Unsupervised Learning via Total Correlation Explanation
Greg Ver Steeg

TL;DR
The paper introduces the CorEx principle, an unsupervised learning approach that explains data dependence using total correlation, demonstrating success across various domains such as behavior, biology, and language.
Contribution
It proposes a novel unsupervised learning framework based on total correlation explanation, unifying and advancing dependence-based representation learning.
Findings
Effective in modeling dependence in sensory data
Applied successfully across multiple domains
Provides a theoretical foundation for unsupervised learning
Abstract
Learning by children and animals occurs effortlessly and largely without obvious supervision. Successes in automating supervised learning have not translated to the more ambiguous realm of unsupervised learning where goals and labels are not provided. Barlow (1961) suggested that the signal that brains leverage for unsupervised learning is dependence, or redundancy, in the sensory environment. Dependence can be characterized using the information-theoretic multivariate mutual information measure called total correlation. The principle of Total Cor-relation Ex-planation (CorEx) is to learn representations of data that "explain" as much dependence in the data as possible. We review some manifestations of this principle along with successes in unsupervised learning problems across diverse domains including human behavior, biology, and language.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8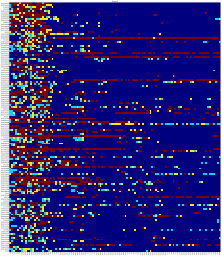 Figure 9
Figure 9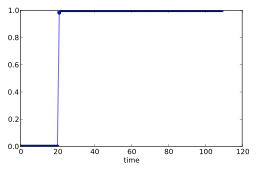 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28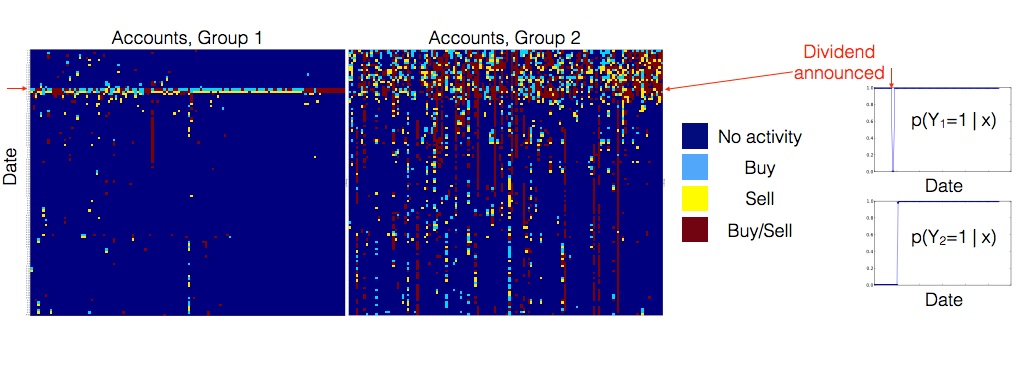 Figure 29
Figure 29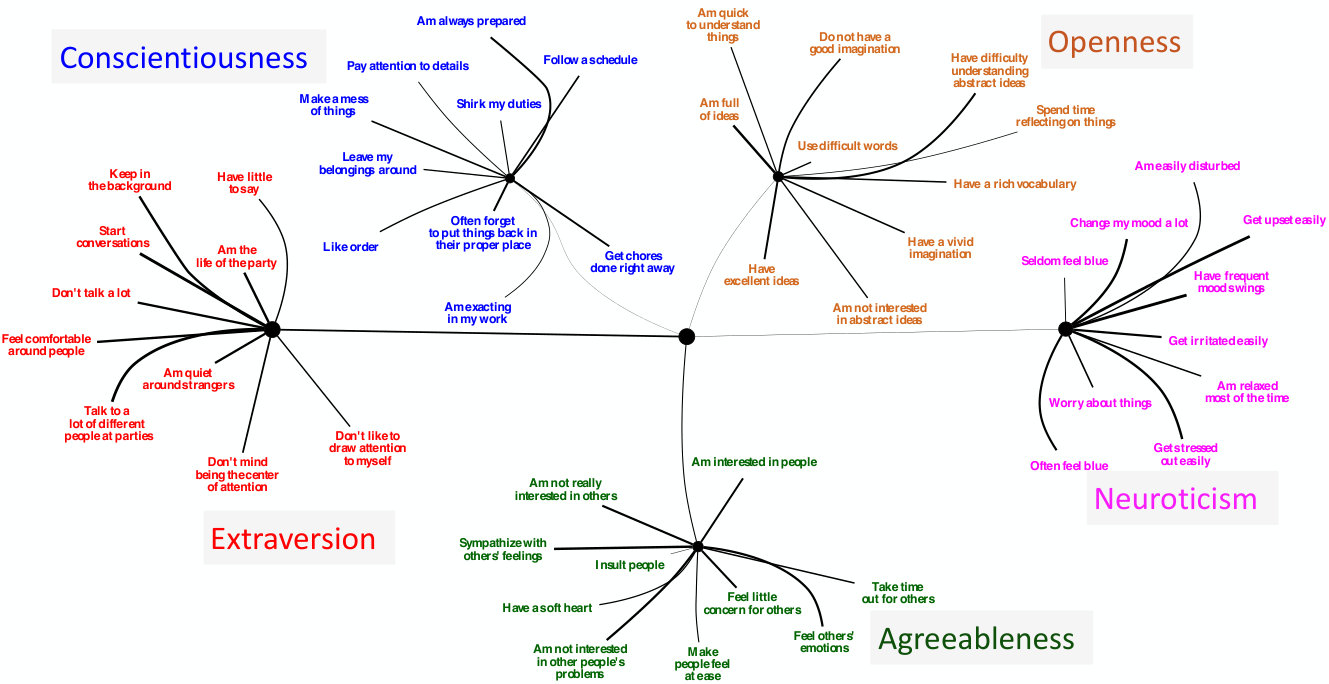 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33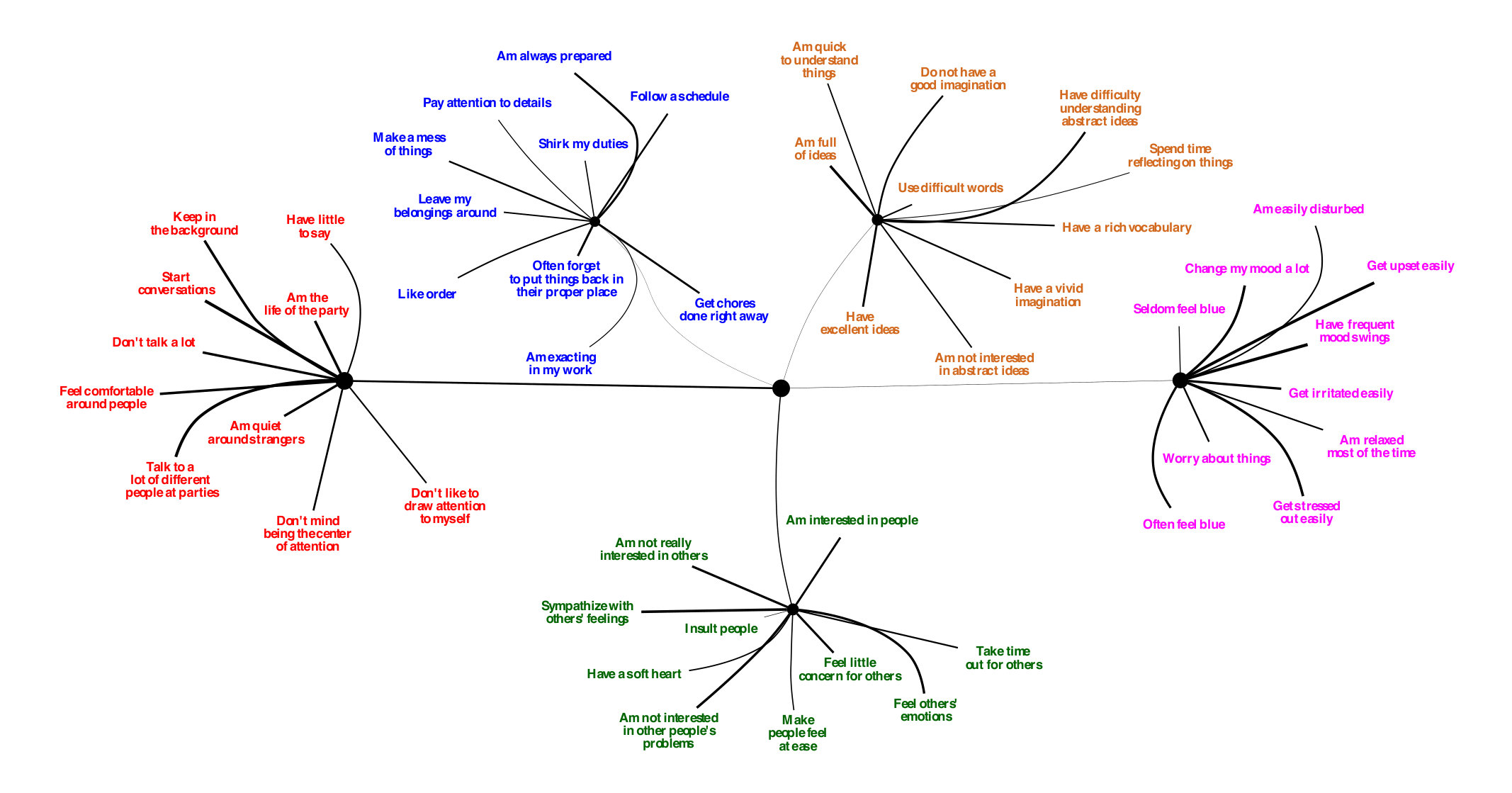 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Method | Objective |
|---|---|
| InfoMax | |
| Info bottleneck | |
| ICA | |
| Common information | |
| CorEx (1 layer) | |
| (1 layer, alternate form) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Unsupervised Learning via Total Correlation Explanation
Greg Ver Steeg
University of Southern California
Information Sciences Institute
Abstract
Learning by children and animals occurs effortlessly and largely without obvious supervision. Successes in automating supervised learning have not translated to the more ambiguous realm of unsupervised learning where goals and labels are not provided. Barlow (1961) suggested that the signal that brains leverage for unsupervised learning is dependence, or redundancy, in the sensory environment. Dependence can be characterized using the information-theoretic multivariate mutual information measure called total correlation. The principle of Total Cor-relation Ex-planation (CorEx) is to learn representations of data that “explain” as much dependence in the data as possible. We review some manifestations of this principle along with successes in unsupervised learning problems across diverse domains including human behavior, biology, and language.
1 Introduction
The brain is an information-processing chunk of meat with some amazing properties. Linsker, inventor of the InfoMax principle, made a statement thirty years ago that still rings true today, with some caveats.
A young animal or child perceives and identifies features in its environment in an apparently effortless way. No presently known algorithms even approach this flexible, general-purpose perceptual capability. Discovering the principles that may underlie perceptual processing is important both for neuroscience and for the development of synthetic perceptual systems. Linsker (1988)
Perception problems like visual object recognition that were once the exclusive domain of humans are now routinely carried out by computers. Surprisingly, this success did not come from profound understanding of the information processing principles in the brain, but more from brute force scaling of deep supervised optimization algorithms trained on large, labeled image datasets Bengio et al. (2013). On the other hand, supervised deep learners are not as flexible or general purpose as Linsker envisioned because they rely heavily on the availability and quality of the training labels. Moreover, the resulting representations can be brittle and hard to interpret Szegedy et al. (2014). Reducing the reliance on labels would greatly broaden the scope of these methods.
Unfortunately, successes in supervised learning have not translated to unsupervised learning Bengio et al. (2012). The inherent ambiguity and open-ended nature of the unsupervised problem makes it difficult to brute force a solution Minsky (1961). Learning principles that are general and flexible enough to apply across diverse domains, like human cognition, are needed. Barlow (1961) posited that the signal that the brain leverages for effective learning in the absence of direct supervision are redundancies or dependencies observed in the sensory environment. Investigating how the brain uses this redundancy has motivated several influential ideas Barlow et al. (1989); Simoncelli and Olshausen (2001).
This paper describes an information-theoretic approach to formalizing Barlow’s idea called Total Cor-relation Ex-planation (CorEx). CorEx constructs a hierarchy of latent factors that progressively explain more dependencies in the observations as measured by multivariate information, also called total correlation. “Explanation” here is meant in the statistical sense that conditioned on the latent factors, , the observed random variables will be statistically independent. While some learning approaches will learn to memorize even random, independent noise, from the CorEx perspective a lack of relationships in the data implies that there is nothing to learn. We will review the CorEx principle in the context of related information-theoretic methods then demonstrate its power and versatility on a wide range of unsupervised learning problems from human behavior to biology.
2 Information Principles for Learning
Claude Shannon launched the field of information theory with a seminal paper in 1948. Consider a random variable, , that can take values like with probability (a coin flip, for example). Shannon defined the entropy of this random variable as H(X)\equiv{\big{\langle}}-\log p(x){\big{\rangle}} where brackets indicate expectation values over random variables. Shannon showed that this is the unique measure (up to scaling) that satisfies reasonable axioms and bounds the best rate of lossless compression. For a deeper intuition, see DeDeo (2015).
Given two random variables, and , the mutual information is just the difference between the sum of individual entropies and the entropy of the variables considered jointly as a single system,
[TABLE]
Shannon demonstrated that this quantity bounds the number of messages that can be reliably sent over a noisy channel.
The definition of mutual information between two parties can be generalized easily to parties. We refer to this generalization as for total correlation following its historical introduction Watanabe (1960).
[TABLE]
In the following, we will often shorten . We also wrote in terms of KL-divergence, . if and only if all the are independent. We can define conditional TC as and this quantity will be zero if and only if are independent conditioned on .
Although Shannon gave a general yet precise definition of information, he warned that using everyday words for terminology can be misleading Shannon (1956). If we consider building a representation of observations, , as , it seems quite intuitive to maximize the “information” that has about by maximizing mutual information, . Indeed, this is the substance of the InfoMax principle Linsker (1988); Bell and Sejnowski (1995). But the information is maximized if we simply memorize the data. Typically, InfoMax is invoked to maximize mutual information under some simplicity constraints. Still, it seems counter-intuitive that adding more resources should degrade learning performance. This phenomenon has been observed using InfoMax for clustering: more data leads to worse clustering Ver Steeg et al. (2014).
An opposite point of view is taken in the information bottleneck Tishby et al. (2000). In that case, is actually minimized under the intuition that we should compress as much as possible. A trade-off is formulated that we should compress while maintaining information about some labels, . While this approach is natural, it requires labeled data.
Unsupervised approaches have also been motivated from the point of view that the brain has to compress information. In particular, Barlow points out that in a compressed representation neurons should fire independently Barlow et al. (1989) (since correlations signal redundancy). In this spirit, independent component analysis (ICA) seeks to minimize , where is a representation of the inputs, Hyvärinen and Oja (2000). Other work suggests that efficient coding of information in the brain should additionally require that the firing of individual neurons be sparse Simoncelli and Olshausen (2001). While ICA has led to many useful results, the CorEx principle suggests a modification with several benefits.
These learning principles are summarized in Table 1. While this list may look old-fashioned to some readers, these ideas are regularly invoked in modern papers on deep learning Vincent et al. (2008); Dinh et al. (2014); Tishby and Zaslavsky (2015); Kolchinsky et al. (2017); Achille and Soatto (2016); Chen et al. (2016b). For brevity, other notable ideas have been omitted in this discussion including learning based on “coarse-graining” observations Goerg and Shalizi (2012); Wolpert et al. (2014), Jaynes’ maximum entropy principle Jaynes (2003), integrated information theory Oizumi et al. (2014), and common information Ver Steeg et al. (2017).
2.1 Total Correlation Explanation
One drawback of InfoMax, ICA, and others is that they are intrinsically shallow. For example, a transformation into independent components using ICA does not provide intermediate representations. Even if intermediate steps are used to get the independent components, there is no reason for these terms to be meaningful since they are not represented in the objective. It would be nice to have a hierarchy of abstraction where lower layers capture local relationships and higher layers reflect more global relationships.
One Layer We will begin with a shallow formulation of CorEx, to see how it compares to other learning principles, then we will show that it has a natural hierarchical extension. Assume that each factor, , (also called neurons or hidden units) is a function of the data, , . More generally, it could be drawn from a probabilistic function, . The ’s are generated according to a graphical model like the left side of Fig. 1 (with for now). Under what conditions can we interpret these ’s as latent factors that generate the data? In other words, when can we flip the arrows to get the graphical model on the right where the ’s generate the dependence in ? The graphical model on the right side of Fig. 1 is equivalent to a set of conditional independence relationships that can be summarized by saying Ver Steeg and Galstyan (2017). In other words, each layer explains the correlations in the layer below or is independent. This is one way to write the CorEx objective (for one layer).
[TABLE]
The objective is non-negative and the global minimum occurs at zero, in which case we can flip the arrows to interpret ’s as generating the dependence in . Looking at Table 1, we see that this optimization has an ICA term plus another term that demands that ’s make the ’s conditionally independent. With some manipulation, it can be seen that this optimization is also equivalent to the following optimization Ver Steeg and Galstyan (2015).
[TABLE]
Again looking at Table 1, this alternate form shows the similarity to the information bottleneck. Instead of requiring labels, , we simply compress into each latent factor while maintaining relevance about each of our observed variables, . From this point of view, we can view CorEx as a special unsupervised version of the information bottleneck.
Multiple Layers Now we extend to the hierarchical case. We start by building a hierarchy with layers as on the left side of Fig. 1. For simplicity we define the variables at layer as and we define and (a constant). Now let each layer explain dependence in the layer below.
[TABLE]
Again, this quantity is non-negative and has a global minimum at zero. At the global minimum, we can flip the arrows and interpret the latent factors as a generative model for the dependence in . We can again re-write the objective as a sum of bottleneck-like optimizations at each layer of the hierarchy.
[TABLE]
An advantage of writing the objective in this second form is that it can be directly plugged into a useful inequality Ver Steeg and Galstyan (2015).
[TABLE]
is the amount of dependence observed in the data. For high-dimensional systems, this is hard to estimate. However, the bound in Eq. 3 allows us to solve a hierarchy of optimization problems giving progressively tighter lower bounds on the dependence in . Because each layer directly contributes to the lower bound on , we can quantify the value of depth and stop adding layers to the hierarchy when the lower bound stops increasing. Local optima of this non-convex optimization can be found using algorithms with low computational and sample complexity.
CorEx hierarchically decomposes multivariate information in in terms of contributions from latent factors at each layer of a hierarchy. This decomposition can be viewed as a generalization of the hierarchical decomposition introduced by Watanabe Watanabe (1960).
Incremental CorEx Just as PCA has an incremental version where one component is extracted at a time, the incremental version of the CorEx principle is the information sieve Ver Steeg and Galstyan (2016). For the incremental version, we consider the special case where is one-dimensional so that and the objective in Eq. 1 reduces to . After learning one that optimizes the objective, we transform the data (a kind of information-theoretic orthogonalization) so that we can learn another factor that extracts more dependence. The sieve optimization is a dual formulation of the optimization defining the Wyner common information Wyner (1975); Op’t Veld and Gastpar (2016) and can be viewed as a decomposition of common information Ver Steeg et al. (2017).
2.2 Implementations of the CorEx Principle
We briefly review implementations of the CorEx principle, including their applicability and limitations. Code is available at http://github.com/gregversteeg.
- •
CorEx Ver Steeg and Galstyan (2014): The original implementation is restricted to discrete variables and tree structured latent factors. The functionality is subsumed by other versions.
- •
bio_corex Ver Steeg and Galstyan (2015); Pepke and Ver Steeg (2017): The most flexible version includes augmentations that were designed for challenges in the biology domain, though there is nothing specific to biology in the implementation. This version handles discrete and continuous variables, overlapping latent factor structure, and missing data. Although CorEx has intrinsically low sample complexity, some biology data is severely under-sampled. This version implements a Bayesian smoothing of the marginal parameter estimates that reduces the appearance of spurious correlations Pepke and Ver Steeg (2017). This version runs quickly for problems with up to thousands of variables.
- •
discrete_sieve Ver Steeg and Galstyan (2016): This is the first implementation of the information sieve for discrete variables. In the discrete case, the information orthogonalization required by the sieve is extremely challenging. The approach is impractical for most real world problems.
- •
LinearSieve Ver Steeg et al. (2017): The linear version of the information sieve (for continuous variables) is fast and practical for finding the top components explaining the most correlation in data. Like other incremental methods, repeated application eventually introduces numerical instability.
- •
LinearCorEx Ver Steeg and Galstyan (2017): The fastest, non-sparse version of CorEx assumes latent factors are linear functions of the inputs. Linear CorEx is very effective for covariance estimation and subspace clustering in high-dimensional, under-sampled data.
- •
corex_topic Reing et al. (2016); Gallagher et al. (2016): This implementation exploits sparsity for major speed-ups, easily handling hundreds of thousands of variables depending on the sparsity of the data. While this version was developed for topic modeling using binary bag of words data, it can be applied to any binary data. This implementation includes a semi-supervised option.
3 Applications
The most successful applications of the CorEx principle involve high-dimensional data in complex domains that are difficult to model a priori. In practice, the learned hierarchical representation is used in several ways. First, the structure induces a hierarchical clustering of input variables. Second, the latent factors at each layer constitute a reduced dimensionality representation of the input data. Third, individual factors often disentangle true latent factors of variation in the data. Finally, like PCA, we can rank factors according to their value. While PCA finds components that explain the most variance, in CorEx we find factors that explain the most dependence.
Social Science Latent factor models like the “Big 5” personality factors are popular in social science because of their simplicity and interpretability. Given data from an online survey with the Big 5 questions, CorEx was able to perfectly reconstruct the Big 5 factors while standard methods failed Ver Steeg and Galstyan (2014). CorEx outperforms traditional factor methods when the number of variables is larger than the number of samples Ver Steeg et al. (2017), as is increasingly common in social science experiments.
Gene Expression If DNA is the software for our biology, then gene expression tells us which code is running. New sequencing methods allow us to read expression levels for thousands of genes but, unfortunately, only a tiny fraction of these processes are understood. Applying CorEx to gene expression reveals a rich array of strong biological signals. Gene clusters discovered by CorEx exhibit four times more enrichment with respect to known biology in gene ontology databases than standard approaches Pepke and Ver Steeg (2017). The CorEx hierarchy also seems to accurately reflect biological organization. For instance, two low-level clusters, immune cell activation and inflammatory response, are combined in a higher-level group related to immune signaling.
Neuroscience Next generation imaging technology gives detailed views of individual brains but even the largest studies can only afford to image a relatively small number of brains. Small sample sizes with high-dimensional data has led to low statistical power in most studies and a crisis of replication in the field Button et al. (2013). Exploratory data analysis using CorEx can help identify only the strongest, most robust dependencies in the data, even with small sample sizes. Early results have identified well-known relationships along with novel, biologically plausible candidate effects that increase predictive power Madsen et al. (2015, 2016); Zavaliangos-Petropulu et al. (2017). Moreover, CorEx outperforms ICA for disentangling spatial modes in imaging data Ver Steeg et al. (2017).
Language Applied to bag of words vectors of text data, CorEx representations can be interpreted as hierarchical topic models Ver Steeg and Galstyan (2014); Hodas et al. (2015). Latent tree based methods like CorEx outperform LDA Chen et al. (2016a) on several measures of topic quality. A semi-supervised version further increases the interpretability of topics by allowing us to “anchor” some latent factors to designated words of interest Reing et al. (2016); Gallagher et al. (2016).
Finance The stock market exhibits a high degree of dependence and measuring this dependence is important for quantifying risk. Applied to monthly returns on the S&P 500, CorEx discovers a hierarchy of latent factors related to industry sectors Ver Steeg and Galstyan (2015). Using a linear version of CorEx allows us to estimate covariance matrices and this approach outperforms state-of-the-art methods like GLASSO for under-sampled, high-dimensional stock market data Ver Steeg and Galstyan (2017).
4 Conclusion
Learning useful representations of observations without supervision across diverse domains is a challenging, unsolved problem. While successes in supervised learning have not immediately translated to comparable results for unsupervised learning, the engineering achievements that have driven those successes now allow us to define flexible, powerful architectures and quickly and easily optimize them under a wide variety objectives TensorFlow (2015). Taking information-theoretic learning principles and applying them within these powerful frameworks has already generated many compelling results Chen et al. (2016b); Kolchinsky et al. (2017); Achille and Soatto (2016). Applying the CorEx principle in the same context is a logical step for future work.
Unlike similar learning principles, CorEx naturally decomposes information in a hierarchical way. This hierarchical structure has numerical advantages since the objective is less reliant on back-propagation for training. Credit for predicting a correct label does not have to be assigned to intermediate representations as in supervised learning Minsky (1961), instead each latent factor in the representation has a quantifiable information value within the hierarchical decomposition. Besides the technical advantages, many applications show that individual latent factors learned via CorEx reflect diverse and meaningful structure in real-world datasets. We hope that ongoing CorEx developments continue to accelerate the discovery of knowledge through unsupervised learning.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Achille and Soatto [2016] Alessandro Achille and Stefano Soatto. Information dropout: Learning optimal representations through noisy computation. Ar Xiv e-prints , 2016.
- 2Barlow et al. [1989] Horace B Barlow, Tej P Kaushal, and Graeme J Mitchison. Finding minimum entropy codes. Neural Computation , 1(3):412–423, 1989.
- 3Bell and Sejnowski [1995] Anthony J Bell and Terrence J Sejnowski. An information-maximization approach to blind separation and blind deconvolution. Neural computation , 7(6):1129–1159, 1995.
- 4Bengio et al. [2012] Yoshua Bengio, Aaron C Courville, and Pascal Vincent. Unsupervised feature learning and deep learning: A review and new perspectives. Co RR, abs/1206.5538 , 1, 2012.
- 5Bengio et al. [2013] Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives. Pattern Analysis and Machine Intelligence , 35(8):1798–1828, 2013.
- 6Button et al. [2013] Katherine S Button, John PA Ioannidis, Claire Mokrysz, Brian A Nosek, Jonathan Flint, Emma SJ Robinson, and Marcus R Munafò. Power failure: why small sample size undermines the reliability of neuroscience. Nature Reviews Neuroscience , 14(5):365–376, 2013.
- 7Chen et al. [2016 a] Peixian Chen, Nevin L Zhang, Leonard KM Poon, and Zhourong Chen. Progressive em for latent tree models and hierarchical topic detection. In Thirtieth AAAI Conference on Artificial Intelligence , 2016.
- 8Chen et al. [2016 b] Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Advances In Neural Information Processing Systems 29 (NIPS) , pages 2172–2180, 2016.