data [13], which makes the data consumers hard to believe the truthfulness of data collection. In addition, the digital signatures on raw data become invalid for the data services, which discourages the data consumers from doing verification as mentioned above. Moreover, although data provenance [14] helps to determine the derivation histories of data processing results, it cannot guarantee the truthfulness of data collection. While knowledge provenance [15], an enhanced version of data provenance, tackles the deficiency of data provenance, but it breaks the property of identity preservation.
The third challenge lies in how to guarantee the truthfulness of data processing, under the information asymmetry between the data consumers and the service provider due to data confidentiality. In particular, to ensure data confidentiality against the data consumers, the service provider can employ a conventional symmetric/asymmetric cryptosystem, and let the data contributors encrypt their raw data. Unfortunately, a hidden problem arisen is that the data consumers fail to verify the correctness and completeness of returned data services. Even worse, some greedy service providers may exploit this vulnerability to reduce operation cost during the execution of data processing, e.g., they might return an incomplete data service without processing the whole data set, or even return an outright fake result without processing the data from designated data sources.
Last but not least, the fourth design challenge is the efficiency requirement of data markets, especially for data acquisition, i.e., the service provider should be able to collect data from a large number of data contributors with low latency. Due to the timeliness of some kinds of person-specific data, the service provider has to periodically collect fresh raw data to meet the diverse demands of high-quality data services. For example, 25 billion data collection activities take place on Gnip every day [1]. Meanwhile, the service provider needs to verify data authentication and data integrity. One basic approach is to let each data contributor sign her raw data. However, classical digital signature schemes, which verify the received signatures one after another, may fail to satisfy the stringent time requirement of data markets. Furthermore, the maintenance of digital certificates under the traditional Public Key Infrastructure (PKI) also incurs significant communication overhead. Under such circumstances, verifying a large number of signatures sequentially certainly becomes the processing bottleneck at the service provider.
In this paper, by jointly considering above four challenges, we propose TPDM, which achieves both data Truthfulness and Privacy preservation in Data Markets. TPDM first exploits partially homomorphic encryption to construct a ciphertext space, which enables the service provider to launch data services and the data consumers to verify the truthfulness of data processing, while maintaining data confidentiality. In contrast to classical digital signature schemes, which are operated over plaintexts, our new identity-based signature scheme is conducted in the ciphertext space. Furthermore, each data contributor’s signature is derived from her real identity, and is unforgeable against the service provider or other external attackers. This appealing property can convince the data consumers that the service provider has truthfully collected data. To reduce the latency caused by verifying a bulk of signatures, we propose a two-layer batch verification scheme, which is built on the bilinear property of admissible pairing. At last, TPDM realizes identity preservation and revocability by carefully adopting ElGamal encryption and introducing a semi-honest registration center.
We summarize our key contributions as follows.
To the best of our knowledge, TPDM is the first secure mechanism for data markets achieving both data truthfulness and privacy preservation.
TPDM is structured internally in a way of Encrypt-then-Sign using partially homomorphic encryption and identity-based signature. It enforces the service provider to truthfully collect and process real data. Besides, TPDM incorporates a two-layer batch verification scheme with an efficient outcome verification scheme, which can drastically reduce computation overhead.
We instructively instantiate TPDM with two kinds of practical data services, namely profile matching and distribution fitting. Besides, we implement these two concrete data markets, and extensively evaluate their performances on Yahoo! Music ratings dataset and 2009 RECS dataset. Our analysis and evaluation results reveal that TPDM achieves good effectiveness and efficiency in large-scale data markets. Specifically, for profile matching, when supporting as many as 1 million data contributors in one session of data acquisition, the computation and communication overheads at the service provider are 0.930s and 0.235KB per matching with 10 attributes in each profile, respectively. In addition, the outcome verification’s overhead per matching is only of the original similarity evaluation’s cost.
The remainder of this paper is organized as follows. In Section 2, we introduce system model, adversary model, and technical preliminary. We show the detailed design of TPDM in Section 3, and analyze its security in Section 4. In Section 5, we elaborate on the applications of TPDM to profile matching and distribution fitting. The evaluation results are presented in Section 6. We briefly review related work in Section 7. We conclude the paper in Section 8.
2 Preliminaries
In this section, we first describe a general system model for data markets. We then introduce the adversary model, and present corresponding security requirements on the design. We finally review technical preliminary.
2.1 System Model
As shown in Fig. 1, we consider a two-layer system model for data markets. The model has a data acquisition layer and a data trading layer. There are four major kinds of entities, including data contributors, a service provider, data consumers, and a registration center.
In the data acquisition layer, the service provider procures massive raw data from the data contributors, such as social network users, mobile smart devices, smart meters, and so on. In order to incentivize more data contributors to actively submit high-quality data, the service provider needs to reward those valid ones to compensate their data collection costs. For the sake of security, each registered data contributor is equipped with a tamper-proof device. The tamper-proof device can be implemented in the form of either specific hardware [16] or software [17]. It prevents any adversary from extracting the information stored in the device, including cryptographic keys, codes, and data.
We consider that the service provider is cloud based, and has abundant computing resources, network bandwidths, and storage space. Besides, she tends to offer semantically rich and value-added data services to data consumers rather than directly revealing sensitive raw data, e.g., social network analyses, probability distributions, personalized recommendations, and aggregate statistics.
The registration center maintains an online database of registrations, and assigns each registered data contributor an identity and a password to activate the tamper-proof device. Besides, she maintains an official website, called certificated bulletin board [18, 19], on which the legitimate system participants can publish essential information, e.g., whitelists, blacklists, resubmit-lists, and reward-lists of data contributors. Yet, another duty of the registration center is to set up the parameters for a signature scheme and a cryptosystem. To avoid being a single point of failure or bottleneck, redundant registration centers, which have identical functionalities and databases, can be installed.
2.2 Adversary Model
In this section, we focus on attacks in practical data markets, and define corresponding security requirements.
First, we consider that a malicious data contributor or an external attacker may impersonate other legitimate data contributors to submit possibly bogus raw data. Besides, some malicious attackers may deliberately modify raw data during submission. Hence, the service provider needs to confirm that raw data are indeed sent unaltered by registered data contributors, i.e., to guarantee data authentication and data integrity in the data acquisition layer.
Second, the service provider in the data market might be greedy, and attempts to maximize her profit by launching the following two types of attacks:
- •
Partial data collection: To cut down the expenditure on data acquisition, the service provider may insert bogus data into the raw data set.
- •
No/Partial data processing: To reduce the operation cost, the service provider may try to return a fake result without processing the data from designated sources, or to provide data services based on a subset of the whole raw data set.
On one hand, to counter partial data collection attack, each data consumer should be enabled to verify whether raw data are really provided by registered data contributors, i.e., truthfulness of data collection in the data trading layer. On the other hand, the data consumer should have the capability to verify the correctness and completeness of a returned data service in order to combat no/partial data processing attack. We here use the term truthfulness of data processing in the data trading layer to represent the integrated requirement of correctness and completeness of data processing results.
Third, we assume that some honest-but-curious data contributors, the service provider, the data consumers, and external attackers, e.g., eavesdroppers, may glean sensitive information from raw data, and recognize real identities of data contributors for illegal purposes, e.g., an attacker can infer a data contributor’s home location from her GPS records. Hence, raw data of a data contributor should be kept secret from these system participants, i.e., data confidentiality. Besides, an outside observer cannot reveal a data contributor’s real identity by analysing data sets sent by her, i.e., identity preservation.
Fourth, a minority of data contributors may try to behave illegally, e.g., launching attacks as mentioned above, if there is no punishment. To prevent this threat, the registration center should have the ability to retrieve a data contributor’s real identity, and revoke it from further usage, when her signature is in dispute, i.e., traceability and revocability.
Last but not least, the semi-honest registration center may misbehave by trying to link a data contributor’s real identity with her raw data. Besides, if there is no detection or verification in the cryptosystem, she may deliberately corrupt the decrypted results. However, to guarantee full side information protection, the requirement on the registration center is that she cannot leak decrypted samples to irrelevant system participants. Moreover, she is required to perform an acknowledged number of decryptions in a specific data service [20], which should be publicly posted on the certificated bulletin board.
2.3 Admissible Pairing
In this section, we introduce admissible pairing, which is the basis of our design.
The multiplicative cyclic groups , and are of the same prime order . Let be a generator of , and be a generator of . An asymmetric bilinear map is a map with the following three properties:
- •
Bilinearity: ,
[TABLE]
In addition,
[TABLE]
- •
Non-degeneracy:
- •
Computability: Given , there exists an efficient algorithm to compute .
We call such a bilinear map an admissible pairing, which can be constructed based on elliptic curves with modified Weil [21] or Tate pairing [22]. Each operation for computing is called pairing operation. The group that possesses such a map is called a bilinear group, where the Decisional Diffie-Hellman (DDH) problem is easy, while the Computational Diffie-Hellman (CDH) problem is hard [21]. For example, given for unknown , it is computationally intractable to compute .
3 Design of TPDM
In this section, we propose TPDM, which integrates data truthfulness and privacy preservation in data markets.
3.1 Design Rationales
Using the terminology from the signcryption scheme [23], TPDM is structured internally in a way of Encrypt-then-Sign, using partially homomorphic encryption and identity-based signature. It enforces the service provider to truthfully collect and process real data. The essence of TPDM is to first synchronize data processing and signature verification into the same ciphertext space, and then to tightly integrate data processing with outcome verification via the homomorphic properties. With the help of the architectural overview in Fig. 2, we illustrate the design rationales as follows.
Space Construction. The thorniest problem is how to enable the data consumer to verify the validnesses of signatures, while maintaining data confidentiality. If the signature scheme is applied to the plaintext space, the data consumer needs to know the content of raw data for verification. However, if we employ a conventional public key encryption scheme to construct the ciphertext space, the service provider has to decrypt and then process the data. Even worse, such a construction is vulnerable to the no/partial data processing attack, because the data consumer, only knowing the ciphertexts, fails to verify the correctness and completeness of the data service. Thus, the greedy service provider may reduce operation cost, by returning a fake result or manipulating the inputs of data processing. Therefore, we turn to the partially homomorphic cryptosystems for encryption, whose properties facilitate both data processing and outcome verification on the ciphertexts.
Batch Verification. After constructing the ciphertext space, we can let each data contributor digitally sign her encrypted raw data. Given the ciphertext and the signature, the service provider is able to verify data authentication and data integrity. Besides, we can treat the data consumer as a third party to verify the truthfulness of data collection. However, an immediate question arisen is that the sequential verification schema may fail to meet the stringent time requirement of large-scale data markets. In addition, the maintenance of digital certificates also incurs significant communication overhead. To tackle these two problems, we propose an identity-based signature scheme, which supports two-layer batch verifications, while incurring small computation and communication overheads.
Breach Detection. Yet, another problem in existing identity-based signature schemes is that the real identities are viewed as public parameters, and are not well protected. On the other hand, if all the real identities are hidden, none of the misbehaved data contributors can be identified. To meet these two seemly contradictory requirements, we employ ElGamal encryption to generate pseudo identities for registered data contributors, and introduce a new third party, called registration center. Specifically, the registration center, who owns the private key, is the only authorized party to retrieve the real identities, and to revoke those malicious accounts from further usage.
3.2 Design Details
Following the guidelines given above, we now introduce TPDM in detail. TPDM consists of 5 phases: initialization, signing key generation, data submission, data processing and verifications, and tracing and revocation.
Phase I: Initialization
We assume that the registration center sets up the system parameters at the beginning of data trading as follows:
The registration center chooses three multiplicative cyclic groups , , and with the same prime order . Besides, is a generator of , and is a generator of . Moreover, these three cyclic groups compose an admissible pairing .
The registration center randomly picks as her two master keys, and then computes
[TABLE]
as public keys. The master keys are preloaded into each registered data contributor’s tamper-proof device.
The registration center sets up parameters for a partially homomorphic cryptosystem: a private key , a public key , an encryption scheme , and a decryption scheme .
To activate the tamper-proof device, each registered data contributor is assigned with a “real” identity and a password . Here, uniquely identifies , while is required in the access control process.
The system parameters
[TABLE]
are published on the certificated bulletin board.
Phase II: Signing Key Generation
To achieve anonymous authentication in data markets, the tamper-proof device is utilized to generate a pair of pseudo identity and secret key for each registered data contributor :
[TABLE]
Here, is a per-session random nonce, represents the Exclusive-OR (XOR) operation, and () is a MapToPoint hash function [21], i.e., . Besides, is an ElGamal encryption [24] of the real identity over the elliptic curve, while is generated accordingly by exploiting identity-based encryption (IBE) [21].
Phase III: Data Submission
For the submission of raw data, we need to jointly consider several security issues, including confidentiality, authentication, and integrity. To provide data confidentiality, we employ partially homomorphic encryption. Besides, to guarantee data authentication and data integrity, the encrypted raw data should be signed before submission, and also should be verified after reception.
Data Encryption
Ahead of submission, each data contributor encrypts her raw data to different powers under the public key , and gets the ciphertext vector
[TABLE]
where is a set of positive integers, and is determined by the requirements of data services, e.g., the location-based aggregate statistics [20] may require , whereas in the fine-grained profile matching [25], .
In general, compared with the time-consuming computation on ciphertexts, the evaluation of plaintexts is quite more efficient. Therefore, we let each data contributor encrypt her raw data to different powers, which can benefit an optimization in data processing while incurring a small overhead at each data contributor.
Encrypted Data Signing
After encryption, each data contributor computes the signature on the ciphertext vector using her secret key:
[TABLE]
where “” denotes the group operation in , is a one-way hash function, e.g., SHA-1 [26], and is derived by concatenating all the elements of together.
Eventually, the data contributor submits her tuple to the service provider. Once receiving the tuple, the service provider is required to post the pseudo identity on the certificated bulletin board for fear of receiver-repudiation. In addition, to prevent a registered data contributor from using the same pair of pseudo identity and secret key for multiple times in different sessions of data acquisition (analogous to the replay attack scenario considered in [17]), one intuitive way is to let the service provider store those used pseudo identities for duplication check later. Yet, another feasible way is to encapsulate the signing phase into the tamper-proof device.
Phase IV: Data Processing and Verifications
In this phase, we consider two-layer batch verifications, i.e., verifications conducted by both the service provider and the data consumer. Between the two-layer batch verifications, we introduce data processing and signatures aggregation done by the service provider. At last, we present outcome verification conducted by the data consumer.
Before introducing the verifications, we first discuss the time period of data acquisition. In practice, is determined by the service provider, and is based on the timeliness of different data items. For example, stock data is streaming with a minimum update frequency of 1 minute on Investing [27], while smart meters collect the electrical usages every 15 minutes [28]. In what follows, we focus on one time period of data acquisition.
First-Layer Batch Verification
We assume that the service provider receives a bundle of data tuples from distinct data contributors, denoted as , by the end of a time period. To prevent a malicious data contributor from impersonating other legitimate ones to submit possibly bogus data, the service provider needs to verify the validnesses of signatures by checking whether
[TABLE]
Compared with single signature verification, this batch verification scheme can dramatically reduce the verification latency, especially when verifying a large number of signatures. Since the three pairing operations in Equation (6) dominate the overall computation cost, the batch verification time is almost a constant if the time overhead of MapToPoint hashings and exponentiations is small enough to be emitted. However, in a practical data market, when the number of data contributors is too large, the expensive pairing operations cannot dominate the verification time. We will expand on this point in Section 6.1.
Data Processing and Signatures Aggregation
Instead of directly trading raw data for revenue, more and more service providers tend to trade value-added data services. Typical examples of data services include social network analyses, personalized recommendations, location-based services, and probability distribution fittings.
To facilitate generating a precise and customized strategy in targeted data services, e.g., personalized recommendation and locate-based service, the data consumer also needs to provide her own ciphertext vector and a threshold . Here, is generated from the data consumer’s information as follows:
[TABLE]
where are parameters determined by a concrete data service. For example, the profile-matching service in Section 5.1 requires and .
Now, the service provider can process the collected data as required by the data consumer. We model such a data processing in the plaintext space as
[TABLE]
for generality. Accordingly, can be equivalently evaluated in the ciphertext space using
[TABLE]
The equivalent transformation from to is based on the properties of the partially homomorphic cryptosystem, e.g., homomorphic addition and homomorphic multiplication , which are arithmetic operations on the ciphertexts that are equivalent to the usual addition and multiplication on the plaintexts, respectively. Hence, only polynomial functions can be computed in a straightforward way. Nevertheless, most non-polynomial functions, e.g., sigmoid and rectified linear activation functions in machine learning, can be well approximated/handled by polynomials [29]. Besides, the function is determined by the data processing method, and the choice of a specific partially homomorphic cryptosystem should support the basic operation(s) in . For example, the primitive of aggregate statistics [20] is addition, so the Paillier scheme [30] can be the first choice; while the distance calculation [31] requires one more multiplication, thus, the BGN scheme [32] may be preferred. Furthermore, in Equation (9), is the data consumer’s ciphertext vector, and indicates that the data contributor is one of the valid data contributors. More precisely, is the size of whitelist on the certificated bulletin board, and its default value is . However, if either of the two-layer batch verifications fails, will be updated in the following tracing and revocation phase. For brevity in notations, we use to denote the indexes of valid data contributors, i.e., .
Next, the service provider sends to the registration center for decryption. We note that the registration center can only perform decryption for acknowledged times, which should be publicly announced on the certificated bulletin board. For example, in the aggregate statistic over a valid dataset of size , the registration center just needs to do one decryption, and cannot do more than required. The reason is that the service provider can still obtain the correct aggregate result by decrypting all encrypted raw data.
Upon getting the plaintext , the service provider can compare it with , and obtain the comparison result . For convenience, the concrete-value result and the comparison result are collectively called outcome. We note that the outcome may be in different formats, e.g., average speed in location-based aggregate statistic [20], shopping suggestion in private recommendation [33], and friending strategy in social networking [25]. We assume that the outcome involves candidate data contributors, and the subscripts of their pseudo identities are denoted as
After data processing, to further reduce communication overhead, the service provider can aggregate candidate signatures into one signature. In our scheme, the aggregate signature Then, the service provider sends the final tuple to the data consumer, including the data service outcome, the aggregate signature , the index set , and candidate ciphertexts .
Second-Layer Batch Verification
Similar to the first-layer batch verification, the data consumer can verify the legitimacies of candidate data sources by checking whether
[TABLE]
Here, the pseudo identities on the right hand side of the above equation can be fetched from the certificated bulletin board according to the index set .
Outcome Verification
The homomorphic properties also enable the data consumer to verify the truthfulness of data processing. Under the condition that the data consumer knows her plaintext , all the cross terms involving in Equation (9) can be evaluated through multiplication by a constant . Hence, part of the most time-consuming homomorphic multiplications in the original data processing are no longer needed in outcome verification. Besides, if for correctness, the data consumer just needs to evaluate on the candidate ciphertexts. Of course, she reserves the right to require the service provider to send her the other valid ones, on which the completeness can be verified.
In fact, if or is too large, the data consumer can take the strategy of random sampling for verification, where the valid pseudo identities on the certificated bulletin board can be used for the sampling indexes. Random sampling is a tradeoff between security and efficiency, and we shall illustrate its feasibility in Section 5 and Section 6.1.
Phase V: Tracing and Revocation
The two-layer batch verifications only hold when all the signatures are valid, and fail even when there is a single invalid signature. In practice, a signature batch may contain invalid one(s) caused by accidental data corruption or possibly malicious activities launched by an external attacker. Traditional batch verifier would reject the entire batch, even if there is a single invalid signature, and thus waste the other valid data items. Therefore, tracing and/or recollecting invalid data items and their corresponding signatures are important in practice. If the second-layer batch verification fails, the data consumer can require the service provider to find out the invalid signature(s). Similarly, if the first-layer batch verification fails, the service provider has to find out the invalid one(s) by herself.
To extract invalid signatures, as shown in Algorithm 1, we propose -depth-tracing algorithm. We consider that the batch contains signatures. In addition, the whitelist, the blacklist, and the resubmit-list of pseudo identities are global variables, and are initialized as empty sets. If a batch verification fails, the service provider first finds out the mid-point as (Line 9). Then, she performs batch verification on the first half ( to ) (Line 10) and the second half ( to ) (Line 11), respectively. If either of these two halves causes a failure, the service provider repeats the same process on it. Otherwise, she adds the pseudo identities from the valid half to the whitelist (Line 4-5). The recursive process terminates, if validnesses of all the signatures have been identified or a pre-defined limit of search depth is reached (Line 2). A special case is the single signature verification, in which the service provider can determine its validness (Line 6-7). After this algorithm, the service provider can form the resubmit-list of pseudo identities by excluding those in the other two lists.
According to the blacklist on the certificated bulletin board, the registration center can reveal the real identities of those invalid data contributors. Given the data contributor ’s pseudo identity , the registration center can use her master key to perform revealing by computing
[TABLE]
Upon getting a misbehaved data contributor’s real identity, the registration center can revoke it from further usage if necessary, e.g., deleting her account from the online registration database. Thus, the revoked data contributor can no longer activate the tamper-proof device, which indicates that she does not have the right to submit data any more.
4 Security Analysis
In this section, we analyze the security of TPDM in terms of the desirable properties preconcerted in Section 2.2.
4.1 Data Authentication and Data Integrity
Data authentication and data integrity are regarded as two basic security requirements in the data acquisition layer. The signature in TPDM is actually a one-time identity-based signature. We now prove that if the Computational Diffie-Hellman (CDH) problem in the bilinear group is hard [21], an attacker cannot successfully forge a valid signature on behalf of any registered data contributor except with a negligible probability.
First, we consider Game 1 between a challenger and an attacker as follows:
- Setup: The challenger starts by giving the attacker the system parameters and . The challenger also offers a pseudo identity to the attacker, which simulates the condition that the pseudo identities are posted on the certificated bulletin board in TPDM.
- Query: We assume that the attacker does not know how to compute the MapToPoint hash function and the one-way hash function . However, she can ask the challenger for the value and the one-way hashes for up to different messages.
- Challenge: The challenger asks the attacker to pick two random messages and , and to generate two corresponding signatures and on behalf of the data contributor .
- Guess: The attacker returns and to the challenger. We denote the attacker’s advantage in winning Game 1 to be
[TABLE]
We further claim that our signature scheme is adaptively secure against existential forgery, if is negligible. We prove our claim using Game 2 by reduction [34].
Second, we assume that there exists a probabilistic polynomial-time algorithm such that it has the same non-negligible advantage as the attacker in Game 1. Then, we will construct Game 2, in which an attacker can make use of to break the CDH assumption with non-negligible probability. In particular, is given for unknown and known , and is asked to compute . We note that computing is as hard as computing , which is the original CDH problem. We present the details of Game 2 as follows:
- Setup: makes up the parameters and , where plays the role of the master key in TPDM. Besides, also provides with a pseudo identity . Here, functions as the random nonce in TPDM.
- Query: then asks for the value , and replies with . We note that is the only MapToPoint hash operation needed to forge the data contributor ’s valid signatures. Besides, picks random messages, and requests for their one-way hash values . answers these queries using a random oracle: maintains a table to store all the answers. Upon receiving a message, if the message has been queried before, answers with the stored value; otherwise, she answers with a random value, which is stored into the table for later usage. Except for the -th and -th queries (i.e., messages and ), answers with the values and , respectively, where .
- Challenge: When the query phase is over, asks to choose two random messages and , and to sign them on behalf of the data contributor .
- Guess: returns two signatures and on the messages and to . We note that and must be within the queried messages; otherwise, does not know and . Furthermore, if and or and , then computes , which is equivalent to:
[TABLE]
After obtaining , solves the given CDH instance successfully. We note that ’s advantage in breaking TPDM is , and the probability that picks and is . Thus, the probability of ’s success is:
[TABLE]
Since is non-negligible, can solve the CDH problem with the non-negligible probability , which contradicts with the assumption that the CDH problem is hard. This completes our proof. Therefore, our signature scheme is adaptively secure under the random oracle model.
Last but not least, the first-layer batch verification scheme in TPDM is correct if and only if Equation (6) holds. By capitalizing the bilinear property of admissible pairing, the left hand side of Equation (6) expands as:
[TABLE]
which is the right hand side as required.
In conclusion, our novel identity-based signature scheme is provably secure, and the properties of data authentication and data integrity are achieved.
4.2 Truthfulness of Data Collection
To guarantee the truthfulness of data collection, we need to combat the partial data collection attack defined in Section 2.2. We note that it is just a special case of Game 1 in Section 4.1, where the service provider is the attacker. Hence, it is infeasible for the service provider to forge valid signatures on behalf of any registered data contributor. Such an appealing property prevents the service provider from injecting spurious data undetectably, and enforces her to truthfully collect real data.
Similar to data authentication and data integrity, the data consumer can verify the truthfulness of data collection by performing the second-layer batch verification with Equation (10). Proof of correctness is similar to Equation (15) for the first-layer batch verification, where we can just replace the aggregate signature with .
4.3 Truthfulness of Data Processing
We now analyze the truthfulness of data processing from two aspects, i.e., correctness and completeness.
Correctness. TPDM ensures the truthfulness of data collection, which is the premise of a correct data service. Then, given a truthfully collected dataset, the data consumer can evaluate the candidate data sources, which is consistent with the original data processing due to the homomorphic properties of the partially homomorphic cryptosystem.
Completeness. In fact, our design provides the property of completeness by guaranteeing the correctness of , , and , which are the numbers of total, valid, and candidate data contributors, respectively:
First, the service provider cannot deliberately omit a data contributor’s real data. The reason is that if the data contributor has submitted her encrypted raw data, without finding her pseudo identity on the certificated bulletin board, she would obtain no reward for data contribution. Therefore, she has incentives to report data missing to the registration center, which in turn ensures the correctness of .
Second, we consider that the service provider compromises the number of valid data contributors in two ways: one is to put a valid data contributor’s pseudo identity into the blacklist; the other is to put an invalid pseudo identity into the whitelist. We discuss these two cases separately: 1) In the first case, the valid data contributor would not only receive no reward, but may also be revoked from the online registration database. Hence, she has strong incentives to resort to the registration center for arbitration. Besides, we claim that the service provider wins the arbitration except with negligible probability. We give the detailed proof via Game 3 between a challenger and an attacker:
- Setup: The challenger first gives the attacker valid data tuples, denoted as . This simulates the data submissions from valid data contributors.
- Challenge: The challenger asks the attacker to pick a random data contributor within the given ones, and then requests the attacker to generate a signature on the ciphertext vector .
- Guess: The attacker returns to the challenger. The attacker wins Game 3, if , passes the challenger’s verification, and fails in the verification.
Next, we demonstrate that the attacker’s winning probability in Game 3, denoted as
[TABLE]
is negligible. On one hand, the verification scheme in TPDM is publicly verifiable, which indicates that the challenger can verify the legitimacies of both and through checking whether
[TABLE]
hold at the same time. We note that the above two equations conform to the formula of single signature verification, i.e., in Equation (6). However, the second one contradicts with our assumption that is a valid data contributor. On the other hand, passes the challenger’s verification, while is not equal to , which implies that is a valid signature forged by the attacker. As shown in Game 1, the probability of successfully forging a valid signature is negligible, and thus the attacker’s winning probability in Game 3 is negligible as well. This completes our proof of thwarting the first case; 2) The second case is essentially the tracing and revocation phase in Section 3.2, where the batch of signatures contains invalid ones. Therefore, this case cannot pass two-layer batch verifications. Besides, the greedy service provider has no incentives to reward those invalid data contributors, which could in turn destabilize the data market. Joint considering above two cases, our scheme TPDM can guarantee the correctness of .
Third, as stated in outcome verification, the data consumer reserves the right to verify over all valid data items, and the service provider cannot just process a subset without being found. Thus, the correctness of is assured.
In a nutshell, TPDM can guarantee the truthfulness of data processing in the data trading layer.
4.4 Data Confidentiality
Considering the potential economic value and the sensitive information contained in raw data, data confidentiality is a necessity in data markets. Since partially homomorphic encryption provides semantic security (e.g., [30, 24, 32]), by definition, except the registration center, any probabilistic polynomial-time adversary cannot reveal the contents of raw data. Moreover, although the registration center holds the private key, she cannot learn the sensitive raw data as well, since neither the service provider nor the data consumer directly forwards the original ciphertexts of the data contributors for decryption. Therefore, data confidentiality is achieved against all these system participants.
4.5 Identity Preservation
To protect a data contributor’s unique identifier in data markets, her real identity is converted into a random pseudo identity. We note that the two parts of a pseudo identity are actually two items of an ElGamal-type ciphertext, which is semantically secure under the chosen plaintext attack [24]. Furthermore, the linkability between a data contributor’s signatures does not exist, because the pseudo identities for different signing instances are indistinguishable. Hence, identity preservation can be ensured.
4.6 Semi-honest Registration Center
Registration center in TPDM performs two main tasks: one is to maintain the online database of legal registrations; the other is to set up the partially homomorphic cryptosystem.
First, as we have clarified in Section 4.4, TPDM guarantees data confidentiality against the registration center. Thus, although she maintains the database of real identities, she cannot link them with corresponding raw data. Second, partially homomorphic encryption schemes (e.g., [30, 24, 32]) normally provide a proof of decryption, which indicates that the registration center cannot corrupt the decrypted results undetectably. Hence, she virtually has no effect on data processing and outcome verification. At last, we will further show the feasibility of distributing multiple registration centers in our evaluation part.
5 Two Practical Data Markets
In this section, from a practical standpoint, we consider two practical data markets, which provide fine-grained profile matching and multivariate Gaussian distribution fitting, respectively. The major difference between these two data markets is whether the data consumer has inputs.
5.1 Fine-grained Profile Matching
We first elaborate on a classic data service in social networking, i.e., fine-grained profile matching. Unlike the directly interactive scenario in [25], our centralized data market breaks the limit of neighborhood finding. In particular, a data consumer’s friending strategy can be derived from a large scale of data contributions. For convenience, we shall not differentiate “profile” from “raw data” in the profile-matching scenario considered here.
During the initial phase of profile matching, the service provider, e.g., Twitter or OkCupid, defines a public attribute vector consisting of attributes , where corresponds to a personal interest, such as movie, sports, cooking, and so on. Then, to create a fine-grained personal profile, a data contributor , e.g., a Twitter or OkCupid user, selects an integer to indicate her level of interest in , and thus forms her profile vector Subsequently, the data contributor submits to the service provider for matching process.
To facilitate profile matching, the data consumer also needs to provide her profile vector and an acceptable similarity threshold , where is a non-negative integer. Without loss of generality, we assume that the service provider employs Euclidean distance to measure the similarity between the data contributor and the data consumer, where . We note that if then the data contributor is a matching target to the data consumer. In what follows, to simplify construction, we covert the matching metric to its squared form
5.1.1 Recap of Adversary Model
Before introducing our concrete construction, we first give a brief review of the adversary model and corresponding security requirements in the context of profile matching.
As shown in Fig. 3, Alice and Bob are registered data contributors, and Charlie is a data consumer. Here, the partial data collection attack means that to reduce data acquisition cost, the service provider may insert unregistered/fake David’s profile. Besides, the partial data processing attack indicates that to reduce operation cost, the service provider may just evaluate the similarity between Charlie and Alice, while generating a random result for Bob. Moreover, the no data processing attack implies that the service provider just returns two random matching results without processing the profiles of both Alice and Bob.
Our joint security requirements of privacy preservation and data truthfulness mainly include two aspects: 1) Without leaking the real identities and the profiles of Alice and Bob, the service provider needs to prove the legitimacies of Alice and Bob to Charlie; 2) Without revealing Alice’s and Bob’s profiles, Charlie can verify the correctness and completeness of returned matching results.
5.1.2 BGN-Based Construction
Given the profile-matching scenario considered here, we utilize a partially homomorphic encryption scheme based on bilinear maps, called Boneh-Goh-Nissim (BGN) cryptosystem [32]. This is because we only require the oblivious evaluation of quadratic polynomials, i.e., . In particular, the BGN scheme supports any number of homomorphic additions after a single homomorphic multiplication. Now, we briefly introduce how to adapt TPDM to this practical data market. Due to the limitation of space, we focus on the major phases, including data submission, data processing, and outcome verification.
Data Submission: When a data contributor intends to submit her profile , she employs the BGN scheme to do encryption, and gets the ciphertext vector:
[TABLE]
Afterwards, the data contributor computes the signature on using her secret key :
[TABLE]
where and “” is a message concatenation operation.
By the end of a time period, distinct data contributors submit their tuples to the service provider, on which the first-layer batch verification can be conducted using Equation (6).
Data Processing: To facilitate generating a personalized friending strategy, the data consumer also needs to provide her encrypted profile vector and a threshold , where
[TABLE]
Now, the service provider can directly do matching on the encrypted profiles. For brevity in expression, we assume that is one of the valid data contributors, i.e., . Besides, to obliviously evaluate the similarity , the service provider first preprocesses and by adding to the first and the last places of two vectors, respectively, and obtains new vectors and , where
[TABLE]
After preprocessing, the service provider can compute the “dot product” of Equation (21) and Equation (22), by first applying homomorphic multiplication and then homomorphic addition , and gets , where
[TABLE]
Next, the service provider applies homomorphic additions to with , and gets
[TABLE]
We note that is actually an encryption of , which indicates the similarity between the data contributor and the data consumer.
Then, the service provider sends to the registration center for decryption. We note that for each data contributor, the registration center just needs to do one decryption, i.e., supposing the size of whitelist on the certificated bulletin board is , she can only perform decryptions in total. The registration center cannot do more decryptions than required, since the service provider may still obtain a correct and complete matching strategy by revealing the profiles of all the valid data contributors and the data consumer. However, this case requires at least decryptions. Furthermore, to speed up BGN decryption in outcome verification, the registration center should retain the decrypted plaintexts in storage for a preset validity period.
When obtaining , the service provider compares it with , and thus can determine whether the data contributor matches the data consumer. We assume that data contributors are matched, and the subscripts of their pseudo identities are denoted as .
After data processing, the service provider aggregates the signatures of matched data contributors into one signature. Then, she sends the aggregate signature, the indexes of matched data contributors, and their encrypted profile vectors to the data consumer, on which the second-layer batch verification can be performed with Equation (10). Besides, to prevent the service provider from changing/revaluating valid but unmatched data contributors in the completeness verification later, their similarities, i.e., should also be forwarded. We note that the pseudo identities of matched data contributors can be viewed as the friending strategy, i.e., outcome in the general model, since the data consumer can resort to the registration center, as a relay, for handshaking with those matched data contributors.
Outcome Verification: During the validity period preset by the registration center, the data consumer can verify the truthfulness of data processing via homomorphic properties. For correctness, the data consumer just needs to evaluate the matched profiles. Of course, for completeness, the data consumer reserves the right to do verification over the other unmatched ones. We note that the data consumer, knowing her own profile vector , can compute Equation (5.1.2) more efficiently through
[TABLE]
Thus, the most time-consuming homomorphic multiplications can be avoided in outcome verification. Moreover, we note that the registration center does not need to do decryption as in data processing, since she can just search a smaller-size table of plaintexts in the storage. If there is no matched one, the outcome verification fails, and the service provider will be questioned by the data consumer.
To further reduce verification cost, the data consumer can take the stratified sampling strategy in practice, e.g., in our evaluation on a real-world ratings dataset, for correctness, she may check all the matched data contributors, accounting for of the total 10000 samples, while only checking of the unmatched ones for completeness. In particular, regarding completeness verification, the data consumer can randomly choose part of the valid but unmatched data contributors, and then request the service provider to send her their aggregate signature and encrypted profile vectors for the second-layer batch verification and the outcome verification. Here, we assume that the greedy service provider cheats by not evaluating each data contributor in the original data processing with a probability . Then, the probability of successfully detecting an attempt to return an incorrect/incomplete result, , increases exponentially with the number of checks , i.e., . For example, when and , the success rate is already . In fact, a concrete sampling strategy should depend on practical , , and .
5.2 Multivariate Gaussian Distribution Fitting
We further consider a different data market, where the service provider captures the underlying probability distribution over the collected dataset, and offers such a distribution as a data service to the data consumer [35, 36]. This data service is called probability distribution fitting. For example, a data analyst, as the data consumer, may want to learn the distribution of residential energy consumptions.
Due to central limit theorem, we assume that the multivariate Gaussian distribution can closely approximate the raw data, which is a widely used assumption in statistical learning algorithms [37]. For convenience, we continue to use the notations in profile matching, i.e., the attribute vector now represents a vector of random variables. In particular, , where is a -dimensional mean vector, and is a covariance matrix. Besides, the covariance matrix can be computed by:
[TABLE]
Here, denotes taking expectation. We below focus on the key designs different from profile matching.
For data submission, the cipertext vector of the data contributor is changed into:
[TABLE]
where its first element is to facilitate computing the mean vector , while its second element is to help the service provider in evaluating the matrix more efficiently.
For data processing, the service provider first employs homomorphic additions to obliviously compute the mean vector , where the ciphertext of its -th element multiplying the number of valid data contributors is:
[TABLE]
Additionally, to derive the covariance matrix , it suffices for the service provider to get . Here, the service provider can avoid the time-consuming homomorphic multiplications. For example, the -th row, -th column entry of , denoted by , can be computed through:
[TABLE]
However, supposing that the data contributor excluded from her ciphertext vector , the service provider would need to perform expensive homomorphic multiplications for the data contributor instead, because in Equation (29) needs to be derived by means of .
For outcome verification, the data consumer can take the stratified random sampling strategy from two aspects: 1) She can randomly check parts of the mean vector and the covariance matrix ; 2) She can reevaluate a random subset of valid data items, and compare the new distribution with the returned distribution. If their distance is within a threshold, the data consumer would accept this outcome; otherwise, she rejects. We note that in the first case, the valid data contributors may need to re-sign those involved ciphertexts for the second-layer batch verification.
6 Evaluation Results
In this section, we show the evaluation results of TPDM in terms of computation overhead and communication overhead. We also demonstrate the feasibility of the registration center and the -depth-tracing algorithm.
Datasets: We use two real-world datasets, called R1-Yahoo! Music User Ratings of Musical Artists Version 1.0 [38] and 2009 Residential Energy Consumption Survey (RECS) dataset [39], for the profile matching service and the distribution fitting service, respectively.
First, the Yahoo! dataset represents a snapshot of Yahoo! Music community’s preference for various musical artists. It contains 11,557,943 ratings of 98,211 artists given by 1,948,882 anonymous users, and was gathered over the course of one month prior to March 2004. For profile matching, we choose common artists as the attributes, append each user’s corresponding ratings ranging from 0 to 10, and thus form her fine-grained profile. Second, the RECS dataset, which was released by U.S. Energy Information Administration (EIA) in January 2013, provides detailed information about diverse energy usages in U.S. homes. This dataset was collected from 12,083 randomly selected households between July 2009 and December 2012. For distribution fitting, we view types of energy consumptions, e.g., electricity, natural gas, space heating, and water heating, as random variables, and intend to obtain the multivariate Gaussian distribution.
Evaluation Settings: We implemented TPDM using the latest Pairing-Based Cryptography (PBC) library [40]. The elliptic curves utilized in our identity-based signature scheme include a supersingular curve with a base field size of 512 bits and an embedding degree of 2, and a MNT curve with a base field size of 159 bits and an embedding degree of 6. In addition, the group order is 160-bit long, and all hashings are implemented in SHA1, considering its digest size closely matches the order of . The BGN cryptosystem is realized using Type A1 pairing, in which the group order is a product of two 512-bit primes. The running environment is a standard 64-bit Ubuntu 14.04 Linux operation system on a desktop with Intel(R) Core(TM) .
Overheads of Key Operations: Table I presents the curve choices along with the computation time of key operations, where SS512 and MNT159 are abbreviated from the settings of the supersingular curve and the MNT curve in the identity-based signature scheme, respectively. denotes the number of bits needed to optimally represent a group element. Besides, all the computation time of key operations is derived from the average of 10000 runs.
6.1 Computation Overhead
We show the computation overheads of four important components in TPDM, namely profile matching, distribution fitting, identity-based signature, and batch verification.
Profile Matching: In Fig. 4a, we plot the computation overheads of profile encryption, similarity evaluation, and outcome verification per data contributor, when the number of attributes increases from 5 to 40 with a step of 5. From Fig. 4a, we can see that the computation overheads of these three phases increase linearly with . This is because the profile encryption requires BGN encryptions, the similarity evaluation consists of homomorphic multiplications and additions, and the outcome verification is composed of homomorphic additions and exponentiations, which are both proportional to . In addition, the outcome verification is light-weight, whose overhead per data contributor is only of the similarity evaluation’s cost. Moreover, when , one decryption overhead at the registration center is 1.648ms in the original data processing, while in outcome verification, it is in tens of microseconds.
We further show the feasibility of the stratified sampling strategy in outcome verification. We analyze the matching ratio based on Yahoo! Music ratings dataset. Given , when a data consumer sets her threshold , she is matched with in average of the 10000 data contributors, who are selected randomly from the dataset. The relatively small matching ratio means that even if all matched data contributors are verified for correctness, it only incurs an overhead of 4.859s at the data consumer, which is roughly of the data processing workload at the service provider. Next, we simulate the partial data processing attack by randomly corrupting of unmatched data contributors, i.e., replacing their similarities with random values. Then, the data consumer can detect such type attack using 26 random checks in average for completeness, which incurs an additional overhead of 0.281s.
Distribution Fitting: Fig. 4b plots the computation overhead of the distribution fitting service, where the number of random variables increases from 1 to 8, and the number of valid data contributors is fixed at 10000. Besides, for outcome verification, the data consumer checks all the elements in the mean vector, while only checks the diagonal elements in the covariance matrix. From Fig. 4b, we can see that the computation overheads of the first two phases increase quadratically with , whereas the computation overhead of the last phase increases linearly with . The reason is that the data encryption phase consists of BGN encryptions for each data contributor, and the distribution evaluation phase mainly comprises homomorphic additions. In contrast, the outcome verification phase mainly requires homomorphic additions. Furthermore, when , these three phases consume 0.402s, 140.395s, and 51.200s, respectively.
Jointly summarizing above evaluation results, TPDM performs well in both kinds of data markets. Therefore, the generality of TPDM can be validated.
Identity-Based Signature: We now investigate the computation overhead of the identity-based signature scheme, including preparation and operation phases. In this set of simulations, we set the number of data contributors to be . Table II lists the average time overhead per data contributor. From Table II, we can see that the time cost of the preparation phase dominates the total overhead in both SS512 and MNT159. This outcome stems from that the pseudo identity generation employs ElGamal encryption, and the secret key generation is composed of one MapToPoint hash operation and two exponentiations. In contrast, the operation phase mainly consists of one exponentiation.
The above results demonstrate that the identity-based signature scheme in TPDM is efficient enough, and can be applied to the data contributors with mobile devices.
Batch Verification: To examine the efficiency of batch verification, we vary the number of data contributors from 1 to 1 million by exponential growth. The performance of the corresponding single signature verification is provided as a baseline. Fig. 4c depicts the evaluation results using SS512 and MNT159, where verification time per signature (abbreviated as VTPS) is computed by dividing the total verification time by the number of data contributors. In particular, such a performance measure in an average sense can be found in [41]. From Fig. 4c, we can see that when the scale of data acquisition or data trading is small, e.g., when the number of data contributors is 10, TPDM saves 48.22 and 87.94 of VTPS in SS512 and MNT159, respectively. When the scale becomes larger, TPDM’s advantage over the baseline is more remarkable. This is owing to the fact that TPDM amortizes the overhead of 3 time-consuming pairing operations among all the data contributors.
We now compare the batch verification efficiency of two settings. Although the baseline of MNT159 increases verification latency than that of SS512, MNT159’s implementation is more efficient when the number of data contributors is larger than 10, e.g., when supporting as many as 1 million data contributors, MNT159 reduces of VTPS than SS512. We explain the reason by analyzing the asymptotic value of VTPS:
[TABLE]
Here, we let , , and denote the time overheads of a pairing operation, a MapToPoint hashing, and an exponentiation in Table I, respectively. From Equation (30), we can draw that if the time overheads of additional operations, e.g., and , are approaching or even greater than that of pairing operation (e.g., in SS512), their effect cannot be elided. Besides, the expensive additional operations will cancel part of the advantage gained by batch verification. Even so, the batch verification scheme can still sharply reduce per-signature verification cost.
These evaluation results reveal that TPDM can indeed help to reduce the computation overheads of the service provider and the data consumer by introducing two-layer batch verifications, especially in large-scale data markets.
6.2 Communication Overhead
In this section, we show the communication overheads of the profile matching service and the distribution fitting service separately.
Fig. 7 plots the communication overhead of profile matching, where the identity-based signature scheme is implemented in MNT159, the number of attributes is fixed at 10, and the threshold takes . Here, the communication overhead merely counts in the amount of sending content. Besides, we only consider the correctness verification. In fact, when the number of valid data contributors is , if we check 26 unmatched ones for completeness, it incurs additional communication overheads of 80.03KB at the service provider, and 3.35KB at the data consumer. Moreover, our statistics on the dataset show a linear correlation between the numbers of matched data contributors and valid ones , where the matching ratio is in average.
The first observation from Fig. 7 is that the communication overheads of the service provider and the data consumer grow linearly with the number of valid data contributors , while the communication overhead of each data contributor remains unchanged. The reason is that each data contributor just needs to do one profile submission, and thus its cost is independent of . However, the service provider primarily needs to send encrypted similarities for decryption, and to forward the indexes and the ciphertexts of matched data contributors for verifications. Regarding the data consumer, her communication overhead mainly comes from one data submission and the delivery of encrypted similarities for decryption. These imply that the communication overheads of the service provider and the data consumer are both linear with . Here, we note that x, y axes in Fig. 7 are log-scaled, and thus the communication overhead of the data consumer, containing a constant of one data submission overhead, seems non-linear. In particular, when , one data submission overhead dominates the total communication overhead, and this interval looks like a horizontal line; while , the communication overhead of delivering encrypted similarities dominates, and that interval appears linear.
The second key observation from Fig. 7 is that when the number of valid data contributors , all the three system participants spend roughly the same network bandwidth. The cause lies in that the small matching ratio implies a small number of matched data contributors involved in the correctness verification. Specifically, when , the average number of matched data contributors is only about , and the communication overheads of each data contributor, the service provider, and the data consumer are 2.60KB, 2.37KB, and 2.59KB, respectively.
We plot the communication overhead of multivariate Gaussian distribution fitting in Fig. 7, where the number of random variables is set to be 8. From Fig. 7, we can see that the communication overhead of the service provider increases linearly with the number of valid data contributors . This is because the service provider mainly needs to send BGN-type ciphertexts for verifications, which is linear with . By comparison, besides each data contributor, the data consumer’s bandwidth overhead stays the same, since she needs to deliver BGN-type ciphertexts for decryption, which is independent of .
We finally note that the transmission of BGN-type ciphertexts dominates the total communication overheads in both data services, while the network overhead incurred by sending the pseudo identities and the aggregate signature is comparatively low. Therefore, we do not plot the cases for SS512, which are similar to Fig. 7 and Fig. 7. In particular, compared with MNT159, SS512 adds 132 bytes and 176 bytes at each data contributor in profile matching and distribution fitting, respectively. Besides, SS512 adds 44 bytes at the service provider in two data services, but incurs no extra bandwidth overhead at the data consumer.
6.3 Feasibility of Registration Center
In this section, we consider the feasibility of the registration center from the perspectives of computation, communication, and storage overheads. We implement the identity-based signature scheme with MNT159. In addition, for profile matching, the number of attributes is fixed at 10, and the number of valid data contributors is set to be 10000. Accordingly, the number of matched ones is 449 at . For distribution fitting, we fix the number of random variables at 8, and set the number of valid data contributors to be 10000.
First, the primary responsibility of the registration center is to initialize the system parameters for the identity-based signature scheme and the BGN cryptosystem. Besides, she is required to perform totally and decryptions in the profile matching service and the distribution fitting service, respectively. The total computation overheads are 16.692s and 3.065s in two data services, respectively, which are only and of the service provider’s overall workloads. Furthermore, the one-time setup overhead can be amortized over several data services. Second, the main communication overheads of the registration center in two data services are incurred by returning decrypted results, which occupies the network bandwidth of 15.31KB and 0.23KB, respectively. Third, the storage overhead of the registration center mostly comes from maintaining the online database of registrations and the real-time certificated bulletin board, and caching the intermediate plaintexts. These two parts take up roughly 600.59KB and 586.11KB storage space in the profile matching service and the distribution fitting service, respectively.
In conclusion, our design of registration center has a light load, and can be implemented in a distributed manner, where each registration center can be responsible for one or a few data services. In particular, consistent hashing [42] can be employed to facilitate the information synchronization among multiple registration centers, e.g., guaranteeing a certain number of decryptions for each data service. Besides, using the standard techniques from [43], the original partially homomorphic cryptosystems can be extended to their threshold multi-authority versions, which implies the improved robustness of TPDM by distributing several registration centers in data markets.
6.4 Feasibility of Tracing Algorithm
To evaluate the feasibility of -depth-tracing algorithm when the batch verification fails, we generate a collection of 1024 valid signatures, and then randomly corrupt an -fraction of the batch by replacing them with random elements from the cyclic group . We repeat this evaluation with various values of ranging from 0 to , and compare verification time per signature (VTPS) in batch verification with that in single signature verification. Here, the overall batch verification latency includes the time cost spent in identifying invalid signatures. Fig. 7 presents the evaluation results using the efficient MNT159.
As shown in Fig. 7, batch verification is preferable to single signature verification when the ratio of invalid signatures is up to . The worst case of batch verification happens when the invalid signatures are distributed uniformly. In case the invalid signatures are clustered together, the performance of batch verification should be better. Furthermore, as shown in the initialization phase of Algorithm 1, the service provider can preset a practical tracing depth, and let those unidentified data contributors do resubmissions.
7 Related Work
In this section, we briefly review related work.
7.1 Data Market Design
In recent years, data market design has gained increasing interest from the database community. The seminal paper [10] by Balazinska et al. discusses the implications of the emerging digital data markets, and lists the research opportunities in this direction. Koutris et al. [44] presented a flexible data trading format, i.e., query-based data pricing. Later, Lin and Kifer [45] designed an arbitrage-free pricing function for arbitrary query formats. For personal data sharing, Li et al. [46] proposed a theory of pricing private data based on differential privacy. Upadhyaya et al. [11] developed a middleware system, called DataLawyer, to formally specify data use policies, and to automatically enforce these pre-defined terms during data usage. Jung et al. [47] focused on the dataset resale issue at the dishonest data consumers.
However, the original intention of above works is pricing data or monitoring data usage rather than integrating data truthfulness with privacy preservation in data markets, which is the consideration of this work111The early version of this paper [48] mainly focused on the profile matching service..
7.2 Signcryption
Data authentication and data confidentiality are two basic requirements in secure communication. To efficiently guarantee these two properties simultaneously, Zheng et al. [49] first introduced the terminology signcryption, which integrates digital signature with public key encryption. To reduce communication overhead, a number of identity-based signcryption schemes [50, 51] were proposed. In most signcryption schemes (e.g., [50, 49]), a third party requires the knowledge of plaintext to verify the message’s origin. In contrast to these works, Encrypt-then-Sign paradigm in [23] and the identity-based signcryption scheme in [51] support public ciphertext authenticity, which convinces a third party (e.g., the data consumer in our model) of data sources’ reliability without revealing the content of raw data.
Unfortunately, when existing signcryption schemes are directly applied to data markets, they only provide the truthfulness of data collection, but fail to support outcome verification. Besides, these schemes don’t facilitate identity preservation and batch verification [52], which are necessary in practical data collection and data trading environments.
7.3 Practical Computation on Encrypted Data
To get a tradeoff between functionality and performance, partially homomorphic encryption (PHE) schemes were exploited to enable practical computation on encrypted data. Unlike those prohibitively slow fully homomorphic encryption (FHE) schemes [53, 54] that support arbitrary operations, PHE schemes focus on specific function(s), and achieve better performance in practice. A celebrated example is the Paillier cryptosystem [30], which preserves the group homomorphism of addition and allows multiplication by a constant. Thus, it can be utilized in data aggregation [20] and interactive personalized recommendation [25, 33]. Yet, another one is ElGamal encryption [24], which supports homomorphic multiplication, and it is widely employed in voting [55]. Moreover, the BGN scheme [32] facilitates one extra multiplication followed by multiple additions, which in turn allows the oblivious evaluation of quadratic multivariate polynomials, e.g., shortest distance query [31] and optimal meeting location decision [56].
These schemes enable the service provider and the data consumer to efficiently perform data processing and outcome verification over encrypted data, respectively. Thus, they can remedy the potential defects in the conventional signcryption schemes. Additionally, we note that the outcome verification in data markets differs from the verifiable computation in outsourcing scenarios [57], since before data processing, the data consumer, as a client, does not hold a local copy of the collected dataset.
8 Conclusion and Future Work
In this paper, we have proposed the first efficient secure scheme TPDM for data markets, which simultaneously guarantees data truthfulness and privacy preservation. In TPDM, the data contributors have to truthfully submit their own data, but cannot impersonate others. Besides, the service provider is enforced to truthfully collect and process data. Furthermore, both the personally identifiable information and the sensitive raw data of data contributors are well protected. In addition, we have instantiated TPDM with two different data services, and extensively evaluated their performances on two real-world datasets. Evaluation results have demonstrated the scalability of TPDM in the context of large user base, especially from computation and communication overheads. At last, we have shown the feasibility of introducing the semi-honest registration center with detailed theoretical analysis and substantial evaluations.
As for further work in data markets, it would be interesting to consider diverse data services with more complex mathematic formulas, e.g., Machine Learning as a Service (MLaaS) [58, 59, 60, 61, 29]. For a specific data service, it is well-motivated to uncover some novel security problems, such as privacy preservation and verifiability.
Acknowledgments
This work was supported in part by the State Key Development Program for Basic Research of China (973 project 2014CB340303), in part by China NSF grant 61672348, 61672353, 61422208, and 61472252, in part by Shanghai Science and Technology fund (15220721300, 17510740200), in part by the Scientific Research Foundation for the Returned Overseas Chinese Scholars, and in part by the CCF Tencent Open Research Fund (RAGR20170114). The opinions, findings, conclusions, and recommendations expressed in this paper are those of the authors and do not necessarily reflect the views of the funding agencies or the government. F. Wu is the corresponding author.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] “Gnip,” https://gnip.com/ .
- 2[2] “Data Sift,” http://datasift.com/ .
- 3[3] “Datacoup,” https://datacoup.com/ .
- 4[4] “Citizenme,” https://www.citizenme.com/ .
- 5[5] E. Ramirez, J. Brill, M. K. Ohlhausen, J. D. Wright, and T. Mc Sweeny, “Data brokers: A call for transparency and accountability,” Federal Trade Commission, Tech. Rep., May 2014. [Online]. Available: https://www.ftc.gov/reports/data-brokers-call-transparency-accountability-report-federal-trade-commission-may-2014
- 6[6] “Gallup Poll,” http://www.gallup.com/ .
- 7[7] M. Barbaro, T. Zeller, and S. Hansell, “A face is exposed for AOL searcher no. 4417749,” New York Times , Aug. 2006.
- 8[8] “2016 TRUS Te/NCSA Consumer Privacy Infographic - US Edition,” https://www.truste.com/resources/privacy-research/ncsa-consumer-privacy-index-us/ .