TL;DR
EvoMSA is a multilingual, domain-independent sentiment analysis system using genetic programming to combine various classifiers, achieving top results across multiple languages and competitions, and is openly available for use.
Contribution
This paper introduces EvoMSA, a novel, language-independent sentiment analysis system that unifies multiple classifiers using genetic programming, demonstrating competitive performance across diverse languages and domains.
Findings
EvoMSA achieves top rankings in several sentiment analysis competitions.
The system is domain independent and works across multiple languages.
Component analysis shows the contribution of each classifier to overall performance.
Abstract
Sentiment analysis (SA) is a task related to understanding people's feelings in written text; the starting point would be to identify the polarity level (positive, neutral or negative) of a given text, moving on to identify emotions or whether a text is humorous or not. This task has been the subject of several research competitions in a number of languages, e.g., English, Spanish, and Arabic, among others. In this contribution, we propose an SA system, namely EvoMSA, that unifies our participating systems in various SA competitions, making it domain independent and multilingual by processing text using only language-independent techniques. EvoMSA is a classifier, based on Genetic Programming, that works by combining the output of different text classifiers and text models to produce the final prediction. We analyze EvoMSA on different SA competitions to provide a global overview of its…
Click any figure to enlarge with its caption.
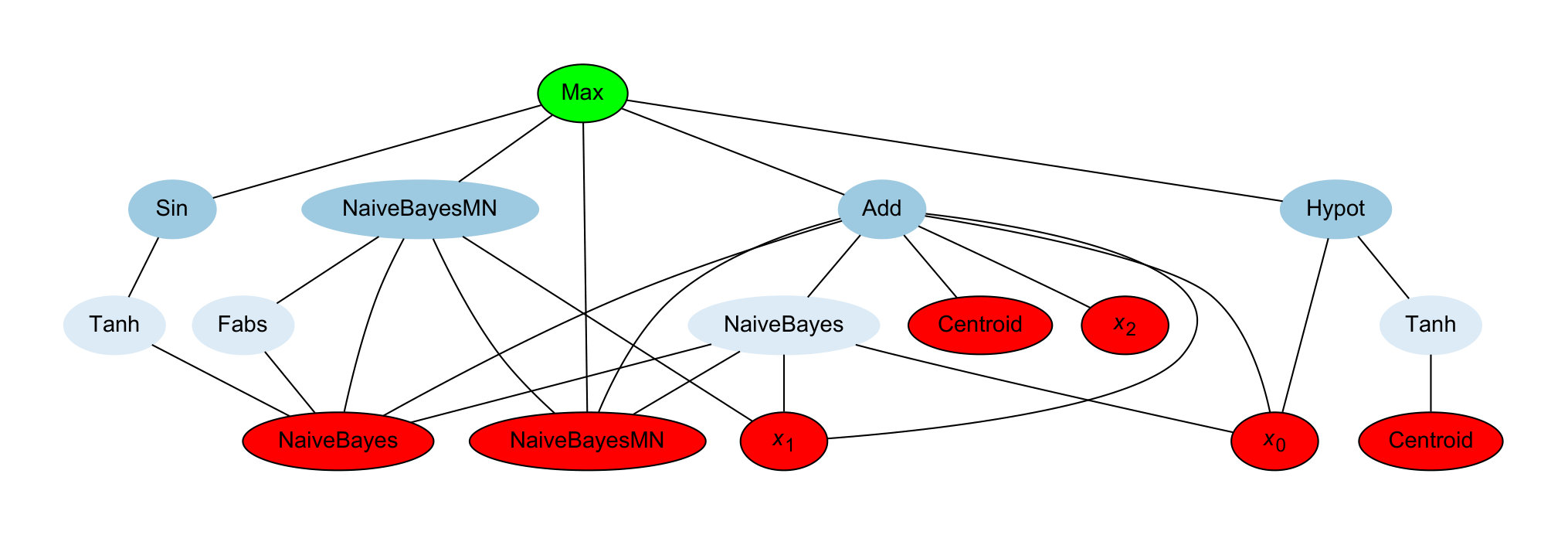 Figure 1
Figure 1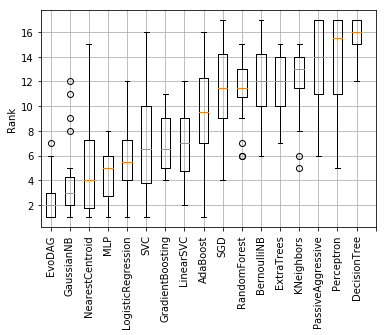 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5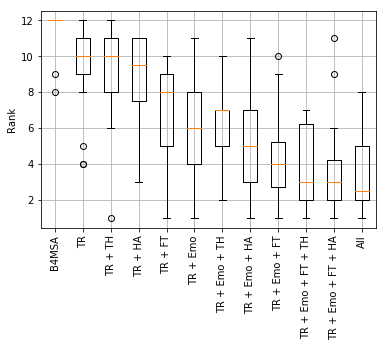 Figure 6
Figure 6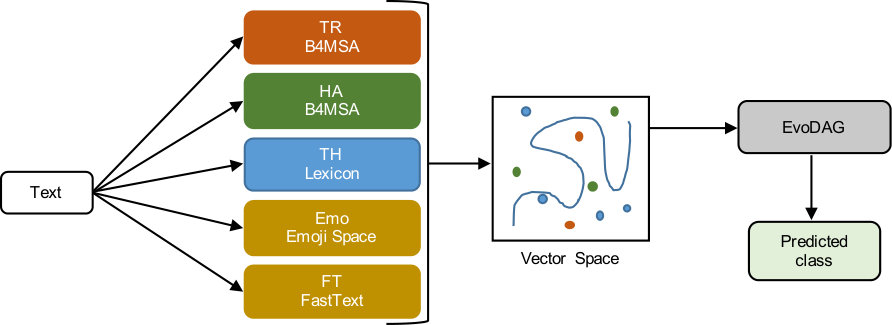 Figure 7
Figure 7| Text transformation | ||||
| Parameter | Default | Arabic | English | Spanish |
| remove diacritics | yes | yes | no | yes |
| remove duplicates | yes | |||
| remove punctuation | yes | |||
| lowercase | yes | |||
| emoticons | group | |||
| numbers | group | group | delete | group |
| urls | group | |||
| users | group | |||
| hashtag | none | |||
| entities | none | delete | none | none |
| negation | false | |||
| stopwords | false | delete | false | false |
| stemming | false | |||
| Tokenizers | ||||
| -words | ||||
| skip-grams | ||||
| -grams | ||||
| Language | Training | Test | |
| SemEval 2017 (SA) | |||
| English | 50,333 | 12,284 | |
| Arabic | 3,355 | 6,100 | |
| SemEval 2018 (EC) | |||
| anger | 1,027 | 373 | |
| fear | 1,028 | 372 | |
| Arabic | joy | 952 | 448 |
| sadness | 1,030 | 370 | |
| valence | 1,070 | 730 | |
| anger | 2,089 | 1,002 | |
| fear | 2,641 | 986 | |
| English | joy | 1,906 | 1,105 |
| sadness | 1,930 | 975 | |
| valence | 1,630 | 937 | |
| anger | 1,359 | 627 | |
| fear | 1,368 | 618 | |
| Spanish | joy | 1,260 | 730 |
| sadness | 1,350 | 641 | |
| valence | 1,795 | 648 | |
| Spanish | |||
| TASS 2017 (SA) | G. Corpus | 7,219 | 60,798 |
| InterTASS | 1,514 | 1,899 | |
| S1-L1 | 1,500 | 500 | |
| TASS 2018 (SUS) | S1-L2 | 1,500 | 13,152 |
| S2 | 274 | 407 | |
| HAHA 2018 (HA) | 16,000 | 4,000 | |
| MEX-A3T (AA) | 5,389 | 2,311 | |
| Systems/Teams | Anger | Fear | Joy | Sadness | Valence |
|---|---|---|---|---|---|
| Arabic | |||||
| EiTAKA | |||||
| EvoMSA | |||||
| AffectThor | |||||
| INGEOTEC | |||||
| UNCC | |||||
| B4MSA | |||||
| UWB [58] | - | ||||
| EMA [59] | |||||
| NileTMRG [7] | - | - | - | - | |
| English | |||||
| SeerNet | |||||
| PlusEmo2Vec | |||||
| Amobee [60] | |||||
| psyML [61] | |||||
| EiTAKA [28] | |||||
| FOI DSS [62] | |||||
| TCS Research [63] | |||||
| NTUA-SLP [64] | |||||
| AffecThor [29] | |||||
| Epita [65] | - | - | - | - | |
| INGEOTEC | |||||
| ELiRF-UPV [66] | |||||
| EvoMSA | |||||
| UNCC [67] | |||||
| YNU-HPCC [68] | |||||
| B4MSA | |||||
| ZMU [7] | |||||
| Spanish | |||||
| Amobee | - | - | - | - | |
| EvoMSA | |||||
| AffectThor | |||||
| ELiRF-UPV [66] | |||||
| INGEOTEC | |||||
| UG18 [69] | |||||
| YNU-HPCC [68] | |||||
| B4MSA | |||||
| UWB [58] | - | ||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
EvoMSA: A Multilingual Evolutionary Approach for Sentiment Analysis
Mario Graff1,3
Sabino Miranda-Jiménez1,3
Eric S. Tellez1,3
Daniela Moctezuma1,2
(1INFOTEC Centro de Investigación e Innovación en Tecnologías de la Información y Comunicación, Circuito Tecnopolo Sur No 112, Fracc. Tecnopolo Pocitos II, Aguascalientes 20313, México
2CentroGEO Centro de Investigación en Ciencias de Información Geoespacial, Circuito Tecnopolo Norte No. 117, Col. Tecnopolo Pocitos II, C.P., Aguascalientes, Ags 20313 México
3CONACyT Consejo Nacional de Ciencia y Tecnología, Dirección de Cátedras, Insurgentes Sur 1582, Crédito Constructor, Ciudad de México 03940 México
This work has been accepted for publication to the
IEEE Computational Intelligence Magazine
©2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. )
Abstract
Sentiment analysis (SA) is a task related to understanding people’s feelings in written text; the starting point would be to identify the polarity level (positive, neutral or negative) of a given text, moving on to identify emotions or whether a text is humorous or not. This task has been the subject of several research competitions in a number of languages, e.g., English, Spanish, and Arabic, among others. In this contribution, we propose an SA system, namely EvoMSA, that unifies our participating systems in various SA competitions, making it domain-independent and multilingual by processing text using only language-independent techniques. EvoMSA is a classifier, based on Genetic Programming that works by combining the output of different text classifiers to produce the final prediction. We analyzed EvoMSA on different SA competitions to provide a global overview of its performance. The results indicated that EvoMSA is competitive obtaining top rankings in several SA competitions. Furthermore, we performed an analysis of EvoMSA’s components to measure their contribution to the performance; the aim was to facilitate a practitioner or newcomer to implement a competitive SA classifier. Finally, it is worth to mention that EvoMSA is available as open-source software.
1 Introduction
Sentiment Analysis (SA) is a task dedicated to developing automatic techniques that can analyze people’s feelings or beliefs expressed in texts [1] such as emotions, opinions, attitudes, appraisals, among others. Sentiment Analysis is not only applied to text data but also voice, video recording, to mention a few, see, for instance [2] and [3]. Regarding text, one of the most analyzed opinion forums is Twitter because it is a massive source of data111https://www.omnicoreagency.com/twitter-statistics/ having potential uses for many decision-making areas. Affective computing and sentiment analysis have attracted a multitude of researchers aiming to understand people’s opinion on an event or entity or even the user’s mood [1, 4]. The dedicated community, i.e., researchers in areas ranging from psychology and sociology to natural language processing (NLP) and machine learning, have proposed a number of approaches to tackle the problem. The community also organizes several challenges to measure the effectiveness of the available approaches over common ground, e.g., TASS (Taller de Análisis Semántico) [5, 6] and SemEval (Semantic Evaluation) [7, 8] which are among the most popular SA competitions. Overall, the challenges’ dynamic provides insightful ideas on how to solve the problem, and an objective procedure to compare different approaches; however, in our opinion, the side effect is that some models are difficult to replicate. Our particular experience is that the rush of the competition leads us to take several decisions which are not systematically tested. Consequently, it produces many details that are impractical to write in a report.
One would expect that in competitions such as SemEval [7, 8] where a task is in English, Arabic, and Spanish languages there would be plenty of multilingual approaches participating in all the languages, or, at least, teams participating in various languages. However, the majority of systems are designed to work only in English. For example, in SemEval 2017 [8] where task 4 was in English and Arabic only 19% (8 out of 42 teams) of the teams participated in both languages, and in SemEval 2018 [7] 16% (7 out of 43 teams) participated in English, Arabic, and Spanish, and 28% (12 out of 43) participated in two of the languages. The reason for the reduced multilingual participation is the inherent difficulties of creating multilingual systems. For example, the resources are only available in a specific language, or the implementation of other languages is challenging. This problem becomes relevant for those languages with weakly developed NLP techniques. As an example, some winning approaches have created text models based on millions of texts (more than 400 million of tweets), clearly, the requirements on information and computing power limit this approach only to the languages where these requirements are satisfied which sometimes are those where the authors have invested most of their time. On the other hand, there are a number of language techniques that are tailored to a specific language, and, to target another language, one needs to be fluent on that particular language.
To overcome these problems, this contribution proposes a multilingual methodology that tackles the sentiment analysis task inspired by our participation as INGEOTEC in TASS 2017 [9] and 2018 [10]; SemEval 2017 [11] and 2018 [12]; and IberEval 2018 in MEX-A3T [13], and HAHA [14] competitions. There are considerable differences between INGEOTEC’s systems and EvoMSA. Firstly, EvoMSA is applied to all the languages and competitions without any modification and with its parameters fixed, per language, to provide a global overview of its performance; whereas, INGEOTEC systems are slightly different in each competition. Secondly, in this contribution, it is included an alternative implementation of the DeepMoji [15], ad-hoc to our approach; we call it Emoji Space. Finally, some text models have not been used in our participating systems such as FastText (except in TASS 2018) and our Emoji Space (see Section 3).
The goal is to propose a competitive multilingual SA system that can be applied to a variety of languages and domains. To achieve this, we disregard those techniques and optimizations that are either only applicable to a particular language or domain, or which net effects (regarding performance) are hard to measure. Moreover, the development of EvoMSA is modular so that each of its parts can be measured separately, facilitating the understanding of which parts contribute the most to the performance. As a result, the methodology presented here can be easily applied to other text categorization problems, and it is easy to implement, given that there are public libraries for most of its components. Moreover, we released our Python implementation as open-source222https://github.com/INGEOTEC/EvoMSA.
The rest of the manuscript is organized as follows: Section 2 presents the related work emphasizing the best or multilingual works presented at SA competitions. EvoMSA is described in Section 3. Section 4 describes the competitions datasets used as testbeds. The performance and comparison of EvoMSA using different models and state-of-the-art SA systems are described in Section 5. The conclusions and possible directions for future work are given in Section 6.
2 Related Work
The sentiment analysis community has stimulated research groups to develop innovative techniques to classify aspects, stances, emotions employing international challenges such as SemEval, TASS, IberEval, among others. In particular, to boost multilingual approaches, SemEval challenge encourages the participation in more than one language; for instance, English, Spanish, and Arabic languages are promoted in tasks such as polarity detection [8] and emotion detection [7].
Existing multilingual approaches rely on lexicons, parallel corpora, machine translation systems, labeled data, or a combination of them [16, 17]. For example, polarity detection [18] uses a machine translation system to translate data from English into four languages (Italian, German, French, and Spanish), and a classifier to train models for each language. The results by language are similar, and the combination of multilingual data sometimes improves the performance; the authors also point out that the use of external labeled data of the target language improves the performance. Meng et al. [19] proposed a generative cross-lingual mixture model (CLMM) using the bilingual parallel corpus for English and Chinese (target), they can learn unseen sentiment words maximizing the likelihood of generating the parallel corpora. Becker et al. [20] used two source corpora (English and Portuguese) of news and their translated versions of the target languages Spanish, French, English, and Portuguese. The combination of features of multilingual translations improves the performance for the classification task; on the other hand, the stacking of monolingual classifiers performs even better.
In the case of contests, we describe those approaches that obtained the first positions in each competition, in SemEval 2017, polarity detection task involves detecting whether a given text has a positive, negative, or neutral sentiment at a global level. The BB_twtr [21] team used an ensemble of Neural Networks combining Convolutional Neural Networks (CNNs) and Long-Short Term Memory Networks (LSTMs). The DataStories [22] system follows a similar deep learning approach using Bidirectional LSTMs (BiLSTM) with an attention mechanism. Both approaches use word embeddings from pre-trained vectors as text representation. In the case of the Arabic language, NileTMRG team [23] used a Naive Bayes classifier augmented with phrase and word level sentiment lexicon for Egyptian and Modern Standard Arabic. Two multilingual systems were proposed for this task, SiTAKA [24] and ELiRF-UPV [25] which participated in English and Arabic. SiTAKA system uses pre-trained embeddings, Word2Vec for English, and SKIP-G300 [26] for Arabic. This system also uses other features such as -words, part of speech tags, and lexicons to give an additional score. It uses a Support Vector Machine (SVM) to perform the classification. ELiRF-UPV system is based on Convolutional Recurrent Neural Networks (CRNNs) and the combination of general and specific word embeddings for English and Arabic, and polarity information from lexicons.
SemEval 2018 [7] consisted of an array of subtasks where the systems have to infer the emotional state of a person based on his/her tweets. The tasks include the automatic determination of emotion intensity (EI) and valence classification (VC). The former tries to determine the emotional intensity of tweets; it considers four basic emotions: anger, fear, joy, and sadness. The latter, VC, consists on, given a tweet, classify it into one of seven ordinal classes related to various levels of positive and negative sentiment intensity. All tasks were run for English, Arabic, and Spanish languages. In this competition, SeerNet system [27], participating only in English, proposed a pipeline of pre-processing and feature extraction steps. The pre-processing uses Tweettokenize333https://github.com/jaredks/tweetokenize tool, and for feature extraction, several deep learning approaches were considered, such as DeepMoji, EmoInt, Sentiment Neuron, and Skip-Thought Vectors. EiTAKA [28] presented results for English and Arabic using an ensemble of two approaches, deep learning and XGBoost regressor based on embeddings and lexicons. As a multilingual system, AffecThor [29] participated in all the languages and emotional intensity and valence task. The AffecThor team proposed a solution build upon several best past-years participating systems and a combination of several approaches based on lexical resources and semantic representations. These resources include 22 lexicons and Word2Vec for word embeddings. In the classification step, they use the architecture of several neural models like CNN with max pooling, BiLSTM with attention, and a set of character and word features BiLSTMs (CHAR-LSTM).
TASS 2017 competition [6] focused on polarity classification at tweet level (positive, negative, neutral, and none) in the Spanish language. The systems were evaluated on two datasets: the International TASS corpus (InterTASS), tweets located inside Spain territory written in the Spanish language; and the General Corpus, tweets of personalities and celebrities written in Spanish from several countries including Spain. ELiRF-UPV [30] employed different approaches, i.e., bag-of-words, bag-of-chars, word embeddings, and one-shot vectors over words and characters representations, as well as, Multilayer Perceptron (MPL), RNNs, CNNs, and LSTM networks.
TASS 2018 edition [5] proposed tasks including the identification of positive or negative emotions that can arouse in news, i.e., classify news articles into SAFE (positive emotions, so safe for ads) or UNSAFE (negative emotions, so better avoid ads), as a kind of stance classification according to reader’s point of view. In this task, there were two subtasks, subtask 1 (S1) consists in the classification of headlines into either SAFE or UNSAFE tweets written only in the Spanish language spoken in Spain; there were two test sets, named L1 and L2, having as only difference their cardinality. Moreover, subtask 2 (S2) consists in evaluating the systems’ ability to generalize. For training, participants were provided with headlines written only in the Spanish language spoken in Spain, and for testing, news articles come from nine different countries of America in order to encourage generalization. ELiRF-UPV [31] team used a deep neural network, Deep Averaging Networks (DANs), and a set of pre-trained word embeddings for representing the news headlines.
The IberEval contest is related to emotions, mostly in the Spanish language. In its 2018 edition, IberEval promoted different tasks such as aggressiveness identification [32] and humor analysis [33]. The aggressiveness identification task (MEX-A3T) is motivated by cyberbullying, hate speech, harassment, among others. It consists of classifying a text, in Spanish from Mexico, into either aggressive or non-aggressive. CGP [34] system used an Attention-based LSTM network, and word embeddings were used over the sentence. Attention is applied over the hidden states to estimate the importance of each word, and this context vector is used into another LSTM model to estimate whether a tweet is aggressive or not. Aragon-Lopez [35] team used both a bag of terms representation and second-order attributes (SOA). They use an -gram representation combined with a CNN as the classifier.
The HAHA task [33] (Humor Analysis based on Human Annotation) consisted of classifying tweets in Spanish as humorous or not. U_O-UPV [36] used a neural network with attention mechanism, word2vec models, and a set of linguistic features such as stylistic (e.g., length, counting of emoticons, hashtags), structural and content (e.g., animal vocabulary, sexual and obscene vocabulary), and affective (e.g., positive or negative words, counting of words related to attitudes). The use of different Neural Networks has not been restricted to the aforementioned tasks. There are essential advances on tasks such as in Sarcasm which could be considered as a verbal form of irony that toggles the explicit sentiment found in a text [37]. Joshi et al. [38] proposed a deep-learning approach with word embeddings as the main feature. Another deep-learning approach was presented in [39]; here, authors use CNN to learn user embeddings with the purpose to learn user-specific context. Ghosh and Veale [40] explored and compared the performance of CNN and RNN regarding sarcasm detection.
3 System Description
EvoMSA is a specialization of Stack Generalization (SG) [41] focused on text classification problems444Stack Generalization was initially proposed to improve the performance of any supervised learning algorithm.. EvoMSA is a two-stage procedure where the first stage is composed by several models that transform a text into decision function values; these values are combined, in the second stage, by a classifier, in particular, EvoDAG [42, 43] which is based on Genetic Programming (GP). Figure 1 depicts the structure of EvoMSA; the prediction flow goes from left to right. On the left, a text is submitted to different models; the outputs of these models compose the vector space which is used by EvoDAG to make the final prediction. Figure 1 illustrates that the difference between EvoMSA and SG is on the first stage, whereas EvoMSA’s first stage receives a text, SG receives a vector; from the vector space through the end of the procedure EvoMSA and SG are equivalent.
The first stage considers five models, that can be selected by the user, and are a composition of two functions, i.e., , where transforms a text into a vector (i.e., where is inherent to ) and is a function with the form where is the number of classes of the text classification problem. Function is a text model obtained from different sources, and is a linear SVM555It was decided to use a linear SVM as based on our experience building B4MSA [44], our previous SA classifier..
The different sources used to compute are: in the first model, , the training set of the competition (TR). The second model, , uses a human annotated (HA) dataset, independent of TR. The third model, , is an emotion and sentiment Lexicon-based model (TH). The fourth model, , is our Emoji Space (Emo). Finally, the fifth model, , corresponds to FastText (FT), frequently used to provide a semantic representation (word embeddings) of the text. Based on this description, it is possible to infer the value of for each . In the first model, corresponds to the vocabulary size. In the second model is the number of classes of HA. The third model equals which corresponds to the count of positive and negative words, respectively. The fourth model has a (see Section 3.3); and finally, (see Section 3.4) for the fifth model.
The second stage starts using the outputs generated by all the models, e.g., , concatenated to form a vector in where is the number of models, and is the number of classes. This last vector is used by EvoDAG to perform the final prediction. Before EvoDAG can be used, it requires to be trained. The naive approach would be to use TR to train and EvoDAG. Nonetheless, this would result in an ill-designed approach, which is not considering the weakness of the classifier(s) at generalization. In SG, it was proposed to train the second stage classifier (e.g., EvoDAG) by using the output of a -fold (five folds) cross-validation approach on TR and . Algorithm 1 presents the procedure used to train EvoDAG. It receives the first-stage text models, , and TR. From lines 2-9, it iterates for the different text models, , transforming the text into vectors (line 3), these vectors are used in -fold cross-validation (lines 5-8) to predict the decision function values of the validation set (). During the folding process, there are two disjoint sets, and , where is used to train an SVM (line 6), and is the set to be predicted (line 7). The predictions obtained for the different models, , are concatenated (line 9) to form EvoDAG’s training set. The last step is to train EvoDAG (line 11) with the predicted values.
The rest of this section describes the different text models, , used in this contribution. It starts with B4MSA using two datasets, the lexicon-based models, Emoji Space and FastText. The last subsection is devoted to describing EvoDAG, the classifier used in EvoMSA’s second stage.
3.1 B4MSA
The first two text models, i.e., and , use our baseline for multilingual sentiment analysis, namely B4MSA666https://github.com/INGEOTEC/b4msa [44]. B4MSA uses an equivalent structure that the models used in EvoMSA’s first stage, i.e., . Function uses a series of simple language-independent text transformations to convert text into tokens, as well as some language-dependent transformation commonly implemented on various open-source libraries. Nonetheless, it avoids the usage of computational expensive linguistic tasks such as part-of-speech tagging, dependency parsing, among others. Then, these tokens are represented into a vector space model using TF-IDF, and, finally, the vectors and their associated classes are learned by a linear SVM (i.e., ).
B4MSA was conceived to serve as a baseline for text categorization. To achieve this, it starts with a search in its parameter space to find an acceptable configuration. However, this search, per problem, increment the time required to find a model, and besides, our previous work on sentiment analysis (see [45]) indicates that some parameters could be fixed with a minimal impact on the performance. Consequently, it was decided to keep constant the parameters of B4MSA per language.
Table 1 shows B4MSA’s parameters per language. These parameters were obtained by measuring their performance (using macro-F1) on all the datasets used in this contribution, and, using -fold cross-validation () on the training set. The parameter space was sampled using a loop of two steps. In the first step, the parameters varied were the tokenizers; it was tested all the combinations of -words , and ; skip-grams , and ; and -grams , and . The second step tested the rest of the parameters shown in the table; these parameters are either dichotomic or treated as such, this is the case of parameters with possible values like group or delete. This process continues until a stable configuration is found, that is, where the best configuration is the one found in the previous step.
Some of B4MSA’s parameters are self-described such as remove diacritics, duplicates, punctuation symbols, and convert text to lowercase. The emoticons were changed to the words _pos, _neg, or _neu depending on the polarity expressed. Numbers, URLs and users are either deleted or replaced with words _num, _url, and _usr, respectively. The tokens are words, bi-grams of words, -grams of different sizes, and skip-grams. The notation used in skip-gram is where indicates the number of words and indices the length of the skip, for example, in have a nice weekend the skip-gram would be have nice and a weekend.
B4MSA is used to create two models ( and ), one using the competition training set (TR) and the other using a human annotated (HA) dataset. Regarding TR, , i.e., is B4MSA’s text model, and, as a result, EvoMSA’s first model is . On the other hand, HA dataset is composed of texts and their associated polarity (negative, neutral, or positive), and, it is not related to TR. Consequently, it is feasible to create a text classifier that outputs the polarity of a given text. That is where is B4MSA’s text model (using the parameters shown in Table 1) and is a linear SVM trained on HA, therefore EvoMSA’s second model is .
3.2 Lexicon-based Model
The text model, , introduces external knowledge into our approach by the use of lexicons such as affective words. Thumbs Up-Down (TH) model, text , counts the number of affective words keeping a separate record for the positive and negative words. We created a positive-negative lexicon based on several affective lexicons for English [46] and Spanish [47, 48, 49] and enriched with WordNet [50]. In the case of Arabic, we translate the English lexicon to Arabic language using Google translate, service employing Googletrans API [51].
3.3 Emoji Space
Inspired by DeepMoji [15], we create the text model, ; the core idea is to predict what emoji would be the most probable one for a given text. For this purpose, we learn a B4MSA model per language using 3.2 million examples of the 64 most frequent emojis in each language. This dataset consists in examples per emoji extracted from our own collected tweets, that is, we filtered out these examples from (approximately) Arabic tweets, English tweets, and to Spanish tweets. A few simple rules were followed to create the datasets: i) each example contains only one type of emoji to reduce the ambiguity among predictions, ii) all re-tweets were removed, iii) a uniform sample was chosen to avoid any seasonality effect. Finally, each selected tweet is transformed into a text and emoji pair, where the emoji is the one in the text. All emojis were removed from the text while training. Consequently, the dataset is a supervised learning dataset.
B4MSA uses this dataset to create the Emoji Space. Each text is transformed to the vector space defined by B4MSA’s text model using Table 1 parameters with a one-vs-rest strategy to train the SVM (i.e., where is B4MSA’s text model and is a linear SVM). Instead of being interested in the most probable emoji given text, we are interested in the decision functions of all the classifiers given a text such that each coordinate represents an emoji. Consequently, a 64-dimension real-valued vector represents a text.
Figure 2 lists the emojis used to create our Emoji-Space for Spanish, English, and Arabic languages; which also correspond to 64 most frequent emojis in these languages. The emojis are ordered row-wise being the most frequent the emoji in the left upper corner. Notice the significant coincidence among the most frequent emojis in all languages.
3.4 FastText
FastText [52] is a tool to create text classifiers and learn a semantic vocabulary from a given collection of documents; this vocabulary is represented with a collection of high dimensional vectors, one per word. FastText is robust to lexical errors supporting out-vocabulary words, and it is used to represent a text into a vector space using the pre-computed models (see [53]) for Arabic, English, and Spanish. In particular, each text is transformed into a vector using the vector sentences flag; these are vectors in 300 dimensions using the default parameters (i.e., ).
3.5 EvoDAG
EvoDAG777https://github.com/mgraffg/EvoDAG [42, 43] is a steady-state GP system with tournament selection (tournament size 2) specifically tailored to tackle classification and regression problems. GP is an evolutionary algorithm with the distinctive characteristic of searching in a program search space, in particular, in this contribution, GP searches in a search space, , of functions. That is, is the set of functions created by recursively composing elements from two sets: function set , and terminal set . The function set is composed by operations such as sum, product, sin, cos, max, and min, among others; and the inputs compose the terminal set, and normally, by an ephemeral random constant. Nonetheless, EvoDAG’s terminal set only contains inputs, and each function, in the function set, is associated with a set of parameters that are identified using the training set. For example, let be a function of cardinality then is an element of the search space, and, is identified with the training set using ordinary least squares, e.g., .
In more detail, EvoDAG’s search space is as follows: let be the functions with cardinality in the function set, and be the elements created at iteration , starting from . Using this notation, the first elements, i.e., , are . The rest of the elements are composed recursively using ; consequently, the search space is defined as . Using this notation, it is difficult to indicate that in the case of a commutative operator it is only included one of them, e.g., is included in the search space and it is not. The second restriction is that some functions require unique arguments. A function is decided to require unique arguments when such as: , and addition, among others.
EvoDAG searches using a similar procedure than the one used to describe it. It is not possible to test all the elements at ; instead, is sampled, storing the elements in population . The initial population, , contains , a set of functions such as Nearest Centroid Classifier, and other elements that are selected using the following procedure. A function, , is randomly selected from , ’s arguments are randomly taken from without replacement. This process continues until either all the elements of have been selected, or the population size has been reached. In the former case, the process is to add one element at a time to , choosing with the difference that ’s arguments are randomly taken from ; this mechanism continues until the population size is reached. For example, let and then starts with , this is followed by selecting a function, assume is selected, is , assume the next function selected is , consequently, . At this point all the inputs have been selected so the process continues by selecting the arguments from , suppose is selected and is its argument, this makes . This process is repeated until reaches the population size.
Once the initial population is created, , the evolution starts. EvoDAG uses a steady-state evolution, and, thus, it is not necessary to keep track of the population through the generations, therefore . The procedure used in the first generation is to create an element by selecting a function from , and its arguments are randomly selected from . The element created replaces an element of which is selected using a negative tournament selection. From the second generation to the end of the run an element is created by first selecting and its argument are selected using tournament selection on , the element created replaces an element selected, from , with a negative tournament.
Traditionally in GP, the evolution stops when the maximum number of generations is reached, or the fitness reaches a particular value; however, EvoDAG uses an early stopping approach. That is, the training set is split into a smaller training set, used to identify and the fitness of the individuals, and a validation set. Then, the best element is the one with the best performance on the validation set. The evolution stops when the best individual has not been updated in some evaluations, is the default.
EvoDAG function set is atan, hypot, . Let us start by describing the addition which is defined as where coefficients are identified with ordinary least squares (OLS) using the training set. Functions such as and trigonometric functions are defined as where is identified using OLS. For classification problems, the technique one-vs-rest is used, producing binary classification problems, and, for each different coefficients are optimized. is the nearest centroid classifier whose output is the distance to each class centroid. and are Naive Bayes classifiers using Gaussian and Multinomial distributions, respectively. The outputs of these classifiers are the log-likelihood. NC, NB, and MN are always included in the initial population having as arguments all the inputs, in the rest of the run, these functions use their default number of arguments.
Figure 3 depicts a model evolved for the Arabic sentiment analysis task. As can be seen, the model is represented using a Direct Acyclic Graph (DAG) where the direction of the edges and dependency is bottom-up, e.g., depends on Centroid, i.e., the hyperbolic tangent function is applied to Centroid’s output. The input nodes are colored in red, the internal nodes are blue (the intensity is related to the distance to the height, the darker, the closer), and the green node is the output node. As mentioned previously, EvoDAG uses as inputs the decision functions of the models, the first three inputs (i.e., , , and ) correspond to the decision function values of the negative, neutral, and positive polarity of B4MSA model, the rest of the red nodes correspond to functions that are always in the initial population. It is important to mention that EvoDAG does not have information regarding whether input comes from a particular polarity decision function, consequently from EvoDAG point of view all inputs are equivalent.
4 Competition, and Human Annotated Datasets
As mentioned before, we use the human annotated (HA) datasets from [54, 55] for Arabic, English, and Spanish languages. These are polarity datasets with three classes positive, neutral and negative, containing tweets for Spanish, for English, and for Arabic.
On the other hand, the datasets used to analyze EvoMSA’s performance are described in Table 2. These datasets include the competitions SemEval 2017 [8] and 2018 [7], TASS 2017 [6] and 2018 [5], HAHA 2018 [33] and MEX-A3T 2018 [32]. It is worth to mention that for corpus InterTASS (TASS 2018) and MEX-A3T, we do not have the gold standard used in the competition; so, we performed cross-validation instead. Therefore, the performances reported are on that cross-validation dataset, and cannot be compared with the official performance presented by the competition.
These competitions present different tasks starting from the traditional sentiment analysis which corresponds to identify the polarity of a text; moving on to emotion ordinary classification where the emotions considered are anger, fear, joy, and sadness; safe-unsafe news classification; humor and aggressiveness detection. The majority of the problems are multi-class problems, and there are three binary classification problems which are safe news, humor, and aggressive detection.
5 Analysis
This section presents EvoMSA’s performance using the models described in Section 3, and on different competitions. The different EvoMSA instances are a combination of B4MSA trained with TR, B4MSA trained with HA, the Lexicon-based model (TH), Emoji Space (Emo), and FastText (FT). In total, there are 31 different combinations of these models; however, we decided to present only those combinations that had a significant impact on performance following a bottom-up approach. The starting point is EvoMSA using only TR, and then the remaining models are incorporated and tested one at a time. The model pair with the best performance is kept, and, the process continues testing the remaining text models until all of them are incorporated into EvoMSA.
Figure 4 presents a boxplot of the ranks of EvoMSA instances as well as the rank of B4MSA. These ranks were calculated using all the datasets used, and, the performance measures used in each particular competition, namely macro-F1, macro-Recall, and Pearson correlation. From the figure, it can be observed that B4MSA has the highest rank, followed by EvoMSA using only TR. The difference in performance between these two systems is statistically significant with the confidence of 95%, using Wilcoxon signed-rank test [56]. Comparing the performance of EvoMSA using only two models, it is observed that the Emoji Space (TR + Emo) is the one with the lowest rank, followed by FastText (TR + FT), the human-annotated dataset (TR + HA), and the Lexicon-based model. This latter model has an equivalent rank that EvoMSA using TR, albeit, it presented an outlier obtaining the best performance in one problem. The combination of TR, Emo, and FT has the lowest rank among the systems with three models, and EvoMSA with fourth (TR + Emo + FT + TH and TR + Emo + FT +HA) and five models (All) obtained similar ranks, having the lowest rank EvoMSA with all the models. In order to complement this boxplot, it was performed a comparison between EvoMSA with all the models (system with the lowest rank) and the rest of the systems. The statistical test used was a Wilcoxon signed-rank test [56], and the -values were adjusted with the Holm-Bonferroni method [57] to consider the multiple comparisons. The result is that the difference in performance between the best system and the next three best-performing systems is not significant with confidence of 95%, whereas it is statistically different with the remaining of the systems.
Table 3 presents the performance of EvoMSA using all the models, B4MSA, our participating system (i.e., INGEOTEC), and a selection of systems that participated in SemEval 2017 [8] and TASS 2017 [6]. Given that more than 30 teams participated in SemEval 2017, we decided to include only those systems that outperformed INGEOTEC in any of the languages. Regarding TASS 2017, the teams selected are the best submission of each team, and, those that obtained better performance than B4MSA which is our baseline. The performance in English sorts all systems. Comparing the performance of EvoMSA against the other competitors in SemEval 2017, it is observed that EvoMSA would have obtained the first place in Arabic and the sixth position in English. Regarding General Corpus (TASS 2017), our INGEOTEC team obtained the best performance, and EvoMSA would have been in the fifth place [6].
Let us move our attention to those teams that participated in more than one language, the table presents only two out of three teams that participated in both languages, namely SiTAKA [24] and ELiRF-UPV [25, 30]; it can be observed that EvoMSA obtained the best performance among these teams, and, in addition only SiTAKA is better than B4MSA (our baseline) in both languages. On the other hand, ELiRF-UPV participated in both languages and competitions. This team had better performance than EvoMSA in TASS 2017 and worst in Arabic and English.
Table 4 shows the results achieved on SemEval 2018 [7] datasets. The table includes the performance of EvoMSA, B4MSA, INGEOTEC, and a selection of competitors. The teams included were those that obtained a better position than INGEOTEC in English and those that outperformed the competition baseline on Arabic and Spanish. The table is organized according to the competition language, namely Arabic, English, and Spanish. Furthermore, the systems are sorted by valence in all the languages. From the table, it can be observed that EvoMSA in Arabic would have obtained the second place in valence, first in sadness, and third in the rest of the tasks. On the other hand, in English, EvoMSA did not outperform INGEOTEC in valence; nonetheless, it did improve INGEOTEC in the rest of the problems. In Spanish, EvoMSA would have been in first place in joy and second place in the rest of the tasks.
Seven teams participated in two or more languages; only AffectThor [29] submitted results for all languages. Their approach in English outperformed EvoMSA in all tasks; in Arabic and Spanish languages AffectThor obtained better performance in anger, fear, and joy. Three teams submitted results for Arabic and English: EiTAKA [28] obtained better performance than EvoMSA in all tasks; UNCC [67] in English had a better position than EvoMSA in anger, fear, and sadness. EvoMSA outperforms UWB [58] in all tasks. Finally, three teams participated in English and Spanish, Amobee [60] obtained a better score than EvoMSA in all the tasks; ELiRF-UPV [66] obtained better results in English and worst in Spanish; and YNU-HPCC [68] only outperformed EvoMSA in fear and sadness in English.
Table 5 shows the performance of EvoMSA (using all models), B4MSA, and the participants of TASS 2018 [5] and IberEval 2018 [33]. The table shows that EvoMSA would have obtained two first places and it did not outperform our participating system, INGEOTEC on the rest of the tasks.
After analyzing the behavior of EvoMSA, it is time to measure the effects that EvoDAG, has in the overall performance. The procedure used is to replace EvoDAG in EvoMSA (using all models) by, almost, all the classifiers implemented in [70] with their default parameters. In total, sixteen different classifiers are used to perform this comparison. Figure 5 presents the boxplot of the ranks of these classifiers as well as EvoDAG. The figure is ordered so that the classifier with the lowest rank is on the left and the classifier with the highest rank is on the right; this is only to facilitate the reading.
It is observed from the figure that EvoDAG obtained the lowest rank (best performance), closely followed by a Gaussian Naive Bayes and the Nearest Centroid classifier, the Decision Trees presented the highest rank. EvoDAG, Gaussian NB, and Nearest Centroid obtained the first position in a number of problems; however, these are not the only ones obtaining the first position, these other classifiers are Logistic regression, SVM, and Ada Boost. The comparison between EvoDAG’s performance against the other systems –using the Wilcoxon signed-rank test [56] and adjusting the -values with Holm-Bonferroni method [57] to consider the multiple comparisons– shows that there is a difference in performance with confidence of 95%. Nonetheless, as mentioned, there are classifiers that in some problems obtained the best place.
6 Conclusions
We presented EvoMSA, a multilingual and domain-independent sentiment analysis system. EvoMSA is designed to combine different resources into one objective; among the possible resources, we use domain-specific training set and other related human-annotated datasets, lexicon-based models, semi-supervised models like our Emoji Space and FastText. These models are combined into a classifier based on GP to produce the final prediction. EvoMSA’s components are analyzed based on performance, including our classifier EvoDAG. The study shows that the resource contributing most to the performance is Emoji Space; on the other hand, the system with the lowest average rank (the lower, the better), was produced by using all the resources. Furthermore, it is worth to mention that replacing EvoDAG with a simpler classifier such as Gaussian Naive Bayes one can reduce computing time, nonetheless, with a performance impact.
EvoMSA performance is analyzed using datasets from different competitions, namely SemEval 2017 and 2018, TASS 2017 and 2018, HAHA 2018, and MEX-A3T 2018. It is important to note that almost all the parameters of EvoMSA and its components are kept constant in all the datasets. Consequently, EvoMSA can be considered an almost free parameter algorithm in a multilingual domain. Furthermore, the result shows that EvoMSA is competitive against the systems participating in those competitions. Based on our experimental results, EvoMSA would have obtained fifth first places (SemEval 2017 in Arabic; SemEval 2018 sadness in Arabic and joy in Spanish; TASS 2018 on S2 dataset; and HAHA 2018), on SemEval 2018 would be on average on the second place in Spanish and third in Arabic. These results are evidence that EvoMSA has a significant generalization potential over several languages.
Finally, we would like to discuss some research avenues briefly. We have tested EvoMSA on different sentiment analysis competitions; however, the scheme is general enough to tackle multi-modal problems such as combining images and texts. We also have tested two semantic resources, i.e., Emoji Space and FastText, in the future, it would be essential to develop and test other semantic representations. An important characteristic that has not been addressed in EvoMSA is that, currently, the models evolved are not intended to be understood. Given that EvoDAG is a GP system, it would be desired that the model evolved would be a white box.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Bing Liu and Lei Zhang. A survey of opinion mining and sentiment analysis. In Mining Text Data , pages 415–463. Springer US, Boston, MA, Jan. 2012.
- 2[2] Soujanya Poria, Erik Cambria, Newton Howard, Guang-Bin Huang, and Amir Hussain. Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing , 174:50–59, Jan. 2016.
- 3[3] Alessandro Ortis, Giovanni M. Farinella, Giovanni Torrisi, and Sebastiano Battiato. Visual sentiment analysis based on objective text description of images. In 2018 International Conference on Content-Based Multimedia Indexing (CBMI) , pages 1–6. IEEE, Sept. 2018.
- 4[4] Erik Cambria. Affective computing and sentiment analysis. IEEE Intelligent Systems , 31(2):102–107, Mar. 2016.
- 5[5] Eugenio Martínez-Cámara, Yudivián Almeida-Cruz, Manuel Carlos Díaz-Galiano, Suilan Estévez-Velarde, Migueí A García-Cumbreras, Manuel García-Vega, Yoan Gutiérrez, Arturo Montejo-Ráez, Andrés Montoyo, Rafael Muñoz, Alejandro Piad-Morffis, and Julio Villena-Román. Overview of TASS 2018: Opinions, health and emotions. CEUR Workshop Proceedings , 2172:13–27, Sept. 2018.
- 6[6] Eugenio Martínez-Cámara, Manuel C Díaz-Galiano, Angel García-Cumbreras, Manuel García-Vega, and Julio Villena-Román. Overview of TASS 2017. CEUR Workshop Proceedings , 1896:13–21, Sept. 2017.
- 7[7] Saif M Mohammad, Felipe Bravo-Marquez, Mohammad Salameh, and Svetlana Kiritchenko. Sem Eval-2018 Task 1: Affect in tweets. In Proc. of the 12th International Workshop on Semantic Evaluation , pages 1–17. ACL, June 2018.
- 8[8] Sara Rosenthal, Noura Farra, and Preslav Nakov. Sem Eval-2017 Task 4: Sentiment analysis in Twitter. In Proc. of the 11th International Workshop on Semantic Evaluation , pages 502–518. ACL, Aug. 2017.
