Lung Cancer Tumor Region Segmentation Using Recurrent 3D-DenseUNet
Uday Kamal, Abdul Muntakim Rafi, Rakibul Hoque, Jonathan Wu, and Md., Kamrul Hasan

TL;DR
This paper introduces Recurrent 3D-DenseUNet, a novel deep learning architecture that improves lung tumor segmentation accuracy from CT scans by capturing detailed spatial and temporal features, outperforming existing methods.
Contribution
The paper presents a new recurrent 3D-DenseUNet architecture with dense connections and ConvLSTM layers for enhanced volumetric lung tumor segmentation from CT images.
Findings
Achieved an average dice score of 0.7228, outperforming other state-of-the-art methods.
Demonstrated the effectiveness of combining dense connections with recurrent ConvLSTM layers.
Showed that selective thresholding and morphological operations improve segmentation accuracy.
Abstract
The performance of a computer-aided automated diagnosis system of lung cancer from Computed Tomography (CT) volumetric images greatly depends on the accurate detection and segmentation of tumor regions. In this paper, we present Recurrent 3D-DenseUNet, a novel deep learning based architecture for volumetric lung tumor segmentation from CT scans. The proposed architecture consists of a 3D encoder block that learns to extract fine-grained spatial and coarse-grained temporal features, a recurrent block of multiple Convolutional Long Short-Term Memory (ConvLSTM) layers to extract fine-grained spatio-temporal information, and finally a 3D decoder block to reconstruct the desired volume segmentation masks from the latent feature space. The encoder and decoder blocks consist of several 3D-convolutional layers that are densely connected among themselves so that necessary feature aggregation can…
Click any figure to enlarge with its caption.
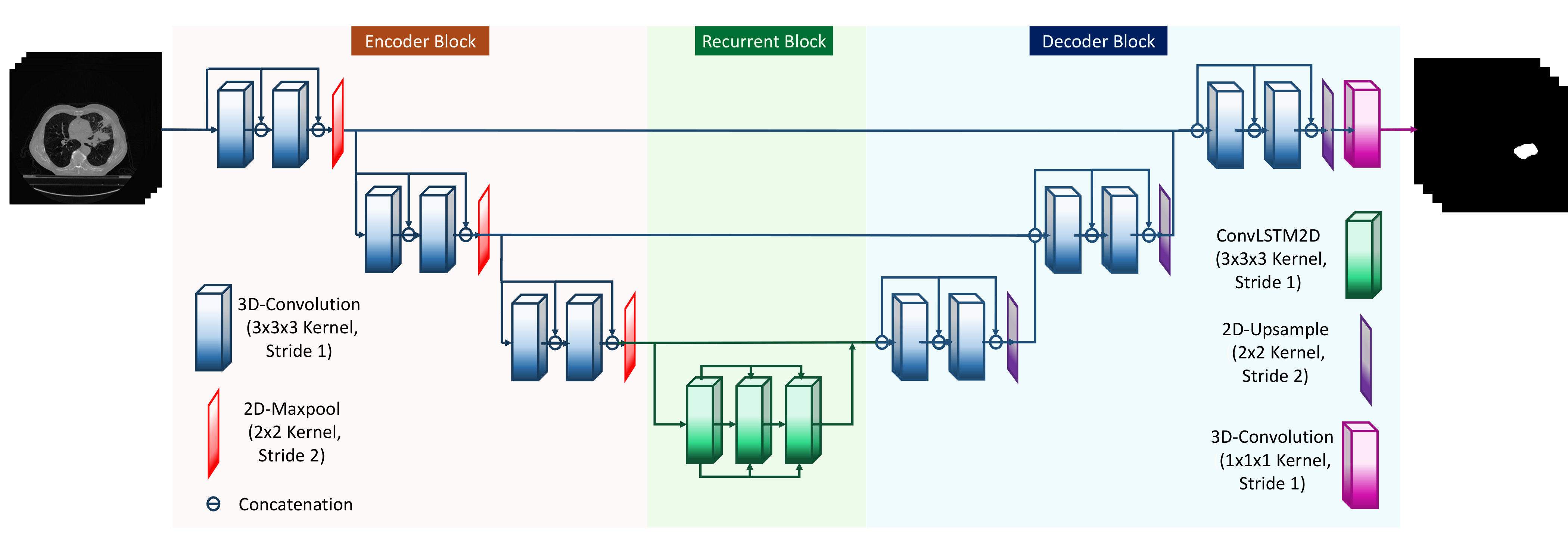 Figure 1
Figure 1 Figure 2
Figure 2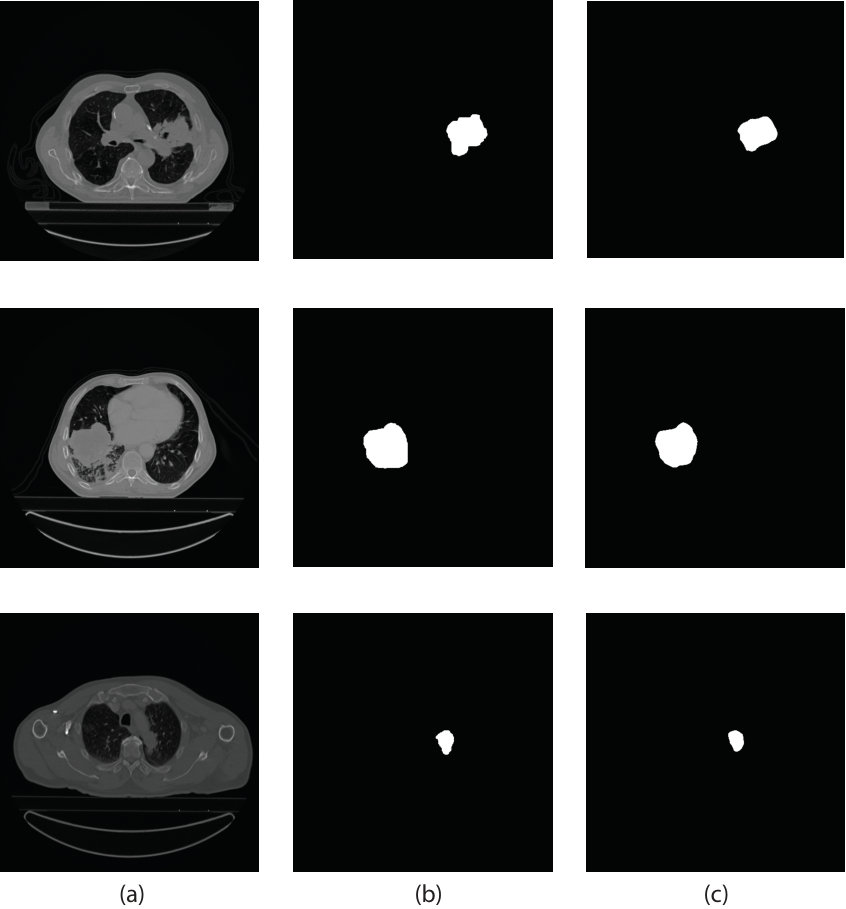 Figure 3
Figure 3| Data | Number of Patients | Tumor | Without Tumor |
|---|---|---|---|
| Train | 260 | 4296 | 26951 |
| Test | 40 | 848 | 3630 |
| Model | Mean Dice coefficient | Median Dice coefficient |
|---|---|---|
| 3D-UNet | 0.6961 | 0.7326 |
| 3D-DenseUNet | 0.6884 | 0.7188 |
| 3D-DenseUNet with recurrent block | 0.7049 | 0.7646 |
| Our proposed network | 0.7228 | 0.7556 |
| Model | Mean Dice coefficient | Median Dice Coefficient | False Positives | False Negatives |
| tversky loss (0.1) | 0.6244 | 0.6637 | 786 | 221 |
| tversky loss (0.3) | 0.6933 | 0.7195 | 453 | 272 |
| tversky loss (0.5) [Dice loss] | 0.6963 | 0.7372 | 375 | 287 |
| tversky loss (0.7) | 0.7056 | 0.7282 | 417 | 324 |
| tversky loss (0.9) | 0.7125 | 0.7462 | 243 | 396 |
| Focal loss [16] | 0.7159 | 0.7493 | 498 | 349 |
| IOU loss | 0.6981 | 0.726 | 437 | 296 |
| binary crossentropy | 0.7228 | 0.7556 | 321 | 331 |
| Model | Mean Dice coefficient | Median Dice Coefficient | False Positives | False Negatives |
| 0.5 threshold | 0.7169 | 0.7296 | 446 | 280 |
| 0.6 threshold | 0.7174 | 0.7383 | 372 | 297 |
| 0.7 threshold | 0.7228 | 0.7556 | 321 | 331 |
| 0.8 threshold | 0.7368 | 0.7685 | 261 | 361 |
| 0.9 threshold | 0.7278 | 0.7763 | 208 | 403 |
| No threshold | 0.6685 | 0.7624 | 120 | 789 |
| No dilation with 0.7 threshold | 0.6604 | 0.7147 | 321 | 332 |
| No dilation with 0.8 threshold | 0.6626 | 0.6859 | 261 | 362 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
11institutetext: Bangladesh University of Engineering and Technology, Dhaka-1205, Bangladesh 22institutetext: University of Windsor, 401 Sunset Ave, Windsor, ON N9B 3P4, Canada
22email: [email protected], {rafi11, jwu}@uwindsor.ca, [email protected]
Lung Cancer Tumor Region Segmentation Using Recurrent 3D-DenseUNet††thanks: source code available at https://github.com/muntakimrafi/TIA2020-Recurrent-3D-DenseUNet
Uday Kamal 11
Abdul Muntakim Rafi 22
Rakibul Hoque 11
Jonathan Wu 22
Md. Kamrul Hasan 11
Abstract
The performance of a computer-aided automated diagnosis system of lung cancer from Computed Tomography (CT) volumetric images greatly depends on the accurate detection and segmentation of tumor regions. In this paper, we present Recurrent 3D-DenseUNet, a novel deep learning based architecture for volumetric lung tumor segmentation from CT scans. The proposed architecture consists of a 3D encoder block that learns to extract fine-grained spatial and coarse-grained temporal features, a recurrent block of multiple Convolutional Long Short-Term Memory (ConvLSTM) layers to extract fine-grained spatio-temporal information, and finally a 3D decoder block to reconstruct the desired volume segmentation masks from the latent feature space. The encoder and decoder blocks consist of several 3D-convolutional layers that are densely connected among themselves so that necessary feature aggregation can occur throughout the network. During prediction, we apply selective thresholding followed by morphological operation, on top of the network prediction, to better differentiate between tumorous and non-tumorous image-slices, which shows more promise than only thresholding-based approaches. We train and test our network on the NSCLC-Radiomics dataset of 300 patients, provided by The Cancer Imaging Archive (TCIA) for the 2018 IEEE VIP Cup. Moreover, we perform an extensive ablation study of different loss functions in practice for this task. The proposed network outperforms other state-of-the-art 3D segmentation architectures with an average dice score of 0.7228.
Keywords:
Lung Tumor CT scan Segmentation U-Net Convolutional LSTM Recurrent Neural Network.
1 Introduction
Lung cancer, also known as lung carcinoma, is a malignant lung tumor characterized by uncontrolled cell growth in tissues of the lung. The abnormal cells do not develop into healthy lung tissue. Instead, they divide rapidly and form tumors. Researchers have found that it takes a series of DNA mutations to create a lung cancer cell. It can be caused by the normal aging process or environmental factors, such as cigarette smoke, breathing in asbestos fibers, and exposure to radon gas [23]. There are two principal types of primary lung cancer, non-small cell lung cancer (NSCLC) and small cell lung cancer (SCLC). These two types are quite different in their behavior and response to treatments. The most common form among these is the NSCLC [26], which accounts for about 85% of all lung cancers.
The primary diagnosis of lung cancer is performed using different non-invasive screening procedures, such as CT scan or Magnetic Resonance Imaging (MRI). A radiologist confirms the existence of malicious cancer cells or tumors from the scanned images before conducting a more formal biopsy test. He extracts and analyzes several features (e.g., attenuation, shape, size, and location) from the medical images. For this purpose, CT scan is a more affordable choice than the MRI. However, it is a daunting task to detect lung tumors from CT scans, and they can often be overlooked [5]. Moreover, the developing and undeveloped countries face a scarcity of expert radiologists, and lung cancers are detected at the final stages in most cases [18]. In this regard, computer-aided diagnosis (CAD) tools have become a necessity to assist the radiologists in making decisions from the raw data of a CT scan quickly with better accuracy.
Several methods have been proposed in the literature to complete the task of lung tumor segmentation. Uzelaltinbulata and Ugur [26] have proposed an image processing based technique to segment the lung tumor in CT images. They have used morphological operations, filtering, seeding, thresholding, and image residue to develop a system that automatically segments lung tumors. Aerts et al. [1] present a radiomic analysis of 440 features that quantify tumor image intensity, shape, and texture, extracted from CT data. In [13], the authors have discussed different statistical approaches to analyze CT data and the associated challenges. Besides lung tumor, a lung image contains many other components, or structures, such as clavicles and lungs. Therefore, detection of a lung tumor can be easily misguided by techniques that solely depend on the image processing technique, where pixel intensity and thresholding are heavily utilized to differentiate the tumor region. Towards this end, researchers are now more focused on machine learning based methods such as Deep Neural Networks(DNN) to solve medical image segmentation problems. These data-driven approaches have radically improved the performance of tumor detection compared to the complete image processing based techniques.
In [19], the authors have introduced V-Net, a fully convolutional neural network (CNN), as well as a unique objective function to conduct volumetric segmentation from MRI [19]. Cicek et al. [4] perform volumetric segmentation through a successful adaptation of U-Net [24] by replacing all the 2D operations with their 3D counterparts. In [3], the authors propose a deep voxel-wise neural network ‘VoxResNet,’ where they explore residual learning for a 3D volumetric segmentation task. Liao et al. [15] have demonstrated the application of a stacked independent subspace analysis (ISA) network to perform 3D prostate segmentation. Another interesting work is the proposition of a novel Hybrid-DenseUNet [14], where the authors utilize the sophisticated connectivity of DenseNet [11] in the U-Net architecture. The dense connections convey associated input features into the deeper levels of the U-Net architecture, which may otherwise suffer from being diminished during the forward propagation. Hossain et al. [10] propose 3D LungNet for performing lung tumor segmentation, where they incorporate a hybrid training method to train their network. In [21], the authors adopt a transfer learning strategy for performing segmentation to alleviate the noisy pixel-level label interruption. Pang et al. [22] propose a unique adversarial learning framework for segmentation. Despite the breadth of works done in the field of volumetric tumor segmentation, none of these approaches have considered the end-to-end recurrent features inherent to the volume CT-scan data. Most of these works heavily rely on the 3D convolutional layers that extract coarse-grained temporal features by utilizing only the neighboring frames instead of the complete volume.
In this paper, we propose a novel Recurrent 3D-DenseUNet architecture for volumetric lung tumor segmentation from CT scans. The core structure of our network is inspired by the widely popular U-Net architecture [24] that consists of a traditional encoder-decoder structure. We modify the network by replacing the 2D convolution operations with their 3D counterparts, except for the pooling layers. Instead of the conventional spatio-temporal pooling operation followed by 3D convolution, we adopt spatial-only pooling layers in order to better preserve the temporal features across slices. We also incorporate the dense connectivity proposed in [11] within our architecture to enable more fine-grained and aggregated feature propagation. In order to transform the coarse-grained output of the 3D encoder into a richer and fine-grained spatio-temporal feature space, we incorporate a recurrent block consisting of several convolutional long short-term memory (ConvLSTM) layers [9] in between the encoder-decoder structure. In addition, the encoder-decoder blocks are interconnected by a hierarchical set of skip connections so that any necessary features lost through the encoding operation can be regenerated during the reconstruction procedure performed by the decoder. The final binary segmentation mask is generated by thresholding the model output followed by dilation, a morphological operation, to reduce the pixel-level anomaly present in the prediction for better representation of the tumor region.
The rest of the paper is organized as follows. Section 2 provides a detailed description of our proposed network. We offer a detailed description of our training procedures, evaluation criteria, experimental results, and ablation study in Section 3. We conclude in section 4.
2 Proposed Network Architecture
In this work, we propose a novel architecture that harnesses the core essence of three fundamental networks: DenseNet [11], U-Net [24], and Convolutional Recurrent Network. Our proposed model is illustrated in Fig. 1 and the outline of the architecture is presented in Table 1.
U-Net [24] is a very popular and well-established network for medical image segmentation and classification problems. Therefore, it is an obvious choice for us to experiment with U-Net for lung tumor segmentation. Thus, in this architecture, we have adopted the U-Net as the core skeleton of our network. Overall, our network consists of three major parts: Encoder, Recurrent block, and a Decoder. The details of each block are as follows:
2.0.1 Encoder Block
The encoder of our network comes with several convolutional blocks, each consisting of two subsequent 3D-Convolutional layers with kernel size , a Batch-Normalization layer, ReLU as an Activation layer and 2D-Maxpooling operation with a kernel size of . The main reason for not using a 3D-pooling operation is to preserve temporal information as much as possible. A spatial dropout layer with a dropout rate of 10% has also been used at the end of every convolutional block in order to prevent overfitting on the training dataset. Since we are interested in pixel-level segmentation, the feature space we are more interested in needs to contain as much high-level information as possible. However, degradation of features strength due to forward propagation of the input data is unavoidable in any feedforward neural network unless the skip connection technique is applied. As shown in [11], dense-blocks, which are the building blocks of DenseNet, are interconnected with each other in the network and thereby prevent loss of acute statistical features due to forward propagation. Inspired by this idea, each convolutional block in the encoder is designed to perform as pseudo-dense-block, which establish inter-connectivity between the input and middle layers of the block.
2.0.2 Recurrent Block
The main intuition of using volume data is to capture the inter-slice continuity of the tumor as a solid object. For this purpose, we have used a recurrent block consisting of several ConvLSTM layers [27] within the transition section from the encoder to the decoder. With the increase in depth of convolutional layers, higher and higher level features are extracted from the input. To capture the interdependencies at the highest level of our network, we have used the recurrent block at the transition section of encoder and decoder, which helps the network to capture more fine-grained spatio-temporal features and inter-dependencies among the output features of the encoder. Each ConvLSTM layer is comprised of 2D-convolutional layers with kernel size .
2.0.3 Decoder Block
The decoder block is the final part of the network that takes the high-level spatio-temporal features captured by the recurrent block as input and generates the volumetric segmentation mask as output. The decoder has a similar architectural structure of the encoder, except the spatial pooling layer is replaced by a spatial Upsample layer that performs the brings the latent feature space to the original input resolution. At decoder block output, a skip connect is established with the corresponding previous encoder block. Finally, a pointwise 3D convolution layer with Sigmoid activation is used to bring the volume mask back to its original input dimension.
3 Experimental Analysis
We perform several experiments to demonstrate the efficacy of our proposed method. In this section, we discuss those experimental procedures and results in detail. All of the experiments regarding training and implementation of the model are performed in hardware environments, which included Intel Core-i7 8700K, 3.70 GHz CPU, and Nvidia GeForce GTX 1080 Ti (11 GB Memory) GPU. The necessary codes are written in Python and, the neural network models are implemented by using the Keras API with Tensorflow-GPU in the backend.
3.1 Description of the Dataset
The dataset we use in our paper consists of 300 patients from the NSCLC-Radiomics dataset [6]. The contour-level annotations for these 300 patients have been prepared for the IEEE VIP Cup 2018 with the help of an expert radiologist [20]. The dataset contains scanned 3D volumes of the chest region for each patient. It is provided in DICOM format with slices of size. We divide the dataset into two sets- train (260) and test (40), the same way as [10]. We use 10% of the training data as our validation set. The distribution of the tumorous and non-tumorous slices are provided in Table 2.
We convert the DICOM data to 2D gray-scale images using the Pydicom [17] Library and extract their respective binary masks from corresponding RTconstruct files. We resize the images from () to () to cope with the memory limitation of GPU. Afterward, we create patches of eight by concatenating eight consecutive images. We can observe in Table 2 that the dataset suffers from severe class imbalance. A large percentage of the CT scan slices do not contain any tumorous region. Moreover, the larger portion of slices containing tumors has non-tumorous regions, as shown in Fig. 2. Therefore, during training, we only use the patches that contain at least one slice with a tumor. Here, the number of slices in a patch is also limited by the computational memory of the GPU. Also, it reduces the training parameters of the network.
3.2 Training procedure
We have used several augmentation schemes to show different data to our neural network in each epoch during training. It helps to prevent the network from overfitting on the training data [25]. The augmentations we use are as follows: random rotation, random cropping, random global shifting, random global scaling, random noise addition, random noise multiplication, horizontal flip, and blurring. They are applied online randomly during training.
We have trained our Recurrent 3D-DenseUNet model using an initial learning rate of and batch size of 2. We do not use a greater batch size number as the computational memory of the GPU limits it. The weights of the different layers are initialized randomly with the uniform distribution proposed by Glorot and Bengio [7]. We use binary cross-entropy as the loss function and Adam [12] as the optimizer with the exponential decay rate factors = 0.9 and = 0.999. We decrease the learning rate by a factor of 0.5 if the validation dice coefficient does not increase in three successive epochs. We train our network for a maximum number of 30 epochs and select the model with the highest validation dice coefficient.
3.3 Evaluation Criteria
We use dice coefficient as our evaluation criterion to compare between generated mask and the ground truth for all test images. Dice coefficient is a measure of relative overlap, where represents perfect agreement and [math] represents no overlap.
[TABLE]
In (1), denotes the intersection operator, and are the predicted binary mask and ground truth. It should be noted that the dice coefficient has a restricted range of . The following two conventions are considered in the computation of Dice coefficient: (i) For True-Negative (i.e., there is no tumor, and the processing algorithm correctly detected the absence of the tumor), the dice coefficient would be 1, and; (ii) For False-Positive (i.e., there is no tumor, but the processing algorithm mistakenly segmented the tumor), the dice coefficient would be 0.
3.4 Results
During testing, we create overlapping patches of from all the CT scan slices of a single patient with stride . Then we use our Recurrent 3D-DenseUNet network to generate volumetric prediction maps. For the masks that belong to multiple patches, we average over multiple predictions. The final binary segmentation mask is generated by thresholding the model output followed by dilation, a morphological operation. The hyperparameters, associated with the post-processing operations, are chosen based on the performance on the validation data. We use a 0.7 threshold to convert the network prediction to binary masks. Afterward, we apply dilation using a circular kernel to improve the IOU (Intersection over Union) value. It reduces the pixel-level anomaly present in the prediction and provides a better representation of the tumor region. We compare our proposed method with several state-of-the-art methods available in the literature for performing segmentation tasks. The performance of the different methods is shown in Table 3. Our proposed method outperforms other approaches by a significant margin. A few predictions from the test set are shown in Fig. 3.
3.5 Ablation study
In this subsection, we perform an ablation study of our proposed methodology and see how different architectural, training, and testing design choices affect our performance. First, we compare the performances of different variants of our network architecture (see Table 4).
A suitable cost function is equally important in training neural networks. The performance is determined by a combination of both the network and the loss function. Moreover, the dice coefficient may not always be the best indicator of a segmentation network’s performance. The number of false positives and false negatives also play a vital role in determining the robustness of a model. Towards this end, we train and test our network with different loss functions and explore how they affect the performance of our network (see Table 5). We see that binary crossentropy outperforms the other loss functions we compare with. Also, the tversky loss function provides an opportunity to reduce the number of false positives or false negatives by changing its parameter [8]. It should be noted that we enable the proposed post-processing operations for the experiments shown in Table 5.
Lastly, we empirically validate the significance of our thresholding and morphological operation. From Table 6, we can see how the performance deteriorates without any thresholding or morphological operations. It can also be noticed that there is a trade-off among the dice coefficient, false positives, and false negatives for different thresholds. The optimum performance can be achieved with a threshold of 0.7 and dilation post-processing operation.
4 Conclusion
In this paper, we have proposed Recurrent 3D-DenseUNet, a novel 3D Recurrent encoder-decoder based Convolutional Neural Network architecture for accurately detecting and segmenting lung tumors from volumetric CT scan data. We adopt spatial-only pooling layers in our architecture, instead of the conventional spatio-temporal pooling operation to better preserve the temporal features. We also use a recurrent block consisting of several ConvLSTM layers between the encoder-decoder structure to capture the inter-slice correlation at the high-level feature space. We have also incorporated short intra-block skip connections between the input and latter layers of every encoder and decoder block throughout the network to reduce the loss of any important feature during forward propagation. We train this model using 3D volume data of size and utilize various types of data augmentations to prevent overfitting during training. Finally, we apply a threshold on top of the network prediction to create binary masks and enhance it with dilation operation. This methodology has enabled us to achieve a better dice score in lung tumor segmentation tasks and reduce the overall number of false positives and false negatives. In our future works, we want to further modify and improve the model architecture, and explore how it performs on other medical imaging tasks.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Aerts, H.J., Velazquez, E.R., Leijenaar, R.T., Parmar, C., Grossmann, P., Carvalho, S., Bussink, J., Monshouwer, R., Haibe-Kains, B., Rietveld, D., et al.: Decoding tumour phenotype by noninvasive imaging using a quantitative radiomics approach. Nature communications 5 (1), 1–9 (2014)
- 2[2] Anthimopoulos, M., Christodoulidis, S., Ebner, L., Geiser, T., Christe, A., Mougiakakou, S.: Semantic segmentation of pathological lung tissue with dilated fully convolutional networks. IEEE journal of biomedical and health informatics 23 (2), 714–722 (2018)
- 3[3] Chen, H., Dou, Q., Yu, L., Heng, P.A.: Voxresnet: Deep voxelwise residual networks for volumetric brain segmentation. ar Xiv preprint ar Xiv:1608.05895 (2016)
- 4[4] Çiçek, Ö., Abdulkadir, A., Lienkamp, S.S., Brox, T., Ronneberger, O.: 3d u-net: learning dense volumetric segmentation from sparse annotation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 424–432. Springer (2016)
- 5[5] del Ciello, A., Franchi, P., Contegiacomo, A., Cicchetti, G., Bonomo, L., Larici, A.R.: Missed lung cancer: when, where, and why? Diagnostic and interventional radiology 23 (2), 118 (2017)
- 6[6] Clark, K., Vendt, B., Smith, K., Freymann, J., Kirby, J., Koppel, P., Moore, S., Phillips, S., Maffitt, D., Pringle, M., et al.: The cancer imaging archive (tcia): maintaining and operating a public information repository. Journal of digital imaging 26 (6), 1045–1057 (2013)
- 7[7] Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the thirteenth international conference on artificial intelligence and statistics. pp. 249–256 (2010)
- 8[8] Hashemi, S.R., Salehi, S.S.M., Erdogmus, D., Prabhu, S.P., Warfield, S.K., Gholipour, A.: Tversky as a loss function for highly unbalanced image segmentation using 3d fully convolutional deep networks. ar Xiv preprint ar Xiv:1803.11078 (2018)