Distributed Hierarchical Control for State Estimation With Robotic Sensor Networks
Charles Freundlich, Yan Zhang, and Michael M. Zavlanos

TL;DR
This paper introduces a scalable hierarchical control framework for active state estimation in robotic sensor networks, combining dynamic programming and decentralized assignment to efficiently manage large state spaces and multiple robots.
Contribution
It proposes a novel hierarchical DP approach and a decentralized cluster assignment algorithm, enabling scalable and efficient active state estimation.
Findings
Framework performs well in simulations and real-world experiments.
Method scales effectively to large numbers of states and sensors.
Achieves near-optimal state estimation with reduced computational complexity.
Abstract
This paper addresses active state estimation with a team of robotic sensors. The states to be estimated are represented by spatially distributed, uncorrelated, stationary vectors. Given a prior belief on the geographic locations of the states, we cluster the states in moderately sized groups and propose a new hierarchical Dynamic Programming (DP) framework to compute optimal sensing policies for each cluster that mitigates the computational cost of planning optimal policies in the combined belief space. Then, we develop a decentralized assignment algorithm that dynamically allocates clusters to robots based on the pre-computed optimal policies at each cluster. The integrated distributed state estimation framework is optimal at the cluster level but also scales very well to large numbers of states and robot sensors. We demonstrate efficiency of the proposed method in both simulations and…
Click any figure to enlarge with its caption.
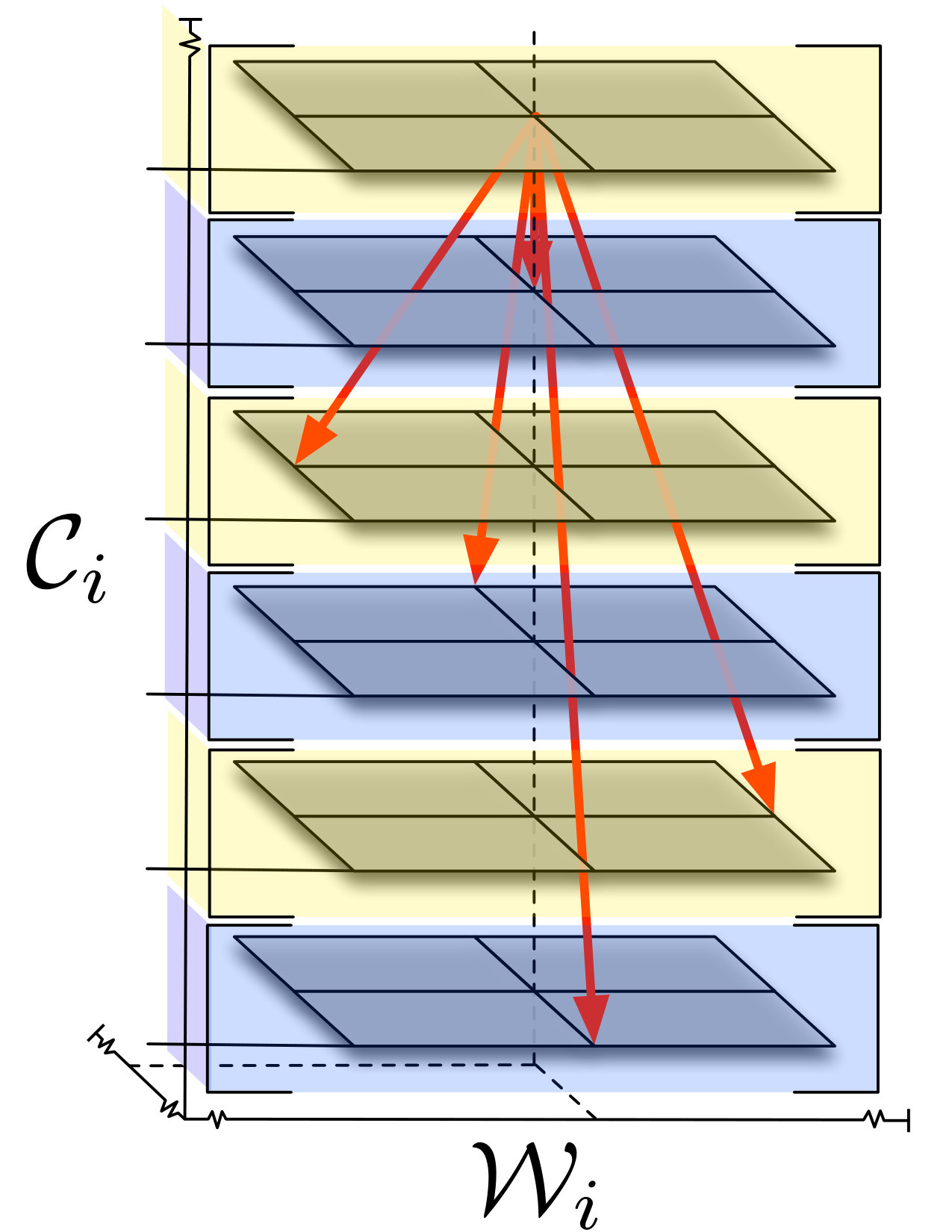 Figure 1
Figure 1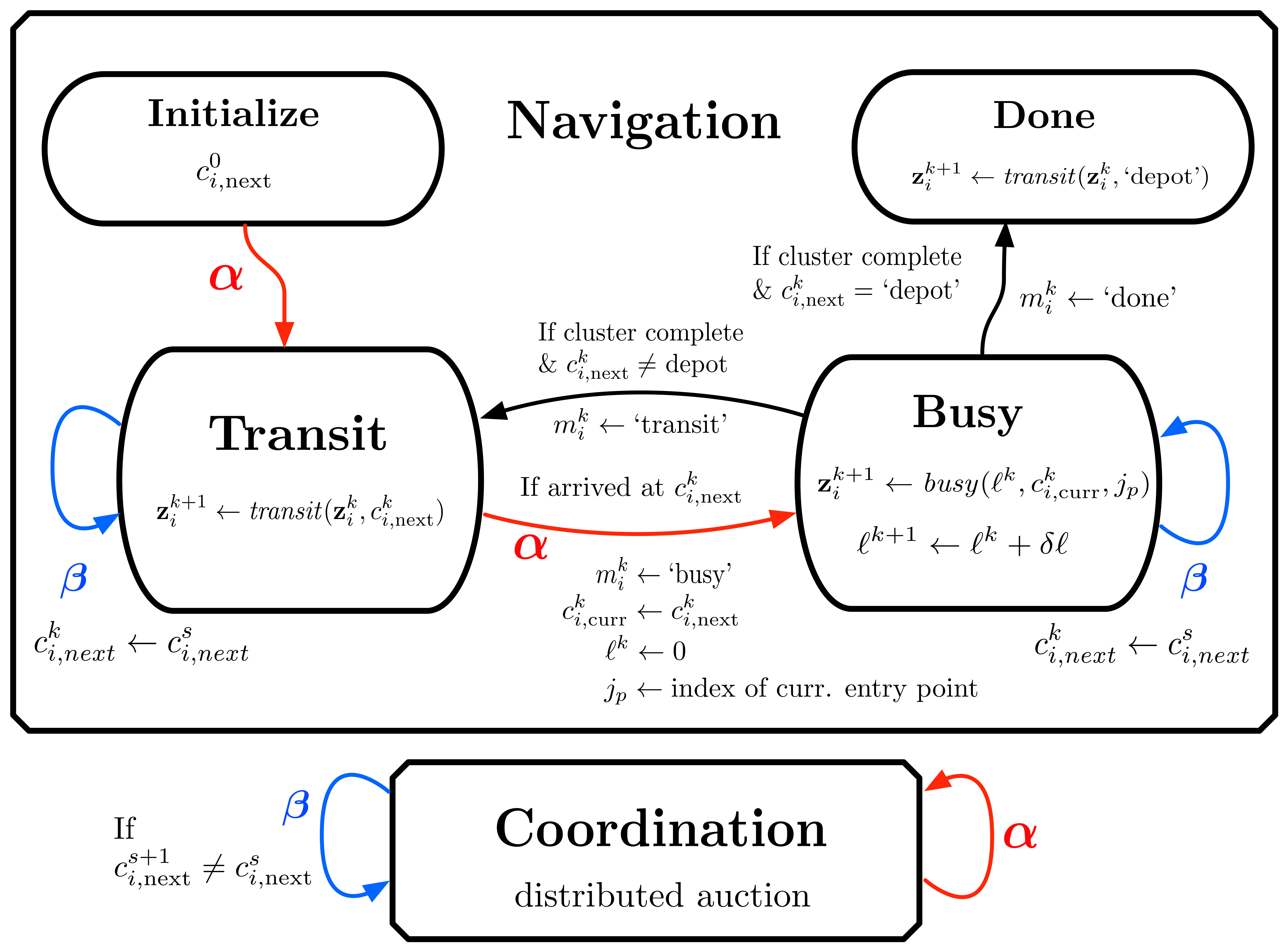 Figure 2
Figure 2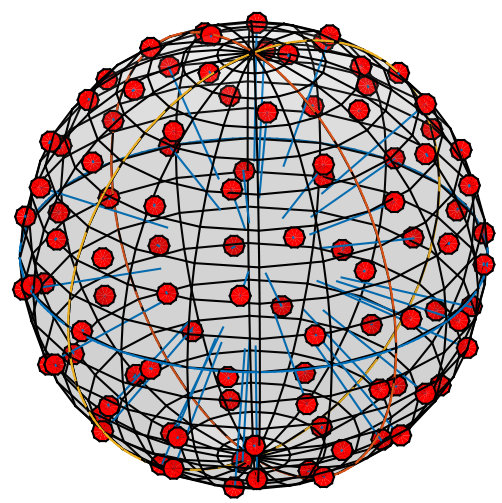 Figure 3
Figure 3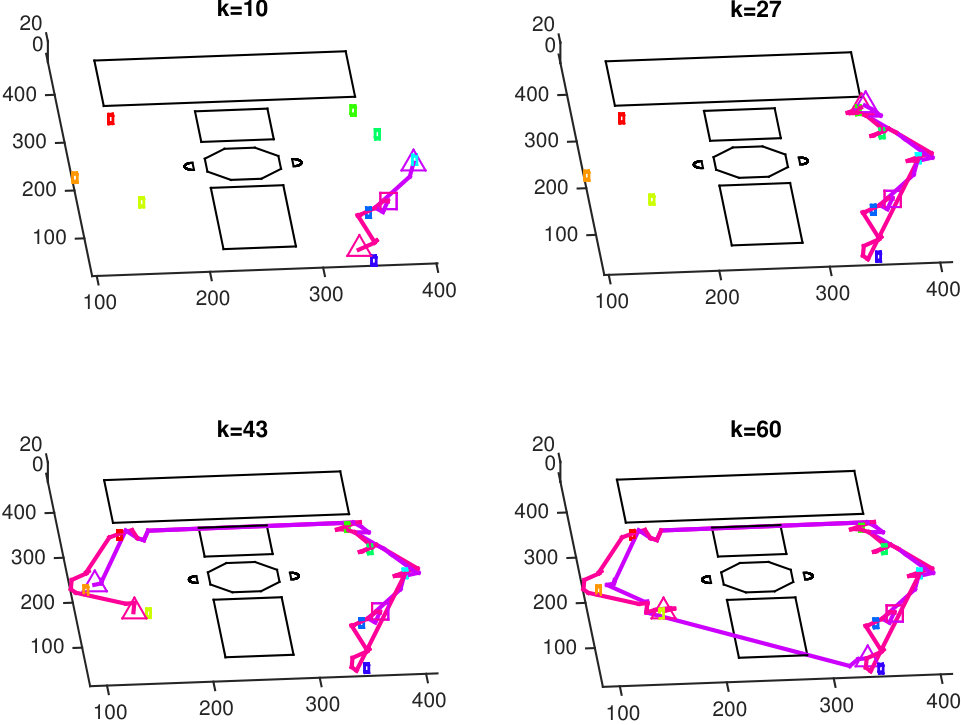 Figure 4
Figure 4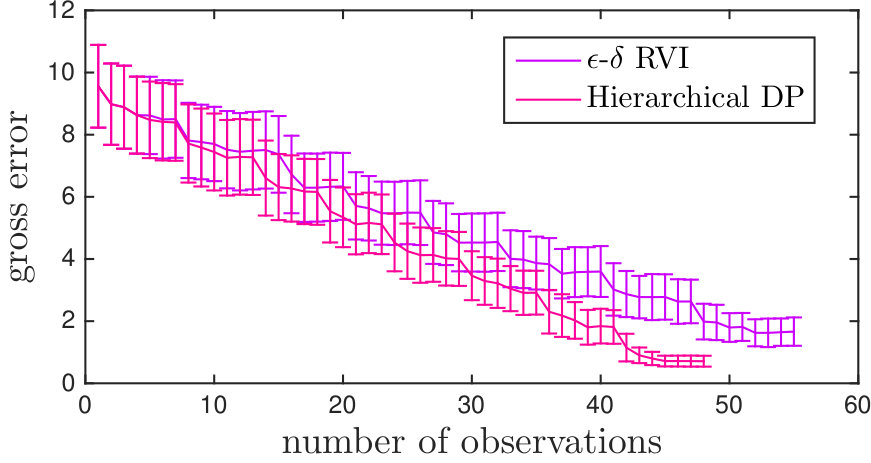 Figure 5
Figure 5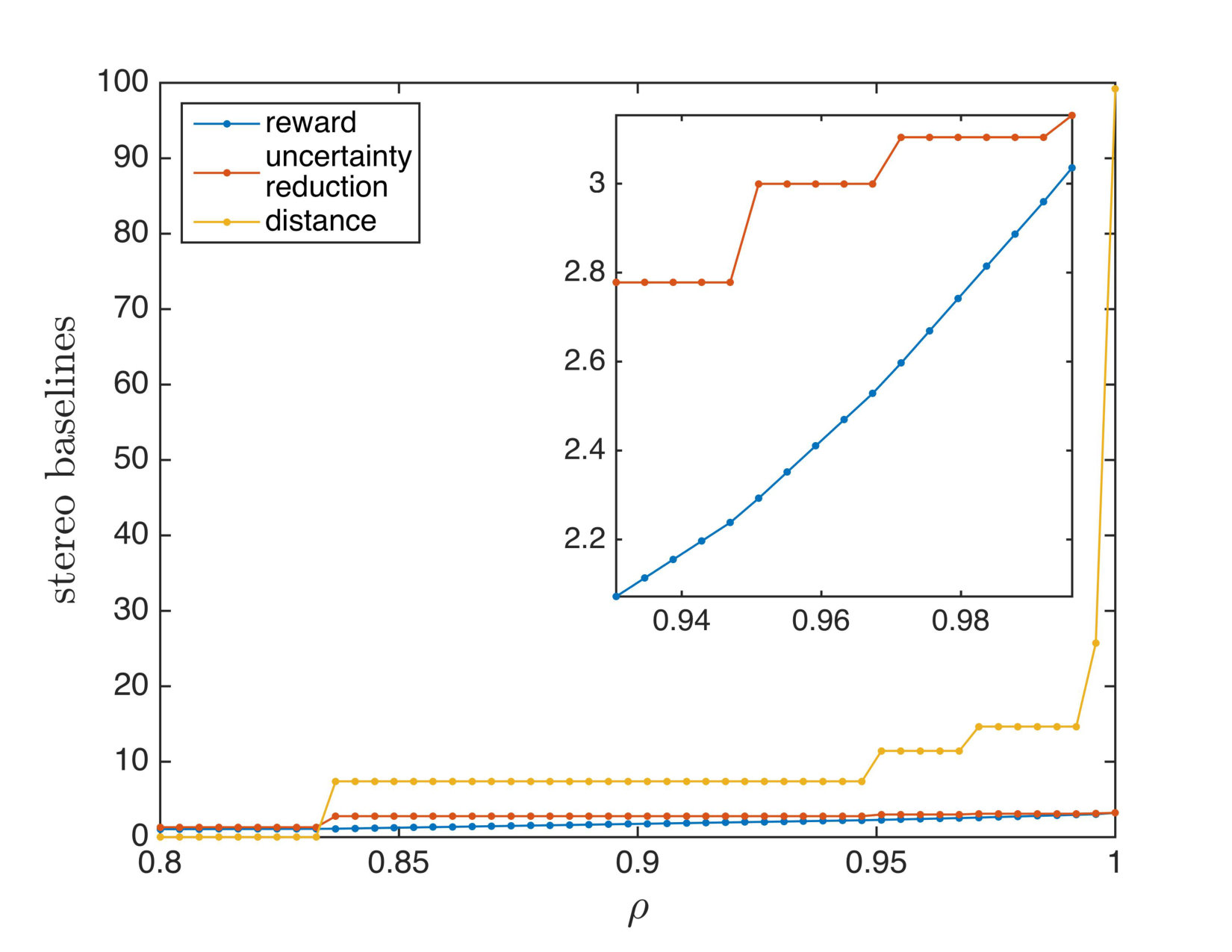 Figure 6
Figure 6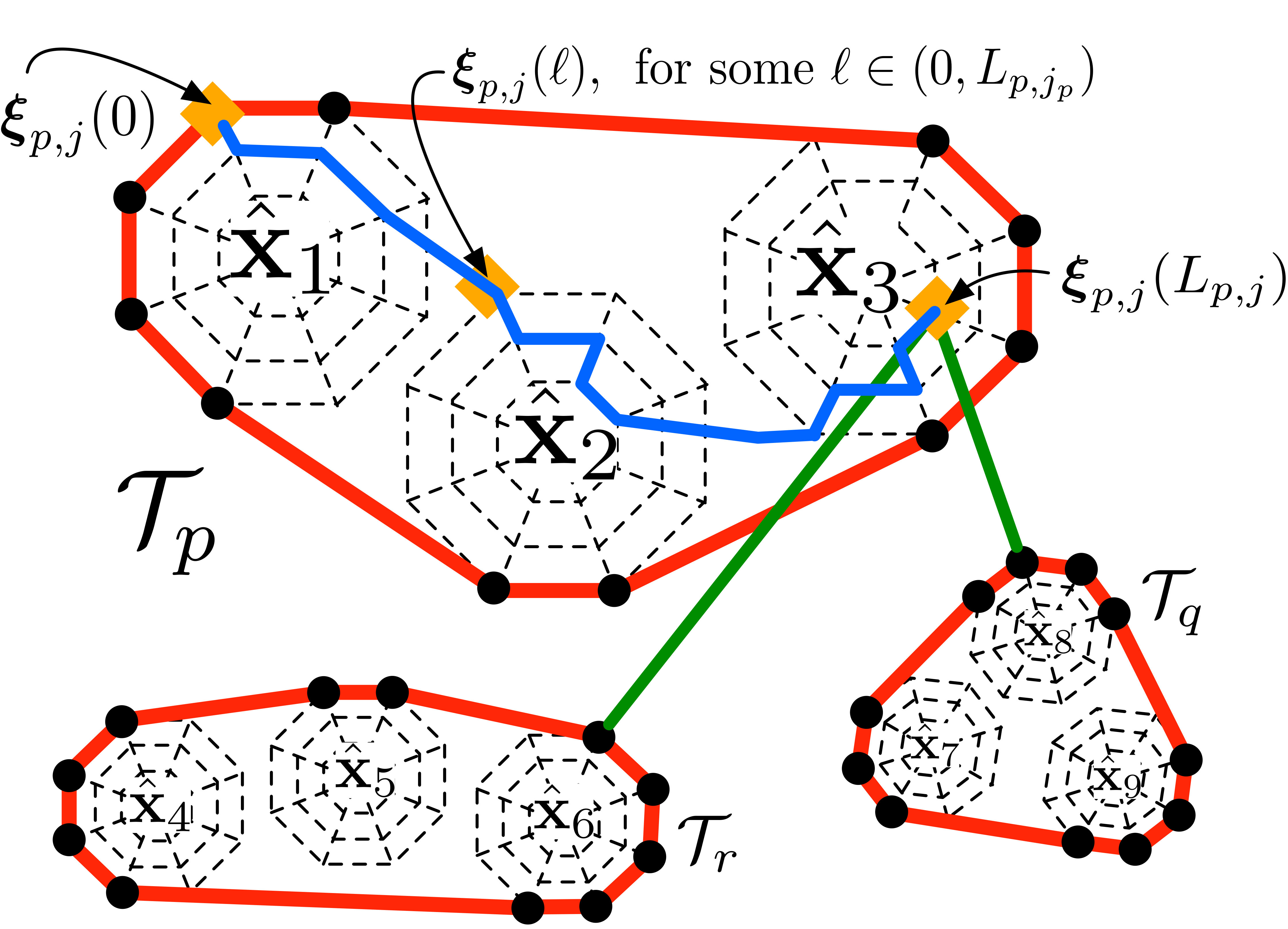 Figure 7
Figure 7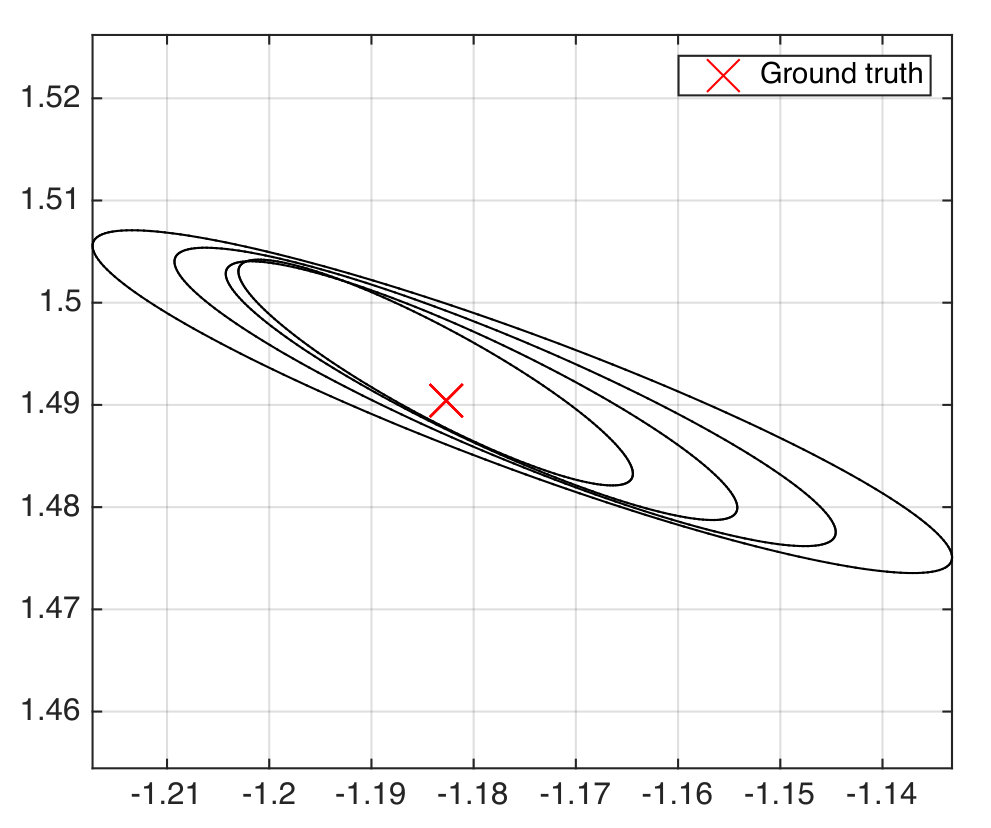 Figure 8
Figure 8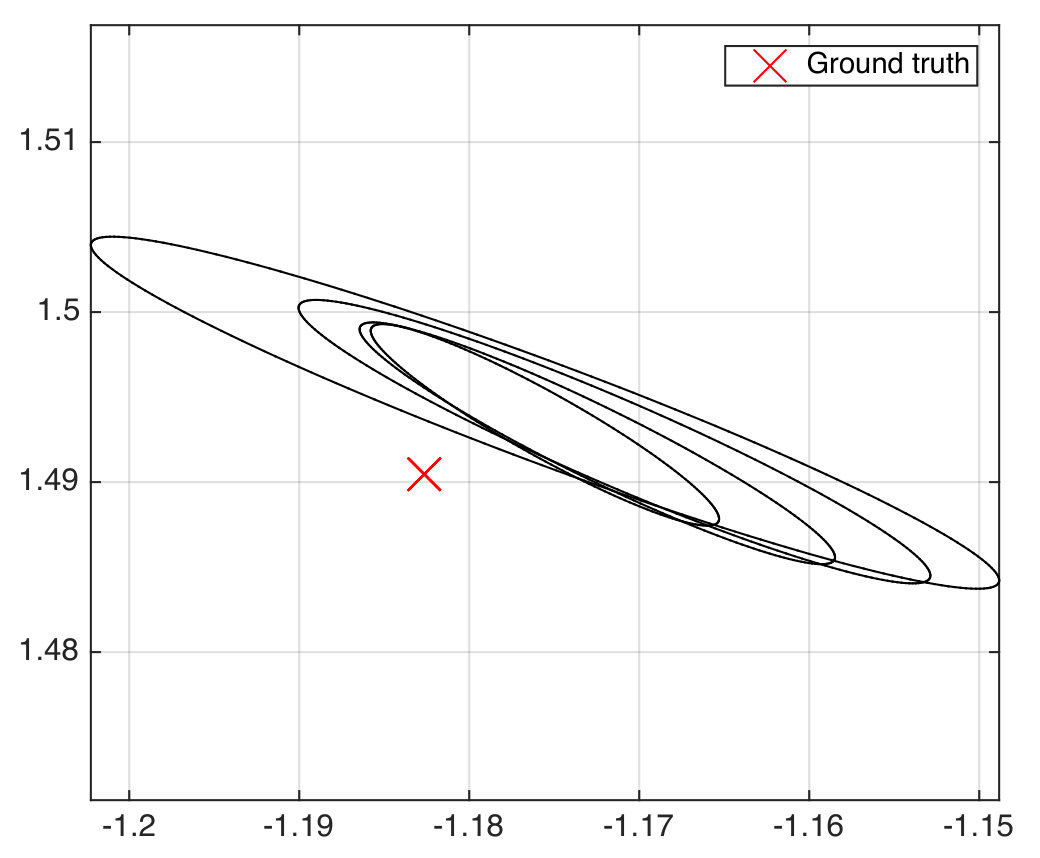 Figure 9
Figure 9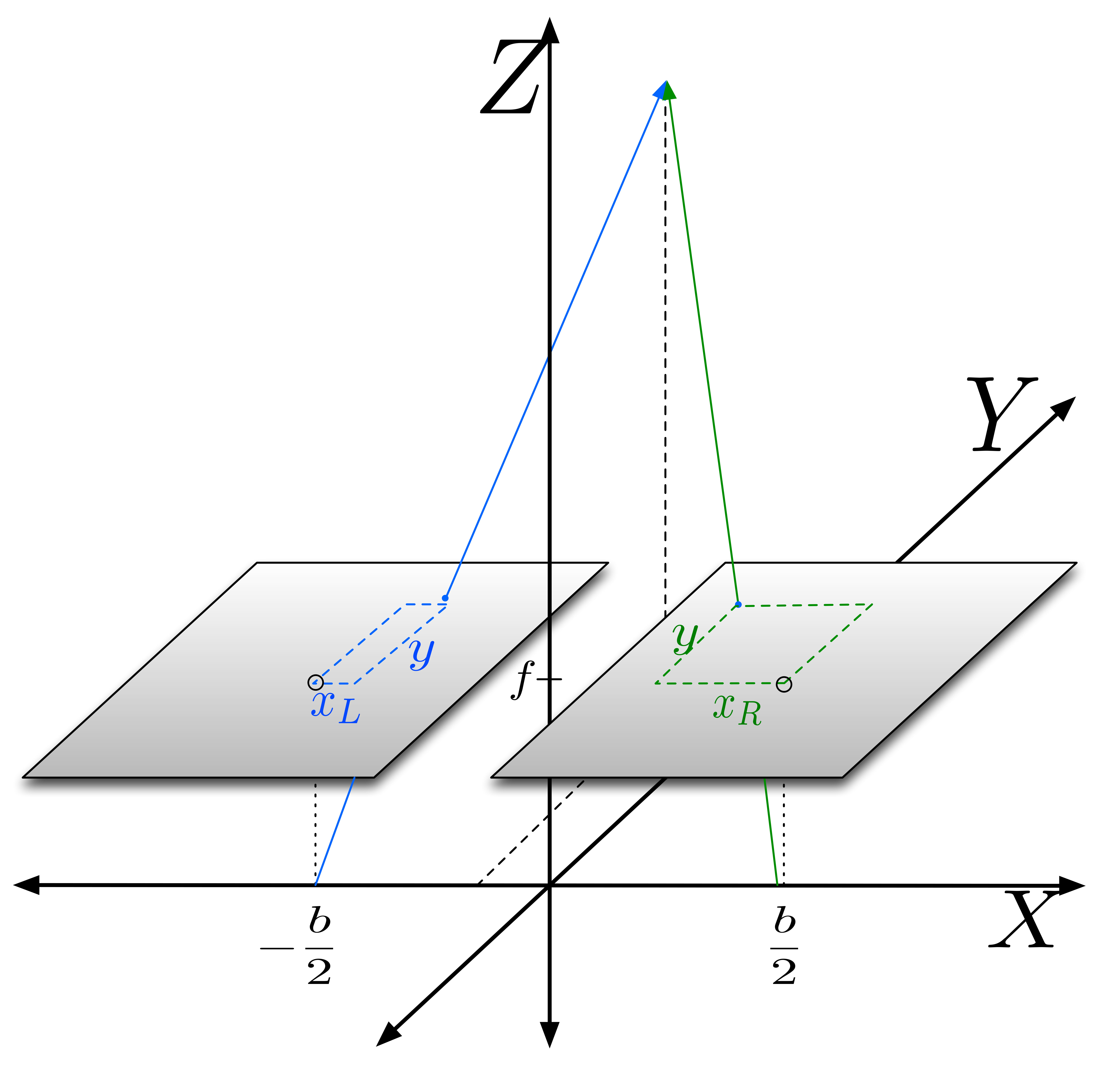 Figure 10
Figure 10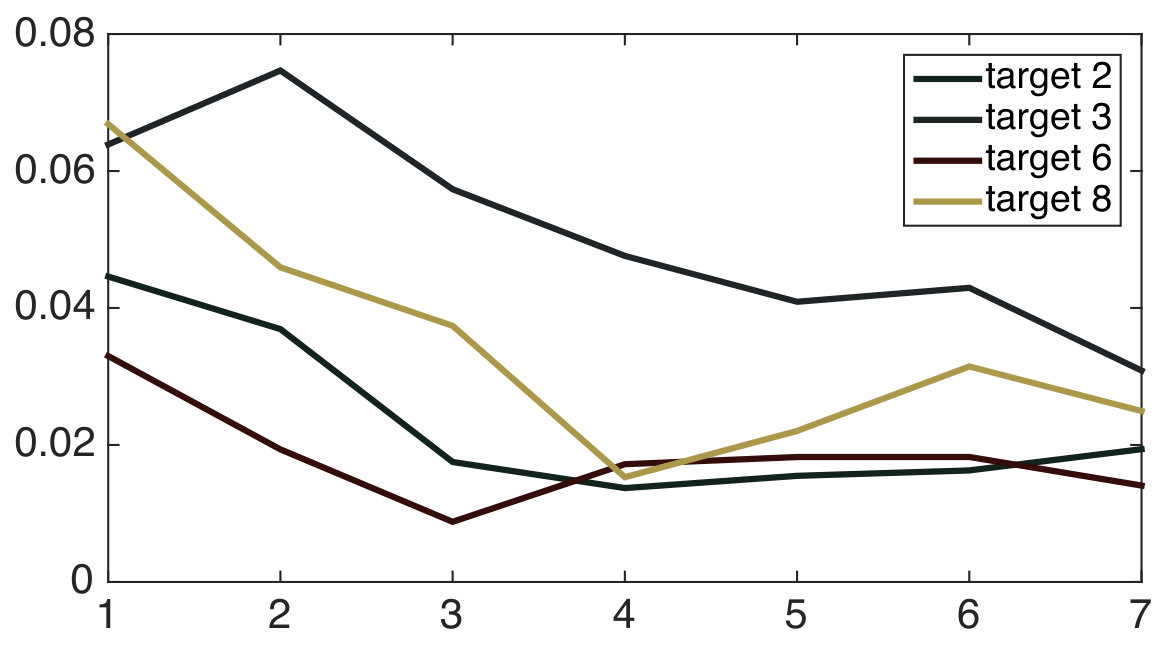 Figure 11
Figure 11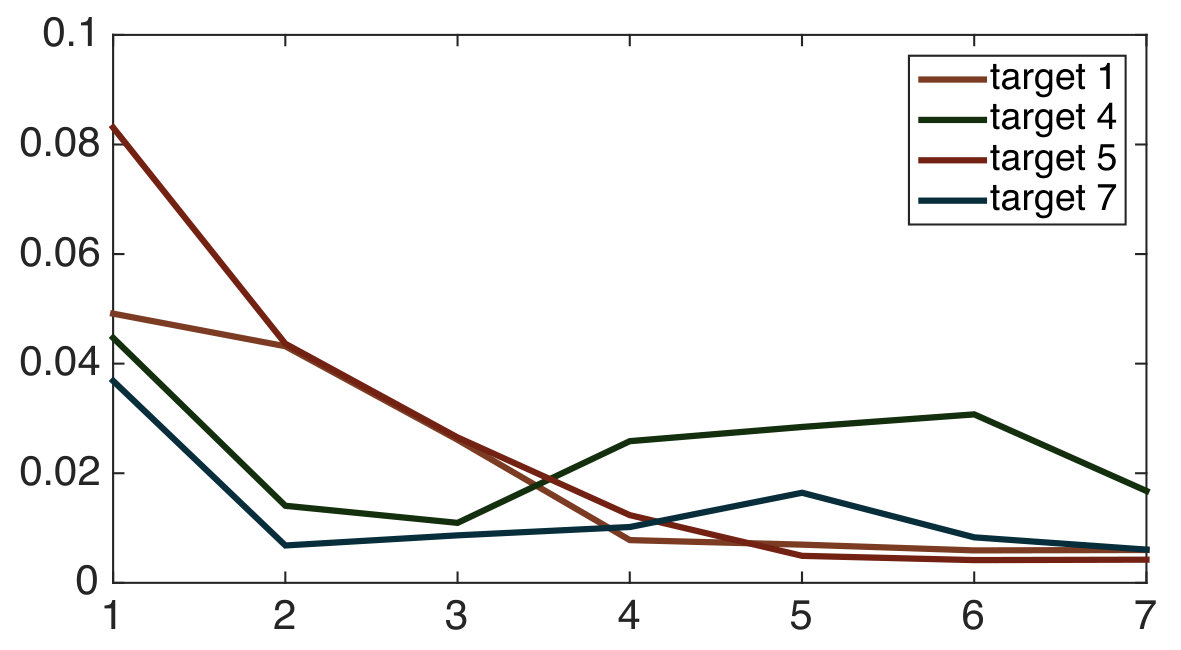 Figure 12
Figure 12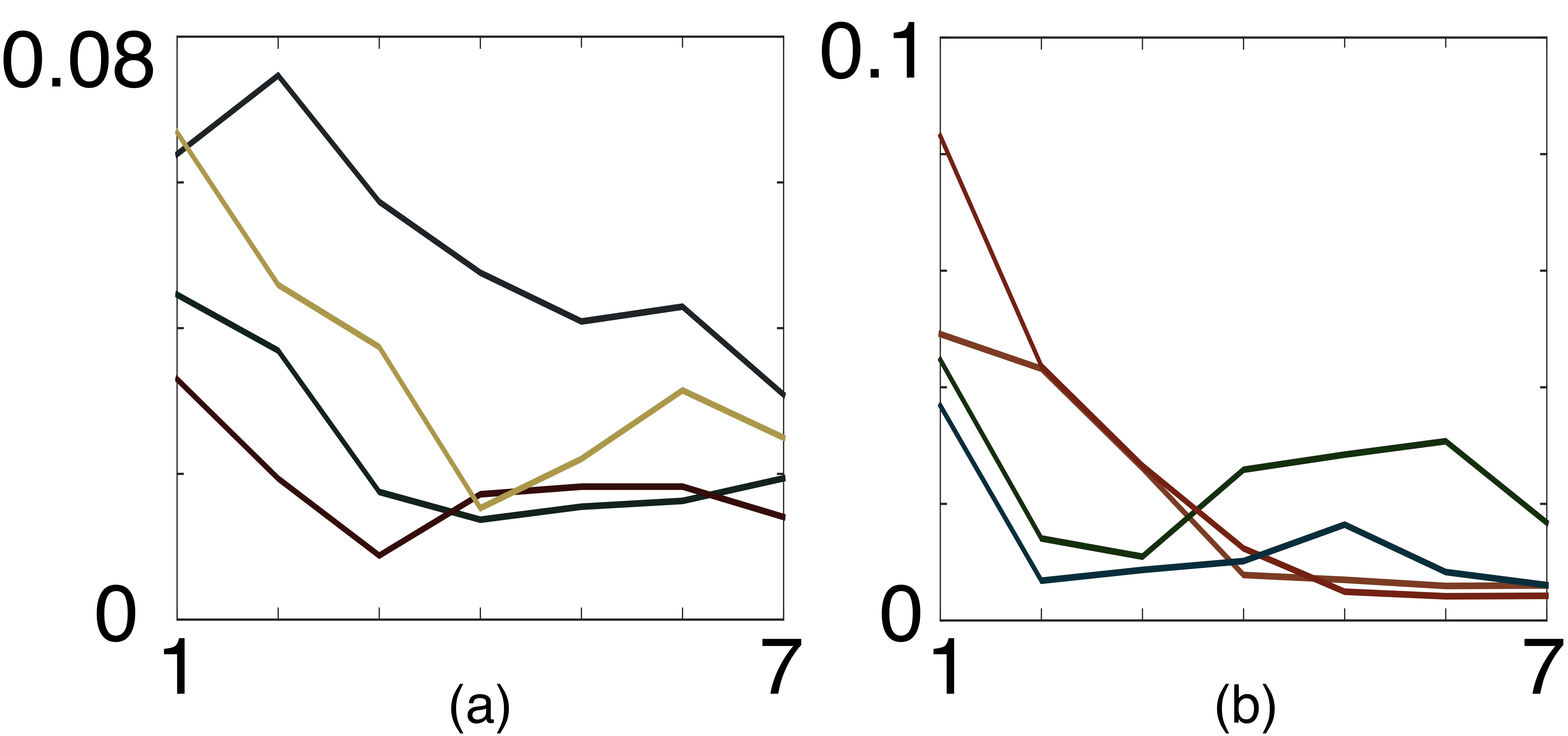 Figure 13
Figure 13 Figure 14
Figure 14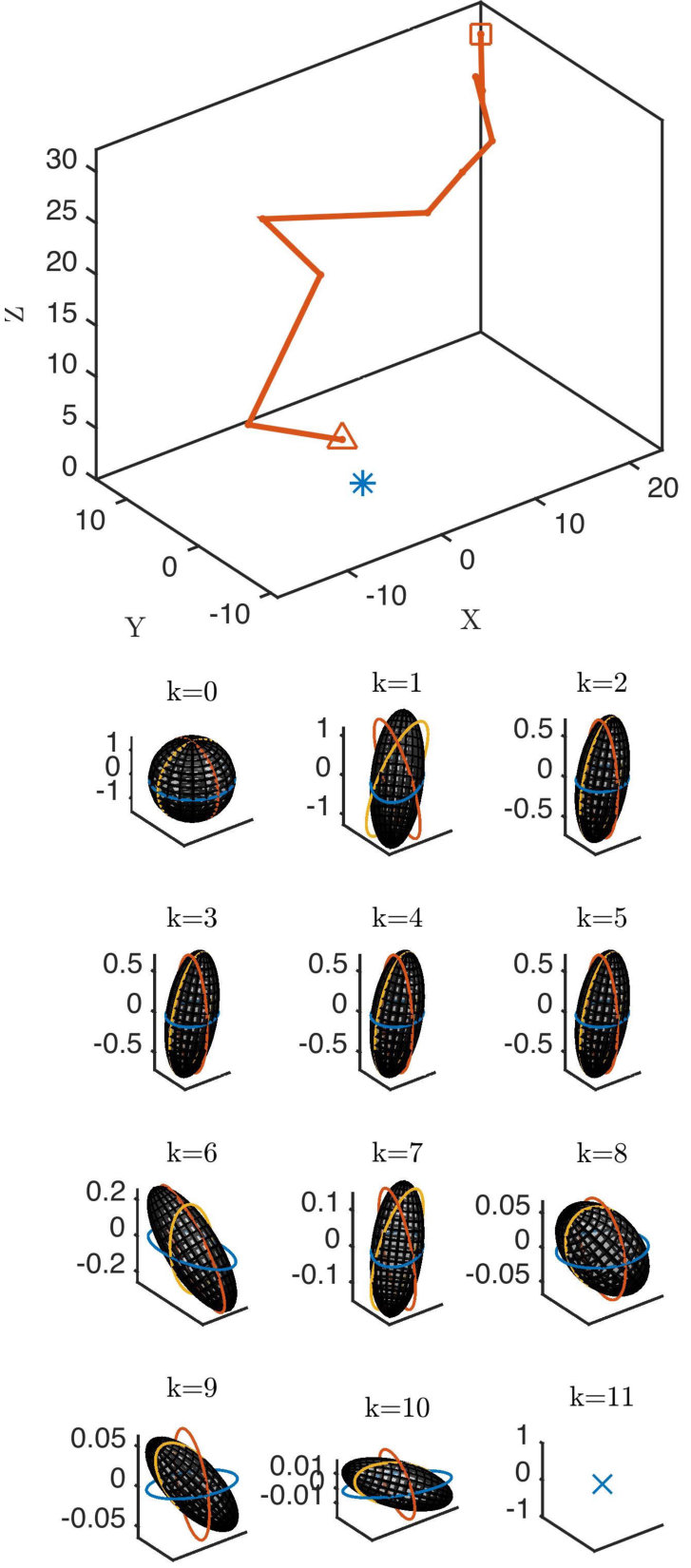 Figure 15
Figure 15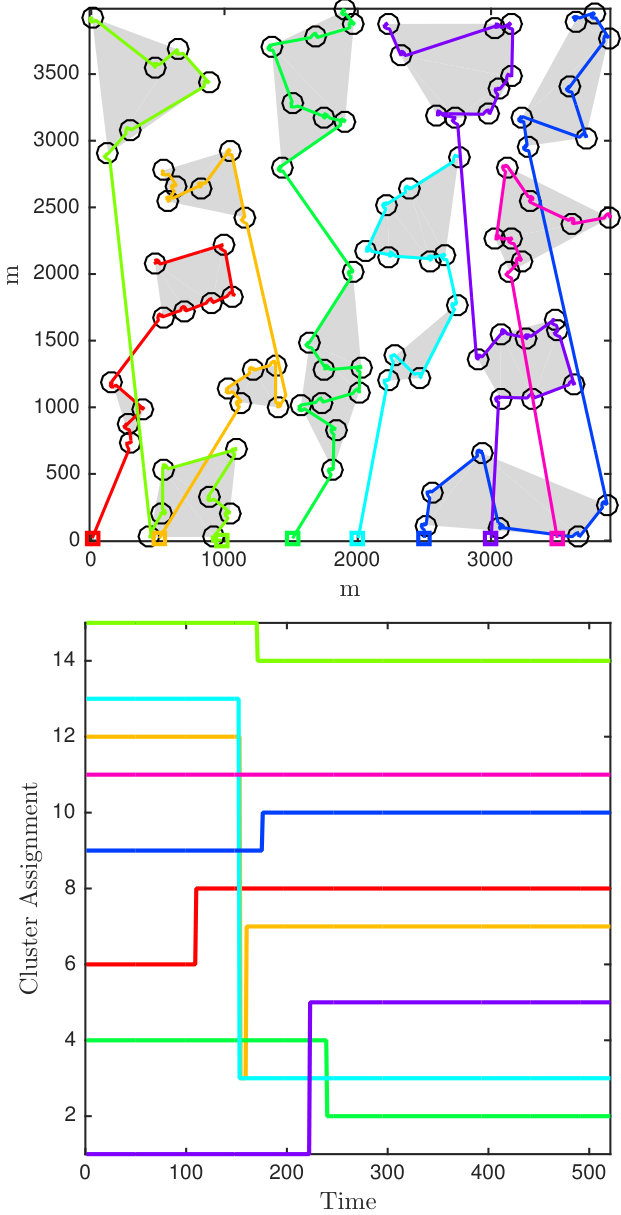 Figure 16
Figure 16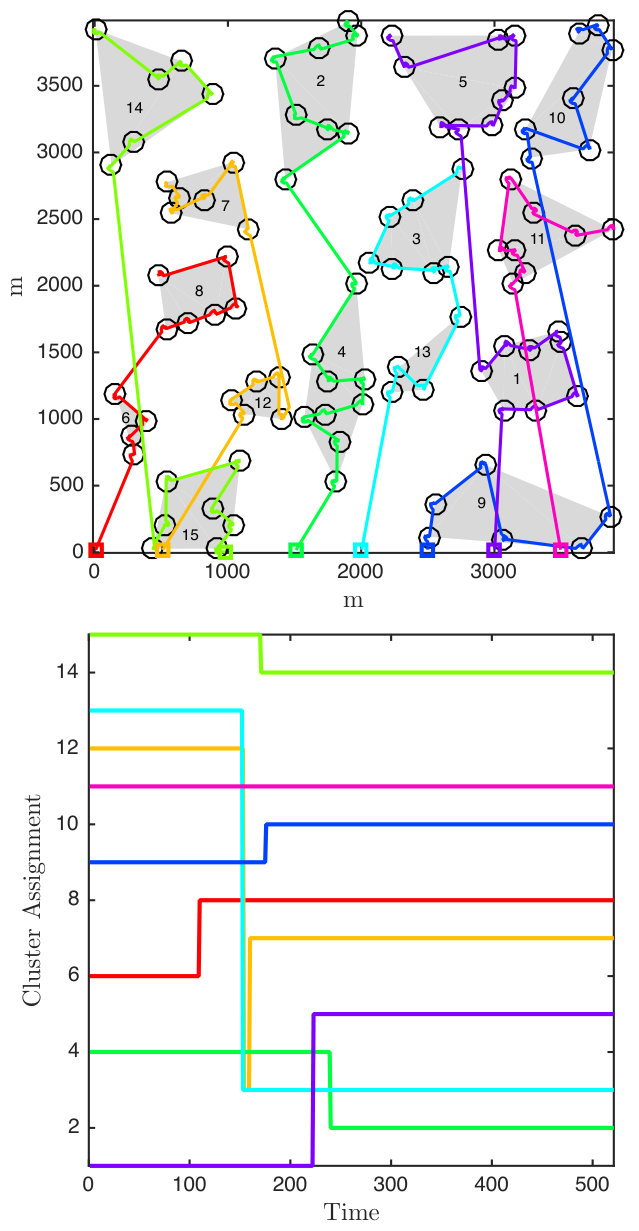 Figure 17
Figure 17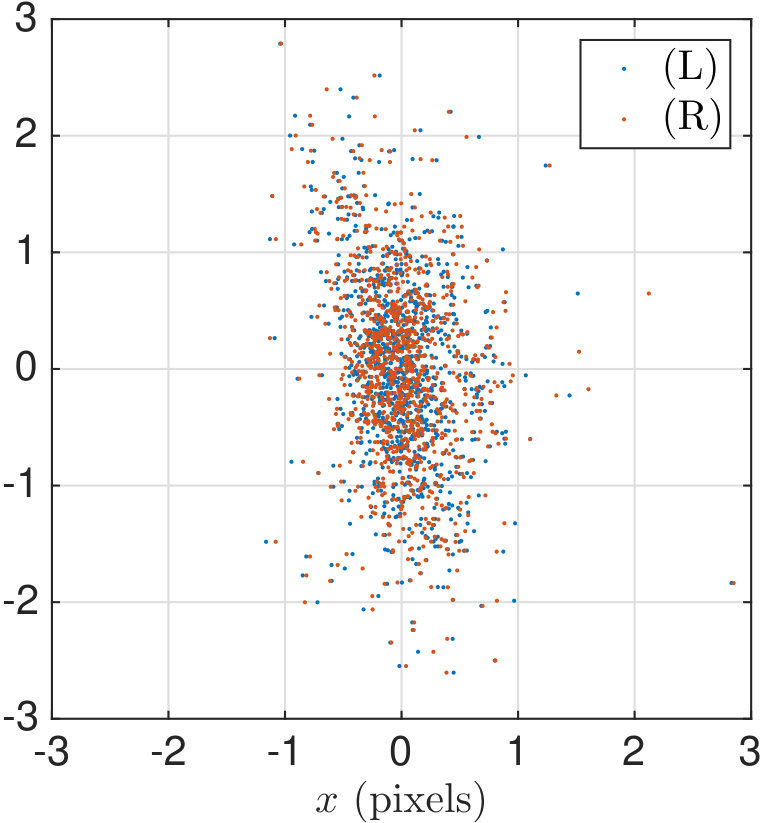 Figure 18
Figure 18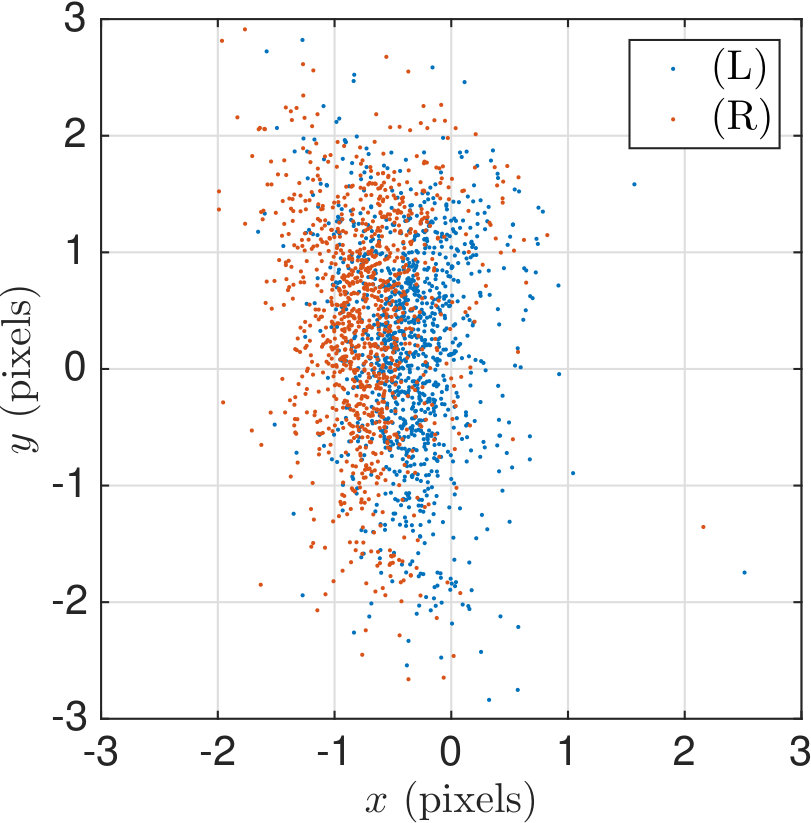 Figure 19
Figure 19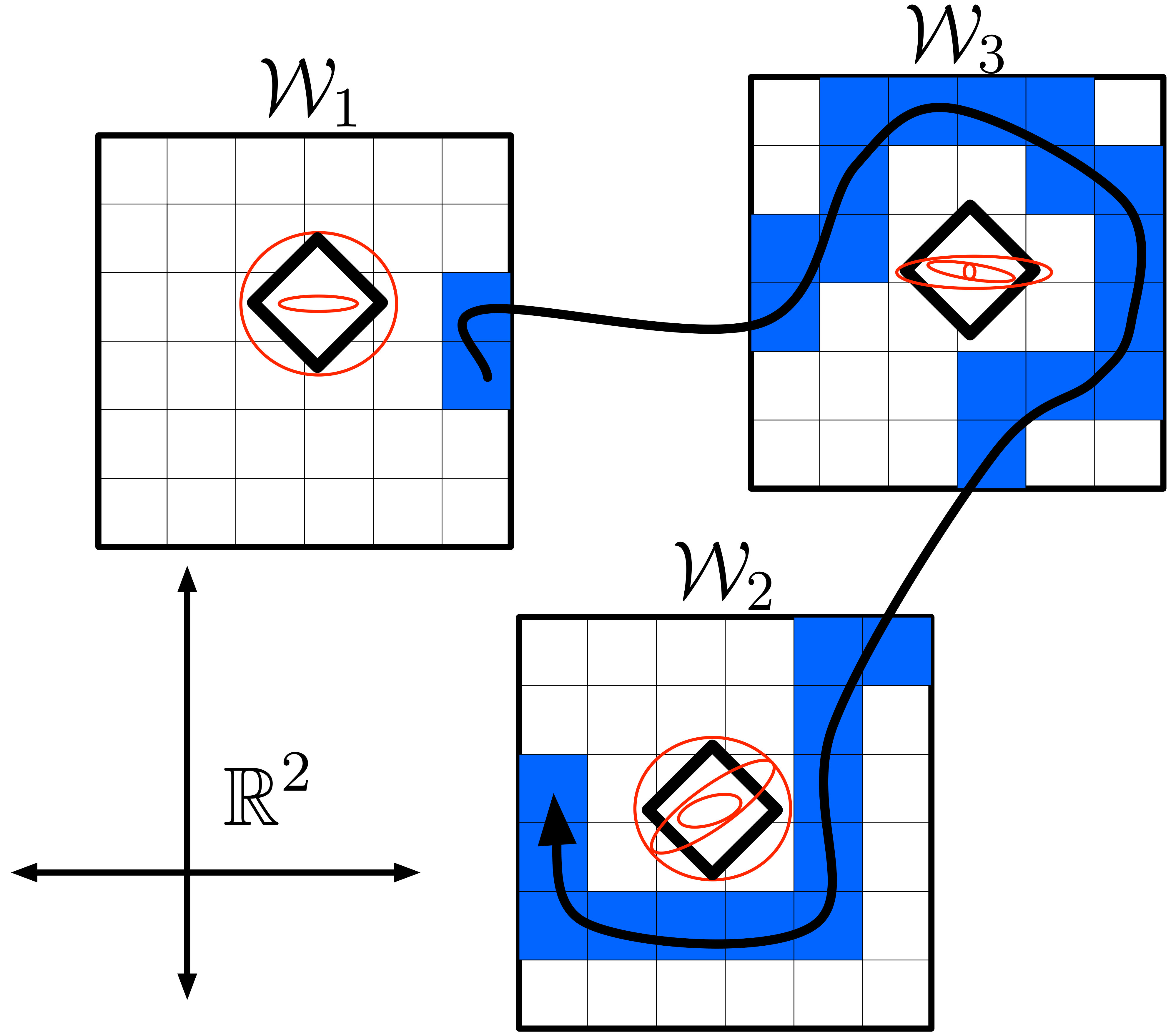 Figure 20
Figure 20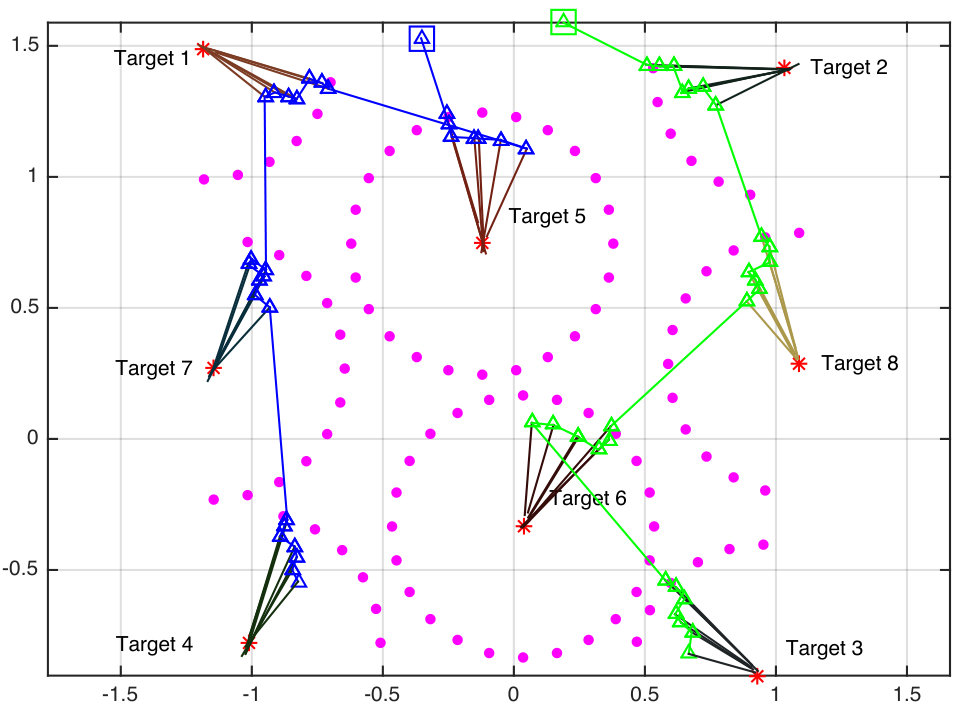 Figure 21
Figure 21| Method | optimal | closer | static | circle | random |
|---|---|---|---|---|---|
| Reward (m) | 3.15 | 2.75 | 1.31 | 1.66 | 2.74 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
*[inlinelist,1]label=(),
Distributed Hierarchical Control for State Estimation With Robotic Sensor Networks
Charles Freundlich, Yan Zhang, and Michael M. Zavlanos Charles Freundlich, Yan Zhang, and Michael M. Zavlanos are with the Dept. of Mechanical Engineering and Materials Science, Duke University, Durham, NC 27708, USA {charles.freundlich, yan.zhang2, michael.zavlanos}@duke.edu. This work is supported in part by the NSF award CNS #1302284. A preliminary version of this work can be found in [1]
Abstract
This paper addresses active state estimation with a team of robotic sensors. The states to be estimated are represented by spatially distributed, uncorrelated, stationary vectors. Given a prior belief on the geographic locations of the states, we cluster the states in moderately sized groups and propose a new hierarchical Dynamic Programming (DP) framework to compute optimal sensing policies for each cluster that mitigates the computational cost of planning optimal policies in the combined belief space. Then, we develop a decentralized assignment algorithm that dynamically allocates clusters to robots based on the pre-computed optimal policies at each cluster. The integrated distributed state estimation framework is optimal at the cluster level but also scales very well to large numbers of states and robot sensors. We demonstrate efficiency of the proposed method in both simulations and real-world experiments using stereoscopic vision sensors.
Index Terms:
Sensor Networks, Decision/Estimation Theory, Distributed Algorithms/Control, Optimal Control
I Introduction
Robotic sensors rely on mobility to gather information. Information acquisition can be subtask in a more complex robotic mission such as SLAM, or the end goal in, e.g., geostatistical surveying, environmental sampling, or mapping missions. The goal of this paper is to determine how a team of robots should collect information so that the aggregate uncertainty in a finite collection of hidden state vectors is minimized. Specifically, given prior beliefs of the geographic location of the hidden states, we seek an optimal sequence of observations which, when fused with the prior beliefs, minimizes the estimation uncertainty. This problem is known in the mobile robotics literature as distributed state estimation. The approach presented herein is similar to recent advancements in linear-Gaussian active sensing that operate in pose-covariance space [2, 3], except that here we propose a novel belief-space discretization that admits exact value iteration and can be readily incorporated in a hierarchical multi-robot controller, enabling decentralized information acquisition of very large collections of hidden states by large teams of robots.
A typical approach to active state estimation is to employ gradient descent methods to generate sensor trajectories and sequences of associated state observations that minimize an information theoretic objective of interest, such as the trace of the covariance matrix. This is the approach followed, e.g., in mobile target tracking [4, 5], sparse landmark localization [1, 6, 7], and active SLAM [8, 9, 3]. Recently, [8] have shown that information-theoretic objectives may fail even to be monotonic in many active sensing tasks, removing performance guarantees for greedy control.
When planning multiple observations, the robot may need to reason over the combinatorial set of future probability distributions (pdfs), efficiently represent them, and solve Bellman’s equation. This is known as the “belief representation problem.” This problem, in the context of information acquisition, has received a great deal of attention recently, both when the robot state is observable[10, 11, 2, 12, 13] and when it is only partially observable[14, 15, 16, 3, 17, 18, 19, 20, 21]. The most widely used approach is to grow a tree with a prior distribution of the hidden states at the root, sampling in this way several sequences of possible future observations to obtain the set of reachable belief states at the leaves. Once the tree has been constructed, one simply selects the leaf with the lowest cost and traces it back to the root to obtain the optimal policy. The horizon length can be set a priori [10, 11, 2, 14] or, e.g., defined implicitly by a budget [12].
Note that nonmyopic active sensing problems, such as the problem addressed in this paper, implicitly exploit a priori knowledge rather than exploring the environment to discover new features. Exploration can be included as a first step as in [14], and incorporating this step within our approach is a subject of further research.
Two approaches that are fundamentally different from choosing a dynamic programming horizon are
1 to represent the reachable belief space with a finite set in a clever way, typically by making an assumption about the family of distributions of the hidden states[15, 1, 2, 16, 7, 13], or
2 to avoid this representation problem altogether by working in policy space [17, 18, 19].
With respect to the latter, [19] defines a generalized policy graph, which nonetheless relies on belief space sampling. In fact, some kind of sampling is at the core of all point-based approaches stemming from the seminal paper [22].
Non-myopic active sensing for teams of decentralized robots often leads to decentralized Partially Observable Markov Decision Process POMDPs (dec-POMDPs) [20, 21]. To our knowledge, decentralization in this context refers to the execution of the planner, as its computation is always done offline at a central location due to the non-separable nature of the value function. Recently, [23] used sequential planning for decentralized active SLAM.
Common in the vast majority of approaches discussed above is that mobile sensor planning relies on sampling-based strategies, e.g., forward search, for partially [14, 15, 16, 3, 20, 21, 17, 18, 19, 15] and fully observable [2, 13] robots, or belief space sampling in the policy domain [17, 18, 19]. Sampling-based approaches will typically run into scalability issues due to one or more of the following reasons:
1 sparsity of information in the environment, which forces longer planning horizons,
2 high dimensional unknowns, which make observation sampling inefficient, or
3 large teams of robots, which significantly increase the size of the action space.
To design an algorithm that avoids these pitfalls, in this paper we introduce a hierarchical approach that decomposes the set of states into clusters, designs optimal controllers for each cluster, and then allocates those controllers among the robots. Specifically, for every hidden state that needs to be estimated, we define a local Dynamic Program (DP) in the joint state-space of robot positions and state uncertainties that determines robot paths and associated sequences of state observations that collectively minimize the estimation uncertainty. Then, we divide the collection of hidden states into clusters based on a prior belief of their geographic locations, and, for each cluster, we define a second DP that determines how far along the local optimal trajectories the robot should travel before transitioning to estimating the next hidden state within the cluster. Finally, a distributed assignment algorithm is used to dynamically allocate controllers to the robot team from the set of optimal control policies for every cluster.
At the cluster level, the problem that we solve can be considered a generalization of the TSP in that the robot must observe high dimensional unknowns over an infinite horizon at each site. This is important to note because our method incurs the same computational complexity as the TSP, , where is the number of hidden states in the cluster. Moreover, the greedy extension of our method to multiple robots and multiple clusters only contributes constant complexity in the size of the robot team and in the number of clusters. In this way, our approach represents an approximation algorithm to a broad class multi vehicle generalized TSPs for which no good approximation exists. While we are not able to guarantee an optimality gap, we are able to bound computational complexity by limiting the cluster size, effectively “dividing and conquering” the hard problem into a number of tractable subproblems that can be solved exactly.
We are not aware of any other non myopic method in the literature that can handle as many hidden states and robot sensors. We also illustrate these claims with experiments on real robots, which are a contribution in and of themselves as the first to demonstrate experimental multi-robot active sensing using stereo vision.
The paper is organized as follows: In Section II, we formulate the distributed state estimation problem addressed in this paper. In Sections III and IV we propose a local and a cluster DP to obtain controllers that are optimal at the cluster level. Section V presents the distributed auction mechanism that can efficiently allocate clusters to the robots in real-time. In Section VI, we simulate large robot teams carrying stereo vision rigs that localize hundreds of sparse landmarks. In Section VII, we report experiments on a team of two robots localizing eight landmarks.
II Problem Formulation
Consider a team of mobile robots tasked with estimating hidden state vectors . Let and denote the configuration and action spaces of a single robot, and let denote its (possibly nonholonomic) dynamical model.
In this paper, the set can be any finite discretization of the robot’s configuration space, as long as transitions in that space can be assumed to be deterministic.
Assume that the robots have access to a Normal prior distribution over the hidden states, with means and covariances . Let denote the observation of by robot that is corrupted by zero mean Gaussian noise, specifically, where We assume that we have a model of that depends on both the state of the robot and the hidden vector.
We will thus write as a (possibly discontinuous) mapping where denotes the set of symmetric matrices and the subscript denotes the restriction of this set to the set of positive definite matrices.
Collectively, the team acquires a sequence of observations with measurement error covariances from various vantage points along controlled trajectories , where denotes a time index. Hereafter, we will sometimes write instead of to emphasize that is actually a function of and
Our goal is to minimize the variance in all hidden vectors as well as the distance the robots need to travel over the course of the controlled trajectories. We denote by a metric that measures the distance an agent needs to travel as a result of actions in . Then, given a parameter , we find a sequence of control inputs that solve
[TABLE]
with initial conditions and prior error covariance . For each stage , the expression inside the square brackets in (1a) is a trade off between variance reduction and distance traveled. The parameter controls this tradeoff. The square root in this expression is used to compare equal units. Setting the discount factor ensures that the value function for the infinite horizon problem remains finite. Equation (1b) explicitly constrains the robot poses by the dynamics , while equation (1c) constraints the covariance dynamics by the Kalman Filter (KF) update for stationary hidden states.
The developments in the remainder of this paper toward solving problem (1) rely on the following assumptions:
Assumption II.1**.**
In this work we assume that the hidden state vectors are sparse and so are the observations. This means that even if the robot passively observes multiple hidden vectors at once, our plans are only optimal with respect to reducing the uncertainty of one at a time.
Assumption II.2**.**
We assume that we have access to a noisy prior distribution for each hidden vector. We assume that the hidden vector is a stationary process, thus we use the prior mean (along with the sensor configuration) to evaluate the observation uncertainty for all time . Similar to the formulation in [2, 13], this means that the dynamics of the error covariance matrices are deterministic, cf. (1). This also implies that under KF dynamics.
III Localization of a Single Target
In this section, we propose a method to solve problem (1) for thus we drop the references to and . We call this the local DP. To construct the local state-space, we approximate the space of reachable covariances by a finite set . Then, we define the local state space to be the product space We discuss the specifics of designing in Section III-A. A state is reachable from if there exists a control input that satisfies the joint dynamical equation , given by
[TABLE]
where . We give exact details of this projection in Section III-A and provide an example of the state-space transitions in Fig. 1 (a). Projection in (2) is necessary because we require that , which is a finite subset of . The function constitutes the transition function for the local DP. Then, denote by the instantaneous reward from problem (1), given by
[TABLE]
In the remainder of this section, we will design a state space that is small enough for exact value leading to a desired stationary optimal policy .
In particular, a stationary optimal policy is one that depends only on the current state of the system.
III-A The Uncertainty State-Space and Transition Function
In this section, we discretize to design the finite set We emphasize that optimally sampling bounded subsets of is an interesting and deep problem [24], and we do not provide a general framework. Our method works well for representing a specific bounded region of which we call the reachable covariance matrices for the problem described herein.
We begin by the following lemmas; proofs are omitted due to space limitations.
Lem III.1**.**
Let denote the identity matrix and let . Then, .
Lem III.2** (Lemma 2.7, [25]).**
Let . If , then
The first implication of Lemma III.2 is that the trace of the largest instantaneous covariance bounds the maximum eigenvalue of the reachable covariance matrices. Define this bound as
[TABLE]
where we have written the measurement covariance as a function of the prior mean of the state estimate , which is fixed during the planning phase, and the configuration of the sensor
Lemma III.2 also implies that the trace is decreasing with additional independent measurements. Therefore, the set of reachable covariances is bounded. Lemma III.2 and the resulting bound can be used to obtain a discretization of the set of possible maximum eigenvalues for the reachable covariance matrices. In particular, we define the logspace set of maximum eigenvalues
[TABLE]
where is the cardinality of and is a sampling gain that controls how clustered the samples are toward zero. Note that is the maximal element of . In (5), we sample in logspace as a heuristic; we have found empirically that the maximum eigenvalues of the filtered covariance matrices accumulate near zero.
To obtain a scalable discretization of the space of covariance matrices we assume that and its corresponding eigenvector are more important than any one of the other eigenvalues and eigenvectors. In particular, we assume that, in comparison to the other eigenvalues are roughly equal, thus all other eigenvalues can be parameterized by a number in the half open interval such that for all This choice alleviates the need to independently consider all possible combinations of eigenvectors corresponding to the nonprincipal eigenvalues. Define the set of ratios, which can be thought of as the set of possible inverse condition numbers, as
[TABLE]
In (6), is the number of eigenvalue ratios we sample and is a sampling gain that controls the ellipticity of the confidence region associated with Again, the logspace discretization is a heuristic based on experience; KF error covariance matrices produced using robotic sensors are typically cigar-shaped, i.e., dominated by uncertainty in the direction of the principal eigenvector.
The set of possible principal eigenvectors is equivalent to the set of lines passing through the origin, known as the real projective space Let be the number of samples needed to capture these possible directions for the principal eigenvalue. Because can be formed by identifying antipodal points on any sphere, this problem can be approximately solved by placing point charges on a sphere of radius allowing them to move until the “electrostatic forces” among them come to equilibrium, cutting the sphere along any equator, discarding one of the hemispheres, and saving the unit directions to each “charge” location on the other hemisphere. It is straightforward to build such a simulation, and for brevity we do not provide the specifics here. The result for 100 charges on the unit 2-sphere is shown in Fig. 1 (b).
To force the sampling density to be consistent, defined in terms of the surface area of the sphere used in the simulation, we create a set of sets ; each element is the set of unit vectors produced by the simulation using as the radius of the sphere. The number of elements in the largest, i.e., the set with the most elements, of these sets is set to a user-specified number . The remaining sets correspond to the other possible principal eigenvalues and, since is the maximal element of the sets must have fewer elements than so that the sampling density is the same. In particular, for some the set has elements, where the ceiling function is used to ensure that the number of elements in is positive.
Using the sets and we can create a discretization of . The result, interpreted geometrically, is concentric sets of cigar-shaped confidence ellipsoids with a variety of major diameters, defined by ellipticities and orientations The full covariance space can thus be described with a map given by
[TABLE]
where is any basis completion for , and is the identity matrix. The function essentially builds a covariance matrix from the parameters supplied by and We define the covariance space as
[TABLE]
The covariance is an artificial state that we include in to denote that no more uncertainty remains in the variable being estimated, i.e., estimation is complete to the user-specified tolerance, defined as
The projection operator guarantees that the fusion of the current covariance state and the new measurement covariance is a member of In particular, for some first computes the principal eigenvalue and its corresponding normalized eigenvector . Then, it rounds to the closest element in Call this map If is nonzero, there will be some that is closest to and then finds the element that forms the largest magnitude inner product with Call this map where In particular, Finally, computes the ratio of with and finds the closest element to that ratio. Call this map By this construction, it holds that so that its image of this triplet under from (7) is guaranteed to be a matrix in . In particular, the projection map is given by
IV Localization of Multiple Targets
Assume the collection of all hidden states discussed in Section II is divided into clusters. Temporarily let denote the number of hidden states in a particular cluster. Denote by the state space local to the -th hidden vector in the cluster. Each has individual states.
Let denote the set of initial states that the robot can visit when it first arrives at to observe We assume that the first observation of will occur at the boundary of the convex hull of local pose space Therefore, we define the entry points to the local state space as Let us index the states in the set using integers such that Since in the neighborhood of every hidden state, the robots follow the local optimal policy determined in Section III, a robot that begins observing the -th hidden state at the entry point and has spent steps at that particular state has a known global location and local covariance matrix. To keep track, let and denote the -th local transition function from (2) and optimal policy. Then, define the -times recursive local optimal transition function as , given by
[TABLE]
The function denotes the local state in in which the robot will land when starting observing at from entry point and after following the local optimal policy for time steps.
In the cluster DP, there are available actions, one for every hidden state in the cluster. In particular, for a robot observing , action is simply to continue observing the same state along the local optimal policy. Note that, since the optimal policy is stationary, there is always a local optimal action to take. The following proposition shows that any local optimal trajectory reaches an absorbing state so that the iteration terminates.
Proposition IV.1**.**
* and , there exists such that .*
Proof.
Since each is finite and the optimal policy is fixed, failure to converge is possible only if the optimal policy drives the robot in a cycle. This is a contradiction to the optimality of . To see why, consider an optimal local trajectory such as If , then the transition from to contradicts Lemma III.2. Similarly, if , then the transition from to is a contradiction. If , then the robot must have moved in a loop without changing the uncertainty, i.e., energy was consumed for no gain in reward, a contradiction to the optimality of ∎
As a result of Proposition IV.1, we do not store local optimal trajectories longer than .
We can now define the state-space for the cluster DP. The cluster state must contain the index of the current hidden vector being estimated the entry point and the amount of time spent observing the current state The cluster state must also contain the visitation history a to prevent rewards from being gained by collecting the same information twice. The cluster state-space is thus
[TABLE]
where the functions are needed to account for the largest local state spaces in the cluster.
Let denote the set of control inputs in the cluster DP. Let also denote the cluster transition function. When the robot is in state then transitions the robot to cluster state Action has the same reward with the corresponding transition in the local DP. The remaining actions set the visitation history of the -th hidden vector to zero and transition the robot to the -th local space, specifically by selecting the closest entry point in in to the robot’s current location. In particular,
[TABLE]
where and
[TABLE]
The reward for continuing the local optimal policy is the same as the reward in the local DP, and the reward for transitioning to a new hidden state in the cluster is the negative distance to the next entry point defined in (11). The only other difference with the local reward is that the robot cannot gain positive reward for taking action when at any state such that In particular, define the reward function in the cluster DP as
[TABLE]
Remark IV.2**.**
One could directly apply the method developed in Section III to the task of sensing multiple targets at once. The state-space in this case would be of the form which has
[TABLE]
states, an intractably large number of states for any sufficiently rich belief space This is the reason why existing approaches have typically employ online policy search or point-based solvers. Our proposed hierarchical approach solves a simple local DP once to find a local optimal policy for every state, mitigating the exponential complexity to the cluster DP, where the state space has size . Solving the cluster DP has similar in complexity to TSP solvers although it solves a substantially more complicated problem.
V Optimal Planning and Resource Allocation for Multiple Robots
Given the single-robot optimal control policies developed in Sections III and IV, in this section we develop a distributed framework to synthesize them in a multi-robot system that can efficiently estimate large groups of hidden vectors. To develop the proposed framework, let denote the index set of all available hidden states, and for every hidden state define the discrete set {\mathcal{Z}}^{t}\triangleq\big{\{}{\mathbf{z}}\in{\mathbb{R}}^{d}\mid({\mathbf{z}},\theta)\in{\mathcal{W}}_{t}\big{\}} containing those states of the local workspace that correspond to robot positions in or dimensions only (excluding other configuration information contained in ). Let denote the set of all possible robot positions. Consider further a partition of the hidden state set into clusters so that two hidden states belong in the same cluster if they are sufficiently close to each other based on the initial belief of their locations. Let {\mathcal{Z}}_{p}\triangleq\big{\{}{\mathbf{z}}\in{\mathcal{Z}}^{t}\mid t\in{\mathcal{T}}_{p}\big{\}} denote the set of all robot positions in cluster . Using the methods developed in Sections III and IV, we can determine an optimal sensing policy for every cluster of hidden states , that is a function from the state-space of robot positions and hidden state uncertainties to the set of robot actions. Then, given an entry point from where a robot can begin sensing cluster this policy can be combined with the system dynamics (1b) and (1c) to generate an optimal robot trajectory within that cluster. In particular, we define the set of entry points of cluster to be the set of states in lying on the boundary of its convex hull, denoted by . We also define an optimal trajectory in cluster starting from a point by , where denotes the total length of that trajectory from the entry point until the cluster is completed and is an index of the -th entry point in .
Consider now mobile robots and let denote their locations at time . While sensing cluster a robot moves along the optimal trajectory . When the exploration of has been completed, the robot needs to transition to a different cluster. For this, it needs to identify an entry point in the new cluster and travel to that point. Therefore, the set of all possible paths that a robot can follow while sensing different clusters of hidden states can be represented by graph , where {\mathcal{V}}=\big{(}\cup_{p=1}^{P}\partial{\mathcal{Z}}_{p}\big{)} denotes the set of vertices (embedded in ) containing the depot and all entry points of the hidden state clusters and is the set of directed edges so that for any entry points and , the edge if and . In other words, the directed edges in connect every entry point in to the closest entry points of different clusters. With every edge in we associate a distance that the robot needs to travel in order to get to entry point having started form point . This distance consists of the distance that the robot needs to travel within cluster plus the distance that the robot needs to travel to reach entry point once it has completed cluster , i.e., We assume that between clusters, robots travel on straight-line paths. An illustration of the graph of possible motion paths for the running example of sparse landmark localization in two dimensions, containing the cluster entry points and trajectories to two possible next clusters, is shown in Figure 2. To avoid having two robots select the same cluster and fail to resolve this conflict, we assume that the communication range of the robots is larger than the largest diameter of any cluster.
In what follows, we develop a distributed framework to allow the team of robots to dynamically allocate the clusters amongst themselves, as they plan trajectories on the graph to visit their assigned hidden state clusters. Specifically, we assume that at every time , every robot can be in one of three modes . We say that a robot is ‘busy’ if it is currently sensing a cluster, it is in ‘transit’ if it is traveling between clusters, and it is ‘done’ if it has completed sensing its last cluster. While in mode ‘busy’ robot moves along the trajectory according to
[TABLE]
where denotes the distance that robot has already travelled in cluster and is a small, user-defined, positive distance increment that the robot travels between times and . While in mode ‘transit’, robot moves according to
[TABLE]
where denotes the index of the cluster that the robot is traveling to, is the selected closest entry point in that cluster defined as and is defined as in (13). Assuming that robot is in transit to cluster after having completed cluster , the line segment defined by the end points and is completely contained in the line segment defined by the points and . Therefore, (14) drives the robot along the path corresponding to the edge . However, the controller (14) also allows robot to diverge from the predefined paths in the graph by selecting an alternative closest cluster while in transit mode, for reasons that we discuss in Section V-A, e.g., if another robot places a higher bid. In this case, the motion of robot temporarily leaves the predefined motion paths in and it re-enters once it has reached cluster . In the remainder of this section, we will refer to the current cluster being sensed by the -th robot as and the next cluster to be sensed by that robot as . Then, our goal is to find a set of distinct paths in whose union visits every cluster exactly once and has a minimum combined travel cost. We achieve this goal by a distributed auction mechanism that we discuss next.
V-A Distributed Auction Mechanism
In this section we propose a distributed auction method to dynamically and sequentially allocate clusters to robots as they move to localize the whole scene.
A proof of the convergence of distributed auctions can be found in [26].
Specifically, let denote a sequence of time instants when the robots communicate with each other, that is in general different from the times when the robots move, and let {\mathcal{N}}_{i}^{s}\triangleq\big{\{}j\mid\|{\mathbf{z}}_{i}^{s}-{\mathbf{z}}_{j}^{s}\|<\Delta\big{\}} denote the set of neighbors of robot at time , where denotes a given communication range. Moreover, assume that every robot carries two lists: the list of ‘free’ clusters and the list of ‘taken’ clusters , so that and for all time . Initially, and . The list of ‘free’ clusters contains clusters that are available to robot , meaning that robot can select from those clusters a cluster to visit next. On the other hand, the list of ‘taken’ clusters contains clusters that have been selected by other robots and are, therefore, not available to robot . During operation, robot coordinates with its neighbors to update its list of ‘taken’ and ‘free’ clusters by and , respectively. In other words, with every communication round, robot removes from its list of free clusters those clusters that are considered taken by other robots.
Given the list of ‘free’ clusters at time , robot can select any cluster from that list to be the next cluster to visit. To minimize the total distance travelled by the robots, we propose a greedy approach where robots select a cluster that is the closest to their current location. In particular, we define
[TABLE]
In (16) and (17), and are the distances that robot needs to travel in order to reach a new cluster from its current location while in modes ‘busy’ and ‘transit’, respectively, and , as in (13). When robot selects a new cluster , then it also updates its lists of ‘free’ and ‘taken’ clusters by removing form and adding it to .
Every time is updated, robot also places a bid that indicates how important the selection of the new cluster is. The bids are inversely proportional to the distance robot needs to travel to reach the new cluster, so that nearby clusters have higher value. Specifically, bids are placed according to
[TABLE]
If at some point in time there exist neighbors of robot so that , then these robots set up a local auction and compare their bids to resolve the underlying conflict. If for all for which , then robot wins the auction and maintains the same next cluster and bid, i.e., and . The robots that lose the auction update their set of ‘free’ clusters by removing cluster , i.e., , and select a new next cluster and bid according to (15) and (18). If , i.e., if there are no other available clusters for robot , we set , effectively controlling the robot to return to a depot after it has completed its current (final) task.
Fig 3 illustrates the integrated, hybrid, controller. The labels and mark events that need to be synchronized across the navigation and coordination control blocks. In particular, transitions labeled by the letter are triggered by the navigation block and generate synchronous transitions in the coordination block aimed to produce new bids or update the next cluster that the robot needs to visit. Similarly, transitions labeled by the letter are triggered by the coordination block when new bids are computed or the next cluster that the robot needs to visit is updated and they generate synchronous transitions in the navigation block aimed to guide the robot its new assigned cluster. Note that while the and time indices used for the navigation and coordination blocks, respectively, can in general be different, the transitions labeled by the letters and can generate transitions in these blocks that can be off-clock. For example, a transition at time in the navigation block labeled by will generate a transition in the coordination block at a time instant .
VI Numerical Simulations
In this section, we present simulations of the proposed distributed state estimation algorithm. In our simulations, we focus on the problem of sparse landmark localization. As a sensor model, we use a stereo camera. We refer the reader to [6, 5] for a discussion of the covariance function for stereo vision. We assume that each camera in the simulated rig has resolution and a 70∘ field of view. The characteristic length in stereo vision is the baseline. Therefore, in these simulations, all units are measured in stereo baselines unless otherwise stated. For a mobile stereo rig, the baseline could be as large as 1 meter or as small as a few centimeters.
To simplify the exposition, we consider fully actuated kinematic robots. The local pose spaces and prior error covariances are identical for each landmark, i.e., and for all , where we recall that the largest eigenvalue in the dimension of the state-space that represents the possible principal eigenvalues is denoted as
VI-A Active sensing of a single target
The local pose space for the single target case is made up of concentric spherical shells with randomly distributed viewpoints on each. There were 177 total views in at six equally spaced radii between 20 and 40 units from the landmark. To discretize the covariance space , we set . In total, the number of possible principal eigenvalues was . We also use condition numbers. We set the number of principal eigenvectors for covariances with as the principal eigenvalue to This means has 98 unit vectors. The number of samples at other principal eigenvectors was For the logspace discretizations, we set and Stereo vision is used as the sensing model; see Appendix A. The discount factor was 0.99. The value of the uncertainty reduction gain is very important, since it controls the tradeoff between traveling cost and uncertainty reduction due to more images. Fig. 4 shows the sensitivity of the total reward gained and the two opposing objectives that comprise it as they depend on . Fig. 5 shows example an optimal trajectory in both pose and covariance space with
In these simulations, we approximate error distributions as state-dependent white noise using the equations given in Appendix A. White noise is uncorrelated in time, thus, under standard KF assumptions, two observations from the same vantage point will reduce variance by Lemma III.2. This is why, in the figures, there are more intermediate covariance ellipsoids than steps in the robot trajectories; it is sometimes optimal to remain stationary and take multiple observations. In real scenarios, noise is seldom well-approximated as white, and duplicate observations will exacerbate bias. We account for such hidden biases in these simulations by using a real model of stereo vision that is subject to the nonlinear effects of quantization on the image plane; see Appendix A. Interestingly, the presence of such noise reveals a secondary benefit of sensor mobility: mobile sensors avoid by default duplicate observations that would plague a static sensor. Although our controller does not explicitly encourage motion for this reason, a basic heuristic adjustment that does would be simple to implement by, e.g., removing the action “remain stationary.”
Table I compares the total reward gained by a robot starting from the same initial condition under the optimal policy with found by our (optimal) local controller with some heuristic policies. The heuristics we chose for comparison were a policy that drives closer to the hidden state (closer), one that circles around the source (circle), one that remains still (static), and one that acts randomly (random). The fact that that ‘random’ performs about as well as ‘closer’ suggests that a sophisticated controller is needed in order to beat ‘random.’ Our ‘optimal’ policy obtains 115% of the reward of the ‘closer’ and ‘random’ policies. Also note that the ‘static’ and ‘circle’ policies perform very poorly in comparison to the others. This is because they stay at a constant depth with respect to the landmark. In triangulation with stereo vision, there is significant bias in the viewing direction, causing poor localization performance given multiple observations at constant depth.
VI-B Active sensing of Target Clusters
We present simulations of the proposed distributed estimation method for a single robot observing a cluster of sparse landmarks. For the landmarks, we model a famous group of sculptures called the Queens of France and Famous Women, which can be found in the Luxembourg Garden, Paris, France. The Luxembourg Garden is actually home to hundreds of sculptures, and the Queens of France and Famous Women is a cluster that surrounds a large pool (octagon in Fig. 6) that is adjacent to the Luxembourg Palace (large rectangle in Fig. 6). We chose a subset of eight queens as individual sparse landmarks to comprise a cluster of statues. The task of the robot in this scenario is to exactly localize each statue to create a precise spatial map of the sculpture garden. For these simulations, we used a discount factor and gain of 0.999. We use the same hemispherical pose state-spaces as in Section VI-A for each local DP.
We also compare the trajectories generated by our cluster DP with a state-of-the-art algorithm [2]. The method in [2], called - Reduced Value Iteration (), grows a tree in belief space that computes an optimal sensor trajectory, i.e., it applies the most widely used approach to the same problem that we solve under similar assumptions. In our implementation of , planning horizons greater than 12 caused our simulation, run on Macbook Air™with 4 GB of RAM, to run out of memory. Because of the sparsity of the scene, 12 step lookahead was sometimes not enough to plan future landmarks to visit. Therefore, if the robot following finishes observing a landmark to the threshold, it greedily selects a new landmark. The top panel in Fig. 6 displays four snapshots of two different trajectories: one produced by the cluster DP optimal policy and one produced using . The bottom panel of Fig. 6 shows the result of the KF output of 100 simulations of observations taken along the trajectories in the top panel. The empirical standard deviations for each error vector are also drawn on the figure. Both methods perform similarly, with our method requiring slightly less observations. The important distinction, however, is that for every new initial condition, any tree-based planner, including , needs to be run again, whereas we can reuse our optimal policy for any initial condition. This is important in the next section, as it allows allocation of clusters dynamically in the multi-robot team from a variety of initial conditions along the cluster boundaries. In other words, our method allows us to compute an optimal policy, rather than a single optimal trajectory.
VI-C Multiple Robots and Multiple Clusters
We present simulations of the proposed distributed estimation framework for multi-robot multi-target active localization in Fig. 7. For these simulations, we uniformly randomly generated targets in a rectangle in The communication range of the robots was set to 1500 m.
In this simulation, first we divide the targets into two sets of roughly equal size based on the prior location estimates Then, we iteratively split the sets based on relative distance until the largest cluster has less than nine targets. In our testing, we have found that a simple clustering strategy can be effectively generated using the prior over the target locations. We leave the clustering strategy as a design choice in this algorithm that should be made once the location prior is available. For example, in our example in Section VI-A, the sculpture garden can be naturally clustered with a priori available tourist maps.
VII Experiments
In this section, we present experiments using a team of two ground robots (iRobot Creates), r1 and r2, that localize a set of stationary targets. The robots each carry a stereo rig mounted atop a servo that can rotate the rig Each rig uses Point Grey Flea3™ cameras with resolution . To simulate long distance localization, all images are downsampled by rate 24 so that the effective resolution is . Each robot is equipped with an on-board computer with 8GB RAM, an Intel Core i5-3450S processor and a 802.11n wireless network card for communication. All implementation is done in C++ and run on Robot Operating System (ROS). We calibrate the intrinsic and the extrinsic parameters of the stereo rig offline using the Bouget Matlab™ camera calibration toolbox [27]. For self-localization of the robots, our laboratory is equipped with an OptiTrack™ array of infrared cameras that act as a motion capture system. The OptiTrack™ system tracks reflective markers that are rigidly attached to the robots. Each robot can thus retrieve its own (and only its own) position and orientation by reading a ROS topic that is broadcast over wifi by a centralized computer. Each robot also broadcasts auction bids and states to public ROS topics that are readable by the other robots for collaboration. Additionally, the OptiTrack™system provides us with the ground truth locations of the targets, which are colored ping pong balls, enabling us to directly check the accuracy of the landmark localization errors after the experiment. The information function was derived using a statistical model of stereo vision, which we defer to Appendix A.
Fig. 8 shows the experimental setup for the multi robot, multi landmark localization experiment. We place eight colored ping pong balls in a square workspace of about 2 m side length for the multi robot, multi landmark localization experiment. We use three types of local workspaces: section, semicircle, and full circular polar grids. To avoid collisions between robots and ping pong balls and avoid overlapping local workspaces, the minimum and maximum radii were set to 30 and 50 cm for all local workspaces, respectively. The available poses within each local workspace were located at five equally spaced radii between these two extrema. The polar grids were also divided into increments of 15∘. We set the covariance space parameters to and We set to be twice the number of viewing angles in the local workspaces For these experiments, we set and .
In ‘transit’ mode, a potential field algorithm guides the robots to the next local workspace and avoids collisions with landmarks. All navigation and waypoint tracking relies on a PID controller using the next waypoint as the set point. In the experiment, robots generally came within 2 cm of their target waypoints. The servo guided the stereo cameras toward the estimate of the target locations with accuracy of . Cooperation of and relies on robots updating individual ROS topics and checking neighbors’ ROS topics. The ROS topic for a given robot contains that robot’s current bid value and the subtask at which the bid is directed.
The filtered estimates generated by observations along the paths followed by the robots in one run of the experiments are compared with the ground truth locations of the ping pong balls in Fig. 9. The filtered errors are computed as the Euclidean distances between filtered estimates and the ground truth locations of the ping pong balls. We note that any non-decreasing aspects of these plots are attributed to stochasticity in the dataset, and the fact that we are only approximating the true noise distribution with a data-driven Gaussian. Note that, due to the relatively constrained space in our lab, the robots are not able to move as freely as in the simulations, which, in addition to unmodeled noise, is responsible for the smaller error reduction in Fig. 9 compared to the simulations.
VIII Conclusion
In this paper, we addressed the task of estimating a finite set of hidden state vectors that have Gaussian priors using a mobile robotic sensor network. We framed the problem using tools from optimal control, ultimately proposing a hierarchical Dynamic Programming solution. By including the covariance matrix in the local state-spaces then discretizing these spaces, we bound the computational complexity for a given error tolerance. This is a desirable property compared to tree-based methods that actively explore the covariance space until the tolerance is reached . Then, we combined the local optimal trajectories in a cluster DP that balances between reducing the uncertainty in the hidden states and traveling among configuration spaces. Our approach is still exponential in the number of hidden states per cluster, but the proposed hierarchical scheme reduces the base of the exponential to two without sacrificing the explicit dependence on the error covariance matrices of the objective function. Then, we proposed distributed auction algorithm to divide the tasks of sensing each cluster among multiple robots. Simulations and experiments on real robots show that the integrated multi-robot system can efficiently localize large groups of landmarks while remaining scalable, a novel pair of characteristics that POMDP and TSP approaches do not have.
Appendix A Noise Model
In this paper, we assume that individual measurements are subject to a known zero mean Normal noise distribution . In what follows, we estimate so that this assumption holds for the stereo rigs used in our laboratory experiments. This is critical for a variety of reasons:
- •
If the mean of is biased, then the KF will not converge to the ground truth.
- •
If is an under approximation to the actual covariance of , then the KF will become inconsistent and will not converge to the ground truth, if it converges at all.
- •
If our choice of is too conservative, it may not be informative enough to be useful in the decision process at the core of the controller.
Making things even more difficult, we want to test the system in relatively extreme conditions, particularly at long ranges, when triangulation error distributions are known to be heavy tailed, biased away from zero, and highly asymmetric [28].
In our experiments we make use of the physics of stereo vision [29]. In particular, following [30] we assume that pixel error are Gaussian, and we propagate them to the localization estimates via triangulation equations, which we can use to give us an accurate distribution for . Specifically, if the robot registers a correspondence in the left (L) and right (R) cameras at pixel coordinates , then the coordinates of the 3-D point that generated the match are
[TABLE]
where is the focal distance, is the stereo baseline, is the disparity. Let denote the Jacobian of (19). If the error in has covariance matrix then the error covariance of is Moreover, if and are the translation vector and rotation matrix from the coordinate frame of the camera to a fixed coordinate frame, then the covariance of is
With this noise propagation formula in mind, we now study errors in the observed pixels. For this we follow a data-driven approach that we have recently developed in [31]. Using a set of pairs of training images for each robot at various ranges and viewing angles, we obtain a regression that maps pixel observations to a corrected tuple of pixels such that the error in the corrected tuple is zero mean. For every image pair, we project the ground truth landmark onto the image planes using the inverse mapping of (19), giving us individual output vectors , which we stack into an matrix of outputs . The ground truth data for this training set includes a marker placed on top of the ping pong ball, and the pose information of the stereo rig, captured by a and We then compute five features and, because the data are not centered, include one constant, for each raw pixel tuple according to the model
[TABLE]
These features are taken from the constituent terms in the nonlinear equation (19) Stacking the into an matrix, we have a linear model where is a matrix of coefficients and is an matrix of zero-mean Normal errors. We experimentally verified that the rows of are roughly Gaussian, as can be seen in the right panel of Fig. 10. We refer to the raw pixels as uncorrected. The associated error vectors (computed with respect to the uncorrected pixels and the projected ground truth) for are plotted in the left panel of Fig 10. In the scatter plot it can be seen that the mean error is nonzero, contributing average bias to individual measurements. Also note the apparent skew of the error distribution in the vertical () direction.
Applying the ordinary least squares estimator, the maximum likelihood estimate of the coefficient matrix is Using the residual covariance in the pixel measurements for the two robots, named , we obtained are
[TABLE]
Note that the standard deviation of the pixel value, corresponding to the variances in the lower right entries of the above matrices, is 0.53 and 0.86 pixels, respectively. This corresponds to errors in the height of the ping pong ball center in vertical coordinates. The right panel of Fig. 10 shows the residual errors in the training set for for the corrected vector on .
For prediction, if makes a new observation , it forms a vector . Then, calculates the corrected pixels which are subject to zero mean Normal errors. Using the corrected pixels, triangulates the relative location of the target via (19), propagates via the Jacobian rotates and translates the estimates to global coordinates, and thus the assumptions that the error terms are zero mean with covariance are approximately satisfied. The case for is analogous.
Finally, note that the regression takes place in three dimensions, whereas the algorithm is designed only for two dimensions. For planning purposes, we consider only the components of that lie on the plane of the workspace, i.e., we do not use the third row and column for planning. Of course, the experiments take place in three dimensions, so we need to use the full covariance matrices in the Kalman Filters. Note that the algorithm proposed in this paper could be implemented in 3D at the expense of increasing the pose and covariance spaces accordingly.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C. Freundlich, P. Mordohai, and M. M. Zavlanos, “Optimal path planning and resource allocation for active target localization,” in IEEE American Control Conf. (ACC) , pp. 3088–3093, 2015.
- 2[2] N. Atanasov, J. Le Ny, K. Daniilidis, and G. J. Pappas, “Information acquisition with sensing robots: Algorithms and error bounds,” in IEEE Int. Conf. on Robotics and Automation (ICRA) , pp. 6447–6454, 2014.
- 3[3] A.-a. Agha-mohammadi, S. Agarwal, S. Chakravorty, and N. M. Amato, “Simultaneous localization and planning for physical mobile robots via enabling dynamic replanning in belief space,” ar Xiv preprint ar Xiv:1510.07380 , 2015.
- 4[4] T. H. Chung, J. W. Burdick, and R. M. Murray, “A decentralized motion coordination strategy for dynamic target tracking,” in IEEE Int. Conf. on Robotics and Automation (ICRA) , pp. 2416 –2422, 2006.
- 5[5] C. Freundlich, P. Mordohai, and M. M. Zavlanos, “Hybrid control for mobile target localization with stereo vision,” in IEEE Conf. on Decision and Control (CDC) , pp. 2635–2640, 2013.
- 6[6] C. Freundlich, P. Mordohai, and M. M. Zavlanos, “A hybrid control approach to the next-best-view problem using stereo vision,” in IEEE Int. Conf. on Robotics and Automation (ICRA) , pp. 4478–4483, 2013.
- 7[7] J. Vander Hook, P. Tokekar, and V. Isler, “Algorithms for cooperative active localization of static targets with mobile bearing sensors under communication constraints,” IEEE Trans. on Robotics , vol. 31, no. 4, pp. 864–876, 2015.
- 8[8] H. Carrillo, Y. Latif, M. L. Rodriguez-Arevalo, J. Neira, and J. A. Castellanos, “On the monotonicity of optimality criteria during exploration in active slam,” in IEEE Int. Conf. on Robotics and Automation (ICRA) , pp. 1476–1483, 2015.