A Latent Trait Model for Multivariate Longitudinal Data With Two Sources of Measurement Error
Amy E. Nussbaum, Cornelis J. Potgieter, Michael Chmielewski

TL;DR
This paper develops a latent trait model for multivariate longitudinal Likert-scale data, accounting for transient and measurement errors, and introduces two estimation methods applied to personality assessment data.
Contribution
It proposes a novel latent trait model with two measurement error sources and compares correlation reconstruction and stochastic EM estimation methods.
Findings
Both estimation methods successfully applied to real data
Model effectively captures latent traits with measurement errors
Provides a framework for analyzing longitudinal Likert-scale data
Abstract
Personality traits are latent variables, and as such, are impossible to measure without the use of an assessment. Responses on the assessments can be influenced by both transient (state-related) error and measurement error, obscuring the true trait levels. Typically, these assessments utilize Likert scales, which yield only discrete data. The loss of information due to the discrete nature of the data represents an additional challenge in assessing the ability of these instruments to measure the latent trait of interest. This paper is concerned with parameter estimation in a model relating a latent variable, as well transient error and measurement error components when data are longitudinal and measured using a Likert scale. Two methods for parameter estimation are detailed: correlation reconstruction, a method that uses polychoric correlations, and maximum likelihood implemented using…
Click any figure to enlarge with its caption.
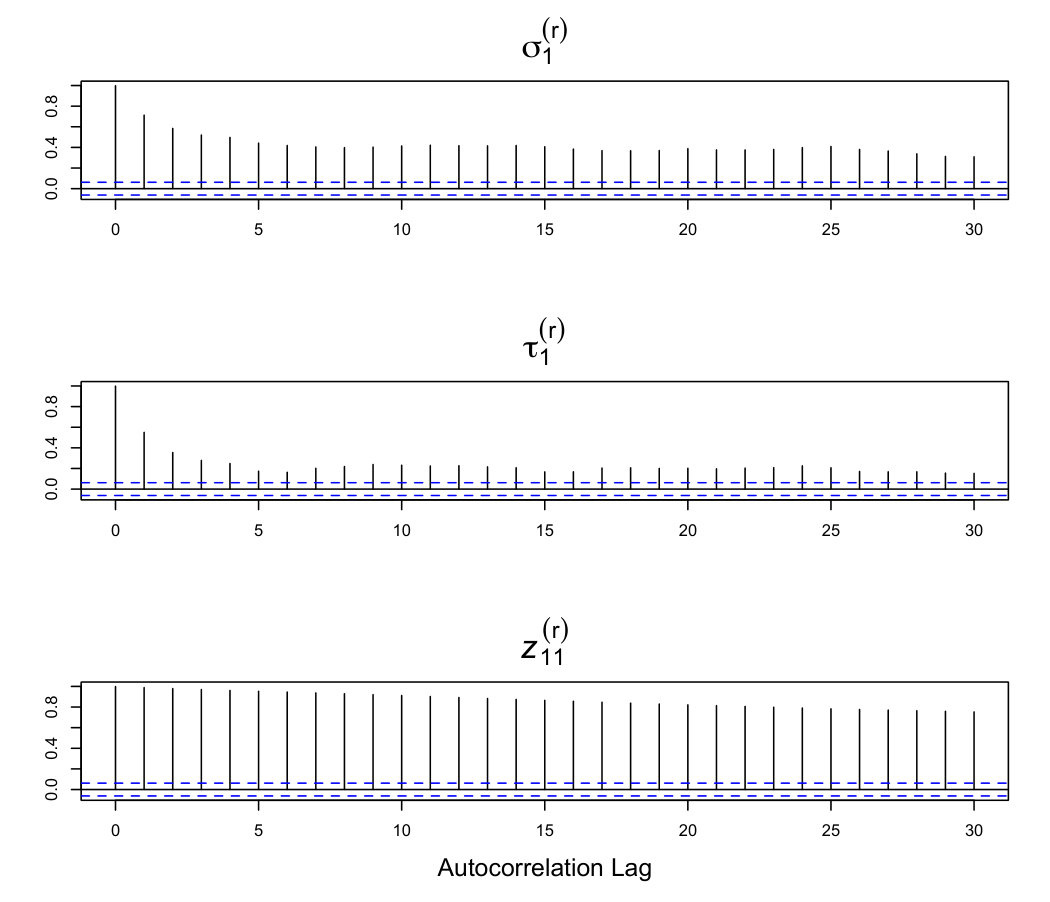 Figure 1
Figure 1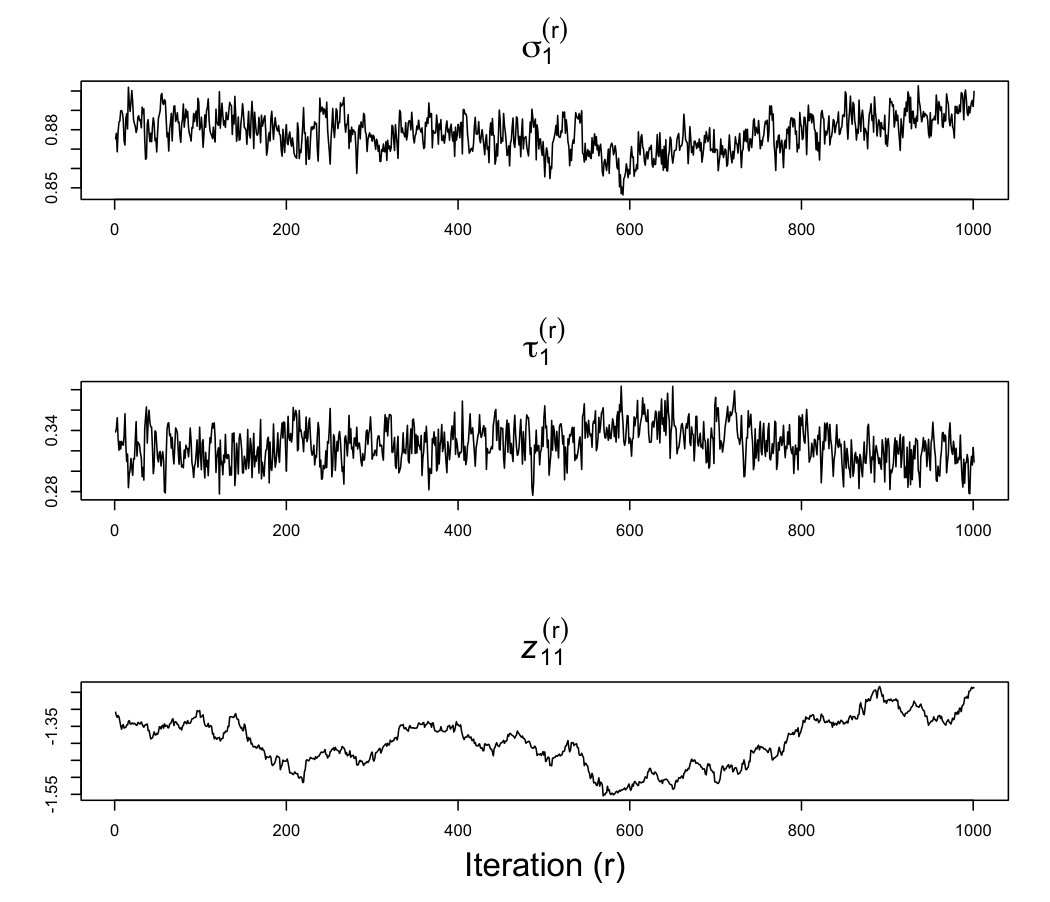 Figure 2
Figure 2| Estimator | CR | StEM | CR | StEM |
| 0.036 | 0.023 | 0.015 | 0.014 | |
| 0.040 | 0.031 | 0.020 | 0.019 | |
| 0.046 | 0.040 | 0.025 | 0.025 | |
| 0.053 | 0.048 | 0.030 | 0.031 | |
| 0.059 | 0.057 | 0.034 | 0.035 | |
| 0.049 | 0.048 | 0.030 | 0.030 | |
| 0.056 | 0.054 | 0.034 | 0.033 | |
| 0.060 | 0.058 | 0.038 | 0.036 | |
| 0.058 | 0.056 | 0.037 | 0.036 | |
| 0.063 | 0.060 | 0.038 | 0.036 | |
| True Value | CR. | StEM | CR | StEM |
| 0.138 | 0.155 | 0.094 | 0.099 | |
| 0.114 | 0.120 | 0.076 | 0.077 | |
| 0.113 | 0.121 | 0.075 | 0.076 | |
| 0.122 | 0.134 | 0.079 | 0.082 | |
| 0.122 | 0.135 | 0.079 | 0.082 | |
| 0.111 | 0.116 | 0.072 | 0.073 | |
| 0.109 | 0.115 | 0.071 | 0.073 | |
| 0.115 | 0.127 | 0.076 | 0.081 | |
| 0.113 | 0.124 | 0.075 | 0.079 | |
| 0.103 | 0.108 | 0.070 | 0.071 | |
| 0.104 | 0.109 | 0.070 | 0.071 | |
| 0.116 | 0.128 | 0.076 | 0.080 | |
| 0.114 | 0.126 | 0.073 | 0.077 | |
| 0.102 | 0.110 | 0.065 | 0.068 | |
| 0.098 | 0.105 | 0.065 | 0.067 | |
| 0.111 | 0.123 | 0.070 | 0.074 | |
| 0.124 | 0.137 | 0.079 | 0.086 | |
| 0.102 | 0.107 | 0.067 | 0.070 | |
| 0.101 | 0.109 | 0.067 | 0.070 | |
| 0.108 | 0.122 | 0.070 | 0.075 | |
| Openness | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Cuts | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 41 | 44 | |
| -1.75 | -2.08 | -1.82 | -1.69 | -1.76 | -1.56 | -1.31 | -1.93 | -1.49 | -1.17 | ||
| -1.00 | -1.43 | -0.80 | -0.87 | -0.64 | -0.80 | -0.21 | -0.90 | -0.53 | -0.38 | ||
| -0.14 | -0.71 | 0.06 | -0.14 | 0.30 | -0.17 | 0.55 | -0.04 | -0.02 | 0.22 | ||
| 1.14 | 0.74 | 1.11 | 0.99 | 1.44 | 0.69 | 1.52 | 1.10 | 0.82 | 1.01 | ||
| Openness | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Cuts | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 41 | 44 | |
| -1.75 | -2.11 | -1.80 | -1.70 | -1.75 | -1.54 | -1.33 | -1.98 | -1.45 | -1.15 | ||
| -0.97 | -1.43 | -0.78 | -0.86 | -0.61 | -0.77 | -0.23 | -0.86 | -0.52 | -0.37 | ||
| -0.12 | -0.70 | 0.08 | -0.14 | 0.31 | -0.14 | 0.55 | -0.03 | -0.01 | 0.22 | ||
| 1.17 | 0.75 | 1.14 | 0.98 | 1.50 | 0.71 | 1.54 | 1.12 | 0.85 | 1.06 | ||
| Openness | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Item () | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 41 | 44 | |
| 0.41 | 0.28 | 0.31 | 0.35 | 0.39 | 0.66 | 0.02 | 0.40 | 0.40 | 0.65 | ||
| 0.15 | 0.06 | 0.18 | 0.08 | 0.14 | 0.02(-) | 0.00(-) | 0.16 | 0.13(-) | 0.04(-) | ||
| 0.43 | 0.66 | 0.51 | 0.57 | 0.47 | 0.33 | 0.99 | 0.44 | 0.47 | 0.31 | ||
| Openness | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Item () | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 41 | 44 | |
| 0.33 | 0.25 | 0.24 | 0.27 | 0.29 | 0.69 | 0.01 | 0.31 | 0.44 | 0.74 | ||
| 0.24 | 0.12 | 0.24 | 0.13 | 0.22 | 0.00 | 0.00 | 0.30 | 0.04(-) | 0.02(-) | ||
| 0.43 | 0.63 | 0.52 | 0.59 | 0.49 | 0.31 | 0.99 | 0.39 | 0.52 | 0.24 | ||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Statistical Modeling Techniques · Mental Health Research Topics · Statistical Methods in Clinical Trials
A Latent Trait Model for Multivariate Longitudinal Data With Two Sources of Measurement Error
Amy E. Nussbaum Corresponding Author: [email protected]
Cornelis J. Potgieter
Department of Statistical Science
Southern Methodist University, Dallas, TX 75205
Michael Chmielewski
Department of Psychology
Southern Methodist University, Dallas, TX 75205
Abstract
Personality traits are latent variables, and as such, are impossible to measure without the use of an assessment. Responses on the assessments can be influenced by both transient (state-related) error and measurement error, obscuring the true trait levels. Typically, these assessments utilize Likert scales, which yield only discrete data. The loss of information due to the discrete nature of the data represents an additional challenge in assessing the ability of these instruments to measure the latent trait of interest.
This paper is concerned with parameter estimation in a model relating a latent variable, as well transient error and measurement error components when data are longitudinal and measured using a Likert scale. Two methods for parameter estimation are detailed: correlation reconstruction, a method that uses polychoric correlations, and maximum likelihood implemented using a Stochastic EM algorithm. These methods are applied to a motivating dataset of 440 college students taking the Big Five inventory twice in a two month period.
1 Introduction
A common approach in latent variable modeling is the assumption that the latent variables follow some type of continuous distribution. Specifically, analysis often proceeds under the assumption of normality (see Fleeson [9], Breckler [4], and Finney and DiStefano [8] for examples and details). However, data collected on individual assessment items are often measured using a Likert scale, and as such, is inherently discrete. For instance, subjects responding to a statement using a five point Likert scale reply with a number from one to five representing how strongly they agree or disagree with the statement. The use of such scales represents data coarsening (a loss of information). To accurately estimate model parameters, the discrete nature of the data must be properly taken into account.
Parameter estimation in latent variable models based on polytomous outcome data is not a new topic, with groundbreaking work being done by Rasch [17] and Andrich [1]. An overview of the topic and references to recent literature can be found in [2]. The contribution of this paper lies in allowing for two independent sources of error, called transient error and measurement error, that obscure the latent trait of interest. Identifiability of both sources of error necessitates data being longitudinal in nature.
Two methods of parameter estimation are considered. The first of these, herein called correlation reconstruction, is a method that relies on polychoric correlation estimation, see the work of Olsson ([15] and [16]) for development. The second method is maximum likelihood, which is implemented using a variation of the EM algorithm. The EM algorithm, developed by Dempster, Laird, & Rubin [7], is a method for implementing maximum likelihood in incomplete data problems with latent variable models being only one common application. In this paper, a Stochastic EM algorithm [14] is implemented. This is a specific application of the more general Monte Carlo EM algorithm, see [22] and [12], which is useful when conditional expectation terms occurring in the EM log-likelihood function are approximated using Monte Carlo integration.
The present work was motivated by data collected from 440 students from the University of Iowa taken at two different time points two weeks apart, see Chmielewski and Watson [6]. These students took the Big Five Inventory (BFI), a widely used personality assessment consisting of forty-four statements on five separate traits: Agreeableness, Conscientiousness, Extraversion, Neuroticism, and Openness. Subjects respond to the statements using a five point Likert scale. The BFI is a widely used measure of the Big Five with well established psychometric properties ([11]).
It is useful to contextualize instruments such as the BFI using latent state-trait models, developed by Rolf Steyer and Manfred Schmitt in the nineties. Steyer and Schmitt [18] define a trait as “an enduring property of a person, at least with respect to the time span considered.” These traits are not expected to change over a short period of time. However, person’s state can obscure the true level of his or her trait. States are less consistent than traits. They can change depending on both internal and external circumstances, such as “one’s present state of mind, mood, self-consciousness, or on specific situational influences” [18]. If the goal of a personality assessment is to measure trait levels, states represent a systematic type of measurement error, otherwise known as transient error or state error.
The stability of trait measurements can have “implications for the diagnosis of clinical disorders, […] help determine the utility of therapeutic interventions, and influence decisions regarding whether individuals should be rehabilitated or placed into long-term supervision” [6]. Because of the serious consequences of trait measurement, it is vital that the instruments built to measure traits are doing so effectively. Neglecting potential sources of error can lead to severe repercussions, and it may be that many psychologists do not consider the ramifications of their decisions. Chmielewski and Watson write, “Indeed, it seems that the potential influence of error is often ignored and that the general tendency is for all observed change to be considered indicative of true change in the underlying construct” [6]. They point out that if the presence of transient error is acknowledged in analysis of personality assessments, traits are actually more stable over time than previously believed. Furthermore, they provide several examples of analyses of data corrected for transient error and show that using a correction can lead to different conclusions than those made without the correction.
The paper proceeds as follows. In the next section, a latent variable model with transient error and measurement error components is proposed. Subsequent sections outline the correlation reconstruction and Stochastic EM algorithm approaches used for parameter estimation. Thereafter, a simulation study is done to compare the performance of these methods. After presenting an application of the methodology to one of the scales of the motivating data, conclusions are presented.
2 Latent Variable Model Structure
Let denote the Likert-scale response of individual to the items at timepoints. The observed data are assumed to represent a coarsened version of the true continuous latent response to each item. Specifically, let denote the latent response vector of individual . For individual , the latent trait is denoted with transient error denoted and measurement error denoted . It is assumed that , and are standard normal random variables. The latent response is assumed to be of the form
[TABLE]
Here, represents the strength with which item measures the true latent trait, while and represent the sizes of the transient error and measurement error associated with item . Note that the transient error is time-specific, but does not vary across items at a given period in time. On the other hand, measurement error is both item-specific and time-specific.
Next, the relationship between the true latent vector and the observed response vector is formalized. One common model is to assume that Likert-scale observations are obtained from a parameter cut point model, which is equivalent to the Likert scale consisting of categories. Formally, the cut points of item are denoted and the observed data are related to the latent response data thought the function where
[TABLE]
This model offers a great deal of flexibility, but requires the estimation of a large number of cut points for any given scale. Future research will explore ways of reducing the number of cut points being estimated while trying to retain flexibility.
Next, note that the data coarsening resulting from the transformation (2) means that the means and variances associated with latent variables are no longer identifiable from the Likert-scale data. It is therefore assumed without loss of generality that and for . The model in (1) now becomes
[TABLE]
Under this simplified model, represents the proportion of total item variance due to signal strength, and and represent the proportions of total item variance due to transient error and measurement error. Furthermore, the covariance matrix and correlation matrix for the model are identical. The correlation structure derived from model (3) has a block-patterned structure. Let denote the covariance matrix of , then
[TABLE]
where
\mathbf{A}=\left[\begin{array}[]{cccc}1&\sigma_{1}\sigma_{2}+\tau_{1}\tau_{2}&\cdots&\sigma_{1}\sigma_{J}+\tau_{1}\tau_{J}\\ \sigma_{2}\sigma_{1}+\tau_{1}\tau_{2}&1&\cdots&\sigma_{2}\sigma_{J}+\tau_{2}\tau_{J}\\ \vdots&\vdots&\ddots&\vdots\\ \sigma_{J}\sigma_{1}+\tau_{J}\tau_{1}&\sigma_{J}\sigma_{2}+\tau_{J}\tau_{2}&\cdots&1\end{array}\right]
and
\mathbf{B}=\left[\begin{array}[]{cccc}\sigma_{1}^{2}&\sigma_{1}\sigma_{2}&\cdots&\sigma_{1}\sigma_{J}\\ \sigma_{2}\sigma_{1}&\sigma_{2}^{2}&\cdots&\sigma_{2}\sigma_{J}\\ \vdots&\vdots&\ddots&\vdots\\ \sigma_{J}\sigma_{1}&\sigma_{J}\sigma_{2}&\cdots&\sigma_{J}^{2}\end{array}\right]_{.}
It seems prudent to emphasize that the block-patterned matrix corresponds to the correlation structure of the latent vector and not the Likert-scale vector . The correlation structure of can be derived in a straight-forward manner, but expressions are double summations of terms involving the bivariate normal cdf. Furthermore, these are neither useful for the purposes of parameter estimation, nor for model interpretation, and are not included here.
3 The Correlation Reconstruction Approach
In this section, a moment-based approach to estimating the item-specific cut points is described. Thereafter, the general idea behind correlation reconstruction, which makes use of polychoric correlation estimation, is outlined.
3.1 Cut Point Estimation
From model (3), each latent variable has a standard normal distribution. Therefore, from which it follows that . Here, and denote the standard normal cdf and quantile functions. This motivates cut point estimators
[TABLE]
where denotes the indicator function. The proposed estimator, hereafter referred to as the inverse normal method of moments estimator, includes a small-sample adjustment (adding one in the numerator and two in the denominator) to avoid the possibility of estimated cut points equal to . Extensive numerical work suggests that this adjustment has a two-fold effect: while it does result in a slight increase in the bias of the cut point estimators, there is an overall reduction in RMSE. Furthermore, the bias introduced is by this adjustment is asymptotically negligible. Recognizing that cut points are not functions of time, data across multiple time points can be combined to improve estimation, namely
[TABLE]
3.2 Polychoric Correlation
Below is a brief outline of how polychoric correlation estimation can be implemented to recover the correlation between two latent variables when only their Likert-scale counterparts are observed. Polychoric correlation was first implemented by . Let follow a bivariate normal distribution with zero mean, unit variance and correlation coefficient . Let denote the associated Likert-scale vector, and where for . For each pair of values , , define . The empirical estimate of based on data , , is given by
[TABLE]
The associated theoretical probability is given by
[TABLE]
where is the bivariate normal cdf with standard normal marginals and correlation coefficient . The likelihood function, expressed in terms of these empirical and theoretical probabilities, is given by
[TABLE]
The above likelihood function can be maximized simultaneously over , but this requires maximizing a nonlinear function in dimensions. Alternatively, a marginal likelihood function for can be constructed by substituting the inverse normal method of moment estimators and , with components calculated as in (6), into the likelihood function. As discussed by Olsson, ([15]), the differences with regards to efficiency between the full likelihood and marginal plug-in likelihood are very small, and the use of a marginal likelihood function has the advantage of reduced computational labor. In this paper, the marginal plug-in approach will be used.
3.3 Correlation Reconstruction
The outlined procedure in the previous subsection for calculating the polychoric correlation between two Likert-type items can be generalized to estimating the correlation structure for all items on the assessment. Recall that denotes the covariance matrix for latent vector . First, all cut points for all items are estimated by applying the inverse normal method according to (5) and (6). Let denote the correlation estimate reconstructed from observed pairs , . Define whenever and otherwise. Also define where . The matrix of so-called reconstructed correlation coefficients, , is given by
[TABLE]
While the reconstructed correlation matrix (8) is asymptotically unbiased for the true correlation structure, it does not typically conform to the block-diagonal structure as described in (4). Therefore, attempting to use directly to estimate the parameters results in an over-identified system of equations. One way to circumvent this problem is to use a matrix norm such as the Frobenius norm to minimize the distance between estimate and parameterized matrix . Specifically, define the Frobenius norm of an matrix ,
[TABLE]
where is the element in the row and column of matrix . Then, the minimum distance estimators of are obtained by minimizing
[TABLE]
Note that and one therefore only needs to minimize this function in terms of and , .
In this paper, the choice of the Frobenius norm is motivated by moderate robustness considerations. As the Frobenius norm is the square root of the Euclidean distance between the two matrices, it is more robust against outliers than, say, the Euclidean distance. However, there may be considerations other than robustness which motivate the practitioner and those could result in the use of a different matrix norm.
4 Maximum Likelihood using a Stochastic EM Algorithm
Direct maximization of the likelihood for the model being considered is numerically difficult, as the latent trait component common to all items at all time points and the transient error component common to all items at a given time point result in likelihood function involving multiple integrals with no closed-form solutions. Difficulties with similar models have been addressed by [14]. However, the EM algorithm is a method for finding maximum likelihood estimators when analyzing data sets with missing values and/or latent responses and is ideal for use in the present setting. First developed by Dempster, Laird, and Rubin [7], the EM algorithm starts with the complete data log-likelihood assuming the latent variables were observed. The algorithm then iterates between an expectation step (E-step) where the expectation of the complete data log-likelihood function is evaluated conditional on the observed data and using an estimate of the model parameters. Next, in the maximization step (M-step), the function obtained in the E-step is maximized to update the parameter estimates. These two steps are alternated until convergence is reached.
To be more precise, let denote the complete data log-likelihood and let denote the value of the parameter estimates after iterations of the algorithm. During the E-step of the algorithm, the function Q(\theta\big{|}\theta^{(r)})=E_{\theta^{(r)}}[\ell(\theta|\mathbf{X},\mathbf{Y})\big{|}\mathbf{Y}] is evaluated and then during the M-step, Q(\theta\big{|}\theta^{(r)}) is maximized in terms of in order to obtain new parameter estimates . This is repeated until convergence of the parameter vector. In the present setting, the parameter vector is given by where , and with . The cut points are defined as before, but for convenience the notation and for is also introduced.
Recall that the latent vector follows a multivariate normal distribution with density function
[TABLE]
where and is the block-patterned covariance matrix in (4). The responses conditional upon the latent variables are independent of one another with
[TABLE]
The joint distribution of response vector and latent vector , found by combining (9) and (10), is
[TABLE]
for and for all . Notice from the above joint distribution of that the distribution of is a multivariate truncated normal.
Now, given individual response vectors and associated unobserved latent response vectors for , the complete-data likelihood is given by
[TABLE]
The function Q(\theta\big{|}\theta^{(r)}) (excluding constants not involving the parameters) is
[TABLE]
This function is separable in that it is the sum of a function depending only on and , the parameters used to define elements of the covariance matrix , and a function depending only on the cut points , . Therefore, define
[TABLE]
and
[TABLE]
Notice that the conditional expectations in (11) and (12) are equivalent to evaluating expectations of functions of multivariate truncated normal random variables. Recently, there has been renewed interest in explicit evaluation of the joint moments of this distribution, for example, see [23] and [10] (references to previous work can be found therein). However, neither the quadratic form in (11) nor the log-indicator function in (12) have been considered in the literature. One approach would be to evaluate these using numerical integration techniques, but in the present paper we choose to follow a different approach.
The Monte Carlo EM (MCEM) algorithm ([22], [14]) is a modification of the EM algorithm used when direct evaluation of the conditional expectations is cumbersome, but it is possible to sample from the conditional distribution. In the present setting, this requires sampling from a multivariate truncated normal distribution. Algorithms for doing so have been considered by [RodriguezYam04], [23], and [3]. The MCEM algorithm replaces the conditional expectations of the form by approximations
[TABLE]
where , are sampled from the distribution assuming . This paper implements a variation of the MCEM algorithm known as the Stochastic EM (StEM) algorithm. The StEM algorithm is an implementation of MCEM that sets , i.e. at each iteration of the algorithm, only one sample point is drawn per observation. This algorithm is discussed in greater detail in [14]. Formally, the StEM equations analogous to (11) and (12) are given by
[TABLE]
and
[TABLE]
where was drawn from the conditional distribution with parameter values .
Equation (13) is continuous in the parameters and and therefore standard optimization methods can be used. In this paper, the Barzilai-Borwein method as implemented in the R package BB was used to maximize (13), see [21] for details. Special care needs to be taken when maximizing (14). In fact, this function does not have a unique maximum and most standard numerical approaches will give erratic results. However, it is possible to define a closed-form estimator of the cut points. Define sets , . Inspection of (14) reveals that it is constant as a function of for all for all . Any value inside this interval would be a valid maximum likelihood estimator of . The non-uniqueness of the maximum is sidestepped by defining
[TABLE]
for the step of the StEM algorithm and for and . Note that this is one possible maximum likelihood estimator.
In implementation, the simulation and maximization steps of the StEM algorithm are repeated times and the final parameter estimates are defined to be the averages of the estimators obtained at each of the steps. Specifically,
[TABLE]
for and . While it is preferable to use larger values of , this also requires more resources in terms of time and computation. The effect of choosing will be investigated in a Monte Carlo simulation study in the next section.
5 Simulation Study
Several simulation studies were performed to assess and compare the performance of correlation reconstruction and StEM-based maximum likelihood methods. For implementation of the StEM algorithm, samples from the multivariate truncated normal distribution were generated using rejection sampling as implemented in [3].
In the simulation study, latent responses were simulated according to model (3) using specified parameter values . The simulated latent responses were then converted to Likert-scale responses according to (2) using specified cut points for the item, .
For the simulation presented here, data were generated from a model with items and time points. The model parameters were , , and . These were chosen to have items ranging from large signal strength (80% of variability) to small signal strength (40% of variability). Samples of size and were simulated from this latent response model and then converted to Likert scales with using cut points for and for .
A total of data sets were generated in this way. For each, both correlation reconstruction and the StEM algorithm were implemented. For the StEM algorithm, iterations were used to also study the effect that the number of iterations has on the final parameter estimates. The StEM algorithm was also implemented with iterations, but results did not differ substantially from the case and are therefore not included.
To illustrate the StEM algorithm, index plots for parameter estimates , corresponding to a simulated data set are shown in Figure 1. Index plots for other parameter estimates have similar appearance and are excluded. Autocorrelation plots for these same parameter estimates are shown in Figure 2.
The index plots for and show good mixing and the corresponding autocorrelation plots show that the autocorrelation quickly decreases. This indicates that fewer iterations of the StEM algorithm are required to estimate the parameters of the covariance matrix. On the other hand, both the index plot and autocorrelation plot for show persistent autocorrelation even at large lags. This indicates that the algorithm may need to run for a large number of iterations to accurately estimate cut points.
Tables 1 and 2 summarize the simulation results using RMSE as a measure of performance.
Consider Table 1. It is clear that the RMSE of the estimators increases as the value of decreases (). This holds true both for correlation reconstruction and StEM. On the other hand, the RMSE of the estimators increases as the (absolute) value of increases (). The StEM estimators, which are approximate maximum likelihood estimators, tend to have smaller RMSE than the correlation reconstruction estimators. This effect is especially pronounced at sample size where, for example, the RMSE of decreases by over when , but decreases by less than when .
The results in Table 2 are noteworthy in that the inverse normal method of moments (MM) cut point estimators consistently have smaller RMSE than the StEM algorithm with . Again, this trend persisted with . As with estimation of the covariance parameters, the difference in performance of the two methods is only pronounced at the smaller sample size .
The superiority of the MM approach for cut point estimation as compared to StEM can easily be explained. Firstly, the MM cut point estimators defined in (5) incorporate an intentional bias - adding one in the numerator and two in the denominator before applying the inverse normal transform. As noted previously, this leads to a reduction in RMSE in small samples. Secondly, the StEM algorithm is, per definition, stochastic in nature. This leads to an added source of variability when computing these estimators. This source of variability decreases as increases, but because of persistent autocorrelation present in at large lags, a very large value of may be required before this source of variablity becomes negligible.
Although the StEM algorithm results in estimators theoretically optimal in an RMSE sense, it comes with a high cost. The average time to calculate estimates for a sample size of individuals taking an assessment with items and time points is slightly over minutes while correlation reconstruction takes around two minutes on the same personal computer. As a general observation based on extensive simulation results, correlation reconstruction performs nearly as well as StEM when or when the sample size becomes large. Based on the considerable computational cost associated with the StEM algorithm, correlation reconstruction is recommended as a convenient alternative that performs nearly as well even in moderate sample sizes.
6 Analysis of Motivating Data
The motivating data for the techniques developed in this paper comes from Chmielewski and Watson (2009). The data was collected from 440 students at the University of Iowa who completed the Big Five Inventory (BFI) twice with assessment opportunities two weeks apart. The inventory consists of forty-four statements on five separate traits: Agreeableness, Conscientiousness, Extraversion, Neuroticism, and Openness. The scales have between eight and ten items associated with them. For the sake of brevity, only estimates for the Openness scale are presented in the paper.
Adjectives associated with Openness include intelligent, imaginative, and perceptive, and researchers have also linked Openness to differentiated emotions, aesthetic sensitivity, and the need for variety to Openness. Individuals with low Openness levels are typically described as favoring conservative values, while those rated high tended to enjoy aesthetic impressions and have wide interests [13]. The Openness scale has a total of ten items.
Estimates of the cut points calculated the inverse normal method of moments and the stochastic EM algorithm are shown in tables 3 and 4. There differences in cut point estimates based on the two methods are negligible. performance.
Estimates of the signal strength, transient error, and measurement error components are shown in Table 5 (correlation reconstruction) and Table 6 (StEM). Note that estimated parameters are reported on a squared scale, as this scale has the natural interpretation of being a proportion of variance attributed to, respectively, the latent trait, transient error and measurement error. Also, as the transient error coefficients are allowed to be negative, a superscript will indicate that the parameter estimate on the original scale was negative. Item number corresponds to numbering on the BFI questionnaire.
Firstly, note that the two estimation methods give very similar results for the measurement error components . On many of the items, close to of the latent item variance can be attributed to measurement error. Item 35 is notable in that around of the latent item variance can be attributed to measurement error. Of course, it is impossible to say whether this is only specific to the target population of this study, or if this item gives poor results in general.
When considering the latent trait components , correlation reconstruction and StEM show a slight difference. Consistently, the signal strength estimate under correlation reconstruction is larger than that under StEM. The converse is true for the transient error components . However, while there are differences, the parameter estimates under both methods of estimation convey similar information: it would seem that item 44 is the single best measure of the latent trait with upward of of variability explained by the latent trait. Item 30 is a close second, while other items are mainly in the to range. As noted previously, item 35 does not seem to measure the latent trait in the present setting.
Also of note is the estimation of transient error components . The work done here was specifically to develop methodology for capturing transient error. It seems this is an important factor in the model. While several items have estimated transient error effects below , items 5, 15, 25 and 40 all have sizeable transient error effects present.
Some may question the interpretation of the transient error component estimates that have negative signs. Conditional on an individual’s trait level, the sign of indicates which direction the responses tend to vary in relation to one another. For instance, item 5 of the BFI reads, “I am someone who is original, comes up with new ideas” whereas item 41 reads, “I am someone who prefers work that is routine.” If transient error caused a higher response for a particular individual to item 5, the response to item 41 would likely be lower for the same individual.
7 Conclusion
In this paper, two methods for estimating parameters in longitudinal Likert-scale study with both transient error and measurement error were developed. The first approach relies on polychoric correlation estimation and then uses a matrix norm to estimate the parameters of interest. On the other hand, a stochastic EM algorithm is presented as a method of approximating the maximum likelihood estimators. While the StEM method has superior performance as measured by RMSE, implementation is computationally intensive and time-consuming. In the simulation study performed, correlation reconstruction performs nearly as well as the StEM algorithm for samples of size .
The techniques developed have been applied to a motivating data set. In doing so, evidence of transient error in a realistic setting was identified and the efficacy of the techniques has been demonstrated. Questions for future research include latent trait prediction at the individual level after model estimation has been performed, as well as model selection when deciding whether or not to include transient error and measurement error components.
8 Tables and Figures
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Andrich, D. (1978). A rating formulation for ordered response categories. Psychometrika , 43, 561-73.
- 2[2] Bartholomew, D. J., Knott, M. & and Moustaki, I. (2011) Latent variable models and factor analysis: A unified approach . Vol. 904. John Wiley & Sons.
- 3[3] Botev, Z. I. (2016). The normal law under linear restrictions: simulation and estimation via minimax tilting. Journal of the Royal Statistical Society: Series B (Statistical Methodology) .
- 4[4] Breckler, J.S., (1990) Applications of covariance structure modeling in psychology: Cause for concern?. Psychological bulletin , 107(2), 260.
- 5[5] Briggs, S.R., & Cheek, J.M. (1986) The role of factor analysis in the development and evaluation of personality scales. Journal of personality , 54(1) 106-148.
- 6[6] Chmielewksi, M. & Watson, D. (2009). What is being assessed and why It matters: the impact of transient error on trait research”. Journal of personality and social psychology , 97(1), 186.
- 7[7] Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm’. Journal of the royal statistical society. Series B (methodological) , 1-38.
- 8[8] Finney, S. J., & Di Stefano, C. (2006). Non-normal and categorical data in structural equation modeling. Structural equation modeling: A second course , 269-314.