Singular Values for ReLU Layers
S\"oren Dittmer, Emily J. King, Peter Maass

TL;DR
This paper introduces ReLU singular values and Gaussian mean width as new tools to analyze ReLU layers, providing theoretical insights and practical metrics for neural network performance and data classification.
Contribution
It presents novel theoretical tools for understanding ReLU layers and demonstrates their practical utility in analyzing neural network behavior.
Findings
ReLU singular values and Gaussian mean width offer new theoretical insights.
These measures can distinguish correctly and incorrectly classified data.
Tools like double-layers and harmonic pruning are introduced based on these findings.
Abstract
Despite their prevalence in neural networks we still lack a thorough theoretical characterization of ReLU layers. This paper aims to further our understanding of ReLU layers by studying how the activation function ReLU interacts with the linear component of the layer and what role this interaction plays in the success of the neural network in achieving its intended task. To this end, we introduce two new tools: ReLU singular values of operators and the Gaussian mean width of operators. By presenting on the one hand theoretical justifications, results, and interpretations of these two concepts and on the other hand numerical experiments and results of the ReLU singular values and the Gaussian mean width being applied to trained neural networks, we hope to give a comprehensive, singular-value-centric view of ReLU layers. We find that ReLU singular values and the Gaussian mean width do not…
Click any figure to enlarge with its caption.
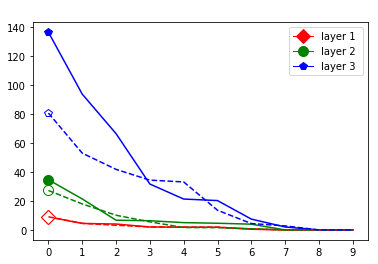 Figure 1
Figure 1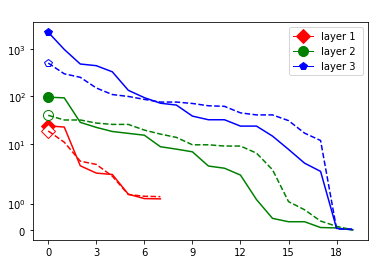 Figure 2
Figure 2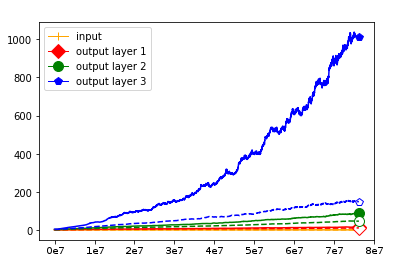 Figure 3
Figure 3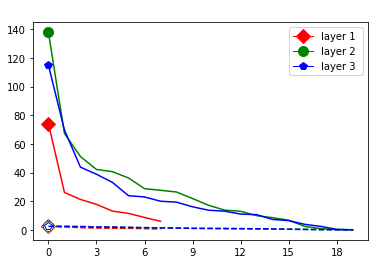 Figure 4
Figure 4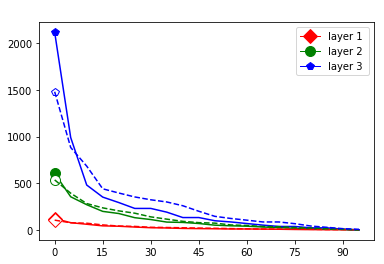 Figure 5
Figure 5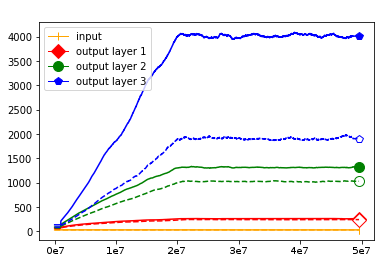 Figure 6
Figure 6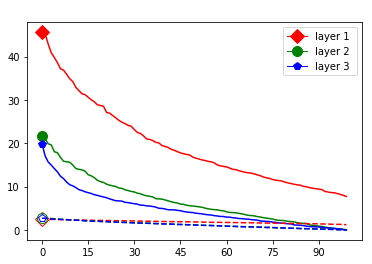 Figure 7
Figure 7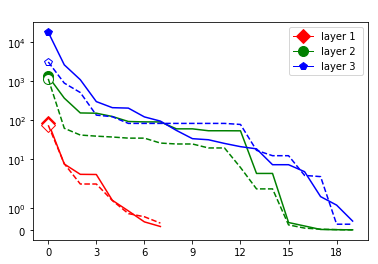 Figure 8
Figure 8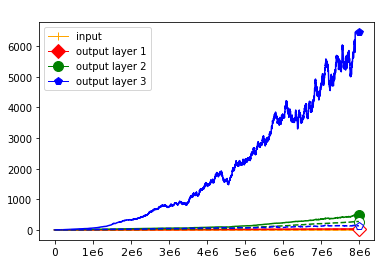 Figure 9
Figure 9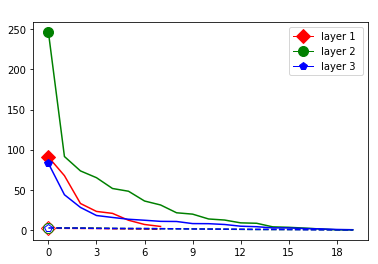 Figure 10
Figure 10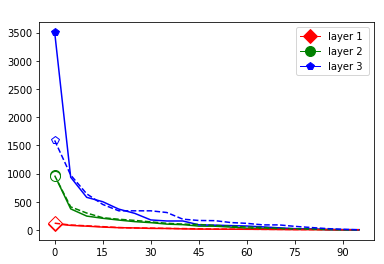 Figure 11
Figure 11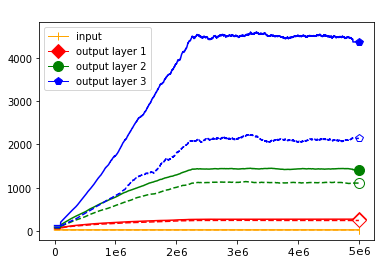 Figure 12
Figure 12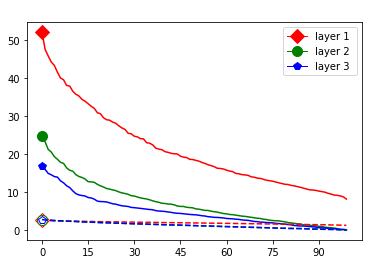 Figure 13
Figure 13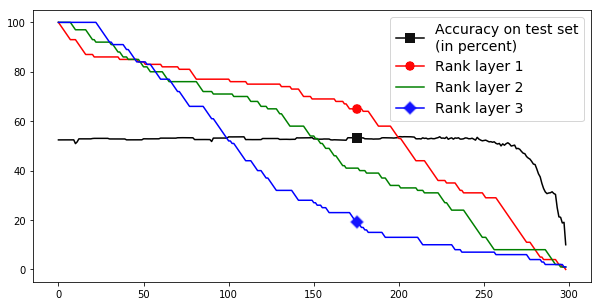 Figure 14
Figure 14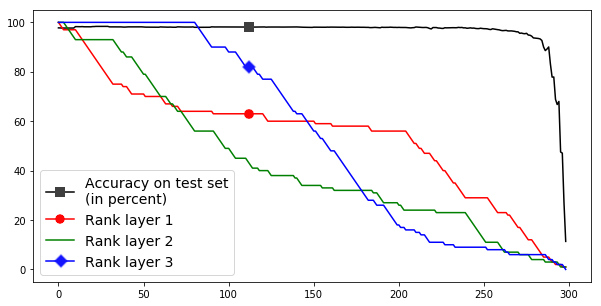 Figure 15
Figure 15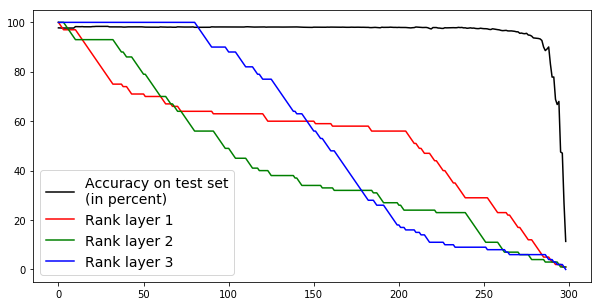 Figure 16
Figure 16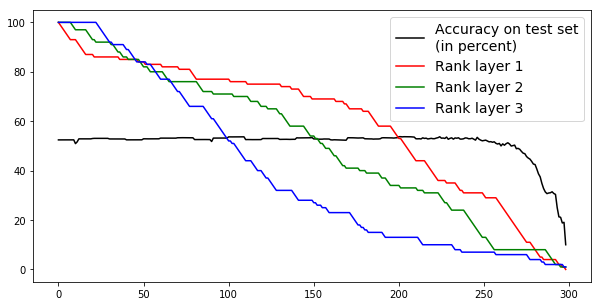 Figure 17
Figure 17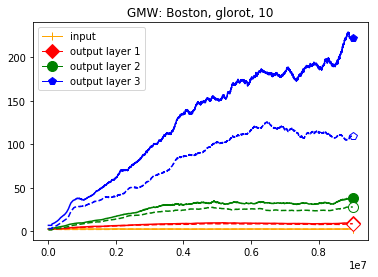 Figure 18
Figure 18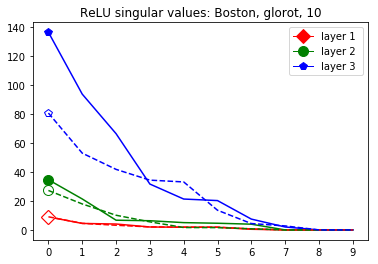 Figure 19
Figure 19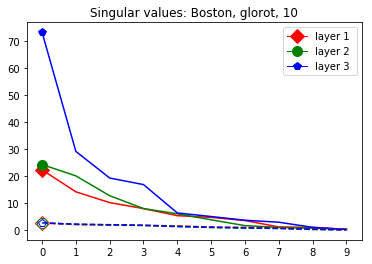 Figure 20
Figure 20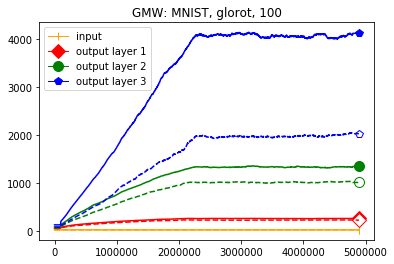 Figure 21
Figure 21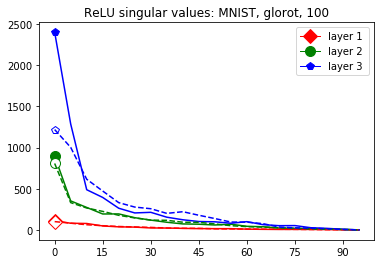 Figure 22
Figure 22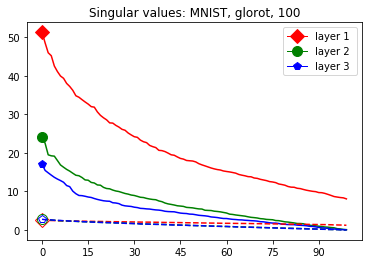 Figure 23
Figure 23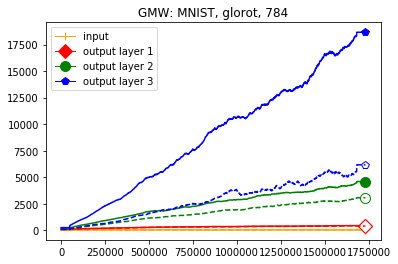 Figure 24
Figure 24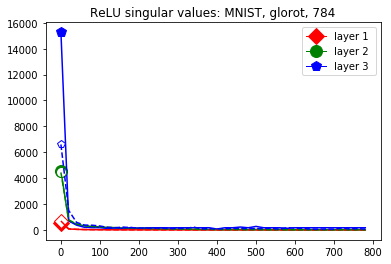 Figure 25
Figure 25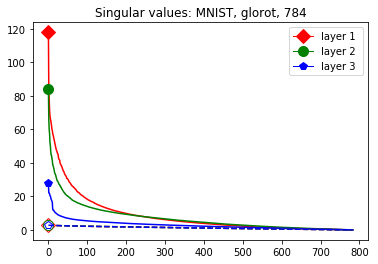 Figure 26
Figure 26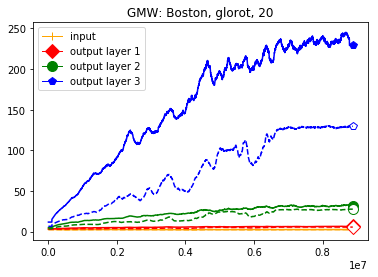 Figure 27
Figure 27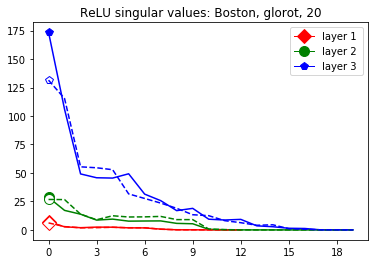 Figure 28
Figure 28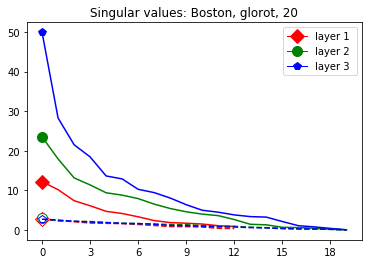 Figure 29
Figure 29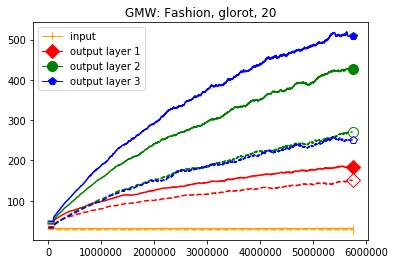 Figure 30
Figure 30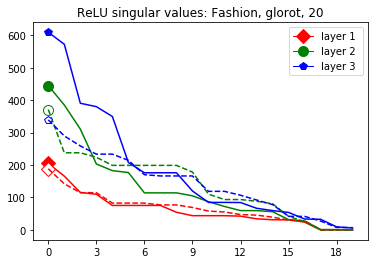 Figure 31
Figure 31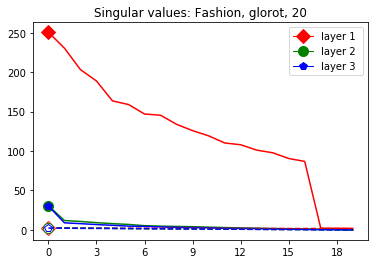 Figure 32
Figure 32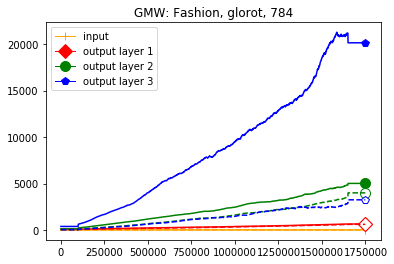 Figure 33
Figure 33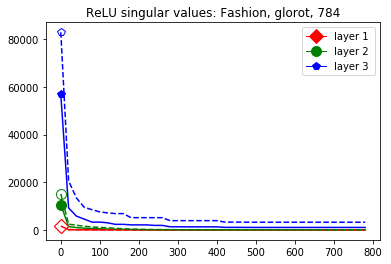 Figure 34
Figure 34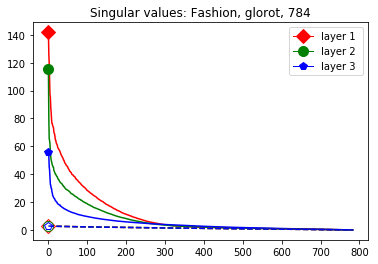 Figure 35
Figure 35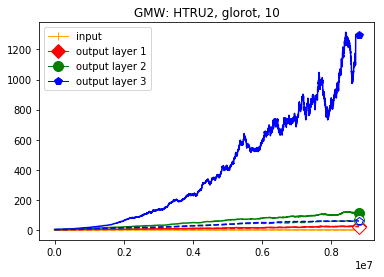 Figure 36
Figure 36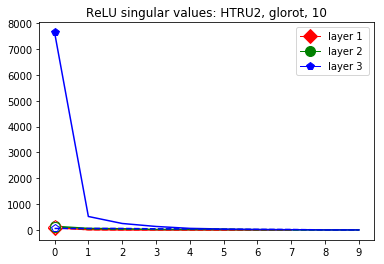 Figure 37
Figure 37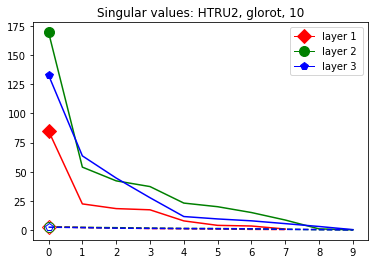 Figure 38
Figure 38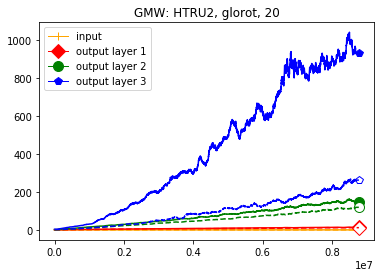 Figure 39
Figure 39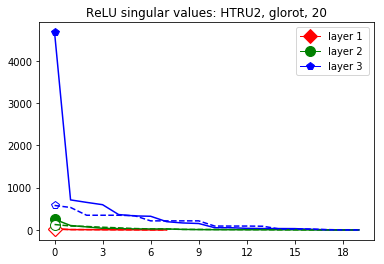 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
Methods*Communicated@Fast*How Do I Communicate to Expedia?
Singular Values for ReLU Layers
Sören Dittmer, Emily J. King, Peter Maass
Abstract
Despite their prevalence in neural networks we still lack a thorough theoretical characterization of ReLU layers. This paper aims to further our understanding of ReLU layers by studying how the activation function ReLU interacts with the linear component of the layer and what role this interaction plays in the success of the neural network in achieving its intended task. To this end, we introduce two new tools: ReLU singular values of operators and the Gaussian mean width of operators. By presenting on the one hand theoretical justifications, results, and interpretations of these two concepts and on the other hand numerical experiments and results of the ReLU singular values and the Gaussian mean width being applied to trained neural networks, we hope to give a comprehensive, singular-value-centric view of ReLU layers. We find that ReLU singular values and the Gaussian mean width do not only enable theoretical insights, but also provide one with metrics which seem promising for practical applications. In particular, these measures can be used to distinguish correctly and incorrectly classified data as it traverses the network. We conclude by introducing two tools based on our findings: double-layers and harmonic pruning.
Index Terms:
Neural Networks, Gaussian Mean Width, n-Width, ReLU, Singular Values
I Introduction
I-A Motivation and Overview
Singular values are an indispensable tool in the study of matrices and their applications. Not only are they used in data science, e.g. in principal component analysis [1] and low-rank approximations in general [2], but they are also used in the computation of the generalized inverse [3], signal processing [4], and the analysis and regularization of inverse problems [5], as well as countless other fields. Since the usual singular values are only applicable in the linear setting, they are unfortunately not directly suitable for the analysis of nonlinear neural networks. This paper addresses this situation in two ways – namely by defining ReLU singular values and by defining the Gaussian mean width for operators. We start by generalizing the operator norm to the class of nonnegatively homogeneous operators which includes operators of the form
[TABLE]
where is a matrix and ReLU is defined component-wise via [6]. Then by leveraging certain traits of singular values, we define ReLU singular values , given by
[TABLE]
Here is a matrix with an upper bounded rank and the unit ball. After giving a simple but useful analytical bound on ReLU singular values we explore their behavior numerically and see that ReLU layers act like functions with lower singular values than the linear component of the layer would seem to indicate. This realization motivates the new tool of harmonic pruning. In Section III, ReLU singular values are further generalized to allow bias in the ReLU layer and be calculated over actual data rather than general mathematical domains. The data-dependent, biased ReLU singular values of correctly classified and incorrectly classified data sets as they travel through a trained network reveals structural differences in how networks treat such data. We follow up on this phenomenon in Section IV where we use the Gaussian mean width [7] to explore the effective dimension of layers and derive how this dimensionality is related to the singular values of linear layers and how the Gaussian mean width can be interpreted with regard to ReLU layers. One of the tools we employ in this analysis is the new concept of Gaussian mean width of operators. We also show that the Gaussian mean width reveals big differences in how networks handle correctly and incorrectly classified data. Before we conclude the paper in Section VI we discuss in Section V practical applications of our findings, i.e. so-called double-layers and with them harmonic pruning.
In a sense this paper provides a study of sparsity, but unlike most papers on sparsity in neural networks, it is concerned with the sparsity of the spectrum.
Finally, we would like to point out that we provide code for calculating the Gaussian mean width [8] and bounds on ReLU singular values [9].
I-B Related Work
Although there are generalizations of singular values to the nonlinear setting like [10], in which the nonlinear operators are assumed to be differentiable; there do not seem to be generalizations appropriate for ReLU layers. However, there are a multitude of applied papers documenting and leveraging positive effects of so-called linear bottlenecks in neural networks, e.g. [11, 12, 13], which we will see are closely connected to ReLU singular values and double-layers. Linear bottlenecks in a network are created by two linear layers (i.e., with no activation function) enforcing a low dimensional representation. These layers are mostly used to deal with huge output dimensions to decrease the number of trainable parameters [13, 14] but also sometimes to boost performance [11, 12]. Note that bottlenecks, albeit nonlinear ones, are also very common in ResNet residual blocks, e.g. [15]. Another related paper which is less concerned with bottlenecks and more concerned with a restriction of the parameters of a neural network is the paper [16], in which the authors demonstrate that one can train a network with virtually no loss in performance when restricting the network’s parameter updates to a very low dimensional subspace of the original parameter space. Additionally the paper [17] ties our approach also to pooling methods in convolutional neural networks (CNNs). With regard to the Gaussian mean width we would like to point to [16] as a general source and to [18] as a paper that applies the Gaussian mean width to untrained neural networks with i.i.d. Gaussian weights. While not directly applicable to the topics discussed here, we would still like to reference paper [19], where the authors investigate the singular values of convolutional layers, ignoring the activation function.
II ReLU Singular Values
II-A Theory – A Generalization of Singular Values.
We would like to open this section by reviewing what singular values are and – more importantly – what their essential property might be. We start by stating the following common definition of singular values (see, e.g., [20]). Let be a real matrix, we then define its th singular value (Note that we start the indexing at [math].) as
[TABLE]
where is the unit ball and the operator norm. This can be phrased as:
The th singular value of a (linear) operator is the minimal operator norm of with regards to , where is a (linear) operator of rank .
We would like to draw the reader’s attention to the point that, apart from its reliance on the notions and operator norm, this definition is fairly general insofar as it is not inextricably linked to the linearity of the operators involved. This is the first of two key observations we will use for our generalization. The second key observation relates to operator norms and is exemplified by the following equalities: Let be a real matrix. Then we than can write
[TABLE]
where is the unit sphere. The equivalence of these formulations suggests that a key aspect of the operator norm is its positive homogeneity (i.e., its covariant behavior with regard to the multiplication by positive factors) and thereby the representativeness of the operator’s restriction to and even . Inspired by this second key observation we will now define nonnegatively homogeneous operators.
Definition 1
Let and be Banach spaces over . A (possibly nonlinear) operator is called nonnegatively homogeneous if for all and . We then denote the space of all nonnegatively homogeneous operators from to as .
Obviously every nonnegatively homogeneous operator is positively homogeneous and every linear operator is nonnegatively homogeneous. Most notably for this paper, , where is a real matrix, is also nonnegatively homogeneous. For an illustration of , where
[TABLE]
see Figure 1.
Having now defined nonnegatively homogeneous operators we are able to extend the usual definition of operator norms.
Definition 2
Let and be Banach spaces over . The operator norm of an is defined as
[TABLE]
where is the unit ball of .
In Section IV, we will see the operator norm of a general function in again. For now, we will focus on the functions in of the form for some matrix and generalize singular values to such maps.
Definition 3
Let be of the form for some matrix . For we define
[TABLE]
Like for linear singular values we have the relation
[TABLE]
Although the calculation of ReLU singular values seems in general intractable, we may compute an upper bound with the help of the following lemmata.
Lemma 4
For we have
[TABLE]
**Proof ** Since ReLU is applied component-wise, it is sufficient to show that
[TABLE]
for . This can is shown by the following analysis of the possible cases.
,
,
[math]
,
,
This lemma allows us to compute the following upper bound.
Lemma 5
Let be given via then
[TABLE]
Proof:
For any we have:
[TABLE]
This gives us
[TABLE]
∎
While Lemma 5 gives a direct and intuitive theoretical connection between (linear) singular values and ReLU singular values, we will compute tighter bounds in the following section. We would like to close this subsection with the following remarks:
Remark 6
Although ReLU singular values do not seem to admit a straightforward way to also generalize the singular value decomposition (SVD), they allow for a straightforward definition of a sequence of operators one would associate with the operators given by a truncated SVD in the linear case.
Remark 7
One of the most useful ways to think about a ReLU singular value is to interpret it as the worst case error one has when approximating with a rank approximation.
Remark 8
The concept of ReLU singular values could be easily extended to arbitrary nonnegatively homogeneous operators, e.g. leaky ReLU [21] layers. In fact, one can easily see that Lemmas 4 and 5 still hold when ReLU is replaced with leaky ReLU.
II-B Numerics – A Short Numerical Exploration of ReLU Singular Values
We will now describe a simple numerical method for approximating upper bounds of ReLU singular values that is stronger than Lemma 5. We will then utilize this method to compare these bounds with the singular values of the weight matrices for some random ReLU layers of the form . The approximation is a two step process:
Approximate
[TABLE]
e.g. via the minimization of the function with some kind of stochastic gradient descent (in our case Adam [22]) for a sufficiently dense finite subset of . 2. 2.
Calculate an approximate upper bound of as
[TABLE]
this is can be done by simply calculating the norm above for each .
The code of the two-step process can be found here [9]. Its computational complexity is dominated by the first step, since the second is a simple linear search. Therefore the algorithm has effectively the overall complexity of Adam [22]. In practice this means that it has computational costs similar to training a single layer. This algorithm yields approximations only, since in practice has to be finite and is therefore only itself an approximation to . While this is a minor problem in low dimensions, it poses an increasingly severe problem in higher dimensions due to the curse of dimensionality – we will deal with this in the next subsection. The algorithm yields an approximation of an upper bound, since it simply “solves” Equation 2 for the suboptimal guess . Figure 2 depicts the comparisons of singular value curves and the corresponding upper bounds of ReLU singular values for some random low dimensional ReLU layers of the form . We define the singular value curve of a real matrix with an SVD as the plot of the (decreasingly) ordered diagonal of over the horizontal axis, i.e., the decreasingly ordered singular values over their indices. As one can see the numerical calculations result – especially for lower indices – in much lower bounds than the linear singular values give us. That is, the approximations of the ReLU singular values show that the composition of ReLU with a linear function effectively acts like a map with smaller and fewer significant singular values. This phenomenon is a main motivation of the harmonic pruning method presented in Section V.
III Data-Dependent, Affine ReLU Singular Values
As it probably has not escaped the notice of the more practically minded readers, most ReLU layers have biases, i.e. are of the form
[TABLE]
This forces us to adapt and rethink our definition of the operator norm in Equation 6, since a direct application of it
[TABLE]
seems hardly appropriate considering that the operator’s application to does not have to be representative of the overall behavior of the operator. Three approaches come to mind: a modification of the set we are maximizing over to adapt it to the bias; the removal of the bias; and the incorporation of the bias in the weight matrix, transforming the affine setting back into a linear one. The removal of the bias does not seem appropriate since it clearly has an influence on the operator and since there is not a unique way of transforming the affine setting to a linear one we will concentrate on the set we maximize over. On the one hand it is unfortunately also not clear which modification of would be appropriate to capture the behavior of the operator over the whole input space. However, one is usually not interested in how a ReLU layer behaves over its entire mathematical domain since in practice its inputs are samples from a tiny subset of the possible input space. On the other hand there already exists a sufficiently dense representation of that subset in the form of the training data of the network, since otherwise one could not have trained the network. We therefore make the following definitions:
Definition 9
Let and . We then generalize the operator norm to the operator over the set as
[TABLE]
and the th ReLU singular value of the operator over a given set as
[TABLE]
Note that the generalization of the norm is itself not a norm.
These data-dependent ReLU singular values can be numerically upper bounded in an analogous fashion as in the unbiased case. Figure 3 shows the results of two of our numerical tests where we calculated upper bounds of the data-dependent ReLU singular values for each of the layers of two different, trained neural networks, once where is a set of a certain size only containing correctly classified data points by the network and once where it is of the same size and only contains incorrectly classified data points. Each of the networks is a multilayer perception (MLP) with three hidden ReLU layers and one classification softmax layer trained via a cross-entropy-with-logits loss function and the Adam optimizer [22] with Tensorflow [23] standard settings solving a classification task. The training details for the two networks are displayed in Table I
The plots in Figure 3 display some properties which where fulfilled by the overwhelming majority of our test cases (see Appendix A): The bounds of the first layer are smaller than those of the second layer, and the bounds of the second layer are smaller than those of the third (last hidden) layer. Also the greatest bounds of a layer for the correctly classified data tend to be greater than the bounds for the incorrectly classified data. The growth of the singular values over the layers can easily be explained by the fact that the datasets over which the bounds are calculated were already propagated through the previous layers. The relation between the correctly and incorrectly classified datasets is the more interesting characteristic and motivates the next section.
IV Gaussian Mean Width and ReLU layers
As we saw in the last section ReLU layers seem to handle data points that will be classified incorrectly differently from those that will be classified correctly. To study this difference we briefly want to consider which mechanisms are at play when one applies a layer of the form
[TABLE]
to a data point . Using the SVD of and an on--dependent diagonal matrix with [math]s and s on its diagonal to represent ReLU, we can express the application of this layer to as
[TABLE]
This expression shows that the norm of the output depends on how much is affected by each singular value of , i.e., how much it is correlated with which right singular vector and how much ReLU can decrease the impact of the singular value for a given by setting entries to [math]. This can be studied, as Lemma 14 will show, using the Gaussian mean width [7].
IV-A Theory – A Short Review and Expansion.
We start by stating the definition of the Gaussian and spherical mean width.
Definition 10
The Gaussian mean width of a set [7] is defined as
[TABLE]
where denotes an n-dimensional standard Gaussian i.i.d. vector and is to be read in the Minkowski sense, i.e., . We now introduce the new concept of the Gaussian mean width of an operator as
[TABLE]
where is the unit ball. By sampling from the uniform distribution over the unit sphere instead of from the standard Gaussian, we analogously define , following [7] and similarly introduce as the spherical mean width of a set and spherical width of an operator, respectively.
An interesting and useful property of the Gaussian mean width is its invariance under convexification, more precisely:
Corollary 11
[7*]**
For all we have*
[TABLE]
where denotes the convex hull.
Corollary 11 shows that – like in the definition of the (linear) operator norm – it does not matter if one defines the operator’s Gaussian mean width via the unit ball or the unit sphere.
For a more rigorous treatment of the basics of the Gaussian mean width and why its square can be interpreted as the “effective dimension,” we refer to [7] but want to state the following remark based on [7].
Remark 12
One can estimate a vector from random linear observations where is proportional to with the proportionality factor solely depending on the acceptable (absolute) approximation error. Therefore the Gaussian mean width can be seen as a measure of complexity.
We now analyze the properties of the Gaussian mean width beginning with Lemma 13, which explicitly relates the Gaussian and spherical mean width. The result follows from combining arguments from [7, Section 3.5.1] with standard results concerning independent gamma random variables [27], but we include the proof here for completeness.
Lemma 13
Let be a set in , then
[TABLE]
where
[TABLE]
and is the usual extension of the factorial function.
Proof:
We start by proving that we can decompose into
[TABLE]
where , are respectively the uniform distribution over the unit sphere and the Chi (not ) distribution – these are orthogonal projections of . Here indicates the random variables arise from the same distribution.
Let be the probability density function (pdf) of the uniform distribution over the sphere of radius centered at [math] i.e. . Also let be the pdf of the Chi distribution of degree . Since is bijective and
[TABLE]
we have Due to the argument above we can write:
[TABLE]
∎
We will now utilize this explicit connection between the Gaussian and spherical mean width in the following lemma.
Lemma 14
Let be a general nonnegatively homogeneous operator. Then we have the following relations:
[TABLE]
[TABLE]
If with SVD , we also have
[TABLE]
Proof:
We calculate
[TABLE]
This proves Equation 20. Then Equation 21 follows from Cauchy-Schwarz.
We now let and claim that for all
[TABLE]
For all , we may apply Cauchy-Schwarz to conclude
[TABLE]
Further, presuming without loss of generality that , and
[TABLE]
as desired. Hence
[TABLE]
∎
This lemma demonstrates that the Gaussian mean width of an operator is, at least in the linear case, in some sense a way to measure the accumulative effect of the singular values of an operator and that the Gaussian mean width can also be upper bounded via our more general definition of the operator norm. This makes the Gaussian mean width a good tool for further numerical explorations of the effects seen in Figure 3 and discussed at the beginning of this section.
IV-B Numerics – A Big Difference Between Correctly and Incorrectly Classified Data
Before we can utilize the Gaussian mean width in numerical testing, we derive an algorithm for calculating it. More specifically we want to calculate a good approximation of
[TABLE]
where is finite. As argued in [7], due to the Gaussian concentration of measure,
[TABLE]
for one already yields a good estimate for . In practice, to make this estimate more stable, we averaged over the results of 100 samples of . Due to Corollary 11 we can replace Formula 22 by
[TABLE]
As we will see now, this can be solved via a linear program. In what follows, we use the notation to represent the horizontal concatenation of the vectors/matrices and
for vertical concatenation. Additionally we will overload the notation for the set to also represent a matrix where each row is given by a different element of the set . This allows us to formulate the solution of Formula 23 via the constraint optimization problem
[TABLE]
where . Rewriting yields the algorithm in form of the following linear program:
[TABLE]
For the problems considered in this paper this algorithm allows us to calculate the Gaussian mean width in well under a second using the SciPy [28] method for linear programming. We will now utilize this algorithm to approximate the Gaussian mean width of a given dataset propagating through the network after each layer; this is equivalent to calculating the Gaussian mean width for the (admittedly biased and therefore not nonnegatively homogeneous) operator given by each layer and again, like in the ReLU singular value case, an appropriate dataset not equal to .
We use the same networks as in Figure 3 and also look at correctly and incorrectly classified data separately. To get a better understanding how these effects come about we monitored how the Gaussian mean width changed over the course of the training. The results are displayed in Figure 4; for more see Appendix A. There are two very clear effects which both seem to correspond to traits of the ReLU singular values seen in Figure 3. First, like in the ReLU singular value curves, the Gaussian mean width of each layer seems to get bigger the deeper we are in the network. Second, like the biggest bounds of the ReLU singular values, the Gaussian mean widths of the correctly classified data are bigger than the Gaussian mean widths of the incorrectly classified data, although the effect seems to be clearer for the Gaussian mean width than for the ReLU singular values. This might be explained by the fact that the Gaussian mean width graphs are more accurate due to being smoothed and having a more stable calculation method. We would also like to point out that in most of our experiments the graph did not “converge,” unlike Subfigure 4(b), but behaved more like the graph in Subfigure 4(a) (even for very small networks after several hours of training).
V Applications
In this section we will first state a hypothesis about the inner functioning of neural networks (or at least MLPs) based on the results of Sections IV and II, more specifically the Figures 3 and 4. We will then build practical tools based on this hypothesis and evaluate them numerically.
V-A A Hypotheses and Summary Based on the Existing Results
We start by considering Figure 3. The figure shows that the singular value curves of the weight matrices of ReLU layers tend to have some singular values dominating the others. Subfigure 3(c) shows a (in our experiments) typical case, while Subfigure 3(d) is more of an extreme case in that does not have fast decay. Interestingly this drop off of the singular value curves can be seen in both networks, even more extremely in the ReLU singular value curves, see Subfigures 3(a) and 3(b). The ReLU singular values are in a sense more representative of the networks since they also reflect the effects of the ReLU activation function and the bias. What this means is that low-rank approximations of a layer, low-rank in the sense that weight matrix has low rank, are already very good approximations of the layer, indicating that the layers are “essentially” low-rank. This in turn means that only a few of the correlations of a data point with the singular vectors of a layer’s weight matrix matter greatly with regard to the outcome of that layer. If we now consider Figure 4, or more generally Section IV, we see that the Gaussian mean widths within the network of sets of correctly classified data points is much higher than the widths of sets of incorrectly classified data points. This suggests that misclassifications are, at least partly, caused by a lack of correlations (of the data point) with singular vectors corresponding to big singular values, that are also not “blocked” by ReLU.
V-B Double-Layers
In this subsection we present a simple tool to deploy the observational hypothesis discussed above in practice: double-layers. We define a (ReLU) double-layer as a layer of the form
[TABLE]
where , and . This structure enables one to enforce the layer’s weight matrix to be low-rank, specifically to be of rank . Some properties of these layers are:
- •
One can create and control the size of a linear bottleneck between and
- •
As soon as , which in the case reduces to , a double-layer has less parameters then a single-layer.
- •
At least in some tasks, as we will see later, they seem to perform better than normal ReLU layer.
- •
Since one can use their rank to adjust their expressibility, one can often permit in practice, which allows for a more effective usage of the variance argument for initialization as proposed by Glorot [24] and He [21]. (Their argument struggles with the case .)
Before we can use double-layers in practice we have to think about how we can initialize them to be in line with the widely used arguments of Glorot [24] and He [21]. The argument results in the suggestion to use ReLU layers whose weight matrix has entries that are randomly sampled with mean [math] and a variance of This is fulfilled for the following class of initializations that can be used for double-layers.
Definition 15
For we define the double-p-product initialization of a ReLU (double-)layer of the form
[TABLE]
where and (for normal layers this initialization can be used by setting ) as follows: and all entries and are products of i. i. d. samples from
Note that the singular value curve of after initialization does, unlike for the usual Glorot initialization, not follow the Marchenko-Pastur distribution [29], since the entries are not independent.
V-C Harmonic Pruning and Double-Layers in Practice
We will now present a principled way to explore the use of linear bottlenecks using double-layers: A pruning algorithm that, inspired by our results, decreases the ranks of the weight matrices of a network and thereby also, at least for double-layers, the number of parameters. We call it harmonic pruning. It successively decreases the ranks of the weight matrices of an already trained MLP. The algorithm has the following steps:
For each layer calculate the change in accuracy of the whole network by setting the smallest non-zero singular value to zero. Denote by the weight matrix that belongs to the layer that decreases the accuracy the least. 2. 2.
Calculate the SVD and let denote after the smallest non-zero singular value was set to zero. Also define as the index of the smallest non-zero singular value. 3. 3.
Reimplement the layer with a split weight matrix replacing by the rank constrained product . Here is given by the first columns of and is given by the first rows of . and are implemented separately to enforce the upper rank (of ) during further steps. Overall we are cutting the rank down by one by setting the smallest non-zero singular value permanently to zero. 4. 4.
Retrain the network for some batches if some retraining criterion is if fulfilled, e. g. every th iteration or if one of the layers has become very low rank. 5. 5.
If some stopping criterion is reached (e. g., the loss increases too much) stop, otherwise goto Step 2).
We applied this algorithm with the retraining criterion to retrain whenever
- •
the accuracy drops by more than 0.5% with regard to the initially trained network,
- •
we are in a th iteration, or
- •
one of the layers already has rank less then .
For demonstrative purposes we set up an experiment that did not use any stopping criterion and pruned until the network had no parameters left. Every retraining used 50 batches (of size 1024). We pruned a network with three hidden ReLU double-layers of size and a softmax classification layer trained via cross-entropy-with-logits loss function and the Adam optimization algorithm. We used a batch size of 1024 and trained until the accuracy settled. The results of this procedure being run on two different classification tasks, on the CIFAR-10 and MNIST datasets, may be seen in Figure 5. We trained for the classification task given by the CIFAR-10 [30] dataset and reached an accuracy of ca. 52% over the test set – in our tests MLPs of similar size and with normal ReLU layers and Glorot initializations reached similar or lower accuracies. We chose CIFAR-10 since we wanted to test a task that MLP is not overwhelmingly successful in achieving in order to reduce possible redundancies in the network. The resulting behavior of the network’s ranks and accuracy over the test set during the pruning are displayed in Figure 5(a). Figure 5(b) shows the same setup, but based on MNIST, which yields a much higher success rate. The graph presents an impressively constant accuracy over the pruning process. We only see a drop in accuracy at the very end when the networks start to fail completely and the accuracy drops to the “guessing baseline” of 10%. The network only drops permanently below 50% mark after the iteration 268. Before that drop under 50% the layer’s weight matrices reached ranks of 18, 8, 6 respectively for the three ReLU layers of the network. This is for multiple reasons very interesting. One of the reasons is that the double-layer network with layer widths of 100, 100, 100 and ranks of 18, 8, 6 has only 61,206 parameters. A normal single-layer network with these layer widths has 328,510, i.e., more than 5 times as many parameters. When we trained a normal ReLU networks (i.e., no double-layers) with a comparable number of parameters (layer widths 20, 9, 7), we only reached about 40% accuracy. But when we trained double-layer networks with layer widths of 100, 100, 100 and ranks 18, 8, 6, we again reached roughly 50% accuracy. Unlike most other pruning methods this one does not decrease the number of active connections or neurons; rather, it synchronizes the neurons within a given layer using their common weight matrix to denoise all of them by removing the harmonics associated with less significant singular values. This is in some sense more related to pooling in CNNs than pruning, since pooling also denoises via dimensionality reduction by approximately removing the harmonics associated with high frequencies in the Fourier basis [17]. The main differences here are that our method does not impose the dimensionality decrease via the Fourier basis but rather in layer-specific eigenbases and that we only decrease the dimensionality and not the number of output parameters. However, one could trivially decrease the number of output parameters by decreasing the layer width.
VI Conclusion and Future Work
In this work we explored the behavior and role of the singular values of ReLU layers and how they interact with the ReLU activation function. To do this we defined and explored ReLU singular values and the Gaussian mean width of operators. Our results do not only explain the success of linear bottlenecks, but also provide a principled way to use them in the form of double-layers. We see a multitude of open questions and future work directions. For example, are there connections to the usual bottlenecks in ResNet blocks? Can the measures presented in this paper be utilized to determine fruitful matches of models and data in transfer learning? Also, can one detect overfitting using these methods?
We think that both tools are theoretically interesting and further our understanding of the inner workings of neural networks. In practice ReLU singular values seem to be useful in the design of new architectures incorporating bottlenecks and the Gaussian mean width of operators promises to be a useful tool to analyze how well a given network is applicable to a given data set.
Acknowledgment
The authors would like to thank Jens Behrmann, Jonathan von Schroeder and Christian Etmann for their fruitful discussions and helpful comments on the paper.
S. Dittmer is supported by the Deutsche Forschungsgemeinschaft (DFG) within the framework of GRK 2224 / : Parameter Identification - Analysis, Algorithms, Applications.
Appendix A Additional Numerical Testing
This appendix displays the same results as presented in the paper but for more networks and classification tasks. All networks are MLPs with three hidden ReLU layers of equal width and a softmax output layer trained via a cross-entropy-with-logits loss function and the Adam optimizer [22] solving a classification task given by some data set. They were all initialized with the Glorot initialization. The plots in each figure from left to right are the singular values of the linear map, the numerical bounds of the ReLU singular values (like in Figure 2), and the Gaussian mean width over the training (like in Figure 4). Solid lines are plots corresponding to correctly classified data, and dashed lines correspond to incorrectly classified data. We turned the Boston housing prices data set [31] into the classification task of classifying whether a house costs more than most houses.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] I. Jolliffe, “Principal component analysis,” in International Encyclopedia of Statistical Science , pp. 1094–1096, Springer, 2011.
- 2[2] G. H. Golub, A. Hoffman, and G. W. Stewart, “A generalization of the Eckart-Young-Mirsky matrix approximation theorem,” Linear Algebra Appl. , vol. 88/89, pp. 317–327, 1987.
- 3[3] R. Penrose, “A generalized inverse for matrices,” Proc. Cambridge Philos. Soc. , vol. 51, pp. 406–413, 1955.
- 4[4] P. Comon and G. H. Golub, “Tracking a few extreme singular values and vectors in signal processing,” Proceedings of the IEEE , vol. 78, no. 8, pp. 1327–1343, 1990.
- 5[5] A. K. Louis and P. Maass, “A mollifier method for linear operator equations of the first kind,” Inverse Probl. , vol. 6, no. 3, p. 427, 1990.
- 6[6] V. Nair and G. E. Hinton, “Rectified linear units improve restricted Boltzmann machines,” in Proceedings of the 27th International Conference on Machine Learning (ICML-10) , pp. 807–814, 2010.
- 7[7] R. Vershynin, “Estimation in high dimensions: a geometric perspective,” in Sampling Theory, a Renaissance , pp. 3–66, Springer, 2015.
- 8[8] S. Dittmer, “On calculating the gaussian mean width of finite sets.” https://github.com/sdittmer/On_Calculating_the_Gaussian_Mean_Width_of_Finite_Sets , 2018.