Predictive Bayesian selection of multistep Markov chains, applied to the detection of the hot hand and other statistical dependencies in free throws
Joshua C. Chang

TL;DR
This paper develops a Bayesian method for selecting the order of multistep Markov chains to model dependencies in sequential data, demonstrated through analyzing free throw shooting in NBA players to detect hot hand effects.
Contribution
It introduces a predictive Bayesian approach for model selection of Markov chain order, applied to real-world sports data to identify statistical dependencies in free throw outcomes.
Findings
Detected statistical dependencies in 23% of NBA player-seasons.
LeBron James shows improved free throw percentage after a miss in some seasons.
A variable length model with error correction outperforms simpler models.
Abstract
Consider the problem of modeling memory effects in discrete-state random walks using higher-order Markov chains. This paper explores cross validation and information criteria as proxies for a model's predictive accuracy. Our objective is to select, from data, the number of prior states of recent history upon which a trajectory is statistically dependent. Through simulations, I evaluate these criteria in the case where data are drawn from systems with fixed orders of history, noting trends in the relative performance of the criteria. As a real-world illustrative example of these methods, this manuscript evaluates the problem of detecting statistical dependencies in shot outcomes in free throw shooting. Over three NBA seasons analyzed, several players exhibited statistical dependencies in free throw hitting probability of various types - hot handedness, cold handedness, and error…
Click any figure to enlarge with its caption.
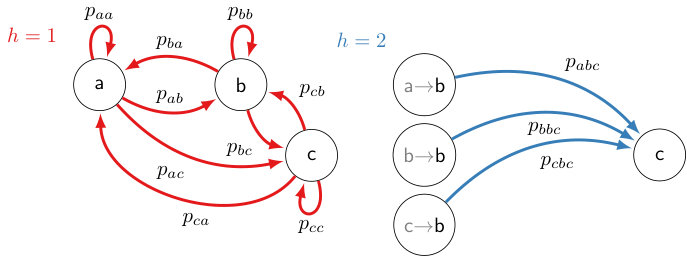 Figure 1
Figure 1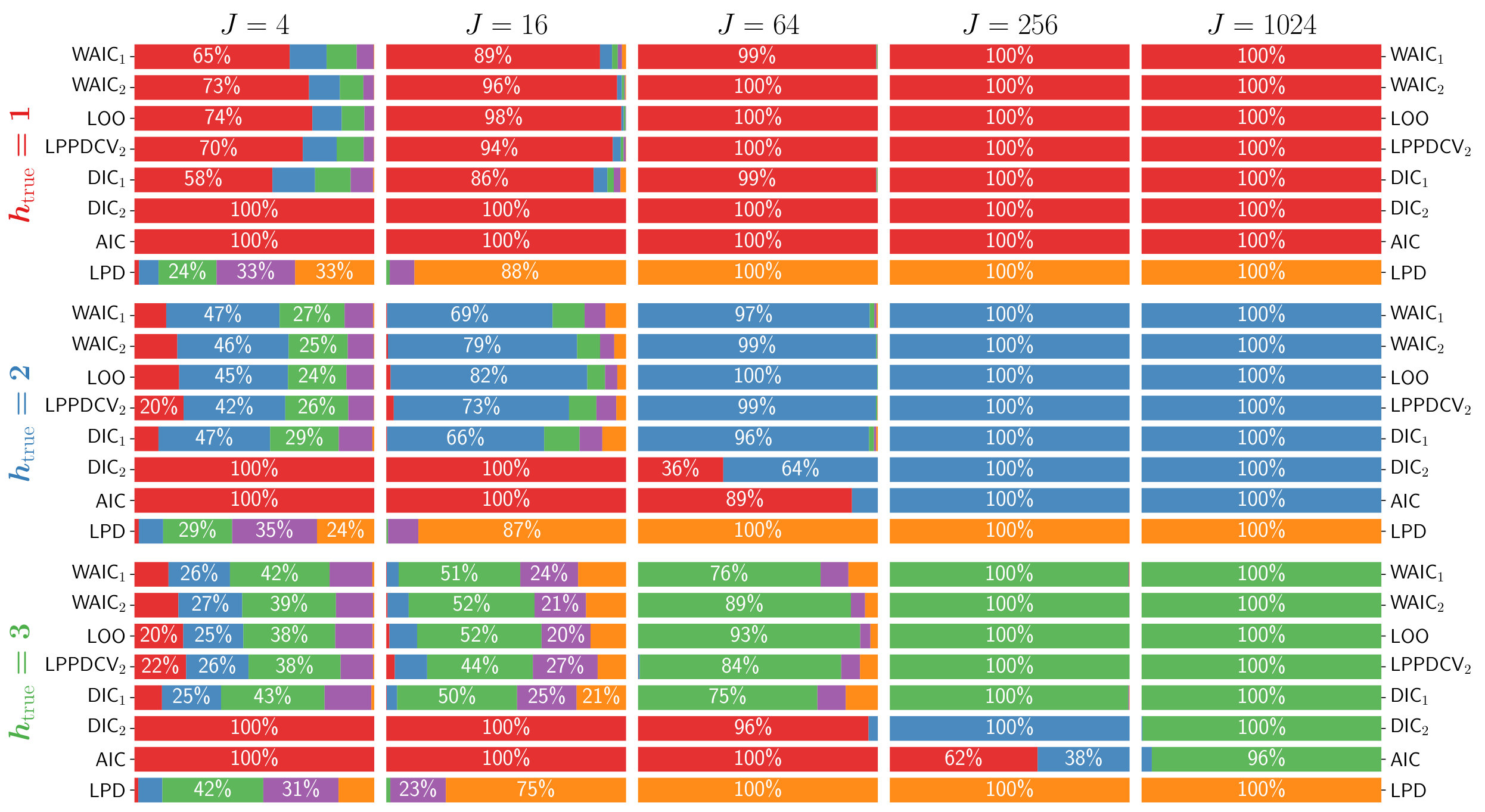 Figure 2
Figure 2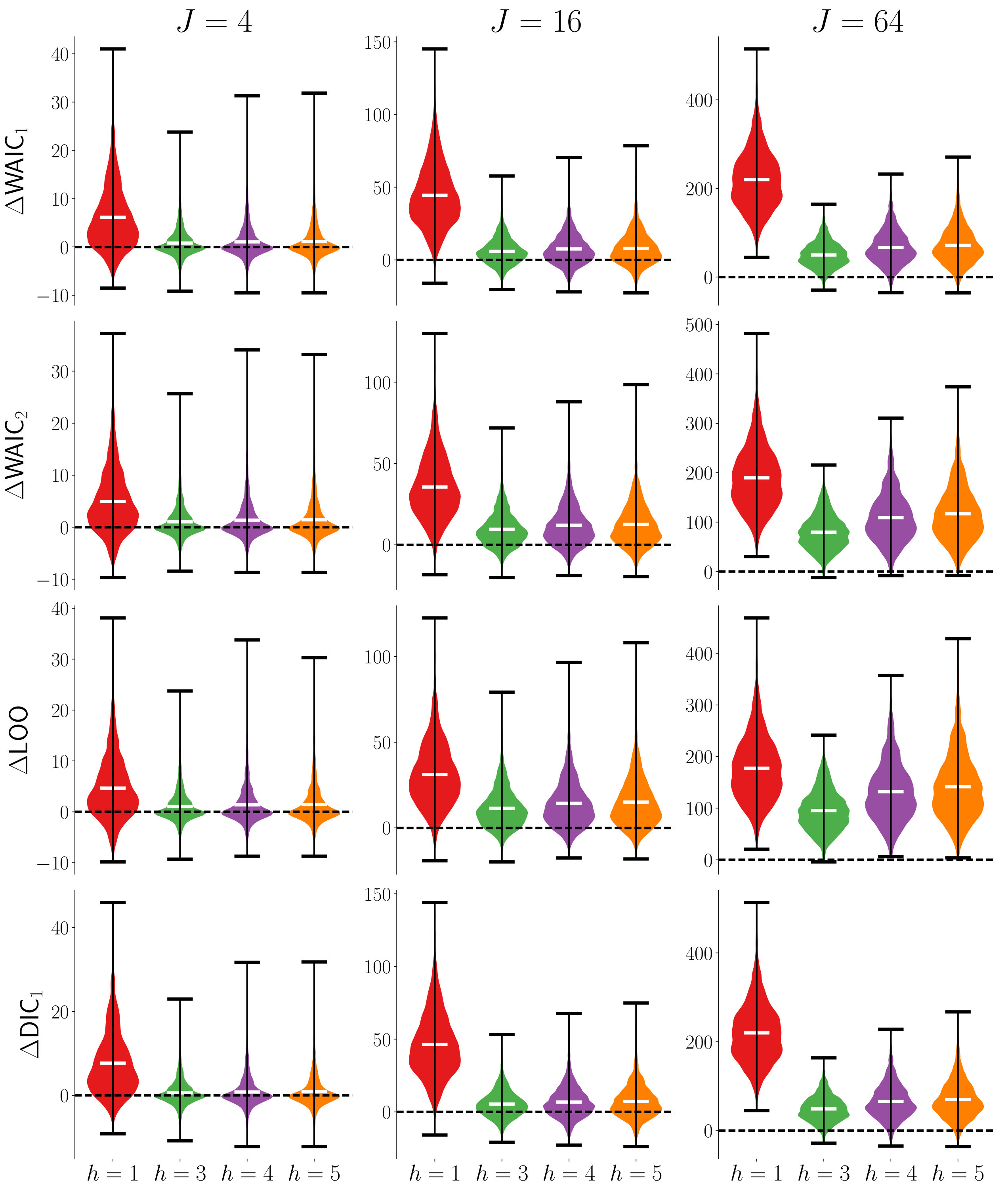 Figure 3
Figure 3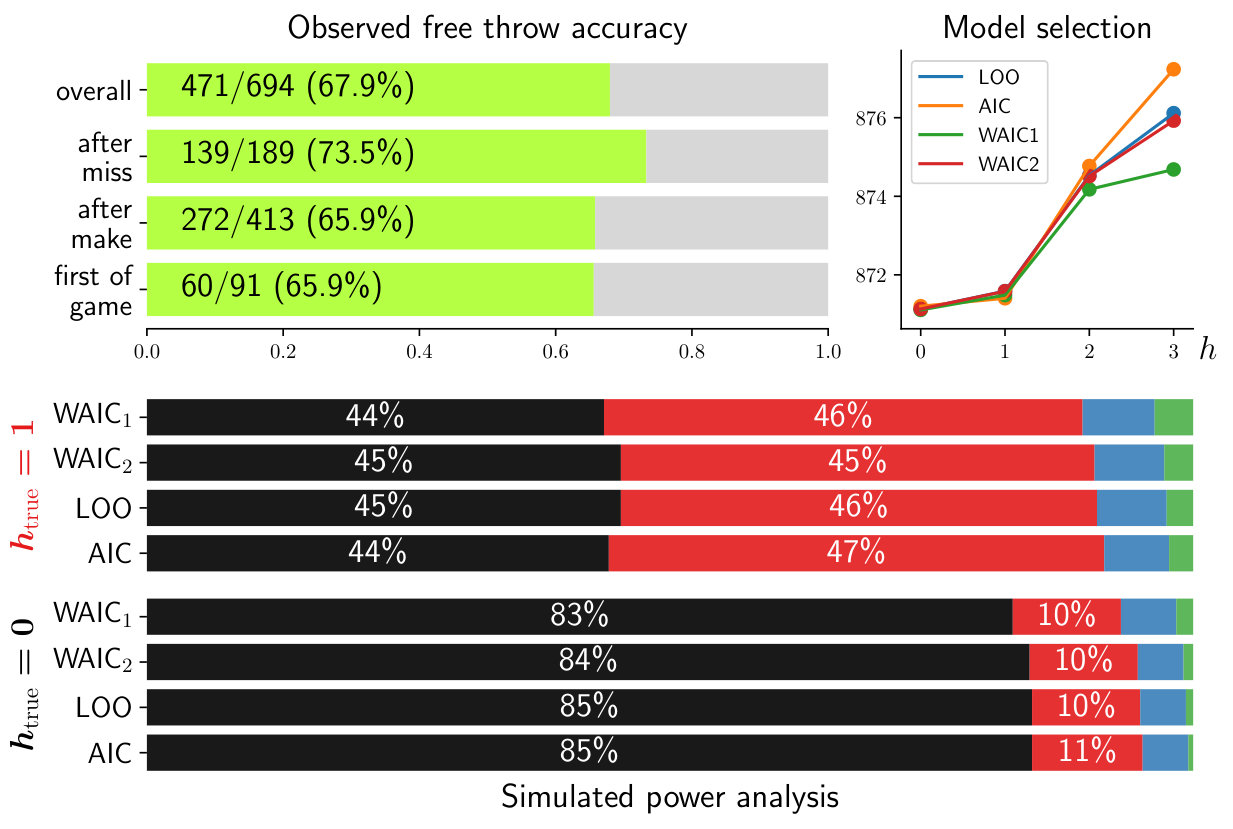 Figure 4
Figure 4 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\corres
Joshua C. Chang
Predictive Bayesian selection of multistep Markov chains, applied to the detection of the hot hand and other statistical dependencies in free throws
Joshua C. Chang1
1 Epidemiology and Biostatistics Section, Rehabilitation Medicine Department, The National Institutes of Health, Clinical Center, Bethesda, Maryland 20892, U.S.A.
Abstract
Consider the problem of modeling memory effects in discrete-state random walks using higher-order Markov chains. This paper explores cross validation and information criteria as proxies for a model’s predictive accuracy. Our objective is to select, from data, the number of prior states of recent history upon which a trajectory is statistically dependent. Through simulations, I evaluate these criteria in the case where data are drawn from systems with fixed orders of history, noting trends in the relative performance of the criteria. As a real-world illustrative example of these methods, this manuscript evaluates the problem of detecting statistical dependencies in shot outcomes in free throw shooting. Over three NBA seasons analyzed, several players exhibited statistical dependencies in free throw hitting probability of various types – hot handedness, cold handedness, and error correction. For the 2013–2014 through 2015–2016 NBA seasons, I detected statistical dependencies in 23% of all player-seasons. Focusing on a single player, in two of these three seasons, LeBron James shot a better percentage after an immediate miss than otherwise. In those seasons, conditioning on the previous outcome makes for a more-predictive model than treating free throw makes as independent. When extended to data from the 2016–2017 NBA season specifically for LeBron James, a model depending on the previous shot (single-step Markovian) is approximately as predictive as a model with independent outcomes. An error-correcting variable length model of two parameters, where James shoots a higher percentage after a missed free throw than otherwise, is more predictive than either model.
{fmtext}
1 Introduction
Multistep Markov chains (also known as -step or higher-order Markov chains) are flexible models that are useful for quantifying any discrete-state discrete-time phenomenon. They have appeared in limitless contexts such as analysis of text Melnyk et al. [2006], human digital trails Singer et al. [2014], DNA sequences, protein folding Yuan [1999], eye movements Bettenbühl et al. [2012], and queueing theory Medhi [2002]. In these models, transition probabilities between states depend on the recent history of states visited. In order to learn these models from data, a choice for the number of states of history to retain must be made. In this manuscript we evaluate contemporary Bayesian methods for making this choice, from the perspective of predictive accuracy.
Bayesian model selection is an active field with many recent theoretical and computational advancements. In the broad setting of Markov Chain Monte Carlo (MCMC) inference, a significant advance has been approximation of leave one out (LOO) cross validation through use of Pareto smoothed importance sampling Vehtari et al. [2015], which has made LOO computationally feasible for a large class of problems. As explored in Gelman et al. [2014], many methods similar to LOO exist. This manuscript adapts these methods to the context of selection for multistep Markovian models, providing closed-form expressions for computing information criterion that summarize the evaluation made by each method.
As a concrete illustration of these methods, I examine the problem of the detection of statistical dependencies broadly using free throw data from the National Basketball Association (NBA). A particular type of statistical dependency is known as the hot hand phenomenon. This phenomenon implies that recent success is indicative of success in the immediate future. While controversial in analytical circles, belief in the hot hand phenomenon is certainly widespread in both the general public and in athletes Gilovich et al. [1985], Camerer [1989], Rao [2009]. Empirically, the phenomenon has proven to be elusive Bar-Eli et al. [2006]. In the 1980s, examinations of the phenomenon in basketball based on analysis of shooting streaks yielded negative results Gilovich et al. [1985], Koehler and Conley [2003], failing to reject null hypotheses of statistically independent shot outcomes. Based on these early analyses, some studies have dismissed the widespread belief in the hot hand by relating it to the Gambler’s fallacy Ayton and Fischer [2004]. The gambler’s fallacy refers to the seemingly mistaken belief that “random” events such as roulette spins exhibit autocorrelation Sundali and Croson [2006]. In the context of the hot hand, an autocorrelation would involve increased probability of making a shot when one is in a “hot” state. Follow-up studies have examined the effects of belief in the hot hand under the supposition that it is a fallacy Burns [2001].
Ignoring the fact that statistical dependencies in even intended games of chance can exist Slotnik [2018], one might reasonably suspect that various latent factors can affect the accuracy of an individual, where the outcome is the result of physical processes. These latent factors, modeled for instance by hidden Markov models Ötting et al. [2018], Green and Zwiebel [2017], would manifest as statistical dependencies in outcomes. Additionally, there were weaknesses in the prior research efforts that failed to find the hot hand effect. Recent analyses, using multivariate methods that can account for factors such as shot difficulty Bocskocsky et al. [2014], Arkes [2010], Miller and Sanjurjo [2018], have supported the phenomenon, finding the original studies to be underpowered Arkes [2010, 2013], Miller and Sanjurjo [2018], or to suffer from methodological issues regarding the weighting of expectation values Miller and Sanjurjo [2018]. A statistical testing approach that did not share this methodological issue Yaari and Eisenmann [2011] found evidence of the hot hand in aggregate game data but also raised the question of whether the observed patterns were a result of the hold/cold hand or of other individual-level states that imply statistical dependencies. In this manuscript I focus on detecting individual-level effects.
As an illustration of model selection for multistep Markov chains, this manuscript re-examines the hot hand phenomenon from a different analytical philosophy. Presently, a broad class of analyses of the phenomenon Gilovich et al. [1985], Koehler and Conley [2003] have been rooted in null hypothesis statistical testing. Rather than follow this approach, which requires a subjective choice of a cut off -value to assess “significance,” this manuscript frames this problem as a model selection task. We are interested in whether models that encompass statistical dependencies like hot handedness are better at predicting free throw outcomes for individual players than models without such effects.
2 Quantitative Methods
2.1 Probabilistic modeling
Multistep Markov chains (also known as n-step Markov Chains) are factorized probability models for discrete-state trajectories, where the probability of a particular trajectory is the product of conditional transition probabilities between possible states. The conditions pertain to the prior locations that a trajectory has visited, or its recent history. In our model of free throw shooting there are two states (make and miss), however, let us consider the more general problem of a model with any number states. Assume that a trajectory consists of steps , where each step takes a value taken from the set We are interested in representations for the trajectory probability of the form
[TABLE]
where , a non-negative counting number, represents the number of states worth of memory needed to predict the next state, with appropriate boundary conditions for the beginning of the trajectory. In the context of the hot hand effect, models with encompass statistical dependencies between shot outcomes. A hot hand would correspond to higher make probabilities after recent makes and cold hands correspond to lower probabilities after misses.
Mathematically, the stochastic process underlying discrete-time Markov chains (implicitly ) is represented by a transition matrix, where each entry is a conditional probability of a transition from a state (row) to a new state (column). Multi-step Markov chains are no different in this respect. Each row corresponds to a given history of states and the corresponding matrix entries provide conditional probabilities of transitioning at the next step to a new state (column).
In the case of absolutely no memory (), the path probability is simply the product of the probabilities of being in each of the separate states in a path, and there are essentially free model parameters, where is the number of states. The memoryless property of Markov chains refers to . It should be noted that is a special sub-case of , where the associated transition matrix has identical rows. If , the model is single-step Markovian (memoryless) in that only the current state is relevant in determining the next state. These models involve free parameters. Knowledge of prior states beyond the current state is considered “memory.” Generally, if states of history are required, then the model is -step Markovian, and parameters are needed (see Fig 1). Hence, the size of the parameter space grows exponentially with memory. Our objective is to determine, based on observational evidence, an appropriate value for .
Note that multistep-Markovian models are nested. Lower-order models (smaller-) can be represented by higher order models (larger-) but not visa-versa. Variable-length models Bühlmann and Wyner [1999] also fit into this paradigm, as pictured in Fig. 1. A model might have an effective order of for instance if many of its parameter vectors are identical.
For a fixed degree of memory , we may look at possible history vectors of length taken from the set . For each , denote the vector where is the probability that a trajectory goes next to state given that represents its most recent history. For convenience, we denote the collection of all as (see below for an example of the notation).
Generally one has available trajectories. Assuming independence between trajectories, one may write the joint probability, or likelihood, of observing these trajectories as
[TABLE]
where is the number of times that the transition occurs in trajectory , and is the total number of times the transition is seen.
For convenience, denote , , and the collection as . The sufficient statistics of the likelihood are the counts, so we will refer to the likelihood as . The maximum likelihood estimator for each parameter vector is found by maximizing the probability in Eq. 2, and can be written easily as .
**Example: ** The outcomes of free throws for a player in a particular game can be represented as string or trajectory of states (miss or make). For example, using “” to denote makes and “” to denote misses, a trajectory of “” corresponds to a game where a player makes the first two free throws, misses the third, and makes the fourth. To clarify our notation, consider a model for free throw shooting informed using observed trajectories (games) given: . Suppose that we set in this model. This choice implies that we need the counts coinciding to the number of makes following makes, misses following makes, misses following misses and makes following misses respectively for each trajectory (game). In addition, since the first state in each trajectory is stochastic as well, we add two special states representing the outcome of the initial free throw, , . Aggregating the counts across the trajectories, in the vector notation above, we have , where the indices are all of length one since our choice of means that we only consider history vectors of length one. Using maximum likelihood, we arrive at the parameter estimates
It is notable that our estimate of the probability of missing the first free throw in a game is null – this is probably an unrealistic inference. Fundamentally, the maximum likelihood estimator precludes the existence of unobserved transitions – a property that is problematic if the sample size is small, as already seen in this example. This problem amplifies when increasing . It is desirable to regularize the problem by allowing a nonzero probability that transitions that have not yet been observed will occur. This manuscript’s approach to rectifying these issues is Bayesian.
2.2 Bayesian modeling
A natural Bayesian formulation of the problem of determining the transition probabilities is to use the Dirichlet conjugate prior on each parameter vector
[TABLE]
hyper-parameterized by , a vector of size . The Dirichlet probability distribution is a distribution over finite-dimensional probability distributions. It has the probability density function
[TABLE]
where refers to the multivariate beta function Abramowitz and Stegun [1964],
[TABLE]
and refers to the gamma function.
This manuscript assumes that , corresponding to a uniform prior. This prior, paired with the likelihood of Eq. 2, yields the posterior distribution on the probabilities,
[TABLE]
In effect, one is assigning a mean probability of to any unobserved transition, where can be made small if it is expected that the transition matrix should be sparse. Other values of are possible, for instance corresponds to the Jeffreys’ prior. Note that other Bayesian treatments of Markov chain inference have used priors within the Dirichlet family Fan and Tsai [1999], Bettenbühl et al. [2012]. In the large-sample limit, as long as the components of are bounded, the posterior distribution is not sensitive to the choice of as the posterior density of Eq. 6 becomes tightly concentrated about the maximum likelihood estimates. This fact is evident by observing that in Eq. 6, as .
2.3 Model selection criteria
The parameter controls the trade-off between complexity and fitting error. From a statistical viewpoint, complexity results in less-precise determination of model parameters, leading to larger prediction errors (overfitting). Conversely, a simple model may not capture the true probability space where paths reside, and fail to catch patterns in the real process (underfit).
There are various existing generalized methods for evaluating how well models predict. Each of these methods summarizes a model using a single quantity. To facilitate comparison between the methods themselves, this manuscript scales the output of all methods to the deviance scale as used in the AIC. The deviance is a measure of information loss when going from a full model to an alternative model Akaike [1974].
The Akaike Information Criterion (AIC), Akaike [1974], Tong [1975], Katz [1981], defined through the formula where is the number of parameters in the model, is an estimate of deviance between an unknown true model and a given model. For the selection of , it may be computed exactly in closed form
[TABLE]
where in this context we define . Rooted in information theory, the AIC is an asymptotic approximation of the deviance Burnham and Anderson [2003]. The model with the smallest AIC is chosen. A limitation of the AIC is inaccuracy for small datasets. A correction to the AIC known as the AICc exists Hurvich and Tsai [1989], however, its exact form is problem specific Burnham and Anderson [2003].
The Bayesian Information Criterion (BIC) is closely related to the AIC but differs in the form of complexity penalty, taking sample size into account. The BIC, obeying the general formula is also available in closed form
[TABLE]
Despite its name, the formulation of the BIC is not Bayesian, using neither the prior nor posterior distributions. Under some conditions, however, the BIC can be seen as an asymptotic approximation of a Bayes factor Bhat and Kumar [2010].
Many of the Bayesian evaluation criteria feature the multivariate beta function (Eq. 5), as found in the normalization constant of the Dirichlet distribution (Eq. 4). To understand the large-sample properties of these methods, asymptotic expansion of the multivariate beta function can help. In the case where , assuming that all components of become unbounded, by Stirling’s approximation the log multivariate beta function has the behavior
[TABLE]
Bayes factors are ratios of the probability of the dataset given two models averaged over their corresponding prior parameter distributions Lavine and Schervish [1999], Posada and Buckley [2004]. In the case of Markov chains, the likelihood completely factorizes into a product of transition probabilities and each model’s corresponding term in a Bayes factor is the exponential of its log marginal likelihood (LML)
[TABLE]
If the expectation is computed instead against a posterior distribution , one arrives at the expected log predictive density (LPD)
[TABLE]
Related to the LPD is the expected log pointwise predictive density (LPPD), where the expectation in the LPD is broken down “point-wise.” For our application, we will consider trajectories to be points and write the LPPD as
[TABLE]
The LPPD features in alternatives to Bayes factors and the AIC Gelman et al. [2014].
The Widely Applicable Information Criterion Watanabe [2010, 2013] (WAIC) is a Bayesian information criterion with two variants, each featuring the LPPD but differing in how they compute model complexity. The WAIC is defined as
[TABLE]
where the effective model sizes are computed exactly as
[TABLE]
and
[TABLE]
In each of these expressions, refers to the digamma function, the derivative of the Gamma function Abramowitz and Stegun [1964]. The WAIC, unlike the AIC, is applicable to singular statistical models and is asymptotically equivalent to Bayesian leave-one-out cross-validation Watanabe [2010]. The two effective model size estimates for the WAIC are posterior expectations of equivalent estimates used in the Deviance Information Criterion (DIC).
The DIC,
[TABLE]
also resembles the WAIC. It consists of two variants in the computation of model complexity,
[TABLE]
and which may be computed
[TABLE]
The two estimates of complexity can be derived asymptotically from the LPD Gelman et al. [2014], both reducing exactly to the number of predictors in the case of linear regression models using uniform priors.
Finally Bayesian variants of cross-validation have recently been proposed as alternatives to information criterion Gelman et al. [2014]. In our problem, -fold CV, where data is divided into partitions, can be evaluated in closed form without repeated model fitting. Using as a metric, this manuscript also evaluates two variants of -fold CV: leave-one-out cross validation (LOO)
[TABLE]
and two-fold (leave-half-out, LHO) cross validation,
[TABLE]
where constitute the transition counts of the last trajectories or the first trajectories respectively, so that , and refers to multivariate beta function.
3 Evaluation of selection criteria
Simulations provided a means for testing how the criteria mentioned perform in finite-sample settings typical of most learning tasks. For the large-sample characteristics of cross-validation, I refer the reader to Stone [1977].
As a test system, consider a system of states, with designated start and absorbing states. For each given value of , I generated for each , a single set of fixed true transition probabilities drawn from Dirichlet() distributions. For each of these random networks of a fixed , I randomly sampled sets of trajectories, times – each trajectory terminating when hitting a designated absorbing state. Note that the number of steps in a given trajectory is itself stochastic and determined by the statistics of the first-passage time to an absorbing state given the true transition probabilities. Then for each sample of trajectories, I computed all the criteria mentioned in the previous section for various values of .
Fig. 2 provides the frequency that each of six models () was chosen based on the selection criteria compared. Each row corresponds to a given true degree of memory and sample sizes increase along columns when viewed from left to right. Generally, as the number of samples increases, all selection criteria except for the LML (Bayes factors) and LPPD improve in their ability to select the true model. The LML consistently selects a more-complex (higher-) model.
The AIC does well if is small, but requires more data than many of the competing methods in order to resolve larger degrees of memory. The BIC behaves like a more-conservative version of the AIC, requiring more data to select the more-complex but true generating model than the other methods.
LOO, the two variants of the WAIC, and DIC1 perform roughly on par. Since one uses each criterion by choosing the model of the lowest value, it is desirable that , for . Fig. 3 explores the distributions of these quantities in the case where . As sample size increases, there is clearer separation of these quantities from zero. By , no models where are selected using any of the criteria. The WAIC2 and LOO criteria perform about the same whereas the WAIC1 criteria and the DIC1 criteria lag behind in separating themselves from zero.
In the Supplemental Materials, the aforementioned experiment is repeated for state systems, finding consistent results. This consistency is evident when comparing Supplemental Fig. S2 to Fig. 2, where the same trends are present in both sets of results.
Informed by these tests, this manuscript recommends the use of leave-one-out cross validation (LOO). LOO performed slightly better than WAIC2 in the included tests, while being somewhat simpler to compute. Eq. 19 decomposes completely into a sum of logarithms of gamma functions, and is hence easy to implement in standard scientific software packages.
4 The hot hand phenomenon
I used the methodology in this manuscript to evaluate the hot hand effect in the controlled context of free throws. The free throw data was manually scraped from game-logs publicly available on the ESPN website. In Fig. 4, LOO is evaluated for , for all player-seasons between 2013–2014 and 2015–2016. LOO favored a model where for approximately of all player-seasons tested. Restricted to player-seasons where at least free throws are attempted, is presented in Fig. 4.
The finding that does not by itself present information about the nature of statistical dependencies. To examine their nature, one must examine the inferred probabilities. In Fig. 5, conditional hitting probabilities are presented, for the same player-seasons represented in Fig. 4, where is favored over . It is evident that many of the players exhibit what one might call a “hot hand” by shooting a better percentage after a previous make than otherwise. Likewise, many players exhibit cold hands, shooting worse after misses, or by shooting a worse free throw percentage on the first attempt in a game. Notably, some players, such as LeBron James, seem to shoot better after a miss than otherwise which would represent a form of error correction.
LeBron James is a volume free throw shooter who appears in Fig. 4 so I singled him out for further analysis. Looking at Fig. 4, James appears in the first two seasons but is not present in the third season (2015–2016). Examining his shooting splits from Fig. 5 two trends stand out. First, he shoots a lower percentage on the first free of the game than otherwise. Second, he appears to consistently hit a higher percentage after a miss than otherwise. In the 2015–2016 season, those patterns do not survive and LOO does not favor over .
During the 2016-2017 season, in games, LeBron James attempted at least a single free throw, hitting of overall (Fig. 6). Conditioning the hit probabilities by the outcome of the preceding free throw in the same game, James shot a slightly better percentage after missing a free throw than otherwise. However, the model is favored slightly over (Model selection pane of Fig 6).
As in Fig. 2 for the test system, we can evaluate the performance of the model selection criteria using simulations. Assuming that the model is true, sets of strings of free throw outcomes were simulated. The length of each string was chosen by drawing from a Poisson distribution where the expectation matched the mean number of free throws attempted by James per game (). The overall hitting percentage in these simulations was matched to , as found in the original game data, and the transition probabilities were matched overall to those in Fig. 6. Despite the fact that was the underlying true model, it was chosen slightly under half the time (Fig. 6). Another variant of the simulated power analysis is given in Fig. S1, where within each game James’ free throw outcomes are resampled from the actual game data, in effect scrambling the order of makes and misses. Shuffling of shot outcomes destroys the correlations between consecutive shots. It is seen in Fig. S1 that the information criteria match up both qualitatively and quantitatively in their model choice with the simulated game data presented in Fig. 6.
Examining the model parameters in the case of , one sees that the hitting probabilities are similar in all cases except after a miss (Fig. 6). This observation suggests a model with jagged variable-length memory: independence of outcome except after a miss. Having one fewer parameter than the full model, this variable-length model is favorable to both the and models (Fig. 7).
Hence, at least for this season and the two present in Fig. 4, the most predictive model of James’ free throw shooting tells a story of error correction rather than a story of hot hand.
5 Discussion and Summary
This manuscript addressed general methods of degree selection for multistep Markov chain models. While the example provided was related to the evaluation of the hot hand phenomenon, the class of models where the included methodology can be used is broad. Notably, multistep Markov Chains have applications in queueing models which feature heavily in operations research.
The simulations yielded insight on the performance of the criteria in the typical small-sample setting. This manuscript provided simulations for state systems, finding consistent results throughout. Importantly, both the AIC and LML (Bayes factors) are biased in opposite situations, in opposite directions. For small datasets, the AIC tends to sparsity, which runs counter to the typical situation in linear regression problems where the AIC can favor complexity with too few data, a situation ameliorated by the more-stringent AICc Claeskens et al. [2008]. The BIC is the most-conservative of the methods tested, however, requires more data to accept the veracity of any given higher-order model.
Bayes factors with flat model priors (via the AIC-scaled log marginal likelihood) as investigated here, on the other hand, consistently select a higher value of given more data. Due to the nested nature of these models (depicted in Fig. 1), such behavior may not be undesirable. One may still learn an effective lower-order model within a higher-order model, finding that the higher-order model makes effectively the same predictions. Notably, alternative Bayes factors methods for selecting the degree of memory also include model-level priors that behave like the penalty term in the AIC Strelioff et al. [2007], Singer et al. [2014]. Since the upper bound of the LML is the logarithm of the likelihood found from the MLE procedure, this selection method is more stringent in the low sample-size regime than the pure AIC and hence will suffer from the same bias towards selecting models with less memory.
Additionally, it is known that Bayes factors are sensitive to the choice of prior Gelman et al. [2014], since they involve an expectation relative to the prior distribution. Examining Eq. 10, the denominator of the term within the logarithm of Eq. 10 is invariant to observations. In contrast, Bayesian alternatives where expectations are taken with respect to the posterior should not be as sensitive to the choice of prior. When looking at LOO of Eq. 19, the prior comes into the formulation only to increment the overall count of a given pattern. Asymptotically, quickly overwhelms . Hence, LOO is not as sensitive to the exact choice of .
5.1 Limitations and extensions
This manuscript addressed only a limited aspect of the overall model selection task – the evaluation of competing models on the basis of predictive accuracy. This manuscript does not tackle the parallel task of model searching, outside of the context of fixed-order multistep models. For fixed order models, search is easy. One fits models by order sequentially. We have seen, however, that at times variable-length histories are appropriate. Notably, in LeBron James’ 2016–2017 free throws, a variable length model is favored over a larger encompassing model, which is itself disfavored relative to a smaller fixed-length model. In that example, with the small number of states, one could easily detect the variable-length model directly. However, when the number of states increases, the number of variable-length models also increases exponentially.
While out of the intended scope of this manuscript, I note that projective search methods Piironen et al. [2018] may have promise for adaptation to the search for variable-length Markov chains. In these methods, one searches for submodels nested within a larger encompassing model. As a baseline for such a procedure, one may choose to begin with a model of slightly higher order than that selected by LOO.
As pertains to the hot hand and related phenomena, fundamentally, these phenomena manifest as observable correlations in shot outcomes. However, the “generating distributions” for free throw outcomes are likely not in the class of multistep Markov models. From a modeling standpoint, a hidden Markov model with “hot” and “cold” states, as implemented by Wetzels et al. [2016], may be more mechanistically-valid. Hidden Markov models map to multistep Markov models of perhaps infinite order at arbitrarily high precision. Hence, this manuscript focused on the detection of any statistical dependency in free throws. However, one could make an argument, as I have done, that the various patterns of statistical dependencies detected: cold first shot, error correction, etc, have real-world physical interpretations. Such an argument may not hold in generality for other processes modeled using multistep Markov chains. Hence, I would like to stress that the focus of the manuscript is on finding predictive models, rather than on mechanistic certainty.
5.2 The hot hand phenomenon
From the modeling perspective, for a given player, there can be large fluctuations in free throw shooting percentage between seasons. It is common, particularly early in careers, for players to drastically improve their accuracy after an offseason of training. However, changes occur often in the other direction as well. Hence, one either needs to model non-stationarity in the percentages or restrict the time interval of the applicability of any given model. In this manuscript I have chosen to restrict modeling to the interval of a single season, ignoring non-stationarity within the season, a trade-off common to other analyses Gilovich et al. [1985]. The downside of such restrictions is that they limit the volume of data that may be used in detecting effects. LeBron James, a volume free throw shooter who does not miss many games and plays well into the playoffs, is perhaps a best-case scenario for detection of statistical dependencies in free throws using such models.
Even for James, the detection of these effects can be difficult. Judging from simulations (Fig 6), it appears that the dataset is underpowered for the selection of a pure model where . On the other hand, in simulations where , is correctly chosen approximately of the time. The and models are both approximately as predictive. In fact, from the model averaging perspective, they would be weighted approximately the same as weights are exponential in the gap between the selection criteria Gelman et al. [2014].
For James’ 2016–2017 attempts, the variable length model (Fig 7) is more predictive than either of the pure and models. While his 2013–2014 and 2014–2015 seasons do favor over , the effective models have the same error-correcting behavior as the variable-length model of 2016–2017. Hence, based on finding the model with the best prediction, one would predict that LeBron James is often more likely to make a free throw after a miss than otherwise.
\conflict
I have no competing interests. \dataccessAll data has been deposited on Dryad
\competingThe author declares no competing interests.
\disclaimer
This section does not apply. \aucontributeThe sole author is responsible for the entirety of the work.
\funding
This work is supported by the Intramural Research Program of the National Institutes of Health Clinical Center and the US Social Security Administration. \ackThis manuscript is dedicated to the memory of Dr. Robert M. Miura. He is survived by his loving family, his numerous mathematical contributions, and the many generations of researchers that he has mentored and advised throughout his decades of generous service. I also thank members of the Biostatistics and Rehabilitation Section in the Rehabilitation Medicine Department at NIH, John P. Collins in particular, and also Carson Chow at NIDDK for helpful discussions.
Appendix A Derivations
The marginal likelihood, also known as Bayes factor, is the expectation of the likelihood under the prior distribution. The logarithm of this quantity (LML) is
[TABLE]
The log predictive density (LPD) given a model defined by an inferred posterior distribution may be computed
[TABLE]
The log pointwise predictive density (LPPD), requires partition of data into disjoint “points.” Treating trajectories as points yields
[TABLE]
The LOO, as defined in this manuscript, is similar to the LPPD. For the LOO, each of the pointwise posterior distributions is computed after leaving out the corresponding trajectory. Hence,
[TABLE]
For the WAIC, the two variants of complexity parameters are
[TABLE]
and
[TABLE]
The commonly used Deviance Information Criterion (DIC)
[TABLE]
also resembles the WAIC, consisting of two variants in the computation of model complexity,
[TABLE]
and which may be computed
[TABLE]
where refers to the Kronecker delta function.
Appendix B Supplemental results
In Fig. 6, it is apparent that models where and have comparable predictive power. As a form of permutation test, we consider resamplings without replacement of James’ 2016–2017 free throws where within each game the order of his shot outcomes are scrambled. The results here are similar to those found in Fig. 6, where the statistical power of the information criteria are evaluated using simulated data.
Fig. S2 presents a version of the same tests performed in the main manuscript (where an eight state system is used) on a four-state system. In comparing Fig. 2 to Fig. S2, one finds consistent results. Note that on average the trajectory lengths are shorter in the four state system relative to the eight state system due to the fact that there are fewer possible states relative to the number of absorbing states.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Melnyk et al. [2006] SS Melnyk, OV Usatenko, and VA Yampol’skii. Memory functions of the additive Markov chains: applications to complex dynamic systems. Physica A: Statistical Mechanics and its Applications , 361(2):405–415, 2006.
- 2Singer et al. [2014] Philipp Singer, Denis Helic, Behnam Taraghi, and Markus Strohmaier. Detecting memory and structure in human navigation patterns using Markov chain models of varying order. Plo S one , 9(7):e 102070, 2014.
- 3Yuan [1999] Zheng Yuan. Prediction of protein subcellular locations using Markov chain models. FEBS letters , 451(1):23–26, 1999.
- 4Bettenbühl et al. [2012] Mario Bettenbühl, Marco Rusconi, Ralf Engbert, and Matthias Holschneider. Bayesian selection of Markov models for symbol sequences: Application to microsaccadic eye movements. Plo S one , 7(9):e 43388, 2012.
- 5Medhi [2002] Jyotiprasad Medhi. Stochastic models in queueing theory . Elsevier, 2002.
- 6Vehtari et al. [2015] Aki Vehtari, Andrew Gelman, and Jonah Gabry. Pareto smoothed importance sampling. ar Xiv preprint ar Xiv:1507.02646 , 2015.
- 7Gelman et al. [2014] Andrew Gelman, Jessica Hwang, and Aki Vehtari. Understanding predictive information criteria for Bayesian models. Statistics and Computing , 24(6):997–1016, 2014.
- 8Gilovich et al. [1985] Thomas Gilovich, Robert Vallone, and Amos Tversky. The hot hand in basketball: On the misperception of random sequences. Cognitive psychology , 17(3):295–314, 1985.