Phase Transitions in Edge-Weighted Exponential Random Graphs: Near-Degeneracy and Universality
Ryan DeMuse, Danielle Larcomb, Mei Yin

TL;DR
This paper extends exponential random graph models to weighted networks by introducing a common distribution for edge weights, addressing limitations of traditional models that only handle simple graphs, and explores properties like near-degeneracy and universality.
Contribution
It proposes a new framework for weighted exponential random graphs with minimal assumptions on edge weight distribution, enabling modeling of more realistic weighted networks.
Findings
Identifies conditions for near-degeneracy in weighted models
Demonstrates universality properties in the extended framework
Provides theoretical insights into weighted network phase transitions
Abstract
Conventionally used exponential random graphs cannot directly model weighted networks as the underlying probability space consists of simple graphs only. Since many substantively important networks are weighted, this limitation is especially problematic. We extend the existing exponential framework by proposing a generic common distribution for the edge weights. Minimal assumptions are placed on the distribution, that is, it is non-degenerate and supported on the unit interval. By doing so, we recognize the essential properties associated with near-degeneracy and universality in edge-weighted exponential random graphs.
Click any figure to enlarge with its caption.
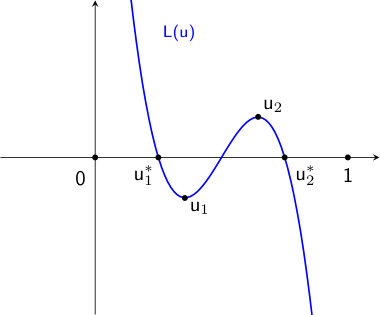 Figure 1
Figure 1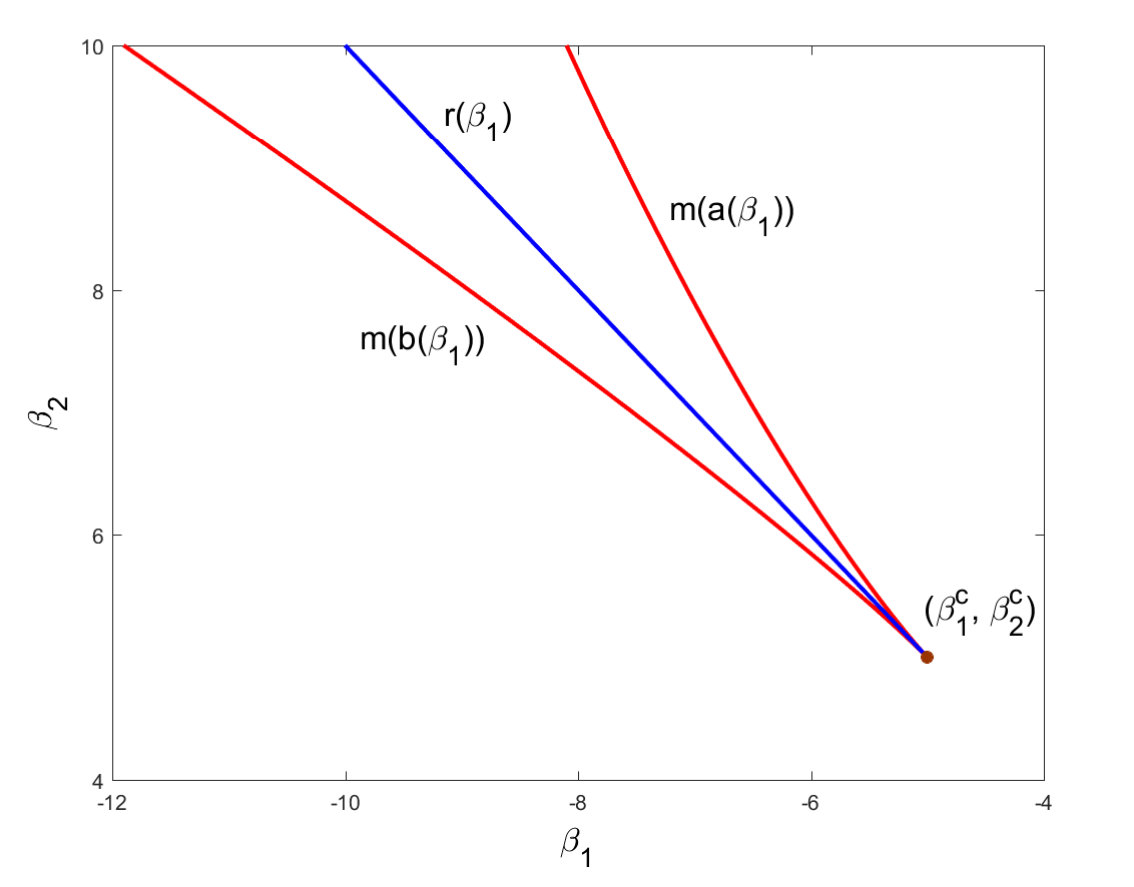 Figure 2
Figure 2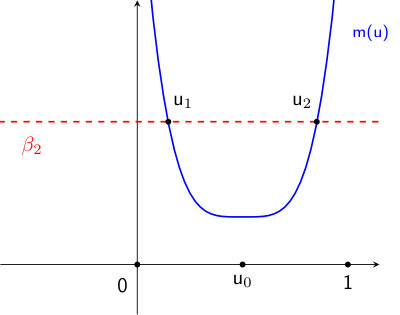 Figure 3
Figure 3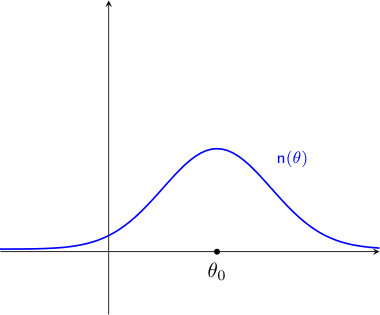 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
11institutetext: Department of Mathematics, University of Denver, Denver, CO 80208, USA
11email: [email protected]
Phase transitions in edge-weighted exponential random graphs: Near-degeneracy and universality
Ryan DeMuse
Danielle Larcomb
Mei Yin Mei Yin’s research was partially supported by NSF grant DMS-1308333.
(Received: date / Accepted: date)
Abstract
Conventionally used exponential random graphs cannot directly model weighted networks as the underlying probability space consists of simple graphs only. Since many substantively important networks are weighted, this limitation is especially problematic. We extend the existing exponential framework by proposing a generic common distribution for the edge weights. Minimal assumptions are placed on the distribution, that is, it is non-degenerate and supported on the unit interval. By doing so, we recognize the essential properties associated with near-degeneracy and universality in edge-weighted exponential random graphs.
Keywords:
Exponential random graphs Legendre duality Phase transitions Near degeneracy and universality
MSC:
05C80 82B26
††journal: Journal of Statistical Physics
1 Introduction
Large networks have become increasingly popular over the last decades, and their modeling and investigation have led to interesting and new ways to apply statistical and analytical methods. Much of the random graph literature has evolved from the famous Erdős-Rényi graph, where edges are joined between vertices independently with the same probability. While the simple formation has attracted significant mathematical interest, this construction lacks the ability to model real world networks, which exhibit many noticeable attributes such as clustering and transitivity. The introduction of exponential random graphs has aided in this pursuit as they are able to capture a wide variety of common network tendencies by representing a complex global structure through a set of tractable local features FS Newman WF . See Besag Besag , Snijders et al. SPRH , Rinaldo et al. RFZ , and Fienberg Fienberg1 Fienberg2 for history and a review of developments.
These rather general models are exponential families of probability distributions over graphs, in which dependence between the random edges is defined through certain finite subgraphs. Inquiries into exponential random graphs have been made on the variational principle of the limiting normalization constant, concentration of the limiting probability distribution, phase transitions, and asymptotic structures. See for example Chatterjee and Varadhan CV , Chatterjee and Diaconis CD1 , Radin and Yin RY , Lubetzky and Zhao LZ1 LZ2 , Radin and Sadun RS1 RS2 , Radin et al. RRS , Kenyon et al. KRRS , Yin Yin2013 , Kenyon and Yin KY , Aristoff and Zhu AZ2 , and Chatterjee and Dembo CD2 . Many of these papers utilize the elegant theory of graph limits as developed by Lovász and coauthors (V.T. Sós, B. Szegedy, C. Borgs, J. Chayes, K. Vesztergombi, …) BCLSV1 BCLSV2 BCLSV3 Lov LS . Building on earlier work of Aldous Aldous1 and Hoover Hoover , the graph limit theory creates a new set of tools for representing and studying the asymptotic behavior of graphs by connecting sequences of graphs , which are discrete objects that lie in different probability spaces, to a unified graphon space , which is an abstract functional space equipped with a cut metric. Though the theory itself is tailored to dense graphs whose number of edges scales like the square of number of vertices, parallel theories for sparse graphs are likewise emerging. See Benjamini and Schramm BS , Aldous and Steele AS , Aldous and Lyons AL , and Lyons Lyons where the notion of local weak convergence is discussed and the recent works of Borgs et al. BCCZ1 BCCZ2 that are making progress towards enriching the existing theory of dense graph limits by developing a limiting object for sparse graph sequences based on graphons.
Despite their flexibility, conventionally used exponential random graphs suffer from some deficiencies that may hamper their utility to researchers. The major shortcomings are degeneracy problems, a sensitivity to missing data, and an inability to model weighted networks CD . Since the underlying probability space of the standard exponential random graph model consists of simple graphs only yet many substantively important networks arising from a host of applications including socio-econometric data and neuroscience are weighted, this limitation is especially problematic. Consider a social network graph with vertices being people and edges indicating a relationship. We contemplate that family members have stronger relationships with one another than do workplace colleagues. This can be reflected by placing a weight on the edges to demonstrate some prior belief in the strength of connection, with coworkers having low weighted edges and family members having high weighted edges in-between. Properly adjusting the edge weights thus allows the modeling of a broad range of networks, be it consisting of more familial ties or more acquaintances.
An alternative interpretation for simple graphs is such that the edge weights are iid and satisfy a Bernoulli distribution. Following this perspective, Yin Yin2016 extended the exponential framework by putting a generic common distribution on the iid edge weights. After deriving a variational principle for the limiting normalization constant and an associated concentration of measure, an explicit characterization of the asymptotic phase transition was obtained for exponential models with uniformly distributed edge weights. This work expands upon the setting in Yin2016 and places minimal assumptions on the edge-weight distribution, that is, it is non-degenerate and supported on the unit interval. By doing so, we strive to discover universal asymptotic behavior, i.e. behavior that does not depend on the particular edge-weight distribution, for the model in the near-degenerate regions of the parameter space corresponding to where the graph is sparse (almost entirely unconnected) or nearly complete (almost fully connected) CD Handcock Yin .
The rest of this paper is organized as follows. In Section 2 we provide basics of graph limit theory and introduce key features of edge-weighted exponential random graphs. In Section 3 we summarize important properties of Legendre duality between the cumulant generating function and the Cramér rate function for the edge-weight distribution. In Section 4 we show the existence of a first order phase transition curve ending in a second order critical point in general edge-weighted exponential random graph models through a detailed analysis of a maximization problem for the normalization constant. Lastly, in Section 5 we explore the universal and non-universal asymptotics concerning the phase transition.
2 Background
Consider the set of all simple edge-weighted complete labeled graphs on vertices (“simple” means undirected, with no loops or multiple edges), where the edge weights between vertex and vertex are iid real random variables satisfying a non-degenerate common distribution that is supported on . Any such graph , irrespective of the number of vertices, may be represented as an element of a single abstract space that consists of all symmetric measurable functions from the unit square into the unit interval (referred to as “graph limits” or “graphons”), by setting as the edge weight between vertices and of . The common distribution for the edge weights yields probability measure and the associated expectation on , and further induces probability measure on the space under the graphon representation.
For a finite simple graph with vertex set and edge set and a simple graph on vertices, there is a notion of density of graph homomorphisms, denoted by , which indicates the probability that a random vertex map is edge-preserving,
[TABLE]
For a graphon , define the graphon homomorphism density
[TABLE]
Then by construction, and we take (2) with as the definition of graph homomorphism density for an edge-weighted complete graph . This graphon interpretation enables us to capture the notion of convergence in terms of subgraph densities by an explicit “cut distance” on :
[TABLE]
for . Except for a technical complication explained below, a sequence of edge-weighted graphs converges under the cut metric if and only if its homomorphism densities converge for all finite simple graphs, and the limiting homomorphism densities then describe the resulting graphon.
The technical complication is that the topology induced by the cut metric is well defined only up to measure preserving transformations of (and up to sets of Lebesgue measure zero), which may be thought of as a vertex relabeling in the context of finite graphs. To tackle this issue, an equivalence relation is introduced in . We say that if for some measure preserving bijection of . Let (referred to as a “reduced graphon”) denote the equivalence class of in . Since is invariant under , one can then define on the resulting quotient space the natural distance by , where the infimum ranges over all measure preserving bijections and , making into a metric space. With some abuse of notation we also refer to as the “cut distance”. After identifying graphs that are the same after vertex relabeling, the probability measure yields probability measure and the associated expectation (which coincides with ). Correspondingly, the probability measure induces probability measure on the space under the measure preserving transformations. The space is a compact space and homomorphism densities are continuous functions on it.
By a -parameter family of edge-weighted exponential random graphs we mean a family of probability measures on defined by, for ,
[TABLE]
where are real parameters, is a single edge, is a finite simple graph with edges, is the density of graph homomorphisms, is the probability measure induced by the common distribution for the edge weights, and is the normalization constant (free energy density),
[TABLE]
Since homomorphism densities are preserved under vertex relabeling, the probability measure and the associated expectation (which coincides with ) may likewise be defined.
Being exponential families with bounded support, one might expect exponential random graph models to enjoy a rather basic asymptotic form, though in fact, virtually all these models are highly nonstandard as increases. The -parameter edge-weighted exponential random graph models are simpler than their -parameter extensions but nevertheless exhibit a wealth of non-trivial characteristics and capture a variety of interesting features displayed by large networks. Furthermore, the relative simplicity provides insight into the expressive power of the exponential construction. In statistical physics, we refer to as the particle parameter and as the energy parameter. Accordingly, the exponential model (4) is said to be “attractive” if is positive and “repulsive” if is negative. In this paper we will concentrate on “attractive” -parameter models. The interest in these models is well justified. Consider the friendship graph for example, where the edge weights between different vertex pairs measure the strength of mutual friendship. Take an edge and a triangle. Since a friend of a friend is likely also a friend, the influence of a triangle that assesses the bond of a -way friendship should be emphasized, and this corresponds to taking . The edge-triangle model thus captures transitivity when is finite, but this transitivity is gradually lost when tends to infinity in the sense that the model produces a graph that looks similar to an Erdős-Rényi graph with respect to the cut metric (see detailed discussions in Sections 4 and 5).
3 Legendre transform and duality
In this section we present properties of the cumulant generating function and the Cramér rate function for the edge-weight distribution relevant to our investigation. We will see that is convex on , which allows the application of the Legendre transform. Let be the Legendre transform of given by
[TABLE]
where , the domain of , consists of all so that . Note that in large deviation theory, is commonly referred to as the Cramér conjugate rate function for the distribution . It follows from theorems proved in Chapter 2: Analytic Properties of Brown that the Legendre transform connecting and is an involution, is smooth and strictly convex everywhere it is defined, and there is a 1-1 relationship between and . Lemma 1 and Proposition 1 then discuss properties of and under the additional assumption that is symmetric. These properties will be useful in Section 5 when we explore universality in edge-weighted exponential random graphs.
Lemma 1
Consider a non-degenerate probability measure supported on . Let be the associated cumulant generating function. If is symmetric about the line , then , and equality is obtained only when .
Proof
Let be a random variable distributed according to . By symmetry, and . This implies that and . Also,
[TABLE]
The claim thus follows.
Lemma 2
Consider a non-degenerate probability measure supported on . Let be the associated Cramér rate function (6). Then the domain of is a subset of .
Proof
Since is supported on , we have if , and if . This gives
[TABLE]
If then and thus is not finite. Similarly, if then and thus is not finite. The conclusion readily follows.
Analyzing properties of and in detail will give a stronger conclusion than Lemma 2. We recognize that the cumulant generating function satisfies , , and , where is a random variable distributed according to . See Table 1 for important limiting properties of as . By Legendre duality, every uniquely corresponds to a , with and . This implies that , and is decreasing on and increasing on . We also note that and , depending on the probability distribution , may be either finite or grow unbounded. In the former case, the domain of is (as for Bernoulli). In the latter case, the domain of is (as for Uniform).
Proposition 1
Consider a non-degenerate probability measure supported on . Let be the associated Cramér rate function (6). If is symmetric about the line , then is also symmetric about the line .
Proof
Let . Under the symmetry assumption, we will show, by a simple change of variable , that .
[TABLE]
Let . Following Legendre duality, for a unique . By (9), this implies that , i.e., and are unique duals of each other. We compute
[TABLE]
This verifies our claim.
4 Maximization analysis
In this section we demonstrate the existence of first order phase transitions in general edge-weighted exponential random graphs. Our main results are Theorem 4.3 and the consequent Corollary 1. In the standard statistical physics literature, phase transition is often associated with loss of analyticity in the normalization constant, which gives rise to discontinuities in the observed graph statistics. In the vicinity of a phase transition, even a tiny change in some local feature can result in a dramatic change of the entire system.
Definition 1
A phase is a connected region of the parameter space , maximal for the condition that the limiting normalization constant is analytic. There is a th-order transition at a boundary point of a phase if at least one th-order partial derivative of is discontinuous there, while all lower order derivatives are continuous.
Following this philosophy, we will make use of two theorems from Yin2016 , which connect the occurrence of an asymptotic phase transition in our model with the solution of a certain maximization problem for the limiting normalization constant.
Theorem 4.1 (Theorem 3.4 in Yin2016 )
Consider a general -parameter exponential random graph model (4). Suppose is non-negative. Then the limiting normalization constant exists, and is given by
[TABLE]
where is a simple graph with edges, is the Cramér rate function (6), and the supremum is taken over all in the domain of , i.e., where .
Theorem 4.2 (Theorem 3.5 in Yin2016 )
Let be an exponential random graph drawn from (4). Suppose is non-negative. Then behaves like an Erdős-Rényi graph in the large limit:
[TABLE]
where is picked randomly from the set of maximizers of (11).
To be more precise, Theorems 4.1 and 4.2 indicate that a typical graph drawn from the exponential random graph model is weakly pseudorandom BBS . Weakly pseudorandomness means that with exponentially high probability, a sampled graph satisfies a number of equivalent properties such as large spectral gap and correct number of all subgraph counts that make it very similar to an Erdős-Rényi graph. Some authors have delved deeper into this “asymptotically equivalent” phenomenon. Mukherjee M considered the two star model in M and found that though the model looks like an Erdős-Rényi mixture in cut distance, the same convergence does not go through in total variation. This says that despite being very close to Erdős-Rényi, a graph sampled from the exponential distribution is not exactly Erdős-Rényi. In the case of edge-triangle model, Radin and Sadun RS2 argued that the two-parameter to one-parameter reduction and the loss of information is essentially due to the inequivalence of grand canonical and microcanonical ensembles of the exponential model in the asymptotic regime. From a practical perspective, however, the Erdős-Rényi approximation for the exponential random graph is already good enough, and we may simply picture an exponential random graph as an Erdős-Rényi graph in the large graph “attractive” limit CD1 .
A significant part of computing phase boundaries for the -parameter exponential model is then a detailed analysis of a calculus problem coupled with probability estimates. However, as straightforward as it sounds, since the exact form of the Cramér rate function is not readily obtainable for a generic edge-weight distribution , getting a clear picture of the asymptotic phase structure is not that easy and various tricks, especially the duality principle for the Legendre transform, need to be employed ZRM . We note that our mechanism for -parameter models may be further generalized to a -parameter setting, and the crucial idea is to minimize the effect of the ordered parameters on the limiting normalization constant one by one. See Yin2013 for an illustration of this procedure in the standard exponential random graph model (where is Bernoulli).
Assumption Let be the number of edges in . Denote by the cumulant generating function associated with the probability measure . We place a technical assumption:
[TABLE]
admits only one zero on .
We remark that this requirement on , which is satisfied by many common distributions including Bernoulli and Uniform etc., is just a technicality that guarantees the existence of a unique phase transition curve. Without this assumption, there may be more than one phase transition curve. Still, all phase transition curves display the same asymptotical behavior as described in (26), and all graph samples drawn from the “attractive” region of the parameter space are approximately Erdős-Rényi (but with varying densities). The parameter space therefore consists of a single (Erdős-Rényi) phase with first order phase transition(s) across one (or more) curves and second order phase transition(s) along the boundaries, and the transitions correspond to a change in density of the Erdős-Rényi graph.
The meaning of a phase transition in the exponential model thus deserves some careful re-examination. As will be shown in Theorem 4.3, there are curves approaching the phase transition curve from either side along which the corresponding weakly pseudorandom Erdős-Rényi distribution stays constant, and a jump in the Erdős-Rényi parameter occurs only when the phase transition curve is crossed. This implies that asymptotically the state of the network (represented by ) does not have a one-to-one correspondence with the associated exponential parameter . (The same defect was observed by Chatterjee and Diaconis CD1 in the unweighted situation.) Some intricate differences between the exponential model and the related Erdős-Rényi model are presented in Sections 4 and 5, particularly through the calculations after Theorem 5.4. The last equation (43) offers a possible way of distinguishing among “equivalent” exponential parameters , since same Erdős-Rényi parameter but different model parameter lead to different limiting normalization constant in the exponential model, which encodes important asymptotic information about the system.
Given an observed network that one wishes to model using an exponential random graph model, there may be many parameter values yielding the same weakly pseudorandom Erdős-Rényi distribution, and practitioners need to determine what is a best choice. Ideally, those parameters would generate a model whose measurements from simulated realizations reflect the observed network as accurately as possible in every aspect (not just the correct number of subgraph counts as determined by the Erdős-Rényi parameter). Restrictions on the run time of the data collection process may be further imposed. These practical considerations have led to continued interest and advances both theoretically and experimentally in improving goodness of fit and parameter learning Handcock Hunter and developing better model specifications SPRH . For a general principle, good models should produce networks that are structurally similar to the observed network using few but effective parameters, while bad models produce networks that bear little resemblance to the observed network using many unnecessary parameters.
Theorem 4.3
Suppose the common distribution for the edge weights is supported on and non-degenerate. For any allowed , the limiting normalization constant of (4) is analytic at all in the upper half-plane except on a certain decreasing curve which includes the endpoint . The derivatives and have (jump) discontinuities across the curve, except at the end point where all the second derivatives , and diverge.
Corollary 1
For any allowed , the parameter space consists of a single phase with a first order phase transition across the indicated curve and a second order phase transition at the critical point , qualitatively like the gas/liquid transition in equilibrium materials.
Proof of Theorem 4.3 Let be the number of edges in . Denote by the Cramér rate function associated with the probability measure . Define
[TABLE]
for . We consider the maximization problem for on the interval , where and are parameters. We note that by Theorem 4.1, the supremum should actually be taken over the domain of , which might differ from at the endpoints from the discussion following Lemma 2. However, when the domain of does not include [math] (or ), (or ) is negative infinity and so can not be the maximum. To locate the maximizers of , we examine the properties of and ,
[TABLE]
[TABLE]
Utilizing the duality principle for the Legendre transform between and , we first analyze properties of on the interval . As a consequence of the Legendre transform,
[TABLE]
where and are unique duals of each other. Taking derivatives, we find that
[TABLE]
Consider the function
[TABLE]
on . By (17), we may analyze the properties of through the function
[TABLE]
where and . From the discussion following Lemma 2, we recognize that
[TABLE]
[TABLE]
[TABLE]
where is a random variable distributed according to . Since
[TABLE]
and always, under Assumption there exists a unique such that . This unique global maximizer for corresponds to a unique global minimizer for , which we denote by . Using duality, for all and grows unbounded on both ends. For , on . For , for and and for , where the transition points and satisfy . Sign properties of translate to monotonicity properties of over . For , is decreasing over . For , is decreasing from [math] to , increasing from to , and decreasing from to . See Figure 2 for an illustrative plot of and .
The analytic properties of and entail analytic properties of on the interval . Utilizing the duality of the Legendre transform (16) (17), is a smooth convex function, and . Therefore and , so cannot be maximized at or . For , is decreasing from at 0 to at 1 passing the -axis only once. This intercept, which we denote by , is the unique global maximizer for . Now consider . If , then has a unique zero greater than and so has a unique global maximizer at . If , then has a unique zero less than and so has a unique global maximizer at . Lastly, suppose that . Then has two local maximizers. Denote them by and , with . See Figure 3 for an illustrative plot of in this case.
Define
[TABLE]
Using (18), and . We compute
[TABLE]
As a consequence of the relation between and , following the previous analysis for , is decreasing on and increasing on . We check that similarly as , grows unbounded on both ends. Taking corresponds to taking in the dual space (16)(17), and the divergence is clear from the discussion following Lemma 2. To see that diverges as , we utilize (23). By the fundamental theorem of calculus,
[TABLE]
and grows to infinity as approaches . Let be a random variable distributed according to , we note some nice formulas for and for future reference:
[TABLE]
[TABLE]
In order for , we must have . Since attains an absolute minimum at , , and then . The only possible region in the plane where is thus bounded by and . Denote these two critical values for and by and .
Recall that . By monotonicity of on the intervals and , there exist continuous functions and of , such that for and for . As , and . is an increasing function of , whereas is a decreasing function, and they satisfy . The restrictions on and yield restrictions on , and we have for and for . As , and . and are both decreasing functions of , and they satisfy when and when . As for every , the curve lies below the curve , and together they generate the bounding curves of the -shaped region in the plane with corner point where two local maximizers exist for . By (23), for sufficiently negative values of , and , so the straight line lies within this region.
Fix an arbitrary . Then shifts upward as increases and downward as decreases. As a result, as gets large, the positive area bounded by the curve increases, whereas the negative area decreases. By the fundamental theorem of calculus, the difference between the positive and negative areas is the difference between and , which goes from negative (, is the global maximizer) to positive (, is the global maximizer) as goes from to . Thus there must be a unique : such that and are both global maximizers, and we denote this by . The parameter values of are exactly the ones for which positive and negative areas bounded by equal each other. An increase in induces an upward shift of , and may be balanced by a decrease in . Similarly, a decrease in induces a downward shift of , and may be balanced by an increase in . This justifies that is monotonically decreasing in . See Figure 1. Here we let be a random variable distributed according to Beta, then and . By Lemma 1, and , which by (25) gives . Also see Figure 1 in RY and Figure 1 in Yin2016 for related phase transition plots when the edge-weight distribution is respectively Bernoulli and Uniform.
The rest of the proof follows as in the proof of the corresponding result (Theorem 2.1) in Radin and Yin RY , where some probability estimates were used. A (jump) discontinuity in the first derivatives of across the curve indicates a discontinuity in the expected local densities, while the divergence of the second derivatives of at the critical point implies that the covariances of the local densities go to zero more slowly than . We omit the proof details.
Remark 1
The maximization problem (11) is solved at a unique value off the phase transition curve , and at two values and along the curve. As (resp. ), and . The jump from to is quite noticeable even for small parameter values of . For example, taking , , and in Beta, numerical computations yield that and .
5 Universal asymptotics
In this section we examine near degeneracy and universality in general edge-weighted exponential random graphs. All our findings in this section are derived based on the assumption that the non-degenerate probability measure for the edge weights is symmetric about the line . We remark that near degeneracy and universality are expected even when the edge weights are not symmetrically distributed, except that the universal straight line gets shifted vertically from .
Proposition 2
Consider a non-degenerate probability measure supported on and symmetric about the line . Take a single edge and a finite simple graph with edges. The phase transition curve lies above the straight line when , and is exactly the portion of the straight line ( when . Here is a random variable distributed according to .
Proof
From the proof of Theorem 4.3, there are two global maximizers and for along the phase transition curve , , where is the unique global minimizer for (18). By Lemma 1, when and when . Furthermore, the -coordinate of the critical point is always positive. On the straight line , we rewrite . By Proposition 1, is symmetric about the line . First suppose . Since and are both symmetric, two global maximizers and exist for and by (25). Next consider the generic case . Analytical calculations give that for . Since is symmetric, this says that for (resp. ), the global maximizer of satisfies and so must be . The conclusion readily follows.
Proposition 3
Consider a non-degenerate probability measure supported on and symmetric about the line . Assume the associated Cramér rate function (6) is bounded on (i.e. is finite). Take a single edge and a finite simple graph with edges. The phase transition curve displays a universal asymptotic behavior as , specifically,
[TABLE]
Proof
Let with fixed. Define and so that by (14). We will show, for sufficiently negative , that the global maximizer of equals . Together with Proposition 2, this implies that for these , , which will prove the desired limit.
Under our assumption, is a continuous symmetric function that increases on and decreases on , with a maximum attained at and . Denote by so that is finite and negative and . Recall that , where and are two local maximizers for and is the unique global minimizer for (18) that does not depend on and . Rigorously, it may be that only one local maximizer or exist for , but this does not affect our argument below. From the continuity and boundedness of on , there exists such that if then . Since on and vanishes at the endpoints [math] and , there exists such that for all and , and therefore , so . Similarly, using that for all and all , we have so . Since , this says that .
Propositions 2 and 3 have advanced our understanding of phase transitions in edge-weighted exponential random graphs, yet some fundamental questions remain unanswered. As explained in Section 4, a typical graph sampled from the exponential model looks like an Erdős-Rényi graph in the large limit, where the asymptotic edge presence probability or is prescribed according to the maximization problem (11). However, the speed of towards these two degenerate states is not at all clear. When a typical graph is sparse (), how sparse is it? When a typical graph is nearly complete , how complete is it? Can we give an explicit characterization of the near degenerate graph structure as a function of the parameters? The following Theorems 5.1 and 5.2 are dedicated towards these goals. Theorem 5.1 shows that , the dual of the Erdős-Rényi parameter , displays universal asymptotic behavior in the sparse region of the parameter space ( and ) whereas itself depends on the specific edge-weight distribution . Theorem 5.2 provides a corresponding result in the nearly complete region of the parameter space ( and ), showing that the dual again displays universal asymptotic behavior whereas the Erdős-Rényi parameter still depends on the edge-weight distribution .
Theorem 5.1
Consider a non-degenerate probability measure supported on and symmetric about the line . Take a single edge and a finite simple graph with edges. Let and . For large and sufficiently far away from the origin, a typical graph drawn from the model looks like an Erdős-Rényi graph , where the edge presence probability depends on the distribution , but its dual universally satisfies .
Proof
Let with . Resorting to Legendre duality, (11) gives a condition on , the dual of :
[TABLE]
By Proposition 2, for sufficiently far away from the origin, which corresponds to in the dual space. From Table 1, as , we have
[TABLE]
The universal asymptotics of is verified.
We claim that on the other hand depends on the specific distribution . We will derive the asymptotics of in two special cases, Bernoulli and Uniform. In both cases, by Legendre duality. For Bernoulli,
[TABLE]
While for Uniform,
[TABLE]
Theorem 5.2
Consider a non-degenerate probability measure supported on and symmetric about the line . Assume the associated Cramér rate function (6) is bounded on (i.e. is finite). Take a single edge and a finite simple graph with edges. Let and . For large and sufficiently far away from the origin, a typical graph drawn from the model looks like an Erdős-Rényi graph , where the edge presence probability depends on the distribution , but its dual universally satisfies .
Proof
Let with . Resorting to Legendre duality, (11) gives condition (27) on , the dual of . By Proposition 3, for sufficiently far away from the origin, which corresponds to in the dual space. From Table 1, as , we have
[TABLE]
The universal asymptotics of is verified.
We claim that on the other hand depends on the specific distribution . We will derive the asymptotics of in two special cases, Bernoulli and Uniform. In both cases, by Legendre duality. For Bernoulli,
[TABLE]
While for Uniform,
[TABLE]
See Tables 2 and 3. Even for with small magnitude, the asymptotic tendency of the optimal (hence the optimal ) is quite evident. Here we take . The asymptotic characterizations of obtained in Theorems 5.1 and 5.2 make possible a deeper analysis of the asymptotics of the limiting normalization constant of the exponential model in the following Theorems 5.3 and 5.4. Interestingly, universality is observed only in the nearly complete region ( and ) of the parameter space as proven in Theorem 5.4, but not the sparse region ( and ) as shown in Theorem 5.3.
Before stating the theorems and their proofs, we offer a possible explanation for this discrepancy. By Theorem 4.1,
[TABLE]
where is chosen so that the above equation is maximized. In statistical physics, is commonly referred to as the energy contribution and as the entropy contribution, with the latter being largely dependent on the specific edge-weight distribution . In the sparse region of the parameter space, the entropy contribution is at least as important as the energy contribution and, for many common distributions such as Bernoulli and Uniform actually dominates the energy contribution. Conversely, in the nearly complete region of the parameter space, the energy contribution dominates the entropy contribution. This leads to universality of in the nearly complete region but not the sparse region.
Theorem 5.3
Consider a non-degenerate probability measure supported on and symmetric about the line . Take a single edge and a finite simple graph with edges. Let and . For sufficiently far away from the origin, the limiting normalization constant depends on the distribution .
Proof
Let with . Theorem 4.1 gives (34), where is chosen so that the equation is maximized and for sufficiently far away from the origin. Resorting to Legendre duality, this gives
[TABLE]
where is the dual of and approaches when diverge. By (27),
[TABLE]
Since as from Theorem 5.1, asymptotically we have
[TABLE]
Remark 2
Many common distributions including Bernoulli and Uniform satisfy as , in which case the asymptotics in Theorem 5.3 may be further reduced to .
Theorem 5.4
Consider a non-degenerate probability measure supported on and symmetric about the line . Assume the associated Cramér rate function (6) is bounded on (i.e. is finite). Take a single edge and a finite simple graph with edges. Let and . For sufficiently far away from the origin, the limiting normalization constant universally satisfies .
Proof
Let with . Similarly as in the proof of Theorem 5.3, Theorem 4.1 gives (34), where is chosen so that the equation is maximized and for sufficiently far away from the origin. Since the first two terms diverge to while the last term is bounded by our assumption, the claim easily follows.
Remark 3
The boundedness assumption on in Theorem 5.4 is only used as a sufficient condition to ensure that for in the upper half-plane and far away from the origin and is not necessary for the derivation of the universal asymptotics for . Indeed, since by Theorem 5.2, using in (36), we have
[TABLE]
This universal asymptotic phenomenon is observed for example in Uniform, whose associated Cramér rate function is not bounded.
In the nearly complete region of the parameter space ( and ) examined in Theorems 5.2 and 5.4, the “asymptotically equivalent” Erdős-Rényi parameter depends on the edge-weight distribution yet the limiting normalization constant for the exponential random graph displays universal asymptotic behavior. Since the Erdős-Rényi model is not an exact statistical physics analog for the exponential model, this seemingly controversial discrepancy does not come as a surprise. We work out the details for standard -parameter families with Bernoulli edge-weight distribution below, and the calculation may be extended to -parameter families with general edge-weight distributions.
Suppose the exponential random graph is indistinguishable in the large limit from an Erdős-Rényi random graph in the graphon sense. In other words, for large , the -parameter exponential random graph is “equivalent” to a simplified -parameter Erdős-Rényi random graph with probability distribution
[TABLE]
where and are related by . The limiting normalization constant for the Erdős-Rényi model is given by
[TABLE]
and the limiting normalization constant for the exponential random graph model is given by
[TABLE]
Utilizing the fact that satisfies
[TABLE]
we have
[TABLE]
This shows that (for the exponential random graph model) and (for the corresponding Erdős-Rényi model) do not coincide unless . The difference is particularly noticeable in the nearly complete region, where when is Bernoulli, and so but .
Acknowledgements
The authors are very grateful to the anonymous referees for the invaluable suggestions that greatly improved the quality of this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) Aldous, D.: Representations for partially exchangeable arrays of random variables. J. Multivariate Anal. 11, 581-598 (1981)
- 2(2) Aldous, D., Lyons, R.: Processes on unimodular random networks. Electron. J. Probab. 12, 1454-1508 (2007)
- 3(3) Aldous, D., Steele, J.M.: The objective method: Probabilistic combinatorial optimization and local weak convergence. In: Kesten, H. (ed.) Probability on Discrete Structures, pp. 1-72. Springer, Berlin (2004)
- 4(4) Aristoff, D., Zhu, L.: Asymptotic structure and singularities in constrained directed graphs. Stochastic Process. Appl. 125, 4154-4177 (2015)
- 5(5) Benjamini, I., Schramm, O.: Recurrence of distributional limits of finite planar graphs. Electron. J. Probab. 6, 1-13 (2001)
- 6(6) Besag, J.: Statistical analysis of non-lattice data. J. R. Stat. Soc. Ser. D. Stat. 24, 179-195 (1975)
- 7(7) Bhamidi, S., Bresler G., Sly A.: Mixing time of exponential random graphs. Ann. Appl. Probab. 21, 2146-2170 (2011)
- 8(8) Borgs, C., Chayes, J., Cohn, H., Zhao, Y.: An L p superscript 𝐿 𝑝 L^{p} theory of sparse graph convergence I. Limits, sparse random graph models, and power law distributions. ar Xiv: 1401.2906 (2014)