Morph-fitting: Fine-Tuning Word Vector Spaces with Simple Language-Specific Rules
Ivan Vuli\'c, Nikola Mrk\v{s}i\'c, Roi Reichart, Diarmuid \'O, S\'eaghdha, Steve Young, and Anna Korhonen

TL;DR
This paper introduces morph-fitting, a simple language-specific rule-based method to refine word vector spaces by leveraging morphological constraints, improving low-frequency word representations and semantic quality for language understanding.
Contribution
The paper presents a novel morph-fitting approach that uses morphological rules instead of curated lexicons to enhance word vector spaces across multiple languages.
Findings
Improves low-frequency word estimates
Enhances semantic quality of word vectors
Boosts performance in dialogue state tracking
Abstract
Morphologically rich languages accentuate two properties of distributional vector space models: 1) the difficulty of inducing accurate representations for low-frequency word forms; and 2) insensitivity to distinct lexical relations that have similar distributional signatures. These effects are detrimental for language understanding systems, which may infer that 'inexpensive' is a rephrasing for 'expensive' or may not associate 'acquire' with 'acquires'. In this work, we propose a novel morph-fitting procedure which moves past the use of curated semantic lexicons for improving distributional vector spaces. Instead, our method injects morphological constraints generated using simple language-specific rules, pulling inflectional forms of the same word close together and pushing derivational antonyms far apart. In intrinsic evaluation over four languages, we show that our approach: 1)…
Click any figure to enlarge with its caption.
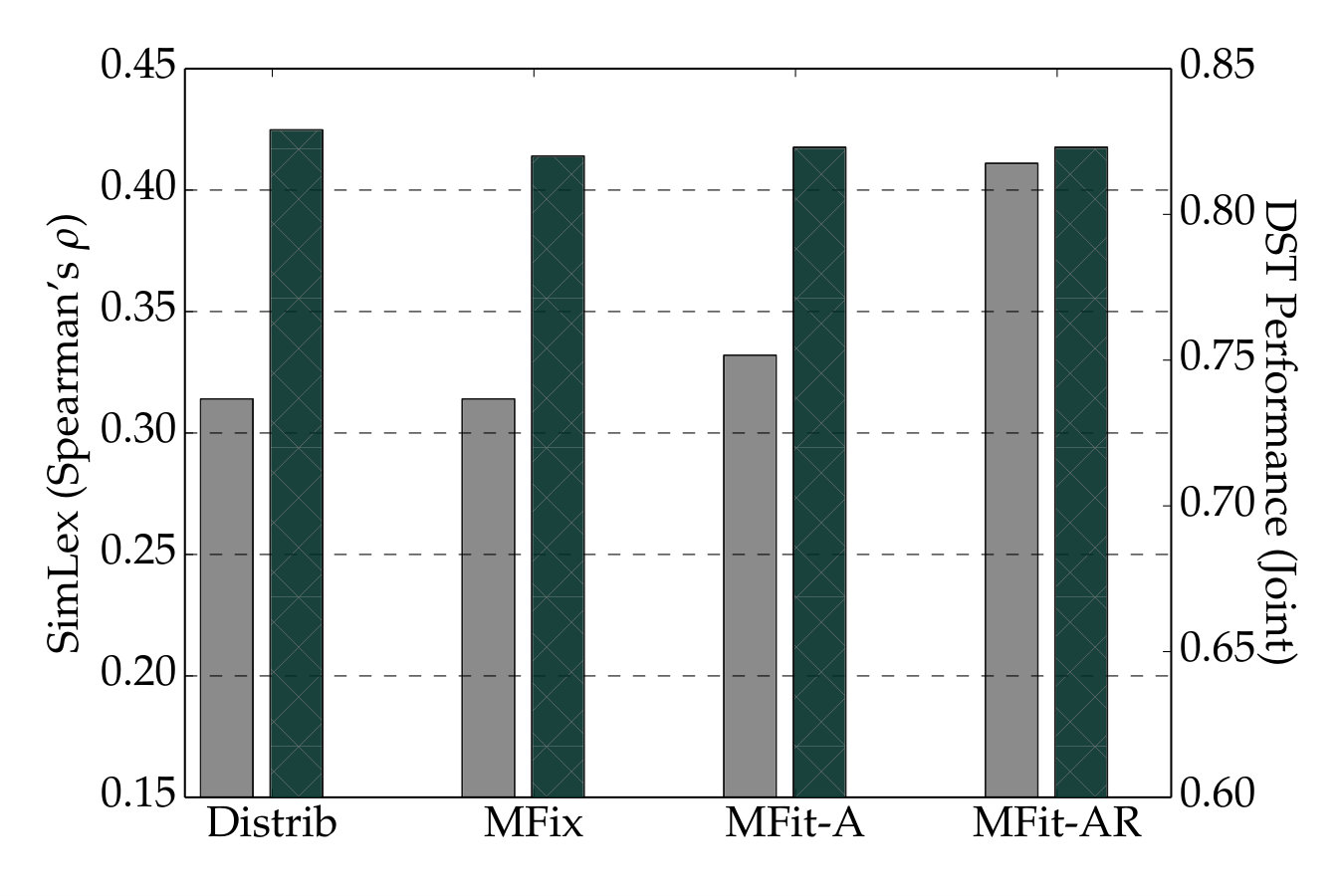 Figure 1
Figure 1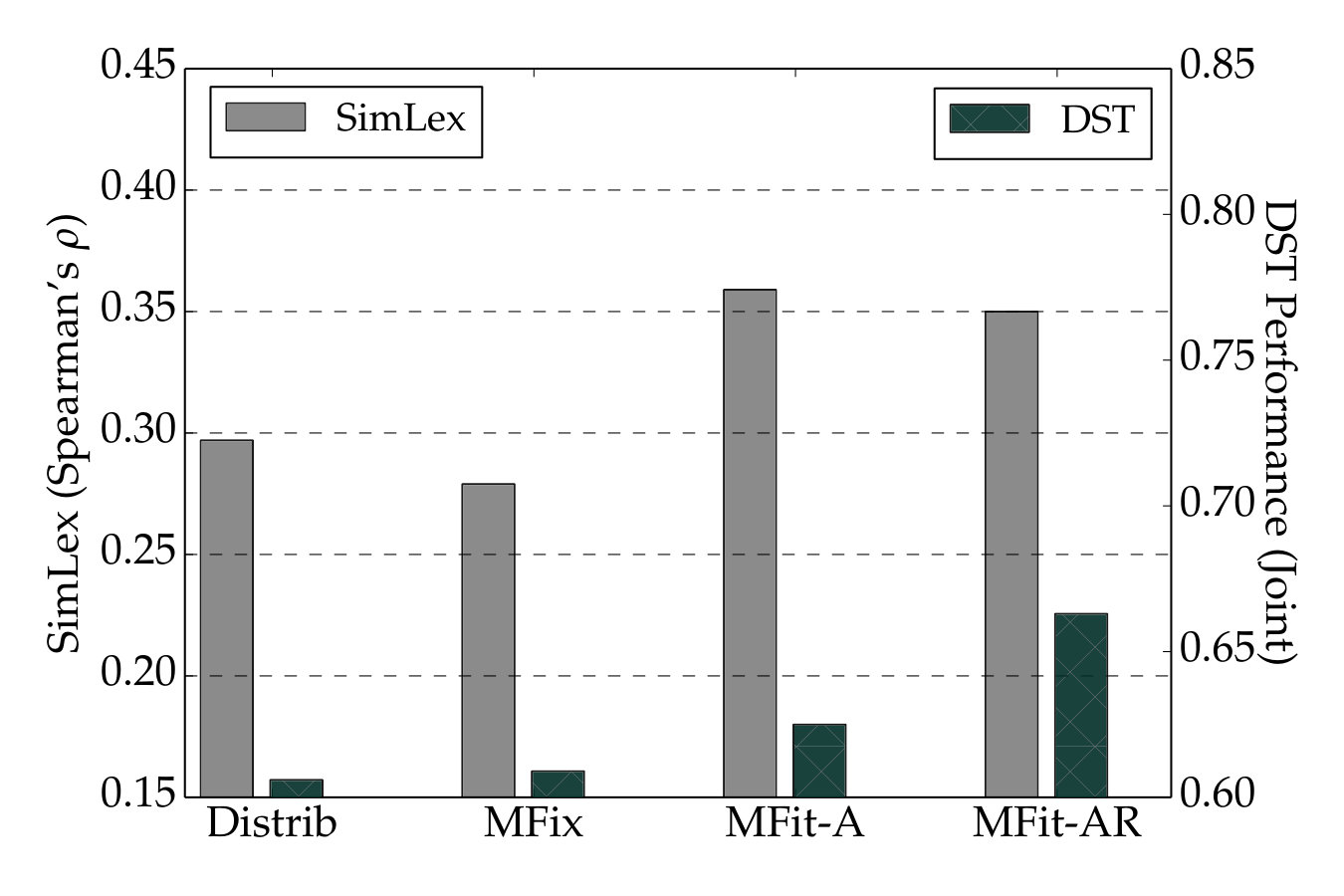 Figure 2
Figure 2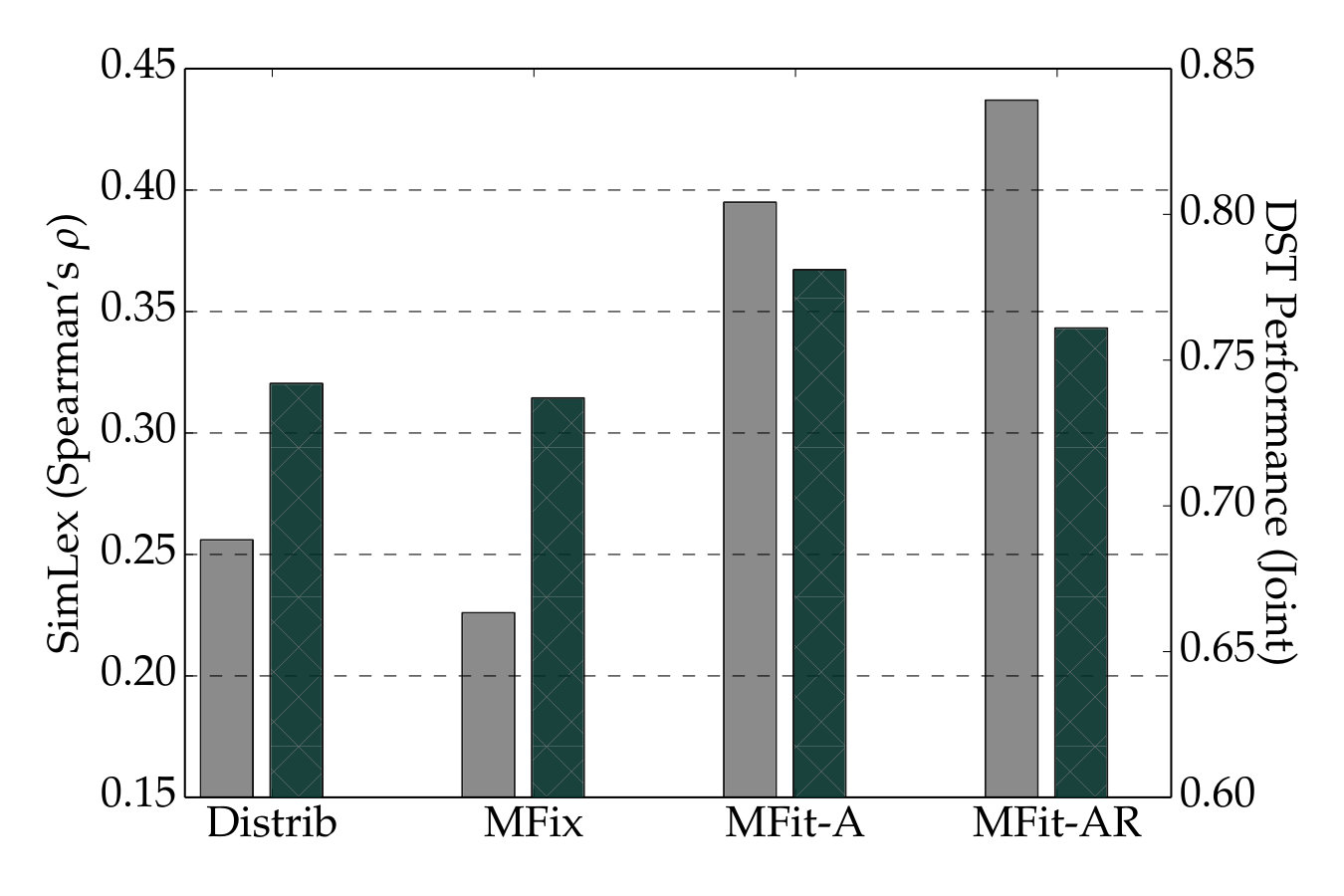 Figure 3
Figure 3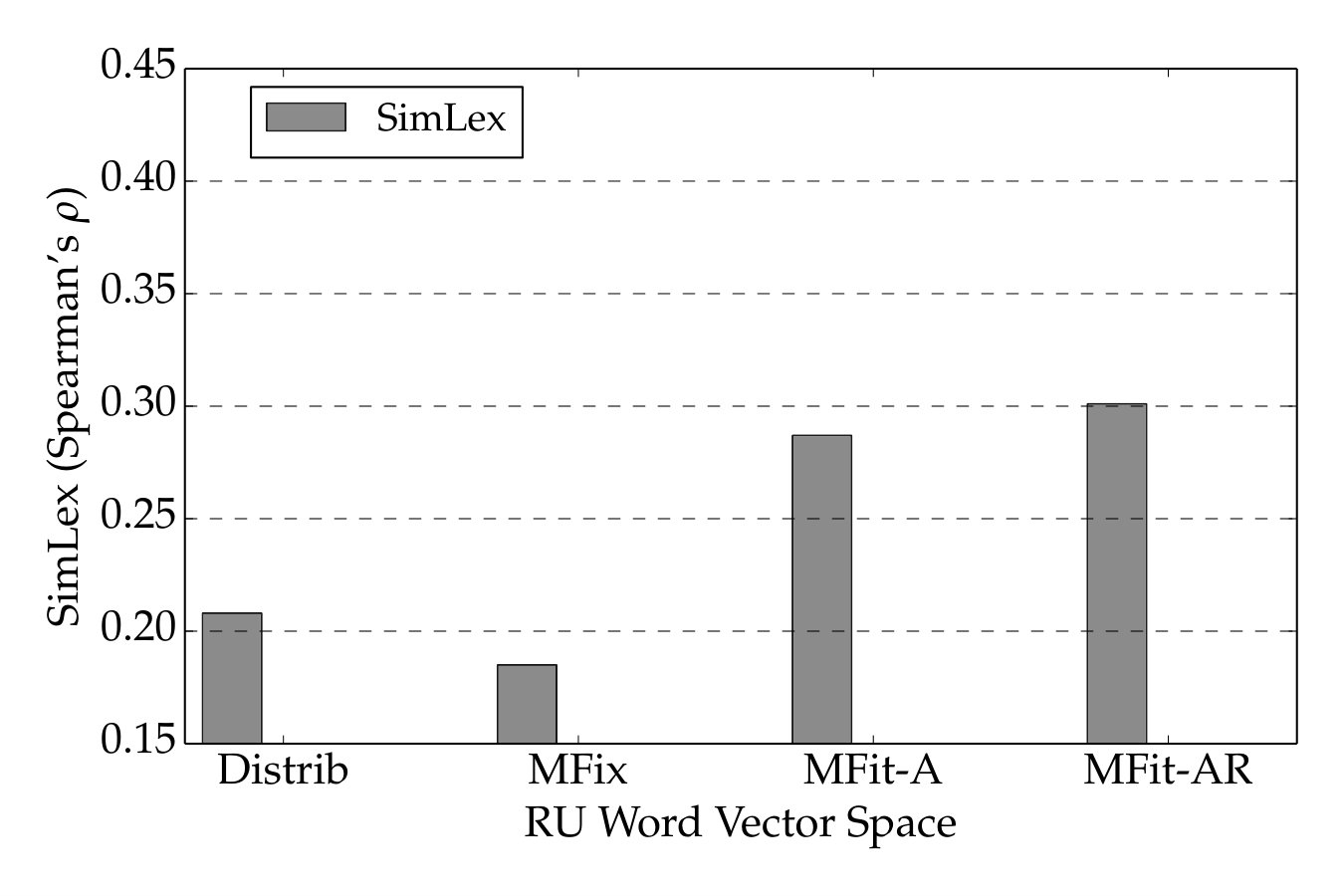 Figure 4
Figure 4 Figure 5
Figure 5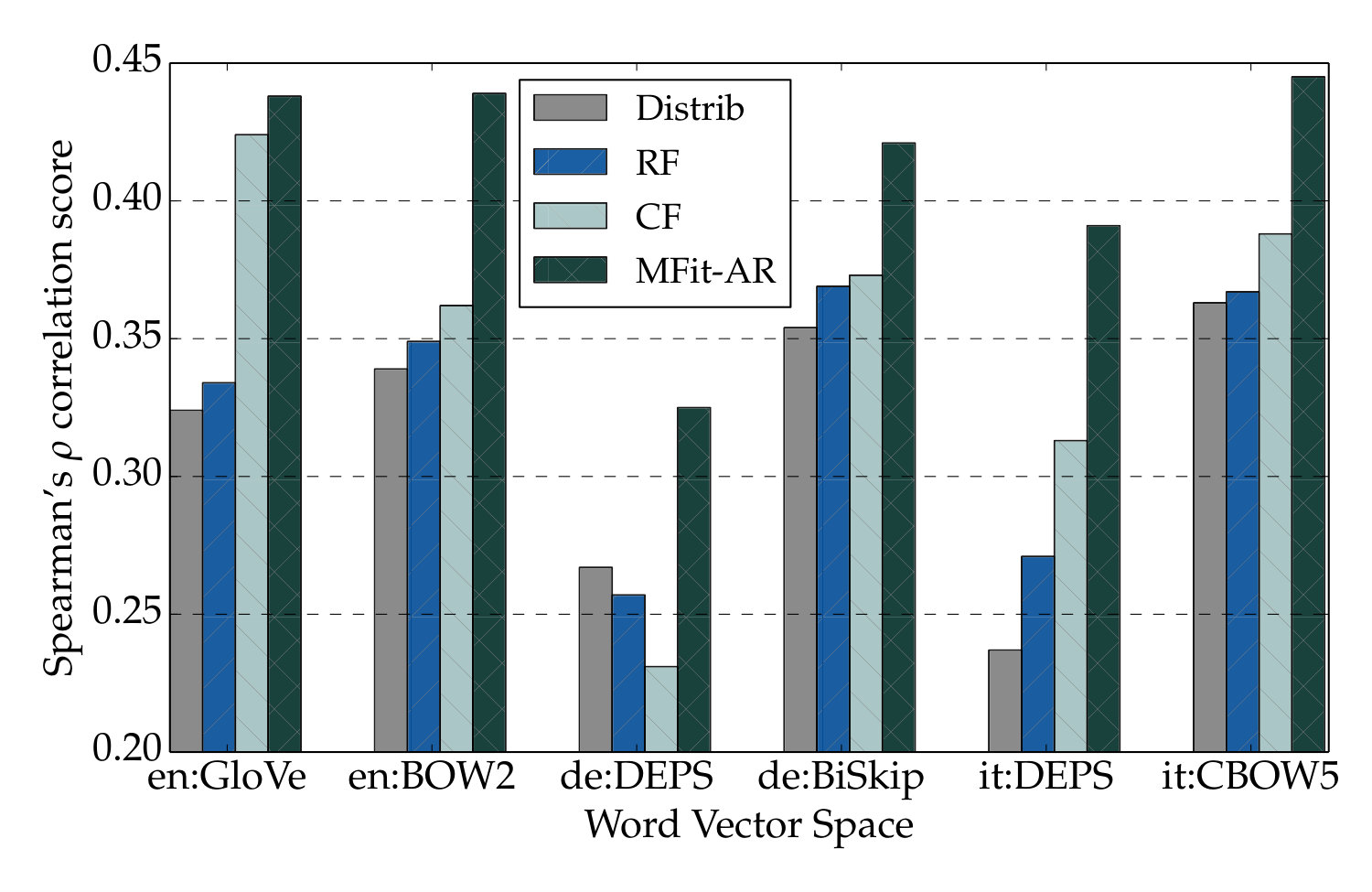 Figure 6
Figure 6| en_expensive | de_teure | it_costoso | en_slow | de_langsam | it_lento | en_book | de_buch | it_libro |
|---|---|---|---|---|---|---|---|---|
| costly | teuren | dispendioso | fast |
| English | German | Italian |
| (discuss, discussed) | (schottisch, schottischem) | (golfo, golfi) |
| (laugh, laughing) | (damalige, damaligen) | (minato, minata) |
| (pacifist, pacifists) | (kombiniere, kombinierte) | (mettere, metto) |
| (evacuate, evacuated) | (schweigt, schweigst) | (crescono, cresci) |
| (evaluate, evaluates) | (hacken, gehackt) | (crediti, credite) |
| (dressed, undressed) | (stabil, unstabil) | (abitata, inabitato) |
| (similar, dissimilar) | (geformtes, ungeformt) | (realtà, irrealtà) |
| (formality, informality) | (relevant, irrelevant) | (attuato, inattuato) |
| || | || | || | |
|---|---|---|---|
| English | 1,368,891 | 231,448 | 45,964 |
| German | 1,216,161 | 648,344 | 54,644 |
| Italian | 541,779 | 278,974 | 21,400 |
| Russian | 950,783 | 408,400 | 32,174 |
| Evaluation | ||
| Vectors | SimLex-999 | SimVerb-3500 |
| 1. SG-BOW2-PW (300) | ||
| Mikolov et al. (2013) | .339 .439 | .277 .381 |
| 2. GloVe-6B (300) | ||
| Pennington et al. (2014) | .324 .438 | .286 .405 |
| 3. Count-SVD (500) | ||
| Baroni et al. (2014) | .267 .360 | .199 .301 |
| 4. SG-DEPS-PW (300) | ||
| Levy and Goldberg (2014) | .376 .434 | .313 .418 |
| 5. SG-DEPS-8B (500) | ||
| Bansal et al. (2014) | .373 .441 | .356 .473 |
| 6. MultiCCA-EN (512) | ||
| Faruqui and Dyer (2014) | .314 .391 | .296 .354 |
| 7. BiSkip-EN (256) | ||
| Luong et al. (2015) | .276 .356 | .260 .333 |
| 8. SG-BOW2-8B (500) | ||
| Schwartz et al. (2015) | .373 .440 | .348 .441 |
| 9. SymPat-Emb (500) | ||
| Schwartz et al. (2016) | .381 .442 | .284 .373 |
| 10. Context2Vec (600) | ||
| Melamud et al. (2016) | .371 .440 | .388 .459 |
| Vectors | Distrib. | MFit-A | MFit-AR |
| en: GloVe-6B (300) | .324 | .376 | .438 |
| en: SG-BOW2-PW (300) | .339 | .385 | .439 |
| de: SG-DEPS-PW (300) | |||
| Vulić and Korhonen (2016a) | .267 | .318 | .325 |
| de: BiSkip-DE (256) | |||
| Luong et al. (2015) | .354 | .414 | .421 |
| it: SG-DEPS-PW (300) | |||
| Vulić and Korhonen (2016a) | .237 | .351 | .391 |
| it: CBOW5-Wacky (300) | |||
| Dinu et al. (2015) | .363 | .417 | .446 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Morph-fitting: Fine-Tuning Word Vector Spaces
with Simple Language-Specific Rules
Ivan Vulić1, Nikola Mrkšić1, Roi Reichart2
**Diarmuid Ó Séaghdha3, Steve Young1, Anna Korhonen1
1 University of Cambridge 2 Technion, Israel Institute of Technology 3 Apple Inc.
{iv250,nm480,sjy11,alk23}@cam.ac.uk
[email protected] [email protected] **
Abstract
Morphologically rich languages accentuate two properties of distributional vector space models: 1) the difficulty of inducing accurate representations for low-frequency word forms; and 2) insensitivity to distinct lexical relations that have similar distributional signatures. These effects are detrimental for language understanding systems, which may infer that inexpensive is a rephrasing for expensive or may not associate acquire with acquires. In this work, we propose a novel morph-fitting procedure which moves past the use of curated semantic lexicons for improving distributional vector spaces. Instead, our method injects morphological constraints generated using simple language-specific rules, pulling inflectional forms of the same word close together and pushing derivational antonyms far apart. In intrinsic evaluation over four languages, we show that our approach: 1) improves low-frequency word estimates; and 2) boosts the semantic quality of the entire word vector collection. Finally, we show that morph-fitted vectors yield large gains in the downstream task of dialogue state tracking, highlighting the importance of morphology for tackling long-tail phenomena in language understanding tasks.
1 Introduction
Word representation learning has become a research area of central importance in natural language processing (NLP), with its usefulness demonstrated across many application areas such as parsing Chen and Manning (2014); Johannsen et al. (2015), machine translation Zou et al. (2013), and many others Turian et al. (2010); Collobert et al. (2011). Most prominent word representation techniques are grounded in the distributional hypothesis Harris (1954), relying on word co-occurrence information in large textual corpora (Curran, 2004; Turney and Pantel, 2010; Mikolov et al., 2013; Mnih and Kavukcuoglu, 2013; Levy and Goldberg, 2014; Schwartz et al., 2015, i.a.).
Morphologically rich languages, in which “substantial grammatical information…is expressed at word level” Tsarfaty et al. (2010), pose specific challenges for NLP. This is not always considered when techniques are evaluated on languages such as English or Chinese, which do not have rich morphology. In the case of distributional vector space models, morphological complexity brings two challenges to the fore:
1. Estimating Rare Words: A single lemma can have many different surface realisations. Naively treating each realisation as a separate word leads to sparsity problems and a failure to exploit their shared semantics. On the other hand, lemmatising the entire corpus can obfuscate the differences that exist between different word forms even though they share some aspects of meaning.
2. Embedded Semantics: Morphology can encode semantic relations such as antonymy (e.g. literate and illiterate, expensive and inexpensive) or (near-)synonymy (north, northern, northerly).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Aharoni and Goldberg (2017) Roee Aharoni and Yoav Goldberg. 2017. Morphological inflection generation with hard monotonic attention . In Proceedings of ACL . https://arxiv.org/abs/1611.01487 .
- 2Al-Rfou et al. (2013) Rami Al-Rfou, Bryan Perozzi, and Steven Skiena. 2013. Polyglot: Distributed word representations for multilingual NLP . In Proceedings of Co NLL . pages 183–192. http://www.aclweb.org/anthology/W 13-3520 .
- 3Avramidis and Koehn (2008) Eleftherios Avramidis and Philipp Koehn. 2008. Enriching morphologically poor languages for statistical machine translation . In Proceedings of ACL . pages 763–770. http://www.aclweb.org/anthology/P/P 08/P 08-1087 .
- 4Baayen et al. (1995) Harald R. Baayen, Richard Piepenbrock, and Hedderik van Rijn. 1995. The CELEX lexical data base on CD-ROM .
- 5Bansal et al. (2014) Mohit Bansal, Kevin Gimpel, and Karen Livescu. 2014. Tailoring continuous word representations for dependency parsing . In Proceedings of ACL . pages 809–815. http://www.aclweb.org/anthology/P 14-2131 .
- 6Baroni et al. (2014) Marco Baroni, Georgiana Dinu, and Germán Kruszewski. 2014. Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors . In Proceedings of ACL . pages 238–247. http://www.aclweb.org/anthology/P 14-1023 .
- 7Bhatia et al. (2016) Parminder Bhatia, Robert Guthrie, and Jacob Eisenstein. 2016. Morphological priors for probabilistic neural word embeddings . In Proceedings of EMNLP . pages 490–500. https://aclweb.org/anthology/D 16-1047 .
- 8Bian et al. (2014) Jiang Bian, Bin Gao, and Tie-Yan Liu. 2014. Knowledge-powered deep learning for word embedding . In Proceedings of ECML-PKDD . pages 132–148. https://doi.org/10.1007/978-3-662-44848-9_9 . · doi ↗