On functional logistic regression: some conceptual issues
Beatriz Bueno-Larraz, Jos\'e R. Berrendero, Antonio Cuevas

TL;DR
This paper critically examines the conceptual foundations of functional logistic regression, proposing an RKHS-based model, analyzing its validity, and addressing issues related to the existence of maximum likelihood estimators in the functional setting.
Contribution
It introduces an RKHS-based approach to functional logistic regression, compares it with traditional $L_2$ models, and explores the conditions for the existence of ML estimators.
Findings
RKHS-based model validity conditions derived
ML estimators often do not exist in the functional case
Proposes a restricted RKHS-based ML estimator
Abstract
The main ideas behind the classical multivariate logistic regression model make sense when translated to the functional setting, where the explanatory variable is a function and the response is binary. However, some important technical issues appear (or are aggravated with respect to those of the multivariate case) due to the functional nature of the explanatory variable. First, the mere definition of the model can be questioned: while most approaches so far proposed rely on the -based model, we suggest an alternative (in some sense, more general) approach, based on the theory of Reproducing Kernel Hilbert Spaces (RKHS). The validity conditions of such RKHS-based model, as well as its relation with the -based one are investigated and made explicit in two formal results. Some relevant particular cases are considered as well. Second we show that, under very general…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6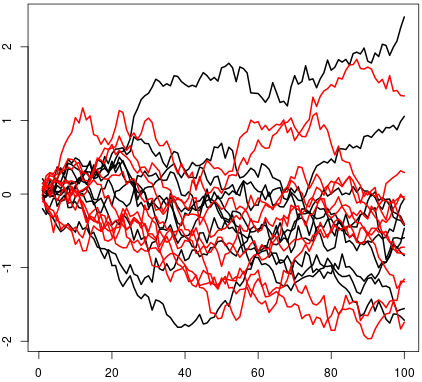 Figure 7
Figure 7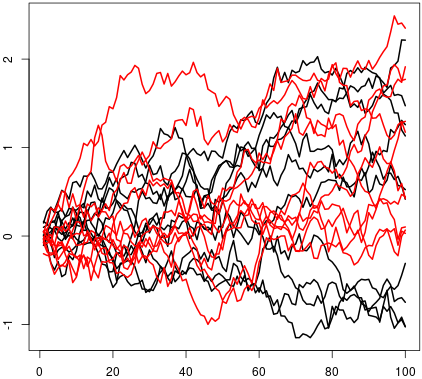 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12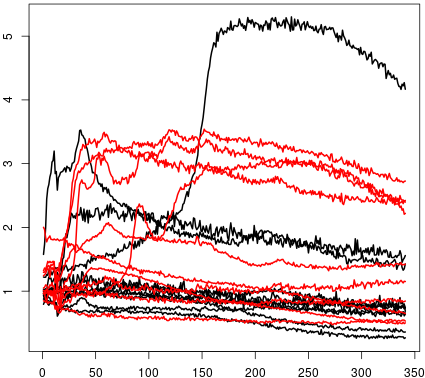 Figure 13
Figure 13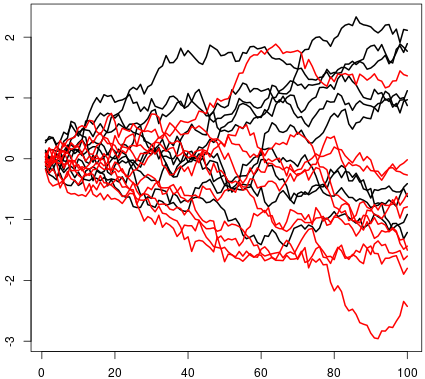 Figure 14
Figure 14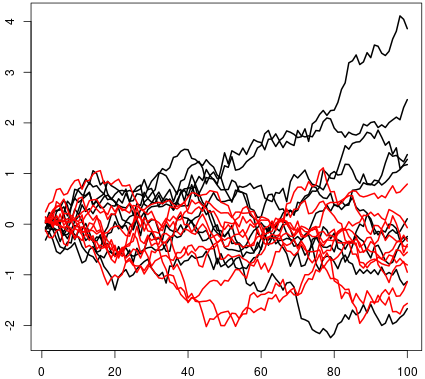 Figure 15
Figure 15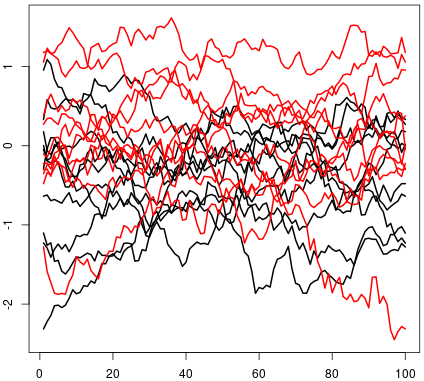 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Statistical Methods and Models · Statistical Methods and Inference · Statistical and numerical algorithms
On functional logistic regression: some conceptual issues
José R. Berrendero1 Beatriz Bueno-Larraz2 and Antonio Cuevas1
1 Departamento de Matemáticas, Universidad Autónoma de Madrid
2 Independent Data Scientist
Abstract
The main ideas behind the classical multivariate logistic regression model make sense when translated to the functional setting, where the explanatory variable is a function and the response is binary. However, some important technical issues appear (or are aggravated with respect to those of the multivariate case) due to the functional nature of the explanatory variable. First, the mere definition of the model can be questioned: while most approaches so far proposed rely on the -based model, we suggest an alternative (in some sense, more general) approach, based on the theory of Reproducing Kernel Hilbert Spaces (RKHS). The validity conditions of such RKHS-based model, as well as its relation with the -based one are investigated and made explicit in two formal results. Some relevant particular cases are considered as well. Second we show that, under very general conditions, the maximum likelihood (ML) of the logistic model parameters fail to exist in the functional case. Third, on a more positive side, we suggest an RKHS-based restricted version of the ML estimator. This is a methodological paper, aimed at a better understanding of the functional logistic model, rather than focussing on numerical and practical issues.
Keywords: Functional data, logistic regression, reproducing kernel Hilbert spaces, kernel methods in statistics.
1 Introduction: statement of the model
Logistic regression: some basic ideas and references
Throughout this work we study the situation in which a binary (0-1) response variable must be predicted in terms of a random explanatory variable , defined on a probability space . The logistic regression model is an extremely popular approach to such problem. The basic ideas of this model date back to the end of nineteenth century (a complete historical overview can be found in Cramer (2003, Ch. 9)) but the logistic methodology is still under constant attention, especially as a (supervised) classification tool. The book by Hilbe (2009) is a fairly complete reference about logistic regression.
The logistic model is a particular case of the wider family of generalized linear models (we refer to McCullagh and Nelder (1989) for details) which presents some interesting characteristics. According to Hosmer et al. (2013, p. 52), one of its most appealing features is that the coefficients of the model are easily interpretable in terms of the values of the predictors. This technique stems from the attempt to apply well-known linear regression procedures to problems with categorical responses, like binary classification. There is no point in imposing that the categorical response is linear in the predictors , but we might instead assume that is linear in , where . In this quotient the logarithm could be replaced with other link functions. However, an important aspect of the logarithm-based model is that it holds whenever the predictor variable in both classes is Gaussian with a common covariance matrix.
This finite-dimensional logistic model has been widely studied. Apart from the already mentioned references, Efron (1975) provides a comparison between logistic predictors and Fisher discriminant analysis. In addition, Munsiwamy and Wakweya (2011) gives a useful overview of asymptotic results of the estimators (firstly proved in Fahrmeir and Kaufmann (1985) and Fahrmeir and Kaufmann (1986)).
Logistic regression in the functional case: the “classical” -model
The motivations for extending logistic regression to functional data are quite obvious given the current increasing availability of functional data in experimental sciences. An historical overview of several approaches to functional logistic regression can be found in Mousavi and Sørensen (2018).
We start by establishing the framework of the problem in this functional context. The goal is to explore the relationship between a dichotomous response variable , taking values on , and a functional predictor . We will assume throughout that is an -stochastic process with trajectories in . Thus, the random variable conditional to the realizations of the process follows a Bernoulli distribution with parameter and the prior probability of class 1 is denoted by . In this setting, the most common functional logistic regression (FLR) model is
[TABLE]
where , and denotes the inner product in . This model is the direct extension of the -dimensional one, where the product in is replaced by its functional counterpart.
The standard approach to this problem is to reduce the dimension of the curves using Principal Components Analysis (PCA). That is, the curves are projected into the subspace defined by the eigenfunctions corresponding to the largest eigenvalues of the covariance operator. Then, we replace every curve in the functional data sample with the -dimensional coordinates of the projections with respect to the basis formed by the eigenfunctions. Finally, standard logistic regression is applied to the resulting -dimensional vectors. Among others, this strategy has been explored by Escabias et al. (2004) and James (2002) from an applied perspective though, in fact, the latter reference deals with generalized linear models (and not only with logistic regression). These more general models are also studied by Müller and Stadtmüller (2005), but with a more mathematical focus.
Some preliminaries and notation for an alternative approach
Our functional data will be trajectories in of an -process with continuous covariance and mean function, denoted by and , respectively. The covariance operator associated with the covariance function of the process is given by
[TABLE]
Since the approach we will explore here for functional logistic regression is based on the theory of Reproducing Kernel Hilbert Spaces (RKHS’s), we will briefly remind here, for the sake of clarity, some basic ideas and notations about RKHS’s; see Berlinet and Thomas-Agnan (2004) and Appendix F of Janson (1997) for further details and references).
Let , be the space of all finite linear combinations of evaluations of . This space is endowed with the inner product , where and .
Then, the RKHS associated with is defined as the completion of . In other words, is made of all functions obtained as pointwise limits of Cauchy sequences in . The inner product is extended accordingly to the whole space .
These spaces are named after the so-called reproducing property, , for all , which is particularly important in the applications. On account of this property it is sometimes said that the RKHS are spaces of “true functions”, in the sense that the pointwise values , at a given do matter, by contrast with whose elements are in fact equivalence classes of functions.
A property of RKHS’s especially useful in statistical applications is given by the following isometry result: let be the Hilbert space of real random variables with finite second moment, endowed with the usual inner product and with associated norm . Define
[TABLE]
where , and let be the completion of in ; hence, in other words, is a subspace of defined as the closure of the linear span of the centred one-dimensional marginals of the process . It turns out that the transformation , from to , defined by
[TABLE]
is an isometry (sometimes called Loève’s isometry) between and , that is, is bijective and preserves the inner product (see Lukić and Beder (2001, Lemma 1.1)). As a consequence, the Hilbert spaces and can be identified. Note that, in informal terms is the completion of the transformation from to given by \sum_{i=1}^{n}a_{i}\big{(}X(t_{i})-m(t_{i})\big{)}\mapsto\sum_{i=1}^{n}a_{i}K(t_{i},\cdot).
It is worth mentioning that while is, in several aspects, a natural Hilbert space associated with the process , typically the trajectories of the process themselves do not belong to with probability one (see, e.g., (Lukić and Beder, 2001, Cor. 7.1), (Pillai et al., 2007, Th. 11)). Then, one cannot directly write , for a realization of the process. However, following Parzen (1961a), we will use the convenient notation interpreting this expression in terms of Loève’s isometry, ; more precisely, we will identify with , for and , which in particular means .
The intuition behind the definition of is reminiscent of the definition of Itô’s isometry, which is used to define the stochastic integral with respect to the Wiener measure (Brownian motion), overcoming the fact that the Brownian trajectories are not of bounded variation. As we will see below, the transformation will play a central role in the alternative functional logistic model we are going to propose.
An RKHS-based proposal for logistic regression in the functional case
We propose a new model for functional logistic regression problems, based on ideas borrowed from the theory of RKHS’s. To be more specific, our proposal is to study the following model, instead of (1),
[TABLE]
where the inner product stands for , the inverse of Loève’s isometry defined in Equation (3). Throughout this paper we motivate this model and study some relevant theoretical aspects about it.
Some RKHS related literature
The book by Hsing and Eubank (2015) provides an excellent mathematical background on mathematical methods, including RKHS theory, for the statistical analysis of functional data. The papers by Hsing and Ren (2009) and Kneip et al. (2020) offer also very general perspectives and results on the applicability of RKHS methods in functional regression models, though not particularly focussed on the logistic case.
Some closely related ideas, aimed at the prediction problem in functional linear models are also present in Shin and Hsing (2012), even if the RKHS methodology is not explicitly mentioned there.
Some other more specific references (a few of them especially dealing with the functional logistic model) will be cited below.
The contents of this work
In the first place (see Theorem 1, Section 2), we will analyze specific conditions under which the RKHS-based logistic model (4) holds.
In the second place (see Theorem 2, Section 3), we will show that model (4) covers some relevant cases of practical interest not included in the standard -model (1), though, in fact, it is also shown in Theorem 2 that the model can also be obtained as a particular case of the RKHS model (4) under some conditions.
In the third place, in Section 4, we will prove two results of non-existence for the maximum likelihood estimator of the slope function in model (4). Such negative results can be seen as an aggravated, functional counterpart of the well-known partial non-existence results arising in finite dimensional logistic models; see Candès and Sur (2020) and references therein.
This is a methodological and theoretical paper: our aim is to contribute to a better understanding of the functional logistic model, rather than focussing on numerical or practical issues. However, we provide in Section 5 an specific suggestion (based on a restricted maximum likelihod approach) to deal with the estimation of the slope function in model 4.
2 The RKHS-based functional logistic model: validity conditions in the Gaussian case
In this section we motivate the reasons why model (4) is meaningful. In Theorem 1 we show that the standard assumption that both and are Gaussian implies (4). We also analyze under which conditions the more standard -model (1) is implied and we clarify the difference between both approaches.
In our functional setting, for , we assume that given is a Gaussian process with continuous mean function and continuous covariance function (the same for ). We will assume throughout that all the eigenvalues of the covariance operator , associated with are strictly positive (so is injective). Note that, as a consequence of Spectral Theorem (see, e.g., (Hsing and Eubank, 2015, p. 98)) , where stands for a unit eigenvector associated with ; thus, the inverse is defined on the range of , , as a linear (not continuous) transformation, by , for .
Let and be the probability measures (i.e., the distributions) induced by the process conditional to and respectively. Recall that when and both belong to , we have that and are mutually absolutely continuous; see Theorem 5A of Parzen (1961a). The following theorem provides a very natural motivation for the RKHS model (4) in this Gaussian setting.
Theorem 1**.**
Let and be as in the previous lines. Then,
- (a)
if , then and are mutually absolutely continuous and model (4) holds,
[TABLE]
with and (where and stands for the expectation when the process has mean function equal to ). If , then and are mutually singular.
- (b)
if , then and are mutually absolutely continuous and model (1) holds.
- (c)
if model (1) is never recovered, but different situations are possible, according to the condition in part (a). In particular if , recovers scenario (a), but if , and are mutually singular.
Proof.
(a) Let be the measure induced by a Gaussian process with covariance function but zero mean function, . From Theorem 7A in Parzen (1961b) implies that and are mutually absolutely continuous, and implies that and are mutually singular. By Lemma 1.1 in Pitcher (1960), and are mutually absolutely continuous if and only if and are mutually absolutely continuous and, in this case, the corresponding Radon-Nikodym derivatives fulfill
[TABLE]
The last equality also follows from Theorem 7A in Parzen (1961b) (or Theorem 5A of Parzen (1961a)). Notice that by the definition of Loève’s isometry we have .
The conditional probability of can be expressed in terms of the Radon-Nikodym derivative of with respect to (see Baíllo et al. (2011, Th.1)) by
[TABLE]
From the last two displayed equations, one can rewrite
[TABLE]
Then, reordering terms in this expression we get the logistic model in part (a).
(b) Under the assumptions, Theorem 6.1 in Rao and Varadarajan (1963) gives the following expression:
[TABLE]
for . This entails (using the Chain Rule for Radon-Nikodym derivatives)
[TABLE]
where and . Now, replacing this expression in (5) we get the -model (1) with \beta_{0}=-\log\big{(}\frac{1-p}{p}C\big{)}.
(c) Also as a consequence of Theorem 6.1 in Rao and Varadarajan (1963), if it is not possible to express the Radon-Nikodym derivative in terms of inner products in or, equivalently, there is not any continuous linear functional and such that . Finally, the last sentence of the statement is a consequence of Theorem 5A of Parzen (1961a). ∎
*Some comments on the meaning of Theorem 1 *
Similarly to the finite-dimensional case, our model holds when the conditional distributions of the process given the two possible values of are Gaussian with the same covariance structure. Another interesting property of this new RKHS-based model is that for some particular choices of the slope function of type , the model (4) amounts to a finite-dimensional logistic regression model for which the explanatory variables are a finite number of projections of the trajectories of the process. Thus, the impact-point model studied by Lindquist and McKeague (2009) appears as a particular case of the RKHS-based model and, more generally, model (4) can be seen as a true extension of the finite-dimensional logistic regression model, which is obtained when a finite-dimensional covariance matrix plays the role of the kernel. As an important by-product, this provides a mathematical ground for variable selection in logistic regression.
Part (b) of this theorem has been recently observed by Petrovich et al. (2019), see Theorem 1, without reference to RKHS theory. Note that, in general, does not imply that and are orthogonal. Parts (a) and (c) of the theorem above clarifies this point.
On the other hand, in order to better interpret the above theorem in RKHS terms, let us recall that the space can be also defined as the image of the square root of the covariance operator defined in (2) (e.g. Definition 7.2 of Peszat and Zabczyk (2007)),
[TABLE]
where now the inner product is defined, for , as
[TABLE]
It can be seen that this definition of is equivalent to that given in Section 1. Then, from part (c) of the theorem it follows that the RKHS functional logistic regression can be seen as a generalization of the usual functional logistic regression model, in the sense that this model is recovered when a higher degree of smoothness on the mean functions is imposed (since clearly ). Indeed, the functions in are convolutions of the functions in with the covariance function of the process. The discussion of the next section makes clear that this difference is of key importance in practice and not merely a technicality.
As mentioned above, in the finite dimensional case the logistic model holds whenever are Gaussian and homoscedastic, but in fact this model is more general in the sense that it also holds for other non-Gaussian assumptions on the conditional distributions . Clearly this is also the case for the functional logistic model (4). In fact, the connection between the functional model and the finite-dimensional one is even deeper, as we will show in the following section.
3 The RKHS model: some important particular cases
Dimension reduction in the functional logistic regression model may be often appropriate in terms of interpretability of the model and classification accuracy. This reduction must be done losing as little information as possible. We propose to perform variable selection on the curves. By variable selection we mean to replace each curve by the finite-dimensional vector , for some chosen in an optimal way. In this section we analyze under which conditions it is possible to perform functional variable selection, which is only feasible under the RKHS-model. In the following section we suggest how to do it: the idea is incorporating the points to the estimation procedure as additional parameters (in particular to the modified maximum likelihood estimator we propose).
Whenever the slope function has the form
[TABLE]
the model in (4) is reduced to the finite-dimensional one,
[TABLE]
The main difference between the standard finite-dimensional model and this one is that now the proper choice of the points is a part of the estimation procedure. In this sense, model (7) is truly functional since we will use the whole trajectories to select the points. This fact leads to a critical difference between the functional and the multivariate problems. Then, our aim is to approximate the general model described by Equation (4) with finite-dimensional models as those of Equation (7). This amounts to get an approximation of the slope function in terms of a finite linear combination of kernel evaluations . This model, for and a particular type of Gaussian process , is analyzed in Lindquist and McKeague (2009).
From the discussion above, it is clear that the differences between the RKHS model and the one are not minor technical questions. The functions of type belong to but do not belong to . This fact implies that within the setting of the RKHS model it is possible to regress on any finite dimensional projection of , whereas this does not make sense if we consider the model. This feature is clearly relevant if one wishes to analyze properties of variable selection methods.
Theorem 2**.**
Assume model (4) holds. Then,
- (a)
If there exist a positive integer , , and such that , then
[TABLE] 2. (b)
If , then
[TABLE]
where fulfills . 3. (c)
Let be an orthonormal basis of . If there exist a positive integer , and such that , then
[TABLE]
Proof.
(a) Observe that for , , and for all ,
[TABLE]
Therefore , and
[TABLE]
(b) Let . It holds that (see e.g. Ash and Gardner (2014), page 34). Moreover, by Fubini’s theorem, for all we have
[TABLE]
because . Therefore, .
(c) Putting in (8) we get . As a consequence,
[TABLE]
∎
*Some comments on the meaning of Theorem 2 *
Part (a) of the previous result means that the impact point model, as that considered in Lindquist and McKeague (2009), is a particular case of the RKHS model (4). Just take as parameter function a finite linear combination of evaluations of .
Part (b) implies that the usual functional model based on the inner product is also a particular case of (4). What we need is that belongs to the image of the covariance operator, . Notice that this condition is stronger than . As illustrated by part (a), the difference between and may be important in practice.
A very common methodology to fit functional regression models requires to project the functional regressors on a subspace defined by a finite set of orthonormal functions , and use the projections as regressor variables. Part (c) implies that model (4) also includes this situation for in the span of . Note that if is the orthonormal basis of eigenfunctions of , we have is proportional to , and the condition on reduces to the fact that belongs to the span of . If this is the case, there is no loss in using the first principal components of the regressors instead of the whole trajectories.
4 Maximum likelihood estimation: non-existence results
In the finite-dimensional setting, it is well-known that the maximum likelihood (ML) estimator does not exist when there is an hyperplane separating the observations of the two classes; see below for details. As we will show in this section, this fact worsens dramatically for the case of functional data; more specifically, we will see that:
- For a wide class of process (including the Brownian motion), the MLE just does not exist, with probability one (see Subsection 4.1).
- Under some different conditions, in the Gaussian case, the probability of non-existence of the MLE tends to one when the sample size tends to infinity (see Subsection 4.2).
A brief overview of the finite dimensional case
Despite the fact that ML estimation of the slope function for multiple logistic regression is widely used, it has an important drawback that is sometimes overlooked. Given a sample for drawn from population zero and another sample for drawn from population one, the classical MLE in logistic regression is the vector that maximizes the log-likelihood
[TABLE]
The existence and uniqueness of such a maximum was carefully studied by Albert and Anderson (1984) (and previously by Silvapulle (1981) and Gourieroux and Monfort (1981)). As stated in Theorem 1 of Albert and Anderson (1984), the latter expression can be made arbitrarily close to zero (note that the log-likelihood is always negative) whenever the samples of the two populations are linearly separable. In that case the maximum can not be attained and then the MLE does not exist (the idea behind the proof is similar to the one of Theorem 3 below). There is another scenario where this estimator does not exist; the samples are linearly separable except for some points of both populations that fall into the separation hyperplane (named “quasicomplete separation”). In this case the supremum of the log-likelihood function is strictly less than zero, but it is anyway unattainable.
The likelihood function in the logistic functional model
Before going on with the functional case (which is our main target here), we need to derive the likelihood function. Let assume that follows the RKHS logistic model described in Equation (4). That is,
[TABLE]
where , and . The random element takes values in the space , which is a measurable space with measure , where is the distribution induced by the process and is the counting measure on . We can define in the measure , the joint probability induced by for a given slope function and an intercept . Then we define,
[TABLE]
In view of this density function, the log-likelihood function for a given sample in is
[TABLE]
where is a sample of the underlying random variable .
The maximum likelihood estimator is the pair that maximizes this function . The population counterpart of is the expected log-likelihood function,
[TABLE]
where denotes the expectation with respect to the measure .
The main idea behind ML-estimation stands in the infinite-dimensional situation. If our “parameter space” is and the “true” value of the parameter is , then a simple, standard argument based on Jensen’s inequality shows that the population log likelihood function fulfils
[TABLE]
This leads to the usual, natural idea of maximizing a consistent estimator of that, in our logistic model, is the log-likelihood function defined above.
4.1 Non-existence of the MLE in functional settings
We first show that, when moving from the finite-dimensional model to the functional one, the problem of the non-existence of the MLE is drastically worsened.
This situation is quite similar to that arising, for example, in non-parametric density estimation where non-parametric (and non-penalized) ML estimators of the density function do not exist, unless some drastic restrictions, such as monotonicity (e.g., Grenander (1981)) or log-concavity (see, Cule et al. (2010)) are imposed on the underlying density function.
Since the analogous non-existence result for the case of the functional logistic regression model is not perhaps so direct, it is established in Theorem 3 below. We confine ourselves to the RKHS-based model (4), although the result can be easily extended, with a completely similar method of proof, for the standard based model of Equation (1).
We first will need to establish a condition which plays, in the functional case, a similar role to that of the linear separability condition mentioned above in the setting of finite-dimensional logistic regression.
Assumption 1** (SC).**
The multivariate process , satisfies the “Sign Choice” (SC) property when for all possible choice of signs , where is either or , we have that, with probability one, there exists some such that .
Now, the non-existence result is as follows. Without loss of generality we confine ourselves to the case .
Theorem 3**.**
Let , , be an stochastic process with . Denote by the corresponding covariance function. Consider a logistic model (4) based on . Let be independent copies of . Assume that the -dimensional process fulfills the SC property. Then, with probability one, the MLE estimator of (i.e., the maximizer of the log-likelihood function ) does not exist for any sample size .
Proof.
Let be a random sample drawn from . From the SC assumption there is (with probability 1) one point such that for all such that and for those indices with . Note that that the sample log-likelihood function can be split in two terms, as follows,
[TABLE]
Note also that for all . Now, take a numerical sequence and define
[TABLE]
Then, by the definition of Loève’s isometry, if ,
[TABLE]
since we have taken such that for those indices with . Likewise, goes to whenever since we have chosen such that for those indices. As a consequence as . Therefore the likelihood function can be made arbitrarily large so that the MLE does not exist. ∎
Remark 1**.**
A non-existence result for the MLE estimator, analogous to that of Theorem 3, can be also obtained with a very similar reasoning for the -based logistic model of Equation (1). The main difference in the proof would be the construction of which, in the case, should be obtained as an approximation to the identity (that is, a linear “quasi Dirac delta”) centered at the point .
Although the SC property could seem a somewhat restrictive assumption, the following proposition shows that it applies to some important and non-trivial situations.
Proposition 1**.**
(a) The -dimensional Brownian motion fulfills the SC property.
(b) The same holds for any other -dimensional process in whose independent marginals have a distribution absolutely continuous with respect to that of the Brownian motion.
Proof.
(a) Given the dimensional Brownian motion , where the are independent copies of the standard Brownian motion , , take a sequence of signs and define the event
[TABLE]
We may express this event by
[TABLE]
where, for each ,
[TABLE]
Now, the result follows directly from Blumenthal’s 0-1 Law for n-dimensional Brownian processes (see, e.g., Mörters and Peres (2010, p. 38)). Such result establishes that for any event we have either or . Here denotes the germ -algebra of events depending only on the values of where lies in an arbitrarily small interval on the right of 0. More precisely,
[TABLE]
From (10) and (11) it is clear that the above defined event belongs to the germ -algebra . However, we cannot have since (from the symmetry of the Brownian motion) for any given the probability of is . So, we conclude as desired.
(b) If is another process whose distribution is absolutely continuous with respect to that of the n-dimensional Brownian motion , then the set , defined by (10) and (11) in terms of has also probability one when it is defined in terms of the process : recall that, from the definition of absolute continuity, if the set has probability zero under the Brownian motion, then its probability must be zero as well when is replaced with . Therefore, the probability of under must be one. ∎
Remark 2**.**
Following the comment in Mörters and Peres (2010) about processes with strong Markov property, this result based on RKHS theory can be extended for Lévy processes whenever the covariance function was continuous (like Poisson process in the real line). However note that, apart from the Brownian motion, this type of processes have discontinuous trajectories.
The situation considered in Theorem 3 would be the functional counterpart of having a finite-dimensional problem where the supports of both classes (0 and 1) are linearly separable. However, as we have just seen, this separability issue does not only appear in degenerate problems in the functional setting. In the next section we suggest a technique to completely avoid the problem.
From a theoretical perspective, in view of Theorem 3, it is clear that there is no hope of obtaining a general convergence result of the standard maximum likelihood estimator (MLE) defined by the maximization of the likelihood function . That is, one should define a different estimator or impose some conditions on the process to avoid the SC property. For instance, Lindquist and McKeague (2009) prove consistency results of the model with a single impact point for processes , where is a two-sided Brownian motion centered in (i.e. two independent Brownian motions starting at and running in opposite directions) and is a real random variable independent of . Then, due to the independence assumption, it is clear that accumulation points (like 0 for the Brownian motion) are avoided.
4.2 Asymptotic non-existence for Gaussian processes
In the previous section we have seen that the problem of non-existence of the MLE is aggravated for the case functional data. But this is not the only issue with MLE in functional logistic regression. In this section we see that the probability that the MLE does not exist goes to one as the sample size increases, for any Gaussian process satisfying very mild assumptions.
We use the following notation: for and , let and let be the matrix whose entry is .
Theorem 4**.**
Let be a random sample of independent observations satisfying model (4). Assume that is a Gaussian process such that is continuous and is invertible for any finite set . It holds
[TABLE]
Proof.
Let be the true values of the parameters. Since , we have , where is the function defined in Candès and Sur (2020), Equation (2.2) (see Remark 3 below). Let be an increasing sequence of natural numbers such that . Consider the set of equispaced points and denote . Define . Now, consider the following sequence of finite-dimensional logistic regression models
[TABLE]
where stands here for the inner product of two vectors in , and the following sequence of events
[TABLE]
Recall that the event amounts to non-existence of MLE for finite-dimensional logistic regression models (see Albert and Anderson (1984)).
Now let us prove the validity of condition (1.3) in Candès and Sur (2020), which is required for the validity of Theorem 2.1. in that paper. In our case, such condition amounts to
[TABLE]
but this directly follows from Theorem 6E of Parzen (1959). Since we apply Theorem 2.1. in Candès and Sur (2020) to get .
Now we define the auxiliary sequence of events
[TABLE]
with strict inequalities. Assume that happens so that there exists a separating hyperplane defined by . Then, in the same spirit as in the proof of Theorem 3, it is possible to show that if , then , where is the log-likelihood function. As a consequence, for all , if happens, then the MLE for the RKHS functional logistic regression model does not exist. The result follows from the fact that and the events have probability zero since we are assuming that the process does not have degenerate marginals. ∎
Remark 3**.**
Theorem 2.1. in Candès and Sur (2020) is a remarkable result. It applies to logistic finite-dimensional regression models with a number of covariables, which is assumed to grow to infinity with the sample size , in such a way that . Of course, the sample is given by data , . Essentially the result establishes that there is a critical value such that, if is smaller than such critical value, one has ; otherwise we have . Such critical value is given in terms of a function (which is mentioned in the proof of the previous result) whose definition is as follows. Let us use the notation whenever , for (note that, in the notation of Candès and Sur (2020), the model is defined for the case that the response variable is coded in ), , and where and . Now, define , where independent of and . Then, Theorem 2.1. in Candès and Sur (2020) proves that the above mentioned critical value for is precisely .
5 ** The estimation of in practice**
The problem of non-existence of the MLE can be circumvented if the goal is variable selection. The main idea behind the proof of Theorem 4 is that one can approximate the functional model with finite approximations as those in (7) with increasing as fast as desired. Therefore, if we constrain to be less than a finite fixed value, Theorem 4 does not apply.
In order to sort out the non-existence problem for a given sample (due to the SC property), it would be enough to use a finite-dimensional estimator that is always defined, even for linearly separable samples. As mentioned, an extensive study of existence and uniqueness conditions of the MLE for multiple logistic regression can be found in the paper of Albert and Anderson (1984).
A simple, RKHS-motivated alternative would be as follows. In many cases one could assume that the “true parameter” belongs to a bounded set , being a compact interval in the real line and the closed ball centered at zero, with radius in the RKHS associated with the covariance function . This restriction of searching for an estimator in a ball within the parameter space resembles other regularization methods in regression such as ridge or lasso.
If is continuous and bounded, all functions in the RKHS space are continuous as well and, using the reproducing property , we get
[TABLE]
If, for simplicity, we assume that , we have (from the definition of the RKHS ) that all functions can be approximated by functions of type
[TABLE]
where are real numbers with , , .
Now, recall that the RKHS functional logistic model corresponding to such function would be given by expression (7) in terms of and . Then, assuming the continuity of the trajectories we can ensure the existence of an approximate maximum likelihood (ML) estimator of expressed in terms of .
The effective calculation of such estimator could be done by a sequential “greedy” method. The idea is to exchange the direct maximization of the likelihood function by the execution of an iterative algorithm, as follows:
Let us fix a grid of equispaced points in . For each on the grid, we fit the logistic model of Equation (7) with and . The log-likelihood achieved for this at the ML estimators and is stored in . Then, the first point is fixed as the point at which achieves its maximum value. 2. 2.
Once has been selected, for each in the grid we fit the model
[TABLE]
As in the previous step, would be the log-likelihood achieved at , and , and is the point at which the maximum of is attained. 3. 3.
We proceed in the same way until a suitable number of points has been selected.
In practical problems, it is also important to determine how many points one should retain. The common approach is to fix this value by cross-validation, whenever it is possible. Another reasonable approach is to increase the initial value by repeating the whole procedure with another grid of equispaced points until the increase achieved in the likelihood function is smaller than a given threshold, in a similar way as in Berrendero et al. (2019).
Acknowledgements
This work has been partially supported by Spanish Grant PID2019-109387GB-I00.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Albert and Anderson (1984) A. Albert and J. A. Anderson. On the existence of maximum likelihood estimates in logistic regression models. Biometrika , 71(1):1–10, 1984.
- 2Ash and Gardner (2014) R. B. Ash and M. F. Gardner. Topics in Stochastic Processes: Probability and Mathematical Statistics: A Series of Monographs and Textbooks . Academic Press, 2014.
- 3Baíllo et al. (2011) A. Baíllo, A. Cuevas, and J. A. Cuesta-Albertos. Supervised classification for a family of Gaussian functional models. Scandinavian Journal of Statistics , 38(3):480–498, 2011.
- 4Berlinet and Thomas-Agnan (2004) A. Berlinet and C. Thomas-Agnan. Reproducing Kernel Hilbert Spaces in Probability and Statistics . Kluwer Academic, Boston, 2004.
- 5Berrendero et al. (2019) J. R. Berrendero, B. Bueno-Larraz, and A. Cuevas. An RKHS model for variable selection in functional linear regression. Journal of Multivariate Analysis , 170:22–45, 2019.
- 6Candès and Sur (2020) E. J. Candès and P. Sur. The phase transition for the existence of the maximum likelihood estimate in high-dimensional logistic regression. The Annals of Statistics , 48(1):27–42, 2020.
- 7Cramer (2003) J. S. Cramer. Logit Models from Economics and Other Fields . Cambridge University Press, 2003.
- 8Cule et al. (2010) M. Cule, R. Samworth, and M. Stewart. Maximum likelihood estimation of a multi-dimensional log-concave density. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 72(5):545–607, 2010.