Optimal models of decision-making in dynamic environments
Zachary P. Kilpatrick, William R. Holmes, Tahra L. Eissa, Kre\v{s}imir, Josi\'c

TL;DR
This paper reviews recent theoretical models of optimal decision-making in dynamic environments, highlighting how animals and humans adapt their strategies to environmental changes and achieve near-optimal performance in 2AFC tasks.
Contribution
It provides a comprehensive review of computational models for decision-making in changing environments and compares these models with experimental behavioral data.
Findings
Animals and humans can perform near-optimally in dynamic 2AFC tasks.
Models effectively capture how decision strategies adapt to environmental changes.
Performance analysis helps understand the neural basis of adaptive decision-making.
Abstract
Nature is in constant flux, so animals must account for changes in their environment when making decisions. How animals learn the timescale of such changes and adapt their decision strategies accordingly is not well understood. Recent psychophysical experiments have shown humans and other animals can achieve near-optimal performance at two alternative forced choice (2AFC) tasks in dynamically changing environments. Characterization of performance requires the derivation and analysis of computational models of optimal decision-making policies on such tasks. We review recent theoretical work in this area, and discuss how models compare with subjects' behavior in tasks where the correct choice or evidence quality changes in dynamic, but predictable, ways.
Click any figure to enlarge with its caption.
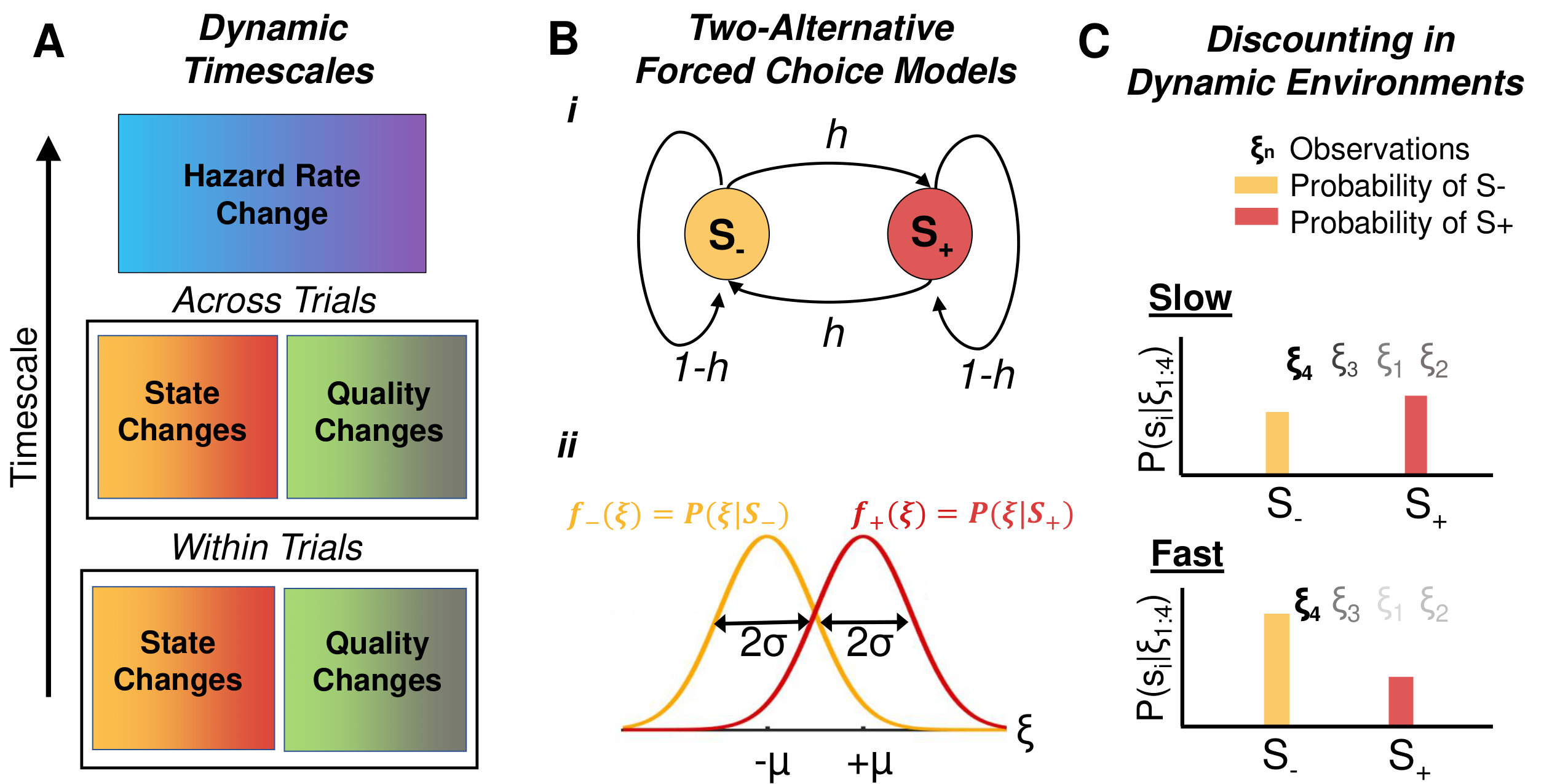 Figure 1
Figure 1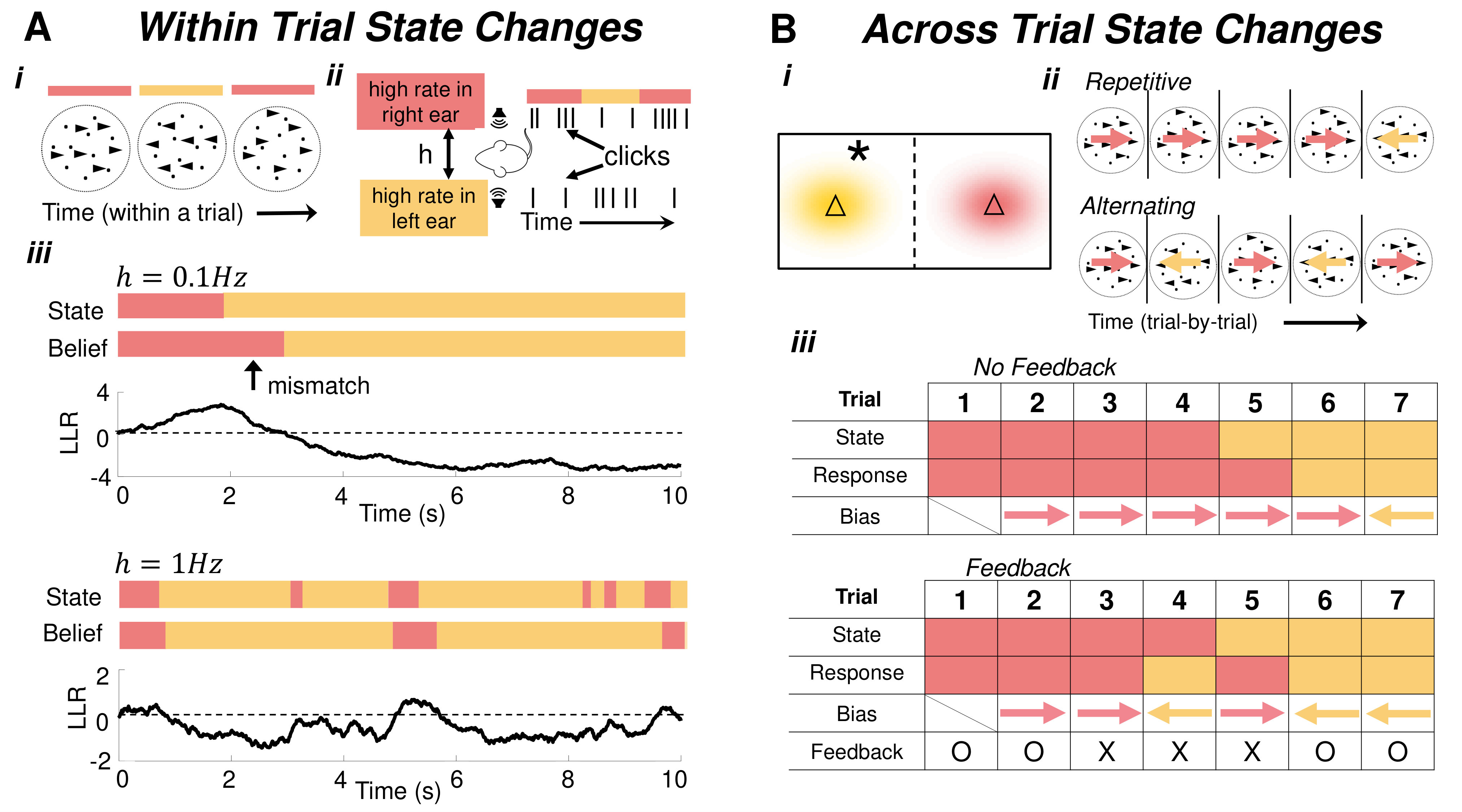 Figure 2
Figure 2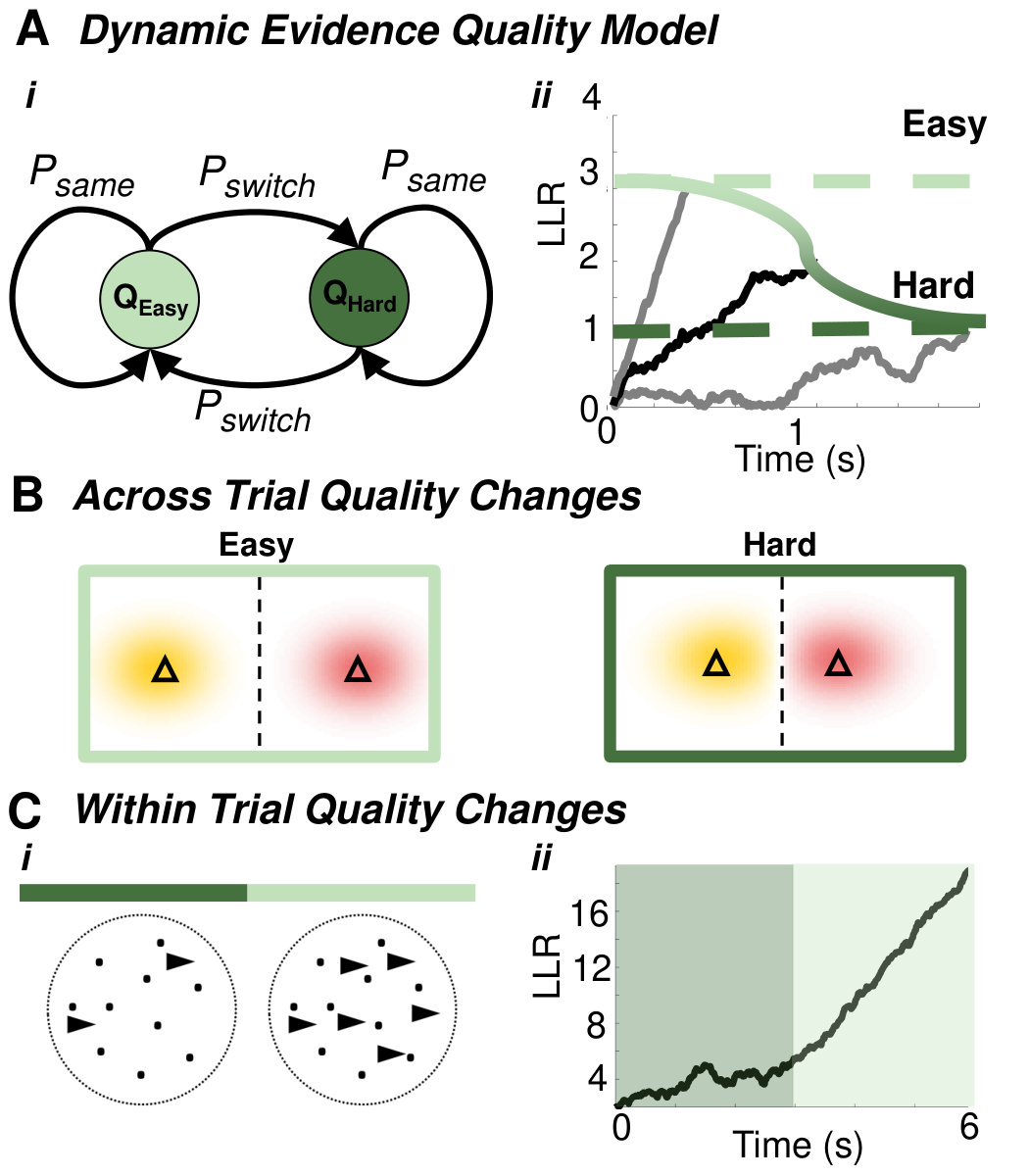 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Optimal models of decision-making in dynamic environments
Zachary P. Kilpatrick
Department of Applied Mathematics, University of Colorado, Boulder, Colorado, USA
William R. Holmes
Department of Physics and Astronomy, Department of Mathematics, Quantitative Systems Biology Center, Vanderbilt University, Nashville, Tennessee, USA
Tahra L. Eissa
Department of Applied Mathematics, University of Colorado, Boulder, Colorado, USA
Krešimir Josić
Department of Mathematics, Department of Biology and Biochemistry, University of Houston, Houston, Texas, USA
Department of BioSciences, Rice University, Houston, Texas, USA
Abstract
Nature is in constant flux, so animals must account for changes in their environment when making decisions. How animals learn the timescale of such changes and adapt their decision strategies accordingly is not well understood. Recent psychophysical experiments have shown humans and other animals can achieve near-optimal performance at two alternative forced choice (2AFC) tasks in dynamically changing environments. Characterization of performance requires the derivation and analysis of computational models of optimal decision-making policies on such tasks. We review recent theoretical work in this area, and discuss how models compare with subjects’ behavior in tasks where the correct choice or evidence quality changes in dynamic, but predictable, ways.
Introduction
To translate stimuli into decisions, animals interpret sequences of observations based on their prior experiences [1]. However, the world is fluid: The context in which a decision is made, the quality of the evidence, and even the best choice can change before a judgment is formed, or an action taken. A source of water can dry up, or a nesting site can become compromised. But even when not fully predictable, changes often have statistical structure: Some changes are rare, others are frequent, and some are more likely to occur at specific times. How have animals adapted their decision strategies to a world that is structured, but in flux?
Classic computational, behavioral, and neurophysiological studies of decision-making mostly involved tasks with fixed or statistically stable evidence [2, 3, 1]. To characterize the neural computations underlying decision strategies in changing environments, we must understand the dynamics of evidence accumulation [4]. This requires novel theoretical approaches. While normative models are a touchstone for theoretical studies [5, 6], even for simple dynamic tasks the computations required to optimally translate evidence into decisions can become prohibitive [7]. Nonetheless, quantifying how behavior differs from normative predictions helps elucidate the assumptions animals use to make decisions [8, 9].
We review normative models and compare them with experimental data from two alternative forced choice (2AFC) tasks in dynamic environments. Our focus is on tasks where subjects passively observe streams of evidence, and the evidence quality or correct choice can vary within or across trials. Humans and animals adapt their decision strategies to account for such volatile environments, often resulting in performance that is nearly optimal on average. However, neither the computations they use to do so nor their neural implementations are well understood.
Optimal evidence accumulation in changing environments
Normative models of decision-making typically assume subjects are Bayesian agents [14, 15] that probabilistically compute their belief of the state of the world by combining fresh evidence with previous knowledge. Beyond normative models, notions of optimality require a defined objective. For instance, an observer may need to report the location of a sound [16], or the direction of a moving cloud of dots [5], and is rewarded if the report is correct. Combined with a framework to translate probabilities or beliefs into actions, normative models provide a rational way to maximize the net rewards dictated by the environment and task. Thus an optimal model combines normative computations with a policy that translates a belief into the optimal action.
How are normative models and optimal policies in dynamic environments characterized? Older observations have less relevance in rapidly changing environments than in slowly changing ones. Ideal observers account for environmental changes by adjusting the rate at which they discount prior information when making inferences and decisions [17]. In Box 1 we show how, in a normative model, past evidence is nonlinearly discounted at a rate dependent on environmental volatility [5, 17]. When this volatility [8] or the underlying evidence quality [18, 13] are unknown, they must also be inferred.
In 2AFC tasks, subjects accumulate evidence until they decide on one of two choices either freely or when interrogated. In these tasks, fluctuations can act on different timescales (Fig. 1a):
- on each trial (Fig. 1b,c) [5, 6], 2) unpredictably within only some trials [19, 20], 3) between trials in a sequence [11, 16], or 4) gradually across long blocks of trials [21]. We review findings in the first three cases and compare them to predictions of normative model.
Within trial changes promote leaky evidence accumulation
Normative models of dynamic 2AFC tasks (Fig. 1b,c and 2a, Box 1) exhibit adaptive, nonlinear discounting of prior beliefs at a rate adapted to expectations of the environment’s volatility (Fig. 1c), and saturation of certainty about each hypothesis, regardless of how much evidence is accumulated (Fig. 2a). In contrast, ideal observers in static environments weigh all past observations equally, and their certainty grows without bound until a decision [3, 1]. Also, in dynamic environments, the performance of ideal observers at change points – times when the correct choice switches – depends sensitively on environmental volatility (Fig. 2aiii). In slowly changing environments, optimal observers assume that changes are rare, and thus adapt slowly after one has occured. In contrast, in rapidly changing environments, observers quickly update their belief after a change point.
The responses of humans and other animals on tasks in which the correct choice changes stochastically during a trial share features with normative models: In a random dot-motion discrimination (RDMD) task, where the motion direction switches at unsignaled changepoints, humans adapt their decision-making process to the switching (hazard) rate (Fig. 2ai) [5]. However, on average, they overestimate the change rates of rapidly switching environments and underestimate the change rates of slowly switching environments. In a related experiment (Fig 2aii), rats were trained to identify which of two Poisson auditory click streams arrived at a higher rate [22]. When the identity of the higher-frequency stream switched unpredictably during a trial, trained rats discounted past clicks near-optimally on average, suggesting they learned to account for latent environmental dynamics [6].
However, behavioral data are not uniquely explained by normative models. Linear approximations of normative models perform nearly identically [17], and, under certain conditions, fit behavioral data well [23, 5, 6]. Do subjects implement normative decision policies or simpler strategies that approximate them? Subjects’ decision strategies can depend strongly on task design and vary across individuals [5, 9], suggesting a need for sophisticated model selection techniques. Recent research suggests normative models can be robustly distinguished from coarser approximations when task difficulty and volatility are carefully tuned [24].
Subjects account for correlations between trials by biasing initial beliefs
Natural environments can change over timescales that encompass multiple decisions. However, in many experimental studies, task parameters are fixed or generated independently across trials, so evidence from previous trials is irrelevant. Even so, subjects often use decisions and information from earlier trials to (serially) bias future choices [25, 26, 27], reflecting ingrained assumptions about cross-trial dependencies [21, 28].
To understand how subjects adapt to constancy and flux across trials, classic 2AFC experiments have been extended to include correlated cross-trial choices (Fig. 2b) where both evidence accumulated during a trial, and probabilistic reward provide information that can be used to guide subsequent decisions [16, 29]. When a Markov process [30] (Fig. 1b) is used to generate correct choices, human observers adapt to these trial-to-trial correlations and their response times are accurately modeled by drift diffusion [11] or ballistic models [16] with biased initial conditions.
Feedback or decisions across correlated trials impact different aspects of normative models [31] including accumulation speed (drift) [32, 33, 34], decision bounds [11], or the initial belief on subsequent trials [35, 12, 36]. Given a sequence of dependent but statistically identical trials, optimal observers should adjust their initial belief and decision threshold [16, 28], but not their accumulation speed in cases where difficulty is fixed across trials [18]. Thus, optimal models predict that observers should, on average, respond more quickly, but not more accurately [28]. Empirically, humans [12, 35, 36] and other animals [29] do indeed often respond faster on repeat trials, which can often be modeled by per trial adjustments in initial belief. Furthermore, this bias can result from explicit feedback or subjective estimates, as demonstrated in studies where no feedback is provided (Fig. 2biii) [16, 36].
The mechanism by which human subjects carry information across trials remains unclear. Different models fit to human subject data have represented intertrial dependencies using initial bias, changes in drift rate, and updated decision thresholds [11, 16, 34]. Humans also tend to have strong preexisting repetition biases, even when such biases are suboptimal [25, 26, 27]. Can this inherent bias be overcome through training? The answer may be attainable by extending the training periods of humans or nonhuman primates [5, 9], or using novel auditory decision tasks developed for rodents [6, 29]. Ultimately, high throughput experiments may be needed to probe how ecologically adaptive evidence accumulation strategies change with training.
Time-varying thresholds account for heterogeneities in task difficulty
Optimal decision policies can also be shaped by unpredictable changes in decision difficulty. For instance, task difficulty can be titrated by varying the signal-to-noise ratio of the stimulus, so more observations are required to obtain the same level of certainty. Theoretical studies have shown that it is optimal to change one’s decision criterion within a trial when the difficulty of a decision varies across trials [18, 37, 13]. The threshold that determines how much evidence is needed to make a decision should vary during the trial (Fig. 3a) to incorporate up-to-date estimates of trial difficulty [18]. There is evidence that subjects use time-varying decision boundaries to balance speed and accuracy on such tasks [38, 39].
Dynamic programming can be used to derive optimal decision policies when trial-to-trial difficulties or reward sizes change. For instance, when task difficulty changes across trials in a RDMD task, optimal decisions are modeled by a DDM with a time-varying boundary, in agreement with reaction time distributions of humans and monkeys [18, 38]. Both dynamic programming [18] and parameterized function [40, 38] based models suggest decreasing bounds maximize reward rates (Fig. 3a,b). This dynamic criterion helps participants avoid noise-triggered early decisions or extended deliberations [18]. An exception to this trend was identified in trial sequences without trials of extreme difficulty [13], in which case the optimal strategy used a threshold that increased over time.
Time-varying decision criteria also arise when subjects perform tasks where information quality changes within trials (Fig. 3c) [40], especially when initially weak evidence is followed by stronger evidence later in the trial. However, most studies use heuristic models to explain psychophysical data [19, 20], suggesting a need for normative model development in these contexts. Decision threshold switches have also been observed in humans performing changepoint detection tasks, whose difficulty changes from trial-to-trial [41], and in a model of value-based decisions, where the reward amounts change between trials [42]. Overall, optimal performance on tasks in which reward structure or decision difficulty changes across trials require time-varying decision criteria, and subject behavior approximates these normative assumptions.
One caveat is that extensive training or obvious across-trial changes are needed for subjects to learn optimal solutions. A meta-analysis of multiple studies showed that fixed threshold DDMs fit human behavior well when difficulty changes between trials were hard to perceive [43]. A similar conclusion holds when changes occur within trials [44]. However, when nonhuman primates are trained extensively on tasks where difficulty variations were likely difficult to perceive, they appear to learn a time-varying criterion strategy [45]. Humans also exhibit time-varying criteria in reward-free trial sequences where interrogations are interspersed with free responses [46]. Thus, when task design makes it difficult to perceive task heterogeneity or learn the optimal strategy, subjects seem to use fixed threshold criteria [43, 44]. In contrast, with sufficient training [45], or when changes are easy to perceive [46], subjects can learn adaptive threshold strategies.
Questions remain about how well normative models describe subject performance when difficulty changes across or within trials. How distinct do task difficulty extremes need to be for subjects to use optimal models? No systematic study has quantified performance advantages of time-varying decision thresholds. If they do not confer a significant advantage, the added complexity of dynamic thresholds may discourage their use.
When and how are normative computations learned and achieved?
Except in simple situations, or with overtrained animals, subjects can at best approximate computations of an ideal observer [14]. Yet, the studies we reviewed suggest that subjects often learn to do so effectively. Humans appear to use a process resembling reinforcement learning to learn the structure and parameters of decision task environments [47]. Such learning tracks a gradient in reward space, and subjects adapt rapidly when the task structure changes [48]. Subjects also switch between different near-optimal models when making inferences, which may reflect continuous task structure learning [9]. However, these learning strategies appear to rely on reward and could be noisier when feedback is probabilistic or absent. Alternatively, subjects may ignore feedback and learn from evidence accumulated within or across trials [28, 46].
Strategy learning can be facilitated by using simplified models. For example, humans appear to use sampling strategies that approximate, but are simpler than, optimal inference [49, 9]. Humans also behave in ways that limit performance by, for instance, not changing their mind when faced with new evidence [50]. This confirmation bias may reflect interactions between decision and attention related systems that are difficult to train away [51]. Cognitive biases may also arise due to suboptimal applications of normative models [52]. For instance, recency bias can reflect an incorrect assumption of trial dependencies [53]. Subjects seem to continuously update latent parameters (e.g., hazard rate), perhaps assuming that these parameters are always changing [21, 29].
The adaptive processes we have discussed occur on disparate timescales, and thus likely involve neural mechanisms that interact across scales. Task structure learning occurs over many sessions (days), while the volatility of the environment and other latent parameters can be learned over many trials (hours) [49, 6]. Trial-to-trial dependencies likely require memory processes that span minutes, while within trial changes require much faster adaptation (milliseconds to seconds).
This leaves us with a number of questions: How does the brain bridge timescales to learn and implement adaptive evidence integration? This likely requires coordinating fast neural activity changes with slower changes in network architecture [8]. Studies of decision tasks in static environments suggest that a subject’s belief and ultimate choice is reflected in evolving neural activity [2, 3, 1, 54]. It is unclear whether similar processes represent adaptive evidence accumulation, and, if so, how they are modulated.
Conclusions
As the range of possible descriptive models grows with task complexity [49, 8], optimal observer models provide a framework for interpreting behavioral data [5, 6, 34]. However, understanding the computations subjects use on dynamic tasks, and when they depart from optimality, requires both careful comparison of models to data and comparisons between model classes [55].
While we mainly considered optimality defined by performance, model complexity may be just as important in determining the computations used by experimental subjects [56]. Complex models, while more accurate, may be difficult to learn, hard to implement, and offer little advantage over simpler ones [9, 8]. Moreover, predictions of more complex models typically have higher variance, compared to the higher bias of more parsimonious models, resulting in a trade-off between the two [9].
Invasive approaches for probing adaptive evidence accumulation are a work in progress [57, 58]. However, pupillometry has been shown to reflect arousal changes linked to a mismatch between expectations and observations in dynamic environments [59, 27, 10]. Large pupil sizes reflect high arousal after a perceived change, resulting in adaptive changes in evidence weighting. Thus, pupillometry may provide additional information for identifying computations underlying adaptive evidence accumulation.
Understanding how animals make decisions in volatile environments requires careful task design. Learning and implementing an adaptive evidence accumulation strategy needs to be both rewarding and sufficiently simple so subjects do not resign themselves to simpler computations [43, 44]. A range of studies have now shown that mammals can learn to use adaptive decision-making strategies in dynamic 2AFC tasks [5, 6]. Building on these approaches, and using them to guide invasive studies with mammals offers promising new ways of understanding the neural computations that underlie our everyday decisions.
Acknowledgements
We are grateful to Joshua Gold, Alex Piet, and Nicholas Barendregt for helpful feedback. This work was supported by an NSF/NIH CRCNS grant (R01MH115557) and an NSF grant (DMS-1517629). ZPK was also supported by an NSF grant (DMS-1615737). KJ was also supported by NSF grant DBI-1707400. WRH was supported by NSF grant SES-1556325.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Gold, J. I. & Shadlen, M. N. The neural basis of decision making. \Journal Title Annual review of neuroscience 30 (2007).
- 2[2] Britten, K. H., Shadlen, M. N., Newsome, W. T. & Movshon, J. A. The analysis of visual motion: a comparison of neuronal and psychophysical performance. \Journal Title Journal of Neuroscience 12 , 4745–4765 (1992).
- 3[3] Bogacz, R., Brown, E., Moehlis, J., Holmes, P. & Cohen, J. D. The physics of optimal decision making: a formal analysis of models of performance in two-alternative forced-choice tasks. \Journal Title Psychological review 113 , 700 (2006).
- 4[4] Gao, P. et al. A theory of multineuronal dimensionality, dynamics and measurement. \Journal Title bio Rxiv 214262 (2017).
- 5[5] Glaze, C. M., Kable, J. W. & Gold, J. I. Normative evidence accumulation in unpredictable environments. \Journal Title Elife 4 , e 08825 (2015).
- 6[6] **Piet, A. T., El Hady, A. & Brody, C. D. Rats adopt the optimal timescale for evidence integration in a dynamic environment. \Journal Title Nature Communications 9 , 4265 (2018). Rats can learn to optimally discount evidence when deciding between two dynamically switching auditory click streams, and they adapted to shifts in environmental change rates.
- 7[7] Adams, R. P. & Mac Kay, D. J. Bayesian online changepoint detection. \Journal Title ar Xiv preprint ar Xiv:0710.3742 (2007).
- 8[8] Radillo, A. E., Veliz-Cuba, A., Josić, K. & Kilpatrick, Z. P. Evidence accumulation and change rate inference in dynamic environments. \Journal Title Neural computation 29 , 1561–1610 (2017).