Graph-Cut RANSAC
Daniel Barath, Jiri Matas

TL;DR
GC-RANSAC introduces a graph-cut based local optimization step that enhances robust model estimation, achieving higher accuracy and real-time performance across various geometric problems in computer vision.
Contribution
It presents a simple, globally optimal, and efficient graph-cut based local optimization method integrated into RANSAC, improving accuracy over state-of-the-art techniques.
Findings
More geometrically accurate than existing methods
Operates in real-time on standard CPU
Effective across multiple geometric estimation problems
Abstract
A novel method for robust estimation, called Graph-Cut RANSAC, GC-RANSAC in short, is introduced. To separate inliers and outliers, it runs the graph-cut algorithm in the local optimization (LO) step which is applied when a so-far-the-best model is found. The proposed LO step is conceptually simple, easy to implement, globally optimal and efficient. GC-RANSAC is shown experimentally, both on synthesized tests and real image pairs, to be more geometrically accurate than state-of-the-art methods on a range of problems, e.g. line fitting, homography, affine transformation, fundamental and essential matrix estimation. It runs in real-time for many problems at a speed approximately equal to that of the less accurate alternatives (in milliseconds on standard CPU).
Click any figure to enlarge with its caption.
 Figure 1
Figure 1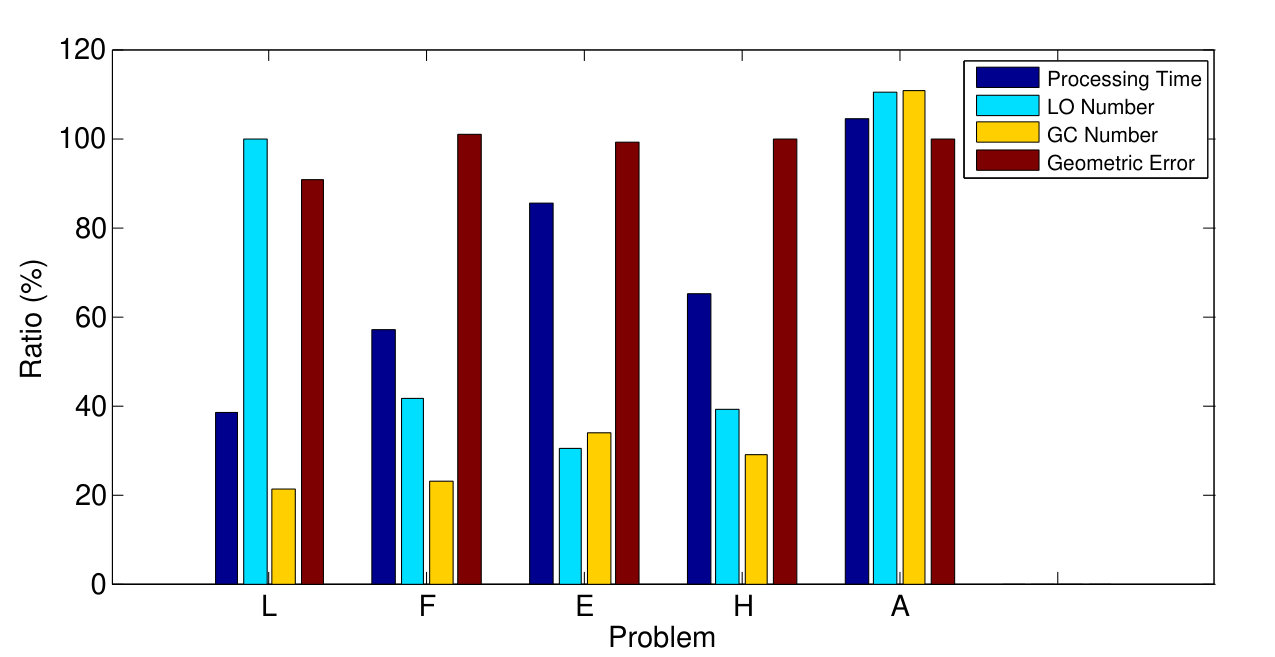 Figure 2
Figure 2 Figure 3
Figure 3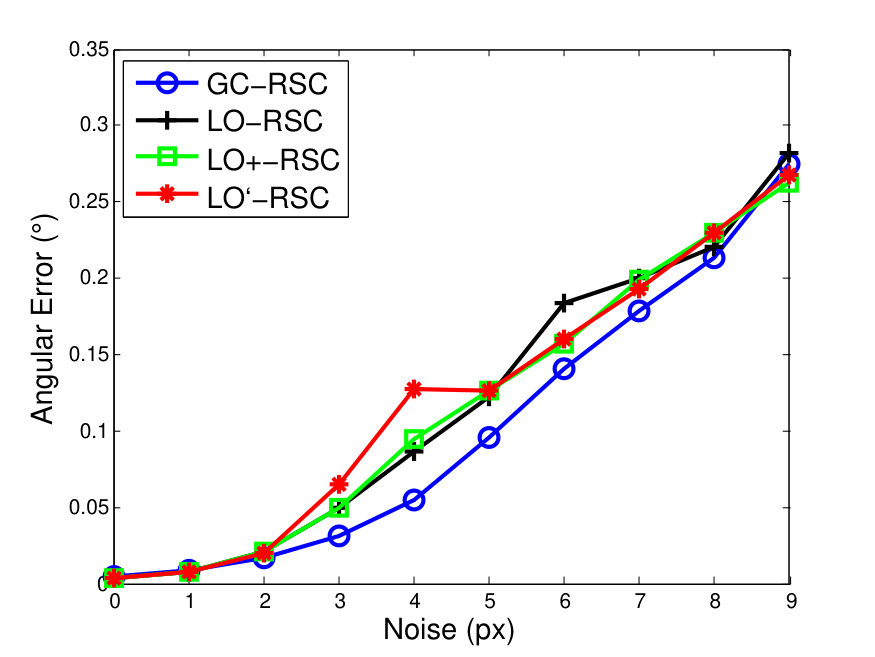 Figure 4
Figure 4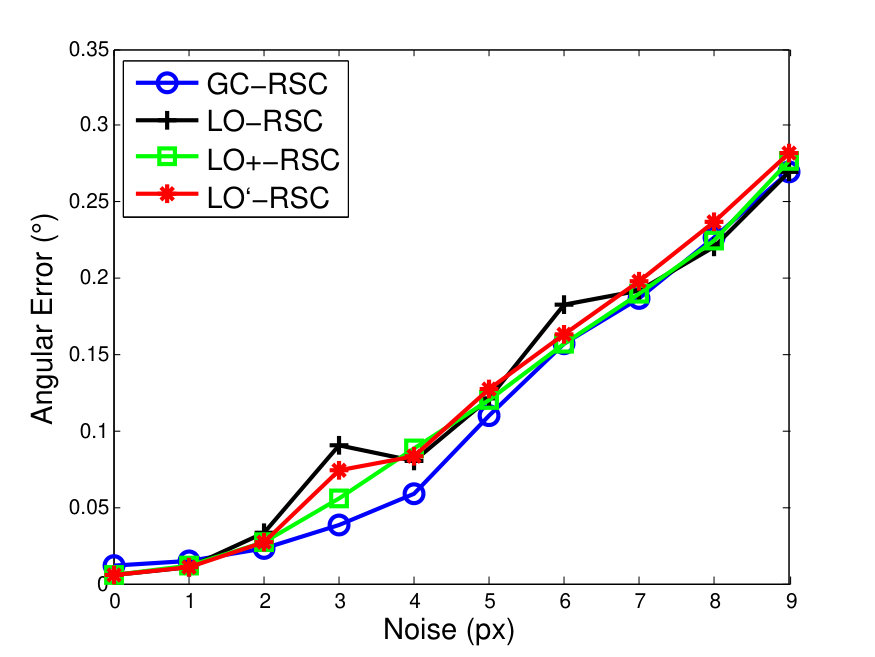 Figure 5
Figure 5 Figure 6
Figure 6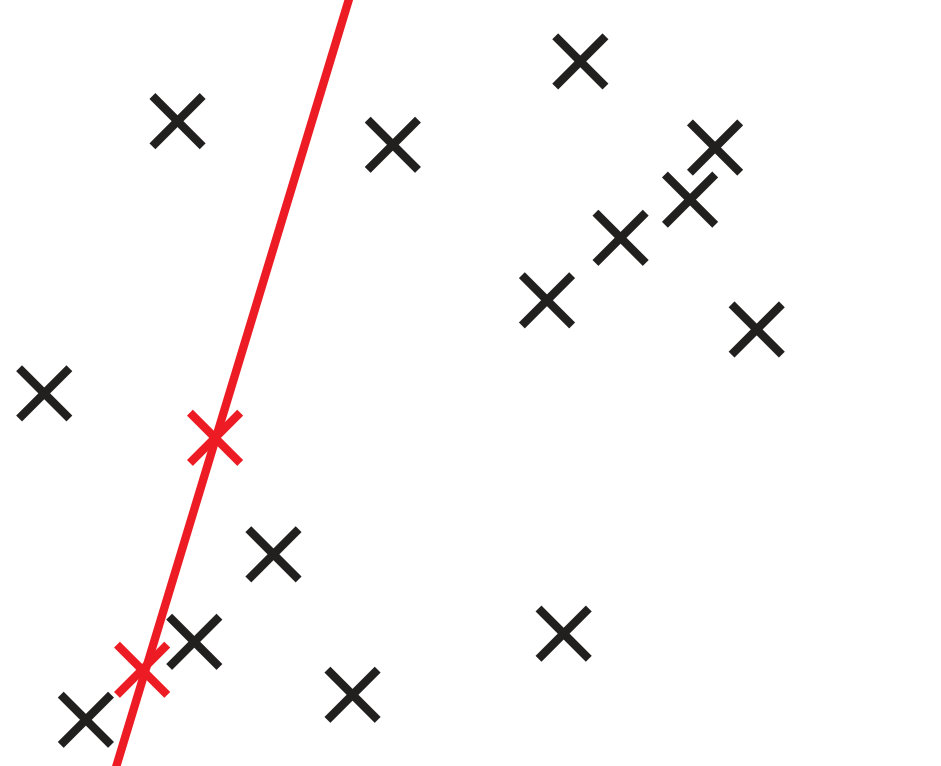 Figure 7
Figure 7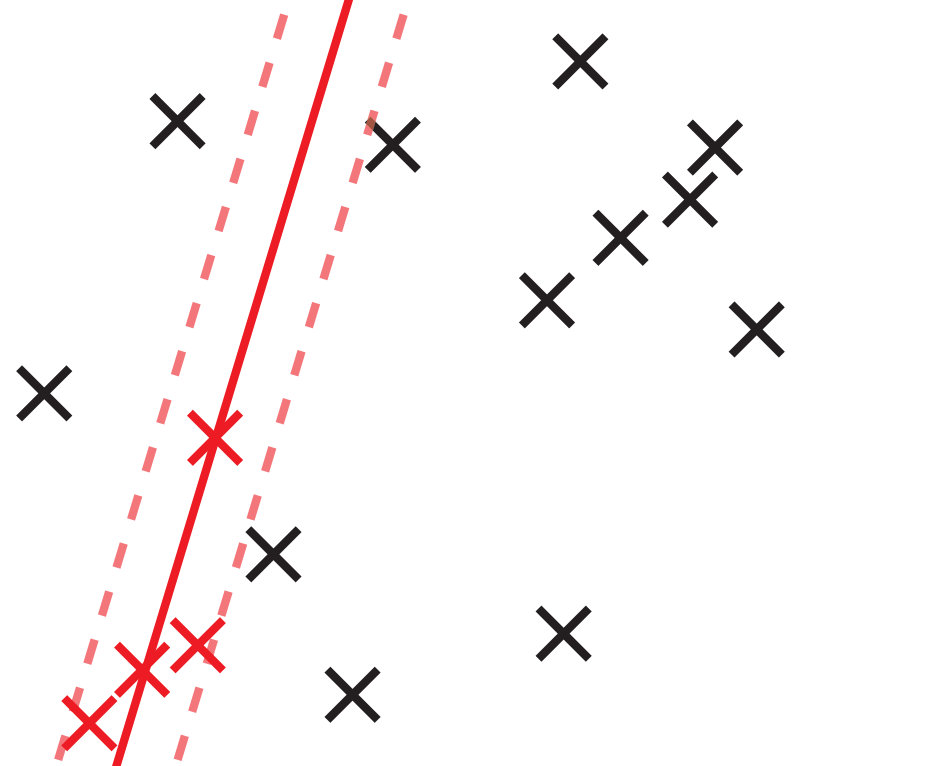 Figure 8
Figure 8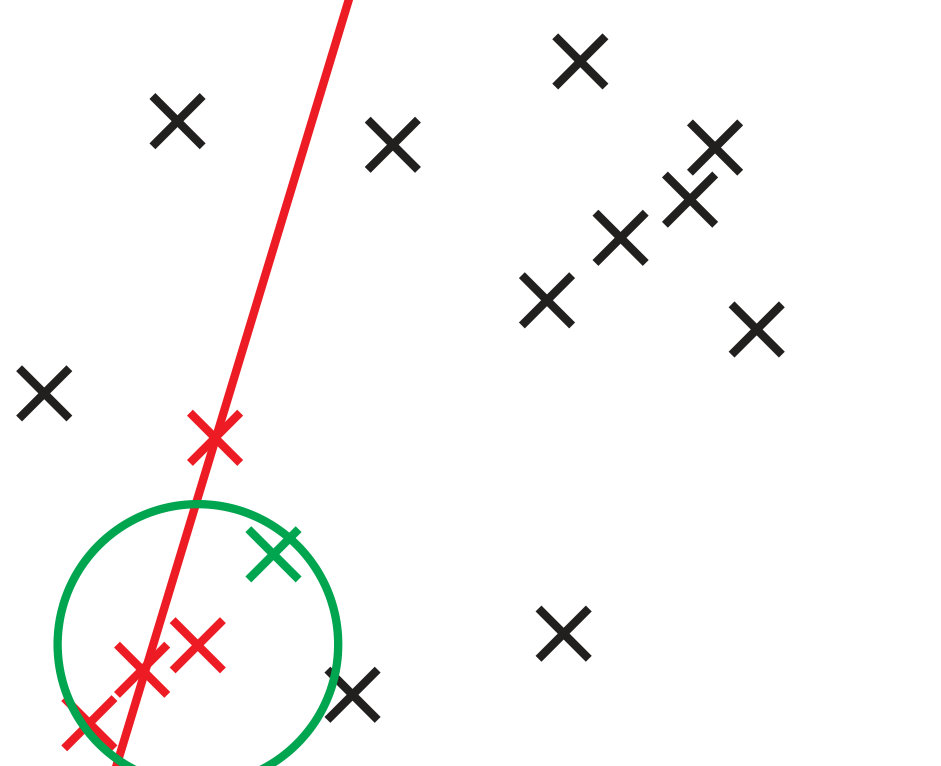 Figure 9
Figure 9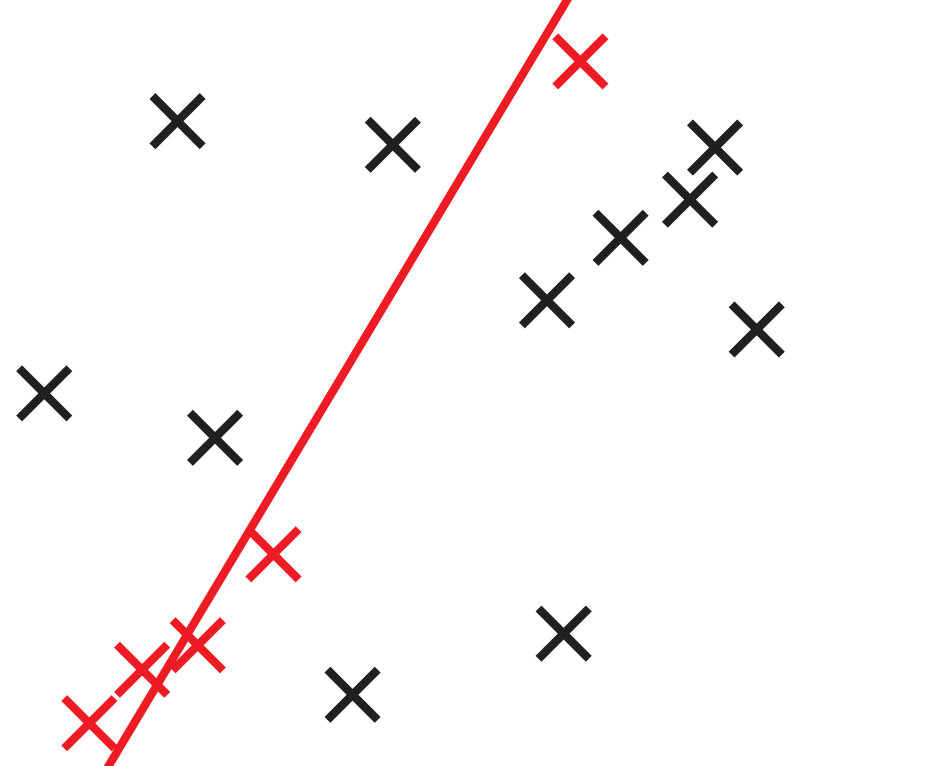 Figure 10
Figure 10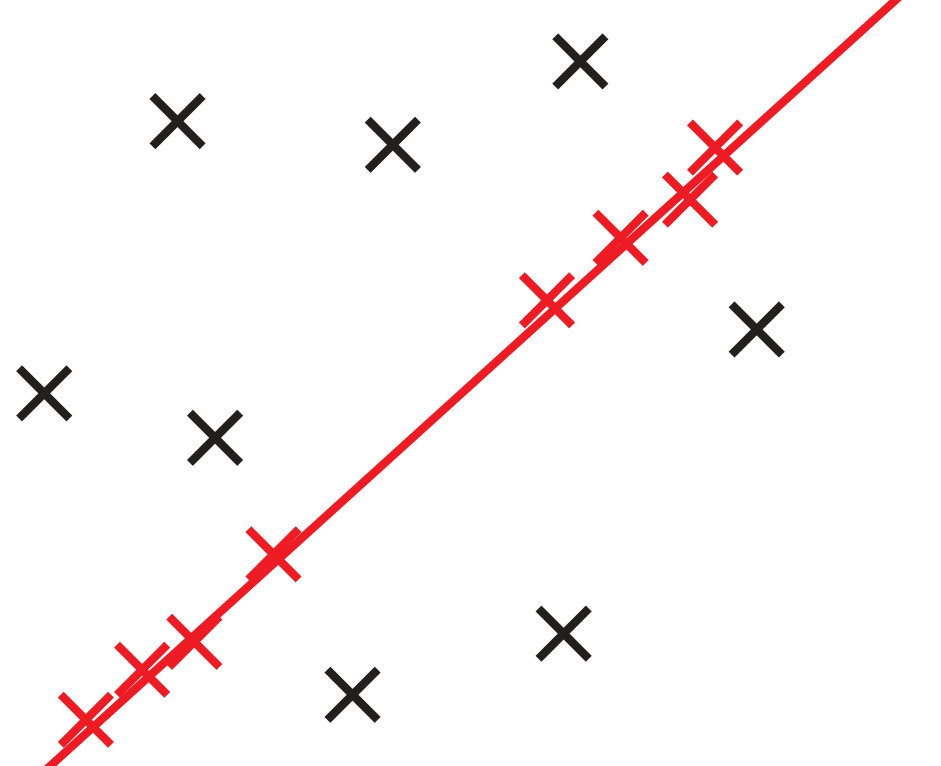 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16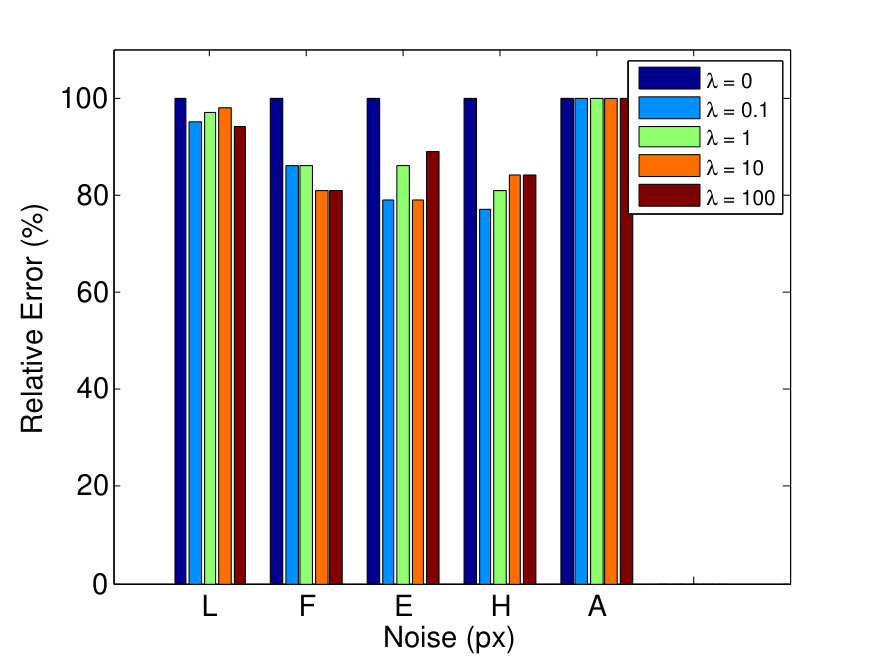 Figure 17
Figure 17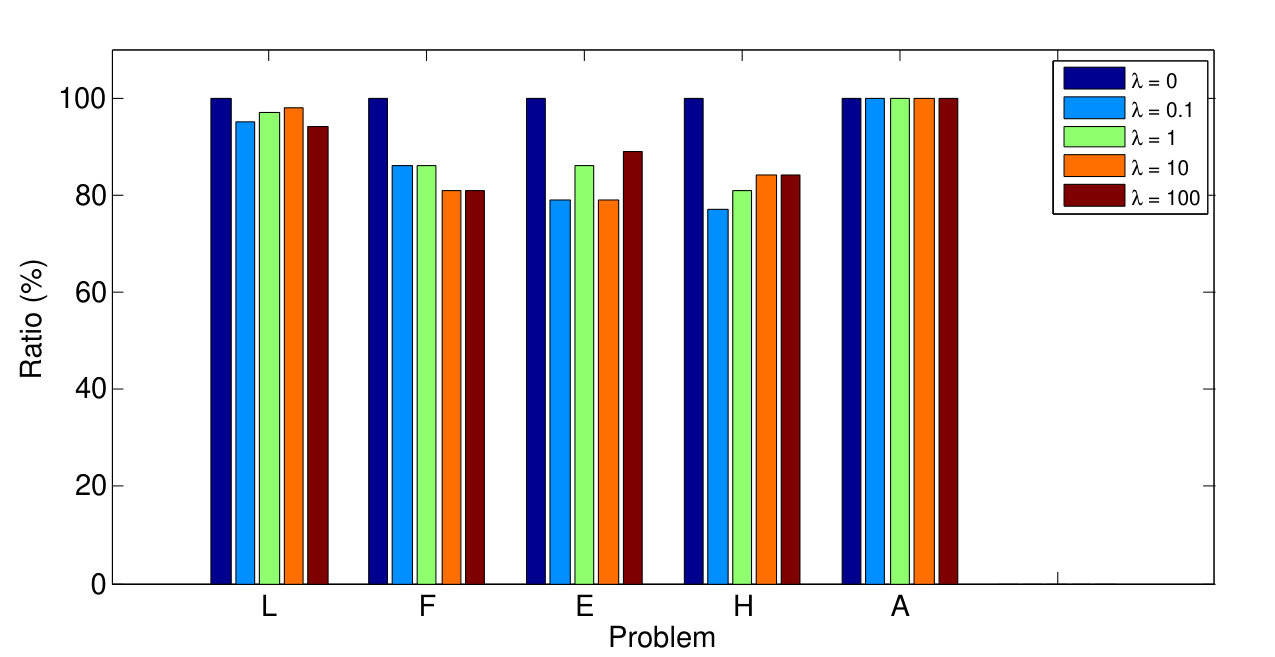 Figure 18
Figure 18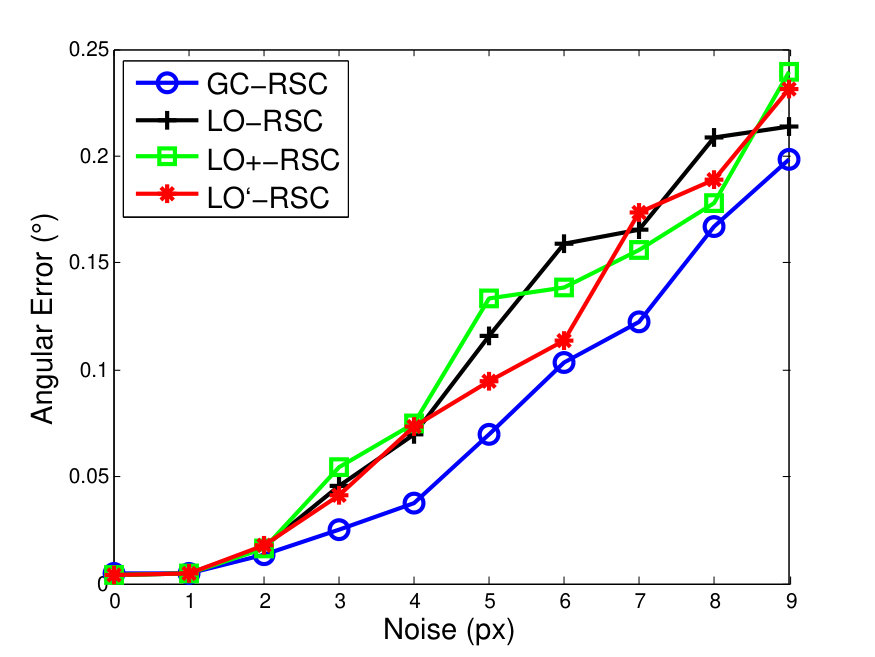 Figure 19
Figure 19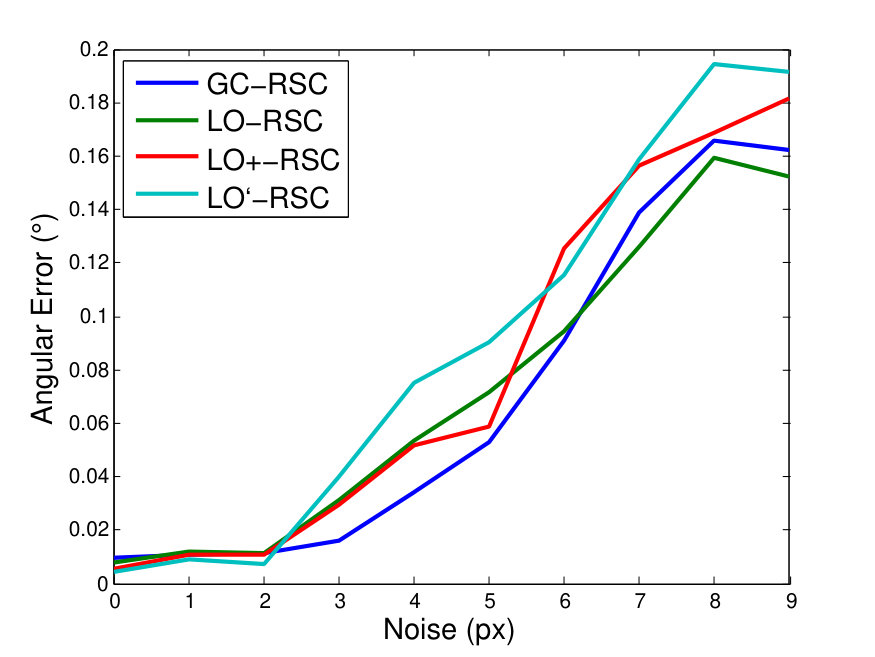 Figure 20
Figure 20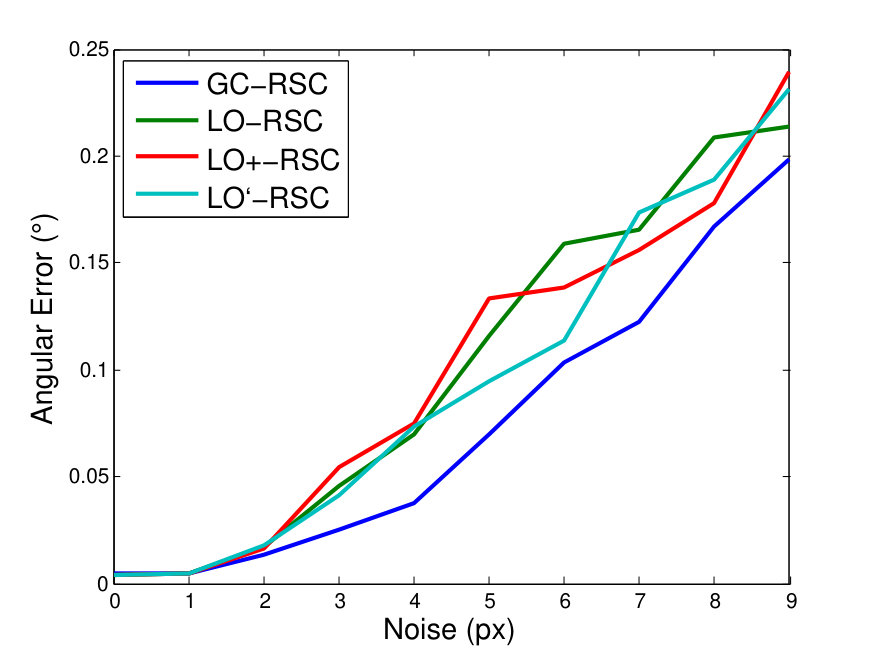 Figure 21
Figure 21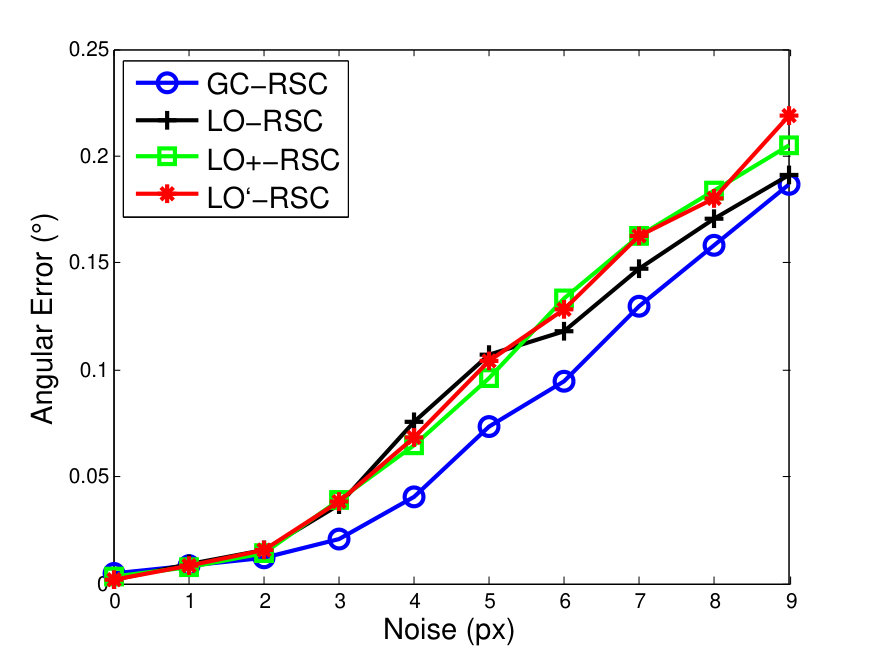 Figure 22
Figure 22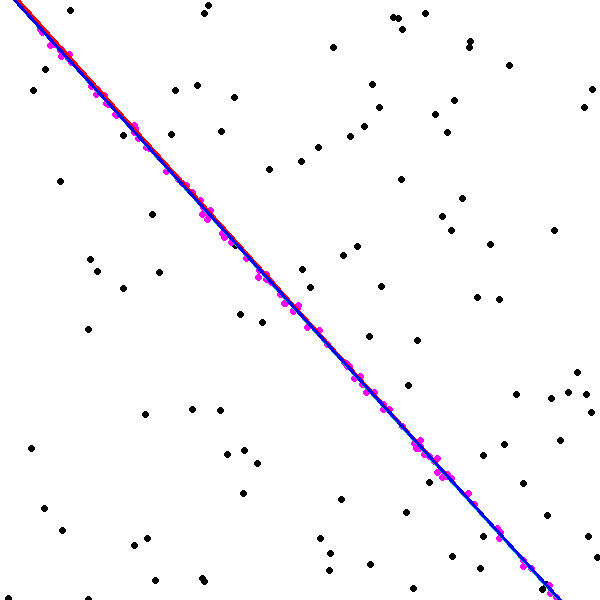 Figure 23
Figure 23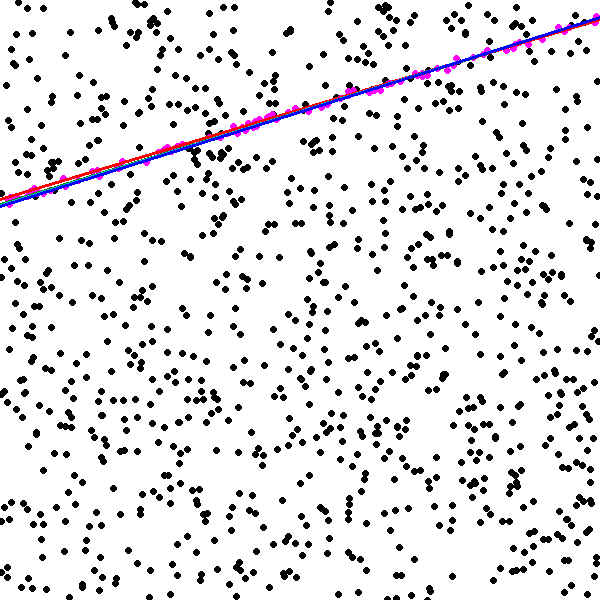 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26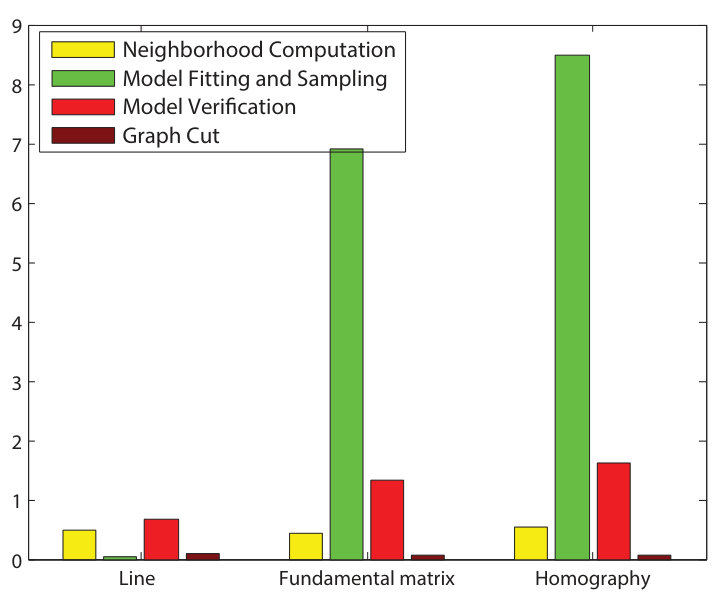 Figure 27
Figure 27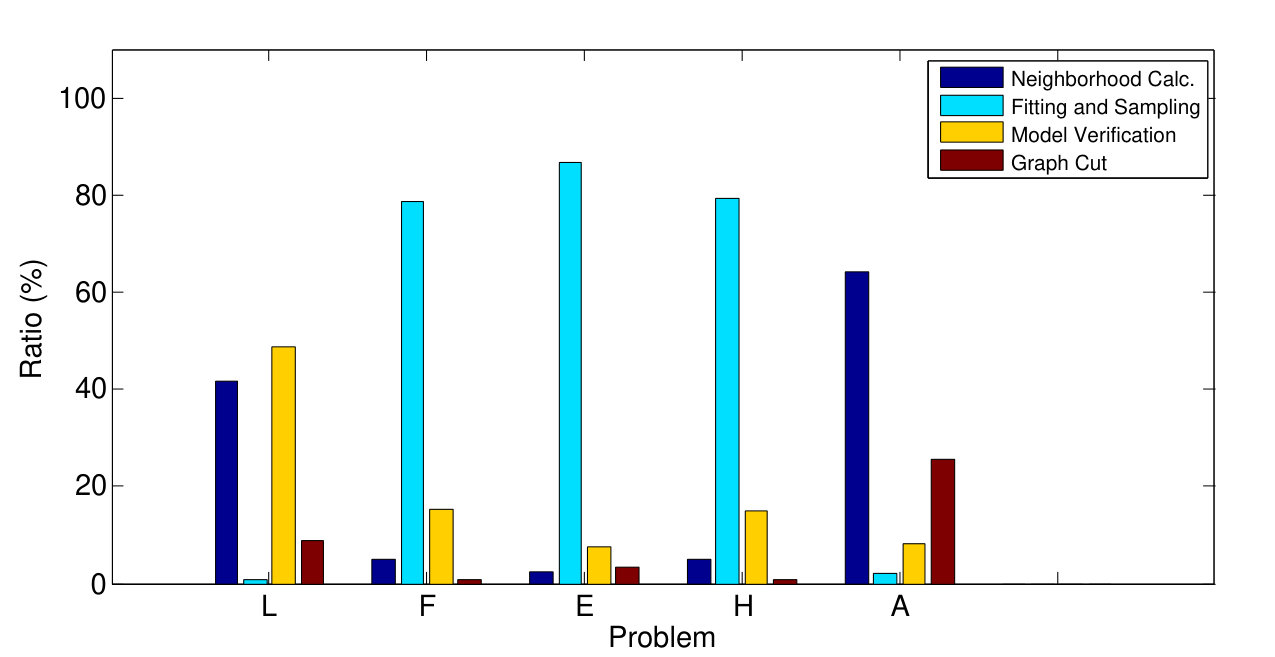 Figure 28
Figure 28 Figure 29
Figure 29| 0.31 | 20 px | 0.10 | 10 |
| LO | LO+ | LO’ | GC | |
|---|---|---|---|---|
| x6% | x5% | x4% | 15% | |
| 29% | 30% | 24% | 32% |
| Approx. 60 FPS (or 99% confidence) | Confidence 95% | ||||||||||||
| RSC | LO | LO+ | LO’ | GC | RSC | LO | LO+ | LO’ | EP-RSC | GC | |||
| kusvod2 | , | LO | – | 2 | 2 | 2 | 1 (3) | – | 1 | 1 | 1 | – | 2 (3) |
| 5.01 | 4.95 | 4.97 | 5.02 | 4.65 | 5.18 | 5.08 | 5.03 | 5.22 | 7.87 | 4.69 | |||
| xx6.2 | x6.1 | x6.3 | x5.9 | x4.6 | 4.9 | x5.2 | x5.1 | x4.9 | 439.9 | x3.6 | |||
| 117 | 96 | 99 | 111 | 70 | 93 | 76 | 78 | 87 | – | 53 | |||
| Adelaide | , | LO | – | 2 | 2 | 2 | 1 (3) | – | 2 | 2 | 3 | – | 2 (4) |
| 0.55 | 0.53 | 0.52 | 0.55 | 0.50 | 0.44 | 0.45 | 0.43 | 0.44 | 0.71 | 0.43 | |||
| 14.2 | 14.8 | 14.9 | 14.1 | 18.9 | 262.7 | 194.2 | 210.9 | 237.1 | 2 121.9 | 227.1 | |||
| 124 | 113 | 113 | 122 | 116 | 1 363 | 1 126 | 1 205 | 1 305.00 | – | 1 115 | |||
| Multi-H | , | LO | – | 1 | 1 | 1 | 1 (3) | – | 2 | 1 | 2 | – | 1 (3) |
| 0.35 | 0.34 | 0.34 | 0.34 | 0.32 | 0.33 | 0.33 | 0.33 | 0.34 | 0.44 | 0.32 | |||
| 10.3 | 11.5 | 11.1 | 10.3 | 14.6 | 12.8 | 15.1 | 14.1 | 12.4 | 2 371.8 | 36.0 | |||
| 83 | 76 | 76 | 82 | 74 | 107 | 89 | 90 | 100 | – | 78 | |||
| EVD | , | LO | – | 2 | 2 | 2 | 2 (2) | – | 4 | 4 | 4 | – | 3 (6) |
| 1.53 | 1.63 | 1.51 | 1.58 | 1.53 | 0.96 | 0.95 | 0.95 | 0.96 | 1.17 | 0.92 | |||
| 16.8 | 18.3 | 18.0 | 16.8 | 19.2 | 247.3 | 248.0 | 251.3 | 247.0 | 249.9 | ||||
| 320 | 298 | 301 | 318 | 301 | 4 303 | 4 203 | 4 248 | 4 291 | – | 4 204 | |||
| homogr | , | LO | – | 2 | 2 | 2 | 1 (3) | – | 2 | 2 | 2 | – | 1 (4) |
| 0.53 | 0.53 | 0.53 | 0.53 | 0.51 | 0.50 | 0.50 | 0.49 | 0.50 | 0.58 | 0.47 | |||
| 7.1 | 10.4 | 9.8 | 7.1 | 7.6 | 17.1 | 10.1 | 9.9 | 8.5 | 3 339.7 | 7.9 | |||
| 193 | 175 | 175 | 189 | 159 | 450 | 212 | 214 | 226 | – | 165 | |||
| strecha | , | LO | – | 1 | 1 | 1 | 1 (1) | – | 7 | 7 | 7 | – | 7 (7) |
| 11.81 | 12.34 | 12.07 | 12.12 | 11.6 | 3.03 | 2.95 | 2.94 | 2.87 | 3.32 | 2.83 | |||
| 11.6 | 17.3 | 17.2 | 17.2 | 17.3 | 3 581.9 | 3 638.5 | 3 648.4 | 3 570.0 | 3 466.4 | ||||
| 31 | 30 | 31 | 31 | 30 | 3 654 | 3 646 | 3 634 | 3 653 | – | 3 651 | |||
| SZTAKI | , | LO | – | 1 | 1 | 1 | 1 (3) | – | 1 | 1 | 1 | – | 1 (3) |
| 0.41 | 0.41 | 0.41 | 0.41 | 0.40 | 0.45 | 0.46 | 0.44 | 0.45 | 0.48 | 0.41 | |||
| 3.5 | 3.2 | 3.2 | 3.2 | 10.3 | 1.7 | 1.7 | 1.7 | 1.7 | 4 718.2 | 10.2 | |||
| 26 | 26 | 26 | 26 | 26 | 9 | 9 | 9 | 9 | – | 9 | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSparse and Compressive Sensing Techniques · Advanced Neural Network Applications · Advanced Image and Video Retrieval Techniques
Graph-Cut RANSAC
Daniel Barath
Machine Perception Research Laboratory
MTA SZTAKI, Budapest, Hungary
Jiri Matas
Centre for Machine Perception, Department of Cybernetics
Czech Technical University, Prague, Czech Republic
Abstract
A novel method for robust estimation, called Graph-Cut RANSAC111Available at https://github.com/danini/graph-cut-ransac, GC-RANSAC in short, is introduced. To separate inliers and outliers, it runs the graph-cut algorithm in the local optimization (LO) step which is applied when a so-far-the-best model is found. The proposed LO step is conceptually simple, easy to implement, globally optimal and efficient. GC-RANSAC is shown experimentally, both on synthesized tests and real image pairs, to be more geometrically accurate than state-of-the-art methods on a range of problems, e.g. line fitting, homography, affine transformation, fundamental and essential matrix estimation. It runs in real-time for many problems at a speed approximately equal to that of the less accurate alternatives (in milliseconds on standard CPU).
1 Introduction
The RANSAC (RANdom SAmple Consensus) algorithm proposed by Fischler and Bolles [7] in 1981 has become the most widely used robust estimator in computer vision. RANSAC and similar hypothesize-and-verify approaches have been successfully applied to many vision tasks, e.g. to short baseline stereo [27, 29], wide baseline stereo matching [22, 17, 18], motion segmentation [27], image mosaicing [9], detection of geometric primitives [25], multi-model fitting [31], or for initialization of multi-model fitting algorithms [12, 21]. In brief, the RANSAC approach repeatedly selects random subsets of the input data and fits a model, e.g. a line to two points or a fundamental matrix to seven point correspondences. In the second step, the model support, i.e. the number of inliers, is obtained. The model with the highest support, polished e.g. by a least squares fit on inliers, is returned.
In the last three decades, many modifications of RANSAC have been proposed. For instance, NAPSAC [20], PROSAC [4] or EVSAC [8] modify the sampling strategy to increase the probability of selecting an all-inlier sample earlier. NAPSAC considers spatial coherence in the sampling of input data points, PROSAC exploits the ordering of the points by their predicted inlier probability, EVSAC uses an estimate of the confidence in each point. Modifications of the model support step has also been proposed. In MLESAC [28] and MSAC [10], the model quality is estimated by a maximum likelihood process, albeit under certain assumptions, with all its beneficial properties. In practice, MLESAC results are often superior to the inlier counting of plain RANSAC and less sensitive to the user-defined threshold. The termination of RANSAC is controlled by a manually set confidence value and the sampling stops when the probability of finding a model with higher support falls below 222This interpretation of holds for the standard cost function only..
Observing that RANSAC requires in practice more samples than theory predicts, Chum et al. [5] identified a problem that not all all-inlier samples are “good”, i.e. lead to a model accurate enough to distinguish all inliers, e.g. due to poor conditioning of the selected random all-inlier sample. They address the problem by introducing the locally optimized RANSAC (LO-RANSAC) that augments the original approach with a local optimization step applied to the so-far-the-best model. In the original paper [5], local optimization is implemented as an iterated least squares re-fitting with a shrinking inlier-outlier threshold inside an inner RANSAC applied only to the inliers of the current model. In the reported experiments, LO-RANSAC outperforms standard RANSAC in both accuracy and the required number of iterations. The number of LO runs is close to the logarithm of the number of verifications, and it does not create a significant overhead in the processing time in most of the cases tested. However, it was shown by Lebeda et al. [15] that for models with high inlier counts the local optimization step becomes a computational bottleneck due to the iterated least squares model fitting. This is addressed by using a -sized subset of the inliers in each LO step, where is the size of a minimum sample; the factor of was set by exhaustive experimentation. The idea of local optimization has been included in state-of-the-art RANSAC approaches like USAC [23]. Nevertheless, the LO procedure remains ad hoc, complex and requires multiple parameters.
In this paper, we combine two strands of research to obtain a state-of-the-art RANSAC. In the large body of RANSAC-related literature, the inlier-outlier decision has always been a function of the distance to the model, done individually for each data point. Yet both inliers and outliers are spatially coherent, a point near an outlier or inlier is more likely to be an outlier or inlier respectively. Spatial coherence, leading to the Potts model [3], has been exploited in many vision problems, for instance, in segmentation [30], multi-model fitting [12, 21] or sampling [20]. In RANSAC techniques, it has only been used to improve efficiency of sampling in NAPSAC [20]. It is computationally prohibitive to formulate the model verification in RANSAC as a graph-cut problem. But when applied as the LO step in [5] just to the so-far-the-best model, the number of graph-cuts is only the logarithm of the number of sampled and verified models, and can be achieved in real-time.
The proposed method, called Graph-Cut RANSAC (GC-RANSAC), is a locally optimized RANSAC alternating graph-cut and model re-fitting as the LO step. GC-RANSAC is superior to LO-RANSAC in a number of aspects. First, it is capable of exploiting spatial coherence of inliers and outliers. The LO step is conceptually a simple, easy to implement, globally optimal and computationally efficient graph-cut with only a few intuitive and learnable parameters unlike the ad hoc, iterative and complex LO steps [5]. Third, we show experimentally that GC-RANSAC outperforms LO-RANSAC and its recent variants in both accuracy and the required number of iterations on a wide range of publicly available datasets. On many problems, it is faster than the competitors in terms of the wall-clock time. Finally, we were surprised to observe that GC-RANSAC terminates before the theoretically expected number of iterations. The reason is that the local optimization that takes spatial proximity into account is often capable of converging to a “good” model even when starting from a sample that is not all-inlier, i.e. it contains outliers.
PEARL [12] introduced pair-wise energy to geometric model fitting. However, it cannot be used for problems solved by RANSAC – in PEARL, the user has to manually set the number of hypotheses tested to the worst-case, i.e. corresponding to the lowest inlier ratio possible. The -expansion step just in the first iteration of PEARL executes a graph-cut as many times as the number of hypotheses tested. The number is calculated from the worst-case scenario and is typically orders of magnitude higher than the number of iterations determined by the RANSAC adaptive termination criterion. Moreover, in GC-RANSAC, applying the local optimization to only the so-far-the-best models ensures that the graph-cut is executed only very few times, paying only a small penalty.
2 Local Optimization and Spatial Coherence
In this section, we formulate the inlier selection of RANSAC as an energy minimization considering point-to-point proximity. The proposed local optimization is seen as an iterative energy minimization of a binary labeling (outlier – 0 and inlier – 1). For the sake of simplicity, we start from the original RANSAC scheme and then formulate the maximum likelihood estimation as an energy minimization. The term considering the spatial coherence will be included into the energy.
2.1 Formulation as Energy Minimization
Suppose that a point set (), a model represented by a parameter vector () and a distance function measuring the point-to-model assignment cost are given.
For the standard RANSAC scheme which applies a top-hat fitness function ( – close, [math] – far), the implied unary energy is as follows:
[TABLE]
where
[TABLE]
Parameter is a labeling, ignored in standard RANSAC, is the label of point , is the number of points, and is the inlier-outlier threshold. Using energy we get the same result as RANSAC since it does not penalize only two cases: (i) when is labeled inlier and it is closer to the model than the threshold, or (ii) when is labeled outlier and it is farer from the model than . This is exactly what RANSAC does.
Since the publication of RANSAC, several papers discussed, e.g. [15], replacing the loss with a kernel function , e.g. the Gaussian-kernel. Such choice is close to maximum likelihood estimation as proposed in MLESAC [28]. This improves the accuracy and reduces the sensitivity to threshold . Unary term exploiting this continuous loss is as follows: where
[TABLE]
and
[TABLE]
which equals to one if the distance is zero. In GC-RANSAC, we use as the unary energy term in the graph-cut-based verification.
2.2 Spatial Coherence
Benefiting from a binary labeling energy minimization, additional energy terms, e.g. to consider spatial coherence of the points, can be included yet keep the problem solvable efficiently and globally via the graph-cut algorithm.
Considering point proximity is a well-known approach for sampling [20] or multi-model fitting [12, 21, 1]. To the best of our knowledge, there is no paper exploiting it in the local optimization step of methods like LO-RANSAC. Applying the Potts model which penalizes all neighbors having different labels would be a justifiable choice to be the pair-wise energy term. The problem arises when the data contains significantly more outliers, probably close to desired model, than inliers. In that case, penalizing differently labeled neighbors using the same penalty for all classes many times leads to the domination of outliers forcing all inliers to be labeled outlier. To overcome this problem, we modified the Potts model to use different penalty for each neighboring point pair on the basis of their inlier probability. The proposed pair-wise energy term is
[TABLE]
where , and is an edge of neighborhood graph between points and . In , if both points labeled outlier the penalty is thus “rewarding” label [math] if the neighboring points are far from the model. The penalty of considering a point as inlier is which rewards the label if the points are close to the model.
The proposed overall energy measuring the fitness of points to a model and considering spatial coherence is , where is a parameter balancing the terms. The globally optimal labeling can easily be determined in polynomial time using graph-cut algorithm.
3 GC-RANSAC
In this section, we include the proposed energy minimization-based local optimization into RANSAC. Benefiting from this approach, the LO step is getting simpler and cleaner than that of LO-RANSAC.
The main algorithm is shown in Alg.1. The first step is the determination of neighborhood graph for which we use a sphere with a predefined radius – this is a parameter of the algorithm – and Fast Approximate Nearest Neighbors algorithm [19]. In Alg. 1, function is as follows [7]:
[TABLE]
where It calculates the required iteration number of RANSAC on the basis of desired probability , the size of the required minimal point set and the inlier number regarding to the current so-far-the-best model. Note that norm applied to the labeling counts the inliers.
Every th iteration draws a minimal sample using a sampling strategy, e.g. PROSAC [4], then computes the parameters of the implied model and its support
[TABLE]
w.r.t. the data points, where function is a Gaussian-kernel as proposed in Eq. 2. If is higher than that of the so-far-the-best model , this model is considered the new so-far-the-best, all parameters are updated, i.e. the labeling, model parameters and support, and local optimization is applied if needed. Note that the application criterion of the local optimization step is discussed later.
The proposed local optimization is written in Alg. 2. The main iteration can be considered as a grab-cut-like [24] alternation consisting of two major steps: (i) graph-cut and (ii) model re-fitting. The construction of problem graph using unary and pair-wise terms Eqs. 1, 3 is shown in Alg. 3. Functions AddTerm1 and AddTerm2 are discussed in [13] in depth. Graph-cut is applied to determining the optimal labeling which considers the spatial coherence of the points and their distances from the so-far-the-best model. Model parameters are computed using a -sized random subset of the inliers in , thus speeding up the process, similarly to [15] does, where is the size of a minimal sample, e.g. for lines. Note that is set by exhaustive experimentation in [15] and this value also suited for us. Finally, the support of is computed and the so-far-the-best model is updated if the new one has higher support, otherwise the process terminates. After the main algorithm, a local optimization step is performed if it has not been yet applied to the obtained so-far-the-best model. Then the model parameters are re-estimated using the whole inlier set similarly to plain RANSAC does.
Remark: Adding to the local optimization step a RANSAC-like procedure selecting -size samples is straightforward. In our experiments, it had a high computational overhead without adding significantly to accuracy.
The criterion for applying the LO step was proposed to be: (i) the model is so-far-the-best and (ii) after a user-defined iteration limit, in [15]. However, in our experiments, this approach still spends significant time on optimizing models which are not promising enough. We introduce a simple heuristics for replacing the iteration limit with a data driven strategy which allows to apply LO only a few times without deterioration in accuracy.
As it is well-known for RANSAC, the required iteration number , w.r.t. the inlier ratio , sample size and confidence , is calculated as . Re-arranging this formula to leads to equation which determines the confidence of finding the desired model in the th iteration if the inlier ratio is .
Suppose that the algorithm finds a new so-far-the-best model with inlier ratio in the th iteration, whilst the previous best model was found in the th iteration with inlier ratio (, ). The ratio of the confidences in those two models is calculated as follows:
[TABLE]
In experiments, we observed that a model that leads to termination if optimized often shows a significant increase in the confidence. Replacing the parameter blocking LO in the first iterations, we adopt a criterion , where is a user-defined parameter determining a significant increase.
4 Experimental Results
In this section, GC-RANSAC is validated both on synthesized and publicly available real world data and compared with plain RANSAC [7], LO-RANSAC [5], LO+-RANSAC, LO’-RANSAC [15], and EP-RANSAC [14]. The parameter setting is reported in Table 1. For EP-RANSAC333The Matlab source is available at http://cs.adelaide.edu.au/~huu/publication/exact_penalty/, we tuned the threshold parameter to achieve the lowest mean error and the other parameters were set to the values reported by the authors. Note that the comparison of the processing time with this method is affected by the availability of a Matlab implementation only. All methods apply PROSAC [4] sampling and encapsulates the point-to-model distance, e.g. re-projection error for homographies, with a Gaussian-kernel using , which is set by an exhaustive search. EP-RANSAC uses inlier maximization strategy since its cost function cannot be replaced straightforwardly. The radius of the sphere to determine neighboring points is pixels and it is applied to the concatenated coordinates of the correspondences. Parameter for GC-RANSAC was set to and .
Synthetic Tests on 2D Lines.
To compare GC-RANSAC with the state-of-the-art in a fully controlled environment, we chose two simple tests: detection of a 2D straight or dashed line. For each trial, a window and a random line was generated in its implicit form, sampled at locations and zero-mean Gaussian-noise with standard deviation was added to the coordinates. For a straight line, the points were generated using uniform distribution (see Fig. 2(a)). For a dashed line, knots were put randomly into the window, then the line is sampled at locations with uniform distribution around each knot, at most pixels far (see Fig. 2(b)). Finally, outliers were added to the scene. tests were performed on every noise level.
Fig. 1 shows the mean angular error (in degrees) plotted as the function of the noise . The first and second rows report the results of the straight and dashed line cases. For the two columns, and outliers were added, respectively. According to Fig. 1, GC-RANSAC obtains more accurate lines than the competitor algorithms.
Estimation of Fundamental Matrix.
Evaluating the performance of GC-RANSAC on fundamental matrix estimation we used kusvod2 (24 pairs)444http://cmp.felk.cvut.cz/data/geometry2view/, Multi-H555http://web.eee.sztaki.hu/~dbarath/ (5 pairs), and AdelaideRMF666cs.adelaide.edu.au/~hwong/doku.php?id=data (19 pairs) datasets (see Fig. 3 for examples). Kusvod2 consists of 24 image pairs of different sizes with point correspondences and fundamental matrices estimated using manually selected inliers. AdelaideRMF and Multi-H consist a total of 24 image pairs with point correspondences, each assigned manually to a homography (or the outlier class). For them, all points which are assigned to a homography were considered as inliers and others as outliers. On total, the proposed method was tested on 48 image pairs from three publicly available datasets for fundamental matrix estimation. All methods applied the 7-point method [10] to estimate F, thus drawing minimal sets of size seven in each RANSAC iteration. For the model re-estimation from a non-minimal sample in the LO step, the normalized 8-point algorithm [11] is used. Note that all fundamental matrices were discarded for which the oriented epipolar constraint [6] did not hold.
The first three blocks of Table 3, each consisting of four rows, report the quality of the epipolar geometry estimation on each dataset as the average of 1000 runs on every image pair. The first two columns show the name of the tests and the investigated properties: (1) LO: the number of applied local optimization steps (graph-cut steps are shown in brackets). (2) is the geometric error (in pixels) of the obtained model w.r.t. the manually annotated inliers. For fundamental matrices and homographies, it is defined as the average Sampson distance and re-projection error, respectively. For essential matrices, it is the mean Sampson distance of the implied fundamental matrix and the correspondences. (3) is the mean processing time in milliseconds. (4) is the average number of minimal samples have to be drawn until convergence, basically, the number of RANSAC iterations.
It can be clearly seen that for fundamental matrix estimation GC-RANSAC always obtains the most accurate model using less samples than the competitive methods.
Estimation of Homography.
In order to test homography estimation we downloaded homogr777http://cmp.felk.cvut.cz/data/geometry2view/ (16 pairs) and EVD888http://cmp.felk.cvut.cz/wbs/ (15 pairs) datasets (see Fig. 3 for examples). Each consists of image pairs of different sizes from up to with point correspondences and manually selected inliers – correctly matched point pairs. Homogr dataset consists of short baseline stereo pairs, whilst the pairs of EVD undergo an extreme view change, i.e. wide baseline. All methods apply the normalized four-point algorithm [10] for homography estimation both in the model generation and local optimization steps. Therefore, each minimal sample consists of four correspondences.
The th and th blocks of Fig. 3 show the mean results computed using all the image pairs of each dataset. It can be seen that GC-RANSAC obtains the most accurate models for all but one, i.e. EVD dataset with time limit, test cases.
Estimation of Essential Matrix.
To estimate essential matrices, we used the strecha dataset [26] consisting of image sequences of buildings. All image sizes are . The ground truth projection matrices are provided. The methods were applied to all possible image pairs in each sequence. The SIFT detector [16] was used to obtain correspondences. For each image pair, a reference point set with ground truth inliers was obtained by calculating the fundamental matrix from the projection matrices [10]. Correspondences were considered as inliers if the symmetric epipolar distance was smaller than pixel. All image pairs with less than inliers found were discarded. In total, image pairs were used in the evaluation.
The results are reported in the th block of Table 3. The reason of the high processing time is that the mean inlier ratio is relatively low () and there are many correspondences, , on average. GC-RANSAC obtains the most accurate essential matrices both in the wall-clock time limited and solution confidence above experiments. A significant drop can be seen in accuracy for all methods if a time limit is given.
Estimation of Affine Transformation.
The SZTAKI Earth Observation dataset999http://mplab.sztaki.hu/remotesensing [2] ( image pairs of size ) was used to test estimation of affine transformations. The dataset contains images of busy road scenes taken from a balloon. Due to the altitude of the balloon, the image pair relation is well approximate by an affine transformation. Point correspondences were detected by the SIFT detector. For ground truth, inliers were selected manually. Point pairs with the distance from the ground truth affine transformation lower than pixel were defined as inliers.
The estimation results are shown in the th block of Table 3. The reported geometric error is , where A is the estimated affine transformation and is the point in the th image (). It can be seen that the methods obtained fairly similar results, however, GC-RANSAC is slightly more accurate. It is marginally slower due to the neighborhood computation. However, it is still faster than real time.
Convergence from a Not-All-Inlier Sample.
Table 2 reports the frequencies when a “not-all-inlier” sample led to the correct model. For lines (), it is computed using runs on each outlier (100, 500 and 1000) and noise level (from up to pixels). Thus runs were performed. A minimal sample is counted as a “not-all-inlier” if it contains at least one point farther from the ground truth model than the ground truth noise .
For fundamental matrices (), the frequencies of success from a “not-all-inlier” sample are computed as the mean of runs on all pairs of the AdelaideRMF dataset. In this dataset, all inliers are labeled manually, thus it is easy to check whether a sample point is inlier or not.
Evaluation of the setting.
To evaluate the effect of the parameter balancing the spatial coherence term, we applied GC-RANSAC to all problems with varying . The evaluated values are: (i) , which turns off the spatial coherence term, (ii) , (iii) , (iv) , and (v) . Fig. 4 a shows the ratio of the geometric errors for and (in percent). For all investigated non-zero values, the error is lower than for . Since led to the most accurate results on average, we chose this setting in the tests.
Evaluation of the criterion for the local optimization.
The proposed criterion (Eq. 6) ensuring that local optimization is applied only to the most promising model candidates is tested in this section. We applied GC-RANSAC to all problems combined with the proposed and the standard approaches. The standard technique sets an iteration limit (default value: ) and the LO procedure is afterwards applied to all models that are so far the best. Fig. 4 b reports the ratio of each property (processing time – dark blue, LO – light blue, and GC steps – yellow, geometric error – brown) of the proposed and standard approaches. The new criterion leads to significant improvement in the processing time with no deterioration in accuracy.
Processing Time.
Fig. 4 c shows the breakdown of the processing times of GC-RANSAC applied to each problem. The time demand of the neighborhood computation (dark blue) linearly depends on the point number. The light blue one is the time demand of the sampling and model fitting step, the yellow and brown bars show the model verification (support computation) and the proposed local optimization step, respectively. The sampling and model fitting part dominates the process.
5 Conclusion
GC-RANSAC was presented. It is more geometrically accurate than state-of-the-art methods. It runs in real-time for many problems at a speed approximately equal to the less accurate alternatives. It is much simpler to implement in a reproducible manner than any of the competitors (RANSAC’s with local optimization). Its local optimization step is globally optimal for the so-far-the-best model parameters. We also proposed a criterion for the application of the local optimization step. This criterion leads to a significant improvement in processing time with no deterioration in accuracy. GC-RANSAC can be easily inserted into USAC [23] and be combined with its ”bells and whistles“ like PROSAC sampling, degeneracy testing and fast evaluation with early termination.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] D. Barath, J. Matas, and L. Hajder. Multi-H: Efficient recovery of tangent planes in stereo images. In British Machine Vision Conference , 2016.
- 2[2] C. Benedek and T. Szirányi. Change detection in optical aerial images by a multilayer conditional mixed markov model. Transactions on Geoscience and Remote Sensing , 2009.
- 3[3] Y. Boykov, O. Veksler, and R. Zabih. Markov random fields with efficient approximations. In Computer Vision and Pattern Recognition . IEEE, 1998.
- 4[4] O. Chum and J. Matas. Matching with PROSAC-progressive sample consensus. In Computer Vision and Pattern Recognition . IEEE, 2005.
- 5[5] O. Chum, J. Matas, and J. Kittler. Locally optimized ransac. In Joint Pattern Recognition Symposium . Springer, 2003.
- 6[6] O. Chum, T. Werner, and J. Matas. Epipolar geometry estimation via RANSAC benefits from the oriented epipolar constraint. In International Conference on Pattern Recognition , 2004.
- 7[7] M. A. Fischler and R. C. Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM , 1981.
- 8[8] V. Fragoso, P. Sen, S. Rodriguez, and M. Turk. EVSAC: accelerating hypotheses generation by modeling matching scores with extreme value theory. In International Conference on Computer Vision , 2013.