Parcellation of Visual Cortex on high-resolution histological Brain Sections using Convolutional Neural Networks
Hannah Spitzer, Katrin Amunts, Stefan Harmeling, Timo Dickscheid

TL;DR
This paper introduces an automatic convolutional neural network-based method for high-resolution histological parcellation of the human visual cortex, improving efficiency and consistency over manual approaches.
Contribution
The study presents a novel CNN model that combines topological and texture features for scalable, accurate brain region parcellation at microscopic resolution.
Findings
Model achieves accurate parcellation of visual cortex areas.
Predictions are transferable across different brains.
Method ensures spatial consistency across sections.
Abstract
Microscopic analysis of histological sections is considered the "gold standard" to verify structural parcellations in the human brain. Its high resolution allows the study of laminar and columnar patterns of cell distributions, which build an important basis for the simulation of cortical areas and networks. However, such cytoarchitectonic mapping is a semiautomatic, time consuming process that does not scale with high throughput imaging. We present an automatic approach for parcellating histological sections at 2um resolution. It is based on a convolutional neural network that combines topological information from probabilistic atlases with the texture features learned from high-resolution cell-body stained images. The model is applied to visual areas and trained on a sparse set of partial annotations. We show how predictions are transferable to new brains and spatially consistent…
Click any figure to enlarge with its caption.
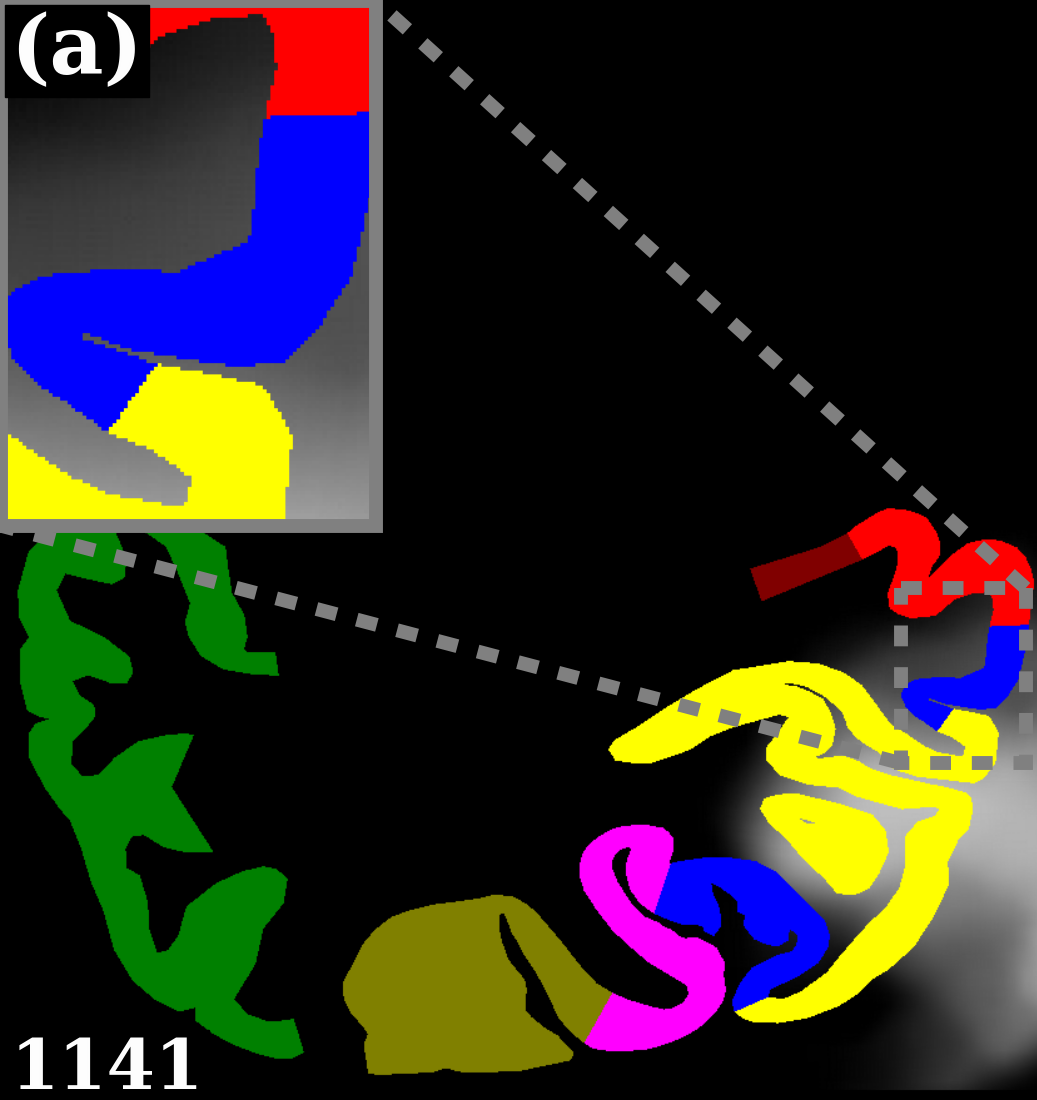 Figure 1
Figure 1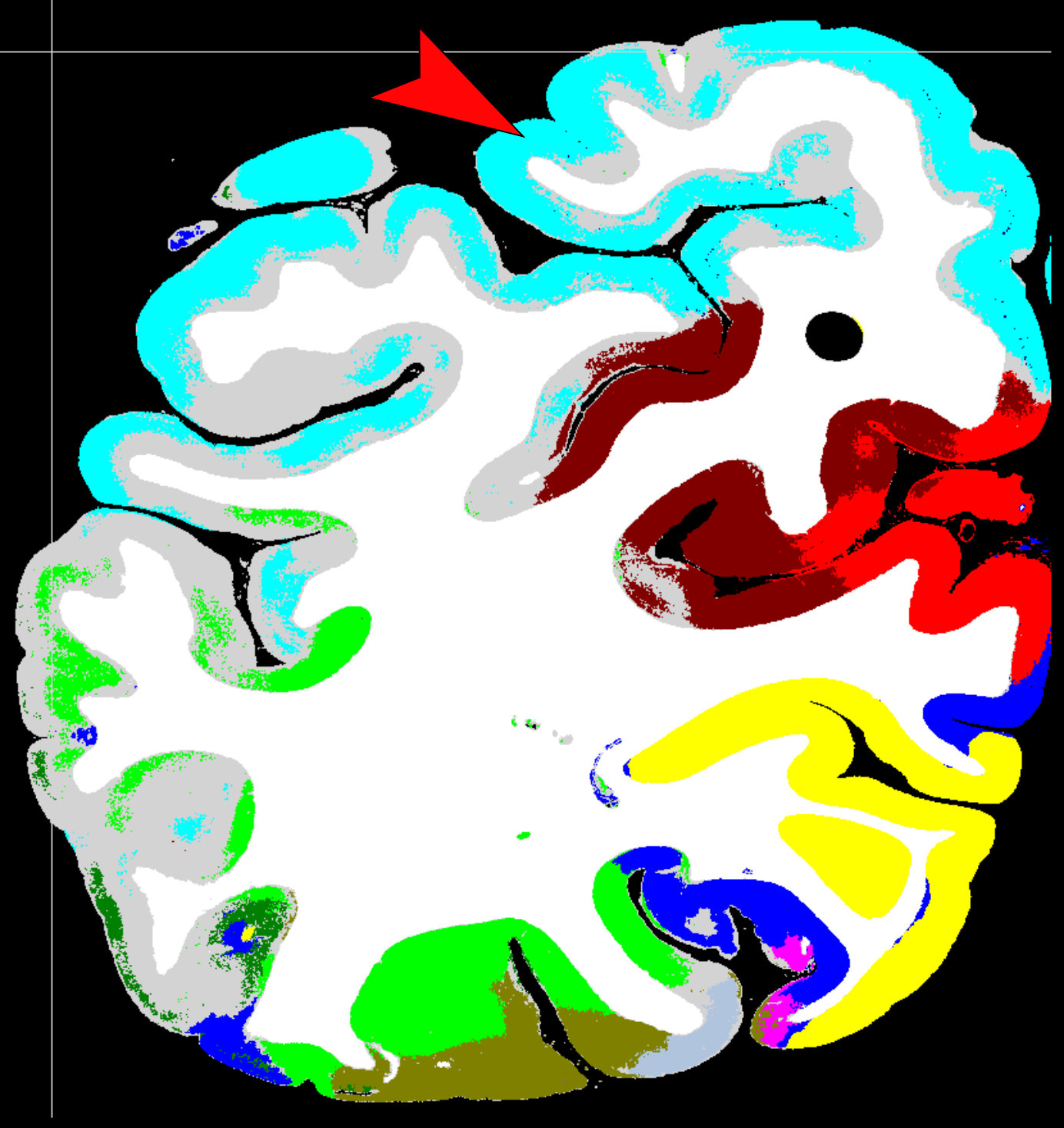 Figure 2
Figure 2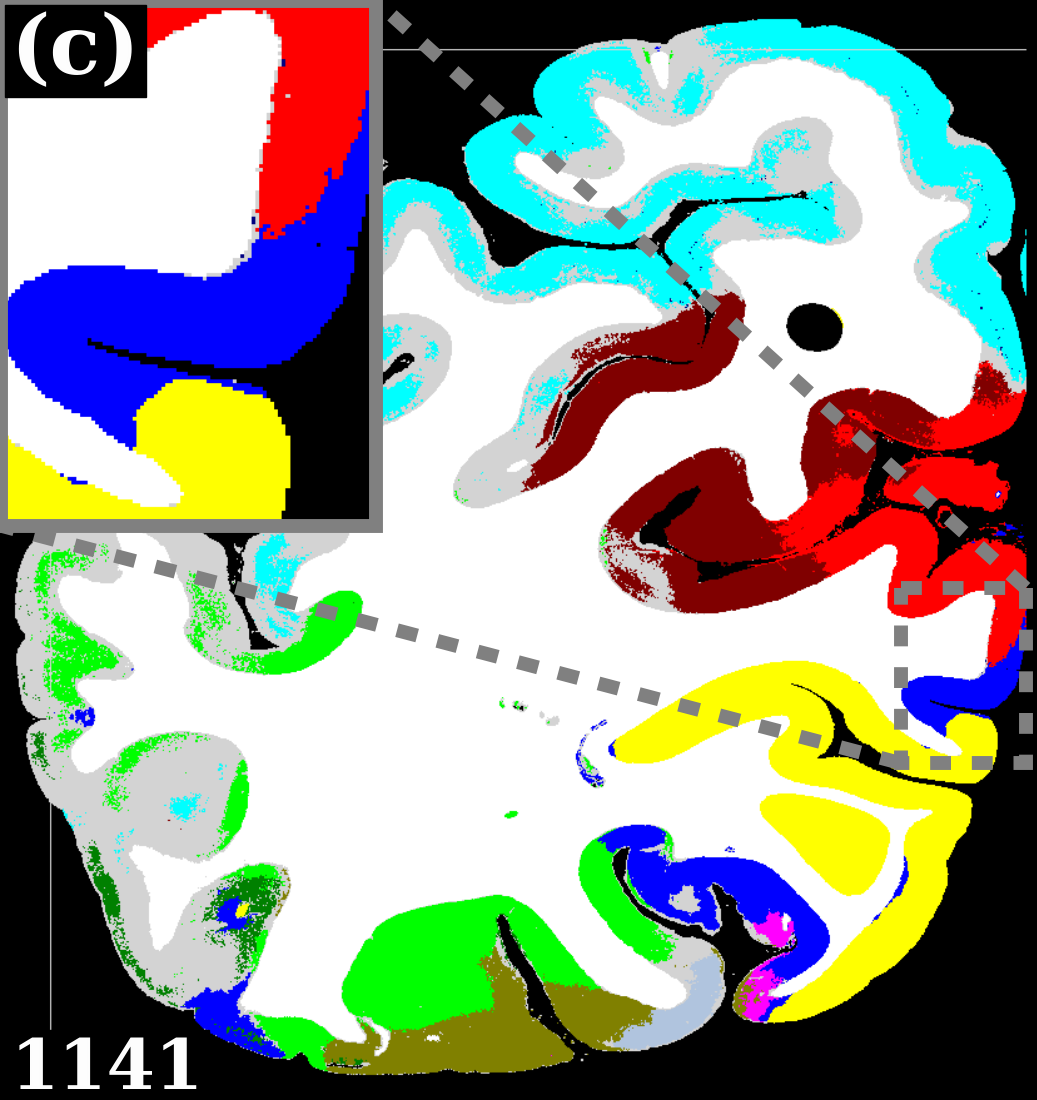 Figure 3
Figure 3 Figure 4
Figure 4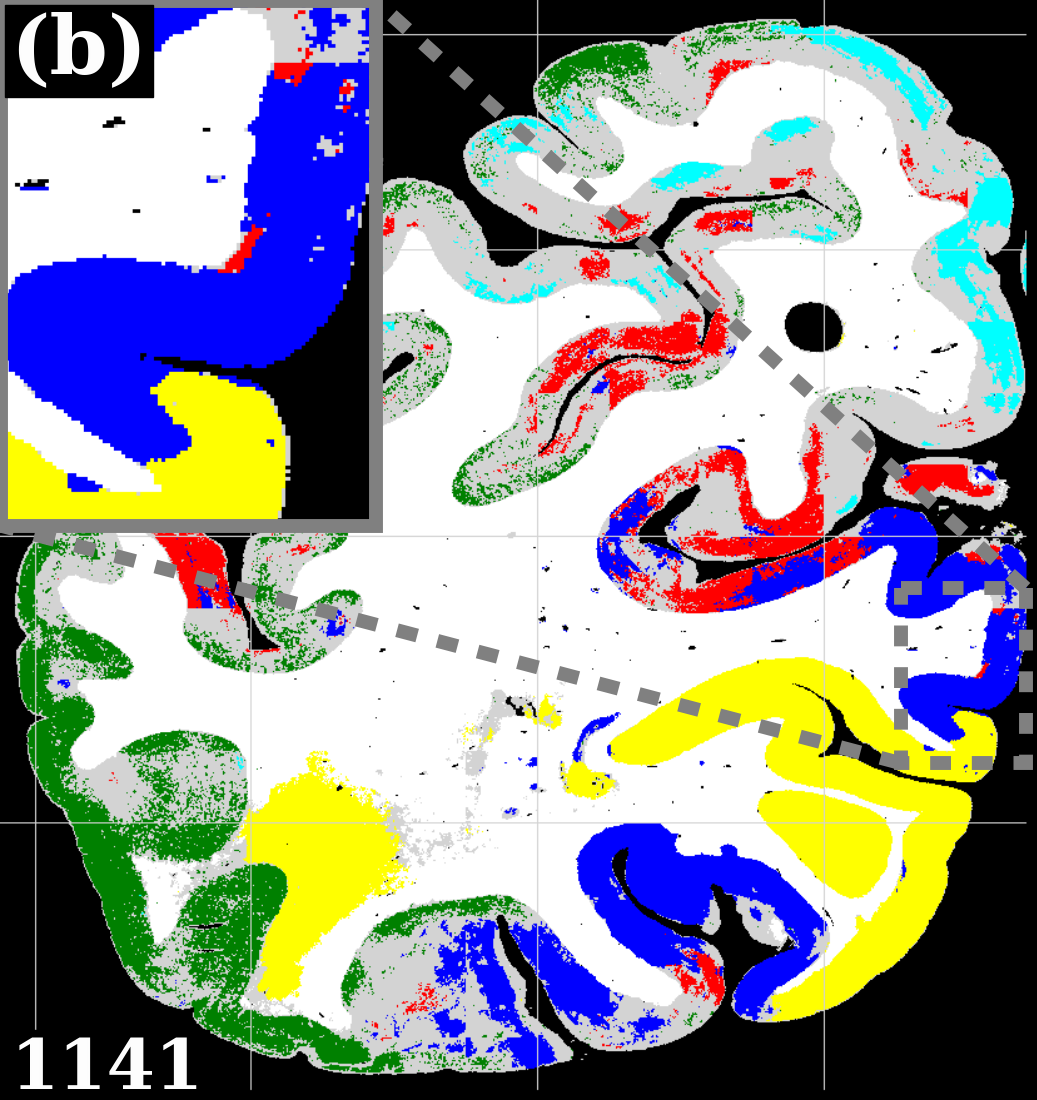 Figure 5
Figure 5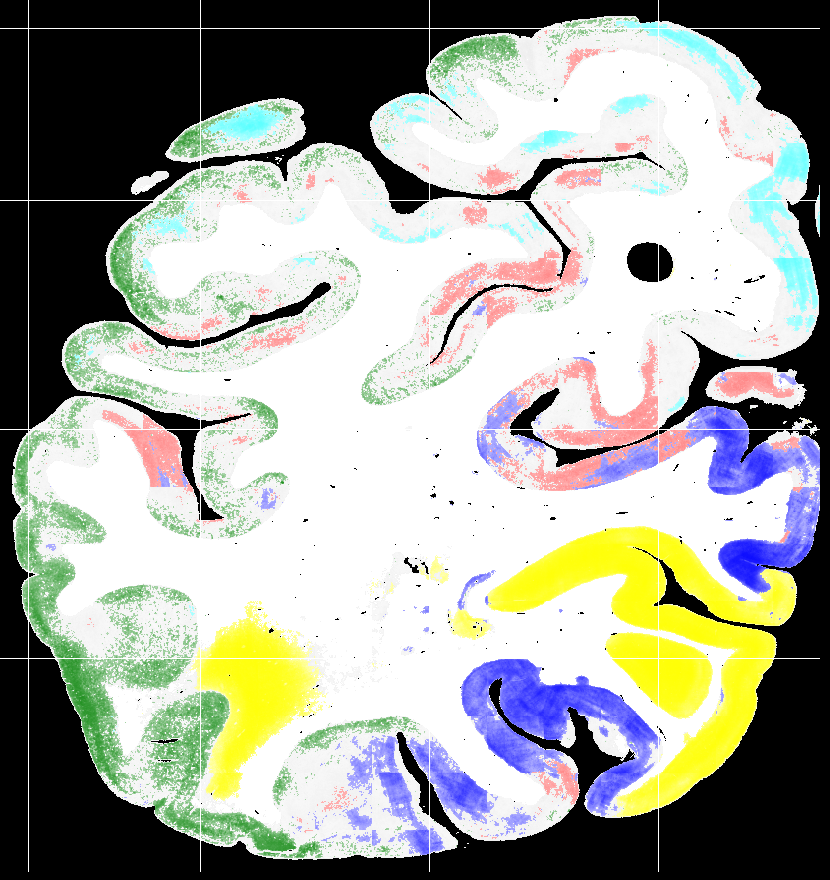 Figure 6
Figure 6 Figure 7
Figure 7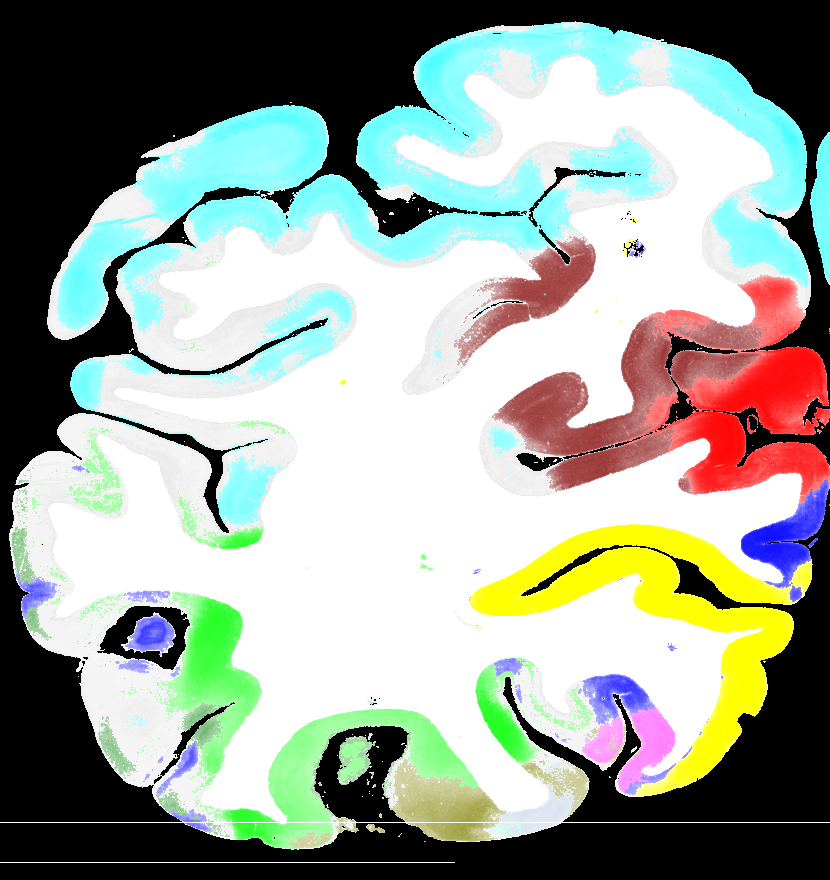 Figure 8
Figure 8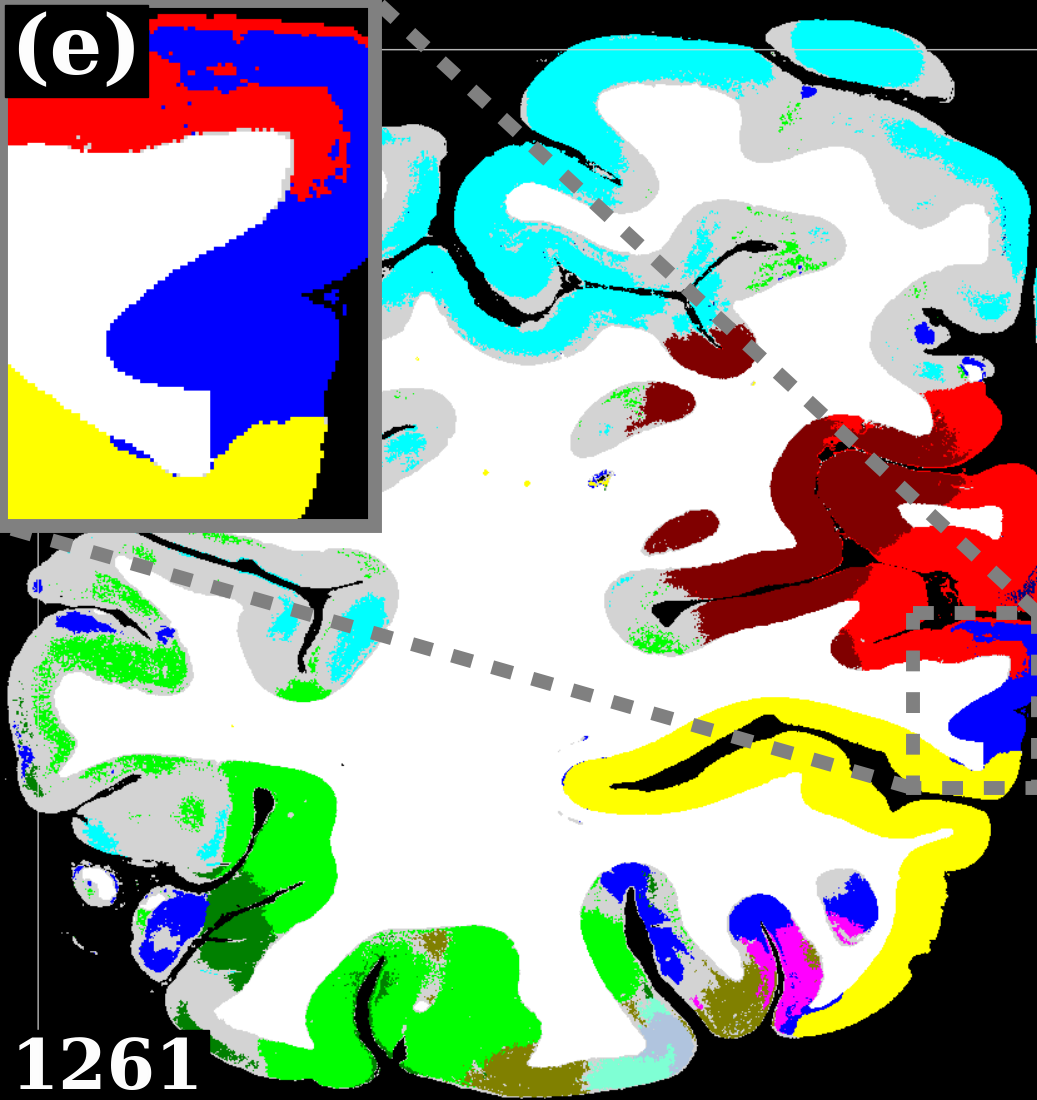 Figure 9
Figure 9 Figure 10
Figure 10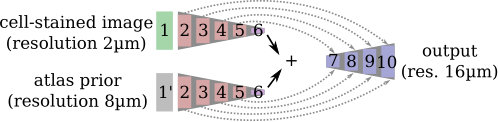 Figure 11
Figure 11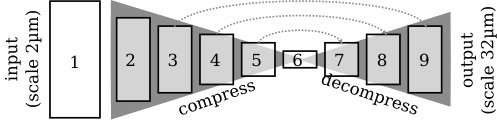 Figure 12
Figure 12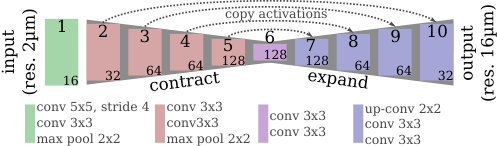 Figure 13
Figure 13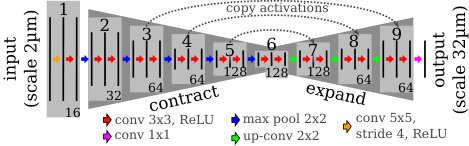 Figure 14
Figure 14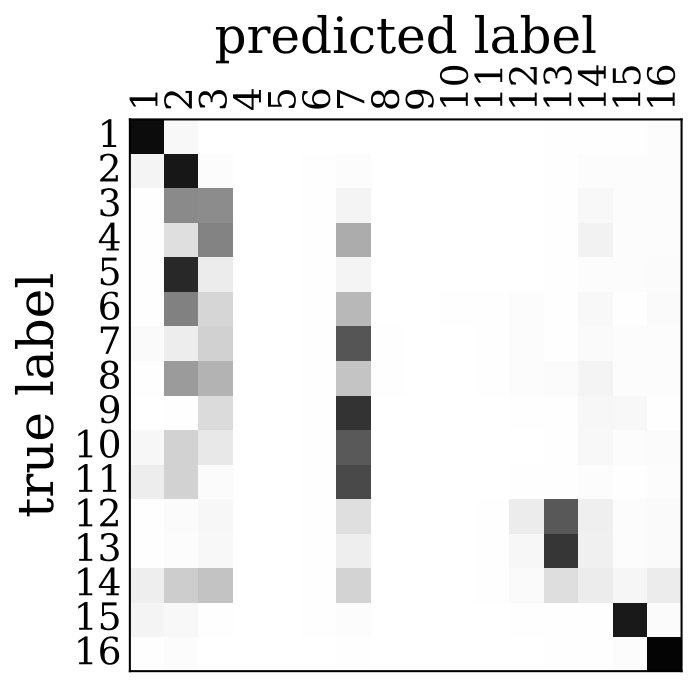 Figure 15
Figure 15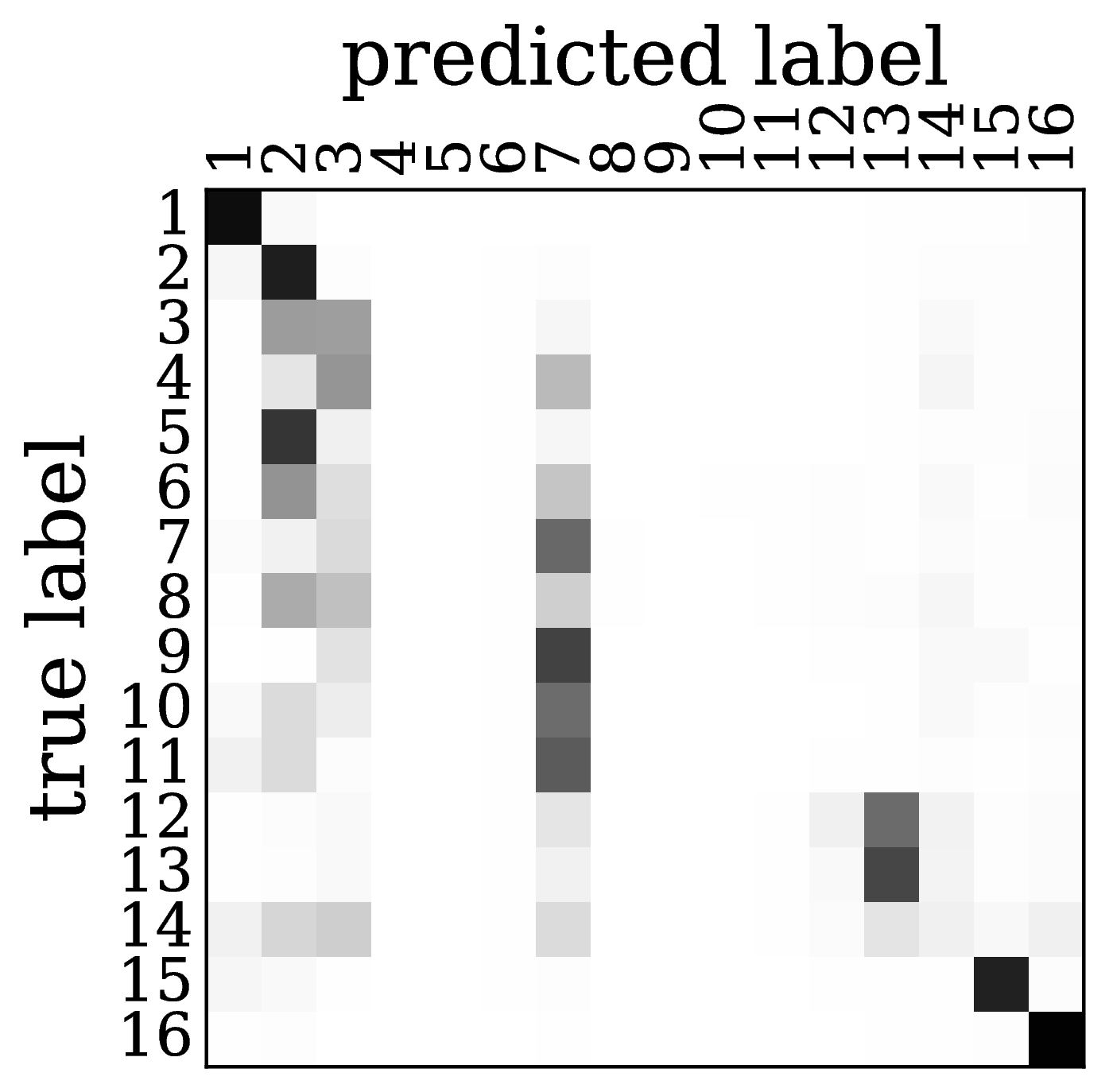 Figure 16
Figure 16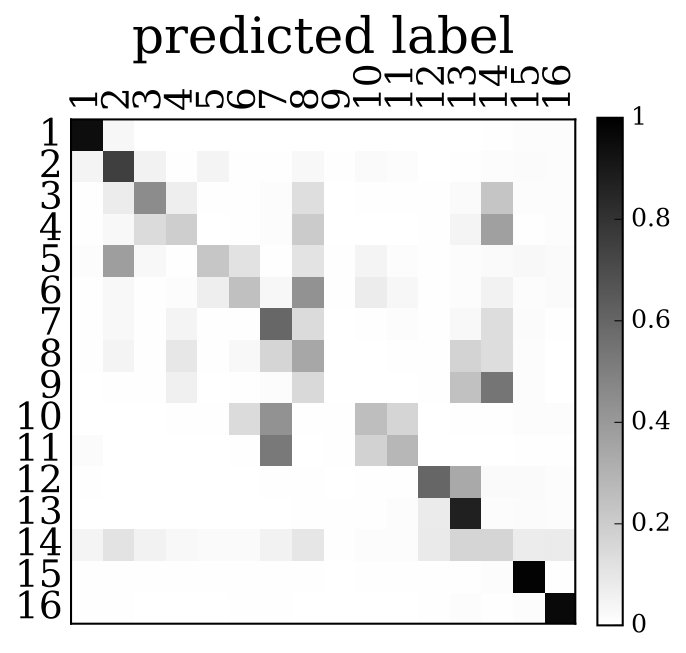 Figure 17
Figure 17 Figure 18
Figure 18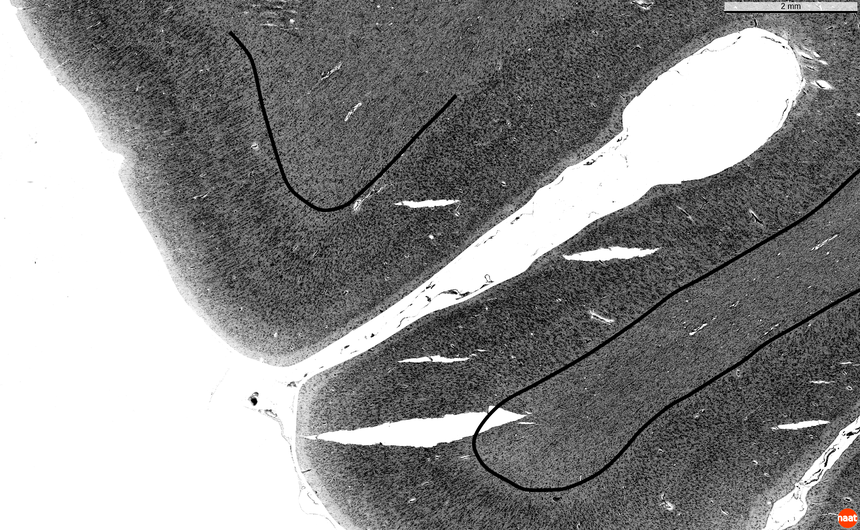 Figure 19
Figure 19 Figure 20
Figure 20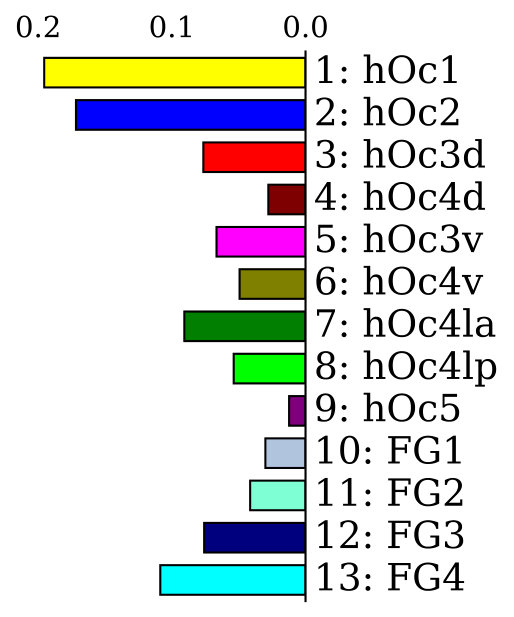 Figure 21
Figure 21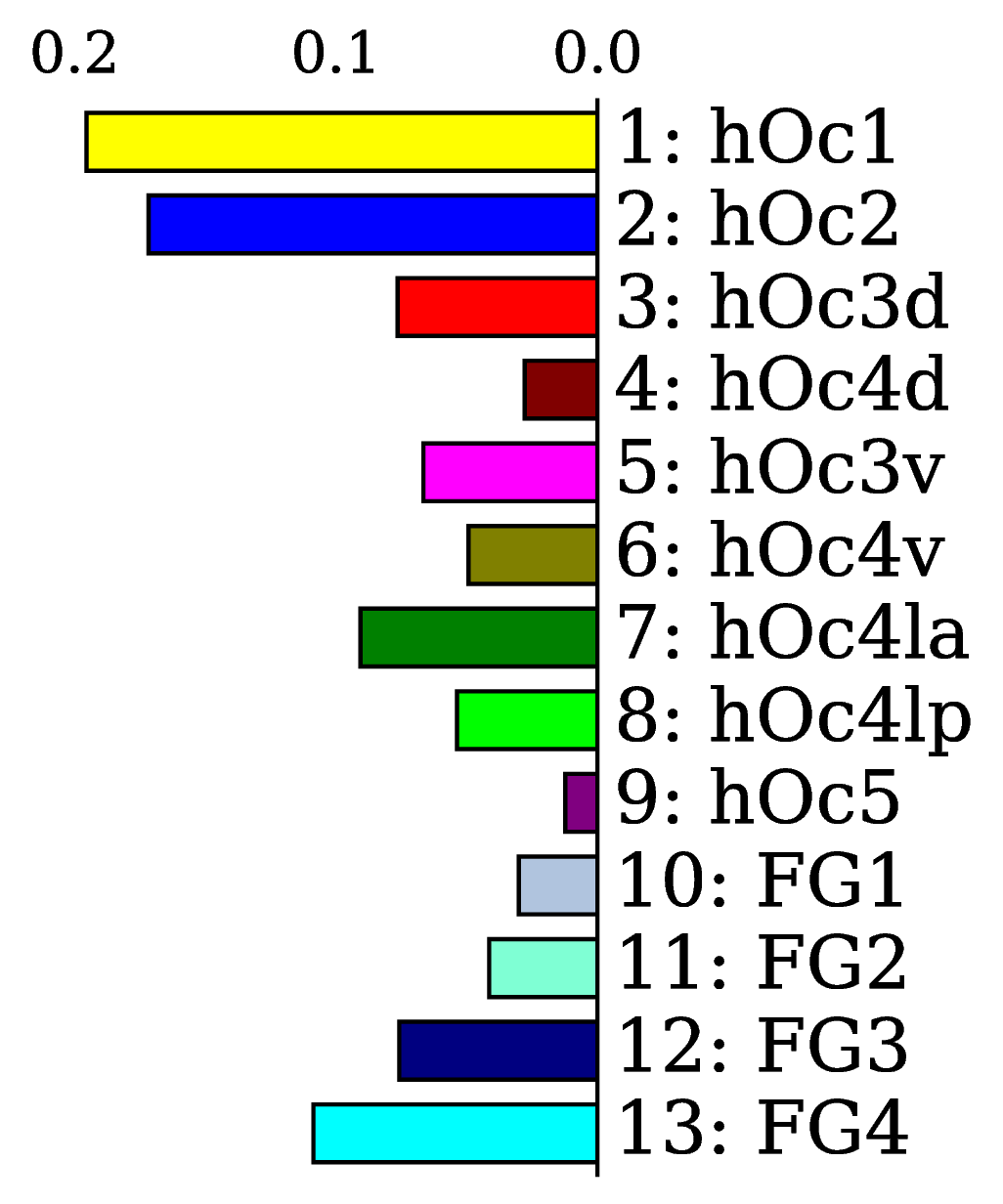 Figure 22
Figure 22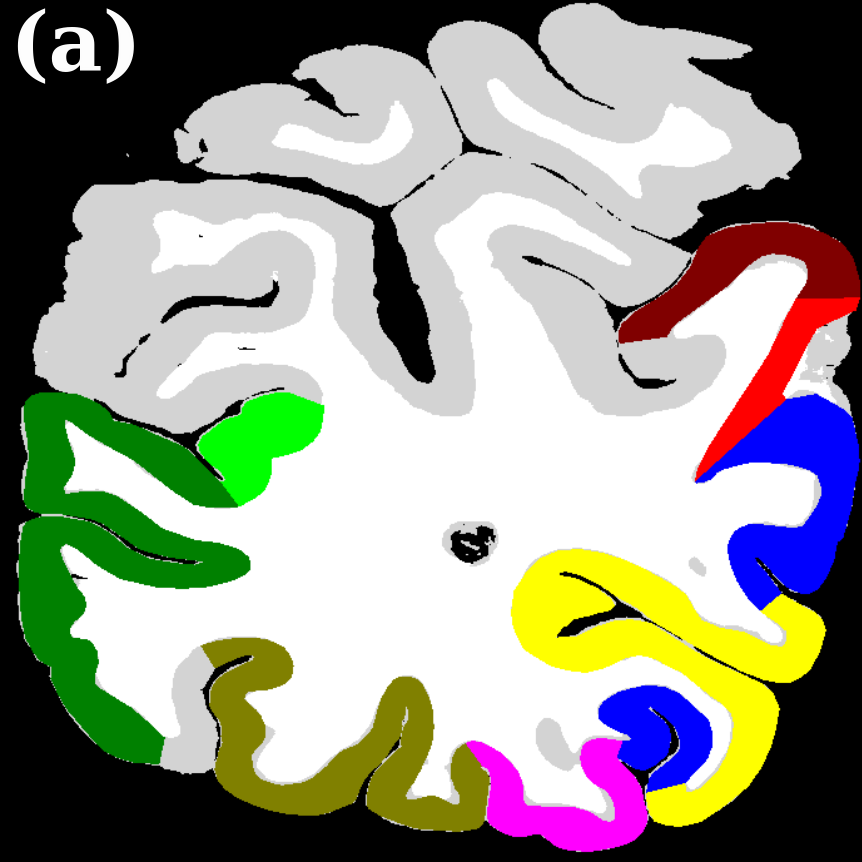 Figure 23
Figure 23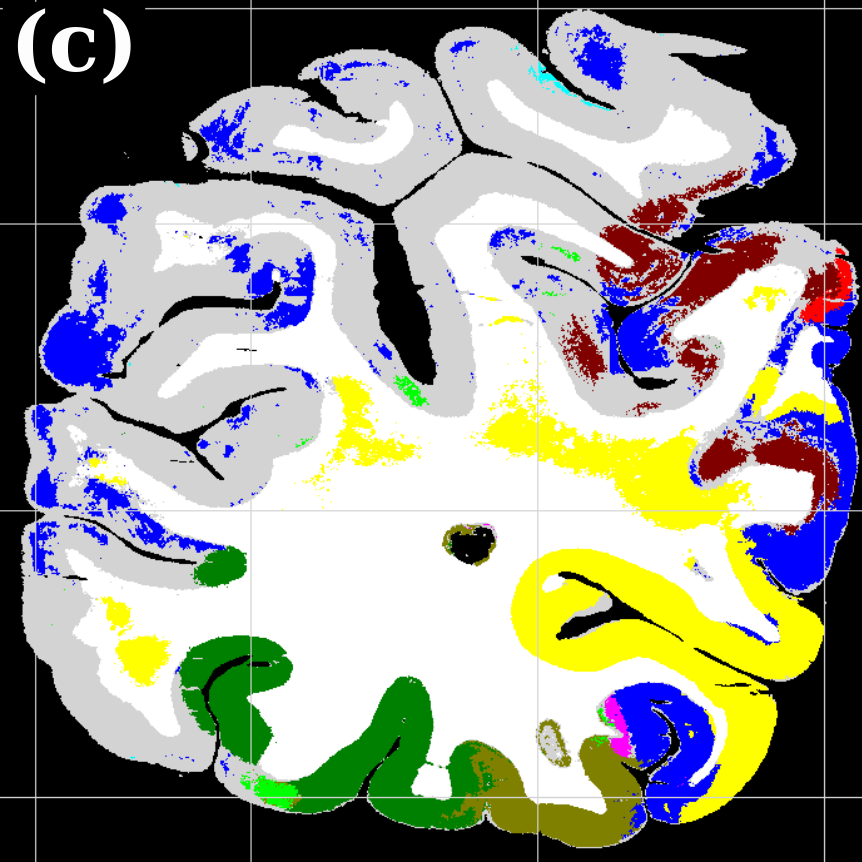 Figure 24
Figure 24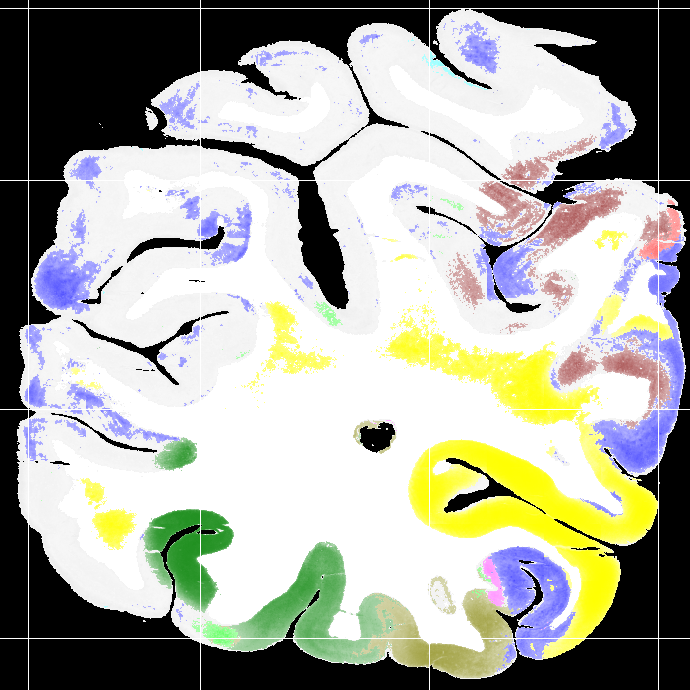 Figure 25
Figure 25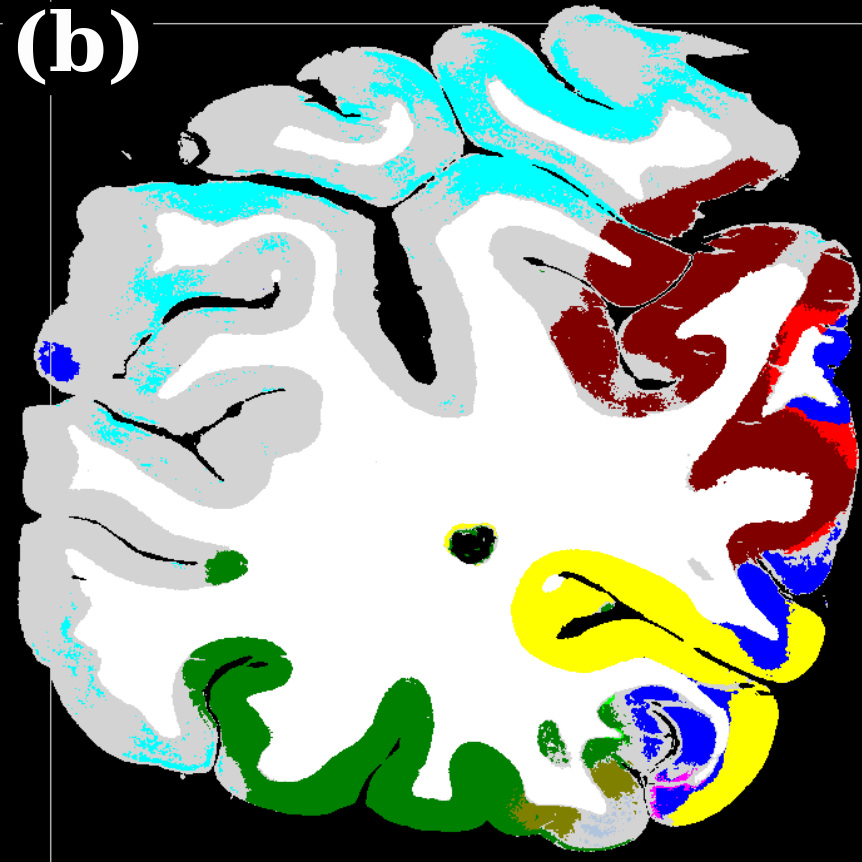 Figure 26
Figure 26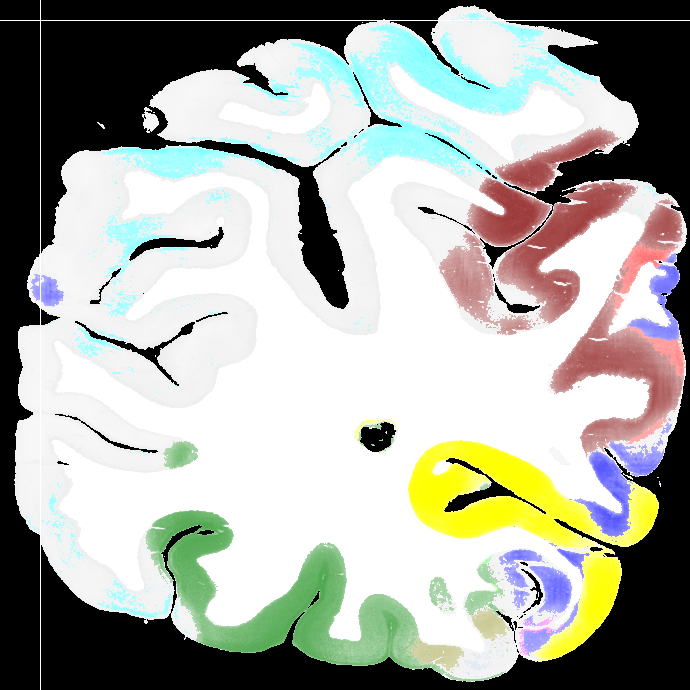 Figure 27
Figure 27Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Parcellation of Visual Cortex on high-resolution histological Brain Sections using Convolutional Neural Networks
Abstract
Microscopic analysis of histological sections is considered the “gold standard” to verify structural parcellations in the human brain. Its high resolution allows the study of laminar and columnar patterns of cell distributions, which build an important basis for the simulation of cortical areas and networks. However, such cytoarchitectonic mapping is a semi-automatic, time consuming process that does not scale with high throughput imaging. We present an automatic approach for parcellating histological sections at resolution. It is based on a convolutional neural network that combines topological information from probabilistic atlases with the texture features learned from high-resolution cell-body stained images. The model is applied to visual areas and trained on a sparse set of partial annotations. We show how predictions are transferable to new brains and spatially consistent across sections.
**Index Terms— ** Brain Parcellation, Human Brain, Mapping, Convolutional Networks, Deep Learning.
1 Introduction
Precise delineations of cytoarchitectonic areas in cell-body stained histological sections of the human brain provide a basis for a multimodal brain atlas. They are indispensable for allocating the multiscale functional imaging, physiological, connectivity, molecular, and/or genetic data to anatomically well specified entities of the human brain organization at high spatial resolution [1]. Cytoarchitectonic areas are distinguished by variations of the cell distribution in the cortical laminae and with respect to the columnar organization of the cortex. Parcellation of cortical areas therefore requires an image resolution of - to distinguish individual neurons, and to capture their morphology. Image analysis and multivariate tools have been introduced to detect boundaries of cortical areas in a reproducible semi-automatic way [2]. This method, however, is time- and labor-intensive, and significantly constraints mapping efforts in a large sample of histological sections and/or brains. Thus, methods with higher degree of automation are needed.
This paper proposes a convolutional neural network (CNN) model that parcellates high-resolution sections from different subjects by exploiting 1) prior knowledge about reasonable topologies as given by existing probabilistic atlases, and 2) precise local features extracted from the cell-stained tissue scan. Our model is trained on partial delineations and produces parcellations that are transferable to new brains and spatially consistent across sections.
After the recent success of CNNs for natural image classification, approaches for efficient semantic segmentation with CNNs were developed (e.g., [3]). There are first works proposing CNN-based models to parcellate entire 3D MR volumes according to different segmentation protocols [4, 5]. In contrast, we aim towards parcellating high-resolution cell-stained histological sections at the quality of a purely cytoarchitectonic reference parcellation.
To our knowledge, our approach is the first to tackle automatic parcellation of cortical areas in histological sections. This paper makes the following contributions: We train a model that automatically predicts 13 areas of the human visual system in histological sections. To deal with the fact that we only have access to partially delineated sections for training, we automatically create accurate gray/white matter segmentations using the same CNN architecture, and use them to distinguish between “unlabeled cortex” and background. We evaluate the influence of exploiting probabilistic atlases on the anatomical correctness of the automatic parcellation, and show results indicating that the model is transferable to previously unseen brains and consistent across multiple consecutive sections in the same brain.
2 Model
2.1 Network Architecture for Semantic Segmentation
We base our CNN architecture on the semantic segmentation approach of [3]. They designed a network with a contracting path, consisting of several “blocks” that contain several convolutional layers and one pooling layer to downsample the activations each. This is followed by an expansive path with “blocks” of one upsampling layer and several convolutional layers. The activations from the contracting path are appended to the expansive path to enable the propagation of context information to higher resolution layers. This architecture produces precise segmentations for any input size and is thus suited for efficient parcellation of entire brain sections.
Cytoarchitectonic parcellation of the cortex relies on the size and composition of cortical laminae [2]. Thus for the classification of any pixel inside the cortex, we choose to take the whole depth of the cortex into account. Assuming a cortical depth of - and an input resolution of , the receptive field of the CNN should be about -.
Following these considerations, we increase the receptive field of the network by inserting one “block” containing convolutional layers with stride 4 before the contracting path. Although a resolution is needed to see the relevant cytoarchitectonic features for mapping, the expected practical localization accuracy of the resulting cytoarchitectonic borders is much lower. We take this into account by setting the output resolution of our network to , which has the practical benefit of significantly reducing the memory requirements of the model during training.
In order to train converging networks we found it necessary to add batch normalization after each convolutional layer and use a relatively high learning rate. Fig. 1 shows details of our network architecture.
2.2 Exploiting probabilistic atlas information
To identify a certain area in the brain, neuroscientists first identify a region of interest (ROI) on a low-resolution global view and then map the precise borders of this area by means of local texture patterns on a high-resolution local view. In a similar manner, our model combines precise local features from high-resolution cell-stained tissue with a relatively imprecise but topologically correct probabilistic atlas prior. We use the JuBrain atlas111available at http://www.jubrain.fz-juelich.de/ which gives our model probability maps for each area, helping to disambiguate areas that have similar texture but are located in different locations of the brain.
Using the probabilistic atlas requires a registration from the atlas space to the space of the individual brain. Since we are only interested in rough estimates of the atlas data on the individual section, we calculated an affine registration from the atlas to the individual sections at resolution. An example of projected probabilities for one area is depicted in Fig. 5a. We add a second contracting path for the atlas data of every area that should be predicted by the model, and join the resulting activations to the bottom of the cell-stained image expansive path (Fig. 2). This enables the network to process each input type individually in the contracting paths and jointly in the expansive path.
We believe that the network learns the atlas prior faster than the image of the cell-body stained section, because the atlas data are less complex and directly represent an estimate of the output labels. This bears the danger that the model converges to an inferior solution, which is the local optimum of predicting a linear combination of the probabilistic maps without learning the underlying texture pattern contained in the cell-stained image. In particular, we observed this behavior in architectures that were joining the atlas and cell-stained image paths earlier in the contractive paths. To overcome this problem, we add noise to the atlas input (set every input node to [math] with a chance of ) and use an iterative training procedure: First, the model is trained on only the cell-stained image and only after convergence training is continued using both cell-stained image and atlas information. This procedure ensures that the model learns to use the information contained in the cell-stained image first, and then adapts to include information gained from the atlas.
2.3 Data preparation
The learned model should be robust to the local shape of the cortex (e.g., gyri, sulci) and recognize cortical areas by their texture. To support this, we normalize the input data by rotating each input crop along the main direction of the gradient of the Laplacian field between outer and inner cortical boundary (using the segmentation from Sec. 3). This “Laplacian field orientation correction” aligns all input data and makes the model more applicable to new subjects (see Sec. 4). In our evaluation, models trained with this rotation of input data performed about two Dice coefficient points (a.k.a. F1 score) better than models trained with random rotation of input data. This mildly improves the results.
2.4 Dealing with complex background class
As groundtruth labels we use partial delineations of visual areas on high-resolution brain sections. We can neither expect all visual areas to be labeled in an annotated section (partial annotation), nor do we have access to groundtruth annotations in all consecutive sections (sparse annotation). Thus the background class is a compound of very different concepts: white matter (wm), non-visual or non-labeled cortex (unknown cortex, gm), and background (bg). This makes it much harder for the net to learn the background class. Thus, we split up the background label in its distinct concepts wm, gm, and bg (see Sec. 3), and extend the groundtruth to include the classes “unknown cortex” and “white matter”.
3 Gray / White Matter Segmentation
For the Laplacian field orientation correction (Sec. 2.3) and the extension of partial annotations (Sec. 2.4), a reliable gray/white matter segmentation is needed. We have devised a two-step procedure with minimal labeling overhead to train a CNN model with the base architecture (Sec. 2.1) for this task. First, we train a model for the two-class cortex segmentation task. As groundtruth all available delineations of the visual cortex were set as “cortex” and the remaining pixels as “background”. Obviously, the generated background class also contains (non-visual) cortex. Thus, we adapt the loss function to weigh the error “predict cortex, true background” with while weighing the other error with 1. In the second step, we labeled sections with wm, gm, and bg, by manually inserting wm labels in the cortex segmentations of the previous step and trained a model on these sections.
The resulting three-class segmentation has a resolution of , is robust to small cuts and rips in the tissue and to noise in the background and sets a precise outer cortical boundary (Fig. 3). Compared to expert segmentations, the automatic segmentation is consistent and reproducible, but seems to systematically underestimate the inner cortical boundary (especially in the curves).
4 Results
Dataset. The dataset used for training and validating the models contains in total cell-body stained histological sections of the human visual cortex originating from four different brains. Mapping resulted in areas (primary and higher visual areas of the dorsal and ventral stream), with an average of mapped areas per section. Fig. 4(a) shows the frequency of the areas in the dataset. As described in Sec. 2.4, the groundtruth was extended by automatic segmentations of unknown cortex, white matter, and background.
Training. The models were trained on of the sections ( held out for test and validation) by drawing patches of size from the images ( from the delineated areas, from background). We used a learning rate of and a batch size of . Usually, training converged after iterations. Although the number of training sections is small, we do not observe any overfitting. We attribute this to the random sampling during training which never produces the same patch twice, and the difficulty of the task. The trained model has expressive filters in the first layers.
Evaluation. Quantitative evaluation scores were computed on the held-out test set. The standard score to assess the quality of a segmentation is the mean Dice coefficient (e.g., [5, 4]). However, this does not take into account the spatial information of the segmentation. For anatomical parcellation, an error made right at the border between two areas is “less severe” than confusing two areas that lie in different regions of the brain. Thus we additionally report the pixel distance error () which assigns to each error a penalty based on the distance between the misclassified pixel and the nearest groundtruth pixel that actually is of the misclassified class [6]: , with the squared Euclidean distance of the th misclassified pixel to the nearest true pixel with this class. Following [6], the error is normalized to range [math] and approx. , so it can be understood as a percentage of the maximum possible error: , with being the total number of pixels that were evaluated.
4.1 Influence of atlas data and anatomical correctness
To evaluate the contribution of the global anatomical information (atlas prior, Sec. 2.1), we trained one model without atlas information (base) and compared it to our model including atlas information (atlas-aware). The base model predicts the most frequent areas (hOc1, hOc2, hOc4la) with good precision (Fig. 5b), but only the atlas-aware model manages to predict areas which are not as much represented in the dataset (Fig. 5c, and confusion matrices in Fig. 4). In general, the model performs better on more frequent areas, yielding higher scores. The error of the atlas-aware model drops points and the score rises by compared to the base model. The results indicate that the network indeed learns to resolve labelling errors by exploiting the atlas prior to limit the number of possible labels per example.
4.2 Spatial consistency and transferability to other brains
Figures 5c-d show predictions of the atlas-aware model on three sections with distance . Although the model has no direct knowledge of spatial inter-slice dependencies, the predictions are consistent in the z-direction. In particular the boundary between hOc1 and hOc2 is consistent.
To see how well our model generalizes w.r.t. different subjects, we trained a new model with one particular brain excluded from training, and evaluated on the latter (see Fig. 6). This model predicts more frequent visual areas reasonably well, and the error only rises points to compared to a model trained on all brains. This suggests that our model is in principle transferable to previously unseen brains.
5 Conclusion
We presented a model that predicts visual areas on high-resolution histological sections exploiting both texture features and probabilistic atlas information. The predictions are spatially consistent and reproducible on sections of previously unseen brains. We have shown that a probabilistic atlas prior has a positive effect on the model performance. In a straightforward two-step process we generated accurate gray/white matter segmentations from a few training data points. In future work we plan to extend this model to include more cortical areas, and further study generalization across subjects. Possible improvements include enforcing topological constraints, and exploiting 3D information as provided in reconstructed volumes.
Acknowledgements: This work was partially supported by the Helmholtz Association through the Helmholtz Portfolio Theme “Supercomputing and Modeling for the Human Brain”, and by the European Union’s Horizon 2020 Framework Research and Innovation under Grant Agreement No. 7202070 (Human Brain Project SGA1).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] K. Amunts and K. Zilles, “Architectonic mapping of the human brain beyond brodmann,” Neuron , vol. 88, no. 6, pp. 1086–1107, 2015.
- 2[2] A. Schleicher et al., “Observer-independent method for microstructural parcellation of cerebral cortex: a quantitative approach to cytoarchitectonics,” Neuroimage , vol. 9, no. 1, pp. 165–177, 1999.
- 3[3] O. Ronneberger et al., “U-net: Convolutional networks for biomedical image segmentation,” in MICCAI . Springer, 2015, pp. 234–241.
- 4[4] A. de Brebisson and G. Montana, “Deep neural networks for anatomical brain segmentation,” in CVPRW . IEEE, 2015, pp. 20–28.
- 5[5] N. Lee et al., “Towards a deep learning approach to brain parcellation,” in International Symposium on Biomedical Imaging . IEEE, 2011, pp. 321–324.
- 6[6] W. A. Yasnoff et al., “Error measures for scene segmentation,” Pattern recognition , vol. 9, no. 4, pp. 217–231, 1977.