TL;DR
DeepVoxels introduces a novel persistent 3D feature embedding that enables view synthesis without explicit geometry modeling, combining 3D scene structure with learned image mappings for high-quality novel view generation.
Contribution
It proposes DeepVoxels, a learned 3D scene representation that encodes view-dependent appearance without explicit geometry, using a Cartesian grid of embedded features and adversarial training.
Findings
Achieves high-quality novel view synthesis across diverse scenes
Does not require 3D reconstruction of scenes
Combines 3D geometric insights with learned image-to-image translation
Abstract
In this work, we address the lack of 3D understanding of generative neural networks by introducing a persistent 3D feature embedding for view synthesis. To this end, we propose DeepVoxels, a learned representation that encodes the view-dependent appearance of a 3D scene without having to explicitly model its geometry. At its core, our approach is based on a Cartesian 3D grid of persistent embedded features that learn to make use of the underlying 3D scene structure. Our approach combines insights from 3D geometric computer vision with recent advances in learning image-to-image mappings based on adversarial loss functions. DeepVoxels is supervised, without requiring a 3D reconstruction of the scene, using a 2D re-rendering loss and enforces perspective and multi-view geometry in a principled manner. We apply our persistent 3D scene representation to the problem of novel view synthesis…
Click any figure to enlarge with its caption.
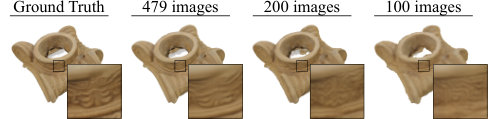 Figure 1
Figure 1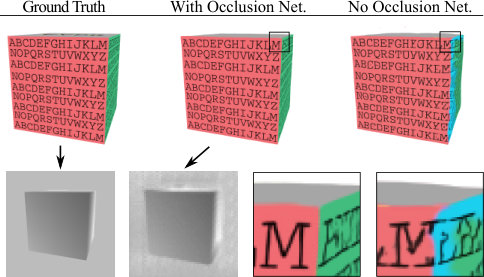 Figure 2
Figure 2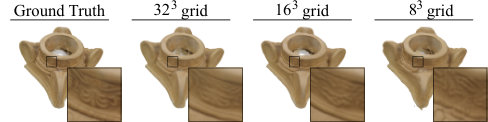 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6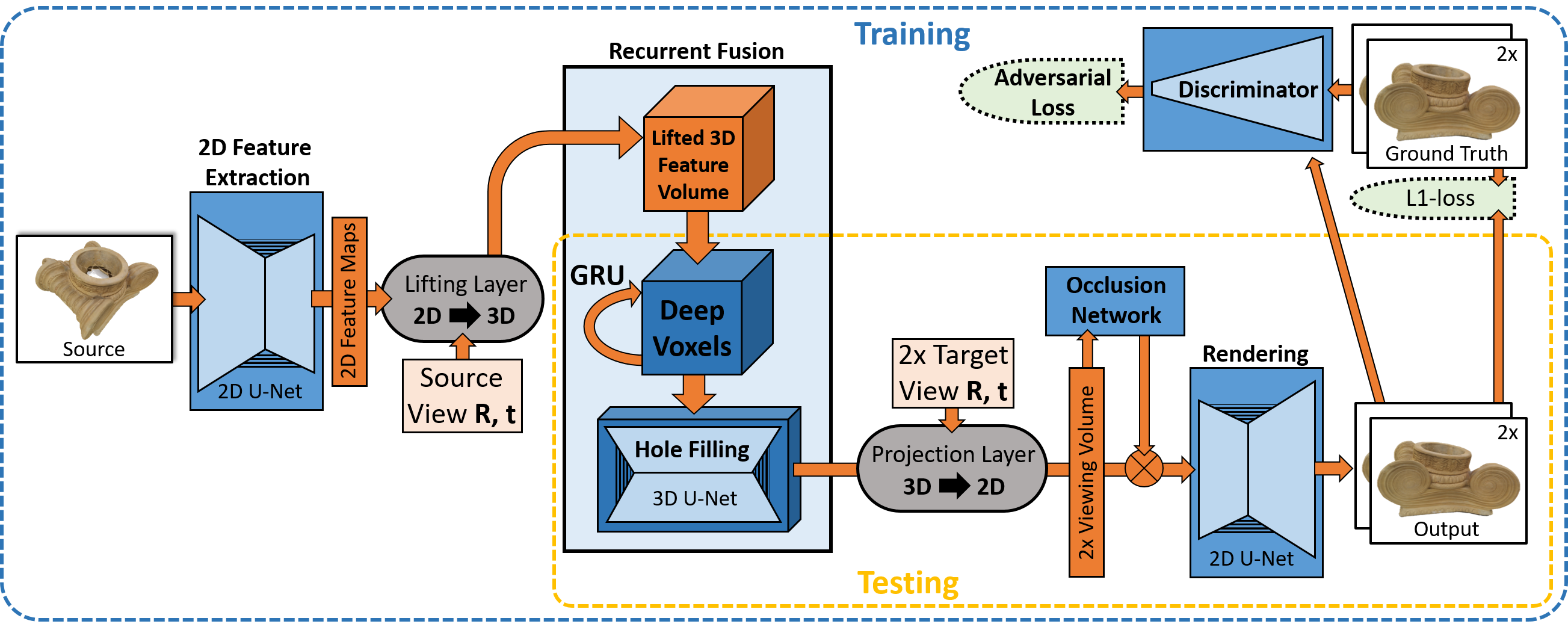 Figure 7
Figure 7 Figure 8
Figure 8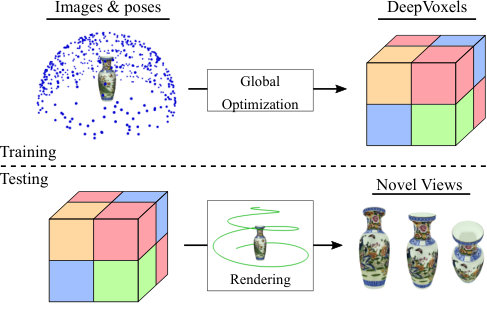 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
