A Sampling Theory Perspective of Graph-based Semi-supervised Learning
Aamir Anis, Aly El Gamal, Salman Avestimehr, Antonio Ortega

TL;DR
This paper offers a theoretical framework for understanding graph-based semi-supervised learning by modeling class indicators as bandlimited signals and analyzing their bandwidth in relation to dataset geometry.
Contribution
It introduces a sampling theory perspective, justifying the bandlimitedness assumption of class indicators in semi-supervised learning.
Findings
Bandwidth of class indicators relates to dataset geometry
The approach applies to general data models with separable and nonseparable classes
Provides a theoretical basis for graph-based semi-supervised classification
Abstract
Graph-based methods have been quite successful in solving unsupervised and semi-supervised learning problems, as they provide a means to capture the underlying geometry of the dataset. It is often desirable for the constructed graph to satisfy two properties: first, data points that are similar in the feature space should be strongly connected on the graph, and second, the class label information should vary smoothly with respect to the graph, where smoothness is measured using the spectral properties of the graph Laplacian matrix. Recent works have justified some of these smoothness conditions by showing that they are strongly linked to the semi-supervised smoothness assumption and its variants. In this work, we reinforce this connection by viewing the problem from a graph sampling theoretic perspective, where class indicator functions are treated as bandlimited graph signals (in the…
Click any figure to enlarge with its caption.
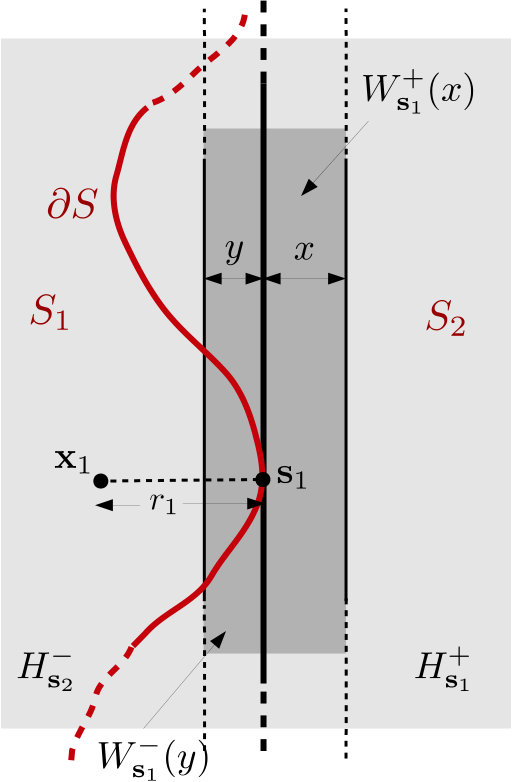 Figure 1
Figure 1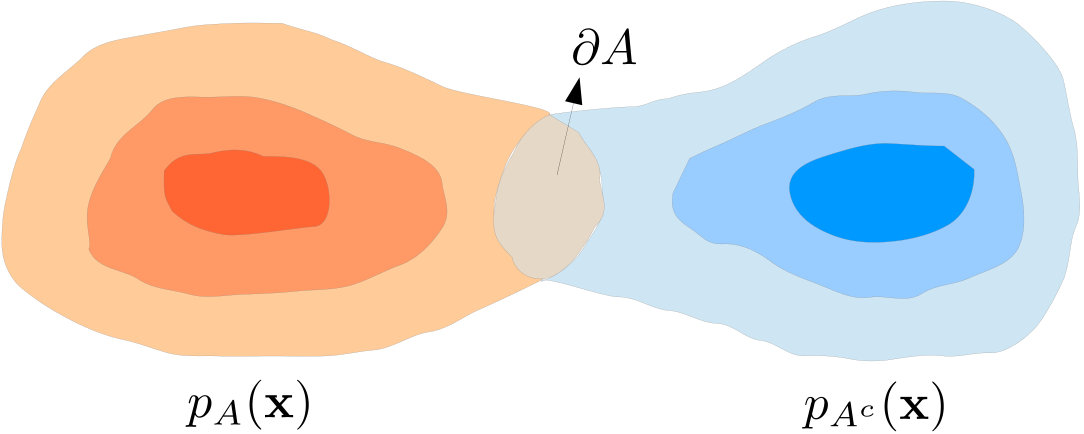 Figure 2
Figure 2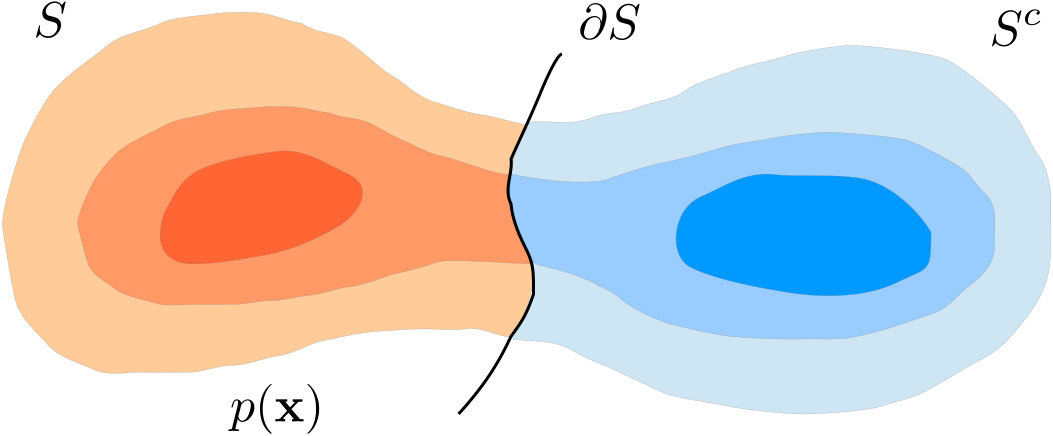 Figure 3
Figure 3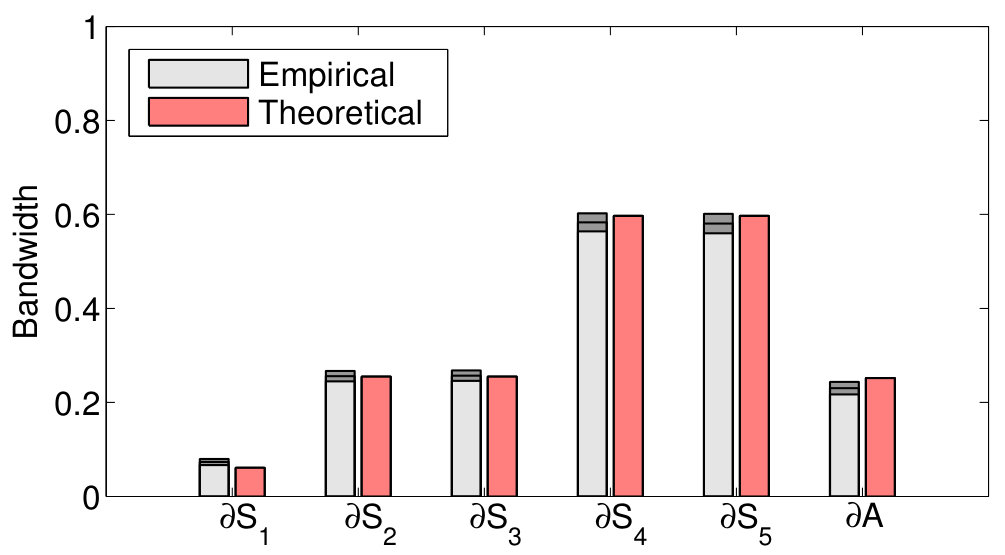 Figure 4
Figure 4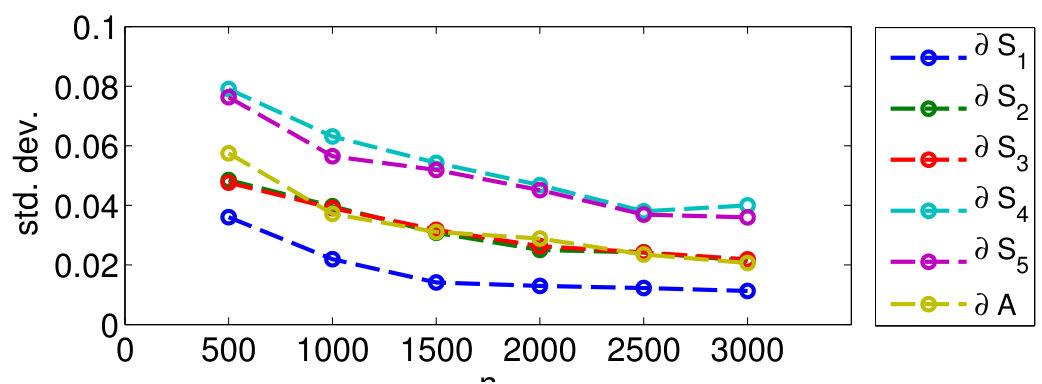 Figure 5
Figure 5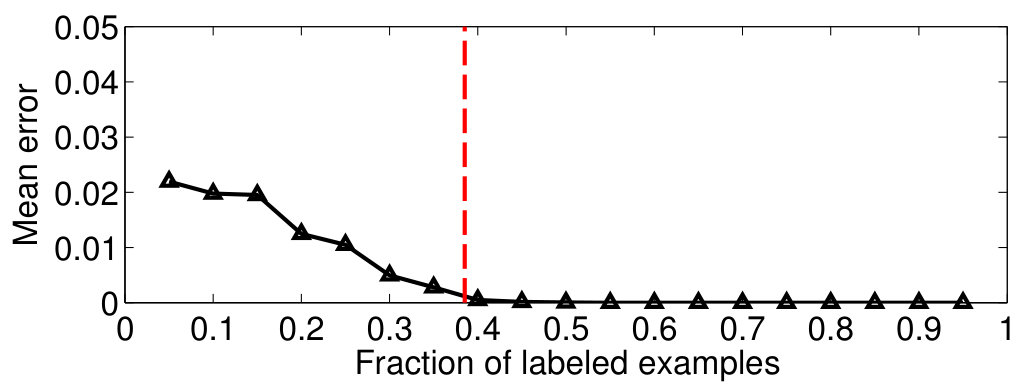 Figure 6
Figure 6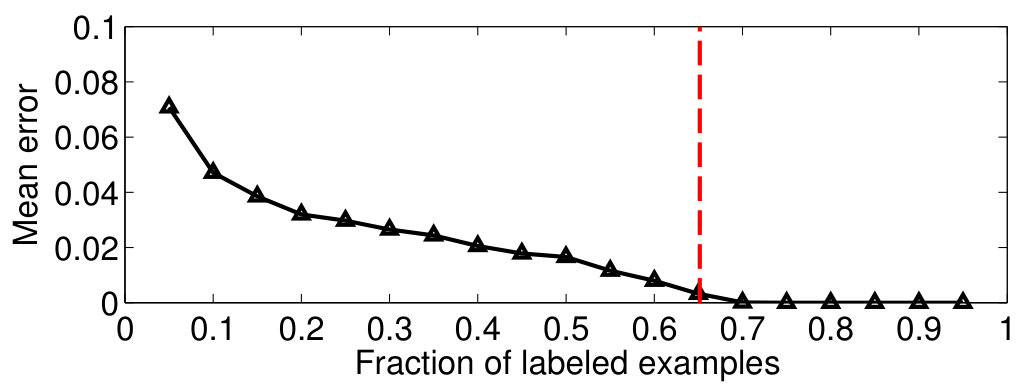 Figure 7
Figure 7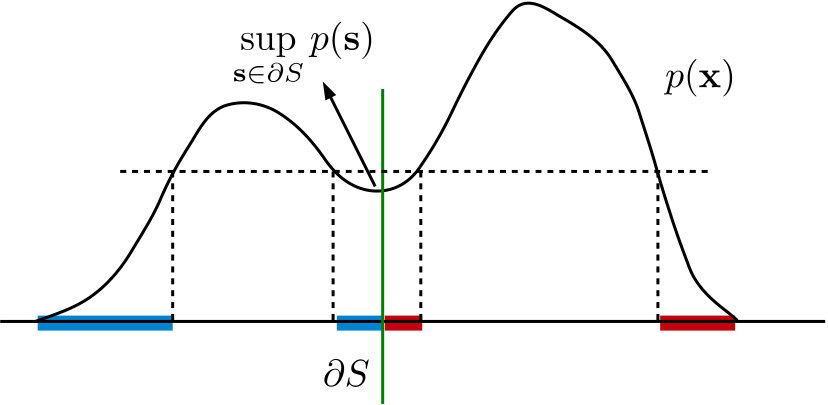 Figure 8
Figure 8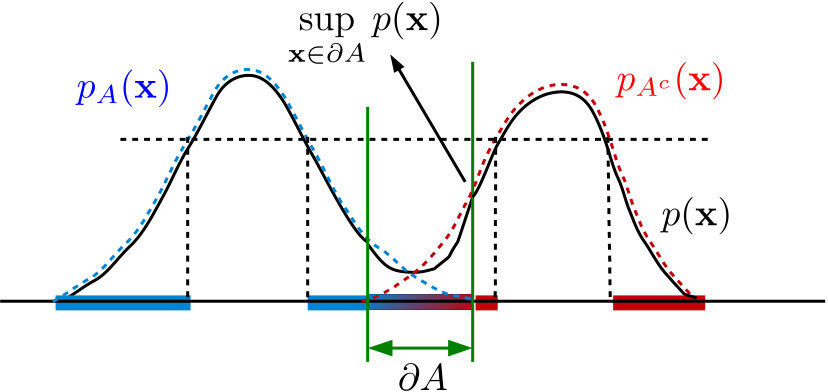 Figure 9
Figure 9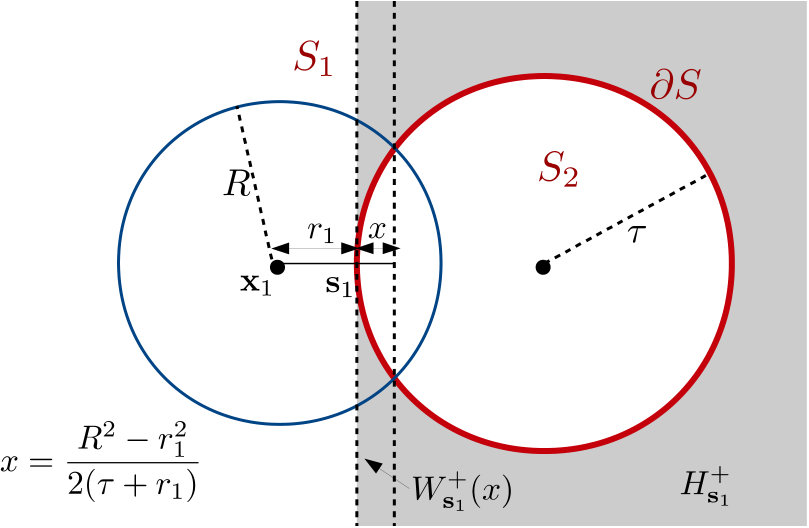 Figure 10
Figure 10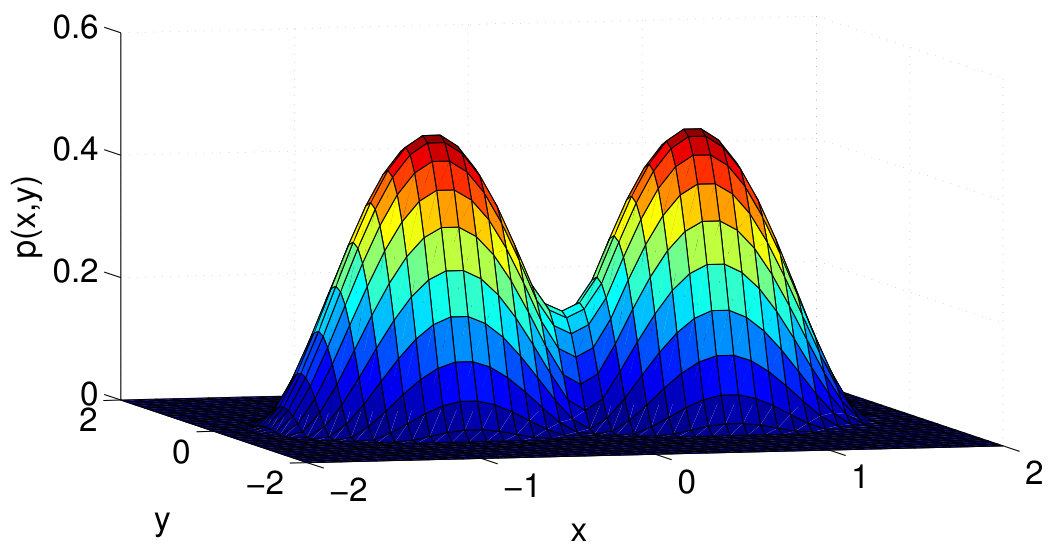 Figure 11
Figure 11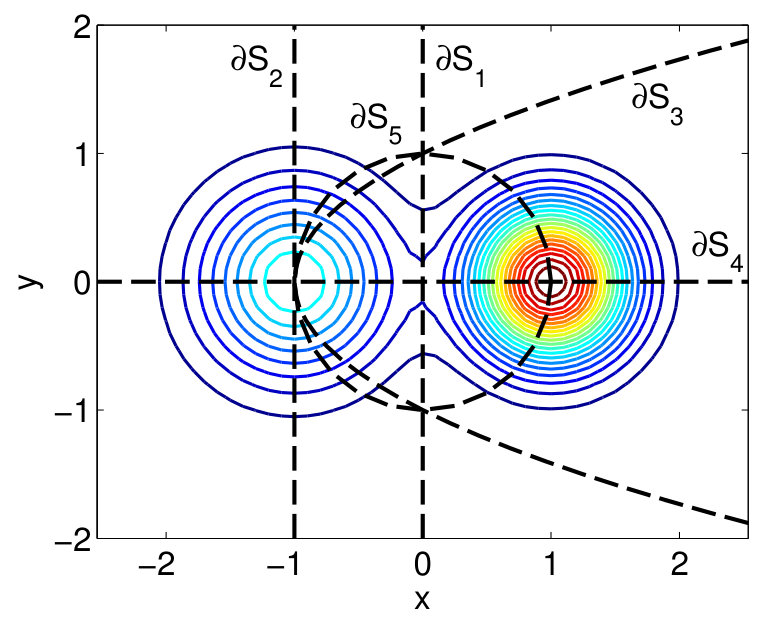 Figure 12
Figure 12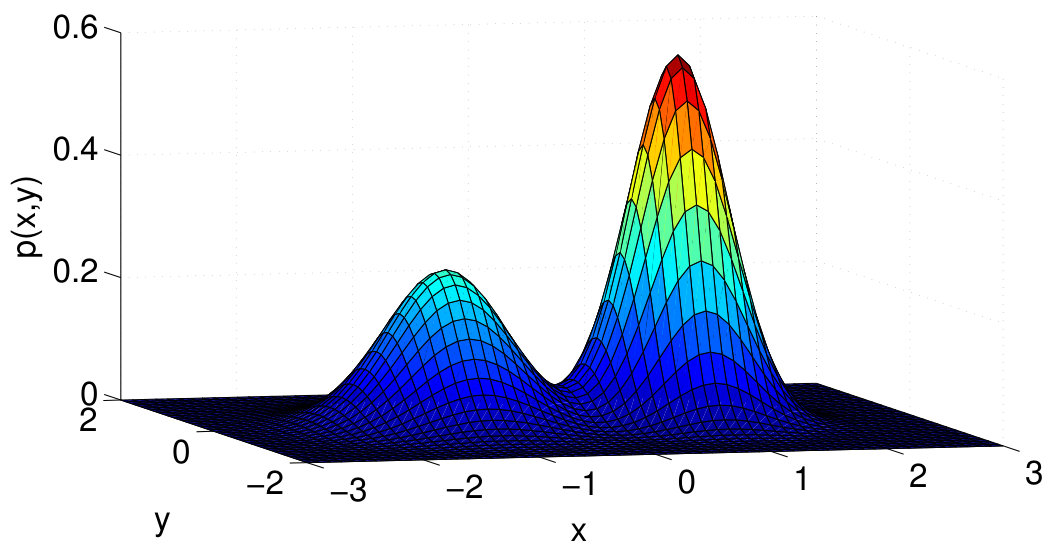 Figure 13
Figure 13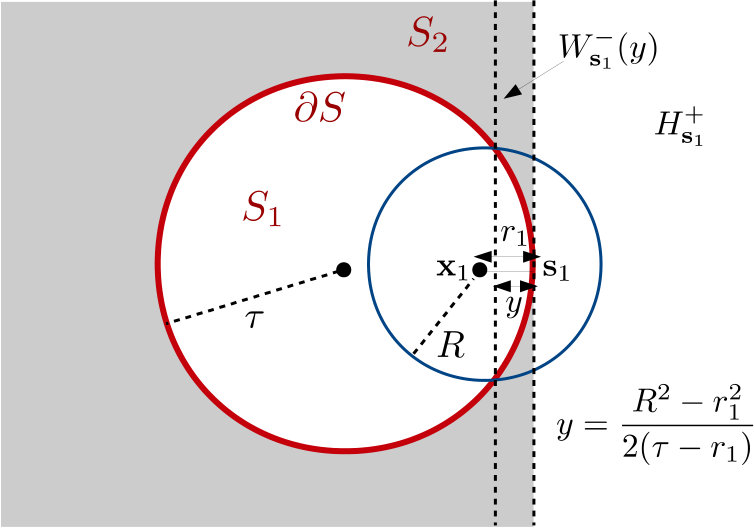 Figure 14
Figure 14| Work | Data model | Graph model | Quantity | Convergence regime | Limit (within constant scaling factor) |
| Narayanan et al [3] | supported on manifold , separated into and by smooth hypersurface | Normalized Gaussian weights | , | ||
| Maier et al [24] | supported on , separated into and by hyperplane | -neighborhood, unweighted | , | ||
| -nn, unweighted, | , | ||||
| fully-connected, Gaussian weights | , | ||||
| Bousquet et al [17], Hein [18] | and supported on | fully-connected, weights , where is a smooth decaying kernel | , | ||
| Zhou et al [6] | Uniformly distributed on -dim. submanifold | fully-connected, Gaussian weights | , | ||
| García Trillos & Slepčev [5] | p(x) supported on | fully-connected, weights , where is a smoothly decaying kernel | , | ||
| El Alaoui et al [8], Slepčev & Thorpe [22] | p(x) supported on , | fully-connected, weights , where is a smoothly decaying kernel | , | ||
| This work | supported on , separated into and by smooth hypersurface | fully-connected, Gaussian weights | , , | ||
| Drawn from and supported on with probabilities and | fully-connected, Gaussian weights | , , |
| Boundary | Description | |
|---|---|---|
| 0.0607 | ||
| 0.2547 | ||
| 0.2547 | ||
| 0.5969 | ||
| 0.5969 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A Sampling Theory Perspective of Graph-based Semi-supervised Learning
Aamir Anis, Aly El Gamal, Salman Avestimehr, and Antonio Ortega This work is supported in part by NSF under grants CCF-1410009, CCF-1527874, CCF-1408639, NETS-1419632 and by AFRL and DARPA under grant 108818.S. Avestimehr and A. Ortega are with the Ming Hsieh Department of Electrical Engineering, University of Southern California. A. Anis is currently with Google Inc., he was affiliated with the University of Southern California at the time this work was completed. A. El Gamal is with the Department of Electrical and Computer Engineering, Purdue University.E-mail: [email protected], [email protected], [email protected], [email protected] (c) 2017 IEEE. Personal use of this material is permitted. However, permission to use this material for any other purposes must be obtained from the IEEE by sending a request to [email protected].
Abstract
Graph-based methods have been quite successful in solving unsupervised and semi-supervised learning problems, as they provide a means to capture the underlying geometry of the dataset. It is often desirable for the constructed graph to satisfy two properties: first, data points that are similar in the feature space should be strongly connected on the graph, and second, the class label information should vary smoothly with respect to the graph, where smoothness is measured using the spectral properties of the graph Laplacian matrix. Recent works have justified some of these smoothness conditions by showing that they are strongly linked to the semi-supervised smoothness assumption and its variants. In this work, we reinforce this connection by viewing the problem from a graph sampling theoretic perspective, where class indicator functions are treated as bandlimited graph signals (in the eigenvector basis of the graph Laplacian) and label prediction as a bandlimited reconstruction problem. Our approach involves analyzing the bandwidth of class indicator signals generated from statistical data models with separable and nonseparable classes. These models are quite general and mimic the nature of most real-world datasets. Our results show that in the asymptotic limit, the bandwidth of any class indicator is also closely related to the geometry of the dataset. This allows one to theoretically justify the assumption of bandlimitedness of class indicator signals, thereby providing a sampling theoretic interpretation of graph-based semi-supervised classification.
I Introduction
The abundance of unlabeled data in various machine learning applications, along with the prohibitive cost of labeling, has led to growing interest in semi-supervised learning. This paradigm deals with the task of classifying data points in the presence of very little labeling information by relying on the geometry of the dataset. Assuming that the features are well-chosen, a natural assumption in this setting is to consider the marginal density of the feature vectors to be informative about the labeling function defined on the points. This assumption is fundamental to the semi-supervised learning problem both in the classification and the regression settings, and is also known as the semi-supervised smoothness assumption [1], which states that the label function is smoother in regions of high data density. There also exist other similar variants of this assumption specialized for the classification setting, namely, the cluster assumption [2] (points in a cluster are likely to have the same class label) or the low density separation assumption [3] (decision boundaries pass through regions of low data density). Most present day algorithms for semi-supervised learning rely on one or more of these assumptions to predict the unknown labels.
In practice, graph-based methods have been found to be quite suitable for geometry-based learning tasks, primarily because they provide an easy way of exploiting information from the geometry of the dataset. These methods involve constructing a distance-based similarity graph whose vertices (nodes) represent the data points and whose edge weights are in general a decreasing function of the distances between them. The learning task then involves predicting the labels of the unknown nodes, given the known labels, often called the transductive learning paradigm. The key assumption here is that the label function is “smooth” over the graph, in the sense that labels of vertices do not vary much over edges with high weights (i.e., edges that connect close or similar points). There are numerous ways of quantitatively imposing smoothness constraints over label functions defined on the vertices of a similarity graph. Most graph-based semi-supervised classification algorithms incorporate one of these criteria as a penalty against the fitting error in a regularization problem, or as a constraint term while minimizing the fitting error in an optimization problem. For example, a commonly used measure of smoothness for a label function is the graph Laplacian regularizer ( being the graph Laplacian), and many algorithms involve minimizing this quadratic energy function while ensuring that satisfies the known set of labels [4, 2]. Another example is the graph total variation [5]. There also exist higher-order variants of the smoothness measure such as iterated graph Laplacian regularizers [6] and the -Laplacian regularizer [7, 8], that have been shown to make the problem more well-behaved. On the other hand, a spectral theory based classification algorithm restricts to be spanned by the first few eigenvectors of the graph Laplacian [9, 10], that are known to form a representation basis for smooth functions on the graph. In each of the examples, the criterion enforces smoothness of the labels over the graph – a lower value of the regularizer , and a smaller number of leading eigenvectors to model imply that vertices that are close neighbors on the graph are more likely to have the same label.
A more recent approach, derived from Graph Signal Processing (GSP) [11], considers the semi-supervised learning problem from the perspective of sampling theory for graph signals [12, 13, 14, 15]. It involves treating the class label function as a bandlimited graph signal, and label prediction as a bandlimited reconstruction problem. The advantage of this approach is that one can also analyze, using sampling theory, the label complexity of graph-based semi-supervised classification, that is, the fraction of labeled vertices on the graph required for predicting the labels of the unlabeled vertices. A key ingredient in this formulation is the bandwidth of signals on the graph, which is defined as the largest Laplacian eigenvalue for which the projection of the signal over the corresponding eigenvector is non-zero. Signals with lower bandwidth tend to be smoother on the graph and have a lower label complexity. Label prediction using bandlimited reconstruction then involves estimating a graph signal that minimizes prediction error on the labeled set under a bandwidth constraint. This can also be carried out without explicitly computing the eigenvectors of the Laplacian, and has been shown to be quite competitive in comparison to state-of-the-art graph-based semi-supervised learning methods [16].
Although graph-based semi-supervised learning methods are well-motivated, their connection to the underlying geometry of the dataset had not been clearly understood so far in a theoretical sense. Recent works focused on justifying these approaches by exploring their geometrical interpretation in the limit of infinitely available unlabeled data. This is typically done by assuming a probabilistic generative model for the dataset and analyzing the graph smoothness criteria in the asymptotic setting for certain commonly-used graph construction schemes. For example, it has been shown that for data points drawn from a smooth distribution with an associated smooth label function (i.e., the regression setting), the graph Laplacian-based regularizers converge in the limit of infinite data points to some density-weighted variational energy functional that penalizes large variations of the labels in high density regions [10, 17, 18, 19, 6, 20, 5, 21, 22]. A similar connection ensues for semi-supervised learning problems in the classification setting (i.e., when labels are discrete in the feature space). If points drawn from a smooth distribution are separated by a smooth boundary into two classes, then the graph cut for the partition converges to a weighted volume of the boundary [3, 23, 24, 25]. This is consistent with the low density separation assumption – a low value of the graph cut implies that the boundary passes through regions of low data density.
To our knowledge, no such connections have been drawn for the sampling theoretic approach to learning. A geometrical interpretation of this approach would help complete our theoretical understanding of graph-based semi-supervised learning approaches and strengthen their link with the semi-supervised smoothness assumption and its variants. Therefore, in this work, we seek answers for the following questions:
- •
What is the connection between the bandwidth of class indicator signals over the similarity graph and the underlying geometry of the data set?
- •
What is the interpretation of the bandlimited reconstruction approach for label prediction?
- •
How many labeled examples does one require for predicting the unknown labels?
To answer these questions, our work analyzes the asymptotic behavior of an iterated Laplacian-based bandwidth estimator for class indicator signals on similarity graphs constructed from a statistical model for the feature vectors. To make our analysis as general as possible, we consider two data models: separable and nonseparable. These generative models are quite practical and can be used to mimic most datasets in the real world. The separable model assumes that data points are independently drawn from an underlying probability distribution in the feature space and each class is separated from the others by a smooth boundary. On the other hand, the nonseparable model assumes a mixture distribution for the data where the data points are drawn independently with certain probability from separate class conditional distributions. We also introduce a notion of “boundaries” for classes in the nonseparable model in the form of overlap regions (i.e., the region of ambiguity), defined as the set of points where the probability of belonging and not belonging to a class are both non-zero. This definition is quite practical and useful for characterizing the geometry of such datasets.
Using the data points, we consider a specific graph construction scheme that applies the Gaussian kernel over Euclidean distances between feature vectors for computing their similarities (our analysis can be generalized easily to arbitrary kernels under simple assumptions). In order to compute the bandwidth of any signal on the graph, we define an estimator based on the iterated Laplacian regularizer. A significant portion of this paper focuses on analyzing the stochastic convergence of this bandwidth estimate (using variance-bias decomposition) in the limit of infinite data points for any class indicator signal on the graph. The analysis in our work suggests a novel sampling theoretic interpretation of graph-based semi-supervised learning and the main contributions can be summarized as follows:
- •
Relationship between bandwidth and data geometry. For the separable model, we show that under certain rate conditions, the bandwidth estimate for any class indicator signal over the graph converges to the supremum of the data density over the class boundary. Similarly, for the nonseparable model, we show that the bandwidth estimate converges to the supremum of the density over the overlap region. Based on these results, we conjecture, with supporting experiments, that the bandwidths also converge to the same values.
- •
Interpretation of bandlimited reconstruction. Using the geometrical interpretation of the bandwidth, we conclude that bandlimited reconstruction allows one to choose the complexity of the hypothesis space while predicting unknown labels (i.e., a larger bandwidth allows more complex class boundaries).
- •
Quantification of label complexity for sampling theory-based learning. For both the separable and nonseparable models, we conjecture, with supporting arguments and experiments, that the fraction of labeled nodes on the graph for reconstructing class indicator signals converges, in the asymptotic limit, to the probability mass of the sublevel set that entirely encompasses the boundary.
Our analysis has significant implications: Firstly, class indicator signals have a low bandwidth if class boundaries lie in regions of low data densities, that is, the semi-supervised assumption holds for graph-based methods. And secondly, our analysis also helps quantify the impact of bandwidth and data geometry in semi-supervised learning problems. Specifically, it enables us to theoretically assert that for the sampling theoretic approach to graph-based semi-supervised learning, the label complexity of class indicator signals over the graph is indeed lower if the boundary lies in regions of low data density, as demonstrated empirically in earlier works [9, 10].
The rest of this paper is organized as follows: In Section II, we formally introduce the statistical data models and the graph construction scheme for analysis, along with a precursor of concepts from graph sampling theory. In Section III, we review prior work and underline their connections with our work. In Section IV, we state our main results and outline their implications. In Section V, we prove the major building blocks for our results. We finally conclude with numerical validation in Section VI, followed by discussion and an outline of future work in Section VII. It is worth noting that the bandwidth convergence result for the separable model and an interpretation of bandlimited reconstruction were given in our preliminary work [26]. This paper presents complete formal proofs for those results, extends them to the nonseparable model, and also analyzes label complexity.
II Preliminaries
II-A Data models
II-A1 The separable model
In this model, we assume that the dataset consists of a pool of random, -dimensional feature vectors drawn independently from some probability density function supported on (this is assumed for simplicity, the analysis can be extended to subsets and low-dimensional manifolds in , but would more technically involved). To simplify our analysis, we also assume that is bounded from above, Lipschitz continuous and twice differentiable. We assume that a smooth hypersurface , with radius of curvature lower bounded by a constant , splits into two disjoint classes and , with indicator functions and . This is illustrated in Figure 1(a). Thus, the -dimensional class indicator signal for class is denoted by the bold-faced vector notation , and defined as , i.e., the entry of is if and [math] otherwise.
II-A2 The nonseparable model
In this model, we assume that each class has its own conditional distribution supported on (that may or may not overlap with other distributions of other classes). The data set consists of a pool of random and independent -dimensional feature vectors drawn independently from any of the distributions with probabilities , such that . For our analysis, we consider a class denoted by an index with selection probability , class conditional distribution and an -dimensional indicator vector whose component takes value if is drawn from class . Note that does not have a continuous domain counterpart, unlike which is sampled from the indicator function on points in . We illustrate the nonseparable model in Figure 1(b). Further, we denote by the probability that a point does not belong to and by the density of all such points. The marginal distribution of data points is then given by the mixture density
[TABLE]
Once again, to simplify our analysis, we assume that all distributions are Lipschitz continuous, bounded from above and twice differentiable in . Next, we introduce the notion of a “boundary” for classes in the nonseparable model as follows: for class , we define its overlap region as
[TABLE]
Intuitively, can be considered as the region of ambiguity, where both points belonging and not belonging to co-exist. In other words, can be thought of as a “boundary” that separates the region where points can only belong to from the region where points can never belong to . Since class indicator signals on graphs will change values only within the overlap region, one would expect that the indicators will be smoother if there are fewer data points within this region. We shall show later that this is indeed the case, both theoretically and experimentally. Note that the definition of the boundary is not very meaningful for class conditional distributions with decaying tails, such as the Gaussian, since the boundary in this case technically encompasses the entire feature space. However, in such cases, one can approximate the boundary with appropriate thresholds in the definition and this approximation can also be formalized for distributions with exponentially decaying tails.
II-B Graph construction
Using the feature vectors, we construct an undirected distance-based similarity graph where nodes represent the data points and edge weights are proportional to their similarity, given by the Gaussian kernel:
[TABLE]
where is the variance (bandwidth) of the Gaussian kernel. Further, we assume , i.e., the graph does not have self-loops. The adjacency matrix of the graph is an symmetric matrix with elements , while the degree matrix is a diagonal matrix with elements . We define the graph Laplacian as . Normalization by ensures that the norm of is stochastically bounded as grows. Since the graph is undirected, is a symmetric matrix with non-negative eigenvalues and an orthogonal set of corresponding eigenvectors . It is known that for a larger eigenvalue , the corresponding eigenvector exhibits greater variation when plotted over the nodes of the graph [11]. Thus, one of the fundamental postulates of Graph Signal Processing consists of using the eigen-decomposition of to provide a notion of frequency for graph signals, with the eigenvalues acting as graph frequencies and the eigenvectors forming the graph Fourier basis [11].
II-C Graph sampling theory: bandwidth, bandlimited reconstruction and label complexity
In traditional sampling theory, bandwidth plays an important role in specifying the inherent dimensionality of a signal and therefore determines the sampling rate required for perfect reconstruction. A similar notion exists for signals defined over graphs – the bandwidth of any signal on the graph is defined as the largest eigenvalue for which the projection of the signal on the corresponding eigenvector is non-zero [27, 12, 15], i.e.,
[TABLE]
Signals with lower bandwidth have low frequency content, and tend to be smoother on the graph.
Bandwidth plays a central role in the sampling theoretic approach to semi-supervised learning, where the class indicator signals are assumed to be bandlimited over the similarity graph and interpolated through bandlimited reconstruction. For a ground-truth signal that we are trying to reconstruct, and whose values are known only on a subset , this approach involves solving the following least-squares problem [28, 16]:
[TABLE]
where and denote the values of and , respectively, on the set . The constraint restricts the hypothesis space to a set of bandlimited signals with bandwidth less than , which is equivalent to enforcing smoothness of the labels over the graph. This method essentially improves upon the Fourier eigenvector approach suggested in [9, 10] in two ways: first, label prediction can be carried out without explicitly computing the eigenvectors of using efficient iterative approaches implemented via graph filtering operations [28, 29]. And second, one can also use the sampling theorem for graph signals to set as the cutoff frequency associated with the labeled set [12, 15], which, for a given , is defined as the bandwidth below which any bandlimited signal is uniquely represented by its values on . This approach is taken in [27, 16], and is particularly useful when , in which case the minimizer of (5) exactly equals , i.e., . Alternatively, one can also reconstruct using the variational problem: ; the minimizer in this case is also exactly equal to if [30, 15]. Further, it also possible to provide error bounds for both methods when is not satisfied [15].
The bandwidth of any indicator signal is also useful in specifying the amount of labeling required for its recovery in the context of sampling theory, as demonstrated by the following key result [15]:
Lemma 1**.**
Let denote the number of eigenvalues of less than or equal to . Then, for any signal with bandwidth , there exists a subset of nodes of size such that can be perfectly recovered from its values on .
Proof.
Since has bandwidth , it is spanned by the first eigenvectors of , i.e., let , then we have
[TABLE]
where for and denotes the rectangular matrix formed using the first eigenvectors of . Since the eigenvectors are orthogonal, has rank . Therefore, there exists a subset of rows, indexed by a set , with cardinality , such that the matrix is full-rank, and thus invertible. Using this in (6), we get and thus can be perfectly recovered from as , thereby proving our claim. Note that this is exactly the closed-form solution of (5), for and , when the eigenvectors of are known. ∎
We shall use this result later, to compute the label complexity of any signal on the graph as . Note, however, that this quantity only specifies the fraction of nodes to label on the graph – selecting which nodes to label is another question altogether. This problem has been well-studied as part of graph sampling theory [12, 15, 13, 14], with consideration of other important issues such as stability of reconstruction and computational complexity.
II-D Estimating bandwidth for graph signals
Ideally, computing the bandwidth of a graph signal requires obtaining the eigenvectors of and the corresponding projections . However, analyzing the convergence of these coefficients is technically challenging. Therefore, we resort to the following estimate of the bandwidth [15]:
[TABLE]
where we call the -order bandwidth estimate. It can be shown that the bandwidth estimates satisfy the property: for all , . In other words, forms a monotonically improving sequence of estimates of the true bandwidth . Further, we can also show [15]:
[TABLE]
II-E Focus of this paper
The discussion in Section II-C indicates that in the discrete setting, with finite number of data points, the notions of bandwidth, bandlimited reconstruction and label complexity are well-motivated and quite useful in highlighting a sampling theory perspective of graph-based semi-supervised learning. However, there is a lack of understanding of these concepts in terms of their geometrical interpretation, i.e., their connection with the underlying geometry of the dataset. Thus, inspired by existing analysis in the literature for popular graph-based smoothness measures, we seek to bridge this gap by analyzing these concepts in the asymptotic regime of infinite data points for the data models and graph construction scheme described earlier.
Analyzing the convergence of the bandwidth estimates of class indicator signals for the separable and the nonseparable models constitutes the main subject for the rest of this paper. Our approach, similar to existing results in the literature, starts in the discrete domain by drawing samples from the data models, constructs a sequence of graphs from the data points, and considers the behavior of
[TABLE]
over the graphs as , and . Intuitively, the condition implies an abundance of unlabeled data, dictates that the connectivity around each node is meaningful and does not blow up, and translates to improving estimates of the bandwidth. Our analysis relates and to the underlying data distribution and class boundaries – the hypersurface in the separable case and the overlap region in the nonseparable case. Using these results, we also comment on the label complexities of reconstructing and over the graph in the asymptotic limit.
III Related work and connections
Existing convergence analyses of the graph-based smoothness measures for various graph construction schemes appear in two different settings – classification and regression. The classification setting assumes that labels indicate class memberships and are discrete, typically with values. Note that both the separable and nonseparable data models considered in our paper are in the classification setting. On the other hand, in the regression setting, one allows the class label signal to be sampled from a smooth function on with soft values, such that , and later applies some thresholding mechanism to infer class memberships. For example, in the two class problem, one can assign and to the two classes and threshold at [math]. Convergence analysis of smoothness measures in this setting requires different scaling conditions than the classification setting, and leads to fundamentally different limit values that require differentiability of the label functions in the continuum. Applying these to class indicator functions may lead to ill-defined results. A summary of convergence results in the literature for both settings is presented in Table I. Although these results do not focus on analyzing the bandwidth of class indicator signals, the proof techniques used in this paper are inspired by some of these works. We review them in this section and discuss their connections to our work.
III-A Classification setting
Prior work under this setting assumes the separable data model where the feature space is partitioned by smooth decision boundaries into different classes. When , the bandwidth estimate for the separable model in our work reduces (within a scaling factor) to the empirical graph cut for the partitions and of the feature space, i.e.,
[TABLE]
Convergence of this quantity has been studied before in the context of spectral clustering, where one tries to minimize it across the two partitions of the nodes. It has been shown in [24] that the cut formed by a hyperplane in converges with some scaling under the rate conditions and as
[TABLE]
where ranges over all -dimensional volume elements tangent to the hyperplane , and denotes convergence in probability. The analysis has also been extended to other graph construction schemes such as the -nearest neighbor graph and the -neighborhood graph, both weighted and unweighted. The condition in (10) is required to have a clear and well-defined limit on the right hand side. We borrow this convergence regime in our work, since it allows a succinct interpretation of the bandwidth of class indicator signals. Intuitively, it enforces sparsity in the similarity matrix by shrinking the neighborhood volume as the number of data points increases. As a result, one can ensure that the graph remains sparse even as the number of points goes to infinity. A similar result for a similarity graph constructed with normalized weights was shown earlier for an arbitrary hypersurface in [3], where denotes the degree of node . In this case, normalization of the graph weights results in convergence to . Similarly, in [23], the convergence of normalized cuts is analyzed for points drawn from a uniform density. All of these results aim to provide an interpretation for spectral clustering – up to some scaling, the empirical cut value converges to a weighted volume of the boundary. Thus, spectral clustering is a means of performing low density separation on a finite sample drawn from a distribution in feature space.
Note that these works provide little insight for the convergence analysis of higher-order regularizers, i.e., for in our case, since these require different scaling factors and rate conditions. Further, we get no clue about the continuum limit values of and from any of these results. However, the definition and some of the proof techniques we use for the separable models in this paper have been inspired by [3, 24].
III-B Regression setting
To predict the labels of unknown samples in the regression setting, one generally minimizes the graph Laplacian regularizer subject to the known label constraints [4]:
[TABLE]
One particular convergence result in this setting assumes that data points are drawn i.i.d. from and are labeled by sampling a smooth function on . Here, the graph Laplacian regularizer can be shown to converge in the asymptotic limit under the conditions and as in [17, 18]:
[TABLE]
where for each , is the -dimensional label vector representing the values of at the sample points, is the gradient operator and is a constant factor independent of and . The right hand side of the result above is a weighted Dirichlet energy functional that penalizes variation in the label function weighted by the data distribution. Similar to the justification of spectral clustering, this result justifies using the formulation in (11) for semi-supervised classification: given label constraints, the predicted label function must vary little in regions of high density. The work of [18, 31] generalizes this result by using arbitrary kernel functions for defining graph weights, and defining data distributions over manifolds in . Convergence results for another regularizer called Graph Total Variation, defined as , are presented in [5, 21]. For data points drawn from defined over a domain , graph weights given by , one has as and :
[TABLE]
where the limit is analyzed in the setting of -convergence [5]. These results extend to the classification setting when is an indicator function, for example, the limit for reduces to that of (10). This approach is used in [25] to analyze convergence of Cheeger and ratio cuts.
Similar convergence results have also been derived for the higher-order Laplacian regularizer obtained from uniformly distributed data [6]. In this case, it was shown that for data points obtained from a uniform distribution on a -dimensional submanifold such that and -differentiable functions , one has as :
[TABLE]
where is the Laplace operator and is a vanishing sequence with . Extensions for non-uniform probability distributions over the manifold can be obtained using the weighted Laplace-Beltrami operator [19, 20]. More recently, an -based Laplacian regularization has been proposed for imposing smoothness constraints in semi-supervised learning problems [7, 8]. This is similar to a higher-order regularizer but is defined as , where and is a smoothly decaying Kernel function. It has been shown for a bounded density defined on that for every , as , followed by ,
[TABLE]
The work of [22] generalizes this result over an open, bounded and connected set and analyzes rate conditions such that the scalings , occur jointly.
Note that although our work also uses higher powers of in the expressions for and , we cannot use the convergence results in (14) and the proof techniques of (15), since they are only applicable for smooth functions (i.e., differentiable up to a certain order) on . Specifically, in our case, in the separable model is sampled from a discontinuous indicator function , hence plugging it into existing results does not give a meaningful result for higher values of . Further, the nonseparable model can only be defined in the classification setting, i.e., in the nonseparable model does not have a continuum counterpart. Therefore, our analysis has to take a different route that has more similarities with the proof techniques used for the classification setting. We shall later see that a bulk of the effort in proving our results goes into expanding and for any by keeping track of every term in the expansion. This is followed by a careful evaluation of the integrals in their expected values by reducing them term-by-term.
IV Main results and Discussion
IV-A Interpretation of bandwidth and bandlimited reconstruction
We first show that under certain conditions, the bandwidth estimates of class indicator signals for both the data models, i.e., and , over Gaussian kernel-based similarity graphs constructed from data points in , converge to quantities that are functions of the underlying distribution and the class boundary for both data models. This convergence is achieved under the following asymptotic regime:
Increasing size of dataset: . 2. 2.
Shrinking neighborhood volume: . 3. 3.
Improving bandwidth estimates: .
Note that an increasing size of the dataset is required for the stochastic convergence of the bandwidth estimate. ensures that the limiting values are concise and have a simple interpretation in terms of the data geometry. Intuitively, as the number of data points increases, the neighborhood around each data point shrinks – as a result, the degree of each node in the graph does not blow up. Finally, leads to improving values of the bandwidth estimate.
The convergence results are precisely stated in the following theorems:
Theorem 1**.**
If , and while satisfying the following rate conditions
, where , 2. 2.
,
then for the separable model, one has
[TABLE]
where “p.” denotes convergence in probability.
Theorem 2**.**
If , and while satisfying the following rate conditions
, where , 2. 2.
,
then for the non-separable model, one has
[TABLE]
The dependence of the results on the rate conditions will be explained later in the proofs section. An example of parameter choices for scaling laws to hold simultaneously is illustrated in the following remark:
Remark 1**.**
Equations (16) and (17) hold if for each value of , we choose and as follows:
[TABLE]
for constants , and . indicates taking the nearest integer value.
Theorems 1 and 17 give an explicit connection between bandwidth estimates of class indicator signals and class boundaries in the dataset. This interpretation forms the basis of justifying the choice of bandwidth as a smoothness constraint in graph-based learning algorithms. Theorem 1 suggests that for the separable model, if the boundary passes through regions of low probability density, then the bandwidth of the corresponding class indicator vector is low. A similar conclusion is suggested for the nonseparable model from Theorem 17, i.e., if the density of data points in the overlap region is low, then the bandwidth is low. In other words, low density of data in the boundary regions leads to smooth indicator functions.
From our results, we also get an intuition behind the smoothness constraint imposed in the bandlimited reconstruction approach (5) for semi-supervised learning. Basically, enforcing smoothness on classes in terms of indicator bandwidth ensures that the algorithm chooses a boundary passing through regions of low data density in the separable case. Similarly, in the nonseparable case, it ensures that variations in labels occur in regions of low density. Further, the bandwidth constraint in (5) effectively imposes a constraint on the complexity of the hypothesis space – a larger value increases the size of the hypothesis space and opens up choices consisting of more complex boundaries.
Note that Theorems 1 and 17 can be improved and their assumptions generalized in several ways:
- •
The convergence results can be generalized to graphs with edge weights computed using any non-increasing kernel , where is a scaling parameter that controls the kernel width and goes to zero as . The limits of and stay the same as in (16) and (17), up to a constant factor.
- •
The domain of the data density can be generalized to open, bounded and connected sets with Lipschitz boundary similar to the work of [5, 25, 21, 22], or a low dimensional compact manifold embedded in as in [3, 18].
- •
Convergence of the bandwidth estimates and does not imply convergence of the actual bandwidths and , respectively, to the same continuum limiting values. This is because the scaling of is tied to and in our rate conditions, whereas ideally, one should take the limit first, and independently of and while analyzing the estimates. In this case, the scaling factor in the left hand side of (16) also disappears. The analysis for this interchange of limits is challenging and we do not know how to approach this problem at the moment, so we leave it for future work. However, based on experiments in Section VI, where we use actual bandwidths instead of their estimates to validate convergence, we conjecture that the same results hold for both, i.e.,
Conjecture 1**.**
As and at appropriate rates, and .
- •
Note that Theorems 1 and 17 show pointwise convergence for fixed underlying data models, i.e., convergence is proven for a given indicator signal specified by , and specified by . This is not sufficient when we want to interpret the behavior of a bandwidth-based learning algorithm, since we cannot guarantee that the solution returned by the algorithm matches the solution of its continuum limit version. We need stronger convergence results for this case, such as those recently covered in [5, 25, 22].
Finally, as a special case of our analysis, we also get a convergence result for the graph cut in the nonseparable model analogous to the results of [24] for the separable model. Note that the cut in this case equals the sum of weights of edges connecting points that belong to class to points that do not belong to class , i.e.,
[TABLE]
With this definition, we have the following result:
Theorem 3**.**
If , such that , then
[TABLE]
The result above indicates that if the overlap between the conditional distributions of a particular class and its compliment is low, then the value of the graph cut is lower. This justifies the use of spectral clustering in the context of nonseparable models.
IV-B Label complexity
In the context of our work, we define the label complexity of learning class indicators over the graph using a sampling theoretic approach, as the fraction of labeled nodes required for perfectly predicting the labels of the unlabeled nodes. Formally, for a given class indicator over the graph , we define it as the fraction of points that need to be labeled so that a sampling theory-based reconstruction algorithm (such as bandlimited reconstruction of (5)) outputs a solution with zero reconstruction error: . Note that perfect reconstruction is a strong requirement that can be relaxed by allowing an error tolerance , in which case the amount of labeling required is lower. However, this requirement simplifies our analysis since we can directly use results from sampling theory to evaluate this quantity. Specifically, we can simply use Lemma 1 to calculate the label complexity for over the graph as . In our context, label complexity is essentially an indicator of how “good” the semi-supervised problem is, i.e., how much help we get from geometry while predicting the unknown labels. A low label complexity is indicative of a favorable situation, where one is able to learn from only a few known labels by exploiting data geometry.
Note that our definition of label complexity is concerned with reconstructing class indicators only on the nodes of the graph. This pertains to the transductive learning philosophy, a common setting considered in most graph-based semi-supervised learning literature, where the goal is to simply predict the labels of the unlabeled points and not learn a general labeling rule/classifier. Further, our definition is different and simpler than the more general definition of sample/label complexity in Probably Approximately Correct (PAC) learning [32], i.e., it is concerned with reconstructing only a given class indicator, with zero error, using a sampling theory-based learning approach, over a graph constructed from a given data model.
Ideal label complexities
A simple way to compute the label complexity, for the data models we consider, is to find the fraction of points belonging to a region that fully encompasses the boundary. To formalize this, let us define the following two sublevel sets in :
[TABLE]
Note that by definition, is fully contained in and is fully contained in (see Figure 2 for an example in ). Therefore, to perfectly reconstruct the indicator signals and for any , it is sufficient to know the labels of all points in and , respectively, as this strategy removes all ambiguity in labeling the two classes; a good learning algorithm can simply propagate the known labels on to the unlabeled points. Based on this and using the law of large numbers, we arrive at the following conclusion:
Remark 2**.**
The ideal label complexities of learning and in the asymptotic limit are given by and , respectively, where .
Label complexity of and using a sampling theory-based approach
Note that from Lemma 1, we know that the label complexities for and are given as and , respectively. Since our bandwidth convergence results relate the bandwidth of indicators for the two data models with data geometry, we only need to asymptotically relate the fraction of eigenvalues of below any constant. This is achieved by first proving the following:
Theorem 4**.**
Let be the number of eigenvalues of below a constant . Then, as and , we have
[TABLE]
Proof.
See Section V-F. ∎
Note that Theorem 4 can be strengthened by proving convergence of rather than its expected value. This requires further analysis, which we leave for future work. Plugging in and in place of in Theorem 4, and using the convergence results from Theorems 1 and 17, and Conjecture 1, we speculate the following convergence for the label complexities of and :
Conjecture 2**.**
As , , we have
[TABLE]
The limiting values in (25) and (26) are the same as those predicted by Remark 2; this is encouraging as far as the validity of Conjecture 2 is concerned. Additionally, we see strong evidence in our experiments to support our claims; specifically, the average error of predicting the labels of the unlabeled nodes goes to zero as the fraction of labeled examples crosses the limit values of (25) and (26) (see Figure 7).
The limiting values in (25) and (26) essentially indicate how the low density separation assumption can benefit semi-supervised learning, since in this case, one can forgo the task of labeling a significant fraction of the points and still reconstruct the indicator by exploiting data geometry. A classic example of where this can be useful is the two-step learning process, where the first step uses semi-supervised learning in a transductive setting to create a large training set using a combination of unlabeled and labeled data, and the second step involves learning a classifier using supervised learning. If the low density separation is satisfied by the data, then semi-supervised learning using a sampling theory-based approach effectively reduces the sample complexity of the supervised learning step by a constant fraction, equal to the limiting values in (25) and (26).
V Proofs
We now present the proofs111A partial sketch of the proof for the separable model is also provided in our parallel work [26]; here we provide the complete proof. of Theorems 1 and 17. The main idea is to perform a variance-bias decomposition of the bandwidth estimate and then prove the convergence of each term independently. Specifically, for any indicator vector , we consider the random variable:
[TABLE]
We study the convergence of this quantity by considering the numerator and denominator separately (it is easy to show that the fraction converges if both the numerator and denominator converge). By the strong law of large numbers, the following can be concluded for the denominator as :
[TABLE]
where denotes almost sure convergence. For the numerator, we decompose it into two parts – a variance term for which we show stochastic convergence using a concentration inequality, and a bias term for which we prove deterministic convergence.
V-A Expansion of
Let . We begin by expanding as
[TABLE]
where denotes the term out of the terms in the expansion of . is composed of a product of matrices, each of which can be either or . In order to write it down explicitly, one can use the -bit binary representation of the index and replace [math]s with and s with , i.e., if denotes the most-significant bit in the -bit binary representation of for and denotes the number of ones in it (i.e., ), then
[TABLE]
where the product notation assumes that the ordering of the matrices is kept fixed, i.e., .
Noting that and are composed of the edge weights , we now describe how to expand the quadratic form by considering each term individually:
The sign of the term is determined by the number of matrices in the product . 2. 2.
By using the definitions of and in the product expansion of , the absolute value of can be expressed through the following template:
[TABLE]
where denotes the element of of the indicator vector, and the locations with a “” need to be filled with appropriate indices in . Note that the template consists of a product of edge weights , each contributed by either a or depending on its location in the expression. 3. 3.
By performing an explicit matrix multiplication, we fill the locations from left to right one-by-one using the following rule: let a term containing a be preceded by an edge-weight , then,
- •
If is contributed by , then .
- •
If is contributed by , then .
Since the binary representation of is closely tied to the ordering of and in the product term , we can once again use it to explicitly express . In order to populate any “*” location according to the rules above, we require a quantity that depends on the position of the last occurring with respect to any location in the product expression of . Therefore, using the -bit binary representation of , we define for location :
[TABLE]
where returns the maximum element in a set of numbers. The template described in (31) can then be completed using the rules to obtain
[TABLE]
Finally, the expansion of can be obtained by summing the quadratic forms in (29):
[TABLE]
where we defined
[TABLE]
V-B Convergence of variance terms
For , we have the following concentration result:
Lemma 2** (Concentration).**
For every , we have:
[TABLE]
where .
Proof.
Note that the expansion of in (34) has the form of a V-statistic. Further, as defined in (35), is composed of a sum of terms, each a product of kernel functions that are non-negative. Therefore, we have the following upper bound:
[TABLE]
In order to apply a concentration inequality for V, we first re-write it in the form of a U-statistic by regrouping terms in the summation in order to remove repeated indices, as given in [33]:
[TABLE]
where denotes summation over all ordered (m+1)-tuples of distinct indices taken from the set , is the falling factorial (or number of (m+1)-permutations of ) and is a weighted arithmetic mean of specific instances of that avoids repeating indices:
[TABLE]
where denotes summation over all -tuples formed from with exactly distinct indices. Note that the number of such -tuples is given by , which is a Stirling number of the second kind. Hence, we have
[TABLE]
where we used the property . Therefore, has the same upper bound as that of derived in (37). Moreover, using the fact that , we can bound the variance of as
[TABLE]
Finally, plugging in the bound and variance of in Bernstein’s inequality for U-statistics as stated in [33, 31], we arrive at the desired result of (36). ∎
Note that as and with rates satisfying , we have for all . The continuous mapping theorem then allows us to conclude that .
V-C Expansion of
The V-statistic expansion of in (34) has summands with repeating indices, hence we first define a U-statistic counterpart that avoids these repetitions:
[TABLE]
where are the kernels defined in (35), and the definitions of and are the same as those for (38). The -statistic definition is convenient since
[TABLE]
as opposed to , where one would have to deal with terms with repeated indices separately. Further, note that
[TABLE]
where denotes summation over all ordered -tuples of indices obtained from such that at least two of them are equal. Note that there are terms in the summation . Therefore, we have
[TABLE]
where we used , and from (37).
We now focus on computing . Based on (35), we can express it as follows:
[TABLE]
where we define:
[TABLE]
with defined as in (32).
V-D Convergence of bias term for the separable model
To evaluate the convergence of bias terms, we shall require the following properties of the -dimensional Gaussian kernel:
Lemma 3**.**
If is twice differentiable, then
[TABLE]
Proof.
Using the substitution followed by a Taylor series expansion about , we have
[TABLE]
where denotes the trace of a matrix, and the third step follows from simple component-wise integration. ∎
Lemma 4**.**
If is twice differentiable, then
[TABLE]
Proof.
Note that
[TABLE]
Therefore, we have
[TABLE]
where the last step follows from Lemma 3. ∎
In order to prove convergence for the separable model, we need the following results:
Lemma 5**.**
If is Lipschitz continuous, then for a smooth hypersurface that divides into and , and whose curvature has radius lower-bounded by ,
[TABLE]
where and are positive integers. Moreover, for positive integers , and such that , we have:
[TABLE]
Proof.
See Appendix A. ∎
We now prove the deterministic convergence of in the following lemma:
Lemma 6**.**
As , such that and , we have
[TABLE]
where .
Proof.
Using (45) and (46), and replacing with , we have
[TABLE]
We pair all even-indexed and odd-indexed terms together to rewrite the summation as:
[TABLE]
Now, and can be evaluated by repeatedly applying (48) for every Gaussian kernel in the definition from (47). Hence, for the first summation pair, we obtain:
[TABLE]
For the rest of the terms, we also require the use of (49). However, in this case, we encounter several terms of the form for some . Since and is assumed to be Lipschitz continuous, we can approximate such terms by or . Further, the number of times we have to apply (49) in any is equal to the number of occurrences of in (which is ). Therefore, for , we have
[TABLE]
where are positive integers such that . Plugging (55) and (56) into (53), we get:
[TABLE]
where we grouped terms based on in the summation (note that there are for a given ).
Using Lemma 5, we conclude that the right hand side of (57) converges as and to
[TABLE]
which is the desired result. ∎
Using the continuous mapping theorem on (52), we can conclude
[TABLE]
Finally, we note that as , we have
[TABLE]
Therefore, we conclude for the separable model
[TABLE]
V-E Convergence of bias term for the nonseparable model
For the nonseparable model, we need to prove convergence of . This is illustrated in the following lemma:
Lemma 7**.**
As , such that and , we have
[TABLE]
Proof.
Similar to the proof of Lemma 6, we use (45) and (46), and replace with to obtain
[TABLE]
Using (48) repeatedly in the definition (47), we get
[TABLE]
where we used the fact that . Similarly, for , we have
[TABLE]
Putting together (63) and (64) into (62), we get
[TABLE]
Taking limits while satisfying the stated rate conditions, we get the desired result. ∎
We finally note that as , we have
[TABLE]
Therefore, we conclude for the nonseparable model
[TABLE]
Note that Lemma 7 for the special case of yields
[TABLE]
which proves Theorem 3.
V-F Proof of Theorem 4
We begin by recalling the definition of the empirical spectral distribution (ESD) of :
[TABLE]
where are the eigenvalues of . For each , is a function of , and thus a random variable. Note that the fraction of eigenvalues of below a constant , and its expected value can be computed from the ESD as
[TABLE]
Therefore, to understand the behavior of the expected fraction of eigenvalues of below , we need to analyze the convergence of the expected ESD in the asymptotic limit. The idea is to show the convergence of the moments of to the moments of a limiting distribution . Then, by a standard convergence result, for intervals . More precisely, let the symbol denote weak convergence of measures, then we use the following result that follows from the Weierstrass approximation theorem:
Lemma 8**.**
Let be a sequence of probability measures and be a compactly supported probability measure. If for all , then .
We then use the following result on equivalence of different notions of weak convergence of measures [34, Theorem 25.2] in order to prove our result for cumulative distribution functions.
Lemma 9**.**
* if and only if for every -continuity set .*
Therefore, we simply need to analyze the convergence of moments of . Note that the moment of can be written as:
[TABLE]
We reuse our analysis in Section V-A, specifically the expansion in (29) to obtain
[TABLE]
Using the binary representation of once again similar to (33), we can compute:
[TABLE]
Note that has a summation over indices for , as a result, a factor of remains in the expectation. Similarly, terms with repeated indices disappear and thus, we have the following for the right hand side of (72) as :
[TABLE]
Using (48) repeatedly in the equation above, we get:
[TABLE]
Therefore, as and , we have:
[TABLE]
From the right hand side of the equation above, we conclude that the moment of the expected ESD of converges to the moment of the distribution of a random variable , where is the probabilty density function of . Moreover, since has compact support, converges weakly to the probability density function of . Hence, the following can be said about the expected fraction of eigenvalues of :
[TABLE]
This proves our claim in Theorem 4. Note that, to prove the stochastic convergence of the fraction itself rather than its expected value, we would need a condition similar to those in Theorems 1 and 17 to hold for each moment. In that case, will go to 0 in a prohibitively slow fashion. We believe that this is an artifact of the methods we employ for proving the result. Hence, our conjecture is that the convergence result holds for itself, and we leave the analysis of this statement for future work.
VI Numerical validation
We now present simple numerical experiments222Link to code: https://github.com/aamiranis/asymptotics_graph_ssl to validate our results and demonstrate their usefulness in practice. A key focus in our experiments is to confirm Conjecture 1, i.e., the convergence results for the bandwidth estimates also hold for the actual bandwidths. In order to achieve this, we work directly with the bandwidths of the indicators instead of their estimates and numerically validate their convergence for both the separable and nonseparable models.
For simulating the separable model, we first consider a data distribution based on a 2D Gaussian Mixture Model (GMM) with two Gaussians: and , and mixing proportions and respectively. The probability density function is illustrated in Figure 3. Next, we evaluate the claim of Theorem 1 on five boundaries, described in Table II. These boundaries are depicted in Figure 4 and are illustrative of typical separation assumptions such as linear or non-linear and low or high density.
For simulating the nonseparable model, we first construct the following smooth (twice-differentiable) 2D probability density function
[TABLE]
Note that data points can be sampled from this distribution by setting the coordinates , , where . We then use to define a nonseparable 2D model with mixture density , where , and . The probability density function is illustrated in Figure 3. The overlap region or boundary for this model is given by
[TABLE]
Further, for this model, we have .
In our first experiment, we validate the statements of Theorems 1 and 17 by comparing the left and right hand sides of (16) and (17) for corresponding boundaries. This is carried out in the following way: we draw points from each model and construct the corresponding similarity graphs using . Then, for the boundaries in the separable model and in the nonseparable model, we carry out the following steps:
We first construct the indicator functions and on the corresponding graphs. 2. 2.
We then compute the empirical bandwidth and in a manner that takes care of numerical error: we first obtain the eigenvectors of the corresponding , then set and to be for which energy contained in the graph Fourier coefficients corresponding to eigenvalues is at most , i.e.,
[TABLE]
The procedure above is repeated 100 times and the mean of and are compared with and respectively. The result is plotted in Figure 5. We observe that the empirical bandwidth is close to the theoretically predicted value and has a very low standard deviation. This supports our conjecture that stochastic convergence should hold for the bandwidth. To further justify this claim, we study the behavior of the standard deviation of and as a function of in Figure 6, where we observe a decreasing trend consistent with our result.
For our second experiment, we validate the label complexity of sampling theory-based learning in Conjecture 2 by reconstructing the indicator function corresponding to and from a fraction of labeled examples on the corresponding graphs. This is carried out as follows: For a given budget , we find the set of points to label of size , using pivoted column-wise Gaussian elimination on the eigenvector matrix of [15]. This method ensures that the obtained labeled set guarantees perfect recovery for signals spanned by the first eigenvectors of [15]. We then recover the indicator functions from these labeled sets by solving the least squares problem in (5) followed by thresholding. Note that is set to the cutoff frequency of , which is equal to the eigenvalue of . The mean reconstruction error is defined as
[TABLE]
We repeat the experiment times by generating different graphs and plot the averaged against the fraction of labeled examples. The result is illustrated in Figure 7. We observe that the error goes to zero as the fraction of labeled points goes beyond the respective limit values stated in (25) and (26). This reinforces the intuition that the bandwidth of class indicators and their label complexities are closely linked with the inherent geometry of the data.
VII Discussions and future work
In this paper, we provided an interpretation of the graph sampling theoretic approach to semi-supervised learning. Our work analyzed the bandwidth of class indicator signals with respect to the Laplacian eigenvector basis and revealed its connection to the underlying geometry of the dataset. This connection is useful in justifying graph-based approaches for semi-supervised and unsupervised learning problems, and provides a geometrical interpretation of the smoothness assumptions imposed in the bandlimited reconstruction approach. Specifically, our results have shown that an estimate of the bandwidth of class indicators converges to the supremum of the probability density on the class boundaries for the separable model, and on the overlap regions for the nonseparable model. This quantifies the connection between the assumptions of smoothness (in terms of bandlimitedness) and low density separation, since boundaries passing through regions of low data density result in lower bandwidth of the class indicator signals. We numerically validated these results through various experiments.
There are several directions in which our results can be extended. In this paper we only considered Gaussian-weighted graphs, an immediate extension would be to consider arbitrary kernel functions for computing graph weights, or density dependent edge-connections such as -nearest neighbors. Another possibility is to consider data defined on a subset of the -dimensional Euclidean space.
Our analysis also sheds light on the label complexity of graph-based semi-supervised learning problems. We showed that perfect prediction from a few labeled examples using a graph-based bandlimited interpolation approach requires the same amount of labeling as one would need to completely encompass the boundary or region of ambiguity. This quantifies the connection between label complexity of a sampling theory-based approach with the underlying geometry of the problem. We believe that the main potential of graph-based methods will be apparent in situations where one can tolerate a certain amount of prediction error, in which case such approaches shall require fewer labeled data. We plan to investigate this as part of future work.
Appendix A Proof of Lemma 5
The key ingredient required for evaluating the integrals in Lemma 5 involves selecting a radius () as a function of that satisfies the following properties as :
, 2. 2.
, 3. 3.
, 4. 4.
, where .
A particular choice of is given by . Note that as . Further,
[TABLE]
Hence, and as . Additionally, substituting the expression for in the tail bound for the norm of a -dimensional Gaussian vector gives us:
[TABLE]
Therefore, for , as . Further, it is easy to ensure for the regime of in our proofs.
We now consider the proof of equation (50), let
[TABLE]
Further, let indicate a tubular region of thickness adjacent to the boundary in , i.e., the set of points in at a distance from the boundary. Then, we have
[TABLE]
is the error associated with approximating by and exhibits the following behavior:
Lemma 10**.**
.
Proof.
Note that
[TABLE]
Using , we get the desired result. ∎
In order to analyze , we need to define certain geometrical constructions (illustrated in Figure 8) as follows:
Definition 1**.**
For each , we define a transformation of coordinates as:
[TABLE]
*where is the foot of the perpendicular dropped from onto , is the distance between and , and is the surface normal at (towards the direction of ). Since the minimum radius of curvature of is and , this mapping is injective. * 2. 2.
For each , let denote the half-space created by the plane tangent on and on the side of . Similarly, let denote the half-space on the side of , that is, . 3. 3.
Let denote an infinite slab of thickness tangent to at and towards the side of . Let denote a similar slab of thickness on the side of . 4. 4.
Finally, for any , let denote the Euclidean ball of radius centered at .
We now consider , the main idea here is to approximate the integral over by an integral over the half-space . Hence, we have:
[TABLE]
where is the error associated with the approximation. Therefore, we have
[TABLE]
We now show that as , , and .
Lemma 11**.**
.
Proof.
Using the change of coordinates , we have
[TABLE]
where denotes the Jacobian of the transformation. Now, an arc of length at a distance away from gets mapped to an arc on whose length lies in the interval . Therefore, for all points within , we have
[TABLE]
Further, since is Lipschitz continuous with constant , is also Lipschitz continuous with constant . Therefore, for any , we have . This leads to the following simplification for :
[TABLE]
where we defined
[TABLE]
Note that every can be written as , where . Hence, we get
[TABLE]
where we used Lipschitz continuity of in the second equality and applied Lemma 3 to arrive at the last step. Further, using the definition of the -function and integration by parts, we note that
[TABLE]
Therefore,
[TABLE]
Combining (95) and (98) and using the fact that as (from the definition of ), we get
[TABLE]
which concludes the proof. ∎
We now consider the error term and prove the following result:
Lemma 12**.**
.
Proof.
Let us first rewrite as follows:
[TABLE]
where we defined
[TABLE]
The key idea is to lower and upper bound for all using worst case scenarios and evaluate the limits of the bounds. Note that is largest in magnitude when or is a sphere of radius , as illustrated in Figures 9(a) and 9(b). We now make certain geometrical observations. For any , we observe from Figure 9(b) that
[TABLE]
where . Similarly, from Figure 9(a), we observe that
[TABLE]
Substituting these in (100) and using a simplification similar to that of in (95), we get
[TABLE]
where we defined
[TABLE]
Similar to the evaluation of in (97), we have
[TABLE]
We now evaluate the two 1-D integrals as follows:
[TABLE]
Similarly,
[TABLE]
Noting that as , and , we conclude that . ∎
The proof of (51) proceeds in a similar fashion by approximating the inner integral using hyperplanes. Specifically, similar to the proof of (50), we can show that the integral on the left hand side can be written as , where
[TABLE]
and is the residual associated with the approximation that can be shown to go to zero as (we skip this proof since it is quite similar to the analysis for (50)). In order to evaluate , we perform a change of coordinates as before to obtain
[TABLE]
where we defined
[TABLE]
By using a change of coordinates for similar to the steps in (97), we obtain
[TABLE]
The 1-D integrals can be evaluated as follows:
[TABLE]
[TABLE]
Using the fact that , and taking the limit after putting everything together, we conclude
[TABLE]
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] O. Chapelle, B. Schölkopf, and A. Zien, Semi-Supervised Learning (Adaptive Computation and Machine Learning) . The MIT Press, 2006.
- 2[2] D. Zhou, O. Bousquet, T. N. Lal, J. Weston, and B. Schölkopf, “Learning with local and global consistency,” in Advances in Neural Information Processing Systems 16 (S. Thrun, L. K. Saul, and B. Schölkopf, eds.), pp. 321–328, MIT Press, 2004.
- 3[3] H. Narayanan, M. Belkin, and P. Niyogi, “On the relation between low density separation, spectral clustering and graph cuts,” in Advances in Neural Information Processing Systems (NIPS) 19 , 2006.
- 4[4] X. Zhu, Z. Ghahramani, and J. Lafferty, “Semi-supervised learning using gaussian fields and harmonic functions,” in IN ICML , pp. 912–919, 2003.
- 5[5] N. García Trillos and D. Slepčev, “Continuum limit of total variation on point clouds,” Archive for Rational Mechanics and Analysis , vol. 220, pp. 193–241, Apr 2016.
- 6[6] X. Zhou and M. Belkin, “Semi-supervised learning by higher order regularization,” in Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2011, Fort Lauderdale, USA, April 11-13, 2011 , pp. 892–900, 2011.
- 7[7] T. Bühler and M. Hein, “Spectral clustering based on the graph p-laplacian,” in Proceedings of the 26th Annual International Conference on Machine Learning , ICML ’09, (New York, NY, USA), pp. 81–88, ACM, 2009.
- 8[8] A. E. Alaoui, “Asymptotic behavior of ℓ p subscript ℓ 𝑝 \ell_{p} -based Laplacian regularization in semi-supervised learning,” in Proceedings of the 29th Conference on Learning Theory, COLT 2016, New York, USA, June 23-26, 2016 , pp. 879–906, 2016.