Multi-View Kernels for Low-Dimensional Modeling of Seismic Events
Ofir Lindenbaum, Yuri Bregman, Neta Rabin, Amir Averbuch

TL;DR
This paper introduces a kernel-fusion based dimensionality reduction method for seismic data, improving event classification and localization accuracy using multi-view high-dimensional observations.
Contribution
It presents a novel kernel-fusion framework for seismic data analysis, enhancing low-dimensional modeling and event identification capabilities.
Findings
Achieves promising classification accuracy for seismic event types.
Effectively estimates the location of seismic events.
Applicable to other geophysical data types.
Abstract
The problem of learning from seismic recordings has been studied for years. There is a growing interest in developing automatic mechanisms for identifying the properties of a seismic event. One main motivation is the ability have a reliable identification of man-made explosions. The availability of multiple high-dimensional observations has increased the use of machine learning techniques in a variety of fields. In this work, we propose to use a kernel-fusion based dimensionality reduction framework for generating meaningful seismic representations from raw data. The proposed method is tested on 2023 events that were recorded in Israel and in Jordan. The method achieves promising results in classification of event type as well as in estimating the location of the event. The proposed fusion and dimensionality reduction tools may be applied to other types of geophysical data.
Click any figure to enlarge with its caption.
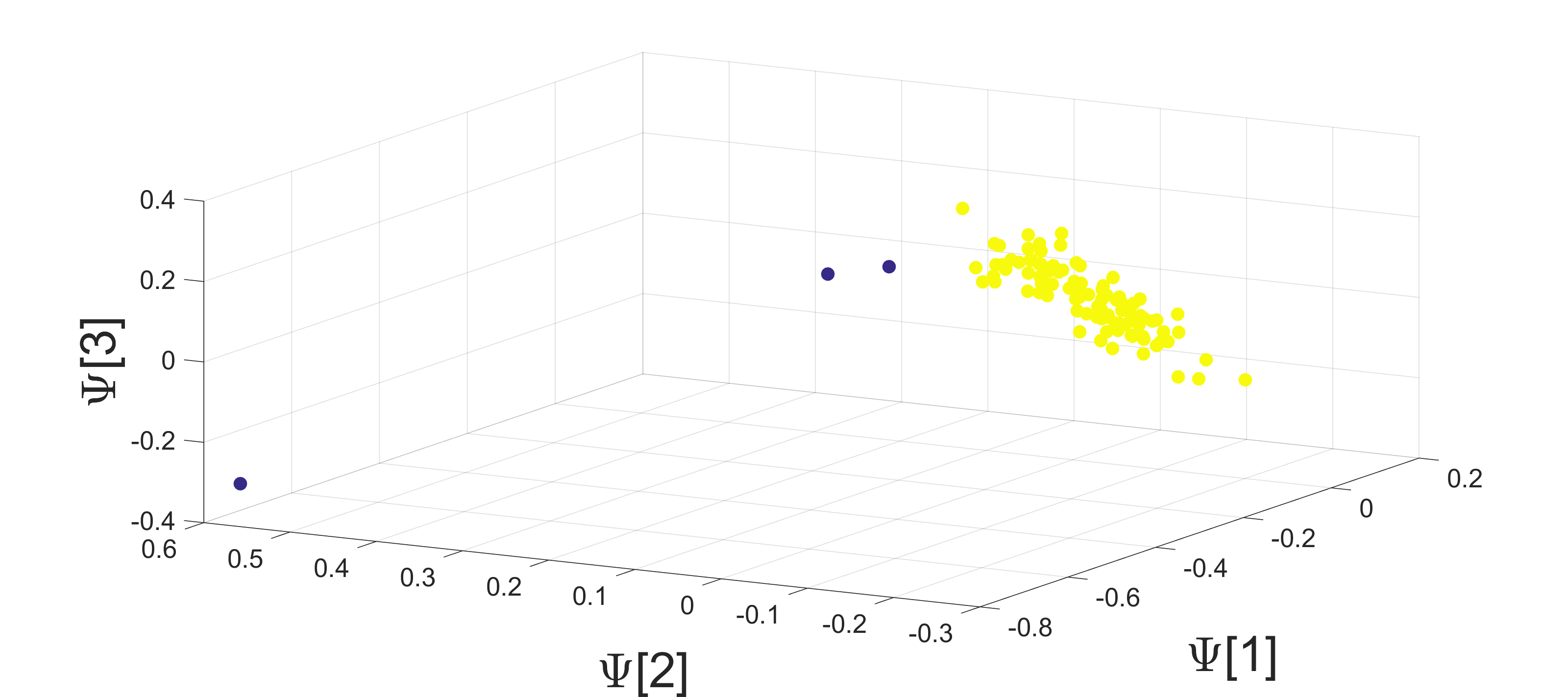 Figure 1
Figure 1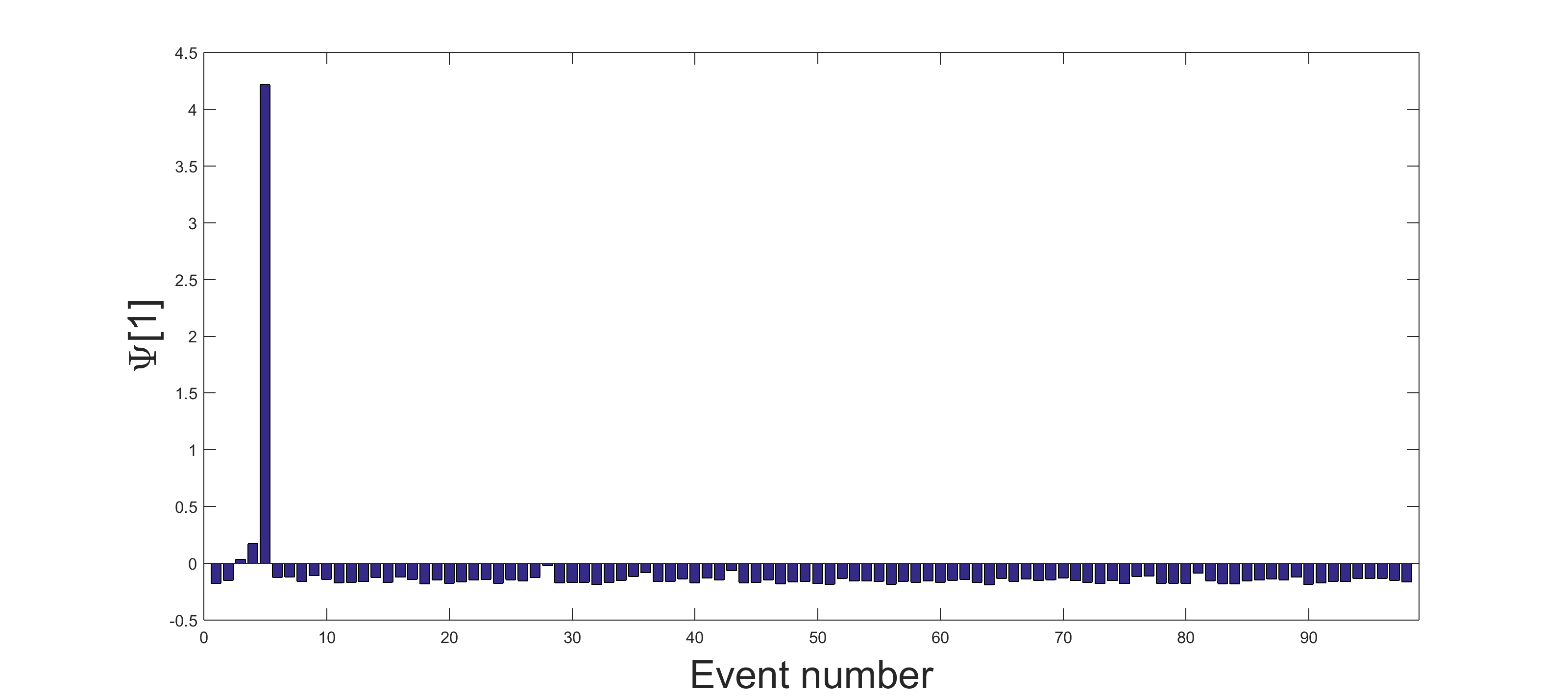 Figure 2
Figure 2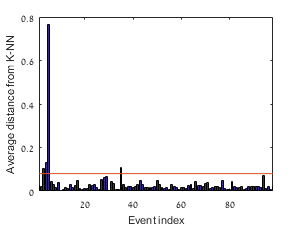 Figure 3
Figure 3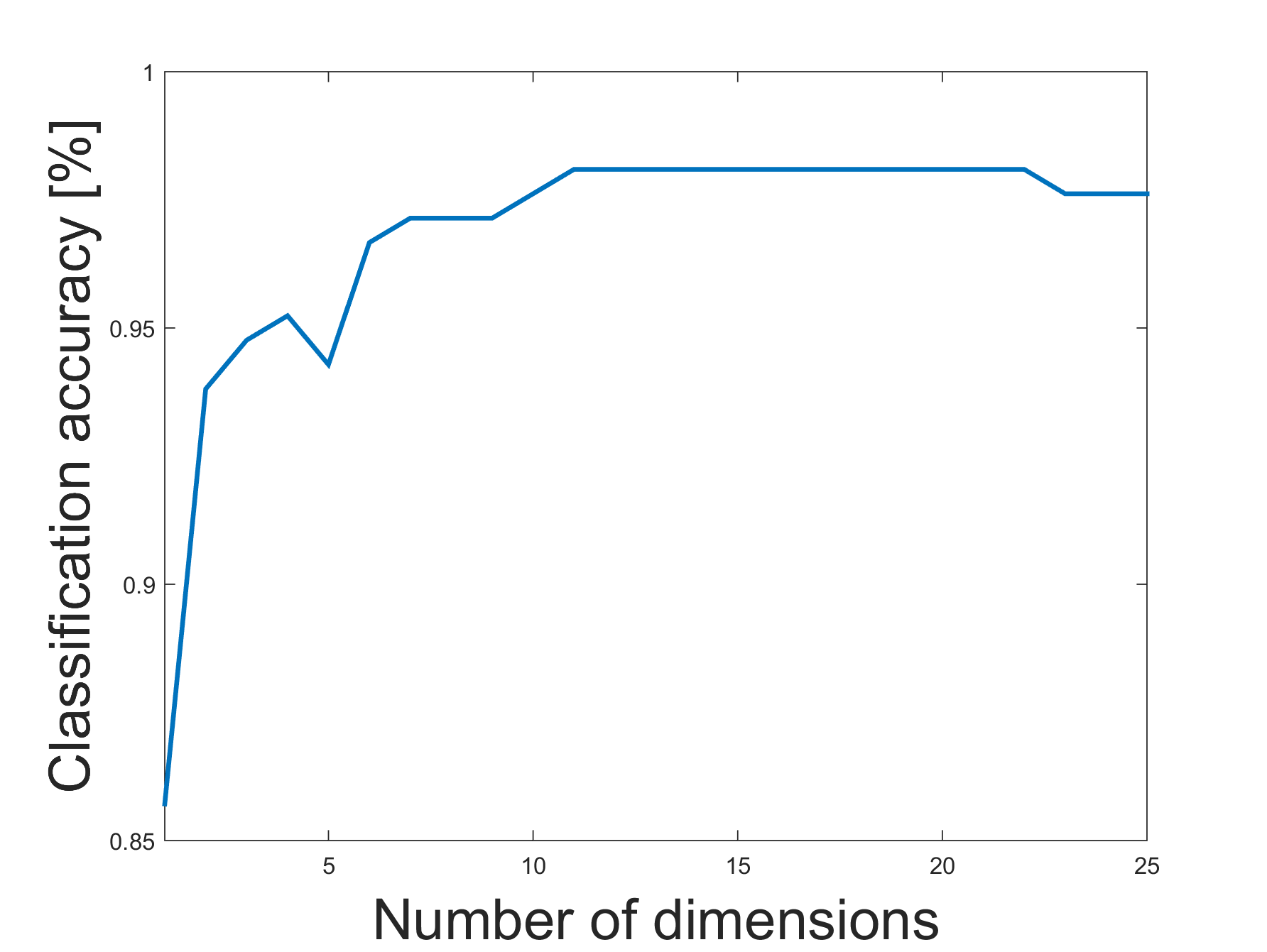 Figure 4
Figure 4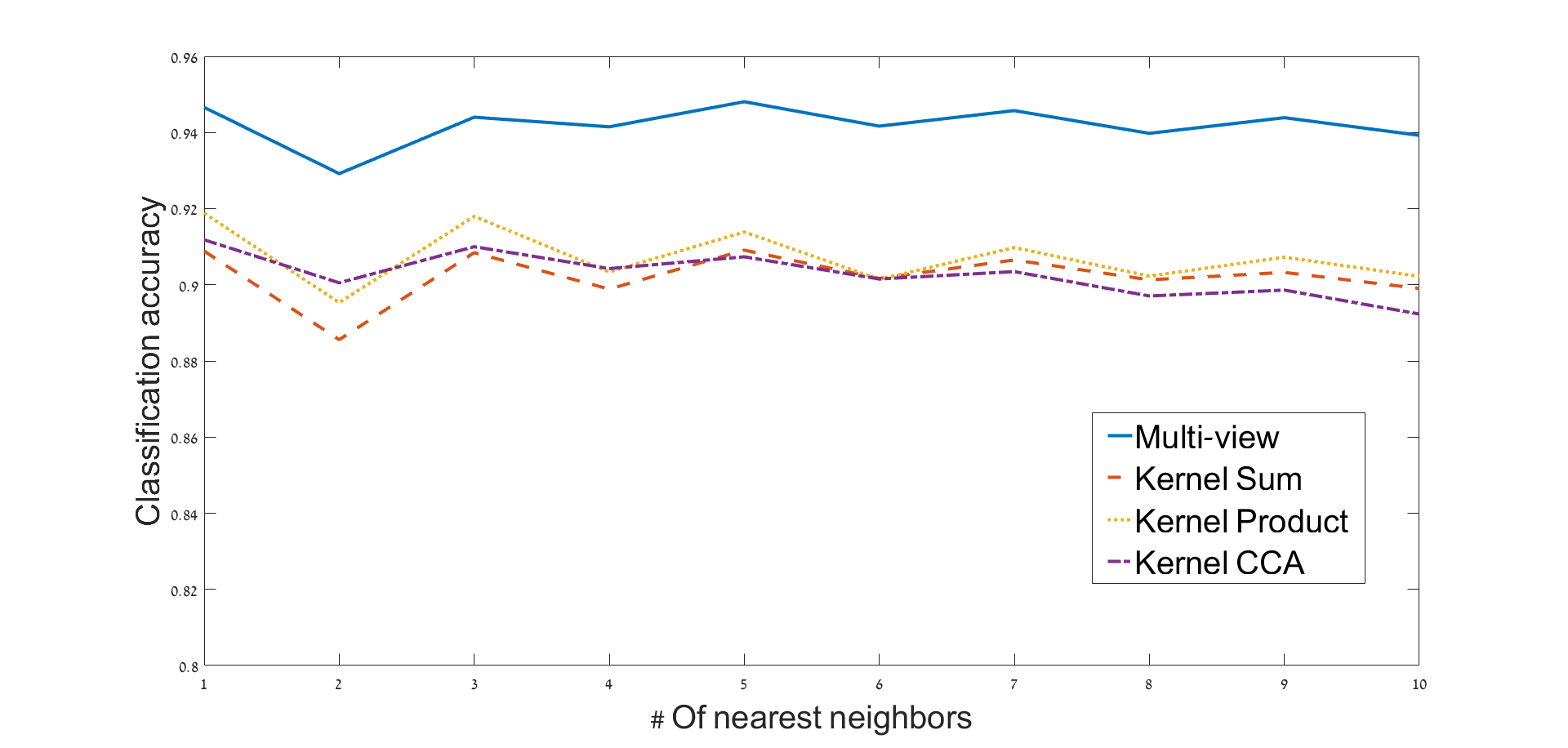 Figure 5
Figure 5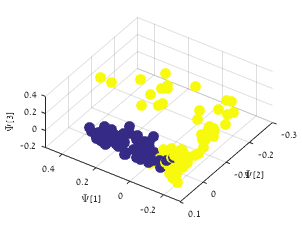 Figure 6
Figure 6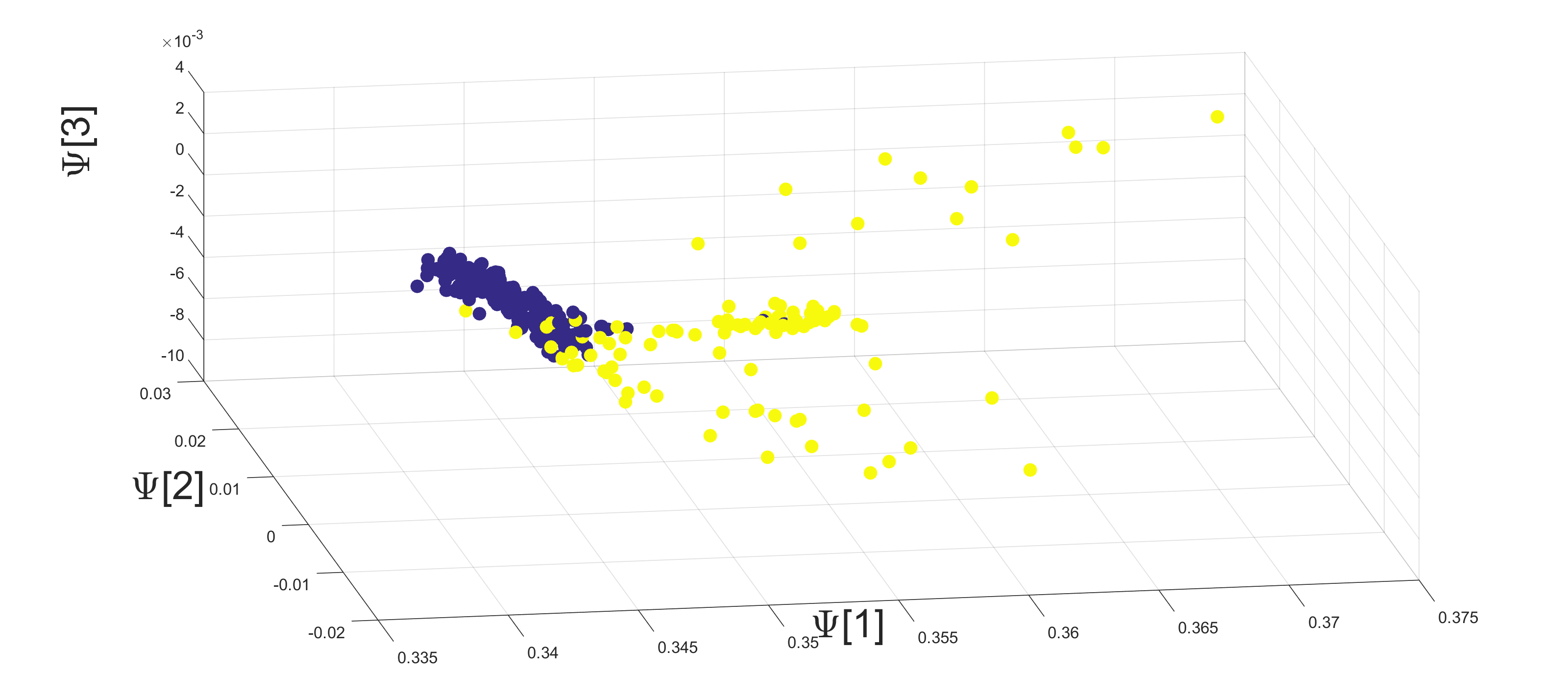 Figure 7
Figure 7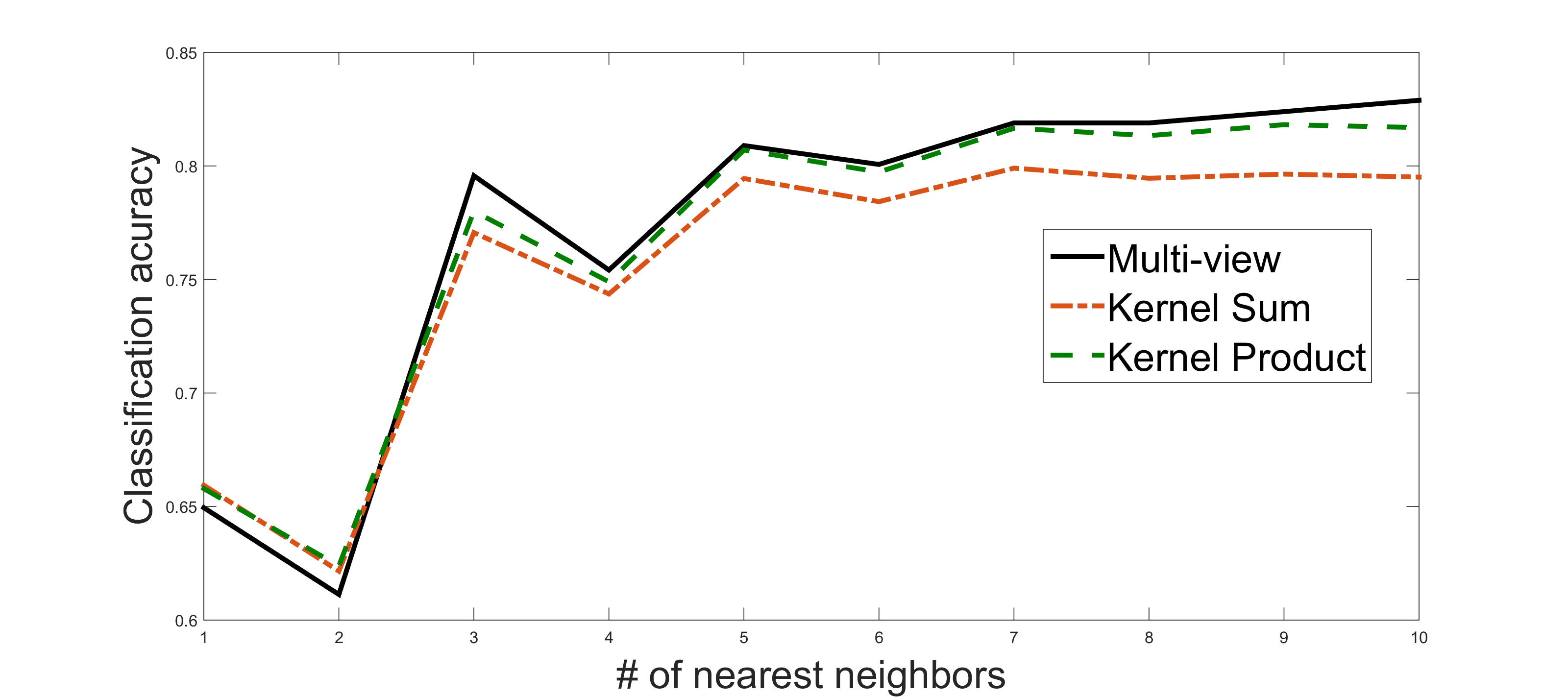 Figure 8
Figure 8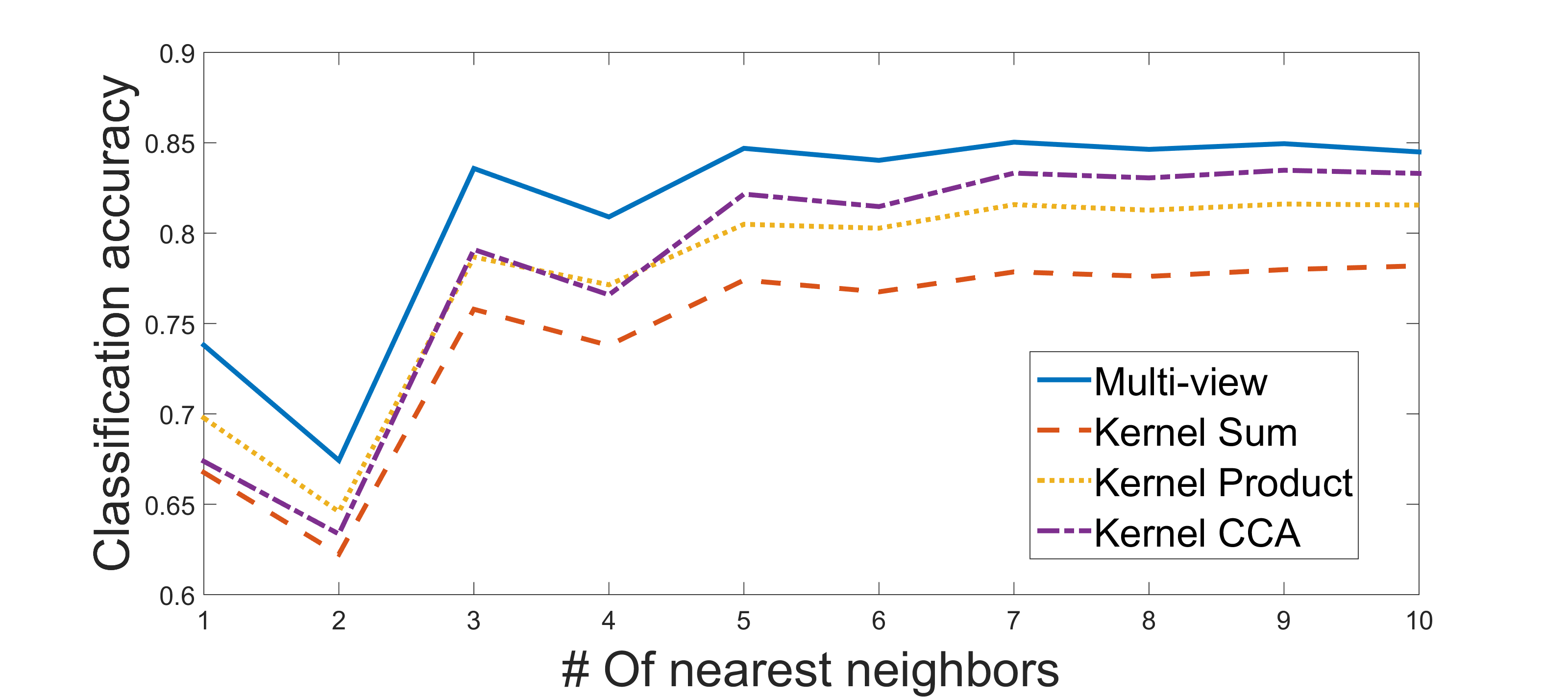 Figure 9
Figure 9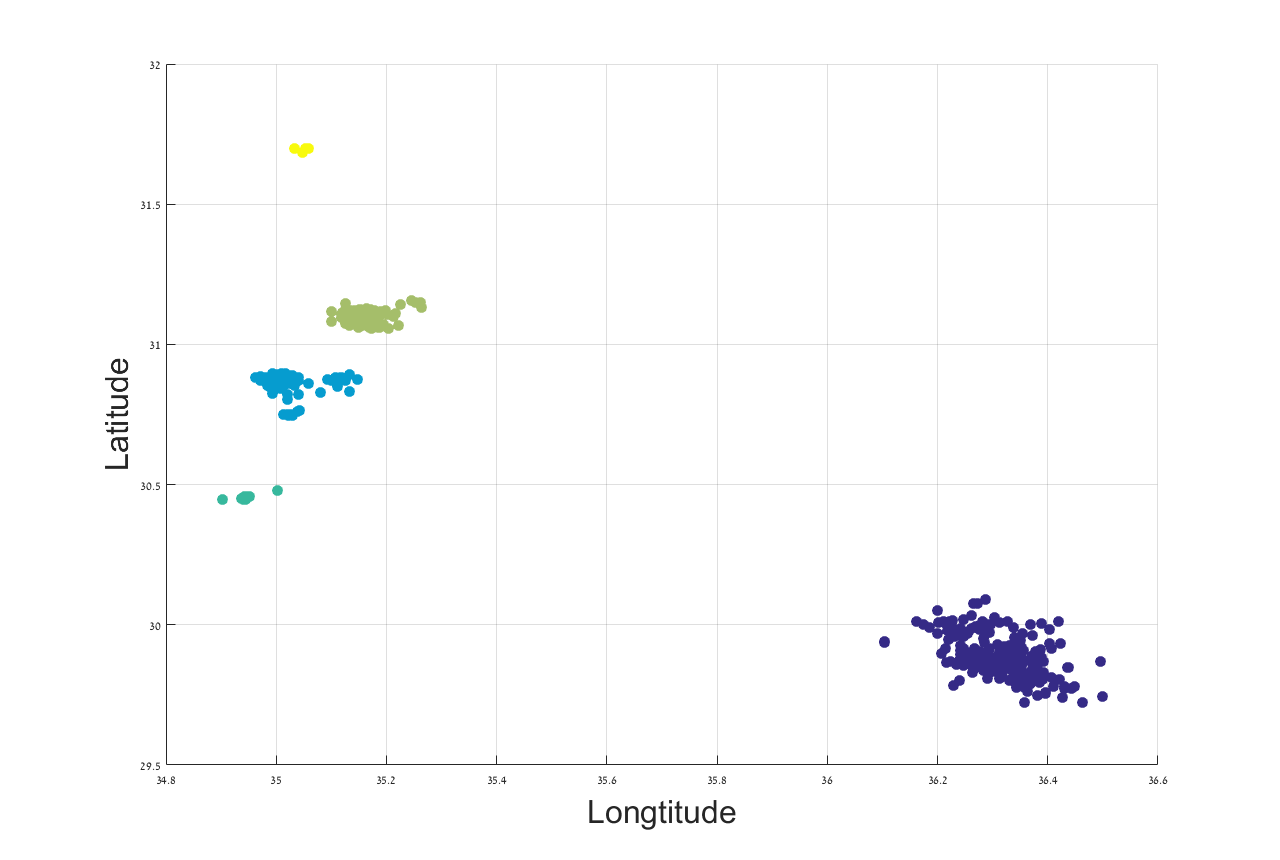 Figure 10
Figure 10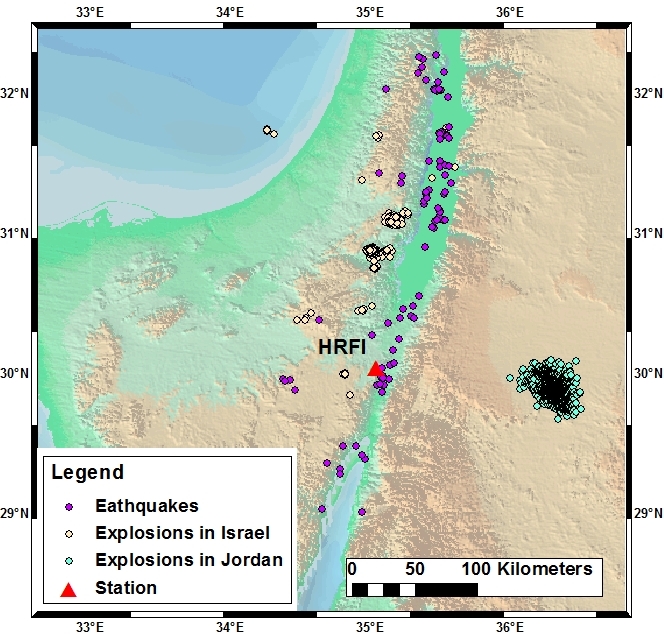 Figure 11
Figure 11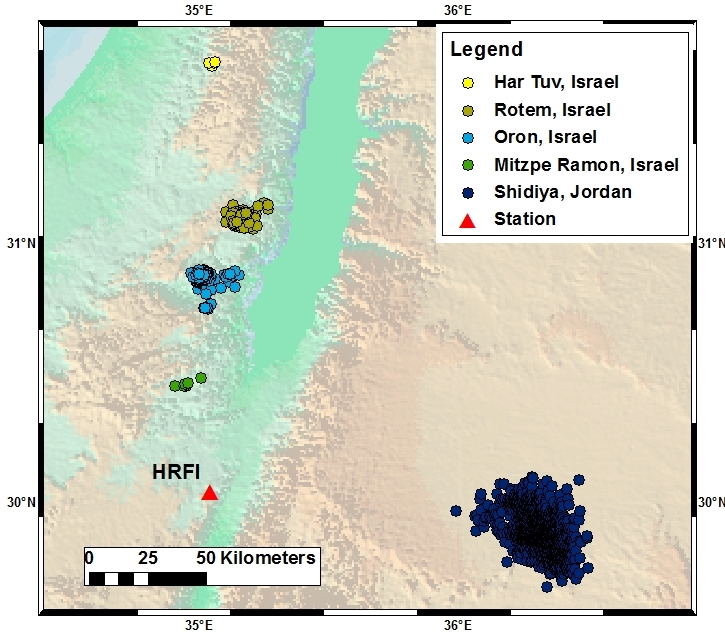 Figure 6
Figure 6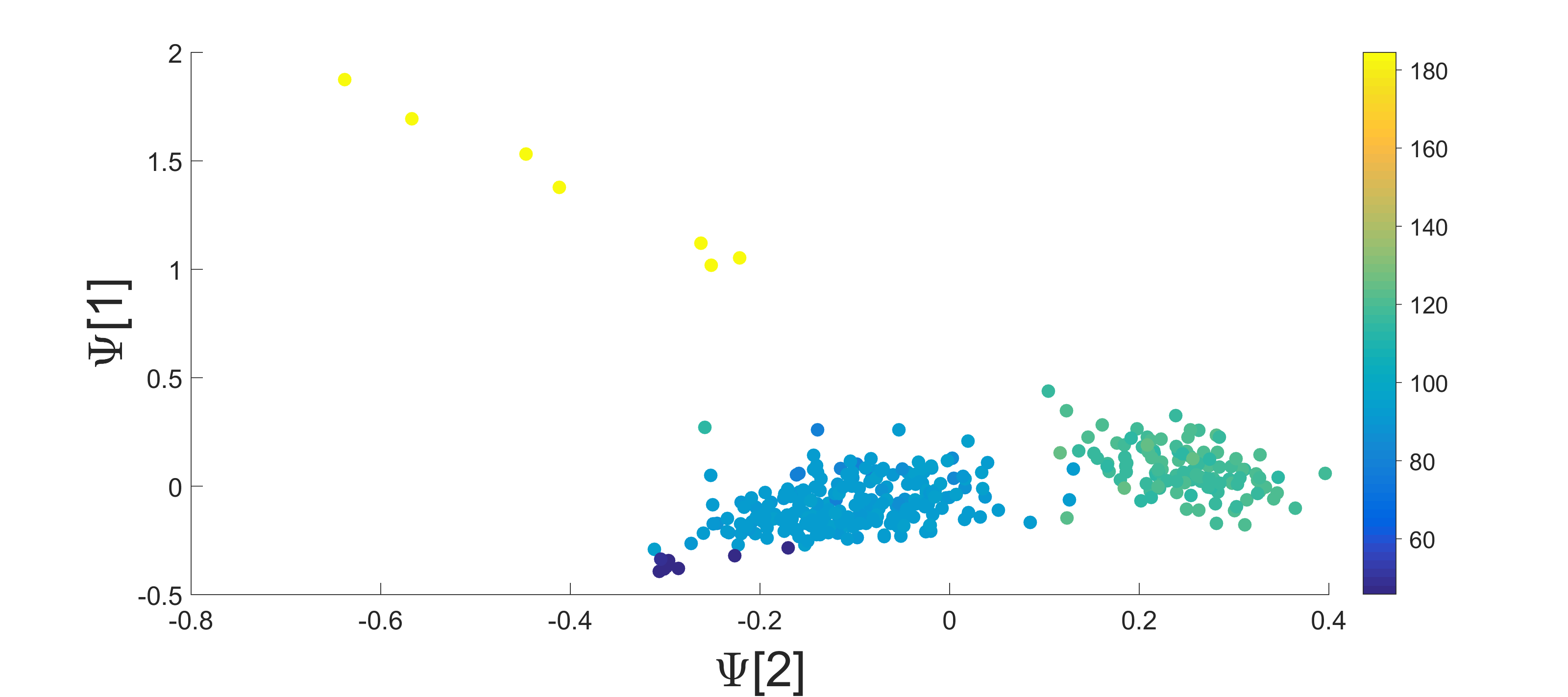 Figure 13
Figure 13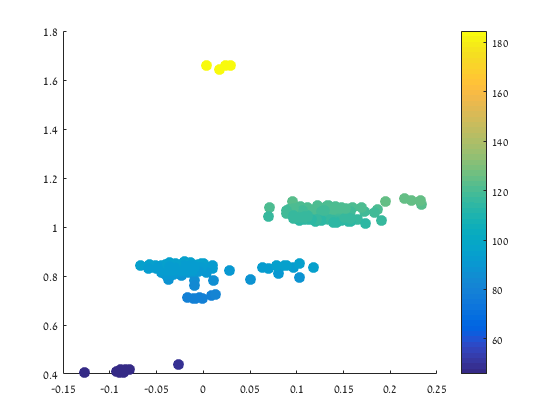 Figure 14
Figure 14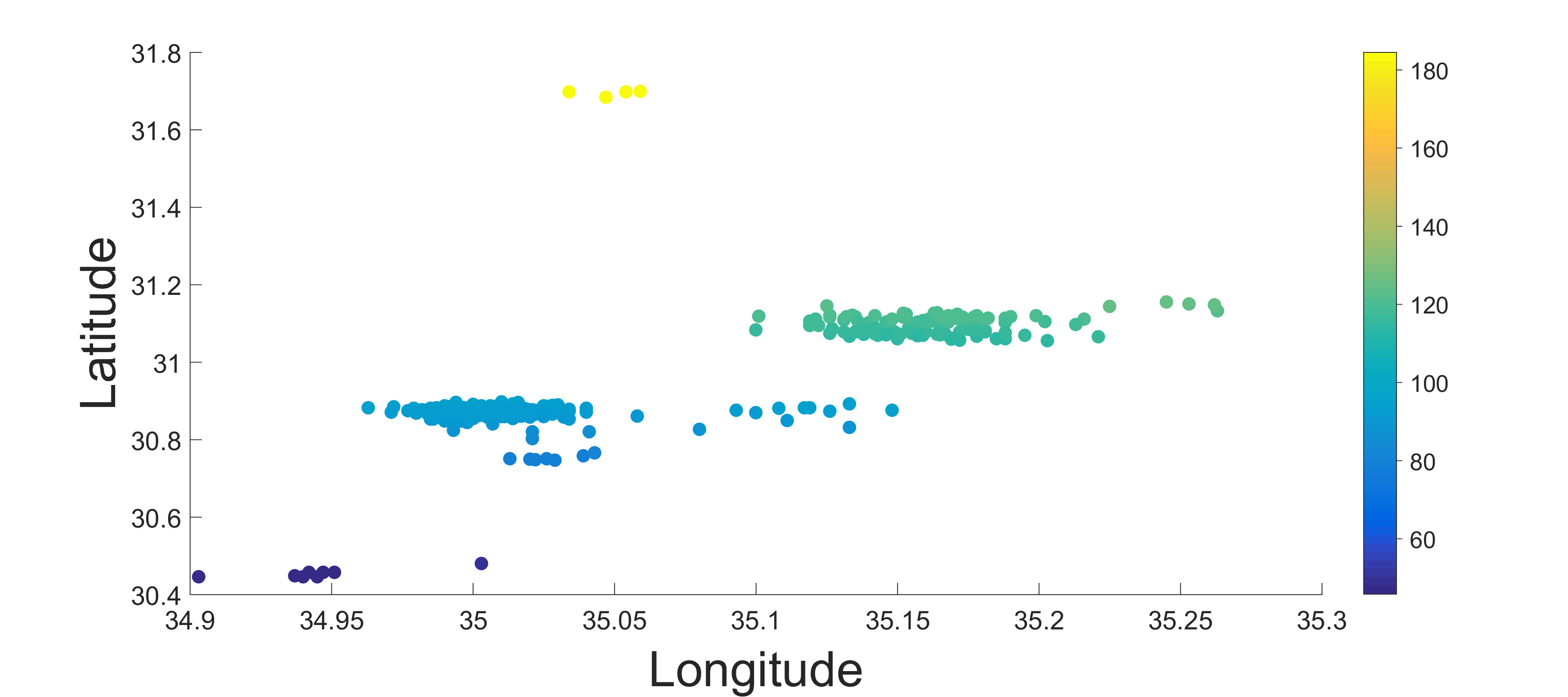 Figure 15
Figure 15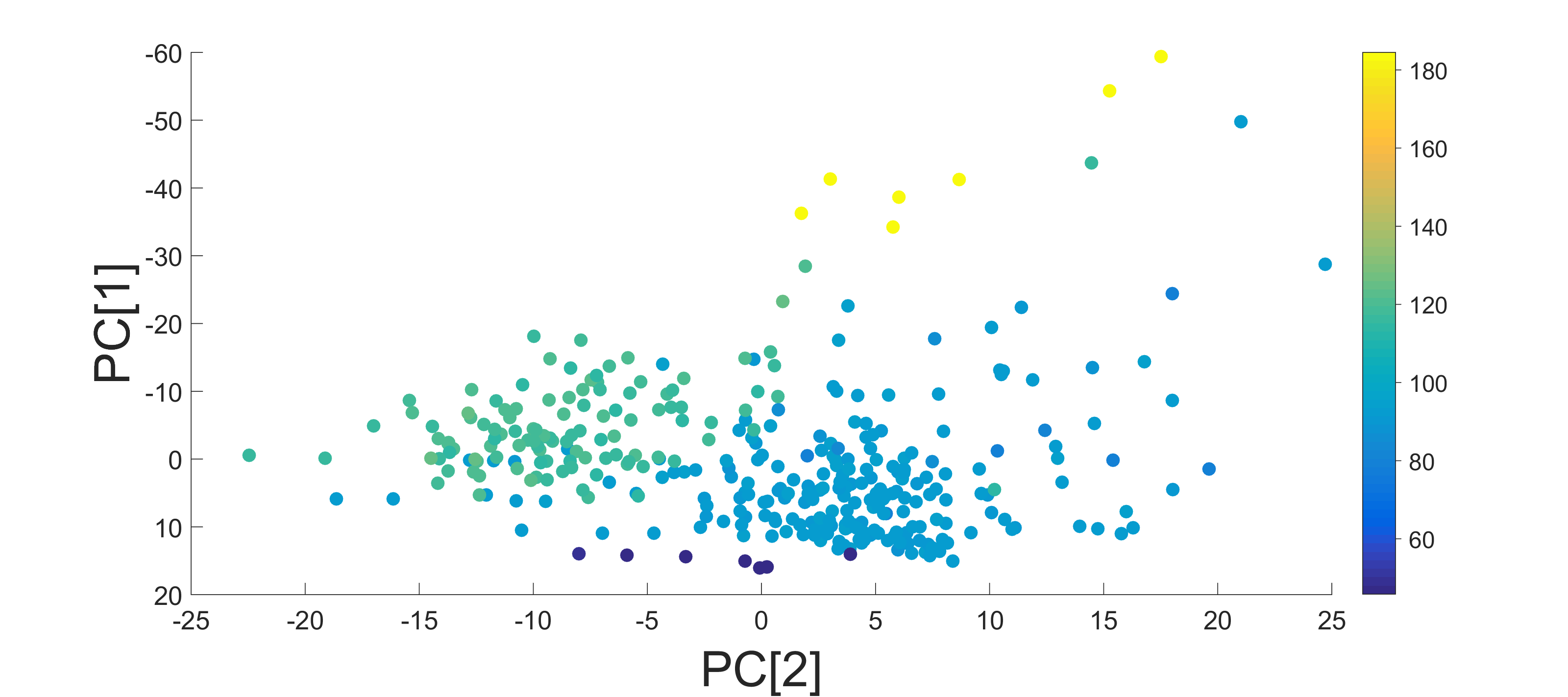 Figure 16
Figure 16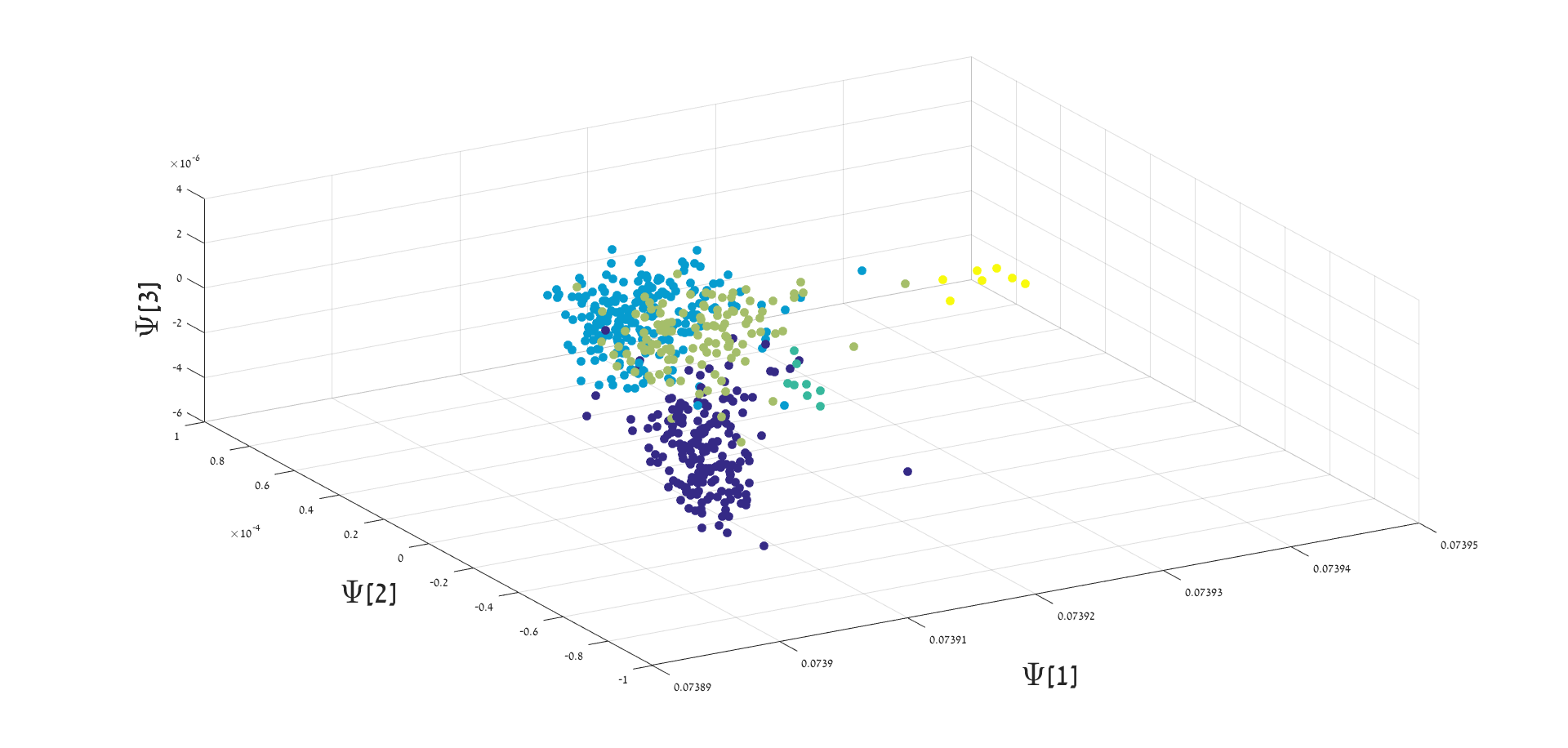 Figure 17
Figure 17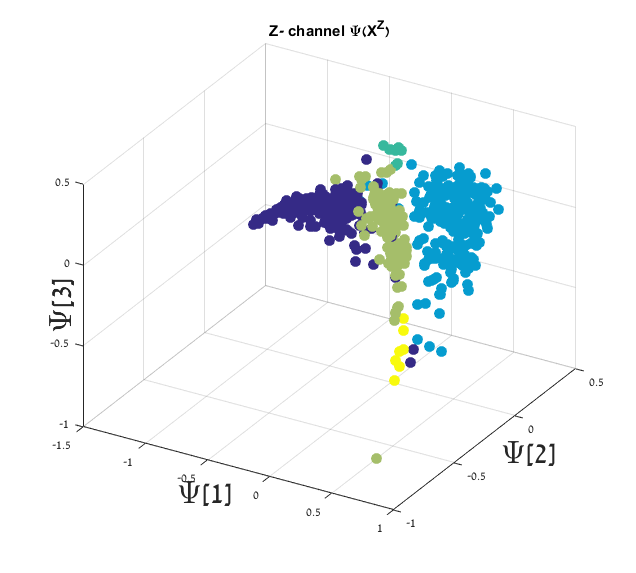 Figure 18
Figure 18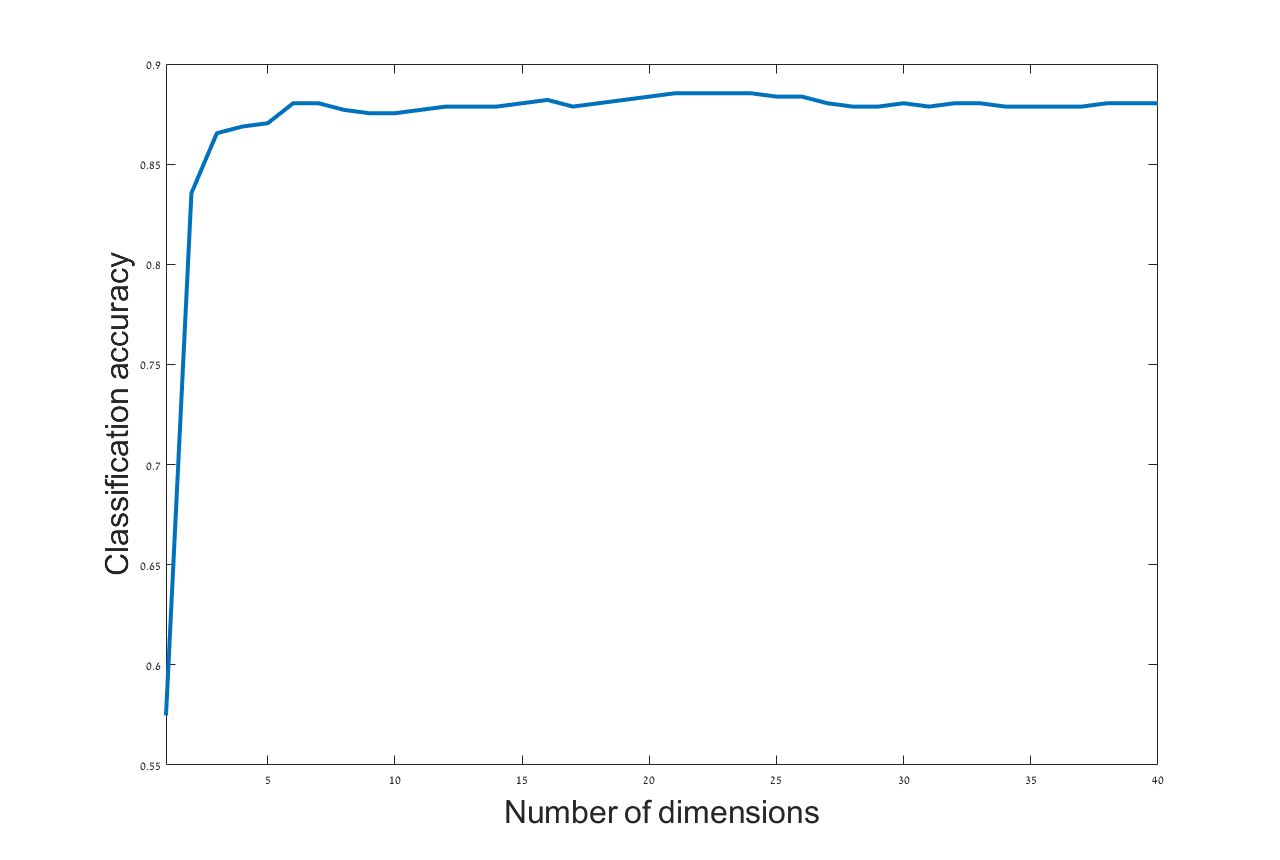 Figure 19
Figure 19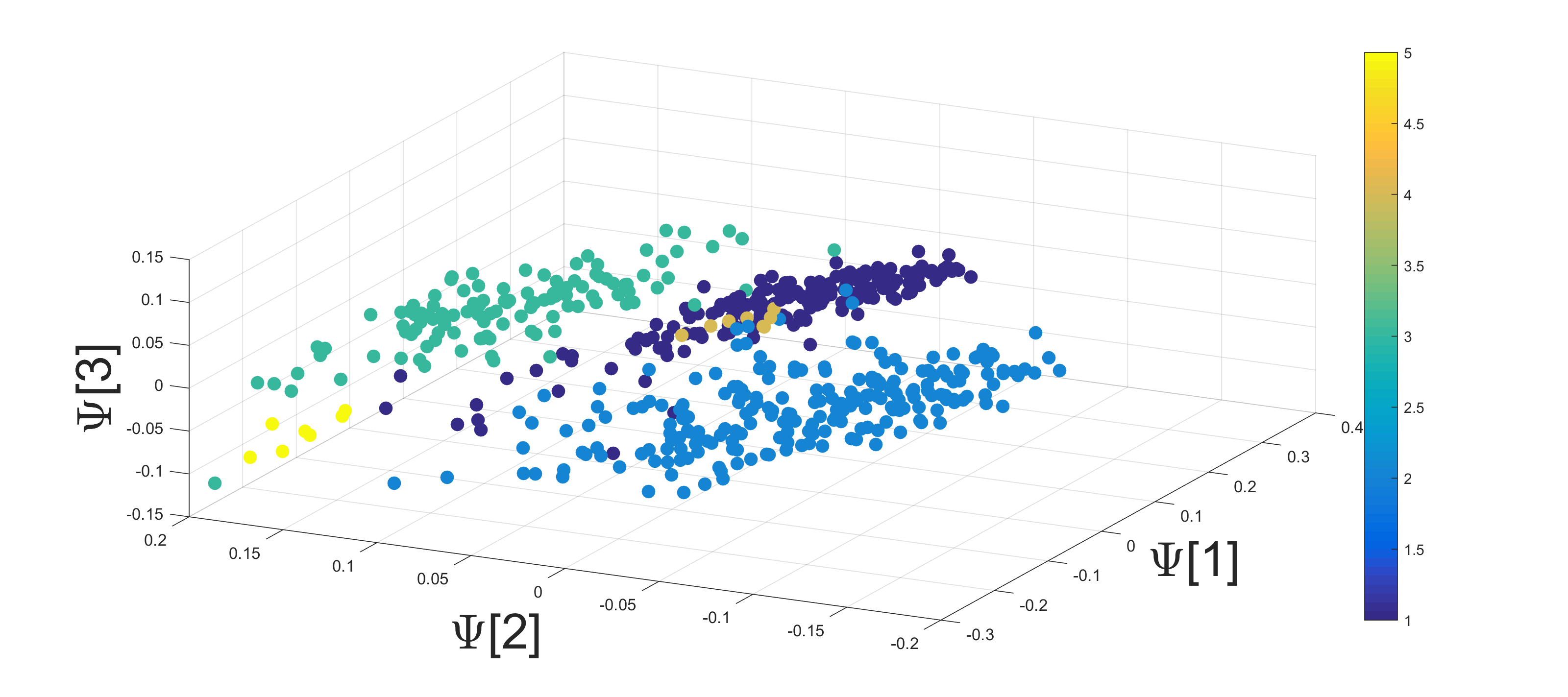 Figure 20
Figure 20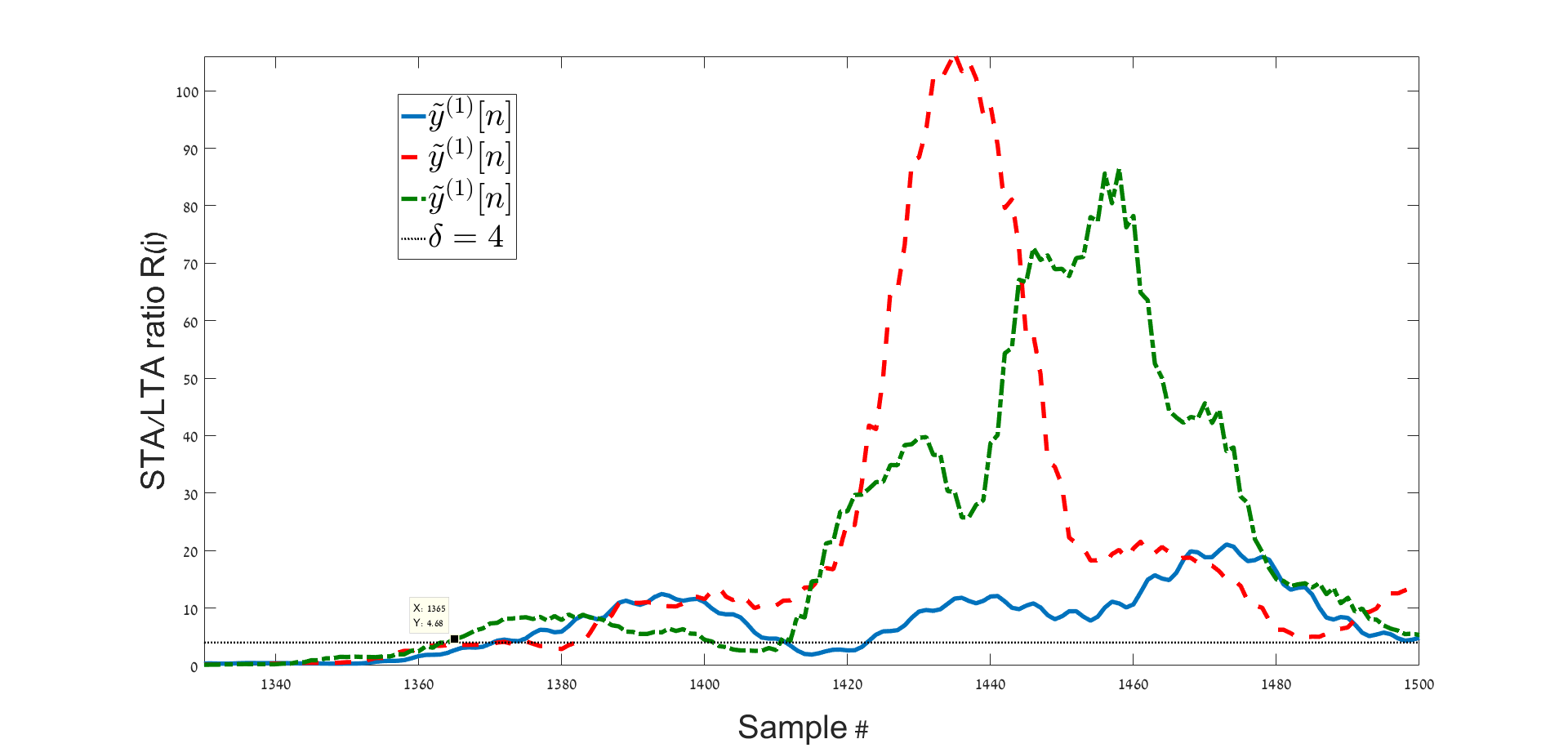 Figure 21
Figure 21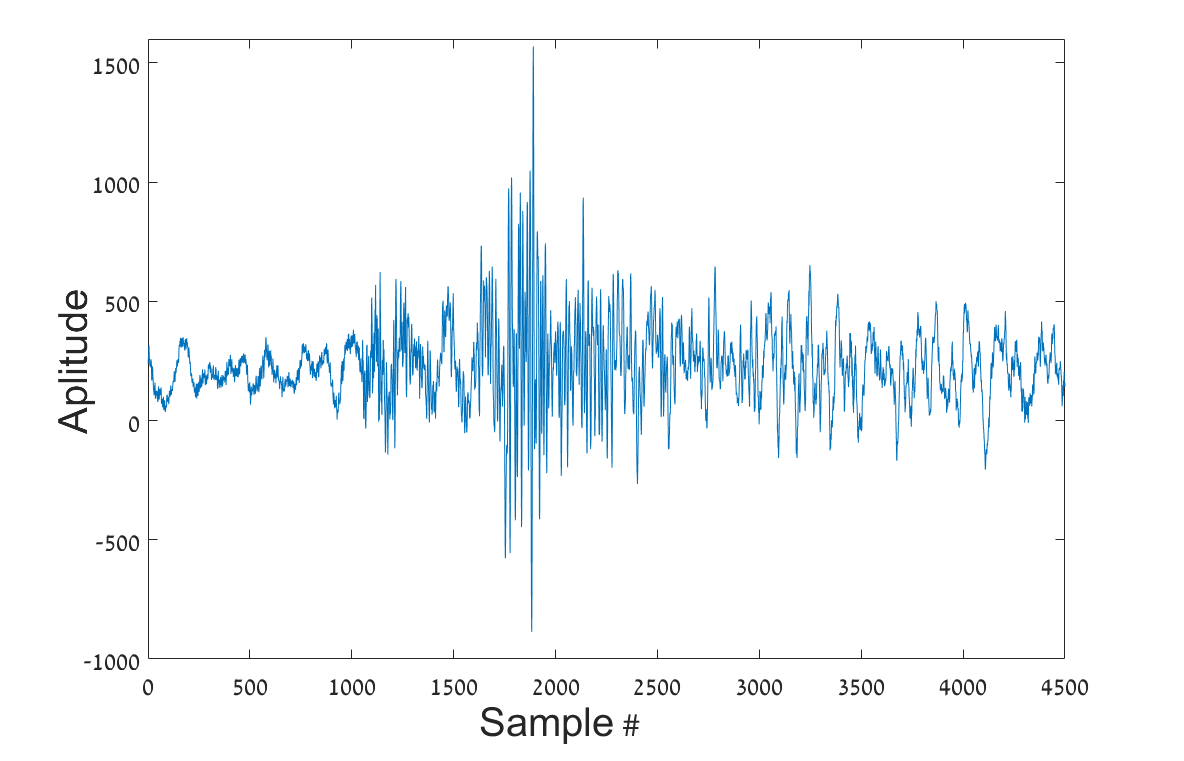 Figure 22
Figure 22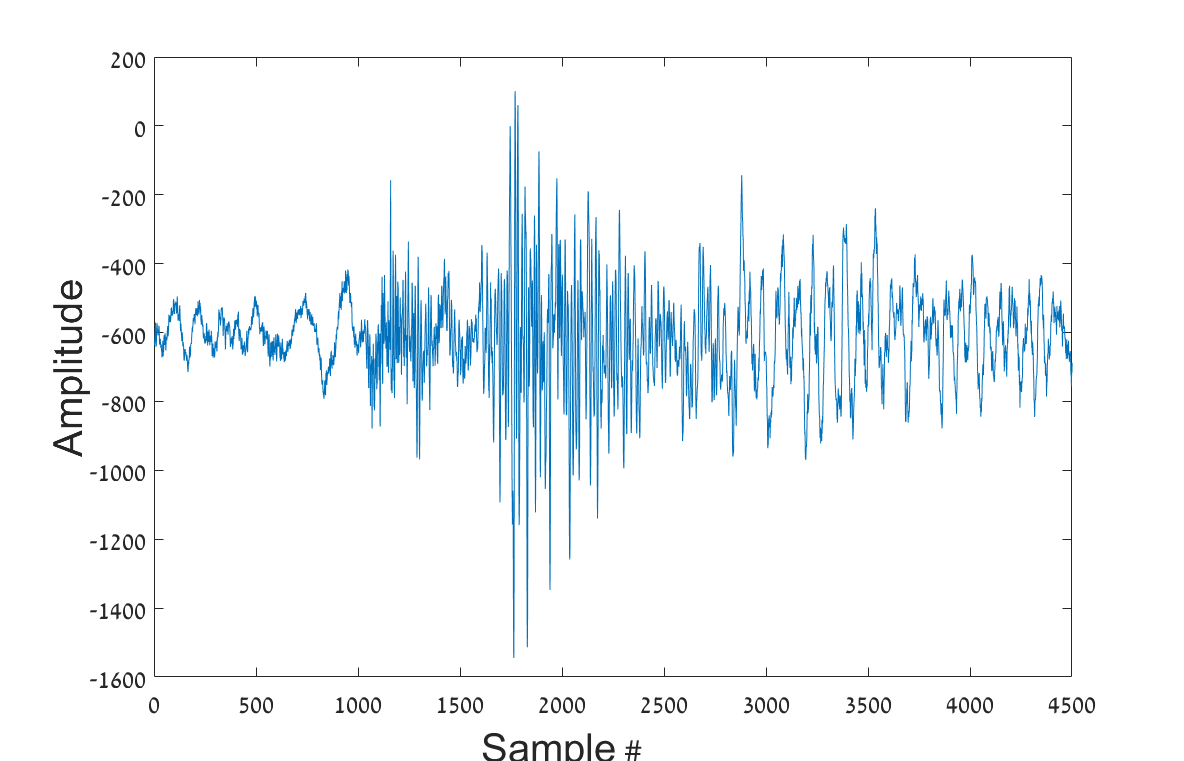 Figure 23
Figure 23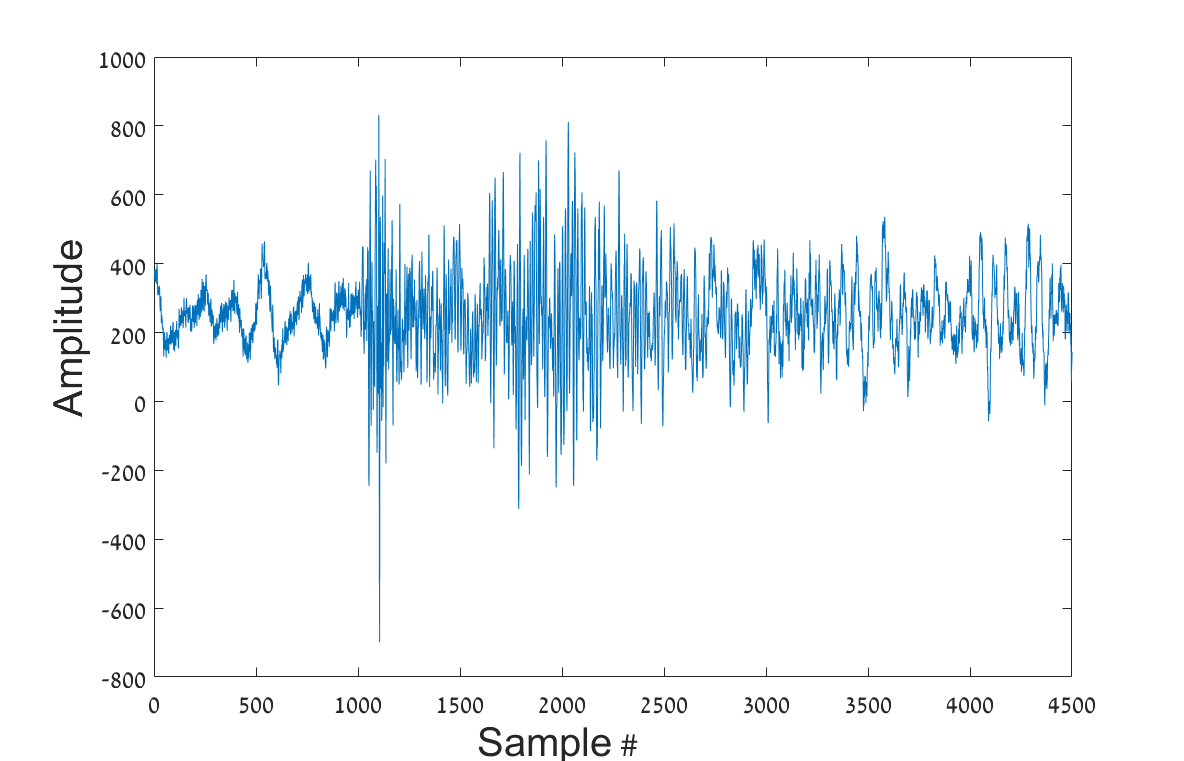 Figure 24
Figure 24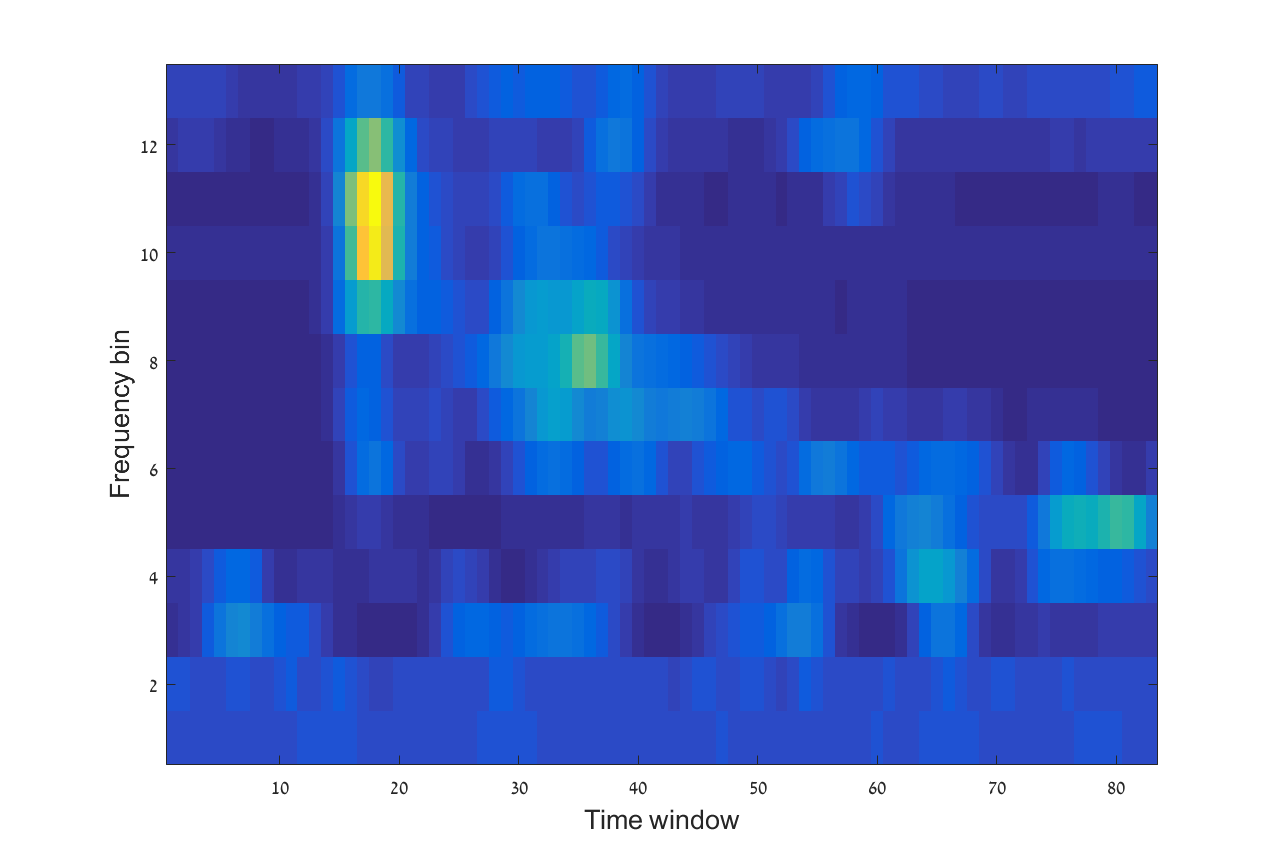 Figure 25
Figure 25| Band Number | f-start | f-end |
|---|---|---|
| #1 | [Hz] | [Hz] |
| #2 | [Hz] | [Hz] |
| #3 | [Hz] | [Hz] |
| #4 | [Hz] | [Hz] |
| #5 | [Hz] | [Hz] |
| #6 | [Hz] | [Hz] |
| #7 | [Hz] | [Hz] |
| #8 | [Hz] | [Hz] |
| #9 | [Hz] | [Hz] |
| #10 | [Hz] | [Hz] |
| #11 | [Hz] | [Hz] |
| Quarry Clusters | # of events | Center Lat | Center Lon | Distances to HRFI |
|---|---|---|---|---|
| Shidiya, Jordan | ||||
| Oron, Israel | ||||
| Rotem, Israel | ||||
| M. Ramon, Israel | ||||
| Har Tuv, Israel |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\AtBeginShipout
Multi-View Kernels for Low-Dimensional Modeling of Seismic Events
Ofir Lindenbaum, Yuri Bregman, Neta Rabin, and Amir Averbuch O. Lindenbaum was with the Department of Electrical Engineering, Tel Aviv University, Israel, P.O. Box 39040, Tel-Aviv, 69978, Israel. e-mail: [email protected].
Abstract
The problem of learning from seismic recordings has been studied for years. There is a growing interest of developing automatic mechanisms for identifying the properties of a seismic event. One main motivation is the ability have a reliable identification of man-made explosions. The availability of multiple high dimensional observations has increased the use of machine learning techniques in a variety of fields. In this work, we propose to use a kernel-fusion based dimensionality reduction framework for generating meaningful seismic representations from raw data. The proposed method is tested on 2023 events that were recorded in Israel and in Jordan. The method achieves promising results in classification of event type as well as in estimating the location of the event. The proposed fusion and dimensionality reduction tools may be applied to other types of geophysical data.
Index Terms:
Dimensionality Reduction, Diffusion Maps, Multi-view, Seismic Discrimination.
I Introduction
Machine learning techniques play a central role in data analysis, data fusion and visualization. As geophysical acquisition tools become more sophisticated and gather more information, data analysts relay more on machine learning techniques for generating meaningful representations of the data. A coherent representation of complex data often includes a feature extraction step followed by a dimensionality reduction step, which results in a compact and visual model. Analysis tasks such as clustering, classification, anomaly detection or regression may be carried out in the constructed low-dimensional space. Common dimensionality reduction methods such as Principal Component Analysis (PCA) [1] and Linear Discriminant Analysis (LDA) [2] project the feature space into a low dimensional space by constructing meaningful coordinated that are linear combinations of the original feature vectors. PCA is widely used for low-dimensional modeling of geoscience datasets. Jones & Christopher [3] applied PCA to infer aerosol specification for research of oceans or more complex land surfaces. Griparis and Faur [4] applied a linear dimensionality reduction tool, Linear Discriminant Analysis (LDA) for a projection of earth observations into a low-dimensional space. Their low-dimensional representation resulted in a cluster organization of the image data by land types. PCA and Self organization maps [5] were applied for pattern recognition in volcano seismic spectra by Unglert et. al. [6] and for geologic pattern recognition by Roden et. al. [7].
Another key issue in processing large amounts of data is the ability to fuse data from different sensors. Typical seismometers record data using three channels. These three channels capture the motion in the horizontal and perpendicular directions to the earth. Each channel may be processed separately and the results can be combined. Alternatively, a fused representation may be formed for common analysis. Recent advances in machine learning and in particular the use of non-linear kernel-based algorithm enable to construct data-driven fusions and to compute geometry-preserving low-dimensional embeddings. Such kernel-based embedding techniques are known as manifold learning methods, among them Local Linear Embedding [8], Lapacian Eigenmaps [9] and Diffusion Maps (DM) [10]. Manifold learning methods overcome limitations of linear dimensionality reduction tools such as PCA and LDA [11]. When the relationship between the original high-dimensional points is complex and non-linear, linear projections may fail to organize the data in a way that is loyal to the intrinsic physical parameters that drives the observed phenomena.
This work focuses on extending manifold learning techniques for low-dimensional modeling and kernel based data-driven fusion of seismic data. Identifying the characteristic of seismic events is a challenging and important task. This includes the discrimination between earthquakes and explosions which is not only an essential component of nuclear test monitoring but it is also important for the maintaining the quality of earthquake catalogs. For example, wrong classification of explosions as earthquakes may cause the erroneous estimation of seismicity hazard. The discrimination task is typically performed based on some extracted seismic parameters. Among such parameters is the focal depth, the ratio between surface wave magnitude and body wave magnitude and the spectral ratio between different seismic phases [12], [13]. Discrimination methods based on seismic parameters give only a partial solution to the problem. For instance, a larger half of seismic events reported by the Comprehensive Nuclear-Test-Ban Treaty Organization (CTBTO) are not “screened out” as natural events or even are not considered for the discrimination at all although most of those events are typically earthquakes [14].
Recently, this problem and other geophysical challenges have been approached using machine learning frameworks. Hidden Markov model were proposed in [15], [16], [17] and modeled the data in an unsupervised manner. Artificial neural networks [18], [19], [20] or support vector machines [21, 22] were also used to construct a classifier in a supervised manner. The study in [23] utilizes Self Organization Maps to distinguish micro-earthquakes from quarry blasts in the vicinity of Istanbul, Turkey. Manifold learning is used in [24] for seismic phase classification. In [25] a graph is used to detect sea mines in side-scan sonar images. The DM method is used in [26] for visualization of meteorological data. A non-linear dimensionality reduction is proposed in [27] to discriminate between earthquakes and explosions.
In this study, the manifold learning approach that was presented in [27] is extended by using a kernel-based fusion method for identification of seismic events. The method is model-free, and it is based on signal processing for feature extraction followed by manifold learning techniques for embedding the data. Furthermore, the method reviles the underlying intrinsic physical properties of the data, which results in a natural organization of the events by type. Since seismic data is recorded at multiple channels, we suggest fusing the information to extract a more reliable representation for the seismic recordings. The fusion framework is based on a recent work by [28, 29]. The study extends Diffusion Maps (DM) [10], which has been successfully applied for phase classification [24], for estimation of arrival times [30] and for events discrimination [31]. Other constructions for fusing kernels were proposed in [32, 33, 34].
The proposed framework begins with a preprocessing stage in which a time-frequency representation is extracted from each seismic event. The training phase includes the construction of a normalized graph that holds the local connections between the seismic events. A low dimensional map is then obtained by the eigen-decomposition of the graph. The constructed embedding is distance preserving. Thus the geometry of the dataset is kept in the new embedding coordinates. By utilizing the low dimensional embedding, we demonstrate capabilities of classification, location estimation and anomaly detection of seismic events.
The paper is organized as follows: Sections II and III present the machine learning frameworks for manifold learning and data fusion. In Section IV the data set is described. The mathematical methods required for analysis of seismic data are provided in Section V. The proposed framework and experimental results are presented in Section VI. We conclude this work in Section VII.
II Manifold Learning
This section reviews the manifold learning method that is applied in this work for non-linear dimensionality reduction, diffusion maps. The method’s main ingredient is a kernel function. Here, radial basis kernel functions are used, their construction is described in detail.
II-A Radial Basis Kernel Function
Kernel functions are vastly utilized in machine learning. Classification, clustering and manifold learning use some affinity measure to learn the relations among data points. A kernel is a pre-defined similarity function designed to capture the fundamental structure of a high dimensional data set. Given a high dimensional data set {{\mbox{\boldmathX}}=\{{{{\mbox{\boldmathx}}_{1},{\mbox{\boldmathx}}_{2},{\mbox{\boldmathx}}_{3},...,{\mbox{\boldmathx}}_{M}}}\}},{\mbox{\boldmathx}}_{i}\in{\mathbb{R}^{D}}, a kernel {{\cal{K}}:{\mbox{\boldmathX}}\times{{\mbox{\boldmathX}}}\longrightarrow{\mathbb{R}}} is an affinity function over all pairs of points in . The discrete kernel is represented by a matrix with following properties
- •
Symmetry {K_{i,j}={\cal{K}}({\mbox{\boldmathx}}_{i},{\mbox{\boldmathx}}_{j})={\cal{K}}({\mbox{\boldmathx}}_{j},{\mbox{\boldmathx}}_{i})}
- •
Positive semi-definiteness: {{\mbox{\boldmathv}}_{i}^{T}{\mbox{\boldmathK}}{\mbox{\boldmathv}}_{i}\geq 0} for all {\mbox{\boldmathv}}_{i}\in\mathbb{R}^{M} and {{\cal{K}}({\mbox{\boldmathx}}_{i},{\mbox{\boldmathx}}_{j})\geq 0.}
These properties guarantee that the matrix has real eigenvectors and non-negative real eigenvalues. In this study radial basis functions (RBF) are used for constructing the kernel. The RBF kernel function is defined by
[TABLE]
Applying the Euclidean distance to high dimensional pairs of distant vectors could somewhat be misleading, as data is typically sparse in the high-dimensional space. For this reason the decaying property of the Gaussian kernel is beneficial. The Gaussian tends to zero for distant points, whereas its value is close to one for adjacent points.
II-B Setting the Kernel’s Bandwidth
The kernel’s bandwidth controls the number of points taken into consideration by the kernel. A simple choice for is based on the standard deviation of the data. This approach is good when the data is sampled from a uniform distribution. In this study, we use a max-min measure. The method was proposed in [35] and aims to find a small scale to maintain local connectivities. The scale is set to
[TABLE]
where . Alternative methods such as [36, 37] have demonstrated similar results in our experiments.
II-C Non-Linear Dimensionality Reduction
Most dimensionality reduction methods are unsupervised frameworks that seek for a low dimensional representation of complex, high dimensional data sets. Each method preserves a certain criteria while reducing the dimension of the data. Principal component analysis (PCA) [38], reduces the dimension of the data while preserving most of the variance. Non linear methods such as Local Linear Embedding [8], Laplacian Eigenmaps [39], Diffusion Maps (DM) [10] preserve the local structure of the high-dimensional data. In particular, in DM [10], a metric that describes the intrinsic connectivity between the data points is defined. This metric is preserved in the low-dimensional space, resulting in a distance-preserving embedding. The metric is refereed to as diffusion distance, it is defined later in this subsection.
The DM framework enforces a fictitious random walk on the graph of a high dimensional data set {\mbox{\boldmathX}}=\{{\mbox{\boldmathx}}_{1},..,{\mbox{\boldmathx}}_{M}\},{\mbox{\boldmathx}}_{i}\in\mathbb{R}^{D}. This results in a Markovian process that travels in the high-dimensional space only in areas where the sampled data exists. The method has been demonstrated useful when applied to audio signals [37], image editing [40], medical data analysis [41] and other types of data sets.
Reducing the dimension of a data set by construction of DM coordinates is performed using the following steps
Given a data set compute an RBF kernel based on Eq. 1. 2. 2.
Normalize the kernel using where . Construct the row stochastic matrix by
[TABLE] 3. 3.
Compute the spectral decomposition of the matrix to obtain a sequence of eigenvalues and normalized right eigenvectors {\{{{\mbox{\boldmath{\psi}}}_{m}}\}} that satisfy {{{\mbox{\boldmathP}}}{\mbox{\boldmath{\psi}}_{m}}=\lambda_{m}{\mbox{\boldmath{\psi}}}_{m},m=0,...,M-1}; 4. 4.
Define the -dimensional () DM representation as
[TABLE]
where denotes the element of {\mbox{\boldmath{\psi}}_{m}}.
The power of the DM framework stems from the Diffusion Distance (Eq. 5). It was shown in [10] that the Euclidean distance in the embedded space {\mbox{\boldmath\Psi}}{({\mbox{\boldmathx}}_{i})} is equal to a weighted distance between rows of the probability matrix . This distance is defined as the Diffusion Distance
[TABLE]
where is a diagonal matrix with elements . Thus, the DM embedding is distance preserving, meaning that neighboring points in the high-dimensional space are embedded close to each other in the diffusion coordinates.
III Data Fusion
Many physical phenomena are sampled using multiple types of sensing devices. Each sensor provides a noisy measurement of a latent parameter of interest. Data fusion is the process of incorporating multiple observation of the same data points to find a more coherent and accurate representation.
Problem Formulation: Given multiple sets of data points {\mbox{\boldmathX}}^{l}\text{ },l=1,...,L. Each view is a high dimensional dataset {{\mbox{\boldmathX}}^{l}=\{{{{\mbox{\boldmathx}}_{1}^{l},{\mbox{\boldmathx}}_{2}^{l},{\mbox{\boldmathx}}_{3}^{l},...,{\mbox{\boldmathx}}_{M}^{l}}}\},{\mbox{\boldmathx}}_{i}^{l}\in{\mathbb{R}^{D}}}. Find a reliable low dimensional representation {\mbox{\boldmath\Psi}}({\mbox{\boldmathX}}^{1},...,{\mbox{\boldmathX}}^{L})\in\mathbb{R}^{d}.
III-A Multi-View Diffusion Maps (Multi-View DM)
An approach for fusion kernel matrices in the spirit of DM framework was presented in [28]. The idea is to enforce a random walk model based on the kernels that model each view by restraining the random walker to “hop” between views in each time step.
The construction requires to compute a Gaussian kernel for each view
[TABLE]
then the multi-view kernel is formed by the following matrix
[TABLE]
Next, re-normalizing using the diagonal matrix where , the normalized row-stochastic matrix is defined as
[TABLE]
where the block is a square matrix located at
. This block describes the probability of transition between view {\mbox{\boldmathX}}^{m} and {\mbox{\boldmathX}}^{l}. The multi-view DM representation for {\mbox{\boldmathX}}^{l} is computed by
[TABLE]
where . The final low dimensional representation is defined by a concatenation of all low dimensional multi-view mappings
[TABLE]
III-B Alternative Methods
Here we provide a brief description of several methods for fusing the views before the application of a spectral decomposition.
Kernel Product (KP): Multiplying the kernel matrices element wise {\mbox{\boldmathK}}^{{\circ}}\triangleq{\mbox{\boldmathK}}^{1}\circ{\mbox{\boldmathK}}^{2}\circ...\circ{\mbox{\boldmathK}}^{L}, , then normalizing by the sum of rows. The resulting row stochastic matrix is denoted as {\mbox{\boldmathP}}^{{\circ}}. This kernel corresponds to the approach in [10].
Kernel Sum (KS): Defining the sum kernel {\mbox{\boldmathK}}^{+}\triangleq\sum^{L}_{l=1}{\mbox{\boldmathK}}^{l}. Normalizing the sum kernel by the sum of rows, to compute {\mbox{\boldmathP}}^{+}. This random walk sums the step probabilities from each view. This approach is proposed in [42].
Kernel Canonical Correlation Analysis (KCCA): This method detailed in [43, 44] extend the well know Canonical Correlation Analysis (CCA).Two kernels {\mbox{\boldmathK}}^{1}\text{and }{\mbox{\boldmathK}}^{2} are constructed in each view as in Eq. (6) and the canonical vectors {\mbox{\boldmathv}}_{1}\text{and }{\mbox{\boldmathv}}_{2} are computed by solving the following generalized eigenvalue problem
[TABLE]
where \gamma{\mbox{\boldmathI}} are regularization terms which guarantee that the matrices ({\mbox{\boldmathK}}^{1}+\gamma{\mbox{\boldmathI}})^{2} and ({\mbox{\boldmathK}}^{2}+\gamma{\mbox{\boldmathI}})^{2} are invertible.
IV Seismic Data Set
The data set that is used for demonstrating the proposed kernel based approaches includes explosions and earthquakes. of the explosions occurred at the Shidiya phosphate quarry in the Southern Jordan between the years - (see a map of the region in Figure 1). These events were reported by the Israel National Data Center at the Soreq Nuclear Research Center with magnitudes seismic. The rest of the events were taken from the seismic catalog of the Geophysical Institute of Israel between the years - . All events were reported in Israel between latitudes N-N and longitudes E-E with duration magnitudes Md .
Most of the earthquakes in the dataset occurred in the Dead Sea transform [45]. The dataset includes the February 11, 2004 earthquake with the duration magnitude of Md = 5.1. This was the strongest event in this area since 1927 [46]. Twelve aftershocks that are included in the dataset are associated with this main shock. The majority of the explosions in the dataset are ripple-fire query blasts. Moreover, the dataset consists of several one shot explosions, for instance, two experimental underwater explosions in the Dead Sea [46] and surface and near-surface experimental explosions at the Oron quarry [47] and at the Sayarim Military Range [48] in the Negev desert.
The dataset consists of seismogram recordings from the HRFI (Harif) station in Israel. The station is part of the Israel National Seismic Network [46]. It is equipped with a three component broad band STS-2 seismometer and a Quanterra data logger. The seismograms are sampled at a frequency of Hz. Waveform segments of -minutes (6000 samples) have been selected for every event. In each waveform, the first P phase onsets reside seconds after the beginning of each waveform. Figure 1 displays the events on the regional map.
V Seismic Preprocessing and Feature Extraction Methods
This section provides background on typical methods that are used for seismic signal processing as well as the description of the feature extraction method that was applied here. First, the STA/LTA detector is reviewed. Next, we describe how the alignment between the different waveforms was implemented. Last, the feature extraction step, which results in a time-frequency representation of the seismic signal, is described.
V-A Short and Long Time Average (STA/LTA)
Detection of seismic signal embedded in the background noise is a classical problem in the signal processing theory. In the context of statistical decision theory it may be formulated as a choice between two alternatives: a waveform contains solely the noise or it contains a signal of interest superimposed on the noise. The STA/LTA trigger is a most widely accepted detection algorithm in seismology [49]. It relies on the assumption that a signal is characterize by a concentration of higher energy level compared with the energy level of the noise. This is done by comparing short-time energy average to a long-time energy average using a Short Time Average/ Long Time Average (STA/LTA) detector. Usually a band-pass filter is applied before the STA/LTA test.
Given a time signal {\mbox{\boldmathy}}(n) the ratio is computed at each time instance is computed as follows
[TABLE]
where are the number of samples used for the long and short average correspondingly. The ratio is compared to a threshold to identify time windows suspected as seismic events.
V-B Seismic Event Alignment
All waveform segments in the dataset were extracted according to the first P phase onset time. Those onset times were manually picked by the analysts. However, our selective waveform inspection showed that the P onsets often have actual offsets of several seconds, sometimes even of ten seconds. In order to increase the accuracy of the alignment, Algorithm 1 is proposed to detect the first P onsets.
Algorithm 1 aligns the seismic events based on the STA/LTA ratios which are computed using three filtered versions of the input signal. We assume that most of the energy of the seismic signature is between and . Figure 2 presents a visual example for the application of Algorithm 1.
V-C Feature Extraction
In this study a time-frequency representations, named sonograms [50], is used, with some modification. The sonogram is a normalized short time Fourier transform (STFT) rearranged to be equal tempered on a logarithmic scale. Each raw single-trace seismic waveform input is denoted by {\mbox{\boldmathy}}(n)\in\mathbb{R}^{\bar{N}}. The length of the signals in this study is with a sampling rate of . An example of seismic signals recorded using three channels is presented in Figure 3.
The sonogram is extracted from {\mbox{\boldmathy}}(n) based on the following steps:
- •
Given a recorded signal {\mbox{\boldmathy}}(n)\in\mathbb{R}^{N} the short time Fourier transform (STFT) is computed by
[TABLE]
where is a Hann window function with a length of and a overlap. The time indexes are . The number of time bins is computed using the following equation
[TABLE]
- •
The Spectrogram is the normalized energy of {\mbox{\boldmathSTFT}}(f,t)
[TABLE]
The Spectrogram {\mbox{\boldmathR}}(f,t) contains time bins and frequency bins.
- •
The frequency scale is then rearrange to be equally tempered on a logarithmic scale, such that the final spectrogram contains frequency bands. The frequency bands are presented in Table V-C.1.
- •
The bins are normalized such that the sum of energy in every frequency band is equal to . The resulted sonogram is denoted by {\mbox{\boldmathS}}(k,t), where is the frequency band number, and is the time window number. Finally, we transpose the sonogram matrix into a Sonovector by concatenating the columns such that
[TABLE]
An example of a sonogram extracted from an explosion is presented in Figure 4.
VI Case Studies
To evaluate the strength of multi-view DM for identifying the properties of seismic events we perform the following experiments.
VI-A Discrimination Between Earthquakes and Explosions
We consider the earthquake-explosion discrimination problem as a supervised binary classification task. A homogeneous evaluation data set is constructed by using data from 105 earthquakes and a random sample of 210 explosions. The sampling is repeated 200 times, and the results are the average of all trials. Algorithm 2 is applied to extract a low dimensional representation of the seismic data. The number of data samples used for each events is 6000, where (samples before onset) and (samples after onset). An example of a 3-dimensional single view DM mapping is presented in Figure 5. In this example, the explosions seem geometrically concentrated, while the earthquakes are spread out. This spread out structure may be associated with the diversity of the time-spectral information describing earthquakes, as oppose to the explosions that were mostly generated in specific quarries. The separation is clearly visible in this example. An evaluation of the separation is performed using a 1-fold cross-validation procedure. Test points are classified by using a simple K-NN classifier in a dimensional representation. The optimal dimension () for classification was found empirically based on our data set. The average accuracy of classification for various values of are presented in Figure 6. Thus, the multi-view approach shows better performance with 95% of correct discrimination.
VI-B Quarry Classification
Identification and separation of quarries by attributing the explosions to the known sources is a challenging task in observational seismology [51], [52]. Here we demonstrate how the DM representation can be utilized to identify the origin of an explosion.
For this study 602 seismograms of explosions are used. The explosions occurred in 5 quarry clusters (see Table VI-B.1 and Figure 7) and the label data was taken from seismic catalogs. It should be noted that the quarry clusters may include several neighboring quarries and the quarry area may be of several kilometers (like Rotem) or more than ten kilometers (like Shidiya). Moreover, the precise (“ground truth”) location for most of explosions inside a quarry are not known. We estimate that the hypo-center accuracy in the used seismic catalogs is about a few kilometers for the explosions in Israel and it is more than ten kilometers for the explosions in Jordan, which are located outside the Israeli seismic network. The mean latitude and longitude are computed for the explosions belonging to each cluster and referred them to the nearby quarry (see Table VI-B.1).
The application of Algorithm 2 yields a low dimensional representation of the seismic recordings. An example of a 3-dimensional single view DM mapping is presented in Figure 8.
The mapping is followed by a classification step that is performed based on a 1-fold cross validation using K-NN with . The accuracy of the classification is presented in Figure 9. The multi-view approach shows a peak performance of 85% of correct classification rate.
VI-C Location Estimation
The following case study demonstrates how the diffusion coordinates extract underlying physical properties of the sampled signal. In particular we show that the low dimensional representation that is generated by diffusion maps organizes the events with respect to their source location, even though this was not an input parameter of the algorithm. The original high-dimensional space holds the sonogram of each event. Nearly co-located events with the similar source mechanisms and magnitudes should have a similar time-frequency content and, consequently, have similar sonograms. Therefore, we expect them to lie close to each other in the high dimensional space. The diffusion distance, which is the metric that is preserved in DM, embeds the data while keeping its geometrical structure. Thus, physical properties (such as the source location) that characterize the sonogram and therefore define the geometric structure of the points in the high-dimensional space, are preserved in low-dimensional DM embedding. Note that such a geometry preserving metric does not exist in linear dimensionality reduction methods like PCA.
The dataset for this study includes 352 explosions that occurred in 4 quarry clustering Israel out 5 clusters above. The explosions in Jordan were removed since they are located at a large distance from the HRFI station. We show that the location of seismic events can be evaluated from the DM embedding coordinates. A similar evaluation based on a linear projection that was calculated with PCA yields a less accurate correlation to the events’ true location.
Figure 10 (top image) displays the longitude and latitude coordinates of catalog locations of the events. These are the source locations of the seismic events. The points are colored by distance in kilometers from HRFI station. The middle and bottom images of Figure 10 present the two-dimensional PCA and DM embeddings of the dataset, respectively. It is clearly evident that the DM (bottom image in Figure 10) representation has captured the location variability, while in the PCA representation this intrinsic factor is less obvious (middle image in Figure 10). In the DM embedding, the clusters are well separated with respect to the event’s location. In PCA the separation is not as clear, meaning that the low-dimensional PCA representation does not reveal this property. The Pearson correlation coefficients between first two diffusion coordinates and relative latitude and longitude are 0.82 and 0.77 for both dimensions respectively. The Pearson correlation coefficients between first two principle and relative latitude and longitude are 0.56 and 0.39 respectively.
VI-D Detecting Anomalous Events
This case study demonstrates the diffusion representation’s ability to detect anomalous events among set of events at specific site. When two events are nearly co-located, have close magnitudes but with different source mechanisms, then their sonograms should be quite different as well.
Ripple-fire explosions are part of routine mining production cycles at the Oron phosphate quarry in Israel. In July 2006, three experimental one shot explosions were conducted by the Geophysical Institute of Israel at the Oron quarry [47]. Our goal is to distinguish between the one shot explosions and the ripple-fire quarry blasts. This is not a trivial task, as all the events were conducted at very close distances.
To remove the variability created by the location of the events, 98 blast from a small region surrounding the ground truth location of the experimental explosions as reported in [47] are used. Algorithm 2 is applied and a mapping extracted from the Z-channel is used to find the suspected anomalies. The diffusion maps embedding is presented in Figure 11. The three anomaly points are colored in blue, they are clearly separated from the main cluster. The anomalies are automatically identified using Algorithm 3 with and a threshold set as four times the median of all distances . The average K-NN distance for the 98 blasts is presented in Figure 12. The four events that were suspected as anomalies include the three experimental explosions (which are described in [47]).
VII Conclusion
In this paper, we have adapted a multi-view manifold learning framework for fusion of seismic recordings and for low-dimensional modeling. The abilities of kernel fusion methods for extracting meaningful seismic parameters were demonstrated on various case studies. Various algorithms for classification of seismic events type, location estimation and anomaly detection were presented. These algorithms can be used as decision support tools for analysts who need to determine the source, location and type of recorded seismic events. Correct classification of events results in improved and more accurate seismic bulletins.
The proposed method is model free, thus it does not require knowledge of physical parameters. The underlying physical parameters are revealed by the diffusion maps and multi-view constructions. This type of kernel based sensor fusion is new in seismic signal processing and it overcomes some of the limitation of traditional model based fusion methods.
Acknowledgments
This research was supported by the research grant of Pazy Foundation. We would like to thank Yochai Ben Horin for his advice and suggestions. We are grateful to Dov Zakosky and Batia Reich for providing us with the seismic catalog of Geophysical Institute of Israel.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] H. Abdi and L. J. Williams, “Principal component analysis,” Wiley interdisciplinary reviews: computational statistics , vol. 2, no. 4, pp. 433–459, 2010.
- 2[2] K. Fukunaga, Introduction to Statistical Pattern Recognition (2nd edition) . Academic Press, New York, 1990.
- 3[3] A. T. Jones and A. Y. Christopher, “Multispectral analysis of aerosols over oceans using principal components.” IEEE Transactions on Geoscience and Remote Sensing , vol. 46, no. 9, pp. 2659–2665, 2008.
- 4[4] A. Griparis, D. Faur, and M. Pinsky, “Dimensionality reduction for visual data mining of earth observation archives.” IEEE Transactions on Geoscience and Remote Sensing Letters , vol. 13, no. 11, pp. 1701–1705, 2016.
- 5[5] T. Kohonen, Self-Organization and Associative Memory . Springer Series in Information Sciences, 1989.
- 6[6] K. Unglert, D. Radić, and A. M. Jellinek, “Principal component analysis vs. self-organizing maps combined with hierarchical clustering for pattern recognition in volcano seismic spectra.” Journal of Volcanology and Geothermal Research , vol. 320, pp. 58––74, 2016.
- 7[7] R. Roden, T. Smith, and D. Sacrey, “Geologic pattern recognition from seismic attributes: Principal component analysis and self-organizing maps.” Interpretation , vol. 3, no. 4, pp. SAE 59–SAE 83, 2015.
- 8[8] S. T. Roweis and L. K. Sau, “Nonlinear dimensionality reduction by local linear embedding,” Science , vol. 290.5500, pp. 2323–2326, 200.