Cooperative Multi-Agent Policy Gradients with Sub-optimal Demonstration
Peixi Peng, Junliang Xing

TL;DR
This paper introduces a self-improving multi-agent policy learning method that leverages sub-optimal demonstrations and Nash Equilibrium concepts to enhance cooperation in complex tasks like combat RTS games.
Contribution
It proposes a novel decentralized policy learning approach that iteratively improves from sub-optimal demonstrations using centralized value updates and Nash Equilibrium guidance.
Findings
Outperforms state-of-the-art demonstration-based methods
Effectively learns multi-agent cooperation in complex scenarios
Demonstrates significant improvements in combat RTS games
Abstract
Many reality tasks such as robot coordination can be naturally modelled as multi-agent cooperative system where the rewards are sparse. This paper focuses on learning decentralized policies for such tasks using sub-optimal demonstration. To learn the multi-agent cooperation effectively and tackle the sub-optimality of demonstration, a self-improving learning method is proposed: On the one hand, the centralized state-action values are initialized by the demonstration and updated by the learned decentralized policy to improve the sub-optimality. On the other hand, the Nash Equilibrium are found by the current state-action value and are used as a guide to learn the policy. The proposed method is evaluated on the combat RTS games which requires a high level of multi-agent cooperation. Extensive experimental results on various combat scenarios demonstrate that the proposed method can learn…
Click any figure to enlarge with its caption.
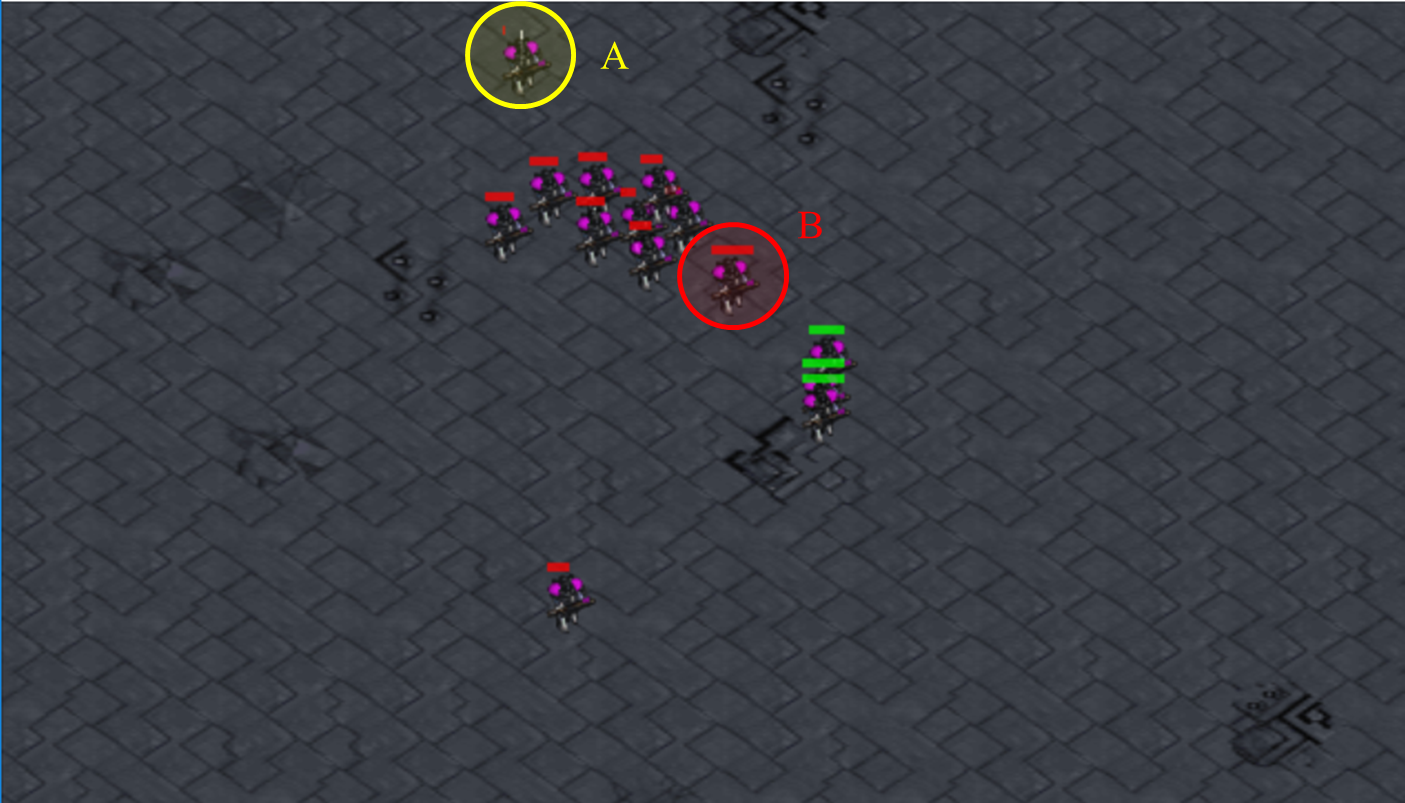 Figure 1
Figure 1 Figure 2
Figure 2| Scenarios | m5v5 | m30v30 | m18v20 | m24v30 | ||||
|---|---|---|---|---|---|---|---|---|
| Metrics | W | R | W | R | W | R | W | R |
| D_c | 0.43 | -0.02 | 0.75 | 0.18 | 0.32 | -0.11 | 0.12 | -0.26 |
| UCT_c | 0.93 | 0.06 | 0.88 | 0.13 | 0.40 | -0.14 | 0.13 | -0.25 |
| A-B_c | 0.96 | 0.07 | 0.85 | 0.16 | 0.36 | -0.17 | 0.12 | -0.24 |
| Profile | 0.84 | 0.14 | 0.99 | 0.33 | 0.61 | 0.06 | 0.30 | -0.11 |
| DQfQ_c | 0.54 | 0.01 | 0.81 | 0.23 | 0.37 | -0.10 | 0.14 | -0.20 |
| DDPGfD_c | 0.86 | 0.21 | 0.95 | 0.05 | 0.48 | -0.19 | 0.16 | -0.17 |
| OGTL_c | 0.89 | 0.24 | 0.93 | 0.16 | 0.38 | -0.05 | 0.13 | -0.21 |
| Ours(O)_c | 0.94 | 0.43 | 0.97 | 0.49 | 0.86 | 0.22 | 0.73 | 0.15 |
| Ours(H)_c | 0.98 | 0.46 | 1.00 | 0.51 | 0.87 | 0.24 | 0.76 | 0.21 |
| D_w | 0.61 | 0.02 | 0.13 | -0.23 | 0.03 | -0.36 | 0.00 | -0.49 |
| UCT_w | 0.93 | 0.01 | 0.73 | 0.09 | 0.37 | -0.19 | 0.00 | -0.36 |
| A-B_w | 0.92 | 0.02 | 0.71 | 0.09 | 0.34 | -0.26 | 0.00 | -0.38 |
| Profile | 0.91 | 0.16 | 0.96 | 0.21 | 0.39 | -0.08 | 0.02 | -0.29 |
| DQfQ_c | 0.69 | 0.08 | 0.34 | -0.13 | 0.27 | -0.19 | 0.04 | -0.35 |
| DDPGfD_w | 0.78 | 0.15 | 0.75 | 0.09 | 0.69 | 0.13 | 0.08 | -0.31 |
| OGTL_w | 0.81 | 0.14 | 0.73 | 0.15 | 0.76 | 0.19 | 0.06 | -0.38 |
| Ours(O)_w | 0.96 | 0.89 | 0.81 | 0.72 | 0.68 | 0.15 | 0.52 | 0.01 |
| Ours(H)_w | 0.99 | 0.48 | 0.84 | 0.26 | 0.71 | 0.16 | 0.58 | 0.03 |
| Scenarios | m5v5 | m30v30 | m18v20 | m24v30 | ||||
|---|---|---|---|---|---|---|---|---|
| Metrics | W | R | W | R | W | R | W | R |
| IQL_c | 0.89 | 0.28 | 0.88 | 0.33 | 0.69 | 0.08 | 0.47 | -0.05 |
| COMA_c | 0.99 | 0.41 | 0.77 | 0.18 | 0.61 | 0.17 | 0.26 | -0.11 |
| Ours_c | 0.98 | 0.46 | 1.00 | 0.51 | 0.87 | 0.24 | 0.76 | 0.21 |
| Scenarios | m5v5 | m30v30 | m18v20 | m24v30 | ||||
|---|---|---|---|---|---|---|---|---|
| Metrics | W | R | W | R | W | R | W | R |
| Oursθ_c | 0.02 | -0.51 | 0.01 | -0.63 | 0.00 | -0.67 | 0.00 | -0.72 |
| OursD_c | 0.96 | 0.38 | 0.96 | 0.27 | 0.79 | 0.18 | 0.67 | 0.16 |
| Ours_c | 0.98 | 0.46 | 1.00 | 0.51 | 0.87 | 0.24 | 0.76 | 0.21 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsReinforcement Learning in Robotics · Optimization and Search Problems · Advanced Bandit Algorithms Research
\UseRawInputEncoding
Cooperative Multi-Agent Policy Gradients with Sub-optimal Demonstration
Peixi Peng1, Junliang Xing1
1, Institute of Automation, Chinese Academy of Sciences
Abstract
Many reality tasks such as robot coordination can be naturally modelled as multi-agent cooperative system where the rewards are sparse. This paper focuses on learning decentralized policies for such tasks using sub-optimal demonstration. To learn the multi-agent cooperation effectively and tackle the sub-optimality of demonstration, a self-improving learning method is proposed: On the one hand, the centralized state-action values are initialized by the demonstration and updated by the learned decentralized policy to improve the sub-optimality. On the other hand, the Nash Equilibrium are found by the current state-action value and are used as a guide to learn the policy. The proposed method is evaluated on the combat RTS games which requires a high level of multi-agent cooperation. Extensive experimental results on various combat scenarios demonstrate that the proposed method can learn multi-agent cooperation effectively. It significantly outperforms many state-of-the-art demonstration based approaches.
Introduction
By combining with deep learning models (?), reinforcement learning (RL) has achieved successful applications to many challenging problems in these years such as Go (?), general Atari game-playing (?) and robot motor control (?). Most of these works involve only a single agent. However, many real-world problems such as autonomous vehicle coordination (?), network packet delivery (?) and playing combat games (?) are naturally modelled as cooperative multi-agent systems (?). The aim is coordinating multiple agents to achieve a unified goal or maximum team benefits by cooperation.
Since the joint state-action space of the agents grows exponentially with the number of agents, RL methods designed for single agents typically fare poorly on such tasks. To cope with this complexity, it is often necessary to resort to decentralised policies, in which each agent selects its own action conditioned only on its local action-observation history (?). RL entails the knowledge of the reward function, or at least observations of immediate reward. Unfortunately, the rewards of multi-agent states need to take into account a wide range of factors such as the joint states of all agents. Hence, it is very difficult to calculate the reward of most states in many reality multi-agent systems. By contrast, it is often quite natural to express a task goal as a sparse reward function (?). For example, the terminal state reward of a combat game can be easily defined by victory or defeat, while it is hard to evaluate the combat situation at non-terminal states. Another typical example is the multiple robot coordination (?; ?) where the rewards are only observed directly in a few situations such as collision or arrival at the destination. A widely-used approach to the sparse rewards is learning from demonstrations (LfD) (?; ?). In many reality applications, although there is very little or no knowledge of the reward function, but there is access to demonstrations performed by experts in the task. A natural method is to recover experts’ strategies from available demonstrations by supervised learning (?). It assumes that the experts are performing well. Agents should also be able to perform well by simply mimicking experts’ moves. Another type of approaches, termed inverse reinforcement learning (IRL) (?), formulates the task as solving an inverse problem, and strives to infer the hidden reward function from expert demonstrations. Most existing IRL methods assume that the demonstrations are generated by an optimal strategy. However, due to the extremely large state action space of multi-agents systems, it’s hard to design an optimal strategy manually even for experts. The available demonstrations are always sub-optimal, and need to be improved rather than just imitating the demonstrator or inferring the reward from the demonstration directly.
Another crucial challenge is multi-agent credit assignment (?): In cooperative setting, the agents actions are performed simultaneously and the state-action value are centralized and shared by all agents. Hence, even if the centralized state-action value can be evaluated from a demonstration, it is still hard to identify each agent action’s own contribution. Some existing works design individual reward functions for each agent by one agent action exploration (?). However, these rewards ignore multi-agent cooperation and often fail to encourage individual agents to sacrifice themselves for team advantages. For example, in a combat, the healthy agents should go forward to draw enemy fire and cover any injured allied agents. This task is always failed when each agent is only driven by its individual reward. Alternative type of methods are designed by centralised learning (?). However, it is inefficient to explore all agents’ actions simultaneously, because the joint state-action space of multiple agents is extremely large.
To cope with these difficulties, a novel RL method is proposed to learn multi-agent cooperation by sub-optimal demonstrations. As shown in Fig. 1, the proposed method involves self-improvement: On the one hand, although the demonstrations are not optimal, it still can be assumed that experts perform well. Hence, the state-action value can be initialized by the experts’ demonstrations at the early stage of learning. To take the sub-optimality of demonstration into account, the state-action value is updated by the learned policy during the learning procedure. In other words, the sub-optimal demonstrations offer initial guidance to ensure that the learned policy is better than experts. On the other hand, the tasks are modeled as the cooperative game and the Nash Equilibrium strategies are found by current centralized state-action value. These Nash Equilibrium strategies can be used to learn decentralised policies and it is the main difference between the proposed method with other multi-agent policy methods (?; ?). The Nash Equilibrium reduces the state-action exploration space and ensures more effective learning of multi-agent cooperation. These two steps can complement and improve each other: the centralized state-action value can be used to find the Nash Equilibrium strategies to learn better decentralized policy; whilst the learned decentralized polices can help to calculate more accurate state-action values.
To summarize, the main contributions of this work are threefold: (1) a novel learning algorithm is proposed to learn multi-agent cooperation with sparse reward by sub-optimal demonstration, (2) the task is modeled as cooperative game and Nash Equilibrium strategy is found to learn decentralized policy, and (3) the state-action value function is updated in learning to tackle the sub-optimality of demonstration. The rest of the paper is organized as follows: Section 2 reviews the related work and highlights our technical contributions. Section 3 formulates the multi-agent learning task by the cooperative game. The learning algorithm is described in Section 4. Extensive experimental analysis and comparisons are discussed in Section 5. The paper concludes with Section 6.
Related Work
Multi-agent Reinforcement Learning (MARL) methods have historically been applied in many settings (?; ?; ?). They have been restricted to tabular methods and simple environments. Motivated from the success of deep RL (?) where value/policy is approximated by deep neural networks, the deep MARL methods can scale to high dimensional input and action spaces (?). Independent Q-learning (?) is proposed to learn decentralised value functions or policies for each agent independently. It is extended to deep neural networks in (?) by combining with DQN (?). Some methods (?; ?) are proposed to address learning stabilisation following this idea. However, these methods always learn each agent independently and ignore the cooperation among agents.
Another type of methods focuses on centralised learning of joint actions which can naturally handle cooperation problems. However, the joint action space will be extremely large when the system contains a lots of agents,which may lead the learning inefficient. Coordination graphs (?) is proposed to exploit conditional independencies between agents by decomposing a global reward function into a sum of agent-local terms. Sparse cooperative Q-learning (?) proposes a tabular Q-learning algorithm that learns to coordinate the actions of a group of cooperative agents only in the states where such coordination is necessary. Recently, more centralised learning methods are proposed to multi-agent communication by combing with deep learning: CommNet, as designed in (?), uses a centralised network architecture to handle communication between agents. The bidirectionally-coordinated network (BiCNet) is introduced in (?) to maintain a scalable and effective communication protocol among multiple units, and it additionally requires estimating individual agent rewards. However, only centralized state-value is known in our cooperative setting. GMEZO (?) models the multi-agent system as a greedy Markov decision procedure and present an RL algorithm using first-order optimisation. To handle an extremely large number of agents, mean field RL (?) is proposed to describe the interaction of an agent with its neighboring agents. Recently, several works are designed as hybrid approaches. QMIX (?) decomposes the centralized state-action values as a group of single agent’s values and enforce that performed on the centralized value yields the same result as a set of individual operations performed on each agent. This assumption fails in some cooperation tasks where an agent should sacrifice itself to the benefit of the team. In addition, several methods are designed by learning decentralized policy using centralized critic. COMA (?) estimates a counterfactual advantage function to update decentralized policy. Similarly, (?) learn a centralised critic for each agent and apply this to competitive games with continuous action spaces. In these methods, one agent’s policy is updated by assuming other agents’ policies is known as on-policy. Hence, they have poor sample efficiency and are prone to getting stuck in sub-optimal local minima (?). Different with them, the proposed method solves the the Nash Equilibrium to learn decentralised policies. The Nash Equilibrium reduces the exploration state-action space and leads to more effective learning of cooperation. A similar method is proposed in (?) where one agent update it’s policy by sampling other agent’s policies from their individual meta-strategies. Compared with (?), the proposed method assumes all agents are performing as Nash Equilibrium jointly and it is more reasonable to multi-agent cooperation. All of these deep MARL methods assume that the reward is available at every state.
Learning from Demonstration (LfD) (?) has received increasing attention as a promising way to tackle the problem of sparse rewards. Imitation learning is primarily concerned with recovering the strategy of the demonstrator in a supervised fashion. DAGGER (?) formulates the task as essentially a regression problem and sets the objective of minimizing the prediction error. Deeply AggreVaTeD (?) extends DAGGER to continuous action spaces by combining with deep neural networks. These methods just imitate the demonstration and can not improve upon the expert. To improve the demonstration, several methods (?; ?) train the network by combining imitation learning and RL together. However, AlphaGo (?) is designed for a single agent and OGTL (?) ignores multi-agent cooperation during learning. Recently, a few approaches are proposed to explore the sparse-reward environment by LfD. For instance, DQfD (?) introduces LfD into DQN adding demonstration data into the replay buffer. Similarly, DDPGfD (?) extends LfD to continuous action domains. POfD (?) leverage demonstrations to guide exploration through enforcing occupancy measure matching between the learned policy and current demonstrations. These methods are all designed for single agent systems and aim at exploring around demonstration to find a better policy. However, the joint state-action space of multiple agents is very large and the optimal policy may be far from experts’ policy with a large probability. Another type of LfD methods is inverse reinforcement learning (IRL) (?) which targets at recovering the reward function of a given task from samples, and it is extended to two-player zero-sum game (?; ?) by alternating between fitting the reward function and selecting the policy. GAIL (?) applies the IRL to high-dimensional continuous control problems. The multi-agent IRL methods (?; ?) are proposed to a non-cooperative game and zero-sum stochastic games respectively. All these methods assume that the demonstration is optimal. Besides these methods, (?) propose to handle sub-optimal demonstrations in two-player zero-sum competitive games. The centralized rewards are inferred by two-player zero-sum constraint. A network is utilized to approximate the rewards by centralized learning. However, the proposed method focuses on learning decentralized policy in multi-agent cooperative tasks which don’t satisfy the two-player zero-sum constraint.
Problem Definition
In the Markov Decision Procedure (MDP) model, the multi-agent system with sparse reward has the following components:
- •
States: The states are modeled by a time series where stands for the state at time and is the terminal state.
- •
Agents: are agents and is the number of the agents. Note the proposed method can be still applicative when is varied at different states.
- •
Actions: defines the action space for agent . is the finite set of candidate action set that can be performed by agent at state . For simplicity, suppose that the candidate actions set of agent is same at every state, then refers to the available action set for agent . At each time step , each agent simultaneously chooses an action , forming a joint action set .
- •
State transition: is the state transition probability. In an MDP, the transition probability depends only on the current state and the agents’ actions at the corresponding state.
- •
Decentralized policy: Given a state and an agent , the decentralized policy is the set of probability distributions over all actions: where . The decentralized policy learning is to find a optimal policy where is the model parameters (i.e, the network parameters in the proposed method).
- •
Rewards: The reward function is bounded and used to measure the reward (or payoff) of the states transition: . We use to represent it for simplicity. In our task, rewards can only be defined in a few states. Without loss of generality, the rewards of the terminal states can be calculated as and at other states.
- •
State-action value (Q): Given a policy , the based state-action value can be calculated by the cumulative rewards:
[TABLE]
where , is a discount factor and is the expectation. The state-action value measures best cumulative rewards as . Since the multiple agents’ actions are performed simultaneously, all the agents share the state-action value.
- •
Demonstrations: The demonstrations usually fall into two types: rule-based heuristics and experience data. The former are always designed by expert’s prior knowledge. The heuristics are task-specific and the proposed method is independent of the knowledge of its internal workings. The only requirement is the heuristics can be simulated. The later are the observation set where shows how experts have performed in the task. Here is the visited state and are each agent’s actions which are performed by experts at the corresponding state . Besides, stands for the th observation and is irrelevant to the time. In order to make the expert’s knowledge available at arbitrary states, a parameterized policy is used to imitate the experts. It can be trained by minimizing the cross-entropy loss function:
[TABLE]
To summarize, these two types of demonstrations can both be written as a policy . A demonstration is optimal if the multi-agent system can get the highest state-action value according to the demonstration policy at every state, i.e, where is a simplification to . Otherwise, the demonstration is sub-optimal.
Learning Algorithm
Cooperative Game and Pure Nash Equilibrium
The multi-agent cooperation can be naturally modelled as a cooperative game which focuses on how much collective payoff a set of agents can gain by forming a coalition. Given the state-action value , the pure Nash Equilibrium (PNE) at state is a set of actions that if for every unilateral deviation :
[TABLE]
where . To solve , the best response dynamic algorithm is utilized in Alg. 1. It can be easily proved that Alg. 1 is convergent to the PNE: In every iteration, the state reward caused by deviator action strictly increases. Since the game is finite and the state-action value is bounded, hence best-response dynamics eventually halts, necessarily at a PNE. Alg. 1 can be considered as joint state-action space exploration. It approximates the optimal policy from a exponential space () in polynomial complexity .
Decentralized Policy Gradient
PNE is a set of discrete actions which may lose useful information. Considering two typical states, the responses (Alg. 1) of two actions and are 0.51 and 0.49 respectively in state 1, while their responses are 0.99 and 0.01 respectively in state 2. It indicates and have a similar effect at state 1, while is superior than significantly at state 2. However, PNE just save in both states and cannot show the difference. To tackle this problem, we recover the response value for each action by where is PNE. can be considered as the continuous form extended from PNE and . Generally speaking, an action with higher should have a larger probability of being performed. Hence, the objective policy of the performed actions of can be estimated by:
[TABLE]
where . Hence, the distribution of parameterized policy should be close to , and can be learned by minimum the Kullback-Leibler divergence () between and :
[TABLE]
Then, the decentralized policy gradient according to can be calculated by (6), and can be learned by where stands for the th iteration of learning and is the learning rate.
[TABLE]
Online Update to Q
As stated in (6) and (4), the parameter can be trained by the policy gradient which is dependent on the . However, is unknown because the optimal policy is unknown. Fortunately, although the available demonstration is sub-optimal, the experts still perform reasonably well. Hence, can be approximated by at the beginning of learning. is similar to expert trajectory return (?), that is, simulating a MDP from until the terminal state where the reward is available. In this case, the Lemma 1 are introduced.
**Lemma 1: **If the PNE (i.e., the output of Alg. 1) are calculated by , then where is the state-action value (1) according to the PNE.
Proof. Consider a MDP initialized by . Since the PNE in Alg. 1 are initialized from the demonstration, and the state-action value strictly increases in every iteration, we have:
[TABLE]
According to Lemma 1, is closer to than (i.e., ). Unfortunately, it is hard to calculate in practice. The calculation of relies Alg. 1 in each state transition of (1). It would be time consuming and leads to the learning inefficient. To reduce computational cost, is used to replace :
[TABLE]
where and . In the learning procedure, the DPN is initialized randomly and can’t model the PNE effectively at some cases during learning procedure. To ensure that the robust, it is calculated as (9) in the proposed method:
[TABLE]
Alg. 2 concludes the proposed learning algorithm. It is based on self-improvement. That is, the are used to guide to update the network and the network can improve in turn. Note that the joint action-state spaces of multiple agents are extremely large and the feasible action-states only occupy a very small portion. To ensure that the train samples effective and abundant, a staged exploration method is utilized. At the early stage of learning, the exploration actions are performed according to the PNE to collect effective train samples efficiently. Then the actions are guided by the network to cover more cases.
Experiments
Combat in RTS Game
The proposed method are tested in combat RTS game where the task is to coordinate multiple allied agents to defeat their enemies controlled by an opponent in a real-time scenario. The combat game has a high requirement for multi-agent cooperation and has been widely utilized to test multi-agent based methods (?; ?; ?; ?; ?; ?; ?; ?; ?). From a machine learning point of view, combat game provides a challenging environment to test AI algorithms because its state-action space is extremely large and the time allowed for planning is on the order of milliseconds. For example, in a specific 15 vs. 15 scenario, the number of points in joint state-action space is almost which is much larger than for Go () (?). The proposed method is testing using SparCraft (?), which is a simulator of the StarCraft local combat game and is widely adopted to test combat game algorithms (?; ?; ?). It is chosen as the experimental platform because of its effective forward simulation function which can make the RL algorithm, especially Alg. 1, more efficiently. In addition, the SparCraft implements several different rule-based heuristics which can be used as our sub-optimal demonstrations. The source code and the trained models will be opened to facilitate further studies of this problem. In our experiment, the combat game is modeled as a sparse-reward task: the reward is only defined at the terminal state (10) where all agents of one player have been wiped out. In (10), are allied agents and are enemies.
[TABLE]
Settings
The decay factor can be set to any positive number because it doesn’t affect the objective policy (4). The iterations in Alg. 1 is set to 10 in our experiments. The win rate over 100 battles and the normalized rewards at terminal states 111/(The sum of all allied agents’ at the initial state) are used as evaluation metrics. We utilize 2 rule-based heuristics implemented in SparCraft as our demonstrators, including: (1) Attack-Closest (c) where agents attack the closest enemy within weapon range, and any agent not within the range of any enemy moves toward the closest enemy, and (2) Attack-Weakest (w):where agents attack the enemy with minimum remaining within weapon range, and an agent not within the range of any enemy moves toward the closest enemy. In our experiments, two types of demonstrations are given for each demonstrator: the heuristic simulator and the observed data. The data are used to recover the policy by imitation learning (2) and the learned policy is further used to calculate (9). As same as most MARL works (?; ?; ?; ?), the opponent’s policy can be simulated as a part of environment in learning. It is reasonable because our goal is to learn multi-agent cooperation rather than competition. In all the tested combat scenarios, two base points in the combat area are chosen for allied and enemy units respectively. The positions of each player’s agents are initialized randomly within a range of the appropriate base point. That is, the scenarios are different in each combat. Our experiments are conducted on a cross-validation setting that the model learned from demonstrator c will fight with w and vice versa. The Terrain Marine (m) is chosen as the test agent type. The test combat scenarios differ in different scales and difficulties: a small scale combat m5v5, a large scale combat m30v30, and two unbalanced combats m18v20 and m24v30 where we control 18 (24) Marines against 20 (30) Marines and our force is much weaker than enemy. These combats, especially the unbalanced combats, require the multiple agents to cooperate effectively to defeat the enemy. The models are trained on GeForce GTX 1080 and tested on a desktop PC with one 2.4 GHz CPU and 8G RAM running in C++. The network can make decision in real time because it only needs forwarding a simple network only once in making each decision.
Feature and Network Architecture
In the experiments, the action space contains two types of discrete actions: move[] and attack[], where is set to 4 corresponding to left, right, up and down, and is the number of enemy units in the start game state of the train combat scenario. To an allied agent , the list [] is the list of attack targets of , and it is arranged in two parts sequentially: the enemy agents inside and outside the weapon range of respectively. In each part, the list is arranged by the ascending order of the remaining hit points . The feature vector () is concatenated of 4 parts: (1) The properties of such as maximum , velocity, weapon damage, maximum cooldown (, the number of frames to wait before being able to attack again), damage per frame, current , position (coordinates on the map) and current . (2) The properties of the enemy agents which are concatenated by the order of []. (3) The properties of the allied agents which are concatenated by ascending order of the distance from the allied agent to the corresponding agent . (4) The statistical properties of the allied and enemy units respectively including the mean, the minimum and the maximum value of the current hit points and the center positions. The positions of the agents except are all the relative coordinates respect to . If the number of allied and enemy agents in a game state is smaller than initial game state, that is, some agents have been wiped out, then these eliminated agents are replaced by nominal agents whose properties are all 0 to make the length of the feature vector identical. In test combat scenarios, the legal action with maximum probability according to the DPN is chosen to be performed. The network is composed of 4 fully connected (FC) layers, 3 batch normalization layers following the first 3 FC layers respectively and a softmax layer to output the probability distribution over the whole action space . The widths of the FC layers are 256, 128, 128 and respectively. The leaky rectified linear function (?) is used as an activation function for the first 3 FC layers.
Comparison Results
Under this setting that the demonstrations are given, the compared methods can be categorised into two groups: (1) Heuristic-based search methods, including UCT (?), Alpha-Beta (A-B) search (?) and profile search (?). The former two methods use the demonstration policy to guide game tree search. Profile search is proposed to search the optimal heuristic for each agent and two demonstration policy are both used as the candidate policies in the experiments. (2) Deep LfD methods, including DQfQ (?), DDPGfD (?) and OGTL (?). These methods are re-implemented with the same feature and experimental setting for fair comparison. The first 2 methods are all designed for single agent, while they can be easily extended to multi-agent setting by combining with IQL (?). OGTL is the latest LfD method designed for multi-agent learning to our knowledge. It utilize the human-made data to pre-train the network and then fine-tuned by RL where rewards are available at every state. For fair comparison, OGTL is pre-trained by the observed data and is calculated as (9).
The comparative results presented in Table 1 are the basis of the following: (1) The search based methods UCT and Alpha-Beta can improve demonstration policy clearly in balanced combats, while the improvement is very limited in unbalanced combats. It is difficult to search the effective policy from the extremely large game tree under real-time limitation (40ms). These methods can only search around the demonstration policy. Profile search select the heuristic without additional exploration, hence it can’t find effective cooperative policy because the used heuristics are both sub-optimal. (2) DQfQ suffer the poor performance because its learning policy is constrained to be close to the demonstration, while it limits the model when the demonstration is sub-optimal. DDPGfD and OGTL perform well in balanced combats, and suffer poorly in unbalanced combats because the cooperation is ignored during learning. (3) The proposed method outperforms other methods as well as the demonstration policy significantly in all testing scenarios. The advantage is more obvious in unbalanced combats. For example, in m24v30 with demonstration w, the win rates of other method are all bellow 0.10, while the proposed method can get 0.58. These advantages indicates the proposed method can significantly improve the demonstration and learn multi-agent cooperation effectively.
Further Evaluation
We perform ablation experiments to validate two key elements of the proposed method. First, the proposed method (6) is compared with two other MARL methods IQL (?) and COMA (?). Since they are both designed for the case in which the reward can be calculated at every state, the used in these methods are all calculated from (9) for fair comparison. As shown in Table 2, IQL performs well in balanced scenarios while fairs poorly in unbalanced scenarios. The reason is that IQL learn each agent independently without effective cooperation. The win rate of COMA is fairly high in small balanced battle but apparently fell in large and unbalanced battles. Different with COMA, the proposed method learn decentralized policies according to Nash Equilibrium. The guidance of Nash Equilibrium reduce the multi-agent exploration space and leads to more effective and stable cooperation learning.
Then, the contribution of “online update of ” is evaluated. In this experiment, the proposed method is compared with two ablation methods: “OursD” and “Oursθ” where are replaced by and respectively throughout the learning procedure. From the results in Table 3, it is evident that: (1) “OursD” performs well, thus demonstrating the effectiveness of using sub-optimal demonstration. (2) The performance of “Oursθ” is very poor because the network cannot provide an effective when the rewards are sparse. (3) “Ours” outperforms “OursD” and “Oursθ” in all cases which demonstrates (9) contribute positively.
To better understand the proposed method, here we give two intuitive examples to show what the proposed method have learned222More demos will be released with the source codes.: (1) Cover and withdraw. Fig 2 is a typical battle scene from m18v20. We can find that the learned policy will keep most units engaged in combat to maximize the damage. Also, the healthy unit (B) will step forward to cover other ally units and the near death unit (A) will escape from the battlefield to keep alive. (2) Fire allocation to maximum team damage. The used demonstration policies focus fire to eliminate a enemy agent quickly, which may lead “over kill”. For example, coordinate all agents to attack a near death unit. In this case, most attacks will be invalid because the target will be eliminated by one attack. The ratio of the invalid attacks are counted to estimate this situation. In m30v30 scenario, the ratio of demonstration is 43%, while it is only 6% to the learned policy. It shows the proposed method can allocate fire more effectively.
Conclusion
This paper introduces a method to learn multi-agent cooperation from sub-optimal demonstration. A self-improving method is proposed to learn a decentralized policy: On the one hand, the state-action value are initialized by the demonstration and updated by the learned strategy to improve its sub-optimality. On the other hand, the Nash Equilibrium strategies are found by the current state-action value to learn better policy. The proposed method is evaluated on the combat of RTS game which has a high requirement for multi-agent cooperation. Extensive experimental results on various combat scenarios demonstrate that the proposed method can learn the multi-agent cooperation effectively and it significantly outperforms many state-of-the-art demonstration based approaches.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Busoniu, Babuska, and De Schutter 2008] Busoniu, L.; Babuska, R.; and De Schutter, B. 2008. A comprehensive survey of multiagent reinforcement learning. IEEE Transactions on Systems Man and Cybernetics 38(2):156–172.
- 2[Cao et al . 2012] Cao, Y.; Yu, W.; Ren, W.; and Chen, G. 2012. An overview of recent progress in the study of distributed multi-agent coordination. IEEE Transactions on Industrial Informatics 9(1):427–438.
- 3[Chen and etc. 2016] Chen, Y. F., and etc. 2016. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning. In Proc. ICRA .
- 4[Churchill and Buro 2013] Churchill, D., and Buro, M. 2013. Portfolio greedy search and simulation for large-scale combat in starcraft. In Proc. CIG , 1–8. IEEE.
- 5[Churchill, Saffidine, and Buro 2012] Churchill, D.; Saffidine, A.; and Buro, M. 2012. Fast heuristic search for rts game combat scenarios. In Proc. AIIDE , 112–117.
- 6[Everett, Chen, and How 2018] Everett, M.; Chen, Y. F.; and How, J. P. 2018. Motion planning among dynamic, decision-making agents with deep reinforcement learning. ar Xiv .
- 7[Foerster et al . 2017] Foerster, J.; Nardelli, N.; Farquhar, G.; Afouras, T.; Torr, P. H. S.; Kohli, P.; and Whiteson, S. 2017. Stabilising experience replay for deep multi-agent reinforcement learning. In Proc. ICML .
- 8[Foerster et al . 2018] Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; and Whiteson, S. 2018. Counterfactual multi-agent policy gradients. In Proc. AAAI .