TL;DR
This paper introduces a dual memory system with pseudo-rehearsal using a generative network to prevent catastrophic forgetting in deep reinforcement learning, enabling sequential learning of Atari games without performance loss.
Contribution
The paper presents a novel model combining dual memory and pseudo-rehearsal to overcome catastrophic forgetting in deep reinforcement learning, outperforming previous methods.
Findings
Successfully learned Atari games sequentially without forgetting
Achieved above human-level performance on all tested games
Did not require storing raw data or increasing storage with tasks
Abstract
Neural networks can achieve excellent results in a wide variety of applications. However, when they attempt to sequentially learn, they tend to learn the new task while catastrophically forgetting previous ones. We propose a model that overcomes catastrophic forgetting in sequential reinforcement learning by combining ideas from continual learning in both the image classification domain and the reinforcement learning domain. This model features a dual memory system which separates continual learning from reinforcement learning and a pseudo-rehearsal system that "recalls" items representative of previous tasks via a deep generative network. Our model sequentially learns Atari 2600 games without demonstrating catastrophic forgetting and continues to perform above human level on all three games. This result is achieved without: demanding additional storage requirements as the number of…
Click any figure to enlarge with its caption.
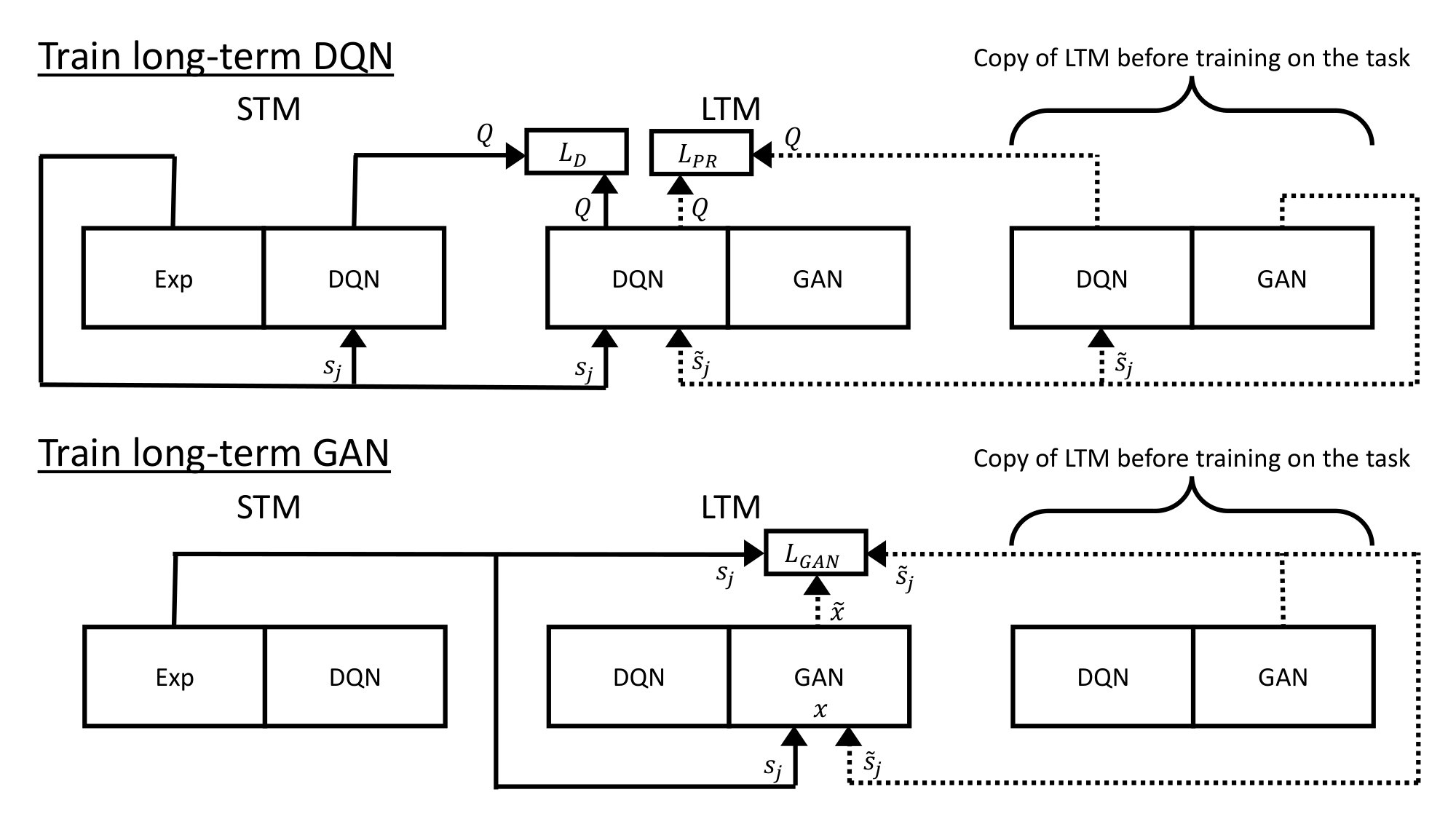 Figure 1
Figure 1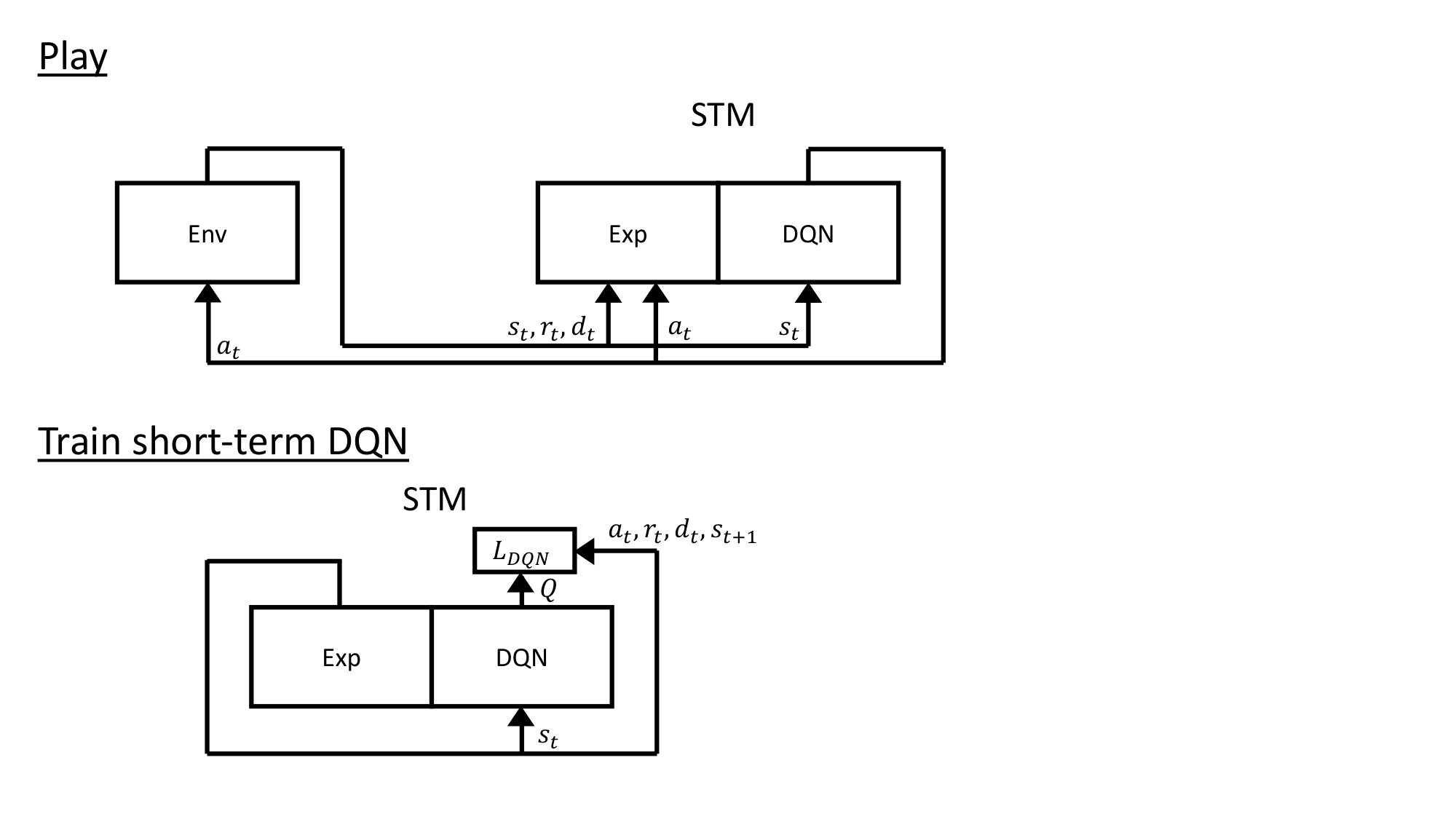 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7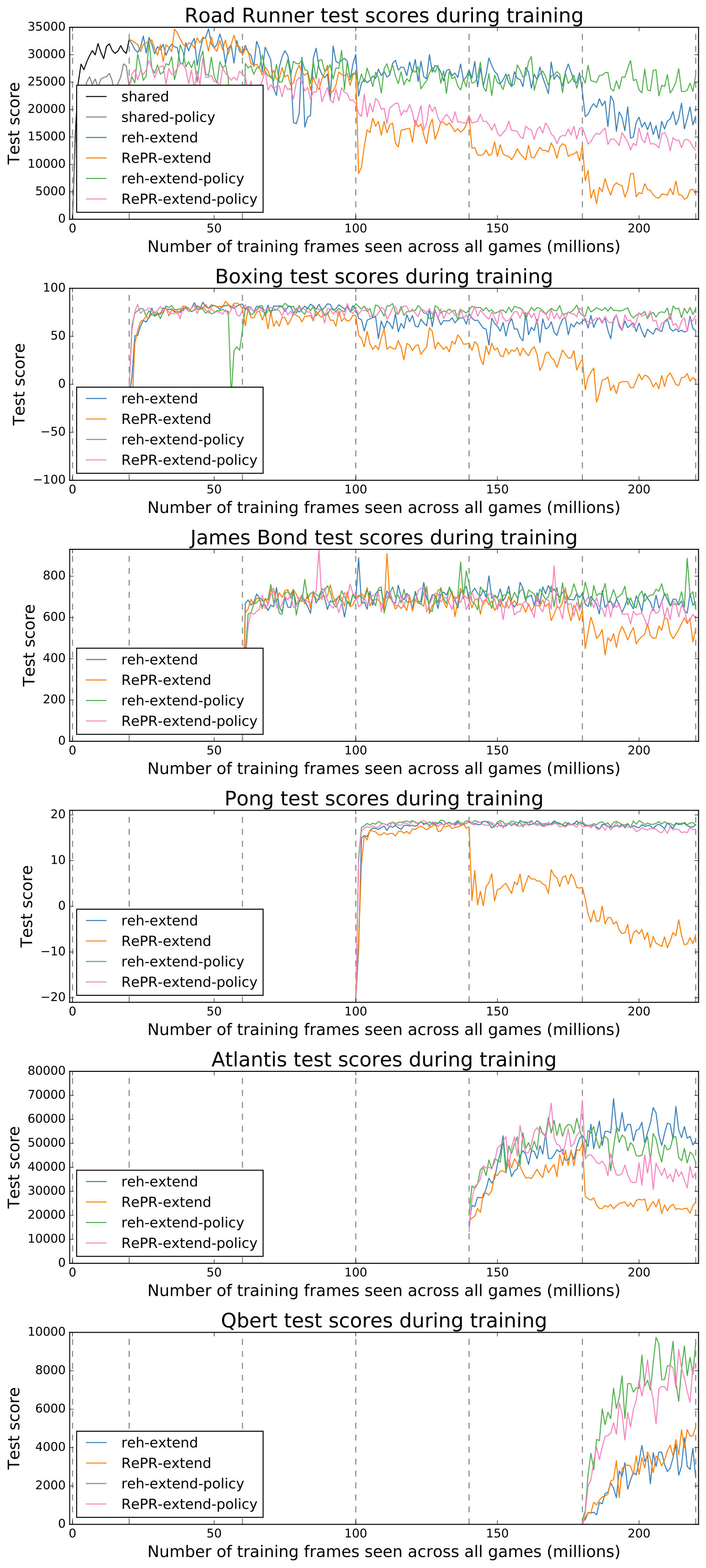 Figure 8
Figure 8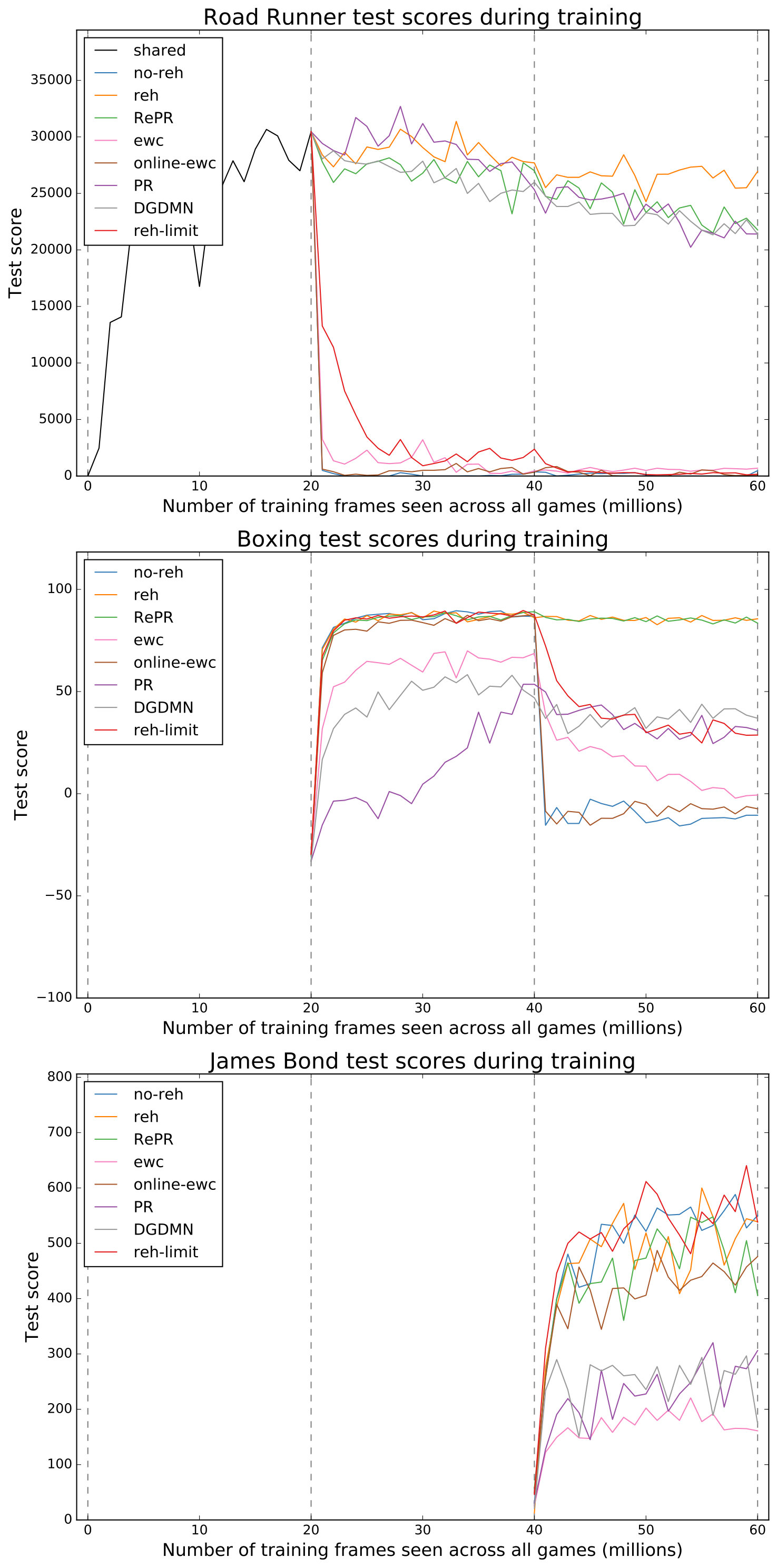 Figure 9
Figure 9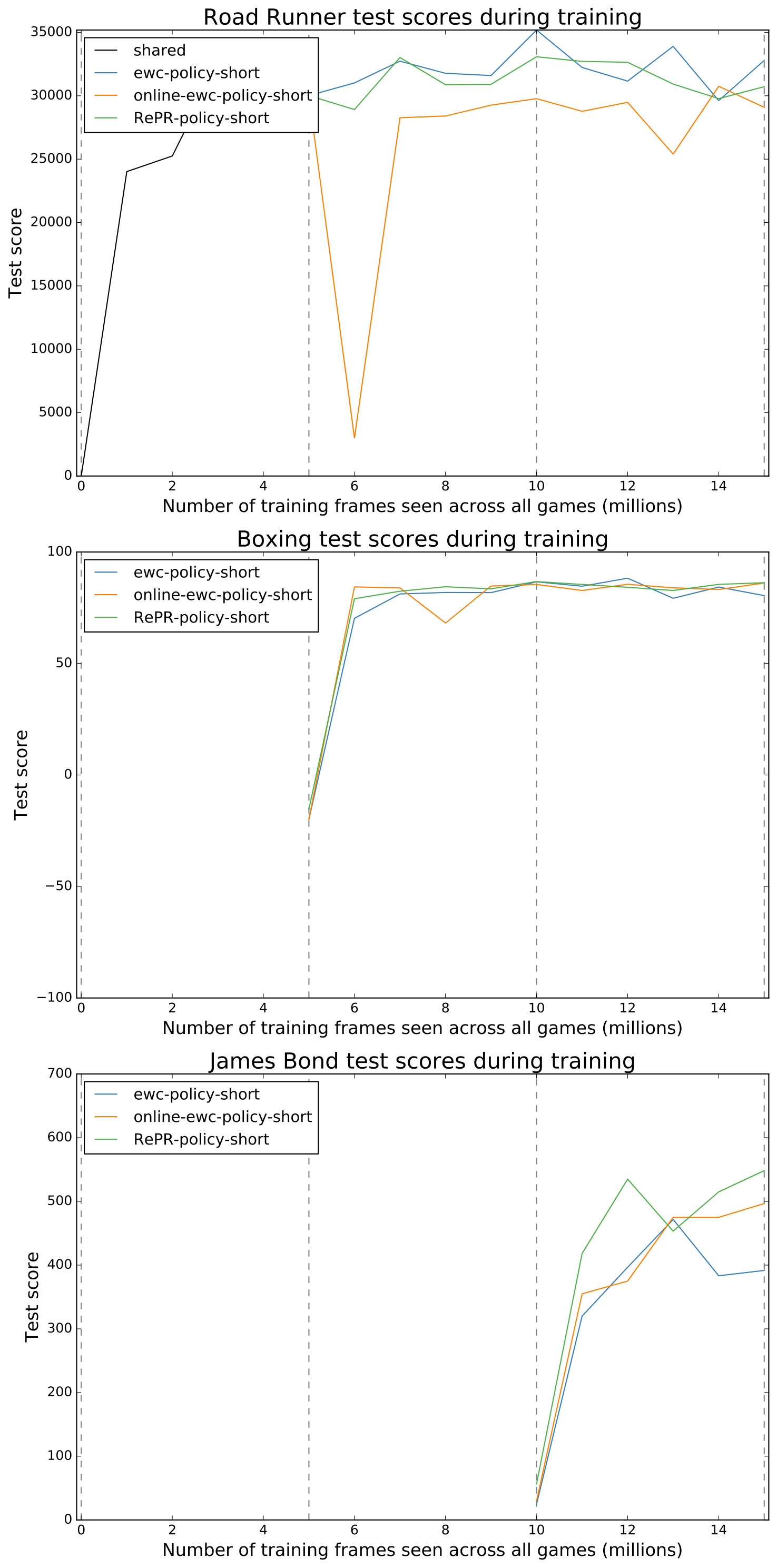 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Pseudo-Rehearsal: Achieving Deep Reinforcement Learning without Catastrophic Forgetting
Craig Atkinson111Department of Computer Science, University of Otago, 133 Union Street East, Dunedin, New Zealand
Accepted for publication in Neurocomputing (https://doi.org/10.1016/j.neucom.2020.11.050). 2020. This manuscript version is made available under the CC-BY-NC-ND 4.0 license http://creativecommons.org/licenses/by-nc-nd/4.0/.
Brendan McCane222Department of Computer Science, University of Otago, 133 Union Street East, Dunedin, New Zealand
Accepted for publication in Neurocomputing (https://doi.org/10.1016/j.neucom.2020.11.050). 2020. This manuscript version is made available under the CC-BY-NC-ND 4.0 license http://creativecommons.org/licenses/by-nc-nd/4.0/.
Lech Szymanski333Department of Computer Science, University of Otago, 133 Union Street East, Dunedin, New Zealand
Accepted for publication in Neurocomputing (https://doi.org/10.1016/j.neucom.2020.11.050). 2020. This manuscript version is made available under the CC-BY-NC-ND 4.0 license http://creativecommons.org/licenses/by-nc-nd/4.0/.
Anthony Robins444Department of Computer Science, University of Otago, 133 Union Street East, Dunedin, New Zealand
Accepted for publication in Neurocomputing (https://doi.org/10.1016/j.neucom.2020.11.050). 2020. This manuscript version is made available under the CC-BY-NC-ND 4.0 license http://creativecommons.org/licenses/by-nc-nd/4.0/.
Abstract
Neural networks can achieve excellent results in a wide variety of applications. However, when they attempt to sequentially learn, they tend to learn the new task while catastrophically forgetting previous ones. We propose a model that overcomes catastrophic forgetting in sequential reinforcement learning by combining ideas from continual learning in both the image classification domain and the reinforcement learning domain. This model features a dual memory system which separates continual learning from reinforcement learning and a pseudo-rehearsal system that “recalls” items representative of previous tasks via a deep generative network. Our model sequentially learns Atari games without demonstrating catastrophic forgetting and continues to perform above human level on all three games. This result is achieved without: demanding additional storage requirements as the number of tasks increases, storing raw data or revisiting past tasks. In comparison, previous state-of-the-art solutions are substantially more vulnerable to forgetting on these complex deep reinforcement learning tasks.
keywords:
Deep Reinforcement Learning , Pseudo-Rehearsal , Catastrophic Forgetting , Generative Adversarial Network
††journal: Neurocomputing
1 Introduction
There has been enormous growth in research around reinforcement learning since the development of Deep Q-Networks (DQNs) [1]. DQNs apply Q-learning to deep networks so that complicated reinforcement tasks can be learnt. However, as with most distributed models, DQNs can suffer from Catastrophic Forgetting (CF) [2, 3]. This is where a model has the tendency to forget previous knowledge as it learns new knowledge. Pseudo-rehearsal is a method for overcoming CF by rehearsing randomly generated examples of previous tasks, while learning on real data from a new task. Although pseudo-rehearsal methods have been widely used in image classification, they have been virtually unexplored in reinforcement learning. Solving CF in the reinforcement learning domain is essential if we want to achieve artificial agents that can continuously learn.
Continual learning is important to neural networks because CF limits their potential in numerous ways. For example, imagine a previously trained network whose function needs to be extended or partially changed. The typical solution would be to train the neural network on all of the previously learnt data (that was still relevant) along with the data to learn the new function. This can be an expensive operation because previous datasets (which tend to be very large in deep learning) would need to be stored and retrained. However, if a neural network could adequately perform continual learning, it would only be necessary for it to directly learn on data representing the new function. Furthermore, continual learning is also desirable because it allows the solution for multiple tasks to be compressed into a single network where weights common to both tasks may be shared. This can also benefit the speed at which new tasks are learnt because useful features may already be present in the network.
Our Reinforcement-Pseudo-Rehearsal model (RePR555Read as “reaper”.) achieves continual learning in the reinforcement domain. It does so by utilising a dual memory system where a freshly initialised DQN is trained on the new task and then knowledge from this short-term network is transferred to a separate DQN containing long-term knowledge of all previously learnt tasks. A generative network is used to produce states (short sequences of data) representative of previous tasks which can be rehearsed while transferring knowledge of the new task. For each new task, the generative network is trained on pseudo-items produced by the previous generative network, alongside data from the new task. Therefore, the system can prevent CF without the need for a large memory store holding data from previously encountered training examples.
The reinforcement tasks learnt by RePR are Atari games. These games are considered complex because the input space of the games is large which currently requires reinforcement learning to use deep neural networks (i.e. deep reinforcement learning). Applying pseudo-rehearsal methods to deep reinforcement learning is challenging because these reinforcement learning methods are notoriously unstable compared to image classification (due to the deadly triad [4]). In part, this is because target values are consistently changing during learning. We have found that using pseudo-rehearsal while learning these non-stationary targets is difficult because it increases the interference between new and old tasks. Furthermore, generative models struggle to produce high quality data resembling these reinforcement learning tasks, which can prevent important task knowledge from being learnt for the first time, as well as relearnt once it is forgotten.
Our RePR model applies pseudo-rehearsal to the difficult domain of deep reinforcement learning. RePR introduces a dual memory model suitable for reinforcement learning. This model is novel compared to previously used dual memory pseudo-rehearsal models in two important aspects. Firstly, the model isolates reinforcement learning to the short-term system, so that the long-term system can use supervised learning (i.e. mean squared error) with fixed target values (converged on by the short-term network), preventing non-stationary target values from increasing the interference between new and old tasks. Importantly, this differs from previous applications of pseudo-rehearsal, where both the short-term and long-term systems learn with the same cross-entropy loss function. Secondly, RePR transfers knowledge between the dual memory system using real samples, rather than those produced by a generative model. This allows tasks to be learnt and retained to a higher performance in reinforcement learning. The source code for RePR can be found at https://bitbucket.org/catk1ns0n/repr_public/.
A summary of the main contributions of this paper are:
the first successful application of pseudo-rehearsal methods to complex deep reinforcement learning tasks;
- 2.
above state-of-the-art performance when sequentially learning complex reinforcement tasks, without storing any raw data from previously learnt tasks;
- 3.
empirical evidence demonstrating the need for a dual memory system as it facilitates new learning by separating the reinforcement learning system from the continual learning system.
2 Background
2.1 Deep Q-Learning
In deep Q-learning [1], the neural network is taught to predict the discounted reward that would be received from taking each one of the possible actions given the current state. More specifically, it minimises the following loss function:
[TABLE]
[TABLE]
where there exist two functions, a deep predictor network and a deep target network. The predictor’s parameters are updated continuously by stochastic gradient descent and the target’s parameters are infrequently updated with the values of . The tuple consists of the state, action, reward, terminal and next state for a given time step drawn uniformly from a large record of previous experiences, known as an experience replay.
2.2 Pseudo-Rehearsal
The simplest way of solving the CF problem is to use a rehearsal strategy, where previously learnt items are practised alongside the learning of new items. Researchers have proposed extensions to rehearsal [5, 6, 7]. However, all these rehearsal methods still have disadvantages, such as requiring excessive amounts of data to be stored from previously seen tasks666An experience replay differs from rehearsal because it only stores recently seen data from the current task and therefore, learning data from the experience replay does not prevent forgetting of previously seen tasks.. Furthermore, in certain applications (e.g. the medical field), storing real data for rehearsal might not be possible due to privacy regulations. Additionally, rehearsal is not biologically plausible - mammalian brains don’t retain raw sensory information over the course of their lives. Hence, cognitive research might be a good inspiration for tackling the CF problem.
Pseudo-rehearsal was proposed as a solution to CF which does not require storing large amounts of past data and thus, overcomes the previously mentioned shortcomings of rehearsal [8]. Originally, pseudo-rehearsal involved constructing a pseudo-dataset by generating random inputs (i.e. from a random number generator), passing them through the original network and recording their output. This meant that when a new dataset was learnt, the pseudo-dataset could be rehearsed alongside it, resulting in the network learning the data with minimal changes to the previously modelled function.
There is psychological research that suggests that mammal brains use an analogous method to pseudo-rehearsal to prevent CF in memory consolidation. Memory consolidation is the process of transferring memory from the hippocampus, which is responsible for short-term knowledge, to the cortex for long-term storage. The hippocampus and sleep have both been linked as important components for retaining previously learnt information [9]. The hippocampus has been observed to replay patterns of activation that occurred during the day while sleeping [10], similar to the way that pseudo-rehearsal generates previous experiences. Therefore, we believe that pseudo-rehearsal based mechanisms are neurologically plausible and could be useful as an approach to solving the CF problem in deep reinforcement learning.
Plain pseudo-rehearsal does not scale well to data with large input spaces such as images [11]. This is because the probability of a population of randomly generated inputs sampling the space of possible input images with sufficient density is essentially zero. This is where Deep Generative Replay [12] and Pseudo-Recursal [11] have leveraged Generative Adversarial Networks (GANs) [13] to randomly generate pseudo-items representative of previously learnt items.
A GAN has two components; a generator and a discriminator. The discriminator is trained to distinguish between real and generated images, whereas the generator is trained to produce images which fool the discriminator. When a GAN is used alongside pseudo-rehearsal, the GAN is also trained on the task so that its generator learns to produce items representative of the task’s input items. Then, when a second task needs to be learnt, pseudo-items can be generated randomly from the GAN’s generator and used in pseudo-rehearsal. More specifically, the minimised cost for pseudo-rehearsal is:
[TABLE]
where is a loss function, such as cross-entropy, and is a neural network with weights while learning task . The tuple is the input-output pair for the current task. The tuple is the input-output pair for a pseudo-item, where is the input generated so that it represents the previous task and is the target output calculated by .
This technique can be applied to multiple tasks using only a single GAN by doing pseudo-rehearsal on the GAN as well. Thus, the GAN learns to generate items representative of the new task while still remembering to generate items representative of the previous tasks (by rehearsing the pseudo-items it generates). This technique has been shown to be very effective for remembering a chain of multiple image classification tasks [12, 11].
3 The RePR Model
RePR is a dual memory model which uses pseudo-rehearsal with a generative network to achieve sequential learning in reinforcement tasks. The first part of our dual memory model is the short-term memory (STM) system777Note that the interpretation of the term “short-term memory” (STM) as used here and in related literature varies somewhat from the use of the same term in the general psychological literature., which serves a role analogous to that of the hippocampus in learning and is used to learn the current task. The STM system contains two components; a DQN that learns the current task and an experience replay containing data only from the current task. The second part is the long-term memory (LTM) system, which serves a role analogous to that of the cortex. The LTM system also has two components; a DQN containing knowledge of all tasks learnt and a GAN which can generate states representative of these tasks. During consolidation, the LTM system retains previous knowledge through pseudo-rehearsal, while being taught by the STM system how to respond on the current task.
Transferring knowledge between these two systems is achieved through knowledge distillation [14], where a student network is optimised so that it outputs similar values to a teacher network. In the RePR model, the student network is the long-term DQN and the teacher network is the short-term DQN. The key difference between distillation and pseudo-rehearsal is that distillation uses real items to teach new knowledge, whereas pseudo-rehearsal uses generated items to retain previously learnt knowledge.
In reinforcement learning (deep Q-learning), the target Q-values are from a non-stationary distribution because they are produced by the target network which is being updated during training. Our dual memory system in RePR is important because it allows the difficult job of reinforcement learning to be isolated to the short-term DQN, so that no other learning can interfere with it. Consequently, this reduces the difficulty of the problem for the long-term DQN as it does not need to learn this non-stationary distribution while also trying to retain knowledge of previous tasks. Instead, the long-term DQN can use supervised learning to learn the final stationary distribution Q-values, while rehearsing previous knowledge through pseudo-rehearsal.
3.1 Training Procedure
The training procedure can be broken down into three steps: short-term DQN training, long-term DQN training and long-term GAN training. This process could be repeated for any number of tasks until the DQN or GAN run out of capacity to perform the role sufficiently.
3.1.1 Training the Short-Term DQN
When there is a new task to be learnt, the short-term DQN is reinitialised and trained solely on the task using the standard DQN loss function (Equation 1). A summary of the information flow while training the STM system can be found in Fig. 1 and the related pseudo-code can be found in the appendices as Algorithm 1.
3.1.2 Training the Long-Term DQN
Knowledge is transferred to the long-term DQN by teaching it to produce similar outputs to the short-term DQN on examples from its experience replay. Alongside this, the long-term DQN is constrained with pseudo-rehearsal to produce similar output values to the previous long-term DQN on states generated from the long-term GAN. More specifically, the loss functions used are:
[TABLE]
[TABLE]
[TABLE]
where is a state drawn from the current task’s experience replay, is the mini-batch size, is the set of possible actions, is the long-term DQN’s weights on the current task, is the short-term DQN’s weights after learning the current task and is the long-term DQN’s weights after learning the previous task. Pseudo-items’ inputs are generated from a GAN and are representative of states in previously learnt games. The trade off between learning the new tasks and retaining the previous ones is controlled by a scaling factor (). A summary of the information flow while training the long-term DQN can be found in Fig. 2 and the related pseudo-code can be found in the appendices as Algorithm 2.
3.1.3 Training the Long-Term GAN
The GAN is reinitialised and trained to produce both states that are representative of states the previous GAN outputs and states drawn from the current task’s experience replay. More specifically, the states the GAN learns are drawn such that:
[TABLE]
where is a random number uniformly drawn from and is a randomly selected state in the current task’s experience replay. is the number of tasks learnt and is a randomly generated state from the long-term GAN before training on task . This state is a pseudo-item which ideally resembles a state from one of the prior tasks (task to ). The GAN in our experiments is trained with the WGAN-GP loss function [15] with a drift term [16]. The specific loss function can be found in B.2. A summary of the information flow while training the long-term GAN can be found in Fig. 2 and the related pseudo-code can be found in the appendices as Algorithm 3.
3.2 Requirements of a Continual Learning Agent
We seek to operate within the constraints that apply to biological agents. As such, we seek a continual learning agent capable of learning multiple tasks sequentially: without revisiting them; without substantially forgetting previous tasks; with a consistent memory size that does not grow as the number of tasks increases; and without storing raw data from previous tasks. The results in Section 6 demonstrate that our RePR model can sequentially learn multiple tasks, without revisiting them or substantially forgetting previous tasks. Furthermore, our model does not store raw data because applying pseudo-rehearsal methods to a single GAN allows it to learn to generate data representative of all previous tasks, without growing in size as the number of tasks increases.
4 Related Work
This section will focus on methods for preventing CF in reinforcement learning and will generally concentrate on how to learn a new policy without forgetting those previously learnt for different tasks. There is a lot of related research outside of this domain (see [17] for a broad review), predominantly around continual learning in image classification. However, because these methods cannot be directly applied to complex reinforcement learning tasks, we have excluded them from this review.
There are two main strategies for avoiding CF. The first of these strategies is restricting how the network is optimised. Some models, such as Progressive neural networks [18], introduce a large number of units, or even separate networks, which are restrictively trained only on a particular task. Although these methods can share some weights, they still have a large number of task specific ones and thus, the model size needs to grow substantially as it continually learns.
Another way which the network’s optimisation can be restricted is through weight constraints. These methods amend the loss function so that weights do not change considerably when learning a new task. The most popular of these methods is Elastic Weight Consolidation (EWC) [3], which augments a network’s loss function with a constraint that forces the network’s weights to yield similar values to previous networks. Weights that are more important to the previous task/s are constrained more so that less important weights can be used to learn the new task. EWC has been paired with a DQN to learn numerous Atari games. One undesirable requirement of EWC is that the network’s weights after learning each task must be stored along with either the Fisher information matrix for each task or examples from past tasks (so that the matrix can be calculated when needed). Other variations for constraining the weights have also been proposed [19, 20]. However, these variations have only been applied to relatively simple reinforcement tasks.
Progress and Compress [21] learnt multiple Atari games by firstly learning the game in STM and then using distillation to transfer it to LTM. The LTM system held all previously learnt tasks, counteracting CF using a modified version of EWC called online-EWC. This modified version does not scale in memory requirements as the number of tasks increases. This is because the algorithm stores only the weights of the network after learning the most recent task, along with the discounted sum of previous Fisher information matrices to use when constraining weights. In Progress and Compress, there are also layer-wise connections between the two systems to encourage the short-term network to learn using features already learnt by the long-term network.
The second main strategy for avoiding CF is to amend the training data to be more representative of previous tasks. This category includes both rehearsal and pseudo-rehearsal, as these methods add either real or generated samples to the training dataset. One example of a rehearsal method in reinforcement learning is PLAID [22]. It uses distillation to merge a network that performs the new task with a network whose policy performs all previously learnt tasks. Distillation methods have also been applied to Atari games [23, 24]. However, these were in multi-task learning where CF is not an issue. The major disadvantage with all rehearsal methods is that they require either having continuous access to previous environments or storing a large amount of previous training data. For other recent examples of rehearsal in reinforcement learning see [25, 26, 27].
To our knowledge, pseudo-rehearsal has only been applied by [28] to sequentially learn reinforcement tasks. This was achieved by extending the Deep Generative Replay algorithm from image classification to reinforcement learning. Pseudo-rehearsal was combined with a Variational Auto-Encoder so that two very simple reinforcement tasks could be sequentially learnt by State Representation Learning without CF occurring. These tasks involved a 2D world where the agent’s input was a small grid representing the colour of objects it could see in front of it. The only thing that changed between tasks was the colour of the objects the agent must collect. This sequential learning environment is simple compared to the one we use and thus, there are a number of important differences in our RePR model. Our complex reinforcement learning tasks are relatively different from one another and have a large input space. This requires RePR to use deep convolutional networks, specifically DQNs and GANs, to learn and generate plausible input items. Furthermore, our model incorporates a dual memory system which isolates reinforcement learning to the STM system, improving the acquisition of the new task.
Without an experience replay, CF can occur while learning even a single task as the network forgets how to act in previously seen states. Pseudo-rehearsal has also been applied to this problem by rehearsing randomly generated input items from basic distributions (e.g. uniform distribution) [29, 30], with a similar idea accomplished in actor-critic networks [31]. However, all these methods were applied to simple reinforcement tasks and did not utilise deep generative structures for producing pseudo-items or convolutional network architectures. Since our work, pseudo-rehearsal has been used to overcome CF in models which have learnt to generate states from previously seen environments [32, 33]. But in both these cases, pseudo-rehearsal was not applied to the learning agent to prevent CF.
The model which most closely resembles RePR is the Deep Generative Dual Memory Network (DGDMN) [34] used in sequential image classification. The DGDMN extends Deep Generative Replay by introducing a dual memory system similar to RePR. The STM system comprises one or more modules made up of a classifier paired with a generative network (i.e. a Variational Auto-Encoder). A separate module is used to learn each of the recent tasks. The LTM system comprises a separate classifier and generative network. When consolidation occurs, knowledge from the short-term modules is transferred to the LTM system while the long-term generator is used to produce pseudo-items for pseudo-rehearsal.
The primary difference between DGDMN and RePR relates to the data used to teach the new task to the LTM system. The short-term modules in DGDMN each contain a generative network which learns to produce input examples representative of the new task. These examples are labelled by their respective classifier and then taught to the LTM system. However, in RePR, the STM system does not contain a generative network and instead uses data from its experience replay to train the LTM system. This experience replay does not grow in memory as it only contains a limited amount of data from the most recent task and as this data is more accurate than generated data, it is more effective in teaching the LTM system the new task. There are also key differences in the loss functions used for DGDMN and RePR. DGDMN was developed for sequential image classification and so, it uses the same cross-entropy loss function for learning new tasks in the STM system as in the LTM system. However, in RePR the learning process is separated. The more difficult reinforcement learning (deep Q-learning) is accomplished in the STM system. This is isolated from the LTM system, which can learn and retain through supervised learning (i.e. mean squared error).
To our knowledge, a dual memory system has not previously been used to separate different types of learning in pseudo-rehearsal algorithms. Although a similar dual memory system to RePR was used in Progress and Compress [21], unlike in RePR, authors of Progress and Compress did not find conclusive evidence that it assisted sequential reinforcement learning.
In real neuronal circuits it is a matter of debate whether memory is retained through synaptic stability, synaptic plasticity, or a mixture of mechanisms [35, 36, 37]. The synaptic stability hypothesis states that memory is retained through fixing the weights between units that encode it. The synaptic plasticity hypothesis states that the weights between the units can change as long as the output units still produce the correct output pattern. EWC and Progress and Compress are both methods that constrain the network’s weights and therefore, align with the synaptic stability hypothesis. Pseudo-rehearsal methods amend the training dataset, pressuring the network’s outputs to remain the same, without constraining the weights and therefore, align with the synaptic plasticity hypothesis. Pseudo-rehearsal methods have not yet been successfully applied to complex reinforcement learning tasks. The major advantage of methods that align with the synaptic plasticity hypothesis is that, when consolidating new knowledge, they allow the network to restructure its weights and compress previous representations to make room for new ones. This suggests that, in the long run, pseudo-rehearsal will outperform state-of-the-art weight constraint methods in reinforcement learning, since it allows neural networks to internally reconfigure in order to consolidate new knowledge.
In summary, RePR is the first variation of pseudo-rehearsal to be successfully applied to continual learning with complex reinforcement tasks.
5 Method
Our current research applies pseudo-rehearsal to deep Q-learning so that a DQN can be used to learn multiple Atari games888A brief summary of the Atari games learnt in this paper can be found in A. in sequence. All agents select between 18 possible actions representing different combinations of joystick movements and pressing the fire button. Our DQN is based upon [1] with a few minor changes which we found helped the network to learn the individual tasks quicker. The specifics of these changes can be found in B.1. Our initial experiments aim to comprehensively evaluate RePR by comparing it to competing methods. In these experiments, conditions are taught Road Runner, Boxing and James Bond. These were chosen as they were three conceptually different games in which a DQN outperforms humans by a wide margin [1]. The tasks were learnt in the order specified above. The final experiment aims to test the capacity of RePR and analyse whether the model fails gracefully or catastrophically when pushed beyond its capacity. In this condition we extend the sequence learnt with the Atari games Pong, Atlantis and Qbert. Due to the exceptionally long computational time required for running conditions in this experiment, only RePR and rehearsal methods were tested with a single seed on this extended sequence. The procedure for this extended experiment is identical to the procedure described below for the initial experiments, except for two differences. Firstly, learning is slowed down by reducing and doubling the LTM system’s training time. Secondly, a larger DQN and GAN is used to ensure the initial size of the networks is large enough to learn some of the extended sequence of tasks999Importantly, even when using larger networks, RePR is still pushed beyond its capacity as the results from this experiment clearly demonstrate forgetting.. Specific details for the extended experiment can be found in B.5. The details of the experimental conditions used in this paper can be found in Table 1.
The architecture of the DQNs is kept consistent across all experimental conditions that train on the same sequence of tasks. Details of the network architectures (including the GAN) and training parameters used throughout the experiments can be found in B. A hyper-parameter search was used in conditions that used a variant of EWC. Details of this search can also be found in this appendix along with other specific implementation details for these conditions. The online-EWC implementation does not include connections from the LTM system to the STM system which try and encourage weight sharing when learning the new task. This was not included because authors of the Progress and Compress method found online-EWC alone was competitive with the Progress and Compress method (which included these connections) and it kept the architecture of the agents’ dual memory system consistent with other conditions.
In some of the conditions listed in Table 1, the policy is transferred and retained in the long-term agent, rather than Q-values. Transfer is achieved by giving samples from the current task to the short-term agent and one-hot encoding the action with the largest associated Q-value. This one-hot encoding is then taught to the long-term agent using the cross-entropy loss function. Similarly, when the policy is being retained in RePR’s long-term agent, generated samples are given to the previous long-term agent and the softmax values produced are then retained using the cross-entropy loss function. More specific details on learning and retaining the policy (including loss functions) can be found in B.4.
Each game was learnt by the STM system for million frames and then taught to the LTM system for m frames. The only exception was for the first long-term DQN which had the short-term DQN’s weights copied directly over to it. This means that our experimental conditions differ only after the second task (Boxing) was introduced. The GAN had its discriminator and generator loss function alternatively optimised for steps.
When pseudo-rehearsal was applied to the long-term DQN agent or GAN, pseudo-items were drawn from a temporary array of states generated by the previous GAN. The final weights for the short-term DQN are those that produce the largest average score over observed frames. The final weights for the long-term DQN are those that produced the lowest error over observed frames. In the initial experiments . However, we have also tested RePR with and , both of which produced very similar results, with the final agent performing at least equivalently to the original DQN’s results [1] for all tasks.
Our evaluation procedure is similar to [1] in that our network plays each task for episodes and an episode terminates when all lives are lost. Actions are selected from the network using an -greedy policy with . Final network results are also reported using this procedure and standard deviations are calculated over these episodes. Unless stated otherwise, each condition is trained three times using the same set of seeds between conditions and all reported results are averaged across these seeds.
6 Results
6.1 RePR Performance on CF
The first experiment investigates how well RePR compares to a lower and upper baseline. The condition is the lower baseline because it does not contain a component to assist in retaining the previously learnt tasks. The condition is the upper baseline for RePR because it rehearses real items from previously learnt tasks and thus, demonstrates how RePR would perform if its GAN could perfectly generate states from previous tasks to rehearse alongside learning the new task101010The condition is not doing typical rehearsal although the difference is subtle. It relearns previous tasks using targets produced by the previous network (as in RePR), rather than targets on which the original long-term DQN was taught..
The results of RePR can be found in Fig. 3, alongside other conditions’ results. All of the mentioned conditions outperform the condition which severely forgets previous tasks. RePR was found to perform very closely to the condition, besides a slight degradation of performance on Road Runner, which was likely due to the GAN performing pseudo-rehearsal to retain states representative of Road Runner. These results suggest that RePR can prevent CF without any need for extra task specific parameters or directly storing examples from previously learnt tasks.
We also investigated whether a similar set of weights are important to the RePR agent’s output on all of the learnt tasks or whether the network learns the tasks by dedicating certain weights as important to each individual task. When observing the overlap in the network’s Fisher information matrices for each of the games (see C for implementation details and specific results), we found that the network did share weights between tasks, with similar tasks sharing a larger proportion of important weights. Overall, these positive results show that RePR is a useful strategy for overcoming CF.
6.2 Quality of Generated Items
In RePR, all pseudo-items generated by the GAN are used in pseudo-rehearsal. Furthermore, we have found that balancing the proportion of new items and pseudo-items by the number of tasks learnt (with Equation 7) is sufficient to ensure the GAN generates items evenly from each of the tasks. Fig. 4 shows some GAN generated images after learning all three tasks, alongside real images from the games. This figure shows that although the GAN is successful at generating images similar to the previous games there are clear visual differences between them.
A further experiment was conducted to analytically assess the quality of pseudo-items. This experiment uses three networks. The first is a DQN trained on a task (or sequence of tasks) and is the teacher network. The second is a GAN trained on the same task/s as the first network. The final network is a freshly initialised DQN and is the student network. The student network is taught how to play the task/s by the teacher network (using the distillation loss function in Equation 5). The data used to teach the task/s is either real items from the task/s () or pseudo-items generated by the GAN (). Therefore, the score which the student network can attain, after training with real or generated data, reflects the quality of the training data. The student network was either taught to play one of the games: Road Runner (), Boxing () or James Bond (), or taught to play all three of these games at once ().
Table 2 shows a clear difference between the quality of real and generated items. When learning a single task with items generated by the GAN, the student network cannot learn the task to the same score as it can with real items. When the GAN has been taught multiple tasks, the condition shows that the quality of generated items is severely lower than real items and cannot be used to learn all three tasks to a reasonable standard. This can be considered a positive result for RePR as it demonstrates that pseudo-items can still be used to effectively prevent CF even when the pseudo-items are considerably poorer quality than real items.
6.3 RePR Versus EWC
We further investigate the effectiveness of RePR by comparing its performance to the leading EWC variants. The results of both the EWC conditions are also included in Fig. 3. These results clearly show that RePR outperforms both EWC and online-EWC under these conditions. We find that EWC retains past experiences better than online-EWC and due to this, online-EWC was more effective at learning the new task.
The poor results displayed by the EWC variants contrast substantially from those originally reported by authors [3, 21]. This can be explained by the differences in our training scheme. More specifically, we do not allow tasks to be revisited, whereas both EWC and Progress and Compress visited tasks several times. Furthermore, we do not allow the networks we tested to grow in capacity when a new task is learnt, whereas the training scheme in [3] allowed EWC to have two task specific weights per neuron. Finally, the networks we have tested so far are retaining Q-values in their LTM system, whereas Progress and Compress [21] retained only the policy of an Actor-Critic network in its LTM system.
In B.3, we test RePR and the EWC variants on a different training scheme where only the policy is retained in the LTM system and the total training time of the LTM system is reduced so that tasks need only to be retained for a shorter period of time. Under this different training scheme, the EWC variants perform comparatively to RePR and thus, the training scheme less comprehensively explores the capabilities of the models.
6.4 Further Evaluating RePR
In this section, RePR is further evaluated through a number of conditions. Firstly, the condition represents an ablation study investigating the importance of the dual memory system. Consequently, the condition is identical to the condition without a dual memory system. In Fig. 3, the condition demonstrates poorer results compared to the condition along with slower convergence times for learning the new task. This shows that combining pseudo-rehearsal with a dual memory model, as we have done in RePR, is beneficial for learning the new task.
The condition represents an implementation of the DGDMN. This network was proposed for sequential image classification and therefore, significant changes were necessary to allow the model to learn reinforcement tasks. These changes made our DGDMN implementation similar to RePR, except for the presence of a separate GAN in the STM system which DGDMN teaches to generate data representative of the new task. This GAN generates the data used to train the LTM system on the new task. The condition also demonstrates poorer results compared to the condition. The most evident difference between these conditions was DGDMN’s inability to completely transfer new tasks to its long-term DQN using items generated by its STM system. More specifically, the DGDMN’s long-term DQN could learn the new tasks Boxing and James Bond to approximately half the performance of RePR. To be consistent with the other conditions tested, the STM system’s networks were copied to the LTM system after learning the first task. Because of this, the LTM system learnt the first task with real data (not data generated from the short-term GAN) and thus, did not struggle to learn the first task Road Runner.
The memory efficiency of RePR is investigated with the and conditions. These conditions only store a small number of either uncompressed or compressed real items for rehearsal, limited by the memory allocation size of RePR’s generative network. The condition shows substantially more forgetting compared to RePR. On Road Runner, the condition quickly forgets everything it has learnt about the task and thus, performs similarly to the condition, which makes no effort to retain the task. On Boxing, forgetting causes the condition to retain roughly half of its performance on the task. The condition only displays forgetting on Road Runner, where, compared to RePR, the condition retains noticeably less knowledge of Road Runner throughout the learning sequence.
The scores for the final long-term networks111111For the condition, as no dual memory system is used, we refer to the DQN which learns new tasks while retaining previous tasks as the final long-term network. in each of the conditions are shown in Table 3 along with the long-term storage space required by the models to be able to continue learning. Additionally, the table includes the scores which can be attained by training three DQNs individually on each of the tasks. Similar to previous results, this table shows that the and conditions are the most successful at learning and retaining this sequence of tasks, with achieving on average of the scores that could be attained from individually learning the tasks and achieving . The scores attained by RePR are found to be well above human expert performance levels (, , ) [1]. The table also shows that the long-term memory allocation used by the condition was smaller than the condition by orders of magnitude121212When the condition is storing compressed items, the size of its long-term memory allocation is still an order of magnitude greater than at approximately GB.. Although, we did not attempt to optimise this size for either of the conditions, the and conditions show that RePR outperforms rehearsal when rehearsal is constrained to approximately the same memory size as the condition.
Finally, Fig. 5 displays the results for the final experiment which compares RePR to rehearsal in the extended sequence of Atari tasks. Overall, the , and conditions retained considerable knowledge of previous tasks, with retaining noticeably more knowledge of Road Runner. The condition underperformed compared to the other conditions, showing mainly a gradual decline in performance of previously learnt tasks.
7 Discussion
Our experiments have demonstrated RePR to be an effective solution to CF when sequentially learning multiple tasks. To our knowledge, pseudo-rehearsal has not been used until now to successfully prevent CF on complex reinforcement learning tasks. RePR has advantages over popular weight constraint methods, such as EWC, because it does not constrain the network to retain similar weights when learning a new task. This allows the internal layers of the network to change according to new knowledge, giving the model the freedom to restructure itself when incorporating new information. Experimentally, we have verified that RePR does outperform these state-of-the-art EWC methods on a sequential learning task.
7.1 Dual Memory
The condition omits using the dual memory system to analyse the system’s importance. This results in the condition trying to learn non-stationary target Q-values (for the new task) through reinforcement learning, while also retaining previous tasks through pseudo-rehearsal. The results for the condition showed that convergence times were longer and the final performance reached was lower on new tasks compared to . Therefore, this demonstrates that omitting the dual memory system increases the interference between new knowledge and knowledge of previous tasks. In D the extent of this interference is explored and it is found that to learn Boxing to a similar standard to RePR, while also omitting the dual memory system, the deep Q-learning loss function must be weighted substantially higher than the pseudo-rehearsal loss function, such that the model considerably suffers from CF. Overall, these results are strong evidence that the dual memory system is beneficial in sequential reinforcement learning tasks. This is particularly interesting because the authors of Progress and Compress [21] did not find clear evidence that their algorithm benefited from a similar dual memory system in their experimental conditions and additionally, the dual memory system in RePR showed more substantial benefits than the dual memory system used by DGDMN in image classification with the same number of tasks [34].
Our results show that the dual memory system used by DGDMN performs substantially worse than RePR in reinforcement learning. This is because DGDMN relies on short-term generative networks to provide the data to teach the LTM system. When these tasks are difficult for the generative network to learn, this data is not accurate enough to effectively teach new tasks to the LTM system. Although this was not an issue for the DGDMN in image classification [34], in Section 6.2 we show that, in these complex reinforcement tasks, the GAN does struggle such that it is much more effective to teach a new task to a freshly initialised DQN using real data than generated data. However, our results also show that generated items that are not of high enough quality for STM to LTM transfer, can be used effectively in pseudo-rehearsal.
To overcome the limited quality of generative items, RePR’s dual memory system assumes real data from the most recent task can be retained in an experience replay so that it can be used to successfully teach the LTM system. We do not believe this assumption is unrealistic because the experience replay is a temporary buffer, with a fixed size, and once the most recent task has been consolidated into LTM, it is cleared to make room for data from the next task.
7.2 Scalability
One main advantage of RePR compared to many other continual learning algorithms is that it is very scalable. Applying pseudo-rehearsal to both the agent and generative model means that the network does not need to use any task specific weights to accomplish continual learning and thus, the model’s memory requirements do not grow as the number of tasks increases. RePR’s generative network also means that it does not retain knowledge by storing raw data from previous tasks. This is advantageous in situations where storing raw data is not allowed because of e.g. privacy reasons, biological plausibility, etc. Furthermore, results show RePR outperforms rehearsal when the number of rehearsal items are limited by the storage space required for RePR’s generative network ( and ). Therefore, RePR can also prevent CF more effectively than rehearsal when memory is limited.
In theory, RePR could be used to learn any number of tasks as long as the agent’s network (e.g. DQN) and GAN have the capacity to successfully learn the collection and generate states that are representative of previously learnt tasks. However, in practice the capacity of RePR’s components could be exceeded and we explored how this affects RePR by investigating it on an extended sequence of tasks. In this test, RePR demonstrated a modest amount of forgetting when required to retain only the policy in its LTM system. However, when RePR is required to retain Q-values in its LTM system, it shows substantial forgetting compared to rehearsal. In this case, RePR’s forgetting was generally gradual, such that learning the new tasks only disrupts retention after millions of training frames. However, the condition does not notably suffer from this gradual forgetting. The only difference between these conditions is that the condition uses real items to rehearse previous tasks. This is important as it identifies that it is the GAN which is struggling to learn the extended sequence of tasks, resulting in the observed forgetting. Therefore, future research improving GANs’ capacity and stability (vanishing gradients and mode collapse [38]) will directly improve RePR’s ability to prevent CF in these challenging conditions.
7.3 Limitations and Future Research
One limitation of rehearsal methods (including RePR) is that they become infeasible when the number of tasks goes to infinity. This is because the items rehearsed in each training iteration will only cover a very small selection of previously seen tasks. However, research in sweep rehearsal [39, 8] shows that rehearsal methods can still be beneficial when rehearsing a comparably small number of items per task, suggesting that this limitation will only become severe in long task sequences. Another limitation of our model is that it currently assumes the agent knows when a task switch occurs. However, in some use cases this might not be true and thus, a task detection method would need to be combined with RePR.
In these experiments we use the same task sequence for all conditions which could bias the results either positively or negatively. However, there is work [40] which suggests that for a given set of tasks, the mean performance of the final model is not affected by the order in which those tasks are learnt.
Currently, our RePR model has been designed to prevent the CF that occurs while learning a sequence of tasks, without using real data. However, our implementation still stores a limited amount of real data from the current task in an experience replay. This data is used to prevent the CF that occurs while learning a single task. We believe this was acceptable as our goal in this research was to prevent the CF that occurs from sequential task learning (without using real data) and consequently, this real data was never used to prevent this form of CF. In future work we wish to extend our model by further modifying pseudo-rehearsal so that it can also prevent the CF that occurs while learning a single reinforcement task.
In this paper, we chose to apply our RePR model to DQNs. However, this can be easily extended to other state-of-the-art deep reinforcement learning algorithms, such as actor-critic networks, by adding a similar constraint to the loss function. We chose DQNs for this research because their Q-values contain both policy and value information whereas Actor-Critics produce policy and value information separately. Although our research suggests that it is easier for the LTM system to retain solely the policy, the policy does not contain information about the expected discounted rewards (i.e. the value) associated with each state which is necessary to continue learning an already seen task. Future research could investigate whether the expected discounted rewards can be quickly relearnt with access to the retained policy, or whether it should also be retained by the LTM system to continue reinforcement learning without disruption.
8 Conclusion
In conclusion, pseudo-rehearsal can be used with deep reinforcement learning methods to achieve continual learning. We have shown that our RePR model can be used to sequentially learn a number of complex reinforcement tasks, without scaling in complexity as the number of tasks increases and without revisiting or storing raw data from past tasks. Pseudo-rehearsal has major benefits over weight constraint methods as it is less restrictive on the network and this is supported by our experimental evidence. We also found compelling evidence that the addition of our dual memory system is necessary for continual reinforcement learning to be effective. As the power of generative models increases, it will have a direct impact on what can be achieved with RePR and our goal of having an agent which can continuously learn in its environment, without being challenged by CF.
Appendix A Details on the Atari Games
Road Runner is a game where the agent must outrun another character by moving toward the left of the screen while collecting items and avoiding obstacles. To achieve high performance the agent must also learn to lead its opponent into certain obstacles to slow it down. Boxing is a game where the agent must learn to move its character around a 2D boxing ring and throw punches aimed at the face of the opponent to score points, while also avoiding taking punches to the face. James Bond has the agent learn to control a vehicle, while avoiding obstacles and shooting various objects. In Pong, the agent learns to hit a ball back to its opponent by moving a paddle. A point is scored by the agent when the opponent does not successfully hit the ball back and the opponent scores a point when the agent does not successfully hit back the ball. For Atlantis, the agent learns to control three stationary cannons and must shoot down enemy ships moving horizontally across the sky. After a ship passes 4 times it will take out one of the city’s bases, starting with the central cannon. The agent scores points for shooting down ships and loses once all bases have been destroyed. Finally, in Qbert the agent learns to control a character which jumps diagonally around a pyramid of cubes, changing the cubes’ colours. Once all the cubes have been changed to a particular colour the level is cleared. In this game, the agent must also learn to avoid various enemies.
Appendix B Further Implementation Details
B.1 DQN
The main difference between our DQN and [1] is that we used TensorFlow’s RMSProp optimiser (without centering) with global norm gradient clipping compared to the original paper’s RMSProp optimiser which clipped gradients between . Our network architecture remained the same. However, our biases were set to and weights were initialised with , where all values that were more than two standard deviations from the mean were re-drawn. The remaining changes were to the hyper-parameters of the learning algorithm which can be seen in bold in Table 4. The architecture of our network can be found in Table 5, where all layers use the ReLU activation function except the last linear layer.
B.2 GAN
The GAN is trained with the WGAN-GP loss function [15] with a drift term [16]. The drift term is applied to the discriminator’s output for real and fake inputs, stopping the output from drifting too far away from zero. More specifically, the loss functions used for updating the discriminator () and generator () are:
[TABLE]
[TABLE]
where and are the discriminator and generator networks with the parameters and . is an input item drawn from either the current task’s experience replay or the previous long-term GAN (as specified in Equation 7). is an item produced by the current generative model () and . is a random number , is an array of latent variables , and . The discriminator and generator networks’ weights are updated on alternating steps using their corresponding loss function.
The GAN is trained with the Adam optimiser (, , and as per [16]) where the networks are trained with a mini-batch size of 100. The architecture of the networks is illustrated in Table 6. All layers of the discriminator use the Leaky ReLU activation function (with the leakage value set to ), except the last linear layer. All layers of the generator use batch normalisation ( and ) and the ReLU activation function, except the last layer which has no batch normalisation and uses the Tanh activation function. This is to make the generated images’ output space the same as the real images which are rescaled between and by applying to each raw pixel value. We also decreased the convergence time of our GAN by applying random noise to real and generated images before rescaling and giving them to the discriminator.
B.3 EWC
The EWC constraint is implemented as per [3], where the loss function is amended so that:
[TABLE]
[TABLE]
where is the distillation loss for learning the current task (as specified in Equation 5) and is the batch-size. is a scaling factor determining how much importance the constraint should be given, is the current long-term network’s parameters, is the final long-term network’s parameters after learning the previous task and iterates over each of the parameters in the network. is an approximation of the diagonal elements in a Fisher information matrix, where each element represents the importance each parameter has on the output of the network.
The Fisher information matrix is calculated as in [3], by approximating the posterior as a Gaussian distribution with the mean given by the optimal parameters after learning a previous task and a standard deviation . More specifically, the calculation follows [41]:
[TABLE]
where an expectation is calculated by uniformly drawing states from the experience replay (). is the Jacobian matrix for the output layer .
When the standard EWC implementation is extended to a third task, a separate penalty is added. This means the current parameters of the network are constrained to be similar to both the parameters after learning the first task and the parameters after further learning the second task.
Online-EWC further extends EWC so that only the previous network’s parameters and a single Fisher information matrix is stored. As per [21], this results in the constraint being replaced by:
[TABLE]
where the single Fisher information matrix is updated by:
[TABLE]
where is a discount parameter and represents the index of the current task. In online-EWC, Fisher information matrices are normalised using min-max normalisation so that the tasks’ different reward scales do not affect the relative importance of parameters between tasks.
For the condition, we applied a grid search over and for our condition we performed a grid search over and . The best parameters found during the grid searches are in bold. In all conditions, the Fisher information matrix is calculated by sampling 100 batches from each task. The final network’s test scores for each of the tasks were min-max normalised and the network with the best average score was selected. The minimum and maximum is found across all testing episodes played during the learning of the task in the STM system.
An additional experiment was run to confirm our EWC variants could successfully retain previous task knowledge under a different training scheme. In these conditions, the LTM system retained the agent’s policy (taught by minimising the cross-entropy) and new tasks were learnt in the LTM system for 5m frames each. Fig. 6 displays results for the EWC, online-EWC and RePR implementations tested under these conditions (, and respectively). All conditions performed similarly and could successfully learn new tasks while retaining knowledge of previous tasks.
B.4 Transferring and Retaining the Policy in the LTM System
Firstly, the policy is extracted from the short-term DQN by giving samples from the current task to the DQN and calculating the Q-values it has learnt to associate with those samples. For each sample, the action with the largest Q-value is then one-hot encoded. After this policy has been extracted, distillation is used to transfer it to the long-term agent, using the loss function:
[TABLE]
where is a state drawn from the current task’s experience replay. is the long-term agent which has a softmax output layer and is the short-term DQN agent which has a linear output layer. is the long-term agent’s weights on the current task and is the short-term agent’s weights after learning the current task. is the standard cross-entropy loss function and is a function that one-hot encodes .
For EWC variants, the long-term agent retains the policy through the same methods it retains Q-values (i.e. using a weight constraint). However, in rehearsal based methods (including RePR) it is necessary to adapt the retention loss function to use cross-entropy. More specifically, the loss function for RePR is changed to:
[TABLE]
where pseudo-items’ inputs are generated from a GAN and are representative of states in previously learnt games. is the long-term agent’s weights after learning the previous task.
B.5 Extended Task Sequence Experiment
The experiment investigating RePR with an extended task sequence is nearly identical to the first experiment’s details from the main text. One of the main differences is that learning is slowed down by initially setting to and after learning the fourth task reducing this to . Consequently, training time is increased to m frames for the long-term DQN. Secondly, both the DQN and generative networks are enlarged by doubling the number of filters and units in hidden layers. More specifically, the convolutional layers in the DQN use , and filters respectively and then the fully connected layer (before the output layer) uses units. For the GAN, the generative network is enlarged by increasing the first fully connected layer to units and increasing the following three deconvolutional layers so that they use , and filters respectively. The training time for the GAN is also increased to steps.
The and conditions learn the extended sequence of tasks with either rehearsal or RePR. In these conditions we standardise the short-term DQN’s Q-values when they are being taught to the long-term DQN. This was beneficial because it reduced the interference between the games’ substantially different reward functions and thus, evened out the importance of retaining each of the games. In the and conditions only the policy was retained in the LTM system. This was achieved by using cross-entropy to learn and retain each game’s policy, as described above.
Appendix C How well does RePR Share Weights?
To investigate whether an agent’s DQN uses similar parameters for determining its output across multiple tasks, [3] suggest that the degree of overlap between two tasks’ Fisher information matrices can be analysed. This Fisher overlap score is bounded between 0 and 1, where a high score represents high overlap and indicates that many of the weights that are important for calculating the desired action in one task are also important in the other task. More specifically, the Fisher overlap is calculated by , where:
[TABLE]
given and are the two tasks’ Fisher information matrices which have been normalised so that they each have a unit trace. Fisher information matrices are approximated by Equation 12 using 100 batches of samples drawn from each tasks’ experience replay.
We compared RePR’s Fisher information matrices for each task using the Fisher overlap calculation. When RePR had learnt the tasks in the order Road Runner, Boxing and then James Bond (as in the condition from Section 6.1), the Fisher overlap score was high between the first two tasks learnt but relatively low between other task pairs. This suggests that there are more similarities between Road Runner and Boxing than other task pairs. We confirm this by calculating the Fisher overlap for each of the task pairs when the RePR model had successfully learnt the tasks in the reverse order (ie. James Bond, Boxing and then Road Runner). In this case, a higher overlap value remains between Road Runner and Boxing, regardless of the order they were learnt in. This demonstrates that the network attempts to share the computation across a similar set of important weights, where the more similar the tasks are the more effective they are at sharing weights. The precise Fisher overlap values for both of these conditions can be found in Table 7.
Appendix D Evaluating the Importance of Dual Memory
To further evaluate the importance of the dual memory system, the and conditions from the main text are trained with varying importance values () on the sequence Road Runner, then Boxing. The condition does not use a dual memory system and thus, its value weights the importance of learning new tasks with deep Q-learning (Equation 1) vs. retaining previous tasks with pseudo-rehearsal (Equation 6). The condition has a dual memory system and thus, its value weights the importance of learning new tasks with distillation (Equation 5) vs. retaining previous tasks with pseudo-rehearsal (Equation 6). The aim of this experiment was to investigate the extent to which omitting the dual memory system increases the interference between new knowledge and knowledge of old tasks. This was investigated by finding the value the condition needed to learn Boxing to the same standard as RePR (i.e. to an approximate score of ) and what effect these varying values had on the two models’ retention.
The results in Table 8 show that without a dual memory system, must be extremely high () for the model to successfully learn Boxing to a similar standard as RePR. However, both models show that high values result in considerable forgetting of Road Runner. Importantly, this means that without a dual memory system there does not exist an value that results in both successful learning of the new task and acceptable retention of the previous task. When using RePR’s dual memory system, learning the new task is considerably easier and thus, comparably lower values will result in both successfully learning the new task and retaining the previous task. Overall, these results suggest that omitting the dual memory system dramatically increases the interference between new knowledge and knowledge of previous tasks.
Acknowledgment
We gratefully acknowledge the support of NVIDIA Corporation with the donation of the TITAN X GPU used for this research. We also wish to acknowledge the use of New Zealand eScience Infrastructure (NeSI) high performance computing facilities. New Zealand’s national facilities are provided by NeSI and funded jointly by NeSI’s collaborator institutions and through the Ministry of Business, Innovation & Employment’s Research Infrastructure programme. URL https://www.nesi.org.nz.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., Human-level control through deep reinforcement learning, Nature 518 (7540) (2015) 529–533.
- 2[2] M. Mc Closkey, N. J. Cohen, Catastrophic interference in connectionist networks: The sequential learning problem, in: Psychology of Learning and Motivation, Vol. 24, Elsevier, 1989, pp. 109–165.
- 3[3] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al., Overcoming catastrophic forgetting in neural networks, Proceedings of the National Academy of Sciences 114 (13) (2017) 3521–3526.
- 4[4] R. S. Sutton, A. G. Barto, Reinforcement learning: An introduction (2nd edition), complete draft (2017).
- 5[5] D. Lopez-Paz, M. Ranzato, Gradient episodic memory for continual learning, in: Advances in Neural Information Processing Systems, Vol. 30, Curran Associates, Inc., 2017, pp. 6467–6476.
- 6[6] S.-A. Rebuffi, A. Kolesnikov, G. Sperl, C. H. Lampert, i Ca RL: Incremental classifier and representation learning, in: IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 5533–5542.
- 7[7] M. Riemer, M. Franceschini, D. Bouneffouf, Generative knowledge distillation for general purpose function compression, in: Neural Information Processing Systems Workshop on Teaching Machines, Robots, and Humans, 2017.
- 8[8] A. Robins, Catastrophic forgetting, rehearsal and pseudorehearsal, Connection Science 7 (2) (1995) 123–146.
