Inactivation Decoding of LT and Raptor Codes: Analysis and Code Design
Francisco L\'azaro, Gianluigi Liva, Gerhard Bauch

TL;DR
This paper provides a detailed analysis of inactivation decoding for LT and Raptor codes, introducing a first order analysis to predict inactivation counts and enabling optimized code design for better complexity-failure trade-offs.
Contribution
It introduces a novel first order analytical framework for inactivation decoding, allowing precise control over decoding complexity and failure probability in LT and Raptor codes.
Findings
Analytical expressions for expected inactivations
Distribution of inactivation counts derived
Numerical simulations confirm accuracy
Abstract
In this paper we analyze LT and Raptor codes under inactivation decoding. A first order analysis is introduced, which provides the expected number of inactivations for an LT code, as a function of the output distribution, the number of input symbols and the decoding overhead. The analysis is then extended to the calculation of the distribution of the number of inactivations. In both cases, random inactivation is assumed. The developed analytical tools are then exploited to design LT and Raptor codes, enabling a tight control on the decoding complexity vs. failure probability trade-off. The accuracy of the approach is confirmed by numerical simulations.
Click any figure to enlarge with its caption.
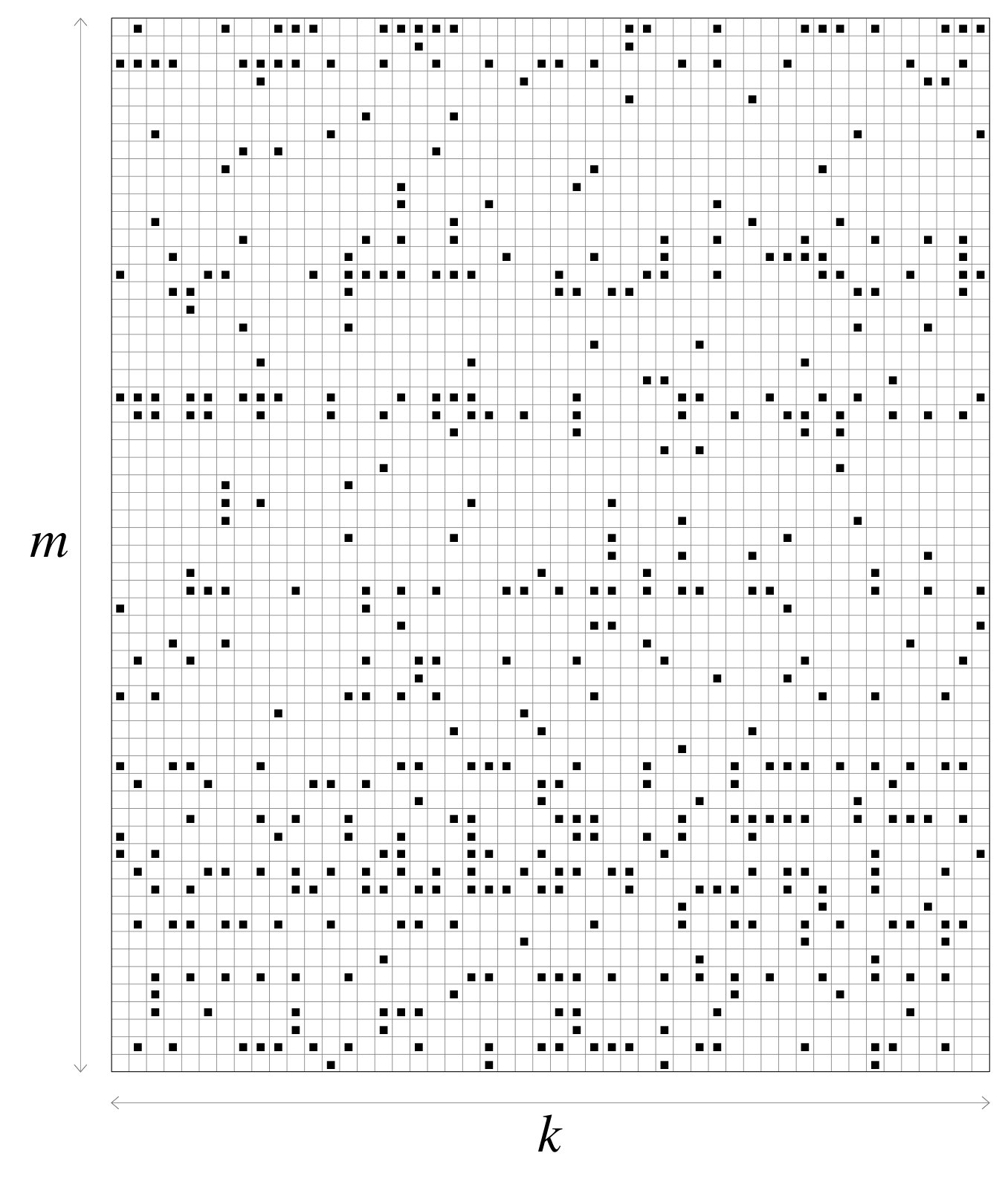 Figure 1
Figure 1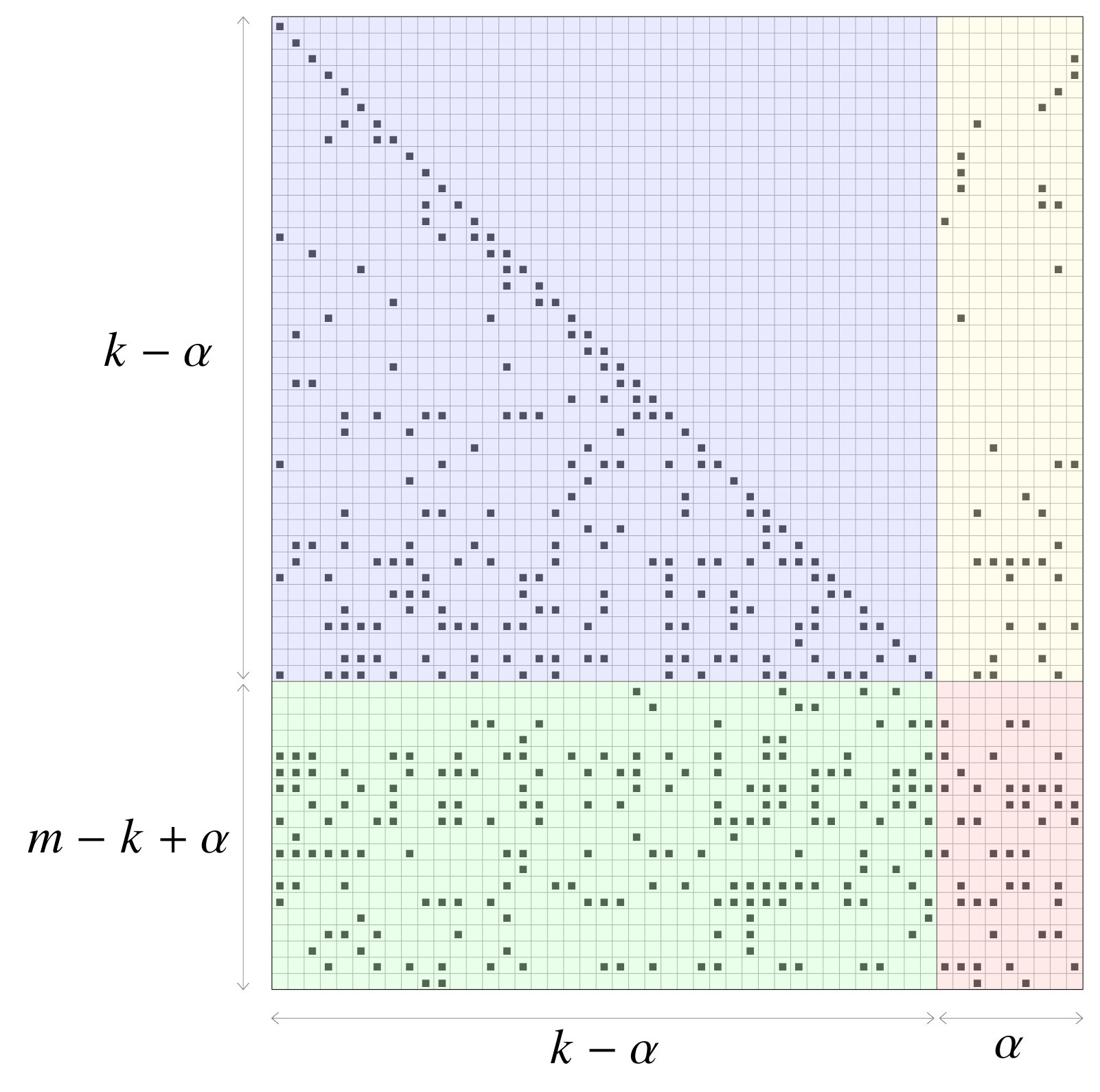 Figure 2
Figure 2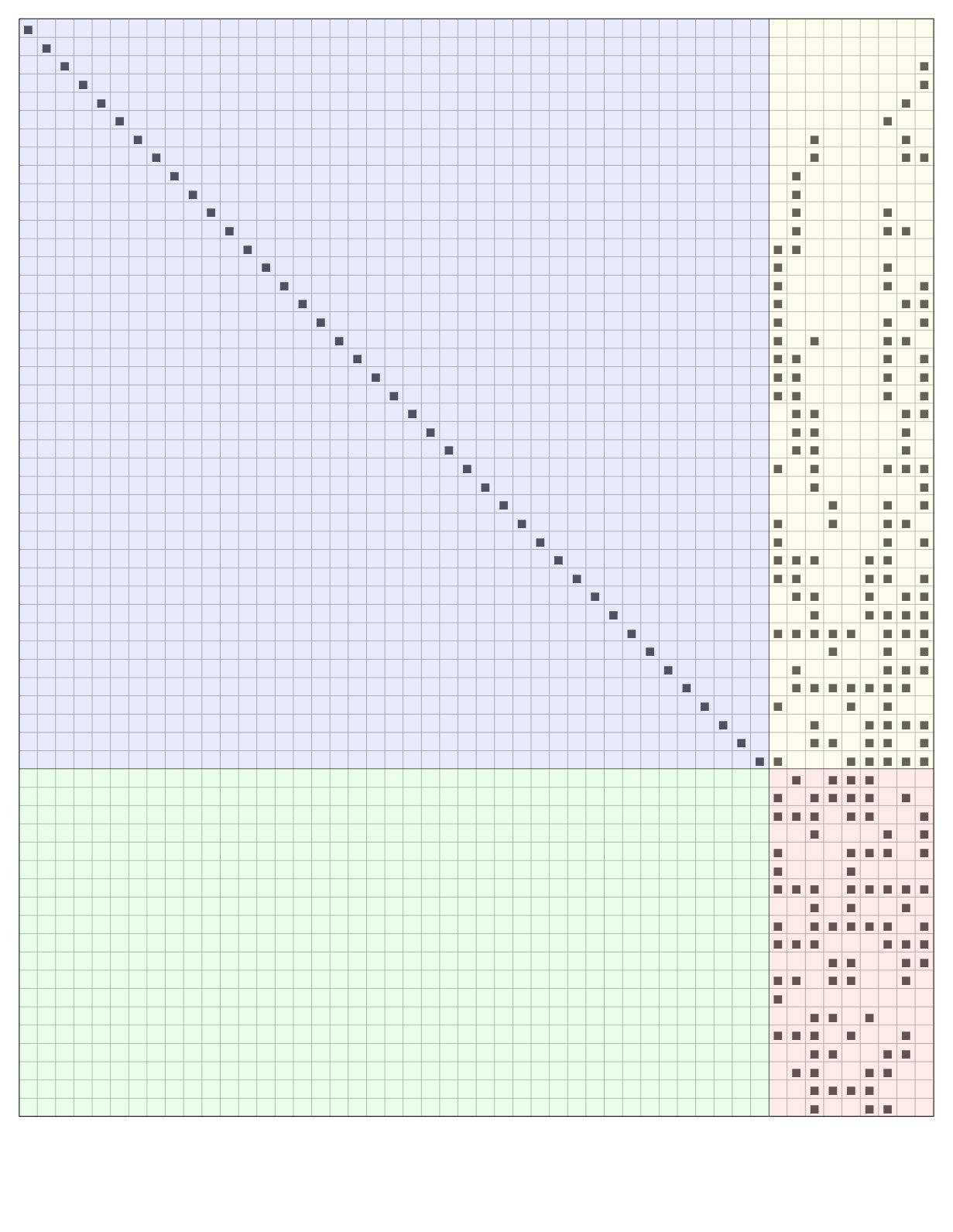 Figure 2
Figure 2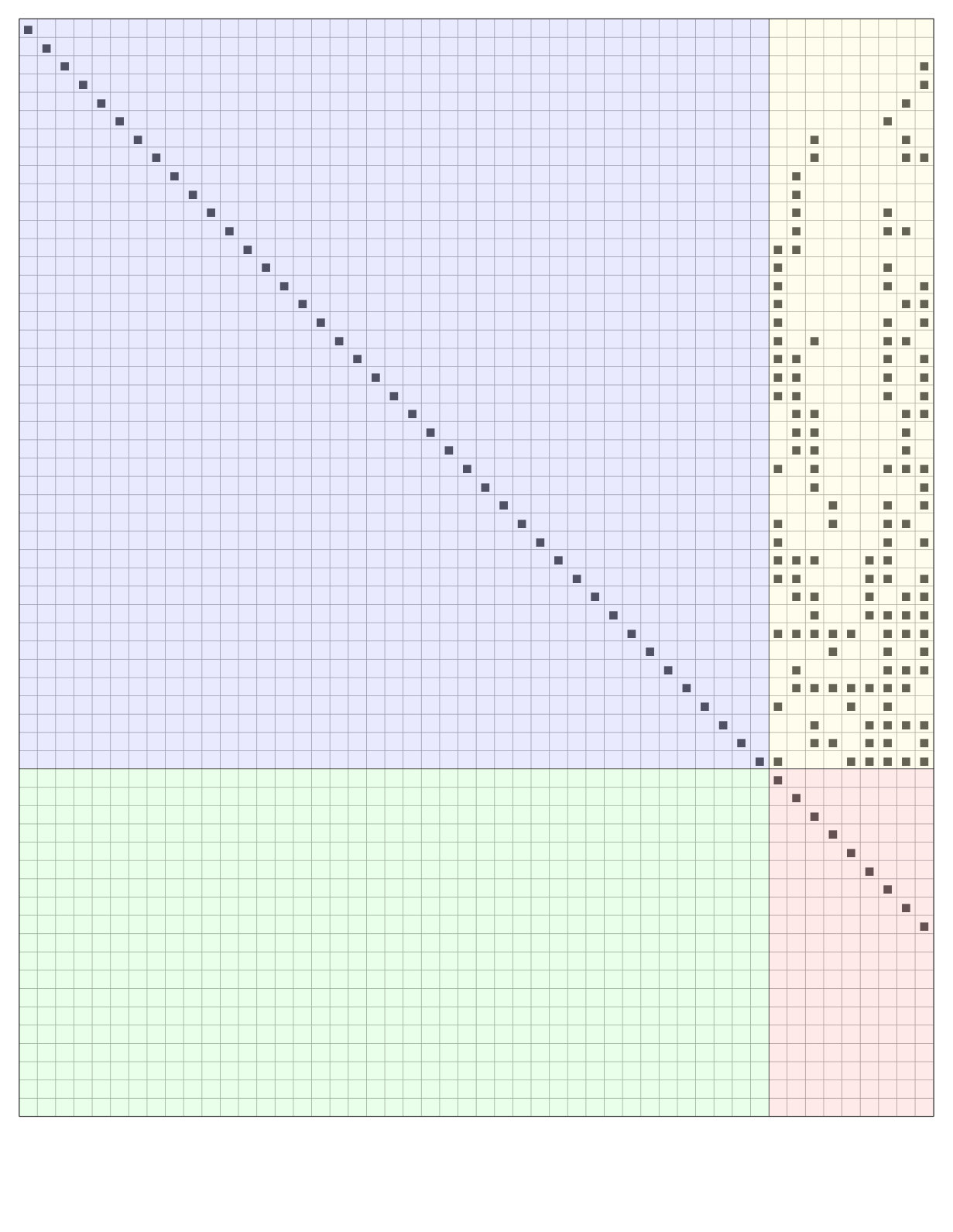 Figure 2
Figure 2 Figure 2
Figure 2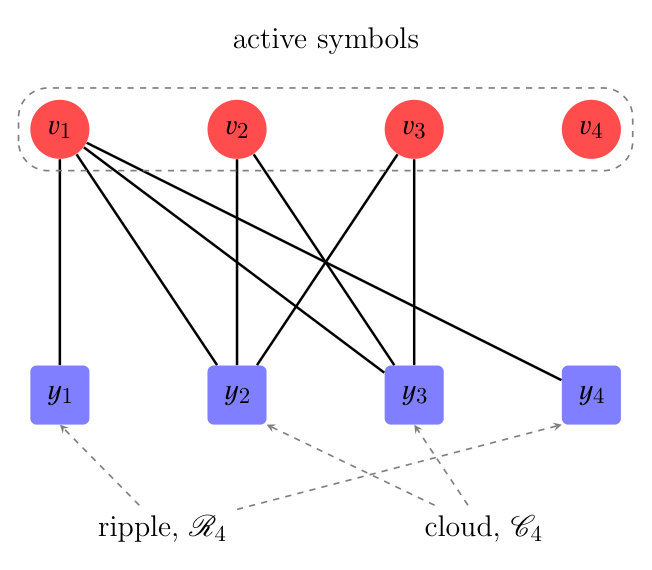 Figure 3
Figure 3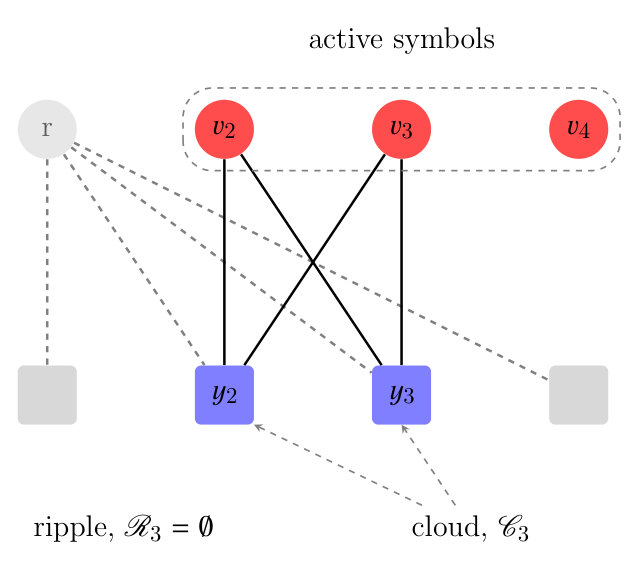 Figure 3
Figure 3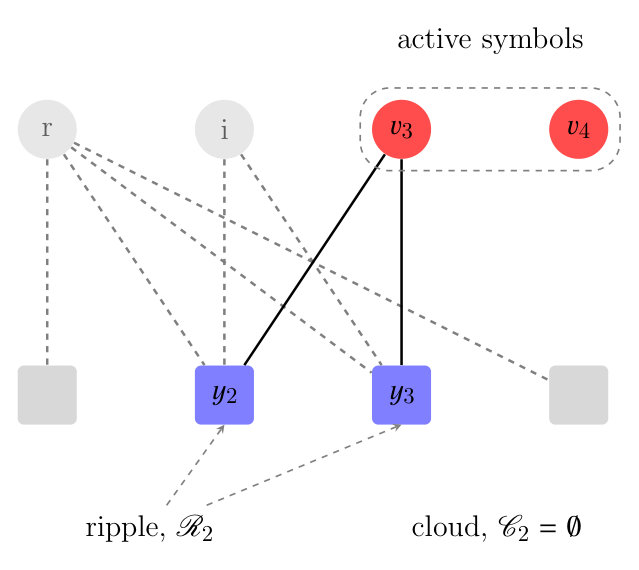 Figure 3
Figure 3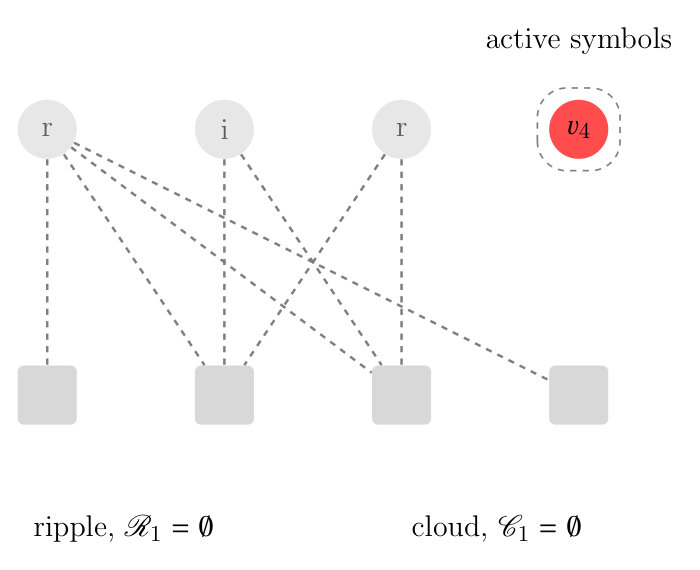 Figure 3
Figure 3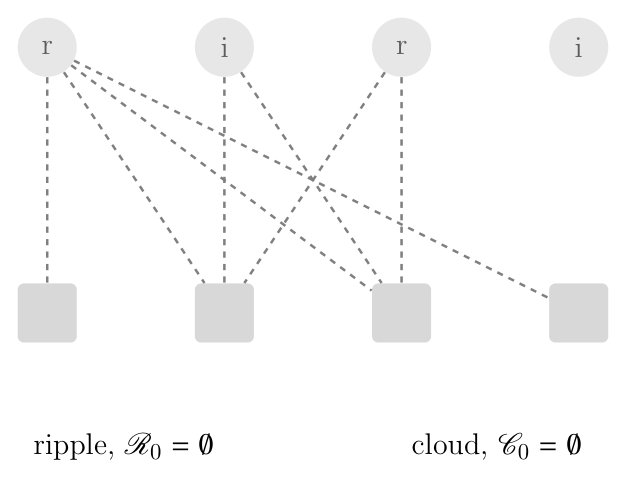 Figure 3
Figure 3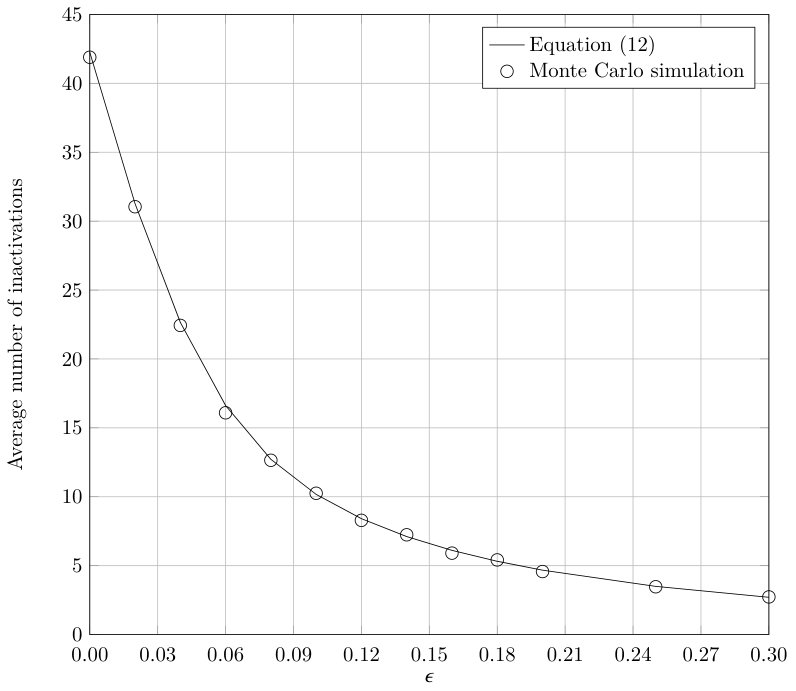 Figure 4
Figure 4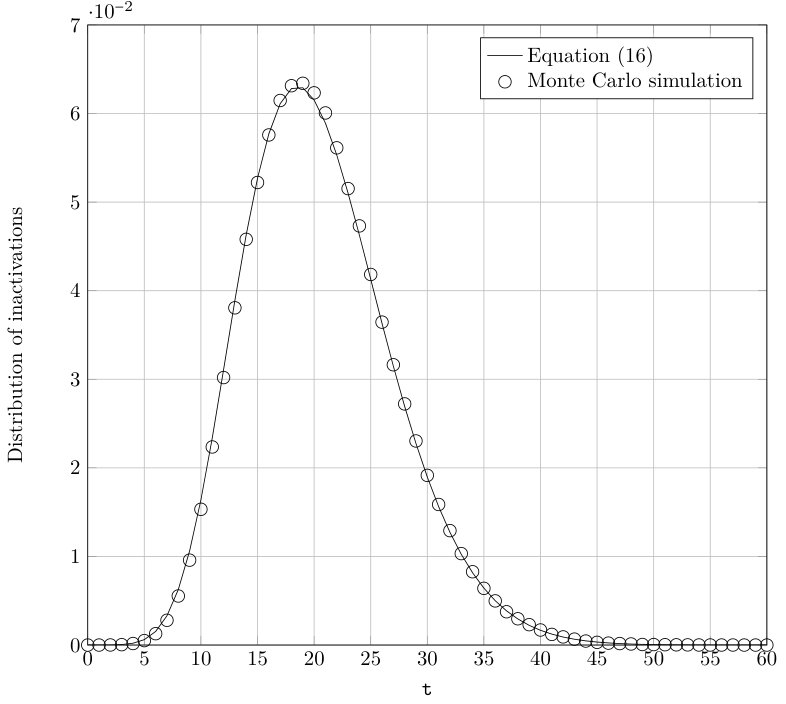 Figure 5
Figure 5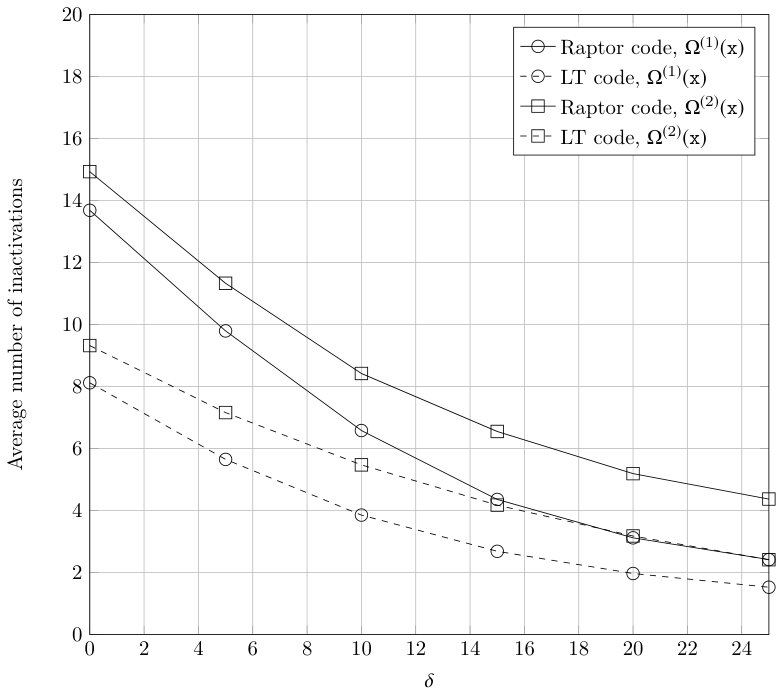 Figure 6
Figure 6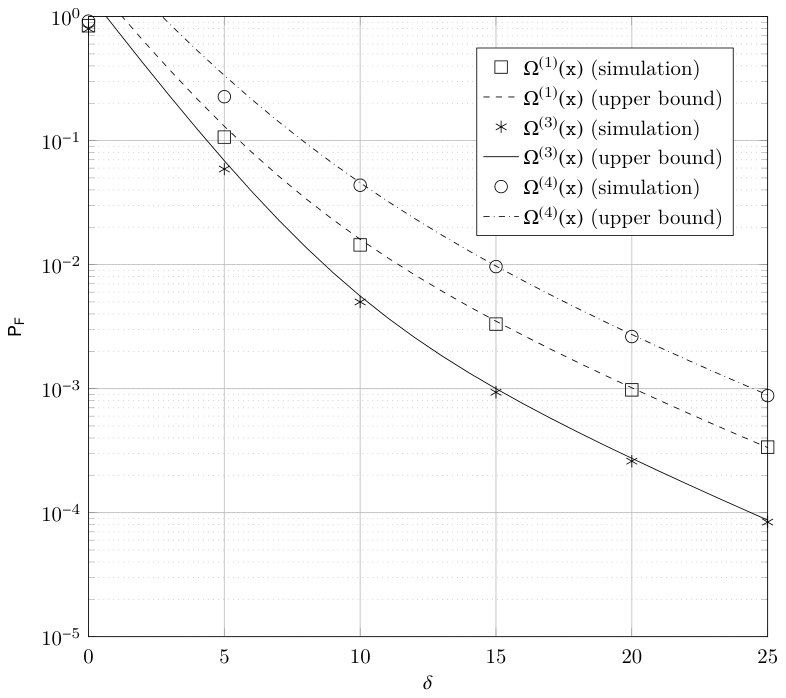 Figure 7
Figure 7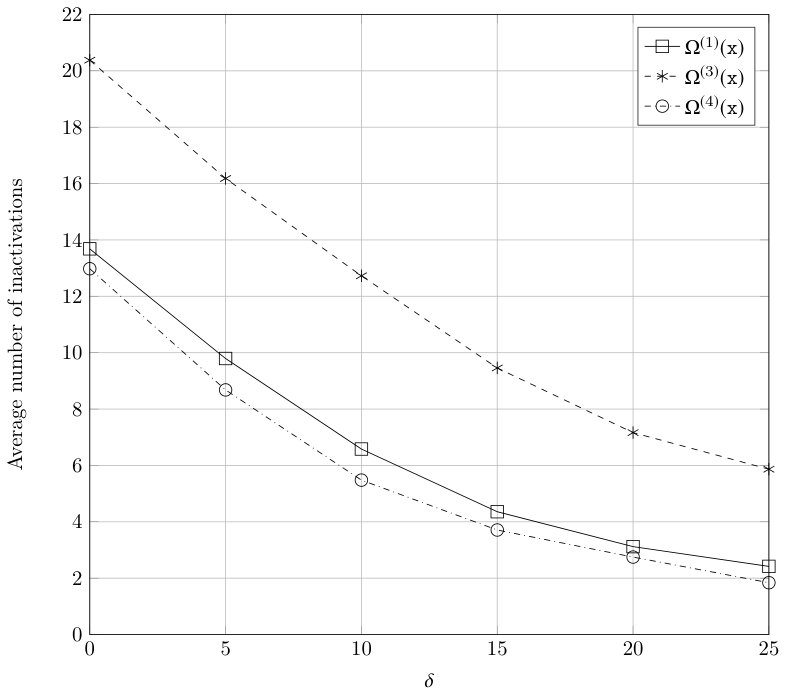 Figure 8
Figure 8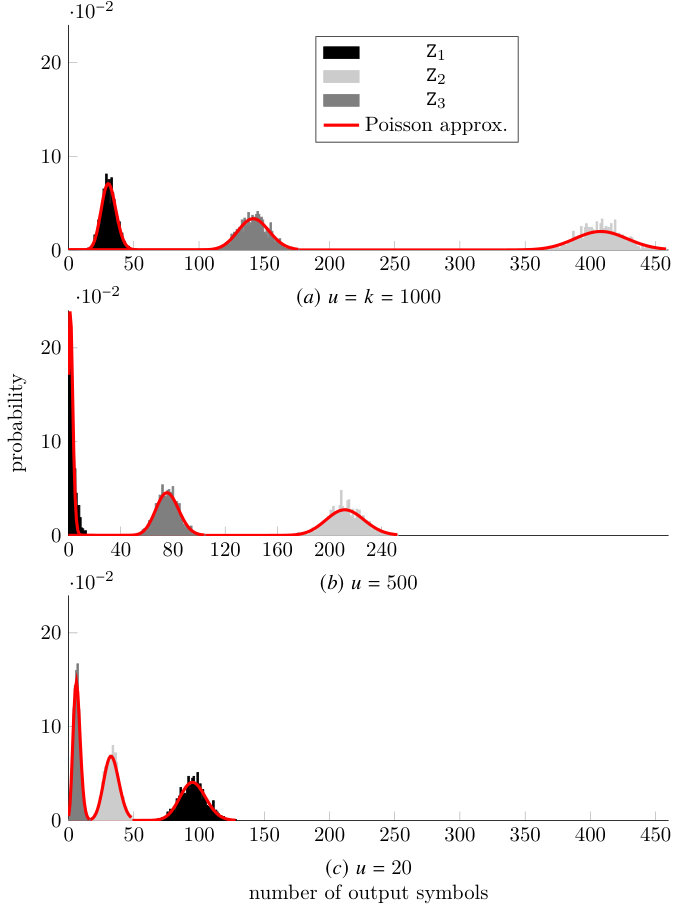 Figure 9
Figure 9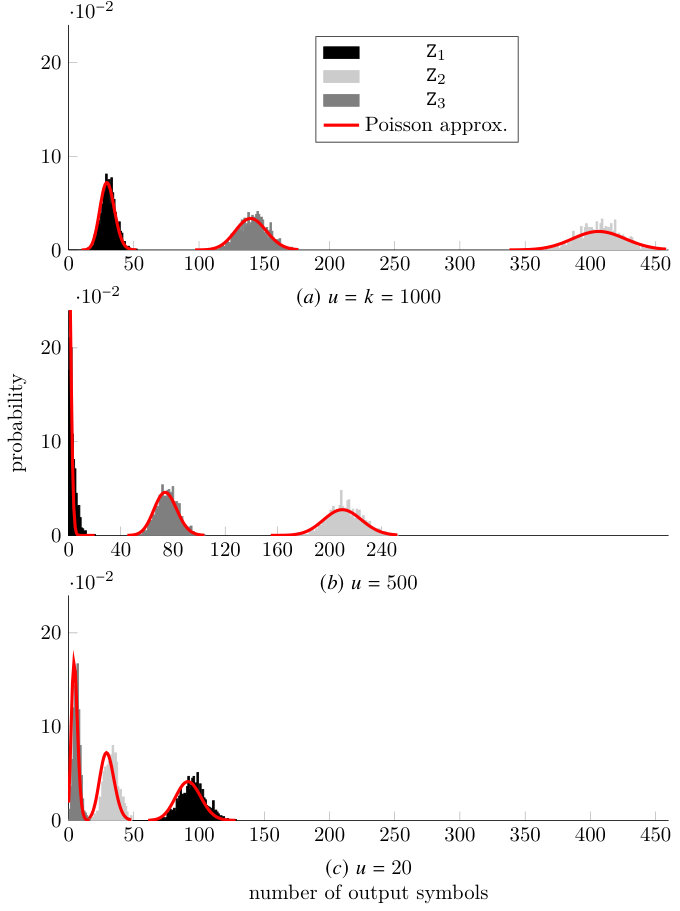 Figure 10
Figure 10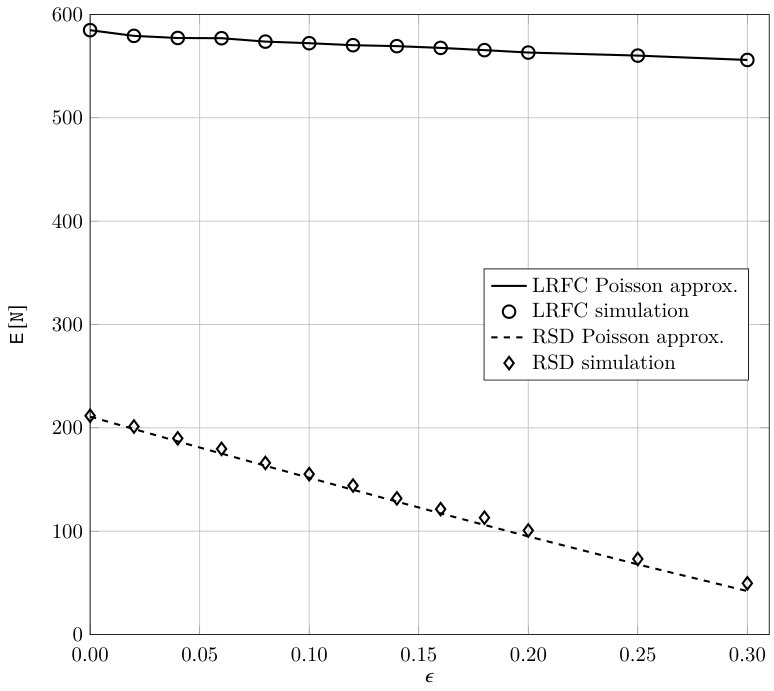 Figure 11
Figure 11Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
ARQ automatic retransmission query AWGN additive white Gaussian noise BCH Bose Chaudhuri Hocquenghem BEC binary erasure channel BSC binary symmetric channel BP belief propagation CER codeword error rate C-OWEF conditional output-weight enumerator function CRC cyclic redundancy check FEC forward error correction GE Gaussian elimination GRS generalized Reed-Solomon HDPC high-density parity-check ID inactivation Decoding i.i.d. independent and identically distributed IOWE input output weight enumerator MDS maximum distance separable ML maximum likelihood MWI maximum weight inactivation LDGM low-density generator matrix LDPC low-density parity-check LRFC linear random fountain code LT Luby transform PMF probability mass function QEC
-ary erasure channel RI random inactivation RS Reed-Solomon RSD robust soliton distribution SA simulated annealing SPC single parity-check TCP Transmission Control Protocol WE weight-enumerator WEF weight-enumerator function
Inactivation Decoding of LT and Raptor Codes: Analysis and Code Design
Francisco Lázaro, , Gianluigi Liva, ,
Gerhard Bauch Francisco Lázaro and Gianluigi Liva are with the Institute of Communications and Navigation of the German Aerospace Center (DLR), Muenchner Strasse 20, 82234 Wessling, Germany. Email:{Francisco.LazaroBlasco, Gianluigi.Liva}@dlr.de.Gerhard Bauch is with the Institute for Telecommunication, Hamburg University of Technology, Hamburg, Germany. E-mail: [email protected] Address: Francisco Lázaro, KN-SAN, DLR, Muenchner Strasse 20, 82234 Wessling, Germany. Tel: +49-8153 28-3211, Fax: +49-8153 28-2844, E-mail: [email protected] work has been presented in part at the 54th Annual Allerton Conference on Communication, Control, and Computing, Monticello, Illinois, USA, September 2015 [1], and at the 2014 IEEE Information Theory Workshop, Hobart, Tasmania, November 2014 [2]. This work has been accepted for publication in IEEE Transactions on Communications, DOI: 10.1109/TCOMM.2017.2715805 ©2017 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting /republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Abstract
In this paper we analyze LT and Raptor codes under inactivation decoding. A first order analysis is introduced, which provides the expected number of inactivations for an LT code, as a function of the output distribution, the number of input symbols and the decoding overhead. The analysis is then extended to the calculation of the distribution of the number of inactivations. In both cases, random inactivation is assumed. The developed analytical tools are then exploited to design LT and Raptor codes, enabling a tight control on the decoding complexity vs. failure probability trade-off. The accuracy of the approach is confirmed by numerical simulations.
Index Terms:
Fountain codes, LT codes, Raptor codes, erasure correction, maximum likelihood decoding, inactivation decoding.
I Introduction
Fountain codes [3, 4] provide an efficient solution for data delivery to large user populations over broadcast channels. The result is attained by encoding the data object (e.g., a file) through an linear code, where the number of output (i.e., encoded) symbols can grow indefinitely, enabling a simple rate adaptation to the channel conditions. Due to this, fountain codes are often regarded as rateless codes. Fountain codes were originally conceived for transmission over erasure channels. In practice, different users experience a different channel quality resulting in a different erasure probability. When an efficient fountain code is employed, after a user has received output symbols, with small, the original input symbols can be recovered with high probability.
Luby transform (LT) codes were introduced in [5] as a first example of practical fountain codes. In [5] an iterative erasure decoding algorithm was introduced that performs remarkably well when the number of input symbols is large. Raptor codes [6, 7, 8] address some of the shortcomings of LT codes. A Raptor code is a serial concatenation of an outer linear block code with an inner LT code.
Most of the literature on LT and Raptor codes considers iterative decoding (see e.g. [9, 10, 11, 12, 13, 14, 15]). In [9, 16, 14] LT codes under iterative decoding were analyzed using a dynamic programming approach. This analysis models the iterative decoder as a finite state machine and it can be used to derive the probability of decoding failure of LT codes under iterative decoding. Iterative decoding is particularly effective for large input block sizes, with at least in the order of several tens of thousands symbols [8]. However, in practice, moderate and small values of are often used, due to memory limitations at the receiver side, or due to the fact that the piece of data to be transmitted is small. For example, the recommended value of for the Raptor codes standardized in [17] is between and symbols. In this regime, iterative decoding of LT and Raptor codes turns to be largely sub-optimum. In actual implementations, different decoding algorithms are used. In particular, an efficient maximum likelihood (ML) decoding algorithm usually referred to as inactivation decoding [18, 19] is frequently employed.
Inactivation decoding belongs to a large class of Gaussian elimination algorithms tailored to the solution of large sparse linear systems [20, 21, 22, 23, 24, 25]. The algorithm can be seen as an extension of iterative decoding, where whenever the iterative decoding process stops, a variable (input symbol) is declared as inactive (i.e., removed from the equation system) and iterative decoding is resumed. At the end of the process, the inactive variables have to be solved using Gaussian elimination. If a unique solution is found, it is possible to recover all the remaining input symbols by back-substitution (i.e., using iterative decoding). A few works addressed the performance of LT and Raptor codes under inactivation decoding. The decoding failure probability of several types of LT codes was thoroughly analyzed via tight lower and upper bounds in [26, 27, 28, 29]. In [30] the distance spectrum of fixed-rate Raptor codes is characterized, which enables the evaluation of their performance under ML erasure decoding (e.g., via upper union bounds [31, 32]). Upper bounds on the failure probability for binary and non-binary Raptor codes are introduced in [33]. However, none of these works addressed inactivation decoding from a complexity viewpoint. In fact, the complexity of inactivation decoding grows with the third power of the number of inactivations [24]. It is hence of large practical interest to develop a code design which leads (on average) to a small number of inactivations.
In [25], inactivation decoding of low-density parity-check (LDPC) codes was analyzed, providing a reliable estimate of the expected number of inactivations. The approach of [25] relies on bridging the inactivation decoder with the Maxwell decoder of [34]. By establishing an equivalence between inactive and guessed variables, it was shown how to exploit the Area Theorem [35] to derive the average number of inactivations. Though, the approach of [25] cannot be extended to LT and Raptor codes due to their rateless nature. In [36] the authors proposed a new degree distribution design criterion to design the LT component of Raptor codes assuming inactivation decoding. However, when this criterion is employed there is not a direct control on the average output degree. In [37], the authors present a finite length analysis of batched sparse codes under inactivation decoding that provides the expected number of inactivations needed for decoding.
In this paper we provide a thorough analysis of LT and Raptor codes under inactivation decoding. A first order analysis is introduced, which allows estimating the expected number of inactivations for an LT code, as a function of the output distribution, the number of input symbols and the decoding overhead. The analysis is then extended to the calculation of the distribution of the number of inactivations. In both cases, random inactivation is assumed. The developed analytical tools are then exploited to design LT and Raptor codes, enabling a tight control on the decoding complexity vs. failure probability trade-off. The work presented in this paper is an extension of the work in [1]. In particular, the different proofs in [1] have been modified and extended. Furthermore, in this work we not only consider LT codes but also a class of Raptor Codes. An analysis based on a Poisson assumption approximation is presented in the Appendix111In the Appendix we provide a simplified analysis, which, though related to the one in [2], is fully developed here on the basis of the analysis provided in Section IV of this paper. The simplified analysis is based on a Poisson approximation, which is analyzed in depth in the Appendix, discussing its limitations and comparing the analytical results with Monte Carlo simulations..
The rest of the paper is structured as follows. In Section II we present the system model considered in this paper. Section III contains a detailed description of inactivation decoding applied to LT codes. In Section IV we focus on the analysis of LT codes under inactivation decoding. Section V shows how to exploit the analysis of the LT component of a Raptor code to estimate the number of inactivations for the Raptor code. A Raptor code design methodology is presented too. The conclusions are presented in Section VI.
II Preliminaries
Let be the input symbols, out of which the LT encoder generates the output symbols , where can grown indefinitely. Each output symbol is generated by first sampling a degree from an output degree distribution , where is the maximum output degree. In the following, we will make use of a polynomial representation of the degree distribution in the form
[TABLE]
where is a dummy variable. Then, distinct input symbols are selected uniformly at random and their x-or is computed to generate the output symbol. The relation between output and input symbols can be expressed as
[TABLE]
where is the generator matrix of the LT code.
The output symbols are transmitted over a binary erasure channel (BEC) at the output of which the receiver collects output symbols, where is referred to as absolute receiver overhead. Similarly, the relative receiver overhead is defined as . Denoting by the received output symbols and by the set of indices corresponding to the non-erased symbols, we have
[TABLE]
This allows us to express the dependence of the received output symbols on the input symbols as
[TABLE]
with given by the columns of with indices in . ML erasure decoding requires the solution of (1). Note that decoding is successful (i.e., the unique solution can be found) if and only if .
III Inactivation Decoding of LT Codes
Inactivation decoding is an efficient ML erasure decoding algorithm, which can be used to solve the system of equations in (1). We will illustrate inactivation decoding by means of an example and with the aid of Figures 1 and 2. In the example, we fix and . The structure of is given in Figure 1 (in the figure, dark squares represent the non-zero elements of ). Inactivation decoding consists of steps.
Step 1** (Triangulation).**
Initially, is put in an approximate lower triangular form by means of column and row permutations only. Given that no operation is performed on the rows or columns of , the density of is preserved. At the end of triangulation process, can be partitioned in four submatrices as
[TABLE]
and as depicted in Figure 2a. In the upper left part we have the lower triangular matrix . The matrix under submatrix is denoted by and it has dimension . The upper right part is given by the submatrix , while the lower right submatrix is denoted by and it has dimension . The rightmost columns of (corresponding to matrices and ) are usually referred to as inactive columns. Note that the manipulation of is typically performed through inactivation or pivoting algorithms (see e.g. [24, 38]), which aim at reducing the number of inactive columns. In the rest of this work, we will assume that the use of the random inactivation algorithm [38], as it will be detailed later in the section.
Step 2** (Zero matrix procedure).**
Matrix is put in a diagonal form and matrix is zeroed out by means of row sums. As a result, on average the density of the matrices and increases (Figure 2b).
Step 3** (Gaussian elimination).**
Gaussian elimination (GE) is applied to solve the system of equations associated with . Being in general dense, the complexity of this step is cubic in the number of inactive columns . As observed in [24], this step drives, for large equation systems, the complexity of inactivation decoding. After performing GE, matrix has the structure shown in Figure 2c.
Step 4** (Back substitution).**
If Step 3 succeeds, after determining the value of the inactive variables (i.e., of the input symbols associated with the inactive columns), back-substitution is applied to compute the values of the remaining variables in . This is equivalent to setting to zero all elements of matrix in Figure 2c. At the end shows a diagonal structure as shown in Figure 2d, and all input symbols are recovered.
Recalling that a unique solution to the system of equations exists if and only if is full rank, we have that decoding succeeds if and only if the rank of at Step 3 equals the number of inactive variables.
Given that the number of inactive variables is determined by the triangulation step, and that the GE on dominates the decoding complexity for large , a first analysis of inactivation decoding can be addressed by focusing on the triangulation procedure.
III-A Bipartite Graph Representation of Inactivation Decoding
We introduce next a bipartite graph representation of the LT code from the receiver perspective. The graph comprises nodes, divided in two sets. The first set consists of input symbol nodes, one per input symbol, while the second set consists of output symbol nodes, one per received output symbol. We denote the set of input symbol nodes as , and the input symbol nodes in as . Similarly, we denote the set of output symbol nodes as with output symbol nodes denoted by . Here, we purposely referred to input and output symbol nodes with the same notation used for their respective input and output symbols to emphasize the correspondence between the two sets of nodes and the sets of input and received output symbols. For simplicity, in the following we will refer to input (output) symbol nodes and to input (output) symbols interchangeably. An input symbol node is connected by an edge to an output symbol node if and only if the corresponding input symbol contributes to the generation of the corresponding output symbol, i.e., if and only if the element of is equal to . We denote by (or ) the degree of a node (or ), i.e., the number of its adjacent edges.
Triangulation can be modelled as an iterative pruning of the bipartite graph of the LT code. At each iteration, a reduced graph is obtained, which corresponds to a sub-graph of the original LT code graph. The sub-graph involves only a subset of the original input symbols, and their neighboring output symbols. The input symbols in the reduced graph will be referred to as active input symbols. We shall use the term reduced degree of a node to refer to the degree of a node in the reduced graph. Obviously, the reduced degree of a node is less than or equal to its original degree. We denote by (or ) the reduced degree of a node (or ). Let us now introduce some additional definitions that will be used to model the triangulation step.
Definition 1** (Ripple).**
We define the ripple as the set of output symbols of reduced degree 1 and we denote it by .
The cardinality of the ripple is denoted by and the corresponding random variable as .
Definition 2** (Cloud).**
We define the cloud as the set of output symbols of reduced degree and we denote it by .
The cardinality of the cloud is denoted by and the corresponding random variable as .
Initially, all input symbols are marked as active, i.e., the reduced sub-graph coincides with the original graph. At every step of the process, one active input symbol is marked as either resolvable or inactive and leaves the graph. After steps no active symbols are present and triangulation ends. In order to keep track of the steps of the triangulation procedure, the temporal dimension will be added through the subscript . This subscript corresponds to the number of active input symbols in the graph. Given the fact that the number of active input symbols decreases by at each step, triangulation will start with active input symbols and it will end after steps with . Therefore, the subscript decreases as the triangulation procedure progresses. Triangulation with random inactivations works as follows. Consider the transition from to active input symbols. Then,
- •
If the ripple is not empty , the decoder selects an output symbol uniformly at random. The only neighbor of is marked as resolvable and leaves the reduced graph, while all edges attached to it are removed.
- •
If the ripple is empty , one of the active input symbols is chosen uniformly at random222This is certainly neither the only possible inactivation strategy nor the one leading to the least number or inactivations. However, this strategy makes the analysis tractable. For an overview of the different inactivation strategies we refer the reader to [38]. and it is marked as inactive, leaving the reduced graph. All edges attached to are removed.
The input symbols marked as inactive are recovered using Gaussian elimination (step 3). After recovering the inactive input symbols, the remaining input symbols, those marked as resolvable, can be recovered by iterative decoding (back substitution in step 4).
Example 1**.**
We provide an example for an LT code with input symbols and output symbols (Figure 3).
- i.
Transition from to . Initially, there are two output symbols in the ripple () (Figure 3a). Thus, one of the input symbols in the ripple is randomly selected and marked as resolvable. In this case symbol is selected and all its adjacent edges are removed. The graph obtained after the transition is shown in Figure 3b. Observe that the nodes and have left the graph since their reduced degree is now zero. 2. ii.
Transition from to . As shown in Figure 3b the ripple is now empty (). Thus, an inactivation has to take place. Node is chosen (according to a random selection) and is marked as inactive. All edges attached to are removed from the graph. As a consequence, the nodes and that were in the cloud enter the ripple (i.e., their reduced degree is now ), as shown in Figure 3c. 3. iii.
Transition from to . Now the ripple is not empty (). The input symbol is selected (again, according to a random choice) from the ripple and is marked as resolvable. All its adjacent edges are removed. The nodes and leave the graph because their reduced degree becomes zero (see Figure 3d). 4. iv.
Transition from to . The ripple is now empty (Figure 3d). Hence, an inactivation takes place: node is marked as inactive and the triangulation procedure ends.
Note that in this example input symbol has no neighbors, i.e., the matrix is not full rank and decoding fails.
IV Analysis under Random Inactivation
In this section we analyze the triangulation procedure with the objective of determining the average number of inactivations, i.e., the expected number of inactive input symbols at the end of the triangulation process. We will then extend the analysis to obtain the probability distribution of the number of inactivations.
IV-A Average Number of Inactivations
Following [9, 16, 14], we model the decoder as a finite state machine with state at time given by the cloud and the ripple sizes at time , i.e.
[TABLE]
We aim at deriving a recursion for the decoder state, that is, to obtain as a function of . We do so by analyzing how the ripple and cloud change in the transition from to . In the transition exactly one active input symbol is marked as either resolvable or inactive and all its adjacent edges are removed. Whenever edges are removed from the graph, the reduced degree of one or more output symbols decreases. Consequently, some of symbols in the cloud may enter the ripple and some of the symbols in the ripple may become of reduced degree zero and leave the graph.
We focus first on the symbols that leave the cloud and enter the ripple during the transition at step , conditioned on . Since for an LT code the neighbors of the output symbols are selected independently and uniformly at random, in the transition each output symbol may leave the cloud and enter the ripple independently from the other output symbols. Hence, the number of symbols leaving and entering is binomially distributed with parameters and with
[TABLE]
where random variable represents a randomly chosen output symbol.
We first consider the numerator of (3). Conditioning on the original degree of , we have the following proposition.
Proposition 1**.**
The probability that an output symbol belongs to the cloud at step and enters the ripple at step , condition to its original degree being , is
[TABLE]
Proof:
For an output symbol of degree to belong to the cloud at step and to the ripple at step we need that the output symbol has reduced degree before the transition and reduced degree after the transition. For this to happen two events must take place:
- •
one of the edges of output symbol is connected to the symbol being marked as inactive or resolvable at the transition,
- •
another edge is connected to one of the active symbols after the transition and at the same time the remaining edges connected to the not active input symbols (inactive or resolvable).
The joint probability of and can be derived as
[TABLE]
Let us focus first on . We consider an output symbols of degree , thus this is simply probability that one the edges of is connected to the symbol being marked as inactive or resolvable at the transition, .
Let us now focus on . Since we condition on we have that one of the edges of is already assigned to one input symbol. We now need to consider the remaining edges and input symbols. The probability that one of the edges is connected to the set of active symbols is . At the same time we must have exactly edges going to the input symbols that were not active before the transition. Hence, we have
[TABLE]
By multiplying the two probabilities, applying few manipulations, and making explicit the conditioning on , we get
[TABLE]
We shall anyhow observe that if , the output symbol cannot belong to the cloud. Moreover, one needs to impose the condition , since output symbols choose their neighbors without replacement (an output symbol cannot have more than one edge going to an input symbol). Hence, for and , the probability is zero. ∎
By removing the conditioning on the degree of in (5), we have
[TABLE]
Let us now focus on the denominator of (3) which gives the probability that a randomly chosen output symbol is in the cloud when input symbols are still active. This probability is provided by the following proposition.
Proposition 2**.**
The probability that the randomly chosen output symbol is in the cloud when input symbols are still active is
[TABLE]
Proof:
The probability of not being in the cloud is given by the probability of having reduced degree [math] or being in the ripple. Given that the two events are mutually exclusive, we can compute such probability as the sum of the probabilities of the two events,
[TABLE]
where denotes the reduced degree of output symbol when input symbols are still active. We first focus on the probability of being in the ripple. Let us assume has original degree . The probability that has reduced degree equals the probability of having exactly one neighbor among the active input symbols and the remaining neighbors among the non-active (i.e., solved or inactive) ones. Thus, we have
[TABLE]
The probability of having reduced degree [math] is the probability that all neighbors of are in the non-active symbols. The total number of different edge assignments is , and the total number of edge assignments in which all neighbors of are in the non-active symbols is . Thus we have
[TABLE]
By removing the conditioning on in (11) and (12) and by replacing the corresponding results in (10) we obtain (8). ∎
The expression of is finally given in the following proposition.
Proposition 3**.**
The probability that a randomly chosen output symbol leaves the cloud enters the ripple after the transition from to active input symbols is
[TABLE]
Proof:
The proof follows directly from (3) and Propositions 1 and 2. ∎
Let us now focus on the number of symbols leaving the ripple during the transition from to active symbols. We denote by the random variable associated with . Two cases shall be considered. In a first case, no inactivation takes place because the ripple is not empty. Thus, an output symbol is chosen at random from the ripple and its only neighbor is marked as resolvable and removed from the graph. By removing from the graph, other output symbols that are connected to and that are in the ripple leave the ripple. Thus, for we have
[TABLE]
with . In the second case, the ripple is empty () and an inactivation takes place. Since no output symbols can leave the ripple, we have
[TABLE]
We are now in the position to derive the transition probability . Let us introduce the cloud drift to denote the variation of number of cloud elements in the transition from to active symbols, i.e.,
[TABLE]
We can now express the cloud and ripple cardinality after the transition respectively as
[TABLE]
Since output symbols are generated independently, the random variable associated to is binomially distributed with parameters and , and making use of (15), we obtain the following recursion
[TABLE]
which is valid for , while for , according to (16), we have
[TABLE]
Note that the probability of can be computed recursively via (19), (21) by initializing the decoder state as
[TABLE]
for all non-negative such that , where is the number of output symbols.
The following proposition establishes how the number of inactivations can be determined using the finite state machine.
Theorem 1**.**
Let denote the random variable associated to the number of inactivations at the end of the triangulation process. The expected value of is given by
[TABLE]
Proof:
Let us denote by the binary vector associated to the inactivations performed during the triangulation process, and let denote the associated random vector. In particular, the -th element of , is set to if an inactivation is performed when input symbols are active, and it is set to [math] if no inactivation is performed. Thus, for a given instance of inactivation decoding, the total number of inactivations corresponds simply to the Hamming weight of , which we denote as . The expected number of inactivations can be obtained as
[TABLE]
where the summation is taken over all possible vectors . We shall now define , i.e., denotes a vector containing all but the -th element of . We have
[TABLE]
If we now observe that by definition
[TABLE]
we obtain (23), and the proof is complete. ∎
Figure 4 shows the expected number of inactivations for a LT code with the output degree distribution
[TABLE]
which is the one adopted by standardized Raptor codes [17, 39]. The figure shows the number of inactivations according to (23) and results obtained through Monte Carlo simulations. In particular, in order to obtain the simulation results for each value of relative overhead 1000 decoding attempts were carried out. A tight match between the analysis and the simulation results can be observed.
The results in this section are strongly based on [16], where LT codes under inactivation decoding were analyzed. The difference is that, when considering the triangulation step of inactivation decoding, the decoding process does not stop when the decoder is at state . Instead, decoding can be resumed after performing an inactivation.
IV-B Distribution of the Number of Inactivations
The analysis presented in Section IV-A provides the expected number of inactivations at the end of the triangulation process under random inactivation decoding. In this section we extend the analysis to obtain the probability distribution of the number of inactivations. To do so, we extend the finite state machine by including the number of inactive input symbols in the state definition, i.e.,
[TABLE]
where is the random variable associated to the number of inactivations at step (when input symbols are active). We proceed by deriving a recursion to obtain as a function of . Two cases shall be considered. When the ripple is not empty () no inactivation takes place, at the transition from to active symbols the number of inactivations is unchanged (). Hence, we have
[TABLE]
The probability of can be computed recursively via (34), (36) starting with the initial condition
[TABLE]
for all non-negative such that and . Finally, the distribution of the number of inactivations needed to complete the decoding process is given by333From (38) we may obtain the cumulative distribution . The cumulative distribution of the number of inactivations has practical implications. Let us assume the fountain decoder runs on a platform with limited computational capability. For example, the decoder may be able to handle a maximum number of inactive symbols (recall that the complexity of inactivation decoding is cubic in the number of inactivations, ). Suppose the maximum number of inactivations that the decoder can handle is . The probability of decoding failure will be lower bounded by .The probability of decoding failure is actually higher than since the system of equations to be solved in the Gaussian elimination (GE) step might be rank deficient.
[TABLE]
In Figure 5 the distribution of the number of inactivations is shown, for an LT code with degree distribution given in (31), input block size and relative overhead . The chart shows the distribution of the number of inactivations obtained through Monte Carlo simulations and by evaluating (38). In order to obtain the simulation results for each value of absolute overhead 10000 decoding attempts were carried out. As before, we can observe a very tight match between the analysis and the simulation results.
V Inactivation Decoding of Raptor Codes
The analysis introduced in Section IV holds for LT codes. We shall see next how the proposed tools can be successfully applied to the design of Raptor codes whose outer code has a dense parity check matrix (see [30]). We proceed by illustrating the impact of the LT component of a Raptor code on the inactivation count. We then develop a methodology for the design of Raptor codes based on the results of Section IV.
V-A Average Number of Inactivations for Raptor Codes
Let us now consider a Raptor code based on the concatenation of a (dense) outer code and an inner LT code. We denote by the parity-check matrix of the outer code. At the input of the Raptor encoder, we have a vector of input symbols, . Out of the input symbols, the outer encoder generates a vector of intermediate symbols . The intermediate symbols serve as input to an LT encoder which produces the codeword , where can grow unbounded. The relation between intermediate and output symbols can be expressed as where is the generator matrix of the LT code. The output symbols are sent over a BEC, at the output of which the receiver collects output symbols, denoted as . The relation between the collected output symbols and the intermediate symbols can be expressed as
[TABLE]
where is a matrix that contains the columns of associated to the received output symbols. Due to the outer code constraints, we have
[TABLE]
where is the length- zero vector. Let us now define the constraint matrix of the Raptor code
[TABLE]
ML decoding can be carried out by solving the system
[TABLE]
If we compare the system of equations that need to be solved for LT and Raptor decoding, given respectively by (1) and (41), we can observed how Raptor ML decoding is very similar to ML decoding of an LT code. The main difference lies in the fact that matrix is formed, for the first columns, by the transpose of the outer code parity-check matrix. The high density of the outer code parity-check matrix lowers the probability that the ripple contains (some of) the output symbols associated to the zero vector in (41) (this is especially evident at the early steps of the triangulation process). As a result, we shall expect the average number of inactivations to increase with , for a fixed overhead 444In practice, the outer codes used are not totally dense, but the rows of their parity check matrix are usually denser that the rows of . This is, for example, usually the case if the outer code is a high rate LDPC code, since the check node degree increases with the rate..
In Figure 6 we provide the average number of inactivations needed to decode two Raptor codes, as a function of the receiver overhead . Both Raptor codes have the same outer code, a Hamming code, but different LT degree distributions. The first distribution is from (31), and the second distribution is
[TABLE]
The Figure also shows the number of inactivations needed to decode the two standalone LT codes. If we compare the number of inactivations required by the Raptor and LT codes, we can see how for both degree distributions, the number of additional inactivations needed for Raptor decoding with respect to LT decoding is very similar. We hence conjecture that the impact of the (dense) outer code on the inactivation count depends mostly on the number of the outer code parity-check equations. This empirical observation provides a hint on a practical design strategy for Raptor codes: If one aims at minimizing the number of inactivations for a Raptor code based on a given outer code, it is sufficient to design the LT code component for a low (i.e., minimal) number of inactivations. Based on this consideration, an explicit design example is provided in the following subsection.
V-B Example of Raptor Code Design
We consider a Raptor code with a outer Hamming code and we assume decoding is carried out when the absolute receiver overhead reaches , i.e., we carry out decoding after collecting output symbols in excess of . Furthermore, we want to have a probability of decoding failure, , lower that a given value . Thus, the objective of our code design will be minimizing the number of inactivations needed for decoding while achieving a probability of decoding failure lower than . Hence, the design problem consists of finding a suitable output degree distribution for the inner LT code. For illustration we will introduce a series of constraints in the output degree distribution. In particular we constraint the output degree distribution to have the same maximum and average output degree as standard R10 Raptor codes ( and , [17]). Furthermore, we constraint the output degree distribution to have the same support as the degree distribution of R10 raptor codes, that is, only degrees and are allowed. These design constraints allow us to perform a fair comparison between the Raptor code obtained through optimization and a Raptor code with the same outer code and the degree distribution from R10 Raptor codes.
The design of the LT output degree distribution is formulated as a numerical optimization problem. For the numerical optimization we used is simulated annealing (SA) [40]. More concretely, we define the objective function to be minimized to be the following function [41]
[TABLE]
where is the number of inactivations needed to decode the LT code and the penalty function is defined as
[TABLE]
being a large positive constant555In our example, was set to . A large factor ensures that degree distributions which do not comply with the target probability of decoding failure are discarded., the target probability of decoding failure at and the upper bound to the probability of decoding failure of the Raptor code in [33], which for binary Raptor codes has the expression666The use of the upper bound on the probability of decoding failure, in place of the actual value of in the objective functions stems from the need of having a fast (though, approximate) performance estimation to be used within the SA recursion. The evaluation of the actual presents a prohibitive complexity since it has to be obtained through Monte Carlo simulations. Note also that the upper bound of [33] is very tight.
[TABLE]
where is the multiplicity of codewords of weight in the outer code, and depends on the LT code output degree distribution as
[TABLE]
In particular, two code designs were carried out using the proposed optimization. In the first case we set the overhead to and the target probability of decoding failure to , and we denote by the distribution obtained from the optimization process. In the second case we chose the same overhead, , and set the target probability of decoding failure to , and we denote by the resulting distribution. The degree distributions obtained are the following
[TABLE]
[TABLE]
Monte Carlo simulations were carried out in order to assess the performance of the two Raptor codes obtained as result of the optimization process. In order to have a benchmark for comparison, a third Raptor code was considered, employing the same outer code (Hamming) and the degree distribution of standard R10 Raptor codes given in (31). Note that in all three cases we consider the same outer code, a Hamming code, and thus, the number of input symbols is . To derive the probability of decoding failure for each overhead value simulations were run until errors were collected, whereas in order to obtain the average number of inactivations, transmissions were simulated for each overhead value .
Figure 7 shows the probability of decoding failure as a function of for the three Raptor codes based on the outer Hamming code and inner LT codes with degree distributions , and . The upper bound to the probability of failure is also provided. It can be observed how the Raptor codes with degree distributions and meet the design goal, being their probability of decoding failure at below and , respectively. It can also be observed that the probability of decoding failure of the Raptor code with degree distribution lies between that of and .
Figure 8 shows the average number of inactivations as a function of the absolute receiver overhead for the three Raptor codes considered. It can observed that the Raptor code requiring the least number of inactivations is , followed by , and finally the Raptor code with degree distribution is the one requiring the most inactivations, and thus has the highest decoding complexity.
The results in Figures 7 and 8 illustrate the tradeoff existing between probability of decoding failure and number of inactivations (decoding complexity): In general if one desires to improve the probability of decoding failure, it is necessary to adopt LT codes with degree distributions that lead to a larger average number of inactivations.
VI Conclusions
In this paper the decoding complexity of LT and Raptor codes under inactivation decoding has been analyzed. Using a dynamic programming approach, recursions for the number of inactivations have been derived for LT codes as a function of their degree distribution. The analysis has been extended to obtain the probability distribution of the number of inactivations. Furthermore, the experimental observation is made that decoding a Raptor code with a dense outer code results in an increase of the number of inactivations, compared to decoding a standalone LT code. Based on this observation, it has been shown how the recursive analysis of LT codes can be used to design Raptor codes with a fine control on the number of inactivations vs. decoding failure probability trade-off.
Appendix A Independent Poisson Approximation
In Section IV we have derived recursive methods that can compute the expected number of inactivations and the distribution of the number of inactivations required by inactivation decoding. The proposed recursive methods, albeit accurate, entail a non negligible computational complexity. In this appendix we propose an approximate recursive method that can provide a reasonably-accurate estimation of the number of inactivations with a much lower computational burden.
The development of the approximate analysis relies on the following definition.
Definition 3** (Reduced degree- set).**
The reduced degree- set is the set of output symbols of reduced degree . We denote it by .
The cardinality of is denoted by and its associated random variable by . Obviously, corresponds to the ripple. Furthermore, it is easy to see how the cloud corresponds to the union of the sets of output symbols of reduced degree higher than , i.e.,
[TABLE]
Moreover, since the sets are disjoint, we have
[TABLE]
We aim at approximating the evolution of the number of reduced degree output symbols, , as the triangulation procedure of inactivation decoding progresses. As it was done in Section IV, in the following a temporal dimension shall be added through subscript (recall that the subscript corresponds to the number of active input symbols in the graph). At the beginning of the triangulation process we have , and the counter decreases by one in each step of triangulation. Triangulation ends when . It follows that is the set of reduced degree output symbols when input symbols are still active. Moreover, and are respectively the random variable associated to the number of reduced degree output symbols when input symbols are still active and its realization. We model the triangulation process by means of a finite state machine with state
[TABLE]
This model is equivalent to the one presented in Section IV-A. However, the evaluation of the state evolution is now more complex due to the large state space. Yet, the analysis can be, greatly simplified by resorting to an approximation. Before decoding starts (for ), due to the independence of output symbols we have that follows a multinomial distribution, which for large number of output symbols can be approximated as the product of independent Poisson distributions. Figure 9 shows the probability distribution of , and for an LT code with a robust soliton distribution and obtained through Monte Carlo simulation, for , and . The figure also shows the curves of the Poisson distributions which match best the experimental data in terms of minimum mean square error. As we can observe, the Poisson distribution tightly matches the experimental data not only for , but also for smaller values of . Hence, we shall approximate the distribution of the decoder state at step as a product of independent Poisson distributions,
[TABLE]
where is the vector defined as , i.e., we assume that the distribution of reduced degree output symbols when input symbols are active follows a Poisson distribution with parameter . We remark that by introducing this assumption, the number of received output symbols is no longer constant but becomes a sum of Poisson random variables. In spite of this mismatch, we will later see how a good estimate of the number of inactivations can be obtained resorting to this approximation.
Next, we shall explain how the parameters can be determined. For this purpose let us define as the random variable associated with the number of output symbols of reduced degree that become of reduced degree in the transition from to output symbols. We have
[TABLE]
If we take the expectation at both sides we can write
[TABLE]
Let us now derive the expression of . We shall distinguish two cases. First we shall consider output symbols with reduced degree . Since output symbols select their neighbors uniformly at random, we have that , , conditioned on is binomially distributed with parameters and , where is the probability that the degree of decreases to in the transition from to , i.e.,
[TABLE]
The following proposition holds.
Proposition 4**.**
The probability that a randomly chosen output symbol , with reduced degree when input symbols are active, has reduced degree when input symbols are active is
[TABLE]
Proof:
Before the transition, has exactly neighbors among the active input symbols. In the transition from to active symbols, input symbol is selected at random and marked as either resolvable or inactive. The probability that the degree of gets reduced is simply the probability that one of its neighbors is marked as resolvable or inactive. ∎
Thus, the expected value of is
[TABLE]
If we now replace (53) in (50) a recursive expression is obtained for , ,
[TABLE]
where we have replaced according to our Poisson distribution assumption.
We shall now consider the output symbols of reduced degree 1. In particular, we are interested in , the random variable associated to the output symbols of reduced degree that become of reduced degree [math] in the transition from to active input symbols. Two different cases need to be considered. In the first one, the ripple is not empty, and hence there are one or more output symbols of reduced degree . In this case, an output symbol is chosen at random from the ripple and its only neighbor is marked as resolvable and removed from the graph. Furthermore, any other output symbol in the ripple being connected to input symbol also leaves the ripple during the transition. Hence, for we have
[TABLE]
whereas for we have
[TABLE]
Hence, we have
[TABLE]
Replacing (61) in (50) a recursive expression is obtained as,
[TABLE]
The decoder state probability is obtained by setting the initial condition and applying the recursions in (54) and (62). Furthermore, the expected number of inactivations after the steps of triangulation, can be approximated as
[TABLE]
In Figure 10 we provide again the probability distribution of , and for an LT code with robust soliton distribution (RSD) (see [5]) and obtained through Monte Carlo simulation, for , and . The figure also shows the curves of the approximation to obtained using the model in this section. We can observe how the proposed method is able to track the distribution of very accurately for and . However, at the end of the triangulation process a divergence appears as it can be observed for in Figure 10 (c). The source of this divergence could, in large part, be attributed to the independence assumption made in (48). As the number of active input symbols decreases, the dependence among the different becomes stronger, and the independence assumption approximation falls apart.
Figure 11 shows the average number of inactivations needed to complete decoding for a linear random fountain code (LRFC)777The degree distribution of a LRFC follows a binomial distribution with parameters and (see [42]). and a RSD, both with average output degree and . The figure shows results obtained by Monte Carlo simulation and also the estimation of the number of inactivations obtained under our Poisson approximation. A tight match between simulation results and the estimation can be observed. The experimental results indicate that, although the independence assumption made does not hold in general, it is a good approximation for most of the decoding process, deviating from simulation results only at the last stages of decoding. Thus, the proposed method can still provide a good approximation of the number of inactivations needed for decoding.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] F. Lázaro, G. Liva, and G. Bauch, “Inactivation decoding analysis for LT codes,” in Proc. 52nd Annu. Allerton Conf. on Commun., Control, and Computing , Monticello, Illinois, USA, Oct. 2015.
- 2[2] F. Lázaro Blasco, G. Liva, and G. Bauch, “LT code design for inactivation decoding,” in Proc. 2014 IEEE Inf. Theory Workshop , Hobart, Tasmania, Australia, Nov. 2014, pp. 441–445.
- 3[3] J. Metzner, “An improved broadcast retransmission protocol,” IEEE Trans. Commun. , vol. 32, no. 6, pp. 679–683, Jun 1984.
- 4[4] J. Byers, M. Luby, and M. Mitzenmacher, “A digital fountain approach to reliable distribution of bulk data,” IEEE J. Select. Areas Commun. , vol. 20, no. 8, pp. 1528–1540, Oct. 2002.
- 5[5] M. Luby, “LT codes,” in Proc. 43rd Annual IEEE Symp. on Foundations of Computer Science , Vancouver, Canada, Nov. 2002, pp. 271–282.
- 6[6] P. Maymounkov, “Online codes,” Technical report, New York University, Tech. Rep., 2002.
- 7[7] A. Shokrollahi, “Raptor codes,” in Proc. of the 2004 IEEE Int. Symp. on Inf. Theory , Chicago, Illinois, US, Jun. 2004, p. 36.
- 8[8] M. Shokrollahi, “Raptor codes,” IEEE Trans. Inf. Theory , vol. 52, no. 6, pp. 2551–2567, Jun. 2006.