Predicting Graph Signals using Kernel Regression where the Input Signal is Agnostic to a Graph
Arun Venkitaraman, Saikat Chatterjee, Peter H\"andel

TL;DR
This paper introduces a kernel regression approach for predicting signals on a graph from potentially unrelated input data, incorporating graph regularization and learning the graph structure when unknown, demonstrating robustness with limited and noisy data.
Contribution
It presents a novel kernel regression framework that handles agnostic inputs and learns the underlying graph structure, extending graph signal prediction capabilities.
Findings
Effective noise reduction and smoothing in predictions.
Robust performance with limited and noisy training data.
Good reconstruction even with highly under-determined sampling.
Abstract
We propose a kernel regression method to predict a target signal lying over a graph when an input observation is given. The input and the output could be two different physical quantities. In particular, the input may not be a graph signal at all or it could be agnostic to an underlying graph. We use a training dataset to learn the proposed regression model by formulating it as a convex optimization problem, where we use a graph-Laplacian based regularization to enforce that the predicted target is a graph signal. Once the model is learnt, it can be directly used on a large number of test data points one-by-one independently to predict the corresponding targets. Our approach employs kernels between the various input observations, and as a result the kernels are not restricted to be functions of the graph adjacency/Laplacian matrix. We show that the proposed kernel regression exhibits a…
Click any figure to enlarge with its caption.
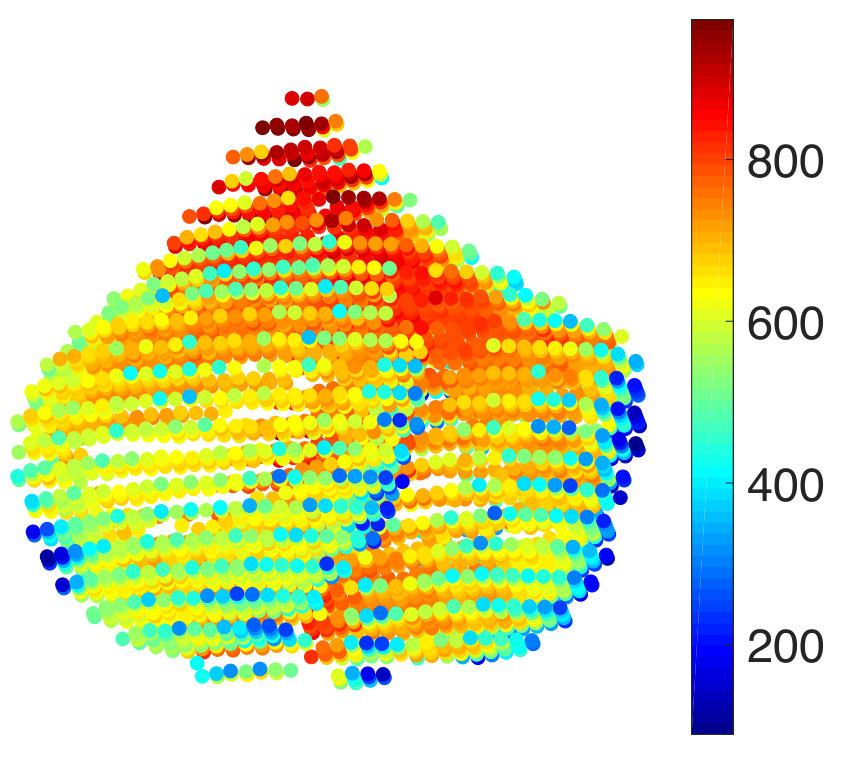 Figure 1
Figure 1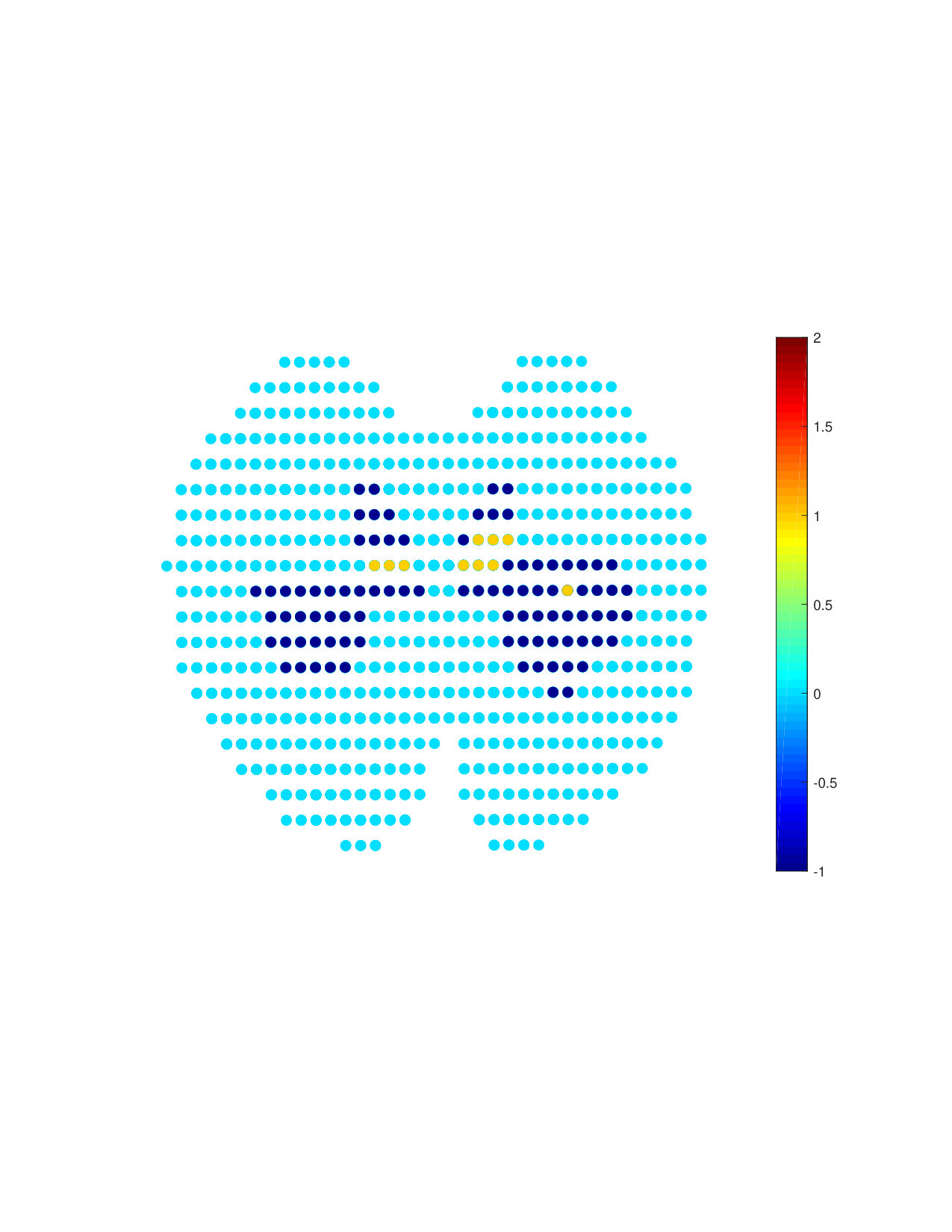 Figure 2
Figure 2 Figure 3
Figure 3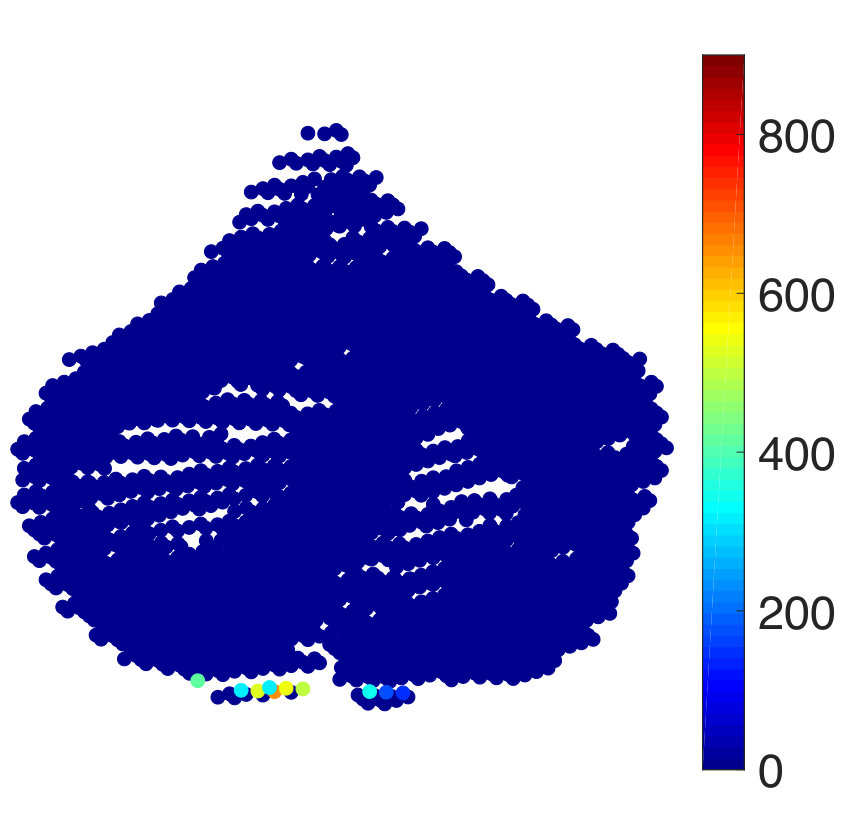 Figure 4
Figure 4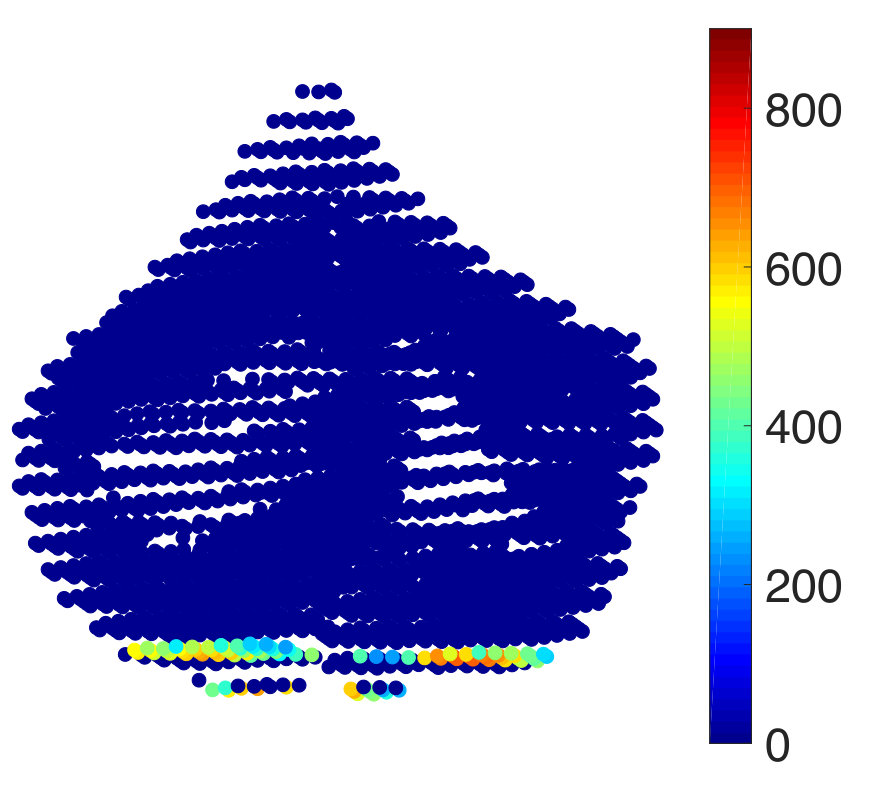 Figure 5
Figure 5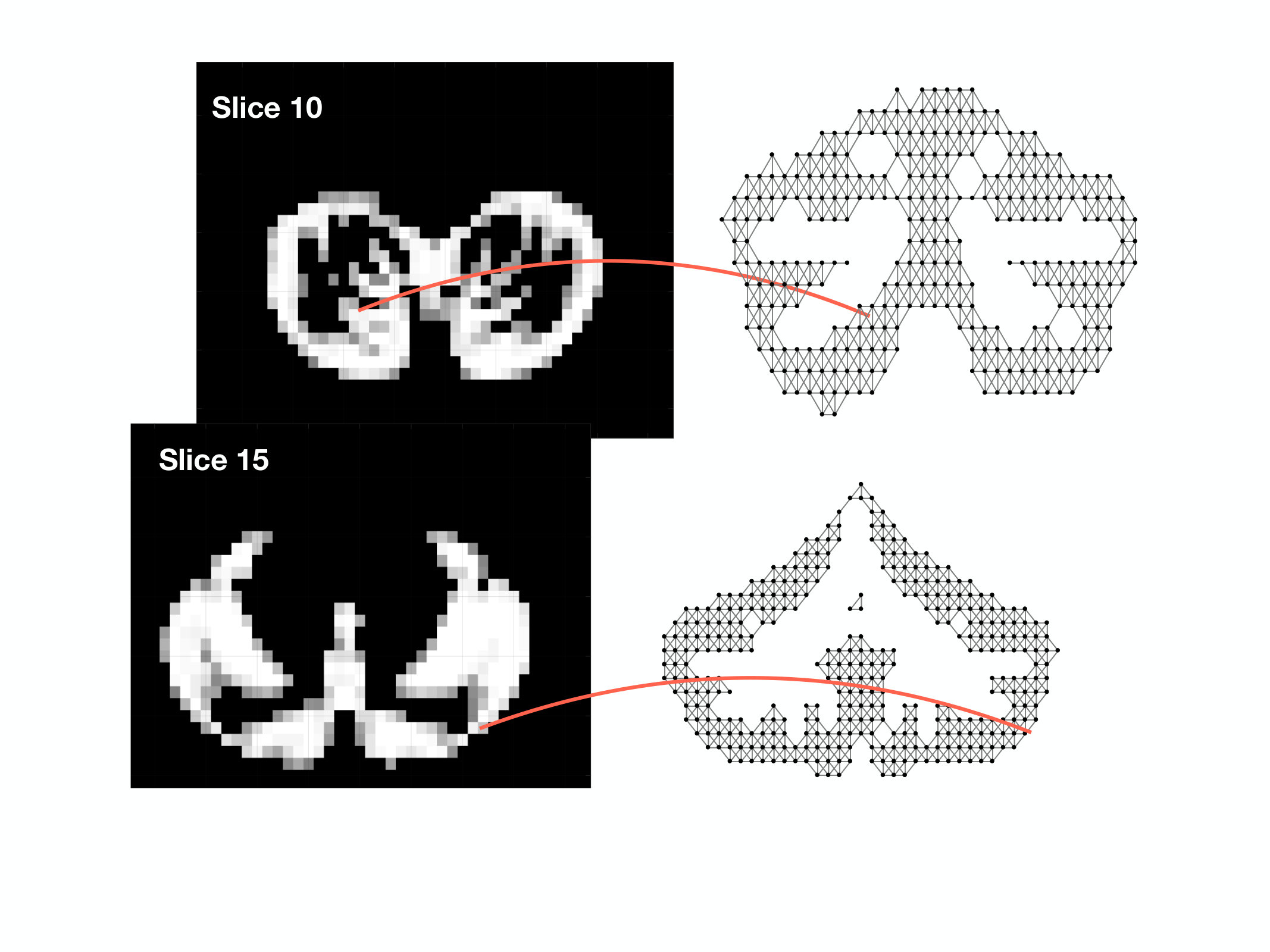 Figure 1
Figure 1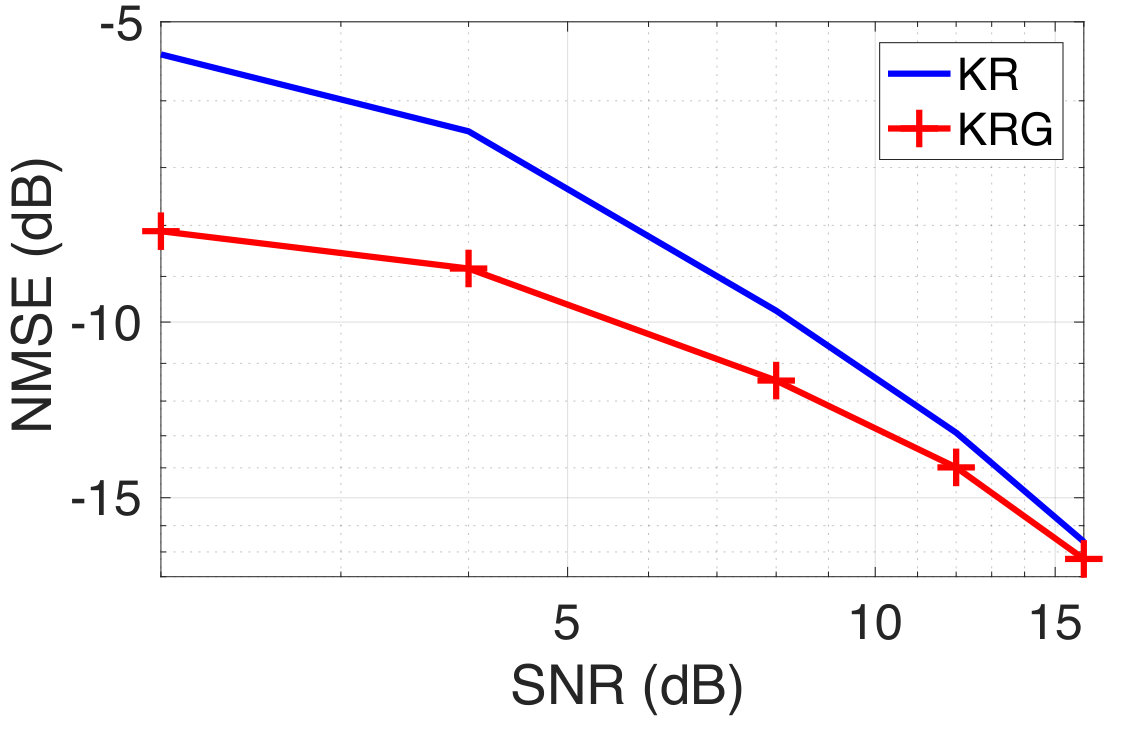 Figure 1
Figure 1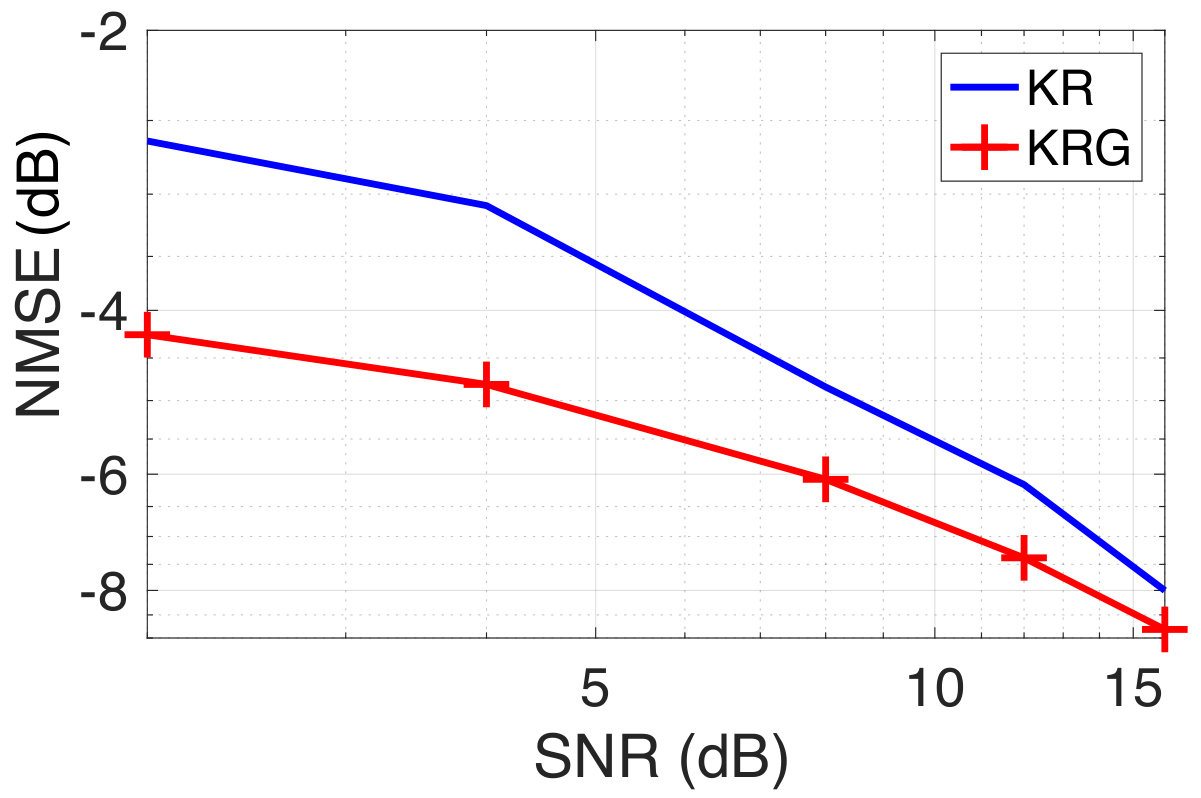 Figure 1
Figure 1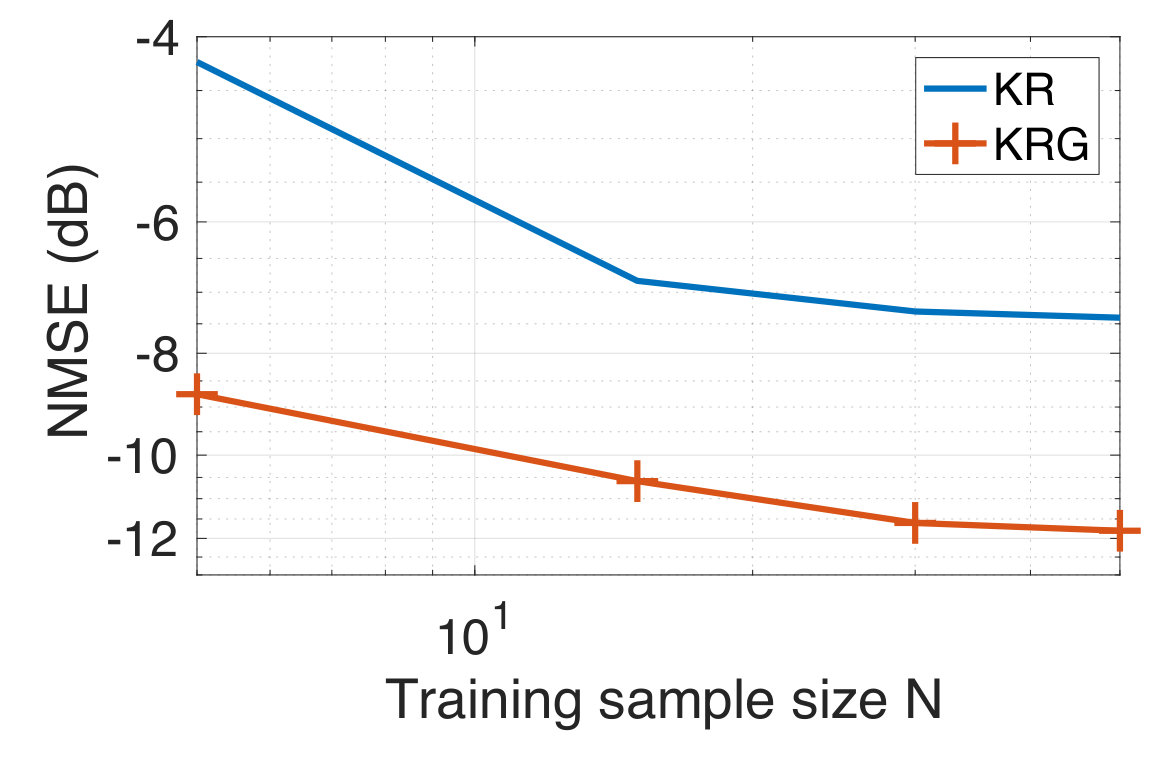 Figure 2
Figure 2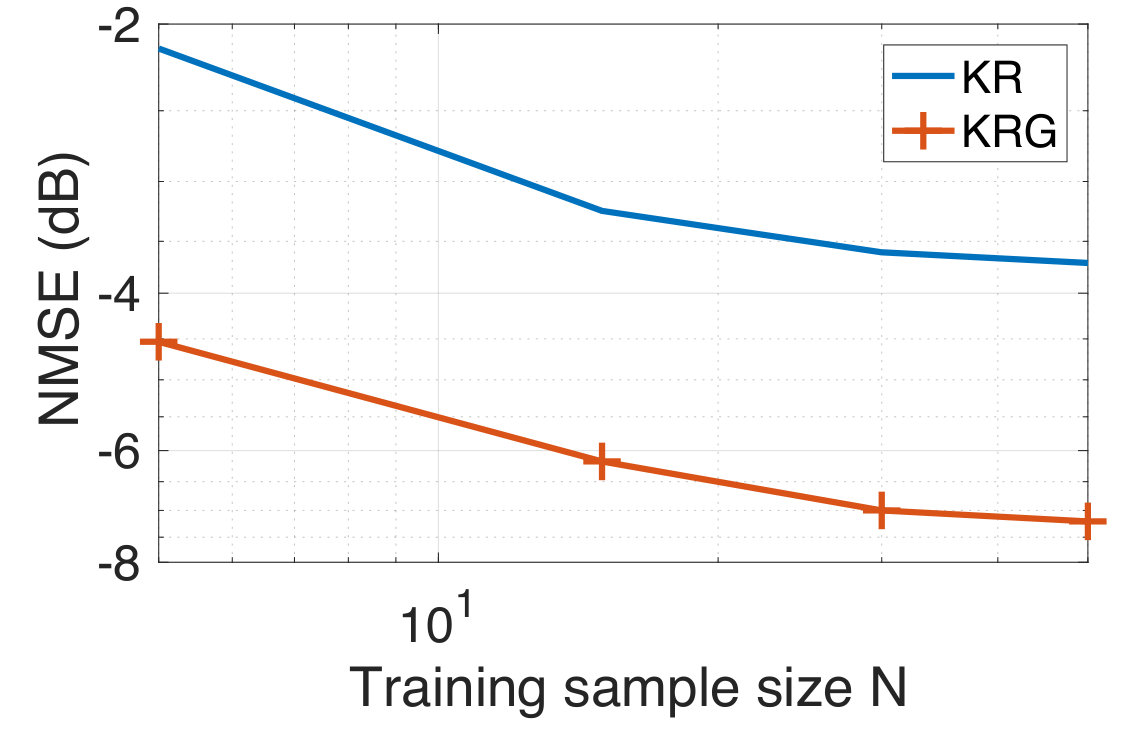 Figure 2
Figure 2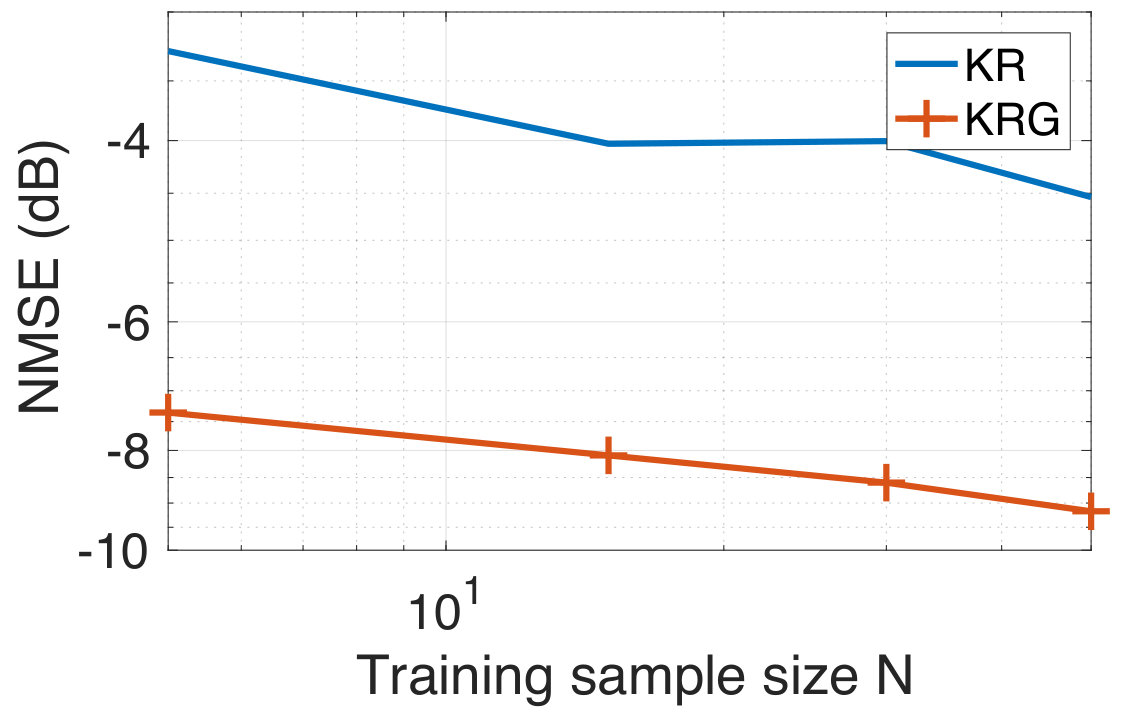 Figure 2
Figure 2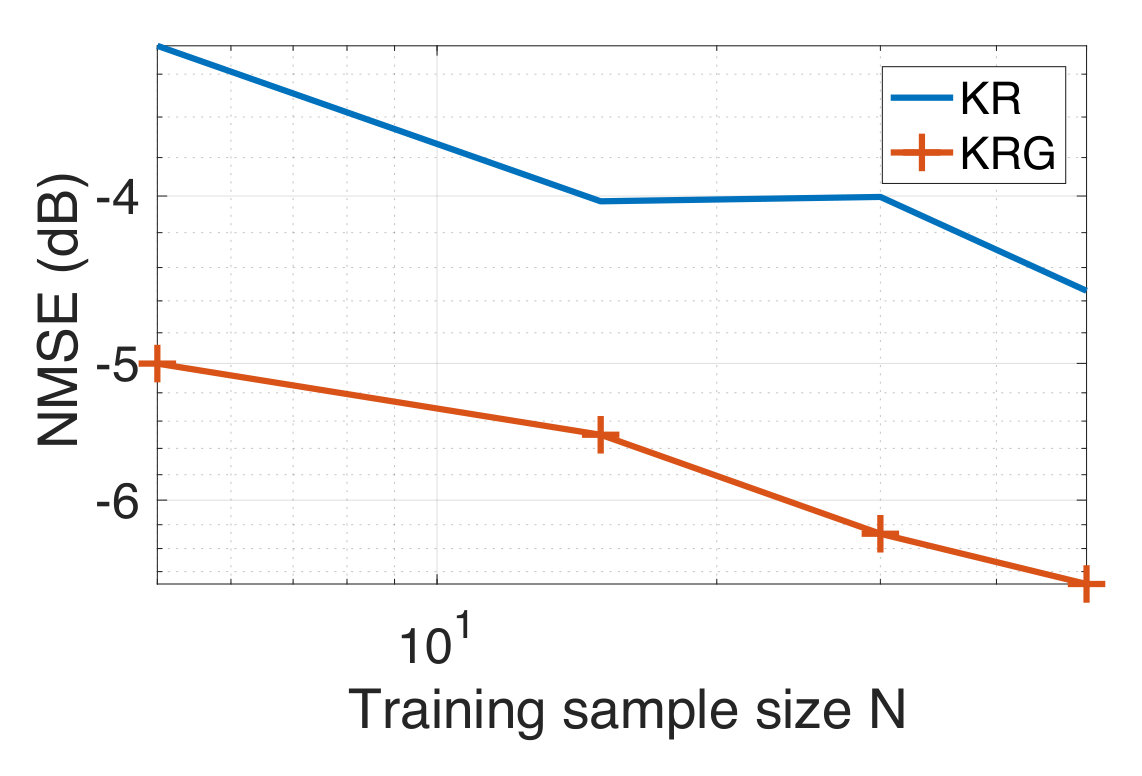 Figure 2
Figure 2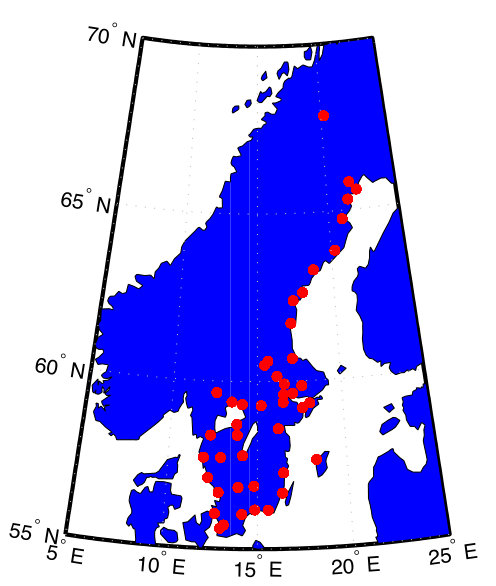 Figure 3
Figure 3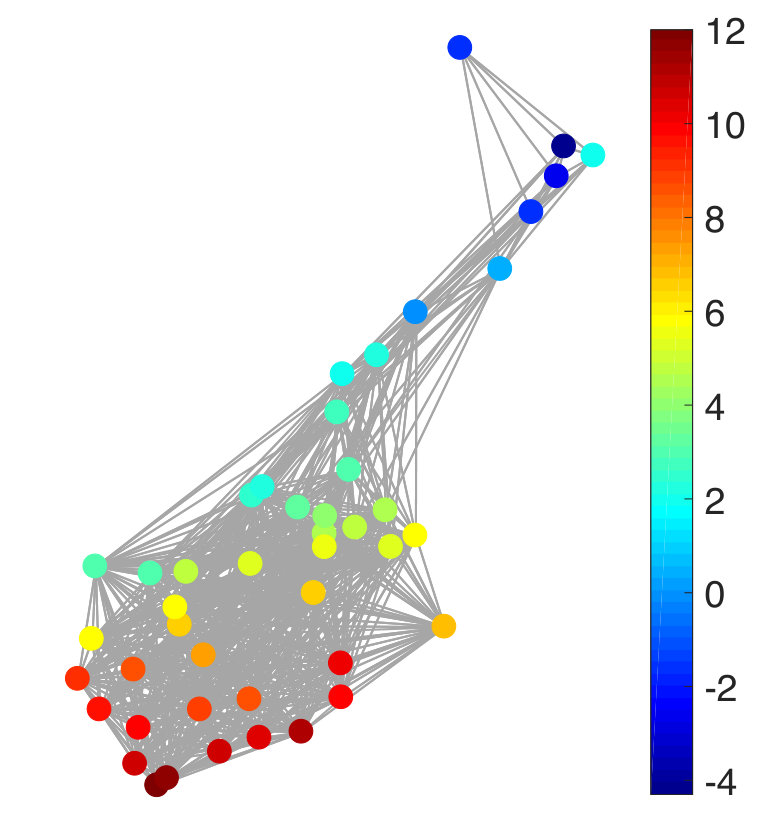 Figure 3
Figure 3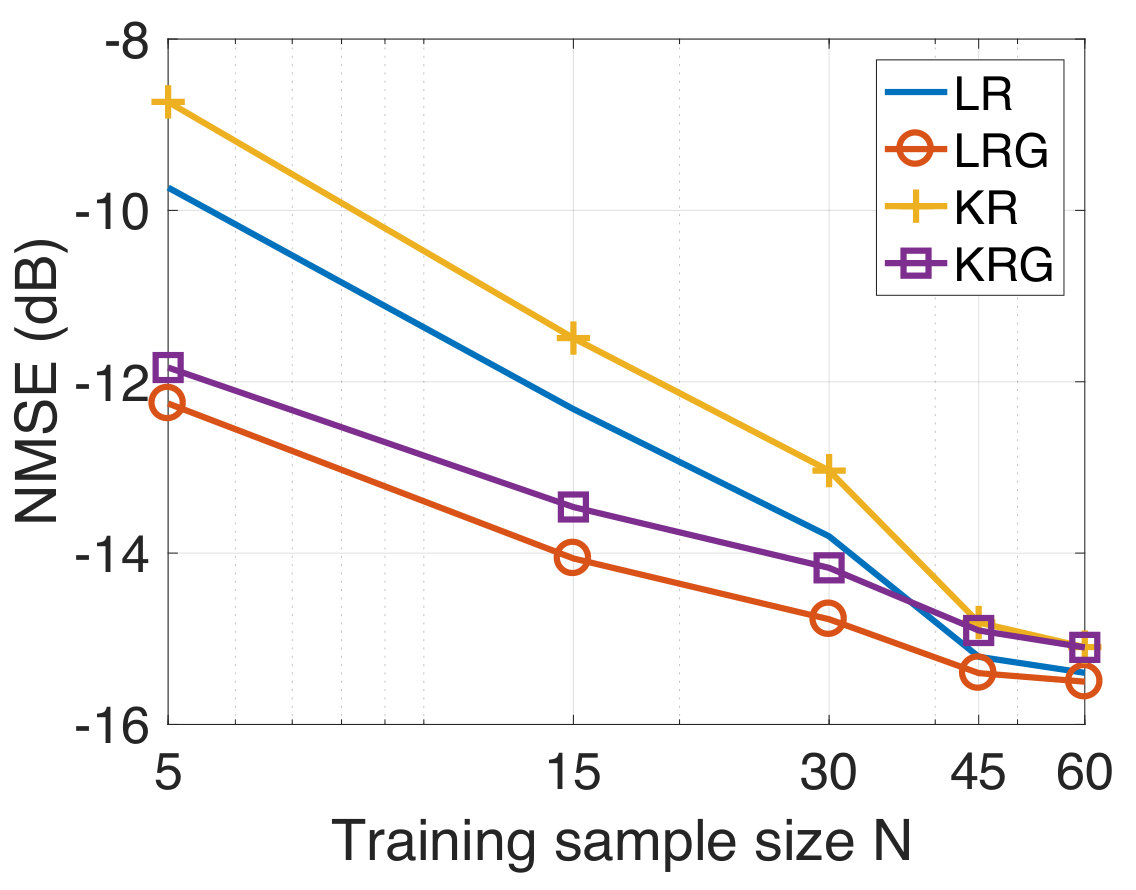 Figure 3
Figure 3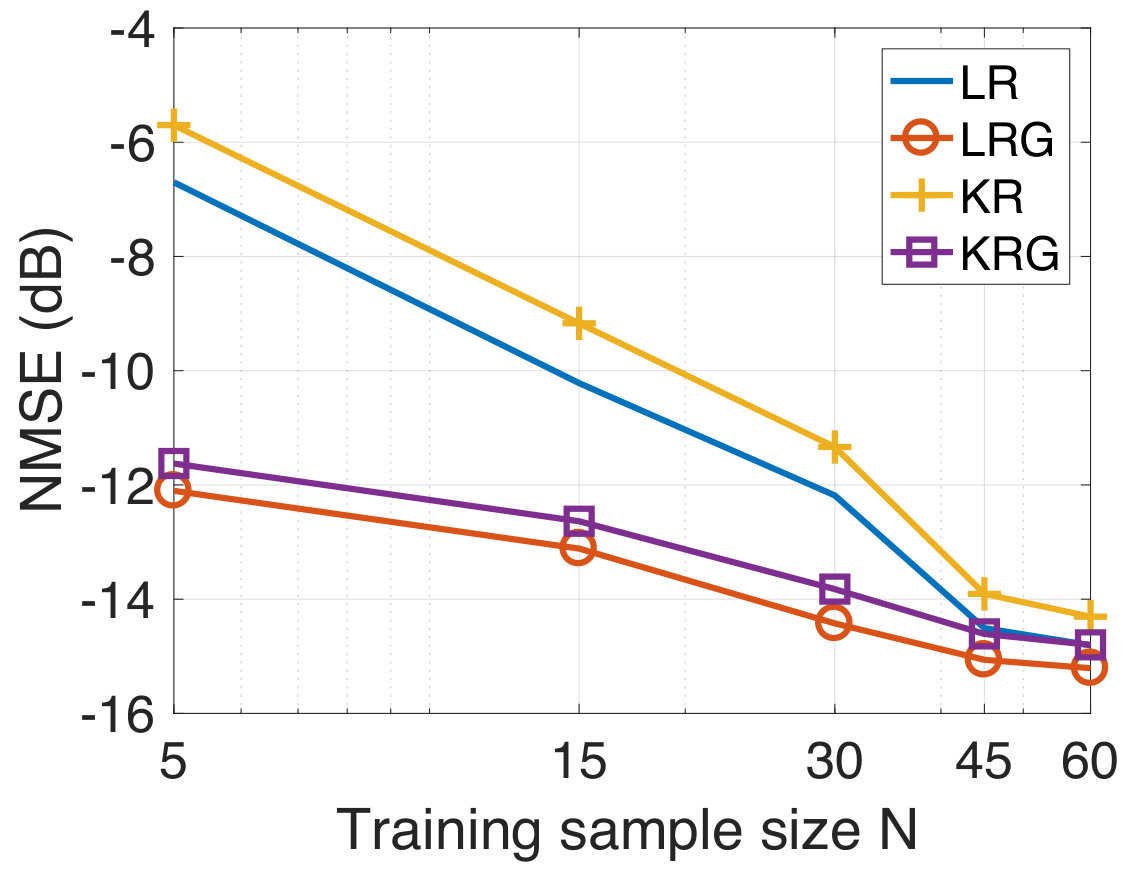 Figure 3
Figure 3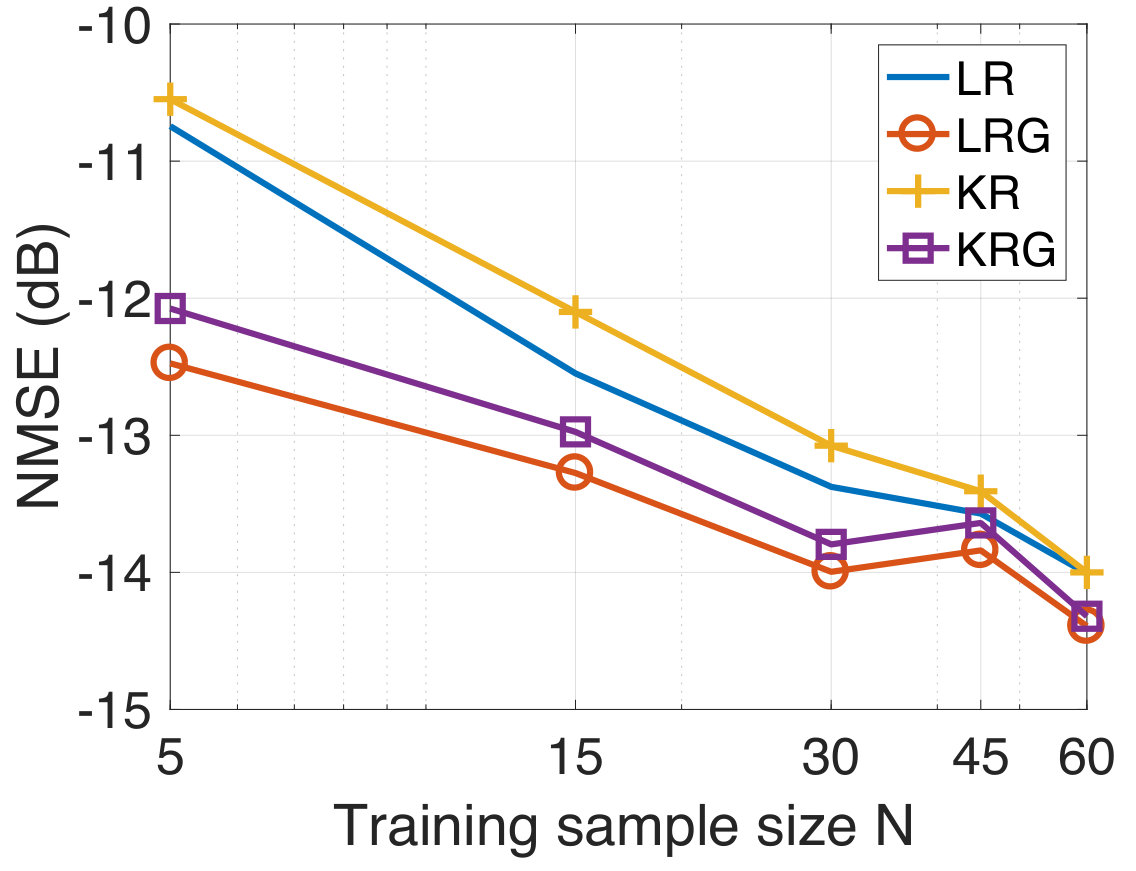 Figure 3
Figure 3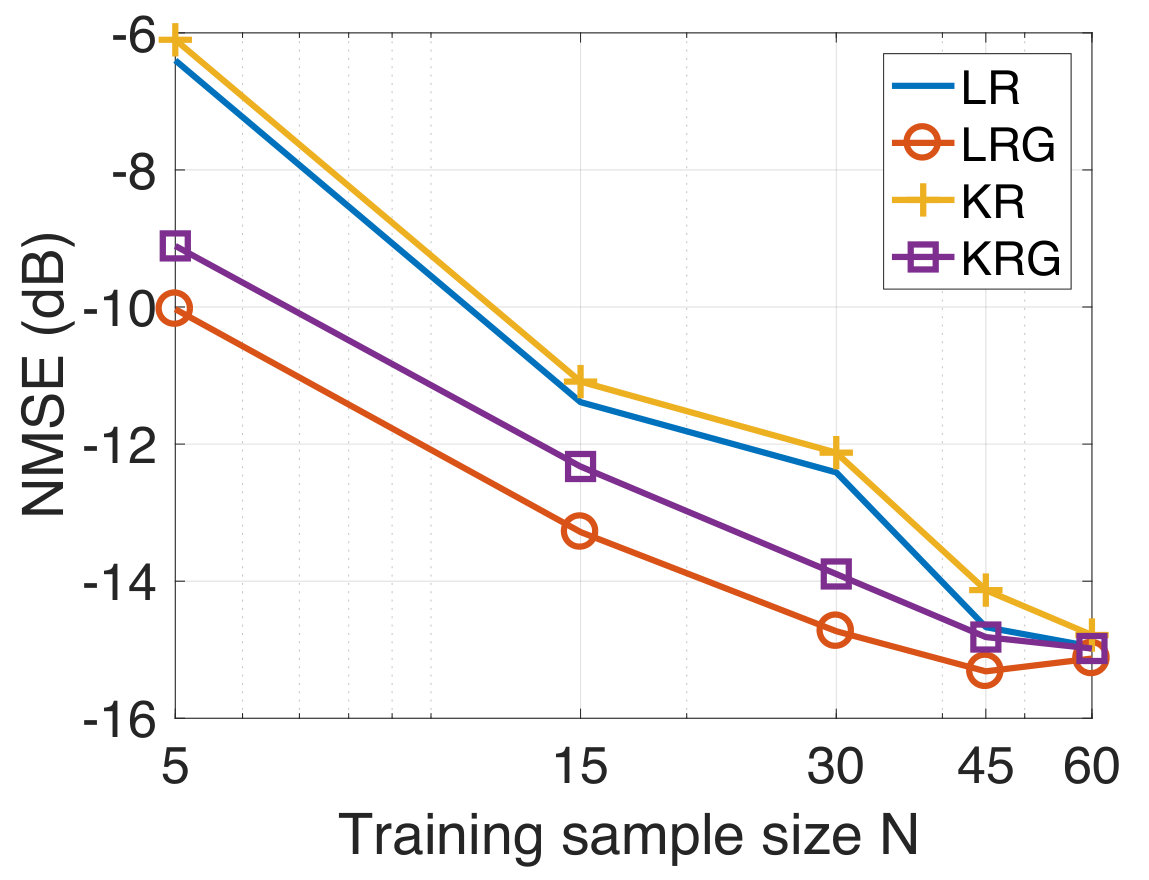 Figure 3
Figure 3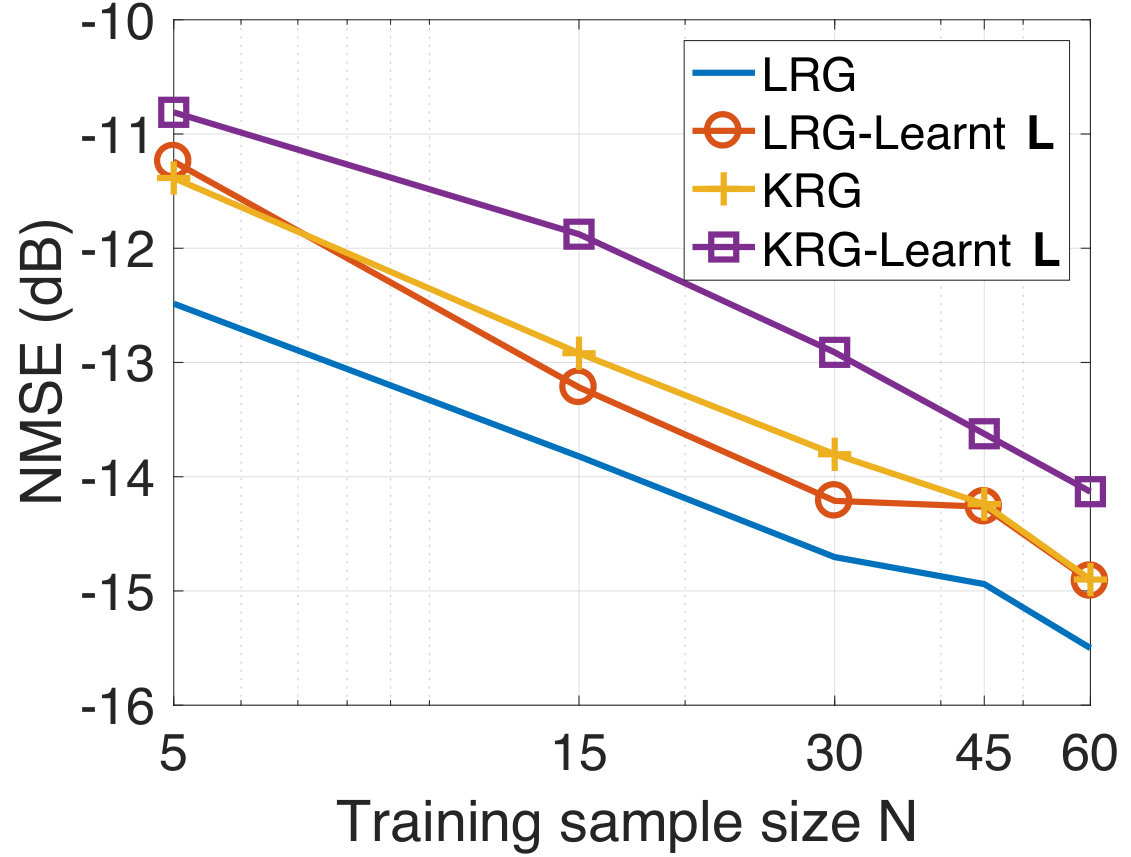 Figure 4
Figure 4 Figure 4
Figure 4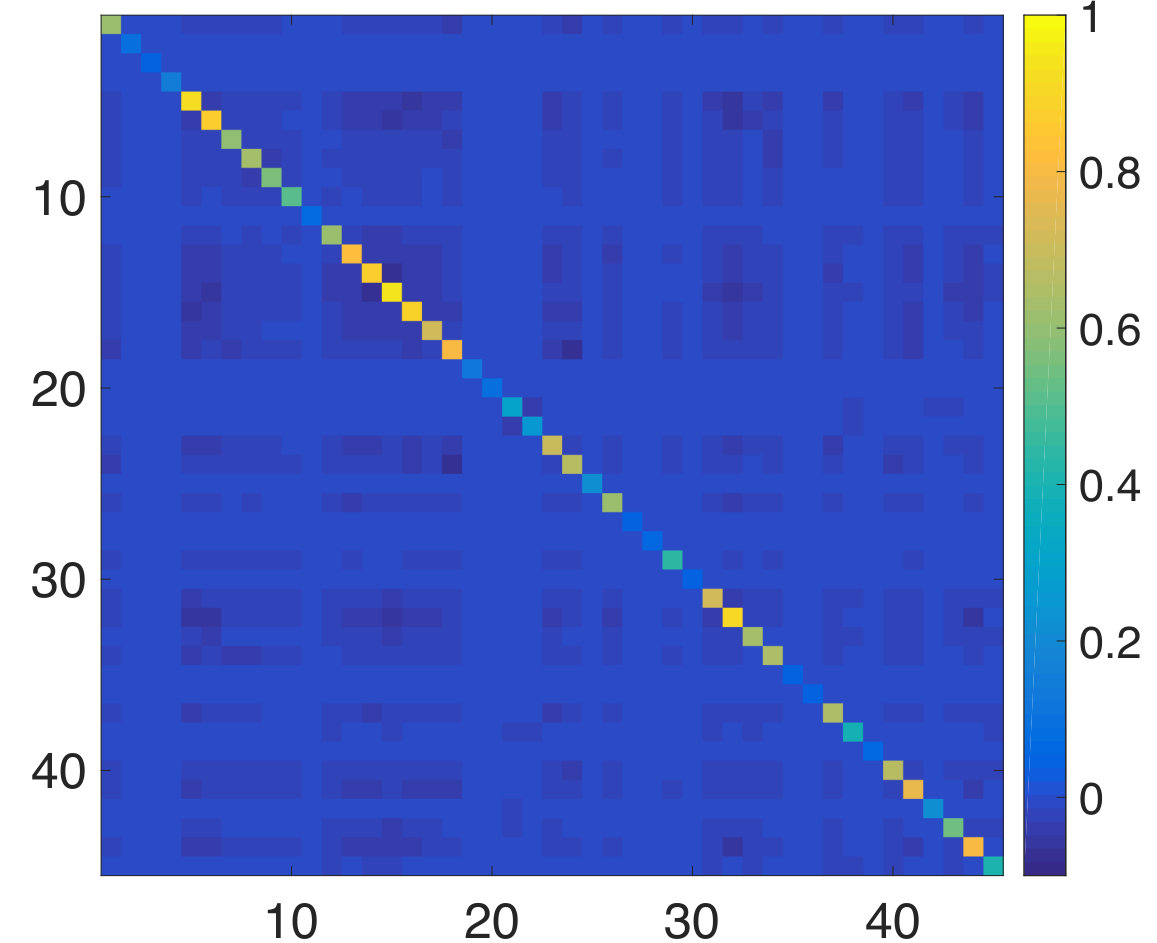 Figure 4
Figure 4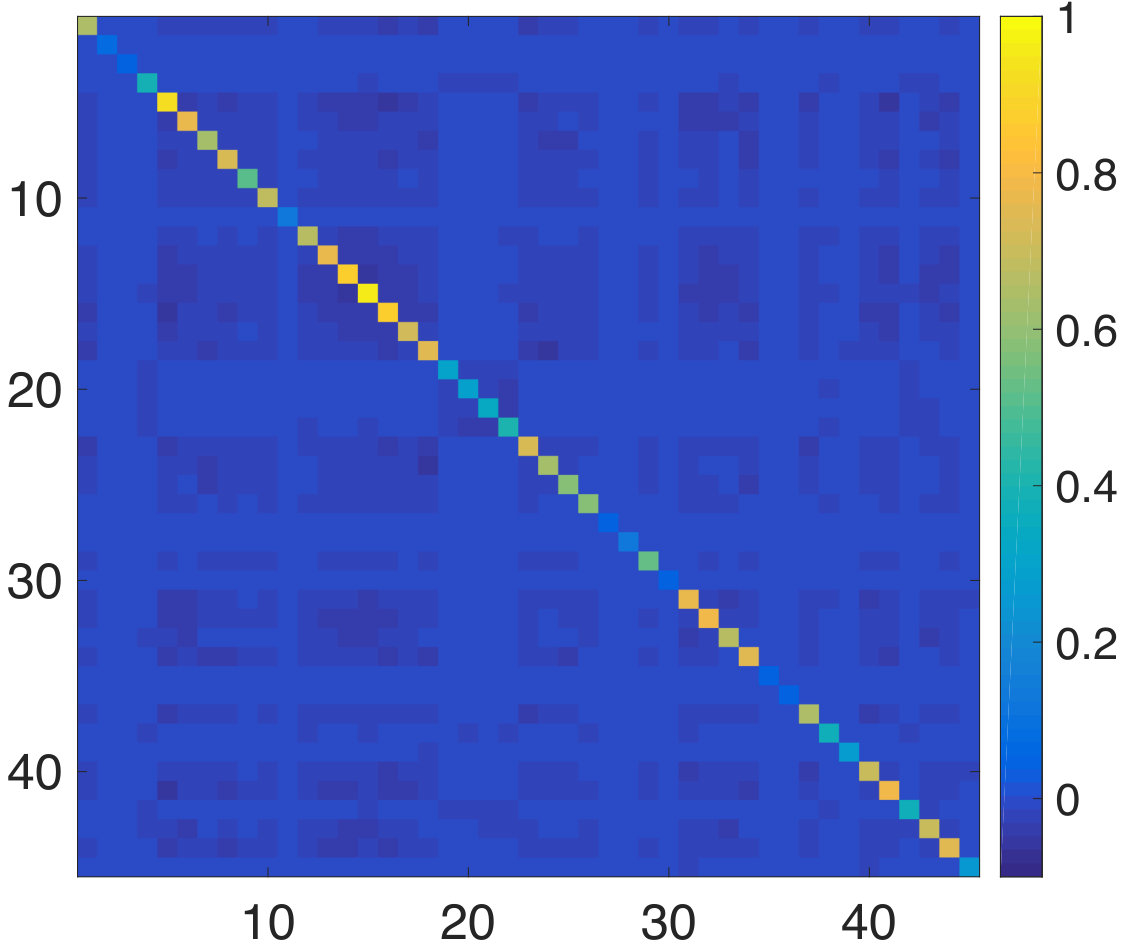 Figure 4
Figure 4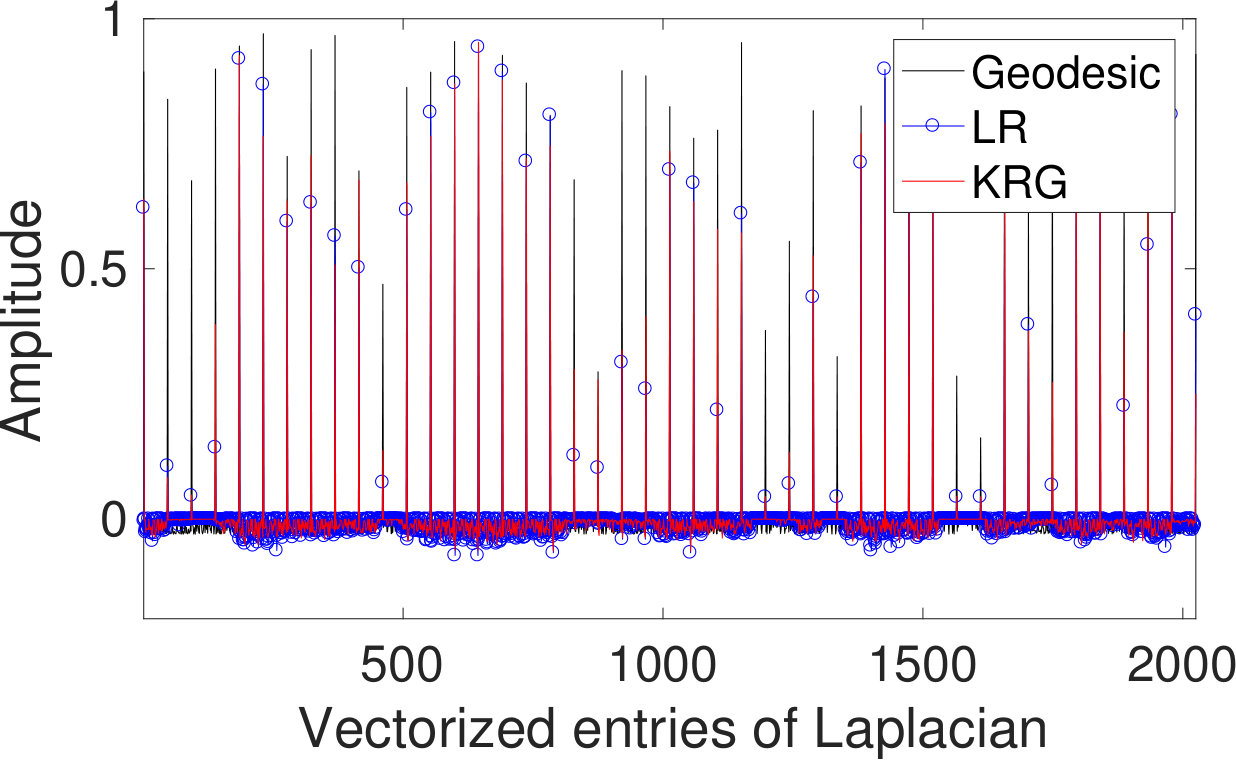 Figure 4
Figure 4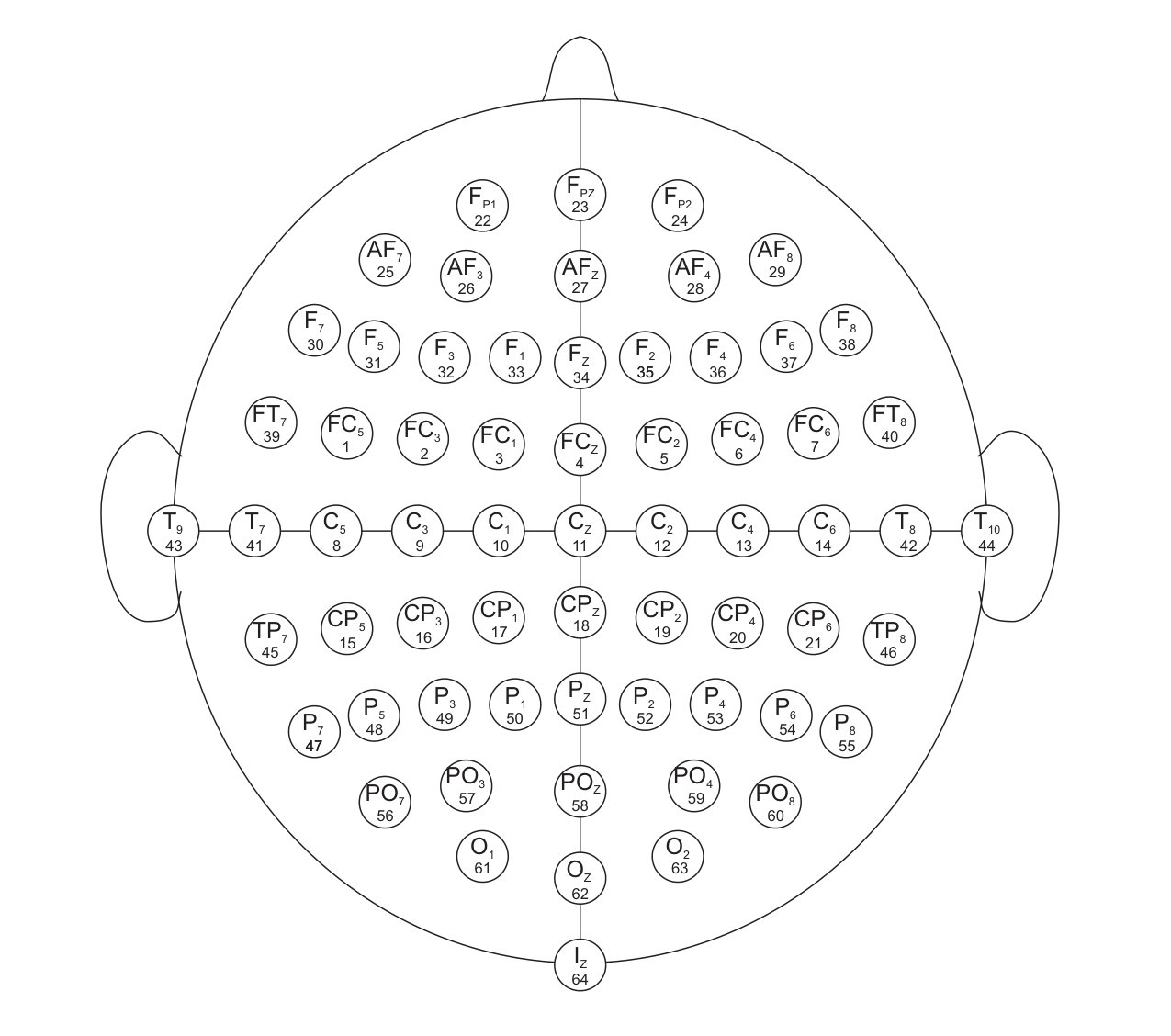 Figure 5
Figure 5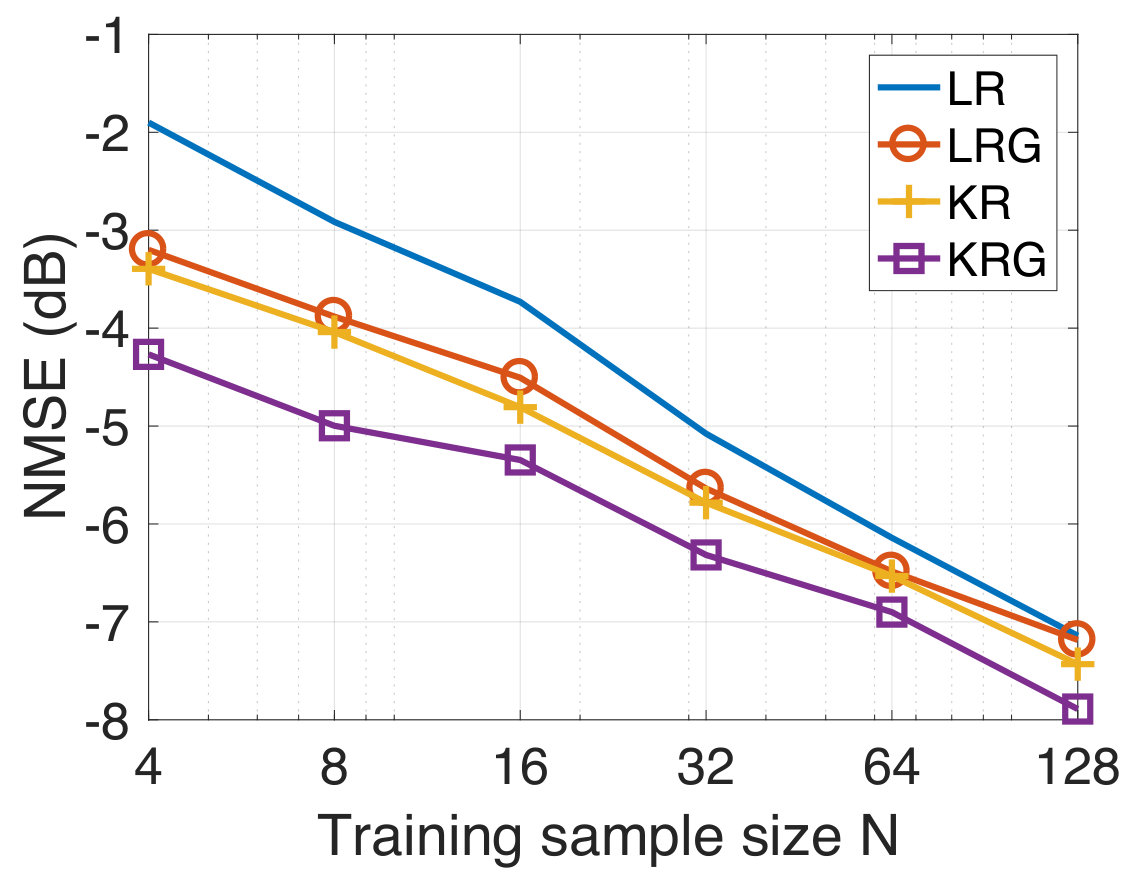 Figure 5
Figure 5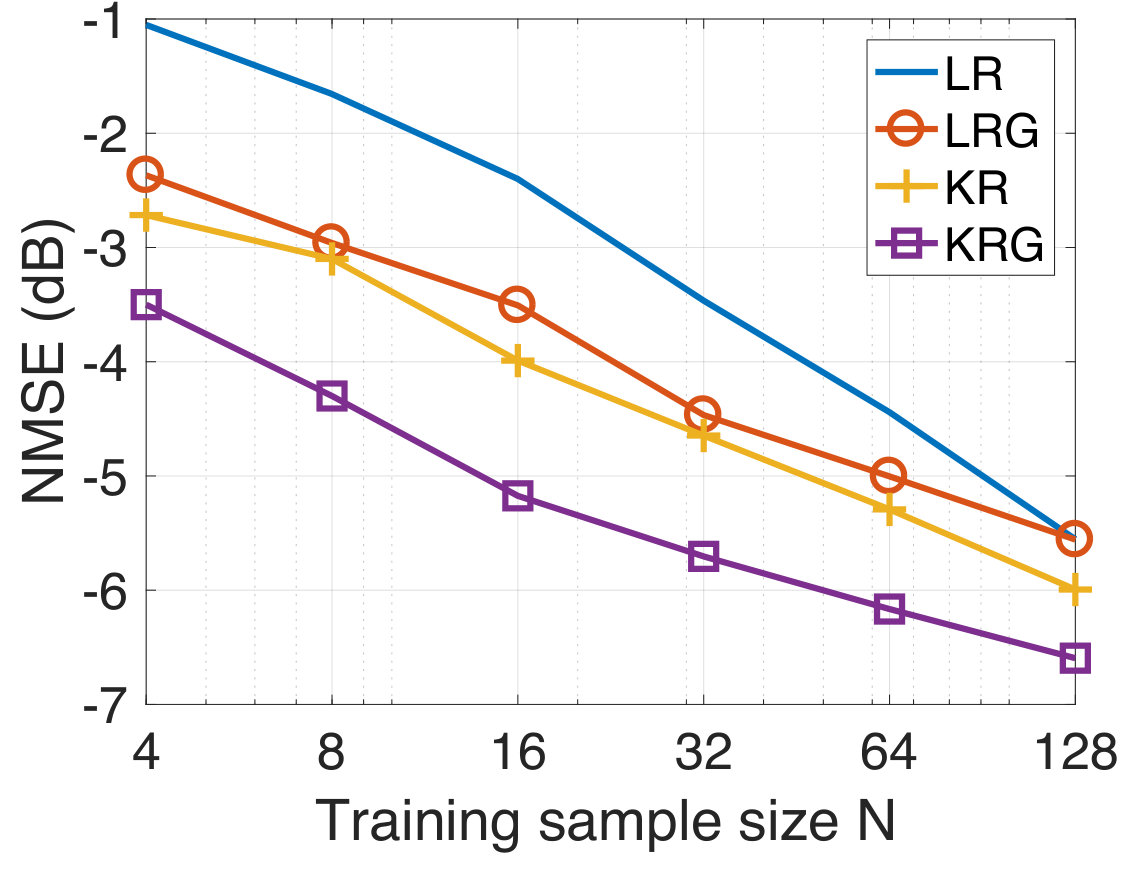 Figure 5
Figure 5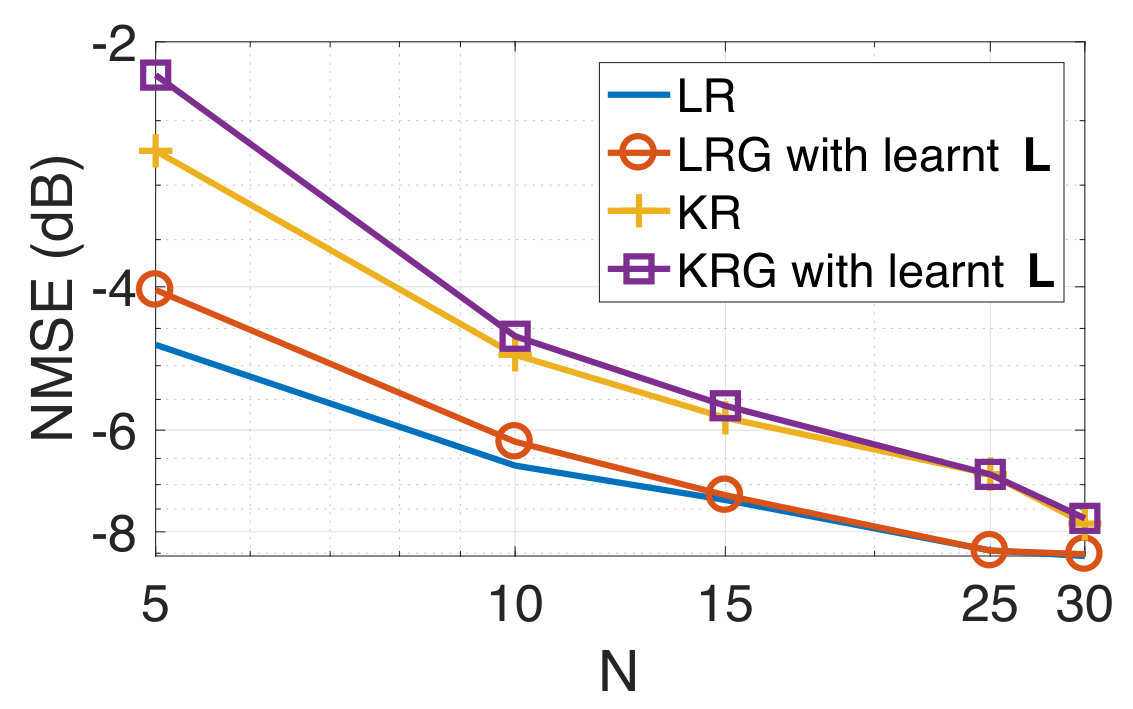 Figure 5
Figure 5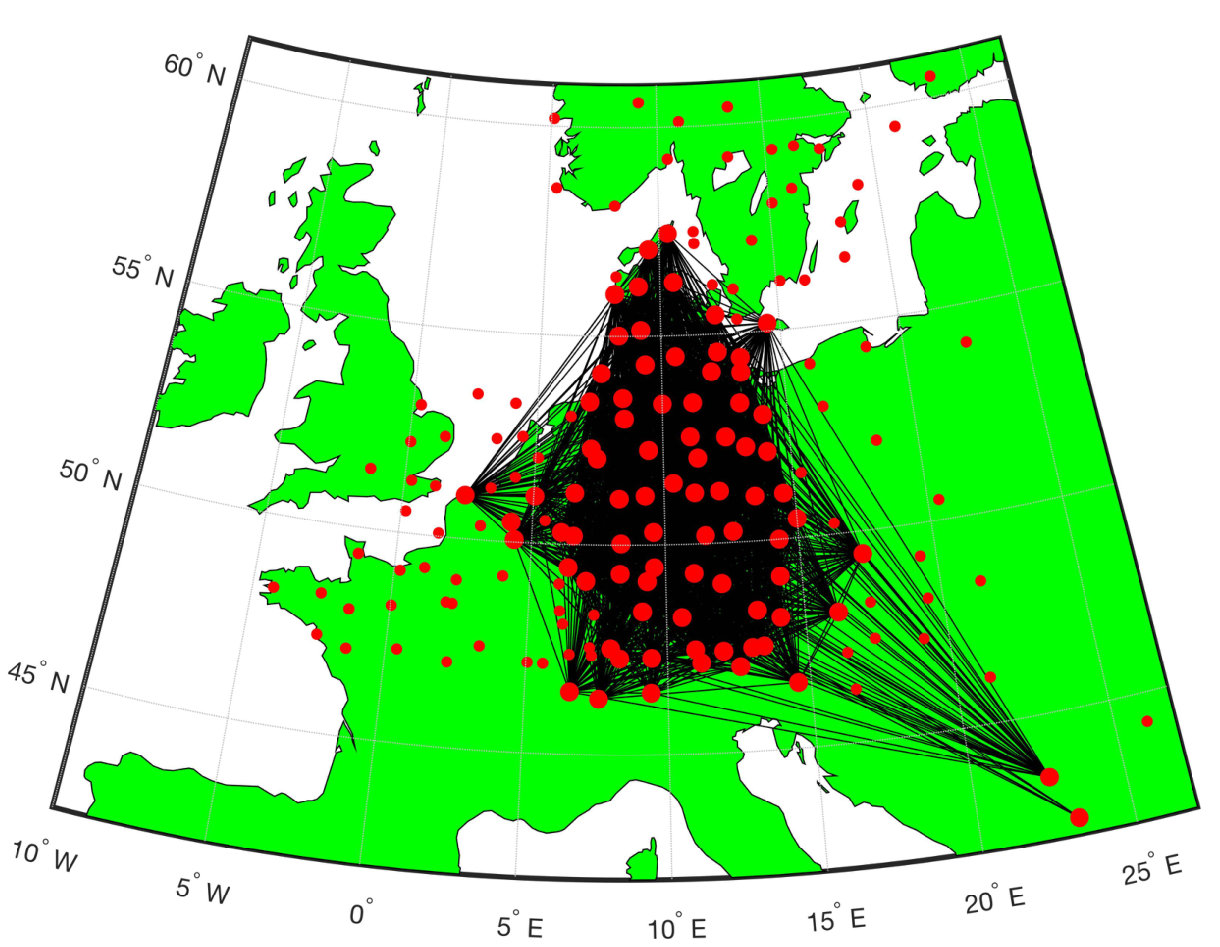 Figure 6
Figure 6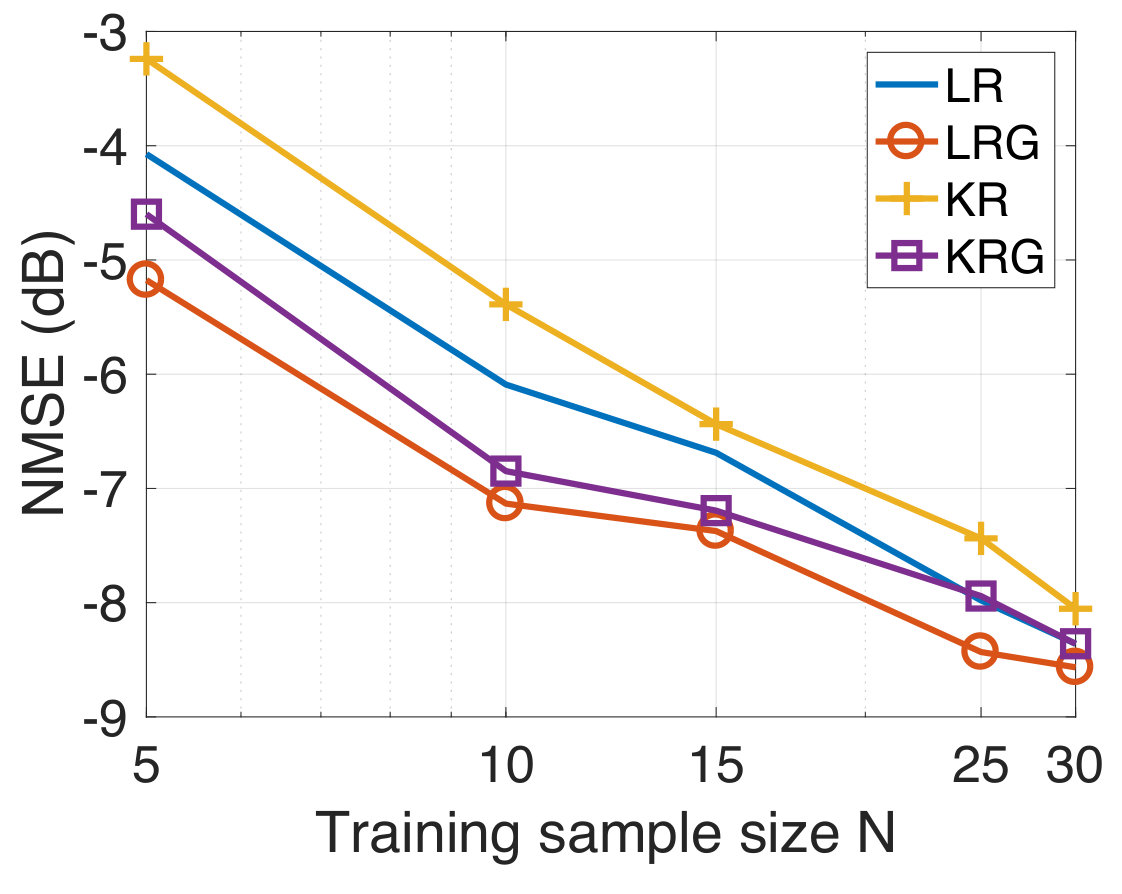 Figure 6
Figure 6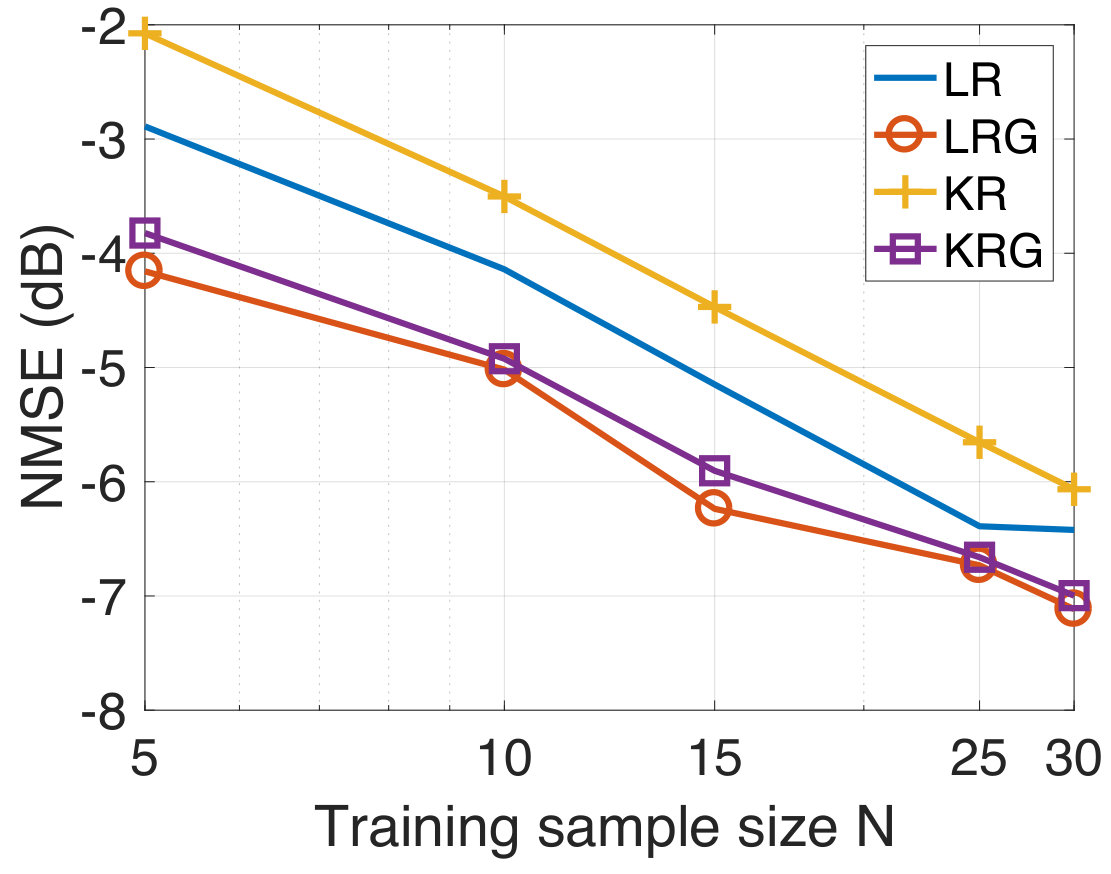 Figure 6
Figure 6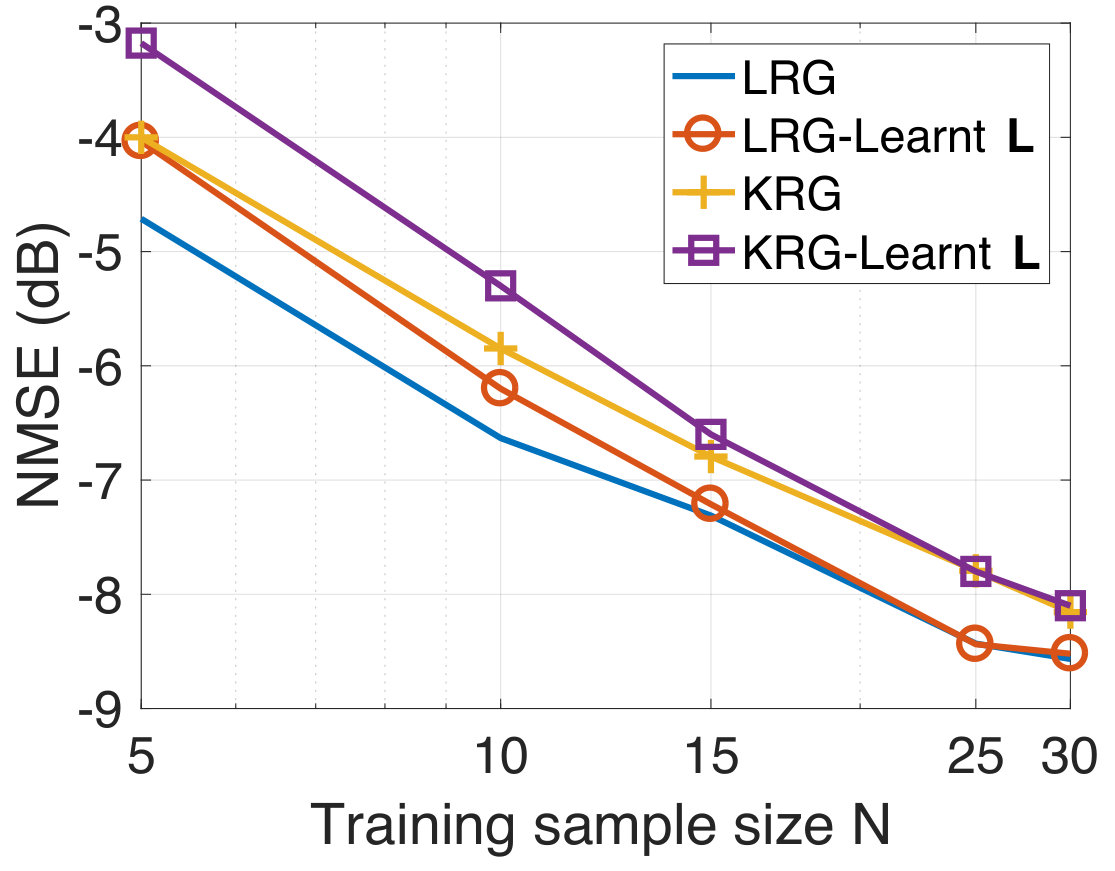 Figure 6
Figure 6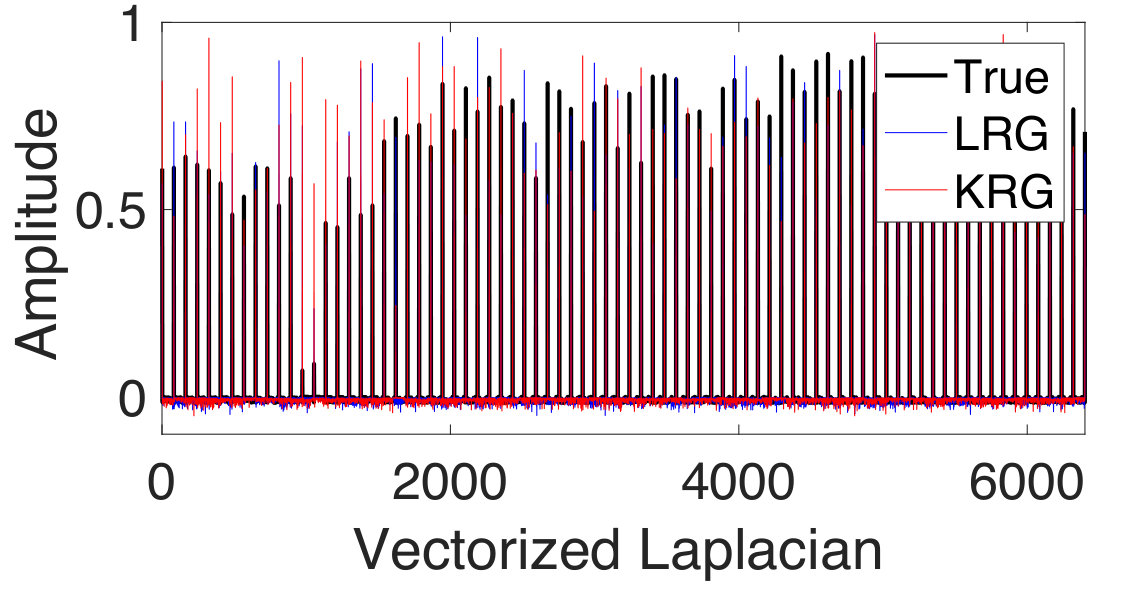 Figure 6
Figure 6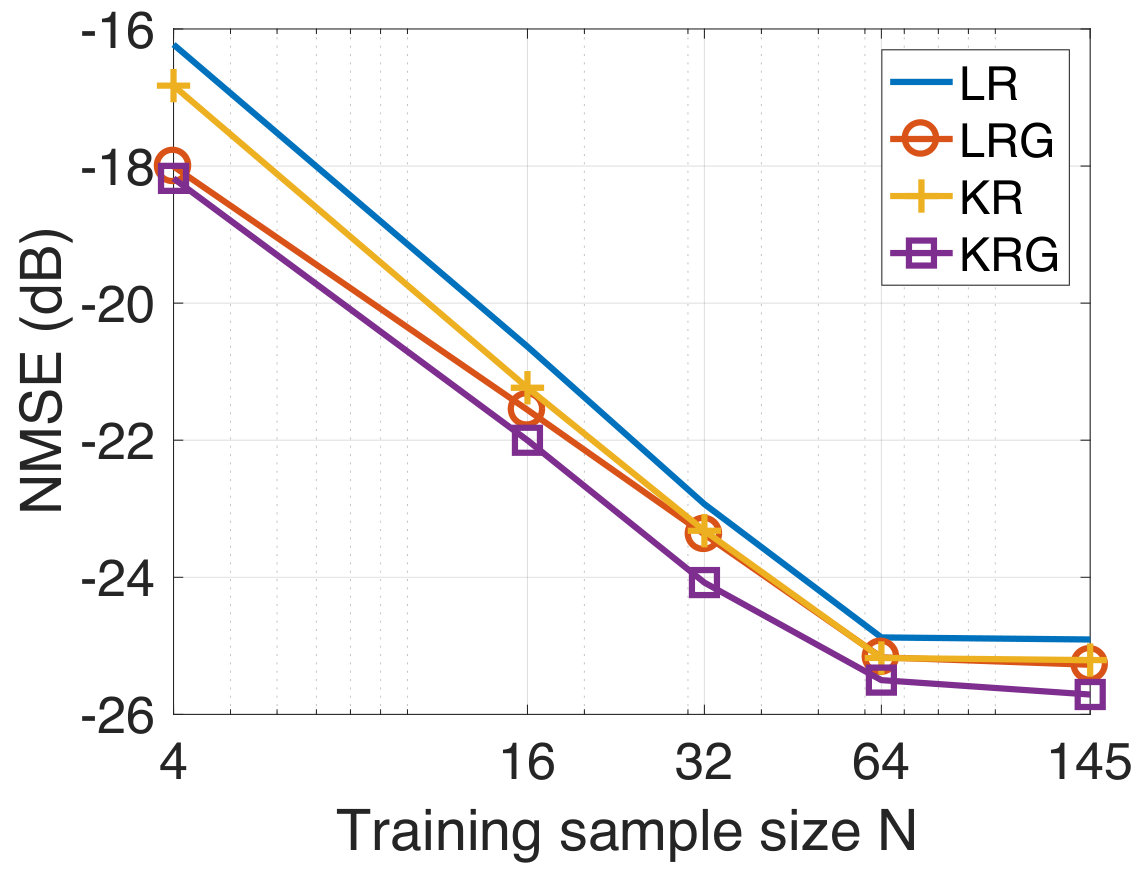 Figure 7
Figure 7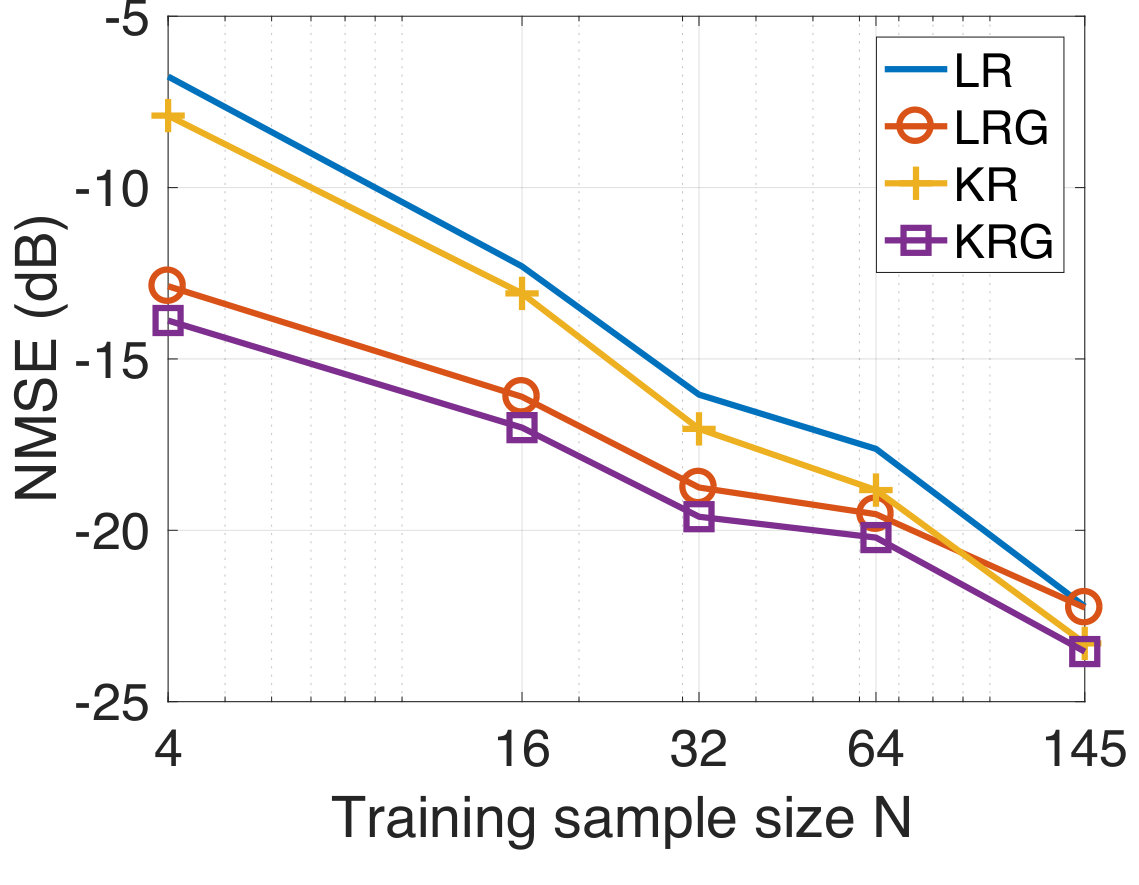 Figure 7
Figure 7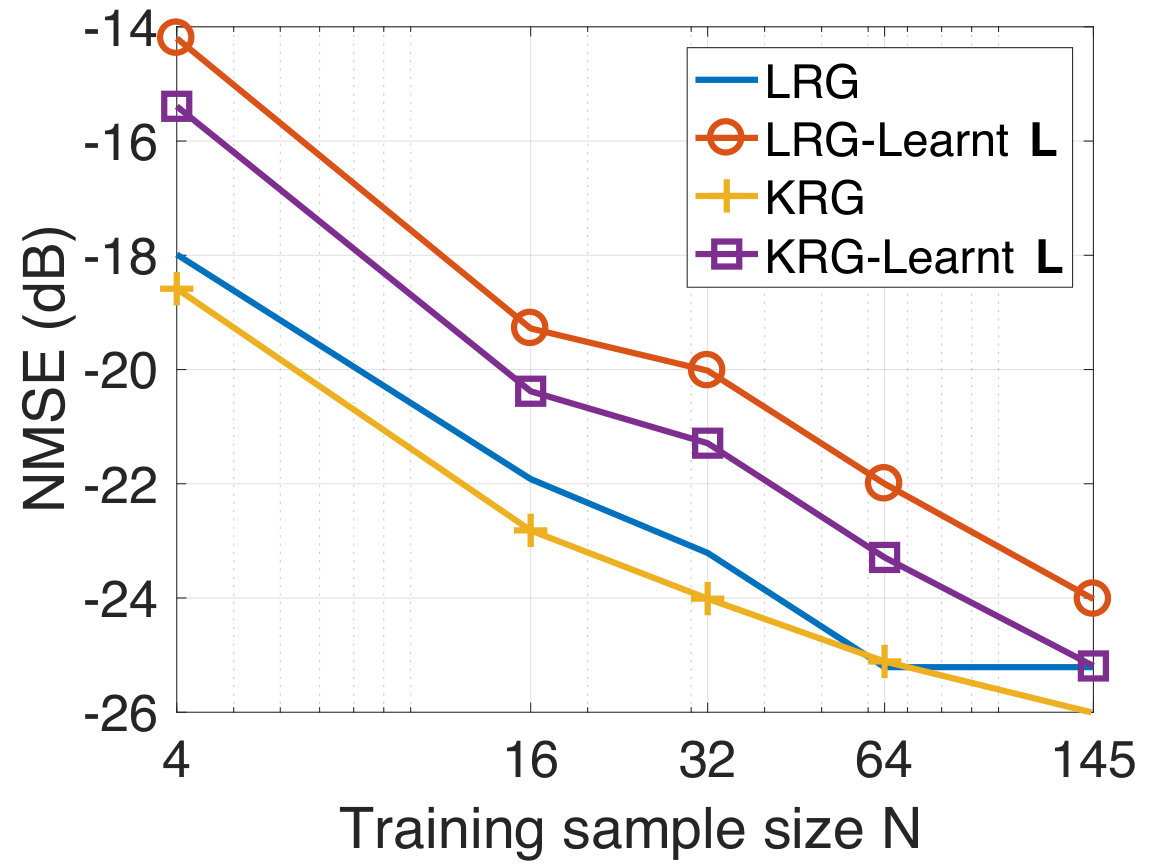 Figure 7
Figure 7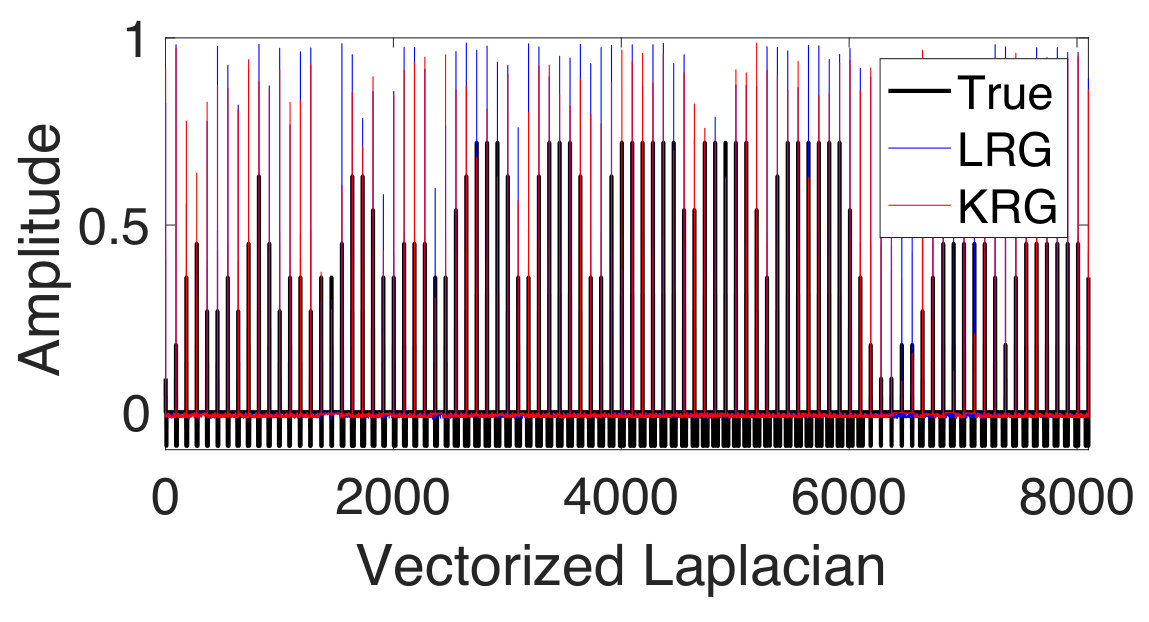 Figure 7
Figure 7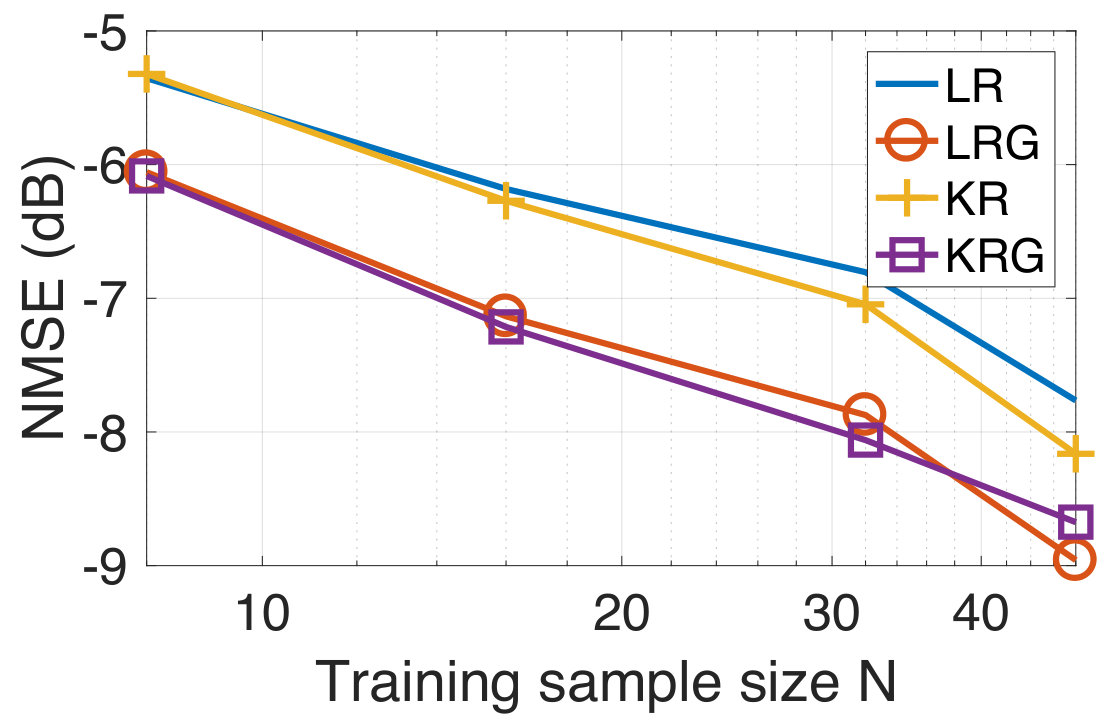 Figure 37
Figure 37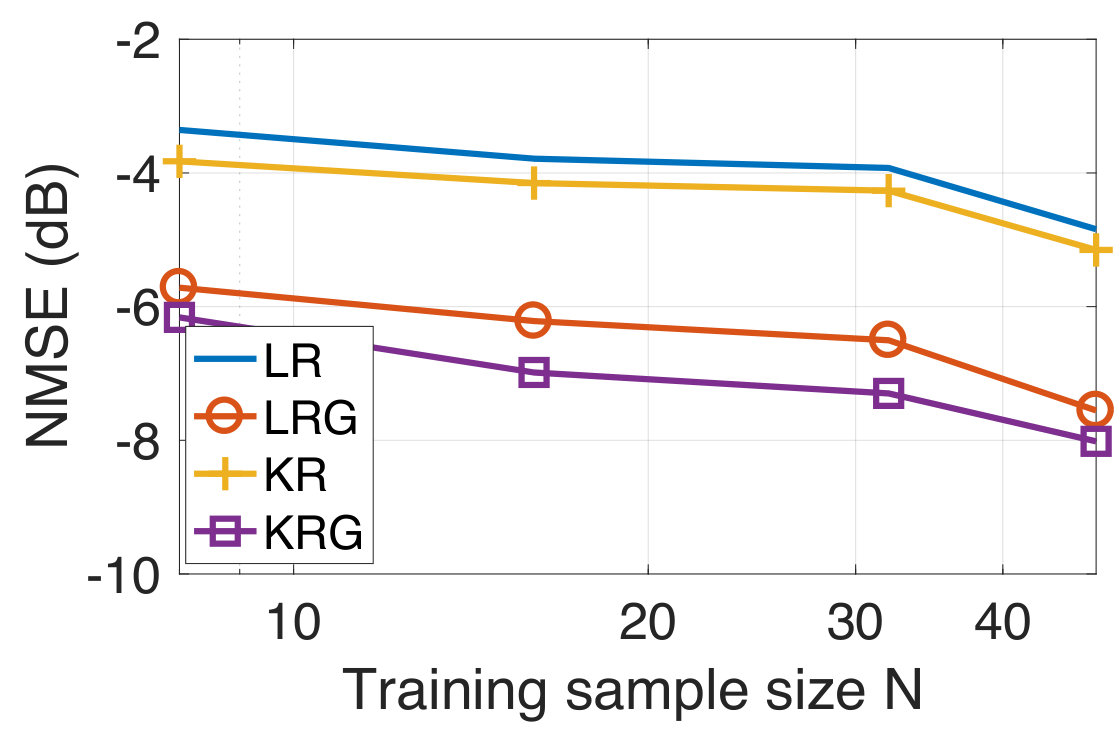 Figure 38
Figure 38| Kernel Ridge Regression (KRR) | Proposed Methods | ||||||
| Training sample | Diffusion | Covariance kernel | Covariance kernel | LRG at | KRG at | LRG at | KRG at |
| size | kernel | at 5dB SNR | at 0dB SNR | 5dB SNR | 5dB SNR | 0dB SNR | 0dB SNR |
| 5 | 2.8 | -6.5 | -3.5 | -12.3 | -11.9 | -12.1 | -11.6 |
| 15 | ” | -7.2 | -4.9 | -14.0 | -13.4 | -13.1 | -12.7 |
| 30 | ” | -9.8 | -6.7 | -14.8 | -14.2 | -14.4 | -13.8 |
| 45 | ” | -10.5 | -7.8 | -15.4 | -14.9 | -15.0 | -14.6 |
| 60 | ” | -12.2 | -9.5 | -15.5 | -15.1 | -15.2 | -14.8 |
| Kernel Ridge Regression (KRR) | Proposed Methods | ||||||
|---|---|---|---|---|---|---|---|
| Training sample | Diffusion | Covariance kernel | Covariance kernel | LRG at | KRG at | LRG at | KRG at |
| size | kernel | at 10dB SNR | at 0dB SNR | 10dB SNR | 10dB SNR | 0dB SNR | 0dB SNR |
| 145 | 0.01 | -1.0 | -0.7 | -25.3 | -25.7 | -22.2 | -23.5 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Predicting Graph Signals using Kernel Regression where the Input Signal is Agnostic to a Graph
Arun Venkitaraman, Saikat Chatterjee, Peter Händel
Department of Information Science and Engineering
School of Electrical Engineering and Computer Science
KTH Royal Institute of Technology, SE-100 44 Stockholm, Sweden
[email protected], [email protected], [email protected]
Abstract
We propose a kernel regression method to predict a target signal lying over a graph when an input observation is given. The input and the output could be two different physical quantities. In particular, the input may not be a graph signal at all or it could be agnostic to an underlying graph. We use a training dataset to learn the proposed regression model by formulating it as a convex optimization problem, where we use a graph-Laplacian based regularization to enforce that the predicted target is a graph signal. Once the model is learnt, it can be directly used on a large number of test data points one-by-one independently to predict the corresponding targets. Our approach employs kernels between the various input observations, and as a result the kernels are not restricted to be functions of the graph adjacency/Laplacian matrix. We show that the proposed kernel regression exhibits a smoothing effect, while simultaneously achieving noise-reduction and graph-smoothness. We then extend our method to the case when the underlying graph may not be known apriori, by simultaneously learning an underlying graph and the regression coefficients. Using extensive experiments, we show that our method provides a good prediction performance in adverse conditions, particularly when the training data is limited in size and is noisy. In graph signal reconstruction experiments, our method is shown to provide a good performance even for a highly under-determined subsampling.
Index Terms:
Linear model, regression, kernels, machine learning, graph signal processing, graph-Laplacian.
EDICSADEL-SIPOG
I Introduction
Graph signal processing (GSP) has emerged recently as a framework which employs graph-structural information in the analysis and processing of vector-valued signals [1, 2]. The framework has been shown to exhibit great potential in a wide range of real-world applications that deal with data over networks or graphs. By actively making use of the graph or the network structure, GSP deals with the extension of several traditional signal processing and machine learning concepts to a graph signal setting. In this article, our contribution to GSP is the development of a supervised kernel regression method for predicting graph signal outputs from general input observations. In the next two subsections, we provide a review of the existing literature, followed by our contributions placed in the context of the existing methods.
I-A Literature review
The extension of traditional signal processing methods to graph signal processing includes many conventional spectral analysis concepts such as the windowed Fourier transforms, filterbanks, multiresolution analysis, and wavelets [2, 3, 4, 1, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]. Spectral clustering approaches based on graph signal filtering have also been proposed [19, 20]. The problems of sub-sampling and interpolation of signals lying over graphs have been considered extensively in diverse settings[21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31]. Techniques for compression and representation of signals such as the principal component analysis (PCA) [32, 33] and dictionary learning approaches [34, 35, 36, 37] have also been proposed for graph signals. Many researchers have considered the statistical analysis of graph signals particularly in the context of stationarity [38, 39, 40, 41, 42, 43]. The reconstruction and estimation of graph signals have also been steadily gaining interest in the community. Berger et al. [44] and Chen et al. [45] considered the recovery of graph signals based on a total-variation minimization formulated as a convex optimization problem. Wang et al. [46] considered a distributed reconstruction of time-varying bandlimited graph signals. Di Lorenzo et al. [47] proposed a least mean squares approach for the adaptive estimation and tracking of bandlimited graph signals. Several approaches have also been proposed for learning an underlying graph structure from the given graph signal data [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58]. GSP is a rich and continually expanding area of research and we refer the reader to [59] for a more comprehensive review of the developments.
We now proceed to briefly survey the relevant literature in kernel regression and kernel methods. Kernel regression constitutes one of the fundamental building blocks of supervised and semi-supervised learning strategies, be it in simple regression tasks or in the more advanced settings. Kernel regression lies at the core of support vector machines [60] and Gaussian processes [61], and finds applications in deep neural networks[62, 63] and extreme learning machines[64, 65]. Kernel regression in the setting of graphs or manifolds has been investigated in the labeling and coloring of graphs and in the context of graph clustering [66, 67, 68, 69, 70, 71, 72, 73]. These works generally deal with signals which are binary-valued. Kernel regression has been employed in image deblurring by using a graph-based constraint on the pixel intensities of the deblurred image[74]. Kernel regression was recently used in object saliency detection and spatial attention modeling in images, wherein the kernel matrix was simultaneously used to define a Laplacian matrix, in order to recover the smooth images[75]. These prior graph-based approaches incorporate a graph-Laplacian based regularization by defining a graph between the various observations/datapoints and are concerned with an output/target that is scalar valued, such as the node label or the pixel intensity. Kernels have also been extensively employed in the smoothing and regression of brain signals, where the functional connectivity or the topology of the brain surface is described using meshes[76, 77, 78, 79, 80, 81].
Kernel-based reconstruction strategies specific to graph signals were proposed recently by Romero et al. in the framework of reproducing kernel Hilbert spaces[82, 83]. Using the notion of joint space-time graphs, Romero et al. have also proposed a kernel based reconstruction of graph signals and an extension of the Kalman filter for kernel-based learning [84, 85]. Along the same lines of thought, Ioannidis et al. proposed a more general approach for inferring functions over graphs in both static and dynamic settings[86]. Kernel regression combined with diffusion wavelets have been employed in the modeling of mandible growth in CT images[87]. Shen et al. used kernels in structural equation models for the identification of network topologies from graph signals[88]. The prior works of [82, 83, 84, 85, 86] use kernels across the nodes of a graph, while considering the input comprising the signal values over a subset of the nodes of the graph. In these prior works, the setting is that all the observed inputs and the corresponding outputs to be predicted lie jointly over a composite or an augmented graph. As a result, the setting results in large-sized graphs which may not provide a scalable solution when the number of inputs and outputs becomes moderately large. Further, the setting naturally requires that the input and the output variables are of the same physical quantities. Therefore, these prior works suffer from limitations when the input is a fundamentally different physical quantity from the predicted output, or when the input is not a graph signal. For example, consider a scenario where we observe the air pressure of several cities in a country as the input, and the task is to predict the temperature of those cities as the output.
I-B Our contributions vis-a-vis existing works
We propose a kernel regression method for graph signals that can handle scenarios where the input and the output may be entirely different physical quantities, or when the input is not a graph signal or is agnostic to a graph. For example, our method is applicable to the case when the hourly air pressure measurements over the cities in a country is taken as the input, and the predicted output is the temperature of those cities. (Such a real signal example is indeed demonstrated in the numerical experiments section.) This is possible because we treat the input variables without any graph constraints, or as being agnostic to a graph. The graph-awareness is employed only for the output: that the predicted output is a vector lying over a graph. Since we do not use kernels between the nodes of the underlying graph but only across the different observations of the graph signal, our kernel is not necessarily defined or dictated by the underlying graph. This is in contrast with the prior works where the kernel matrix is an explicit function of the graph adjacency matrix and the kernel is across the different nodes of the same graph. In several applications where the input is also a graph signal, experiments with real-world datasets show that our method performs better than those which exploit the graph structure in the input.
The success of our method can be attributed to a standard machine learning concept where a set of training data is used to learn a regression model and then the trained model is used to make predictions on the test data. The prediction at each test datapoint is made independent of the other test datapoints, and is based only on the kernels between the training datapoints and the relevant test datapoint (and not all the test datapoints together). In contrast, in the prior works involving kernels and graph signals [82, 85], the estimation of the graph signal value at even one of the nodes involves the computation of the entire kernel matrix for all the nodes over the graph, and not just over the input or the training nodes. In other words, they employ the entire kernel matrix across all the available training and test datapoints and do not treat a relevant test datapoint independently with respect to the other test datapoints. This is true even for the cases where one predicts a subset of the unobserved nodes or test datapoints.
Further, the independent treatment of the test datapoints allows us to use our regression method on any number of test datapoints. The method does not assume that the number of test datapoints is known from the beginning. Therefore, our method scales well with a large amount of test datapoints and naturally extends to a dynamic tracking setup, such as the Gaussian process model [89]. On the other hand, the works of [82, 83, 84, 85] assume that the number of test datapoints is specified from the beginning.
I-C Signal processing over graphs
We next briefly review some of the basic concepts from graph signal processing. Let denote a graph with nodes indexed by the vertex set . Let and denote the edge set containing pairs of nodes, and the weighted adjacency matrix, respectively. The th entry of the adjacency matrix denotes the strength of the edge between the th and th nodes. There exists an edge between the th and the th nodes if and the edge pair . In our analysis, we consider only undirected graphs with symmetric edge-weights or . The graph-Laplacian matrix of the graph is then defined as
[TABLE]
where is the diagonal degree matrix with the th diagonal element given by the sum of the elements in the th row of . A vector is said to be a graph signal if denotes the value of the signal at the th node of . The quadratic form of with is given by
[TABLE]
We observe that is minimized when the signal takes the same value across all the connected nodes, which agrees with the intuitive concept of a smooth signal. In general, a graph signal is said to be smooth or a low-frequency signal if it has similar values across all the connected nodes in a graph, and is said to be a high-frequency signal if it has dissimilar values across the connected nodes, being the measure of similarity. This motivates the use of as a constraint in the applications where either the signal or the graph-Laplacian is to be estimated[48, 50]. The eigenvectors of are referred to as the graph Fourier transform basis for , and the corresponding eigenvalues are referred to as the graph frequencies. The smaller eigenvalues (the smallest being zero by construction) are referred to as the low frequencies since the corresponding eigenvectors result in small values of the quadratic form of , and vary smoothly over the nodes. Similarly, the larger eigenvalues are referred to as the high frequencies. Then, a smooth graph signal is one which has the energy of the GFT coefficients predominantly in the low graph frequencies.
II Kernel Regression over Graphs
II-A Linear basis model for regression over graphs
Let denote a set of input observations. Each input is paired with a target . Our goal is to model the target with given by:
[TABLE]
where is a known function of and denotes the regression coefficient matrix. Equation (1) is referred to as the linear basis model for regression, often shortened to linear regression in the machine learning parlance (cf. Chapters 3 and 6 in [90]). For brevity, we hereafter follow this shortened nomenclature and refer to the outcome of using (1) as linear regression. Our central assumption is that the target is a smooth signal over an underlying graph with nodes. We learn the optimal parameter matrix by minimizing the following cost function with respect to :
[TABLE]
where the regularization coefficients , denotes the trace operator, and denotes the norm of , and we emphasize that is a function of . The cost in (9) is convex in , since is positive semidefinite on the virtue of it being the graph-Laplacian matrix. The choice of depends on the problem, and in our analysis we compute these parameters through crossvalidation. The penalty ensures that remains bounded. The penalty or regularization enforces to be smooth over . We note that the smoothness over a graph could be quantified in a number of alternative ways, specially if domain-specific knowledge is available. However, since the graph-Laplacian based regularization has been the most popular metric in the graph signal processing literature with respect to undirected graphs, we employ the same in our work. Another aspect is that being quadratic in helps us arrive at a unique and closed-form solution for the regression model, as we show next. We define matrices , and as follows:
[TABLE]
Using (1) and (13), the cost function (9) is expressible as (8) where we use the properties of the matrix trace operation. Since the cost function is quadratic and convex in , we get the optimal and unique solution by setting the gradient of with respect to equal to zero. Using the following matrix derivative relations
[TABLE]
where and are matrices, and setting we get that
[TABLE]
On vectorizing both sides of (17), we get that
[TABLE]
where denotes the standard vectorization operator and denotes the Kronecker product operation [91]. Then, the optimal , denoted by , follows the relation:
[TABLE]
The predicted target for a new input is then given by
[TABLE]
From (18), it appears that the proposed target prediction approach requires the explicit knowledge of the function . We next show that using the ‘kernel trick’ or ‘kernel substitution’ this explicit requirement of is circumvented and that the target prediction may be done using only the knowledge of the inner products , . Towards this end, we next discuss a dual representation of the cost in (9). We hereafter refer to (18) as the output of the linear regression over graphs (LRG).
II-B Dual representation of cost using kernel trick
We now use the substitution and express the cost function in terms of the parameter . This substitution is motivated by observing that on rearranging the terms in (17), we get that
[TABLE]
where . On substituting in (8), where becomes the dual parameter matrix that we wish to learn, and omitting terms that do not depend on , we get that
[TABLE]
where denotes the kernel matrix for the training samples such that its th entry is given by
[TABLE]
Equation (II-B) is referred to as a dual representation of (8) in the kernel regression literature (cf. Chapter 6 of [90]). Taking the derivative of with respect to and setting it to zero, we get that
[TABLE]
We define the matrices
[TABLE]
Then, we have that
[TABLE]
Once is computed, the predicted output of the kernel regression for a new test input is given by
[TABLE]
where and . Here denotes the reshaping operation of an argument vector into an appropriate matrix of size by concatenating the subsequent length sections as the columns. We refer to (25) as the output of the method named kernel regression over graphs (KRG). The kernel regression is arrived at by noting that the entire formulation remains valid if the inner products are replaced with a general kernel function associating pairs of the inputs and .
In general, a variety of valid kernel functions may be employed. Any kernel function is a valid kernel as long as it can be expressed in the form , and the associated kernel matrix is positive semi-definite for all observation sizes [90]. The Gaussian kernel is a popularly employed kernel and we use the same in our experiments later. We note that KRG is a generalization over the conventional kernel regression (KR), where the latter does not use any knowledge of the underlying graph structure. On setting , the KRG output (25) reduces to the conventional KR output as follows
[TABLE]
where we have used the Kronecker product equality: . Further, we note that KRG reduces to LRG on setting .
II-C Interpretation of KRG – a smoothing effect
We next discuss how the output of KRG is smooth across the training samples and over the nodes of the graph. Before proceeding with KRG, we review a similar property exhibited by the KR output [92]. Using (26) and concatenating the KR outputs for the training samples, we get that
[TABLE]
where we use . Assuming is diagonalizable, let , where and denote the eigenvalue and the eigenvector matrices of , respectively. Let denote the th column of . We note that consists of values of the th component of collected over all the time instances. Then, we have that
[TABLE]
where and denote the th eigenvalue and eigenvector of , respectively, and denotes the vector containing the th component of the target vector for all the training samples (th column of ). Thus, we observe that the KR output performs a shrinkage of along the various eigenvector directions for each . The contribution from the eigenvectors corresponding to the smaller eigenvalues are effectively eliminated, and only those corresponding to the larger eigenvalues are retained. Since the eigenvectors corresponding to the larger eigenvalues of represent smooth variations across the observations , we observe that KR performs a smoothing of . We next show that such is also the case with KRG: KRG acts as a smoothing filter across both the observations and the graph nodes. Using (25) and concatenating the KRG outputs, we have that
[TABLE]
On vectorizing both sides of (27), we get that
[TABLE]
where we have used (21) in (a). Let be diagonalizable with the eigendecomposition:
[TABLE]
where and denote the eigenvalue and the eigenvector matrices of , respectively. We also assume that is diagonalizable as earlier. Let and denote the th eigenvalue and the th eigenvector of , respectively. Then, we have that
[TABLE]
Now, using (20), we have
[TABLE]
where is the eigenvector matrix and is the diagonal eigenvalue matrix given by
[TABLE]
In (31)(a), we have used the distributivity property of the Kronecker product: where are four matrices. We note that is a diagonal matrix of size . Let . Then, is a function of . On dropping the subscripts for simplicity, we observe that any eigenvalue has the form
[TABLE]
where and are the appropriate eigenvalues of and , respectively. Similarly, we have that
[TABLE]
and note that is also a diagonal matrix of size . Then, on substituting (32) and (36) in (30), we get that
[TABLE]
We note again that is a diagonal matrix with size . Let . Then, on dropping the subscripts, any is of the form
[TABLE]
From (40), we have that
[TABLE]
where are the column vectors of . In the case when , the component in along is effectively eliminated. For most covariance or kernel functions used in practice, the eigenvectors corresponding to the largest eigenvalues of are the low-frequency components across time or observations. Similarly, the eigenvectors corresponding to the smaller eigenvalues of are smooth over the graph [1]. We observe that the condition is achieved when is small and/or is large. This condition in turn corresponds to effectively retaining only the components of which vary smoothly across the samples as well as over the nodes of the graph.
II-D Learning an underlying graph
In developing KRG, we have so far assumed that the underlying graph is known apriori in terms of the graph-Laplacian matrix . Such an assumption may not hold true in many practical applications, since there is not necessarily one best graph to describe the given networked data. This motivates us to develop a joint learning approach where we learn both the graph-Laplacian and the KRG parameter matrix (or its dual representation parameter ). Our goal in this section is to provide a simple means of estimating a graph that helps enhance the prediction performance, if a graph is not known apriori. We note that a vast and expanding body of literature exists in the domain of estimating graphs from graph signals [50, 48, 51, 52, 53, 93, 94, 49, 54, 95], and that many of these techniques may be used in the learning approach proposed in this section. Nevertheless, we pursue the particular approach taken in this section due to the ease of implementation and the minimal assumptions involved.
We propose the minimization of the following cost function to achieve our goal:
[TABLE]
where . Since our goal is to recover an undirected graph, we impose the appropriate constraints [96]. Firstly, any non-trivial graph has a graph-Laplacian matrix which is symmetric and positive semi-definite[96]. Secondly, the vector of all ones forms the eigenvector of the graph-Laplacian corresponding to the zero eigenvalue. Since , we have that being positive semi-definite is equivalent to the constraint that all the off-diagonal elements of are non-positive. This is a simpler constraint than the direct positive semi-definiteness constraint. Then, the solution to the joint estimation of and is obtained by solving the following:
[TABLE]
The optimization problem (II-D) is jointly non-convex over and , but convex on given and vice-versa. Hence, we adopt an alternating minimization approach and solve (II-D) in two steps alternatingly as follows:
- •
For a given , solve using the KRG approach of Section II.
- •
Given the matrix , solve \mbox{such that}\quad{\color[rgb]{0,0,0}\mathbf{L}(i,j)\leq{0}\,\,\forall i\neq j},\mathbf{L}=\mathbf{L}^{\top}, and . Here .
We start the alternating optimization using a suitable initialization; initializing yields the KR. In order to keep the successive estimates comparable, we scale such that the largest eigenvalue modulus is unity at every iteration.
III Experimental results
We evaluate the performance of the relevant methods under adverse conditions where we use limited training data and noisy training data. Our hypothesis is that KRG and LRG provide better prediction performance than KR and LR, respectively. A state-of-the-art method is also compared with in the experiments of graph signal reconstruction. We experiment with both synthesized and real-world signal examples. The experiment with the synthesized data is carried out using small-world graphs; this being a standard practice in several existing works to demonstrate the efficiency of a model. For real applications, we consider three different real-world data experiments:
- (D1)
Prediction of the temperature as the output, using the air-pressure observations as the input, for the cities in Sweden. 2. (D2)
Temperature prediction for the cities in Sweden from the current day to the next day. 3. (D3)
Prediction for the fMRI voxel intensities of the cerebellum region.
Among these three experiments, D1 is the experiment where the input observation and the output to be predicted are two different physical quantities. To the best of our knowledge, none of the existing graph-signal processing approaches address such a dataset and we therefore, make comparisons only with conventional linear/kernel regression. The other two experiments D2 and D3 are performed for two reasons. The first reason is to compare our method against the kernel-ridge regression (KRR) method of [82, 85]. In these experiments, the input and the output both lie on the same graph and are the same physical quantities, making it applicable to the KRR method. We choose KRR as the competing method in these two experiments because it has been claimed to provide a state-of-the-art performance [82]. The second reason is to investigate the performance of our method when we simultaneously learn an underlying graph from the available data.
We use the normalized-mean-square-error (NMSE) as the measure of the prediction performance:
[TABLE]
where denotes the regression output matrix and the true value of target matrix, meaning that does not contain any noise. The expectation operation is realized as the sample average over multiple experiment trials. In the case of real-world examples, we compare the performance of the following four regression approaches:
linear regression (LR): , where and , 2. 2.
linear regression over graphs (LRG): and , where , 3. 3.
kernel regression (KR): Using and the radial basis function (RBF) kernel , and 4. 4.
kernel regression over graphs (KRG): Using and the RBF kernel .
The regularization parameters , , and for different training data sizes are found through a five-fold crossvalidation on the training set. While performing the crossvalidation, we assume that clean target vectors are available. We wish to emphasize that our goal here is to illustrate that LRG and KRG are better than LR and KR, respectively. Depending on the choice of the kernel used, one kernel may perform better than the other and that there is generally no guarantee that a Gaussian kernel always outperforms the linear kernel in practice. As regards determining which kernel is best suited to an application, there is often no direct answer than a trial-and-error approach of using different kernels and comparing their performance. An alternative is to use a kernel selection approach in the form of multi-kernel regression [97, 98, 83] which ‘selects’ the best kernels from a bag of kernels.
III-A Regression for synthesized data
We perform regression for the synthesized dataset where the target vectors to be predicted are smooth over a specified graph. We generate synthesized data where we know the ground truth. A part of the data is used for the training in presence of additive noise, and our task is to predict for the remaining part of the data, given the information about correlations in form of kernels. In order to generate the synthesized data, we use random small-world graphs from the Erdős-Rényi and the Barabási-Albert models [99] with the number of nodes equal to . We generate a total of target vector realizations. We adopt the following data generation strategy: We first pick independent vector realizations from an -dimensional Gaussian vector source , where is an -dimensional covariance matrix drawn from the inverse Wishart distribution with an identity hyperparameter matrix. We use a highly correlated covariance matrix such that each -dimensional vector has strongly correlated components. Thus, we create a data matrix with columns such that each column is an -dimensional Gaussian vector. Each row vector of the data matrix has a size and the row vectors of the data matrix are correlated to each other. We denote a row vector by . We then select the row vectors one-by-one and project them onto the specified graph to generate target vectors that are smooth over the graph while maintaining the correlation between observations, by solving the following optimization problem:
[TABLE]
We randomly divide the data samples into training and test sets of equal size . We define the kernel function between the th and th data samples and to be
[TABLE]
considering the same kernel for all the graph nodes. The choice of the kernel is motivated by the assumed generating model. Given the training set of size , we choose a subset of data samples to make predictions for the test data samples using the kernel regression over graphs. The training target vectors are corrupted with additive white Gaussian noise at varying levels of signal-to-noise ratio (SNR). We repeat our experiments over 100 realizations of the graphs and noise realizations. We compare the performance of KRG with KR. We observe from Figure 1 that for a fixed training data size of , KRG outperforms KR by a significant margin at low SNR levels (below 10dB). As the SNR-level increases, the NMSE of KRG and KR almost coincide. A similar trend is also observed in the case of Barabási-Albert graphs, which is not reported for brevity. In Figure 2, we show the NMSE obtained with KRG and KR on both the graph models, as a function of the training data size at an SNR-level of dB. We observe that KRG consistently outperforms KR and that the gap between the NMSE of KRG and KR reduces as the training data size increases. The results shown in Figure 1 and 2 verify our hypothesis.
III-B Experiment D1: Prediction of the temperature of the cities using air-pressure observations
We now consider the experiment where the input and the output of the kernel regression are two different physical quantities. The task is to predict the temperature of the cities in Sweden from the air pressure observations at those cities. We predict the temperature as the average daily temperature for 24 hours of a day; the input consists of the air pressure observations collected on an hourly basis for the same day.
For the experiment, we collected the temperature and air-pressure measurements from the 25 most populated cities in Sweden. The data was collected for a period of two months from February to March of 2018. In Figure 3(a), we indicate the 45 most populated cities in Sweden. We consider 25 of these 45 cities in this experiment since the relevant data was not available at the remaining cities. The data is available publicly from the Swedish Meteorological and Hydrological Institute [100]. We predict the temperature of the 25 cities as the output vector or the target. The input is taken to be the air pressure measurement at all those 25 cities collected on hourly basis. This results in an input vector with components, which means that we have and . The data from the first 48 days is taken as the training set, and the data from the remaining 12 days is used for testing. Let denote the geodesic distance between the th and th cities in kilometres, . Then, we construct the adjacency matrix for the graph by setting
[TABLE]
In our experiments, we randomly sample for the training observations from the full training set for various . We consider the case when the training targets are corrupted with additive white Gaussian noise at a 10 dB SNR level. We compare the performances of LR, LRG, KR, and KRG. For the test data, the NMSE as a function of the training sample size is shown in Figure 3. We observe that LRG and KRG outperform LR and KR, respectively, by a significant margin, particularly at smaller training sample sizes. In addition to this, we find that KRG outperforms LRG for this experiment, though this is not necessarily guaranteed for all the datasets and under all experimental conditions.
III-C Experiment D2: Temperature prediction from the current day to the next day
In this experiment, the task is to predict the temperature of several Swedish cities for the next day from the temperature observations of the current day. For the experiment, we consider the temperature measurements from the 45 most populated cities in Sweden taken for a period of three months from September to November 2017. Since both the input and the output are temperatures, this experiment represents a graph signal reconstruction/recovery problem and hence, we compare our method with the KRR method. We have already mentioned that KRR is a state-of-the-art method in graph signal recovery[82, 85]. Further, we also consider the case when the underlying graph is not known a-priori. In this case, we learn an underlying graph and compare the performance of our approach against the case where the graph is known a-priori. The data is available publicly from the Swedish Meteorological and Hydrological Institute [100]. The cities are indicated in the map of Sweden in Figure 3(a). We consider the target vector to be the temperature measurement of a particular day, and to be the temperature measurements (in degree celsius units) from the previous day. We have 90 input-target data pairs in total, divided into the training set and the test set of sizes and , respectively. Once again, we consider the geodesic distance based graph. For each training dataset size , we compute the NMSE by averaging over 50 different random training subsets of size drawn from the full training set of size . In Figure 4, we show the NMSE for the test set at SNR-levels of dB and [math] dB. We observe that KRG outperforms other regression methods by a significant margin, particularly at low sample sizes . Next, we compare our methods with KRR.
III-C1 Comparison with KRR
KRR deals with a sub-sampling problem where the signal values are predicted at a set of nodes from the signal values given at the remaining set of nodes. Therefore, we formulate the one-day temperature prediction problem in a suitable sub-sampling setup where KRR can be used. In the sub-sampling setup, KRR minimizes the following convex cost:
[TABLE]
where is the input observation signal corresponding to a subset with nodes, from the total set of nodes. Here, denotes the sampling matrix obtained by concatenating the zero matrix and the -dimensional identity matrix; is the kernel matrix across all nodes of the graph, and is the vector of KRR coefficients, and is the estimate of the graph signal produced by KRR at . The estimate of the entire graph signal is then given by:
[TABLE]
Thus, KRR achieves an extrapolation of the graph signal from the nodes in to those outside it using the graph topoplogy employed in the extrapolation kernel. The parameters related to the above prediction and kernels are found by cross-validation. In all the experiments employing KRR[82, 84], we have used the same diffusion kernels and the covariance kernels used by the authors in the corresponding articles[82, 84].
Since we consider the one-day temperature prediction problem, we use the space-time variant of the KRR proposed in [84], by taking the adjacency matrix given by the Cartesian product of the geodesic graph and the temporal dynamics graph for one time step , meaning that each node at time is connected to the corresponding node at time by an edge with unity weight. The composite or augmented graph[84] for the two days is then given by the Cartesian product . We observe from Table I, that our approach significantly outperforms KRR for both the covariance and the diffusion kernels. We note that the performance of the covariance kernel is better than that of the diffusion kernel, and this trend is in agreement with the results reported in [84]. We also observe that the performance of KRR and our approaches improve as more training data becomes available.
The performance of our approach is significantly better than that of KRR. This can be attributed to two factors. The first factor is that KRR deals with an under-determined setup where the subsampling matrix has a special structure. The special structure is formed by concatenating the identity matrix and the zero matrix. This sampling matrix structure may not be well suited for sub-sampling. The second aspect or factor pertains to our approach: we use the advantage of explicit training and testing. This assumes the availability of a training dataset for our approach, whereas KRR does not have that as a requirement.
III-C2 Learning an underlying graph
We next consider the performance of our approach when the graph is also simultaneously learnt from the training data. This experiment serves the purpose of illustrating the effectiveness of our approach in inferring a graph suited to the prediction task even in the absence of a prior graph. We use the alternating optimization strategy of Section II-D initialized with . We consider the training data at an SNR level of dB at different sample sizes. We find experimentally that the algorithm converges typically after five to ten iterations. In Figure 5, we plot the NMSE values obtained for the test data using both the fixed based on the geodesic distances, and with the learnt graph. We observe that our approach learns a graph which provides agreeable performance even when initialized with the zero graph. This validates our intuition that the graph signal holds sufficient information to both infer both a meaningful underlying graph structure and perform target predictions.
III-D Experiment D3: Prediction for the fMRI voxel intensities of the cerebellum region
Finally, we consider the prediction of voxel intensities in the functional magnetic resonance imaging (fMRI) data obtained for the cerebellum region of the brain. We apply our approach to predict the intensities at some of the voxels of the MRI, given the intensities at the other voxels. As before, we consider the training samples to be corrupted with additive white Gaussian noise. In the beginning, the graph is constructed from the voxels at the different slices of the MRI scans connected together to form a composite graph as shown in Figure 6(a). The details of the image acquisition and the dataset may be found publicly at https://openfmri.org/dataset/ds000102. Each voxel is considered as a node of the graph and the voxel intensity to be the signal. The full data graph is of dimension 4000 obtained by mapping the 4000 cerebellum voxels anatomically following the atlas template [102]. We refer the reader to [103] for further details on the construction of the voxel graph. In our analysis, we consider only the first 100 voxels from the 4000 voxels to construct the dataset in our experiments. This is to reduce the computational complexity in performing the experiments. We use the intensity values at 10 of the voxels from the first slice as the input to make predictions for the output comprising the voxel instensities at 90 voxels present in the first and second slice. In Figure 6(b), we show an instance of the voxel intensity signal over the full 4000 voxel graph. In Figures 6(c) and (d), we show the corresponding input and output signals used in our experiments. The dataset consists of 290 input-target data points or observation pairs. We use one half of the data for training and the other half for testing. We construct noisy training data at SNR levels of 10 dB and 0 dB. The NMSE is obtained by computing the average over 100 different random partitions of the entire data into the training and test sets. The results are shown in Figure 6(e)-(f). We observe that LRG and KRG have a superior performance over their conventional counterparts, particularly for small and at low SNR-levels.
The performance of our methods and that of KRR with the maximum number of training samples is reported in Table II. We observe that KRR performs poorly in comparison with our approaches. The poor performance of KRR may be attributed to the relatively small number of samples available for reconstruction: only 10% of the total number of nodes are observed. Further, we note that KRR does not explicitly employ training data other than that used in the construction of the covariance kernel. The covariance kernel approach in turn also requires sufficient number of samples for a reliable reconstruction, which is not the case in our experiments owing to the adverse training data. All these factors explain why KRR performs rather poorly in this experiment.
We now consider the experiment with the learning of an underlying graph. We observe from Figure 7(a) that when initialized with the zero graph, the prediction performance of our method is comparable to that obtained using the fixed atlas-template graph (given graph). We further consider the case when the graph learning iterations are initalized with corresponding to the atlas-template. This is motivated by the observation that in many applications such as biomedical data, there is no single graph which is guaranteed to work the best for prediction. The goal of this experiment is then to investigate if a graph better suited to the regression task could be learnt starting from an existing non-trivial graph. The prediction NMSE obtained for the test data in this case is shown in Figure 7(b). We observe that our method learns a graph better suited to the prediction in terms of the NMSE. This in turn shows that for this dataset, it is more suitable to jointly learn an underlying graph.
IV Conclusions
We proposed a kernel regression method for predicting graph signal outputs from inputs that are not necessarily lying over a graph or for inputs agnostic to a graph. The resulting problem was shown to be a convex one resulting in an analytically tractable solution. Our approach presents a generalization of the standard kernel regression for graph signals. Experiments with synthesized and real-world graph signal datasets demonstrated the merit of our approach, particularly in the adverse scenarios of training with noise and limited datasizes. Our approach was shown to outperform a state-of-the-art method in real-world graph signal reconstruction problems. We further showed that our approach is also applicable in cases where an underlying graph is simultaneously estimated from the training data.
V Reproducible research
In the spirit of reproducible research, all the codes relevant to the experiments in this article are made available at https://www.researchgate.net/profile/Arun_Venkitaraman and https://www.kth.se/ise/research/reproducibleresearch-1.433797.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] D. I. Shuman, S. Narang, P. Frossard, A. Ortega, and P. Vandergheynst, “The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains,” IEEE Signal Process. Mag. , vol. 30, no. 3, pp. 83–98, 2013.
- 2[2] A. Sandryhaila and J. M. F. Moura, “Discrete signal processing on graphs,” IEEE Trans. Signal Process. , vol. 61, no. 7, pp. 1644–1656, 2013.
- 3[3] ——, “Big data analysis with signal processing on graphs: Representation and processing of massive data sets with irregular structure,” IEEE Signal Process. Mag. , vol. 31, no. 5, pp. 80–90, 2014.
- 4[4] ——, “Discrete signal processing on graphs: Frequency analysis,” IEEE Trans. Signal Process. , vol. 62, no. 12, pp. 3042–3054, 2014.
- 5[5] D. I. Shuman, B. Ricaud, and P. Vandergheynst, “A windowed graph Fourier transform,” IEEE Statist. Signal Process. Workshop (SSP) , pp. 133–136, Aug 2012.
- 6[6] S. K. Narang and A. Ortega, “Local two-channel critically sampled filter-banks on graphs,” Proc. IEEE Int. Conf. Image Process. (ICIP) , pp. 333–336, 2010.
- 7[7] ——, “Perfect reconstruction two-channel wavelet filter banks for graph structured data,” IEEE Trans. Signal Process. , vol. 60, no. 6, pp. 2786–2799, 2012.
- 8[8] ——, “Compact support biorthogonal wavelet filterbanks for arbitrary undirected graphs,” IEEE Trans. Signal Process. , vol. 61, no. 19, pp. 4673–4685, 2013.