Improved Knowledge Graph Embedding using Background Taxonomic Information
Bahare Fatemi, Siamak Ravanbakhsh, and David Poole

TL;DR
This paper introduces a simple yet effective method to incorporate background taxonomic information into knowledge graph embeddings, improving their expressiveness and prediction accuracy.
Contribution
It presents minimal modifications to existing models to enable the injection of taxonomic information and proves the model's full expressiveness under certain conditions.
Findings
Enhanced embedding models respect subclass and subproperty constraints.
Experimental results show improved performance on public knowledge graphs.
Model remains simple yet effective in leveraging taxonomic background information.
Abstract
Knowledge graphs are used to represent relational information in terms of triples. To enable learning about domains, embedding models, such as tensor factorization models, can be used to make predictions of new triples. Often there is background taxonomic information (in terms of subclasses and subproperties) that should also be taken into account. We show that existing fully expressive (a.k.a. universal) models cannot provably respect subclass and subproperty information. We show that minimal modifications to an existing knowledge graph completion method enables injection of taxonomic information. Moreover, we prove that our model is fully expressive, assuming a lower-bound on the size of the embeddings. Experimental results on public knowledge graphs show that despite its simplicity our approach is surprisingly effective.
Click any figure to enlarge with its caption.
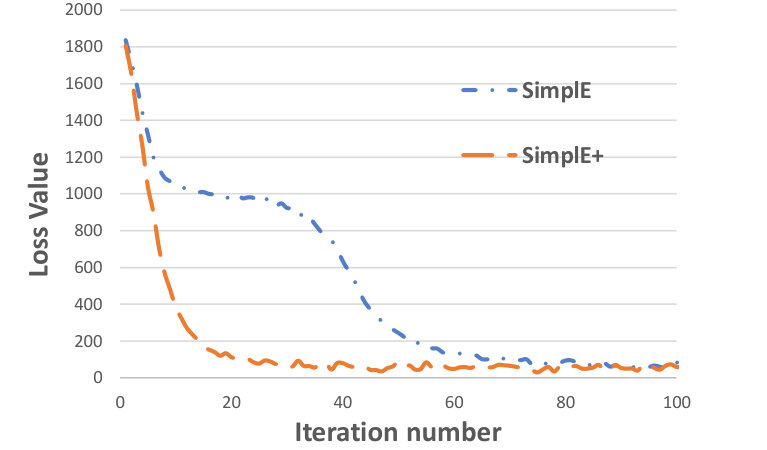 Figure 1
Figure 1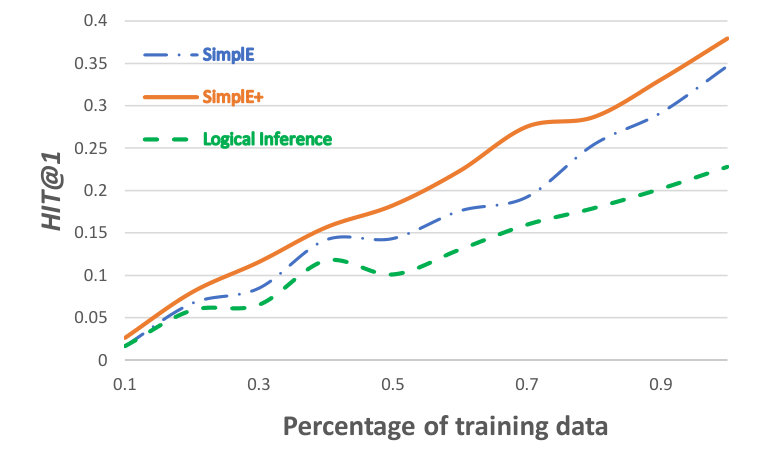 Figure 2
Figure 2 Figure 3
Figure 3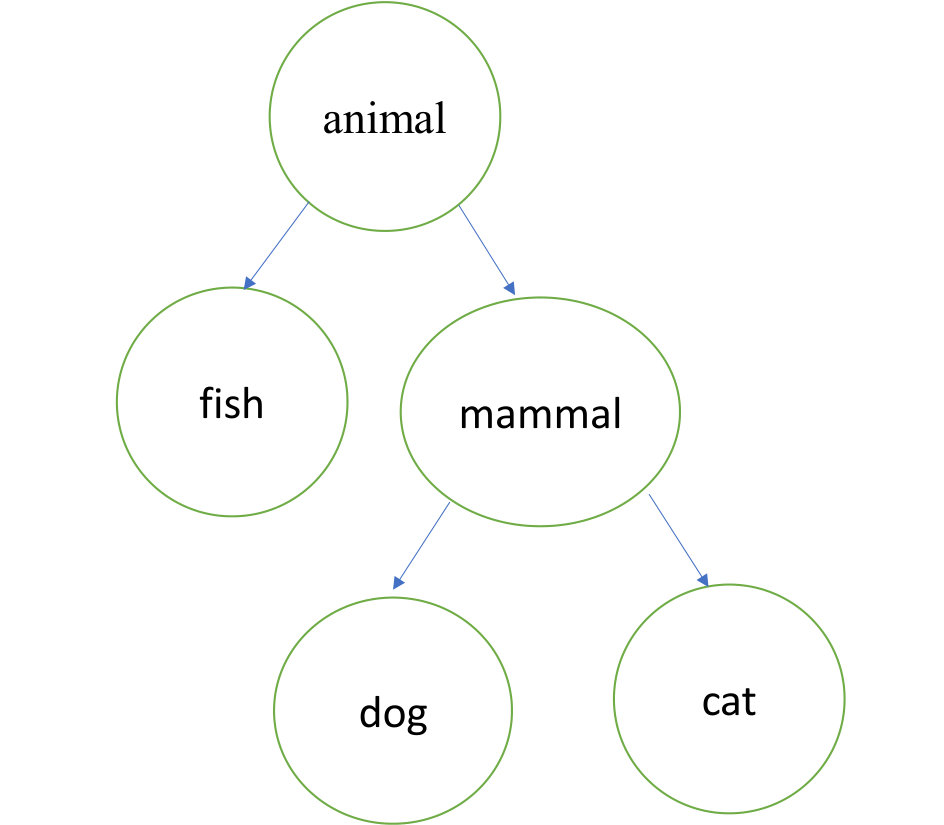 Figure 4
Figure 4| WN18 | FB15k | |||||||||
| MRR | Hit@ | MRR | Hit@ | |||||||
| Function | Filter | Raw | 1 | 3 | 10 | Filter | Raw | 1 | 3 | 10 |
| SimplE+-Exponential | ||||||||||
| SimplE+-Logistic | ||||||||||
| SimplE+-ReLU | ||||||||||
| Dataset | #train | #valid | #test | ||
| WN18 | 40,943 | 18 | 141,442 | 5,000 | 5,000 |
| FB15k | 14,951 | 1,345 | 483,142 | 50,000 | 59,071 |
| Sport | 1039 | 5 | 1312 | - | 307 |
| Location | 445 | 5 | 384 | - | 100 |
| Relations | Subsumptions | |
| Sport | AthleteLedSportsTeam AthletePlaysForTeam CoachesTeam OrganizationHiredPerson PersonBelongsToOrganization | |
| Location | CapitalCityOfCountry CityLocatedInCountry CityLocatedInState StateHasCapital StateLocatedInCountry |
| WN18 | FB15K | |||||||||
| MRR | Hit@ | MRR | Hit@ | |||||||
| Model | Filter | Raw | 1 | 3 | 10 | Filter | Raw | 1 | 3 | 10 |
| ComplEx | ||||||||||
| SimplE | ||||||||||
| SimplE+ | ||||||||||
| Sport | Location | |||||||||
| MRR | Hit@ | MRR | Hit@ | |||||||
| Model | Filter | Raw | 1 | 3 | 10 | Filter | Raw | 1 | 3 | 10 |
| Logical inference | - | - | - | - | - | - | - | - | ||
| SimplE | ||||||||||
| SimplE+ | 0.404 | 0.337 | 0.349 | 0.440 | 0.508 | 0.440 | 0.434 | 0.430 | 0.440 | 0.450 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Improved Knowledge Graph Embedding using Background Taxonomic Information
Bahare Fatemi, Siamak Ravanbakhsh, and David Poole
The University of British Columbia
Vancouver, BC, V6T 1Z4
{bfatemi, siamakx, poole}@cs.ubc.ca
Abstract
Knowledge graphs are used to represent relational information in terms of triples. To enable learning about domains, embedding models, such as tensor factorization models, can be used to make predictions of new triples. Often there is background taxonomic information (in terms of subclasses and subproperties) that should also be taken into account. We show that existing fully expressive (a.k.a. universal) models cannot provably respect subclass and subproperty information. We show that minimal modifications to an existing knowledge graph completion method enables injection of taxonomic information. Moreover, we prove that our model is fully expressive, assuming a lower-bound on the size of the embeddings. Experimental results on public knowledge graphs show that despite its simplicity our approach is surprisingly effective.
The AI community has long noticed the importance of structure in data. While traditional machine learning techniques have been mostly focused on feature-based representations, the primary form of data in the subfield of Statistical Relational AI (StaRAI) (Getoor and Taskar, 2007; Raedt et al., 2016) is in the form of entities and relationships among them. Such entity-relationships are often in the form of triples, which can also be expressed in the form of a graph, with nodes as entities and labeled directed edges as relationships among entities. Predicting the existence, identity, and attributes of entities and their relationships are among the main goals of StaRAI.
Knowledge Graphs (KGs) are graph structured knowledge bases that store facts about the world. A large number of KGs have been created such as NELL (Carlson et al., 2010), Freebase (Bollacker et al., 2008), and Google Knowledge Vault (Dong et al., 2014). These KGs have applications in several fields including natural language processing, search, automatic question answering and recommendation systems. Since accessing and storing all the facts in the world is difficult, KGs are incomplete. The goal of link prediction for KGs – a.k.a. KG completion – is to predict the unknown links or relationships in a KG based on the existing ones. This often amounts to infer (the probability of) new triples from the existing triples.
A common approach to apply machine learning to symbolic data, such as text, graph and entity-relationships, is through embeddings. Word, sentence and paragraph embeddings (Mikolov et al., 2013; Pennington, Socher, and Manning, 2014), which vectorize words, sentences and paragraphs using context information, are widely used in a variety of natural language processing tasks from syntactic parsing to sentiment analysis. Graph embeddings (Hoff, Raftery, and Handcock, 2002; Grover and Leskovec, 2016; Perozzi, Al-Rfou, and Skiena, 2014) are used in social network analysis for link prediction and community detection.
In relational learning, embeddings for entities and relationships are used to generalize from existing data. These embeddings are often formulated in terms of tensor factorization (Nickel, Tresp, and Kriegel, 2012; Bordes et al., 2013; Trouillon et al., 2016; Kazemi and Poole, 2018c). Here, the embeddings are learned such that their interaction through (tensor-)products best predicts the (probability of the) existence of the observed triples; see (Nguyen, 2017; Wang et al., 2017) for details and discussion. Tensor factorization methods have been very successful, yet they rely on a large number of annotated triples to learn useful representations. There is often other information in ontologies which specifies the meaning of the symbols used in a knowledge base. One type of ontological information is represented in a hierarchical structure called a taxonomy. For example, a knowledge base might contain information that DJTrump, whose name is “Donald Trump” is a president, but may not contain information that he is a person, a mammal and an animal, because these are implied by taxonomic knowledge. Being told that mammals are chordates, lets us conclude that DJTrump is also a chordate, without needing to have triples specifying this about multiple mammals. We could also have information about subproperties, such as that being president is a subproperty of “managing”, which in turn is a subproperty of “interacts with”.
This paper is about combining taxonomic information in the form of subclass and subproperty (e.g., managing implies interaction) into relational embedding models. We show that existing factorization models that are fully expressive cannot reflect such constraints for all legal entity embeddings. We propose a model that is provably fully expressive and can represent such taxonomic information, and evaluate its performance on real-world datasets.
Factorization and Embedding
Let represent the set of entities and represent the set of relations. Let be a set of triples that are true in the world, where are head and tail, and is the relation in the triple. We use to represent the triples that are false – i.e., . An example of a triple in can be and an example of a triple in can be . A KG is a subset of all the facts. The problem of the KG completion is to infer from its subset KG. There exists a variety of methods for KG completion. Here, we consider embedding methods and in particular using tensor-factorization. For a broader review of the existing KG completion that can use background information see Related Work.
Embeddings: An embedding is a function from an entity or a relation to a vector (or sometimes higher order tensors) over a field. We use bold lower-case for vectors – that is is an embedding of an entity and is an embedding of a relation.
Taxonomies: It is common to have structure over the symbols used in the triples, see (e.g., Shoham, 2016). The Ontology Web Language (OWL) (Hitzler et al., 2012) defines (among many other meta-relations) subproperties and subclasses, where is a subproperty of if , that is whenever is true, is also true. Classes can be defined either as a set with a class assertion (often called “type”) between an entity and a class, e.g., saying is in class using or in terms of the characteristic function of the class, a function that is true of element of the class. If is the characteristic function of class , then is in class is written . For representations that treat entities and properties symmetrically, the two ways to define classes are essentially the same. is a subclass of if every entity in class is in class , that is, or . If we treat as an entity, then subclass can be seen as a special case of subproperty. For the rest of the paper we will refer to subsumption in terms of subproperty (and so also of subclass). A non-trivial subsumption is one which is not symmetric; is a subproperty of and there is some relations that is true of that is not true of . We want the subsumption to be over all possible entities; those entities that have a legal embedding according to the representation used, not just those we know exist. Let be the set of all possible entities with a legal embedding according to the representation used.
Tensor factorization: For KG completion a tensor factorization defines a function that takes the embeddings , and of a triple as input, and generates a prediction, e.g., a probability, of the triple being true . In particular, is often a non-linearity applied to a multi-linear function of . The family of methods that we study uses the following multi-linear form: Let , , and be vectors of length . Define to be the sum of their element-wise product, namely
[TABLE]
where is the -th element of vector .
Here, we are interested in creating a tensor-factorization method that is fully expressive and can incorporate background information in the form of taxonomy. A model is fully expressive if given any assignment of truth values to all triples, there exists an assignment of values to the embeddings of the entities and relations that accurately separates the triples belonging to and using .
ComplEx
ComplEx (Trouillon et al., 2016) defines the reconstruction function , such that the embedding of each entity and each relation is a vector of complex numbers. Let and denote the real and imaginary part of a complex vector . In ComplEx, the probability of any triple is
[TABLE]
where is the sigmoid or logistic function, and (where ) is the element-wise conjugate of the complex vector . Note that, if the tail did not use the conjugate, the head and tail would be treated symmetrically and it could only represent symmetric relations; e.g., see DistMult in Yang et al. (2014).
Trouillon et al. (2017) prove that ComplEx is fully expressive. In particular, they prove that any assignment of ground truth can be modeled by ComplEx embeddings of length . The following theorem shows that we cannot use ComplEx to enforce our prior knowledge about taxonomies.
Theorem 1**.**
*ComplEx cannot enforce non-trivial subsumption. *
Proof**.**
Assume a non-trivial subsumption so that , and so , and there are entities such that . Let be an entity such that . Then and , so , a contradiction to the subsumption we assumed.
Recently, Ding et al. (2018) proposed a method which they call ComplEx-NNE+AER to incorporate a weaker notion of subsumption in ComplEx. For a subsumption , they suggest adding soft constraints to the loss function to encourage and . When the constraints are satisfied, ComplEx-NNE+AER ensures . This is a weaker notion than the definition in the Factorization and Embedding section which requires (that is, is replaced with ).
Theorem 2**.**
*ComplEx-NNE+AER cannot satisfy its constraints and be fully expressive if symmetry constraints are allowed. *
Proof**.**
In ComplEx a relation is symmetric for all possible entities if and only if (Trouillon et al., 2016, Section 3). In order to satisfy constraints for , Ding et al. (2018) assign . Therefore, if relation is symmetric, it enforces relation to be symmetric too which is not generally true. As a counter example, might be the married_to relation, which is symmetric (so the ), but is the knows relation, and is true in real-world, but setting the = will imply knows is symmetric, which is not true (as many people know celebrities but celebrities do not know many people).
SimplE
SimplE (Kazemi and Poole, 2018c) achieves state-of-the-art in KG completion by considering two embeddings for each relation: one for the relation itself and one for its inverse. We use to denote the “forward” embedding of and to denote the embedding of its inverse. The embedding for a relation is a concatenation of these two parts. Similarly, the embedding for each entity has two parts: its embedding as a head and as a tail – that is . Using this notation, SimplE calculates the probability of for each triple in both forward and backward directions using
[TABLE]
Kazemi and Poole (2018c) prove SimplE is fully expressive and provide a bound on the size of the embedding vectors: For any truth assignment , there exists a SimplE model with embedding vectors of size that represent the assignment. The following theorem shows the limitation of SimplE when it comes to enforcing subsumption.
Theorem 3**.**
*SimplE cannot enforce non-trivial subsumptions. *
Proof**.**
Consider as a non-trivial subsumption. So we have , and there are entities such that . Let be an entity such that . Then and , so a contradiction to the subsumption we assumed.
Neural network models
The neural network models (Socher et al., 2013; Dong et al., 2014; Santoro et al., 2017) are very flexible, and so without explicit mechanisms to enforce subsumption, they cannot be guaranteed to obey any subsumption knowledge.
Proposed Variation: SimplE*+*
In this section we propose a slight modification on SimplE so that the resulting method can enforce subsumption. The modification is restricting entity embeddings to be non-negative – that is , where the inequality is element-wise. Next we show that the resulting model is fully expressive and is able to enforce subsumption.
Theorem 4** (Expressivity).**
*For any truth assignment over entities and relations containing true facts, there exists a SimplE+model with embeddings vectors of size that represent the assignment. *
Proof**.**
Assume is the -th relation in and is the -th entity in . For a vector we define as the -th element of . We define if except the last element , and for each entity we define if or and 0 otherwise. In this setting, for each and product of and is [math] everywhere except for the element at and the last element in the embeddings. In order for the triple to hold, we define to be a vector where all elements are [math] except the ()-th element which is . This proves that SimplE+is fully expressive with the bound of for size of the embeddings.
We use induction to prove the bound . Let (base of induction). We can have embedding vectors of size 1 for each entity and relation, setting the value for entities to 1 and to relations to -1. Then + is negative for every entities and and relation . So there exist an assignment of size 1 that represent this ground truth.
Let’s assume for any ground truth where , there exists an assignment of values to embedding vectors of size that represent the ground truth (assumption of induction). We must prove for any ground truth where , there exist an assignment of values to embedding vectors of size that represent this ground truth.
Let be one of the true facts. Consider a modified ground truth which is identical to the ground truth with true facts, except that is assigned false. The modified ground truth has true facts and based on the assumption of the induction, we can represent it using some embedding vectors of size . Let . We add an element to the end of all embedding vectors and set it to [math]. This increases the vector size to but does not change any scores. Then we set to , to 1 and to . This ensure this triple is true for the new vectors, and no other probability of triple is affected.
Theorem 5** (Subsumption).**
*SimplE+ guarantees subsumption using an inequality constraints. *
Proof**.**
Assume as a non-trivial subsumption. As legal entity embeddings in SimplE+have non-negative elements, by adding the element-wise inequality constraint , we force for all which is forcing the subsumption.
Objective Function and Training
Given the function , that maps embeddings to the probability of a triple, ideally we would like to minimize the following regularized negative log-likelihood function:
[TABLE]
where {} represents entity embeddings, {} represents relation embeddings and is a regularization term. We use L2-regularization in our experiments. Optimizing poses two challenges: I) we do not know the sets and , as the purpose of KG completion is to produce these sets in the first place; II) the number of triples (specially in ) is often too large, and for larger KGs exact calculation of these terms is often computationally unfeasible.
To address I, we use as a surrogate for and use its complement instead of . To address the computational problem in II, we use stochastic optimization and follow the contrastive approach of Bordes et al. (2013): for each mini-batch of positive samples from KG, we produce a mini-batch of negative samples of the same size, by randomly “corrupting” the head or tail of the triple – i.e., replacing it with a random entity.
Enforcing the subsumptions
In order to enforce , we add an equality constraint as , where is a non-negative vector that specifies how differs from . We learn for all relations that are in such a subsumption. This equality constraint guarantees the inequality constraint of Theorem 5.
Experimental Results
The objective of our empirical evaluations is two-fold: First, we want to see the practical implication of non-negativity constraints in terms of effectiveness of training and the quality of final results. Second, and more importantly, we would like to evaluate the practical benefit of incorporating prior knowledge in the form of subsumptions in sparse data regimes.
Datasets: We conducted experiments on four standard benchmarks: WN18, FB15k, Sport and Location. WN18 is a subset of Wordnet (Miller, 1995) and FB15k is a subset of Freebase (Bollacker et al., 2008). Sport and Location datasets are introduced by Wang et al. (2015), who created them using NELL (Mitchell et al., 2015). The relations in Sport and Location, along with the subsumptions, are listed in Table 3. Table 2 gives a summary of these datasets. For evaluation on WN18, FB15k, we split the existing triples in KG into the same train, validation, and test sets using the same split as (Bordes et al., 2013).
Evaluation Metrics: To evaluate different KG completion methods we need to use a train and test split, where . We use two evaluation metrics: hit@t and Mean Reciprocal Rank (MRR). Both these measures rely on the ranking of a triple in the test set , obtained by corrupting the head (or the tail) of the relation with and estimating . An indicator for a good KG completion method is that ranks high in the sorted list among corrupted triples.
Let be the ranking of among all head-corrupted relations, and let denote a similar ranking with tail corruptions. MRR is the mean of the reciprocal rank:
[TABLE]
To provide a better metric, Bordes et al. (2013) suggest removing any corrupted relation that is in KG. We refer to the original definition of MRR as raw MRR and to Bordes et al. (2013)’s modified version as filtered MRR.
hit@t measures the proportion of triples in that rank among top after corrupting both heads and tails.
Effect of Non-Negativity Constraints
Non-negativity has been a subject studied in various research fields. In many NLP-related tasks, non-negativity constraints are studies to learn more interpretable representations for words (Murphy, Talukdar, and Mitchell, 2012). In matrix factorization, non-negativity constraints are used to produce more coherent and independent factors (Lee and Seung, 1999). Ding et al. (2018) also proposed using non-negativity constraint to incorporate subsumption into ComplEx. We use the non-negativity constraint in SimplE+ to enforce monotonousity of probabilities as dictated by subsumption. In order to get non-negativity constraint on the embedding of entities, we simply apply an element-wise non-linearity before evaluation – that is we replace with .
Table 1 shows the result of SimplE*+* with for different choices of : I) exponential ; II) logistic ; and III) rectified linear unit (ReLU) . ReLU outperforms other choices, and therefore moving forward we use ReLU for non-negativity constraints.
Next, we evaluate the effect of non-negativity constraint on the performance of the algorithm. Table 4 shows our result on WN18 and FB15k datasets. Note that this is effectively comparing SimplE+with SimplE and ComplEx, without accommodating any subsumptions. As the results indicate, this constraint does not deteriorate the model’s performance.
Sparse Relations
In this section, we study the scenario of learning relations that appear in few triples in the KG. In particular, we observe the behaviour of various methods as the amount of training triples varies. We train SimplE, SimplE+, and logical inference on fractions of the Sport training set and test them on the full test set. Logical inference refers to inferring new triples based only on the subsumptions.
Figure 1 shows the hit@1 of the three methods when they are trained on different fractions (percentages) of the training data. According to Figure 1, when training data is scarce, logical inference performs better than (or on-par with) SimplE, as SimplE does not see enough triples to be able to learn meaningful embeddings. As the amount of training data increases, SimplE starts to outperform logical inference as it can better generalize to unseen cases than pure logical inference. The gap between these two methods becomes larger as the amount of training data increases. For all tested fractions, SimplE+outperforms both SimplE and logical inference as it uses both the generalization power of SimplE and the inference power of logical rules.
In order to test the effect of incorporating taxonomical information on the number of epochs required for training to converge, we tested SimplE and SimplE+on the Sport dataset with the same set of parameters and the same initialization and plotted the loss function for each epoch. The plot in Figure 2 shows that SimplE+requires fewer epochs than SimplE to converge.
KGs with no Redundant Triples
Tensor factorization techniques rely on large amounts of annotated data. When background knowledge is available, we might expect a KG to not include redundant information. For instance if we have in a kg and we know , then the triple is redundant. Similar to the experiment for incorporating background knowledge in Kazemi and Poole (2018c), we remove all redundant triples from the training set and compare SimplE with SimplE+and logical inference. The obtained results in Table 5 demonstrate that SimplE+outperforms SimplE and logical inference on both Sport and Location datasets with a large margin. As an example, SimplE+gains almost 90 percent and 230 percent improvement over SimplE in terms of hit@1 for Sport and Location datasets respectively. These results represent the clear advantage of SimplE+over SimplE when background taxonomic information is available.
Related Work
Incorporating background knowledge in link prediction methods has been the focus of several studies. Here, we categorize these approaches emphasizing the shortcomings that are addressed in our work; see (Nickel et al., 2016) for a review of KG embedding methods.
Soft rules There is a large family of link prediction models based on soft first-order logic rules Richardson and Domingos (2006); De Raedt, Kimmig, and Toivonen (2007); Kazemi et al. (2014). While these models can be easily integrated with background taxonomic information, they typically cannot generalize to unseen cases beyond their rules. Exceptions include Fatemi, Kazemi, and Poole (2016); Kazemi and Poole (2018b) which combine (stacked layers of) soft rules with entity embeddings, but these models have only applied to property prediction. Approaches based on path-constrained random walks (e.g., Lao and Cohen (2010)) suffer from similar limitations as they have been shown to be a subset of probabilistic logic-based models Kazemi and Poole (2018a).
Augmentation by grounding of the rules The simplest way to incorporate a set of rules in the KG is to augment the KG with their groundings (Sedghi and Sabharwal, 2018) before learning the embedding. Demeester, Rocktäschel, and Riedel (2016) address the computational inefficiency of this approach through lifted rule injection. However, in addition to being inefficient, the the resulting model does not guarantee the subsumption in the completed KG.
Augmentation through post-processing A simple approach is to augment the KG after learning the embedding using an existing method (Wang et al., 2015; Wei et al., 2015). That is, as a post processing step we can modify the output of KG completion so as to satisfy the ontological constraints. The drawback of this approach is that the background knowledge does not help learn a better representation.
Regularized embeddings Rocktäschel, Singh, and Riedel (2015) regularize the learned embeddings using first-order logic rules. In this work, every logic rule is grounded based on observations and a differentiable term is added to the loss function for every grounding. For example, grounding the rule would result in a very large number of loss terms to be added to the loss function in a large KG. This method as well as other approaches in this category (e.g., Rocktäschel et al., 2014; Wang et al., 2015; Wang and Cohen, 2016) do not scale beyond a few entities and rules, because of the very large number of regularization terms added to the loss function (Demeester, Rocktäschel, and Riedel, 2016). Guo et al. (2018) proposed a methods for incorporating entailment into ComplEx called RUGE which models rules based on t-norm fuzzy logic, which imposes an independence assumption over the atoms. Such an independence assumption is not necessarily true, especially in the case of subsumption, e.g. in for which the left and the right part of the subsumption are strongly dependent. In addition to being inefficient, the resulting model of the regularized embedding approaches does not guarantee the subsumption in the completed KG.
Constrained matrix factorization Several recent works incorporate background ontologies into the embeddings learned by matrix factorization (e.g., Rocktäschel, Singh, and Riedel, 2015; Demeester, Rocktäschel, and Riedel, 2016). While these methods address the problems of the two categories above, they are inadequate due to the use of matrix factorization. Application of matrix factorization for KG completion (Riedel et al., 2013) learns a distinct embedding for each head-tail combination. In addition to its prohibitive memory requirement, since entities do not have their own embeddings, some regularities in the KG are ignored; for example this representation is oblivious to the fact that and share the same tail.
Constrained translation-based methods In translation-based methods, the relation between two entities is represented using an affine transformation, often in the form of translation. Most relevant to our work is KALE (Guo et al., 2016) that constrains the representation to accommodate logical rules, albeit after costly propositionalization. Several recent works show that a variety of existing translation-based methods are not fully expressive (Wang et al., 2017; Kazemi and Poole, 2018c), putting a severe limitation on the kinds of KGs that can be modeled using translation-based approaches.
Region based representation Gutiérrez-Basulto and Schockaert (2018) propose representing relations as convex regions in a -dimensional space, where is the length of the entity embeddings. A relation between two embeddings is deemed true if the corresponding point is in the convex region of the relation. Although this framework allows Gutiérrez-Basulto and Schockaert (2018) to incorporate a subset of existential rules by restricting the convex regions of relations, they did not propose a practical method for learning and their method is restricted to a subset of existential rules.
Conclusion and Future Work
In this paper, we proposed SimplE+, a fully expressive tensor factorization model for knowledge graph completion when background taxonomic information (in terms of subclasses and subproperties) is available. We showed that existing fully expressive models cannot provably respect subclass and subproperty information. Then we proved that by adding non-negativity constraints to entity embeddings of SimplE, a state-of-the-art tensor factorization approach, we can build a model that is not only fully expressive but also able to enforce subsumptions. Experimental results on benchmark KGs demonstrate that SimplE+is simple yet effective. On our benchmarks, SimplE+outperforms SimplE and offers a faster convergence rate when background taxonomic information is available. In future, we plan to extend SimplE+to further incorporate ontological background information, and rules such as .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bollacker et al . (2008) Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; and Taylor, J. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data , 1247–1250. Ac M.
- 2Bordes et al . (2013) Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; and Yakhnenko, O. 2013. Translating embeddings for modeling multi-relational data. In NIPS , 2787–2795.
- 3Carlson et al . (2010) Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka Jr, E. R.; and Mitchell, T. M. 2010. Toward an architecture for never-ending language learning. In AAAI , volume 5, 3. Atlanta.
- 4De Raedt, Kimmig, and Toivonen (2007) De Raedt, L.; Kimmig, A.; and Toivonen, H. 2007. Problog: A probabilistic prolog and its application in link discovery.
- 5Demeester, Rocktäschel, and Riedel (2016) Demeester, T.; Rocktäschel, T.; and Riedel, S. 2016. Lifted rule injection for relation embeddings. ar Xiv preprint ar Xiv:1606.08359 .
- 6Ding et al . (2018) Ding, B.; Wang, Q.; Wang, B.; and Guo, L. 2018. Improving knowledge graph embedding using simple constraints. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics .
- 7Dong et al . (2014) Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; and Zhang, W. 2014. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining , 601–610. ACM.
- 8Fatemi, Kazemi, and Poole (2016) Fatemi, B.; Kazemi, S. M.; and Poole, D. 2016. A learning algorithm for relational logistic regression: Preliminary results. ar Xiv preprint ar Xiv:1606.08531 .