SUGAMAN: Describing Floor Plans for Visually Impaired by Annotation Learning and Proximity based Grammar
Shreya Goyal, Satya Bhavsar, Shreya Patel, Chiranjoy Chattopadhyay,, Gaurav Bhatnagar

TL;DR
SUGAMAN is a framework that converts floor plan images into textual descriptions to assist visually impaired individuals in navigation, using supervised learning and grammar-based description synthesis.
Contribution
It introduces the first system for describing floor plans and guiding obstacle-free indoor navigation for the visually impaired, combining supervised room classification with description generation.
Findings
Achieved state-of-the-art performance on real-world floor plans.
Learned 5 room categories from 1355 samples using supervised classifiers.
Provided a comparative analysis with human descriptions.
Abstract
In this paper, we propose SUGAMAN (Supervised and Unified framework using Grammar and Annotation Model for Access and Navigation). SUGAMAN is a Hindi word meaning "easy passage from one place to another". SUGAMAN synthesizes textual description from a given floor plan image for the visually impaired. A visually impaired person can navigate in an indoor environment using the textual description generated by SUGAMAN. With the help of a text reader software, the target user can understand the rooms within the building and arrangement of furniture to navigate. SUGAMAN is the first framework for describing a floor plan and giving direction for obstacle-free movement within a building. We learn classes of room categories from room image samples under a supervised learning paradigm. These learned annotations are fed into a description synthesis framework to yield a holistic…
Click any figure to enlarge with its caption.
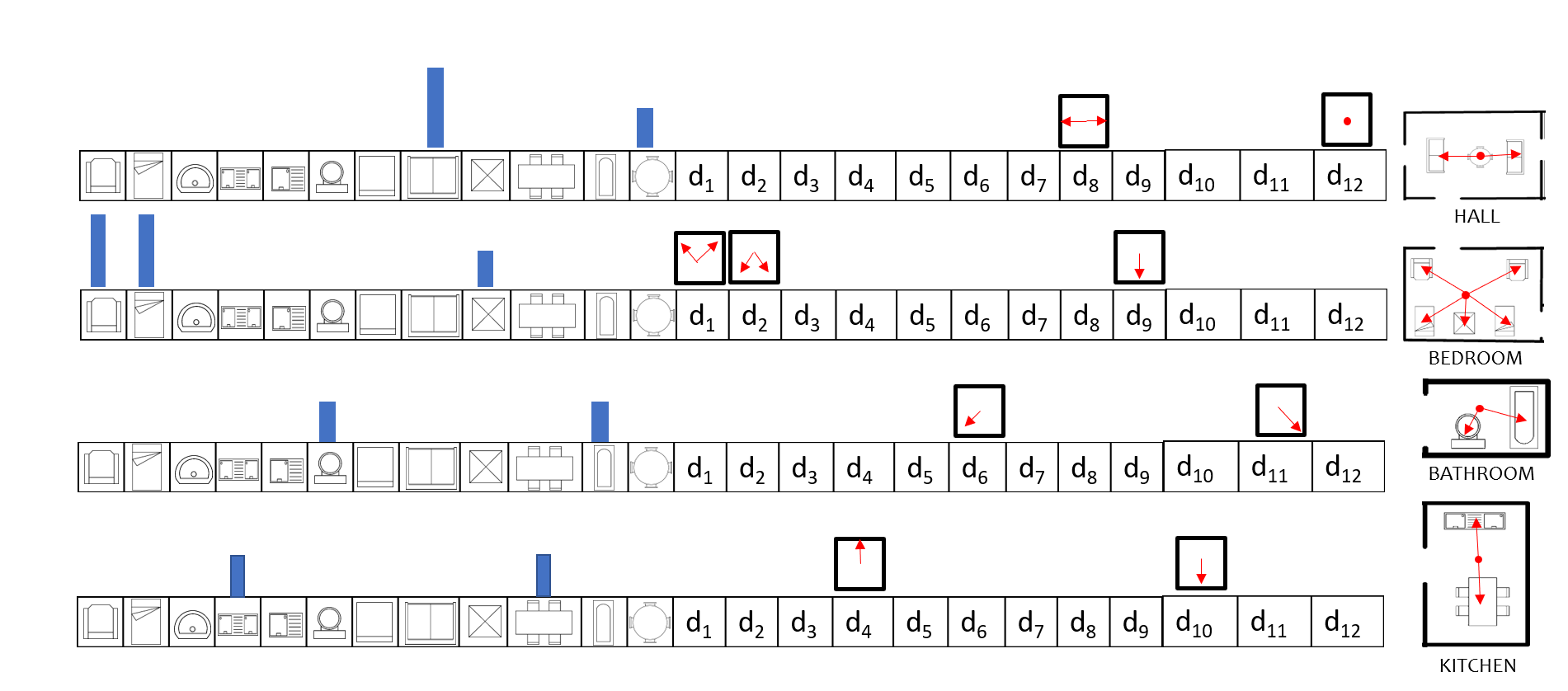 Figure 1
Figure 1 Figure 2
Figure 2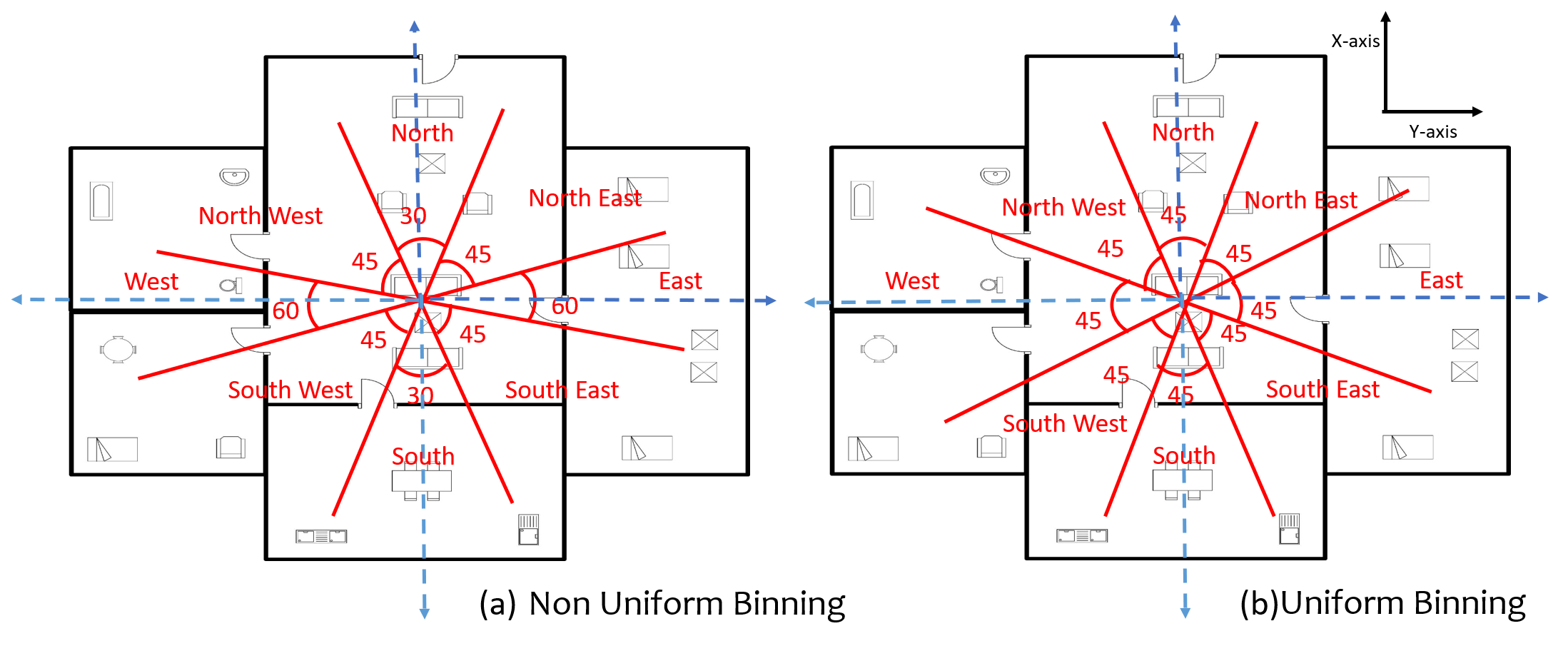 Figure 3
Figure 3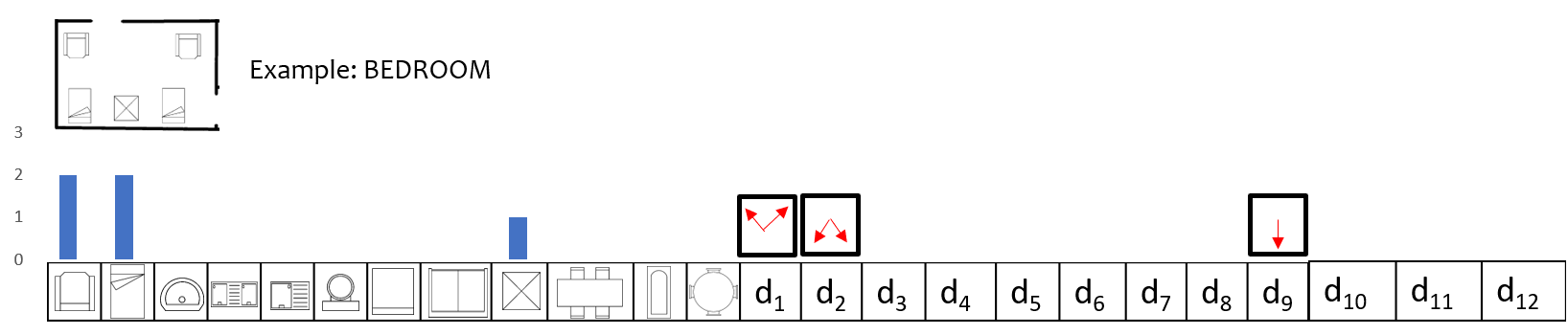 Figure 4
Figure 4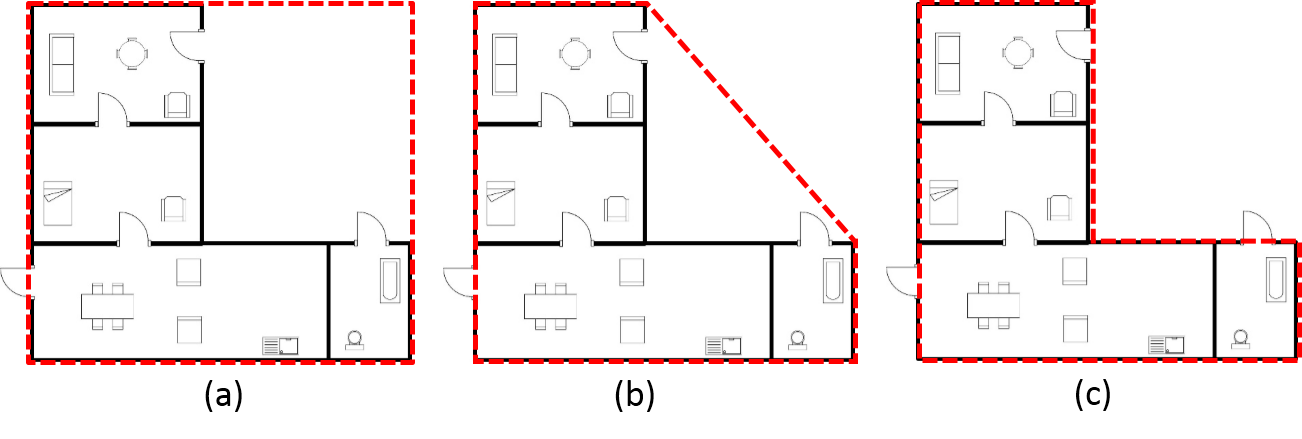 Figure 5
Figure 5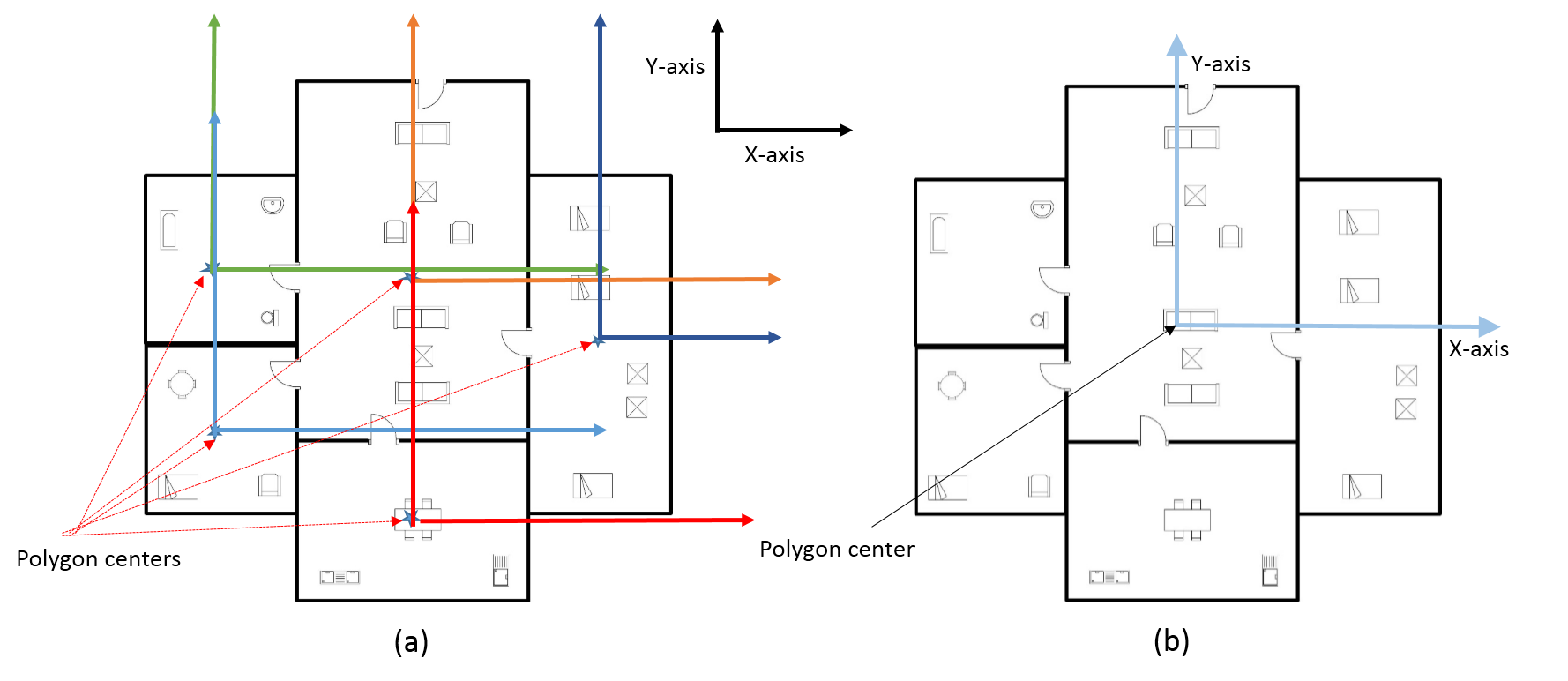 Figure 6
Figure 6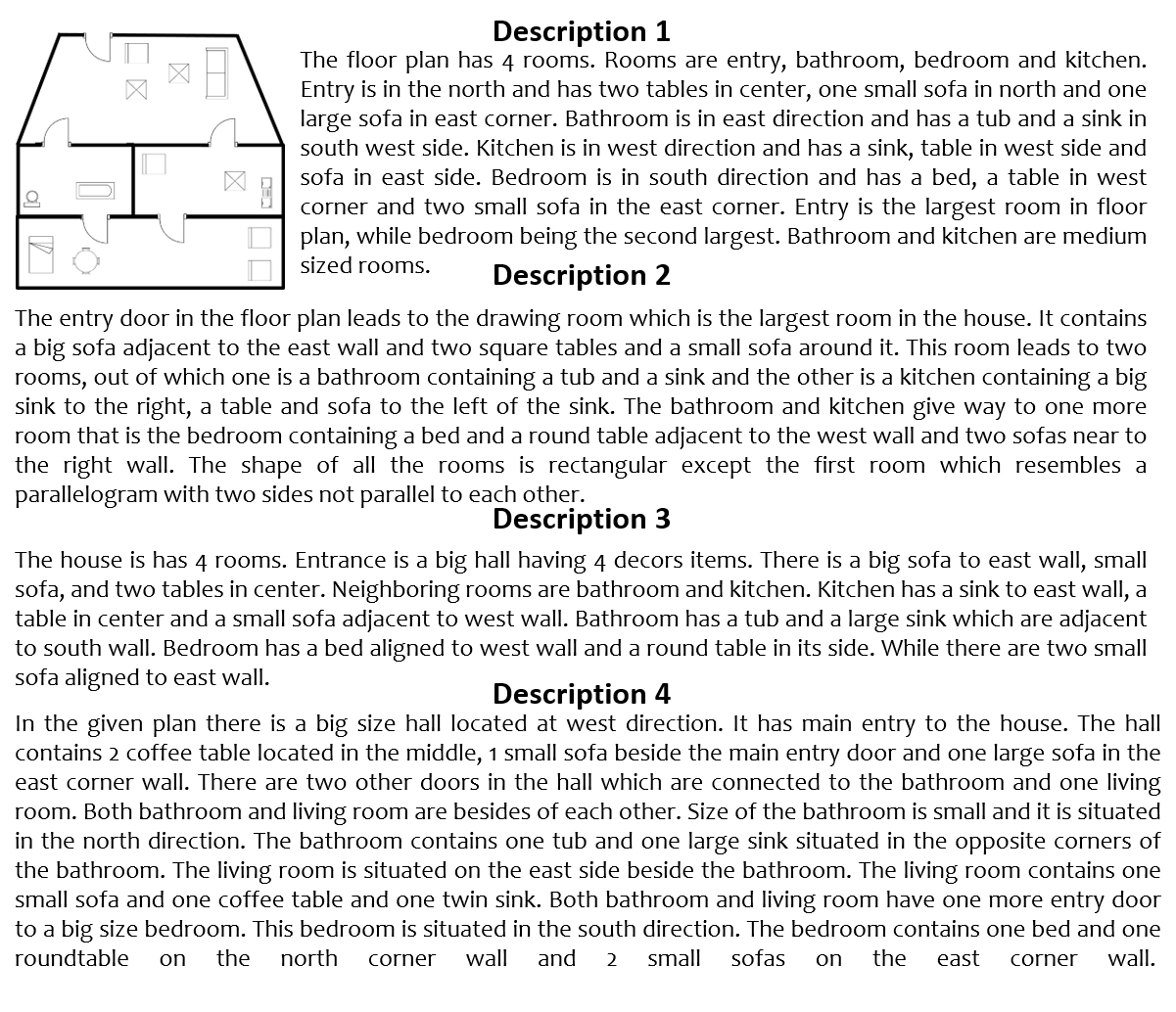 Figure 7
Figure 7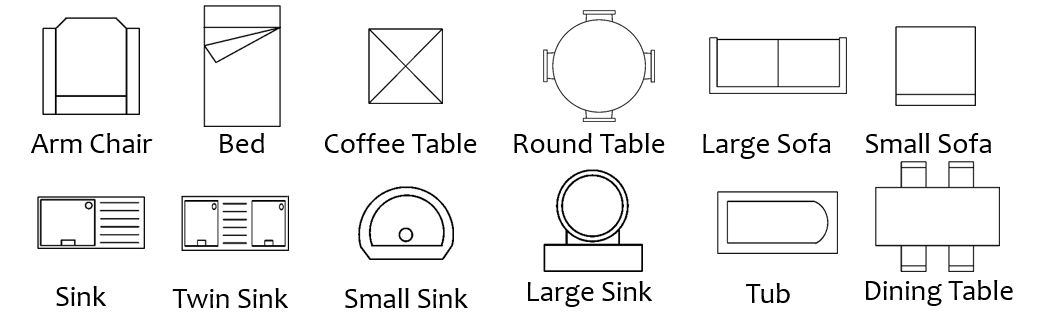 Figure 8
Figure 8 Figure 9
Figure 9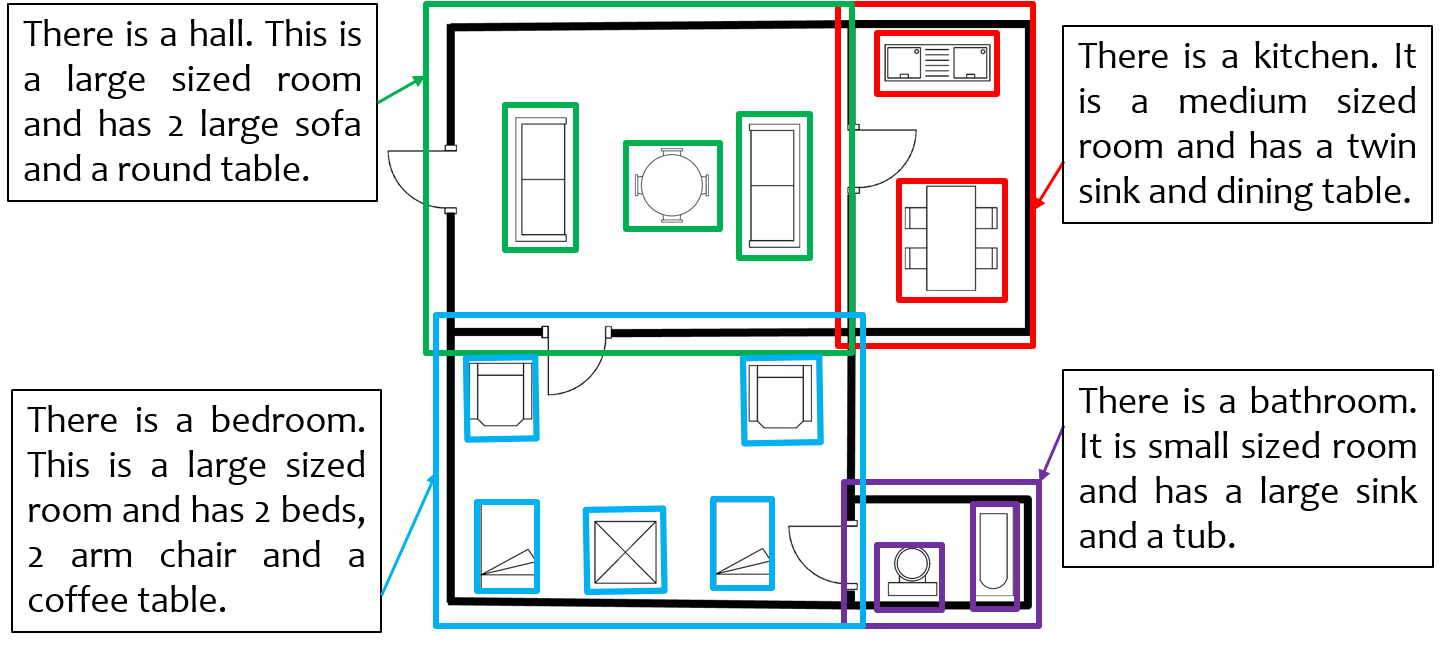 Figure 10
Figure 10 Figure 11
Figure 11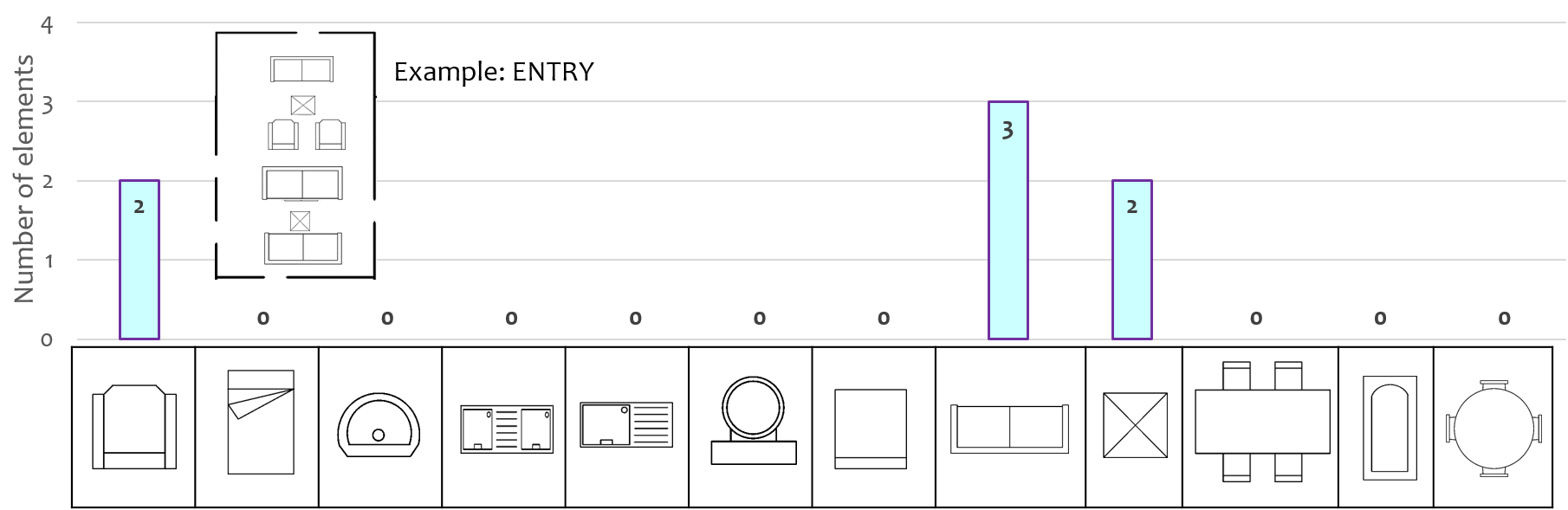 Figure 12
Figure 12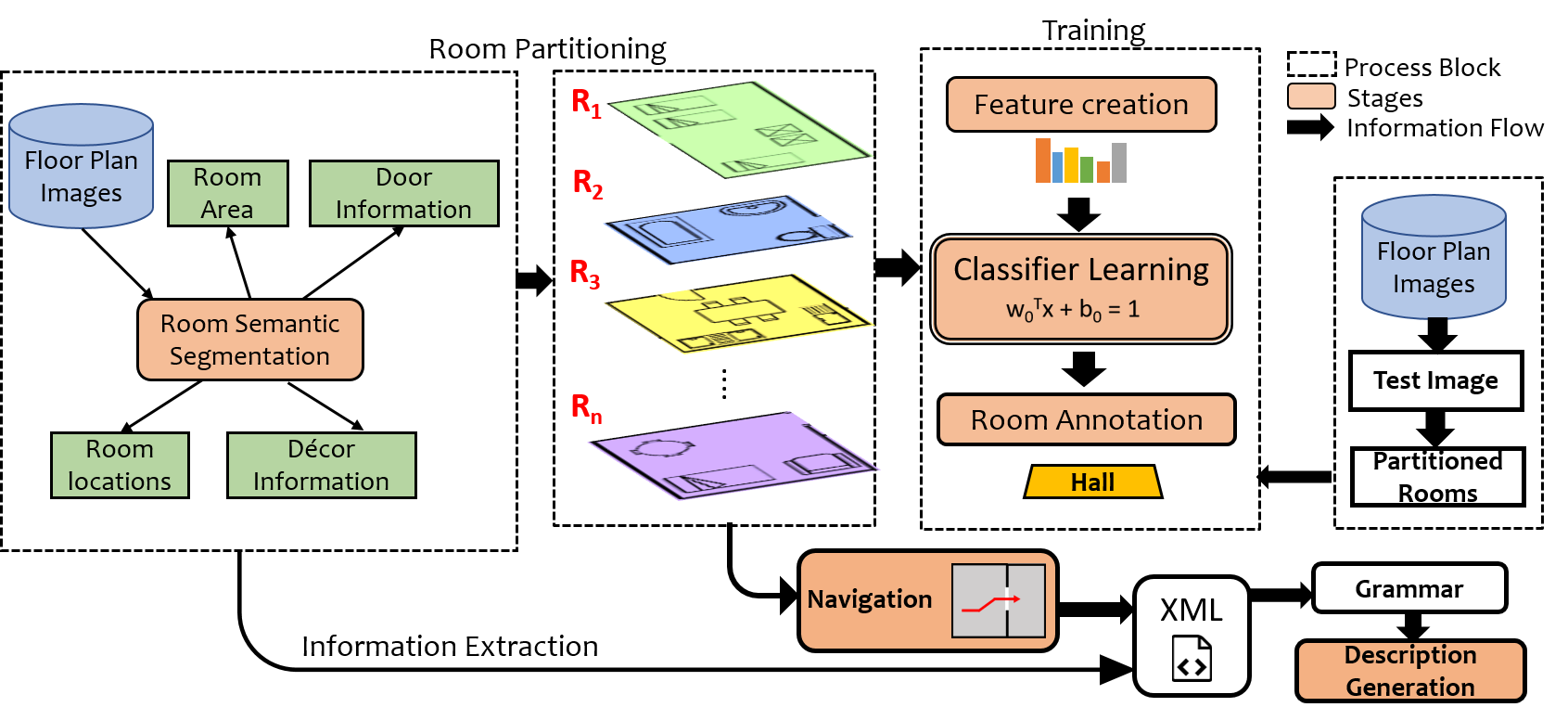 Figure 13
Figure 13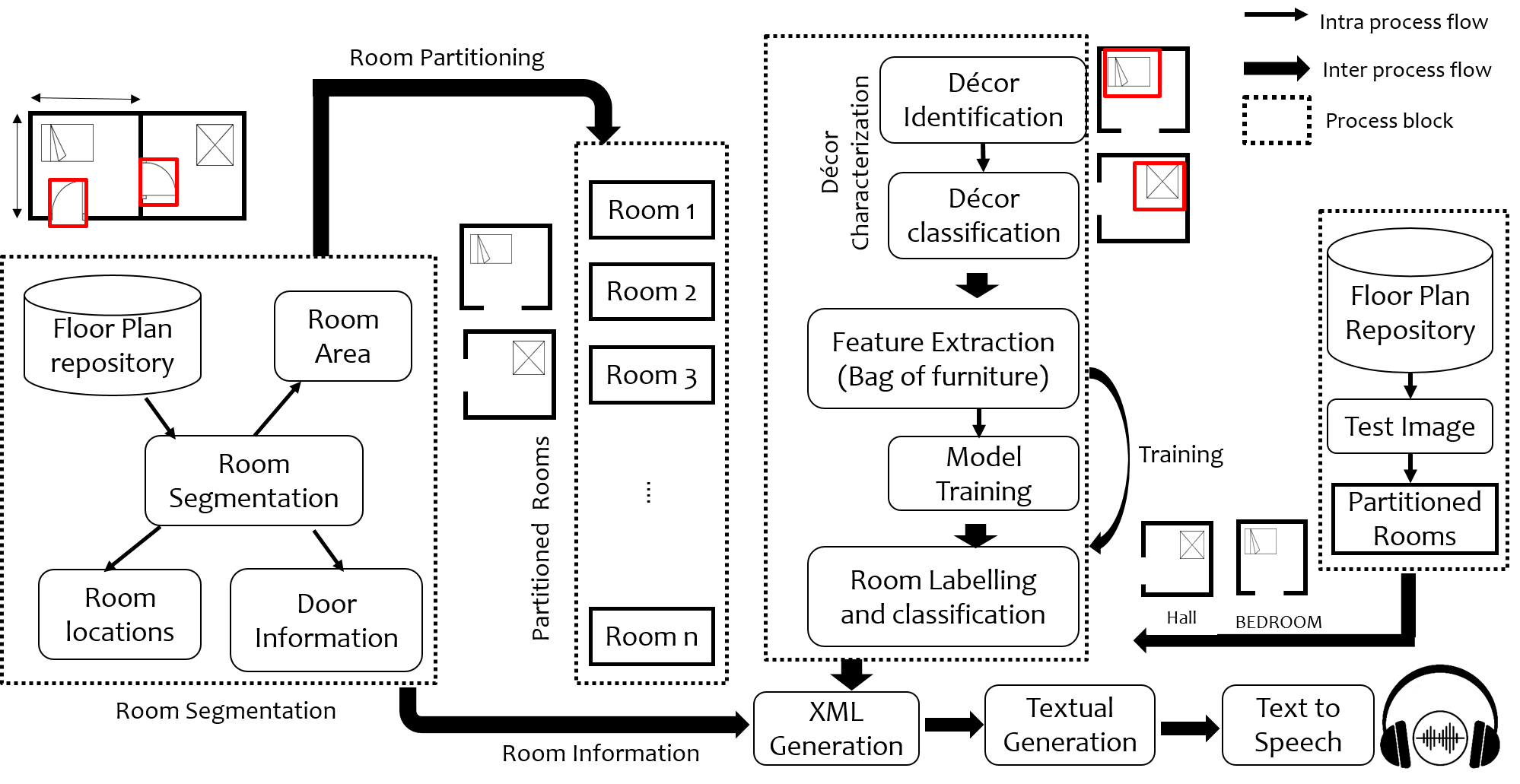 Figure 14
Figure 14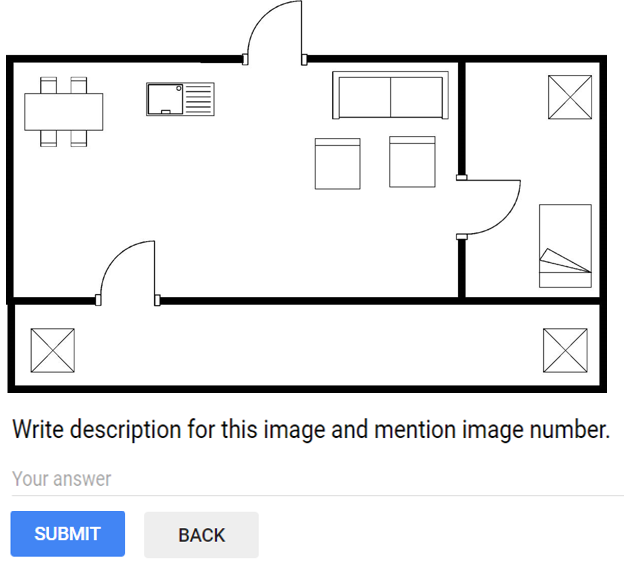 Figure 15
Figure 15 Figure 16
Figure 16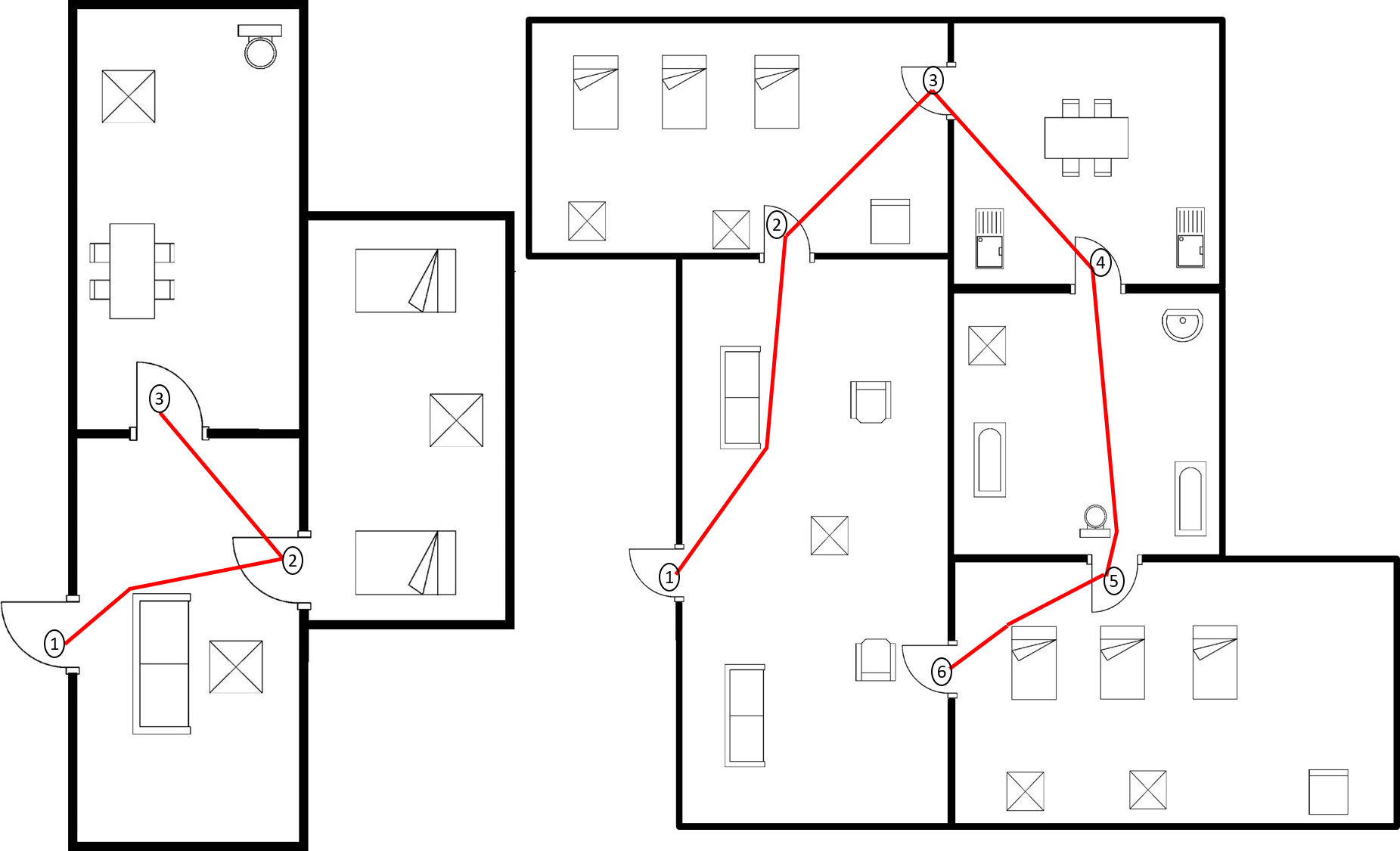 Figure 17
Figure 17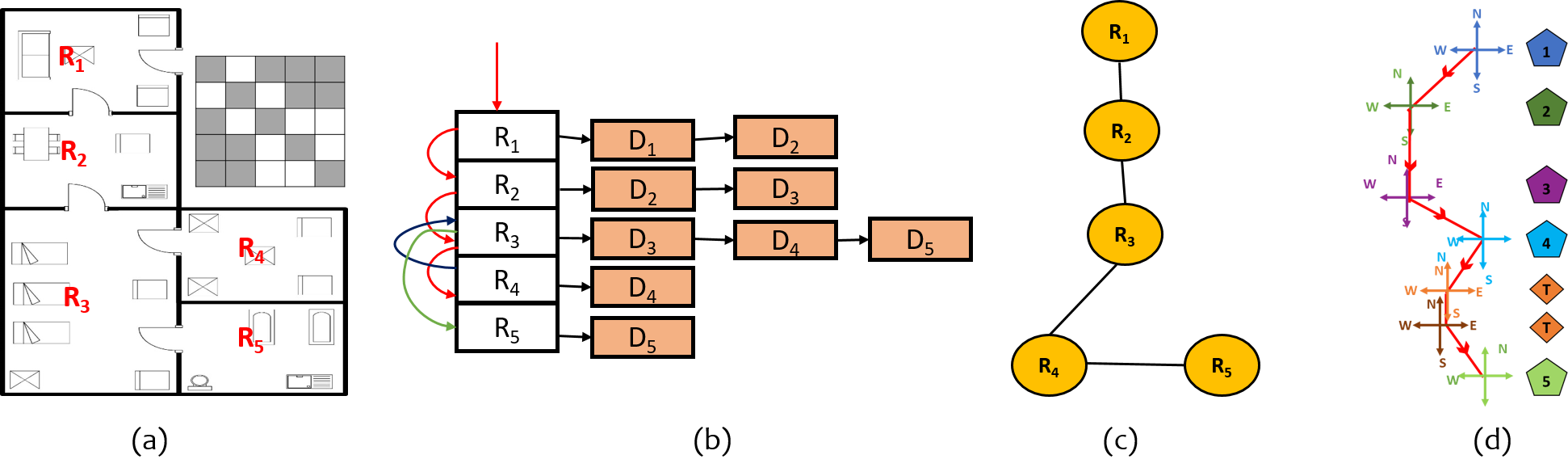 Figure 18
Figure 18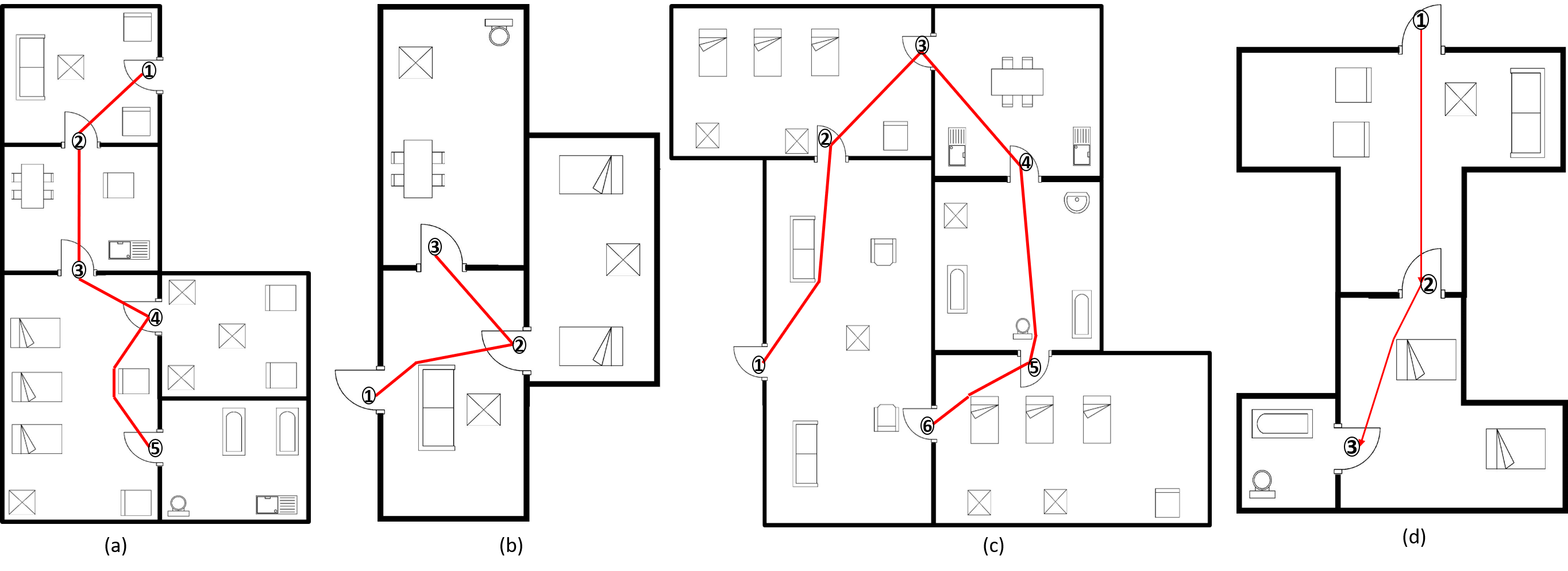 Figure 19
Figure 19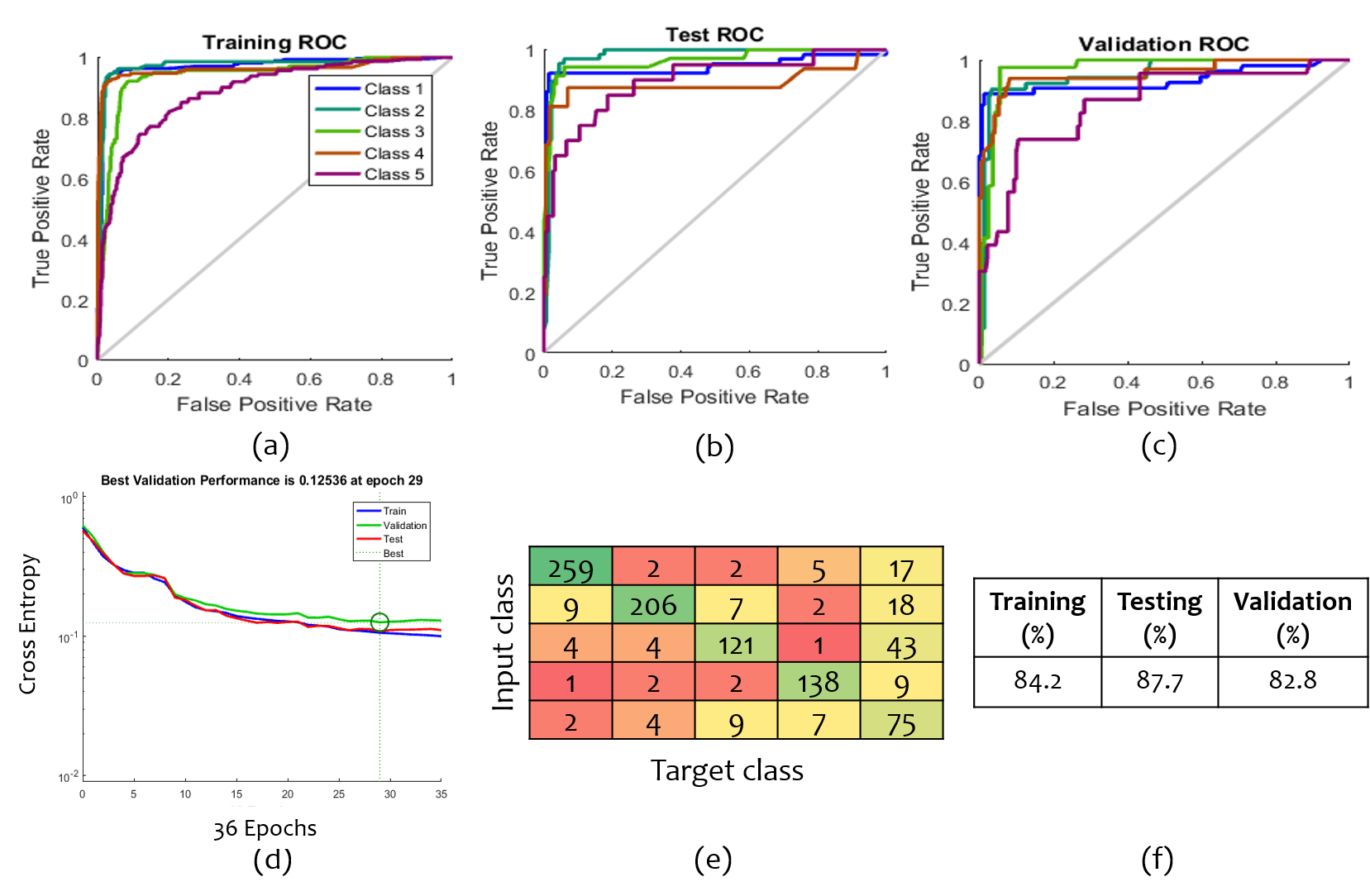 Figure 20
Figure 20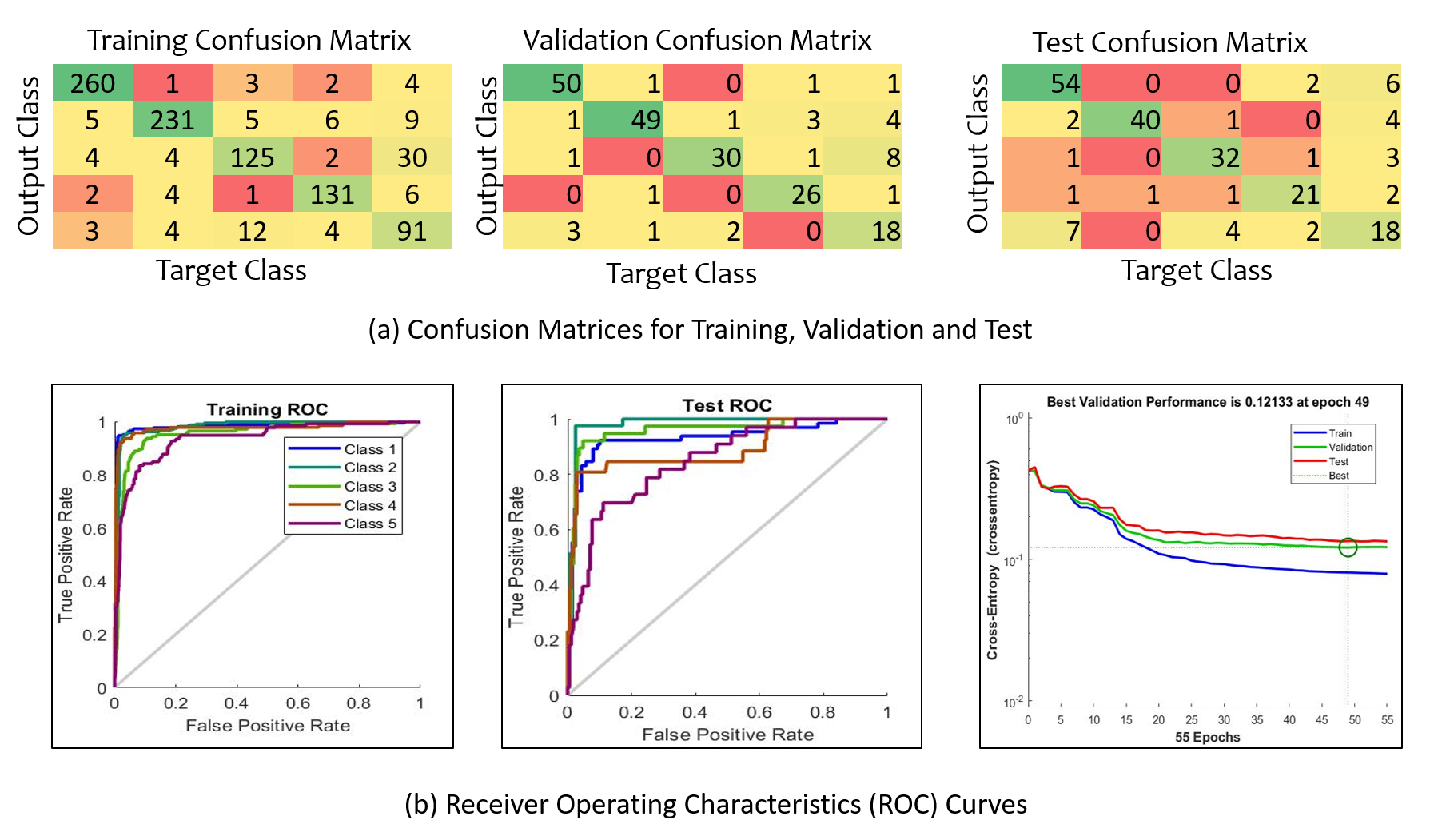 Figure 21
Figure 21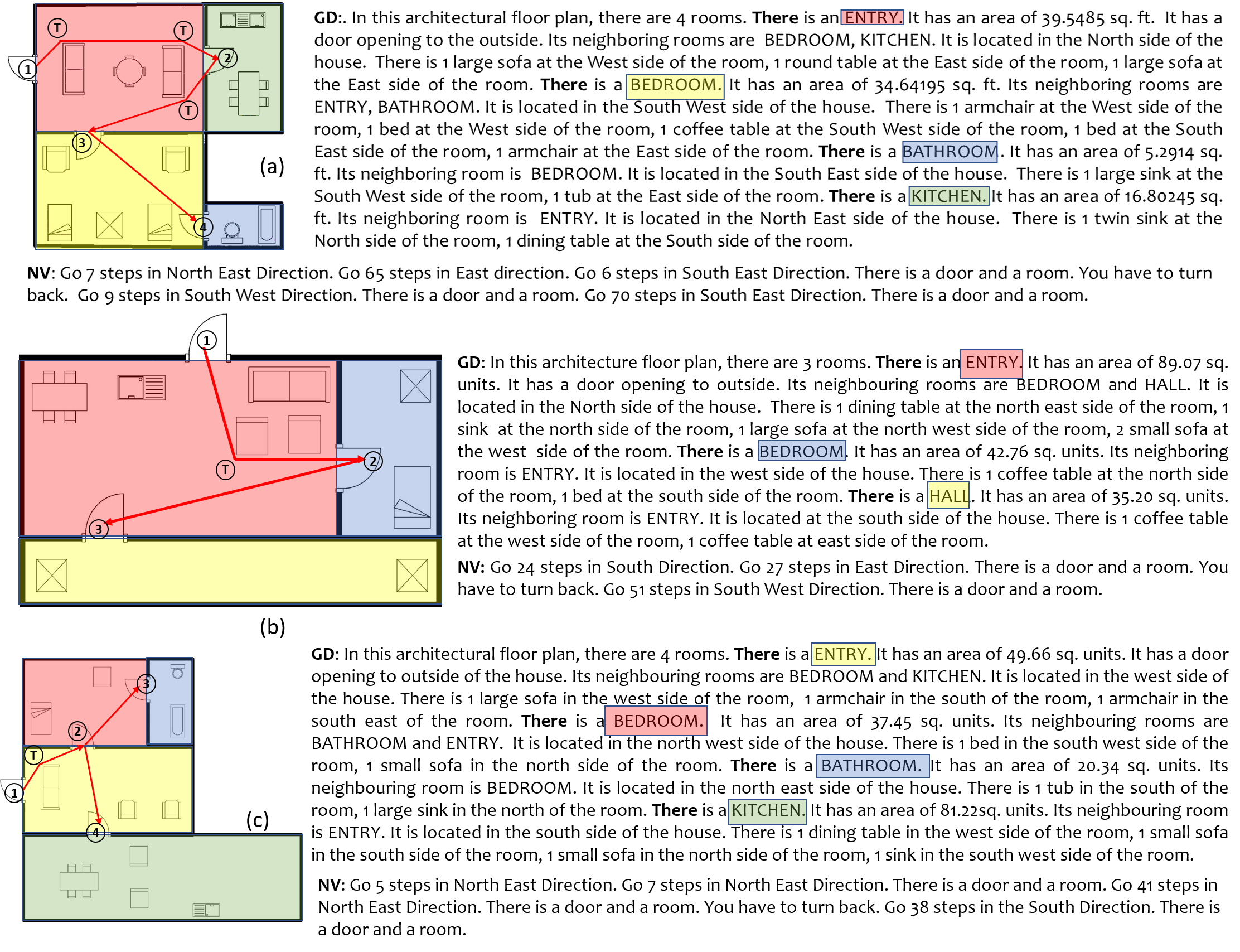 Figure 22
Figure 22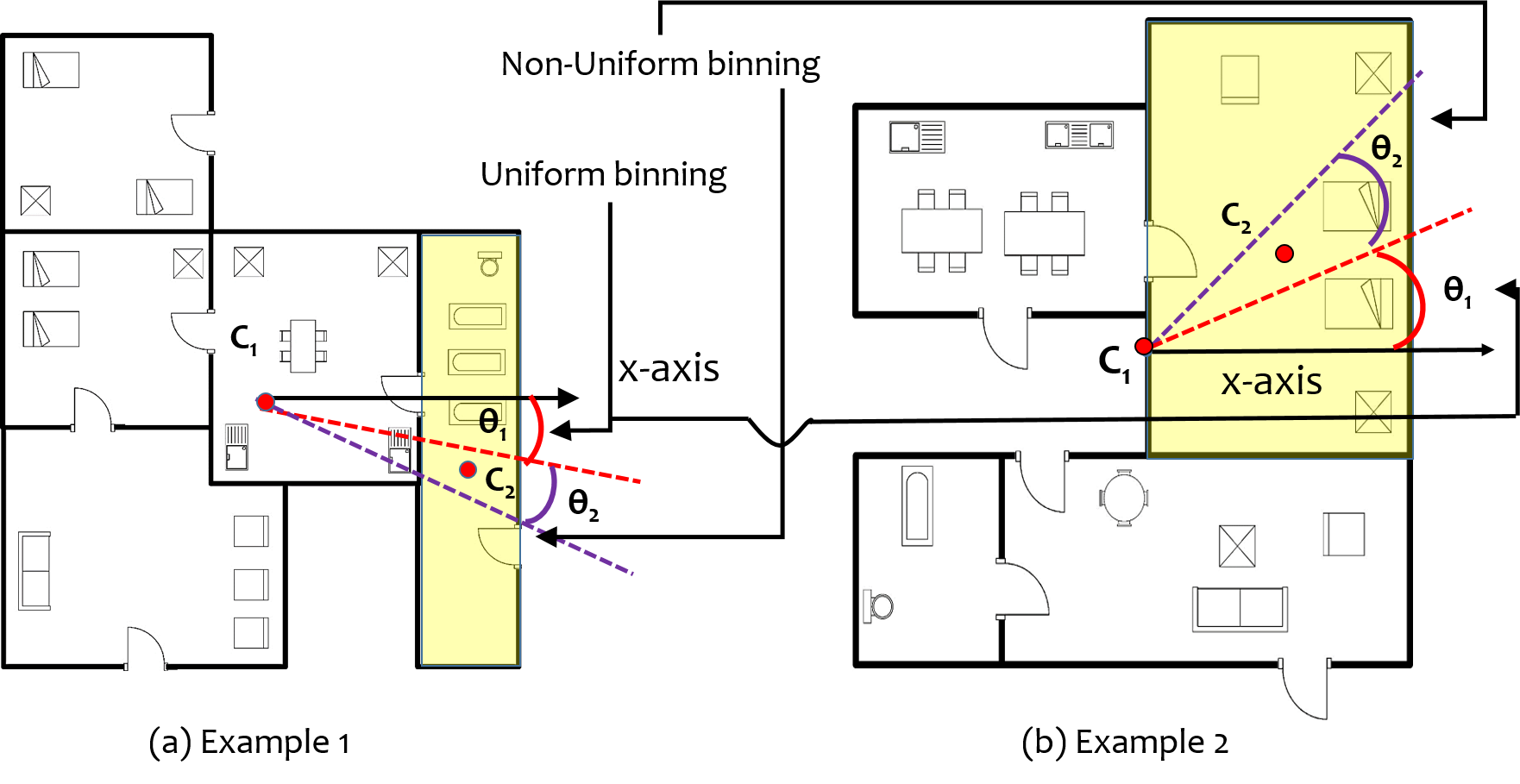 Figure 23
Figure 23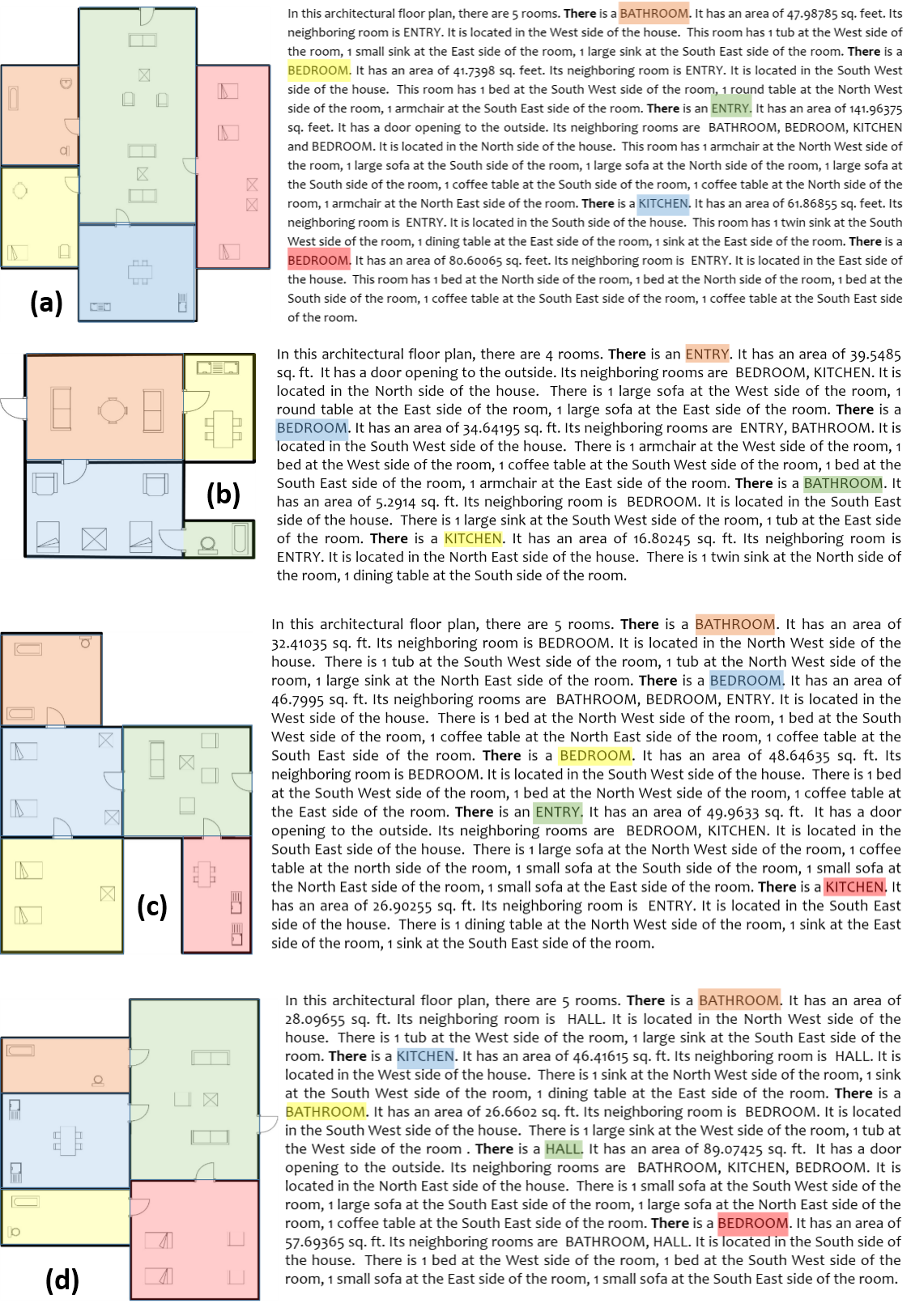 Figure 24
Figure 24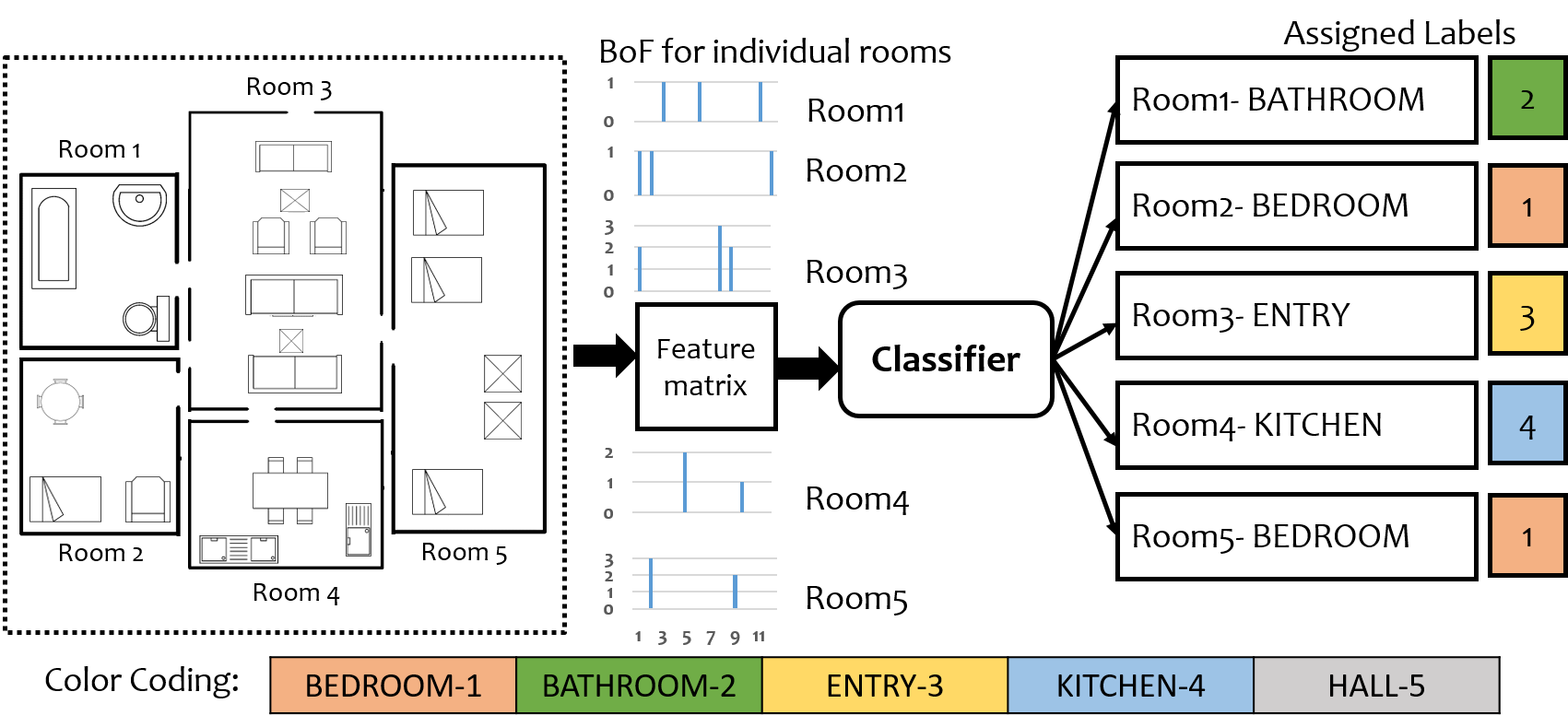 Figure 25
Figure 25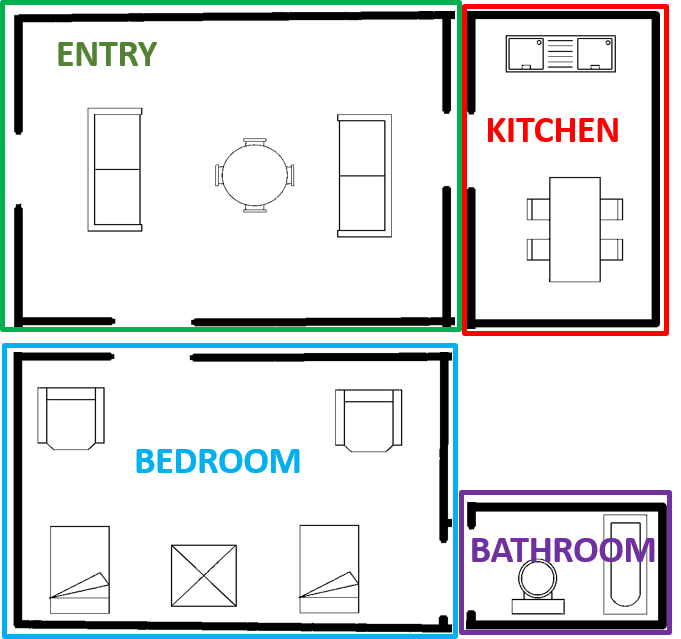 Figure 26
Figure 26 Figure 27
Figure 27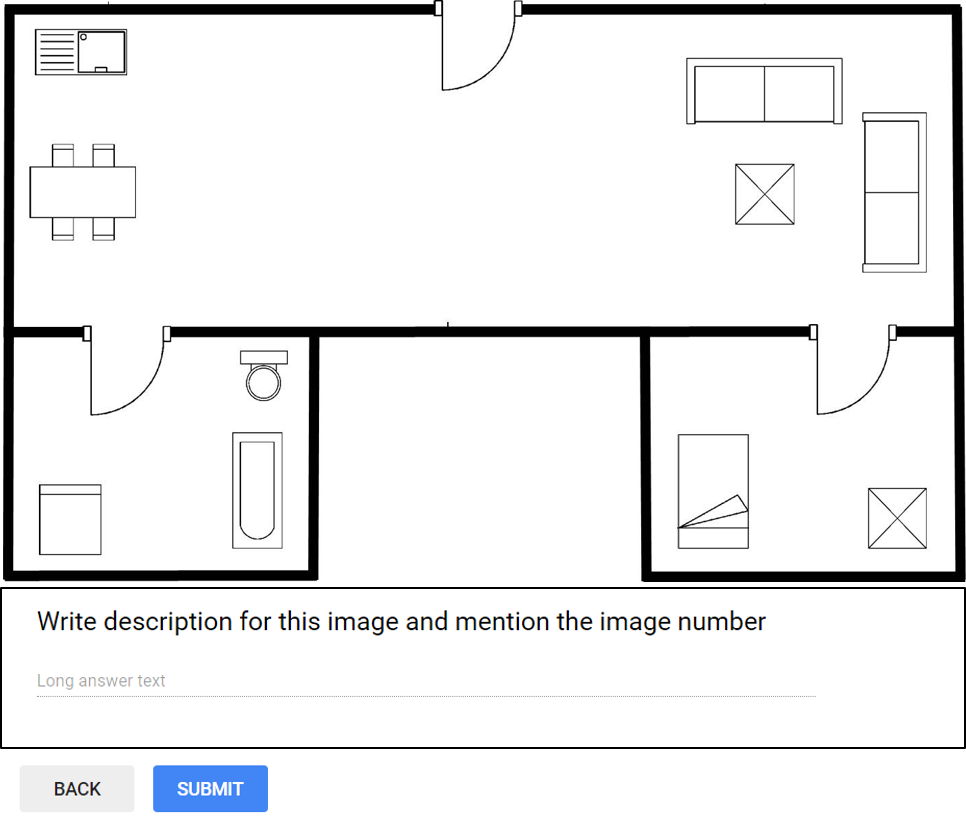 Figure 28
Figure 28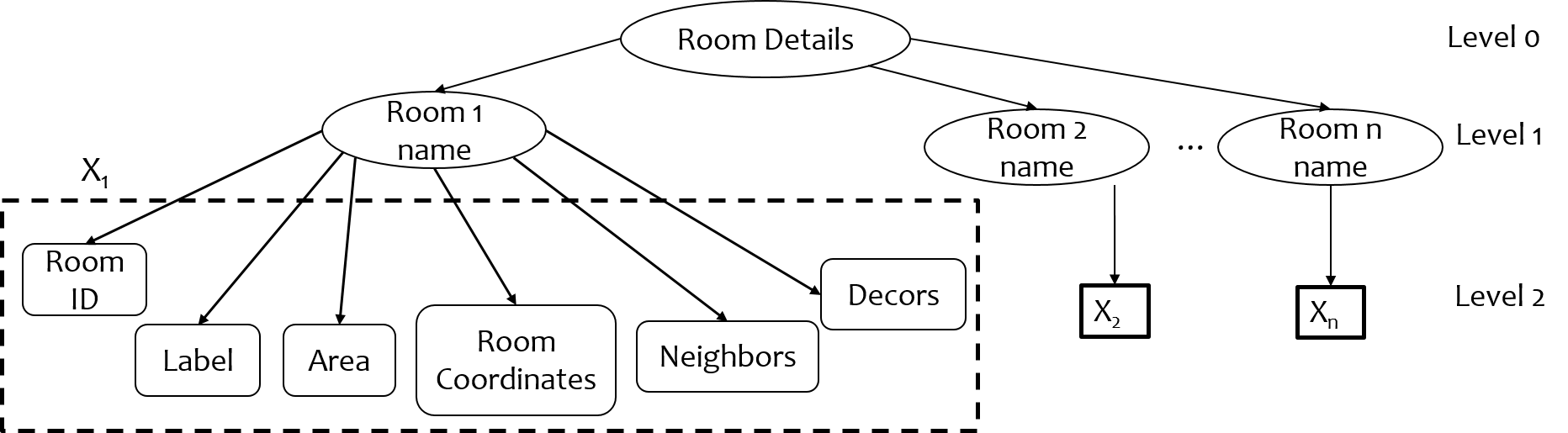 Figure 29
Figure 29| Sentence | Rule |
|---|---|
| This floor plan has rooms | |
| There is DT | |
| It has an area of AREA | |
| Its neighboring room{s} AUX NR_j | |
| It is located in the LOC | |
| This room has | |
| There is a door and a room. | |
| . | |
| You have to turn back. |
| Variant | Training | Testing | Testing | Training | Testing |
|---|---|---|---|---|---|
| (R) | (R) | (S) | (R+S) | (R+S) | |
| linear svm OVO | |||||
| Quadratic SVM OVA | |||||
| Cubic SVM OVA | |||||
| Medium Gauss SVM OVO | |||||
| Quadratic SVM OVO | |||||
| Complex Tree |
| ROUGE | Average Recall | Average Precision | F score |
|---|---|---|---|
| ROUGE-1 | |||
| ROUGE-2 | |||
| ROUGE-3 |
| METRIC | Score |
|---|---|
| BLEU-1 | |
| BLEU-2 | |
| BLEU-3 | |
| BLEU-4 |
| Average Recall | Average Precision | F1 | F mean | Final Score |
|---|---|---|---|---|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
SUGAMAN: Describing Floor Plans for Visually Impaired by Annotation Learning and Proximity based Grammar
Shreya Goyal, Satya Bhavsar, Shreya Patel, Chiranjoy Chattopadhyay, Gaurav Bhatnagar
Abstract
In this paper, we propose SUGAMAN (Supervised and Unified framework using Grammar and Annotation Model for Access and Navigation). SUGAMAN is a Hindi word meaning “easy passage from one place to another”. SUGAMAN synthesizes textual description from a given floor plan image for the visually impaired. A visually impaired person can navigate in an indoor environment using the textual description generated by SUGAMAN. With the help of a text reader software the target user can understand the rooms within the building and arrangement of furniture to navigate. SUGAMAN is the first framework for describing a floor plan and giving direction for obstacle-free movement within a building. We learn classes of room categories from room image samples under a supervised learning paradigm. These learned annotations are fed into a description synthesis framework to yield a holistic description of a floor plan image. We demonstrate the performance of various supervised classifiers on room learning. We also provide a comparative analysis of system generated and human written descriptions. SUGAMAN gives state of the art performance on challenging, real-world floor plan images. This work can be applied to areas like understanding floor plans of historical monuments, stability analysis of buildings, and retrieval.
I Introduction
One of the primary goals of a combined framework involving computer vision (CV) and natural language processing (NLP) is to understand an image and describe it. The techniques available in CV and digital image processing (DIP) helps to localize the objects in the image, identify key attributes and provide a relationship among them. On the other hand, NLP provides us with an end to end description of that image, and thereby connecting the output of CV with the text. For the purpose of having a better understanding of a floor plan image, we propose SUGAMAN (Supervised and Unified framework using Grammar and Annotation Model for Access and Navigation), which is an attempt to connect the these two modalities, i.e. CV and NLP, in the context of document images and text data. SUGAMAN is a Hindi word which translates to easy passage from one place to another. Apart from describing the general information about the floor plan images, it also generates room to room navigation information, while avoiding the obstacles. This navigation information can be very useful for visually impaired people as it becomes difficult for them to move in an indoor environment. It will be really helpful for them if there is a system that tells about the surroundings environment in natural language. SUGAMAN generates such natural language description of an indoor environment from building floor plan images, which gives a detailed idea of the indoor environment. Here the input is a building floor plan image and the output is a textual description of the same. The description includes detail about the (i) rooms, (ii) connectivity among the rooms, (iii) type of decor within every room, and (iv) their relative position, and (v) navigational information, while avoiding obstacles.
In the past few years, unconventional documents like floor plans, engineering drawing gained a lot of attention from the document analysis and recognition (DAR) community. Engineering drawings contains many symbols, texts, line drawings, which need to be recognized and understood. Understanding of circuit diagrams, floor plan images, machine designs, building diagrams, maps etc. has its own importance. While researchers have looked into the problems of segmentation, symbol spotting, text recognition, symbol classification etc., the problem of narration synthesis from those documents was overlooked. Generating a textual description (narration) from an engineering drawing document image can be very useful for a layman to understand the document. As a particular example, building floor plan images involve a lot of technicalities such as symbols, dimension of the building, its design, orientation, as well as the interior decors, which are not known by common users. Various techniques have been proposed for its wall segmentation, text, room and decor segmentation in order to understand them. Even though text synthesis has been an area covered under natural language processing for years and also explored with real world images, document images were always ignored.
Figure 1 exemplifies the problem and the potential solution for a real-world floor plan images. The key characteristics that makes this work unique are: (i) proposing a unified framework for narration synthesis from floor plan images, (ii) improvement in the previously available techniques for decor characterization, (iii) proposal of a novel feature to represent a room within a floor plan, (iv) learning the room annotations for room classification, and (v) augmentation of an publicly available dataset by annotating floor plan images with textual descriptions.
The paper is organized in the following manner: in Sec. II we discuss the known results that are published in the literature and are related to our framework. Overview of the proposed system is given in Sec. III. Description about the dataset used is given in Sec. IV. Room annotation learning and classification framework is presented in Sec. V. The method of description synthesis is discussed in Sec. VI. Results of the intermediate processing stage is discussed in Sec. VII. Results of description synthesis is given in Sec. VIII. Finally, the paper is concluded in Sec. IX.
II Related Work
In this section, first we describe works related to the document image processing and recognition tasks, followed by the ones proposed for description synthesis.
II-A Document image processing and recognition
Symbol spotting, character recognition and feature extraction has been an evergreen research topic for classification of document images. An overview of graphics symbol recognition can be found in [51]. In this matter [65] provides a detailed state of the art survey for symbol spotting techniques and there performance analysis. In [49], a class of drawings are analyzed which includes flow charts by pre-processing scanned binary images, symbols and connection lines followed by extraction of features like shapes, orientation of lines and connections. Trier et al. [45] have also imparted knowledge based systems for interpreting symbols in engineering drawings. In [43], with respect to engineering drawings, an approach for detecting and classifying dashed line segments was proposed. In [8], a new rule based algorithm was proposed to differentiate between text and graphics part from engineering drawings.
In a floor plan, the decors are an inseparable component and visually similar to characters. Properties of characters and their recognition methods could be adopted for recognizing decors. The authors of [47] used topological analysis method to recognize characters and lines from gray scale scanned images of hand printed documents, whose information has been lost after binarization. In [5], CCA and histogram based thresholding is applied to separate text and graphics and Hough transform is used to group together components into logical strings, which was later improved by Tombre et al. [6] through right choice of threshold and its stability.
Language invariant script recognition was proposed in [72] using spatial relationships of features. Two classes of languages are determined using optical density distribution and most frequently occurring word shapes characteristics. Decors symbols can also be considered as line drawing images. In that context Freeman [71] discusses various forms of line drawing representations, processing of line drawing structures derived from images by extracting their features like chain coding scheme, polygon approximation. Qureshi et al. [67] have proposed a solution for symbol spotting using a graph representation of graphical documents. In the same line Dutta et al. [27] has proposed a symbol spotting technique in graphical documents, in which graph represents the document and a sub-graph matching is used to spot symbols. Viola and Jones [69] proposed a learning algorithm by selecting salient visual features and a novel representation called “integral image”, which allows the features used by detector to be computed very quickly. They combined increasingly more complex classifiers in a “cascade”, which allows background regions of the image to be quickly discarded speeding up object detection. [68], proposed a new rotated Haar like features was proposed, which improves the accuracy of object detection by great extent. In [62],Joachims discussed about bag of words approach for objects categorization. However in another work [11], an image is divided into blocks, and blocks with higher density are considered as text by grouping them, where key points are extracted by using FAST [12] method.
In the context of floor plans text/graphic segmentation were performed in [1, 2, 7]. In [32], a new algorithm to segment the ancient maps and floor plans was proposed by removing non textual elements and recognizing characters to identify the plans. In [7], various rooms are detected and labelled by Optical Character Recognition (OCR) on localized text regions. Heras et al. [3] have proposed a Statistical patch based Bag of visual words (BoVW) model to segment floor plan image. Attributed graph of line segments is generated with nodes labelled for wall segmentation, followed by DFS search to obtain walls in [3]. In [3], doors and windows are detected using symbol spotting techniques using SURF feature by detecting the key points in the image. In [9], walls in a floor plan image are detected by exploiting the properties of Hough transform on vectorized image. Also they have used bag of visual words for the same task and later A* search is performed to find a path between doors. In [3], rooms are detected in the floor plan images by finding the closed regions in WDWC graph, preceded by removal of all the terminals of the graph. Wall contained image is decomposed into convex regions to detect the rooms and holes in the polygons are resolved. Later convex regions are checked for over segmentation by identifying the fitting rectangle of that region in [9]. In [24], a method for recognizing “uniform” binary patterns was proposed.
II-B Image description generation
Description generation from images has been an interesting area for aligning images to their corresponding text. Although literature is available on natural images, description of document images is still an untouched domain. In one of our earlier work [18] we have introduced the problem of description generation from floor plan. An extensive survey of the existing techniques is given in [55]. Vinyals et al. [60] presented a generative model, based on deep recurrent architecture, which takes an input image , and trained to maximize the likelihood of producing a target sequence of words . In the same line [34] discusses a model to generate descriptions from images, which automatically learns to describe the content of images. The work in [59] have presented a holistic data-driven approach to image description generation, which uses vast amount of image data and associated description available over internet. They recognize and predict the contents of an image and then use existing human composed description to generate natural captions for images. In [58, 37], authors have generated dense description of images, by developing a deep neural network model. They introduced a multimodal Recurrent Neural Network architecture that takes an input image and generates its description in text. In [57], authors have used image meta-data for automatically generating textual image collection descriptions that include both image content and context information. Moreover, they convert and expand the meta-data, by using publicly available information and services over internet. Kulkarni et al. [56] generated description of images by detecting objects, modifiers (adjectives) and spatial relationships (prepositions) in an image, comparing and smoothing these detection using pre-available description text.
In the same context Farhadi et al. [38] proposed a system that can obtain a score by linking an image to a sentence. In [59], authors have proposed a data driven approach for description generation by giving a query image and retrieving existing human composed phrases which describe similar images. Combining those phrases they generate a description for the given image. Verma and Jawahar [35] have proposed a system that achieve task like given an image, generating a textual description and vise versa, where both approaches are retrieval based. In the same line Zhu et al. [33] provides an approach to align visual contents of a movie release to their corresponding book by providing a description of the visuals. Image description is generated by creating visual dependency representation of natural images in [25]. Natural language description generation is also done for video for their retrieval purpose in [26], in which they capture relations between keywords associated with videos. Evaluation of machine translation with human generated description is also necessary. For that purpose several metrics for example BLEU [54], ROUGE [53], METEOR [52] etc, have been proposed. In [39], authors provided a correlation between automatic metrics and human judgments, using previously mentioned metrics and their variants. Various approaches have been developed to connect two domains, natural language processing and document image analysis. For example in [28] authors have gained performance by integrating features from linguistic analysis, image text recognition and image layout analysis. Looking at the existing literature we see that even though description synthesis from natural images has become common, the same from document images is still not there, and thus we propose SUGAMAN to bridge the gap. SUGAMAN is an extension of our earlier work [18]. The key differences between SUGAMAN and [18] are: (1) A feature based automatic room annotation learning method is proposed, as compared to OCR based method, (2) An improved proximity based sentence model is proposed in SUGAMAN, in stead of a template based model, (3) introduction of room to room navigational information for obstacle free movement.
III System Overview
Figure 2 shows a block diagram depicting various modules and work-flow within SUGAMAN. The whole system is divided into two stages (i) room annotation learning and (ii) description synthesis. At first, room semantic information is extracted by room segmentation process, which gives all the required information about an input floor plan image. For example, individual room area, door information which gives room neighborhood information, room locations (room coordinates). With those room locations, the floor plan image is partitioned into individual room image and taken as sample for room annotations learning. Decor characterization is applied over these room images and decors present in a room are labeled. We have proposed a Local Orientation and Frequency Descriptor (LOFD) feature, which is extracted from these room samples for automatic room annotation. A classifier is trained using LOFD feature matrix of room samples by assigning class labels to them. After this a new input image is taken as a test sample, features are extracted and room annotations are identified for it using previously trained model. An XML file is generated using the semantic information extracted by room segmentation and room classification. By parsing this XML file, textual description is generated. SUGAMAN also gives navigation path within the entire floor plan, starting from the entry door to the building. All such information about floor plan and navigation are fed to the proposed grammar model. The first stage of the proposed description synthesis method deals with “what to say” about the floor plan and the second stage will deal with ”how to say it”. For ease of understanding, in rest of the paper, we demonstrate all our analysis on the input image shown in Fig. 1. Later, in the experimental results, we also show the results on other floor plan images. Next we discuss about the dataset used for experimentation.
IV Floor Plan Dataset
For room segmentation, symbol spotting, retrieval in floor plan images three public dataset were proposed. They are: (i) Systems Evaluation SYnthetic Documents (SESYD) [30] (ii) Computer Vision Center Floor Plan (CVC-FP) [31] and (iii) Repository Of BuildIng plaNs (ROBIN) [29]. SESYD has ten classes of floor plans, with samples/class. On the other hand, CVC-FP has scanned floor plan documents divided into four categories based on the origin and style. In ROBIN there are three broad categories, which are different from each other in terms of the number and type of rooms present in a floor plan. The three categories are (i) room, (iv) room, and room floor plans. Each category is further classified into sub-categories depending upon the global layout of the floor plan. ROBIN helps in better visualization of the floor plans and aids in efficient capturing of various high-level features while fine-grained retrieval. Since ROBIN has significant number of floor plans, as well as intra-class similarity and inter-class dissimilarity, it is suitable in our case. However, in ROBIN there is no textual description available for a given floor plan. For our purpose we further augmented ROBIN dataset by introducing textual description for each floor plan image.
IV-A A-ROBIN
In order to understand the floor plan images better, and produce automated textual description narrating them we propose a dataset Augmented ROBIN (A-ROBIN). In A-ROBIN there are four human written descriptions for each image in ROBIN dataset. In there literature, there are a few image datasets for example Flicker8k [22], COCO dataset [23], which has associated descriptions of the image samples. However, these datasets describes the natural images. In the context of document images, dataset consisting description of floor plan images was lacking. Hence we require a novel dataset which contains annotations and descriptions for document images. The descriptions for a floor plan images were collected from the volunteers in the following manner. Each volunteer was supplied with a set of images in a Google form and asked to describe them in their own words based on a set of instructions. Each form was given to volunteers, so that each image has set of descriptions. These descriptions focus on the rooms and their decor content in the floor plan images. Also they focus on their relative positioning in respective rooms, and relative position of each room within the floor plan image. These descriptions vary in the sequence of the information given, the details of information provided, the sentence conjunctions and the vocabulary used for components in floor plan image. Figure 3 shows one of the floor plan and its corresponding descriptions. It can be observed that different descriptions of the same image vary in the amount of information provided, the sequence of describing each room, the names for each decor item could be different for different user. Also, a room may have variations in its name for different user. The length of the descriptions provided for each image is also varied. After the descriptions were collected, each set of description were tagged to their respective images using image identifiers.
Following were the instructions given to users:
- •
Write information about the whole plan (number of rooms, name of the rooms).
- •
Write information of individual rooms- name, decor contained, relative size (small, medium, large, etc).
- •
Write information about the relative positioning of decors (north, east, west, south, aligned with wall, adjacent with something, etc).
- •
Write information about the relative position of each rooms ( north, east, west, south, adjacent with bathroom, north of kitchen, etc).
- •
The description can have this information but they are not restricted to this. You can choose your own words and language.
Figure. 4 shows the user interface used to collect the descriptions. For images in ROBIN datasets, there were descriptions collected in total. The dataset is tokenized and pre-processed for further processing. In our experiments we have compared machine generated description with these descriptions and an analysis regarding closeness of machine translations with human written descriptions is given. Next, we describe the steps in our framework in details.
V Semantic Segmentation and Room Classification
In all the previous approaches available in the literature, rooms have been classified by recognizing the textual label present in the floor plan image using Optical Character Recognition (OCR) techniques. Room classification in floor plans is not done by extracting salient feature from it. Room classification on the basis of their functionality is very useful in building information modelling (BIM). When a person enters a room in a house, he or she tells the functionality (class) of the room by looking at the decor items present inside the room. This inspired us to propose a unique feature for room classification. We have proposed a new feature called Local Orientation and Frequency Descriptor (LOFD), which represents the frequency of decors present in a room and their normalized distance from the center of the room. We proposed room classification approach as a class classification problem, which annotates each room in a floor plan into one of the classes namely, BEDROOM (label-), BATHROOM (label-), ENTRY (label-), KITCHEN (label-), HALL (label-). The following subsections describes the details of room label learning and classification.
V-A Room Segmentation
We have adopted the technique proposed in [14] for the identification of rooms. Walls are detected by performing morphological closing on the input floor plan image (see Fig. 5(c)). To delineate room boundaries, we detect doors using scale invariant features and close the gaps in wall image corresponding to the door locations. To obtain the rooms, we identified the connected components in the wall image by applying flood fill technique. The obtained connected components are the required rooms and their locations are obtained. Also, we calculate the areas of the respective rooms (polygon area), converted them into square feet (taking pixels= feet) and store all the information obtained, that is neighborhood, room area, room location coordinates, in a separate data structure.
V-B Floor Plan Partitioning
A floor plan image is partitioned into rooms using the room coordinates extracted from the previous steps as shown in Fig. 5(d). These individual room images are the samples taken for training the room annotations. We have applied decor characterization in further stages on each of these individual room images to extract the features.
V-C Decor Classification
In this section we describe the procedure employed for decor characterization and their classification. Figure 6 shows the decor symbols used in the dataset [29]. We have improved the technique of decor characterization proposed in [14] by applying sequence of morphological operations. The technique in [14] uses a normalized area ratio of largest three components of a decor symbol for classification and characterization of decors. We have improved the technique by first collecting different signatures for each symbol, taking an mean over them (symbols with different orientations) and stored them in a signature library. During classification, we first pre-process the symbol by applying a sequence of morphological operations (erosion and dilation), so that the symbol do not have broken lines. Then we applied blob detection over the image an cropped each decor symbol for signature comparison. Now we compare the test image’s signature with the signature stored in library and closest one is classified in its respective category. This modification in the technique greatly improved the classification accuracy for some symbols. Figure. 5 (b) depicts the detection of symbols in the floor plan input image Fig. 5 (a) with bounding boxes. These decors are classified in their respective categories shown in Fig. 6.
V-D Local Orientation and Frequency descriptor (LOFD)
Once the decors inside a room are recognized, we compute the feature to classify a room. For room classification, we proposed a new feature named Local Orientation and Frequency descriptor (LOFD). The LOFD feature is required since no other feature descriptor for example SIFT [61], LBP [24] or SURF[21] could capture the room images clearly. The LOFD feature is a vector containing the decor information of a room sample and their locally aggregated spatial information. Figure. 7 shows the LOFD feature matrix for the sample floor plan image. In LOFD, we have aggregated local information of room image in a vector form. LOFD is compact representation of frequency of the decor items and normalized distance of their centers from center of the room. The first cells of the vectors are occupied by the decor items from and next cells are occupied by their normalized distances as where is the distance of each decor item from the center of the room. Here, is calculated as:
[TABLE]
Here, is the normalized distance for each decor item, is the count of each decor which may go up to , which is the maximum number of a that decor item in the room, is the Manhattan distance between room center and decor center , is the maximum of all the distances obtained for all the decors to normalize the distance value. Hence LOFD feature distinguishes each room uniquely by the frequency of each decor item and their spatial location in the room.
Since there are decor models as shown in Fig. 6, first elements of LOFD represents count of one decor item. However it is not necessary for any room to have all types of decor present, therefore LOFD is sparse in nature. In Fig. 7, depicts the room image followed by the corresponding LOFD feature vector. The colored bar over each cell represents the frequency count for each decor item, while arrows in red represents their relative spatial location in the room. In the next section training of the classifier using LOFD feature for room classification is explained.
V-E Room annotations Learning and Room classification
Room annotations for training samples (divided the room images into and for training and testing respectively) are learned by LOFD feature and classifier. For training purpose, we have manually annotated the room samples, and used those annotations during training. Extensive experiments were performed using various classifiers and the best classifier in term of highest training accuracy is taken for testing the model. For testing purpose, an image from test set is taken and class labels are evaluated accordingly for the room samples of that floor plan image. For each new test floor plan image, feature vector is evaluated for every room. Therefore dimension of feature matrix for a test floor plan image will be where is the number of rooms in the floor plan. Trained classifier is used for this feature matrix and output class labels are evaluated. Figure 8 depicts the annotations obtained for each room in a floor plan image, where different colors signifies different rooms and their respective annotations. Thus for a given floor plan we obtain room names and the decors within the rooms.
VI Description Synthesis
Rooms are classified and their annotations are learned in Sec.V-E. Information extracted from room segmentation are combined and used for generating the description of the floor plan image. Information related to individual rooms are combined and stored in an XML file, which is parsed to generate description of the floor plan.
VI-A XML File generation
An XML file has many benefit in terms of cross platform portability, ease of understanding by novices, and extendability. We have created an XML file by combining the semantic information extracted from room segmentation and room annotations learned in previous steps. As shown in Fig. 9, the tree like structure of XML file contains “Room details” as root node at level [math], “Room names” as nodes at level , and information of rooms as nodes at level (leaf nodes), which are Room ID, Room annotations, Room area, Room Coordinates, Room neighbors and Room Decors. Apart from room annotations, a room ID is given to each room since room annotations can be same for two rooms. to generate a description.
VI-B Coordinates systems
For defining the positions of rooms and decors present in the floor plan, we have defined two coordinate systems. The global coordinate system is to identify the global location of rooms with respect to the entire document. Local coordinate system is to define relative position of decors with respect to each room.
VI-B1 Boundary Tracing
The origin of the global coordinate system is the center of the polygon, which makes the boundary of the floor plan. To identify the center of the floor plan, its boundary is traced. In order to trace the boundary, coordinates which compose individual rooms are plotted and an outer boundary is tracked which encloses all the outer points, since these points collectively makes the floor plan image. However, by tuning the value of shrinkage factor between [math] and we can switch between a convex hull of those points and a more close knit boundary. Shrinkage factor defines how closely the hull envelops the boundary points. For example, in Fig. 10 (a), the boundary traced is a convex hull for the floor plan image for the shrinking factor value , Fig. 10 (b) is the traced boundary for shrinking factor value and Fig. 10 (c) is the close knit boundary for . Hence by tuning the shrinking factor value we can obtain a close knit boundary for the floor plan image.
VI-B2 Global and local coordinate systems
A global coordinate system defines the global position of all the rooms in a floor plan image (see Fig. 11 (b)). From the traced boundary obtained in the previous step, we calculate the origin of the global coordinate system. Equation 2 and 3 lists the governing equations.
[TABLE]
Where, in Eq. 2 is twice the signed area of the elementary triangle formed by and and the origin. in Eq. 2 is the area of the polygon.
[TABLE]
In Eqn. 3, is the center of the polygon. The local coordinate system (see Fig. 11 (a)) identifies the relative positions of all decors with respect to each room. Center of each room, for a local coordinate system is computed using Eq. 2 and 3.
VI-C Binning
We have performed global and local binning or radial partitioning of the floor plan (see Fig. 12). The non uniform binning angles were empirically determined. For identifying the direction of a decor, the center of the surrounding bounding box is taken as the reference point. While for the rooms, their respective centers, obtained in the previous steps is taken as reference point. As shown in the Fig. 12(a), the entire coordinate system is divided into directions, north, north-east, east, south-east, south, south-west, west, north-west, in the clockwise direction. The binning depicted in Fig. 12(a) is a non uniform binning, while in Fig. 12(b) is a uniform binning.
The rationale behind non-uniform binning is to provide a more realistic direction information for rooms and decors. The idea of taking the direction from the center of the surrounding polygon may misguide the framework about the actual position of a room. E.g., if a room location in the west direction and stretched towards north, its center will lie in north west direction even if the room is in west. In order to avoid these kind of ambiguities, binning is done non uniformly and the angles are empirically taken. Figure 13 highlights examples for the above rationale. The highlighted room (Fig: 13 (a)) is more toward east direction, however it is also extended towards south. With non uniform binning we try to increase the span of east direction, shown purple line and arc where is the angle of non uniform binning. While red line and arc shows the span of uniform binning which makes the room fall in south east direction and create ambiguity. Here is the angle of uniform binning, and are the centers for floor plan and room respectively.
VI-D Navigation
Navigation in the indoor environment by avoiding the obstacles is an integral part of SUGAMAN. We have proposed a grammar based model that yields navigational directives to navigate through the house for a natural movement, from one door to the other door of each room. The algorithm is divided into two parts, first we create a data structure, which stores the room labels along with their respective doors and their corresponding index. The room information and the door coordinates are obtained from semantic segmentation in the earlier stages (see Sec. V-A). If a door is shared between two rooms then that door will be present in both room’s door structure and the index will represent the door’s identity. Next, we identify the entry room and the corresponding door, and generate a Depth First Search (DFS) ordering of the region adjacency graph of the floor plan taking the entry room as the start node. After that, a path to the next room is generated avoiding obstacles, by checking the visibility from first door to the other. We also create a door based adjacency matrix (), which stores the shared doors between rooms.
VI-D1 Creating door structure
The room coordinates, room labels and door coordinates are obtained in the semantic segmentation. After that an index is assigned to each door. We have checked whether a given door belongs to a particular room or not. We have performed an inside-outside test between the bounding polygons of the doors and the rooms to achieve the belongingness. The door structure contains each room with its corresponding doors having marked with their index . As shown in Fig. 15(b), room and door information is stored in a door structure.
VI-D2 Path Finding
DFS search is performed over the region adjacency graph of the floor plan image taking the entry room as starting node. The door connected to the outer wall of the entry room is considered as the entry door and stored in the door structure. Here, entry door for the house is detected by the algorithm discussed in [18]. Algorithm. 1 describes the process of room to room navigation by obstacle avoidance. The route in each room is stored in the form of coordinates of movement and included in the description for narration of the path. Algorithm 1 traverse the rooms starting from the first room in the DFS graph, by checking if there is a door shared between them. This is checked by door based adjacency matrix (). If they do not share a door, the algorithm backtrack and explore other rooms. Also, it determines the route across the rooms for navigation. In Alg. 1, line 2 declares the flag, if the algorithm has to enter into backtracking. Line 1 describes the loop which traverse room to room finding the path. Line 5, algorithm checks if there is a shared door between the current room and the next room and continues traversal between rooms if there is a shared door. Line 6 directs the algorithm to further processing if backtracking is not required. Line 7 to 10, detects the coordinates of bounding box of decor items and centroid of doors of current room and include in a vertex list. In 11, doors are removed from room image because they are not required for avoiding obstacles. Line 12 to 15 detect the corner points in the room image using Harris corner detector after detecting the blobs, and include maximum 1000 strongest corners in the vertex list. Line 16 to line 22 describes the construction of adjacency matrix for navigation (). It checks the visibility between every point in the vertex list and include the Euclidean distance between them in as the weight at ((j),(k)). Visibility between two points is checked by filling the line between equal intervals in those points and checking if there is a black pixel present. If there is a black pixel present, then there must be an obstacle between those two points and hence those points are not visible. ((j),(k)) will have a [math] in that case. Line 26 and 27 defined the entry () and exit () door for current traversal, where entry door is the entry of current room and exit door is the entry of the next room. Line 29 evaluates a route () for current traversal by applying Disjkstra’s shortest path algorithm over taking and as start and end nodes. Line 31 to 34 defines the backtracking process if there is no shared door found between current room and next room. Algorithm will backtrack in the DFS path and find the navigation path between corresponding rooms. The route for room () is a set of coordinates, which contains the start point, end point and intermediate turns which a person have to make for obstacle avoidance. Figure. 15 describes the entire process for the input image Fig. 15(a). The checker box (inset) depicts , where the dark box represents a [math] and a white box represents a .
Figure. 15(b) shows the door structure created in the previous step and the order of traversal with backtrack step, Fig. 15(c) shows the DFS search graph generated over the region adjacency matrix to obtain the order to traverse the each room and Fig. 15(d) shows the local coordinate system fitted over every point in a route while traversing through the floor plan, also showing the direction of movement by arrows. Figure. 16(a) represents the door to door path generated for navigation, avoiding obstacles in each room for the input image. Figure. 16 shows some other examples describing the path generated on various floor plan images.
VI-E Proximity based sentence model
Parsing of the XML file yields types of information for each room, defined in separate sentences; Room name, area, neighbouring rooms, global position and contained decors with their relative position in room. For that purpose we defined, sentence model having rules, which is based on proximity as shown in Tab. VI-E. The first sentence () of description for every floor plan is a general sentence stating the number of rooms () in the floor plan. In , DT is a determiner which takes its value from the set {a, an}. Also, is the object which takes its value from level nodes (Room names), where value varies from to . In , AREA takes its value from the RoomArea tag when XML file is parsed. In , takes its value from the set {s,}, which is a proximity based value depends upon its previous word. Value is chosen if the word in proximity (room) is a plural and otherwise. Also, AUX is an auxiliary verb, which takes its value from {is, are}, depending upon its proximity word and takes its value from Neighbors tag (neighboring rooms), when XML file is parsed. Here, value of j varies from 1 to which is number of neighboring rooms. In , LOC is the global position of room which takes its value from the set {North, North East, East, South East, South, South West, West, North West} described by binning. In , the value of varies from 1 to i.e. decor count. Here, is the count of individual decor item, takes its value from the Decor tag in XML file, takes its value from {s,} and is the relative location of decor in the room which takes its value from {North, North East, East, South East, South, South West, West, North West} described by binning.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] S. Ahmed, M. Liwicki, M. Weber and A. Dengel Text graphics segmentation in architectural floor plans , ICDAR, 2011
- 2[2] S. Ahmed, M. Liwicki, M. Weber and A. Dengel Improved automatic analysis of architectural floor plans , ICDAR, 2011
- 3[3] L.P.d.l. Heras, O.R. Terrades, S. Robles, and G. Sanchez Statistical segmentation and structural recognition for floor plan interpretation , IJDAR, 17(3), pp. 221–237, (2014).
- 4[4] S. Suzuki and others Topological structural analysis of digitized binary images by border following , CGVIP, 30(1), pp. 32-46, 1985
- 5[5] L.A. Fletcher and R. Kasturi A robust algorithm for text string separation from mixed text/graphics images , IEEE T-PAMI, 10(6), pp. 910–918, (1988).
- 6[6] K. Tombre and S. Tabbone and L. Pélissier, B. Lamiroy and P. Dosch Text/graphics separation revisited , DAS, (2002).
- 7[7] S. Ahmed, M. Liwicki, M. Weber and A. Dengel Automatic room detection and room labeling from architectural floor plans , DAS, 2012
- 8[8] Z. Lu Detection of text regions from digital engineering drawings , IEEE T- PAMI