SUSiNet: See, Understand and Summarize it
Petros Koutras, Petros Maragos

TL;DR
SUSiNet is a multi-task spatio-temporal neural network that jointly addresses saliency estimation, action recognition, and video summarization, achieving competitive results with reduced computational cost.
Contribution
It introduces a unified, end-to-end trainable network that handles multiple video analysis tasks simultaneously with deep supervision from eye-tracking data.
Findings
Performs on par or better than single-task methods across seven datasets.
Reduces computational cost compared to independent networks.
Effectively integrates diverse datasets for multi-task learning.
Abstract
In this work we propose a multi-task spatio-temporal network, called SUSiNet, that can jointly tackle the spatio-temporal problems of saliency estimation, action recognition and video summarization. Our approach employs a single network that is jointly end-to-end trained for all tasks with multiple and diverse datasets related to the exploring tasks. The proposed network uses a unified architecture that includes global and task specific layer and produces multiple output types, i.e., saliency maps or classification labels, by employing the same video input. Moreover, one additional contribution is that the proposed network can be deeply supervised through an attention module that is related to human attention as it is expressed by eye-tracking data. From the extensive evaluation, on seven different datasets, we have observed that the multi-task network performs as well as the…
Click any figure to enlarge with its caption.
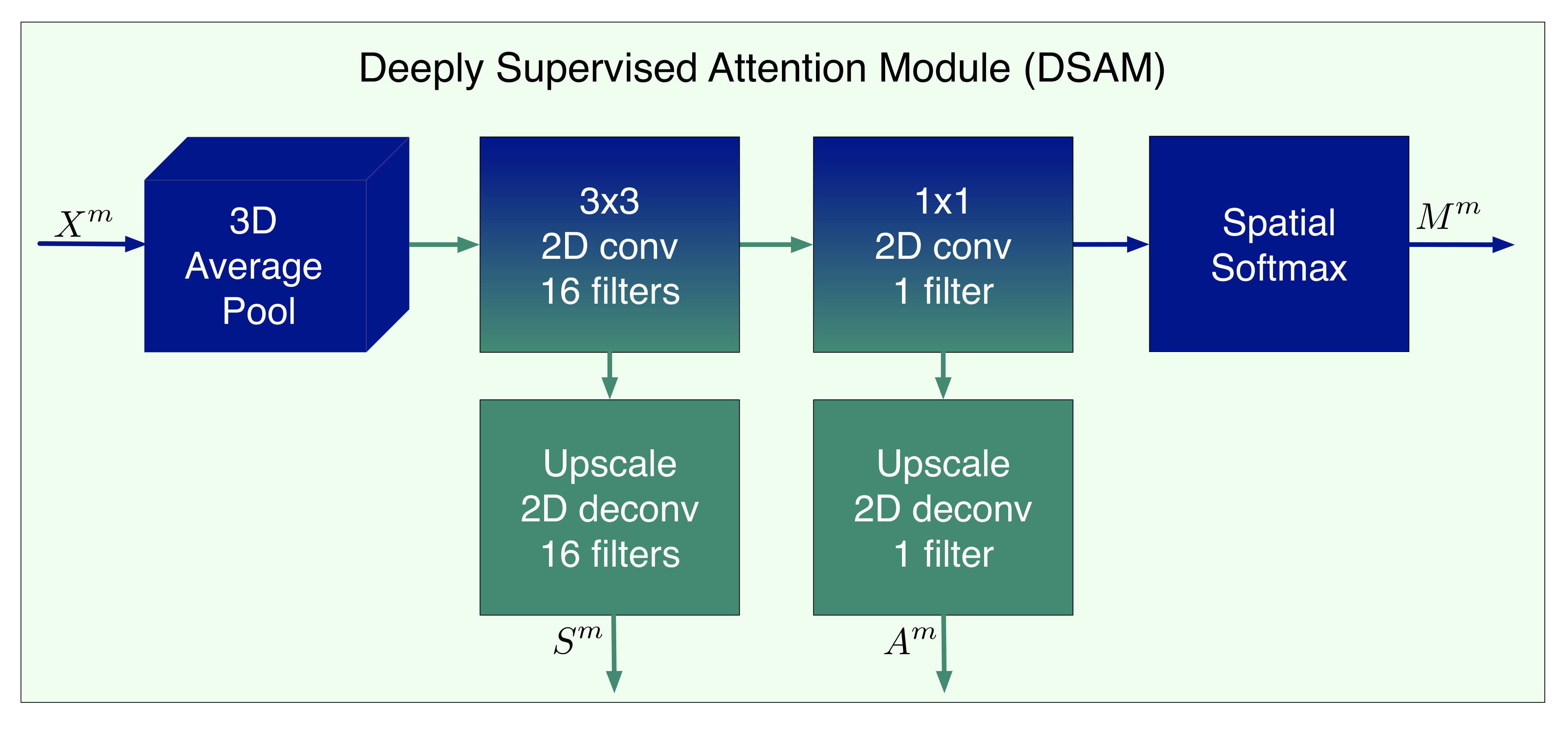 Figure 1
Figure 1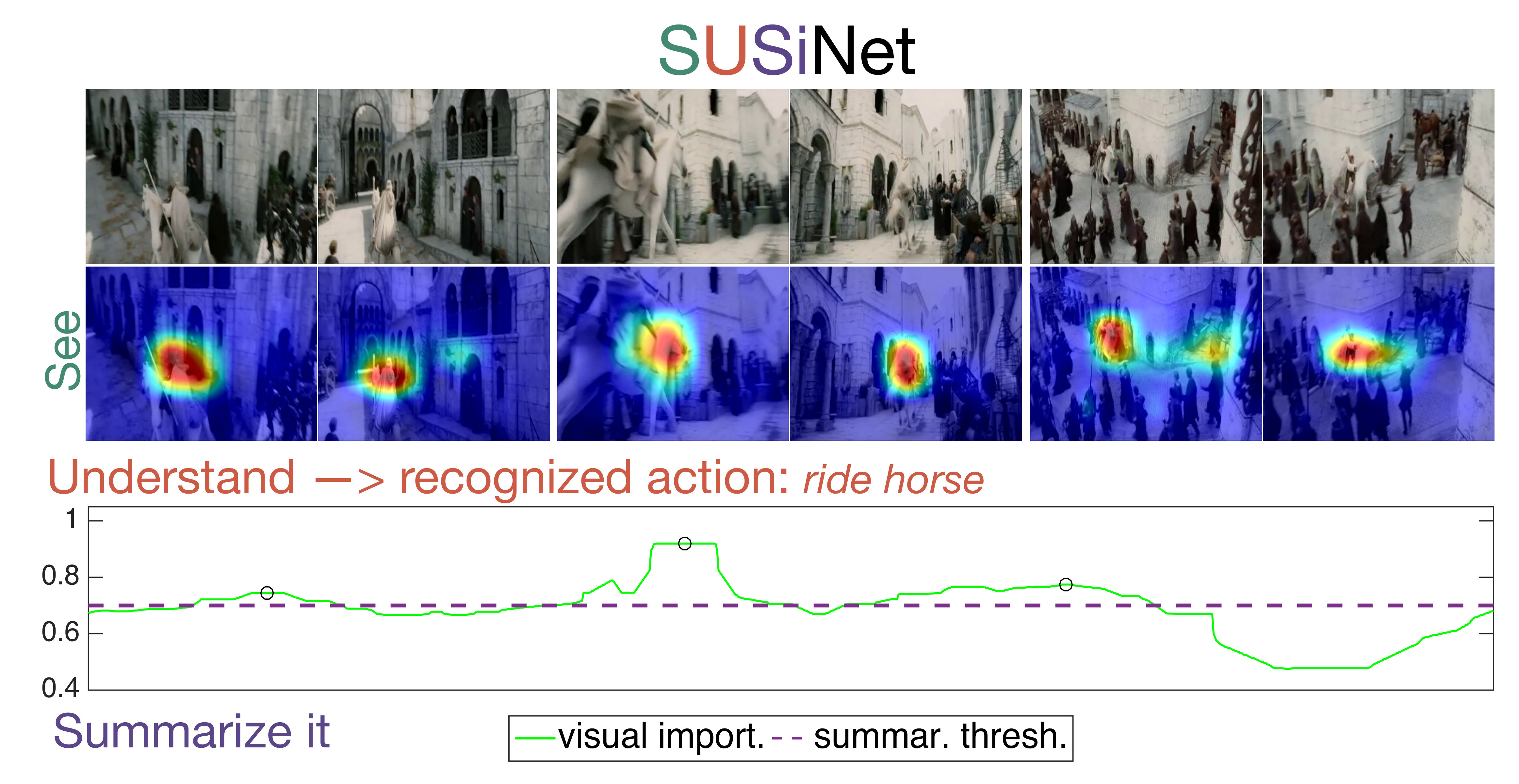 Figure 2
Figure 2 Figure 3
Figure 3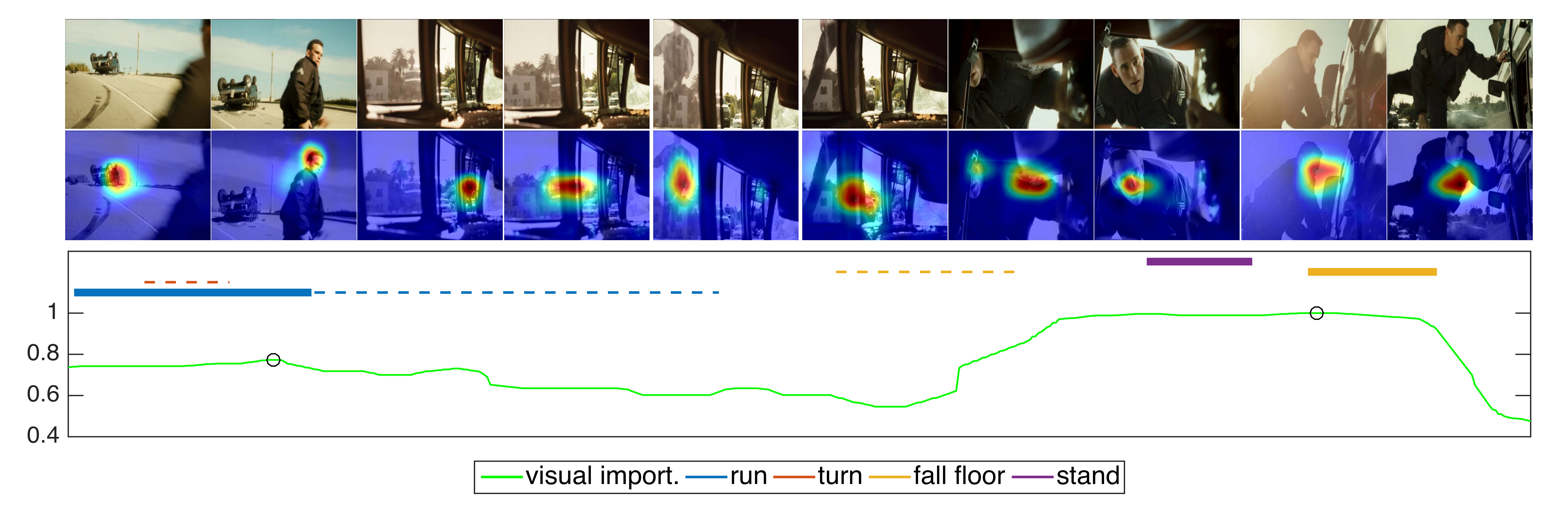 Figure 4
Figure 4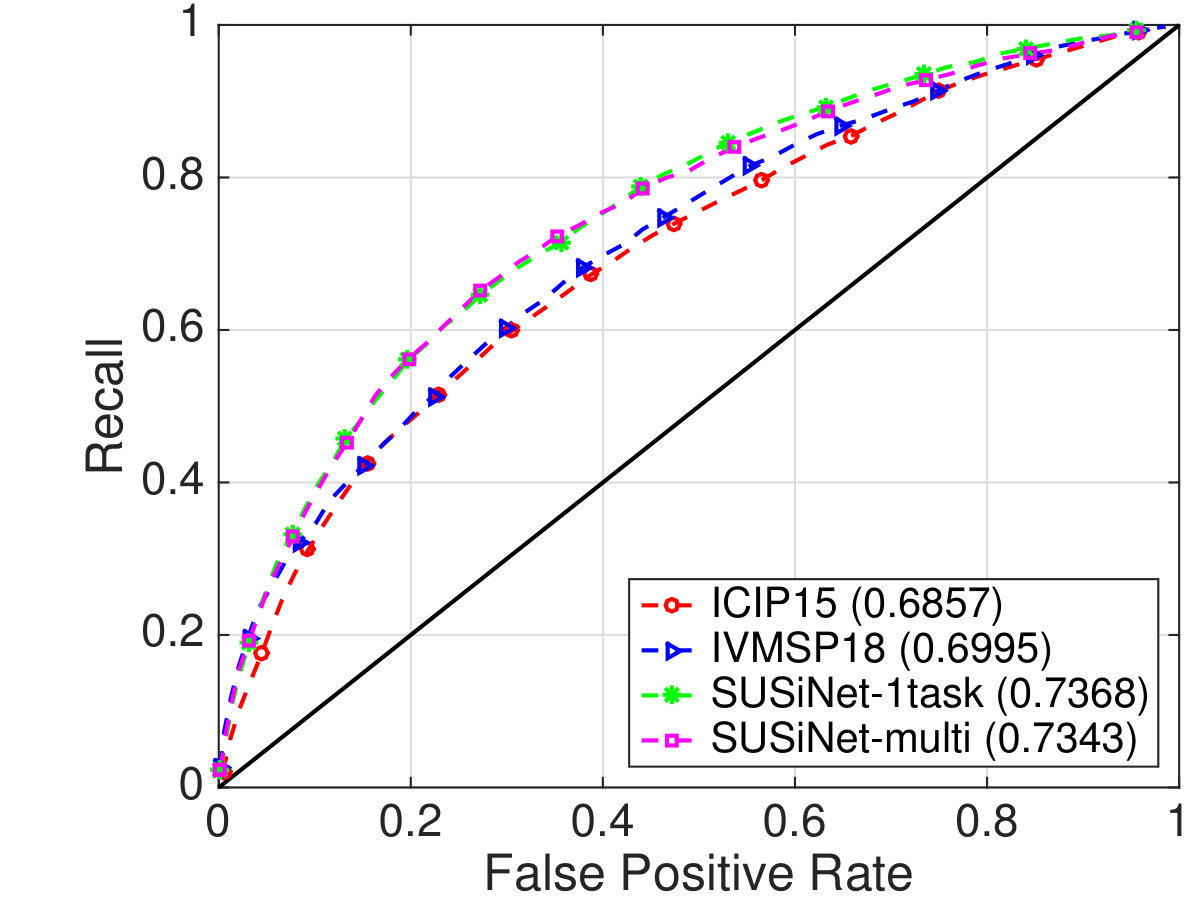 Figure 5
Figure 5| DIEM | DFK1K | ETMD | ||||||||||
| CC | NSS | AUC-J | sAUC | CC | NSS | AUC-J | sAUC | CC | NSS | AUC-J | sAUC | |
| SUSiNet (1-task) [ST] | 0.6138 | 2.4267 | 0.8736 | 0.6747 | 0.4676 | 2.5908 | 0.8843 | 0.6991 | 0.5523 | 2.8365 | 0.9173 | 0.7312 |
| SUSiNet (multi) [ST] | 0.5614 | 2.1398 | 0.8810 | 0.6736 | 0.4116 | 2.2092 | 0.8910 | 0.6980 | 0.4780 | 2.3642 | 0.9162 | 0.7272 |
| Deep-Net [45] [S] | 0.4305 | 1.6238 | 0.8401 | 0.6262 | 0.2969 | 1.5804 | 0.8421 | 0.6432 | 0.3438 | 1.6523 | 0.8712 | 0.6588 |
| DVA [62] [S] | 0.5179 | 2.1607 | 0.8599 | 0.6400 | 0.3593 | 2.0644 | 0.8609 | 0.6572 | 0.4228 | 2.2507 | 0.8848 | 0.6843 |
| SAM [12] [S] | 0.5352 | 2.2482 | 0.8651 | 0.6429 | 0.3684 | 2.1180 | 0.8680 | 0.6562 | 0.4345 | 2.3155 | 0.8890 | 0.6875 |
| ACLNet [63] [ST] | 0.5626 | 2.2168 | 0.8717 | 0.6228 | 0.4167 | 2.2962 | 0.8883 | 0.6523 | 0.4508 | 2.2058 | 0.9073 | 0.6482 |
| DeepVS [31] [ST] | 0.4885 | 2.0352 | 0.8448 | 0.6248 | 0.3500 | 1.9680 | 0.8561 | 0.6405 | 0.4316 | 2.3030 | 0.8955 | 0.6672 |
| Method | Pre-train dataset | Aver. Accuracy |
|---|---|---|
| SUSiNet (1-task) | Kinetics | 60.2 |
| SUSiNet (multi) | Kinetics | 62.7 |
| C3D [55] | Sports-1M | 51.6 |
| 3D ResNet-18 [25] | Kinetics | 56.4 |
| 3D ResNet-50 [25] | Kinetics | 61.0 |
| 3D ResNeXt-101 [25] | Kinetics | 63.8 |
| RGB I3D (64f) [10] | ImageNet & miniKinetics | 66.4 |
| Other Methods | ||
| [54] | ImageNet | 59.1 |
| ARTNet [59] | Kinetics | 67.6 |
| R(2+1)D-RGB [56] | Kinetics | 74.5 |
| Two-Stream TSN [61] | ImageNet | 68.5 |
| Two-Stream STM-Nets [19] | ImageNet | 68.9 |
| Two-Stream I3D (64f)[10] | ImageNet & Kinetics | 80.7 |
| Two-Stream R(2+1)D [56] | Kinetics | 78.7 |
| Method | SumMe (F-score) | TVSum50 (F-score) |
|---|---|---|
| SUSiNet (1-task) | 41.10 | 59.20 |
| SUSiNet (multi) | 40.80 | 57.00 |
| vsLSTM [67] | 37.6 [41.6] | 54.2 [57.9] |
| HSA-RNN [69] | 44.1 | 59.8 |
| SEQ2SEQ [68] | 40.8 | 56.3 |
| SUM-FCN [50] | 47.5 [51.1] | 56.8 [59.2] |
| Other Methods | ||
| Gygli et al. [24] | 39.7 | - |
| dppLSTM [67] | 38.6 [42.9] | 54.7 [59.6] |
| SUM-GAN [41] | 41.7 [43.6] | 56.3 [61.2] |
| re-SEQ2SEQ [68] | [44.9] | [63.9] |
| Task | Saliency (sAUC) | Action (Acc.) | Summar. (AUC) | |||
|---|---|---|---|---|---|---|
| SUSiNet | 1-task | multi | 1-task | multi | 1-task | multi |
| BMI | - | - | 51.54 | 49.88 | 0.7831 | 0.8023 |
| GLA | 0.6859 | 0.6727 | 48.92 | 46.77 | 0.7863 | 0.7843 |
| CHI | 0.7601 | 0.7565 | 49.41 | 50.82 | 0.7901 | 0.7826 |
| FNE | 0.7224 | 0.7236 | - | - | 0.5490 | 0.5306 |
| LOR | 0.7297 | 0.7325 | 50.70 | 54.93 | 0.7602 | 0.7557 |
| CRA | 0.7056 | 0.7058 | 49.83 | 47.83 | 0.7424 | 0.7105 |
| DEP | 0.7837 | 0.7721 | 58.86 | 60.76 | 0.8069 | 0.8279 |
| GWW | - | - | 36.24 | 37.70 | 0.6762 | 0.6806 |
| Aver. | 0.7312 | 0.7272 | 49.36 | 49.81 | 0.7368 | 0.7343 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHuman Pose and Action Recognition · Video Analysis and Summarization · Video Surveillance and Tracking Methods
SUSiNet: See, Understand and Summarize it
Petros Koutras and Petros Maragos
School of E.C.E., National Technical University of Athens, Greece
{pkoutras, maragos}@cs.ntua.gr
Abstract
In this work we propose a multi-task spatio-temporal network, called SUSiNet, that can jointly tackle the spatio-temporal problems of saliency estimation, action recognition and video summarization. Our approach employs a single network that is jointly end-to-end trained for all tasks with multiple and diverse datasets related to the exploring tasks. The proposed network uses a unified architecture that includes global and task specific layer and produces multiple output types, i.e., saliency maps or classification labels, by employing the same video input. Moreover, one additional contribution is that the proposed network can be deeply supervised through an attention module that is related to human attention as it is expressed by eye-tracking data. From the extensive evaluation, on seven different datasets, we have observed that the multi-task network performs as well as the state-of-the-art single-task methods (or in some cases better), while it requires less computational budget than having one independent network per each task.
1 Introduction
††This research has been co-financed by the European Regional Development Fund of the European Union and Greek national funds through the Operational Program Competitiveness, Entrepreneurship and Innovation, under the call Research - Create - Innovate (project code: T1EDK-01248, i-Walk)
During the last decade, the extensive usage of Convolutional Neural Networks (CNNs) has boosted the performance throughout the majority of spatial tasks in computer vision, such as object detection or semantic segmentation [52, 27, 26]. Nowadays, automatic video understanding becomes one of the most essential and demanding challenges and research directions due to the increased amount of video data (i.e. YouTube videos, movies, documentaries, home videos). The new problems that have arisen in this field, such as activity recognition, video saliency, scene analysis or video summarization, require the integration and modelling of the temporal evolution instead of applying image based algorithms to each frame independently, such as in video segmentation or pose estimation. In addition, as large-scale video datasets have appeared, an increased performance regarding the video related tasks, i.e., action recognition, can also be achieved [10, 25].
However, till recently, the majority of this great progress in computer vision has been achieved by facing each task independently, without trying to jointly solve multiple tasks or investigating relationships between them. Recent works towards this direction have proceeded by training multi-task networks [34] or finding the structure among visual tasks and apply transfer learning [65]. These approaches open the road for investigating simpler and faster ways to solve multiple task simultaneously, rather than maximize the task-specific performance, and thus providing useful computer vision tools to other scientific communities, i.e., robotics or cognitive sciences.
In this work we propose the See, Understand and Summarize it Network (SUSiNet) a multi-task spatio-temporal network that can jointly tackle the problems of saliency estimation, visual concept understanding and video summarization. Some examples of visual concepts that often appear in videos are human faces, actions, scenes or objects [7, 49]. Let’s consider the example that is depicted in Fig. 1. During watching a video, first we “see” the visual information and we focus on the most salient spatio-temporal regions, a process which is related with the visual saliency estimation task. Afterwards, we try to “understand” what we have seen by recognizing the underlying visual concept, which in this work is approached through the action recognition task. Finally, if someone ask us to “summarize it” we will think about keeping in the summary the most important parts of the video, which in many cases may include the recognized concept.
Our approach employs a single network that is jointly end-to-end trained for all spatio-temporal tasks and incorporates a unified architecture that includes both global and task specific layers. The proposed mutli-task network produces multiple output types, i.e., saliency maps or classification labels, by employing the same video input in the form of 3D video clips. To the best of our knowledge, our approach is the first that deals with these multiple spatio-temporal problems using one single network trained in an end-to-end manner. In [4] the authors have weighted the video clips by the predicted saliency map estimated by their proposed spatio-temporal attention model, in order to compute better feature representations and perform action classification using SVMs classifiers. The work of [49] concatenates deep features, learned independently for the different tasks (scenes, object actions), in order to investigate possible relationships between them. However, none of this approaches employ an end-to-end trained multi-task network for jointly solving multiple spatio-temporal problems simultaneously. Furthermore, one additional contribution is that our new network can be deeply supervised through a proposed attention module that is related to human attention as it is expressed by eye-tracking data.
For the end-to-end training of the SUSiNet we wish to have available a large scale video database that will contain all the required annotations (i.e., eyetracking data, action labels, human created summaries). However, this is not a realistic scenario since the creation of a such dataset requires a lot of human effort for the continuous labelling of a significant amount of videos with all these annotations. So, one important aspect of our proposed network is its ability to be trained with many but diverse datasets, which have been developed for each task independently, following ideas from spatial multi-task networks [34].
We have extensively evaluated SUSiNet performance for all the three tasks on seven different datasets. As we will see the multi-task network performs very close to other state-of-the-art single-task methods that are based on more sophisticated architectures or employ heavyweight inputs [10] (two streams networks and long high-resolution clips) and have been fine-tuned for maximizing a task-specific performance. On the other hand, our approach employs a single network for all tasks and requires less computational budget than having one independent network per each task.
2 Related Work
Since the literature regarding the recognition of the three spatio-temporal tasks we are exploring is quite broad, we refer only some of the most recent deep learning based work about each task. For general reviews about more classical approaches you can see [5, 46, 17].
Visual Saliency: The early CNN-based approaches for saliency were based on the adaptation of pretrained CNN models for visual recognition tasks [39, 58]. Later, in [45] both shallow and deep CNN were trained end-to-end for saliency prediction while [28, 29] trained the networks by optimizing common saliency evaluation metrics. In [44] the authors employed end-to-end Generative Adversarial Networks (GAN), while [62] has utilized multi-level saliency information from different layer through skip connections. Long Short-term Memory (LSTM) networks have also been used for tracking visual saliency both in static images [12] and video stimuli [63]. In order to improve saliency estimation in videos, many approaches employ multi-stream networks, such as RGB/Optical Flow (OF) [3], RGB/OF/Depth [40], or multiple subnets such as objectness/motion [31] or saliency/gaze [22] pathways.
Action Recognition: The work of [32] explored several approaches for fusing information over temporal dimension, while in [30] 3D spatio-temporal convolutions have been proposed, whose performance can be boosted when trained on large datasets [55, 57] or employing ResNet architectures [25]. Recently, many approaches have tried to separate the spatial and temporal parts of 3D convolutions [54, 59, 56], which has achieved improvements over the conventional 3D networks. The work of [51] introduced the two-stream networks that employ RGB and optical flow inputs for modelling the appearance and motion information. This framework has become the basis for many other methods [60, 20, 18, 61, 11, 19]. In [10] the two-stream networks were combined with 3D convolutions, forming the I3D model that holds the state-of-the-art performance on the most action datasets.
Video Summarization: Many of the recent methods approach video summarization as an optimization problem [24, 53, 66, 16, 47], or they employ recurrent neural networks [67, 69], i.e., LSTMs, in order to model long-time dependencies inside the video which are very important in summary creation. In [41] the authors proposed a summarization framework based on GANs, where generator consists of an LSTM-based autoencoder and the discriminator is another LSTM. The work of [68] combines sequential models for the summary creation with a retrospective encoder which maps the summaries to an abstract semantic space. Following a different framework, the authors of [50], inspired by the progress in semantic segmentation, proposed fully convolutional sequence networks as an alternative approach to recurrent networks.
3 Multi-task Spatio-Temporal Network
The proposed spatio-temporal network deals with three different tasks simultaneously and produces different types of outputs by employing the same video input in the form of small video clips. For the saliency estimation, where we face a spatial estimation problem, the network output consists of a saliency map, while for the action classification task we have the classical softmax scores. For the video summarization we need to estimate video’s segments importance scores, which indicate whether a segment will be included in the summary, as the sigmoid scores of a binary classification problem.
3.1 Global Architecture with Deep Supervision
The whole architecture of our multi-task network, which is shown in Fig. 2, is based on the general ResNet architecture [27] and specifically the 3D extension proposed in [25] for the problem of action classification. The global pathway of the network with parameters (dark blue), which is shared among all the tasks, includes the first four convolutional blocks from the employed ResNet version that provides outputs in different spatial and temporal scales. In order to enhance the most salient regions of these feature representations, we apply an attention mechanism by taking the element-wise product between each channel of the feature map and the attention map :
[TABLE]
The attention map is obtained by our proposed Deeply Supervised Attention Module (DSAM) based on the idea of deep supervision that has been used in edge detection [64], object segmentation [9] and static saliency [62]. In contrary to these previous works the proposed module is used for both enhancing the feature representations of the global network as well as providing the multi-level saliency maps for the task of spatio-temporal saliency. Thus, the DSAM parameters are trained by both the main-path of the network, which is shared among all the tasks, and the eye-tracking data that are used for the task of saliency estimation through the skip connections of the Fig. 2. In this way, we enrich our network with an attention module that is related to human attention as it is expressed by eye-tracking data.
Figure 3 shows the architecture of the attention module applied at level . It includes an averaging pooling in the temporal dimension followed by two spatial convolution layers that provide the saliency features and the activation map . Both of these representations are up-sampled (using the appropriate deconvolution layers) to the initial image dimensions and used for the deep supervision of the module as well as for the multi-level saliency estimation. The attention map is given through a spatial softmax operation applied at the activation map :
[TABLE]
3.2 Task-specific Sub-Networks
3.2.1 Visual Saliency Module
Since in the saliency estimation we face a dense prediction problem, we need to employ a fully convolution sub-network with parameters (see green parts of Fig. 2) that takes advantage from the concatenated multi-level saliency features of the DSAM components and produces the final fused saliency map which corresponds to the given video clip. For the training of the network parameters , which are associated with visual saliency, the deep attention supervision of the whole multi-task network and the global branch we construct a loss that compares the saliency map and the activations with the ground truth maps obtained by the eye-tracking data:
[TABLE]
where denotes the sigmoid non-linearity and is a loss function between the estimated and the ground truth 2D maps. In the saliency evaluation several different metrics are employed in order to compare the predicted saliency map with the eyetracking data [8]. As ground truth maps we are using either the map of fixation locations on the image plane of size or the dense saliency map , which arises by convolving the binary fixation map with a gaussian kernel. Thus, as we employ three loss functions associated with the different aspects of saliency evaluation. The first is the cross-entropy loss between the predicted map and the thresholded dense map :
[TABLE]
In order to handle the strong imbalance between the salient and non-salient pixels we take a variant of the above loss, which has been effectively used in other imbalanced tasks as boundrary detection [64, 33, 42]:
[TABLE]
where , are the set of salient and non-salient pixels respectively and .
The second employed loss function is based on the linear Correlation Coefficient (CC) that is widely used in saliency evaluation and measures the linear relationship between the predicted saliency and the dense ground truth map :
[TABLE]
where denote the covariance and the standard deviation respectively.
The last loss is derived from the Normalized Scanpath Saliency (NSS) metric, which is computed as the estimated map values , after zero mean normalization and unit standardization, at human fixation locations ():
[TABLE]
where denotes the total number of fixation points.
The final loss of the -th input sample for the task of visual saliency estimation is given by a weight combination of the losses , which are given by (3) using the corresponding loss functions :
[TABLE]
where are the weights of each loss type.
3.2.2 Action Recognition Module
For the action recognition problem, which constitutes a classical multi-class problem, we build the task specific layers (with parameters ) after the output of the global branch. As we can see from Fig. 2 (orange blocks), we have a 3D convolutional block, which has identical structure as the block of the employed ResNet architecture, a global average pooling across the temporal dimension and a -dimension fully connected layer, where is the number of classes. For the training of action-related parameters we employ the standard multi-class cross-entropy for the softmax activations of the final layer:
[TABLE]
where denote the activation and the ground truth class of the -th input sample respectively.
3.2.3 Summarization Module
Regarding the summarization task we employ a sub-network with parameters (Fig. 2 - purple blocks) that has a similar structure with the one we used for action recognition, with the difference that the last fully connected layer has only one dimension since we have a binary classification problem (important vs. non-important video segments). The importance score of each video clip is given by the sigmoid activation of the final full-connected layer , while for the training of the all task-related parameters we employ the binary cross-entropy (BCE) loss. Since in most annotated databases only a small portion of the whole video is annotated as important and selected for final summary, the ground truth data are heavily biased. Thus we use a weighted variant of the BCE based on the ratio between the number of negative and positive samples in the whole training dataset:
[TABLE]
where denotes the ground truth annotation regarding the importance of the -th video clip.
3.3 Multi-task Training
For the end-to-end training of the whole multi-task spatio-temporal network () we can simply minimize the sum of the above task-specific losses over all the samples of the batch :
[TABLE]
where are weights that control the contribution of each task. This approach, which has been followed in many static multi-task networks [13, 15, 21], assumes that each sample of the batch has annotations for all tasks. However, as [34] has mentioned, this is not a realistic scenario, especially for our tasks where none of the annotations can be derived from the other tasks’ annotations, as in object detection and semantic segmentation. Thus, we use the Asynchronous Stochastic Gradient Descent (SGD) algorithm, which has been proposed in [34], that allows us to have different effective batchsizes and update the parameters of the task-specific layers once we have seen enough samples. The updates for the shared parameters of the multi-task network are based on the sum of the gradients from all losses:
[TABLE]
where is the total minibatch that contains all the training samples. The updates for the task-specific parameters depend only on the gradient of each different loss:
[TABLE]
3.4 Implementation
Our implementation and experimentation with the proposed multi-task network uses as backbone the 3D ResNet-50 architecture [25] that has showed competitive performance against other deeper architectures for the task of action recognition in terms of performance and computational budget. As starting point we used the weights from the pretrained model in the Kinetics 400 database.
Training: For the training we used the asynchronous version of stochastic gradient descent with momentum 0.9 while we also assign a weight decay of 1e-5 for regularization. We have also employed effective batchsizes of 128 samples for all tasks while the learning rate has started from 0.01 and divided by 10 when the loss saturated. The weights for the saliency loss are selected 0.1, 2, 1 after experimentation, while the ratio in the summarization loss was set to 3.06 based on the statistics of the employed training datasets. The weights , which control the importance of each task, have been experimentally tuned to 0.1, 1, 1 (based on the losses’ ranges) in order to avoid the overfitting of the network to one task.
Data Augmentation: The input samples in the network consist of 16-frames RGB video clips spatially resized at pixels. We have also applied data augmentation for random generation of training samples. For the action recognition task we randomly sampled a 16-frame clip from each training video and afterwrds we followed the procedure of random multi-scale spatial cropping and flipping, which is described in [61]. For the summarization task we divided the initial long-duration videos into 90-frames non-overlapping segments and generated the 16-frames clip following the same procedure as in action recognition task. Regarding the human annotations we took its average inside the created clips, that gave training samples with slightly different annotation scores and helped us to avoid the network’s overfitting. For data augmentation in the saliency estimation task, we followed a similar approach as in summarization task without the random cropping step. We applied the same spatial transformations to the 16 frames of the video clip and the eye-tracking based saliency maps of the median frame, which has been considered as the the ground truth map of the whole clip.
Testing: During the testing phase, for the action recognition task we extracted the network predictions using a 16-frames non-overlapping sliding window where each clip is spatially cropped at the center position with scale 1. Then, we computed the final action label for each video by simply averaging the clips’ predictions, while for the summarization task we took frame-wise importance scores by repeating the values of the 16-frame clips’ scores. Finally, for saliency estimation we obtained an estimated saliency map per frame using a 16-frame sliding window with step 1 without any spatial cropping.
4 Multiple Tasks Evaluation
4.1 Datasets
For the training and the evaluation of the proposed multi-task network we wish to have a large scale video database that will contain eyetracking annotation, labelling of the performed actions as well as continuous human annotation of the frames importance or equivalently human created summaries. However, this is not a realistic scenario since many datasets have been developed for each task but none of them contains all of the three required types of annotation. Very recently, [49] proposed a multi-task and multi-label video dataset aiming to the recognition of different visual concepts (scenes, objects, actions) which are different from our investigated tasks. Note that since our multi-task network is modular, it could be extended to recognize and understand more visual concepts such as objects or scenes.
The most relevant dataset to our tasks is the COGNIMUSE database [70, 1], which constitutes a video database annotated with ground-truth annotations for frame-wise sensory and semantic importance as well as audio and visual events. It is a generic database that has been used for video summarization [36], as well as audio-visual concept recognition [7]. The creators of the database have also developed the Eye-Tracking Movie Database (ETMD) [35], which contains eyetracking annotations for a subset of the COGNIMUSE videos. For our experiments we have used the 30-minutes excerpts from the seven movies 111“A Beautiful Mind” (BMI), “Gladiator” (GLA), “Chicago” (CHI), “Finding Nemo” (FNE), “Lord of the Rings - the Return of the King” (LOR), “Crash” (CRA), “The Departed” (DEP) as well as the full movie “Gone With the Wind” (GWW) that they have at least two of the three annotation types (see Table 4). For the training we followed an 8-fold (leaving one movie out) cross-validation approach.
One important aspect of the proposed multi-task network is its ability to be trained with diverse datasets. So, we employ five more state-of-the-art datasets, containing annotations only for a specific task in order to increase the training set as well as compare our results with other state-of-the-art methods. Specifically, for the visual saliency estimation we employ the DIEM dataset [43], which contains eyetracking data for 84 videos with duration between 27-217 sec from 50 observers, and the DFK1K [63], with eyetracking data from 17 observers over 1000 videos with duration 17-42 sec. During the experiments, for the DIEM we followed the “train-test” split of [6], while for the DFK1K we used the validation set for our testing since the test set is not publicly available. Regarding the action recognition task we employ the HMDB51 dataset [38] that includes 6766 video from 51 human action classes. We decided to use this additional dataset because its classes have also been included in the COGNIMUSE dataset. Finally, for the summarization task we used the SumMe [23] and the TVSum50 [53] datasets that include 25 (1.5 to 6.5 minutes length) and 50 (1 to 5 minutes length) videos respectively, mainly from YouTube resources. For the experiment that involves these datasets we have followed a 5-fold cross validation.
4.2 Experimental Results
For the evaluation of the multi-task network we have constructed two types of experiments. In the first, which we refer as “SUSiNet (1-task)” we trained our network independently for each task using only the task-related datasets. In the “SUSiNet (multi)” we trained the multi-task network jointly for all the three task employing all the available datasets. Next, we evaluate our results for each different task and compare them with several methods that have achieved state-of-the-art performance for each task independently.
Saliency Estimation Evaluation: In Table 1 we present the evaluation results of the proposed SUSiNet on the 3 different datasets and compare its performance against 5 state-of-the-art methods (using their publicly available codes). We employed four widely-used evaluation metrics [8]: CC, NSS, AUC-Judd (AUC-J) and shuffled AUC (sAUC). In the sAUC we have selected the negative samples from the union of all viewers’ fixations across all other frames except the frame for which we compute the AUC. As we see, our method outperforms all the other methods over all the datasets according to all employed metrics. Note there is a small decrease in the CC and NSS scores of the multi-task network compared to the single-task, while according to AUC-based metrics the multi-task network performs in equally or better than the single one. Moreover, the SUSiNet, which is based on 3D spatio-temporal convolutions, achieves to outperform other spatio-temporal methods (ACLNet, DeepVS) that rely on the LSTM based modelling of the visual saliency. In Figures 1, 4 we see examples of our saliency predictions, which in most cases are focused on humans or actions.
Action Classification Evaluation: In Table 2 we see the evaluation results of our method on the HMDB51. We can observe that the multi-task network achieves better performance than the single-task. Comparing our method against several other approaches, which are based on 3D CNN networks, we see that our network performs better than the most of them. Note that our network is based on ResNet-50 architecture and uses 16-frames inputs, while 3D ResNeXt or I3D are employing more complex networks or longer clips. For completeness we also report several other methods from literature, which are based on techniques for decoupling the spatial and temporal parts of 3D convolutions or employ two-streams (RGB, Optical Flow) networks, that are not directly compared with our method. However, our proposed network is modular and can be modified and extended to include such techniques but we leave this direction for future work as the scope of this paper is to propose a multi-task spatio-temporal network rather than achieve the best performance for each single task.
Finally, in Table 4 we report our method’s results for action recognition in COGNIMUSE database, where we see again that the multi-task network slightly outperforms the single-task. Regarding the lower recognition scores (comparing with HMDB51), we have observed that COGNIMUSE dataset contains many background actions or supplementary actions that may overlap with a main action (i.e., in Fig. 4 the action “turn” overlaps with the “run”) and thus it constitutes a very challenging dataset.
Video Summarization Evaluation: For the evaluation over the SumMe and TVSum50 datasets we have employed the evaluation protocol of [67] that is based on the F-score between a generated keyshot-based summary (shots are temporally segmented using KTS [48]), with length 15% of the original video duration, and the user created summaries. In Table 3, we present the evaluation results for the summarization task over the SumMe and TVSum50 datasets compared against various other state-of-the-art approaches. Brackets “[]” denote results obtained using an augmented dataset that includes videos from auxiliary datasets (YouTube [14], OVP [14, 2]) and it is not directly compared to our method. As we see, the multi-task SUSiNet performs very close to its single-task variant and outperforms many methods that are based on the sequential estimation of the clip based importance score, i.e., using LSTM networks. On the other hand, our network cannot perform better than other methods of literature that operate on the whole video (i.e., using retrospective encoders [68]) or employ a larger number of video frames (i.e., 128 frames in SUM-FCN [50]), especially when they are trained on the augmented dataset. However, these approaches could be added as post-hoc task-specific components and increase the performance of our network.
Regarding the evaluation of the summarization task in the COGNIMUSE database we have followed the evaluation procedure described in [70]. Specifically, the summarization task is approached as a two-class classification problem, where multiple thresholds are applied to the estimated frame-wise importance scores in order to obtain results for various compression rates and thus produce summaries of various lengths. Then, the AUC metric is computed from the ROC curve that results from the different thresholds. Table 4 presents the AUC scores for each movie independently as well as the average across all movies. We see that the evaluation scores of the multi- and single-task network are very close to each other, while in some cases, such us the full-length movie GWW, the multi-task network achieves better performance. It is worth to note that the low performance (around chance) for the FNE movie can be attributed to the absence of any other animation movie in the training set. As in the other cases, we have also compared our method with two other approaches that have been appeared in literature for the COGNIMUSE database: ICIP15 [36] which employs hand-crafted features and IVMSP18 [37] that is based on C3D network. As we see in Fig. 5 the SUSiNet outperforms the two other baseline methods according to the ROC-AUC metric.
Discussion: In Table 4 we present evaluation results for the proposed SUSiNet in all the three different tasks over the COGNIMUSE database. We see that the multi-task SUSiNet, which has been jointly trained end-to-end over all tasks using very diverse datasets, can efficiently face three different problems, achieving almost the same (or in some cases better) performance to a similar single-task network, which has been trained explicitly for the specific task. In addition, as we have observed, the multi-task network performs very close to other state-of-the-art single-task methods that are based on more complex architectures or employ multiple streams networks. Figure 4 depicts a qualitative example of SUSiNet on a movie excerpt from COGNIMUSE database, which contains sequential actions. Our network focuses on the salient regions of the video, performs action recognition and computes frame-wise importance scores simultaneously. We also observe in Fig. 4 that segments with the correctly recognized actions have been selected by multi-task network to be included in the video summary.
5 Conclusions
In this work, we have proposed a multi-task spatio-temporal network that can jointly tackle the problems of saliency estimation, action recognition and video summarization. Our method employs only a single network for all tasks, which is jointly trained for all tasks using diverse datasets. The extensive evaluation indicates that the multi-task network performs equally well or in some cases even better than the single-task methods while it requires less computational budget than having one different network for each task. As future work, we intend to extend our network by employing more complex or multiple-streams architectures and improve the task-specific layers by incorporating recent advances from state-of-the-art single-task methods.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] http://cognimuse.cs.ntua.gr/database .
- 2[2] Open Video Project. http://www.open-video.org/ .
- 3[3] Cagdas Bak, Aysun Kocak, Erkut Erdem, and Aykut Erdem. Spatio-temporal saliency networks for dynamic saliency prediction. IEEE Trans. Multimedia , 20(7):1688–1698, 2018.
- 4[4] Loris Bazzani, Hugo Larochelle, and Lorenzo Torresani. Recurrent mixture density network for spatiotemporal visual attention. In Int. Conf. on Learning Representations (ICLR) , 2017.
- 5[5] Ali Borji and Laurent Itti. State-of-the-art in visual attention modeling. IEEE Trans. Pattern Anal. Mach. Intell. (PAMI) , 35(1):185–207, 2013.
- 6[6] Ali Borji, Dicky N. Sihite, and Laurent Itti. Quantitative analysis of human-model agreement in visual saliency modeling: A comparative study. IEEE Trans. Image Process. , 22(1):55–69, 2013.
- 7[7] Giorgos Bouritsas, Petros Koutras, Athanasia Zlatintsi, and Petros Maragos. Multimodal visual concept learning with weakly supervised techniques. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) , 2018.
- 8[8] Zoya Bylinskii, Tilke Judd, Aude Oliva, Antonio Torralba, and Frédo Durand. What do different evaluation metrics tell us about saliency models? corr abs/1604.03605 (2016), 2016.