General Compound Hawkes Processes in Limit Order Books
Anatoliy Swishchuk, Aiden Huffman

TL;DR
This paper introduces and analyzes general compound Hawkes processes within limit order books, establishing their theoretical properties and applying them to understand the relationship between price volatility and order flow.
Contribution
It constructs new compound Hawkes processes, proves LLN and FCLT for these models, and links these results to price volatility analysis in limit order books.
Findings
Established LLN and FCLT for compound Hawkes processes
Linked price volatility to order flow parameters
Provided theoretical foundation for modeling limit order books
Abstract
In this paper, we study various new Hawkes processes. Specifically, we construct general compound Hawkes processes and investigate their properties in limit order books. With regards to these general compound Hawkes processes, we prove a Law of Large Numbers (LLN) and a Functional Central Limit Theorems (FCLT) for several specific variations. We apply several of these FCLTs to limit order books to study the link between price volatility and order flow, where the volatility in mid-price changes is expressed in terms of parameters describing the arrival rates and mid-price process.
Click any figure to enlarge with its caption.
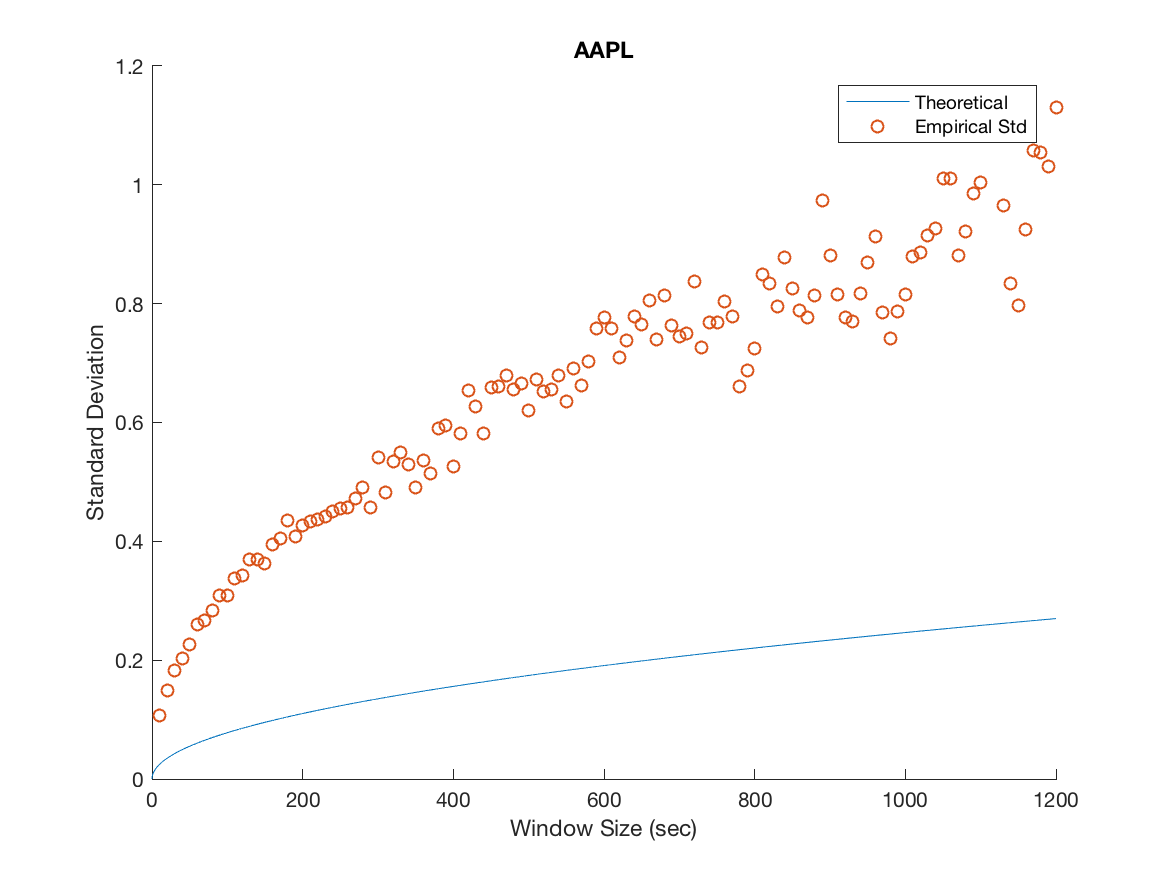 Figure 1
Figure 1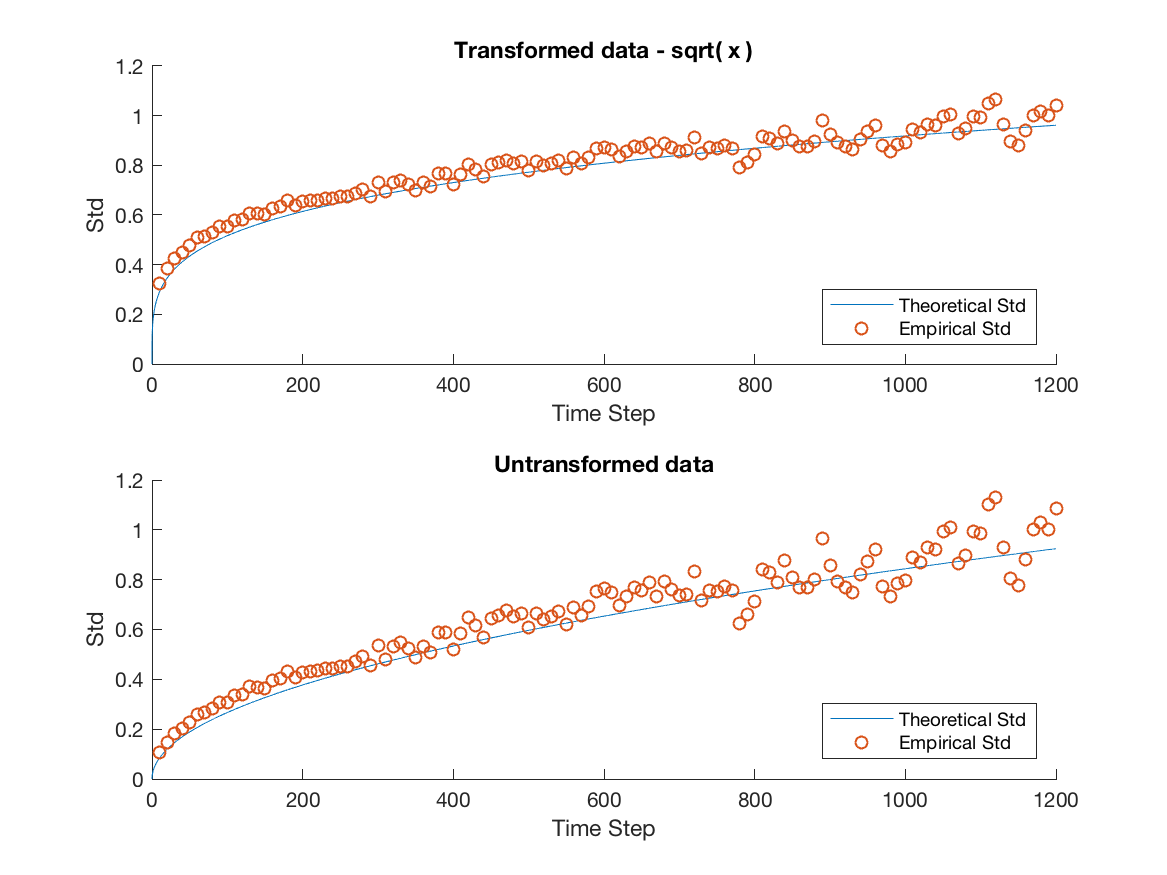 Figure 2
Figure 2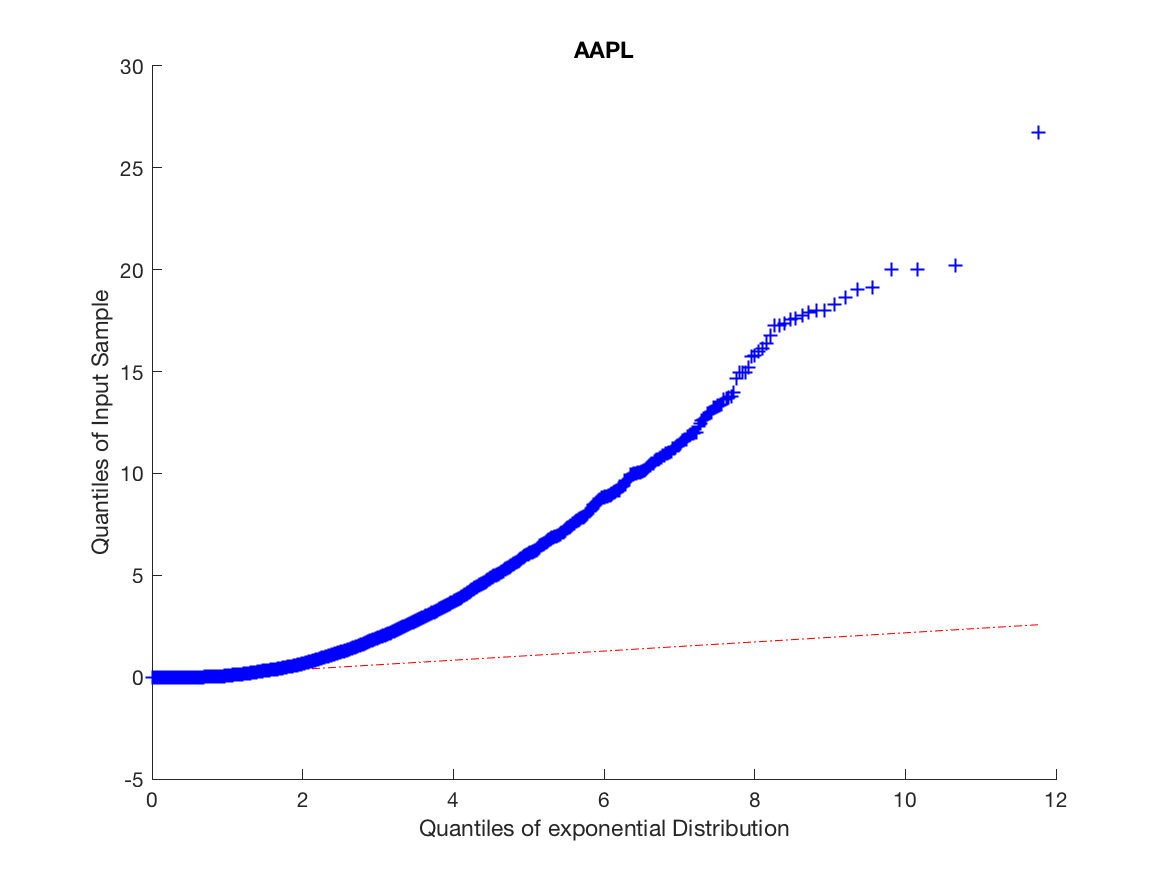 Figure 3
Figure 3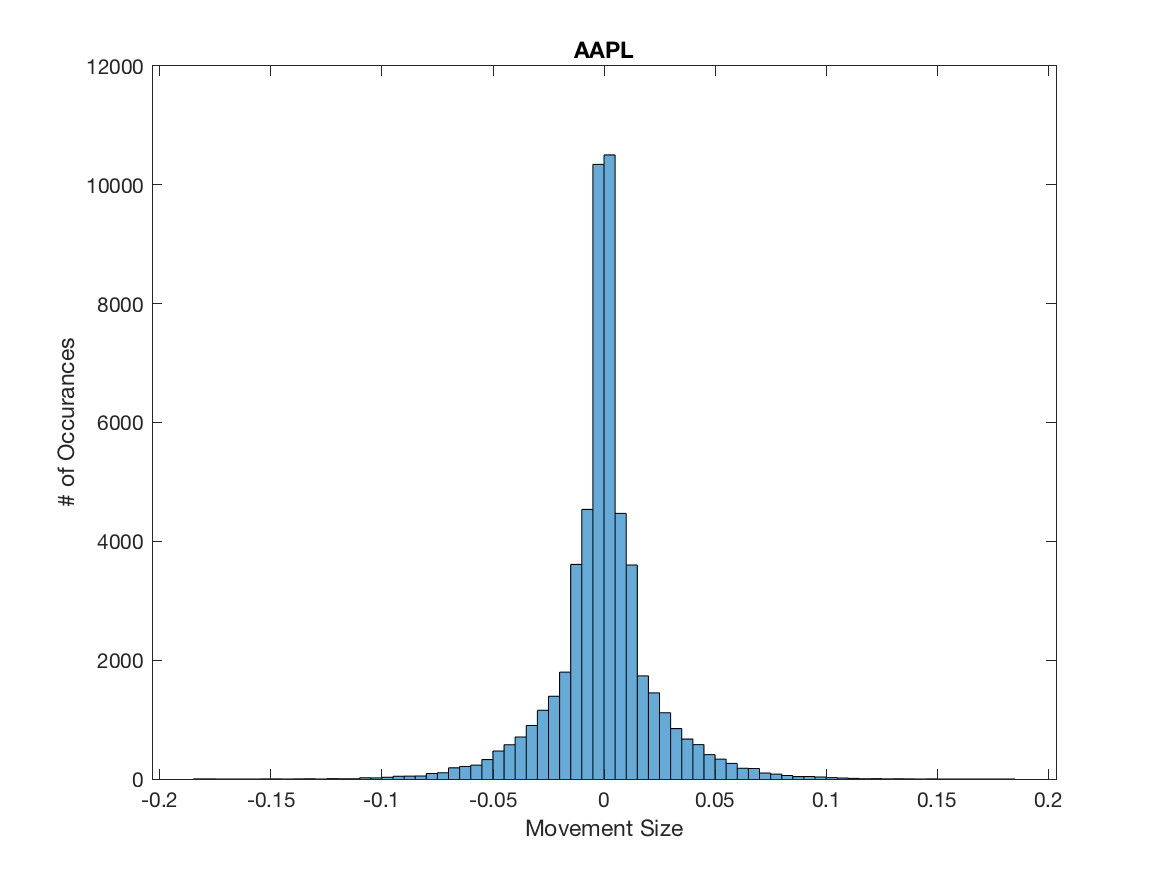 Figure 4
Figure 4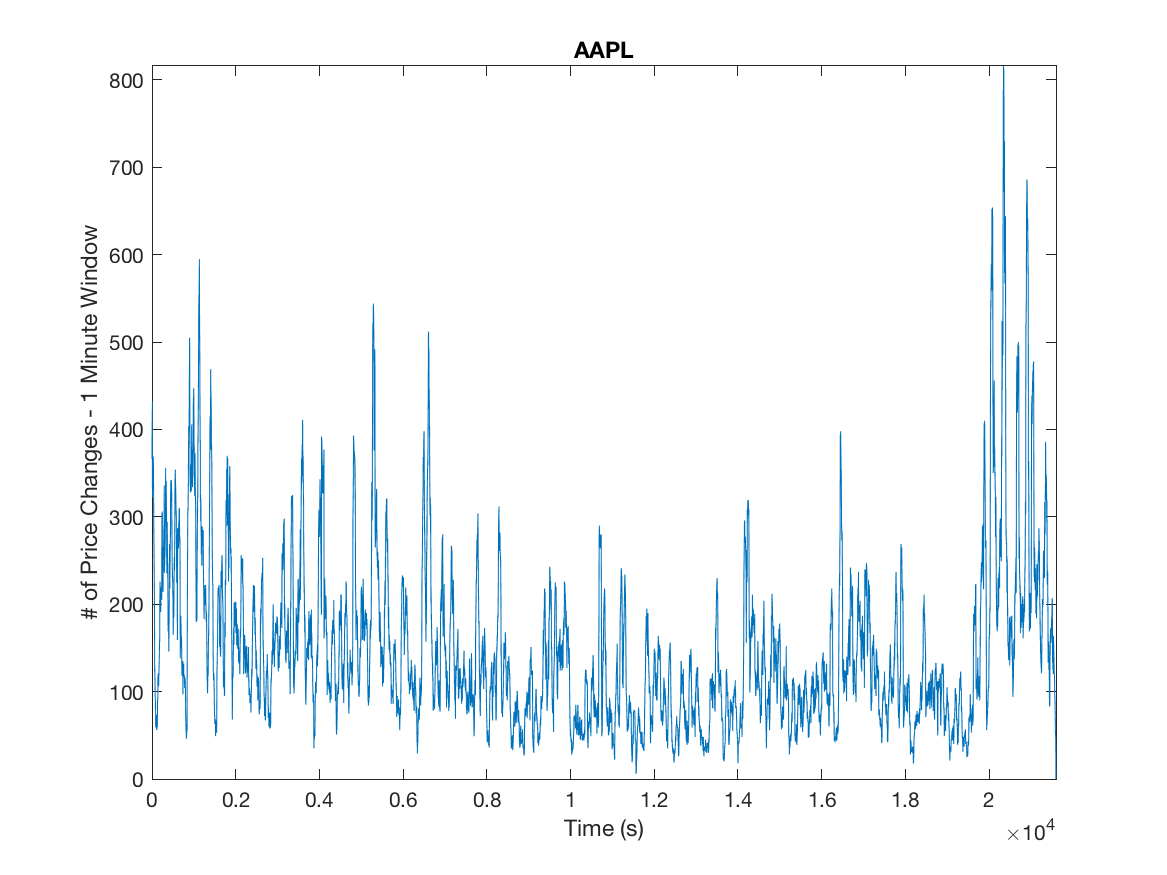 Figure 5
Figure 5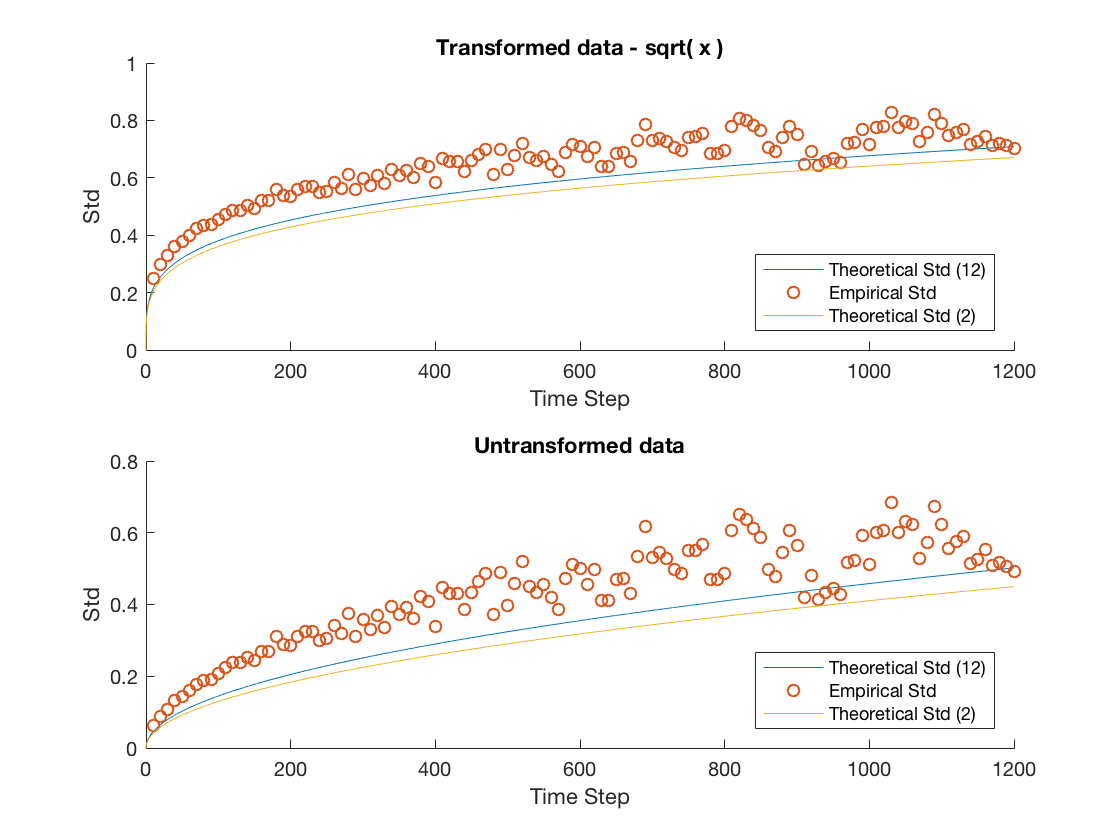 Figure 6
Figure 6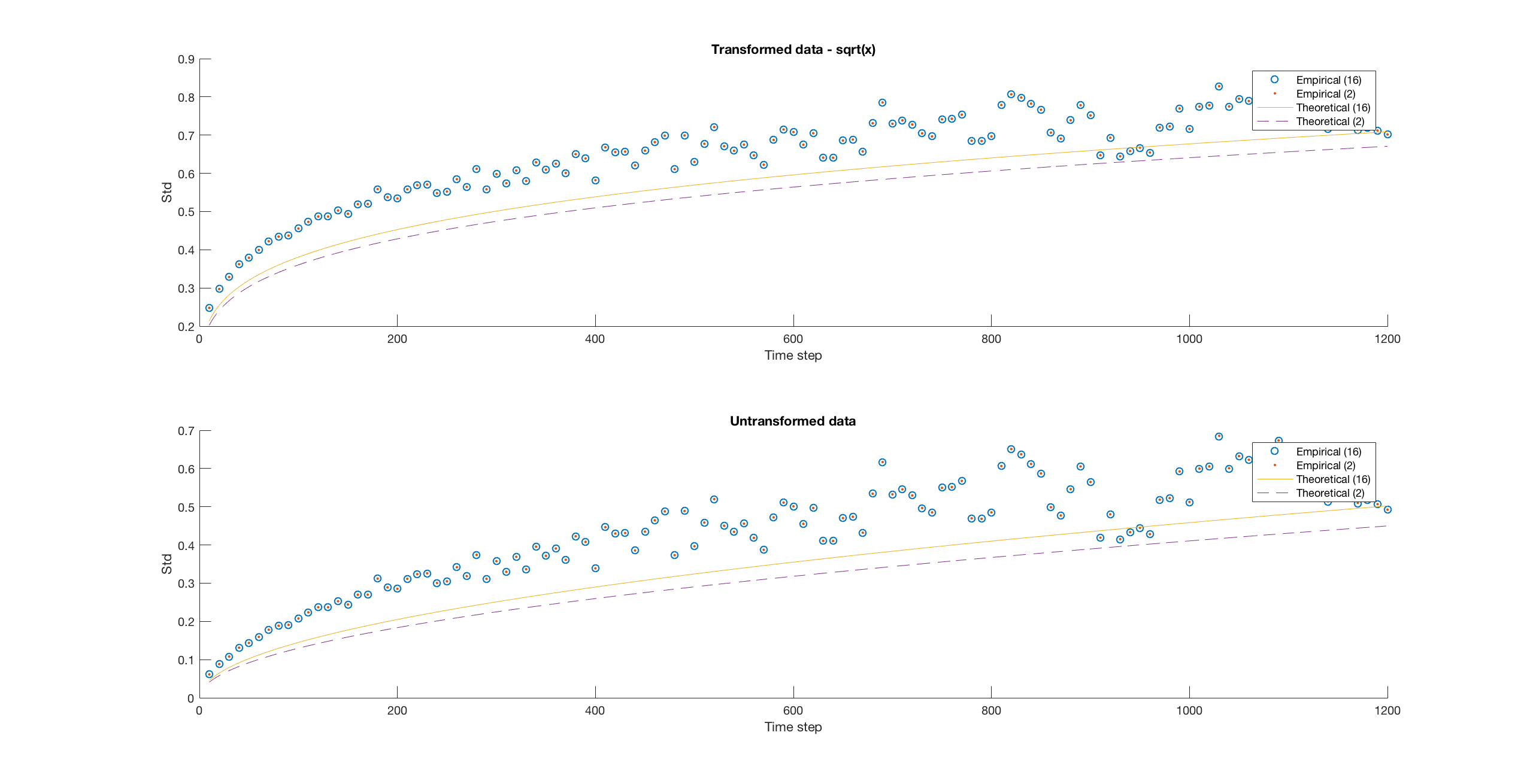 Figure 7
Figure 7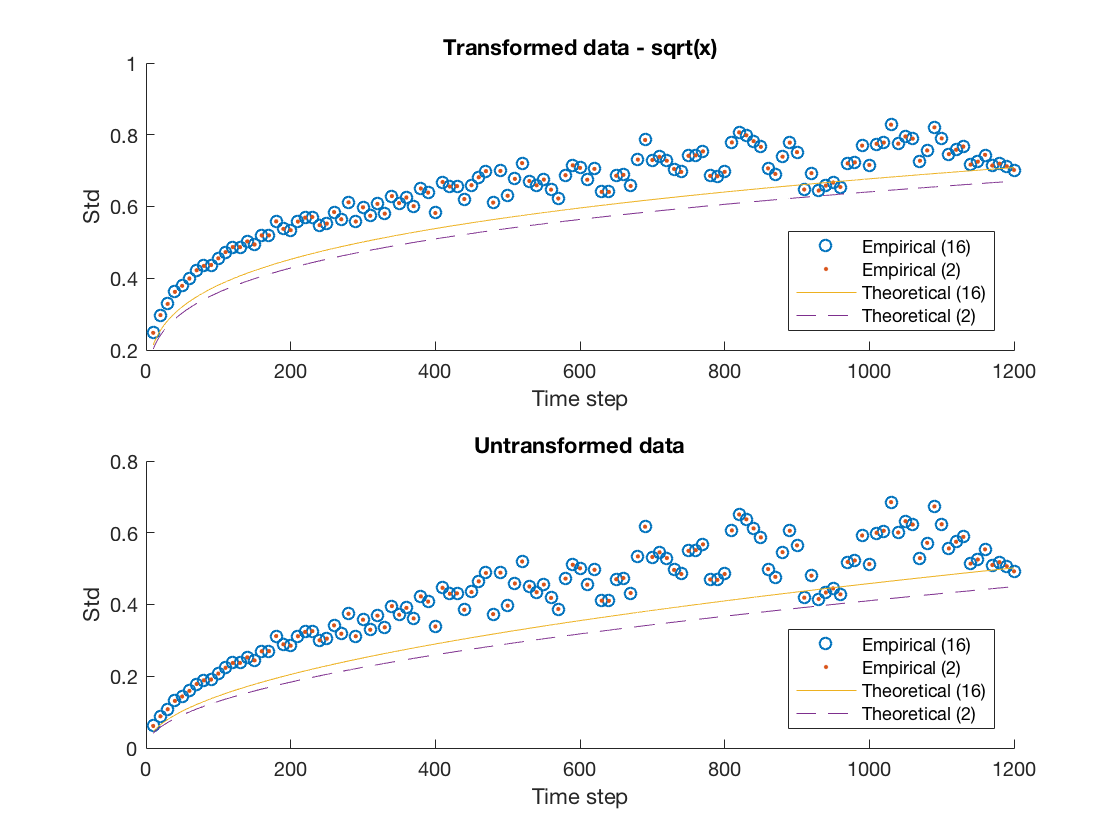 Figure 8
Figure 8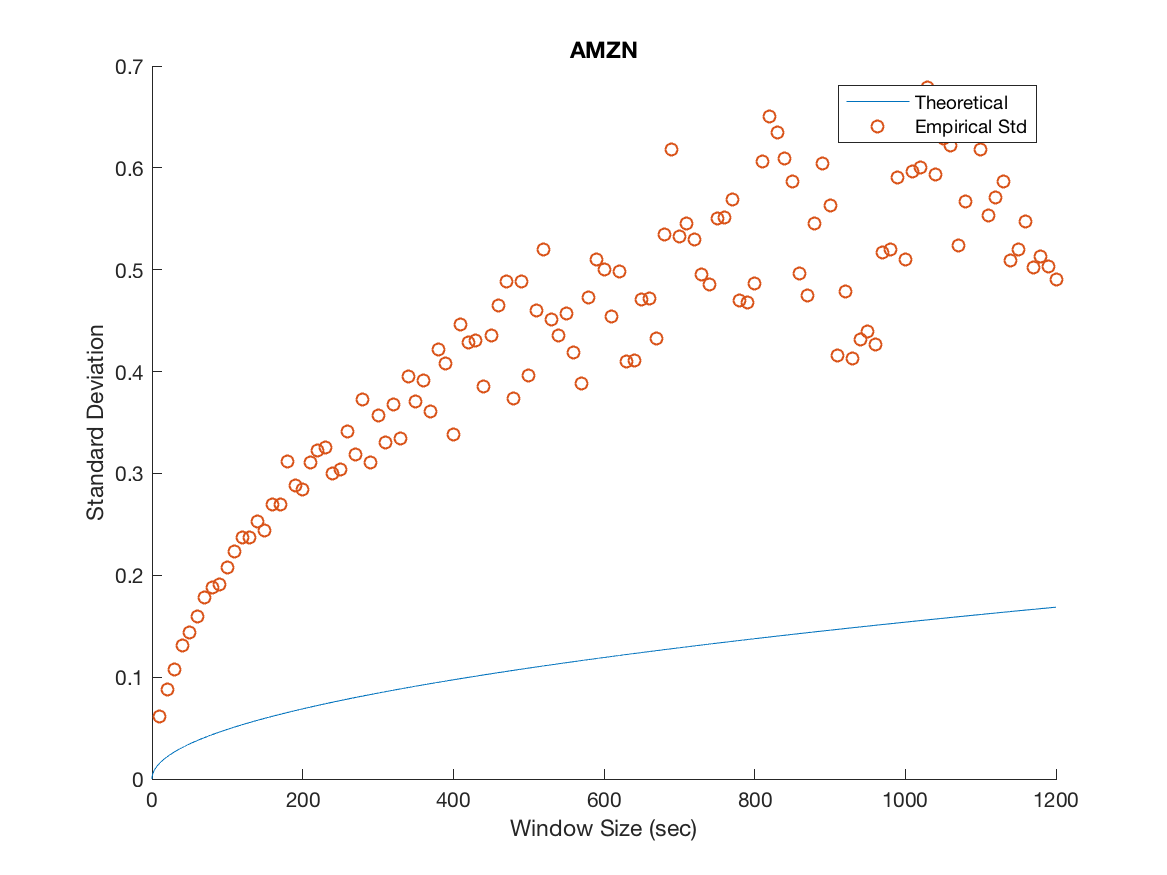 Figure 9
Figure 9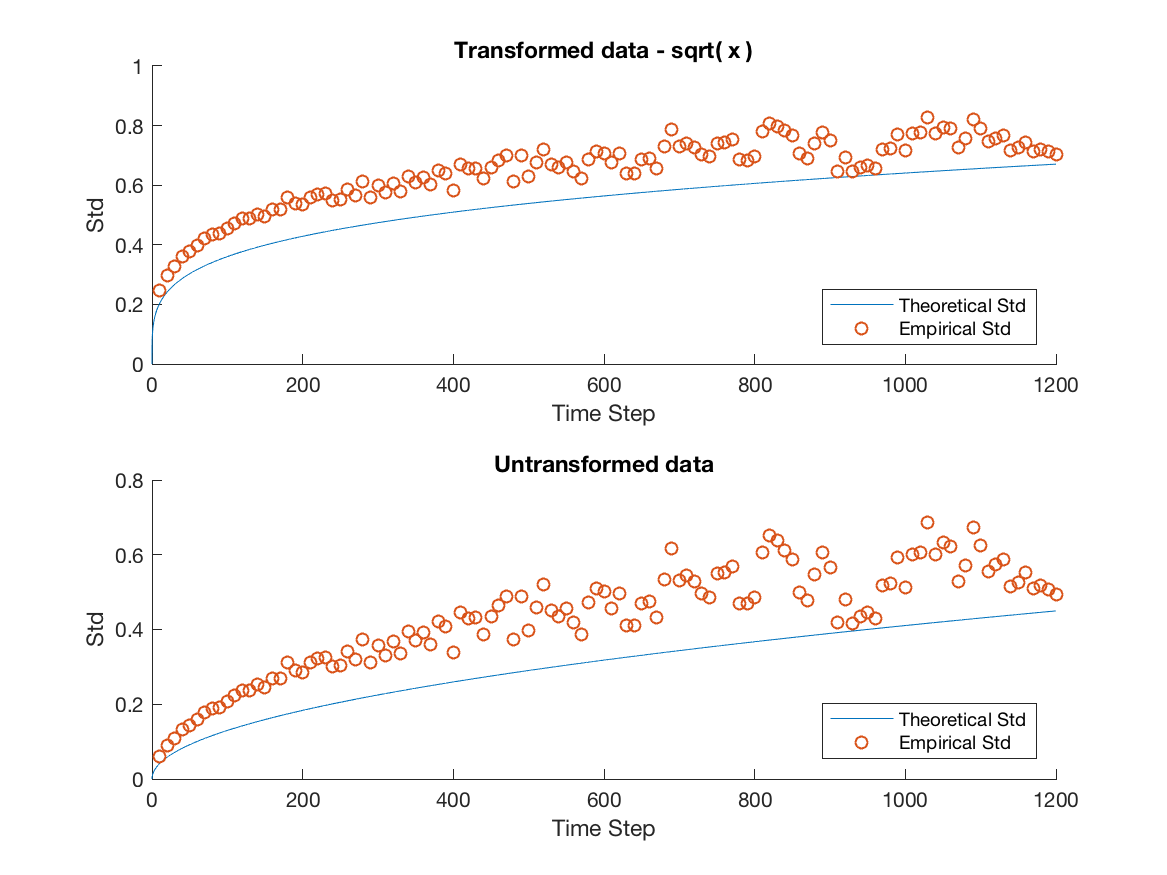 Figure 10
Figure 10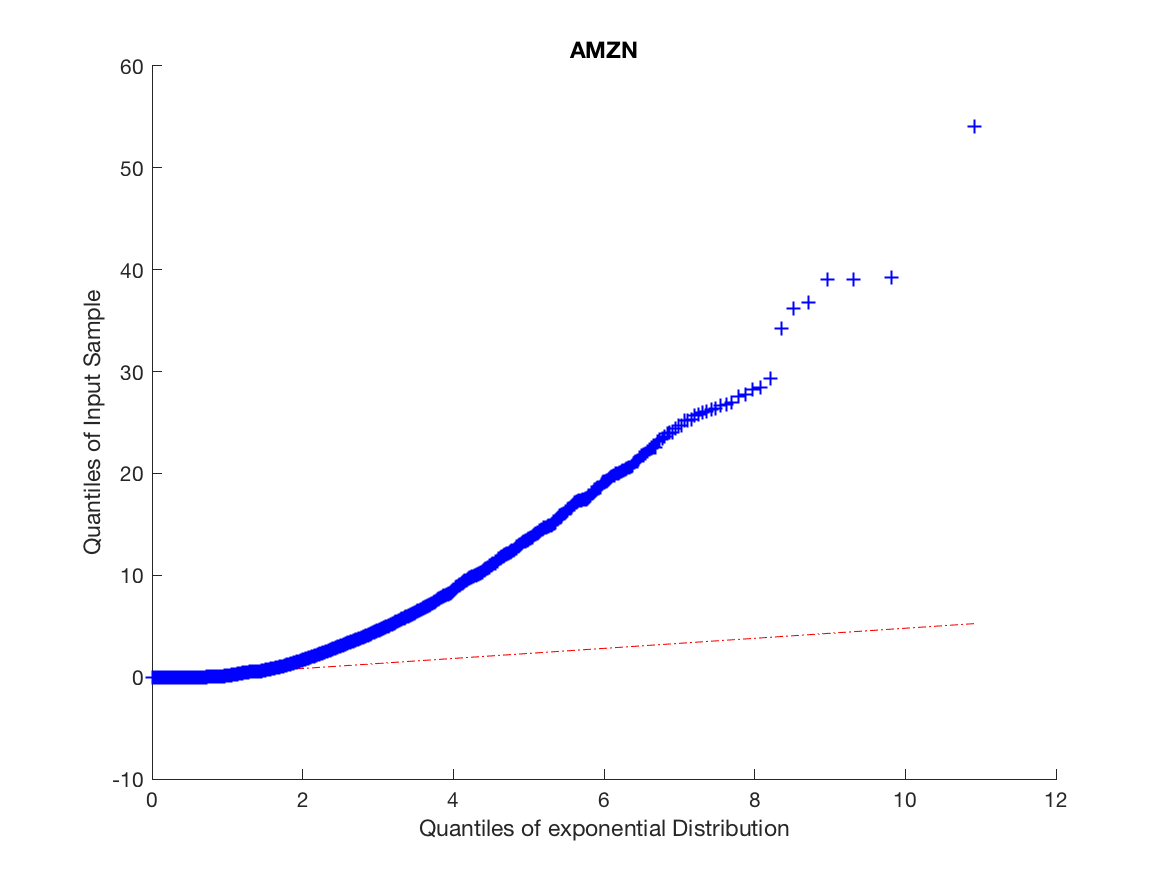 Figure 11
Figure 11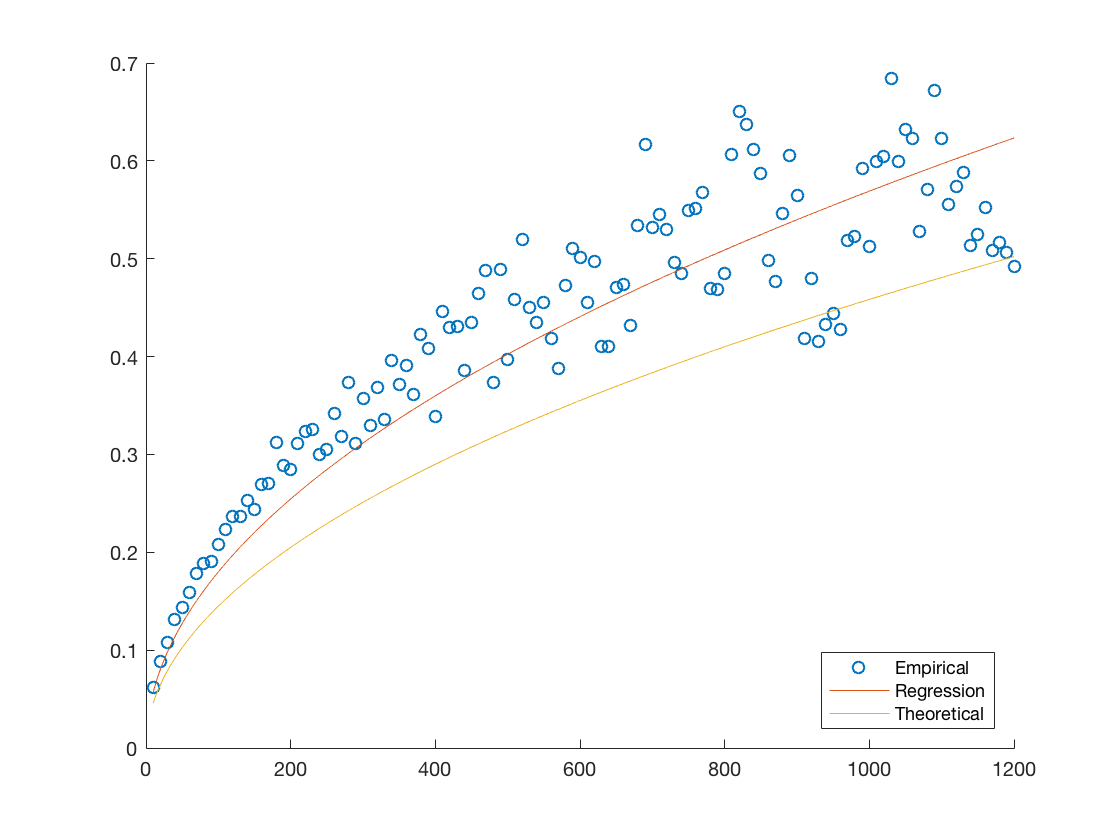 Figure 12
Figure 12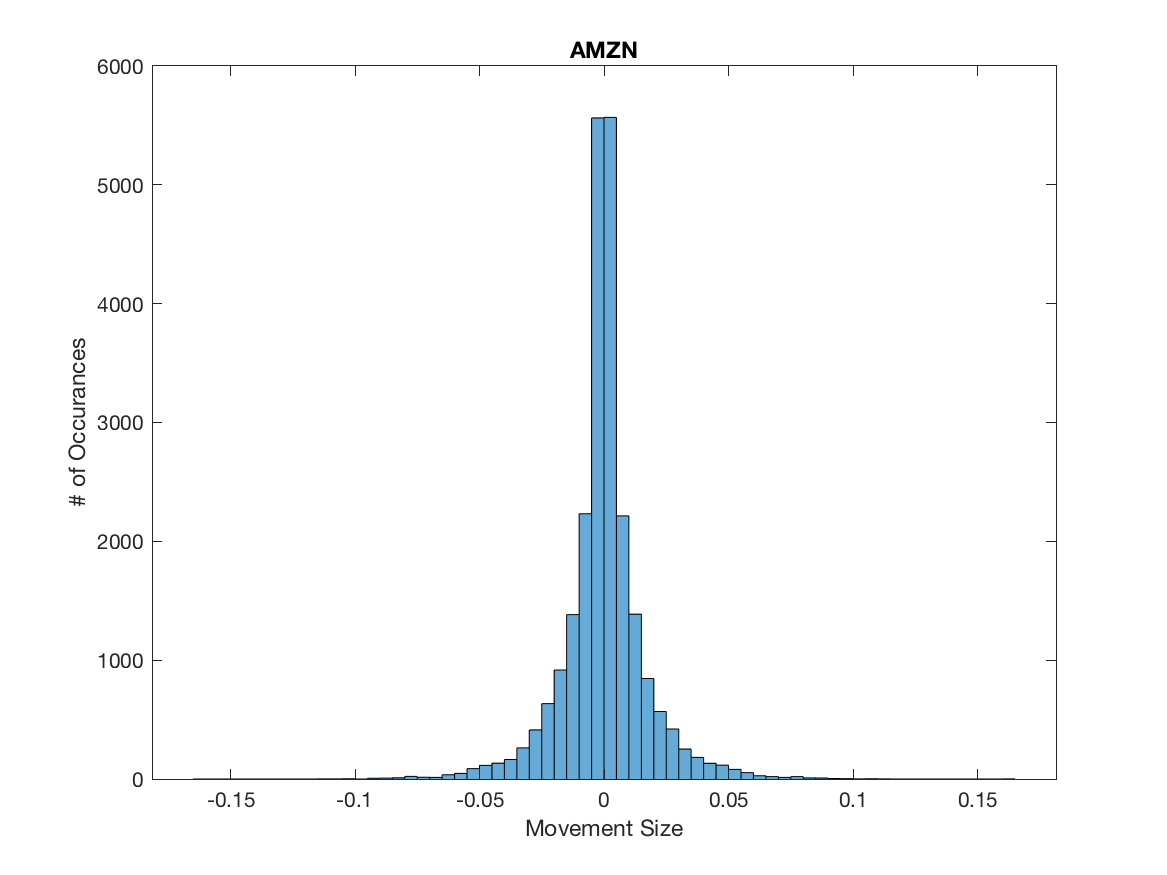 Figure 13
Figure 13 Figure 14
Figure 14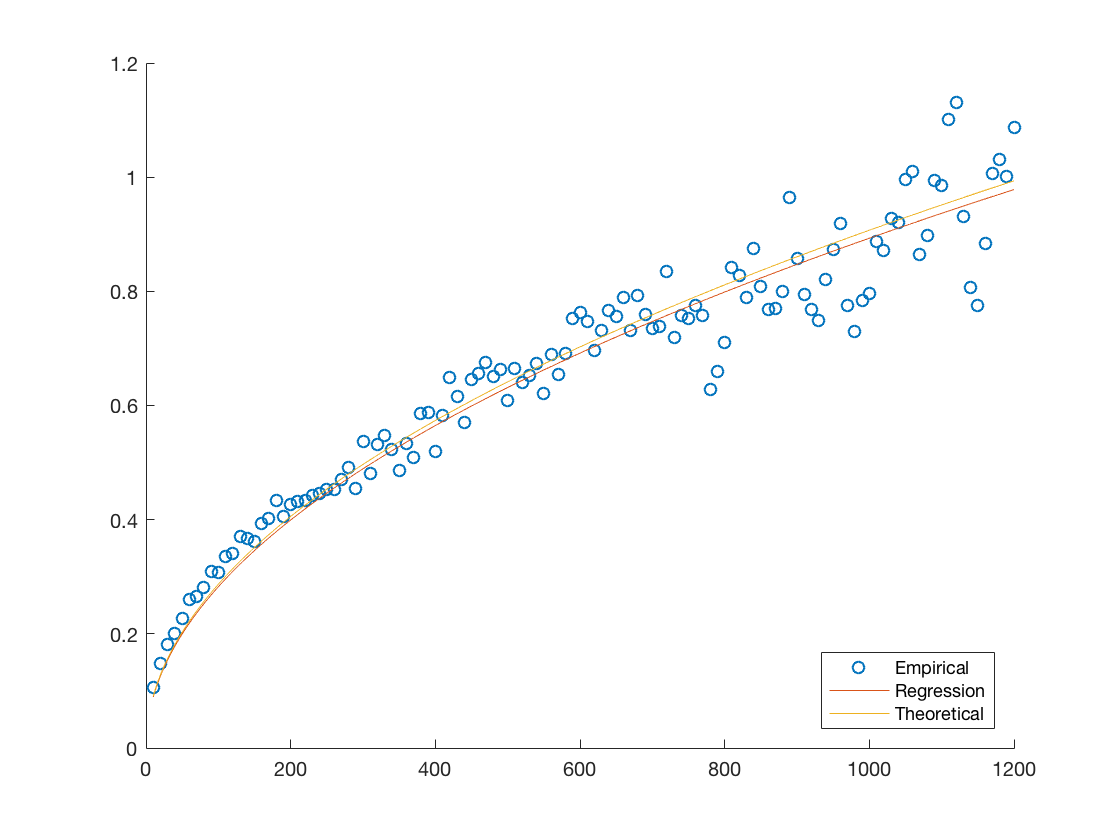 Figure 15
Figure 15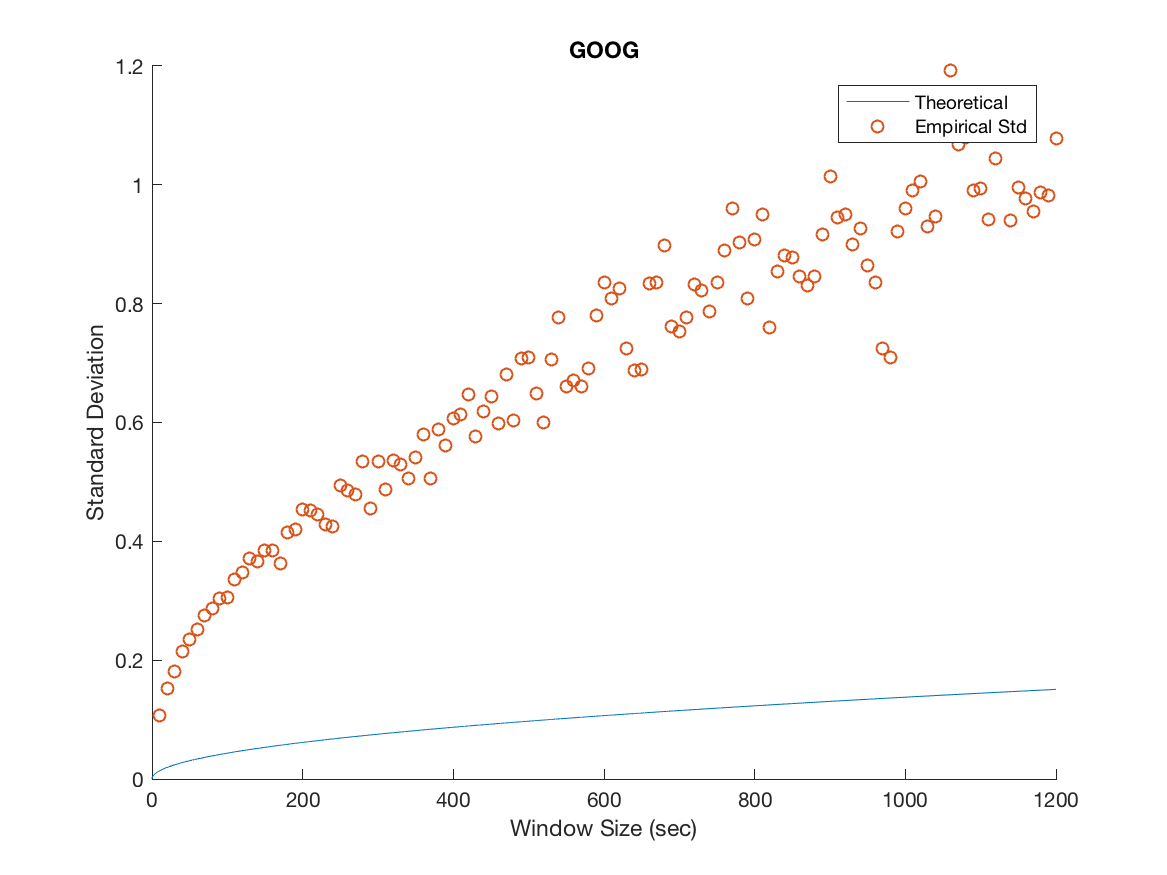 Figure 16
Figure 16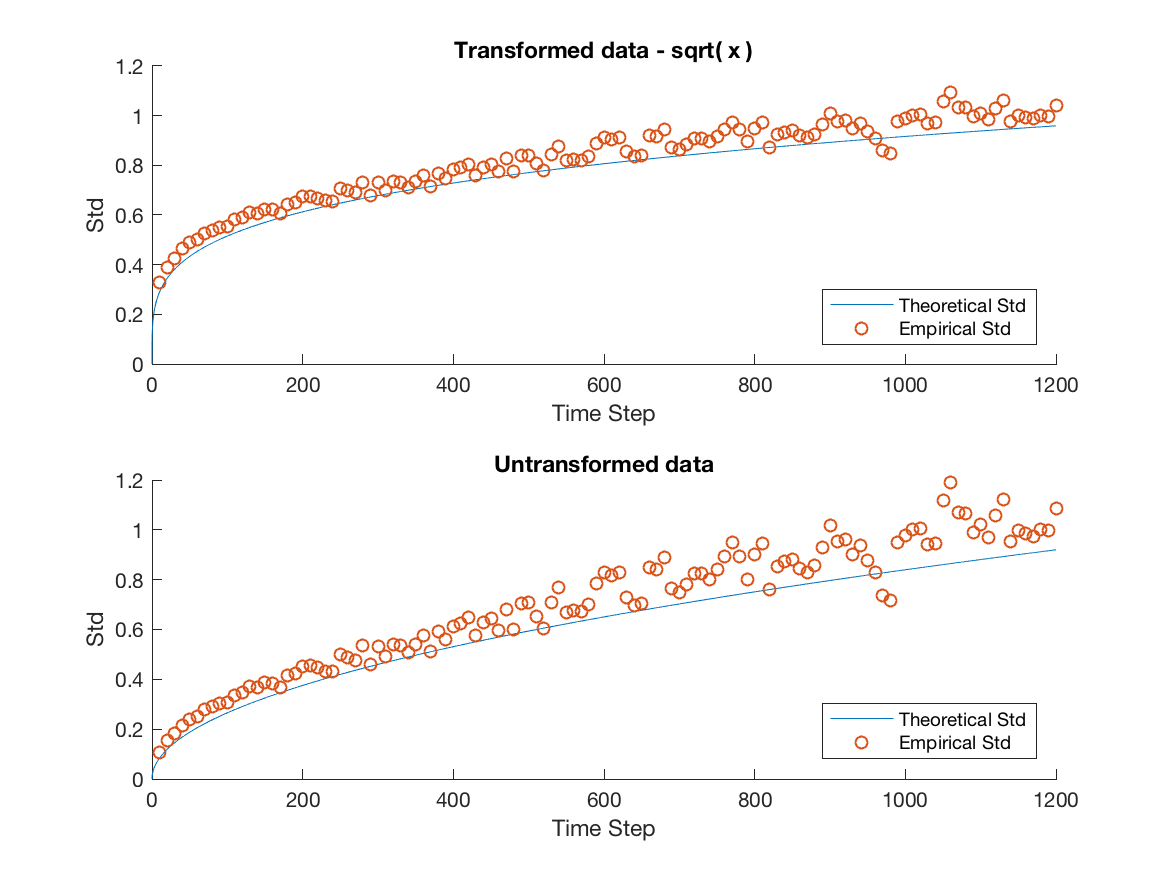 Figure 17
Figure 17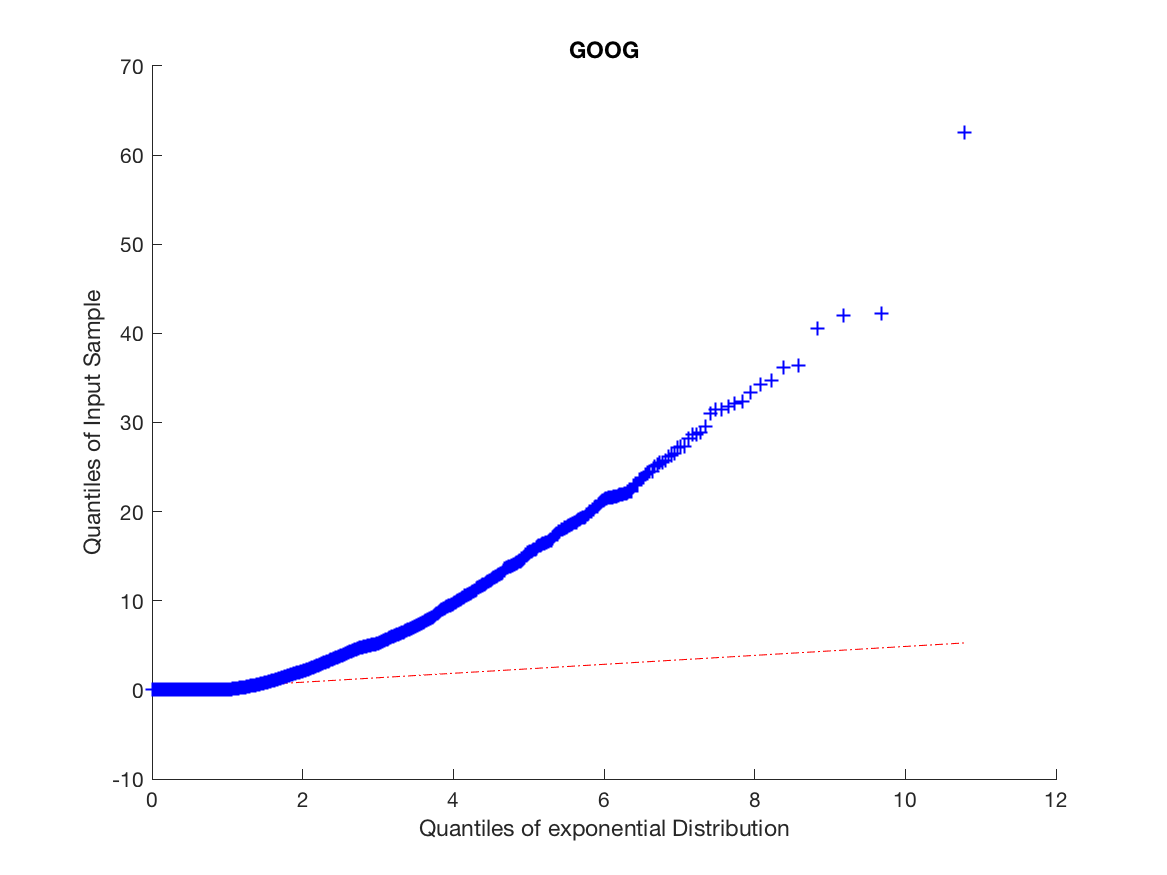 Figure 18
Figure 18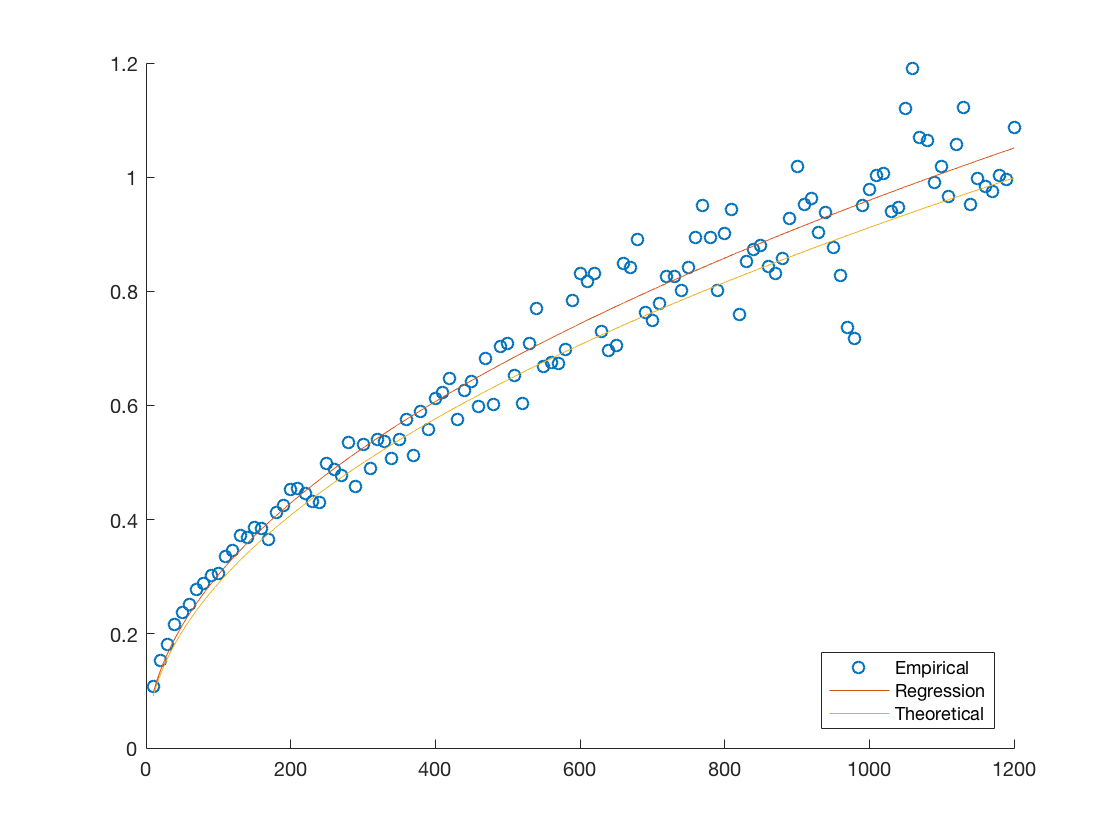 Figure 19
Figure 19 Figure 20
Figure 20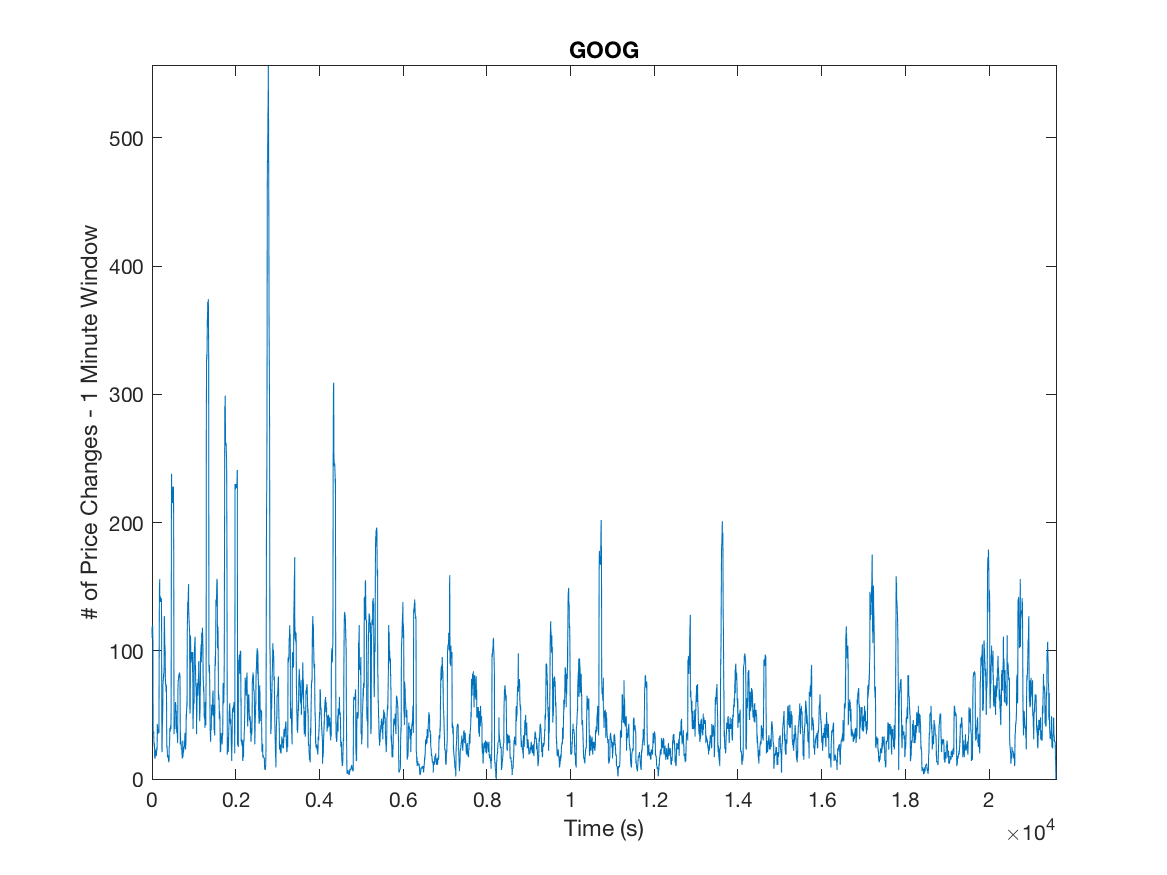 Figure 21
Figure 21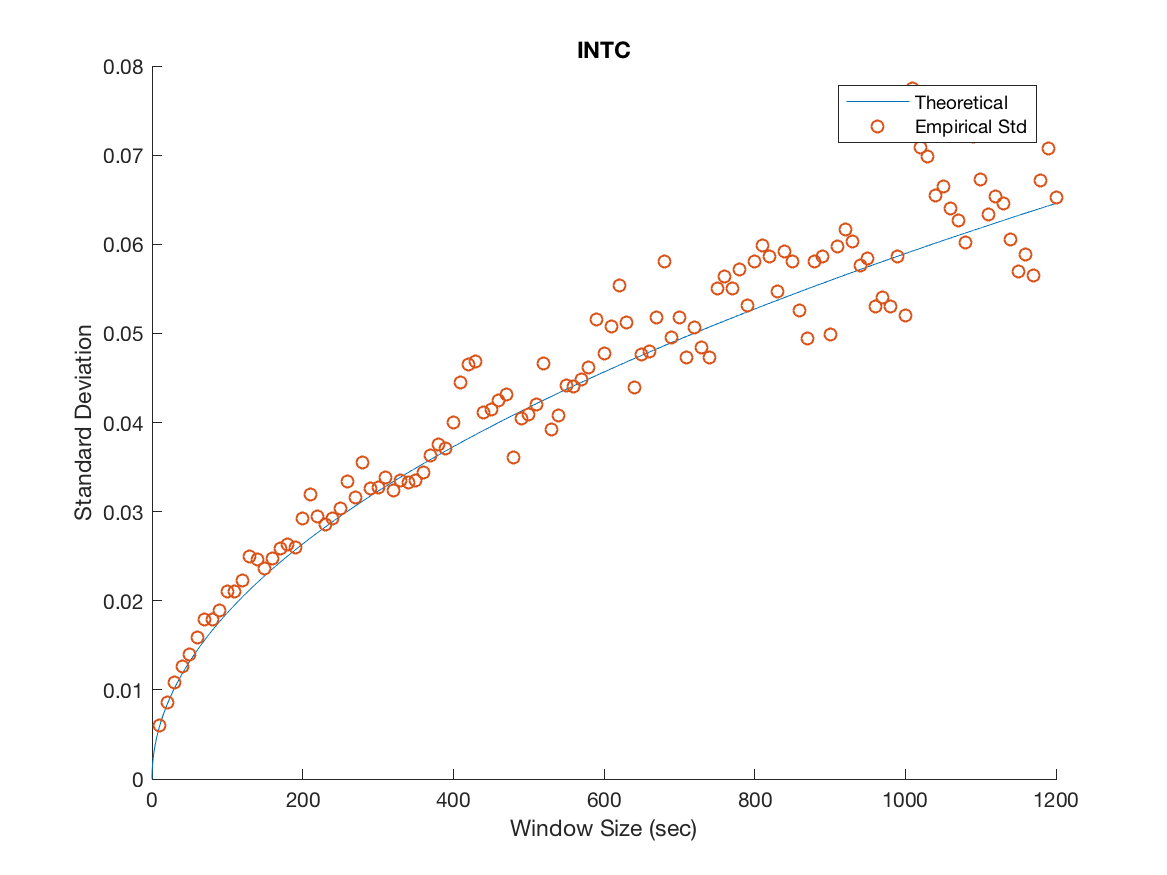 Figure 22
Figure 22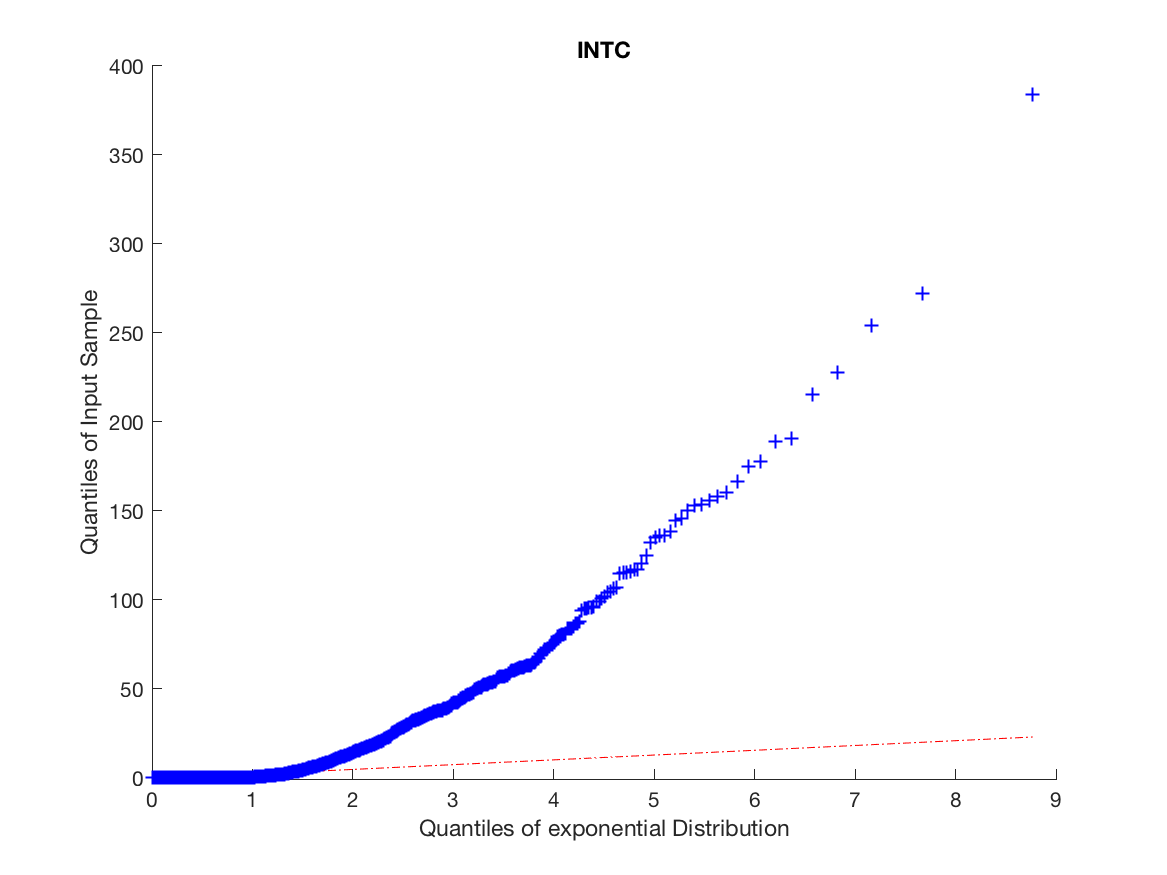 Figure 23
Figure 23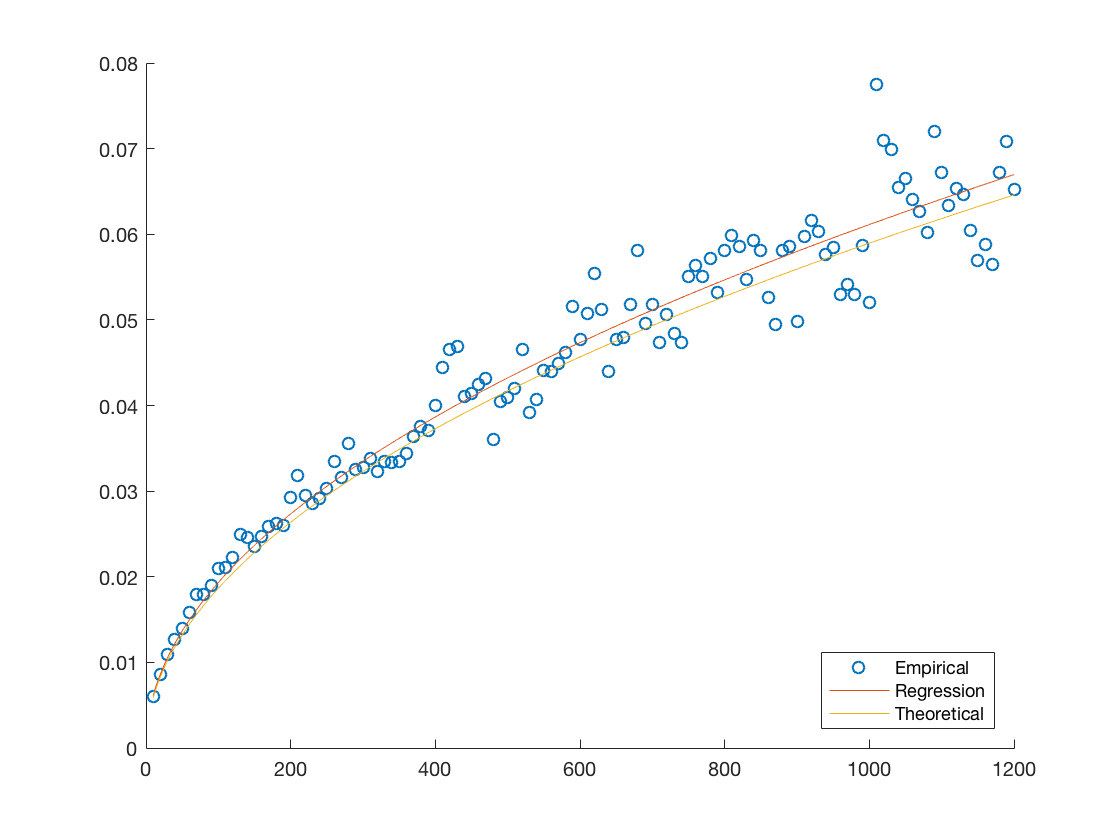 Figure 24
Figure 24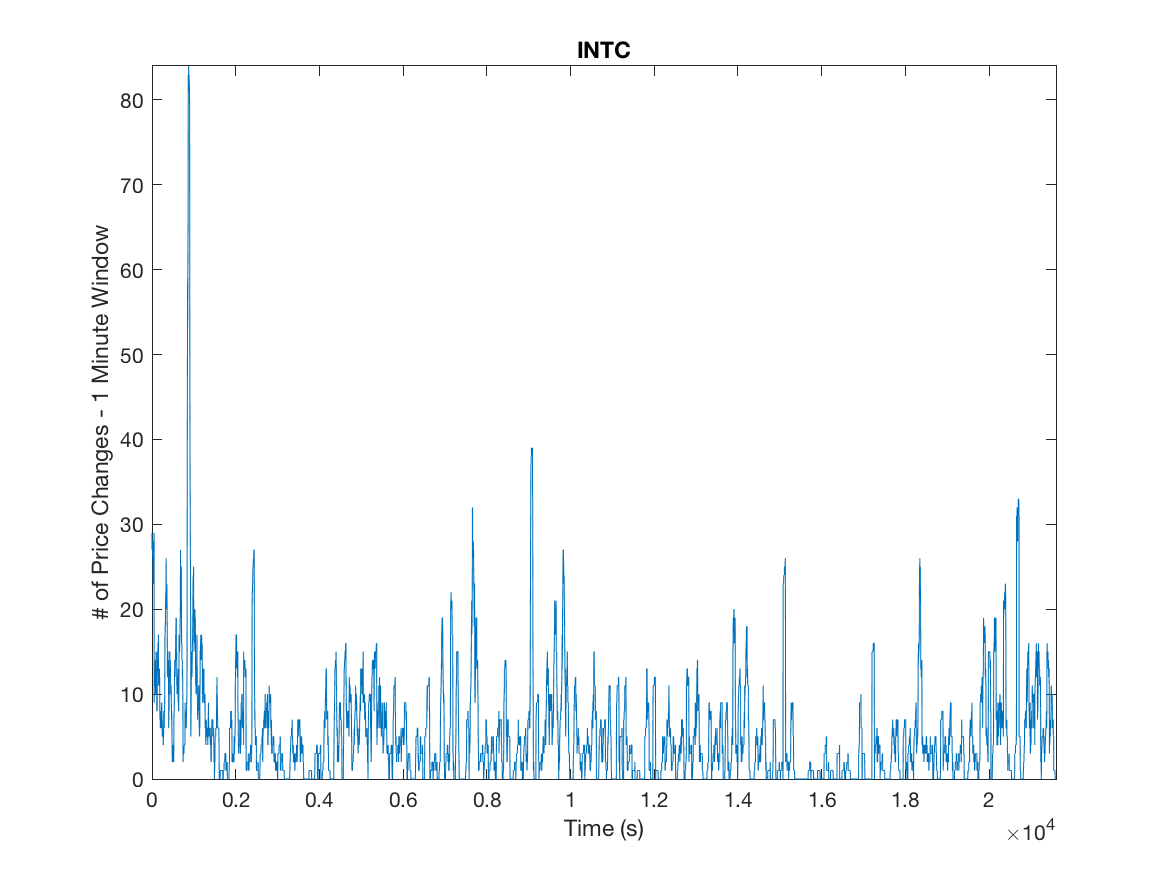 Figure 25
Figure 25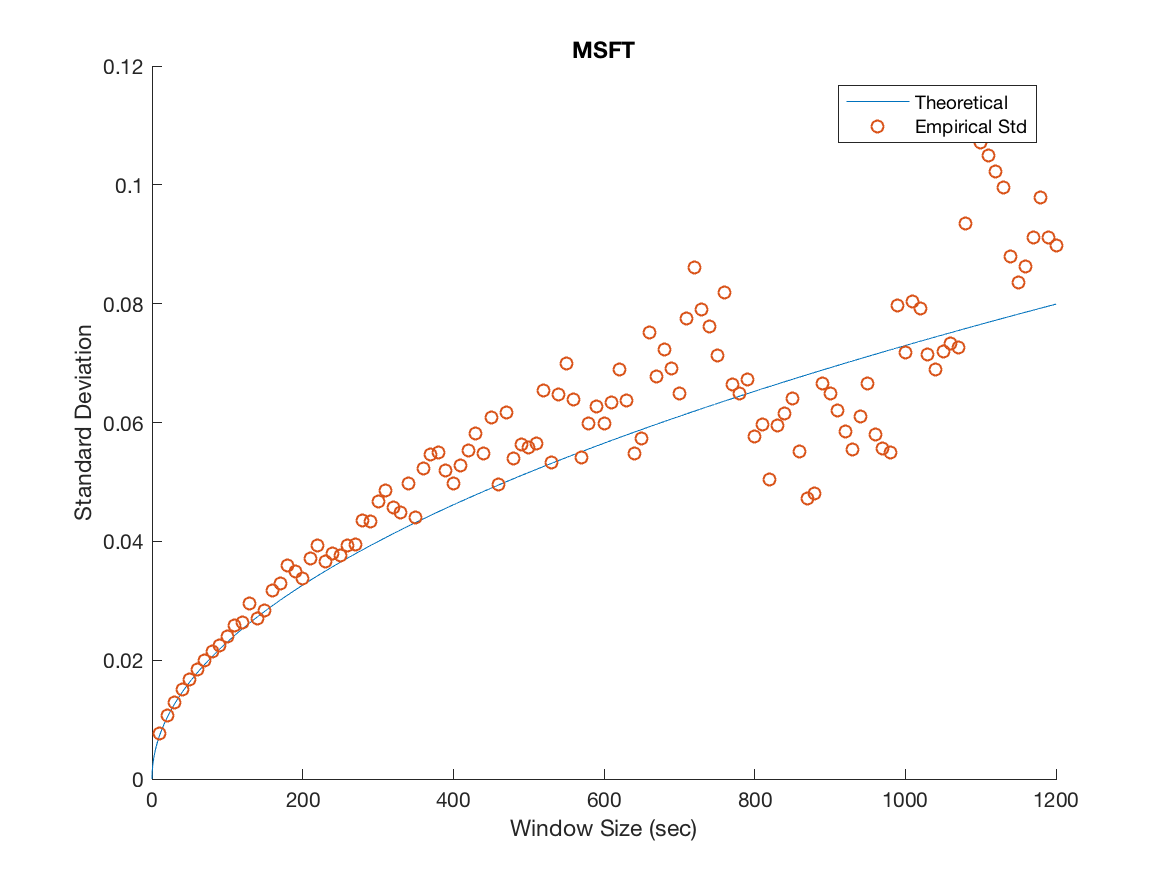 Figure 26
Figure 26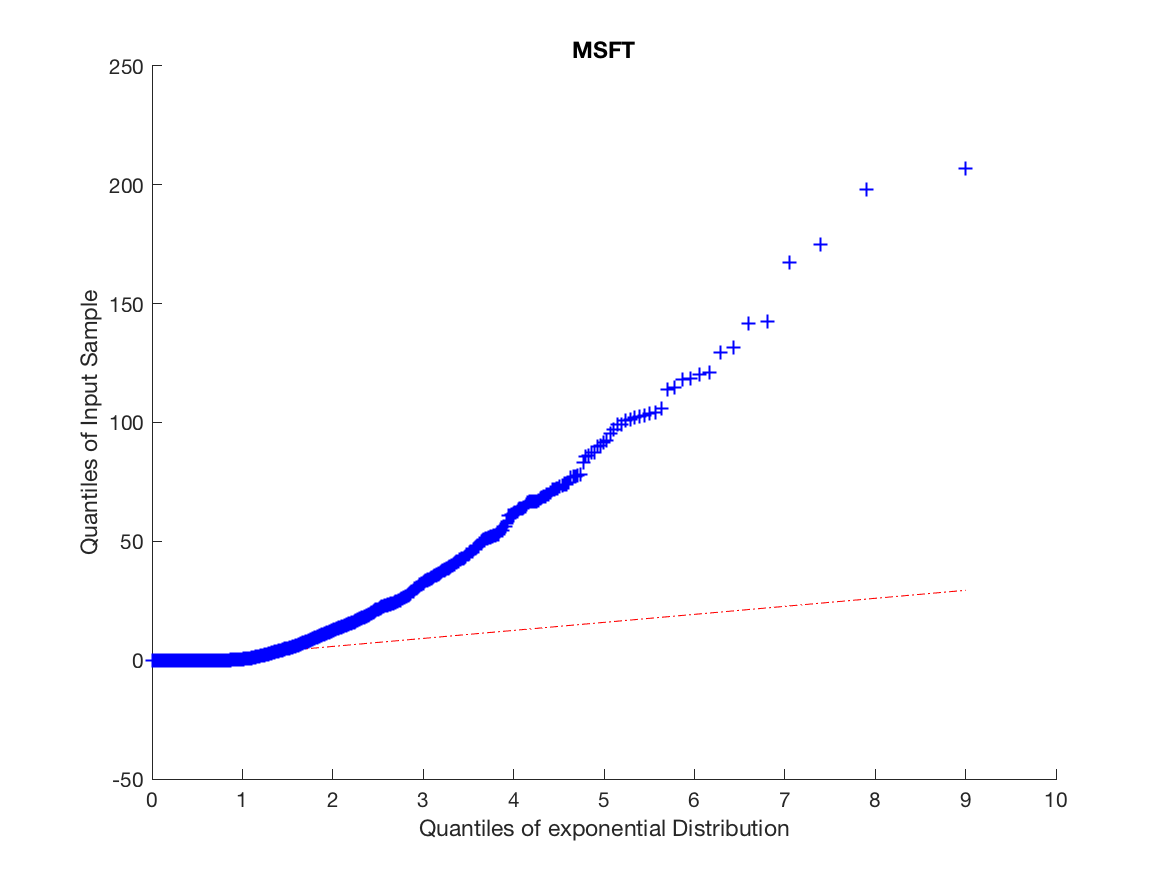 Figure 27
Figure 27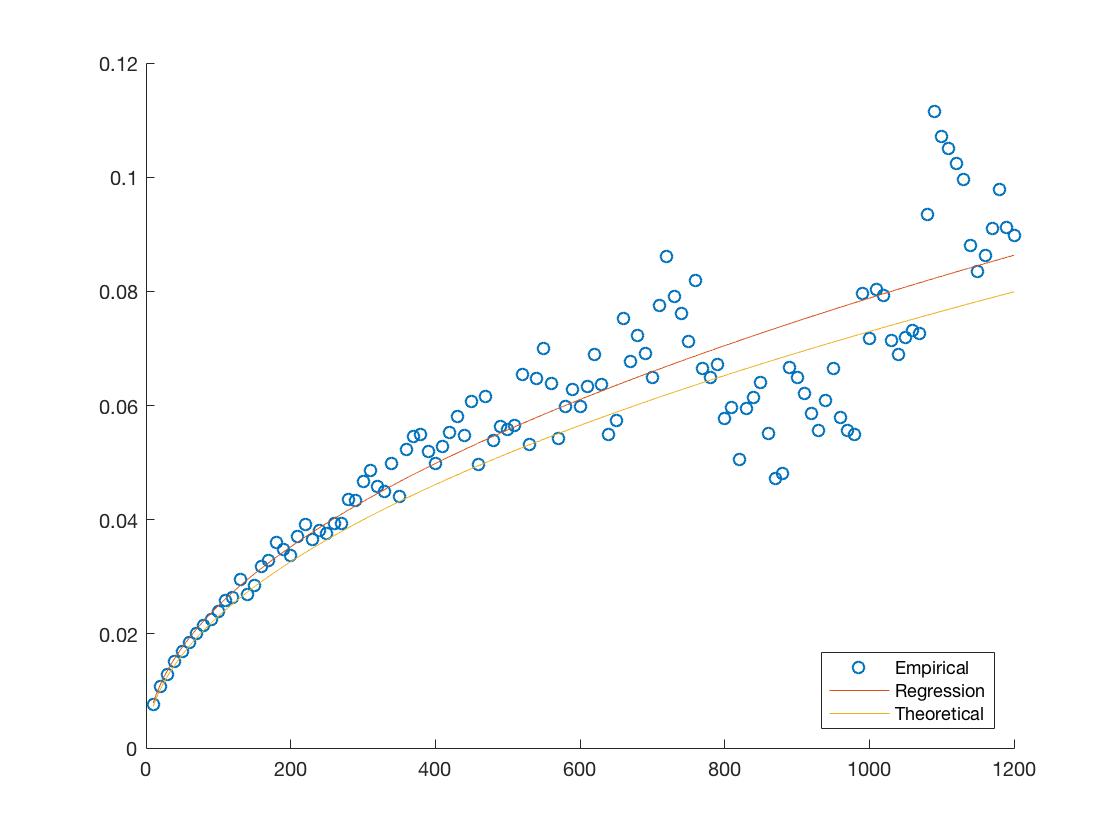 Figure 28
Figure 28 Figure 29
Figure 29| Ticker | Avg # of Orders per Second | Price Changes in 1 Day |
| AAPL | 51 | 64,350 |
| AMZN | 25 | 27,557 |
| GOOG | 21 | 24,084 |
| MSFT | 173 | 3,217 |
| INTC | 176 | 4,060 |
| AAPL | 1.4683 | 1045.2676 | 2556.1844 |
| AMZN | 0.6443 | 653.7524 | 1556.1702 |
| GOOG | 0.4985 | 865.8553 | 1980.4409 |
| MSFT | 0.0659 | 479.3482 | 908.0032 |
| INTC | 0.0471 | 399.6389 | 760.4991 |
| Emp. | MLE | |
|---|---|---|
| AAPL | 2.4840 | 2.4841 |
| AMZN | 1.1110 | 1.1110 |
| GOOG | 0.8857 | 0.8857 |
| MSFT | 0.1395 | 0.1396 |
| INTC | 0.0991 | 0.0992 |
| AAPL | 0.4956 | 0.4933 | 0.0049 | -1.1463e-5 |
| AMZN | 0.4635 | 0.4576 | 0.0046 | -2.7373e-5 |
| GOOG | 0.4769 | 0.4461 | 0.0046 | -1.4301e-4 |
| MSFT | 0.6269 | 0.5827 | 0.0062 | -2.7956e-4 |
| INTC | 0.6106 | 0.5588 | 0.0059 | -3.1185e-4 |
| AAPL | -0.0172 | 0.0170 |
| AMZN | -0.0134 | 0.0133 |
| GOOG | -0.0302 | 0.0308 |
| AAPL | 0.4956 | 0.4933 | 0.0169 | -1.5624e-4 |
| AMZN | 0.4635 | 0.4576 | 0.0123 | -1.0475e-4 |
| GOOG | 0.4769 | 0.4461 | 0.0282 | -5.5095e-4 |
| i | ||
|---|---|---|
| 1 | 0.0275 | -0.0524 |
| 2 | 0.0281 | -0.0318 |
| 3 | 0.0264 | -0.0250 |
| 4 | 0.0382 | -0.0200 |
| 5 | 0.0576 | -0.0150 |
| 6 | 0.3249 | -0.0064 |
| 7 | 0.2321 | 0.0050 |
| 8 | 0.0923 | 0.0100 |
| 9 | 0.0578 | 0.0150 |
| 10 | 0.0353 | 0.0200 |
| 11 | 0.0412 | 0.0271 |
| 12 | 0.0387 | 0.0476 |
| CHPDO | 2 | 8 | 16 | 32 | |
|---|---|---|---|---|---|
| AAPL | 0.2679 | 0.0050 | 0.0036 | 0.0036 | 0.0036 |
| AMZN | 0.1122 | 0.0208 | 0.0131 | 0.0124 | 0.0123 |
| GOOG | 0.4036 | 0.0115 | 0.0048 | 0.0045 | 0.0047 |
| INTC | 1.7917e-5 | 1.7917e-5 | 1.7917e-5 | 1.7917e-5 | 1.7917e-5 |
| MSFT | 1.0586e-4 | 1.0586e-4 | 1.0586e-4 | 1.0586e-4 | 1.0586e-4 |
| Theoretical Coefficient | Regression Coefficient | Percent Error | |
|---|---|---|---|
| AAPL | 0.02868 | 0.02828 | 1.42% |
| AMZN | 0.01450 | 0.01831 | 20.8% |
| GOOG | 0.02883 | 0.03023 | 4.63% |
| INTC | 0.00186 | 0.00193 | 3.4% |
| MSFT | 0.00231 | 0.00246 | 6.4% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
General Compound Hawkes Processes in Limit Order Books
Abstract.
In this paper, we study various new Hawkes processes. Specifically, we construct general compound Hawkes processes and investigate their properties in limit order books. With regards to these general compound Hawkes processes, we prove a Law of Large Numbers (LLN) and a Functional Central Limit Theorems (FCLT) for several specific variations. We apply several of these FCLTs to limit order books to study the link between price volatility and order flow, where the volatility in mid-price changes is expressed in terms of parameters describing the arrival rates and mid-price process.
Key words and phrases:
Hawkes processes, general compound Hawkes processes, limit order books, functional central limit theorems, LOBSTER data
1991 Mathematics Subject Classification:
Primary: 58F15, 58F17; Secondary: 53C35.
The first and second authors are supported by NSERC
∗ Corresponding author: Aiden Huffman
Anatoliy Swishchuk∗
2500 University Dr. NW
Calgary, AB, Canada
T2N 1N4
Aiden Huffman
2500 University Dr. NW
Calgary, AB, Canada
T2N 1N4
(Communicated by Tony Ware)
1. Introduction
The Hawkes process (HP) is named after its creator Alan Hawkes (1971, 1974), [27], [28]. The HP is a simple point process equipped with a self-exciting property, clustering effect and long run memory. Through its dependence on the history of the process, the HP captures the temporal and cross sectional dependence of the event arrival process as well as the ’self-exciting’ property observed in our empirical data on limit order books. Self-exciting point processes have recently been applied to high frequency data for price changes [54] or order arrival times [55]. HPs have seen their application in many areas, like genetics (2010) [11], occurrence of crime (2010) [50], bank defaults [51] and earthquakes [52].
Point processes gained a significant amount of attention in statistics during the 1950s and 1960s. Cox (1955) [16] introduced the notion of a doubly stochastic process Poisson process (called the Cox process now) and Bartlett (1963) [8] investigated statistical methods for point processes based on their power spectral densities. Lewis (1964) [34] formulated a point process model (for computer power failure patters) which was a step in the direction of the HP. A nice introduction to the theory of point processes can be found in Daley et al. (1988) [17]. The first type of point process in the context of market microstructure is the autoregressive conditional duration (ACD) model introduced by Engel et al. (1998) [19].
A recent application of HP is in financial analysis, in particular limit order books. In this paper, we study various new Hawkes processes, namely general compound Hawkes processes to model the price process in limit order books. We prove a Law of Larges Numbers (LLN) and a Function Central Limit Theorem (FCLT) for specific cases of these processes. Several of these FCLTs are applied to limit order books where we use asymptotic methods to study the link between price volatility and order flow in our models. The volatility of the price changes is expressed in terms of parameters describing the arrival rates and price changes. We also present some numerical examples. The general compound Hawkes process was first introduced in [40] to model the risk process in insurance and studied in detail in [41]. In the paper [43] we obtained functional CLTs and LLNs for general compound Hawkes processes with dependent orders and regime-switching compound Hawkes processes.
Bowsher (2007) [6] was the first one who applied the HP to financial data modelling. Cartea et al. (2011) [9] applied HP to model market order arrivals. Filimonov and Sornette (2012) [25] and Filimonov et al. (2013) [26] applied the HPs to estimate the percentage of price changes caused by endogenous self-generated activity rather than by the exogenous impact of news or novel information. Bauwens and Hautsch (2009) [7] used a five dimensional HP to estimate multivariate volatility between five stocks, based on price intensities. Hewlett (2006) [29] used the instantaneous jump in the intensity caused by the occurrence of an event to qualify the market impact of that event, taking into account the cascading effect of secondary events causing further events. Hewlett (2006) [29] also used the Hawkes model to derive optimal pricing strategies for market makers and optimal trading strategies for investors given that the rational market makers have the historic trading data. Large (2007) [32] applied a Hawkes model for the purpose of investigating market impact, with a specific interest in order book resiliency. Specifically, he considered limit orders, market orders and cancellations on both the buy and sell side, and further categorizes these events based on their level of aggression, resulting in a ten dimensional Hawkes process. Other econometric models based on marked point processes with stochastic intensity include autoregressive conditional intensity (ACI) models with the intensity depending on its history. Hasbrouck (1999) [30] introduced a multivariate point process to model the different events of an order book but did not parametrize the intensity. We note that Brémaud et al. (1996) [4] generalized the HP to its nonlinear form. Also, a functional central limit theorem for nonlinear Hawkes processes was obtained in Zhu (2013) [49]. The ’Hawkes diffusion model’ introduced in Ait-Sahalia et al. (2013) [1] attempted to extend previous models of stock prices to include financial contagion. Chavez-Demoulin et al. (2012) [12] used Hawkes processes to model high-frequency financial data. An application of affine point processes to portfolio credit risk may be found in Errais et al. (2010) [24]. Some applications of Hawkes processes to financial data are also given in Embrechts et al. (2011) [23].
Cohen et al. (2014) [14] derived an explicit filter for Markov modulated Hawkes processes. Vinkovskaya (2014) [47] considered a regime-switching Hawkes process to model its dependency on the bid-ask spread in limit order book. Regime-switching models for pricing of European and American options were considered in Buffington et al. (2000) [2] and Buffington et al. (2002) [3], respectively. Semi-Markov processes were applied to limit order books in [44] to model the mid-price. We also note that level-1 limit order books with time dependent arrival rates were studied in [13], including the asymptotic distribution of the price process.
The paper by Bacry et al. (2015) [5] proposes an overview of the recent academic literature devoted to the applications of Hawkes processes in finance. It is a nice survey of applications of Hawkes processes in finance. In general, the main models in high-frequency finance can be divided into univariate models, price models, impact models, order-book models and some systemic risk models, models accounting for news, high-dimensional models and clustering with graph models. The book by Cartea et al. (2015) [10] developed models for algorithmic trading such as methods for executing large orders, market making, trading pairs of collections of assets, and executing in the dark pool. This book also contains a link from which several datasets can be downloaded, along with MATLAB code to assist in experimentation with the data.
A detailed description of the mathematical theory of Hawkes processes is given in Liniger (2009) [33]. The paper by Laub et al. (2015) [35] provides background, introduces the field and historical development, and touches upon all major aspects of Hawkes processes. The results of the current paper were first annouced in in [42]
The paper is organized as follows. A definition of a Hawkes process and description of its properties are given in Section 2. General compound Hawkes processes are described in Section 3. Law of Large Numbers (LLN) and Functional Central Limit Theorems (FCLT) for various general compound Hawkes processes, including non-linear, in limit order books are proved in Section 4. Section 5 contains a numerical exploration of the derived diffusion limits to several datasets and finally Section 6 concludes the paper.
2. Definition of Hawkes Processes (HPs)
In this section we give various definitions and some properties of Hawkes processes which can be found in the existing literature (see, e.g., [27], [28], [23] and [48], to name a few). They include in particular one dimensional and non-linear Hawkes processes.
Definition 2.1** (Counting Process).**
A counting process is a stochastic process with , where takes positive integer values and satisfies . It is almost surely finite and a right-continuous step function with increments of size .
Denote by , , the history of the arrival up to time t, that is, , , is a filtration (an increasing sequence of -algebras).
A counting process can be interpreted as a cumulative count of the number of arrivals into a system up to the current time . The counting process can also be characterized by the sequence of random arrival times at which the counting process has jumped. The process defined by these arrival times is called a point process (see [17]).
Definition 2.2** (Point Process).**
If a sequence of random variables , taking values in has , and the number of points in a bounded region is almost surely finite, then is called a point process.
Definition 2.3** (Conditional Intensity Function).**
Consider a counting process with associated histories , . If a non-negative function exists such that
[TABLE]
then it is called the conditional intensity function of (see [35]). We note that originally this function was called the hazard function (see [16]).
Definition 2.4** (One-dimensional Hawkes Process).**
The one-dimensional Hawkes process (see [35], [28]) is a point process which is characterized by its intensity with respect to its natural filtration:
[TABLE]
where , and the response function is a positive function that satisfies .
The constant is called the background intensity and the function is sometimes called the excitation function. To avoid the trivial case of a homogeneous Poisson process, we assume . Thus, the Hawkes process is a non-Markovian extension of the Poisson process.
With respect to the Definitions of in 2.3 and in 2.4, it follows that
[TABLE]
The interpretation of Equation (2) is that the events occur according to an intensity with a background intensity which increases by at each new event, eventually decaying back to the background intensity value according to the evolution of the function . Choosing leads to a jolt in the intensity at each new event, and this feature is often called the self-exciting feature. In other words, if an arrival causes the conditional intensity function in Equations (1)-(2) to increase then the process is called self-exciting.
We would like to mention that the conditional intensity function in Equations (1)-(2) can be associated with the compensator of the counting process , that is
[TABLE]
We note that is the unique non-decreasing, , , predictable function, with such that
[TABLE]
where is an , , local martingale (existence of which is guaranteed by the Doob-Meyer decomposition).
A common choice for the function in Equation (2) is the one of exponential decay (see [27])
[TABLE]
where parameters , . In this case, the Hawkes process is called the Hawkes process with exponentially decaying intensity.
In the case of Equation (4), Equation (2) becomes
[TABLE]
We note that in the case of Equation (4), the process is a continuous-time Markov process, which is not the case for a general choice of excitation function in Equation (1).
With some intitial condition , the conditional intensity in Equation (5) with exponential decay in Equation (4) satisfies the SDE
[TABLE]
which can be solved using stochastic calculus as
[TABLE]
which is an extension of Equation (5).
Another choice for is a power law function
[TABLE]
with positive parameters . This power law form for in Equation (8) was applied in the geological model called Omori’s law, and used to predict the rate of aftershocks caused by an earthquake.
Definition 2.5** (D-dimensional Hawkes Process).**
The D-dimensional Hawkes process (see [23]) is a point process which is characterized by its intensity vector such that:
[TABLE]
where , and is a matrix-valued kernel such that:
- (1)
it is component-wise non-negative: for each 2. (2)
it is component-wise -integrable
In matrix-convolution form, Equation (9) can be written as
[TABLE]
where .
Definition 2.6** (Non-linear Hawkes Process).**
The non-linear Hawkes process (see, e.g., [48]) is defined by the intensity function in the following form:
[TABLE]
where is a non-linear function with support in . Typical examples for are and .
Remark 1**.**
Many other generalizations of Hawkes processes have been proposed. They include mixed diffusion-Hawkes models [24], Hawkes models with shot noise exogenous events [18] and Hawkes processes with generation dependent kernels [37], to name a few.
3. Compound Hawkes Processes
In this section we define non-linear compound Hawkes process with -state dependent orders. We also consider special cases of this general compound Hawkes process.
Definition 3.1** (Non-Linear Compound Hawkes Process with -state Dependent Orders (NLCHPnSDO) in Limit Order Books).**
Consider the mid-price process
[TABLE]
where is a continuous time -state Markov chain, is a continuous and bounded function on the state space , is the non-linear Hawkes process (see, e.g., [48] defined by the intensity function in the following form (see Equation (11)):
[TABLE]
where is a non-linear increasing function with support in . We note that in [4] it was shown that if is -Lipschitz (see [4]) such that then there exists a unique stationary and ergodic Hawkes process satisfying the dynamics of Equation (11). We shall refer to the process in Equation (12) as a Non-linear Compound Hawkes Process with -State Dependent Orders (NLCHPnSDO).
This non-linear compound Hawkes process will be the foundation for our studies throughout this paper. In the following subsection we will introduce four specific examples, which will be used for our empirical investigations of the mid-price processes.
3.1. Special Cases of Compound Hawkes Processes in Limit Order Books
Definition 3.2** (General Compound Hawkes Process With N-state Dependent Orders (GCHPnSDO)).**
Suppose that is an ergodic continuous-time Markov chain, independent of , with state space , is a one-dimensional Hawkes process defined in Definition 2.4 and is any bounded and continuous function on . We define the General Compound Hawkes process with N-state Dependent Orders (GCHPnSDO) by the following process
[TABLE]
Note that this process can be recovered from Equation (12) by letting .
Definition 3.3** (General Compound Hawkes Process with Two-State Dependent Orders (GCHP2SDO)).**
Suppose that is an ergodic continuous time Markov chain, independent of , with two states . Then Equation (13) becomes
[TABLE]
where takes only the values and . Of course we can view this as a special case of the n-state case, where . This model was used in [45] for the mid-price process in limit order books with non-fixed tick and two-valued price changes.
Definition 3.4** (General Compound Hawkes Process with Dependent Orders (GCHPDO)).**
Suppose that and that , then in Equation (13) becomes
[TABLE]
This type of process can be a model for the mid-price in limit order books, where is a fixed tick size and is the number of order arrivals up to time . We shall call this process a General Compound Hawkes Process with Dependent Orders (GCHPDO). This is a generalization of the previous process, obtained by letting and .
Having defined several mid-price processes, we now prove diffusion limit theorems and LLNs for each price process in the following Section. These diffusion processes will be used for our exploration of the applicability of this model to real world limit order book data.
4. Diffusion Limits and LLNs
4.1. Diffusion Limit and LLN for NLCHPnSDO
We consider the mid-price process defined in Definition 3.1, namely
[TABLE]
where is a continuous time n-state Markov chain and a(x) is a continuous bounded function on the state space . is the number of price changes up to time , described by the non-linear Hawkes process given in Equation (11).
Theorem 4.1** (Diffusion Limit for NLCHPnSDO).**
Let be an ergodic Markov chain with states and with ergodic probabilities . Let also be as defined in Definition 3.1, then
[TABLE]
where is a standard Wiener process and is the mean of the number of arrivals on a unit interval under the stationary and ergodic measure. Furthermore
[TABLE]
[TABLE]
P is the transition probability matrix for , i.e. . denotes the matrix of stationary distributions of and is the th entry of .
Proof.
From Equation (13) we have
[TABLE]
and
[TABLE]
therefore
[TABLE]
As long as , we need only find the limit for
[TABLE]
when . Consider the following sums
[TABLE]
and
[TABLE]
where is the floor function. Following the martingale method from [45], we have the following weak convergence in the Skorokhod topology (see [39]):
[TABLE]
We note that the results from [4] imply by the ergodic theorem that
[TABLE]
or
[TABLE]
Using the change of time , we find that
[TABLE]
or
[TABLE]
The result now follows from Equations (19)-(21) ∎
Lemma 4.2** (LLN for NLCHPnSDO).**
The process in Equation (19) satisfies the following weak convergence in the Skorokhod topology (see [40]):
[TABLE]
where is defined in Equation (18) respectively.
Proof.
From Equation (12) we have
[TABLE]
The first term goes to zero when . On the right hand side, with respect to the strong LLN for Markov chains (see, e.g. [38])
[TABLE]
Then taking into account Equation (26), we obtain
[TABLE]
from which the desired result follows. ∎
4.2. Diffusion Limit and LLN for GCHPnSDO
We consider here the mid-price process which was defined in Definition 3.2, namely
[TABLE]
where is a continuous time n-state Markov chain, a(x) is a continuous and bounded function on the state space , and is the number of price changes up to time t, described by a one-dimensional Hawkes process defined in Definition 2.4. This can be interpreted as the case of non-fixed tick sizes, n-valued price changes and dependent orders.
Theorem 4.3** (Diffusion limit for GCHPnSDO).**
Let be an ergodic Markov chain with states and with ergodic probabilities . Let also be as defined in Definition 3.2, then
[TABLE]
where W(t) is a standard Wiener process,
[TABLE]
[TABLE]
P is the transition probability matrix for , i.e. . denotes the matrix of stationary distributions of and is the th entry of .
Proof.
As in the previous theorem we have that
[TABLE]
and
[TABLE]
where is as defined above.
Therefore, we can conclude that
[TABLE]
as long as , we need only find the limit for
[TABLE]
as . We consider the following sums
[TABLE]
and
[TABLE]
where is the floor function.
Then following the martingale method from [45], we have the following weak convergence in the Skorokhod topology (see [39])
[TABLE]
where is as defined above.
We note again that with respect to the LLN for Hawkes processes (see, e.g., [17]) we have
[TABLE]
or
[TABLE]
where is as defined above. Then using the change of time defined before where we can find from Equations (42)-(44):
[TABLE]
or
[TABLE]
The result in Equation (34) now follows from Equations (37)-(44) ∎
Lemma 4.4** (LLN for GCHPnSDO).**
The process defined in Definition 3.2, satisfies the following weak convergence in the Skorokhod topology (see [40])
[TABLE]
where and are defined in Equations (35) and (36) respectively.
Proof.
From Equation (13) we have
[TABLE]
The first term goes to zero when . On the right hand side, with respect to the strong LLN for Markov chains (see, e.g., [38])
[TABLE]
Then taking into account Equation (44) we obtain
[TABLE]
from which the desired result follows. ∎
4.3. Diffusion Limits and LLNs for Special Cases of GCHPnSDO
Theorem 4.3 can be reduced to some of the special cases we outlined previously in Subsection3.1. Specifically in Definitions 3.3 and 3.4, we consider the case of a 2-state Markov chain for which we provide the diffusion limit and LLN result as Corollaries below.
We begin by considering the mid-price process (GCHP2SD) which was defined in 3.3, namely
[TABLE]
where is a continuous-time 2-state Markov chain, a(x) is a continuous and bounded function on and is the number of price changes up to moment t, described by a one-dimensional Hawkes process defined in Definition 2.4. This can be interpreted as the case of non-fixed tick sizes, two-valued price changes and dependent orders.
Corollary 1** (Diffusion Limit for GCHP2SDO).**
Let be an ergodic Markov chain with two states and with ergodic probabilities . Further, let be defined as in Definition 3.3. Then
[TABLE]
where is standard Wiener process,
[TABLE]
[TABLE]
where are the transition probabilities of the Markov chain.
Corollary 2** (LLN for GCHP2SDO).**
The process defined in Definition 3.3 satisfies the following weak convergence in the Skorokhod topology (see [40])
[TABLE]
where and are defined in Equations (51) and (52) respectively.
Now let us consider the process defined in Definition 3.4, specifically
[TABLE]
where is a continuous-time 2-state Markov chain, is the fixed tick size, and is the number of price changes up to moment t, described by a one-dimensional Hawkes process defined in Definition 2.4. This case we have a fixed tick size, two-valued price changes and dependent orders.
Corollary 3** (Diffusion Limit for CHPDO).**
Let be an ergodic Markov chain with two states and with ergodic probabilities , then taking as defined in Definition 3.4 then
[TABLE]
where is a standard Wiener process,
[TABLE]
[TABLE]
and are the transition probabilities of the Markov chain . We note that and are defined in Equation (2).
We note that the LLN for both GCHP2SDO and CHPDO is identitical to the result given in Lemma 4.4, after some simplification.
5. Empirical Results
In order to test the validity of our models and determine which best fits empirical data, we have considered level 1 LOB data for Apple, Amazon, Google, Microsoft and Intel on June 21st, 2012 [53]. We first verify that the data is reasonable for our model by checking it’s liquidity, this is illustrated in Table 1.
The high number of daily price changes motivates the idea that we can use asymptotic analysis in order to approximate long-run volatility using order flow by finding the diffusion limit of the price process. Because we do not want to include opening and closing auctions we omit the first and last fifteen minutes of our data. We motivate the arrival process by analyzing the inter-arrival times and clustering to a ensure the arrival process is not Poisson and exhibits the characteristics of a Hawkes Process, this is illustrated in Figures 1 and 2.
Furthermore, the relationship between our diffusion coefficient and arrival process is limited to the expected number of arrivals on a unit interval. This implies that results for a simple exponential model can be easily generalized to a non-linear one. This makes it possible to work with a simplified model for our Hawkes process which is still rich enough to capture our observations. Keeping this in mind, we restrict ourselves to an exponential kernel and estimate parameters using a MLE [35]. We provide these estimates in Table 2 and compare the empirical expected number of arrivals and compare with the MLE estimate in Table 3
Obviously the MLE method accurately estimates the expected number of arrivals on the unit interval. This means we can confidently say for our data that our parameters will work reasonably with our models. We provide the estimated parameters in Table 2
5.1. CHPDO
We first consider a compound Hawkes process with dependent orders defined in Definition 3.4, namely
[TABLE]
where is a continuous-time two state Markov chain, is of fixed size and is the number of mid-price movements up to time described by a Hawkes process.
We have opted to study the mid-price changes of our model. Thus can be computed by averaging the best bid and ask price. Noting that the price is recorded in cents the smallest possible jump in the mid-price is a half a cent which we will use as . Furthermore, in order to estimate the transition matrix for the Markov chain we count the absolute frequencies of upward and downward price movements and from this calculate the relative frequencies giving an estimate for and which represent the conditional probabilities of an up/down movement given an up/down movement. Later we will consider several different sizes of mid-price movements and will work with the convention that each movement will be assigned a state based off of its ordering in the reals. In this case, will be state one, and with be state two. This results in the transition matrix given below.
[TABLE]
After determining our parameters and transition probabilities we calculate and in Table 4 together with and .
Provided these values we can test our claim that our model accurately describes the mid-price process satisfies we will use the diffusion limit proved earier, namely
[TABLE]
If the data satisfies our proposed model then when considering large windows of time (5min, 10min, 20min), then when we would expect to see the empirical and theoretical standard deviations to follow each other closely. To test this we compare the equivalent process, constructed by multiplying the LHS and RHS by . Then cutting our data into disjoint windows of size , specifically with and by setting the left bound as our starting time we can calculate for each individual window and give a generalized formula for this below.
[TABLE]
This gives a collection of values over which we compute the standard deviation. If our model is accurate would would expect that
[TABLE]
We plot the empirical standard deviation against the theoretical one for various window sizes starting at 10 seconds and increasing in steps of 10 seconds until we reach 20 minutes, this is illustrated in Figure 3.
Several important remarks should be made at this point. It is clear that while the model accurately predicts the overall trend for MSFT and INTC, we severely underestimate the variability in the mid-price process for APPL, AMZN and GOOG. Furthermore, as the window size increases the overall spread in the data increases. We attribute this to the decreasing sample size imposed on us as we increase the window size. For example when we consider a 20 minute window, we can only construct 27 disjoint windows in the 9 hour trading day forcing us to deal with the problem of predicting a ’population’ standard deviation from a increasingly small sample. We remedy this by using a variance stabilizing transformation in later sections. Specifically, a popular method for a Poisson process is to take the square root of our empirical and theoretical standard deviations. This makes it possible to qualitatively view the overall trend in the data, gaining a clearer idea of goodness of fit from there.
5.2. GCHP2SDO
As of now we have considered a fixed delta related to the trading tick size. However, if we consider the mid-price changes for APPL, AMZN and GOOG the assumption of a fixed tick size is violated. In fact, we observe that approximately approximately 61%, 53% and 71% of all mid-price changes are larger than half a tick size, which is opposed to what we observe for MSFT and INTC where all mid-price changes occur at the half tick size, we illustrate this for AAPL, AMZN and GOOG in Figure 4.
It is clear in Figure 4 additional considerations need to be made. A simple way to include the variability in mid-price movements in our model is to introduce as described in Definition 3.3. It is of course necessary to determine the values of for each state of our Markov chain. A naive method is to take the mean of the downward and upward mid-price movements and assign them to and respectively. We provide these values in Table 5.
In this step we have only endeavoured to better realize the actual price movements in our data. Therefore, when we observe a downward mid-price movement we continue to assign it to state one and similarly for an upward price movement we continue to assign it to state two. It follows that our transition matrix will remain the same. Then using these new state values we recalculate and , providing them in Table 6. The effect of these changes is investigated in Figure 5. Note that in Figure 5 we have used the variance stabilizing transformation discussed earlier in order to better visualize the overall trend in our data.
Notice that there is a significant qualitative improvement in the fits for AAPL and GOOG in Figure 5 but the variability in mid-price movements for AMZN is still clearly underestimated by our model. The unexplained variance may be captured by investigating an n-state Markov chain since the additional transition probabilities could explain the variability missing in the 2-state case.
5.3. GCHPNSDO
We recall the N-state model described in Definition 3.2. The immediate question becomes how best to choose the state values. We modify the quantile based approach from [45]. After calculating the mid-price changes we separate the data into upward and downward price movements. Then we calculate evenly distributed quantiles for both data sets. Depending on the data, several quantiles may be identical, we reject any duplicates. We thus obtain a list of bounds which we complete by adding the minimum observed value if necessary.
To determine the state values , we take the average of all mid-price changes located between two neighbouring boundary values. Furthermore, we assign a mid-price change to state if it is greater than or equal to the th boundary and strictly less than the th boundary. An exception is made for the largest upper bound where equality is permitted at both ends.
As we could not capture the full variability of mid-price changes for AMZN in the previous method we investigate for this case. Furthermore, for tractability we only consider 14 boundary values from which we obtain a 12-state Markov chain. Instead of providing the transition matrix, we provide the ergodic probabilities for the transition matrix and the associated states in Table 7.
In order to compare the two state and N-state approaches we first take a qualitative approach and plot the two theoretical and empirical standard deviations against each other in Figure 6. When we compare the mean squared residuals, the 2-state model discussed before has mean squared error while our 12-state Markov chain brings that down to . Considering an even larger Markov chain with 24-states we are only able to obtain a meager improvement to , suggesting that there is some underlying variance in the mid-price process not captured by our model. We investigate these more quantitative measures in the following Subsection. First comparing the models against a numerical best fit and then investigating the mean squared error to gain a better quantitative understanding of the overall improvement obtained from each model as we increase the number of quantiles.
5.4. Quantitative Analysis
While our model does visually appear to fit the expected variability in four of the five cases, it still fails to capture the complete dynamics of mid-price changes seen in our AMZN data. We investigate the mean square error of our models with a varying number of quantiles in Table 8, this gives a good indication as to whether the N-state model is a better fit for our data. If we look closely at AAPL and GOOG we see the N-state case can still improve our results from the two state case. For AAPL we constructed a 17 state Markov chain by taking 16 quantiles on the downward movements and 16 quantiles upward movements. This resulted in a mean squared error of which is approximately a 28% improvement to the two state case where the mean squared error was . Even more extreme, using a 25 state Markov chain for GOOG which was constructed similarly, we observed a mean squared error of which is a 60% improvement from the two state case with a mean squared error of . We conclude with Table 8 which provides the mean residuals for AAPL, AMZN and GOOG with several of Markov chains constructed from various numbers of quantiles. We also include mean residuals for INTC and MSFT for comparison.
Another quantitative measure of our the fit would be to compare them to the best theoretical one available given the data. Notice that each of our models assumes that the standard deviation evolves according to the square root of the time step times some determinable coefficient. Therefore we can estimate the best possible coefficient by minimizing the mean squared residual, we provide plots of these hypothetical best fits against the empirical data and theoretical fits in Figure 7. We also provide the coefficients for the theoretical fits and hypothetical best fit in Table 9 in order to have a more quantitative comparison.
We notice that in each case the errors are close to, or under five percent with AMZN being the biggest offender. This is consistent with the discussion provided throughout our analysis and highlights the general applicability of our model.
5.5. Remarks
Overall the N state model out performs the others, generating fits for four out of the five datasets that are reasonable and providing reductions in the mean squared error by upwards of 25%. While not able to capture the full dynamics observed in AMZN it appears to be a strong candidate for a simple model of price dynamics observed in our data. Further investigation would be necessary to determine what causes the additional volatility observed in AMZN, and potentially implement a more robust model which captures this.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Ait-Sahalia, Y., Cacho-Diaz, J. and Laeven, R. (2010): Modelling of financial contagion using mutually exciting jump processes. Tech. Rep. , 15850, Nat. Bureau of Ec. Res., USA.
- 2[2] Buffington, J., Elliott, R. J. (2000): Regime Switching and European Options. Lawrence, K.S. (ed.) Stochastic Theory and Control. Proceedings of a Workshop, 73-81. Berlin Heidelberg New York: Springer. (2002).
- 3[3] Buffington, J., Elliott, R.J. (2002): American Options with Regime Switching. International Journal of Theoretical and Applied Finance 5, 497-514.
- 4[4] Brémaud, P. and Massoulié, L. (1996): Stability of nonlinear Hawkes processes. The Annals of Probab., 24(3), 1563.
- 5[5] Bacry, E., Mastromatteo, I. and Muzy, J.-F. (2015): Hawkes processes in finance. ar Xiv:1502.04592 v 2 [q-fin.TR] 17 May 2015.
- 6[6] Bowsher, C. (2007): Modelling security market events in continuous time: intensity based, multivariate point process models. J. Econometrica , 141 (2): 876-912.
- 7[7] Bauwens, L. and Hautsch, N. (2009): Modelling Financial High Frequency Data Using Point Processes. Springer.
- 8[8] Bartlett, M. (1963): The spectral analysis of point processes. J. R. Stat. Soc., ser. B, 25 (2), 264-296.