Domain Attentive Fusion for End-to-end Dialect Identification with Unknown Target Domain
Suwon Shon, Ahmed Ali, James Glass

TL;DR
This paper introduces a domain attentive fusion method for end-to-end dialect identification that maintains high performance across unknown target domains without prior domain knowledge, tested on diverse broadcast and YouTube data.
Contribution
The study proposes a novel domain attentive fusion approach that enhances end-to-end dialect identification robustness in domain-mismatched scenarios without needing target domain information.
Findings
Significant performance improvements over traditional methods.
Effective on broadcast and YouTube data from multiple domains.
Robustness to unknown target domains demonstrated.
Abstract
End-to-end deep learning language or dialect identification systems operate on the spectrogram or other acoustic feature and directly generate identification scores for each class. An important issue for end-to-end systems is to have some knowledge of the application domain, because the system can be vulnerable to use cases that were not seen in the training phase; such a scenario is often referred to as a domain mismatched condition. In general, we assume that there is enough variation in the training dataset to expose the system to multiple domains. In this work, we study how to best make use a training dataset in order to have maximum effectiveness on unknown target domains. Our goal is to process the input without any knowledge of the target domain while preserving robust performance on other domains as well. To accomplish this objective, we propose a domain attentive fusion…
Click any figure to enlarge with its caption.
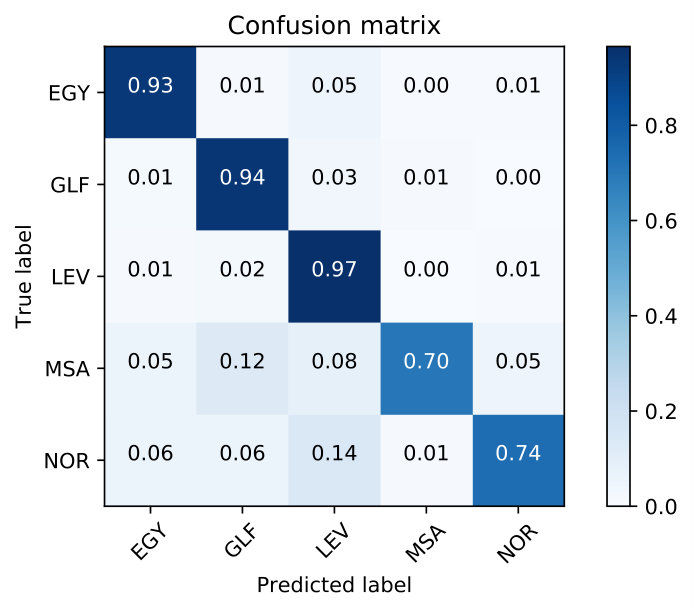 Figure 1
Figure 1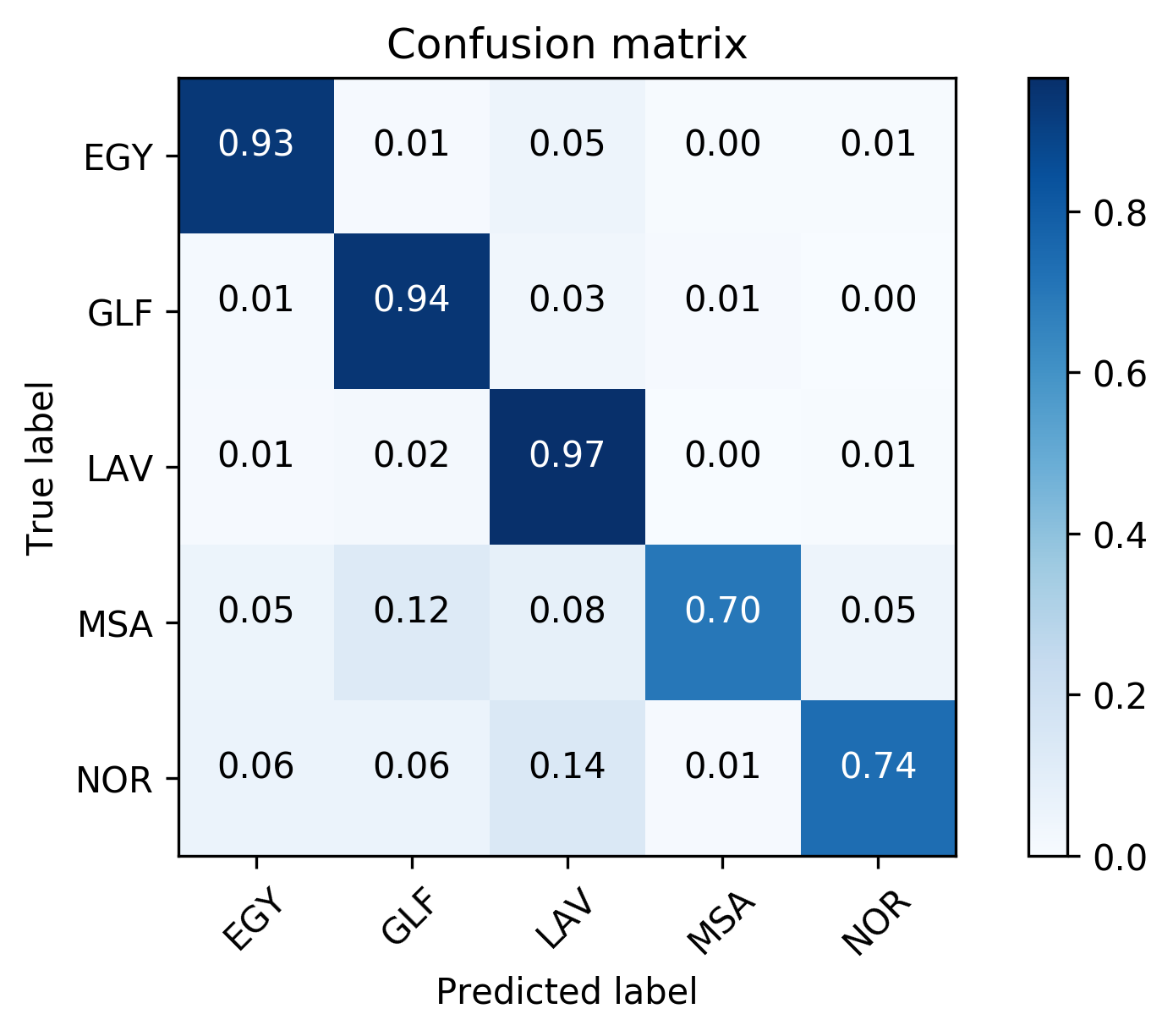 Figure 2
Figure 2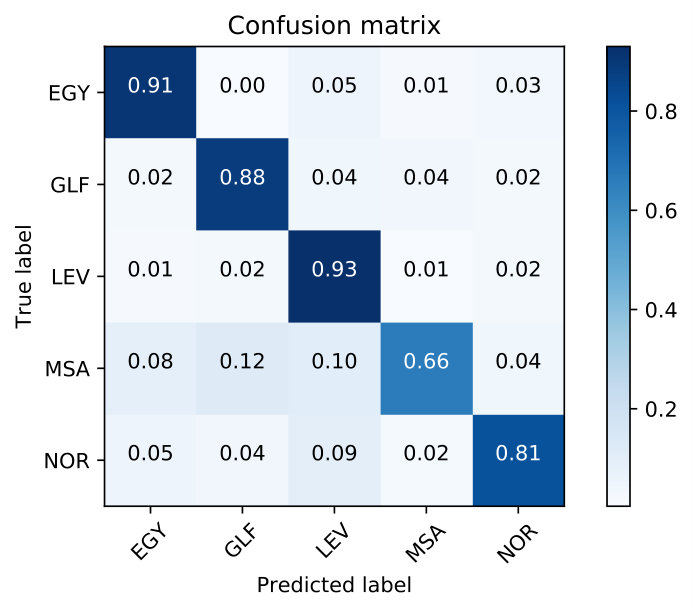 Figure 3
Figure 3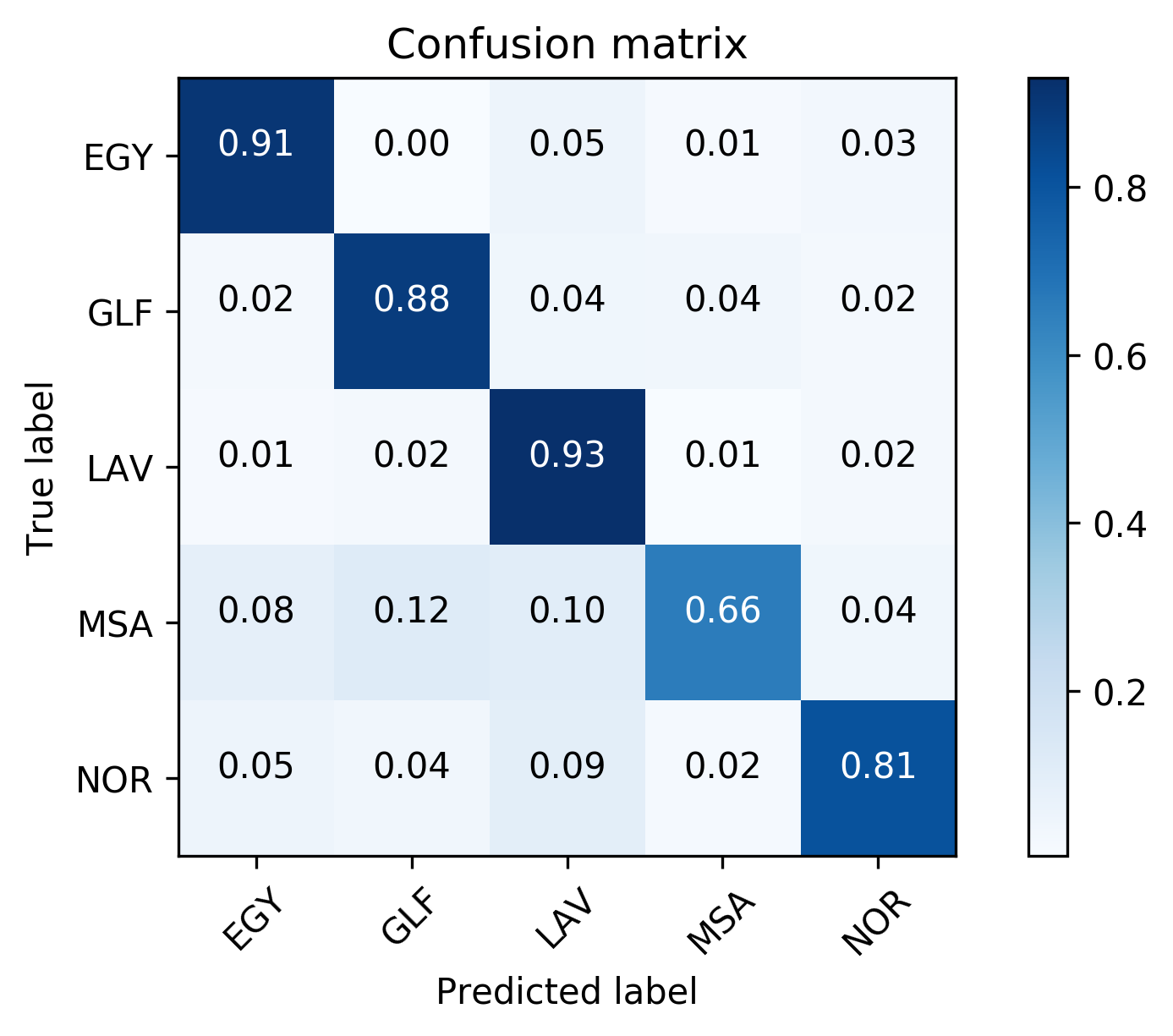 Figure 4
Figure 4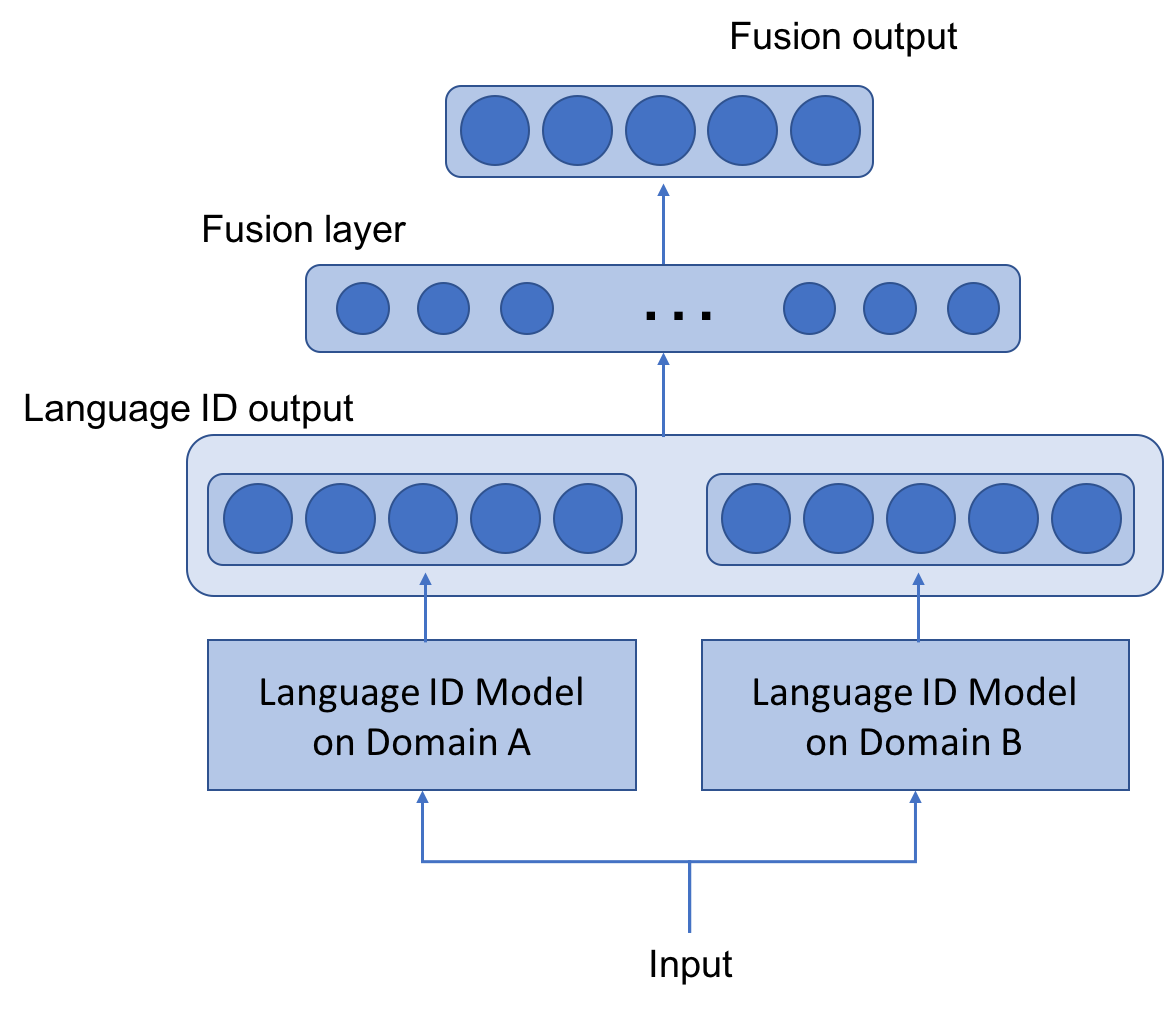 Figure 5
Figure 5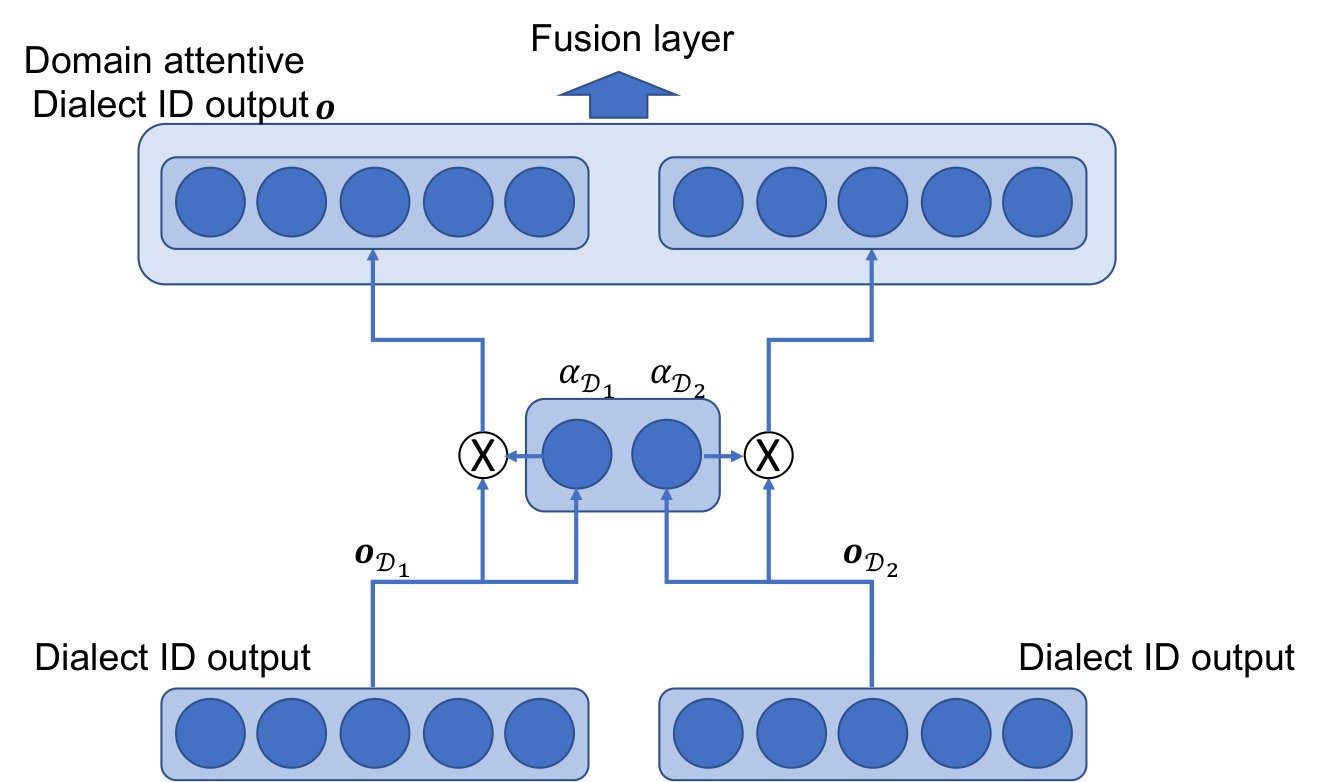 Figure 6
Figure 6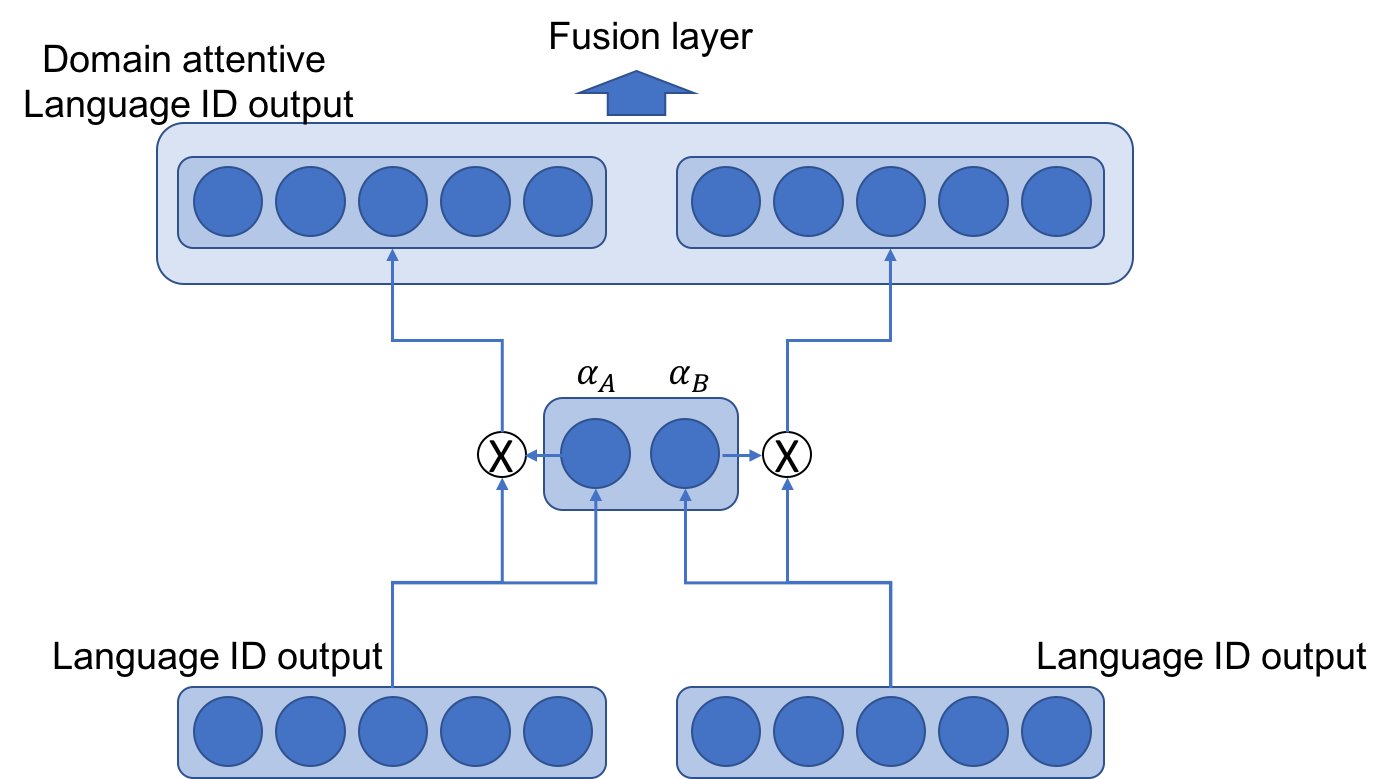 Figure 7
Figure 7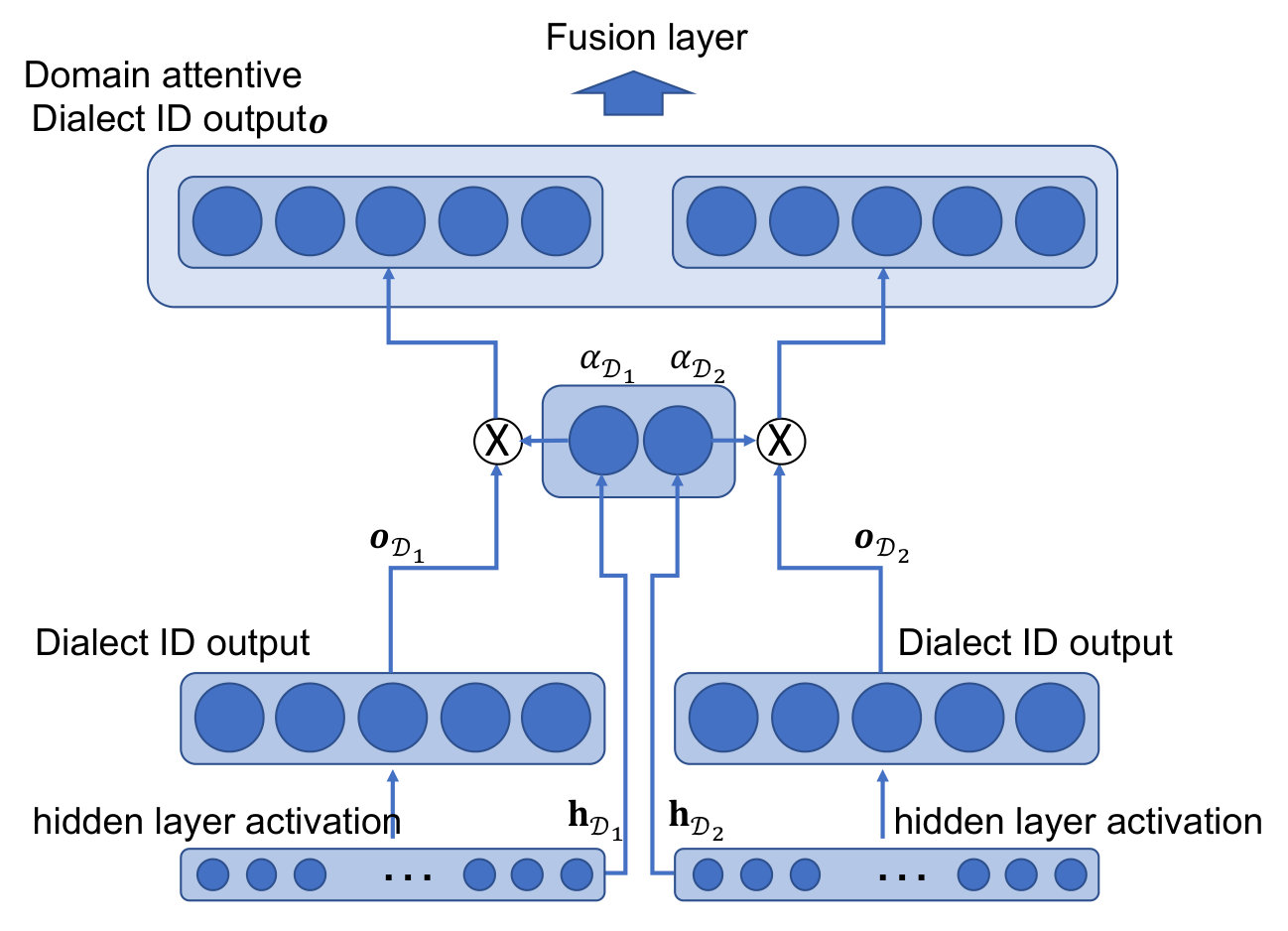 Figure 8
Figure 8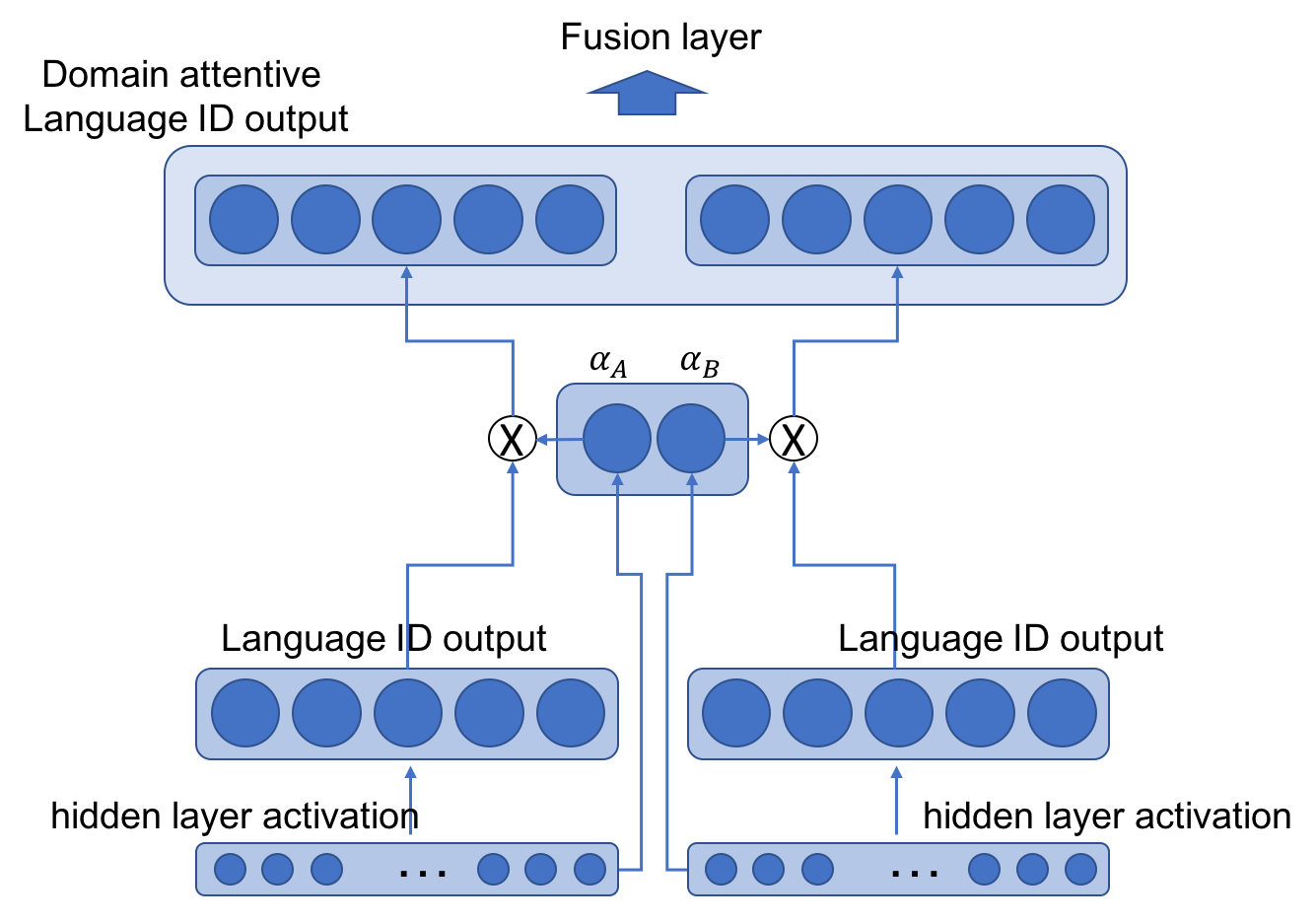 Figure 9
Figure 9| \hlineB2 Data name | MGB-3 | VarDial 2018 | |||||||||
| Type | Training | Development | Testing | Training | Testing | ||||||
| Domain | Recorded Broadcast | High-quality Broadcast | YouTube | ||||||||
| Dialect | Ex. | Dur. | Ex. | Dur. | Ex. | Dur. | Ex. | Dur. | Ex. | Dur. | |
| \hlineB2 EGY | 3,093 | 12.4 | 298 | 2.0 | 302 | 2.0 | 93,408 | 206.3 | 1,143 | 5.5 | |
| GLF | 2,744 | 10.0 | 264 | 2.0 | 250 | 2.1 | 92,603 | 204.5 | 1,147 | 5.6 | |
| LEV | 2,851 | 10.3 | 330 | 2.0 | 334 | 2.0 | 232,585 | 513.6 | 1,131 | 5.5 | |
| MSA | 2,183 | 10.4 | 281 | 2.0 | 262 | 1.9 | 9,518 | 21.0 | 944 | 4.6 | |
| NOR | 2,954 | 10.5 | 351 | 2.0 | 344 | 2.1 | 24,841 | 54.9 | 980 | 4.8 | |
| Total | 13,825 | 53.6 | 1,524 | 10.0 | 1,492 | 10.1 | 452,955 | 1000.3 | 5,345 | 26.0 | |
| \hlineB2 | |||||||||||
| Training data | System ID | DID Accuracy (%) | |||
| MGB-3 Test | VarDial 2018 Test | ||||
| MGB-3 Train + MGB-3 Dev | 65.82 | 48.87 | |||
| YouTube Train | 51.27 | 86.40 | |||
|
61.86 | 81.53 | |||
| Fusion of and (optimized for ) | - | 68.63 | 77.57 | ||
| Fusion of and (optimized for ) | - | 57.84 | 86.94 | ||
| \hlineB2 Training data | Test on | ||||||||
| MGB-3 Test | VarDial 2018 Test | Averaged | |||||||
| Acc. | EER | Cavg | Acc. | EER | Cavg | Acc. | EER | Cavg | |
| \hlineB2 MGB-3 Train + MGB-3 Dev () | 65.82 | 20.43 | 19.60 | 48.87 | 28.39 | 28.50 | 58.35 | 24.41 | 24.05 |
| YouTube Train () | 51.27 | 28.37 | 27.41 | 86.40 | 9.57 | 9.96 | 68.84 | 18.97 | 18.69 |
| MGB-3 Train + MGB-3 Dev + YouTube Train (+) | 61.86 | 22.92 | 21.41 | 81.53 | 11.13 | 11.76 | 71.70 | 17.03 | 16.59 |
| Logistic regression fusion of and (optimized for ) | 68.63 | 19.05 | 18.04 | 77.57 | 13.78 | 14.16 | 73.10 | 16.42 | 16.10 |
| Logistic regression fusion of and (optimized for ) | 57.84 | 24.36 | 23.35 | 86.94 | 9.23 | 9.56 | 72.39 | 16.80 | 16.46 |
| Using fusion layer on and (Figure 1) | 67.69 | 19.30 | 18.39 | 82.86 | 11.19 | 11.58 | 75.28 | 15.25 | 14.99 |
| Domain Attentive fusion of and (Figure 2 (a)) | 67.49 | 18.52 | 18.01 | 83.93 | 10.03 | 10.22 | 75.71 | 14.28 | 14.12 |
| Domain Attentive fusion of and (Figure 2 (b)) | 68.23 | 18.30 | 17.69 | 85.01 | 9.13 | 9.40 | 76.62 | 13.72 | 13.55 |
| \hlineB2 | |||||||||
| \hlineB2 Training data | Test on | ||||||||
| MGB-3 Test (Unseen) | VarDial 2018 Test (Seen) | Averaged | |||||||
| Acc. | EER | Cavg | Acc. | EER | Cavg | Acc. | EER | Cavg | |
| \hlineB2 MGB-3 Train () | 48.79 | 31.80 | 30.74 | 41.14 | 34.70 | 34.27 | 44.97 | 33.25 | 32.51 |
| YouTube Train () | 51.27 | 28.37 | 27.41 | 86.40 | 9.57 | 9.96 | 68.84 | 18.97 | 18.69 |
| MGB-3 Train + YouTube Train (+) | 56.37 | 25.07 | 24.10 | 83.85 | 9.87 | 10.30 | 70.11 | 17.47 | 17.20 |
| Logistic regression fusion of and (optimized for ) | 55.29 | 25.67 | 24.84 | 83.26 | 11.09 | 11.15 | 69.28 | 18.38 | 18.00 |
| Logistic regression fusion of and (optimized for ) | 54.22 | 26.69 | 25.67 | 87.56 | 8.96 | 9.36 | 70.89 | 17.83 | 17.52 |
| Using fusion layer on and (Figure 1) | 54.76 | 26.29 | 25.48 | 85.11 | 9.97 | 10.28 | 69.94 | 18.13 | 17.88 |
| Domain Attentive fusion of and (Figure 2 (a)) | 55.83 | 25.67 | 24.92 | 85.63 | 9.84 | 9.97 | 70.73 | 17.76 | 17.45 |
| Domain Attentive fusion of and (Figure 2 (b)) | 55.76 | 25.03 | 24.05 | 86.90 | 8.36 | 8.71 | 71.33 | 16.70 | 16.38 |
| \hlineB2 | |||||||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech Recognition and Synthesis · Speech and Audio Processing · Music and Audio Processing
Domain attentive fusion for End-to-End Dialect Identification
with unknown target domain
Abstract
End-to-end deep learning language or dialect identification systems operate on the spectrogram or other acoustic feature and directly generate identification scores for each class. An important issue for end-to-end systems is to have some knowledge of the application domain, because the system can be vulnerable to use cases that were not seen in the training phase; such a scenario is often referred to as a domain mismatched condition. In general, we assume that there is enough variation in the training dataset to expose the system to multiple domains. In this work, we study how to best make use a training dataset in order to have maximum effectiveness on unknown target domains. Our goal is to process the input without any knowledge of the target domain while preserving robust performance on other domains as well. To accomplish this objective, we propose a domain attentive fusion approach for end-to-end dialect/language identification systems. To help with experimentation, we collect a dataset from three different domains, and create experimental protocols for a domain mismatched condition. The results of our proposed approach, which were tested on a variety of broadcast and YouTube data, shows significant performance gain compared to traditional approaches, even without any prior target domain information.
Index Terms— Dialect identification, language identification, self-attention, fusion
1 Introduction
Channel or domain mismatch between training and test data can be a significant factor affecting performance for language and dialect identification (DID) systems, but mismatch has not been addressed as seriously for these tasks as it has been in the speaker recognition arena. In 2013, a domain adaptation challenge (DAC13) was held on domain mismatch for speaker recognition [1]. From the success of DAC13, many researchers explored the domain mismatch problem on the speaker recognition task [2, 3, 4, 5]. However, the same mismatch issue for language/dialect recognition was not actively studied until the NIST 2017 Language Recognition Evaluation (LRE) [6] provided speech datasets from multiple domains. At both challenges, many studies tried to adapt the Gaussian Back-end or PLDA back-end on top of the i-vector or x-vector speaker embeddings [7, 8, 2, 9, 3, 4]. Although these approaches cannot be directly applied to end-to-end deep learning systems for these same tasks, they achieved reasonable performance when the target speech domain was known a priori.
For dialect identification task, the Multi-Genre Broadcast 3 (MGB-3) challenge also provided domain mismatched data. Unsupervised learning of dialectal speech was investigated by Zhang [10] and Shon [11, 12] to extract domain invariant features from MGB-3 dataset. By exploiting speech data from several domains without explicit language and domain labels, the networks could extract domain invariant representations from input speech. The approaches still needed some amount of labeled data to train subsequent identification systems. They achieved large performance gains when there were no language labels on the target domain training dataset compared to traditional acoustic features like MFCCs. Although the performance gap closed when enough labeled target domain data were available, they have an advantage for scenarios where large amounts of unannotated speech is available [11].
In this research, we do not assume any resource limitation or challenging situations like unlabeled target domain data. Instead we assume that we have enough data from multiple domains with labels for dialect identification. However, we also assume that we don’t have any domain information about the target speech. In this case, a training model with labeled multiple domain data would easily provide superior performance over the previous efforts which adapt the back-end scoring to a target domain. Another possible approach is that score-level fusion of subsystems which are trained on single domain data. In the periodic series of NIST evaluations, it was observed that linear fusion of multiple subsystems consistently outperforms the single best system [13]. However, the performance of the fusion system depends strongly on the logistic regression fusion, whose parameters need to be calibrated to specific trials which reflect the test conditions. Thus, the system fusion was optimized to the specific domain of the test trials, so that if the test speech came from a random domain, the fusion system cannot guarantee the best performance.
To address the unknown domain speech input, we propose to use a self-attention layer in our end-to-end model and have fusion parameters which are calculated from the input speech. Once the domain attentive layer is trained using the training data, it automatically generates the best fusion weight of domain-specific systems by taking the output of each subsystem. Thus, ideally, the optimal fusion weight would be generated for every single input.
In the following sections, we examine baseline systems for unknown domain inputs and propose domain attentive layers. We also describe our data collection from YouTube, called Varieties and Dialects (VarDial) 2018, to provide a dataset for our experiments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] “JHU 2013 Speaker Recognition Workshop”, Available : http://www.clsp.jhu.edu/wp-content/uploads/sites/75/2015/10/ WS 13-Speaker-DAC.pdf.
- 2[2] Hagai Aronowitz, “Compensating Inter-Dataset Variability in PLDA Hyper-Parameters for Robust Speaker Recognition,” in Proceedings of Odyssey - The Speaker and Language Recognition Workshop , 2014, pp. 280–286.
- 3[3] Daniel Garcia-Romero, Alan Mc Cree, Stephen Shum, Niko Brummer, and Carlos Vaquero, “Unsupervised Domain Adaptation for I-Vector Speaker Recognition,” in Proceedings of Odyssey - The Speaker and Language Recognition Workshop , 2014, pp. 260–264.
- 4[4] Jesus Villalba and Eduardo Lleida, “Unsupervised Adaptation of PLDA by Using Variational Bayes Methods,” in IEEE ICASSP , 2014, pp. 744–748.
- 5[5] Suwon Shon, Seongkyu Mun, Wooil Kim, and Hanseok Ko, “Autoencoder based Domain Adaptation for Speaker Recognition under Insufficient Channel Information,” in Interspeech , 2017, pp. 1014–1018.
- 6[6] Seyed Omid Sadjadi, Timothee Kheyrkhah, Audrey Tong, Craig Greenberg, Douglas Reynolds, Elliot Singer, Lisa Mason, and Jaime Hernandez-Cordero, “The 2017 nist language recognition evaluation,” in Proc. Odyssey 2018 The Speaker and Language Recognition Workshop , 2018, pp. 82–89.
- 7[7] Mitchell Mclaren, Mahesh Kumar Nandwana, Diego Castán, and Luciana Ferrer, “Approaches to multi-domain language recognition,” in Proc. Odyssey 2018 The Speaker and Language Recognition Workshop , 2018, pp. 90–97.
- 8[8] Jesus Antonio Villalba Lopez, Niko Brummer, and Najim Dehak, “End-to-end versus embedding neural networks for language recognition in mismatched conditions,” in Proc. Odyssey 2018 The Speaker and Language Recognition Workshop , 2018, pp. 112–119.