Inferential results for a new measure of inequality
Youri Davydov, Francesca Greselin

TL;DR
This paper introduces a new inequality index tailored to detect significant changes in both tails of income distributions, providing estimators with proven asymptotic properties and applying them to real Italian income data.
Contribution
It proposes a novel inequality measure, develops two estimators, and establishes their asymptotic properties, including consistency and normality, with application to real income data.
Findings
Estimators are asymptotically equivalent.
The proposed estimator is consistent and asymptotically normal.
Application to Italian income data demonstrates practical relevance.
Abstract
In this paper we derive inferential results for a new index of inequality, specifically defined for capturing significant changes observed both in the left and in the right tail of the income distributions. The latter shifts are an apparent fact for many countries like US, Germany, UK, and France in the last decades, and are a concern for many policy makers. We propose two empirical estimators for the index, and show that they are asymptotically equivalent. Afterwards, we adopt one estimator and prove its consistency and asymptotic normality. Finally we introduce an empirical estimator for its variance and provide conditions to show its convergence to the finite theoretical value. An analysis of real data on net income from the Bank of Italy Survey of Income and Wealth is also presented, on the base of the obtained inferential results.
Click any figure to enlarge with its caption.
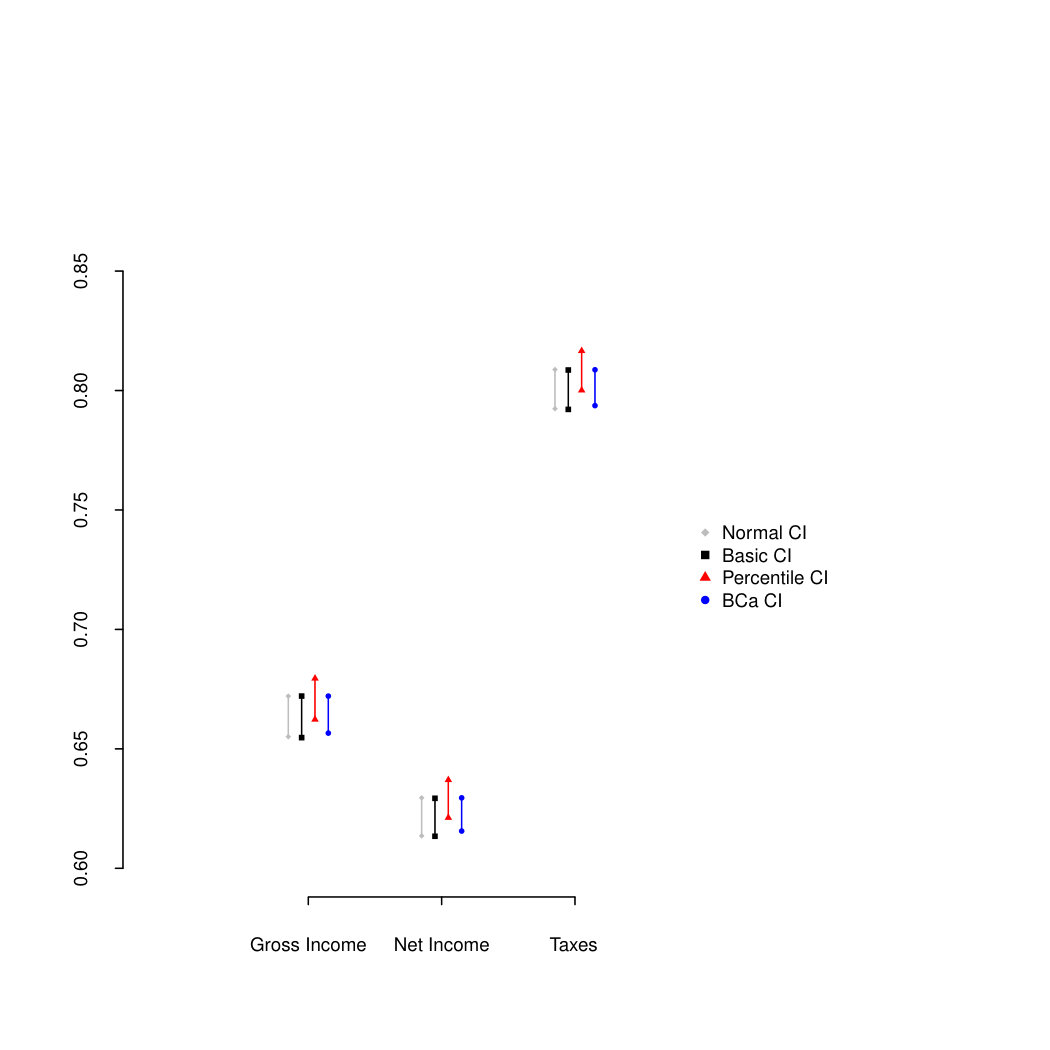 Figure 1
Figure 1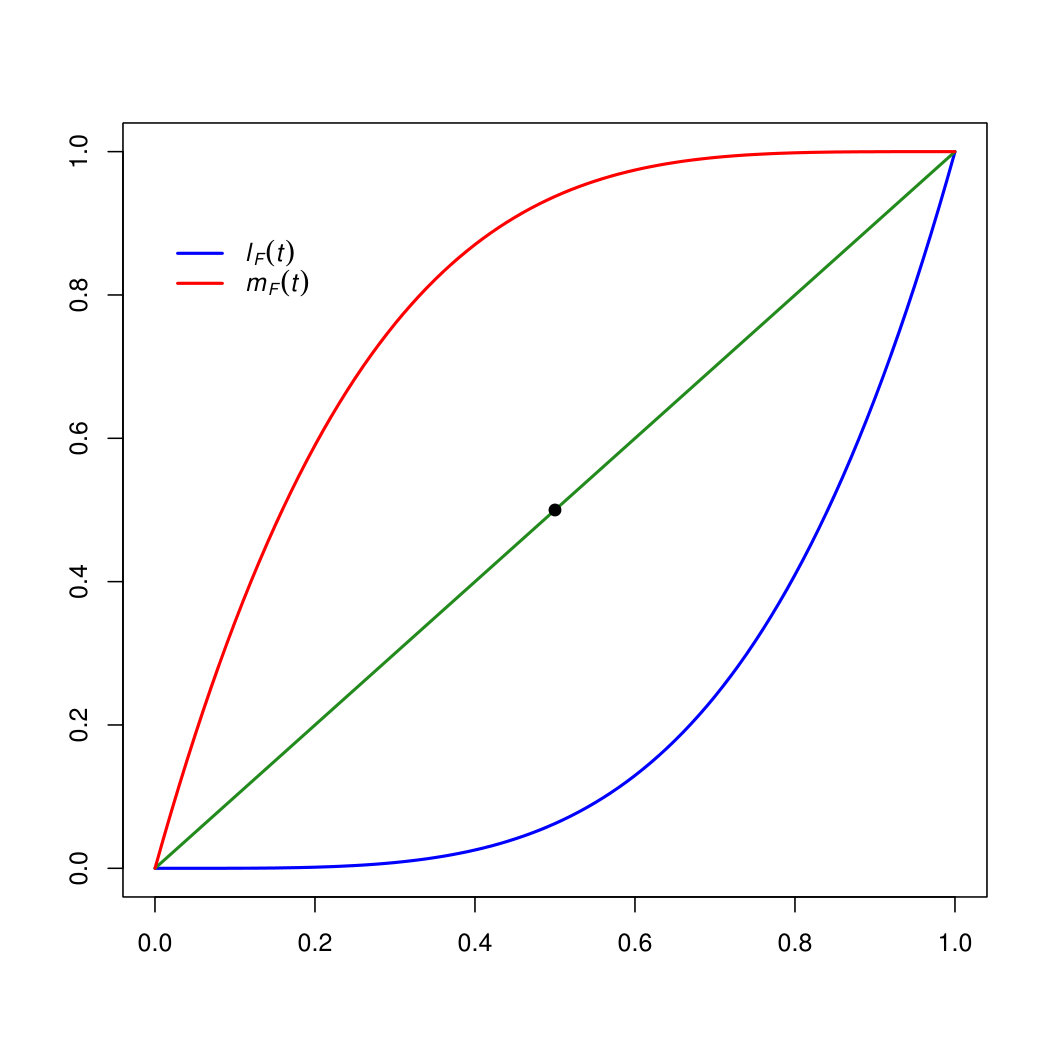 Figure 2
Figure 2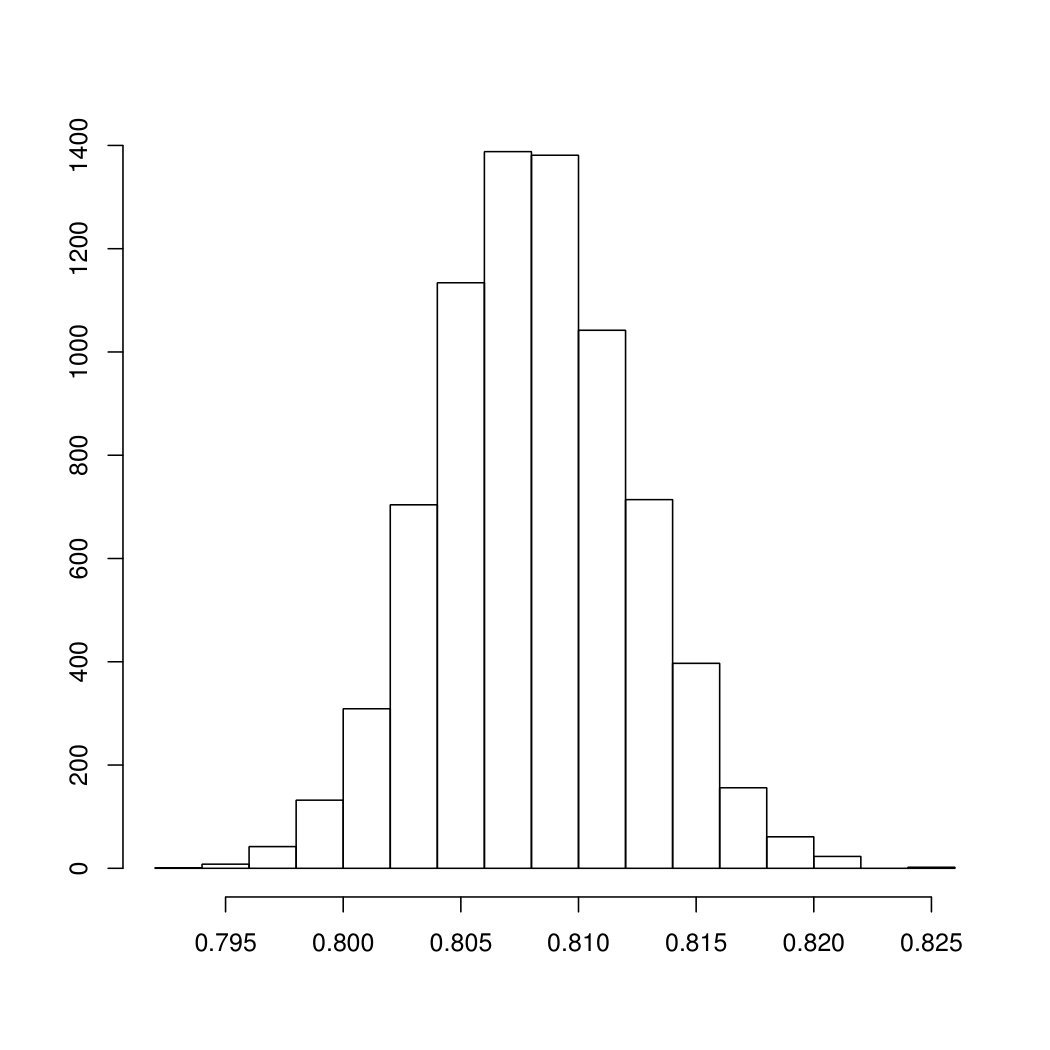 Figure 3
Figure 3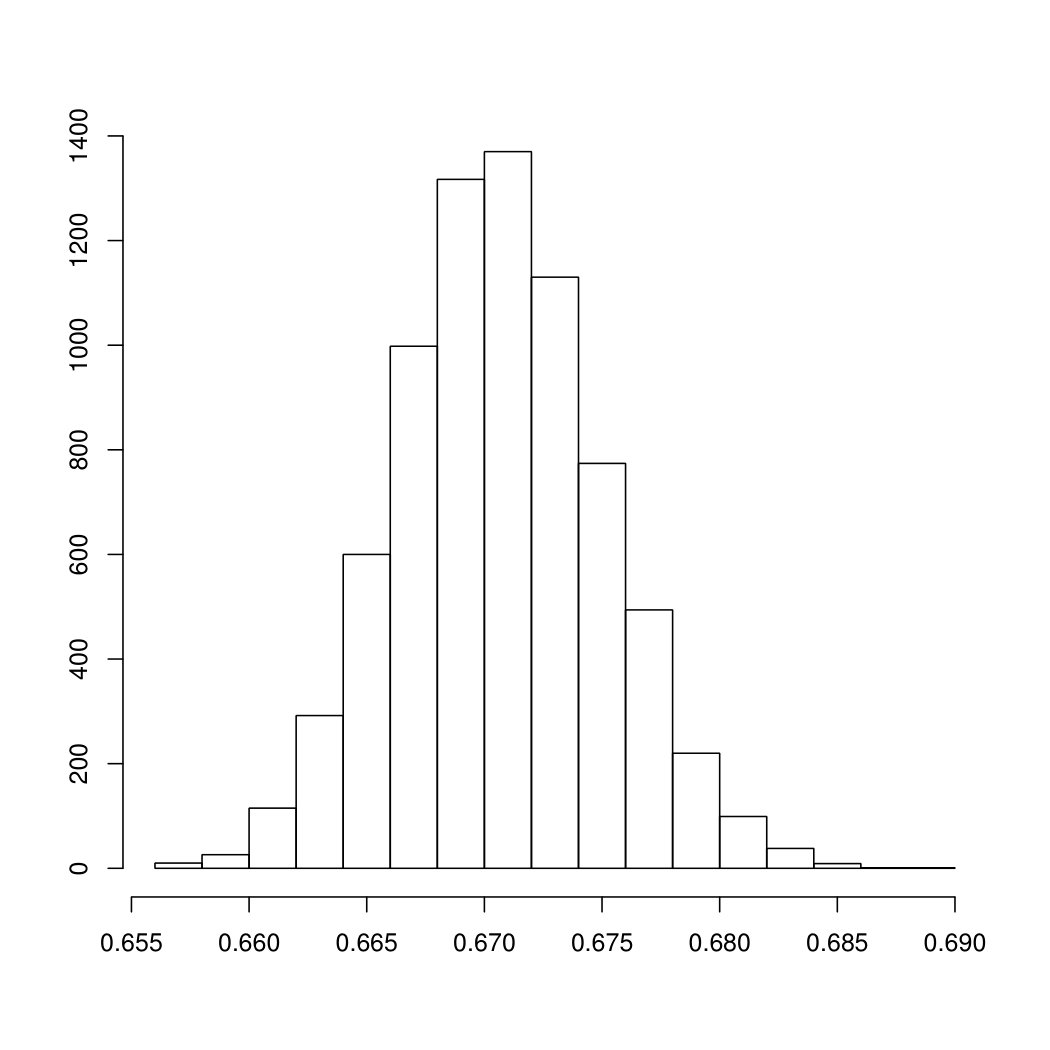 Figure 4
Figure 4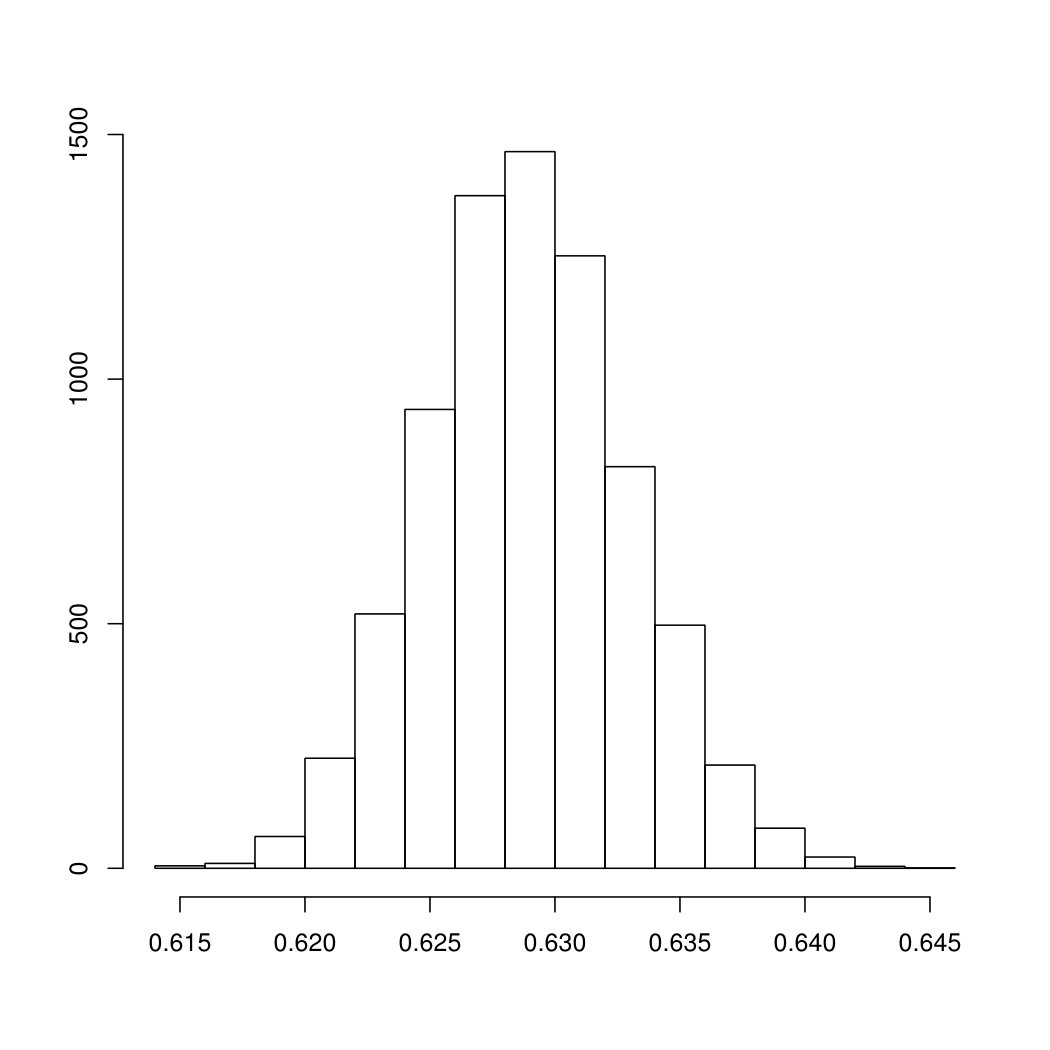 Figure 5
Figure 5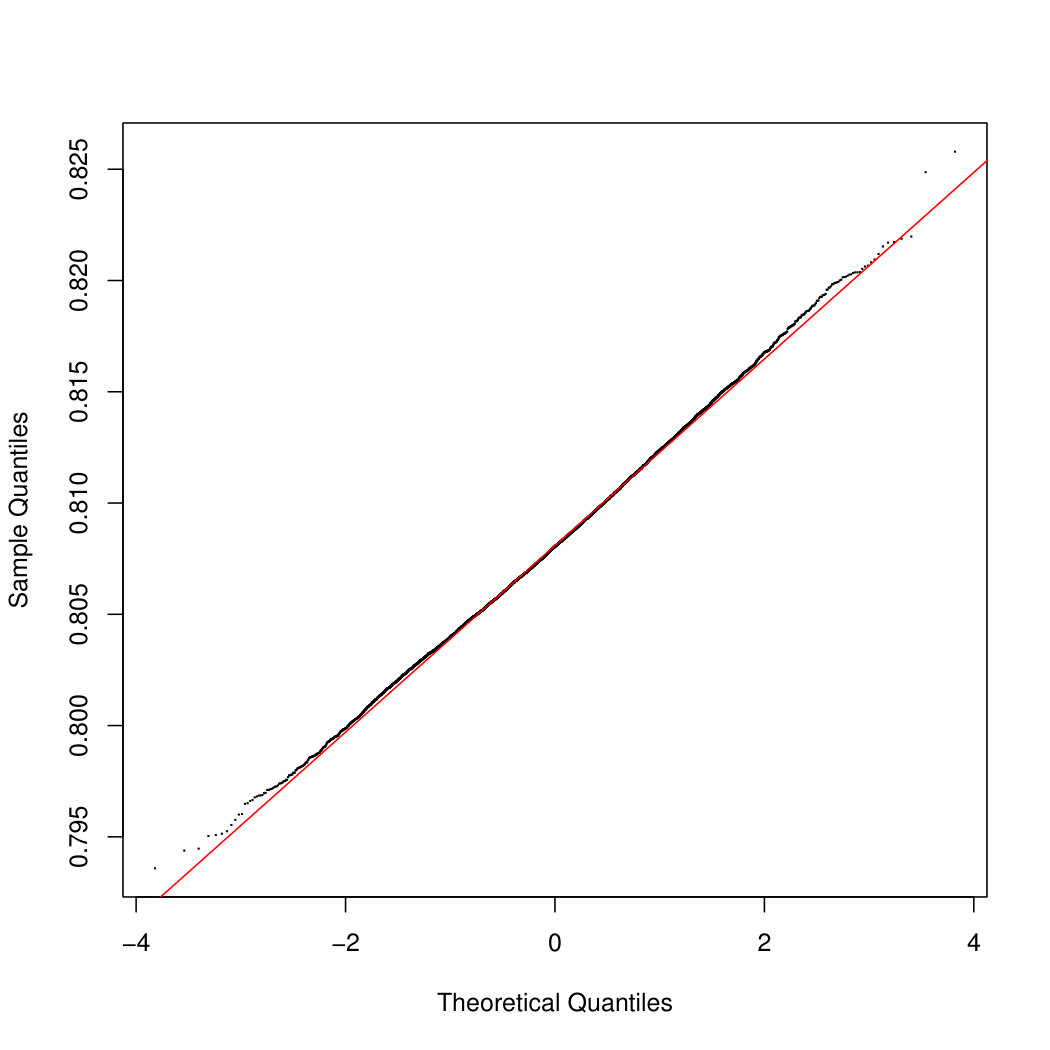 Figure 6
Figure 6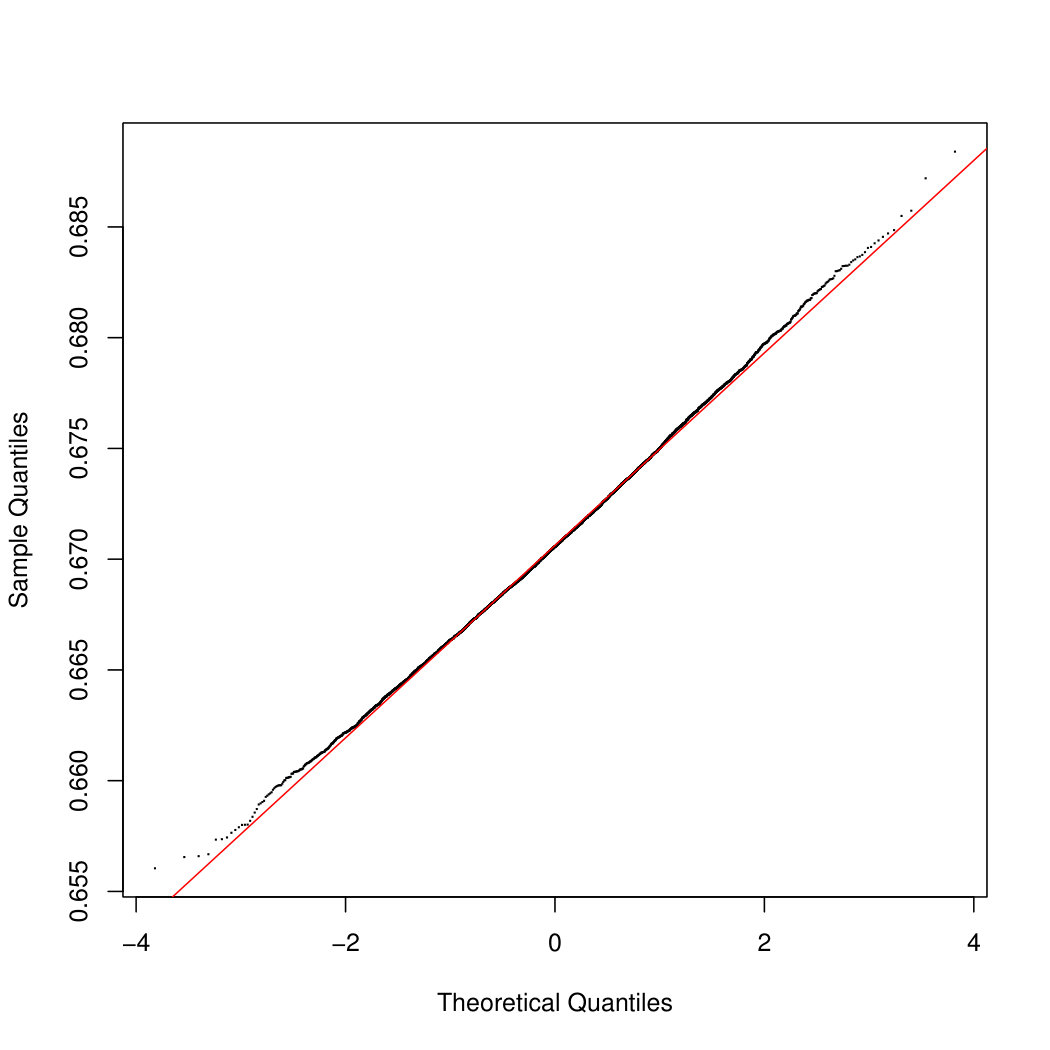 Figure 7
Figure 7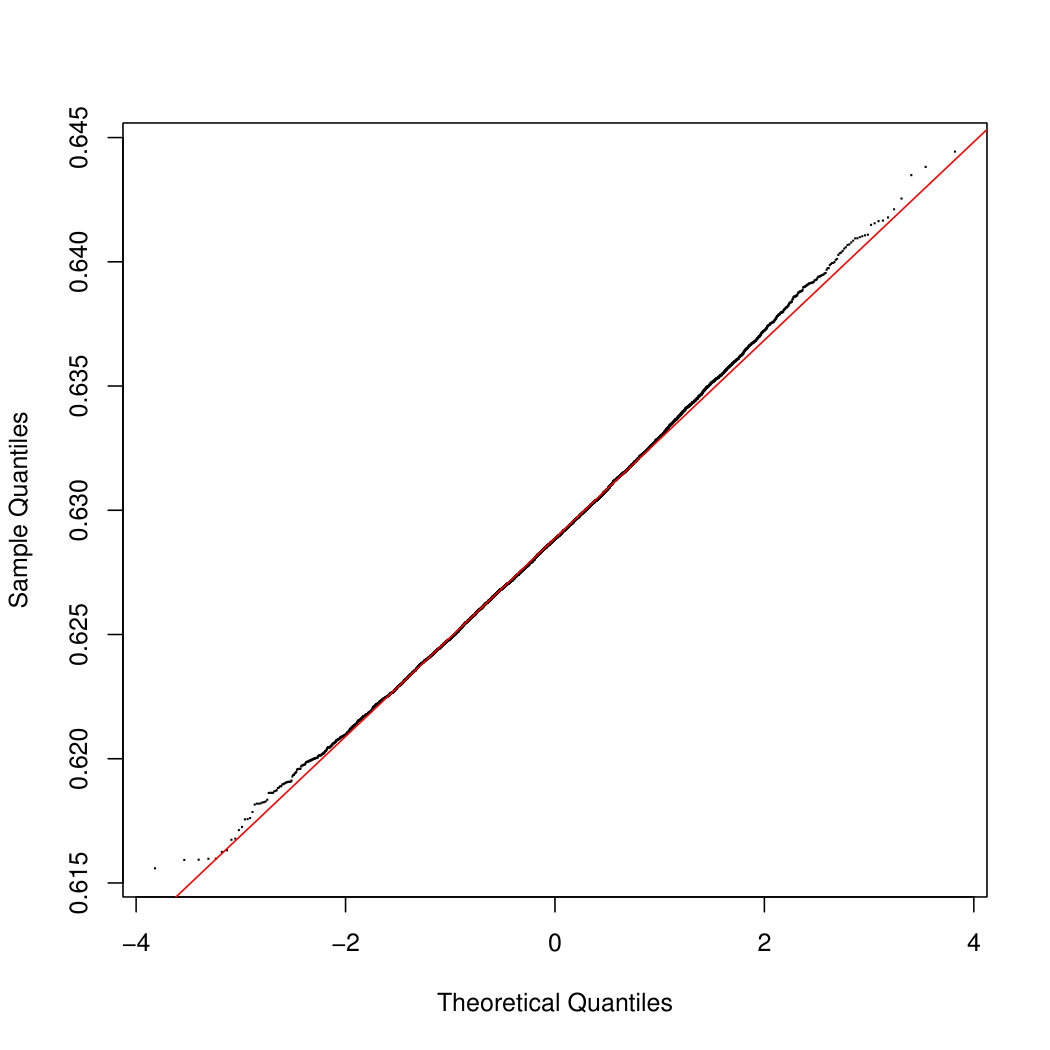 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Inferential results
for a new measure of inequality
Youri Davydov, Francesca Greselin
*Laboratoire Paul Painlevé, Université des Sciences et Technologies de Lille (Lille 1), Lille, France
and Saint Petersburg State University, Saint Petersburg, Russia*
Dipartimento di Statistica e Metodi Quantitativi, Università di Milano Bicocca, Milan, Italy
Abstract. In this paper we derive inferential results for a new index of inequality, specifically defined for capturing significant changes observed both in the left and in the right tail of the income distributions. The latter shifts are an apparent fact for many countries like US, Germany, UK, and France in the last decades, and are a concern for many policy makers. We propose two empirical estimators for the index, and show that they are asymptotically equivalent. Afterwards, we adopt one estimator and prove its consistency and asymptotic normality. Finally we introduce an empirical estimator for its variance and provide conditions to show its convergence to the finite theoretical value. An analysis of real data on net income from the Bank of Italy Survey of Income and Wealth is also presented, on the base of the obtained inferential results.
Keywords and phrases: Income inequality, Lorenz curve, Gini Index, consistency, asymptotic normality, economic inequality, confidence interval, nonparametric estimator.
1 Introduction
In view of measuring economic inequality in a society, suppose that we are interested, for instance, in incomes. Let be an ’income’ random variable with non negatively supported cdf .
Next, define as the -th quantile of , and suppose that possesses a finite mean
[TABLE]
The Lorenz curve, introduced by Lorenz (1905), is an irreplaceable tool in this domain. It is defined by
[TABLE]
The curve expresses the share of income possessed by the % poorer part of population. It has been expressed firstly by Pietra (1915, with English translation now available as Pietra, 2014), and mathematically formulated as in (1.1) by Gastwirth (1971).
In the following we will also employ which provides the share of income owned by the richer % of the population. Obviously, is the curve obtained by applying a central symmetry to , with respect to the center of the unit square, as shown in Figure 1.1 and allows us also to rephrase the Gini into .
We recall that the Gini can be rephrased as the weighted average of all comparisons made among the mean income of the poorest and the overall mean (Greselin et al. 2012, Greselin 2014). When dealing with skewed distributions, as it is the case for many economic size distributions, the median should be preferred to the mean, in such a way that Gastwirth (2014) proposed to modify the Gini accordingly.
Very recently, motivated by the observed shifts toward the extreme values in income distributions, a new focus is introduced in Gastwirth (2016), almost contemporarily to Davydov and Greselin (2016). Policy makers are nowadays interested in understanding what happens in the more critical portions of the population, as significant changes have been observed both in the left and in the right tail of the income distributions in countries like US, Germany, UK, France in the last decades. Notice that the classical Lorenz curve provides useful pointwise information with reference to poorest people, while on the other hand, as approaches 1 as approaches 1, it does not display the variation within the upper end (f.i., top 5% or 1%) of the distribution clearly. The novel approach is to consider equally sized and opposite groups of population, and compare their mean income. Aiming at contrasting the economic position of the group of the poorer % to the one of the % of the richest, the following inequality curve has been introduced
[TABLE]
In the case of perfect equality, each fraction of population has same mean income, hence for all . While the income distribution moves toward more variability, the mean income of the of richest people will be moving far from the mean income of the of poorest part of the population, and raises toward . Hence, we can represent the pointwise measure of inequality in the population by plotting .
Naturally, we can summarize all the information given by the curve in a single measure of inequality , by taking the expected value
[TABLE]
Notice that is the area between the observed inequality curve and the curve of perfect equality, which is the horizontal line passing through the origin of the axes.
The structure of the paper is as follows. Section 2 introduces two estimators for the new inequality measure, and provide reasons for selecting them in view of their main purpose. The third section, which is the core of the paper, states the main inferential results, in more detail we will show the consistency of the estimators, state their asymptotical distribution, and the asymptotic negligibility of their difference. We also introduce an empirical estimator for the variance, and establish its convergence to the finite variance of the estimator. Some lemmas useful for the inferential theory have been presented in Section 4, along with their proof. Section 5 shows how the inferential results can be employed to develop an analysis on real income data. Final considerations are given in Section 6.
2 Estimators
Economic data on the entire (or complete) population is rarely available, so most studies are based on data obtained from well-designed sample surveys. Hence we usually have to estimate summary measures from samples. We introduce here two empirical estimators, say and for estimating . The first one is derived, in a very natural way, by replacing the population cdf and mean value in (1.3) by their empirical counterparts F_{n}(x)=\frac{1}{n}\sum_{i=1}^{n}\mathds{1}_{[0,x]}\big{(}X_{i}\big{)}, and \hbox{\vbox{\hrule height=0.5pt\kern 2.15277pt\hbox{\kern-1.00006ptX}}}_{n}=\frac{1}{n}\sum_{i=1}^{n}X_{i}, and then considering the empirical Lorenz curve, say
[TABLE]
as follows
[TABLE]
where we set .
Then, the second estimator is defined in terms of the order statistics of the i.i.d. sample drawn from , therefore we define
[TABLE]
where expresses the ratio between the mean income of the poorest and of the richest elements in the sample.
We will show later, in Theorem 3.25, that the two estimators and are asymptotically equivalent. While the estimator is suitable for developing inferential results, is much simpler when it comes to implement code for the analysis of real data.
3 Inferential results
In this Section we will present our main results, starting from the consistency of the estimator , next we state its asymptotic normal distribution, and then we deal with its variance estimation. Finally, we will show the asymptotic equivalence of the two estimators and .
Unless explicitly stated otherwise, we assume throughout that the cdf of is a continuous function. This is a natural choice when modeling income or wealth distributions, and for many other economic size distributions.
3.1 Consistency of
Theorem 3.1**.**
* is a consistent estimator for .*
Proof.
From the normalized definition of the empirical Lorenz curve and its dual, say and , it is useful here to introduce their absolute versions, given by and . We may rephrase as
[TABLE]
For all , we have that converges, with probability 1, uniformly to (see Goldie, 1977). With the same approach, we have that converges, with probability 1, uniformly to . As , due to the Lebesgue dominated convergence theorem we get the thesis. ∎
3.2 Asympthotic normality of the estimator
Theorem 3.2**.**
If the moment is finite for some , then we have the asymptotic representation
[TABLE]
where denotes a random variable that converges to 0 in probability when , and
[TABLE]
with the weight function , where
[TABLE]
Corollary 3.3**.**
Under the conditions of Theorem 3.2, we have that is asymptotically normally distributed, that is
[TABLE]
where
[TABLE]
The proof follows immediately from (3.2) by applying the Central Limit Theorem of P. Lévy.
*Proof of Theorem 3.2
*From the definition of and , we get
[TABLE]
where the remainder term is given by and
[TABLE]
We will later show (Lemma 4.1 and 4.2, respectively) that and are of order The proof follows the approach of Greselin, Pasquazzi and Zitikis (2010), to state the asymptotic normality for the Zenga inequality index (Zenga, 2007). Hence we now proceed our analysis of the first two terms in (3.4), by using the Vervaat process
[TABLE]
and its dual,
[TABLE]
for which we know that . For mathematical and historical details on the Vervaat process, see Zitikis (1998), Davydov and Zitikis (2004), and Greselin et al. (2009). Now, denoting the uniform on empirical process by and using one property of the Vervaat process, namely
[TABLE]
we find a bound for the first term in (3.4) as follows
[TABLE]
where
[TABLE]
We will later show (Lemma 4.3) that
Now we deal with the second term in (3.4), and we obtain, using similar arguments as before
[TABLE]
where
[TABLE]
In Lemma 4.4 we show that therefore we have
[TABLE]
We notice that the first term in the right hand side of equation (3.10) could be rewritten as
[TABLE]
where
[TABLE]
and
[TABLE]
For the second term in the right hand side of equation (3.10), using the change of variable , we obtain:
[TABLE]
where
[TABLE]
and
[TABLE]
This completes the proof of Theorem 3.2. ∎
3.3 Convergence of the empirical variance
We deal here with the theoretical variance Var\big{(}h(X_{1})\big{)}, that is
[TABLE]
and its empirical counterpart
[TABLE]
Let be the minimum value in the support of , i.e. the value such that for and if . Analogously, let be maximum value in the support of , i.e. such that and . Notice that we may have . Then we have
- •
because a.s.,
- •
,
- •
.
Therefore, without loss of generality, we can take .
Theorem 3.4**.**
Assume that for some . Then, we have a.s.
[TABLE]
Proof.
The proof is composed by three steps.
Step 1:
For all such that , we will show that, with probability 1, for almost all , and with given by (3.3) we have
[TABLE]
We begin by the study of the first part of (3.14) related to , i.e.
[TABLE]
We know that
- •
as a.s. (uniformly), we have the convergence with probability 1 for almost all and ,
- •
and with probability 1, we have that
[TABLE]
- •
M_{n}(s)\geq s\,\hbox{\vbox{\hrule height=0.5pt\kern 2.15277pt\hbox{\kern-1.00006ptX}}}_{n}\quad\forall s\in[0,1].
As \hbox{\vbox{\hrule height=0.5pt\kern 2.15277pt\hbox{\kern-1.00006ptX}}}_{n}\to\mu_{F} a.s., with probability 1 there exists a constant such that
[TABLE]
Hence, Lebesgue theorem gives (3.14), with replaced by .
Now we consider the second part of (3.14), where takes the place of :
[TABLE]
and observe that
- •
with probability 1 for almost all and ,
- •
, with probability 1, we have that , and ,
- •
.
Therefore
[TABLE]
Once more using Lebesgue theorem we get
[TABLE]
which completes the proof of (3.14).
Step 2:
For all such that and given
[TABLE]
where
[TABLE]
we will show that, with probability 1,
[TABLE]
Due to the previous step, for every we know that converges, with probability 1, to
[TABLE]
We have shown that, with probability 1,
[TABLE]
and using
[TABLE]
it follows that we have a.s.
[TABLE]
Hence
[TABLE]
Observing now that the function at the right hand side in (3.16) is integrable on , we can apply Lebesgue’s dominated convergence theorem and prove (3.15).
Step 3:
To complete the proof of Theorem 3.13 we need to obtain a bound for the integrals and . We use the following more delicate estimation of , for all : there exists a positive constant such that
[TABLE]
Indeed, as , for , we have
[TABLE]
and
[TABLE]
Hence, for every , there exists a constant , depending only on , such that for all
[TABLE]
which jointly give the estimation (3.17).
For , we have
[TABLE]
We have similarly
[TABLE]
Let us introduce a new probability space and a new random variable , taking the values , for , such that \widetilde{\mathbb{P}}\big{(}Y=X_{i}\big{)}=\frac{1}{n}. Then
[TABLE]
If then, due to the strong law of large numbers,
[TABLE]
hence, with probability 1, we have
[TABLE]
Observing now that, for , the integral converges, and defining such that \big{(}1-(1-2\gamma)(2+\delta)\big{)}=-(1+\beta), then (3.20) takes the form
[TABLE]
Evidently, replacing by in (3.18) and (3.21), we obtain their theoretical counterparts
[TABLE]
and
[TABLE]
Now, collecting the bounds (3.18) and (3.22), the convergence stated in (3.15), and finally bounds (3.21) and (3.23) from the three steps
[TABLE]
Taking and in (3.24), we arrive at (3.13). ∎
Having established the consistency and asymptotic normality for the estimator , we would like to prove similar properties for the second estimator defined in (2.2). To do this, we will focus on their difference and prove its asymptotic negligibility.
Theorem 3.5**.**
If the moment is finite for some , then we have
[TABLE]
Before proving Theorem 3.25, it is worth to state two useful Corollaries.
Corollary 3.6**.**
If the moment is finite for some , then we have
[TABLE]
where \sigma_{F}^{2}=Var\big{(}h(X_{1})\big{)} is the theoretical variance.
Corollary 3.7**.**
*Under the same assumptions, we have also *
[TABLE]
where is the empirical counterpart for given by (3.12).
The same is true if we replace by .
Proof.
(of Theorem 3.25). Let , where . We have
[TABLE]
where is the modulus of continuity of on the interval given by
[TABLE]
Let , then
[TABLE]
where we used and the inequalities , s\,\,\hbox{\vbox{\hrule height=0.5pt\kern 2.15277pt\hbox{\kern-1.00006ptX}}}_{n}\leq M_{n}(s) that hold true . From the bounds in (3.28) and (3.29) we get
[TABLE]
As for
[TABLE]
we get
[TABLE]
Therefore, due to (3.30), we obtain
[TABLE]
As and \hbox{\vbox{\hrule height=0.5pt\kern 2.15277pt\hbox{\kern-1.00006ptX}}}_{n}\rightarrow\mu_{F}, it is sufficient to state the convergence in probability of to 0. We have, for
[TABLE]
as we have chosen . ∎
4 Proofs
Lemma 4.1**.**
Under the conditions of Theorem 3.2, we have that
[TABLE]
Proof.
We estimate by splitting the integral in two parts, by choosing
[TABLE]
We now look for getting a bound for and initially deal with its first part, given by
[TABLE]
Provided that , we have that , and
[TABLE]
Now we consider the lefthand term in (4.3), and set
[TABLE]
where e_{n}(t)=\sqrt{n}\big{(}F_{n}(F^{-1}(t))-t\big{)}. We know that (see (9.2) in Greselin et al. 2010)
[TABLE]
Therefore, employing the inequality in (3.9) related to the Vervaat process, and choosing such that , we obtain
[TABLE]
As , by Lebesgue dominated convergence theorem the integral
[TABLE]
Hence
[TABLE]
The righthand term in (4.3) may be estimated as follows
[TABLE]
for all , where we set , and C_{1}=\int_{0}^{+\infty}\big{(}1-F(x)\big{)}^{1/2-\epsilon}dx<+\infty. The latter quantity is finite, due to the existence of the moment of .
To complete the analysis of we have to deal now with its second part, given by
[TABLE]
As for and , the bound for (4.7) can be found by following the same steps as for (4.2).
We continue our proof now by finding a bound for the second term in (4.1). As , then
[TABLE]
and
[TABLE]
Therefore, setting , we have
[TABLE]
We observe that (4.8) is if the following two equalities hold true:
[TABLE]
and
[TABLE]
by recalling that
[TABLE]
due to
[TABLE]
To get (4.9), remark that \sqrt{n}\,\,\big{|}\hbox{\vbox{\hrule height=0.5pt\kern 2.15277pt\hbox{\kern-1.00006ptX}}}_{n}-\mu_{F}\big{|}=O_{\textbf{P}}(1), and
[TABLE]
Finally, to get (4.10), we begin with the inequality
[TABLE]
and use the following bound for the latter integrand
[TABLE]
Recalling that
[TABLE]
and exploiting (4.4) we get
[TABLE]
Integrating in on we hence obtain the desired bound.
From the previous estimates it follows that we have
[TABLE]
where
[TABLE]
Fixing , let be such that , and let be such that for we have . Then, having
[TABLE]
we get, for ,
[TABLE]
which finally gives ∎
Lemma 4.2**.**
*Under the conditions of Theorem 3.2, we have that *
[TABLE]
Proof.
We start from the definition of in (3.6) here recalled for convenience
[TABLE]
Observing that for and using (4.11) to rewrite \big{(}M_{n}(t)-M(t)\big{)}, the proof can be established following the proof of Lemma (4.1) with minor modifications. ∎
Lemma 4.3**.**
Under the conditions of Theorem 3.2, we have that
[TABLE]
Proof.
We estimate by splitting it in two integrals as follows
[TABLE]
Let us consider the first term and observe that
[TABLE]
where we assume that , otherwise we may replace by , with appropriately chosen. Hence, by choosing , and recalling that e_{n}(t)=\sqrt{n}\left(F_{n}\big{(}F^{-1}(t)\big{)}-t\right), we arrive at
[TABLE]
as and for .
Now we deal with , i.e. the second term in (4.12). Observing that , we obtain
[TABLE]
∎
Lemma 4.4**.**
Under the conditions of Theorem 3.2, we have that
[TABLE]
Proof.
We will deal with , as for the previous Lemma, by splitting it as follows
[TABLE]
and we initially consider . Observing that for , we have
[TABLE]
Finally, the result on comes from observing that for there exists a constant such that , and that , we have
[TABLE]
due to the assumption on the second (hence the first) moment finite on . ∎
5 The new inequality measure on real data
The purpose of this section is to show, through a real data application, the theoretical results obtained in the previous sections. We employ the Bank of Italy Survey on Household Income and Wealth (hereafter named by its acronym, SHIW) dataset, published in 2016. This survey contains information on household post-tax income and wealth in the year 2014, covering 8,156 households, and 19,366 individuals. The sample is representative of the Italian population, which is composed of about 24,7 million households and 60,8 million individuals. The SHIW provides information on each individual’s Personal Income Tax net income, but does not contain the corresponding gross income. We employ an updated version of the microsimulation model described in Morini and Pellegrino (2016) to estimate the latter for each taxpayer. A comparison of the results from the microsimulation model with the official statistics published by the Italian Ministry of Finance (2016) shows that the distribution of gross income and of net tax, according to bands of gross income and type of employment, are close to each other. The empirical analysis we develop here is based on the observed net income from the SHIV, while tax data and gross income arise from the microsimulation model.
To appreciate the asymptotic results of Section 3 on the empirical estimator , we calculate four types of confidence intervals: the normal, the basic, the percentile and the BCa confidence intervals. After drawing the bootstrap samples, the empirical estimator is evaluated at each sample, and Figure 5.1 show the histograms of the obtained values when considering Gross Income in panel (a), Net Income in panel (b) and Taxes in panel (c). While inequality estimators have a skewed distribution in case of low sample size, here the accuracy of the normal approximation is apparent, due to the large sample size. As a further check of the quality of the first order approximation, Figure 5.2 shows the Q-Q plots obtained for the three cases.
Finally, from Figure 5.3 we observe that the four methods for constructing Confidence Intervals have a substantial agreement. They all agree in assuring that there is a statistically significant increase in inequality when passing from Net Income to Gross Income (the redistributive effect of taxation) and from Gross Income to Taxes. We recall that adjusted percentile methods (also named BCa) for calculating confidence limits are inherently more accurate than the basic bootstrap and percentile methods (Davison and Hinkley, 1997).
6 Concluding remarks
Moved from the considerations that nowadays, in many developed countries, the more critical (i.e the extremes) portions of the population are facing great reshaping of their economic situation, a new index for measuring inequality have been proposed in Davydov and Greselin (2016). In the cited paper, a discussion of the properties of the index has been given, to motivate its introduction in the literature and to show its descriptive features. Inferential results for the index were still missing, and this paper is a first contribution to fill the gap. After proposing two empirical estimators, we have shown their asymptotic equivalence. Then, consistency and asymptotic normality for the first estimator have been derived. We also proved the convergence of the empirical estimator for the variance to its finite theoretical value. Finally, we used the new statistical inferential results to analyze data on Net Income from the Bank of Italy Survey on Household Income and Wealth, and to compare them with Gross Income and Taxes.
References
Atkinson A. B. 1970. On the Measurement of Inequality, Journal of Economic Theory, 2, 244–263.
Cobham A., Sumner A. 2013. Putting the Gini back in the bottle? The Palma as a Policy-Relevant Measure of Inequality, Technical report, Kings College London.
Davydov Yu., Zitikis R. 2004. Convex rearrangements of random elements in Asymptotic Methods in Stochastics, vol. 44 of Fields Institute Communications, pp. 141–171, American Mathematical Society, Providence, RI, USA.
Davydov Yu., Greselin F. 2016. Comparisons between poorest and richest to measure inequality, (under revision)
Davison A. C., Hinkley D. V. 1997. Bootstrap methods and their application (Vol. 1). Cambridge University Press.
Gastwirth J.L. 2016. Measures of Economic Inequality Focusing on the Status of the Lower and Middle Income Groups, Statistics and Public Policy, 3:1, 1-9.
Gastwirth J.L. 2014. Median-based measures of inequality: reassessing the increase in income inequality in the U.S. and Sweden, Journal of the International Association for Official Statistics, 30, 311–320.
Gini C. 1914. Sulla misura della concentrazione e della variabilità dei caratteri, Atti del Reale Istituto Veneto di Scienze, Lettere ed Arti, 73, 1203–1248. (English translation in Gini, C. 2005. On the measurement of concentration and variability of characters. Metron, 63, 3–38.)
Greselin F. 2014. More equal and poorer, or richer but more unequal?, Economic Quality Control, 29, 2, 99–117.
Greselin F., Pasquazzi L., Zitikis R. 2010. Zenga’s new index of economic inequality, its estimation, and an analysis of incomes in Italy, Journal of Probability and Statistics, 26 pp., DOI:10.1155/2010/718905.
Greselin F., Pasquazzi L., Zitikis R. 2012. Contrasting the Gini and Zenga indices of economic inequality, Journal of Applied Statistics, 40, 2, 282–297.
Greselin F., Puri M. L., Zitikis R. 2009. L-functions, processes, and statistics in measuring economic inequality and actuarial risks, Statistics and Its Interface, 2, 2, pp. 227–245.
Goldie C. M. 1977. Convergence theorems for empirical Lorenz curves and their inverses
- Advances in Applied Probability*, 9, 765–791.
Lorenz M.C. 1905. Methods of measuring the concentration of wealth, Journal of the American Statistical Association, 9, 209–219.
Morini M., Pellegrino S. 2016. Personal income tax reforms: A genetic algorithm approach, European Journal of Operational Research, first online, https://doi-org.proxy.unimib.it/10.1016/j.ejor.2016.07.059 Pietra G. 1915. Delle relazioni tra gli indici di variabilità. Note I. Atti del Reale Istituto Veneto di Scienze, Lettere ed Arti, 74, 775–792
Pietra G. 2014. On the relationships between variability indices. Note I. Metron, 72, 5–16
Zenga M. 2007. Inequality curve and inequality index based on the ratios between lower and upper arithmetic means, Statistica & Applicazioni, 5, 3–27.
Zitikis R. 1998. The Vervaat process, in Szyszkowicz, B. (ed.), Asymptotic Methods in Probability and Statistics, Elsevier Science, Amsterdam, pp. 667-694.