Distributed Optimization of Multi-Beam Directional Communication Networks
Theodoros Tsiligkaridis

TL;DR
This paper develops a distributed optimization framework for multi-beam airborne networks to maximize data rates, employing convex programming and augmented Lagrangian methods, demonstrating fast convergence and improved performance over traditional routing.
Contribution
It introduces a convex multi-commodity flow formulation and a distributed augmented Lagrangian algorithm for optimizing multi-beam directional communication networks.
Findings
Fast convergence compared to primal-dual methods
Significant performance gains over minimum distance routing
Effective handling of intra-network rate demands
Abstract
We formulate an optimization problem for maximizing the data rate of a common message transmitted from nodes within an airborne network broadcast to a central station receiver while maintaining a set of intra-network rate demands. Assuming that the network has full-duplex links with multi-beam directional capability, we obtain a convex multi-commodity flow problem and use a distributed augmented Lagrangian algorithm to solve for the optimal flows associated with each beam in the network. For each augmented Lagrangian iteration, we propose a scaled gradient projection method to minimize the local Lagrangian function that incorporates the local topology of each node in the network. Simulation results show fast convergence of the algorithm in comparison to simple distributed primal dual methods and highlight performance gains over standard minimum distance-based routing.
Click any figure to enlarge with its caption.
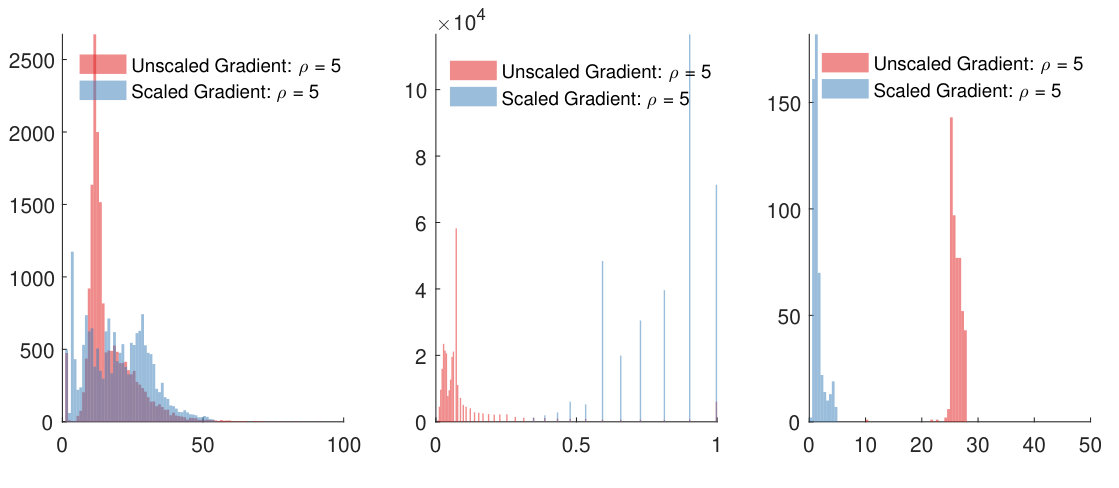 Figure 1
Figure 1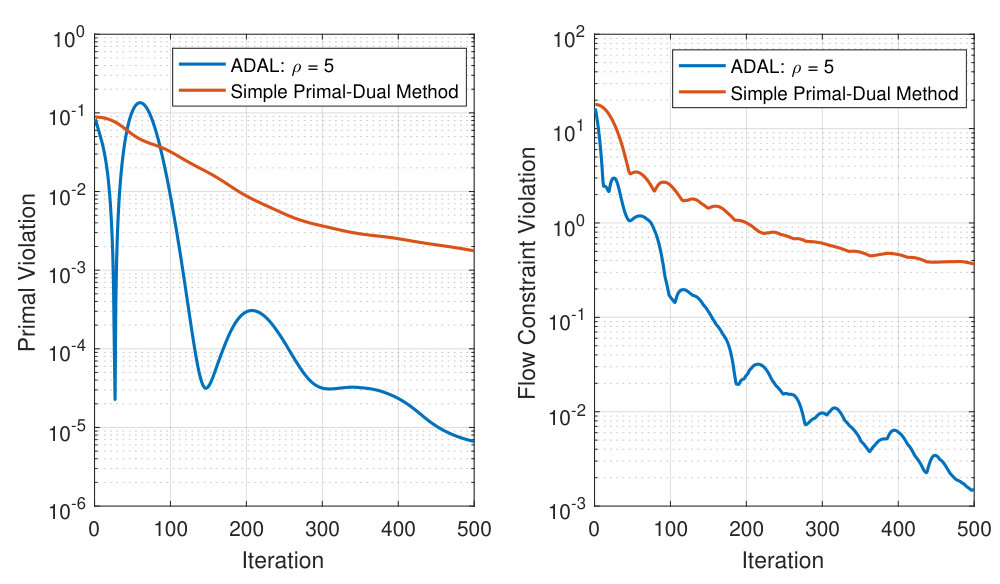 Figure 2
Figure 2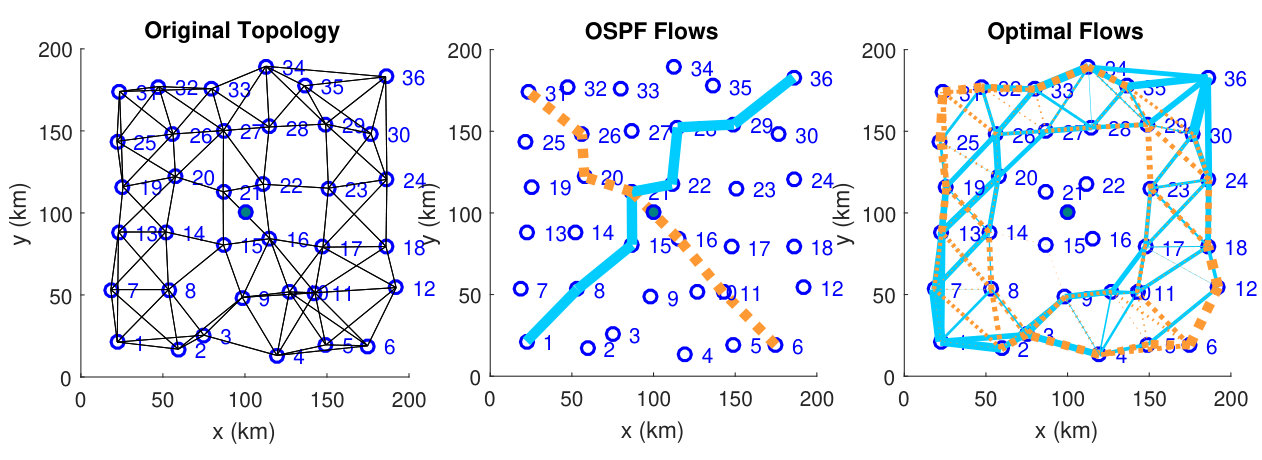 Figure 3
Figure 3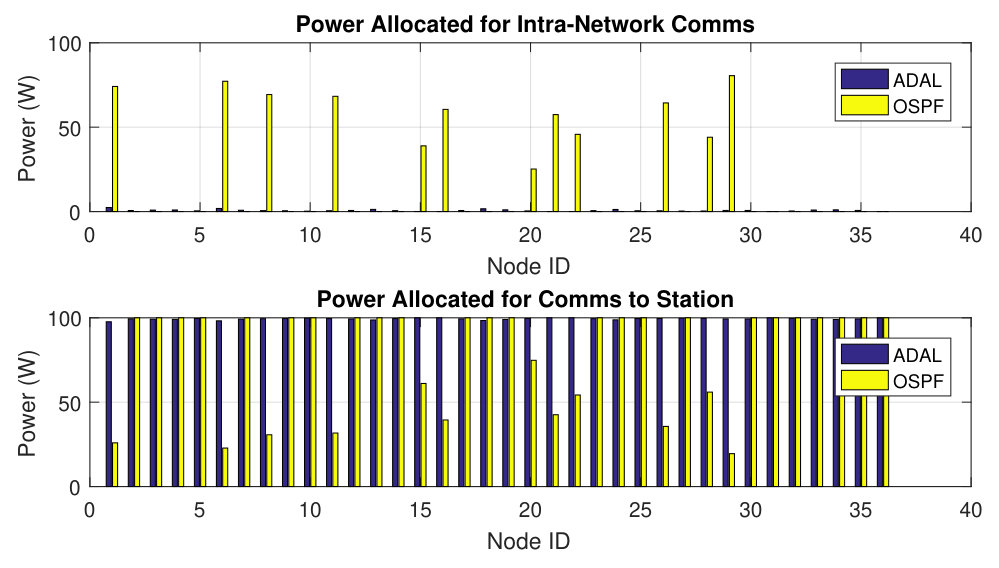 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Distributed Optimization of Multi-Beam Directional Communication Networks
Theodoros Tsiligkaridis
MIT Lincoln Laboratory
Lexington, MA 02141, USA
Email: [email protected]
Abstract
We formulate an optimization problem for maximizing the data rate of a common message transmitted from nodes within an airborne network broadcast to a central station receiver while maintaining a set of intra-network rate demands. Assuming that the network has full-duplex links with multi-beam directional capability, we obtain a convex multi-commodity flow problem and use a distributed augmented Lagrangian algorithm to solve for the optimal flows associated with each beam in the network. For each augmented Lagrangian iteration, we propose a scaled gradient projection method to minimize the local Lagrangian function that incorporates the local topology of each node in the network. Simulation results show fast convergence of the algorithm in comparison to simple distributed primal dual methods and highlight performance gains over standard minimum distance-based routing.
††This work is sponsored by Air Force Contract FA8721-05-C-0002. Opinions, interpretations, conclusions and recommendations are those of the author and are not necessarily endorsed by the Department of Defense or the U.S. Government. Approved for Public Release, Distribution Unlimited.
I Introduction
Missions where multiple communication goals are of interest are becoming more prevalent in military applications. Multilayer communications may occur within a coalition; for example, a team consisting of ground vehicles and an airborne set of assets may desire to maximize data rate for communication from the ground team to the airborne team and vice-versa while simultaneously maintaining various types of communications within each team. This paper considers such a particular scenario where a team of nodes capable of multi-beam directional communications wants to send a common message to another team, while maintaining various routing demands within pairs of nodes. The optimization variables are the powers allocated to each beam and correspond to flows across edges in the network.
Digital antenna arrays capable of adaptive multi-beam communications are getting closer to practice. Using transmit and receive beamforming, these arrays can form multiple links over the same frequency and may even steer nulls to mitigate interference from nearby nodes yielding higher spatial reuse and enhancing network throughput [1]. These advanced PHY techniques have to be coupled with a MAC layer. Recent prior work on this networking topic considered different MAC layer policies and proposed a new uncoordinated random access MAC policy for such systems and evaluated its throughput performance as a function of various parameters [2]. The recent work of [3] explored various spatial processing strategies for multi-beam transmission with a simple MAC layer in a simulation study. Full-duplex communications ease the burden on the MAC layer design and are projected to soon become a reality [4, 5] and can significantly increase network capacity [6] at the expense of carefully managing self-interference [7].
In this paper, we assume full-duplex capabilities and ideal multi-beam technology in order to focus on higher level issues of distributed optimization of resources for several tasks. We adopt a constrained optimization framework to balance the power tradeoff for maximizing data rate for a common message sent to a central station and maintaining data demands for routing packets within the network. The optimal flows that arise from the solution of the optimization problem can be used to route different messages across the network. We simplify this optimization problem into a convex multicommodity flow problem and solve using a distributed augmented Lagrangian (AL) decomposition technique. We derive a scaled gradient algorithm to minimize each local AL function at each node and rigorously show its implementation requires local computations. Simulations are performed on an illustrative example to highlight gains over standard minimum distance routing protocols, and also show convergence rate improvements over simple primal dual optimization methods.
II Problem Formulation
The blue team network is composed on nodes, and is modeled as a graph . The graph may be undirected or directed. Node may transmit data to node if . We let denote a desired data rate for the traffic originating at a source node and ending at a sink node . Each of these data traffic demands must be satisfied within the blue team. Define as the power allocated by node for transmitting data to node , and its associated channel capacity bits/s/Hz for a path loss constant . Let denote the maximum transmit power of a particular node. Each node may allocated power for communications within its own team equal to , and power for communication to the central station, . We define as the information flow from node to for commodity , where the total number of commodities are . Each commodity here corresponds to a desired message to be sent from one node to the other.
The links are line-of-sight with path loss , where is the distance between nodes and , and is the noise figure of the receiver. The path loss from node to the central station is denoted as and is similarly defined.
We seek to optimally allocate power among several transmit beams per node in order to maximize the total signal-to-interference noise ratio at the central station receiver since the data rate is given by bits/s. This framework may be generalized further to include multiple central stations. The optimization problem is as follows:
[TABLE]
This problem is equivalent to the primal optimization problem shown below by eliminating variables .
[TABLE]
where
[TABLE]
We note that the primal problem (P) is a convex optimization problem. For large enough and appropriate rates , Slater’s condition can be shown to hold. This implies strong duality and existence of optimal dual and primal solutions. We note however that there is no simple way to test if a solution exists to this problem for an arbitrary and desired rates .
Next, we reformulate the problem (P) by eliminating the variables by making use of the following proposition.
Proposition 1**.**
Assume that an optimal solution to the convex optimization problem (P) exists and is given by . Then, we must have
[TABLE]
Proof.
Assume that (1) is violated. Then there exists an edge and such that
[TABLE]
Now, set
[TABLE]
By the continuity and monotonicity of the function , . Define the new solution . This solution also satisfies all the constraints, but achieves a better objective function value, i.e., . This contradicts the optimality of . The proof is complete. ∎
Proposition 1 allows us to eliminate the power variables and transform the problem (P) into a multi-commodity optimization problem:
[TABLE]
where are positive weights.
The problem (Q) is also a convex optimization problem since the constraints are convex and the objective is a sum of convex functions, each one being a composition of a convex function () with a linear combination of the variables (). This optimization can be interpreted as trying to minimize the flows along each arc based on relative importance weights subject to the flow conservation constraints. For large , the flow along arc tends to be minimized in order to put more power into communicating to the central station since node tends is closer to the station than the node it is communicating with, while for small there is less emphasis placed on communicating to the station since node is closer to node . The relative path loss ratio controls the tradeoff between communication to the central station and node for each node pair .
Once the optimal solution to (Q) is obtained, the optimal power levels may be obtained using:
[TABLE]
and feasibility is easily checked by ensuring for all nodes . This solution coincides with the solution of (P).
III Simple Distributed Primal-Dual Algorithm for Solving (Q)
The Lagrangian for problem (Q) is given by:
[TABLE]
where are the Lagrange multipliers associated with the flow of conservation. Using the primal-dual method approach of [8, 9] to find approximate solutions to (Q), the primal and dual updates become: Primal Variable Updates
[TABLE]
Dual Variable Updates
[TABLE]
where is a small step size.
The primal solution after iterations is obtained by averaging the iterates:
[TABLE]
It is known that this primal solution will be feasible asymptotically. We note that the averages may be implemented recursively as shown above to save memory. Under some mild conditions, this iterative algorithm converges to a saddle point of the Lagrangian function. We remark that these updates can be computed using local computations, so the algorithm may be implemented in a decentralized manner.
IV Distributed Augmented Lagrangian Method for Solving (Q)
The objective function of problem (Q) is convex, twice-differentiable, and monotonically nondecreasing with respect to the flows . Furthermore, the only constraints present are flow conservation constraints and the flow nonnegativity constraints. This makes the path flow formulation applicable [10]. From the monotonicity of the objective function, an optimal flow vector may be constructed using only simple path flows. Optimizing over the path flows is not very practical since the paths from a source to a destination need to be enumerated first. The problem of finding all such simple paths cannot be accomplished in polynomial time. Furthermore, these types of algorithm in addition to the path augmentation, blocking flows and linear programming require global coordination.
We adopt the augmented Lagrangian (AL) algorithm of [11]. Define as the vector of flows of commodity that node routes towards all other nodes , and is the collection of all such vectors making up a local variable of node . The demand vector for commodity is given by . This vector is defined as for , for and for the remaining nodes . Define the local neighborhood of node as (not including ), and the two-hop neighborhood of node as . Note that .
Problem (Q) can be equivalently written as:
[TABLE]
where the matrix is defined as
[TABLE]
In matrix form, , where and zero elsewhere.
The local AL of node at iteration is given by:
[TABLE]
where is a regularization parameter. The selection vectors are given as . The accelerated distributed augmented Lagrangian (ADAL) method of [11] is summarized in Algorithm 1.
IV-A Minimizing Local AL
The minimization problem (3) can be solved by a projected gradient method [12]. We assume an initial condition of and perform iterative updates on the flow vector using Algorithm 2.
In practice to keep computational complexity bounded, we perform only several projected gradient descent iterations until a local convergence criterion is satisfied, i.e., for some small .
IV-A1 Gradient Calculation
The gradient takes the form:
[TABLE]
where , and .
We next prove that the gradient may be calculated using local information within two-hop neighbors . The gradient vector may be decomposed as:
[TABLE]
where
[TABLE]
Since the rows for all , it follows that .
We first note that the term is locally computable since:
[TABLE]
so access to from all neighbors is only needed.
We then focus our attention to the term . This is locally computable since:
[TABLE]
Finally, we consider the term , where . Since from (4), we only focus on calculating this vector for coordinates . Then, for , we have:
[TABLE]
Next, we show that involves only for .
[TABLE]
Thus, to compute the gradient, nodes only need information from their two-hop neighbors and do not require global knowledge of the network.
IV-A2 Hessian Calculation
The Hessian matrix of takes the form:
[TABLE]
The Hessian is rank-deficient with rank , depending on the size of the local neighborhood. The full Hessian matrix can be decomposed as:
[TABLE]
where each blockwise component is
[TABLE]
The matrix depends on the local neighborhood as:
[TABLE]
We also note that the reduced-dimension Hessian (restricted to ) is always positive definite since . Each submatrix has support: .
IV-A3 Scaled Gradient Direction Calculation
Let denote the set of indexes corresponding to the neighborhood of node , i.e., . The reduced-dimension Hessian has full-rank, and the reduced-dimension gradient has nonzero components in general. Using this index set, we may work over a reduced-dimension space and calculate a scaled gradient-descent direction as:
[TABLE]
with its expanded version defined as where for appropriate and . The diagonal approximation to the Hessian becomes a simple scaling of the gradient. Using this tends to have faster convergence than the unscaled gradient projection method, as the experiments show.
V Simulation Results
We simulate a two-dimensional scenario where a network broadcasts a common message to a central station while maintaining desired data rates among two origin-destination node pairs using multiple beams. A center frequency of GHz and bandwidth of MHz is used, with a peak transmit power per node of Watts. In the simulation, we compare our distributed optimization algorithm (denoted as ADAL) with the OSPF routing protocol which routes messages at a certain rate through the minimum distance route, which is efficiently obtained using Dijkstra’s algorithm.
The network consists of nodes arranged approximately in a grid as the left panel of Fig. 1 shows. The central station is placed in the center of the grid and two messages are to be routed from node to , and from node to node , each with desired data rate bits/s/Hz. The middle panel of Fig. 1 shows the OSPF flows which correspond to the minimum distance routes. The right panel shows the optimal flows obtained using the ADAL algorithm, which show that routes around the central station are preferred with appropriate load balancing than full loading the shortest routes. This makes sense since the nodes in the center allocate more power for communicating to the central station and the nodes away from the center are more responsible for carrying out the intra-network communications.
The power used for intra-network communications and communications to the central station is shown in Fig. 2 for each node. ADAL uses significantly less power overall for communications, W, in comparison to OSPF, W, which is a factor of reduction. As a result, nodes have more power left over to use for maximizing the data rate of the common message to the station receiver. The received power at the central station receiver for OSPF is kW corresponding to a data rate of Mbps, while for ADAL is kW corresponding to a data rate of Mbps. Depending on the distances of nodes to the central receiver and the network topology, this gap in received power may significantly boost the data rate. Our optimization algorithm performs optimal load balancing among different paths which leads to considerably less transmit power used for intra-network communications and allows for more power to be used for broadcasting the common message to the central receiver.
Next, we examine the convergence of the augmented Lagrangian (ADAL) algorithm and compare it with the simple primal-dual method. The constraint violation metric used is
[TABLE]
which is expected to converge to zero as grows. The objective function error measures the distance from the optimal primal value. Fig. 3 shows that ADAL achieves significantly faster convergence than the simple primal-dual method. The simple primal-dual algorithm is fully decentralized and has guaranteed convergence to the unique minimizer but has slow convergence.
The computational complexity of unscaled and scaled gradient methods for minimizing the local AL function in each iteration of the ADAL algorithm is addressed next. A tolerance threshold of was set to stop the inner minimization with stopping criterion:
[TABLE]
Figure 4 on the left panel shows a histogram of the number of inner iterations needed to achieve the tolerance for the unscaled and scaled gradient methods, respectively, and they are on the same order on average. This metric determines the number of gradient evaluations of the local AL function. The middle panel shows a histogram of the number of Armijo step sizes. The scaled method tends to require step sizes close to unity while the unscaled method requires a lot of tuning and requires significantly smaller step sizes, which implies reduced latency during optimization. The right panel displays the average number of Armijo steps per inner iteration. This is an important complexity metric since it determines the number of local AL function evaluations. The scaled gradient method requires an average of only steps while the unscaled gradient method requires steps on average.
VI Conclusion
We proposed distributed algorithms for power allocation in multibeam directional airborne networks for maximizing data rate for a common message sent by all nodes to a central station receiver while guaranteeing multiple rate demands for intra-network communications. A decomposition approach was applied to the augmented Lagrangian (AL) algorithm for solving the convex optimization problem that arises, and an efficient method for solving each subproblem in each AL iteration was presented in detail. Simulation results show the benefits of our approach in comparison to simple primal dual methods in terms of convergence. Finally, significant power savings are observed for intra-network communications with our optimized routing algorithms in comparison to standard minimum distance routing.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Litva and T. K. Lo, Digital Beamforming in Wireless Communications . Artech House, Inc., 1996.
- 2[2] G. Kuperman, R. Margolies, N. M. Jones, B. Proulx, and A. Narula-Tam, “Uncoordinated MAC for Adaptive Multi-Beam Directional Networks: Analysis and Evaluation,” in International Conference on Computer Communication and Networks (ICCCN) , 2016.
- 3[3] R. B. Mac Leod and A. Margetts, “Networked Airborne Communications using Adaptive Multi-Beam Directional Links,” in IEEE Aerospace Conference , 2016.
- 4[4] S. E. Johnston and P. D. Fiore, “Full-duplex Communication via Adaptive Nulling,” in Asilomar Conference on Signals, Systems and Computers , 2013.
- 5[5] S. Han, C. Lin, Z. Xu, C. Pan, and Z. Pan, “Full duplex: Coming into reality in 2020?” in IEEE Global Communications Conference (GLOBECOM) , 2014.
- 6[6] X. Wang, H. Huang, and T. Hwang, “On the Capacity Gain from Full-Duplex Communications in a Large Scale Wireless Network,” IEEE Transactions on Mobile Computing , vol. 15, no. 9, September 2016.
- 7[7] X. Quan, Y. Liu, S. Shao, C. Huang, and Y. Tang, “Impacts of Phase Noise on Digital Self-Iinterference Cancellation in Full-Duplex Communications,” IEEE Transactions on Signal Processing , vol. 65, no. 7, April 2017.
- 8[8] A. Nedić and A. Ozdaglar, “Approximate Primal Solutions and Rate Analysis for Dual Subgradient Methods,” SIAM Journal on Optimization , vol. 19, no. 4, pp. 1757–1780, 2009.