Increasing the Efficiency of Sparse Matrix-Matrix Multiplication with a 2.5D Algorithm and One-Sided MPI
Alfio Lazzaro, Joost VandeVondele, Juerg Hutter, Ole Schuett

TL;DR
This paper demonstrates that a 2.5D algorithm combined with one-sided MPI communication significantly improves the efficiency of sparse matrix-matrix multiplication, especially in large-scale electronic structure calculations.
Contribution
It extends the DBCSR library with a 2.5D approach and one-sided MPI, showing substantial performance gains over traditional methods in sparse matrix multiplication.
Findings
Up to 1.80x speedup with the 2.5D RMA algorithm
Performance increases with the number of processes involved
Implementation details for non-ideal processor topologies provided
Abstract
Matrix-matrix multiplication is a basic operation in linear algebra and an essential building block for a wide range of algorithms in various scientific fields. Theory and implementation for the dense, square matrix case are well-developed. If matrices are sparse, with application-specific sparsity patterns, the optimal implementation remains an open question. Here, we explore the performance of communication reducing 2.5D algorithms and one-sided MPI communication in the context of linear scaling electronic structure theory. In particular, we extend the DBCSR sparse matrix library, which is the basic building block for linear scaling electronic structure theory and low scaling correlated methods in CP2K. The library is specifically designed to efficiently perform block-sparse matrix-matrix multiplication of matrices with a relatively large occupation. Here, we compare the performance…
Click any figure to enlarge with its caption.
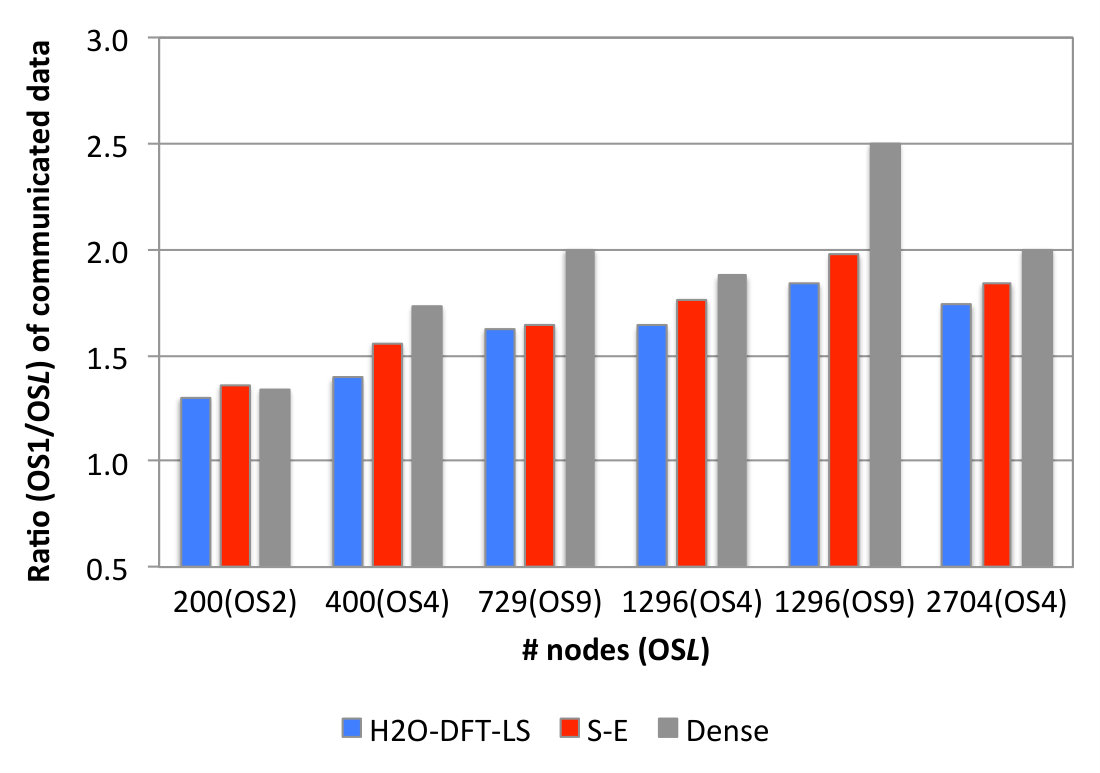 Figure 1
Figure 1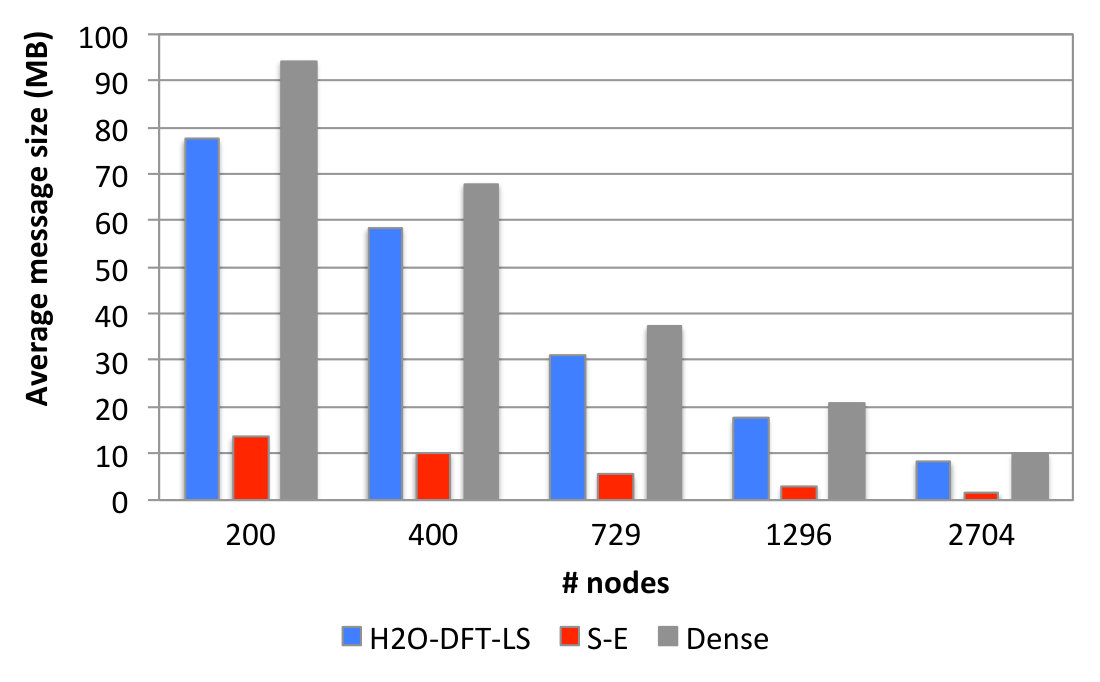 Figure 2
Figure 2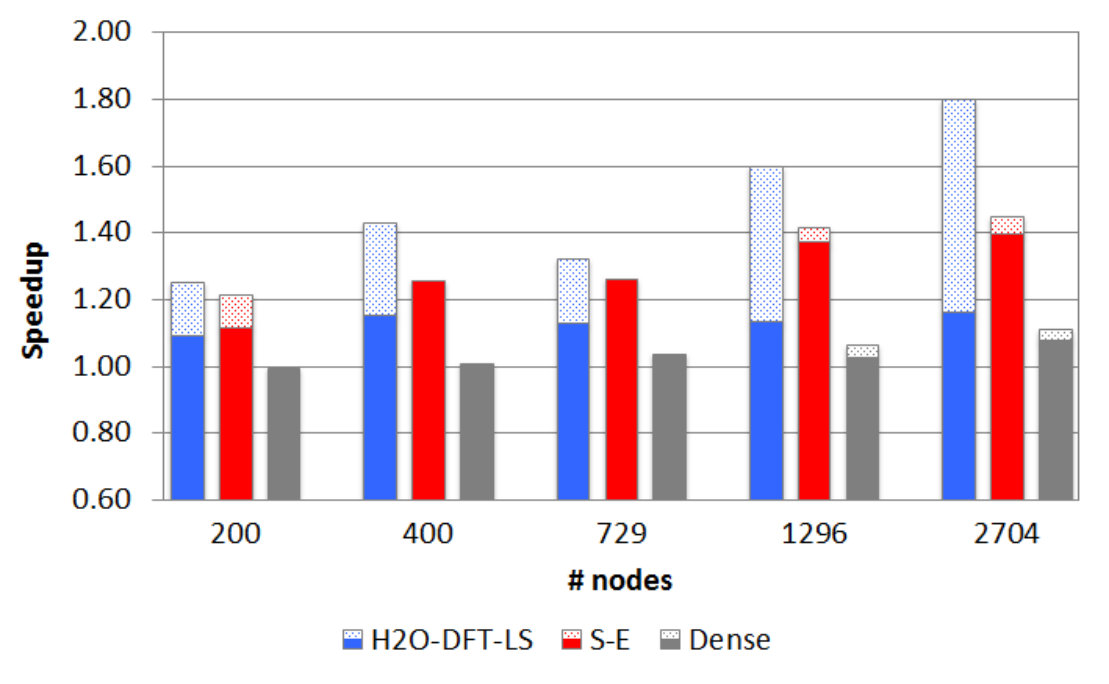 Figure 3
Figure 3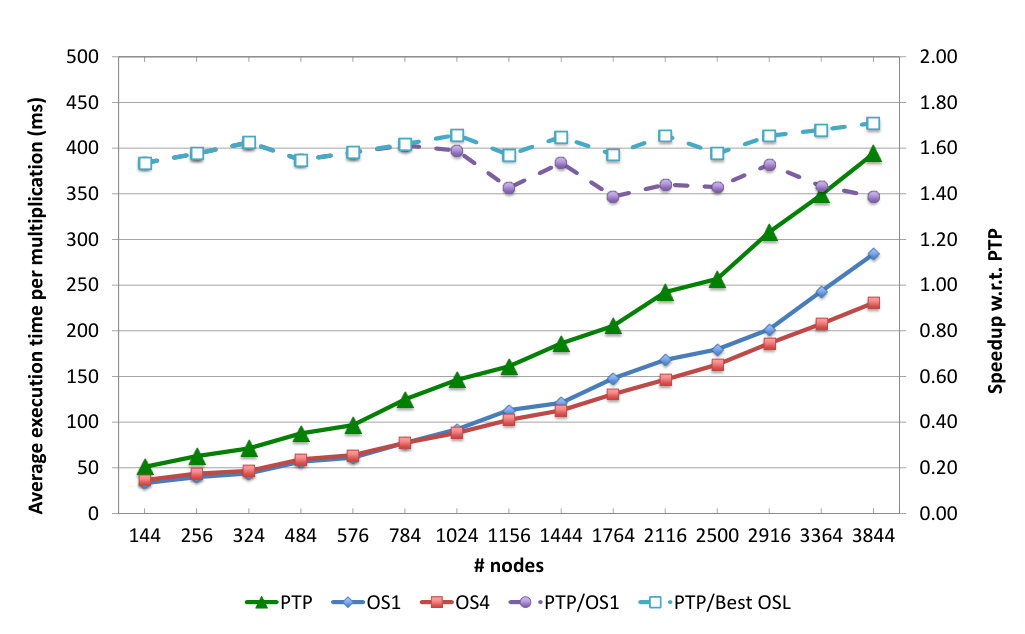 Figure 4
Figure 4| H2O-DFT-LS | S-E | Dense | |
|---|---|---|---|
| Block sizes | |||
| # Rows/columns | |||
| Occupancy range (%) | |||
| # Multiplications | |||
| DBCSR FLOPs () |
| # nodes | H2O-DFT-LS | S-E | Dense | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PTP | OS1 | OS2 | OS4 | OS9 | PTP | OS1 | OS2 | OS4 | OS9 | PTP | OS1 | OS2 | OS4 | OS9 | ||
| DBCSR execution time (seconds) | 200 | 325 | 298 | 260 | – | – | 558 | 500 | 459 | – | – | 42.8 | 43.0 | 43.9 | – | – |
| 400 | 212 | 184 | – | 148 | – | 390 | 310 | – | 310 | – | 22.1 | 21.9 | – | 23.6 | – | |
| 729 | 155 | 137 | – | – | 117 | 310 | 246 | – | – | 314 | 13.3 | 13.3 | – | – | 15.5 | |
| 1296 | 136 | 120 | – | 85 | 92 | 282 | 205 | – | 199 | 254 | 11.2 | 10.9 | – | 10.5 | 11.6 | |
| 2704 | 99 | 85 | – | 55 | – | 249 | 178 | – | 172 | – | 10.8 | 10.0 | – | 9.7 | – | |
| DBCSR total communicated data per process (GB) | 200 | 640 | 640 | 491 | – | – | 856 | 856 | 630 | – | – | 51 | 51 | 38 | – | – |
| 400 | 318 | 318 | – | 228 | – | 445 | 445 | – | 286 | – | 26 | 26 | – | 15 | – | |
| 729 | 236 | 236 | – | – | 145 | 329 | 329 | – | – | 200 | 20 | 20 | – | – | 10 | |
| 1296 | 177 | 177 | – | 108 | 96 | 247 | 247 | – | 140 | 125 | 15 | 15 | – | 8 | 6 | |
| 2704 | 122 | 122 | – | 70 | – | 171 | 171 | – | 93 | – | 10 | 10 | – | 5 | – | |
| CP2K peak memory footprint (GB) | 200 | 5.16 | 5.36 | 7.40 | – | – | 3.99 | 4.28 | 4.93 | – | – | 2.54 | 2.68 | 3.41 | – | – |
| 400 | 3.20 | 3.26 | – | 6.11 | – | 3.00 | 3.10 | – | 4.41 | – | 1.47 | 1.61 | – | 2.52 | – | |
| 729 | 2.07 | 2.11 | – | – | 7.60 | 2.45 | 2.74 | – | – | 4.67 | 0.95 | 1.01 | – | – | 2.18 | |
| 1296 | 1.69 | 1.72 | – | 3.33 | 6.11 | 2.19 | 2.34 | – | 2.78 | 3.84 | 0.85 | 0.88 | – | 1.19 | 1.75 | |
| 2704 | 0.95 | 0.98 | – | 1.77 | – | 2.10 | 2.17 | – | 2.40 | – | 0.57 | 0.58 | – | 0.78 | – | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Increasing the Efficiency of Sparse Matrix-Matrix Multiplication with a 2.5D Algorithm and One-Sided MPI
Alfio Lazzaro
University of Zürich, Department of Chemistry CWinterthurerstrasse 190ZürichSwitzerland8057
,
Joost VandeVondele
CSCSWolfgang-Pauli-Strasse 27ZürichSwitzerland8093
,
Jürg Hutter
University of Zürich, Department of Chemistry CWinterthurerstrasse 190ZürichSwitzerland8057
and
Ole Schütt
EmpaÜberlandstrasse 129DübendorfSwitzerland8600
(2017)
Abstract.
Matrix-matrix multiplication is a basic operation in linear algebra and an essential building block for a wide range of algorithms in various scientific fields. Theory and implementation for the dense, square matrix case are well-developed. If matrices are sparse, with application-specific sparsity patterns, the optimal implementation remains an open question. Here, we explore the performance of communication reducing 2.5D algorithms and one-sided MPI communication in the context of linear scaling electronic structure theory. In particular, we extend the DBCSR sparse matrix library, which is the basic building block for linear scaling electronic structure theory and low scaling correlated methods in CP2K. The library is specifically designed to efficiently perform block-sparse matrix-matrix multiplication of matrices with a relatively large occupation. Here, we compare the performance of the original implementation based on Cannon’s algorithm and MPI point-to-point communication, with an implementation based on MPI one-sided communications (RMA), in both a 2D and a 2.5D approach. The 2.5D approach trades memory and auxiliary operations for reduced communication, which can lead to a speedup if communication is dominant. The 2.5D algorithm is somewhat easier to implement with one-sided communications. A detailed description of the implementation is provided, also for non ideal processor topologies, since this is important for actual applications. Given the importance of the precise sparsity pattern, and even the actual matrix data, which decides the effective fill-in upon multiplication, the tests are performed within the CP2K package with application benchmarks. Results show a substantial boost in performance for the RMA based 2.5D algorithm, up to 1.80x, which is observed to increase with the number of involved processes in the parallelization.
sparse algebra, matrix-matrix multiplications, MPI parallelization, one-sided communications, point-to-point communications, communication-reducing
††journalyear: 2017††copyright: acmlicensed††conference: PASC ’17; June 26-28, 2017; Lugano, Switzerland††price: 15.00††doi: http://dx.doi.org/10.1145/3093172.3093228††isbn: 978-1-4503-5062-4/17/06††ccs: Computing methodologies Massively parallel algorithms††ccs: Applied computing Chemistry††ccs: Software and its engineering Software libraries and repositories
1. Introduction
Multiplication of two sparse matrices (SpGEMM) is a key operation in the the simulation of the electronic structure of systems containing thousands of atoms and electrons (VandeVondele et al., 2012). Examples of such systems include electronic devices, complex interfaces, macromolecules or large disordered systems, with applications in the fields of renewable energy and electronics. The theory that enables such studies is linear scaling Density Functional Theory (DFT) (Bowler and Miyazaki, 2012). In the atomistic simulations package CP2K (Hutter et al., 2014), the linear scaling DFT implementation exploits the fact that operators in a localized atomic basis are sparse. The matrices have several thousands of non-zero elements per row and a priori unknown sparsity patterns. This includes the Kohn-Sham matrix (), the overlap matrix (), and the density matrix (). If can be computed from and without explicit reference to eigenvectors of , the traditional, cubically scaling approach of diagonalization can be avoided, and potentially replaced with a linear scaling method. We can obtain the density matrix from its functional definition
[TABLE]
where is the identity matrix and is the chemical potential. The matrix sign function is defined as
[TABLE]
Eigenvectors of are eigenvectors of , with the eigenvalues of being or for negative or positive eigenvalues of , respectively. In its simplest form, we exploit the fact that the matrix sign function can be computed with a simple iterative scheme based only on matrix multiplications (two multiplications per iteration)
[TABLE]
where converges to the sign of (Higham, 2008). A linear scaling cost results from the fact that all matrix operations are performed on sparse matrices, which have a number of non-zero entries that scale linearly with system size. A particular characteristic of the involved matrices is that they are block-sparse, instead of element-wise sparse, where the dimensions of the blocks depend on the atomic kinds present in the studied systems. In order to retain sparsity during the iterations of the above algorithm, a filtering multiplication is employed in two phases: on-the-fly during the product of two atomic blocks and after each multiplication to ignore small matrix elements (VandeVondele et al., 2012).
In general, SpGEMM accounts for more than 80% of the total runtime. The computational cost depends strongly on the evolution of the sparsity during the iterations, which in turn depends on the chemical properties of the system studied, the precise algorithm employed, the system size, and the required accuracy (VandeVondele et al., 2012). The highly optimized sparse linear algebra library DBCSR (Distributed Block Compressed Sparse Row) has been specifically designed to efficiently perform block-sparse matrix-matrix multiplications (Borstnik et al., 2014; Schütt et al., 2015). It is parallelized using MPI and OpenMP, and can exploit GPU accelerators by means of CUDA and OpenCL. Prior to this work, Cannon’s algorithm was used to parallelize the matrix-matrix multiplication (Cannon, 1969), using MPI point-to-point communications.
In this paper we present a novel approach to MPI parallelization of the DBCSR sparse matrix-matrix multiplication algorithm based on the communication-reducing 2.5D algorithm (Solomonik and Demmel, 2011). This algorithm speeds up the execution by reducing the volume of transferred data with respect to the original DBCSR algorithm. The implementation is based on MPI one-sided communications. For the next generation of computing systems, the number of nodes is expected to increase at an higher rate than the network performance. Therefore, reducing time for communications by reducing the volume of exchanged data is crucial. The paper is organized as follows. In the section 2 we introduce DBCSR, focusing on the MPI parallelization, followed by the description of the new communication-reducing implementation in section 3. Finally, in section 4 the performance results for representative CP2K benchmarks are reported. The source code of the implementation as well as the benchmarks are freely available to encourage reproducing these results.
1.1. Related work
The classical serial SpGEMM algorithm was first described by Gustavson (Gustavson, 1978). The parallel implementation in a distributed memory system presents several challenges, such as load-balance and communication costs relative to arithmetic operations (Buluc and Gilbert, 2008). To tackle these problems, in the past decade several methods have been presented. When there is a domain related knowledge about the input matrix sparsity structure, this information can be used to improve performance (Weber et al., 2015). Similarly, by employing an initially (Ballard et al., 2016) computed symbolic SpGEMM, a prior knowledge of a fixed pattern of the sparsity structure of the output matrix can be exploited. DBCSR considers the general case where a priori knowledge of the input and output matrix sparsity is not employed, and is aimed at delivering good performance if the matrix contains many non-zeros per row or is nearly dense. It uses a random permutation of the rows and columns of the matrix to achieve a good average load-balance (see section 2). Consequently, the data and the corresponding operations are statically distributed across processes in the same way as for dense matrices, and existing algorithms for dense matrix-matrix multiplications (e.g. (Ballard et al., 2013)) can be adopted and refined for the sparse case. In particular, the development of so-called 3D algorithms for dense matrix multiplication allows to reduce the communication costs relative to arithmetic operations (Dekel et al., 1981; Agarwal et al., 1995; Irony et al., 2004; Solomonik and Demmel, 2011). Recently, Azad et al. have reported the implementation of a multi-threaded 3D SpGEMM algorithm and presented performance results for applications in several fields (Azad et al., 2016). However, this implementation does not consider block-sparse matrices and is not enabled for hybrid multi-cores CPU and GPU systems, both aspects are key and heavily optimized (Schütt et al., 2015) in DBCSR. Rubensson and Rudberg reported a parallel implementation based on a different approach: instead of randomization, data locality is employed in their implementation for reducing communications, while the mapping of data and work to physical resources is performed dynamically during the calculation (Rubensson and Rudberg, 2016). Like DBCSR, this implementation is able to work effectively with block-sparse matrices and runs on hybrid multi-cores CPU and GPU systems. This implementation does not employ optimized libraries for the small block multiplications, nor on-the-fly filtering. To the best of our knowledge, the new DBCSR implementation described in this paper is the only library for SpGEMM based on MPI one-sided communications that runs on hybrid multi-cores CPU and GPU systems.
2. DBCSR Library
DBCSR is written in Fortran and is freely available under the GPL license from public repositories at sourceforge.net and github.com repositories. It has a flexible and powerful API that can be explored online (The CP2K Developers Group, 2017). The DBCSR library is designed to be highly efficient in the limit of high occupation (10%) of block sparse matrices, typically several thousands of non-zeros per row, but no specific sparsity structure. DBCSR matrices are stored in the blocked compressed sparse row (CSR) format distributed over a two-dimensional grid of processes (each process holds a panel of the matrix). Individual matrix elements are grouped into blocks by rows and columns. The blocked rows and columns form a grid of blocks. Randomized permutation of rows and columns is used to obtain a good average load-balance, and a static decomposition of the data across processes. Note that, sparsity patterns of the three matrices involved in multiplications are not identical. The result matrix has a non-fixed sparsity pattern, that is determined as the result of the computation, with blocks that are smaller than a given threshold removed after or skipped during the multiplication process.
In the original DBCSR, inter-process communication is based on Cannon’s algorithm (Cannon, 1969), the data of the matrix multiplication is decomposed such that panels are always local, i. e. each process computes a given panel, which is thus not communicated. The algorithm is generalized to an arbitrary two-dimensional process grid , with process rows and process columns. To achieve that, an additional virtual process dimension, is defined to match matrices in multiplication, i. e. matrix is mapped to a virtual process grid and matrix is mapped to a process grid. After a pre-shift of the data following Cannon’s scheme on the virtual process grid (based on MPI point-to-point blocking calls), the algorithm performs steps for each multiplication (ticks). The number of ticks is minimal when , which implies , therefore a square number of processes is optimal, or at least when and have most of their factors in common. A local multiplication and a data transfer for and panels between virtual neighboring processes are required, allowing a natural overlap between communications and computation. The volume of communicated data by each process scales as . Transfer of all data between neighboring processes in the 2D grid (row-wise and column-wise shifts for and matrices, respectively) is performed using non-blocking MPI calls (mpi_isend / mpi_irecv) for each tick. The multiplication starts as soon as all data have arrived at the destination process (by using a mpi_waitall call). In total, the implementation requires 4 temporary buffers, meaning 2 buffers each (communication and computation) for matrices and . A schematic description of the algorithm is presented in Algorithm 1.
The local multiplication consists of multiplications of matrix blocks. They are organized in batches of block-wise small matrix-matrix multiplications that are processed by the CPU or alternatively by a GPU (Schütt et al., 2015). A filtering procedure is applied on the multiplication (on-the-fly filtering) of the blocks so that only blocks for which the product of their norms exceeds a given threshold will be actually multiplied. This filtering increases sparsity but also avoids performing calculations that fall below the filtering threshold, which results in a significant speed-up of the entire operation (VandeVondele et al., 2012). Multiple batches can be computed in parallel on the CPU by means of OpenMP threads. Processing these batches has to be highly efficient. For this reason specific libraries were developed, that outperform vendor basic linear algebra libraries (BLAS)(Bethune, 2012; Heinecke et al., 2016; Schütt et al., 2015).
3. Communication-reducing DBCSR implementation
In the new implementation of the DBCSR library, based on a 2.5D algorithm, panels for matrices and , which are distributed over the process grid following the same scheme described in the section 2, are first copied in two buffers. These buffers are read-only within each multiplication, and reused between multiplications, by reallocating them only if the required size is larger than their actual size. The panels are used for creating MPI windows. To avoid the unnecessary blocking collective operation of creating and destroying the windows for each multiplication (i. e. two collectives per and ), an mpi_iallreduce operation is executed beforehand to check if any of the memory pool in the windows requires a reallocation. This mpi_iallreduce operation overlaps with the initialization of the multiplication, so that it has a negligible impact in the overall execution time (). In this way we are able to limit the number of blocking collectives since the sparsity of the matrix will stabilize after a few initial iterations, and a maximum size of the buffers will be reached. Tests show that this optimization can give up to overall speedup, mainly due to reduced synchronization.
The matrix is distributed over the process grid. Then the computation to obtain each resulting panel is split among processes, where represents the additional dimension when compared to the Cannon’s algorithm. As is usually small, gradually transitioning from 2D to fully 3D, it is referred to as 2.5D (Solomonik and Demmel, 2011). In turn, each process computes the partial multiplications for different panels. For , at the end of a multiplication, these panels have to be communicated to the corresponding process in the 2D grid and accumulated to obtain the final resulting panel, i. e. communications and accumulations, where we exclude the panel that already resides on the final process.
We distinguish two cases for the values of , in addition to the trivial value :
- •
Non-square topology (). Assuming and , we require to be an integer multiple of and . If so, we set and the corresponding 3D topology becomes
[TABLE]
i. e. only the maximum dimension is scaled by .
- •
Square topology (). In this case can assume any square integer value such that has to be an integer multiple of . The 3D topology becomes
[TABLE]
where both and are scaled by .
As a direct consequence of these definitions, the value of is such that is a square number.
The communications of and panels are based on RMA passive target (Gropp et al., 2014), using MPI one-sided calls (mpi_rget), by always accessing the data in the initial positions in the 2D processes grid during the entire multiplication operation. Which means, it does not require any pre-shift and subsequent communication between process neighbors. Furthermore, contrary to the algorithm described in Ref. (Solomonik and Demmel, 2011), our algorithm does not employ any redistribution of the data in a 3D processes grid, but instead the 2D data partitioning is retained for performance, which is a consequence of the cost of such an operation in the presence of the sparsity, and one motivation for the use of RMA. MPI sub-communicators are used for the communications of the and panels between the corresponding MPI windows. The communications of the partial results employ MPI point-to-point communications (mpi_isend / mpi_irecv calls), where MPI sub-communicators are specifically set for these communications.
Besides the two buffers used for the MPI windows, the number of temporary buffers for each process to store , and panels are:
- •
computation buffers for the partial result of the panels and a communication buffer used in their final accumulation (when );
- •
in the case of square topology there are buffers for the and panels, while only buffers are needed for the non-square case.
In total, the implementation requires temporary buffers when (two more buffers than the DBCSR implementation based on MPI point-to-point communications), buffers for the non-square topology, and for the square topology. Note that, as a result of multiplication of sparse matrices, the size of the panels () is in general larger than and panel sizes (, ). Therefore the increases in memory footprint for the temporary buffers with respect to case become
[TABLE]
On the other hand, the amount of data communicated by each process for and panels reduces by a factor as a consequence of to ability to reuse and panels in the evaluation of the panels of . In this respect the algorithm trades memory for communications (McColl and Tiskin, 1999; Schatz et al., 2012). In summary, the total amount of requested data by each process scales as
[TABLE]
which leads to scaling for the amount of communicated data, whereas the memory footprint and overhead increase by . Thus the value for has to be tuned such that the contribution to the communications of the second term in Equation (7) remains small and the memory increase (Equation (6)) is reasonable. Finally, the benefit from the 2.5D implementation becomes larger with higher number of processes.
Compared to the Cannon’s algorithm, the number of ticks for the new implementation becomes . As previously mentioned in section 2, also in this case a square topology is preferable since it leads to the minimum number of ticks. Then, for each tick, each process performs the operations for the local panels, by considering the data panels in the 2D data layout. The local multiplication for each panel will start as soon as all the data has arrived at the destination process (as a result of a mpi_waitall call). Furthermore, the communication of the panels starts during the last tick execution, allowing also overlap for this operation. Then, the accumulation to the local panels is organized such that the panel belonging to the local process, which does not need to be communicated, is used for the accumulation of the incoming partial results from the other processes. Note that the accumulation operations are entirely executed by the CPU, while the local operations can be also executed by the GPU.
A schematic description of the algorithm is presented in Algorithm 2.
4. Performance results
We present the results of running DBCSR with CP2K benchmark applications, resulting in matrices with different block sizes and occupation. This is important, as performance and scalability depend on these parameters. We compare the performance of the 2.5D implementation to the Cannon’s algorithm implementation as available in the DBCSR library, considering only the execution time of the DBCSR multiplication part, and not any other application specific parts. Timings are taken as the average from 4 independent application runs, each consisting of tens of multiplications. Fluctuation are found to be less than 1%. Measured performance numbers are representatives of large-scale and long-running science runs of CP2K for linear scaling calculations. Tests cover both strong and weak scaling. Elements of the generated matrices are double precision floating point numbers.
All performance tests were carried out on Piz Daint, hosted at the Swiss National Supercomputing Centre (CSCS). At the time of the benchmark, Piz Daint was a CRAY XC30 machine with 5,272 compute nodes. Each node comprises a single socket 8-core Intel® Xeon® E5-2670 (code-named Sandy Bridge) CPU at 2.6 GHz TDP frequency, one NIVIDA Tesla K20X, and 32 GB of RAM. All CPU cores have Intel Turbo and Intel Hyper Threading Technology enabled. The latter is not used in our benchmark runs, i. e. threads are pinned to cores individually. From an interconnect point of view, Piz Daint features CRAY’s Aries network including dedicated communication ASICs (shared by a group of four nodes) which are connected by a Dragonfly high-radix network with a bisection bandwidth of 33 TB/s. The code is compiled with GCC 4.9.2 against CRAY-MPICH 7.2.5 and CUDA 6.5.14. For the RMA runs DMAPP 7.0.1 is linked in, and the CRAY environment variable MPICH_RMA_OVER_DMAPP=1 is set. Tests without linking DMAPP show an increase in execution time by a factor 2.4x on average.
A single MPI rank with 8 OpenMP threads is used on each node, which by itself reduces the amount of MPI communication. We found that this configuration gives the best performance with respect to a corresponding configuration with multiple ranks in a node (up to speedup) at the same total number of nodes.
4.1. Strong scaling results
We present the results of three benchmarks performed with CP2K, representative of matrices with a broad range of sparsity values:
- •
H2O-DFT-LS: single-point energy calculation with linear scaling DFT, consisting of 20,736 atoms in a 39 Å3 box (6,912 water molecules in total). An LDA functional is used with a DZVP-MOLOPT basis set and a 300 Ry cutoff. This system implies matrices with medium sparsity (average occupancy 10%).
- •
S-E: semi-empirical setup benchmark with 186,624 water molecules. This system implies matrices with large sparsity (average occupancy 0.05%).
- •
Dense: fully occupied matrices, synthetic benchmark.
The block sizes, total number of rows/columns (all matrices are square), typical occupancy during the simulations, number of multiplications, and FLOPs executed by DBCSR part only are reported in Table 1.
The DBCSR multiplication execution time, the DBCSR total amount of communicated data per process (average between all processes of the total exchanged data for , , and panels, see Equation (7)), and the CP2K peak memory footprint (maximum over all processes) for executions involving different numbers of nodes for the two implementations with MPI point-to-point (PTP) and one-sided communications with different values (OS) are reported in Table 2. The reported peak memory footprint refers to the entire CP2K application, i. e. not just the DBCSR part, therefore it shows the impact of changing in DBCSR with respect to the entire CP2K memory footprint (see Equation (6)). The speedups of OS relative to PTP are shown in Figure 1. Already the OS1 implementation gives faster executions than the original DBCSR PTP implementation, with a speedup that increases with the number of nodes ranging from: 1.09x–1.16x for H2O-DFT-LS, 1.12x–1.40x for S-E, and 1.00x–1.08x for Dense. This speedup directly results from a reduction in the time spent in the mpi_waitall call that waits for the and panel communications to complete. This part of the algorithm is the limiting factor for the scalability of the DBCSR multiplication execution. For instance, at 2704 nodes, which is the most prominent example for this effect, the fractions of this time with respect to the corresponding DBCSR execution time for PTP and OS1 are, respectively: 57% and 50% (H2O-DFT-LS), 32% and 5% (S-E), 41% and 37% (Dense).
At this point, we remark that the timings are obtained from a CP2K internal timing framework, annotating carefully the most important functions. Nevertheless, interpretation of the data is difficult, as the algorithm is largely asynchronous, both with computation on the GPU and with communication across the network. For example, the time spent in the mpi_waitall call is not the full communication time, but only the part that did not overlap with the other operations. In the future, tools that can analyze and visualize this at the scale of the experiments (several hundreds of nodes) will be useful. Nevertheless, we try to explain these timings with the following observations:
- (1)
The one-sided algorithm implements a new communication scheme, which does not require the pre-shift of the data following Cannon’s scheme. 2. (2)
The mpi_waitall completion in the point-to-point implementation requires synchronization on the sender and receiver processes, while the one-sided implementation has only synchronization on the receiver process. 3. (3)
The seemingly large improvement in the S-E benchmark could be related to the average sizes of the exchanged messages in Figure 2. The message sizes for the S-E benchmark are in average between 5.7x and 6.7x smaller than the other two benchmarks sizes. It is possible that the one-sided implementation performs especially better than point-to-point for smaller message sizes.
The OS implementation with allows to further improve the performance, especially for the communication-dominated H2O-DFT-LS benchmark (total speedup with respect to the PTP implementation at 2704 nodes is 1.80x). As expected, the boost increases when more nodes are involved. The effect of introducing is the further reduction of the mpi_waitall timing for the and panels communications. However, this is offset by some overhead for handling partial panels and their communications and accumulations, executed by the CPU only (see Equation (7)). The Dense benchmark, which has a large number of blocks to handle, is particularly affected by these factors: at 2704 nodes, the mpi_waitall timing for the and panels communications goes from 37% for to 4% for of the corresponding total DBCSR execution time, but the overall speedup with respect to the PTP execution time is just 1.11x. For the S-E benchmark, the mpi_waitall timing for the and panels communications is already small with (5%), therefore the effect of using is limited. We can analyze the effect of on the DBCSR total amount of communicated data per process for the , , and panels (see values in Table 2). The ratios of these values between and are shown in Figure 3. They are in agreement with the expectations obtained with the Equation (7), where the average ratios of sizes are: 2.7 for H2O-DFT-LS, 2.1 for S-E, and 1.0 for Dense. Although the volume of communicated data of and panels alone goes as , the reduction in overall volume is less as the contribution of becomes more dominant as increases. On the other hand, the overhead increases linearly with , so that large values of are expected to pay off only at larger number of processes.
Finally, we analyze the memory consumption. The CP2K peak memory footprint values are reported in Table 2. A direct comparison with the ideal values as obtained from Equation (6) is only partially satisfactory. The measured peak memory usage is influenced by various other factors such as details on how the operating system allocates memory, or internal buffers of MPI and the rest of CP2K that might vary depending on the run type. Nevertheless, we can understand the trends as the results vary between the benchmarks. The OS1 implementation requires on average 5% more memory than the PTP implementation per process at the same number of nodes. Then, the memory footprint increases with , also depending on and buffer sizes. In particular, the H2O-DFT-LS benchmark shows the largest increment (average values with respect to OS1: 1.38x for OS2, 1.87x for OS4, and 3.58x for OS9), which is directly related to the largest buffers sizes (average maximum values at 2704 nodes: MB, MB). The other two benchmarks present smaller increments (1.07x–2.07x) since their and are smaller (average maximum values at 2704 nodes: MB, MB for S-E, MB for Dense).
To conclude this section, the 2.5D implementation based on MPI one-sided communications gives good performance in terms of execution time and memory consumption for reasonably small values.
4.2. Weak scaling results
In this section, the performance of the weak scaling test is analyzed. The S-E benchmark is employed, fixing the number of water molecules to 76 per process, which leads to a constant amount of FLOPs and data per process, but growing communication and overhead costs. The sparsity of the matrices decreases linearly with the number of processes, from an average of 1.1% on 144 nodes to 0.04% on 3844 nodes. Based on the conclusion of the strong scaling benchmarks, we only considered square number of processes and . The comparison of the execution time of the DBCSR multiplication part for the PTP, OS1 and OS4 runs is shown in Figure 4. Also in this case, OS1 outperforms PTP (the speedup is smaller with increasing number of nodes, because of the constant message sizes), and OS4 becomes beneficial for a large enough number of processes, reaching 1.7x with 3844 nodes.
5. Conclusions
The new DBCSR implementation based on a 2.5D algorithm and MPI one-sided communications allows for reaching the same or better performance than the previous implementation based on Cannon’s algorithm and MPI point-to-point communications. In the best case, a 1.80x speedup has been observed in our tests. The new communication scheme avoids the pre-shift of data that is required in Cannon’s scheme and effectively trades memory for network bandwidth.
Acknowledgments
This work was supported by grants from the Swiss National Supercomputing Centre (CSCS) under projects CH5 and D50 and received funding from the Swiss University Conference through the Platform for Advanced Scientific Computing (PASC). JV acknowledges financial support by the European Union FP7 in the form of an ERC Starting Grant under contract No. 277910.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Agarwal et al . (1995) Ramesh Agarwal, Susanne Balle, Fred G. Gustavson, Mahesh Joshi, and Prasad V. Palkar. 1995. A Three-Dimensional Approach to Parallel Matrix Multiplication. IBM Journal of Research and Development 39 (1995), 575–582.
- 3Azad et al . (2016) Ariful Azad, Grey Ballard, Aydin Buluç, James Demmel, Laura Grigori, Oded Schwartz, Sivan Toledo, and Samuel Williams. 2016. Exploiting Multiple Levels of Parallelism in Sparse Matrix-Matrix Multiplication. SIAM Journal on Scientific Computing 38, 6 (2016), C 624–C 651.
- 4Ballard et al . (2013) Grey Ballard, Aydin Buluc, James Demmel, Laura Grigori, Benjamin Lipshitz, Oded Schwartz, and Sivan Toledo. 2013. Communication Optimal Parallel Multiplication of Sparse Random Matrices. In Proceedings of the Twenty-fifth Annual ACM Symposium on Parallelism in Algorithms and Architectures (SPAA ’13) . ACM, New York, NY, USA, 222–231.
- 5Ballard et al . (2016) Grey Ballard, Alex Druinsky, Nicholas Knight, and Oded Schwartz. 2016. Hypergraph Partitioning for Sparse Matrix-Matrix Multiplication. ACM Trans. Parallel Comput. 3, 3, Article 18 (Dec. 2016), 34 pages.
- 6Bethune (2012) Iain Bethune. 2012. CP 2K - Sparse Linear Algebra on 1000 s of Cores . Technical Report. http://www.hector.ac.uk/cse/distributedcse/reports/cp 2k 03/cp 2k 03.pdf .
- 7Borstnik et al . (2014) Urban Borstnik, Joost Vande Vondele, Valery Weber, and Juerg Hutter. 2014. Sparse Matrix Multiplication: The Distributed Block-Compressed Sparse Row Library. Parallel Comput. 40, 5-6 (2014), 47–58.
- 8Bowler and Miyazaki (2012) David Bowler and Tsuyoshi Miyazaki. 2012. O(N) methods in electronic structure calculations. Rep. Prog. Phys. 75, 036503 (2012).