
TL;DR
This paper introduces efficient algorithms for generating conjugacy classes and relators in free groups, corresponding to necklaces and bracelets, with evidence suggesting they operate in constant amortized time.
Contribution
The paper presents novel algorithms for generating freely and cyclically reduced necklaces and bracelets in free groups, improving efficiency in combinatorial group theory.
Findings
Algorithms run in constant amortized time
Effective generation of conjugacy classes and relators
Applicable to combinatorial group theory problems
Abstract
Lists of equivalence classes of words under rotation or rotation plus reversal (i.e., necklaces and bracelets) have many uses, and efficient algorithms for generating these lists exist. In combinatorial group theory elements of a group are typically written as words in the generators and their inverses, and necklaces and bracelets correspond to conjugacy classes and relators respectively. We present algorithms to generate lists of freely and cyclically reduced necklaces and bracelets in free groups. Experimental evidence suggests that these algorithms are CAT -- that is, they run in constant amortized time.
Click any figure to enlarge with its caption.
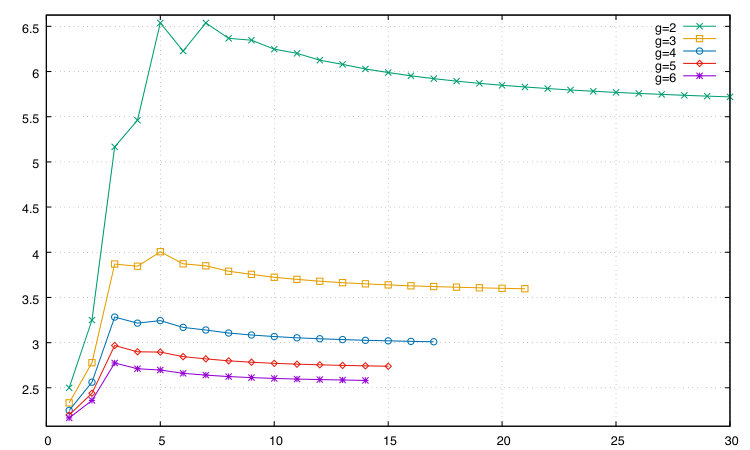 Figure 1
Figure 1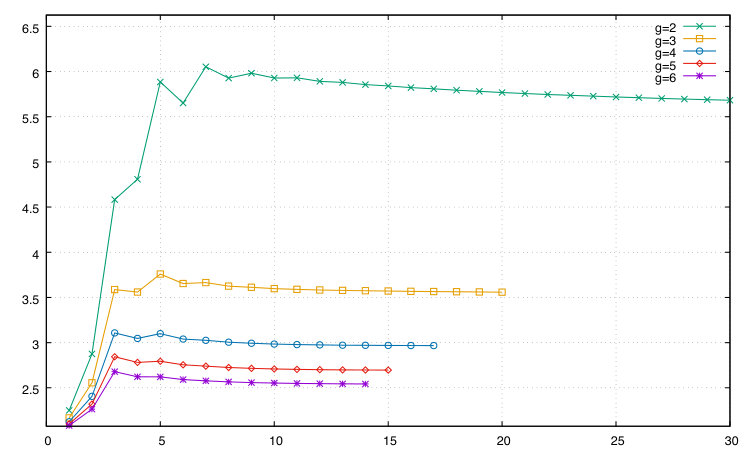 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
Topicssemigroups and automata theory · Algorithms and Data Compression · Geometric and Algebraic Topology
\headers
Listing Words in Free GroupsC. Ramsay
Listing Words in Free Groups
Colin Ramsay School of Information Technology and Electrical Engineering, The University of Queensland, Australia (). [email protected]
Abstract
Lists of equivalence classes of words under rotation or rotation plus reversal (i.e., necklaces and bracelets) have many uses, and efficient algorithms for generating these lists exist. In combinatorial group theory elements of a group are typically written as words in the generators and their inverses, and necklaces and bracelets correspond to conjugacy classes and relators respectively. We present algorithms to generate lists of freely and cyclically reduced necklaces and bracelets in free groups. Experimental evidence suggests that these algorithms are CAT – that is, they run in constant amortized time.
keywords:
necklace, bracelet, CAT algorithm, free group, reduced word, conjugacy class
{AMS}
05A05, 20E05, 20E45, 20F05
1 Introduction
Given an ordered alphabet of size , a necklace of length is the lexicographically least element of an equivalence class of -ary strings of length under rotation. A word is called a prenecklace if it is the prefix of some necklace. An aperiodic necklace is called a Lyndon word. A bracelet of length is the lexicographically least element of an equivalence class of -ary strings of length under string rotation and string reversal.
For a fixed the number of necklaces (also Lydon words, prenecklaces and bracelets) grows exponentially with the length. See, for example, [3, 13] for exact counts and bounds. So generating a complete list of the length necklaces takes exponential time, and our goal is an algorithm where the computation (the total amount of change to the data structures, not including any processing of the generated necklaces) is proportional to the number of necklaces generated. Such an algorithm is a constant amortized time, or CAT, algorithm.
In group theory, elements of a group can be represented by strings (or words) in the group’s generators and their inverses. Symbolic algebra systems such as GAP and Magma [1, 2] make sophisticated testing of large numbers of examples straightforward, and efficient algorithms for generating complete lists of words, up to some equivalence, are an important part of this. The extant enumeration algorithms do not take into account the group structure, and we demonstrate how they can be recast to address this. For necklaces this process is trivial, while for bracelets we need modify the reversal checking code materially.
The remainder of this paper is organized as follows. Section 2 gives some background material on necklaces and bracelets and on free groups and group presentations, and discusses the analogues of necklaces and bracelets in groups. Sections 3 and 4, respectively, describe our necklace and bracelet listing algorithms, and we discuss our results in Section 5. Appendix A describes the tests we performed on the running times of our algorithms.
2 Background
The first algorithm for generating necklaces, the FKM algorithm (due to Fredericksen, Kessler and Maiorana [6, 7]), was proved to be CAT in [11]. A simple recursive CAT algorithm to generate prenecklaces, necklaces and Lyndon words was given in [3], and it is this algorithm which forms the basis of our work.
Duval’s algorithm for factoring a string, of length , into Lyndon words [5] yields an algorithm for generating the necklace of the string in time. Thus a straightforward approach to generating bracelets is to generate the necklaces and to reject those where the necklace of the reversal is less than the necklace. However, this does not yield a CAT algorithm. The algorithm given in [13] is based on the recursive algorithm of [3] and maintains auxiliary data regarding the current prenecklace, using this to guide testing against its reversal and control the computation. The total amount of extra work, amortized over all bracelets, is constant, so this bracelet generating algorithm is CAT.
Given a set of symbols define the set . The set of all words on is , the free group of rank . The group operation is concatenation, is read as the inverse of , and the empty word is the identity element. Words with no substrings of the form or are called freely reduced. Two words represent the same element of if and only if they are identical after being freely reduced. (See [8, 9] for more details on combinatorial group theory.)
Let . If and are not inverses of each other, then is cyclically reduced. Given an then the word is the conjugate of by , denoted . If (resp., ) and the substring (resp., ) is canceled from then the resulting word is a rotation of by one position. If then canceling and performs a cyclic reduction step and reduces the length of by two. Repeated conjugation of a word may render it cyclically reduced or freely reduced, rotate it arbitrarily, or increase its length arbitrarily.
Conjugation partitions the words in into conjugacy classes. Given an order on , we take as class representatives the lexicographically least element of the freely and cyclically reduced words in the class. So, in the context of , listing the freely and cyclically reduced necklaces of length is equivalent to listing the conjugacy classes whose shortest words have length . A word which is both freely reduced and cyclically reduced will be called simply reduced.
Reversing a word is not meaningful in . However reversing and then replacing each of its elements by its inverse generates (i.e., freely reducing or results in the empty word). Given a set of words in , the normal closure of in is the set of all words which are concatenations of conjugates of the words in and their inverses. Groups are often described as quotient groups of free groups and is a normal subgroup of , so the quotient describes some group . (Formally, there is a homomorphism from onto with kernal , see [8, 9].)
The pair is a presentation for , written as . The elements of are the generators of . The words in are equal to the identity in and are called relators. So, in the context of , listing the reduced bracelets of length is equivalent to listing equivalence classes of possible relators of length in a presentation.
Enumerating reduced necklaces and bracelets in groups is equivalent to enumerating general necklaces and bracelets with forbidden substrings. An efficient algorithm exists to enumerate necklaces with a forbidden substring [12], however the analysis therein assumes that the substring has length at least three. For substrings of length one or two, [12] notes that “trivial algorithms can be developed”. In our case, we simply test each potential addition to the current prenecklace, and skip those which cannot yield a reduced necklace.
In the remainder of this paper, unless explicitly stated otherwise, we are always working in the free group . The number of group generators will be denoted by and the word length by (both assumed positive), with the set of possible symbols in our words having size . From [10, Theorems 1.1 & 14.2] we have the following result.
Theorem 2.1**.**
The number of reduced words of length in is equal to
[TABLE]
Let denote the Euler totient function. Then the number of reduced necklaces of length in is equal to
[TABLE]
In the general case (i.e, not in ) it is possible for a necklace and its reversal to be equal, up to rotation – consider the necklace and its reversal . However, in a reduced necklace cannot be equal to its inverse or any of its inverse’s rotations. More generally, we have the following result.
Lemma 2.2**.**
*Let be a freely reduced word of length in . Then no conjugate of equals . *
Proof 2.3**.**
Let , and write for the empty word and for .
(i) We first prove that . If then is its own inverse and so . Now put , where are freely reduced and has maximal length. Since is freely reduced, is non-empty and, by ’s maximality, there is no free reduction in . Thus is a freely reduced non-empty word, contradicting .
(ii) Now assume that , , is a proper rotation of which equals . If then free reduction of yields a word of length , so . Thus must be freely reduced, and implies that . However this is impossible (part (i), with ), so is not a proper rotation of .
*(iii) Now consider arbitrary conjugation of , followed by free reduction. If this yields a word of length , then . If not, then part (i) or (ii) applies. *
Thus the set of reduced necklaces in of length can be partitioned into pairs, where the words in a pair are inverses (up to rotation) and are not equal under rotation. So precisely one member of each pair is a bracelet, and the number of reduced bracelets of length in is .
In some applications we may only be interested in aperiodic (or prime) words, and it is trivial to modify our algorithms to generate these (see Section 5). From [4, Equation (2.2)] we have the following result.
Theorem 2.4**.**
Let denote the Möbius function. Then the number of reduced prime words of length in is equal to
[TABLE]
Thus, in there are reduced necklaces and reduced bracelets of length which are not proper powers.
For , with generator , there are only two reduced necklaces ( and ) and one reduced bracelet () for all , so we ignore this case and assume throughout that . Obviously, for and there are no reduced prime words. The algorithms we give are valid for but they are not CAT, since it takes time to set the word to or to .
3 Listing Necklaces
We first need to decide on the conventions we adopt for representing the group generators and their inverses, and how to order these symbols. Using the integers , , is straightforward and is convenient for generating and checking inverses. However, it is awkward for running through the symbols in order and checking symbol ordering, since we require a generator to precede its inverse and for to precede , etc. Accordingly, we use the integers [math], , with the usual numeric ordering, where even integers denote the generators and odd integers their inverses.
To handle inverses we introduce the two utility functions areInv() and getInv() of Algorithms 1 and 2. These, respectively, check whether or not two symbols are inverses and return the inverse of a symbol. These functions are common to both the necklace and bracelet algorithms and run in constant time. We separate out these functions for simplicity – in practice they can be compiled as inline functions or replaced by macros.
Our recursive necklace generation procedure genNeck() in Algorithm 3 is now a simple modification of [3, Algorithm 2.1], with the if statements at 9 and 13 ensuring that the prenecklaces remain freely reduced and that the final necklaces are cyclically reduced. For clarity we do not use the guard value of [3] and instead use the wrapper code of Algorithm 4. This explicitly sets (recording its inverse in to facilitate cyclic reduction checking) and ensures that the prenecklaces at entry to genNeck() are non-empty.
4 Listing Bracelets
Our bracelet algorithm is inspired by that in [13], with reversal of a prenecklace being replaced by word inversion (i.e., reversal and element-to-inverse mapping). The recursive bracelet generation procedure genBrace() and its wrapper code are given in Algorithms 5 and 6, while Algorithm 7 is the checkInv() function for comparing a prenecklace with its inverse. The genBrace() procedure is an augmented version of genNeck(), with the additional code checking each prenecklace (i.e., the putative “prebracelets”) against its inverse and rejecting those that cannot yield bracelets. Thus each rotation of the inverse of the final words is tested, and necklaces which are not bracelets are not generated.
The use of inverses as opposed to reversals actually results in a somewhat simpler algorithm compared with that in [13]. Firstly, note that our order is chosen so that a generator immediately precedes its inverse. This implies that bracelets cannot start with a generator inverse and so these can be skipped in the wrapper code. Secondly, although the checkInv() function can return “equal” as well as “less than” or “greater than” (as does the CheckRev() function in [13]), by Lemma 2.2 it never does so since our preneckaces are always freely reduced. This simplifies the code in the genBrace() procedure, which needs only four parameters compared with the six of GenBracelets() in [13].
The and arguments of genBrace() are, respectively, the index of the next position in the array and the length of the longest prefix of that is a Lyndon word. The and arguments are, respectively, the number of copies of at the start of and the number of copies of at the end of , with the initial value of saved in the local variable . The code at 9 to 14 and 22 and 25 adjusts and as necessary for the next call to genBrace() (if any), using the current value of (i.e., the next potential value for ) and the current word length .
The recursive calls to genBrace() are inside the if-statements of 17 to 20 and 27 to 30. If then the current prenecklace is less than its inverse, so we can immediately call genBrace(). If then the inverse is less than the prenecklace, the prenecklace cannot yield a bracelet, so we do nothing. If then we need to call the checkInv() function to compare the prenecklace with its inverse. If the prenecklace is less we call genBrace(), otherwise we do nothing.
When the checkInv() function is called, the current prenecklace starts with copies of and ends with copies of . The remainder, , is non-empty, does not start with or end with , and is freely reduced. The arguments and are the current prenecklace length and the index of the start of . The for-loop compares with its inverse, returning if (and thus the prenecklace) precedes its inverse and if precedes . The upper limit on the for-loop is simply a convenient placeholder – the loop is guaranteed to return or for some .
5 Concluding Remarks
We have implemented our algorithms in the C and Magma languages and incorporated them into programs for generating and testing lists of conjugacy classes and presentations. The generation of word lists has proved very fast, with the programs’ running times being dominated by the times to process the necklaces and bracelets in the lists. Empirical evidence (see Appendix A) suggests that our algorithms are CAT, but we have no proof of this.
The genNeck() and genBrace() procedures as given process all reduced necklaces and bracelets. If the “” tests are replaced by “” then only the reduced aperiodic necklaces (Lyndon words) and bracelets are processed by these procedures.
The recursive nature of our necklace and bracelet algorithms induces a tree structure on their search spaces. These trees can easily be split into subtrees, allowing an enumeration to be parallelised [3] or distributed across a set of heterogeneous machines.
Appendix A Complexity Tests
Implementations of our necklace and bracelet listing algorithms for reduced words in groups have proved very effective. However we have no proof that they run in constant amortized time. Accordingly, in a similar manner to [14, §5 & §6.2.5], we produced experimental results for the amount of work done compared with the number of necklaces or bracelets generated. For these tests the “process … ” actions in genNeck() and genBrace() were replaced by code to accumulate the total number of necklaces and of bracelets. These counts were checked against the expected counts from Section 2 and used to calculate the work per necklace and per bracelet data.
The areInv() and getInv() functions are used by both algorithms and are constant time. Each algorithm starts with a for-loop, each iteration of which makes a call to genNeck() or to genBrace(). For necklaces we count the total number of calls, both direct and recursive, to genNeck(). Apart from its embedded for-loop, each call to genNeck() is constant time. So our measure of the amount of work done is the total number of calls to genNeck() plus the total number of iterations of the embedded for-loop across all calls to genNeck(). Figure 1 plots, for various values of the number of group generators , the word length against the ratio of total work to number of necklaces.
For bracelets we count the total number of calls to genBrace() and the total number of iterations of its embedded for-loop. We also need to account for the checkInv() function, which is not constant time. This function is only called if and (in genBrace()) are equal, so at least one iteration of checkInv()’s embedded for-loop is guaranteed for each call. Thus, we count the total number of iterations of this loop across all calls to checkInv() and add this to our total. Figure 2 plots, for various values of the number of group generators , the word length against the ratio of total work to number of bracelets.
For both necklaces and bracelets, for all , the ratio of the total amount of work done to the number of reduced words generated is decreasing (after an initial peak) as the word length increases. This strongly suggests that the algorithms are CAT.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] GAP – Groups, Algorithms, and Programming, Version 4.8.7 , 2017, http://www.gap-system.org .
- 2[2] W. Bosma, J. Cannon, and C. Playoust , The Magma algebra system, I: The user language , J. Symbolic Comput., 24 (1997), pp. 235–265.
- 3[3] K. Cattell, F. Ruskey, J. Sawada, M. Serra, and C. R. Miers , Fast algorithms to generate necklaces, unlabeled necklaces, and irreducible polynomials over GF(2) , J. Algorithms, 37 (2000), pp. 267–282.
- 4[4] M. Coornaert , Asymptotic growth of conjugacy classes in finitely-generated free groups , Internat. J. Algebra Comput., 15 (2005), pp. 887–892.
- 5[5] J. P. Duval , Factorizing words over an ordered alphabet , J. Algorithms, 4 (1983), pp. 363–381.
- 6[6] H. Fredericksen and I. J. Kessler , An algorithm for generating necklaces of beads in two colors , Discrete Math., 61 (1986), pp. 181–188.
- 7[7] H. Fredericksen and J. Maiorana , Necklaces of beads in k 𝑘 k colors and k 𝑘 k -ary de Bruijn sequences , Discrete Math., 23 (1978), pp. 207–210.
- 8[8] R. C. Lyndon and P. E. Schup , Combinatorial Group Theory , Springer-Verlag, 1977.