Multiple Manifold Clustering Using Curvature Constrained Path
Amir Babaeian

TL;DR
This paper introduces a curvature-constrained path approach to improve multiple surface clustering, especially near intersections, by modifying Isomap and using binary features for clustering.
Contribution
It proposes a novel curvature constraint in the shortest path algorithm within Isomap, enhancing clustering accuracy on intersecting surfaces.
Findings
Performs comparably to state-of-the-art methods like K-manifold.
Effective in simulated and real datasets.
Improves clustering near surface intersections.
Abstract
The problem of multiple surface clustering is a challenging task, particularly when the surfaces intersect. Available methods such as Isomap fail to capture the true shape of the surface nearby the intersection and result in incorrect clustering. The Isomap algorithm uses the shortest path between points. The main draw back of the shortest path algorithm is due to the lack of curvature constrained where causes to have a path between points on different surfaces. In this paper, we tackle this problem by imposing a curvature constraint to the shortest path algorithm used in Isomap. The algorithm chooses several landmark nodes at random and then checks whether there is a curvature constrained path between each landmark node and every other node in the neighbourhood graph. We build a binary feature vector for each point where each entry represents the connectivity of that point to a…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3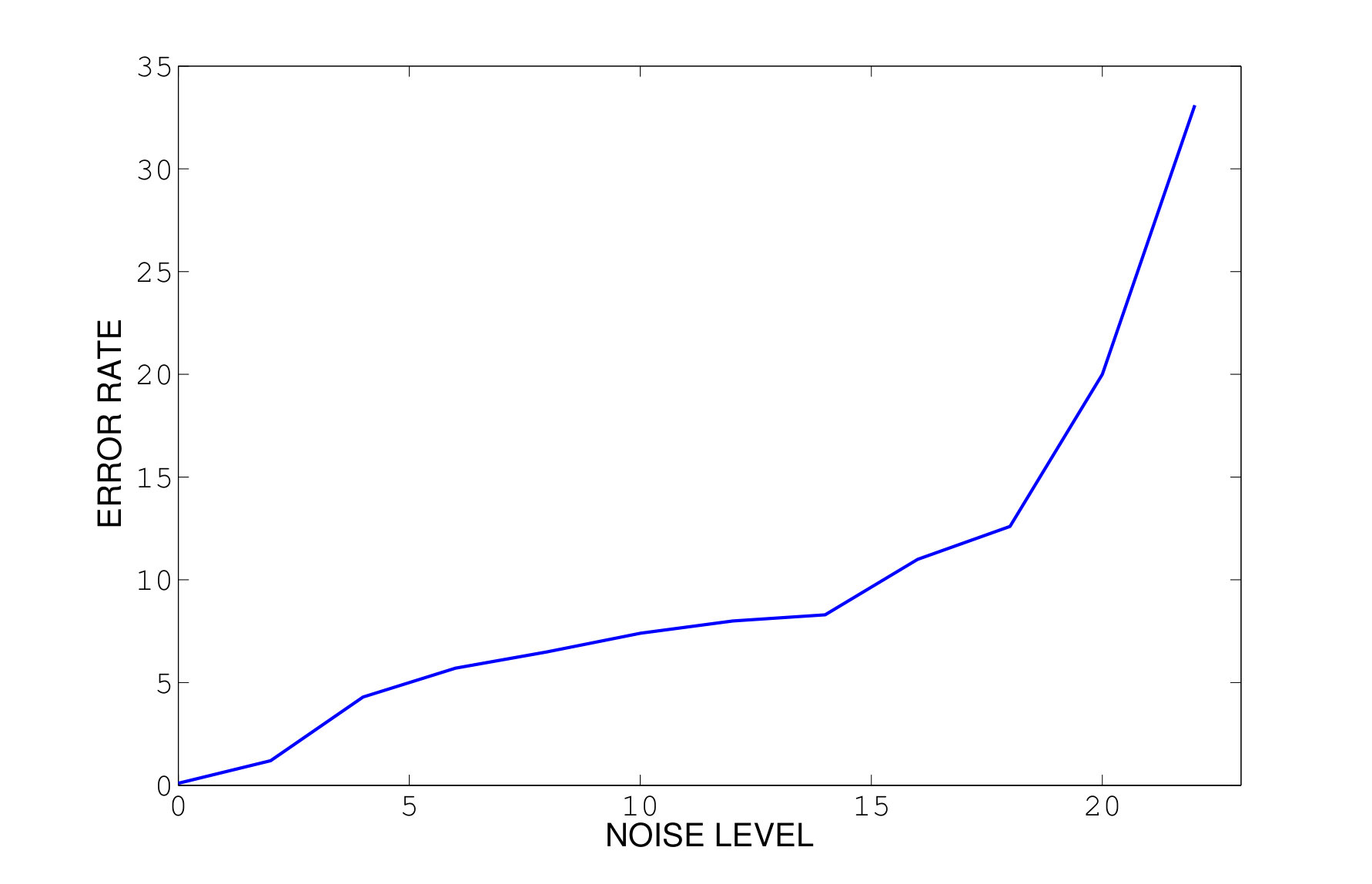 Figure 4
Figure 4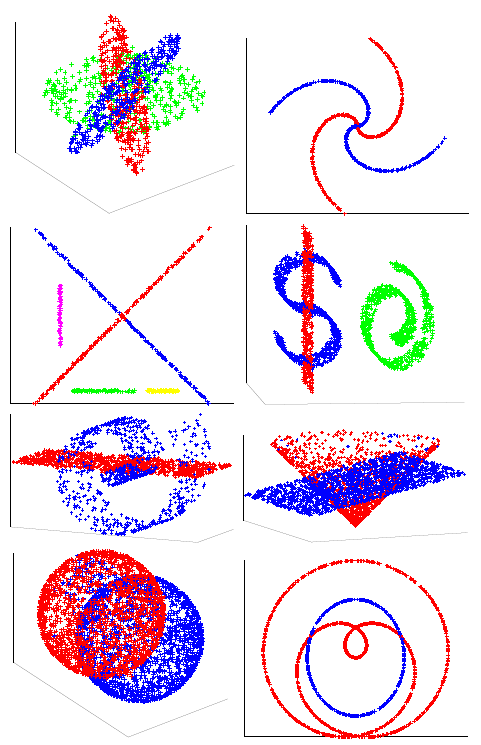 Figure 3
Figure 3 Figure 6
Figure 6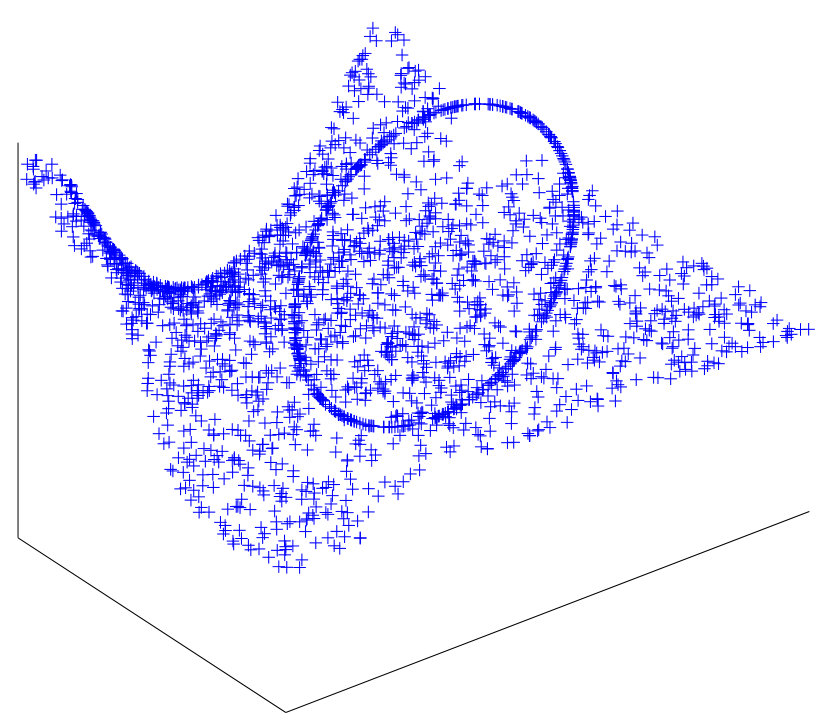 Figure 7
Figure 7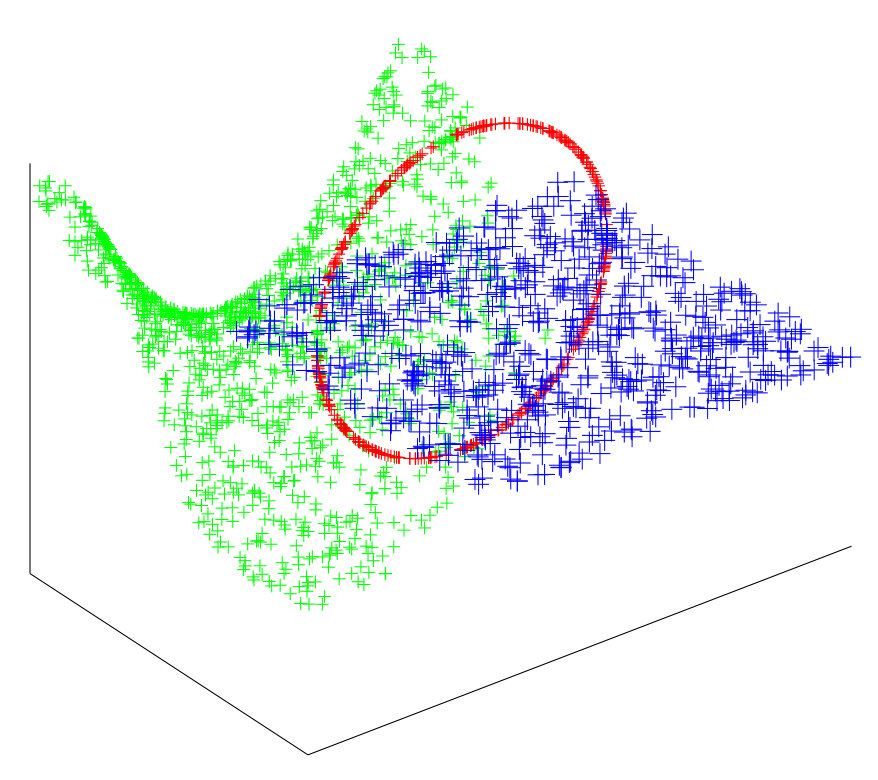 Figure 8
Figure 8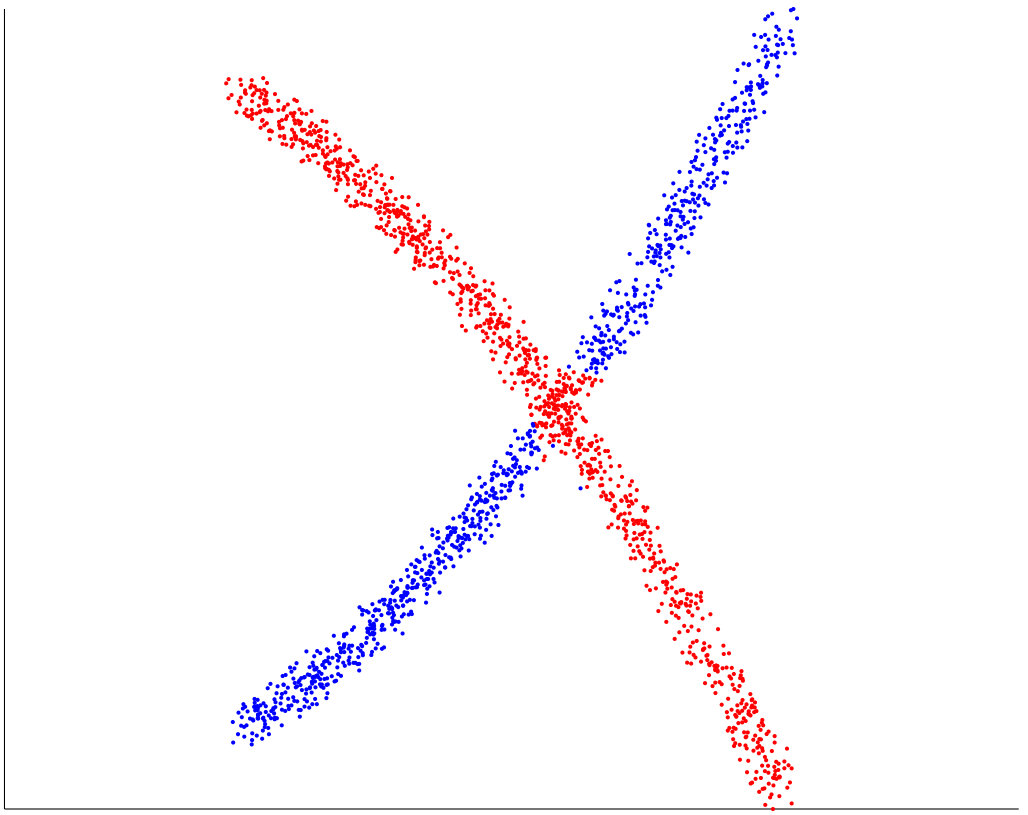 Figure 9
Figure 9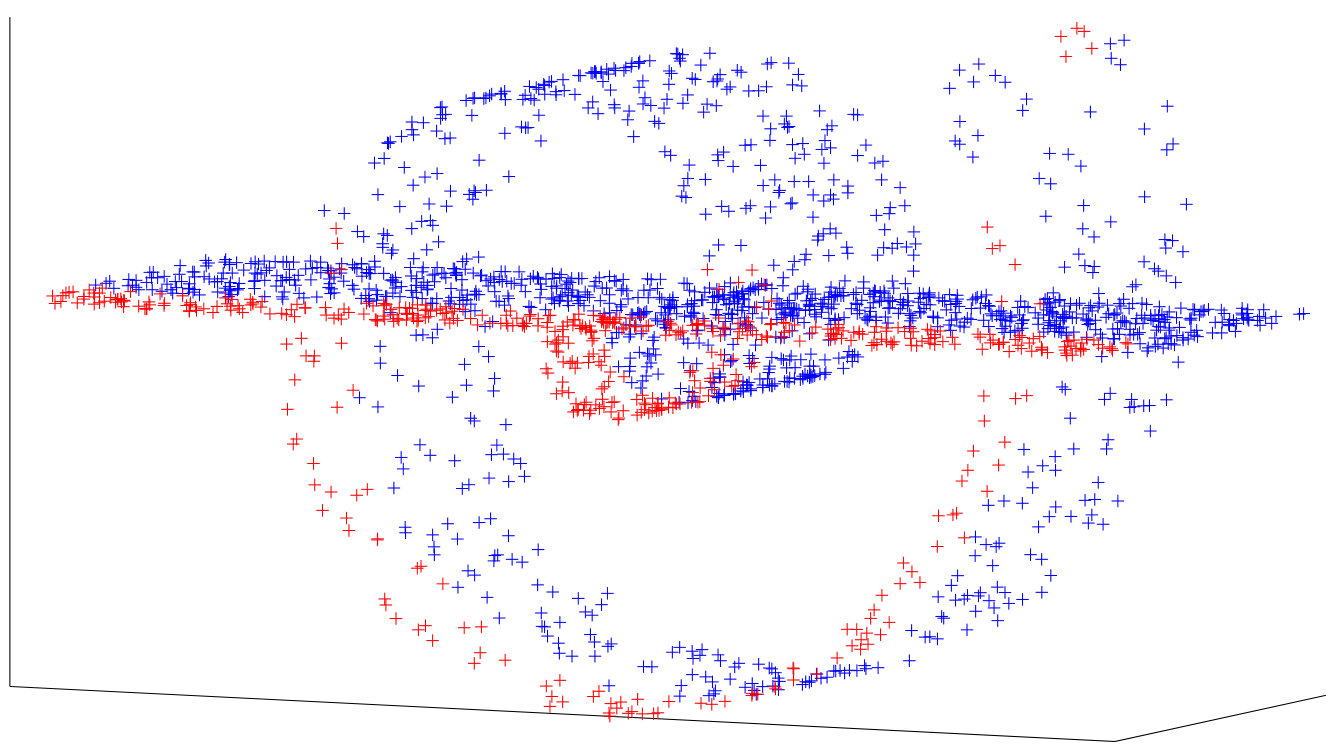 Figure 10
Figure 10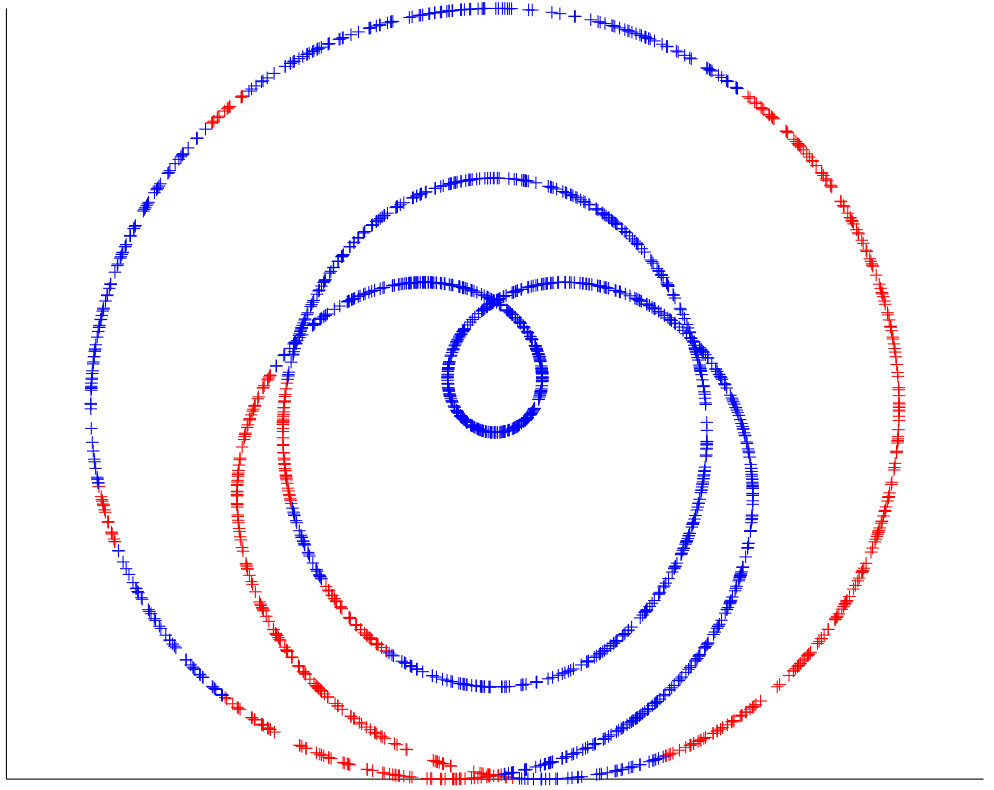 Figure 11
Figure 11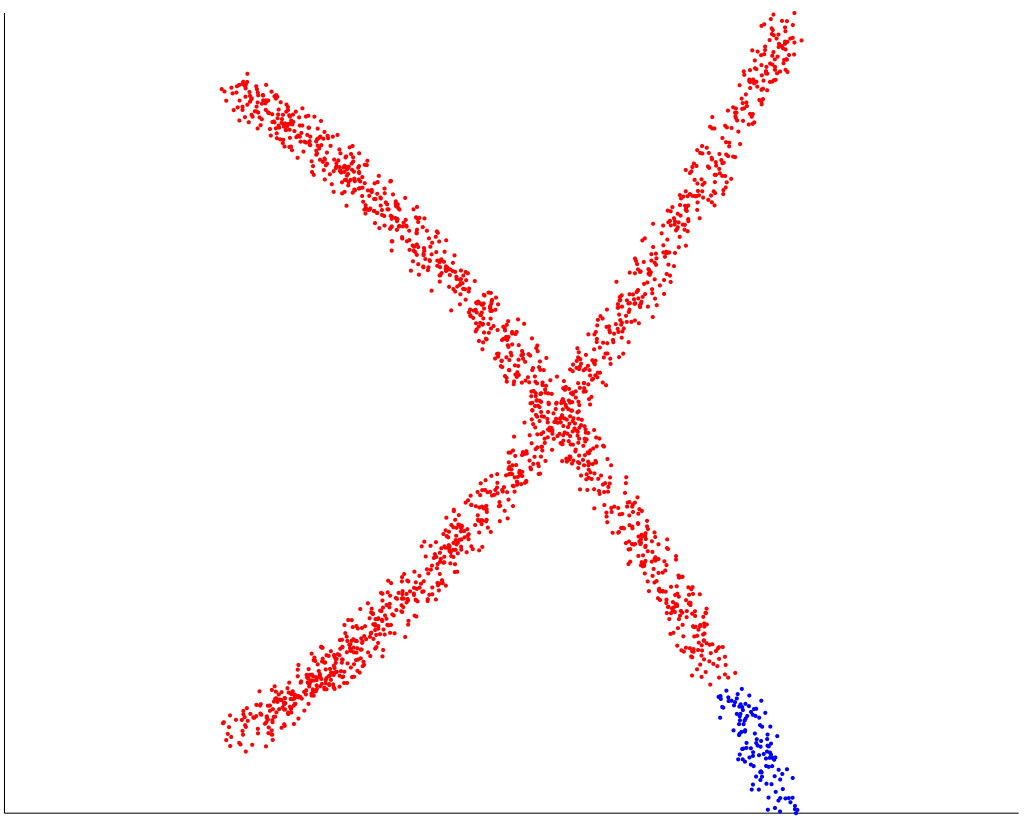 Figure 12
Figure 12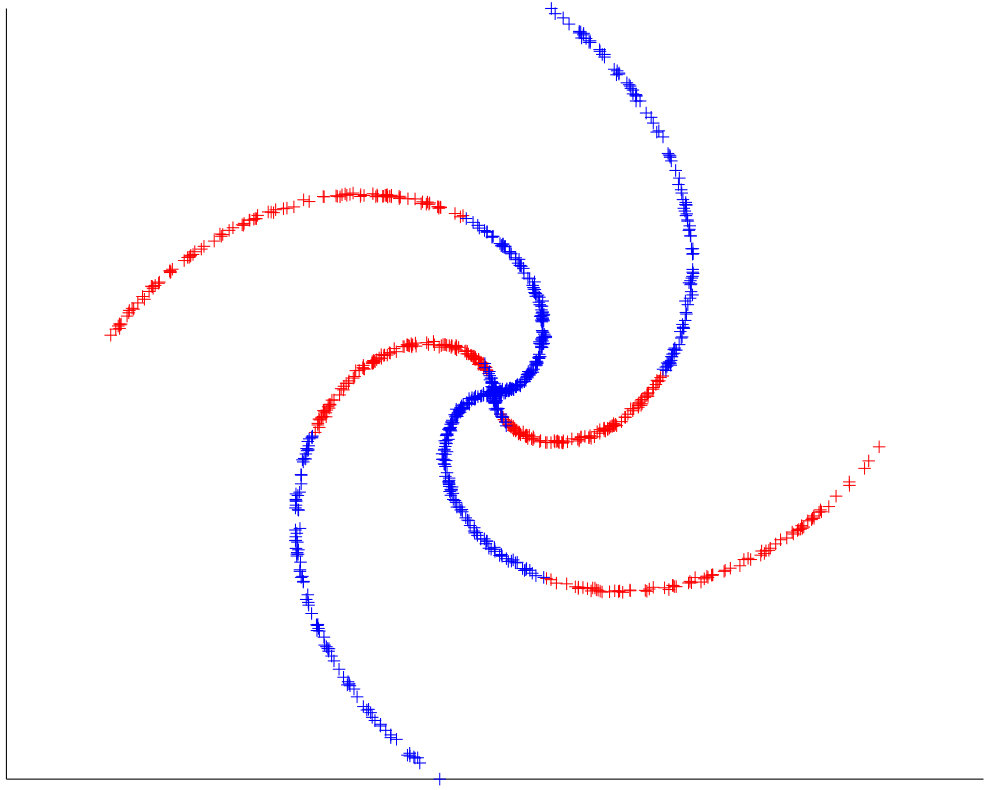 Figure 13
Figure 13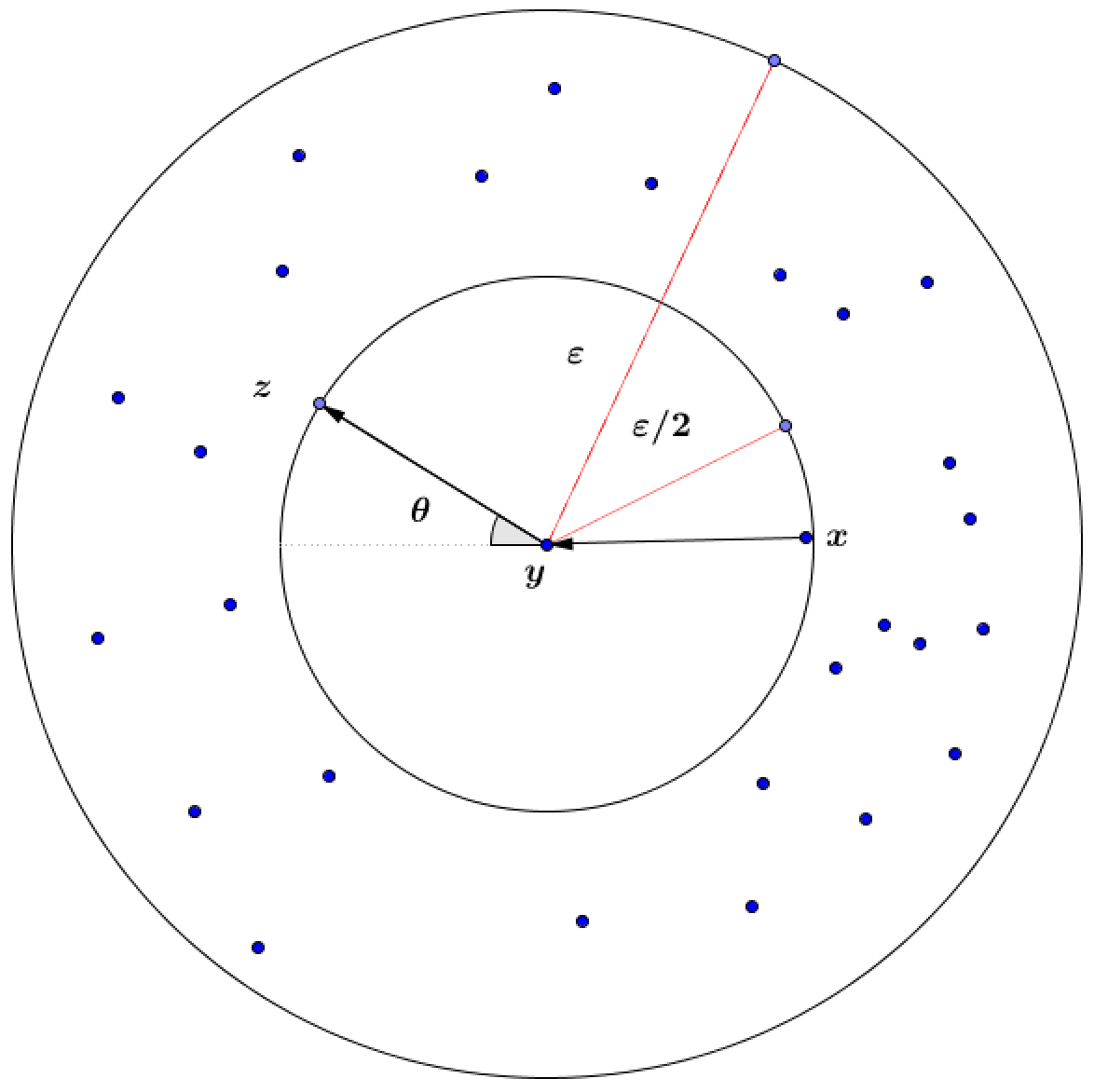 Figure 14
Figure 14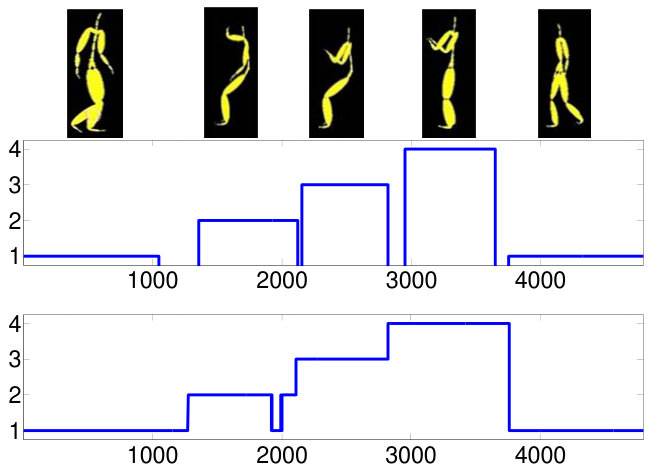 Figure 15
Figure 15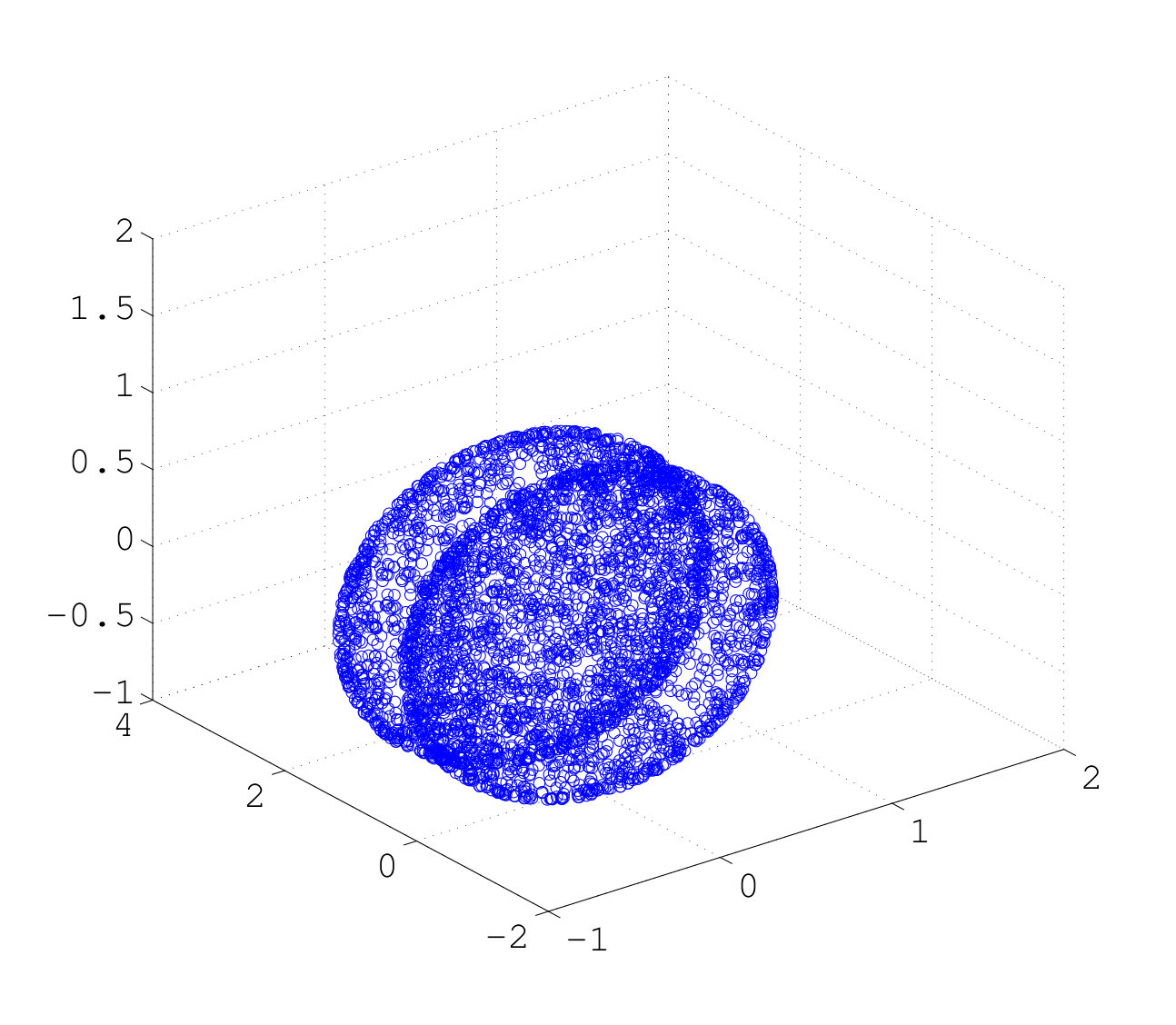 Figure 16
Figure 16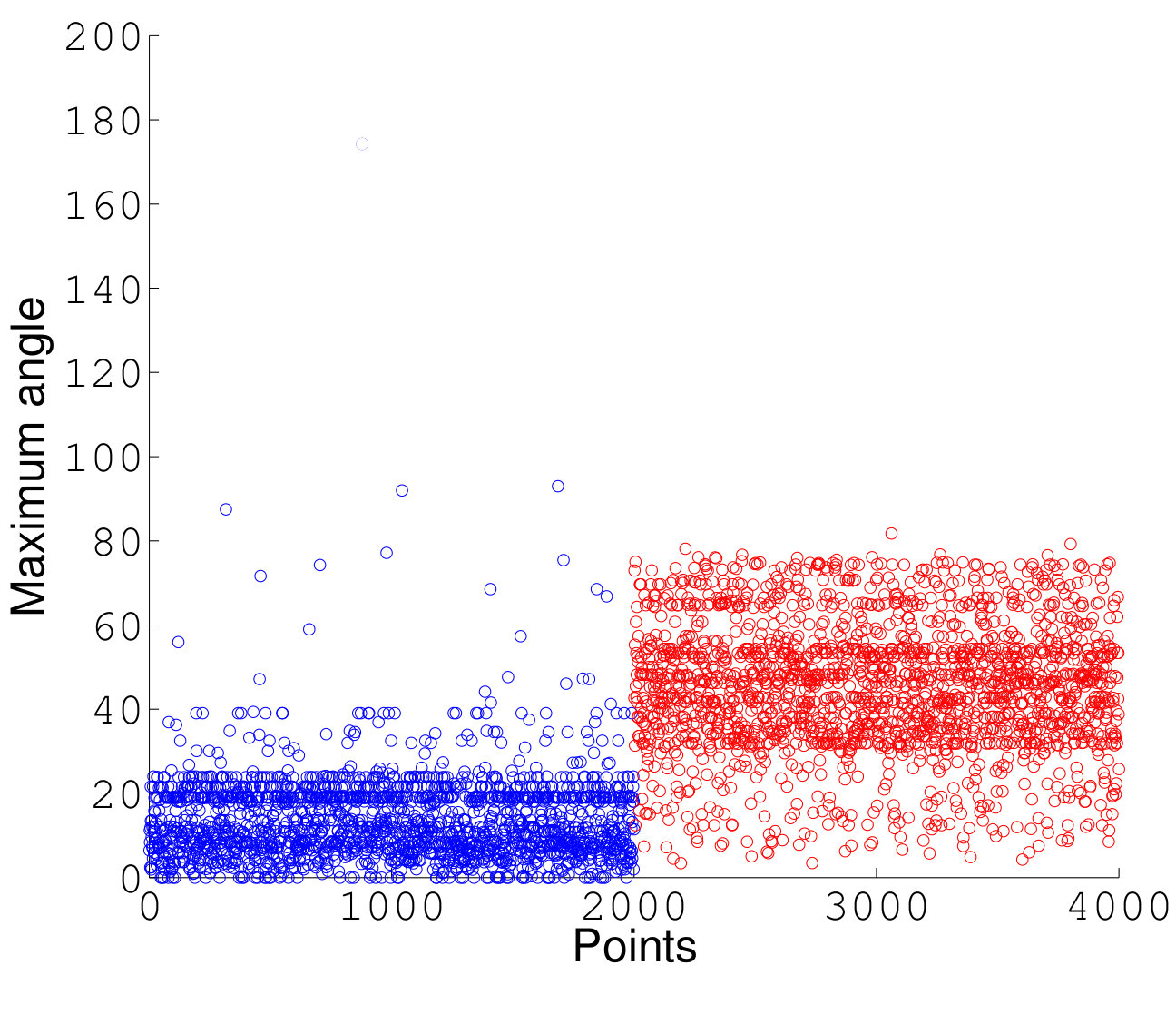 Figure 17
Figure 17 Figure 18
Figure 18| Data set | K-Manifolds | SCC | SMMC | PBC-Angle-Annulus | PBC-Curvature |
|---|---|---|---|---|---|
| Three Planes | 97.1% | 97.8% | 99.5% | 99.6% | 99.6% |
| Two Spirals | 95.2% | 54.8% | 99.7% | 99.2% | 99.1% |
| Five Segments | 59.1% | 94.9% | 99.6% | 98.1% | 98.0% |
| Dollar-Sign, Plane and Roll | 50.2% | - | 99.6% | 99.7% | 99.5 % |
| Roll and Plane | 56.5% | - | 97.6% | 96.7% | 96.9% |
| Cone and Plane | - | - | 99.6% | 97.9% | 98.1% |
| Two Spheres | - | - | 96.7% | 98.6% | 98.4% |
| Rose Curve and Circle | 62.9% | - | 64.8% | 99.8% | 99.7% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData Management and Algorithms · 3D Shape Modeling and Analysis · Topological and Geometric Data Analysis
Multiple Manifold Clustering Using Curvature Constrained Path
Amir Babaeian
University of California, San Diego, USA
March 17, 2024
Email: [email protected]
Abstract
The problem of multiple surface clustering is a challenging task, particularly when the surfaces intersect. Available methods such as Isomap fail to capture the true shape of the surface near by the intersection and result in incorrect clustering. The Isomap algorithm uses shortest path between points. The main draw back of the shortest path algorithm is due to the lack of curvature constrained where causes to have a path between points on different surfaces. In this paper we tackle this problem by imposing a curvature constraint to the shortest path algorithm used in Isomap. The algorithm chooses several landmark nodes at random and then checks whether there is a curvature constrained path between each landmark node and every other node in the neighborhood graph. We build a binary feature vector for each point where each entry represents the the connectivity of that point to a particular landmark. Then the binary feature vectors could be used as a input of conventional clustering algorithm such as hierarchical clustering. We apply our method to simulated and some real datasets and show, it performs comparably to the best methods such as K-manifold and spectral multi-manifold clustering.
1 Introduction
The application of unsupervised learning is considerably increased in different fields despite the current advancements in supervised learning (particularly deep learning [19, 20, 15]). We consider the problem of clustering points that are sampled in the vicinity of multiple surfaces embedded in Euclidean space, with a particular interest in the case where these intersect. The goal is multi-manifold clustering, which amounts to labeling each point according to the surface it comes from.
This stylized problem may be relevant in a number of applications, such as the extraction of galaxy clusters [18] and road tracking [7] after some preprocessing. In motion segmentation [16, 6, 26], Human action recognition [29, 31, 30, 33, 32] and in face recognition [13, 2, 5], the underlying surfaces are usually assumed to be affine or, more generally, algebraic.
Here we focus on a nonparametric setting where the main assumption is that the surfaces are smooth - see 1 for an example. This appears to be necessary to remove ambiguities in the problem of separating intersecting surfaces.
Several approaches have been proposed in this context. Most methods are designed for the case where the surfaces do not intersect [22, 21, 4], while others work only when the surfaces that intersect have different intrinsic dimension or density [8, 12]. The method of [1] is only able to separate intersecting curves. Methods that purposefully aim at resolving intersections are fewer. [23] implement some variant of K-means where the centers are surfaces. [11] propose to minimize a (combinatorial) energy that includes local orientation information, using a tabu search. The state-of-the-art method lies in methods based on local principal component analysis (PCA). An early proposal was the elaborate multiscale spectral method of [14], while the clustering routine of [9] — developed in the context of semi-supervised learning — inspired the works of [28] and [10].
We propose a markedly different approach based on connecting points to landmarks via curvature-constrained paths. It can be seen as a constrained variant of Isomap [24]. Isomap was specifically designed for dimensionality reduction in the single-manifold setting, and in particular, cannot handle intersections. The curvature constraint on paths is there to prevent connecting points from one cluster to points from a different, intersecting cluster. The resulting algorithm is implemented as a simple variation of Dijkstra’s algorithm. Our method is simpler than the previous proposals in the literature and performs comparably to the best methods, both on simulated and real datasets.
The rest of the paper is organized as follows. In 2.2 we explain the notion of curvature constrained shortest-path and it’s connection with the curvature constrained shortest-path. In 3 we present our algorithm for multi-manifold clustering and compare it with three currently applied methods and give a theoretical guarantee for that. In 4 we performed multiple numerical experiments on simulated and real data. Robustness of method to noise and choice of constraint is discussed as well. In 5 We discuss and outline our future work and development of our algorithm.
2 Constrained path
2.1 Curvature constraint
Neighborhood graphs play a central role in manifold learning, exploiting the fact that smooth submanifolds are locally flat. Recall that a neighborhood graph is a graph with vertices the sample points . We consider two types of neighborhood structure [17]:
- •
-ball. and are connected if , where denotes the Euclidean norm.
- •
-nearest neighbor. and are connected if is among the -nearest neighbors of (in the Euclidean metric), or vice-versa.
The central idea in this paper is the use of constrained shortest-path distances in a neighborhood graph. The paths are constrained in order to control their smoothness. The constrained shortest-path distances are used to estimate geodesic distances reliably, even when the surface self-intersects, thus allowing us to mimic Isomap. We use the fact that the constrained and unconstrained shortest-path distances are similar for points belonging to the same submanifold, while usually different for points belonging to different submanifolds.
For an ordered triplet of points in , we define the curvature as:
[TABLE]
where stands for the angle and is the radius of the circle passing through .
[TABLE]
with if are aligned.
Definition 2.1**.**
For a curvature , we say that a path is -constrained if .
To compute these constrained shortest-path distances we use a simple modification of Dijkstra’s algorithm. See 1 below. When applied to a neighborhood graph with maximum degree , its computational complexity is per source point.
2.2 Angle constraint
For an ordered triplet of points in , define its angle as
[TABLE]
We say that a sequence of points is -angle constrained if the angles between successive segments are all bounded by , meaning
[TABLE]
2 shows three D-dimensional points which form vertices of a triangle such that and belong to the annulus neighborhood of point . Under above assumption the angle constraint where implies curvature constraint where .
In 3.5.1 we analysis the correctness of our algorithm for simple case of two curves with intersection based on the angle constraint.
3 Multi-Manifold Clustering
3.1 Existing methods
The last decade saw a flurry of propositions aiming at clustering data points when the underlying clusters are not convex, and in particular, in the situation where the points are sampled near low-dimensional objects. We gave a few references in the Introduction and now want to elaborate on three of them, [23], [3] and [28], as we will use them as benchmarks in our experiments. Our choice was dictated by performance, code availability and relevance to our particular setting.
The method of [14] renders impressive results but is hard to tune, having many parameters, while the method of [10] is very similar to that of [28] and the code was not publicly available at the moment of writing this paper. The other methods for multi-manifold clustering that we know of were not designed to resolve intersections of clusters of possibly identical intrinsic dimensions and sampling densities.
We chose the subspace clustering method of [3] among a few others methods that perform well in this context.
3.2 K-Manifolds
[23] suggest an algorithm that mimics K-means, replacing centroid points with centroid submanifolds. The method starts like Isomap by building a neighborhood graph and computing shortest path distances within the graph. After randomly initializing a -by- weight matrix , where represent the probability that point belongs to the th cluster, it alternates between an M-Step and an E-Step. In the M-Step, for each , the points are embedded in using a weighted variant of multidimensional scaling using the weights . In the E-Step, for each and , the normal distance of point to the cluster is estimated as
[TABLE]
where denotes the shortest path distance in the neighborhood graph and denotes the Euclidean distance in the th embedding, between points and . The weights are then updated as such that for all , where is chosen automatically.
3.3 Spectral Curvature Clustering
[3] proposed a spectral method for subspace clustering — the setting where the underlying surfaces are affine. We will compare our method to theirs when the surfaces are affine, and also when the surfaces are curved. The latter is done as a proof of concept, for it will be very clear that it cannot handle curved surfaces, like any other method for subspace clustering we know of. The procedure assumes that all subspaces are of same dimension , which is a parameter of the method. For each -tuple, , it computes a notion of curvature which measure how well approximated this -tuple is by an affine subspace of dimension . After reducing the tensor spectral graph partitioning [21] is applied.
3.4 Spectral Multi-Manifold Clustering
[28] is a spectral method using a dissimilarity that factors in the Euclidean distance and the discrepancy between the local orientation of the data. The surfaces are assumed to be of same dimension known to the user. First, a mixture of probabilistic principal component analyzers [25] are fitted to the data, approximating the point cloud by a union of -planes. This is used to estimate the tangent subspace at each data point. The dissimilarity between two points is then an increasing function of their Euclidean distance and the principal angles between their respective affine subspaces. These dissimilarities are fed to the spectral graph partitioning method of [21].
3.5 Our algorithm
We consider the following problem of surface clustering:
Given a sample sampled from , where for each , is a smooth, but possibly self-intersecting surface, label each point according to the surface it belongs to.
Our algorithm is quite distinct from all the other methods for multi-manifold clustering we are aware of, although it starts by building a -nearest neighbor graph like many others. The idea is very simple and amounts to clustering together points that are connected by an angle-constrained path in the neighborhood graph.
Take two surfaces and intersecting at a strictly positive angle. Then for ‘most’ pairs of data points and , a path in the graph going from to has at least one large angle between two successive edges, on the order of the incidence angle between the surfaces; while for ‘most’ pairs of data points , there is a path with all angles between successive edges relatively small.
To speedup the implementation, we select landmarks (with slightly larger than ) at random among the data points and only identify what data points are connected to what landmark via a -constrained path in the graph. and are parameters of the algorithm.
Let if point and landmark are connected that way, and if not. We use as feature vectors that we group together and cluster using hierarchical clustering with complete linkage.
3.5.1 Intersections
We are most interested in the case where the surfaces intersect.
Concretely, given compact, simply connected submanifolds of maximum pointwise curvature bounded by , we consider the noisy mixture distribution
[TABLE]
where denotes the uniform distribution over set .
4 Numerical Expriments
4.1 Synthetic Data
The synthetic datasets we generated are similar to those appearing in the literature. 3 shows the performance of our algorithm on eight synthetic data set. The misclustering rates for our method, and the other three methods, are presented in Table 1, where we see that our method achieves a performance at least comparable to the best of the other three methods on each dataset. We implemented path-based clustering using both curvature constraint and angle constraint with annuals graph. To compute the accuracy of clustering we remove a few ambiguous points close by intersection. Spectral Curvature Clustering (SCC) works well on linear manifolds (as expected) while it fails when there is curvature 4. K-Manifolds fails in the more complicated examples 5 . We found that this algorithm is very slow since it has to compute the shortest path between all the points, so that we could not apply it to some of the largest datasets. We mention that it assumes that clusters intersect, and otherwise does not work properly. Our method and Spectral Multi-Manifolds Clustering (SMMC) perform comparably on most datasets, but SMMC fails in the Rose Curve and Circle example 6 . We note that K-Manifold, SCC and SMMC all require that all surfaces are of same dimension, which is a parameter of these methods, why our method does not need knowledge of the intrinsic dimensions of the surfaces and can operate even when these are different.
4.2 Clustering of 2D Image Data
In this section we apply our method on the COIL-20 dataset which includes 1440 gray-scale images of 20 objects. Each object contains 72 images taken by a camera at different angles. The original resolution of each image is . We first projected the dataset onto the top 10 principal components, then apply our path-based clustering algorithm. We tested our method on the three very similar objects 3, 6 and 19. The algorithm is 99% accurate (misclusters only 2 images out of 216) bringing a significant improvement over the state-of-the-art result of 70% reported in [28]. Lastly, we evaluated our method on the whole dataset obtaining an accuracy, improving on the 70.7% accuracy reported in [28]. (Here we used the top 20 principal components.) Since in this case we have 20 different classes, we increased the number of landmarks to 100 to make sure we sampled that at least a few landmarks from each class.
4.3 Clustering of Human Motion Sequences
In computer vision clustering of human motion sequences into different class of activities performed by a subject is referred to temporal segmentation. In this section we test our algorithm on a sequence of video frames including different activities performed by a subject. We choose 4 mixed actions from subject 86, trial number 9 of the CMU MoCap dataset. The data consists in a temporal sequence of 62-dimensional representation of the human body via markers in . One motion sequence of 4794 frames and corresponding result of path-based multi-manifold clustering are given in 8. Four activities are labeled from 1 to 4. We do not label the frames where the subject switches from one action to another because of the uncertainty about the true activity.
4.4 Segmentation of Video Sequences
In this section we consider the problem of partitioning a video sequence into different scenes. We consider the same video sequence used in [3, 27]. The video is an interview from Fox News containing 135 image frames of size ; a sample is depicted in 9. Firstly we change each RGB image frame to the gray scale intensity image, then resize it to an image. After concatenating all pixels of each image and putting into a vector of size , we construct a matrix of size where each row represents a frame of the original video sequence. Applying our algorithm on this matrix we get a perfect clustering (100%). We repeated the experiment, this time projecting the data onto the top 10 principal components as done in [3, 27], obtaining a matrix of size . We still get a 100% accuracy, for an even wider range of parameters.
4.5 Robustness to Noise
We note that all the other methods we know of for multi-manifold clustering do not perform well unless the noise level is quite small. As it appears in our method when we increase the amount of noise the possibility of connecting points from different surface with curvature constrained path increases. 10 shows the error rate for two intersecting curves with addition of standard uniform noise, as it can be illustrated, when we increase the noise, notion of two different surface or manifold would be ambiguous where we can say all the points belong to one manifold. All other three methods fail to capture the correct manifold with even small noise where our method still perform well with noise. See 11 for an example with a substantial amount of noise, where SMMC fails while PBC succeeds.
4.6 The choice of constraint
One of the main challenges of our algorithm is the choice of the angle constraint with annulus graph, since we deal with multiple manifolds with intersection. The large angle constraint causes the points from different manifolds to be connected using constrained shortest-path. This ultimately leads to multiple manifolds being clustered as one class. We also considered implementing the small constraint, however, this constraint does not allow us to accurately capture the structure of the manifold. 12 shows two intersecting spheres and the distribution of maximum angle in an unconstrained shortest-path between all the points and a given landmark. The distributions of maximum angle for the points within the same sphere as landmark belongs to (blue) is separable from the distributions of maximum angle for the points within the sphere that landmark does not belong to (red). This illustration guides us to the idea that with the small amount of labeled points we are able to find the appropriate angle constraint. In another experiment we started with an angle constraint of and used of the points in each cluster as labeled data. We then compared the performance of our algorithm on the labeled data. In order to find the optimum angle constraint we increased or decreased our angle constraint by a certain factor. We initially begin with dividing our angle constraint by a factor of , until the error ceases to decrease. In the case that the error increases, we increase the angle constraint by a factor of . In most cases we were able to find the optimal angle constraint within iterations. As it can be understood from 12 the distribution of the maximum angle of the points within a class follows a flat distribution. By having a small number of labeled points we are able to capture the distribution of the maximum angle for the rest of the points in that class.
5 Discussion and Conclusion
We are currently experimenting with variants — some based on other constraints — that would lead to path-based clustering algorithms that perform at least as well in practice as 2, and are consistent in the large-sample limit.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] E. Arias-Castro, G. Chen, and G. Lerman. Spectral clustering based on local linear approximations. Electron. J. Statist. , 5:1537–1587, 2011.
- 2[2] R. Basri and D. Jacobs. Lambertian reflectance and linear subspaces. IEEE PAMI , 25(2):218–233, 2003.
- 3[3] G. Chen and G. Lerman. Spectral curvature clustering (SCC). IJCV , 81(3):317–330, 2009.
- 4[4] E. Elhamifar and R. Vidal. Sparse manifold clustering and embedding. In J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K. Weinberger, editors, Advances in Neural Information Processing Systems 24 , pages 55–63. 2011.
- 5[5] R. Epstein, P. Hallinan, and A. Yuille. 5 ± 2 plus-or-minus 5 2 5\pm 2 eigenimages suffice: An empirical investigation of low-dimensional lighting models. In IEEE Workshop on Physics-based Modeling in Computer Vision , pages 108–116, June 1995.
- 6[6] Z. Fu, W. Hu, and T. Tan. Similarity based vehicle trajectory clustering and anomaly detection. In ICIP , pages II–602–5, 2005.
- 7[7] D. Geman and B. Jedynak. An active testing model for tracking roads in satellite images. IEEE Trans. Pattern Anal. Mach. Intell. , 18:1–14, 1996.
- 8[8] A. Gionis, A. Hinneburg, S. Papadimitriou, and P. Tsaparas. Dimension induced clustering. In KDD ’05: Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining , pages 51–60, New York, NY, USA, 2005. ACM.