TL;DR
This paper introduces an adaptive MCMC framework for efficiently sampling from multimodal distributions by combining local moves and mode-jumping strategies, learning optimal parameters dynamically.
Contribution
It presents a novel auxiliary variable adaptive MCMC method that automatically learns parameters and effectively explores multimodal distributions.
Findings
Proves ergodic properties of the proposed class of algorithms.
Develops an auxiliary variable scheme for adaptive MCMC.
Demonstrates improved sampling efficiency in multimodal contexts.
Abstract
We propose a new Monte Carlo method for sampling from multimodal distributions. The idea of this technique is based on splitting the task into two: finding the modes of a target distribution and sampling, given the knowledge of the locations of the modes. The sampling algorithm relies on steps of two types: local ones, preserving the mode; and jumps to regions associated with different modes. Besides, the method learns the optimal parameters of the algorithm while it runs, without requiring user intervention. Our technique should be considered as a flexible framework, in which the design of moves can follow various strategies known from the broad MCMC literature. In order to design an adaptive scheme that facilitates both local and jump moves, we introduce an auxiliary variable representing each mode and we define a new target distribution on an augmented state…
Click any figure to enlarge with its caption.
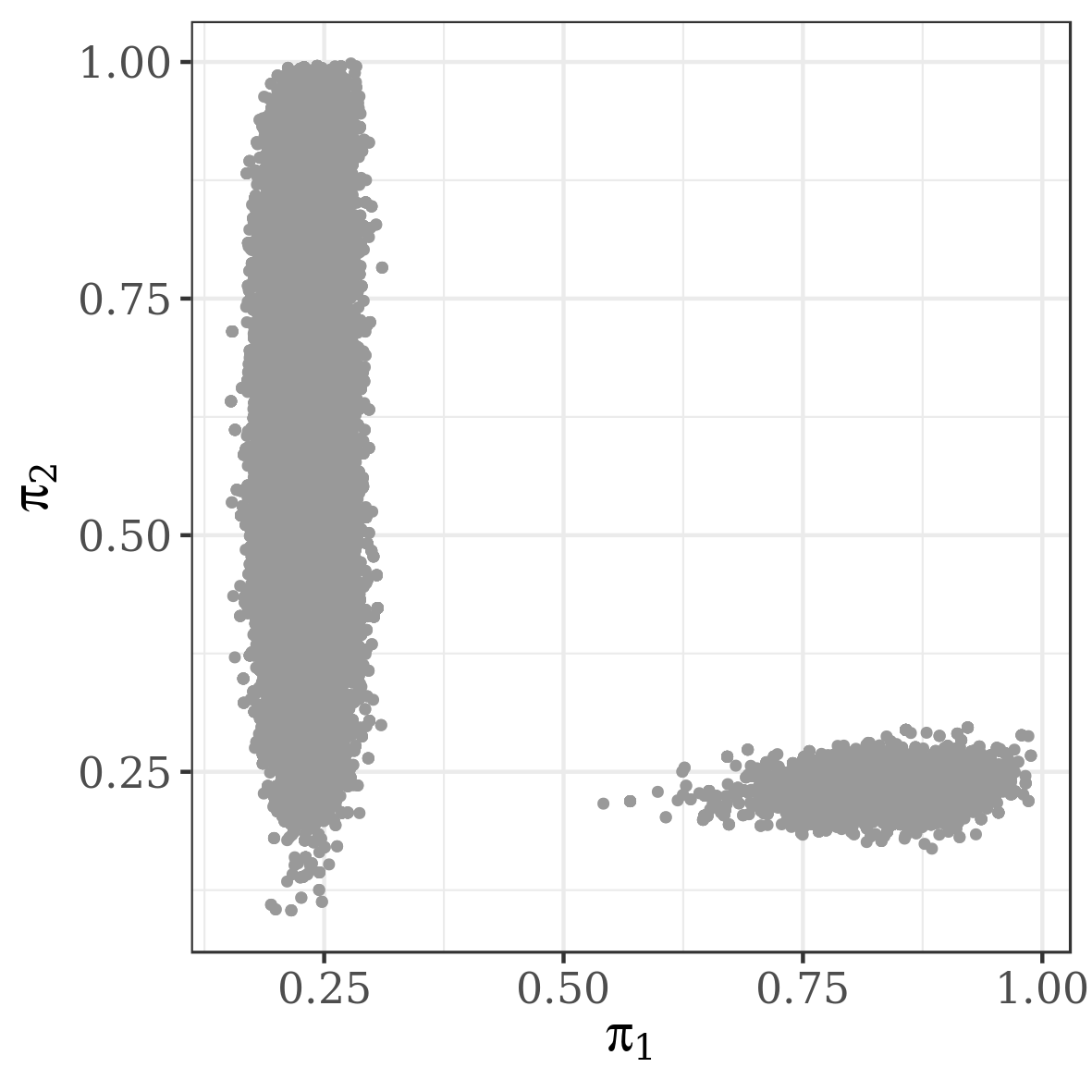 Figure 1
Figure 1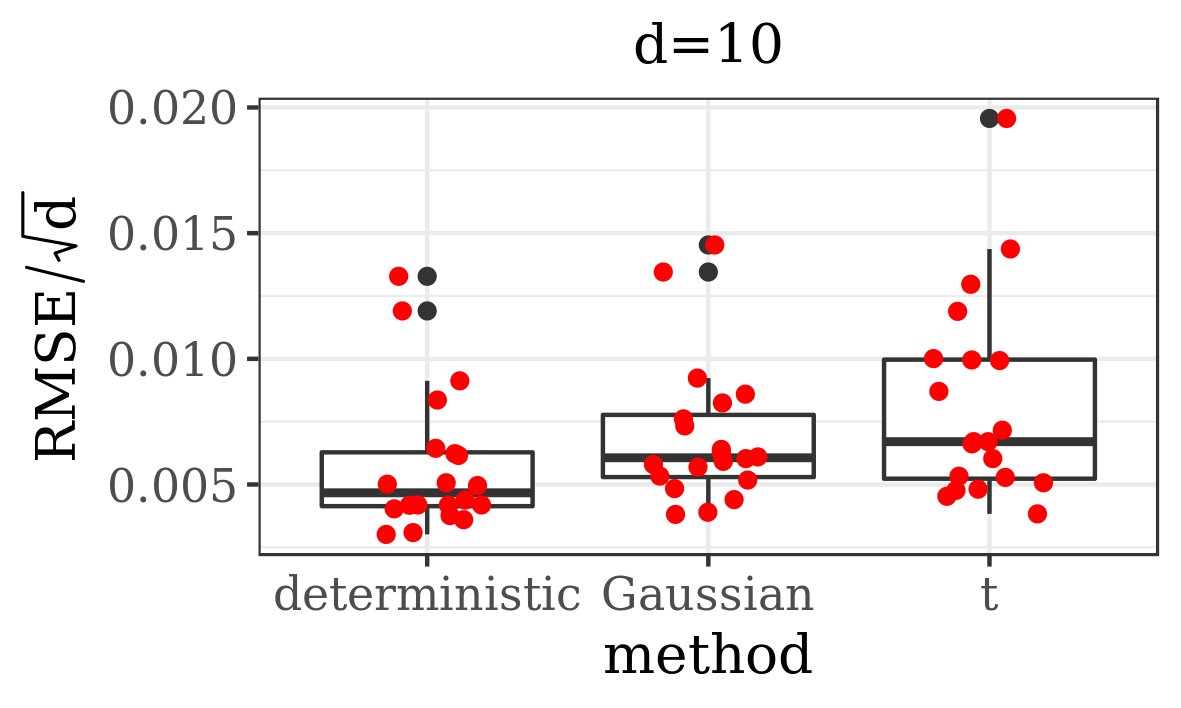 Figure 2
Figure 2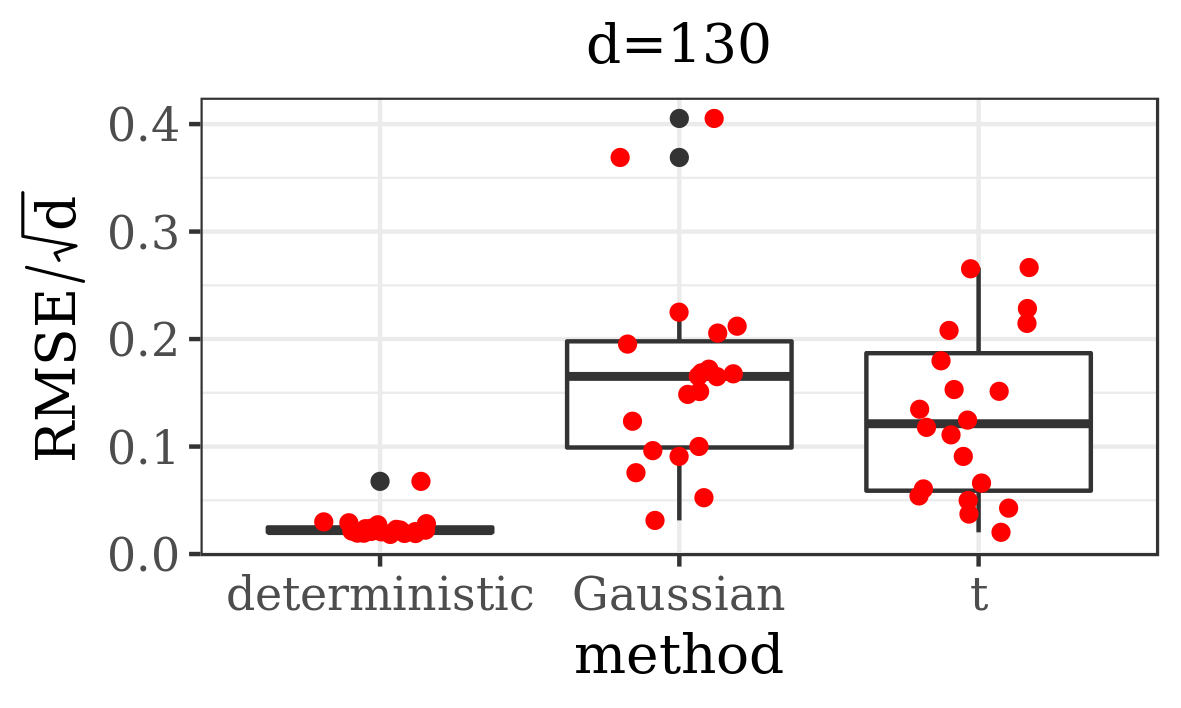 Figure 3
Figure 3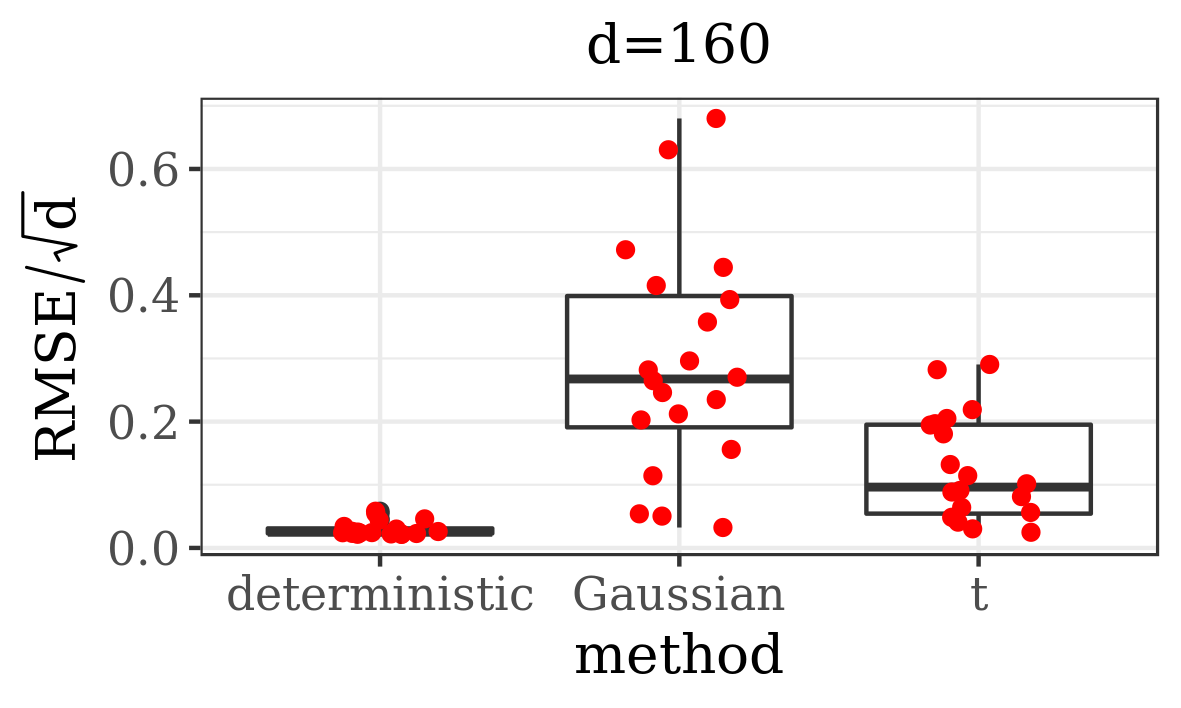 Figure 4
Figure 4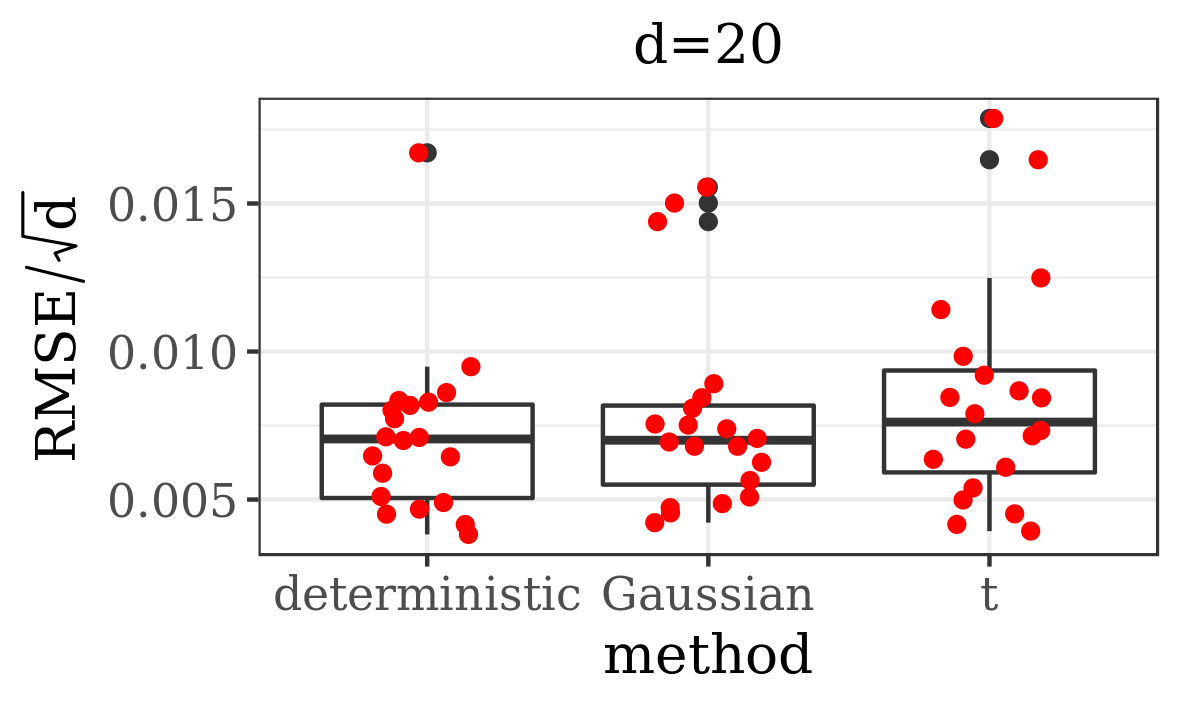 Figure 5
Figure 5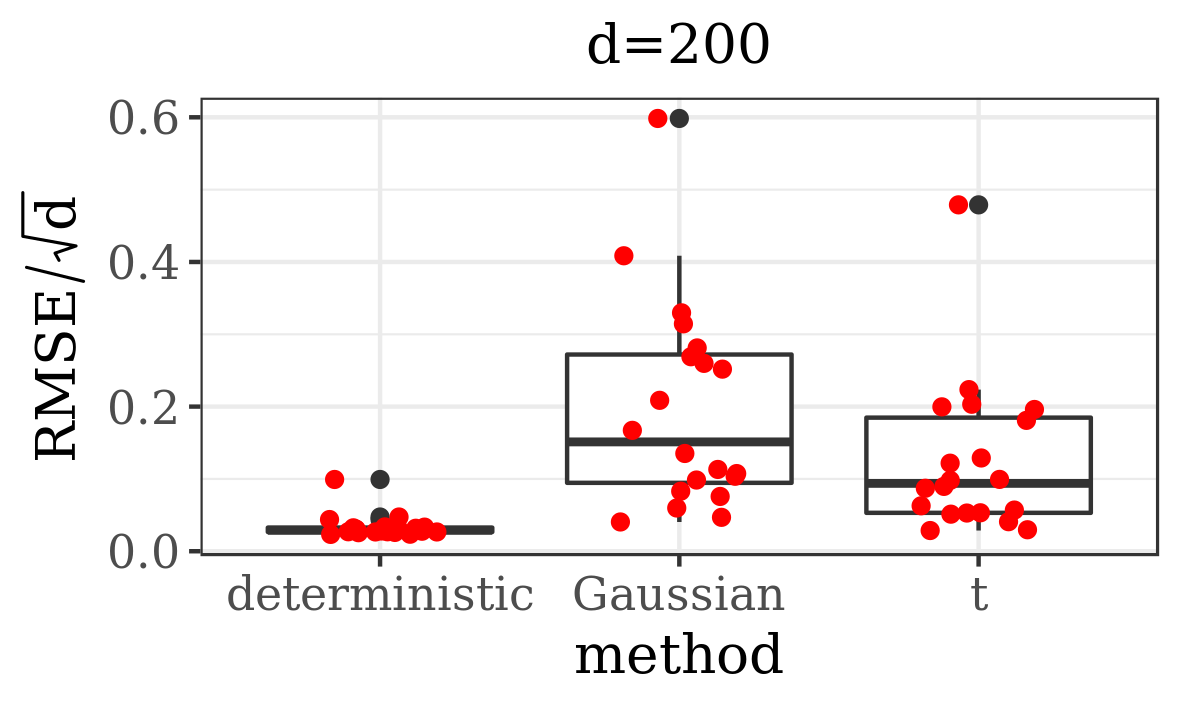 Figure 6
Figure 6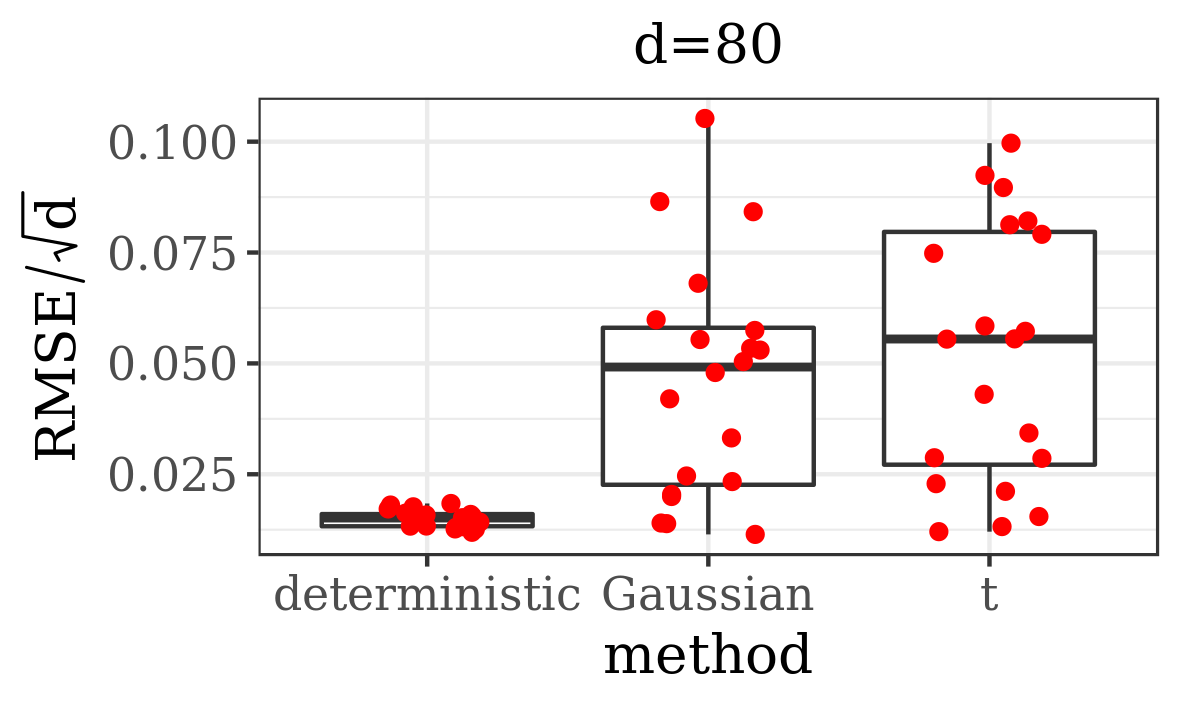 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12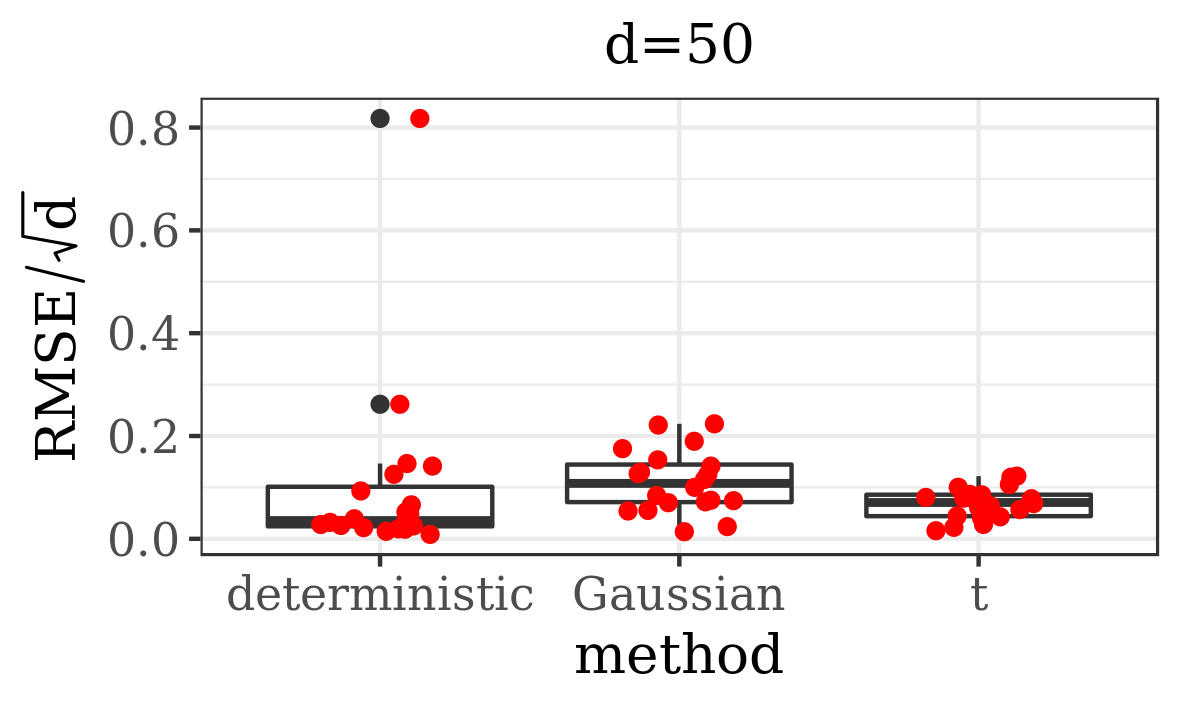 Figure 13
Figure 13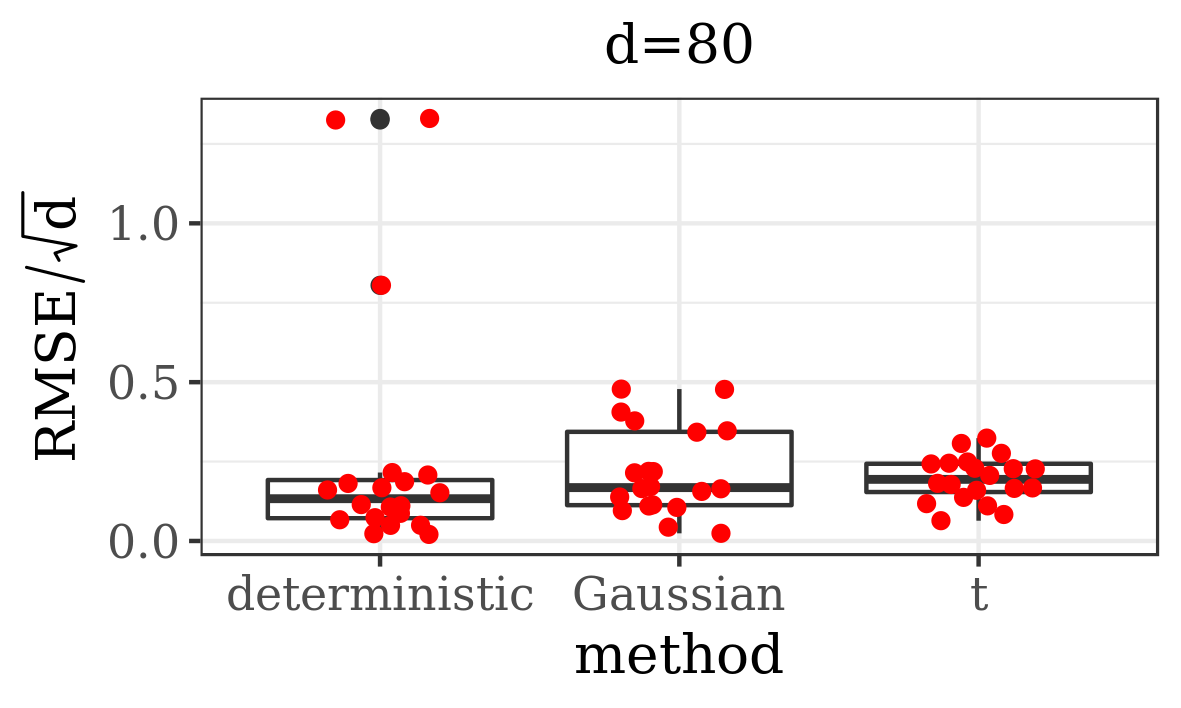 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16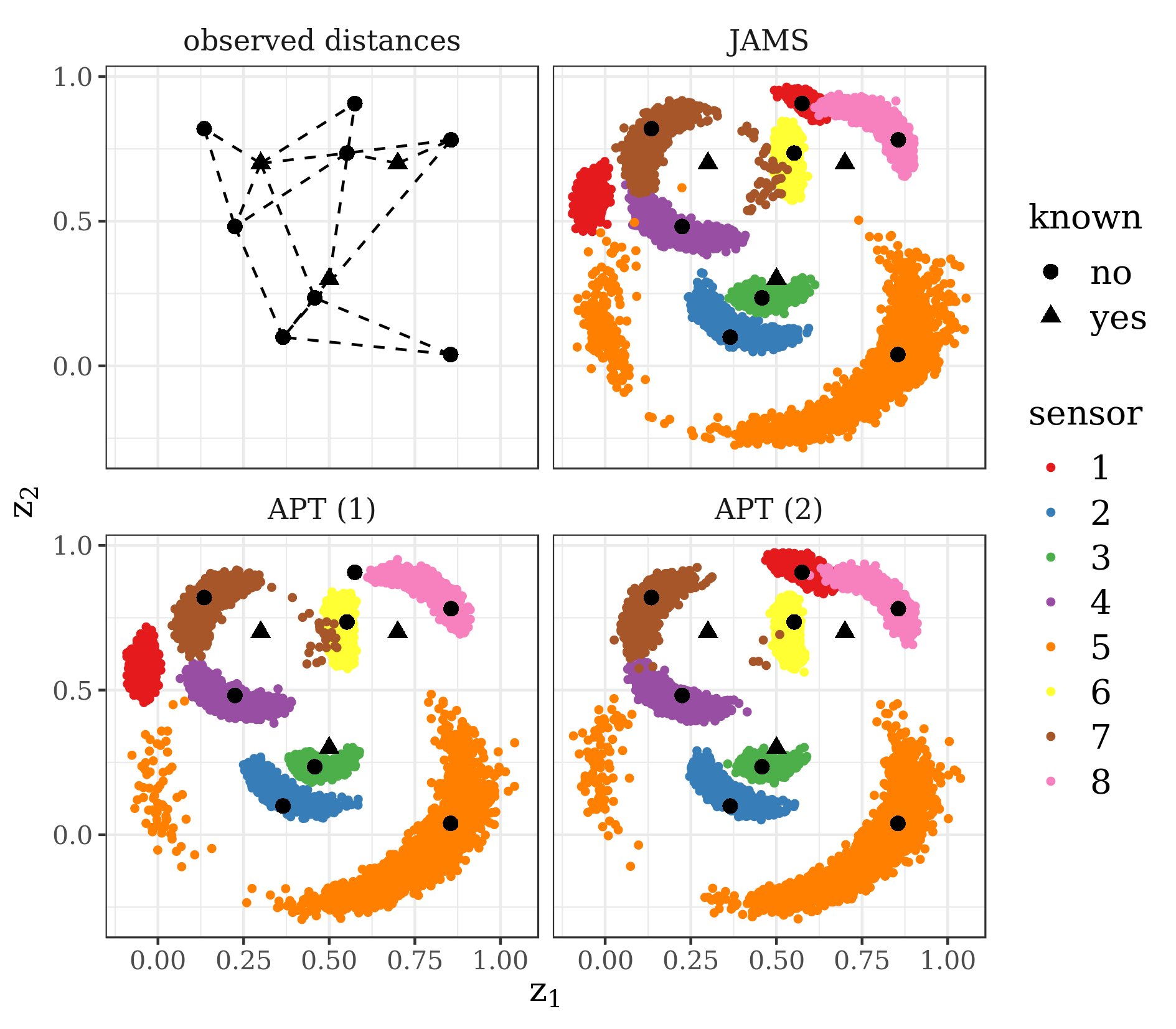 Figure 17
Figure 17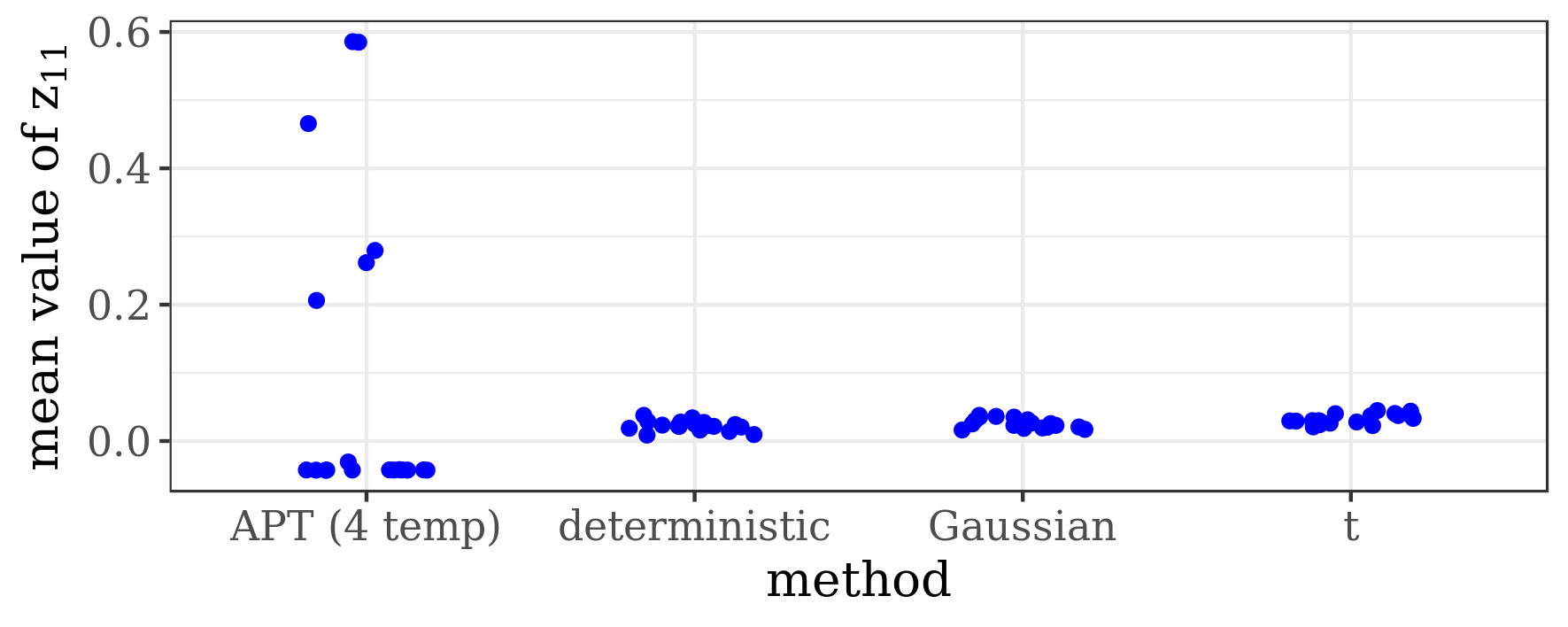 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20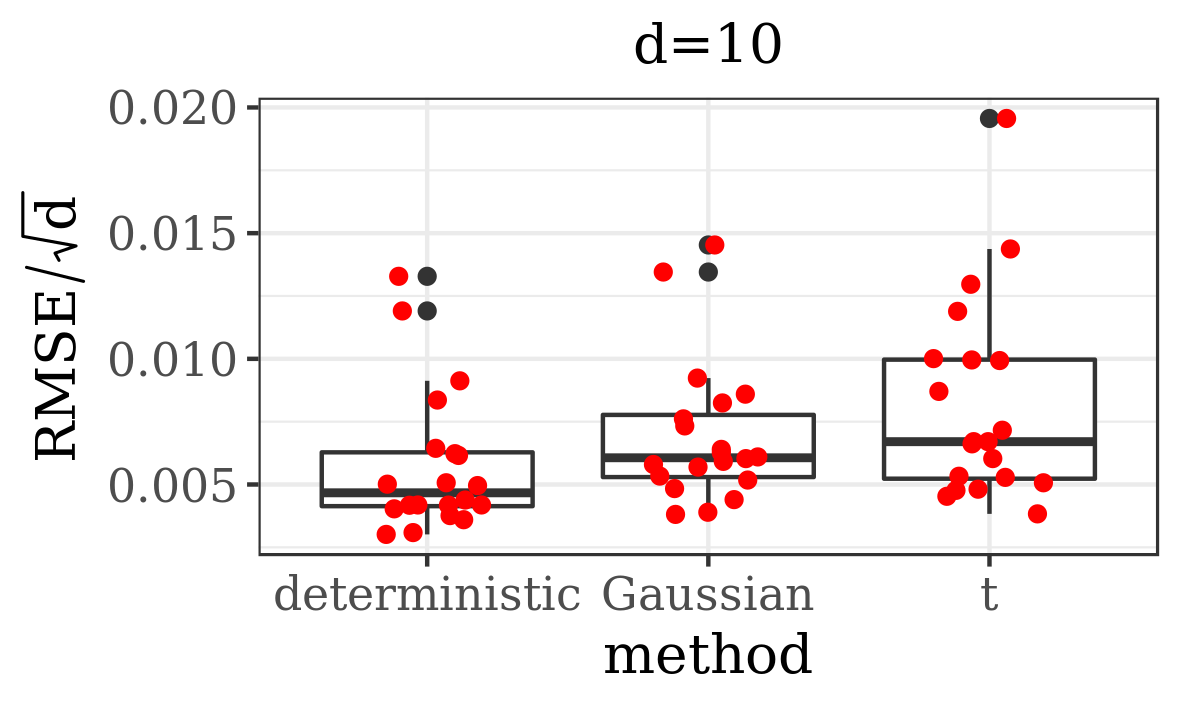 Figure 21
Figure 21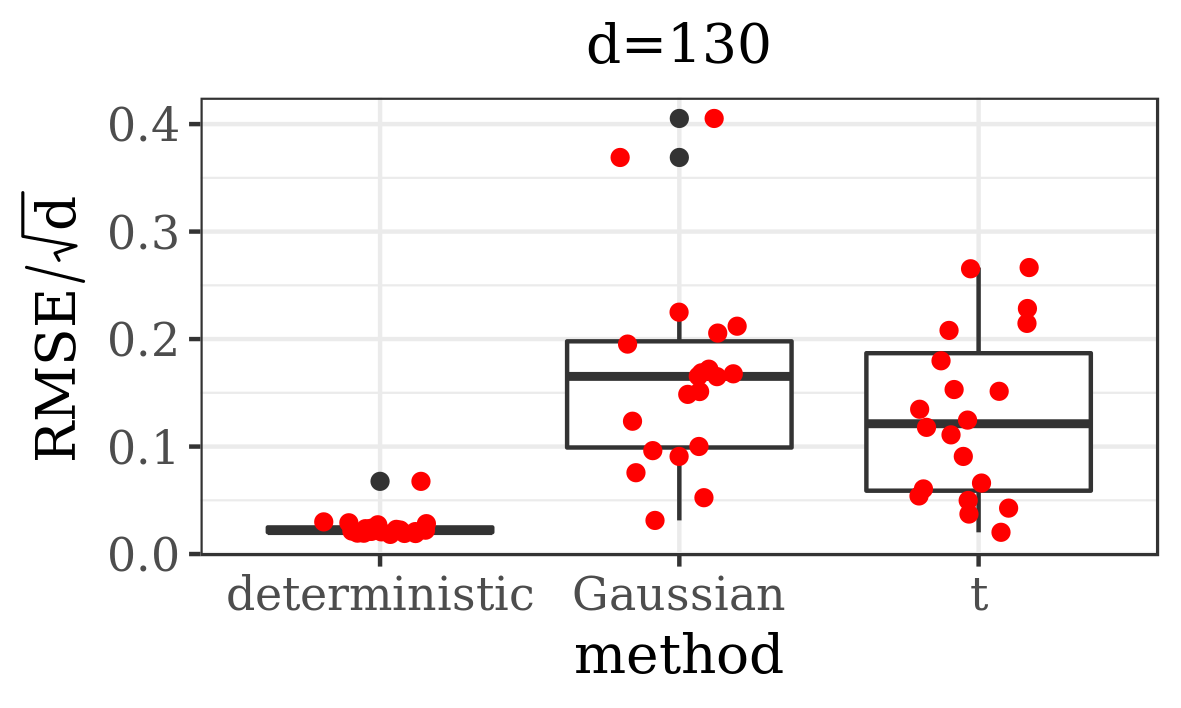 Figure 22
Figure 22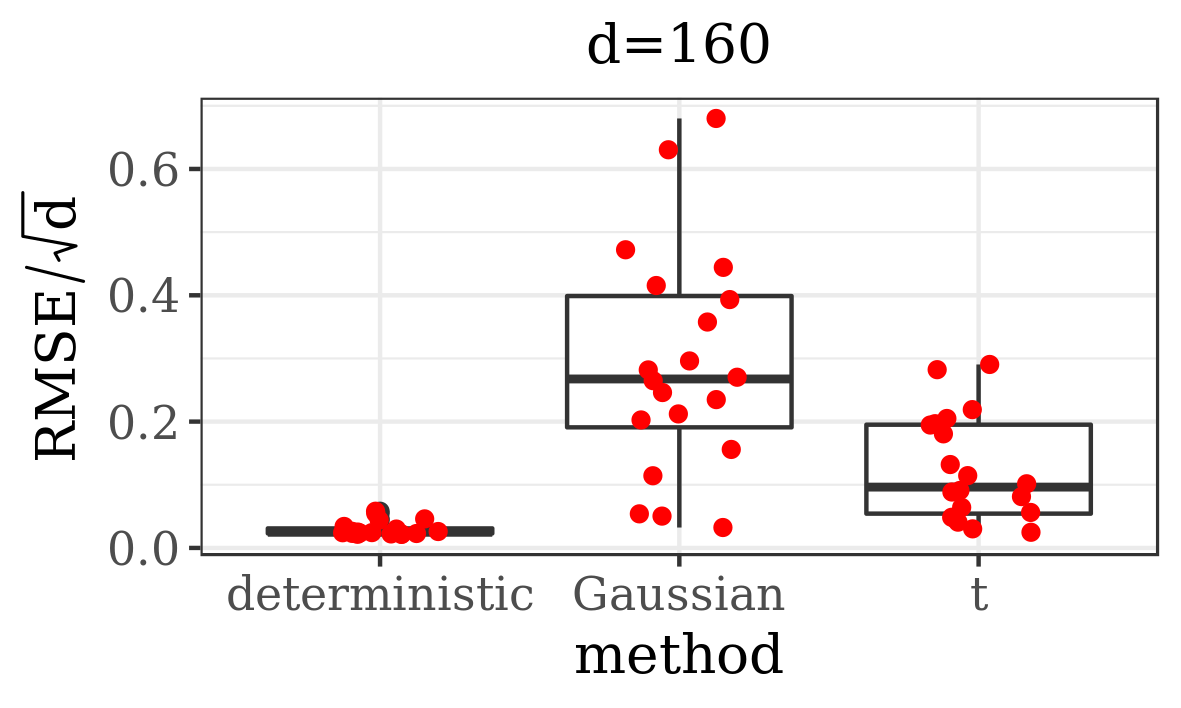 Figure 23
Figure 23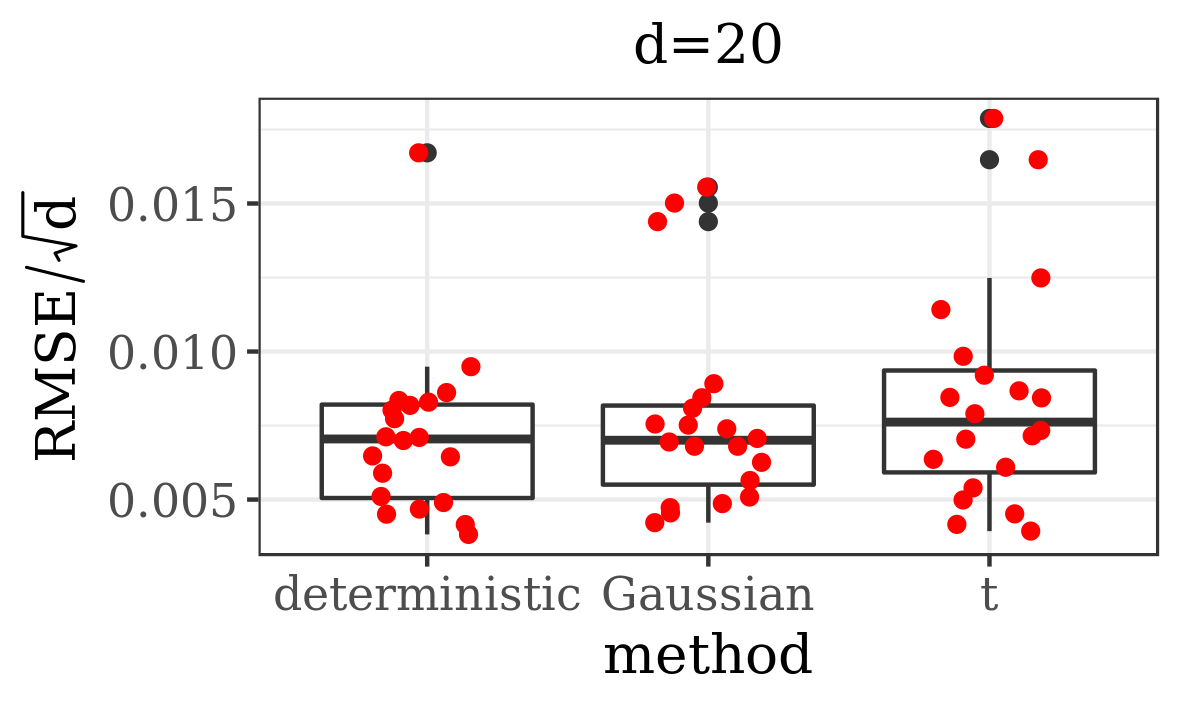 Figure 24
Figure 24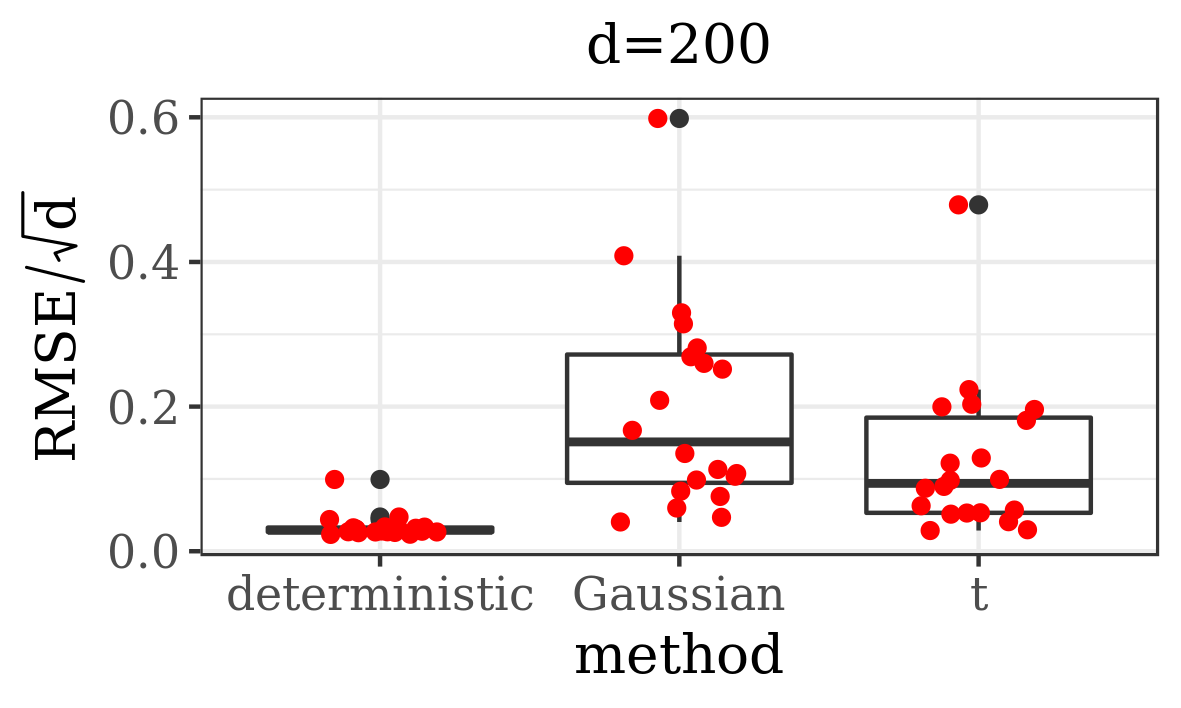 Figure 25
Figure 25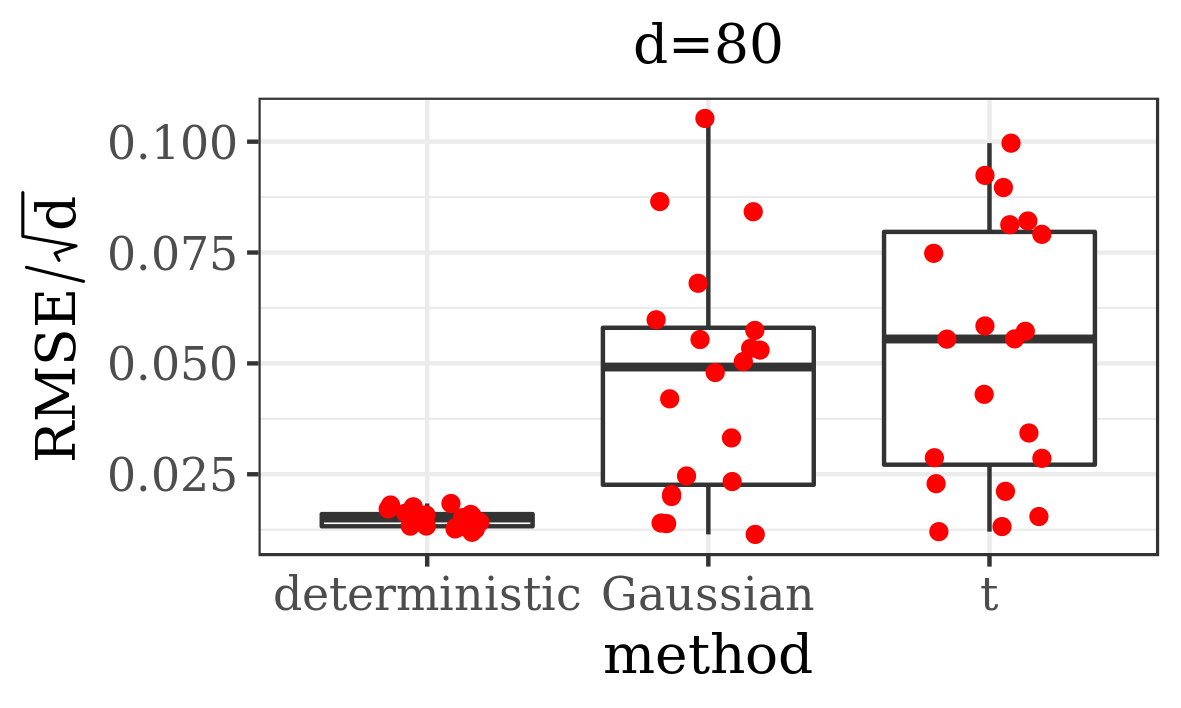 Figure 26
Figure 26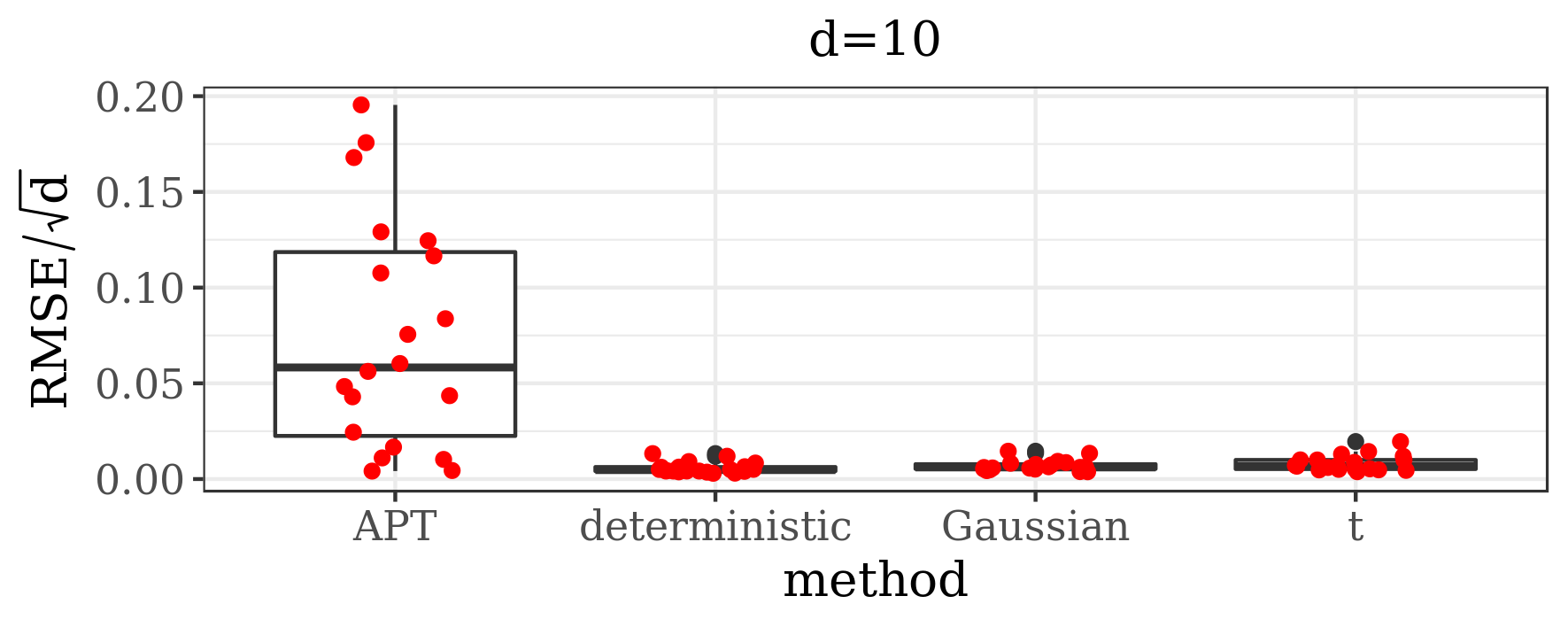 Figure 27
Figure 27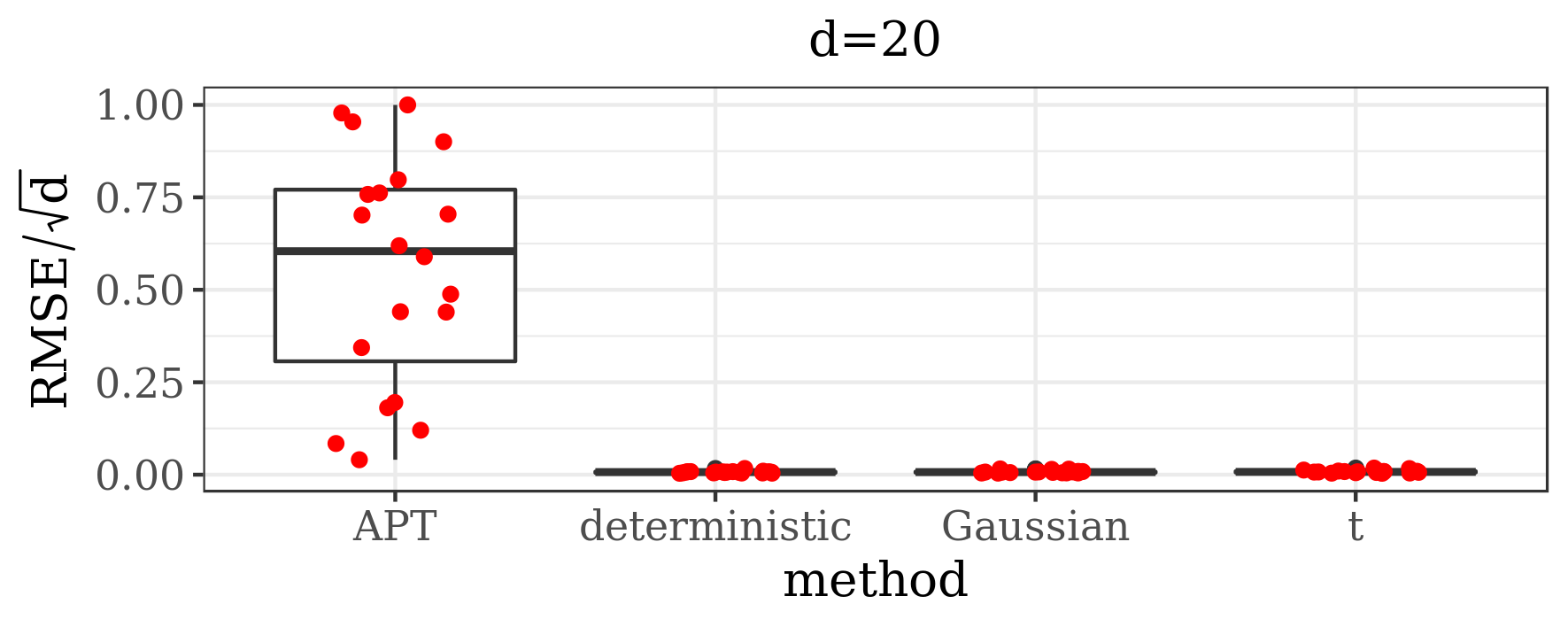 Figure 28
Figure 28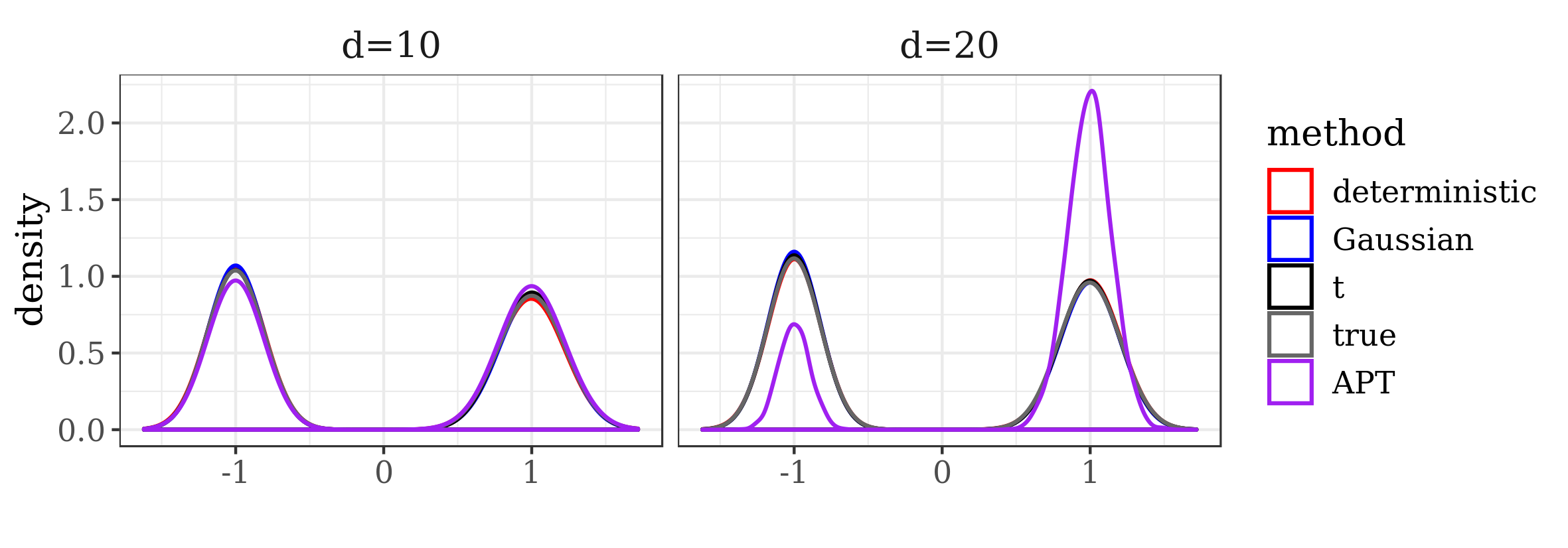 Figure 29
Figure 29 Figure 30
Figure 30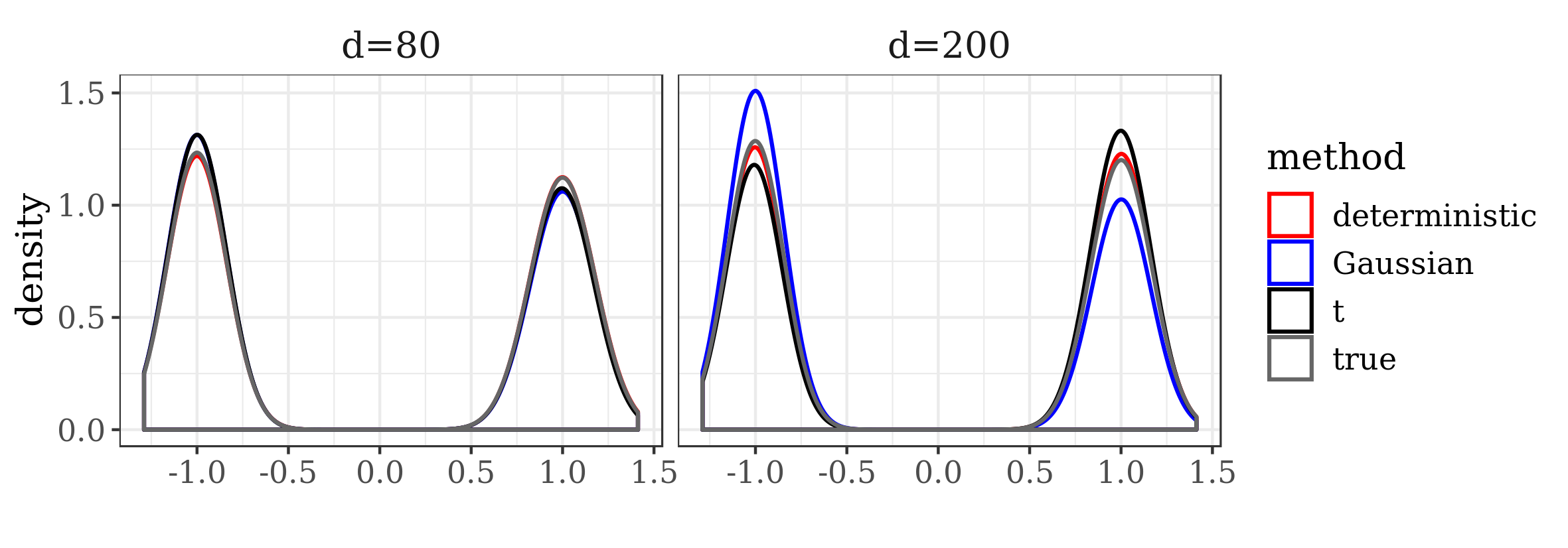 Figure 31
Figure 31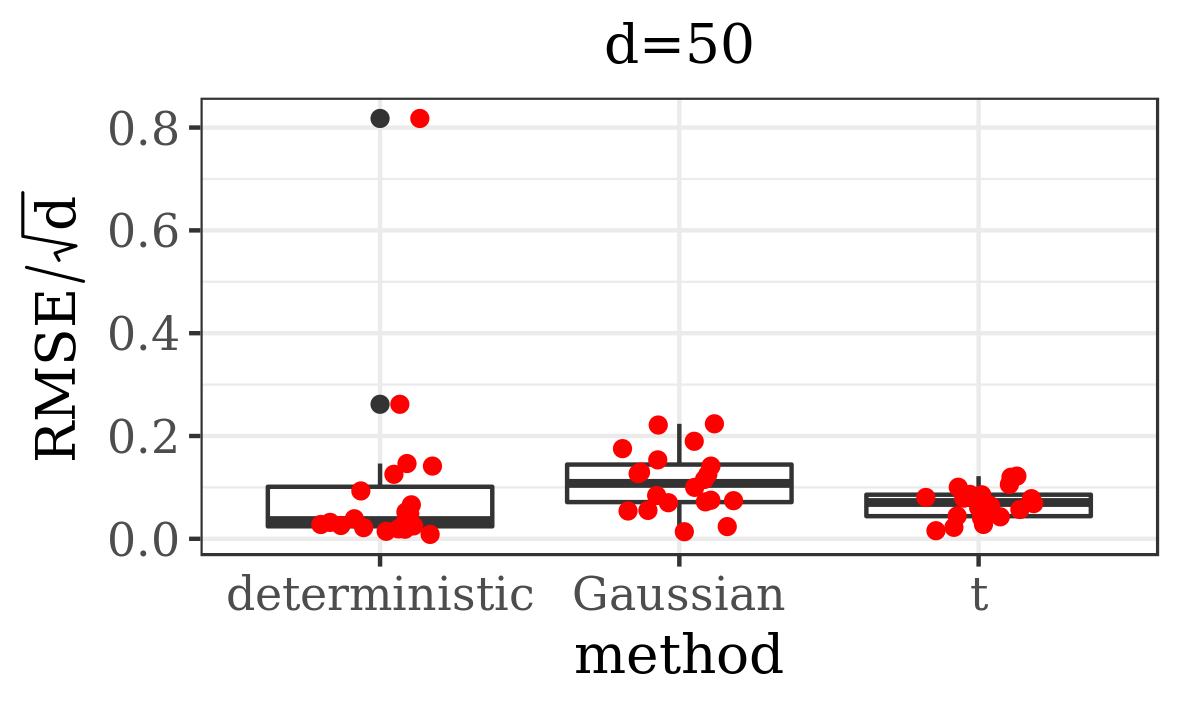 Figure 32
Figure 32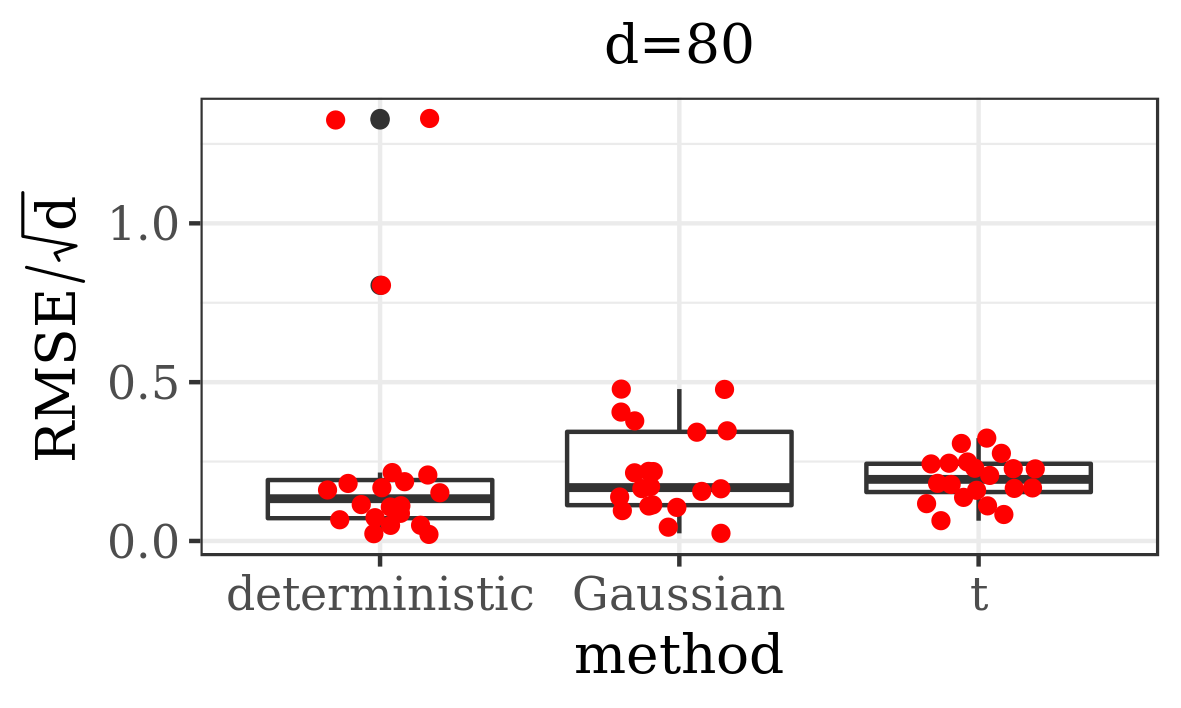 Figure 33
Figure 33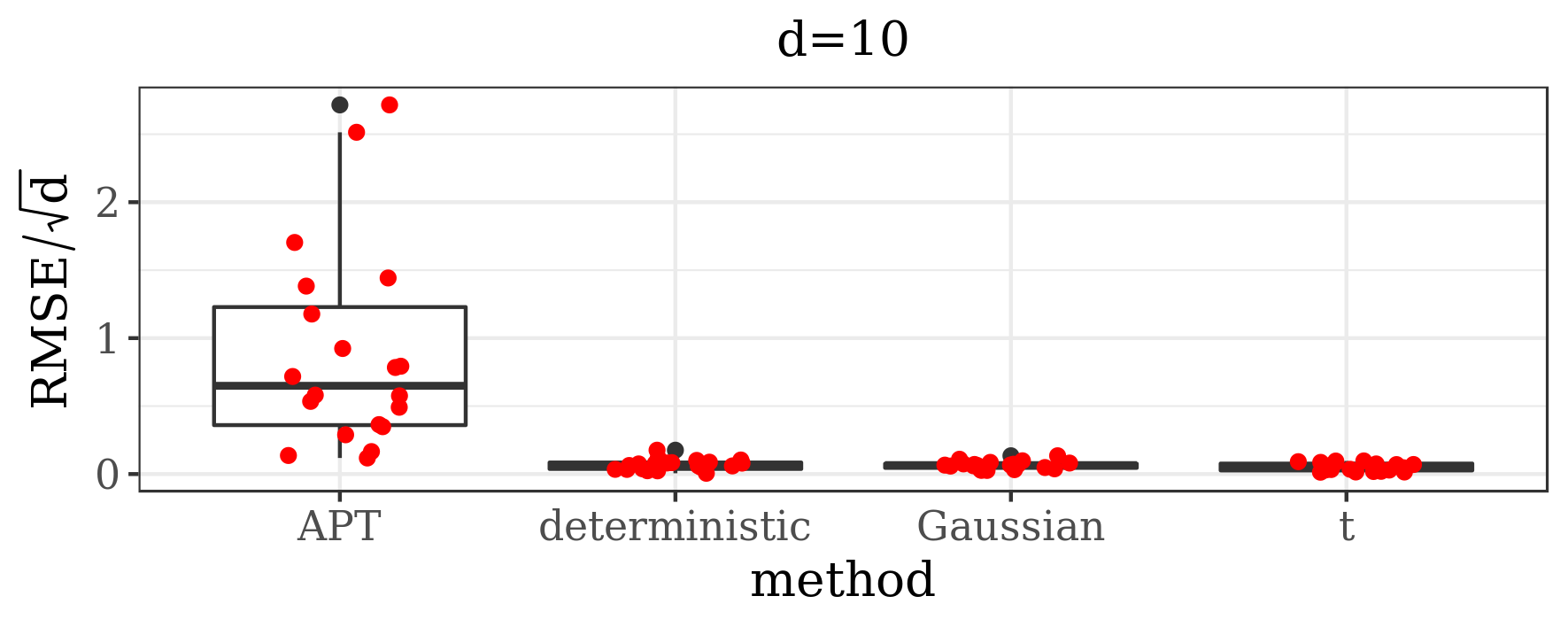 Figure 34
Figure 34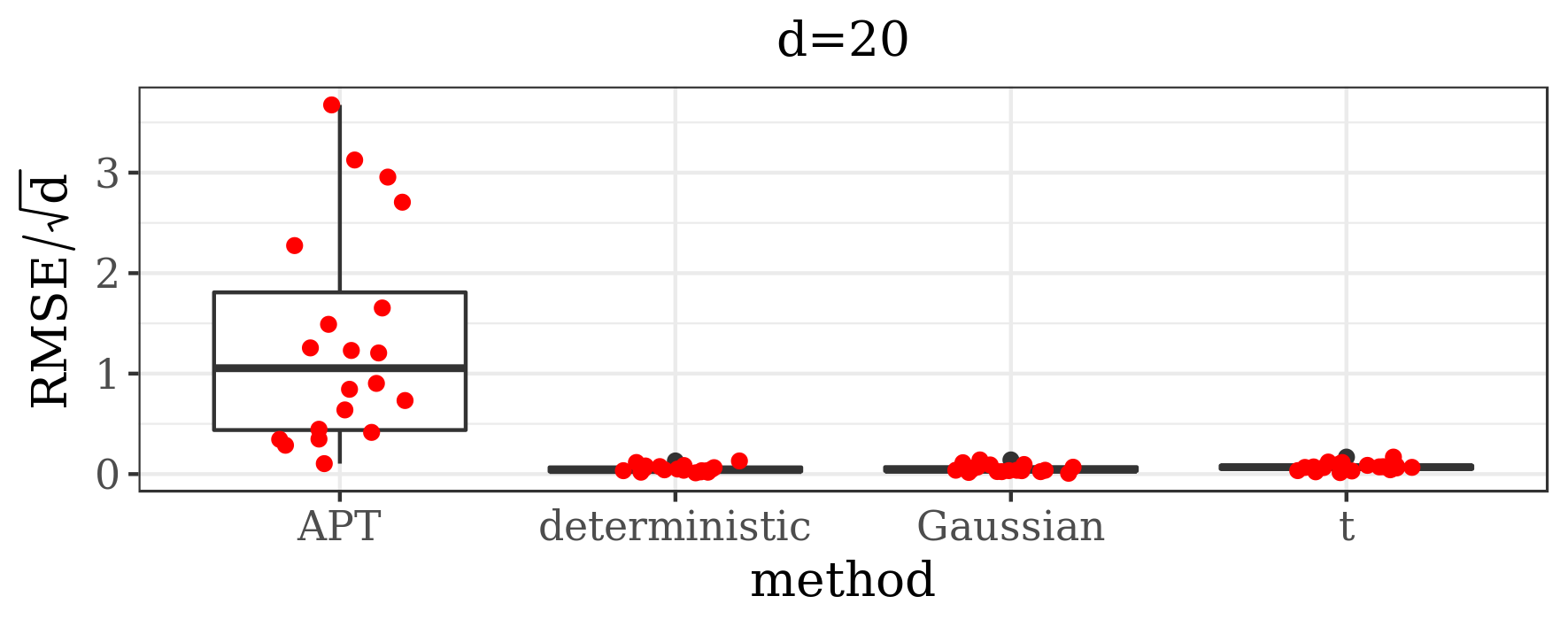 Figure 35
Figure 35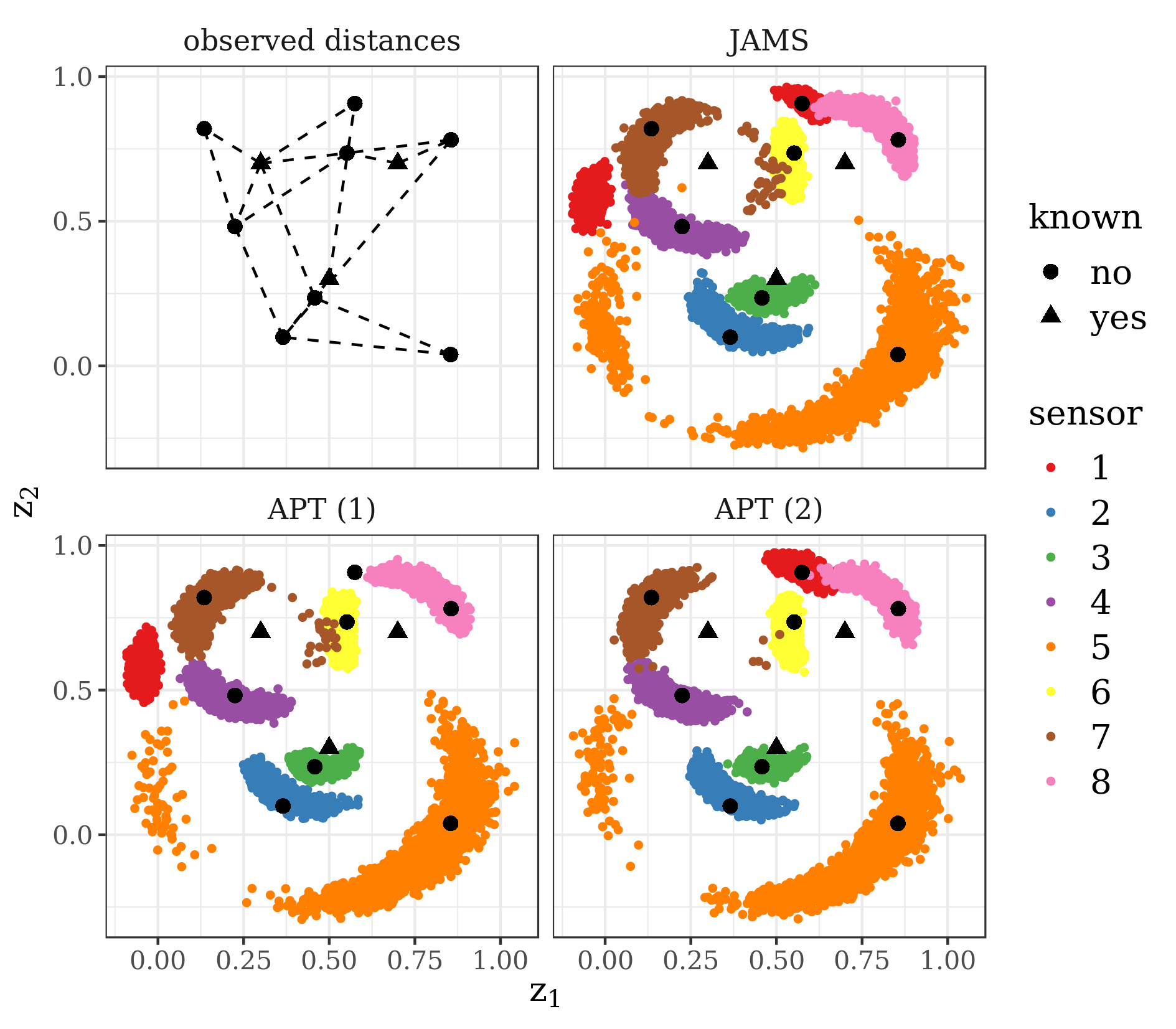 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38| deterministic | Gaussian | -distributed | ||||
| Lowest | Highest | Lowest | Highest | Lowest | Highest | |
| d=10 | 0.98 | 0.99 | 0.85 | 0.87 | 0.71 | 0.73 |
| d=20 | 0.98 | 0.99 | 0.79 | 0.83 | 0.66 | 0.68 |
| d=80 | 0.91 | 0.98 | 0.23 | 0.41 | 0.24 | 0.39 |
| d=130 | 0.72 | 0.98 | 0.04 | 0.13 | 0.06 | 0.15 |
| d=160 | 0.79 | 0.97 | 0.01 | 0.07 | 0.03 | 0.07 |
| d=200 | 0.64 | 0.97 | 0.01 | 0.05 | 0.02 | 0.06 |
| deterministic | Gaussian | -distributed | ||||
| Lowest | Highest | Lowest | Highest | Lowest | Highest | |
| d=10 | 0.27 | 0.77 | 0.12 | 0.52 | 0.20 | 0.65 |
| d=20 | 0.20 | 0.75 | 0.09 | 0.35 | 0.11 | 0.48 |
| Mixture of Gaussians | Mixture of banana-shaped and t-distributions | Sensor network | LOH example | |
| Main algorithm | ||||
| number of iterations | 500,000 | 500,000 | 500,000 | 200,000 |
| 0.7 | 0.7 | 0.7 | 0.7 | |
| 0.0001 | 0.0001 | 0.0001 | 0.0001 | |
| 0.1 | 0.1 | 0.1 | 0.1 | |
| 0.01 | 0.01 | 0.01 | 0.01 | |
| 1000 | 1000 | 500 | 500 | |
| optimal acceptance rate | 0.234 | 0.234 | 0.234 | 0.234 |
| local proposal | Gaussian | Gaussian | Gaussian | Gaussian/ -distributed |
| distributions | with 7 df | with 7 df | with 7 df | with 7 df |
| df of the proposal (if -distributed) | 7 | 7 | 7 | 7 |
| Burn-in algorithm | ||||
| number of BFGS runs | 1500 | 40,000 | 10,000 | 500 |
| 1.1 | 1.1 | 1.1 | 1.1 | |
| deterministic | Gaussian | -distributed | ||||
| Lowest | Highest | Lowest | Highest | Lowest | Highest | |
| Gaussian local proposal | ||||||
| mode 1 to mode 2 | 0.01 | 0.02 | 0.02 | 0.02 | 0.02 | 0.03 |
| mode 2 to mode 1 | 0.44 | 0.71 | 0.70 | 0.76 | 0.71 | 0.77 |
| -distributed local proposal | ||||||
| mode 1 to mode 2 | 0.01 | 0.03 | 0.02 | 0.03 | 0.02 | 0.02 |
| mode 2 to mode 1 | 0.50 | 0.78 | 0.61 | 0.76 | 0.63 | 0.76 |
| Optimisation runs | Covariance matrix estimation | ||||
| minimum | mean | maximum | minimum | maximum | |
| d=10 | 9 | 11.39 | 42 | 3000 | 3000 |
| d=20 | 9 | 10.61 | 39 | 3000 | 7000 |
| d=80 | 6 | 7.36 | 27 | 255,000 | 511,000 |
| d=130 | 8 | 8.07 | 24 | 511,000 | 511,000 |
| d=160 | 6 | 8.02 | 22 | 511,000 | 511,000 |
| d=200 | 6 | 6.85 | 23 | 1,023,000 | 1,023,000 |
| Optimisation runs | Covariance matrix estimation | ||||
| minimum | mean | maximum | minimum | maximum | |
| d=10 | 21 | 49 | 220 | 7000 | 15,000 |
| d=20 | 21 | 48 | 216 | 15,000 | 63,000 |
| d=50 | - | - | - | 255,000 | 255,000 |
| d=80 | - | - | - | 511,000 | 511,000 |
| deterministic | Gaussian | -distributed | ||||
| Lowest | Highest | Lowest | Highest | Lowest | Highest | |
| d=50 | 0.26 | 1.00 | 0.03 | 0.14 | 0.06 | 0.23 |
| d=80 | 0.16 | 1.00 | 0.01 | 0.07 | 0.03 | 0.12 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A Framework for Adaptive MCMC Targeting Multimodal Distributions
Emilia Pompelabel=e1][email protected] [
Chris Holmeslabel=e2][email protected] [
Krzysztof Łatuszyński label=e3][email protected] [ University of Oxford\thanksmarkm1 and University of Warwick\thanksmarkm2
Department of Statistics
University of Oxford
24–29 St Giles’
Oxford OX1 3LB
United Kingdom
E-mail: e2
Department of Statistics
University of Warwick
Coventry, CV4 7AL
United Kingdom
Abstract
We propose a new Monte Carlo method for sampling from multimodal distributions. The idea of this technique is based on splitting the task into two: finding the modes of a target distribution and sampling, given the knowledge of the locations of the modes. The sampling algorithm relies on steps of two types: local ones, preserving the mode; and jumps to regions associated with different modes. Besides, the method learns the optimal parameters of the algorithm while it runs, without requiring user intervention. Our technique should be considered as a flexible framework, in which the design of moves can follow various strategies known from the broad MCMC literature.
In order to design an adaptive scheme that facilitates both local and jump moves, we introduce an auxiliary variable representing each mode and we define a new target distribution on an augmented state space , where is the original state space of and is the set of the modes. As the algorithm runs and updates its parameters, the target distribution also keeps being modified. This motivates a new class of algorithms, Auxiliary Variable Adaptive MCMC. We prove general ergodic results for the whole class before specialising to the case of our algorithm.
60J05,
65C05,
62F15,
multimodal distribution,
adaptive MCMC,
ergodicity,
keywords:
[class=MSC]
keywords:
\startlocaldefs\endlocaldefs
,
and
t1Supported by the EPSRC and MRC Centre for Doctoral Training in Next Generation Statistical Science: the Oxford-Warwick Statistics Programme, EP/L016710/1, and the Clarendon Fund. t2Supported by the MRC, the EPSRC, the Alan Turing Institute, Health Data Research UK, and the Li Ka Shing foundation. t3Supported by the Royal Society via the University Research Fellowship scheme.
1 Introduction
Poor mixing of standard Markov Chain Monte Carlo (MCMC) methods, such as the Metropolis-Hastings algorithm or Hamiltonian Monte Carlo, on multimodal target distributions with isolated modes is a well-described problem in statistics. Due to their dynamics these algorithms struggle with crossing low probability barriers separating the modes and thus take a long time before moving from one mode to another, even in low dimensions. Sequential Monte Carlo (SMC) has often empirically proven to outperform MCMC on this task, its robust behaviour, however, relies strongly on the good between-mode mixing of the Markov kernel used within the SMC algorithm (see [38]). Therefore, constructing an MCMC algorithm which enables fast exploration of the state space for complicated target functions is of great interest, especially as multimodal distributions are common in applications. The examples include, but are not limited to, problems in genetics [15, 31], astrophysics [20, 21, 49] and sensor network localisation [28].
Moreover, multimodality is an inherent issue of Bayesian mixture models (e.g. [30]), where it is caused by label-switching, if both the prior and the likelihood are symmetric with respect to all components, or more generally, it may be caused by model identifiability issues or model misspecification (see [18]).
Designing MCMC algorithms for sampling from a multimodal target distribution on a -dimensional space needs to address three fundamental challenges:
- (1)
Identifying high probability regions where the modes are located;
- (2)
Moving between the modes by crossing low probability barriers;
- (3)
Sampling efficiently within the modes by accounting for inhomogeneity between them and their local geometry.
These challenges are fundamental in the sense that the high probability regions in (1) are typically exponentially small in dimension with respect to a reference measure on the space . Furthermore, the design of basic reversible Markov chain kernels prevents them from visiting and crossing low energy barriers, hence from overcoming (2). Besides, accounting for inhomogeneity of the modes in (3) requires dividing the -dimensional space into regions, which is an intractable task on its own that requires detailed a priori knowledge of .
Existing MCMC methodology for multimodal distributions usually identifies these challenges separately and a systematic way of addressing (1-3) is not available. Section 1.1 discusses main areas of the abundant literature on the topic in more detail.
In this paper we introduce a unifying framework for addressing (1-3) simultaneously via a novel design of Auxiliary Variable Adaptive MCMC. The framework allows us to split the sampling task into mode finding, between-region jump moves and local moves. In addition, it incorporates parameter adaptations for optimisation of the local and jump kernels, and identification of local regions. Unlike other state space augmentation techniques for multimodal distributions, where the auxiliary variables are introduced to improve mixing on the extended state space, auxiliary variables in our approach help to design an efficient adaptive scheme. We present the adaptive mechanics and main properties of the resulting algorithm in Section 1.2 after reviewing the literature.
1.1 Other approaches
Numerous MCMC methods have been proposed to address the issue of multimodality and we review briefly the main strands of the literature.
The most popular approach is based on tempering. The idea behind this type of methods relies on an observation that raising a multimodal distribution to the power makes the modes ”flatter” and as a result, it is more likely to accept moves to the low probability regions. Hence, it is easier to explore the state space and find the regions where the modes of are located, addressing challenge (1) above, and also to move between these regions, addressing challenge (2). The examples of such methods, which incorporate by augmenting the state space, are parallel tempering proposed by [23] and its adaptive version [34], simulated tempering [33], tempered transitions [36] and the equi-energy sampler [31]. Despite their popularity, tempering-based approaches, as noticed by [56], tend to mix between modes exponentially slowly in dimension if the modes have different local covariance structures. Addressing this issue is an area of active research [50].
Another strand of research is optimisation-based methods, which address challenge (1) by running preliminary optimisation searches in order to identify local maxima of the target distribution. They use this information in their between-mode proposal design to overcome challenge (2). A method called Smart Darting Monte Carlo, introduced in [2], relies on moves of two types: jumps between the modes, allowed only in non-overlapping -spheres around the local maxima identified earlier; and local moves (Random Walk Metropolis steps). This technique was generalised in [48] by allowing the jumping regions to overlap and have an arbitrary volume and shape. [1] went one step further by introducing updates of the jumping regions and parameters of the proposal distribution at regeneration times, hence the name of their method Regeneration Darting Monte Carlo (RDMC). This includes a possibility of adding new locations of the modes at regeneration times if they are detected by optimisation searches running on separate cores.
Another optimisation-based method, Wormhole Hamiltonian Monte Carlo, was introduced by [32] as an extension of Riemanian Manifold HMC (see [19] and [24]). The main underlying idea here is to construct a network of ”wormholes” connecting the modes (neighbourhoods of straight line segments between the local maxima of ). The Riemannian metric used in the algorithm is a weighted mixture of a standard metric responsible for local HMC-based moves and another metric, influential in the vicinity of the wormholes, which shortens the distances between the modes. As before, updates of the parameters of the algorithm, including the network system, are allowed at regeneration times.
As we will see later, the algorithm we propose also falls into the category of optimisation-based methods.
The Wang-Landau algorithm [54, 53] or its adaptive version proposed by [12] belong to the exploratory strategies that aim to push the algorithm away from well-known regions and visit new ones, hence addressing challenge (1). The multi-domain sampling technique, proposed in [57], combines the idea of the Wang-Landau algorithm with the optimisation-based approach. This algorithm relies on partitioning the state space into domains of attraction of the modes. Local moves are Random Walk Metropolis steps proposed from a distribution depending on the domain of attraction of the current state. Jumps between the modes follow the independence sampler scheme, where the new states are proposed from a mixture of Gaussian distributions approximating .
Other common approaches include Metropolis-Hastings algorithms with a special design of the proposal distribution accounting for the necessity of moving between the modes [51, 49] and MultiNest algorithms based on nested sampling [20, 21].
1.2 Contribution
As mentioned before, the existing MCMC methods for multimodal distributions struggle to tackle challenges (1-3) simultaneously. In particular, challenge (3) typically fails to be addressed. The difficulty behind this challenge is that when modes have distinct shapes, different local proposal distributions will work well in regions associated with different modes. Note that the majority of the methods described above (all tempering-based techniques, the equi-energy sampler, the adaptive and non-adaptive Wang-Landau algorithm) only employ a single transition kernel, regardless of the region.
In applied problems optimal parameters of the MCMC kernels are unknown, therefore recent approaches involve tuning them while the algorithm runs. In case of unimodal target distributions Adaptive MCMC techniques prove to be useful [43, 5, 25]. The parameters, such as covariance matrices, the scaling, the step size and the number of leapfrog steps of the involved Metropolis-Hastings, MALA, or HMC kernels can be learned on the fly as the simulation progresses, based on the samples observed so far. The adaptive algorithms remain ergodic under suitable regularity conditions [3, 42, 22, 7, 14].
In case of multimodal distributions an analogous idea would be to apply these Adaptive MCMC methods separately to regions associated with different modes, to improve the within-mode mixing. Note that in order to sample from different proposal distributions in regions associated with different modes, one needs to control at each step of the algorithm which region the current state belongs to. Besides, adapting parameters of the local proposal distributions on the fly must be based on samples that actually come from the corresponding region. The only known approach to assigning samples to regions is that of the multi-domain sampler [57]. However, in their setting keeping track of the regions requires running a gradient ascent procedure at each MCMC step, which imposes a high computational burden on the whole algorithm. Other optimisation-based approaches known in the literature (e.g. [48] and [1]) tend to ignore the necessity of assigning samples to regions and the possibility of moving between the modes via local steps.
An issue that we have not raised so far is that the adaptive optimisation-based methods presented above, such as those of [1] and [32], allow for adaptations only at regeneration times. Although this approach seems appealing from the point of view of the theory, since no further proofs of convergence are needed, it does not work well in practice in high dimensions. The reason for this is that regenerations happen rarely in large dimensions, which makes the adaptive scheme prohibitively inefficient. Besides, identifying regeneration times using the method of [35], as authors of both algorithms propose, requires case-specific calculations which precludes any generic implementation of an algorithm based on regenerations. Moreover, the resulting identified regenerations are of orders of magnitude more infrequent than the ”true” ones which are already rare.
We aim to remedy these shortcomings by proposing a framework for designing an adaptive algorithm on an augmented state space , where , and the auxiliary variable of the resulting sample encodes the corresponding region for . Local MCMC kernels update only, while jump kernels that move between the modes update and simultaneously. Furthermore, the design of the target distribution on the augmented state space prevents the algorithm from moving to a region associated with a different mode via local steps. In the sequel we make specific choices for the adaptive scheme, the local and jump kernels, as well as the burn-in routine used for setting up initial values of the parameters of the algorithm. However, the design is modular and different approaches can be incorporated in the framework. Besides, it allows for a multicore implementation of a large part of the algorithm.
This approach motivates introducing the Auxiliary Variable Adaptive MCMC class, where not only transition kernels are allowed to be modified on the fly, but also the augmented target distributions. It turns out that apart from our method, there is a wide range of algorithms that belong to this class, including adaptive parallel tempering or adaptive versions of pseudo-marginal MCMC. Thus our general ergodicity results, proved for the whole class under standard regularity conditions, can potentially be useful for analysing other methods.
The remainder of the paper is organised as follows. In Section 2 we present our algorithm, the Jumping Adaptive Multimodal Sampler (JAMS) and discuss its properties. In Section 3 we define the Auxiliary Variable Adaptive MCMC class and establish convergence in distribution and a Weak Law of Large Numbers for this class, under the uniform and the non-uniform scenario. We present theoretical results specialised to the case of our proposed algorithm in Section 4. Ergodicity is derived here from the analogues of the Containment and Diminishing Adaptation conditions introduced in [42], as opposed to identifying regeneration times, which allows us to circumvent the issues described above. The proofs of all our theorems along with some additional comments about the theoretical results are gathered in Supplementary Material A. Section 5 demonstrates the performance of our method on two synthetic and one real data example. Additional details of our numerical experiments are available in Supplementary Material B. We conclude with a summary of our results in Section 6.
2 Jumping Adaptive Multimodal Sampler (JAMS)
2.1 Main algorithm
Let be the multimodal target distribution of interest defined on . We introduce a collection of target distributions on the augmented state space , where is the finite set of indices of the modes of . We defer the discussion about finding the modes to Section 2.2. Here denotes the design parameter of the algorithm that may be adapted on the fly. For a fixed , is defined as
[TABLE]
where is an elliptical distribution (such as the normal or the multivariate distribution) centred at with covariance matrix . We shall think of and as locations and covariances of the modes of , respectively. Firstly, notice that constructing a Markov chain targeting provides a natural way of identifying the mode at each step by recording the auxiliary variable . Besides, for each and we have
[TABLE]
Hence, is the marginal distribution of for each , so sampling from can be used to generate samples from .
The sampling algorithm that we propose is summarised in Algorithm 1. The method relies on MCMC steps of two types, performed with probabilities and , respectively.
- •
Local move: Given the current state of the chain and the current parameter , a local kernel invariant with respect to is used to update , while remains fixed, hence the mode is preserved.
- •
Jump move: Given the current state of the chain and the current parameter , a new mode is proposed with probability . Then a new point is proposed using a distribution . The new pair is accepted or rejected using the standard Metropolis-Hastings formula such that jump kernel is invariant with respect to .
Our choice for the local kernel is Random Walk Metropolis (RWM) with proposal that follows either the normal or the distribution. This allows us to employ well-developed adaptation strategies for RWM and build on its stability properties to establish ergodicity of JAMS in Section 4. However, in practice any other MCMC kernel, such as MALA or HMC, may be used. The standard Metropolis-Hastings acceptance probability formula that admits as the invariant distribution for the local move becomes:
[TABLE]
As for the jump moves, we consider two different methods of proposing a new point associated with mode . The first one, which we call independent proposal jumps, is to draw from an elliptical distribution centred at with covariance matrix , independently from the current point . Since there is no dependence on and , in case of independent proposal jumps the proposal distribution to mode will be denoted by . For independent proposal jumps, the acceptance probability is equal to
[TABLE]
Alternatively, given that the current state is , we can propose a ”corresponding” point in mode such that
[TABLE]
The required equality is satisfied for
[TABLE]
where
[TABLE]
Herein this method will be called deterministic jumps. The acceptance probability is then given by
[TABLE]
Note that in both cases the design of the jump moves takes into account the shapes of the two modes involved, which helps achieving high acceptance rates and consequently improves the between-mode mixing.
As presented in Algorithm 1, the method involves learning the parameters on the fly. We design an adaptation scheme of three lists of parameters: covariance matrices (used both for adapting the target distribution and the proposal distributions), weights and probabilities of proposing mode in a jump from mode . Hence, formally refers to the product space of , and for restricted by and for each and each . An adaptive scheme for and that follows an intuitive heuristic is discussed briefly in Section 10 of Supplementary Material B.
Our method of adapting the covariance matrices is presented in Algorithm 2. For every the matrix is based on the empirical covariance matrix of the samples from the region associated with mode obtained so far. This is possible in our framework by keeping track of the auxiliary variable . Updates are performed every certain number of iterations (denoted by in Algorithm 2). This method follows the classical Adaptive Metropolis methodology (cf. [27, 43]) applied separately to the covariance structure associated with each mode. For the local proposal distributions the covariance matrices are additionally scaled by the factor , which is commonly used as optimal for Adaptive Metropolis algorithms [40, 44]. Since representing a covariance matrix in high dimensions reliably typically requires a large number of samples, we do not apply this method straight away. Instead, we perform adaptive scaling, aiming to achieve the optimal acceptance rate (typically fixed at 0.234; see [40, 44]) for local moves, until the number of samples observed in a given mode exceeds a pre-specified constant (denoted by in Algorithm 2).
It is worth outlining that this special construction of the target distribution makes it unlikely for the algorithm to escape via local steps from the mode it is assigned to and settle in another one. Indeed, if a proposed point is very distant from the current mode and close to another mode , the acceptance probability becomes very small due to the expression in the numerator of (2.3) and in the denominator, as will typically be tiny in such case and will be large. This allows for controlling from which mode a given state of the chain was sampled. The property of our algorithm described above is crucial for its efficiency as it enables estimating matrices based on samples that are indeed close to mode , which in turn improves both the within-mode and the between-mode mixing. If we were working directly with , the corresponding acceptance probability would be given by and we would not have a natural mechanism for preventing the sampler from visiting different regions via local moves.
2.2 Burn-in algorithm
Note that Algorithm 1 takes mode locations and initial values of the matrices as input. Recall also that further improvements in the estimation of are possible after some samples in mode have been observed (see Algorithm 2). Hence, the matrices need to represent well the shapes of the corresponding modes so that jumps to all the modes are accepted reasonably quickly.
We address the issues of finding the local maxima of , setting up the starting values of the covariance matrices and other aspects of the implementation of our method by introducing a burn-in algorithm, summarised by Algorithm 3.
The burn-in algorithm runs in advance, before the main MCMC sampler (Algorithm 1) is started, in order to provide initial values of the parameters. Since it needs to find the locations of the modes of , and this may be arbitrarily hard, one may prefer a version of this method in which the burn-in algorithm continues running in parallel to the main sampler on multiple cores. These cores communicate with the main sampler every certain number of iterations so that it can incorporate recently discovered modes into the augmented target distribution . For clarity of presentation, we focus on the sequential setting where the burn-in routine runs before the main algorithm, and in Sections 3 and 4 we develop ergodic theory that covers this case. However, the ergodic theory is immediately applicable to the version where the burn-in and the main algorithm run in parallel, as explained in Remark 4.4.
We sketch different stages of the burn-in routine below, in Sections 2.2.1 – 2.2.4, additional details are given in Supplementary Material B. The flowchart illustrating how the full algorithm works is shown in Figure 1.
2.2.1 Starting points for the optimisation procedure
We sample the starting points for optimisation searches uniformly on a compact set which is a product of intervals provided by the user
[TABLE]
where is the dimension of the state space . Note that if the domain of attraction of each mode overlaps with , then asymptotically all modes will be found, as we will have at least one starting point in each domain.
When dealing with Bayesian models, one can alternatively sample the starting points from the prior distribution.
2.2.2 Mode finding via an optimisation procedure
The BFGS optimisation algorithm [37] is initiated from every starting point. The BFGS method method provides the optimum point and the Hessian matrix at this point which is particularly useful in the next step of mode merging.
For numerical reasons, instead of working directly with , we typically use the BFGS algorithm to find the local minima of .
2.2.3 Mode merging
Starting the optimisation procedure from different points belonging to the same basin of attraction will take us to points which are close to the true local maxima, but numerically different, an issue that seems to be ignored in optimisation-based MCMC literature.
We deal with this in a heuristic way (lines 5-16 of Algorithm 3) by classifying two vectors and as corresponding to the same mode if the squared Mahalanobis distance between them is smaller than some pre-specified value . If we let and denote the Hessian matrices of at and , respectively, the above Mahalanobis distance is calculated for and (for symmetry, we average over these two values). This method is scale invariant as the Hessian captures the local shape and scale.
2.2.4 Initial covariance matrix estimation
In order to find initial covariance matrix estimates that accurately reflect the geometry of different modes, we employ the augmented target machinery of Algorithm 1 in the following way. We run Algorithm 1 without jumps, i.e. with , in parallel, starting from each of the modes . This implies that we run chains and each of them adapts only the matrix corresponding to the mode which was its starting point. We make a number of rounds (denoted by ) of this procedure and after each round we update the target distribution by exchanging the knowledge about the adapted covariance matrices between cores. The final covariance matrices passed to the main MCMC sampler are calculated based on the samples collected in all rounds.
The reason why we exchange information between rounds, despite the additional cost of communication between cores, is that we want the sampler adapting to know where the regions associated with other modes are so that it is less likely to visit those regions and contaminate the estimate. Essentially the initial covariance estimation revisits the problem of collecting samples only from the corresponding regions, discussed in the previous parts of this paper.
The initial value of the matrix corresponding to mode is the inverse of the Hessian evaluated at (see line 17 of Algorithm 3). The values of the other parameters of the algorithm, such as , and , are set to be the same as in the main algorithm. The values of and are not updated during those runs. Besides, are set to .
The intuition for the choice of the number of rounds of the above procedure is to stop the burn-in algorithm when running an additional round does not yield much improvement in the accuracy of the estimation of . We use the inhomogeneity factor (see [43] and [47]), a well-established measure of covariance estimation accuracy in the MCMC context, to choose automatically. We quantify the dissimilarity between and for by their inhomogeneity factor, denoted by , and stop the covariance estimation when this factor drops below a pre-specified threshold for all . Details are given in Supplementary Material B.
2.3 Further comments
From the point of view of the fundamental challenges (1-3) discussed in Section 1, JAMS deals with (1) through its mode finding stage. Challenges (2) and (3) are addressed via jumps and local moves, respectively. As explained in Section 2.1, the auxiliary variable approach facilitates moving efficiently between modes as well as accounting for inhomogeneity between them by using different local proposal distributions in different regions.
It is important to point out that the auxiliary variable approach presented above should be thought of as a flexible framework rather than one specific method. The BFGS algorithm used for mode finding could be replaced with another optimisation procedure and similarly, local moves could be performed using a different MCMC sampler, e.g. HMC. One could also consider another scheme for updating the parameters, for example, combining adaptive scaling with covariance matrix estimation (see [52]).
3 Auxiliary Variable Adaptive MCMC
We introduce a general class of Auxiliary Variable Adaptive MCMC algorithms, as follows.
Recall that is a fixed target probability density on . For an auxiliary pair , define and for an index set , consider a family of probability measures on such that
[TABLE]
Let be a collection of Markov chain transition kernels on such that each has as its invariant distribution and is Harris ergodic, i.e. for all
[TABLE]
Here is the usual total variation distance, defined for two probability measures and on a algebra of sets as
To define the dynamics of the Auxiliary Variable Adaptive MCMC sequence where represents a random variable taking values in , denote its filtration as
[TABLE]
Now, the conditional distribution of given will be specified by the adaptive algorithm being used, such as Algorithm 1, while the dynamics of the coordinate follows
[TABLE]
Note that depending on the adaptive update rule for , the sequence defined above is not necessarily a Markov chain. By denote the distribution of the -marginal of at time , conditionally on the history up to time i.e.
[TABLE]
for , and in particular for , we shall write
[TABLE]
By and denote the further marginalisation of and , respectively, onto the space of interest where the target measure lives, namely
[TABLE]
Finally, in order to define ergodicity of the Auxiliary Variable Adaptive MCMC, let
[TABLE]
Definition 3.1**.**
We say that the Auxiliary Variable Adaptive MCMC algorithm generating is ergodic, if
[TABLE]
As we shall see in Section 4, JAMS belongs to the class defined above. There exist other algorithms falling into this category, therefore the results presented in this paper, in particular Theorems 3.2, 3.3 and 3.4, may be useful for analysing their ergodicity. Examples of other algorithms in this class include adaptive parallel tempering [34] and adaptive versions of pseudo-marginal algorithms [4, 6]. A more detailed discussion on this may be found in Supplementary Material A.
3.1 Theoretical results for the class
The two main approaches to verifying ergodicity of Adaptive MCMC are based on martingale approximations [3, 22, 7] or coupling [42]. Here we extend the latter to the Auxiliary Variable Adaptive MCMC class by constructing explicit couplings. In particular, ergodicity of this class of algorithms will be verified for the uniform and the non-uniform case, providing results analogous to Theorems 1 and 2 of [42].
For the uniform case analogues of the usual conditions of Simultaneous Uniform Ergodicity and Diminishing Adaptation will be required.
Theorem 3.2** (Ergodicity – uniform case).**
Consider an Auxiliary Variable Adaptive MCMC algorithm on a state space , following dynamics (3.3) with a family of transition kernels satisfying (3.1) and (3.2). If conditions (a) and (b) below are satisfied, then the algorithm is ergodic in the sense of Definition 3.1.
- (a)
(Simultaneous Uniform Ergodicity). For all there exists such that
[TABLE] 2. (b)
(Diminishing Adaptation). The random variable
[TABLE]
converges to [math] in probability.
In fact assumption (a) of Theorem 3.2 can be relaxed. To this end, define the convergence time as
[TABLE]
It is enough that the random variable is bounded in probability. Precisely, the following ergodicity result holds for the non-uniform case.
Theorem 3.3** (Ergodicity – non-uniform case).**
Consider an Auxiliary Variable Adaptive MCMC algorithm, under the assumptions of Theorem 3.2 and replace condition (a) with the following:
- (a)
(Containment). For all and all , there exists such that
[TABLE]
for all .
Then the algorithm is ergodic in the sense of Definition 3.1.
We establish the Weak Law of Large Numbers for the class of Auxiliary Variable Adaptive MCMC algorithms for both the uniform and the non-uniform case. By letting be a singleton, our result applies to the standard Adaptive MCMC setting and extends the result of [42] where the WLLN was provided for the uniform case only.
Theorem 3.4** (WLLN).**
Consider an Auxiliary Variable Adaptive MCMC algorithm, as in Theorem 3.3, together with assumptions a) and b) of this theorem. Let be a bounded measurable function. Then
[TABLE]
in probability as .
While Containment is a weaker condition than Simultaneous Uniform Ergodicity, it is less tractable and in the standard Adaptive MCMC setting drift conditions are typically used to verify it [42, 10]. Lemma 3.5 helps verifying Containment via geometric drift conditions in the Auxiliary Variable framework. The lemma additionally assumes that the adaptation happens on a compact set only (cf. condition e) below). Adapting on a compact set has been theoretically investigated in [16] and used in certain adaptive Gibbs sampler contexts in [13]. We shall use Lemma 3.5 as the main tool for establishing ergodic theorems for JAMS.
Lemma 3.5**.**
Assume that the following conditions are satisfied.
- a)
For each as . 2. b)
There exists , and a collection of functions for , such that the following simultaneous drift condition is satisfied:
[TABLE]
where for
[TABLE]
Moreover, is bounded on compact sets as a function of . 3. c)
There exist , and a positive integer , such that the following minorisation condition holds: for each we can find a probability measure on satisfying
[TABLE] 4. d)
* is compact in some topology.* 5. e)
There exists a compact set such that if , then . 6. f)
.
Then the Containment condition (3.5) holds.
3.2 Adaptive Increasingly Rarely version of the class
Adaptive Increasingly Rarely (AIR) MCMC algorithms were introduced in [14] as an alternative to classical Adaptive MCMC methods. While they share the same self-tuning properties, their ergodic properties are mathematically easier to analyse and their computational cost of adaptation is smaller.
The key idea behind the AIR algorithms is to allow the updates of parameters only at pre-specified times with and increasing sequence of lags between them. is therefore defined as
[TABLE]
For the sequence [14] proposed using any scheme that satisfies for some positive , and . In order to ensure that the random variable
[TABLE]
converges to [math] in probability (which is equivalent to Diminishing Adaptation), the following modification is introduced. The updates happen at times , where
[TABLE]
and
[TABLE]
Observe that is only positive if . Besides, if then so in particular goes to 0 as tends to infinity.
We apply the same idea to Auxiliary Variable Adaptive MCMC algorithms, by adapting the parameters of the transition kernels and the target distributions only at times , as described above, so that Diminishing Adaptation is automatically satisfied for these algorithms. In Section 4 we study in detail an AIR version of JAMS (see Algorithm 4).
4 Ergodicity of the Jumping Adaptive Multimodal Sampler
We will use our results from Section 3 to prove ergodicity of JAMS. Firstly observe that this algorithm indeed belongs to the Auxiliary Variable Adaptive MCMC class. To see this, recall that the method utilises a collection of distributions on , which corresponds to the notation introduced for the Auxiliary Variable Adaptive MCMC class, with . Indeed, for each and we have (see (2.2)).
Let denote the kernel associated with the local move around mode and analogously let be the kernel of the jump to mode . The full transition kernel is thus defined as
[TABLE]
It is easily checked that the acceptance probabilities (2.3) and (2.4) or (2.6) ensure that detailed balance holds for the above kernels , admitting as their invariant distributions. They also satisfy the Harris ergodicity condition. The above discussion shows that the algorithm indeed falls into the category of the Auxiliary Variable Adaptive MCMC, so Theorems 3.2 and 3.3 can be used to establish its ergodicity.
The main results of this section are stated in Theorems 4.1 and 4.2, which establish convergence of our algorithm to the correct limiting distribution under the uniform and the non-uniform scenario, respectively.
4.1 Overview of the assumptions
In order to prove ergodic results for JAMS, we consider Algorithm 4, which is a slightly modified version of Algorithm 1. While being easier to analyse mathematically, it inherits the main properties of Algorithm 1. The modifications are two-fold: firstly, we update the parameters only if the most recent sample is such that belongs to some fixed compact set and secondly, we adapt them ”increasingly rarely” (see Section 3.2). If jumps are proposed deterministically, we additionally assume that they are allowed only on ”jumping regions” defined as
[TABLE]
for and some . Note that equation (2.5) ensures that if belongs to and we propose a deterministic jump from to , then must be in . Thus the detailed balance condition is satisfied. The reasons for these modifications will become clearer when we present the proofs of the ergodic theorems.
Even though the theory presented below works for any choice of the compact sets , we propose to define these sets in the following way. Recall that the burn-in routine (Algorithm 3) provides the list of mode locations and initial estimates of covariance matrices . By denote the maximum eigenvalue of and let . Let be the convex hull of and its diameter. Define
[TABLE]
where is the dimension of
Observe that Algorithm 4 is constructed in such a way that all the covariance matrices are based on samples belonging to a compact set . This implies that these matrices are bounded from above. Since we keep adding to the covariance matrix at each step, they are also bounded from below. Recall also that the covariance matrices for the local proposal distributions are scaled by a fixed factor . Consequently, there exist positive constants and for which
[TABLE]
As for the adaptive scheme for and , we only require that these values be bounded away from 0, i.e. there exist and such that
[TABLE]
Therefore, the parameter space may be considered as compact.
4.2 Theoretical results for JAMS
We begin with the case when the jump moves are proposed independently from distributions with heavier tails than the tails of the target distribution for all and , i.e.
[TABLE]
We prove that under this assumption Simultaneous Uniform Ergodicity is satisfied for Algorithm 4 and consequently, by Theorem 3.2, the algorithm is ergodic.
Theorem 4.1**.**
Consider Algorithm 4 and assume that the relationship between the target distribution and the proposal distributions satisfies (4.4). Then Algorithm 4 is ergodic.
When the tails of the distribution are heavier then the tails of the proposal distributions , or when the jumps follow the deterministic scheme, Simultaneous Uniform Ergodicity does not hold. However, it turns out that under some additional regularity conditions Algorithm 4 is still ergodic, as it satisfies the assumptions of Lemma 3.5.
Theorem 4.2**.**
Consider Algorithm 4 and assume that the following conditions are satisfied.
- a)
For each the proposal distribution for local moves follows an elliptical distribution parametrised by . Furthermore, the family of distributions , , has uniformly bounded probability density functions, and for any compact set we have
[TABLE] 2. b)
Let be the rejection set for local moves, i.e. . We assume that
[TABLE] 3. c)
The target distribution is super-exponential, i.e. it is positive with continuous first derivatives and satisfies
[TABLE] 4. d)
Every is an elliptical distribution parametrised by positive on and additionally, the following condition is satisfied:
[TABLE]
Additionally, one of the following two conditions for jump moves holds.
- e1)
Jump moves follow the procedure for deterministic jumps, as described in Section 2.1. 2. e2)
Jump moves follow the independent proposal procedure, as described in Section 2.1. The proposal distributions for jumps have uniformly bounded probability density functions and satisfy
[TABLE]
where is a ball of radius and centre . Moreover, the relationship between the target distribution is given by
[TABLE]
Then Algorithm 4 is ergodic.
When proving the above result, we will refer to the proof of Theorem 4.1 of [29]. Assumptions b) and c) are analogues of the regularity conditions considered in [29]. Condition a) holds automatically for our algorithm if we assume that the proposal distributions for local moves follow either the normal or the distribution (see Section 2.1) and when (4.2) holds. Condition (4.9) is satisfied if the proposal distributions for jumps follow, for example, the normal distribution. Condition d) can be easily verified if every , follows the distribution with the same number of degrees of freedom.
The result stated below establishes the Weak Law of Large Numbers for our algorithm.
Theorem 4.3**.**
Consider Algorithm 4 and assume that conditions of either Theorem 4.1 or Theorem 4.2 are satisfied. Then the Weak Law of Large Numbers holds for all bounded and measurable functions.
Remark 4.4*.*
Note that Theorems 4.1, 4.2 and 4.3 are based on an assumption that the list of modes is fixed. Let us now consider Algorithm 4 in the version with mode finding running in parallel to the main MCMC sampler, as shown in Figure 1. Assume additionally that
[TABLE]
where is the time of adding the last mode. In this case Theorems 4.1, 4.2 and 4.3 still hold. Indeed, as the parallel burn-in algorithm runs independently of JAMS, we can rephrase all the probabilistic limiting statements in the proofs on the set and then let
The following lemmas are useful in verifying assumption b) of Theorem 4.2.
Lemma 4.5**.**
Let and . Consider Algorithm 4 together with conditions a), c) and d) of Theorem 4.2. Assume additionally that for some
[TABLE]
Then condition (4.6) holds.
Lemma 4.6**.**
Consider Algorithm 4 together with conditions a), c) and d) of Theorem 4.2. Assume additionally that the target distribution satisfies
[TABLE]
Then condition (4.6) holds.
The following corollary shows Algorithm 4 in a standard setting is successful at targeting mixtures of normal distributions.
Corollary 4.7**.**
Let the target distribution be given by
[TABLE]
where and is a polynomial of order for each . If additionally for follows the multivariate distribution with the same number of degrees of freedom, and follows the normal distribution, the assumptions of Lemma 4.6 are satisfied.
5 Examples
In this section we present empirical results for our method (Algorithm 1 preceded by the Algorithm 3). We test its performance on three examples – the first one is a mixture of two Gaussians motivated by [56]; the second one is a mixture of fifteen multivariate distributions and five banana-shaped ones; the third one is a Bayesian model for sensor network localisation. Our implementation admits three versions, varying in the way the jumps between modes are performed. In particular, we consider here the deterministic jump and two independent proposal jumps, with Gaussian and -distributed proposals.
Additionally, we compare the performance of our algorithm against adaptive parallel tempering [34], which was chosen here as it is the refined version of the most commonly used MCMC method for multimodal distributions (parallel tempering). What is more, this algorithm has a generic implementation, where the user only needs to provide the target density function. In order to make a comparison between the efficiency of these algorithms, among other things, we analyse the Root Mean Square Error (RMSE) divided by the square root of the dimension of the state space, given a computational budget. We measure the computational cost by the number of evaluations of the target distribution (and its gradient, if applicable), as this is typically the dominating factor in real data examples. Herein we define RMSE as the Euclidian distance between the true -dimensional expected value (if known) and its empirical estimate based on MCMC samples.
In order to depict the variability in the results delivered by both methods, each simulation was repeated 20 times. For exact settings of the experiments, as well as some additional results, we refer the reader to Supplementary Material B.
5.1 Mixture of Gaussians
The following target density was studied by [56]:
[TABLE]
for . In particular, they showed that the parallel tempering algorithm will tend to stay in the wider mode and, if started in the wider mode, may take a long time before getting to the more narrow one. We looked at the results for the target distribution (5.1) in several different dimensions ranging between 10 and 200, for and . The results for our method shown below are based on 500,000 iterations of the main algorithm, preceded by the burn-in algorithm including 1500 BFGS runs. The length of the covariance matrix estimation was chosen automatically using the rule described in Supplementary Material B and varied between 3000 iterations (for ) to 1,023,000 iterations (for ) per mode. For dimensions and we ran also the adaptive parallel tempering (APT) algorithm, with 700,000 iterations and 5 temperatures. Overall this requires 3,500,000 evaluations of the target density that cannot be performed in parallel, despite the name of the method, as the communication between chains running at different temperatures is needed after every iteration. In the light of the tendency of the parallel tempering algorithm to stay in wider modes, each time the APT algorithm was started in . In order to base our analysis on the same sample size of 500,000 for the two methods, in case of adaptive parallel tempering we applied an initial burn-in period of 200,000 steps.
The results presented in the boxplots of Figure 2, as well as the upper panel of density plots (Figure 4) show that our method outperforms adaptive parallel tempering on this example, even when the latter method is given a much larger computational budget. The summary of the acceptance rates of the jump moves presented in Table 1 demonstrates that the algorithm preserves good mixing between the modes in all its jump versions up to dimension 80. It is remarkable that the deterministic jump ensures excellent mixing even in much higher dimensions, outperforming the remaining two methods (see Figure 3 and the lower panel of Figure 4), with the acceptance rate between 0.64 and 0.97 in dimension 200.
5.2 Mixture of and banana-shaped distributions
A classic example of a multimodal distribution is a mixture of 20 bivariate Gaussian distributions introduced in [31] (in two versions, with equal and unequal weights and covariance matrices). It was later studied also by [34] and [49]. Our algorithm works well on both versions, however, since the example is relatively simple and the performance of the existing methods on it is already satisfying, we do not expect our method to yield much improvement. Therefore, we decided to modify this example in the way described below in order to make it more challenging. Instead of the Gaussian distribution, the first five modes follow the banana-shaped distribution with tails and the remaining ones – multivariate with 7 degrees of freedom and the covariance matrices , where is the dimension (the covariance matrices in the original example were given by ). The weights are assumed to be equal to 0.05. We consider dimensions and by repeating the original coordinates of the centres of the modes five and ten times, respectively.
Recall the definition of the -dimensional banana-shaped distribution introduced by [26]111Originally in the paper by Haario et. al. [26] the function was the density of the Gaussian distribution .. Let be the density of the centred distribution with 7 degrees of freedom and shape matrix , for . Then the density of the banana-shaped distribution (with -tails) is given by
[TABLE]
where
[TABLE]
In order to decrease the variance of the banana-shaped elements of the mixture, we used the following transformation of (setting )
[TABLE]
Furthermore, the formula on the second coordinate of (5.2) was assigned to coordinate 2, 4, 6, 8, 10 for mode 1, 2, 3, 4 and 5, respectively.
The results below are based on 500,000 iterations, preceded by 40,000 BFGS runs. The number of iterations of the covariance matrix estimation varied between 7,000 and 15,000 steps per mode for dimension and between 15,000 and 63,000 steps per mode for dimension . For adaptive parallel tempering we used 2,100,000 iterations and 5 temperatures. We applied an initial burn-in period of 600,000 steps and we thinned the chain keeping every third sample.
In Supplementary Material B we present results for the same example obtained using JAMS in dimensions and assuming that the modes of the target distribution are known, since mode finding (in particular, getting to each basin of attraction) is the main bottleneck for this example.
For dimensions and all modes were found by the BFGS runs in each of the 20 simulations. Even though the banana-shaped modes are highly skewed, our method exhibits good between-mode mixing properties, as shown in Table 2. Figure 5 illustrates that the empirical means based on JAMS samples approximate well the true expected value of the target distribution, consistently across all experiments, and that our method significantly outperforms APT with a smaller computational cost.
5.3 Sensor network localisation
We consider here an example from [28], analysed later by [1], [32] and, in a modified version by [49]. There are 11 sensors with locations scattered on a space . The locations of sensors are unknown, the remaining three locations are known. For any two sensors and we observe the distance between them with probability . Once observed, the distance follows the normal distribution given by . Let be equal to 1 when is observed and [math] otherwise, and denote and . The goal of the study is to make inference about the unknown locations for given and . Following [1] and [32] we put an improper uniform prior on each of the coordinates and for . The resulting posterior distribution is given by
[TABLE]
where
[TABLE]
Since there are few observed distances with known locations (see: top left panel of Figure 6), the model is non-identifiable which results in multimodality of the posterior distribution.
We ran JAMS on this example for 500,000 iterations of the main algorithm. This was preceded by 10,000 BFGS runs and covariance matrix estimation (between 7000 and 15,0000 iterations per mode). For parallel tempering we used 700,000 iterations (with a burn-in period of 200,000) and 4 temperatures. If JAMS is implemented on 8 cores, this means that running an APT simulation is about twice as costly as running a JAMS one (see Supplementary Material B for details).
Despite the fact that for all 20 APT experiments the acceptance rates at all temperature levels, as well as for between-temperature swaps, converged to the optimal acceptance rate 0.234 (see [8]), the behaviour of this algorithm was unstable. As shown in Figure 6, in case of APT the estimation of the location of sensor 1 depends on the starting point. In case of JAMS, both modes for (in red) are represented.
Figure 7 illustrates stability of JAMS across all experiments and jump methods. In Supplementary Material B we assign an even higher computational budget to adaptive parallel tempering allowing for 5 temperatures and observe a substantial improvement in mixing and stability, but the results are still worse than those of JAMS.
6 Summary and discussion
The approach we proposed here is based on three fundamental ideas. Firstly, we split the task into mode finding and sampling from the target distribution. Secondly, we base our algorithm on local moves responsible for mixing within the same mode and jumps that facilitate crossing the low probability barriers between the modes. Finally, we account for inhomogeneity between the modes by using different proposal distributions for local moves at each mode and adapting their parameters separately. Similarly, the jump moves account for the difference in geometry of the two involved modes. This is possible thanks to the auxiliary variable approach which enables assigning each MCMC sample to one of the modes and ensuring that it is unlikely to escape to another mode via local moves. This improves over the popular tempering-based approaches, which do not have the mechanism of controlling the mode at each step, and therefore their adaptive versions [34] only learn the global covariance matrix rather than the local ones. This is highly inefficient if the shapes of the modes are very distinct and results in exponential efficiency decay.
The optimisation-based approaches are naturally well-suited for the task of collecting the MCMC samples separately for each mode and learning the covariance matrices on this basis. However, the approaches known in the literature do not have a suitable framework for adaptation and tend to be either very costly (e.g. [57]) or to ignore the issue of the possibility of moving between the modes via local steps (e.g.[1]). Moreover, some of the other fundamental issues of optimisation-based methods have not been systematically addressed by the researchers so far. These include an efficient design of the mode finding phase, distinguishing between newly discovered modes and replicated ones, as well as adapting beyond the infrequent regeneration times, which does not require case-specific calculations. We hope that the method we proposed will fill this gap.
Furthermore, an important advantage of our approach from the point of view of the modern compute resources is that a large part of the algorithm can be implemented on multiple cores.
To develop a methodological approach and prove ergodic results for our algorithm, we introduced the Auxiliary Variable Adaptive MCMC class. As discussed briefly in Section 3, there are other adaptive algorithms falling in this category, so our theoretical results may potentially be useful beyond the scope of the Jumping Adaptive Multimodal Sampler. We have also shown that the Auxiliary Variable Adaptive MCMC methods enjoy robust ergodicity properties analogous to Adaptive MCMC under essentially the same well-studied regularity conditions.
Currently the main bottleneck of the method is mode finding, and in particular, sampling starting points for optimisation runs in such a way that there is at least one point in the basin of attraction of each mode. Therefore in our future work we will focus on designing more efficient algorithms for identifying high probability regions.
Acknowledgements
We thank Louis Aslett, Ewan Cameron, Arnaud Doucet, Geoff Nicholls and Jeffrey Rosenthal for helpful comments, and Shiwei Lan for pointing us to the data for the sensor network example. We would also like to thank Radu Craiu for providing the data set for the LOH example considered in Supplementary Material B.
Supplementary Material A
In Section 7 we present the proofs of our theoretical results stated in Section 3. In Section 8 we prove the results stated in Section 4. In Section 9 we give some comments about other algorithms in the Auxiliary Variable Adaptive MCMC class.
7 Proofs for Section 3
To prove our results presented in Section 3 we will use the coupling construction analogous to [42] (see also [45] for a more rigorous presentation).
Our proofs will be rigorous and will rely on an explicit coupling construction. The more complex setting of Auxiliary Variable Adaptive MCMC necessitates a few preliminary steps: to interpolate between the adaptive process and the target distribution we shall construct two processes to be thought of as ”Markovian” and ”intermediate”. These processes will facilitate application of the triangle inequality in the proofs.
Recall the adaptive process on defined in Section 3 with dynamics governed by equation (3.3). On the same probability space define two additional sequences, namely and which are identical to before pre-specified time , i.e.
[TABLE]
After time the adaptive parameter of freezes and becomes a Markov chain with the marginal dynamics defined for as:
[TABLE]
The second sequence interpolates between and . We first define the dynamics of for as:
[TABLE]
and define an auxiliary stopping time that records decoupling of and as
[TABLE]
with the convention Now, define the dynamics of as:
[TABLE]
for and .
Define also the filtration as an extension of by:
[TABLE]
Let the distributions
[TABLE]
and
[TABLE]
be analogues of , , , , where in the definitions of the above terms, instead of we use the sequences and , respectively, and condition on the extended -algebras defined in (7.9).
Lemma 7.1**.**
Let and be probability measures on and let and be their marginals on . Then
[TABLE]
Proof.
Total variation distances on involve suprema over larger classes of sets than those on , in particular . ∎
Lemma 7.2**.**
Let Simultaneous Uniform Ergodicity, i.e. condition (a) of Theorem 3.2, hold. Then for all there exists such that for all
[TABLE]
Proof.
First observe that for any the object is a -measurable random variable and apply Jensen’s inequality to obtain (7.12) below. Next, use Lemma 7.1 in (7.13). To get (7.14) recall that is a Markov chain started from with dynamics . Then use monotonicity of the total variation for Markov chains, and finally pick via assumption (a) of Theorem 3.2 to conclude (7.16).
[TABLE]
∎
Lemma 7.3**.**
Let Containment, i.e. condition (a) of Theorem 3.3, hold. Then for all and there exists such that for all and all
[TABLE]
Proof.
Reiterate the argument in the proof of Lemma 7.2 to get the first part of (7.17) and then to arrive on (7.14). Next, use the Containment condition, namely choose such that
[TABLE]
for all . Let , then and on . Therefore we get
[TABLE]
as required. ∎
Lemma 7.4**.**
Let Diminishing Adaptation, i.e. condition (b) of Theorem 3.2, hold. Then for all and there exists such that for every and every
[TABLE]
Proof.
Recall defined in condition (b) of Theorem 3.2 and let
[TABLE]
Note that by Diminishing Adaptation for every we have Now, for define
[TABLE]
Consider the process with . Note that on we have , for and therefore the coupling inequality (see e.g. Section 4.1 of [41]) for every yields as claimed
[TABLE]
∎
Lemma 7.5**.**
For every and , the distributions of and satisfy the following:
[TABLE]
Proof.
First apply Jensen’s inequality
[TABLE]
and recall equations (7.1) and (7.2) to note that
[TABLE]
that is is a Markov chain started from with dynamics . Combining (7.27) with (7.28) yields (7.25).
Now recall (7.5), (7.7), (7.8), i.e. the dynamics of and observe that (7.5) yields
[TABLE]
Hence, for every if then by (7.29) and Proposition 3(g) of [41], there exists a coupling of and such that
[TABLE]
Reiterating this construction times from to implies that there exists a coupling such that
[TABLE]
Hence by the coupling inequality
[TABLE]
as required. ∎
Proof of Theorem 3.2
Proof.
By the triangle inequality, for any and we have
[TABLE]
where in the second inequality, for the first two terms, we have used Lemma 7.1.
Now fix . To prove the claim, it is enough to construct a target time , s.t.
[TABLE]
We shall find such target time of the form . To this end let .
First, use Lemma 7.2 to fix so that
[TABLE]
Next, take and use Lemma 7.5 to conclude that
[TABLE]
Finally, use Lemma 7.4 to find such that
[TABLE]
Letting allows to decompose every into , so that (7.33), (7.34), (7.35) are satisfied, which yields the claim. ∎
Proof of Theorem 3.3
Proof.
The proof is identical, except that we use Lemma 7.3 instead of Lemma 7.2 to find in (7.33). ∎
Proof of Theorem 3.4
Proof.
To prove that the Weak Law of Large Numbers holds for the Auxiliary Variable Adaptive MCMC class, recall again the sequences and defined above. Without loss of generality we will assume that and that .
By Markov’s inequality
[TABLE]
hence to obtain the WLLN it is enough to show that for every there exists such where are the starting points of that for all
[TABLE]
We shall deal with (7.37) by considering second moments and therefore will have to deal with mixed terms of the form . Let be fixed and we shall pick a specific value later. Firstly, for consider the following calculation.
[TABLE]
where has been obtained from Lemma 7.2, if assuming Simultaneous Uniform Ergodicity, or from Lemma 7.3, if assuming Containment.
Secondly, given in (7.38), fix such that and consider pairs satisfying Set and compute
[TABLE]
Finally, use Lemma 7.4 to find and conclude
[TABLE]
We are ready to address the mixed term. Since , trivially for any
[TABLE]
Moreover, for , pairs such that , and equations (7.38), (7.39) and (7.40) yield
[TABLE]
Consequently, for any and , chosen as above, we can compute
[TABLE]
where we have used (7.42) and (7.41) to bound the first and second summation, respectively.
By the Cauchy-Schwartz inequality (7.43) implies
[TABLE]
for and .
Following the proof of Theorem 5 of [42], fix so large that
[TABLE]
Use (7.44) and (7.45) to observe that
[TABLE]
Setting in the above argument yields (7.37) as desired. ∎
Proof of Lemma 3.5
Proof.
We will begin the proof by showing that assumption (3.6) implies that an analogous drift condition is satisfied for , defined in (3.7), perhaps with different constants and , which we define below. For any we have
[TABLE]
For we have
[TABLE]
By similar calculations and induction we obtain
[TABLE]
as required.
By Theorem 12 of [46] and conditions (3.7) and (7.48), there exists and , depending only on , , , and , such that for each and for any we have
[TABLE]
We now use the monotonicity of in (see Proposition 3b) of [41]) to argue that
[TABLE]
Let . It follows that for every
[TABLE]
The next step of the proof will be to show that the sequence is bounded in probability. By Lemma 3 in [42], it suffices to show that . Firstly, let us show that is bounded for and . Note that
[TABLE]
Since and were assumed to be compact, . Additionally, the drift condition (3.6) yields
[TABLE]
Therefore we can define . It follows that
[TABLE]
By the law of total expectation,
[TABLE]
which combined with (7.51) gives
[TABLE]
This implies, using Lemma 2 in [42] that
[TABLE]
Lemma 3.5 will now follow from combining the fact that the sequence is bounded in probability with (7.50). Note that for any fixed and , there exists such that
[TABLE]
for all . The last inequality holds since as and is bounded in probability. ∎
8 Proofs for Section 4
Proof of Theorem 4.1
Proof.
The aim of the proof is to verify the assumptions of Theorem 3.2 and conclude. Diminishing Adaptation has been addressed in Section 3.2, so it is enough to prove that Simultaneous Uniform Ergodicity holds. Note that assumption (4.4) implies that for some positive constant
[TABLE]
for each , and . For any , any set and any we can compute
[TABLE]
where is as in equation (4.3).
Furthermore, any set may be decomposed as , therefore
[TABLE]
Since is a probability measure on for each and (8.2) holds for all , by Theorem 8 of [41] we have
[TABLE]
which completes the proof. ∎
Proof of Theorem 4.2
We will show that the assumptions of Theorem 3.3 are satisfied. Since Diminishing Adaptation was discussed in Section 3.2, it suffices to prove that the Containment condition holds, which we will do using Lemma 3.5. Assumptions a) and d) were discussed in Section 4.1. Assumption e) follows directly from the construction of the algorithm for . Assumption f) holds trivially, since and are deterministic (chosen by the user of the algorithm). The remaining part of the proof is organised as follows.
We show that the drift condition expressed in assumption b) of Lemma 3.5 is satisfied under the assumptions of Theorem 4.2. To this end, we consider a drift function of the form
[TABLE]
for some and such that (thus enforcing ). We first focus on obtaining the appropriate result for the local kernels and subsequently we combine it with the result for jumps. Finally, we prove that assumption c) of Lemma 3.5 is satisfied for .
Assumption b) of Lemma 3.5 (local kernels)
Proof.
The drift function defined as above is a jointly continuous function of so it is bounded on compact sets in for each , as required by assumption b) of Lemma 3.5. Therefore, it is also bounded on compact sets in . The proof will be continued for but analogous reasoning would be valid for any .
We will prove that there exists such that for the local move kernels we have
[TABLE]
for all . We will refer multiple times to the proof of Theorem 4.1 of [29]. Following the notation used there, let denote the radial -zone around , where is the contour manifold corresponding to . Firstly, there exists such that for the contour manifold is parametrised by and encloses the acceptance set for defined as (we refer to Section 4 of [29] for the details of this argument). In our proof we will only consider . Define also
[TABLE]
By assumption (4.6) .
Fix and . We will show that for sufficiently large
[TABLE]
The idea of this proof is to split into disjoint sets , and and show that for any with a sufficiently large norm the integral representing acceptance, that is, of the function on those sets is bounded from above by , and , respectively. We fix the values of and below. As for the rejection part, we use (8.5) to show that the corresponding integral is bounded by , for all at a sufficient distance from 0. Putting all these upper bounds together, we obtain the required .
Firstly, observe that by assumption a) and condition (4.2) the family of distributions is tight. Thus, there exists such that
[TABLE]
Furthermore, as shown the proof of Theorem 4.1 of [29], under assumption c) of Theorem 4.2 for any positive and
[TABLE]
Fix satisfying (8.7). Since , there exists such that for
[TABLE]
Recall that by assumption a) for any we have . Now let us choose such that for
[TABLE]
therefore getting
[TABLE]
Let and . We now split into and and we estimate the value of on each of those sets separately. Fix such that
[TABLE]
This is possible by assumption d) combined with conditions (4.2) and (4.3). Since is super-exponential, there exists so large that for :
If , then . 2. 2)
If , then .
In the first case we have (using (8.10)):
[TABLE]
Similarly for we get . Hence, on we have
[TABLE]
Furthermore, by assumption (8.5) we can choose such that for
[TABLE]
Finally, for we obtain
[TABLE]
which ends the proof of (8.6). Consequently, by setting such that , we obtain (8.4). Observe that there exists such that if , then
[TABLE]
For we have
[TABLE]
Now analogously to , let us define the acceptance region for as
[TABLE]
Note that
[TABLE]
Besides
[TABLE]
as for each the function is jointly continuous with respect to and . By setting
[TABLE]
we obtain
[TABLE]
for all . ∎
Assumption b) of Lemma 3.5 (jump kernels)
Proof.
Firstly recall that under assumption e1) of Theorem 4.2 we have:
[TABLE]
if belongs to the jumping region , and otherwise. Recall as well that all the jumping regions for , are contained within a compact set and consequently any point proposed in a deterministic jump satisfies . Let us now define
[TABLE]
Observe that
[TABLE]
and so for all
[TABLE]
Finally, setting and yields (3.6) under assumption e1).
Let us now consider assumption e2). Recall that for any if , then (8.14) holds for some , and . Furthermore,
[TABLE]
By assumption (4.10) there exists a constant such that for each , and and as a consequence,
[TABLE]
where the last inequality follows from (8.10). Fix and observe that
[TABLE]
where the last inequality follows from being super-exponential and positive.
Recall additionally that under e2) (8.15) holds for all . Putting together (8.14), (8.16), (8.17) and (8.15) yields
[TABLE]
By setting and , we obtain the drift condition as given by (3.6). ∎
Assumption c) of Lemma 3.5
Proof.
Proving the minorisation condition (3.7) amounts to specifying , and , and verifying that for all measurable sets and all satisfying . Let be defined as , where is defined in (8.3). We specify the value of below, separately for assumptions e1) and e2).
Note that if , then for each and each . Observe also that is a compact set. Let be the uniform distribution on (and 0 everywhere else) i.e. for we have . To prove the claim, it is enough to show that
[TABLE]
for of the form , for any and any .
Firstly, note that for any
[TABLE]
where the last inequality is satisfied by assumption c) and equation (8.10).
We will first focus on verifying the minorisation condition under assumption e1). Recall that is a compact set in such that for each and we have . Recall also that by the construction of the jumping regions there exists such that for each and the ball . Let us now pick so large that and for .
The minorisation condition will be proved for . Indeed, three steps of the algorithm are enough to get from a point to a set (a local step within mode to reach its jumping region, a jump to mode and a local move within mode to set ).
Fix and a set for (we allow for the case ). Note that since for all and we have
[TABLE]
By equations (4.5) and (8.18) we get that defined above is strictly positive for . Considering the probability of accepting a deterministic jump from mode to mode , we obtain
[TABLE]
It follows from equations (8.18), (4.3) and (4.2) that for . Analogous arguments show that
[TABLE]
Combining (8.19), (8.20) and (8.21) yields
[TABLE]
Setting ends the proof.
We will now verify the minorisation condition under assumption e2). Let be so large that (see assumption (4.9)) for and , for . We will prove that indeed the minorisation condition holds for . Note that if we want to move from to a set , it is enough to make a local step to , and then a jump to followed by a local step to .
As before, fix and a set for . Again we include the case . Analogous calculations to (8.19) show that
[TABLE]
For the jump kernel involved we obtain
[TABLE]
Note that is positive by equations (8.18) and (4.3), and assumption e2). Finally, similar calculations to (8.21) yield
[TABLE]
for defined in the previous part of the proof. We now combine (8.22), (8.23) and (8.24) to get
[TABLE]
Setting ends the proof. ∎
Proof of Theorem 4.3
Proof.
This theorem is a direct corollary from Theorem 3.4. The assumptions of this theorem were verified in the proofs of Theorems 4.1 or 4.2, under the uniform and the non-uniform scenario, respectively. ∎
Proof of Lemma 4.5
Proof.
Fix and let be such that for larger than some
[TABLE]
(such can be found due to assumption (4.12)). Hence, for sufficiently large
[TABLE]
which implies that for any
[TABLE]
and consequently
[TABLE]
By assumption a) of Theorem 4.2 is indeed positive.
Let the acceptance region be given by (8.13). We will show that for sufficiently large and for each
[TABLE]
which will prove the claim. We shall now repeat similar arguments to those used in the proof of Theorem 4.2, in the part for the local kernels. Firstly, we use formula (8.8) to conclude that for larger than some (which may depend on ) and for sufficiently small (which may depend on , and ), we have
[TABLE]
We put (8.25) together with (8.26) to obtain
[TABLE]
for . Now recall that for each there exists such that for if then for defined in (8.10). Therefore in particular for each . Finally, for we have
[TABLE]
which ends the proof. ∎
Proof of Lemma 4.6
Proof.
Fix any and . To prove the required result, we will use analogous arguments to those from the proof of Theorem 4.3 of [29]. Let and be such that for
[TABLE]
Fix and define the cone as
[TABLE]
We now refer to the proof of Theorem 4.3 of [29] to see that for sufficiently large . What is more,
[TABLE]
Hence, since was chosen arbitrarily, assumption (4.12) is satisfied for .
We would like to point out here that originally Theorem 4.3 of [29] was proved under a stronger assumption, that is, . However, careful inspection of this proof shows that it is enough to assume that , which is satisfied in our case as follows an elliptical distribution. ∎
Proof of Corollary 4.7
Proof.
We will again refer multiple times to [29]. Firstly, by Theorem 4.4 of this paper, if and are super-exponential and satisfy (4.13), then also is super-exponential and satisfies (4.13) for positive and . By Theorem 4.6 of the same paper, each density of the form is super-exponential and satisfies (4.13), if is a polynomial of order . Therefore, the assumptions of Lemma 4.6 hold, as required. ∎
9 Other algorithms in the Auxiliary Variable Adaptive MCMC class
As mentioned in Section 3, an instance of an algorithm in the Auxiliary Variable Adaptive MCMC class is adaptive parallel tempering introduced by [34]. Indeed, let us consider and and
[TABLE]
Then for any we have
[TABLE]
where the last equality follows since for all . Additionally, the transition kernels used in adaptive parallel tempering are defined in such a way that detailed balance holds.
Another example of a group of algorithms in the Auxiliary Variable Adaptive MCMC class is an adaptive version of pseudomarginal algorithms. Recall that pseudomarginal algorithms are a powerful tool used in situations when the target density on cannot be evaluated pointwise or this evaluation would be very expensive, but an unbiased estimator of is available. In the simplest setting an importance sampling estimator is used for this purpose. Then the pseudomarginal algorithm is equivalent to the Metropolis-Hastings algorithm targeting a distribution on an augmented state space , where is a vector representing samples on which the importance sampling estimator is based. A remarkable property of the pseudomarginal algorithms is that is the marginal distribution of regardless of (see [4] and [6]) . The number of samples and, in more complex settings, the amount of correlation between those samples (see [17]), may follow an adaptive scheme. Therefore, conditions and are satisfied for , where corresponds to the number of samples used for estimation.
Supplementary Material B
In Sections 10 and 11 we present details of the implementation of our method. An additional simulation example and settings of our numerical experiments are shown in Section 12.
10 Updating and
Recall that denotes the number of modes. The weights are set to at the beginning of the algorithm and they are adapted while the algorithm runs in such a way that they represent the proportion of samples observed so far in each mode. At the same time we do not allow any of the weights to get below some pre-specified value ; otherwise the target distribution could run the risk of being severely distorted by weights very close or equal to 0. In particular we use the update scheme described below.
Let be the number of samples in mode for observed after iterations of the main algorithm. Then . Define
[TABLE]
It is easily checked that if there are no observations in mode , i.e. is equal to 0, then . Since must satisfy and the number of modes is typically unknown in advance, in our implementation the user provides and the algorithm sets .
Even though the theory we present in Section 4 holds when follow some adaptive rule, we propose to keep these values fixed throughout the run of the algorithm, with a default choice and for , and . If is not very large the benefit of adapting is rather marginal while it may add to finite sample instability. A natural alternative improving acceptance rates would be to keep and . However, consider a scenario when a mode with a significant weight in the target distribution is particularly difficult to jump into (for example, because the covariance matrix estimation has not been run for long enough). The jumps to this mode will very likely get rejected many times before we observe the first sample in this mode and start adapting its covariance matrix. In such case proposing modes proportionally to the number of samples collected so far in those modes would effectively make moves to this ”difficult” mode even less frequent. Consequently we could face the risk of underestimating the weight of this mode for a fixed computational budget. Hence, we adopt the more conservative approach of keeping these values fixed to avoid the risk described above.
Note also that we in our implementation we use even though formally we assumed in Section 4 that . This is because in practice we do not want to propose jumps to the same mode. In case of deterministic jumps this would mean proposing a move to the same state (recall equation (2.5)), which would have a negative impact on the mixing of the algorithm.
11 Burn-in algorithm
For the mode finding part in our implementation we use the BFGS method from the optimx package in R [39]. We only pass to the next stage of the burn-in algorithm (mode-merging) those vectors for which first and second order Kuhn, Karush, Tucker (KKT) optimality conditions are satisfied. Checking these conditions is necessary in order to avoid including points that are not local minima of (but, for example, saddle points) in the list of modes. Besides, we recommend that the user codes up their own function for calculating the gradient and the Hessian, whenever possible, or uses packages that compute those values with high numerical precision. This will help ensure numerical stability of the optimisation runs. What is more, working with variables with bounded support tends to be problematic – the optimisation algorithm will typically struggle in the neighbourhood of the boundary. In such cases it is usually beneficial to work with transformed variables, defined on the whole space (see Section 12.1).
Recall that the initial value of the matrix corresponding to mode at the beginning of round 1 of the covariance matrix estimation is the inverse of the Hessian evaluated at (see line 17 of Algorithm 3). The heuristics behind this idea is that in case of the Gaussian distribution the inverse of the Hessian of would correspond to the covariance matrix, so intuitively for a large class of target distributions this will be a good starting value.
As mentioned in Section 2.2, we propose a semi-automatic way of choosing the number of rounds of the covariance matrix estimation, denoted by . Recall that is the matrix corresponding to mode updated during round . The choice of is based on monitoring the following quantity, called inhomogeneity factor (see [43] and [47]), given by
[TABLE]
where is the dimension of the state space of and for are the eigenvalues of . Note that this factor is always a real number even though does not need to be symmetric. If is a complex eigenvalue of , its conjugate is also an eigenvalue of and so the imaginary components cancel both in the numerator and the denominator of . Moreover, by Jensen’s inequality satisfies and if and only if and are proportional to each other. In particular, the value of is always equal to 1 in the scaling phase.
The procedure we propose is the following: perform scaling steps for each matrix (perhaps split into several rounds). Then perform at least one covariance-based round for each mode. Continue running covariance-matrix rounds until the inhomogeneity factor drops below a certain threshold for all matrices. In other words, having performed scaling steps and at least one covariance-based round, we set to the smallest value of satisfying In the version in which the modes can be added when the main algorithm runs, one could consider stopping the burn-in algorithm separately for each mode and passing the covariance matrix to the main algorithm once its corresponding inhomogeneity factor goes below .
As for the choice of the lengths of the rounds, by default we use a geometric sequence with a common ratio 2. The number should grow with the dimension of the state space since the initial covariance matrix will be based on samples for each mode. In our experiments is equal to .
Note that this construction implies that adapting the matrices by scaling will happen only during the burn-in algorithm, as the number of samples in each mode at the beginning of the main algorithm will be equal to the total length of the number of iterations in the burn-in algorithm, so in particular this number will exceed .
The adaptation scheme of the main algorithm is based on updating the covariance matrices passed from the burn-in algorithm.
12 Examples – further details
Below we present one more example, a hierarchical Bayesian model for cancer data. We also discuss some further details related to the simulations described in Section 5. The exact parameters settings of our experiments are summarised in Table 3. For all examples shown in this paper we used an implementation of the algorithm in which the burn-in algorithm runs only before the main algorithm (without adding modes on the fly).
12.1 Hierarchical Bayesian model for LOH data
The example presented here is based on the Seattle Barrett’s Oesophagus study (see [11]) analysed later by [55], [15] and [9]. Loss of Heterozygosity is the process by which a region of the genome is deleted on either the paternal or maternal inherited chromosomes leading to a loss of diversity. Loss of Heterozygosity (LOH) rates were collected from oesophageal cancers for 40 regions, each on a distinct chromosome arm. They are of interest since chromosome regions with high rates of LOH are thought to contain so-called Tumour Suppressor Genes (TSGs) whose functionality is adversely affected by the reduction in genetic diversity. There exists also a proportion of ”background” (not cancer-related) LOH. The aim of this study is to provide, for each LOH rate, the probability of being in the TSG group and in the ”background” group. Following the approach adopted in the above papers, we consider the following mixture model:
[TABLE]
where is the number of events of interest (Loss of Heterozygosity) observed in region , and – the corresponding sample size. Besides, denotes the probability of a location being a member of the binomial group, is the probability of LOH in the binomial group, is the probability of LOH in the beta-binomial group, and controls the variability of the beta-binomial group. That is, the likelihood function for this model is given by for
[TABLE]
where B denotes the beta function and . The following prior distributions were used for the parameters of interest:
[TABLE]
The resulting target distribution has two non-symmetric and well-separated modes, as depicted in Figure 8, one of which has a significantly bigger weight than the other; below we denote them by mode 1 and 2, respectively. We based our analysis on 200,000 steps of the main algorithm and 500 BFGS runs for the mode-finding stage. The length of the covariance matrix estimation in burn-in algorithm was equal to 3000 iterations for each experiment (chosen automatically). Table 4 summarizes the acceptance rates of jumps between the modes for the three versions of the implementation of the algorithm.
As stated above, the prior distribution for all the variables has its support on a compact set. Since this typically has an adverse effect on both mode-finding and sampling, we decided to work with transformed variables, which live on the real line. For the first three variables we applied the logit transformation, i.e. we transformed them using a function . For the last variable we used the transformation given by .
The starting points for the optimisation runs were sampled from the prior distribution and transformed the way described above. The number of function and gradient evaluations for the BFGS runs varied between 27 and 428, with an average of 73.
12.2 Mixture of Gaussians
The starting points for the optimisations runs were sampled uniformly on . In Table 5 we gathered information about the number of the target density and its gradient evaluations (jointly) in the BFGS runs. We reported the minimum, the mean and the maximum value required for the optimisation algorithm to converge. The last two columns show the minimum and the maximum number of iterations used for the estimation of the covariance matrices in the burn-in algorithm. These figures show that indeed the computational budget used by our method for dimensions and was significantly smaller than the budget of APT (see Section 5.1).
Figures 9 and 10 illustrate good performance of our method in dimensions and , especially for the deterministic jumps. Interestingly, the Gaussian proposal for jumps gives results of the poorest quality on this example.
12.3 Mixture of and banana-shaped distributions
The starting points for the optimisation runs were sampled uniformly on . Table 6 presents analogous information to Table 5, for the mixture of and banana-shaped distributions considered in Section 5.2. For dimensions and we did not run the mode-finding part, assuming the locations of the modes were known. Overall, our method in all its versions proved to perform well on this high-dimensional example, despite the complicated shapes of the modes. Table 7 shows that, as before, the deterministic jump method ensures best between-mode mixing. However, it can be noticed that given 20 runs of the experiment, a few times this method delivered results that deviated significantly from the truth (see Figure 11).
12.4 Sensor network localisation
Starting points for the BFGS procedures were sampled uniformly on . The number of function and gradient evaluations for these runs varied between 175 and 876, with an average of 400. The starting points for the APT simulations were the 14 modes identified by the BFGS optimiser and 6 points sampled uniformly on .
Recall that the results for APT presented in Section 5.3 were based on 4 temperatures. In Figure 12 we present analogous results to those shown in Figure 7, with the number of temperatures increased to 5 (and the same number of iterations equal to 700,000). Under such settings the APT algorithm mixes better between the modes, however, as illustrated in Figure 12, it still yields less stability than our method. Note that APT required or target evaluations, for and temperature levels, respectively. Assuming an implementation of JAMS on a standard desktop computer with 8 cores, the computational cost measured by the number of target and gradient evaluations per core would be at most:
- •
for mode finding: (as for each BFGS run we had at most 875 such evaluations);
- •
for the burn-in-algorithm: target evaluations (as the estimation of 14 covariance matrices needed to be split across 8 cores);
- •
for the main algorithm: target evaluations.
Altogether this would give evaluations, and the additional overhead resulting from the communication between cores. This figure shows that APT required a larger computational cost than JAMS in our setup even though the above analysis was carried out under a pessimistic scenario. Firstly, on average there were 400 evaluations per BFGS procedure and plugging this value into the above calculations would decrease the overall number of evaluations to 1,000,030. What is more, typically a user would run our algorithm on a server or a cloud service, which we in fact did as well. This would allow to split the computational cost (in particular, that of BFGS runs) across a much larger number of cores.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ahn et al., [2013] Ahn, S., Chen, Y., and Welling, M. (2013). Distributed and adaptive darting Monte Carlo through regenerations. In Artificial Intelligence and Statistics , pages 108–116.
- 2Andricioaei et al., [2001] Andricioaei, I., Straub, J. E., and Voter, A. F. (2001). Smart darting Monte Carlo. The Journal of Chemical Physics , 114(16):6994–7000.
- 3Andrieu and Moulines, [2006] Andrieu, C. and Moulines, E. (2006). On the ergodicity properties of some adaptive MCMC algorithms. Ann. Appl. Probab. , 16(3):1462–1505.
- 4Andrieu and Roberts, [2009] Andrieu, C. and Roberts, G. O. (2009). The pseudo-marginal approach for efficient Monte Carlo computations. The Annals of Statistics , 37(2):697–725.
- 5Andrieu and Thoms, [2008] Andrieu, C. and Thoms, J. (2008). A tutorial on adaptive MCMC. Stat. Comput. , 18(4):343–373.
- 6Andrieu and Vihola, [2015] Andrieu, C. and Vihola, M. (2015). Convergence properties of pseudo-marginal Markov chain Monte Carlo algorithms. The Annals of Applied Probability , 25(2):1030–1077.
- 7Atchadé and Fort, [2010] Atchadé, Y. and Fort, G. (2010). Limit theorems for some adaptive MCMC algorithms with subgeometric kernels. Bernoulli , 16(1):116–154.
- 8Atchadé et al., [2011] Atchadé, Y. F., Roberts, G. O., and Rosenthal, J. S. (2011). Towards optimal scaling of Metropolis-coupled Markov chain Monte Carlo. Statistics and Computing , 21(4):555–568.
