Multiscale unfolding of real networks by geometric renormalization
Guillermo Garc\'ia-P\'erez, Mari\'an Bogu\~n\'a, M. \'Angeles Serrano

TL;DR
This paper introduces a geometric renormalization group for complex networks, revealing their multiscale structure and self-similarity, which enables better understanding, modeling, and navigation of large-scale networks.
Contribution
It develops a novel geometric renormalization method to analyze and unfold real networks across multiple scales, highlighting their self-similar properties and practical applications.
Findings
Real networks exhibit geometric scaling consistent with underlying models.
Multiscale unfolding reveals coexisting scales and their interactions.
The approach improves network modeling and navigation in hyperbolic space.
Abstract
Multiple scales coexist in complex networks. However, the small world property makes them strongly entangled. This turns the elucidation of length scales and symmetries a defiant challenge. Here, we define a geometric renormalization group for complex networks and use the technique to investigate networks as viewed at different scales. We find that real networks embedded in a hidden metric space show geometric scaling, in agreement with the renormalizability of the underlying geometric model. This allows us to unfold real scale-free networks in a self-similar multilayer shell which unveils the coexisting scales and their interplay. The multiscale unfolding offers a basis for a new approach to explore critical phenomena and universality in complex networks, and affords us immediate practical applications, like high-fidelity smaller-scale replicas of large networks and a multiscale…
Click any figure to enlarge with its caption.
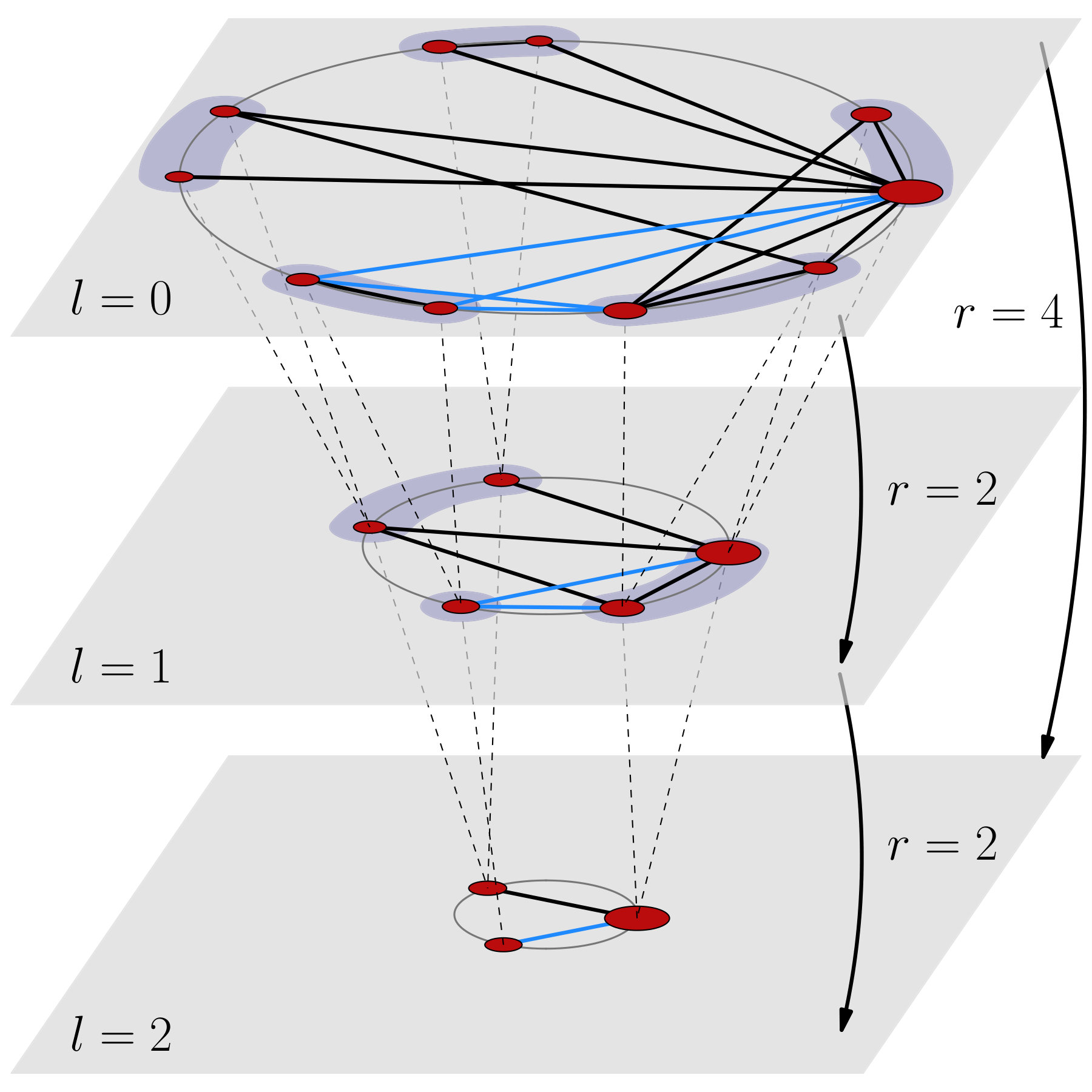 Figure 1
Figure 1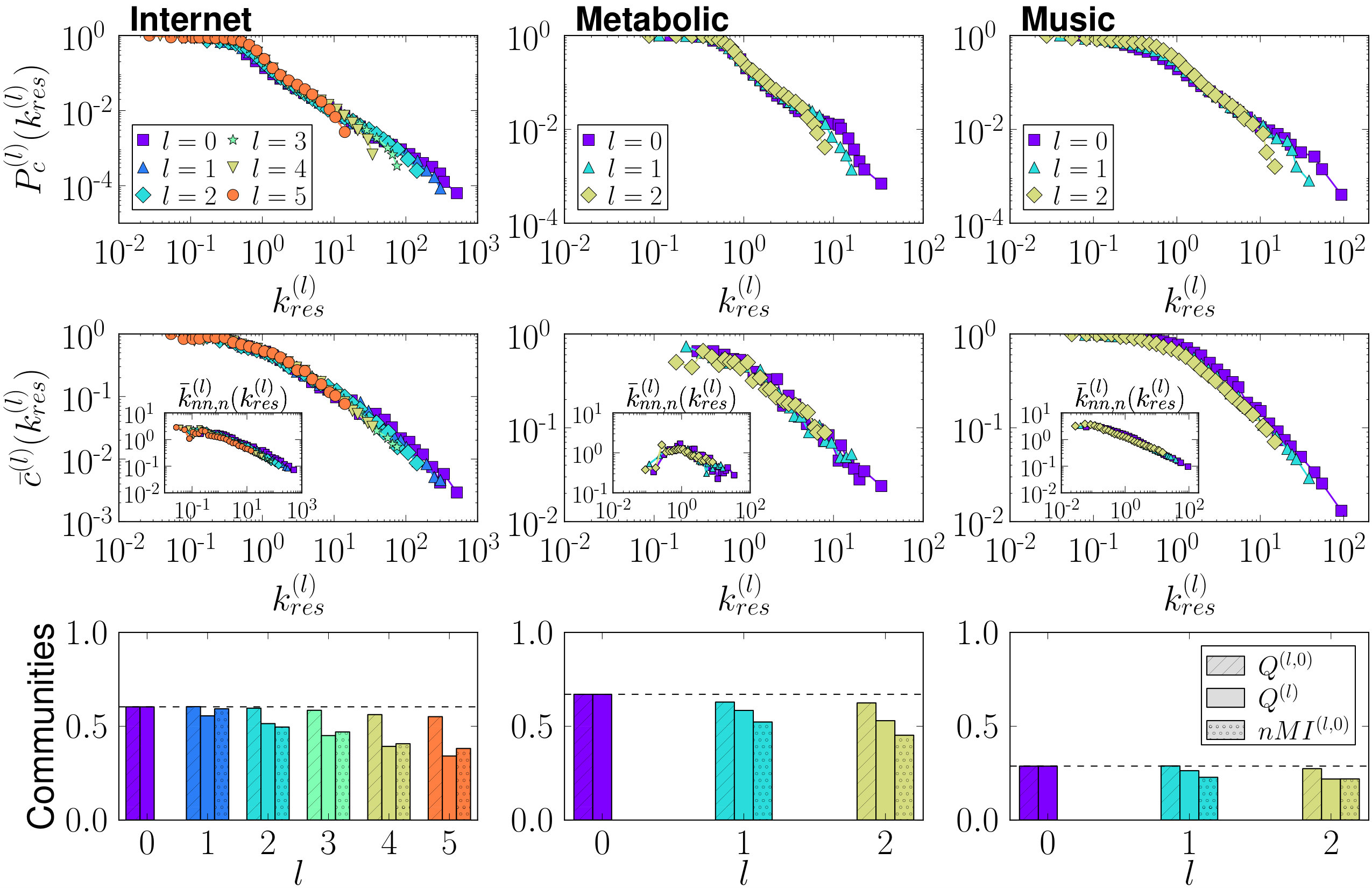 Figure 2
Figure 2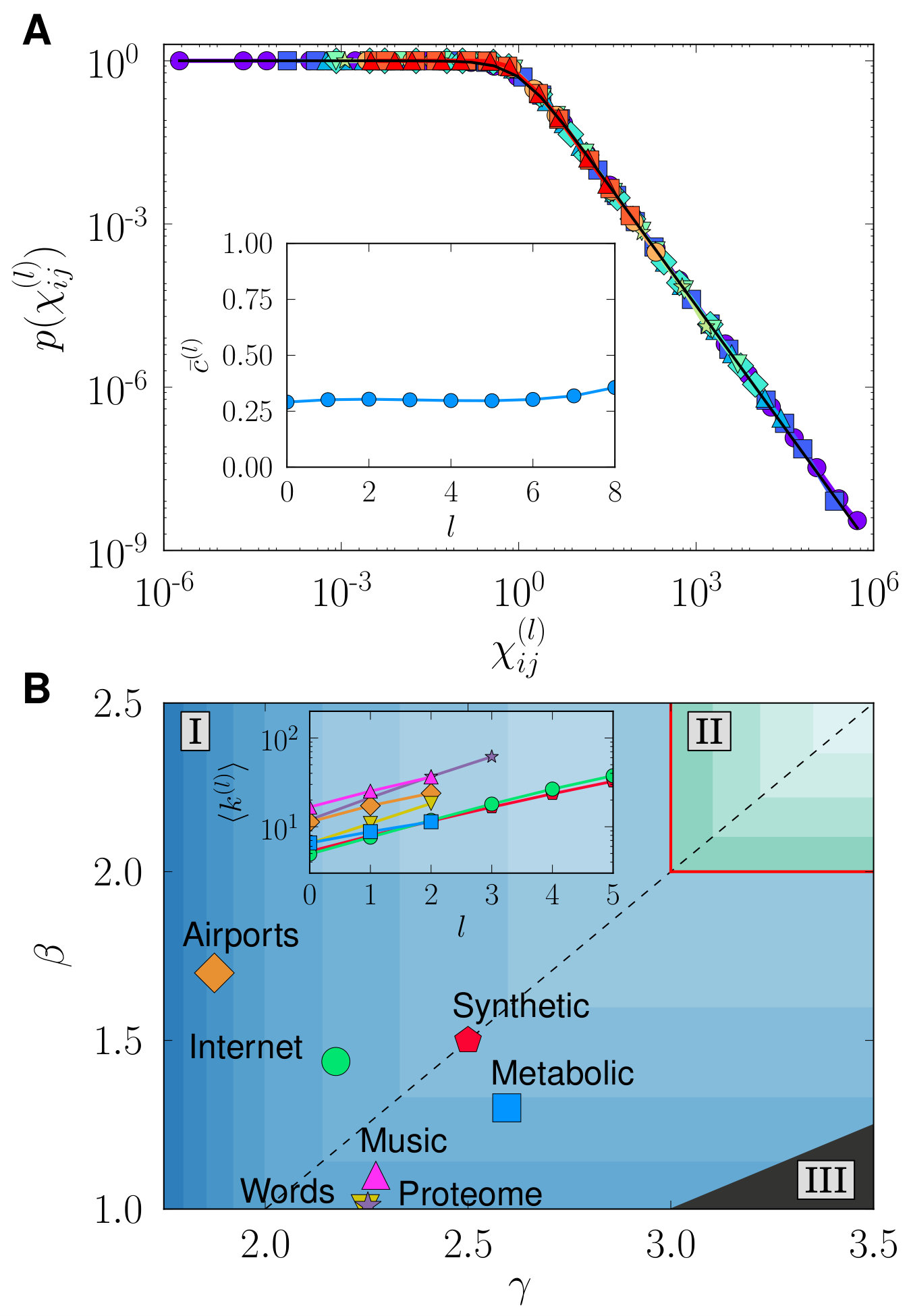 Figure 3
Figure 3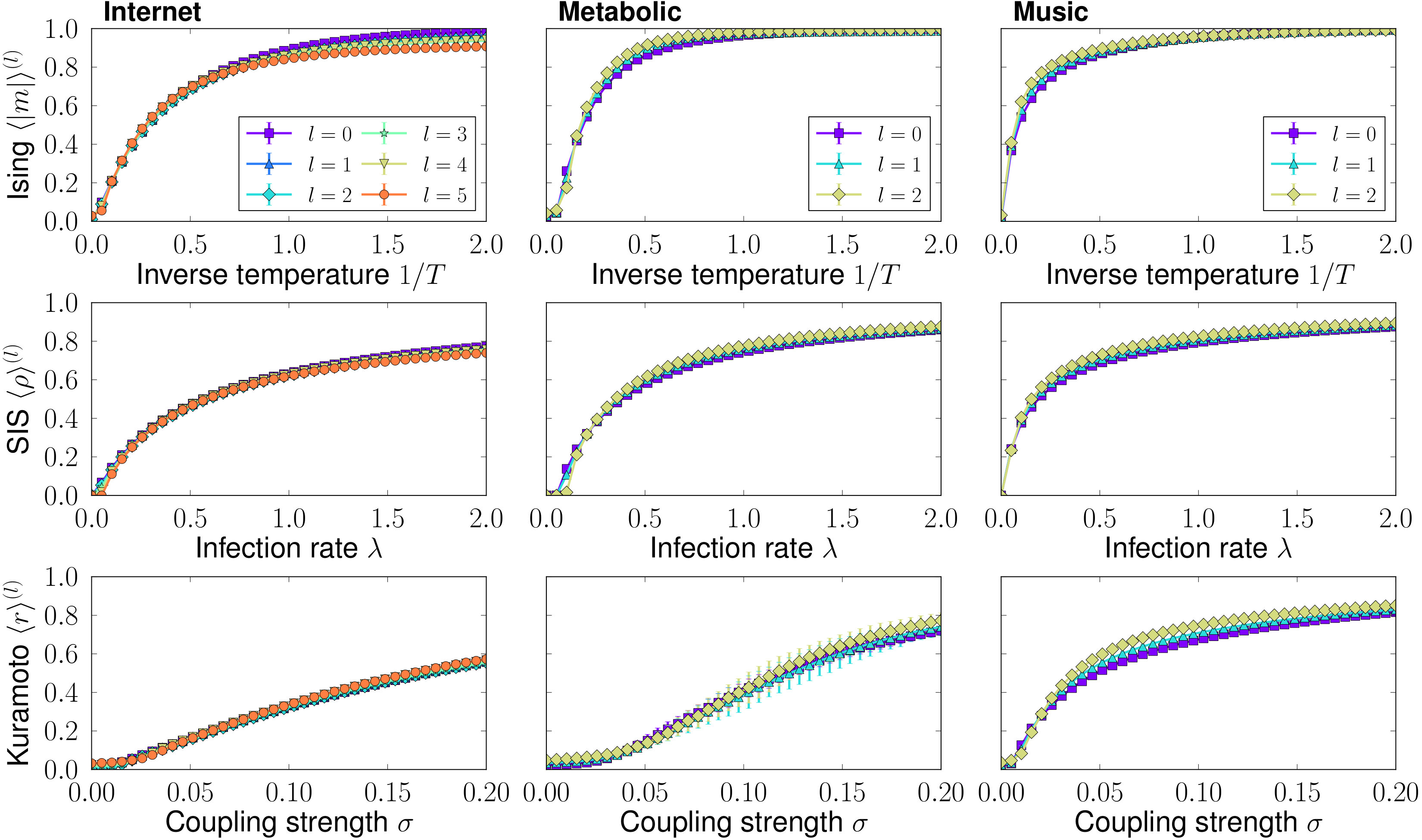 Figure 4
Figure 4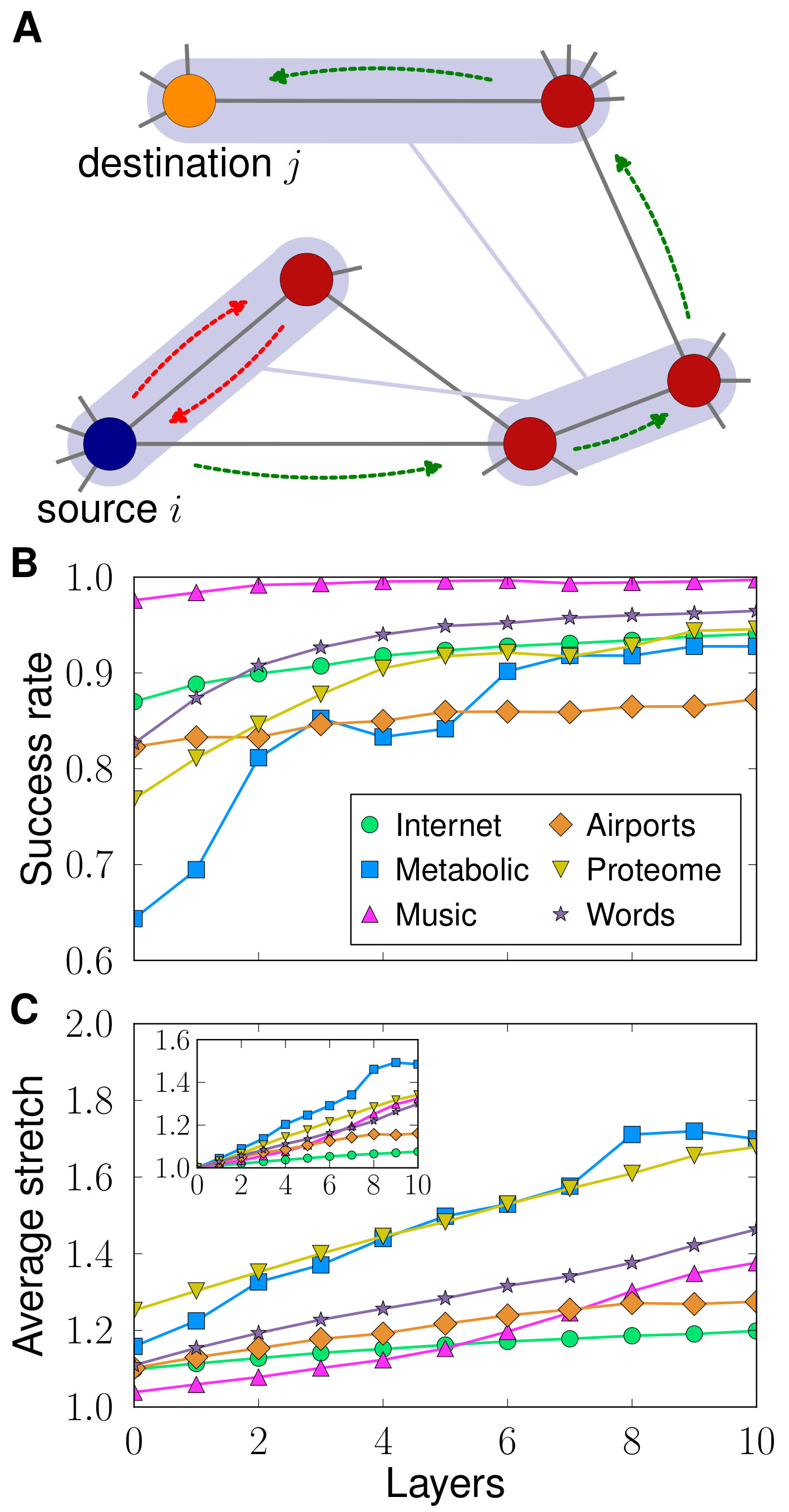 Figure 5
Figure 5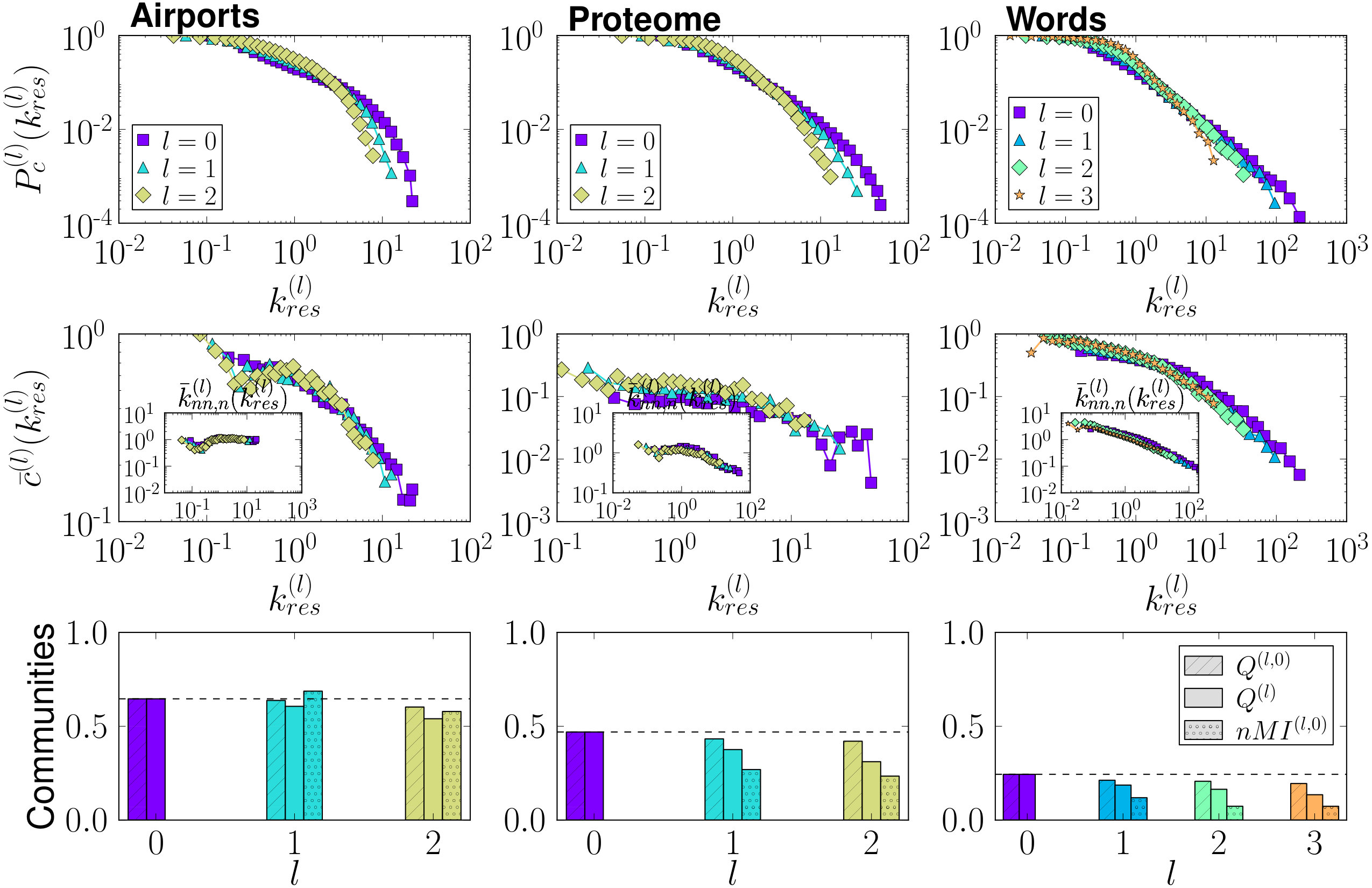 Figure 6
Figure 6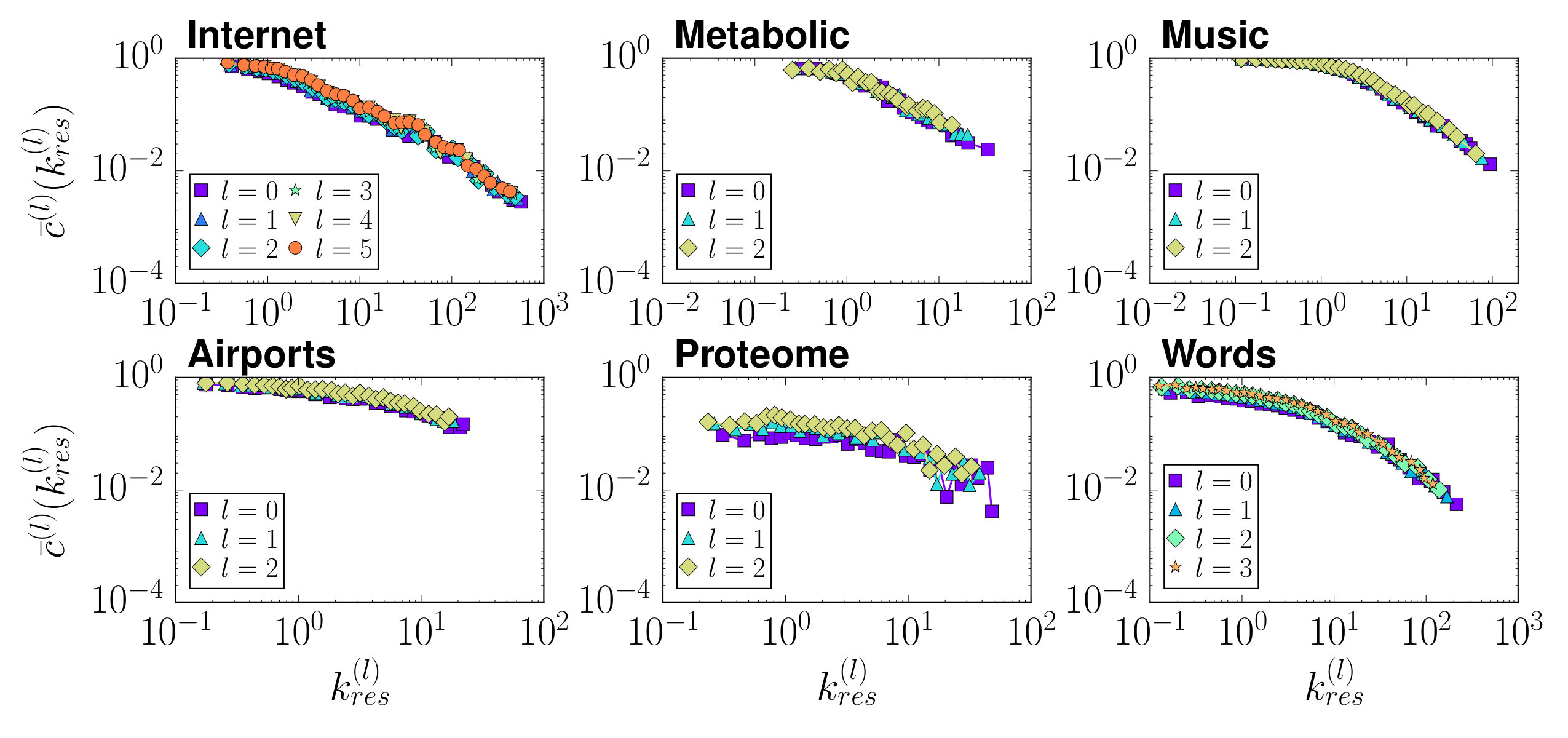 Figure 7
Figure 7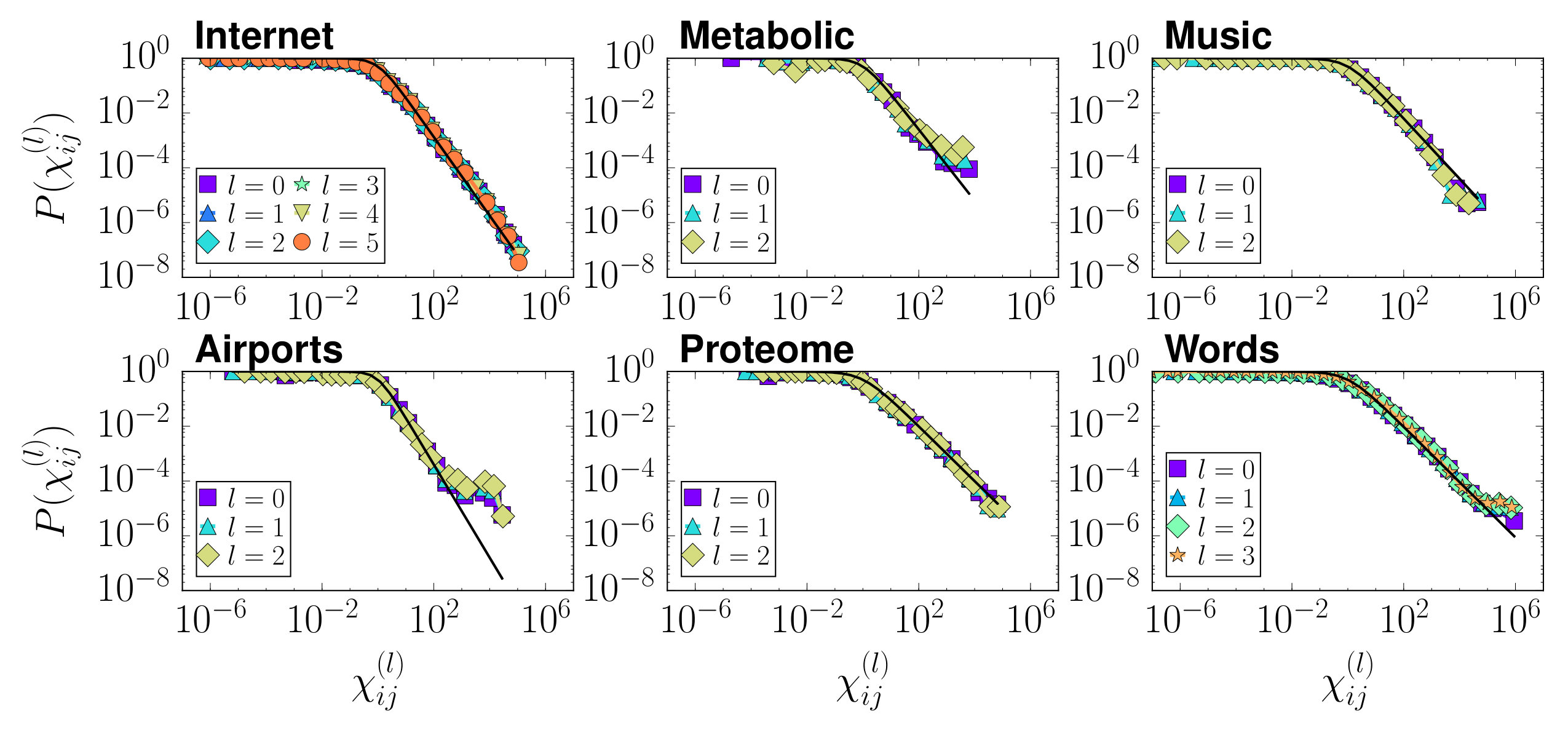 Figure 8
Figure 8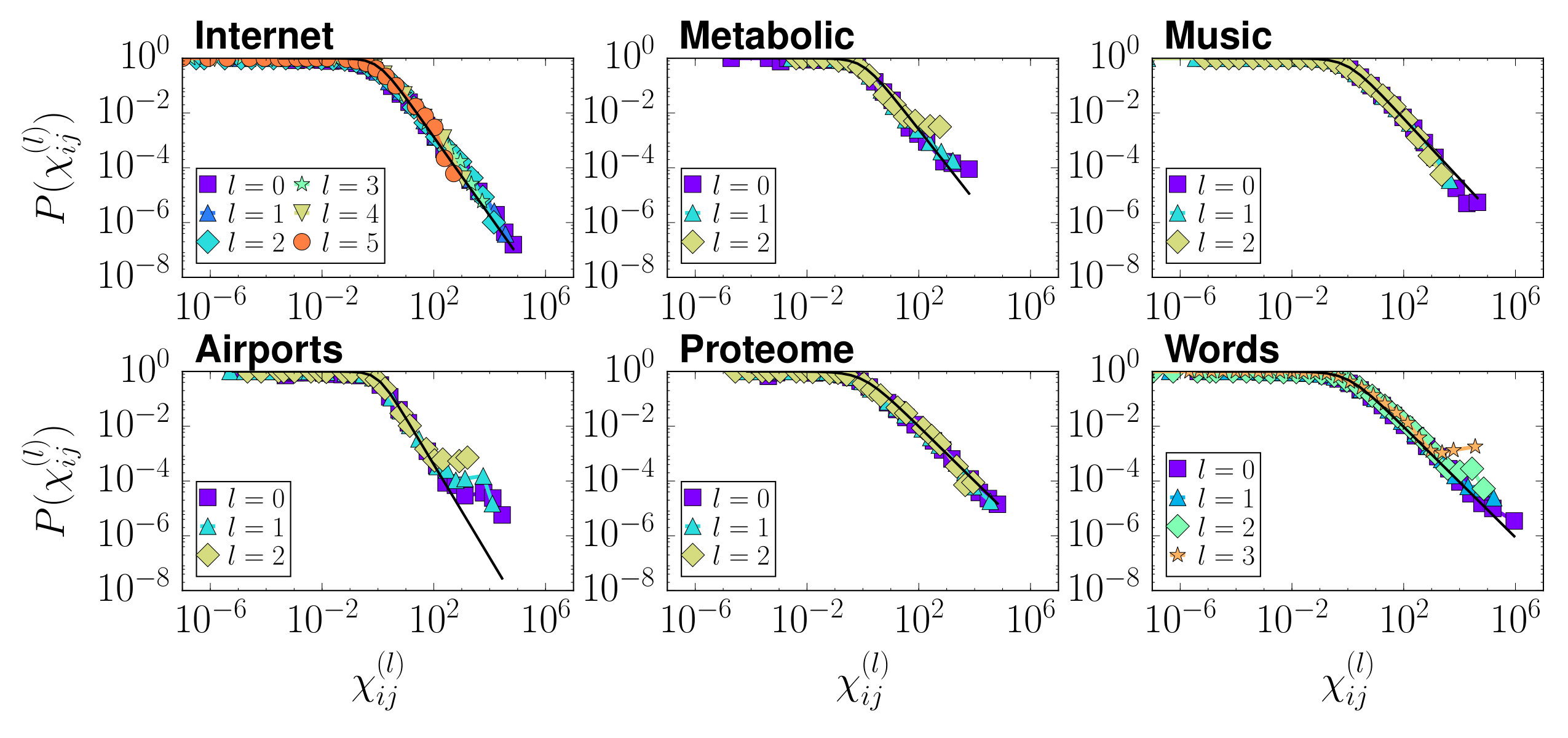 Figure 9
Figure 9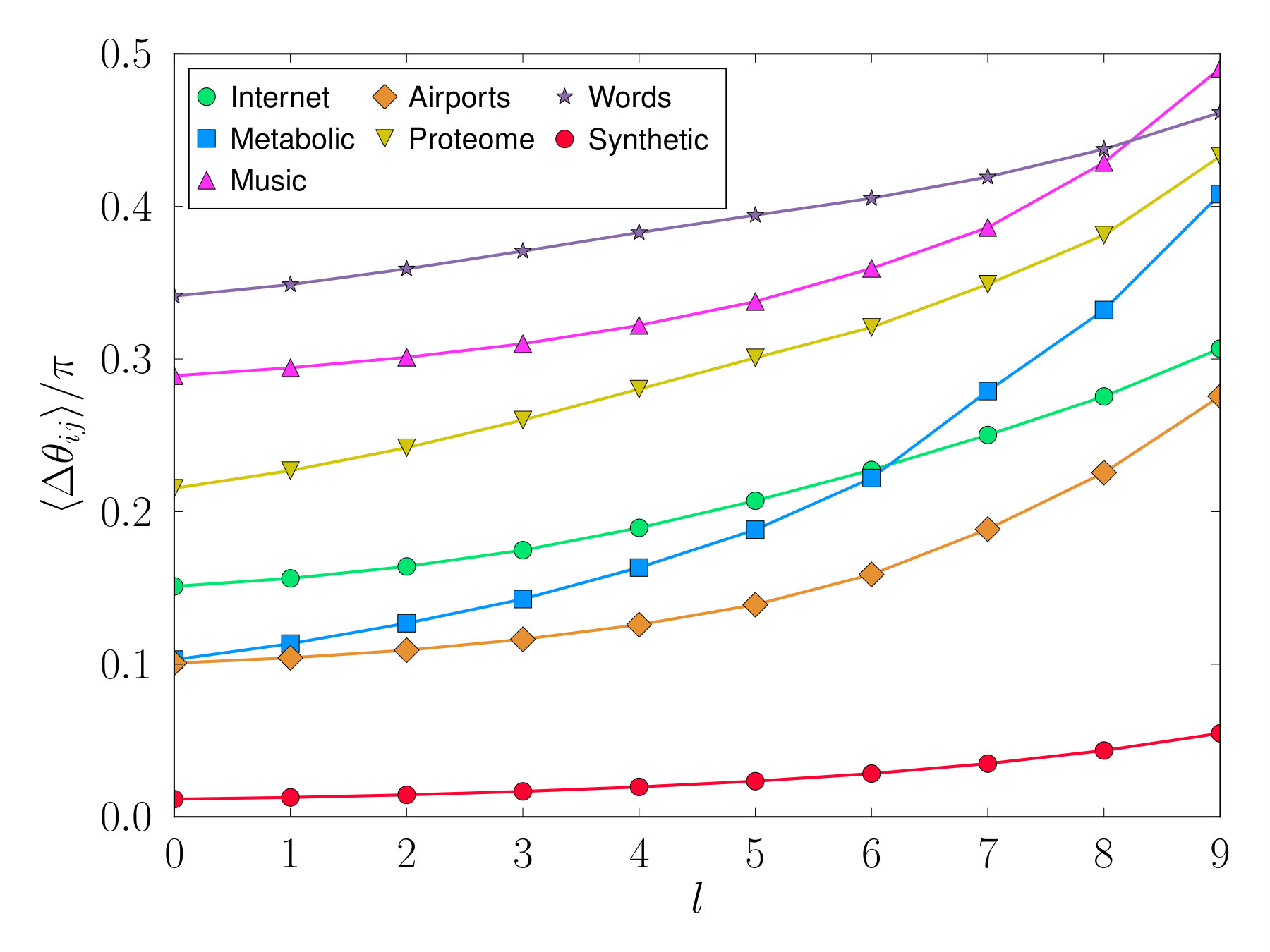 Figure 10
Figure 10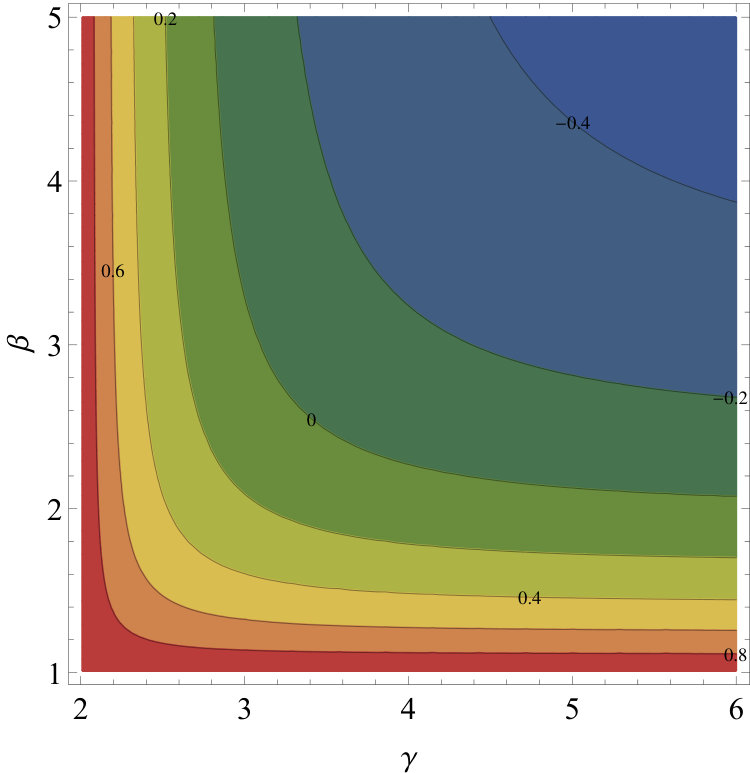 Figure 11
Figure 11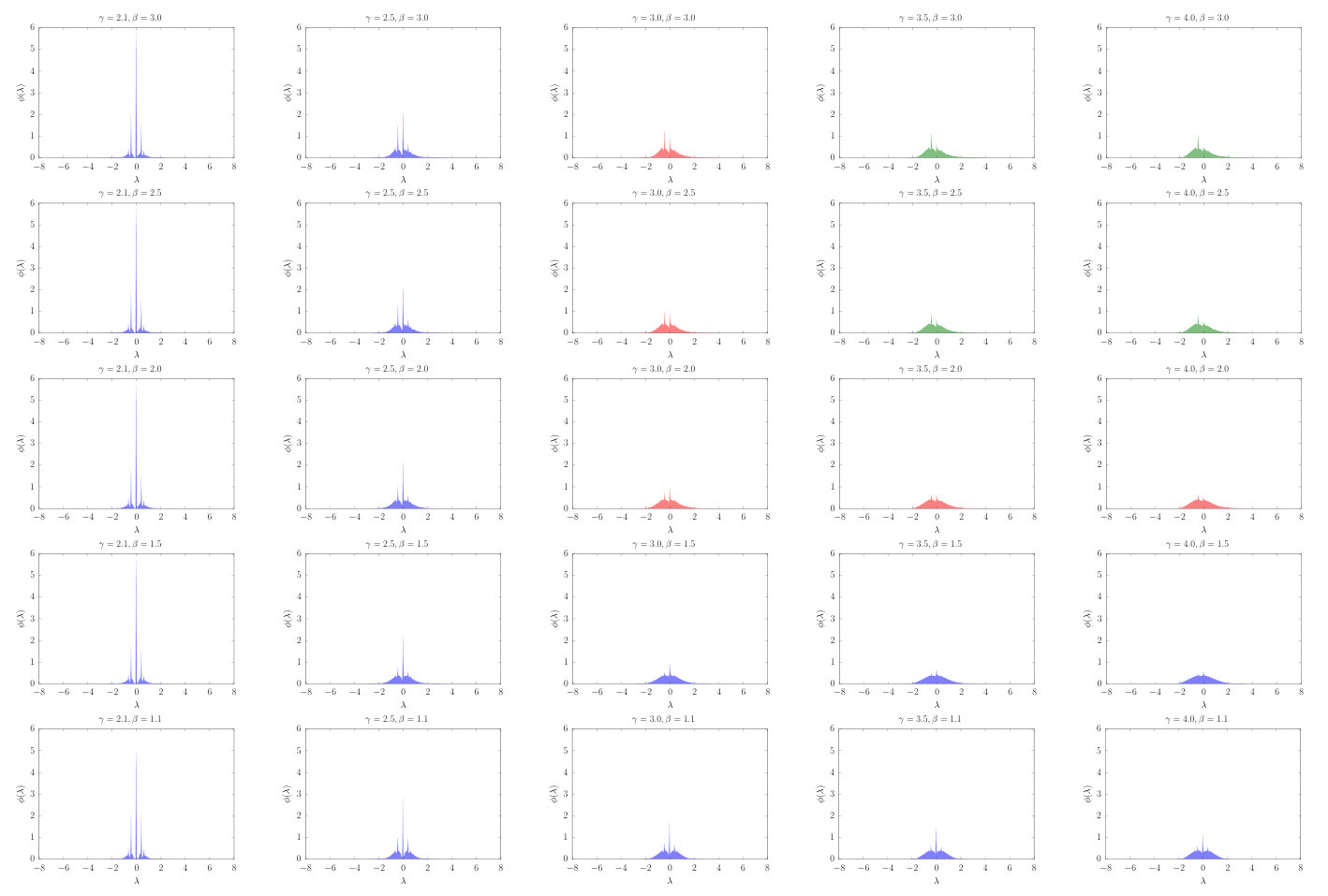 Figure 12
Figure 12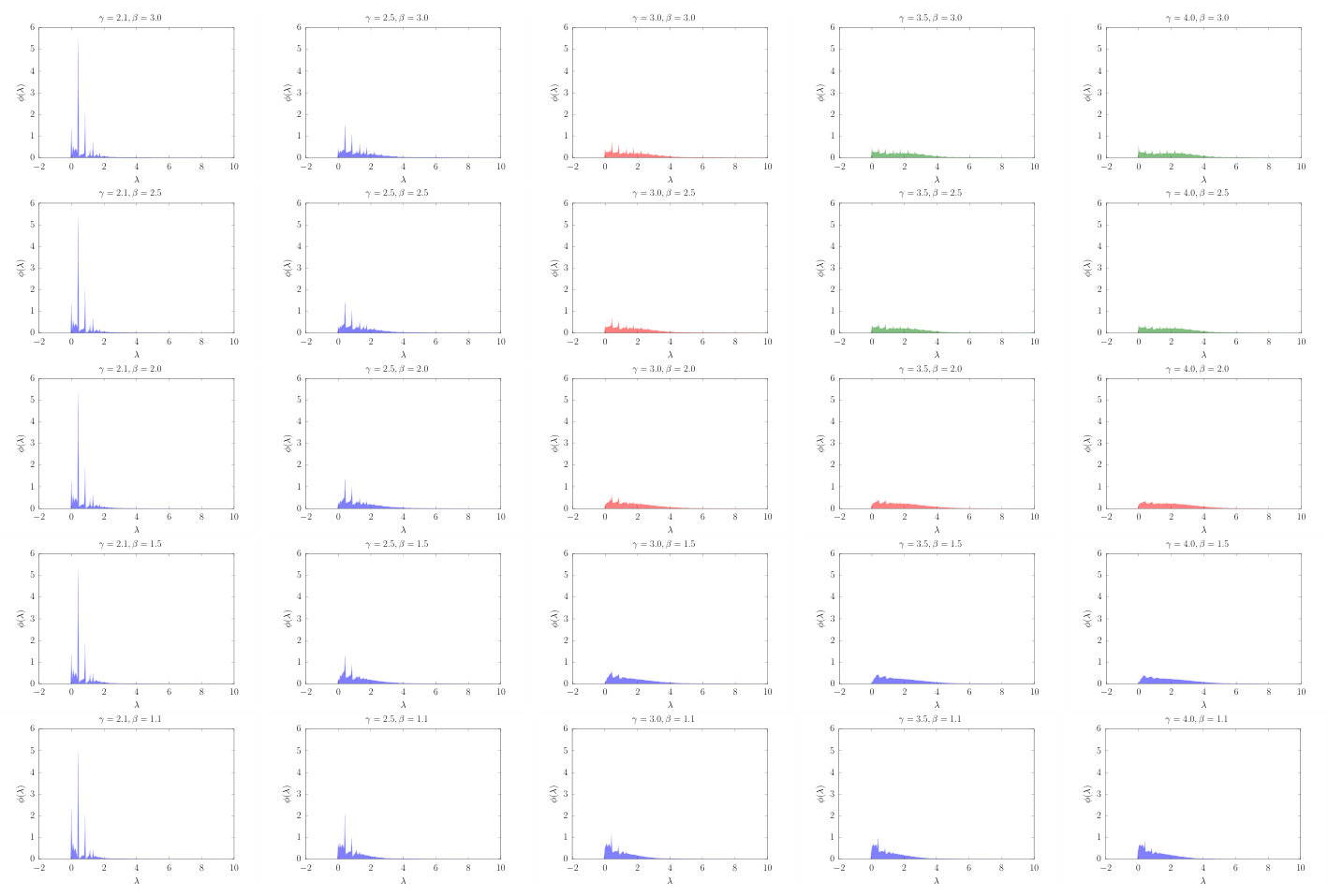 Figure 13
Figure 13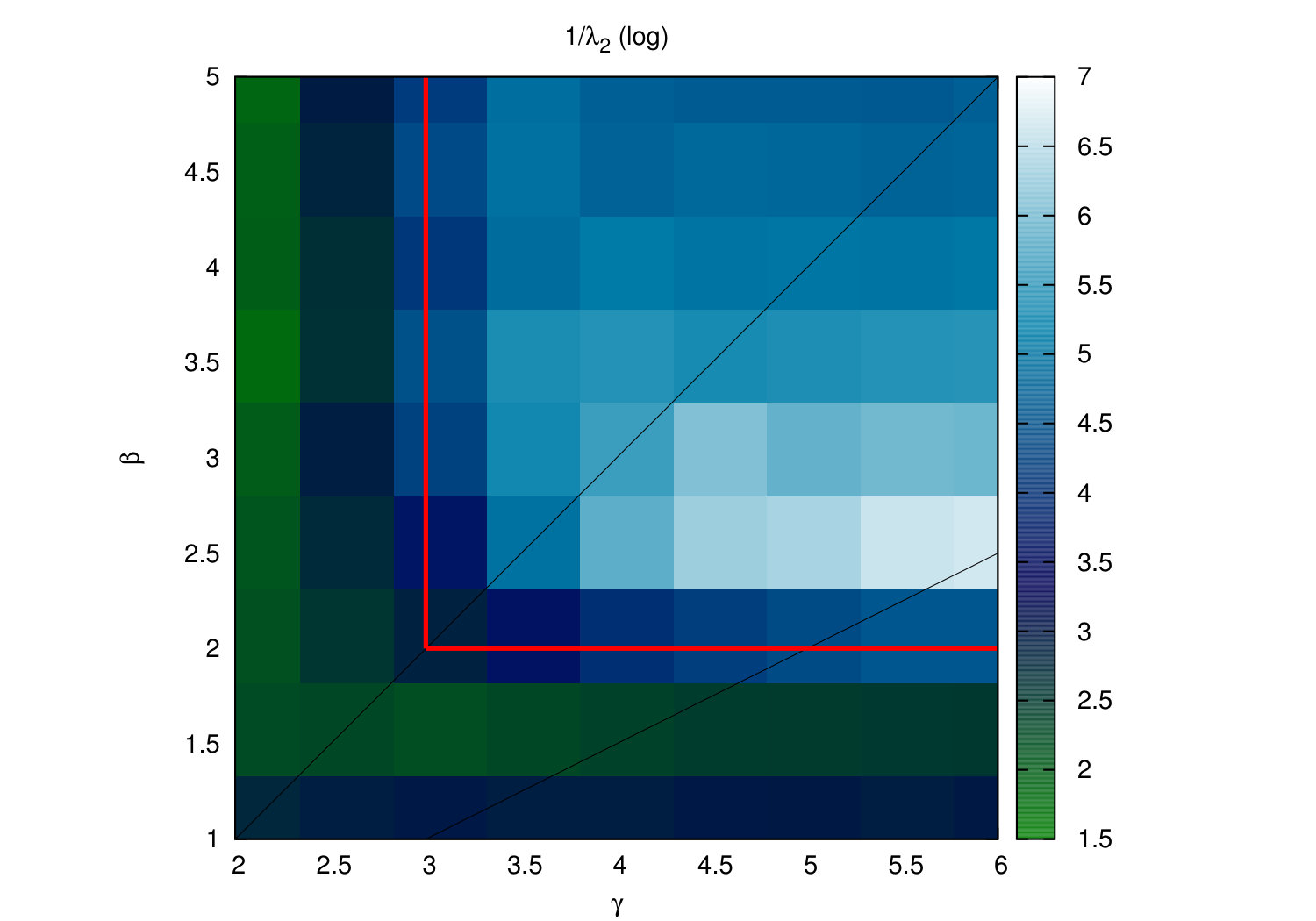 Figure 14
Figure 14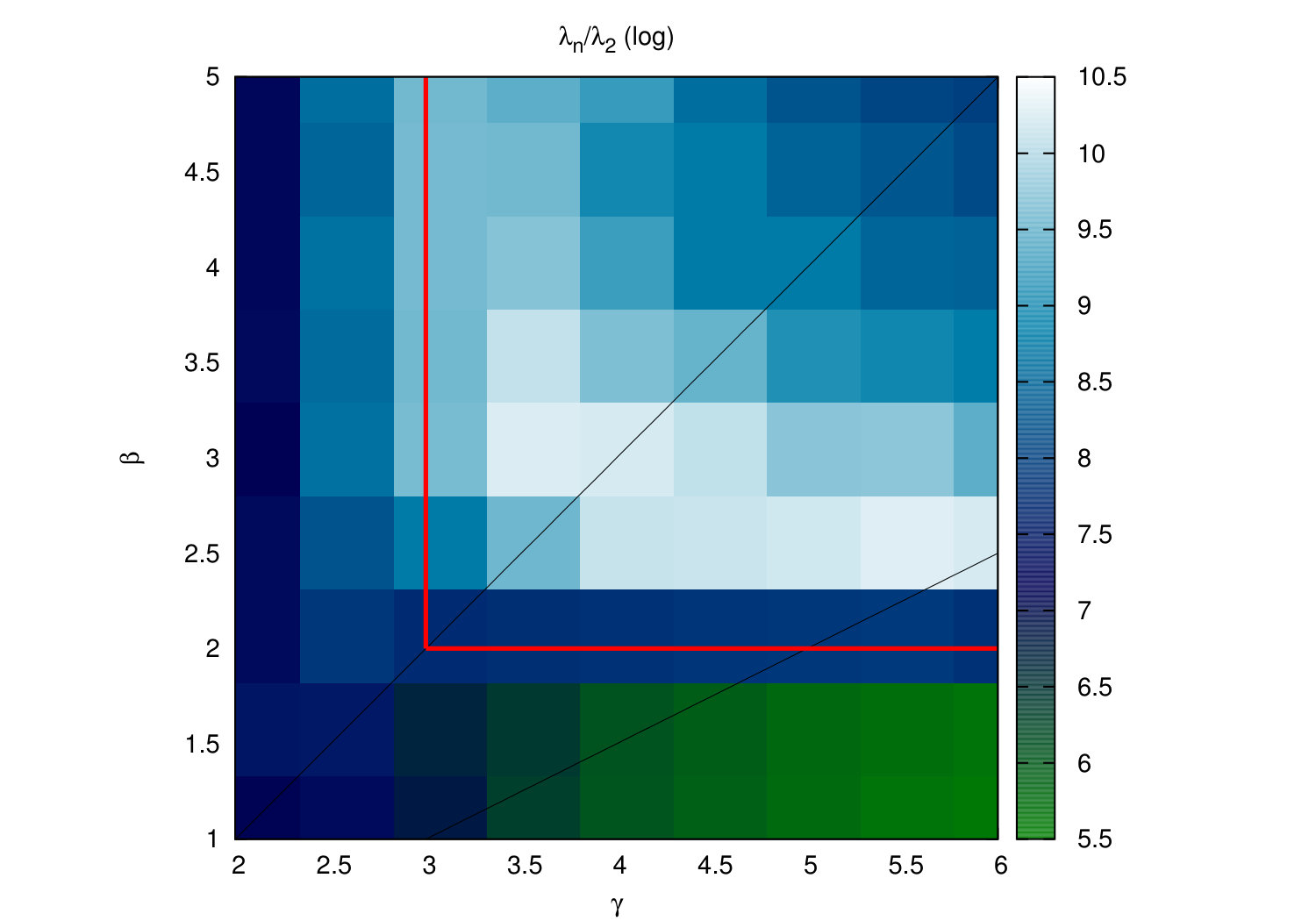 Figure 15
Figure 15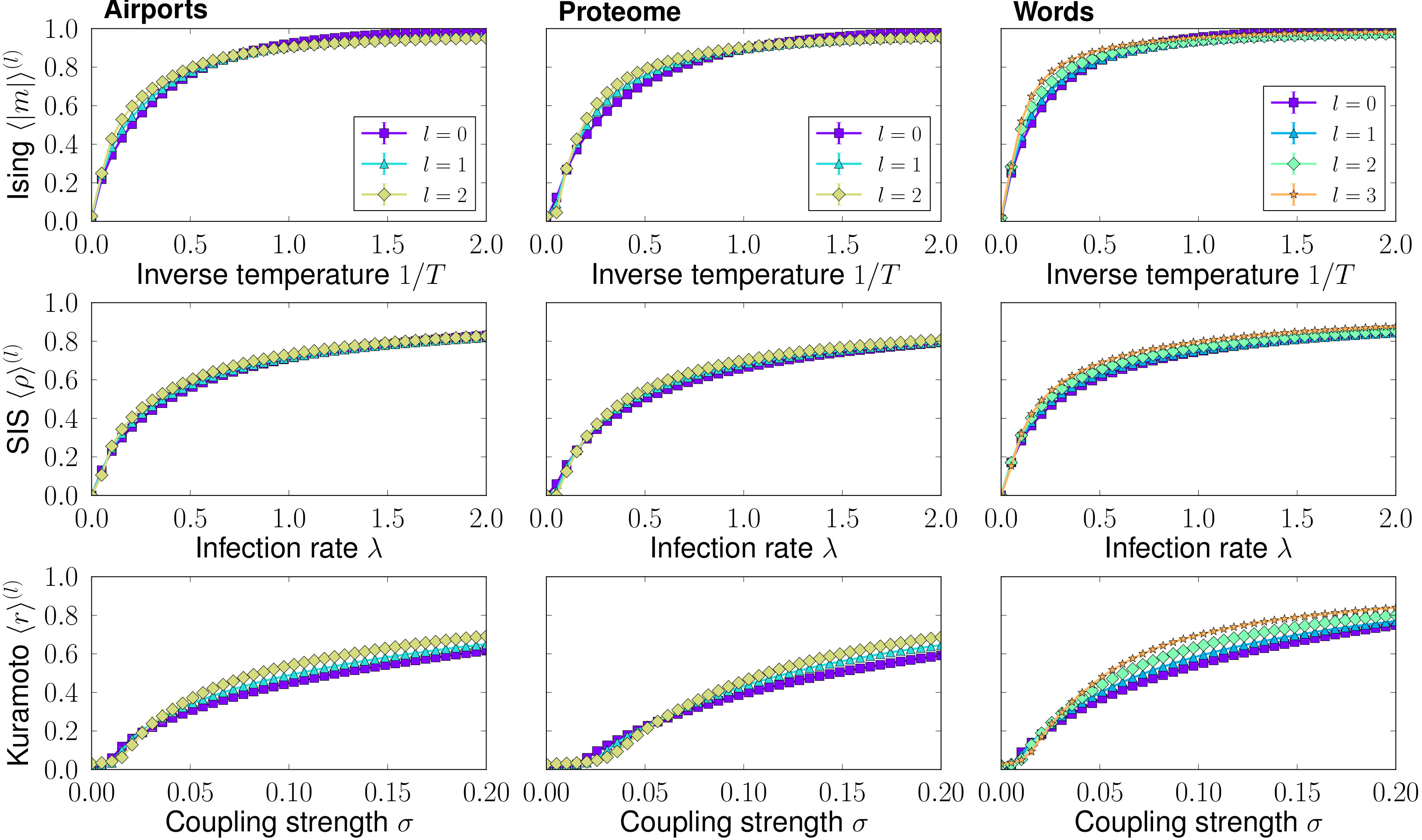 Figure 16
Figure 16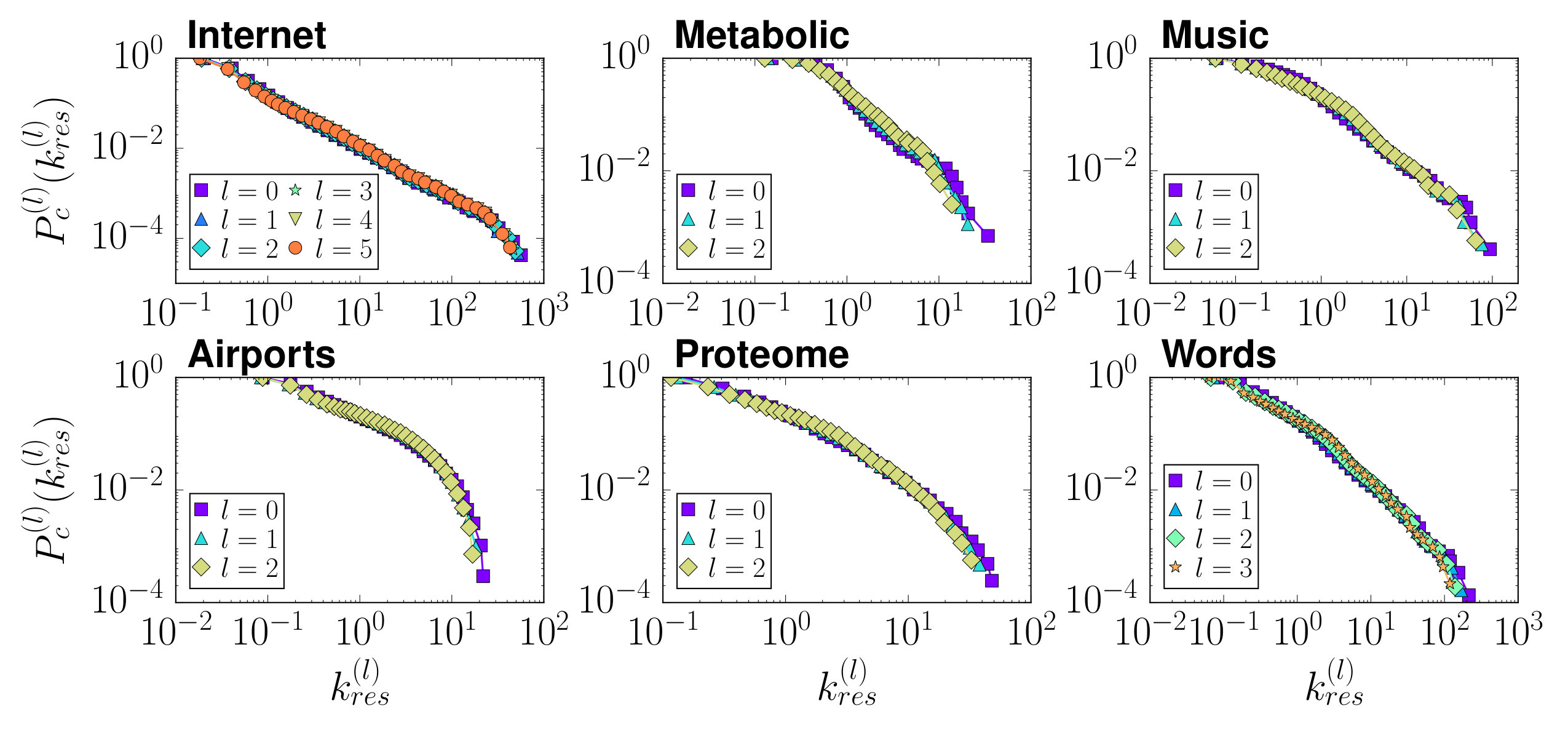 Figure 17
Figure 17| Name | Type | Nodes | |||||
|---|---|---|---|---|---|---|---|
| Internet | Technological | Autonomous systems | 23748 | 2.17 | 1.44 | 4.92 | 0.61 |
| Metabolic | Biological | Metabolites | 1436 | 2.6 | 1.3 | 6.57 | 0.54 |
| Music | Script | Chords | 2476 | 2.27 | 1.1 | 16.66 | 0.82 |
| Airports | Transportation | World airports | 3397 | 1.88 | 1.7 | 11.32 | 0.63 |
| Proteome | Biological | Proteins | 4100 | 2.25 | 1.001 | 6.52 | 0.09 |
| Words | Script | Words | 7377 | 2.25 | 1.01 | 11.99 | 0.47 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Multiscale unfolding of real networks by geometric renormalization
Guillermo García-Pérez
Departament de Física de la Matèria Condensada, Universitat de Barcelona, Martí i Franquès 1, 08028 Barcelona, Spain
Universitat de Barcelona Institute of Complex Systems (UBICS), Universitat de Barcelona, Barcelona, Spain
Marián Boguñá
Departament de Física de la Matèria Condensada, Universitat de Barcelona, Martí i Franquès 1, 08028 Barcelona, Spain
Universitat de Barcelona Institute of Complex Systems (UBICS), Universitat de Barcelona, Barcelona, Spain
M. Ángeles Serrano
Departament de Física de la Matèria Condensada, Universitat de Barcelona, Martí i Franquès 1, 08028 Barcelona, Spain
Universitat de Barcelona Institute of Complex Systems (UBICS), Universitat de Barcelona, Barcelona, Spain
ICREA, Pg. Lluís Companys 23, E-08010 Barcelona, Spain
Abstract
Multiple scales coexist in complex networks. However, the small world property makes them strongly entangled. This turns the elucidation of length scales and symmetries a defiant challenge. Here, we define a geometric renormalization group for complex networks and use the technique to investigate networks as viewed at different scales. We find that real networks embedded in a hidden metric space show geometric scaling, in agreement with the renormalizability of the underlying geometric model. This allows us to unfold real scale-free networks in a self-similar multilayer shell which unveils the coexisting scales and their interplay. The multiscale unfolding offers a basis for a new approach to explore critical phenomena and universality in complex networks, and affords us immediate practical applications, like high-fidelity smaller-scale replicas of large networks and a multiscale navigation protocol in hyperbolic space which boosts the success of single-layer versions.
I Introduction
Symmetries permeate reality and our theories to understand it. From very simple to very subtle, all of them denote invariance under a transformation, and thus similarity or even exact correspondence between different parts of a system or between the system and itself when observed at different scales of length, or other variable. As paradigmatic examples, fractals are geometric objects showing physical scale invariance and self-similarity Mandelbrot (1961). Moreover, these properties can also apply to phenomenological behaviours like systems dynamics near critical points of phase transitions Stanley (1971).
In complex networks, multiple scales coexist but they are so entangled that the definition of self-similarity and scale-invariance has been limited by the lack of a valid source of geometric length scale transformations. Previous efforts to study these symmetries are based on topology and include coarse-graining to preserve the large-scale behaviour of random walks Gfeller and De Los Rios (2007), or box-covering procedures based on shortest path lengths between nodes Song et al. (2005); Goh et al. (2006); Song et al. (2006); Kim et al. (2007); Radicchi et al. (2008); Rozenfeld et al. (2010). The latter revealed that certain real networks have finite fractal dimensions and exhibit self-similarity, although scaling in the topological properties was not observed beyond the degree distribution and the maximum and average degrees. However, the collection of shortest paths, albeit a well-defined metric, is a poor source of length-based scaling factors in networks due to the small-world Watts and Strogatz (1998) or even ultrasmall-world Cohen and Havlin (2003) property, and the problem remained controversial. Other studies have faced the multiscale structure of network models in a somewhat more geometric way Newman and Watts (1999); Boettcher (2011), but their findings cannot be directly applied to real-world networks.
The development in the last years of plausible models of complex networks based on an underlying metric space Serrano et al. (2008); Boguñá et al. (2010a) opens now the door to a proper geometric definition of self-similarity and scale invariance and to an unfolding of the different scales present in the connectivity structure of real networks. Hidden metric space network models couple the topology of a network to an underlying geometry through a universal connectivity law which combines popularity and similarity dimensions Serrano et al. (2008); Krioukov et al. (2010); Papadopoulos et al. (2012), such that more popular and similar nodes have more chance to interact. Naturally, the geometricalization of networks allows a reservoir of distance scales so that we can borrow concepts and techniques from the renormalization group in statistical physics Leo P. (2000); Wilson (1975), which has been used to study systems where widely different length scales are present simultaneously. By recursive averaging over short-distance degrees of freedom, the renormalization group has successfully explained, for instance, the universality properties of critical behavior in phase transitions Wilson (1983).
In this work, we introduce a geometric renormalization group for complex networks (RGN). The method is based on a geometric embedding of the networks to construct renormalized versions of their structure by coase-graining neighbouring nodes into supernodes and defining a new map which progressively selects longer range connections by identifying relevant interactions at each scale. The RGN technique is inspired by the block spin renormalization group devised by L. P. Kadanoff Leo P. (2000).
II Evidence of geometric scaling in real networks
The map of a complex network embedded in a hidden metric space, , contains information about both its topology and geometry (in terms of the positions of the nodes in the hidden metric space). Given , we define a geometric renormalization operator of resolution which coarse-grains the original network by a factor and defines a new topology and a new geometry conforming the renormalized map
[TABLE]
The transformation zooms out by changing the minimum length scale from that of the original network to a larger value. This operation can be iterated starting from the original network at ,
[TABLE]
In the limit , it can be applied up to any desired scale of observation, whereas it is bounded to iterations in systems with a finite number of nodes .
The simplest hidden metric space that can embed a network is a one-dimensional sphere on which nodes have specific angular positions . In this space, the transformation proceeds by, first, defining non-overlapping blocks of consecutive nodes of size along the circle and, second, coarse-graining the blocks into supernodes, regardless of whether they are connected or not to each other. Each supernode is then placed within the angular region defined by the corresponding block so that the order of nodes in the original embedding is preserved in the renormalization process. All the links between some node in one supernode and some node in the other, if any, are renormalized into a single link between the two supernodes. Figure 1 illustrates the process. This coarse-graining procedure is not restricted to equal size blocks and can be defined in different ways as long as the angular distance between the nodes inside the blocks is smaller than the distance between nodes in different blocks. For instance, one could divide the circle in equally sized sectors of a certain arc length such that they contain on average a constant number of nodes. The geometric renormalization operator has abelian semigroup structure with respect to the composition, meaning that a certain number of iterations of a given resolution are equivalent to a single transformation of higher resolution, as shown in Fig. 1 111For instance, in Fig. 1 the same transformation with leads from to in a single step. Whenever the number of nodes is not divisible by , the last supernode in a layer contains less than nodes, as in the example at ; however, the RGN equations are valid for uneven supernode sizes as well. Notice that the set of transformations does not include an inverse element to reverse the process.. Finally, the set of renormalized network layers , each times smaller than the original one, forms a multiscale shell of the network.
In this work, we apply the RGN to six different real scale-free networks from very different domains: technology (Internet), transportation (Airports), biology (Cell metabolism and Proteome) and scripts (Music and Words); see Appendix A for details. Many real networks can be embedded in the one-dimensional sphere using the model Serrano et al. (2008), which places nodes into a circle and connects every pair with a probability that decreases with their distance along the circle, as a measure of their similarity, and increases with the product of their hidden degrees , as a measure of their popularity (see Appendix A). The hidden degrees are well approximated by the observed degrees in the network Boguñá and Pastor-Satorras (2003); Serrano et al. (2008), and the embedding method uses statistical inference techniques to identify the angular coordinates which maximize the likelihood that the topology of the real network is reproduced by the model Boguñá et al. (2010b); Papadopoulos et al. (2015). Once the hidden degrees and coordinates of the real scale-free networks considered in our study are known, we apply the coarse-graining by defining blocks of size consecutive nodes in the circle, and place the supernodes within the coordinates of their corresponding nodes with the only restriction of preserving the original ordering. We iterate the process so that at each coarse-graining step the size of the system is reduced by a half.
The resulting topological features of the renormalized networks are shown in Fig. 2 (see also Fig. 6 in Appendix B). We observe that the degree distributions, degree-degree correlations —as measured by the average nearest neighbours degree—, and the clustering spectra, all show self-similar behaviour with curves for the different renormalized layers collapsing if the degrees in the layers are rescaled by their average degree. Also, for every layer we obtained a partition into communities, , using the Louvain method Blondel et al. (2008); Fig. 2 bottom shows their modularities . We also defined the partition induced by on the original network, , obtained by considering that two nodes and of the original network are in the same community in if and only if the supernodes of and in layer belong to the same community in . Both the modularity of and the normalized mutual information between both partitions and are shown in Fig. 2 bottom. Strikingly, the community structure is preserved along the flow to the extent of allowing us to find high-modularity partitions of the original network from much smaller versions of it. This property suggests a new and efficient multiscale community detection algorithm Arenas et al. (2008); Ronhovde and Nussinov (2009); Ahn et al. (2010).
III Geometric renormalization of the S1 model
The self-similarity exhibited by real-world networks can be understood in terms of their congruency with the underlying hidden metric space model. As we show analytically (see Appendix C for details), the model is renormalizable in a geometric sense, and that means that real scale-free networks with a geometric structure —i. e., which admit a good embedding— necessarily display the same scaling behaviour.
To see why the model exhibits this self-similarity, we need to consider the renormalization transformation of the geometric layout as well, that is, of hidden degrees, angular positions, , and . As we show in Appendix C, by assigning a new hidden degree to supernode in layer as a function of the hidden degrees of the nodes it contains in layer according to
[TABLE]
as well as an angular coordinate given by
[TABLE]
and by rescaling the global parameters as , and , the renormalized networks remain maximally congruent with the hidden metric space model. This means that the probability for two supernodes and to be connected in layer (which, according to the RGN procedure is given by the probability for at least one link to exist between some node in and some node in in layer ), maintains its original form Eq. (7), as shown in Fig. 3A. This applies both to the model and to real networks as long as they admit a good embedding, see also Fig. 7 in Appendix B. In addition, notice that the transformation of the geometric layout also has the abelian semi-group structure.
Since the networks remain congruent with the model, hidden degrees remain proportional to observed degrees , which allows us to explore the degree distribution of the renormalized layers analytically. It can be shown that, if the original distribution of hidden degrees is a power law with characteristic exponent , the hidden degree distribution in the renormalized layers is also a power law with the same exponent asymptotically, as long as (see Appendix C). Interestingly, the global parameter controlling the clustering coefficient, , does not change along the flow, which explains the self-similarity of the clustering spectra. Finally, the transformation for the angles Eq. (4) preserves the ordering of nodes and the heterogeneity in their angular density and, as a consequence, the community structure is preserved in the flow Boguñá et al. (2010b); Serrano et al. (2012); Zuev et al. (2015). The model is therefore renormalizable, and RGN realizations at any scale belong to the same ensemble with a different average degree, which should be rescaled to produce self-similar replicas.
A good approximation of the behaviour of the average degree for very large networks can be calculated by taking into account the transformation of hidden degrees in the RG flow Eq. (3) (see Appendix C for details). We obtain , with a scaling factor depending on the connectivity structure of the original network. If , the flow is dominated by the exponent of the degree distribution , and the scaling factor is given by
[TABLE]
whereas the flow is dominated by the strength of clustering if , and
[TABLE]
Therefore, if or (phase I in Fig. 3B), then and the model flows towards a highly connected graph; the average degree is preserved if and or and , which indicates that the network is at the edge of the transition between the small-world and non-small-world phases; and if and , causing the RGN flow to produce sparser networks approaching a unidimensional ring structure as a fixed point (phase II in Fig. 3B). In this case, the renormalized layers eventually lose the small-world property.
In Fig. 3B, several real networks are displayed in the connectivity space. All of them lay in the region having the fully connected network as the fixed point, meaning that the RGN flow progressively selects more and more long range connections as a consequence of their small-worldness (see Appendix C). Furthermore, all of them, except the Internet and the Airports networks, belong to the -dominated region. The inset also shows the behaviour of the average degree of every layer , ; as predicted, it grows exponentially in all cases.
Interestingly, global properties of the model, like those reflected in the spectrum of eigenvalues of both the adjacency and laplacian matrices, and quantities like the diffusion time and the restabilization time (Mieghem, 2011), show a dependence on and which is in consonance with the one displayed by the RGN flow of the average degree, see results in Figs. 10, 11 and 12 of Appendix C for synthetic networks. The model seems to be more sensitive to small changes in degree heterogeneity in the region , whereas changes in clustering are better reflected when .
IV Applications
The RGN enables us to unfold scale-free complex networks in a self-similar multilayer shell which unveils the coexisting scales and their interplay. Beyond the theoretical implications of the discovery that self-similarity under the RGN flow seems to be an ubiquitous symmetry in real networks, their multiscale unfolding can be exploited in immediate practical applications. Next, we propose two among many others; one which singles out a specific scale and another which exploits multiple scales simultaneously.
IV.1 Mini-me network replicas
The self-similarity unveiled by the RGN in real networks allows the construction of high-fidelity reduced versions that we call Mini-me network replicas. The downscaling of the topology of large real-world complex networks finds useful applications, for instance, in networked communication systems like the Internet, as a reduced testbed to analyze the performance of new routing protocols Papadopoulos et al. (2006); Papadopoulos and Psounis (2007); Yao and Fahmy (2008, 2011). However, the success of such program is based upon the quality of the downscaled version of the original network, that should reproduce not only local properties but also the mesoscopic structure of the network. Mini-me replicas can also be used to perform finite size scaling of critical phenomena taking place on real networks, so that critical exponents could be evaluated starting from a single size instance network. The Mini-me networks can be produced at any scale in the range in which self-similarity is preserved. For their construction, we exploit the fact that, under renormalization, a scale-free network remains self-similar and congruent with the underlying geometric model in all the self-similarity range of the multilayer shell. The idea is to single out a specific scale after a certain number of renormalization steps.
Typically, the renormalized average degree of real networks increases in the flow, since they belong to the small-world phase (see inset in Fig. 3B), meaning that the network layer at the selected scale is more densely connected. To reduce the density to the level of the original network, we apply a pruning of links, see Appendix A. Basically, we readjust parameter , controlling the number of links in the underlying geometric model, so that the expected average degree in the renormalized version is that of the original network, which in turn modifies the connection probability Eq. (7). We keep in the Mini-me network only the links present in the renormalized layer which are consistent with the readjusted connection probability. In this way, we obtain a reduced version of the real network which is statistically equivalent to a very good approximation.
To illustrate the high-fidelity that Mini-me network replicas can achieve, we use them to reproduce the behaviour of dynamical processes in real networks. We selected three different dynamical processes, the classic ferromagnetic Ising model, the susceptible-infected-susceptible (SIS) epidemic spreading model, and the Kuramoto model of synchronization, see Appendix A for details. We test these dynamics in all the self-similar network layers of the real networks analysed in this work. Results are shown in Fig. 4 and Fig. 13 in Appendix D. Quite remarkably, for all dynamics and all networks, we observe very similar results between the original and Mini-me replicas at all scales. This is particularly interesting as these dynamics have a strong dependence on the mesoscale structure of the underlying networks. This strongly supports our claim that both the micro and meso-scales are preserved in the downscaled replicas, as expected given the self-similarity of the network layers in the RGN flow.
IV.2 Multiscale navigation
Applications that simultaneously exploit more than one or even all the layers in the self-similar multiscale shell are also possible. Next, we introduce a new multiscale navigation protocol for networks embedded in hyperbolic space, which improves single-layer results Boguñá et al. (2010b). To this end, we exploit the quasi-isomorphism between the model and the model in hyperbolic space Krioukov et al. (2009, 2010) to produce a purely geometric representation of the multiscale shell (see Appendix A). In hyperbolic space, each node is characterised by a radial coordinate directly related to its degree, and an angular coordinate identical to that in the circle. The connection probability becomes a decreasing function of the hyperbolic distance between nodes and, therefore, the most likely path connecting two distant nodes is typically the topological shortest path.
The multiscale protocol is based on greedy routing, in which a source node transmitting information or a packet to a target node sends it to its neighbour closest to destination in the metric space. As performance metrics we consider the success rate (fraction of successful greedy paths), and the stretch of successful path (ratio between the number of hops in the greedy path and the topological shortest path). Notice that, in general, greedy routing cannot guarantee the existence of a successful greedy path among all pairs of nodes in the network; the packet can get trapped into a loop if sent to an already visited node. In this case, the multiscale protocol can find alternative paths by taking advantage of the increased efficiency of greedy forwarding in the coarse-grained layers. When node needs to send a packet to some destination node , node performs a virtual greedy forwarding step in the highest possible layer to find which supernode should be next in the greedy path. Based on this, node then forwards the packet to its physical neighbour in the real network which guarantees that it will eventually reach such supernode. The process is depicted in Fig. 5A (full details can be found in Appendix A). To guarantee navigation inside supernodes, we require an extra condition in the renormalization process and only consider blocks of connected consecutive nodes. A single node can be left alone forming a supernode by itself, so blocks are of size one or two nodes. Notice that the new requirement does not alter the self-similarity of the renormalized networks forming the multiscale shell (Figs. 14 and 15 in Appendix E) nor the congruency with the hidden metric space (Fig. 16 in Appendix E).
Figure 5B shows the increase of the success rate as the number of layers used in the navigation process is increased for the different real networks considered in this work. Interestingly, as seen in Fig. 5C, this improvement alters the stretch of successful paths only mildly. The multiscale navigation protocol boosts the success rate by finding paths just slightly longer on average as compared with standard greedy routing in the original network in almost all cases, see inset in Fig. 5C. The improvement comes at the expense of adding information about the supenodes to the knowledge needed for standard greedy routing in single-layered networks. However, the trade-off between improvement and information overload is advantageous as for many systems the addition of just one or two renormalized layer produces already a notable effect.
V Discussion
Hidden metric space network models Serrano et al. (2008); Krioukov et al. (2010); Papadopoulos et al. (2012) are able to explain non-trivial structural features of real networks—including scale-free degree distributions, clustering, and self-similarity of the nested hierarchy of subgraphs produced by degree pruning Serrano et al. (2011)—, and also fundamental mechanisms like preferential attachment in growing networks Papadopoulos et al. (2012) and the emergence of communities Zuev et al. (2015). Interestingly, the existence of a metric space underlying complex networks allows us to define a geometric renormalization group that reveals the multiscale nature of these systems. Quite strikingly, models of scale-free networks are shown to be self-similar under such renormalization, revealing different structural properties depending on the level of coupling with the metric space and degree heterogeneity. The importance of these results, however, stems from the observed self-similarity under geometric renormalization as an ubiquitous symmetry of real world scale-free networks, which moreover stands as a new evidence in favour of the conjecture that hidden metric spaces underlie real networks.
The renormalization group presented in this work is similar in spirit to the topological renormalization studied in Song et al. (2005). However, it has clear advantages. First, the ordering in the construction of the boxes is dictated by the embedding of the original network in the underlying space. Second, the congruency between real scale-free networks and the underlying metric space explains the self-similarity of real systems and reveals a multiscale organization that preserves the mesoscopic structure across different observation scales. In the case of topological renormalization, on the other hand, the lack of an underlying model implies that it is not obvious to advance when the network will be self-similar before applying the transformation and whether or not the mesoscopic structure will be mantained.
From a fundamental point of view, the geometric renormalization group introduced here has proven to be an exceptional tool to unravel the global organization of complex networks across scales and promises to become a standard methodology to analyze real complex networks. It can also help in areas like the study of metapopulation models, in which transportation fluxes or population movements happen both on a local and a global scale Colizza et al. (2007). From a practical point of view, we envision many applications besides the two studied in this paper. For instance, the development of a new community detection method that would use the mesoscopic information encoded in the different observation scales, and the use of downscaled versions of the network to perform finite size scaling. This last application would allow for the determination of critical exponents of real complex networks, a task that it not possible with current methods.
Acknowledgments
We acknowledge support from a James S. McDonnell Foundation Scholar Award in Complex Systems; the ICREA Academia prize, funded by the Generalitat de Catalunya; Ministerio de Economía y Competitividad of Spain projects no. FIS2013-47282-C2-1-P and no. FIS2016-76830-C2-2-P (AEI/FEDER, UE); the Generalitat de Catalunya grant no. 2014SGR608.
Author contributions
G. G.-P., M. B., and M. Á. S. contributed to the design and implementation of the research, to the analysis of the results, and to the writing of the manuscript.
Additional information
Competing financial interests: The authors declare no competing financial interests.
Appendix A Methods
A.1 Real networks data
The real networks analyzed in this paper are:
- •
The Internet at the Autonomous Systems level. The data was collected by the Cooperative Association for Internet Data Analysis (CAIDA) (Claffy et al., 2009) and corresponds to mid 2009.
- •
The Airports network. It was obtained from Ref. (kon, 2016; Kunegis, 2013). Directed links represent flights by airlines. We consider the undirected version obtained by keeping bidirectional edges only.
- •
The one-mode projection onto metabolites of the human metabolic network at the cell level, as used in Ref. (Serrano et al., 2012).
- •
The human HI-II-14 interactome. This proteome network was obtained from Ref. (Rolland et al., 2014). We removed self-loops.
- •
The Music network. Nodes are chords—sets of musical notes played in a single beat—and connections represent observed transitions among them in a set of songs, see Ref. (Serrà et al., 2012). The original network is weighted, directed and very dense. Hence, we applied the disparity filter (Serrano et al., 2009) with to obtain a sparser network. Finally, we kept bidirectional edges only to construct the undirected network.
- •
The network of adjacency between words in Darwin’s book “On the Origin of Species”, from Ref. (Milo et al., 2004).
In all cases, we only considered the largest connected components.
A.2 model and transformation to
The model Serrano et al. (2008) places the nodes of a network into a one-dimensional sphere of radius and connects every pair with probability
[TABLE]
where controls the average degree of the network, its clustering, and is the distance between the nodes separated by an angle ; is set to , where is the number of nodes, so that the density of nodes along the circle is equal to 1. The hidden degrees and are proportional to the degrees of nodes and , respectively.
The model is isomorphic to a purely geometric model, the model (Krioukov et al., 2010), in which nodes are placed in a two-dimensional hyperbolic disk of radius
[TABLE]
where . By mapping every mass to a radial coordinate according to
[TABLE]
the connection probability, Eq. (7), becomes
[TABLE]
where is a good approximation to the hyperbolic distance between two points with coordinates and in the native representation of hyperbolic space. The exact hyperbolic distance is given by the hyperbolic law of cosines,
[TABLE]
A.3 Adjusting the average degree of Mini-me network replicas
To reduce the average degree in a renormalized network to the level of the original network, we apply a pruning of links using the underlying metric model with which the networks in all layers are congruent. The procedure is detailed in this section.
The renormalized network in layer has an average degree generally larger (in phase I) from the original network’s . Moreover, the new network is congruent with the underlying hidden metric space with a parameter controlling its average degree. The main idea is to decrease the value of to a new value —which implies that the connection probability of every pair of nodes , , decreases to . We then prune the existing links by keeping them with probability
[TABLE]
Therefore, the probability for a link to exist in the pruned network reads,
[TABLE]
whereas the probability for it not to exist is
[TABLE]
that is, the pruned network has a lower average degree and is also congruent with the underlying metric space model with the new value of . Hence, we only need to find the right value of so that . In the thermodynamic limit, the average degree of an network is proportional to , so we could simply set
[TABLE]
However, since we consider real-world networks, finite-size effects play an important role. Indeed, we need to correct the value of in Eq. (15). To this end, we use a correcting factor , initially set to , and use ; for every value of , we prune the network. If , we give the new value , where is a random variable uniformly distributed between 0 and 1. Similarly, if , . The process ends when is below a given threshold (in our case, we set it to 0.1).
A.4 Simulation of dynamical processes
The Ising model is an equilibrium model of interacting spins Dorogovtsev et al. (2002). Every node is assigned a variable with two possible values , and the energy of the system is, in the absence of external field, given by the Hamiltonian
[TABLE]
where are the elements of the adjacency matrix and are coupling constants which we set to one. We start from an initial condition with for all and explore the ensemble of configurations using the Metropolis-Hastings algorithm: we randomly select one nod and propose a change in its spin, . If , we accept the change; otherwise, we accept it with probability , where is the temperature acting as a control parameter. The order parameter is the absolute magnetization per spin , where ; if all spins point in the same direction, , whereas if half the spins point in each direction.
In the SIS dynamical model of epidemic spreading Pastor-Satorras and Vespignani (2001), every node can present two states at a given time , susceptible () or infected (). Both infection and recovery are Poisson processes. An infected node recovers with rate 1, whereas infected nodes infect their susceptible neighbours at rate . We simulate this process using the continuous-time Gillespie algorithm with all nodes initially infected. The order parameter is the prevalence or fraction of infected nodes .
The Kuramoto model is a dynamical model for coupled oscillators. Every node is described by a natural frequency and a time-dependent phase . A node’s phase evolves according to
[TABLE]
where are the adjacency matrix elements and is the coupling strength. We integrate the equations of motion using Heun’s method. Initially, the phases and the frequencies are randomly drawn from the uniform distributions and respectively, as in Ref. (Moreno and Pacheco, 2004). The order parameter measures the phase coherence of the set of nodes; if all nodes oscillate in phase, , whereas if nodes oscillate in a disordered manner.
In every realization, we compute an average of the order parameter in the stationary state. In the case of the SIS model, the single-realization mean of prevalence values is weighted by time. The curves presented in this work correspond to statistics over 100 realizations.
A.5 Multiscale navigation
Given a network and its embedding (layer 0), we merge pairs of consecutive nodes only if they are connected, which guarantees navigation inside supernodes; this process generates layer 1. We repeat the process to generate layers. The multiscale navigation protocol requires every node to be provided with the following local information:
The coordinates of node in every layer .
- 2.
The list of (super)neighbours of node in every layer as well as their coordinates.
- 3.
Let SuperN be the supernode to which belongs in layer . If SuperN is connected to SuperN in layer , at least one of the (super)nodes in layer belonging to SuperN must be connected to at least one of the (super)nodes in layer belonging to SuperN; such node is called gateway. For every superneighbour of node SuperN in layer , node knows which (super)node or (super)nodes in layer are gateways reaching it. Notice that both the gateways and SuperN belong to SuperN in layer so, in layer , they must either be the same (super)node or different but connected (super)nodes.
- 4.
If SuperN is a gateway reaching some supernode , at least one of its (super)neighbours in layer belongs to ; node knows which.
This information allows us to navigate the network as follows. Let be the destination node to which wants to forward a message, and let node know ’s coordinates in all layers . In order to decide which of its physical neighbours (i. e., in layer 0) should be next in the message-forwarding process, node must first check if it is connected to ; in that case, the decision is clear. If it is not, it must:
Find the highest layer in which SuperN and SuperN still have different coordinates. Set .
- 2.
Perform a standard step of greedy routing in layer : find the closest neighbour of SuperN to SuperN. This is the current target SuperT.
- 3.
While , look into layer :
- –
Set .
- –
If SuperN is a gateway connecting to some (super)node within SuperT, node sets as new current target SuperT its (super)neighbour belonging to SuperT closest to SuperN.
- –
Else node sets as new target SuperT the gateway in SuperN connecting to SuperT (its (super)neighbor belonging to SuperN).
- 4.
In layer , SuperT belongs to the real network and she is a neighbour of , so node forwards the message to SuperT.
Appendix B Evidence of geometric scaling in real networks
The global topological parameters of all six networks are contained in Table 1.
Fig. 2 compares the topological properties of the renormalized networks for three real networks. We show the equivalent results for the Airports, Proteome and Words networks in Fig. 6.
In Fig. 7, we show the empirical connection probabilities of the six real-world networks considered in this paper as well as their renormalized versions.
Appendix C The Geometric Renormalization Group
This section contains the calculations related to the theoretical aspects of the geometric renormalization transformation. In particular, we show the semi-group structure of the transformation, derive the corresponding recurrence relations for the renormalization of the model and calculate the flow of the average degree. We also discuss the connection with statistical mechanics by using the isomorphism between the and the models and, finally, we include some numerical results regarding the relation between global properties of the networks generated by the model and the flow of the average degree.
C.1 The semigroup structure of the coarse-graining step
It is easy to show that the geometric coarse-graining presented in this paper has the semigroup structure. To this end, we need to see that node is mapped to the same supernode whether we apply the coarse-graining with first and then a second time with or just once with . In the first case, the step with maps to supernode (where represents the integer part of ), and then is mapped to in the second step. In the second case, is mapped to supernode . Notice that , where . Now,
[TABLE]
so
[TABLE]
which is always fulfilled since and
[TABLE]
Thus, , and node is mapped to the same supernode in both cases. It follows immediately from this result that both processes yield the same final link structure.
C.2 Selecting long-range connections
As we apply the renormalization transformation, some links are integrated inside the supernodes, so they do not contribute to the topology of the renormalized network. In Fig. 8, we show that links joining nodes separated a large angular distance require larger values of to be integrated; in other words, the connections in a renormalized network represent long-range connections in the original graph.
C.3 Geometric renormalization of the S1 model
In this subsection, we derive the RG equations of the model. In order to simplify the notation, all unprimed quantities will refer to layer , whereas primed ones will correspond to layer . Moreover, we consider the particular case in which all supernodes contain the same number of nodes () for simplicity, although the following calculations are also valid for supernodes of different sizes.
Consider the probability for two supernodes and in layer to be connected, which is given by the probability for at least one link between a pair of the nodes within the supernodes in layer to exist,
[TABLE]
where runs over all pairs of nodes with in supernode and in supernode . The term is the probability for and to be connected in layer ,
[TABLE]
Eq. (21) takes the same functional form as Eq. (22),
[TABLE]
with
[TABLE]
Since the angular distance between the nodes inside each block is generally smaller than the distance between and , all the are approximately equal (), so we can write
[TABLE]
The model assumes a uniform density of nodes , which means that , whereas is a constant independent of . Indeed, , so the first term leads Eq. (25) in most cases. Thus,
[TABLE]
Introducing this result into Eq. (23),
[TABLE]
we see that, in order for the resulting expression to be congruent with the model, we need a set of equations that transform the parameters according to
[TABLE]
Let us now assume that the angular coordinate of a supernode is some generalised center of mass of the nodes it integrates, so the separation between the two renormalised nodes is approximately equal to the angular separation between the nodes that belong to different blocks, i.e. ; thus, . The choice leads to , that is, to the rescaling step. Setting , Eq. (28) further requires
[TABLE]
which is fulfilled if
[TABLE]
The transformation of masses preserves the semi-group structure exactly, since
[TABLE]
We should require the transformation of angles to preserve it as well. This can be achieved using the following generalised center of mass
[TABLE]
given that
[TABLE]
C.4 RG flow of the average degree
As discussed in the previous subsection, as we renormalize, we move in the space of realizations of the model, always keeping the congruency between the network and the hidden metric space, i.e. Eq. (22). Therefore, we can use the model to compute the average degree of the renormalised networks. According to Ref. (Krioukov et al., 2010),
[TABLE]
where does not change as we renormalize. We thus need to compute , where is given by Eq. (30) and the original distribution of masses is assumed to be a power-law,
[TABLE]
The strategy to compute is as follows: 1. We define and find their distribution . 2. We then calculate (where is the Laplace transform of ); according to the convolution theorem, this is the Laplace transform of the variable . 3. Finally, we compute as the -th moment of , that is, , from .
- 1.
From Eq. (35),
[TABLE]
so
[TABLE]
where .
- 2.
If , , which means that and, consequently, are also power-law distributed since the central limit theorem does not apply (the opposite case corresponds to phase III in Fig.2B) (Gnedenko and Kolmogorov, 1968). The Laplace transform of Eq. (37) is given by
[TABLE]
where is the incomplete gamma function,
[TABLE]
From this result, it follows that
[TABLE]
- 3.
We need to compute
[TABLE]
To do so, consider the integral
[TABLE]
Taking into account that for
[TABLE]
we see that
[TABLE]
Now, setting and , . However, since and , the smallest we can choose is , so . Finally, we can write
[TABLE]
where is given in Eq. (40).
Particular case
To start solving Eq. (45), let us first take the limit of , which means that becomes
[TABLE]
Using the same change of variable as in Eq. (38), we see that
[TABLE]
Let us now evaluate ,
[TABLE]
and introduce this result into Eq. (45),
[TABLE]
We thus need to solve an integral of the form
[TABLE]
In our case, . Integrating by parts,
[TABLE]
We can find a recurrence relation for the integrals in the last expression,
[TABLE]
Iterating yields
[TABLE]
Introducing this result into Eq. (51),
[TABLE]
Finally, Eq. (49) becomes
[TABLE]
Using this result, Eq. (34) and we can write an expression for the exponent (defined by the expression ):
[TABLE]
The above result is shown in Fig. 9.
Solution in the power-law approximation
From Eq. (55), we see that the exact solution for large can be extremely convoluted, thus making the limit inaccessible. However, if we consider that is a power-law (which is a reasonable approximation if , as discussed above), the computation of becomes simpler. Under this assumption, are also power-law distributed with exponent , that is,
[TABLE]
We study two cases separately:
- i.
: In this case, we determine the value of and, with it, . If the assumption in Eq. (57) is correct, must behave as (Handelsman and Lew, 1974)
[TABLE]
According to Eqs. (40) and (46),
[TABLE]
In the above expression, we see that the term that does not depend on is given by the product of the terms with , whereas the term of order is given by the sum of the products of with the remaining terms with . Thus, we find
[TABLE]
We can now identify as
[TABLE]
so
[TABLE]
and
[TABLE]
Finally, plugging this result into Eq. (34),
[TABLE]
- ii.
: This case is much simpler, since and hence are finite and can be easily computed. Indeed, given that , we see that
[TABLE]
This result and Eq. (34) together imply
[TABLE]
Both solutions, Eqs. (64) and (66), are equivalent at , since
[TABLE]
Therefore, we can conclude that the network flows towards a fully connected graph if or . The line and or and is an unstable fixed point, whereas if and . Notice that this assertion is only valid under the assumption in Eq. (57), which is not true in general. However, we expect it to be a good approximation of the flow’s behaviour as .
C.5 Mapping to hyperbolic space and the partition function
In this section, we show how the RGN presented in this work can be described in the formalism of statistical physics. As explained in Appendix A, using the mapping to hyperbolic space, the connection probability, Eq. (22), becomes
[TABLE]
where is a good approximation to the hyperbolic distance between two points with coordinates and in the native representation of hyperbolic space.
Now, let if the link between nodes and exists and otherwise; Eq. (68) can be written as
[TABLE]
which means that, in the model, every pair of nodes represents a fermionic state of energy in the grand-canonical ensemble with playing the role of the chemical potential. Indeed, since a network can be represented by the set , the likelihood of a given network is given by
[TABLE]
that is, by the probability of the corresponding microstate of the gas of non-interacting fermions. The partition function of the system is
[TABLE]
When we apply the renormalization transformation, every node () is mapped to a supernode (). We can rearrange the terms in the partition function according to such mapping as
[TABLE]
The first double product in the above expression corresponds to the partial sum over the links among the nodes within every supernode (hence, there are such terms), whereas the second double product represents the partial sum over the links among nodes in different supernodes and ; thus, it contains terms. According to Eqs. (8) and (9),
[TABLE]
so the rightmost term in Eq. (72) reads
[TABLE]
where is given by Eq. (24). Using Eq. (26) and Eq. (28), which is fulfilled with the RG transformations Eqs. (30) and (31), yields
[TABLE]
The leftmost term in Eq. (72) can be written as
[TABLE]
In the particular case of , we integrate consecutive nodes separated by a typical angular distance . Hence, , so
[TABLE]
Defining
[TABLE]
we can write Eq. (72) as
[TABLE]
where .
C.6 Local vs. global properties
In the model, we impose three parameters, and , all three related to local properties of nodes (degree and clustering). However, the RG flow of observables like the average degree should be related to global properties of the system; indeed, we would expect two networks with similar average degree flows to exhibit similarities at the global scale as well, whereas two networks with very different RG trajectories (even in the same phase, i.e., flowing towards the same fixed point) should be easier to distinguish by looking at their global properties. To check this hypothesis, we have generated synthetic networks with different values of and and compared the eigenvalues of both the adjacency and laplacian matrices. The results are shown in Figs. 10, 11 and 12. As we see, the RG analysis of the model allows us to assess the stability of the global properties of networks against perturbations of their local ones, and hence the importance of clustering and degree heterogeneity on a given system.
Appendix D Mini-me network replicas
Appendix E Multiscale navigation networks
This section includes some results showing the topological properties of the coarse-grained for navigation networks; Fig. 14 shows the complementary cumulative degree distributions, whereas Fig. 15 contains their clustering spectra.
We also present the empirical connection probabilities of the networks after the coarse-graining for navigation (in which pairs of nodes are merged together into a supernode only if they are connected) in Fig. 16. Notice that the congruency with the underlying metric space is preserved even is the sizes of the blocks are different.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Mandelbrot (1961) B. Mandelbrot, in Proceedings of the Twelve Symposia in Applied Mathematics, Roman Jakobson editor. Structure of Language and its Mathematical Aspects, New York, USA (1961) pp. 190–219.
- 2Stanley (1971) H. E. Stanley, Introduction to Phase Transitions and Critical Phenomena (Oxford Univ. Press, Oxford, 1971).
- 3Gfeller and De Los Rios (2007) D. Gfeller and P. De Los Rios, Phys. Rev. Lett. 99 , 038701 (2007) . · doi ↗
- 4Song et al. (2005) C. Song, S. Havlin, and H. A. Makse, Nature 433 , 392 (2005).
- 5Goh et al. (2006) K. I. Goh, G. Salvi, B. Kahng, and D. Kim, Phys. Rev. Lett. 96 , 018701 (2006).
- 6Song et al. (2006) C. Song, S. Havlin, and H. A. Makse, Nature Physics 2 , 275 (2006).
- 7Kim et al. (2007) J. S. Kim, K. I. Goh, B. Hahng, and D. Kim, New J. Phys. 9 , 177 (2007).
- 8Radicchi et al. (2008) F. Radicchi, J. J. Ramasco, A. Barrat, and S. Fortunato, Phys. Rev. Lett. 101 , 148701 (2008) . · doi ↗